
Website dùng React, Vue, Next.js có làm SEO tốt được không?
Website dùng React, Vue hay Next.js hoàn toàn có thể làm SEO tốt nếu nội dung quan trọng được render đúng cách, bot có thể crawl được và mỗi URL có tín hiệu kỹ thuật rõ ràng. Vấn đề không nằm ở bản thân JavaScript framework, mà nằm ở cách triển khai rendering, metadata, internal link, structured data, sitemap, robots và hiệu suất tải trang. Với các trang cần organic traffic như homepage, category, product, blog, landing page hoặc tài liệu, nên ưu tiên SSR, SSG, ISR hoặc prerender để HTML ban đầu đã có title, meta description, canonical, H1, nội dung chính, breadcrumb, internal link và JSON-LD.

Ngược lại, nếu phụ thuộc hoàn toàn vào client-side rendering, nội dung chỉ xuất hiện sau API call, hydration lỗi hoặc tương tác người dùng, Google có thể index thiếu nội dung, hiểu sai intent hoặc đánh giá trang là thin content/soft 404. Next.js, Nuxt và các meta-framework hiện đại hỗ trợ SEO tốt hơn SPA thuần nhờ routing sạch, metadata theo route, render phía server, cache, image optimization và khả năng kiểm soát status code. Tuy vậy, để SEO bền vững, website vẫn cần tối ưu Core Web Vitals, giảm bundle JavaScript, lazy load đúng phần, dùng thẻ <a href> cho internal link, tạo schema khớp nội dung hiển thị và đưa audit SEO vào CI/CD để tránh deploy lỗi noindex, canonical, sitemap hoặc robots. Với website JavaScript, SEO cần được tính ngay từ kiến trúc triển khai thay vì xử lý sau khi giao diện đã hoàn thiện. Quy trình thiết kế web chuẩn SEO giúp xác định trang nào cần SSR, SSG hoặc ISR, đồng thời kiểm soát metadata, canonical, sitemap và cấu trúc liên kết nội bộ theo từng loại URL.
React, Vue, Next.js có thể làm SEO tốt nếu nội dung được render và crawl đúng cách
Các framework như React, Vue, Next.js chỉ thực sự “thân thiện SEO” khi chiến lược render được thiết kế đúng: HTML quan trọng phải sẵn sàng cho bot, cấu trúc heading rõ ràng, metadata và structured data được render ổn định trên mỗi URL. Vấn đề không nằm ở bản thân JavaScript, mà ở việc phụ thuộc quá nhiều vào client-side rendering, hydration dễ lỗi và nội dung chỉ xuất hiện sau khi chạy script hoặc gọi API chậm. Để giảm rủi ro thin content, soft 404 và index thiếu, cần ưu tiên SSR/SSG/ISR hoặc prerender cho các trang cần SEO, hạn chế lazy load nội dung cốt lõi, tránh điều kiện render phức tạp theo user agent. Các meta-framework như Next.js, Nuxt hỗ trợ routing sạch, metadata theo route và HTML có nội dung sẵn, giúp Googlebot crawl, render, index hiệu quả hơn. Next.js và Nuxt hỗ trợ nhiều lựa chọn rendering, nhưng hiệu quả vẫn phụ thuộc vào cách doanh nghiệp phân loại mục tiêu của từng trang. Một chiến lược thiết kế web rõ ràng giúp cân bằng giữa tốc độ phát triển, hiệu năng tải trang, khả năng quản trị nội dung và nhu cầu mở rộng trong tương lai.
JavaScript framework không tự làm website kém SEO nếu HTML quan trọng có thể truy cập được
React, Vue hay Next.js về bản chất là các thư viện và framework hỗ trợ xây dựng giao diện người dùng theo hướng component hóa, quản lý state và tối ưu trải nghiệm front-end hiện đại. Chúng không mang thuộc tính “kém SEO” hay “tốt SEO” một cách mặc định. Yếu tố quyết định nằm ở cách render HTML, cách Googlebot crawl, render và index nội dung, cũng như cách kiến trúc URL, internal link và metadata được triển khai.
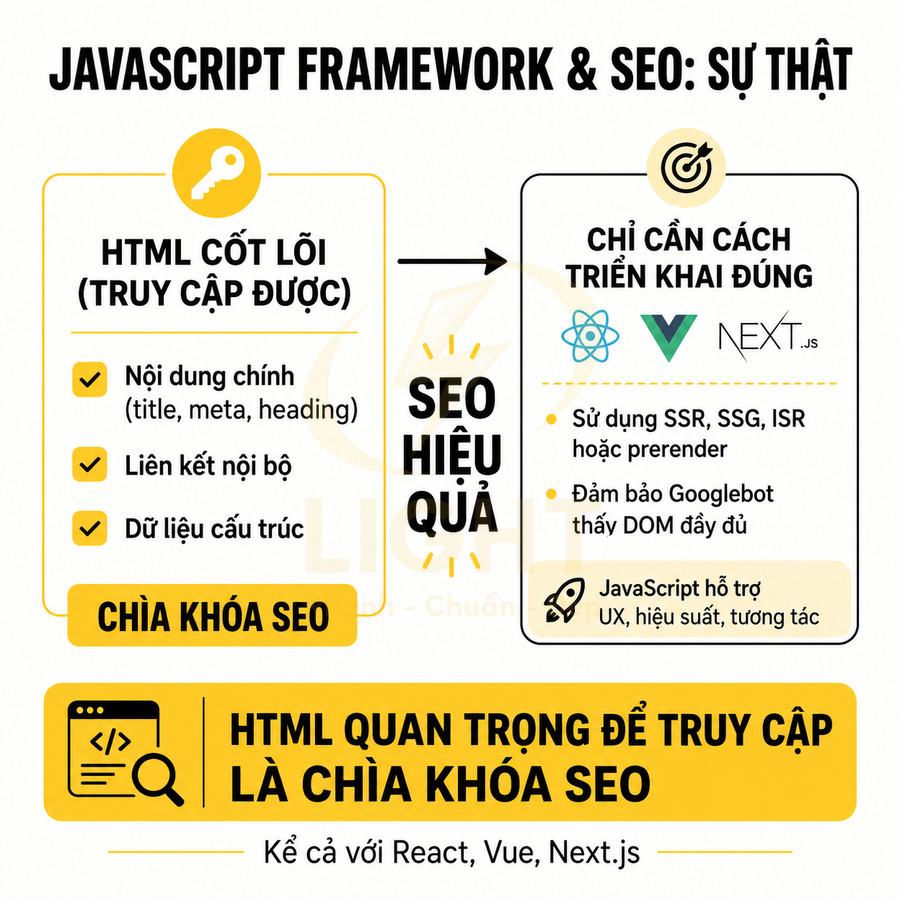
Đối với SEO, điều quan trọng không phải là dùng React hay Vue, mà là mỗi URL quan trọng có trả về được một HTML có nội dung chính, heading, internal link, metadata, structured data mà bot có thể truy cập hay không. Nếu HTML trả về từ server (hoặc sau quá trình render mà Googlebot có thể thực hiện) đã chứa:
- Các thẻ title, meta description, meta robots phù hợp.
- Cấu trúc heading H1–H2–H3 rõ ràng, phản ánh chủ đề nội dung.
- Internal link dạng HTML anchor bình thường, không ẩn sau event JavaScript phức tạp.
- Content chính (text, list, bảng, schema) xuất hiện trực tiếp trong DOM.
- Các thẻ link rel="canonical", hreflang (nếu có) được render ổn định.
Khả năng hiển thị nội dung cho công cụ tìm kiếm cần được xem là một yêu cầu kiến trúc, không phải bước chỉnh sửa sau cùng của đội SEO. Nghiên cứu về các yếu tố xếp hạng trong môi trường Web hiện đại cho thấy hiệu quả SEO chịu ảnh hưởng bởi nhiều tín hiệu phối hợp, gồm chất lượng nội dung, cấu trúc liên kết, khả năng truy cập kỹ thuật và hiệu suất trang, thay vì phụ thuộc vào một công nghệ giao diện cụ thể. Vì vậy, React, Vue hay Next.js chỉ là lớp triển khai; giá trị SEO thực tế nằm ở việc URL có thể cung cấp nội dung nhất quán, có cấu trúc và có thể được thu thập hay không. Một trang dùng JavaScript vẫn có thể cạnh tranh tốt khi nội dung, liên kết và dữ liệu mô tả được xuất bản rõ ràng theo từng URL. (Mavridis & Symeonidis, 2015).
thì website dùng React, Vue, Next.js hoàn toàn có thể đạt hiệu quả SEO tương đương, thậm chí vượt trội so với site HTML tĩnh truyền thống nhờ khả năng tối ưu UX, tốc độ và kiến trúc thông minh.
Google hiện sử dụng hệ thống two-wave indexing (crawling HTML trước, sau đó render JavaScript), nhưng không phải lúc nào cũng render hoàn hảo mọi script. Do đó, chiến lược an toàn là đảm bảo HTML quan trọng có thể truy cập được ngay trong response đầu tiên hoặc trong một quá trình render mà Googlebot chắc chắn thực hiện được. Khi HTML đã chứa nội dung chính, cấu trúc heading, link và structured data, JavaScript chỉ đóng vai trò:
- Tăng trải nghiệm người dùng (UX): chuyển trang mượt, animation, interactive component.
- Tối ưu hiệu suất: code splitting, lazy load asset không quan trọng, prefetch route.
- Hỗ trợ tính năng động: filter, sort, personalization ở mức không làm thay đổi nội dung cốt lõi.
Từ góc độ kỹ thuật, sự phụ thuộc quá mức vào JavaScript làm tăng số bước mà hệ thống thu thập dữ liệu phải hoàn thành trước khi hiểu đầy đủ một trang. HTML ban đầu nghèo thông tin buộc bot phải tải thêm tài nguyên, thực thi mã nguồn, chờ dữ liệu từ API và dựng lại cấu trúc trang trước khi có thể đánh giá nội dung. Điều này làm tăng rủi ro khi bundle lớn, request phụ thuộc lẫn nhau hoặc môi trường render không xử lý được một API trình duyệt cụ thể. HTML response đầu tiên càng đầy đủ thì mức độ phụ thuộc vào quá trình render bổ sung càng thấp. Đây là lý do các trang có mục tiêu organic traffic như bài viết, danh mục, sản phẩm và landing page nên ưu tiên render sẵn phần nội dung quyết định chủ đề trang. (Butkiewicz et al., 2011; Pati & Zaki, 2025).
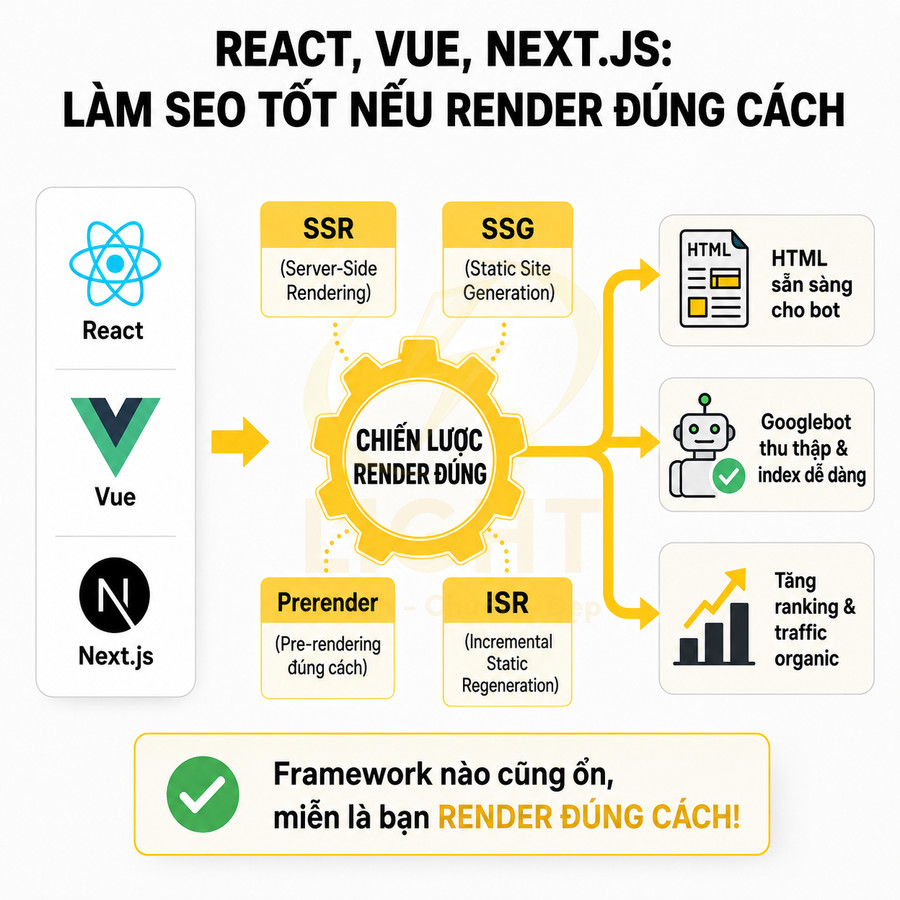
Trong bối cảnh đó, React SPA, Vue SPA, Next.js, Nuxt hay bất kỳ framework JavaScript nào khác đều có thể “thân thiện SEO” nếu được triển khai với chiến lược render đúng. Các kỹ thuật như SSR (Server-Side Rendering), SSG (Static Site Generation), ISR (Incremental Static Regeneration) hoặc prerender giúp đảm bảo Googlebot luôn nhìn thấy một DOM đầy đủ nội dung, không bị phụ thuộc hoàn toàn vào client-side rendering.
Thực tế, nhiều website lớn về tin tức, thương mại điện tử, SaaS, marketplace đang sử dụng React, Vue, Next.js và vẫn đạt hàng triệu organic traffic mỗi tháng. Điểm chung của các hệ thống này thường bao gồm:
- Sử dụng SSR/SSG/ISR/prerender cho các trang cần SEO (category, product, blog, landing).
- Tối ưu routing để URL sạch, có cấu trúc, dễ crawl và dễ quản lý canonical.
- Quản lý metadata và structured data theo từng route, không để phụ thuộc vào client-only script.
- Đảm bảo Googlebot có thể crawl nội dung mà không bị chặn bởi robots.txt, header HTTP, cấu hình server hoặc firewall.
- Giảm thiểu các pattern anti-SEO như infinite scroll không có pagination HTML, hoặc navigation chỉ hoạt động qua event JS.
Khi các nguyên tắc này được tuân thủ, việc dùng JavaScript framework không chỉ không gây hại cho SEO, mà còn tạo nền tảng tốt để tối ưu Core Web Vitals, trải nghiệm người dùng và tỷ lệ chuyển đổi – những yếu tố ngày càng liên quan chặt chẽ đến hiệu quả SEO tổng thể.
Rủi ro SEO đến từ client-side rendering, hydration lỗi và nội dung phụ thuộc JavaScript
Rủi ro SEO của website dùng React, Vue, Next.js chủ yếu xuất phát từ cách triển khai client-side rendering (CSR) và quá trình hydration, không phải từ bản thân framework. Trong mô hình CSR thuần, server thường trả về một HTML gần như rỗng, chỉ chứa một root div và bundle JavaScript. Nội dung thực tế chỉ xuất hiện sau khi JavaScript được tải, parse, execute và render component. CSR thuần thường tạo ra chuỗi phụ thuộc dài: tải HTML khung, tải JavaScript, chạy ứng dụng, gọi API, nhận dữ liệu rồi mới render nội dung thật. Khi một mắt xích gặp lỗi, trang vẫn có thể hiển thị với người dùng đã có cache hoặc mạng ổn định, nhưng lại không cung cấp nội dung đầy đủ cho bot, công cụ social preview hoặc người dùng dùng thiết bị yếu. Nghiên cứu đo lường độ phức tạp website cho thấy số lượng tài nguyên, miền bên thứ ba và logic tải trang có thể làm gia tăng đáng kể chi phí xử lý ở phía trình duyệt. Mục tiêu không phải loại bỏ JavaScript, mà là không để JavaScript trở thành điều kiện duy nhất để nội dung cốt lõi tồn tại. (Butkiewicz et al., 2011).
Nếu Googlebot vì bất kỳ lý do gì không render được JavaScript đúng cách, nội dung chính sẽ không xuất hiện trong DOM để index. Điều này đặc biệt nguy hiểm với các trang mà:
- Toàn bộ content được fetch từ API sau khi load.
- Navigation, pagination, filter đều phụ thuộc event JS.
- Không có fallback HTML hoặc no-JS content.
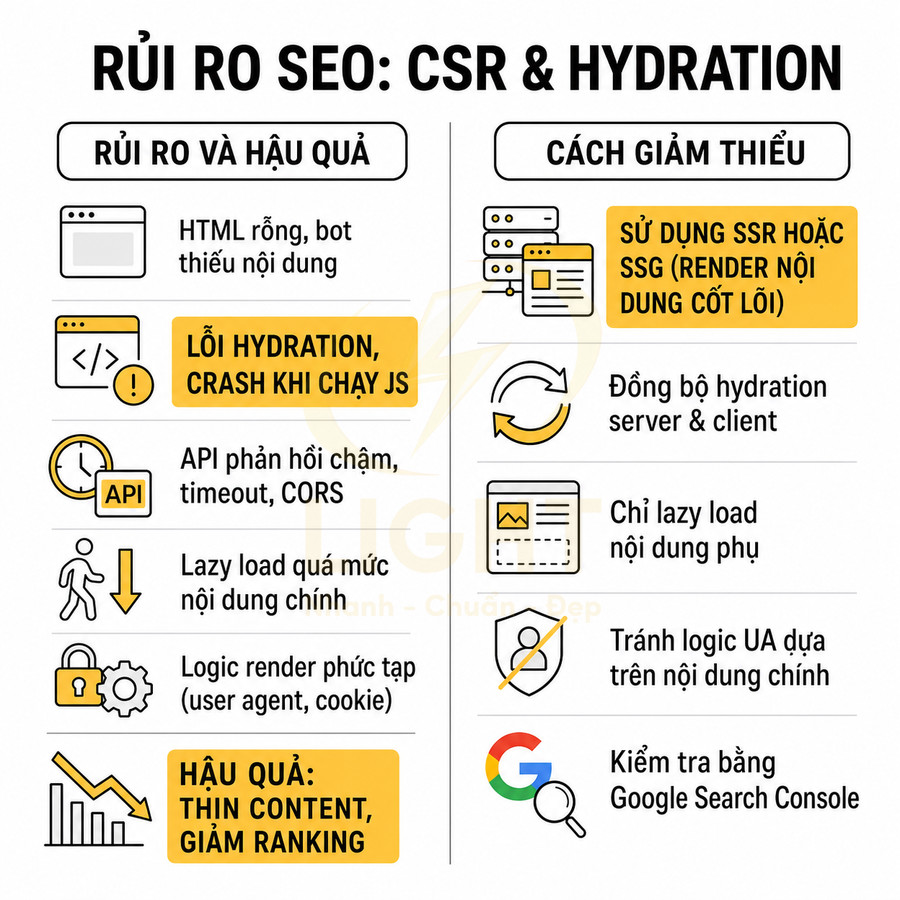
Các vấn đề thường gặp gồm:
- Hydration lỗi: JavaScript không chạy hết hoặc crash giữa chừng (lỗi runtime, mismatch giữa HTML SSR và client, lỗi dependency), khiến component không mount, nội dung không hiển thị đầy đủ cho bot. Trong log server có thể không thấy lỗi, nhưng trong DevTools console sẽ có error, và Googlebot có thể chỉ index phần HTML thô ban đầu. Lỗi hydration cần được coi là lỗi nội dung, không chỉ là lỗi giao diện. Khi HTML do server trả về khác với cây component phía client, framework có thể phải thay thế một phần DOM, bỏ qua component hoặc sinh cảnh báo không dễ nhìn thấy trong log server. Hệ quả là tiêu đề, nội dung mô tả, liên kết điều hướng hoặc dữ liệu có cấu trúc có thể không ổn định giữa lần tải đầu và trạng thái sau khi JavaScript chạy. Một URL SEO tốt phải giữ tính nhất quán về thông tin cốt lõi giữa server render và client render. Việc kiểm thử nên bao gồm HTML response, DOM sau hydration và phiên bản mà công cụ tìm kiếm thu thập, thay vì chỉ kiểm tra giao diện trên trình duyệt của đội phát triển. (Pati & Zaki, 2025; Butkiewicz et al., 2011).
- Nội dung phụ thuộc API chậm: dữ liệu chính chỉ xuất hiện sau khi gọi API (REST, GraphQL), nhưng request chậm, timeout hoặc bị chặn bởi CORS, auth, rate limit. Googlebot có thời gian render giới hạn, nếu API phản hồi muộn, bot sẽ snapshot DOM trước khi nội dung được inject, dẫn đến trang bị đánh giá là thin content hoặc không liên quan truy vấn.
- Điều kiện render phức tạp: logic if/else dựa trên user agent, cookie, localStorage, geolocation, A/B testing… có thể khiến bot nhận HTML khác người dùng, thậm chí nhận trang rỗng. Việc cloaking vô tình xảy ra khi code phân nhánh “nếu không có cookie thì không render content”, trong khi Googlebot thường không có cookie như user thật.
- Lazy load quá mức: nội dung quan trọng bị lazy load dựa trên scroll, intersection observer hoặc event mà Googlebot không kích hoạt. Nếu phần text chính, heading hoặc internal link chỉ xuất hiện sau khi user scroll sâu, bot có thể không bao giờ thấy chúng, làm giảm khả năng hiểu chủ đề trang.
Khi các rủi ro này xảy ra, Google có thể chỉ index một phần nội dung, hiểu sai chủ đề trang, hoặc đánh giá trang là thin content, soft 404 hoặc không đủ chất lượng để xếp hạng cao. Điều này làm giảm khả năng ranking, CTR và hiệu quả SEO tổng thể, dù giao diện với người dùng thật vẫn trông bình thường.
Để giảm thiểu rủi ro, cần chú ý một số nguyên tắc kỹ thuật:
- Ưu tiên render nội dung cốt lõi trên server (SSR/SSG) thay vì đợi client fetch.
- Đảm bảo hydration không lỗi: đồng bộ markup giữa server và client, tránh render khác nhau dựa trên state chỉ có ở client.
- Không dùng điều kiện render dựa trên user agent cho nội dung chính; nếu cần, dùng cho cosmetic hoặc tracking.
- Chỉ lazy load nội dung không quan trọng cho SEO (hình ảnh dưới màn hình đầu tiên, widget phụ), giữ text chính và internal link ở HTML ban đầu.
- Kiểm tra bằng URL Inspection trong Google Search Console và công cụ “View crawled page” để xem Google thực sự thấy gì trong DOM.
Next.js, Nuxt và SSR giúp giảm rào cản crawl so với SPA thuần
Các meta-framework như Next.js (cho React) và Nuxt (cho Vue) được thiết kế để giải quyết trực tiếp các vấn đề SEO, hiệu suất và DX (developer experience) của SPA thuần CSR. Thay vì chỉ render phía client, chúng hỗ trợ nhiều chiến lược render:
- SSR (Server-Side Rendering): mỗi request được render trên server, trả về HTML đầy đủ nội dung, sau đó mới hydrate trên client.
- SSG (Static Site Generation): HTML được build sẵn tại build time, lưu thành file tĩnh, server chỉ serve lại mà không cần render động.
- ISR (Incremental Static Regeneration): kết hợp SSG với khả năng regenerate trang theo chu kỳ, phù hợp site nội dung lớn, thường xuyên cập nhật.
- Hybrid rendering: cùng một project có thể dùng SSR cho một số route, SSG cho route khác, CSR cho phần dashboard nội bộ.
Ưu điểm quan trọng của SSR, SSG và các mô hình render lai không nằm ở việc “thay thế SEO”, mà ở khả năng đưa thông tin có thể đọc được vào response đầu tiên. Khi tiêu đề, đoạn mở đầu, đường dẫn điều hướng, dữ liệu sản phẩm và dữ liệu có cấu trúc đã xuất hiện trong HTML, các hệ thống thu thập không cần phụ thuộc hoàn toàn vào việc chạy JavaScript để hiểu chủ đề URL. Nghiên cứu so sánh Next.js với React cho thấy mô hình framework có hỗ trợ render phía server và tối ưu tài nguyên có tiềm năng cải thiện hiệu suất tổng thể mà không làm suy giảm trải nghiệm tương tác. Tuy vậy, lợi ích chỉ xuất hiện khi dữ liệu, metadata và cấu trúc route được triển khai đúng theo từng trang. (Pati & Zaki, 2025).

So với SPA thuần, lợi ích SEO của Next.js, Nuxt thể hiện ở:
- HTML có nội dung sẵn: Googlebot nhận được DOM đầy đủ ngay khi crawl, không phải chờ render JavaScript hai bước. Điều này giảm phụ thuộc vào khả năng render JS của bot và tránh rủi ro timeout, lỗi hydration.
- Routing thân thiện SEO: file-based routing tạo URL sạch, ổn định, dễ kiểm soát canonical và metadata. Cấu trúc thư mục phản ánh cấu trúc thông tin (information architecture), giúp tổ chức category, tag, product, blog logic hơn.
- Metadata theo route: dễ cấu hình title, meta description, robots, canonical, Open Graph, structured data cho từng trang thông qua API framework (ví dụ: next/head, app router metadata, hoặc Nuxt useHead). Điều này giúp tránh tình trạng metadata bị render muộn hoặc không đồng bộ giữa server và client.
- Hiệu suất tốt hơn: SSR/SSG giảm thời gian hiển thị nội dung đầu tiên (FCP, LCP), cải thiện Core Web Vitals, hỗ trợ ranking và trải nghiệm người dùng. Với SSG, server load giảm, TTFB ổn định, dễ cache qua CDN.
Trong bối cảnh website nội dung, ecommerce, SaaS cần organic traffic lớn, việc kết hợp Next.js/Nuxt với chiến lược render phù hợp cho từng loại trang là rất quan trọng:
- Trang landing, blog, category: ưu tiên SSG hoặc ISR để có HTML tĩnh, nhanh, dễ cache.
- Trang product detail: có thể dùng SSR hoặc ISR tùy tần suất cập nhật giá, tồn kho.
- Trang dashboard, account, admin: có thể dùng CSR vì không cần SEO, tập trung UX.
Khi triển khai, cần kết hợp thêm các thực hành SEO kỹ thuật:
- Đảm bảo sitemap XML và robots.txt được serve đúng, không chặn nhầm route SSR/SSG quan trọng.
- Quản lý canonical để tránh duplicate giữa phiên bản SSR và các biến thể URL (query param, pagination).
- Tối ưu linking nội bộ bằng component link của framework nhưng vẫn render thành thẻ <a> chuẩn trong HTML.
- Đảm bảo structured data (JSON-LD) được render trên server, không chỉ inject sau khi client load.
Nhờ các cơ chế này, Next.js và Nuxt giúp giảm đáng kể rào cản crawl và index so với SPA React/Vue thuần CSR, đồng thời cung cấp một nền tảng kỹ thuật vững chắc để kết hợp SEO, hiệu suất và trải nghiệm người dùng trong cùng một kiến trúc front-end hiện đại.
Cách Googlebot xử lý JavaScript trên website React, Vue, Next.js
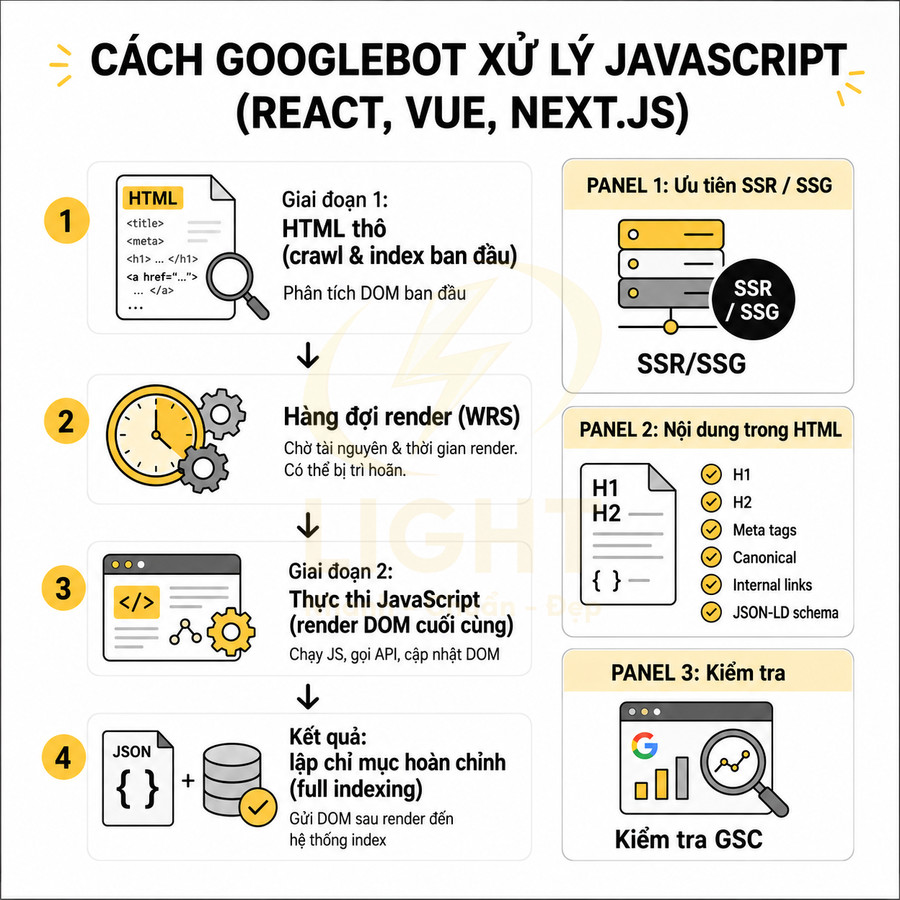
Googlebot xử lý JavaScript trên các website React, Vue, Next.js thông qua hai lớp chính: crawl & index HTML thô và render JavaScript. Ở lớp đầu, bot thu thập HTML response, phân tích DOM ban đầu để lấy link, thẻ meta, heading, structured data và nội dung văn bản có sẵn. Sau đó URL được chuyển sang Web Rendering Service, nơi JavaScript được thực thi, routing client-side hoạt động, API được gọi và DOM được cập nhật trước khi gửi sang hệ thống index.
Do chi phí render cao, Google ưu tiên các trang có HTML giàu nội dung ngay từ server. Các mô hình SSR, SSG, ISR trong Next.js hoặc framework hỗ trợ SSR cho React/Vue giúp nội dung chính, internal link và schema xuất hiện sớm, giảm rủi ro render chậm, lỗi script và đảm bảo khả năng index ổn định cho các trang quan trọng.
Googlebot cần tải, render và phân tích DOM sau khi JavaScript chạy
Googlebot hiện đại sử dụng một môi trường render tương tự Chrome (Chromium-based) để xử lý JavaScript, nhưng về mặt kiến trúc, hệ thống tìm kiếm của Google vẫn tách bạch rõ hai giai đoạn: crawling & indexing HTML thô và rendering JavaScript. Điều này đặc biệt quan trọng với các website dùng React, Vue, Next.js, nơi phần lớn nội dung được sinh ra sau khi JavaScript chạy. Việc bot có khả năng chạy JavaScript không đồng nghĩa mọi cách triển khai JavaScript đều an toàn như nhau. Một website có thể chứa nội dung trong DOM cuối cùng nhưng vẫn gặp rủi ro nếu nội dung đó chỉ xuất hiện sau nhiều request tuần tự, bị trì hoãn bởi điều kiện tương tác hoặc phụ thuộc vào dịch vụ ngoài không ổn định. Nghiên cứu về crawler và kiến trúc tìm kiếm web cho thấy việc thu thập dữ liệu ở quy mô lớn luôn cần ưu tiên tài nguyên, vì không thể xử lý vô hạn mọi URL và mọi trạng thái trang với cùng mức độ sâu. Do đó, nội dung cần xếp hạng phải có đường đi kỹ thuật ngắn, rõ ràng và ít phụ thuộc nhất có thể từ request ban đầu đến HTML hoàn chỉnh. (Brin & Page, 1998; Butkiewicz et al., 2011).
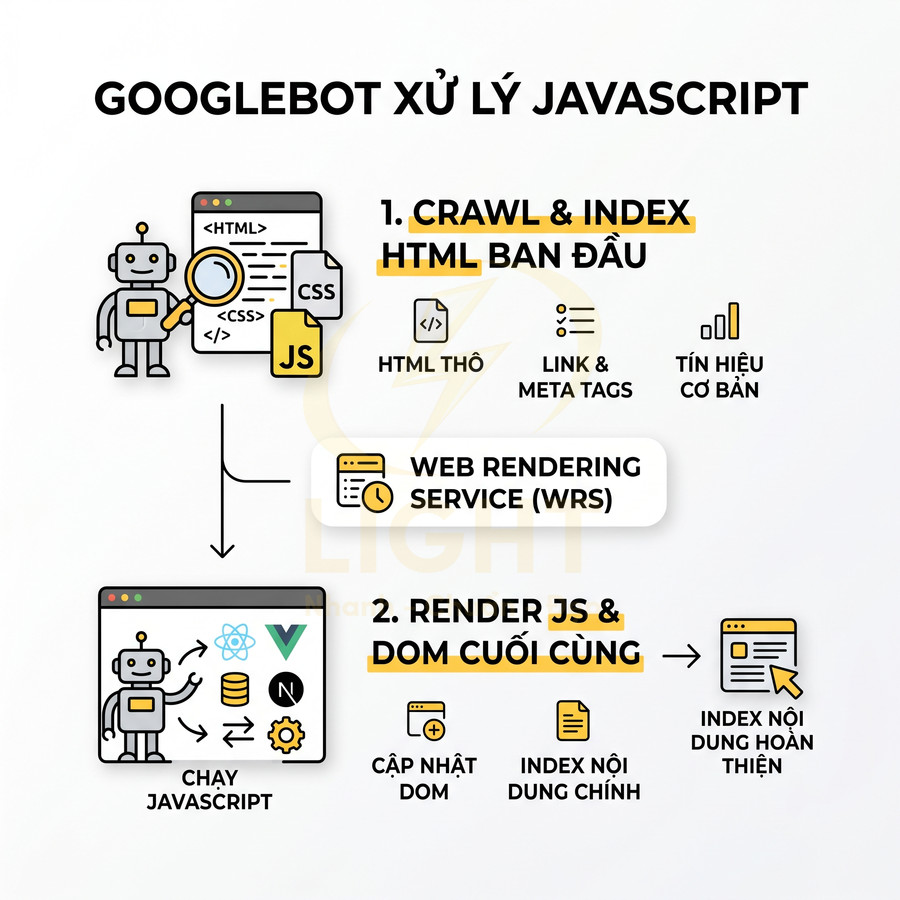
Ở giai đoạn đầu, Googlebot nhận HTML response từ server, phân tích nhanh cấu trúc DOM ban đầu và trích xuất các tín hiệu có sẵn mà không cần chờ JavaScript. Sau đó, URL được đưa vào hàng đợi của Web Rendering Service (WRS). Tại đây, Google chạy JavaScript, xử lý routing client-side, gọi API, cập nhật DOM, rồi mới gửi phiên bản DOM cuối cùng sang hệ thống index. Do tài nguyên render có hạn, không phải lúc nào mọi URL cũng được render ngay lập tức hoặc đầy đủ.
Quy trình xử lý JavaScript của Googlebot có thể tóm tắt chi tiết hơn:
- Tải HTML và tài nguyên: Googlebot yêu cầu HTML, CSS, JS, ảnh, font, file JSON… miễn là không bị chặn bởi robots.txt hoặc các directive khác. Nếu file JS quan trọng bị chặn, Google không thể thực thi logic sinh nội dung.
- Phân tích HTML ban đầu: Hệ thống parsing HTML trích xuất:
- Link nội bộ và external để đưa vào crawl queue.
- Thẻ
<title>,<meta name="description">,<meta robots>,<link rel="canonical">. - Structured data có sẵn trong HTML (JSON-LD, Microdata, RDFa).
- Các heading H1, H2 và đoạn nội dung văn bản xuất hiện trực tiếp trong HTML.
- Đưa vào hàng đợi render JavaScript (WRS): URL được xếp hàng, có thể bị trì hoãn tùy mức độ ưu tiên, chất lượng site, crawl budget, và tài nguyên hệ thống. Các site lớn, nhiều URL phụ thuộc JS có thể bị render chậm hơn.
- Chạy JavaScript và cập nhật DOM: WRS tải và thực thi bundle JS, xử lý:
- Hydration của React/Vue/Next.js.
- Routing client-side (React Router, Vue Router, Next.js client navigation).
- Các request API (REST, GraphQL, fetch, XHR) để lấy dữ liệu động.
- Thao tác DOM, lazy-load component, render danh sách sản phẩm/bài viết.
- Index nội dung sau render: DOM cuối cùng sau khi JS chạy (trong giới hạn thời gian) được gửi sang hệ thống index. Nếu xảy ra lỗi JS, timeout, hoặc API không trả về dữ liệu kịp, nội dung tương ứng sẽ không được index.
Vì quá trình render JS tốn CPU và tài nguyên, Google ưu tiên các trang có HTML giàu nội dung ngay từ response đầu tiên. Các website React, Vue, Next.js chỉ dùng CSR (Client-Side Rendering) khiến HTML ban đầu gần như rỗng (div#root, div#app), buộc Google phải phụ thuộc nặng vào bước render JS. Trong khi đó, SSR (Server-Side Rendering), SSG (Static Site Generation) hoặc ISR (Incremental Static Regeneration) giúp:
- Cung cấp nội dung chính ngay trong HTML ban đầu.
- Giảm rủi ro khi WRS bị chậm hoặc không render được.
- Cải thiện khả năng index ổn định, đặc biệt với trang quan trọng (category, product, article).
Với Next.js, việc sử dụng getServerSideProps, getStaticProps, hoặc app router với rendering trên server giúp Googlebot nhận được DOM đã có nội dung, sau đó hydration chỉ bổ sung tương tác. Với React/Vue thuần, cần cân nhắc dùng framework hỗ trợ SSR (Next.js, Nuxt, Remix, Astro…) hoặc giải pháp pre-render cho các trang quan trọng.
Render chậm hoặc lỗi script khiến nội dung chính không được index đầy đủ
Googlebot không chờ vô hạn để JavaScript chạy. Môi trường WRS có giới hạn thời gian và tài nguyên, nên các bundle JS lớn, nhiều request API nối tiếp, hoặc logic phức tạp dễ dẫn đến việc nội dung chưa kịp render đã hết “quota” thời gian. Khi đó, DOM cuối cùng mà Google thấy sẽ thiếu nhiều phần quan trọng so với trải nghiệm người dùng thật. Tốc độ render không chỉ tác động đến điểm kỹ thuật mà còn ảnh hưởng trực tiếp đến cách người dùng đánh giá chất lượng website. Nghiên cứu về hành vi tìm kiếm trên thiết bị di động cho thấy độ trễ cao làm giảm trải nghiệm chủ quan và thay đổi hành vi tương tác của người dùng; khi thời gian chờ vượt một ngưỡng nhất định, mức độ khó chịu tăng rõ rệt. Trong bối cảnh React hoặc Vue, bundle lớn, nhiều thư viện bên thứ ba và chuỗi API nối tiếp có thể khiến phần nội dung chính xuất hiện muộn hơn rất nhiều so với khung giao diện. Nên ưu tiên tải và render tiêu đề, nội dung đầu trang, điều hướng chính và dữ liệu sản phẩm trước các thành phần trang trí hoặc tương tác phụ. (Arapakis et al., 2021; Nah, 2004).
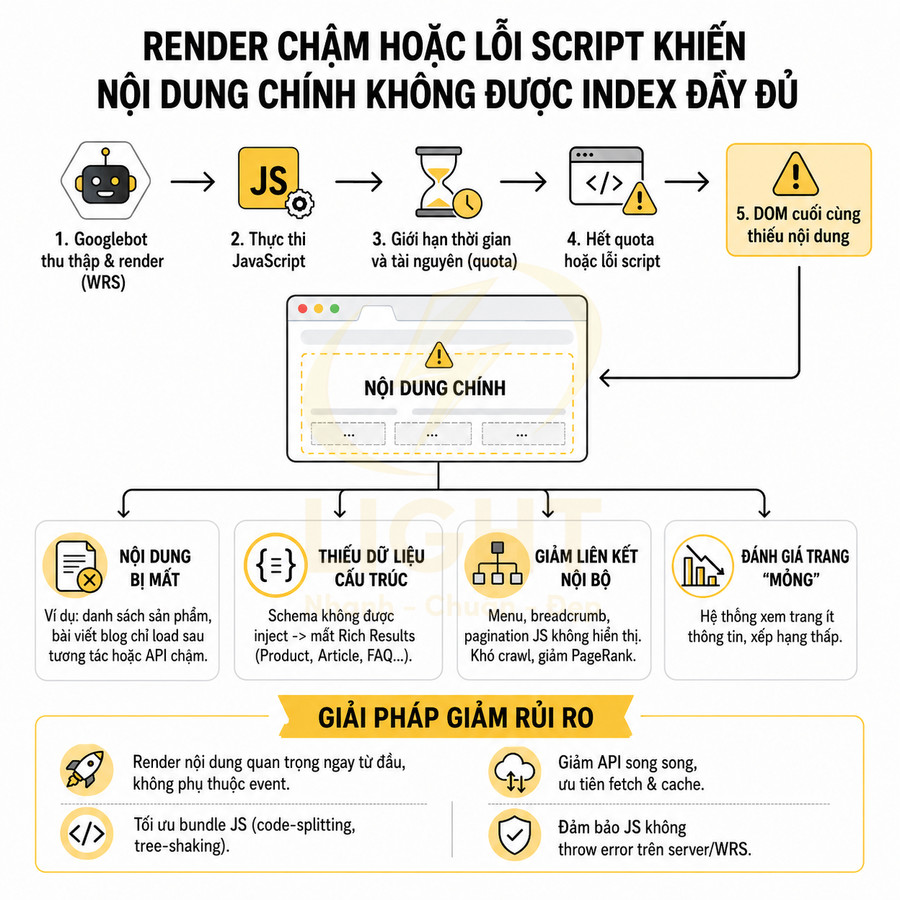
Các vấn đề thường gặp khi render chậm hoặc lỗi script:
- Nội dung chính không xuất hiện trong DOM cuối cùng: Ví dụ:
- Danh sách sản phẩm chỉ render sau khi gọi API chậm (timeout, rate limit).
- Bài viết blog chỉ load sau khi user scroll hoặc click tab.
- Component quan trọng lazy-load nhưng không có fallback HTML.
- Structured data bị thiếu hoặc không inject: Nếu JSON-LD được sinh ra bằng JS sau khi API trả dữ liệu, nhưng API chậm hoặc lỗi, Googlebot sẽ không thấy schema, dẫn đến mất rich result (Product, Article, FAQ, Breadcrumb…).
- Internal link động không hiển thị: Menu, breadcrumb, pagination, related posts sinh bằng JS có thể không xuất hiện trong DOM render cuối cùng, làm giảm khả năng crawl sâu, giảm phân bổ PageRank nội bộ.
- Trang bị đánh giá là “mỏng nội dung”: Khi HTML ban đầu rỗng và DOM sau render cũng thiếu nội dung, hệ thống ranking có thể xem trang không đủ thông tin, không liên quan truy vấn, hoặc chất lượng thấp.
Với React, Vue SPA thuần, rủi ro lớn nằm ở chỗ nội dung chính phụ thuộc vào:
- API chậm hoặc không ổn định: Googlebot không retry nhiều lần như trình duyệt người dùng, nên một lần lỗi có thể khiến nội dung không được index.
- Event người dùng: Nếu nội dung chỉ xuất hiện sau khi click, hover, scroll sâu, hoặc tương tác phức tạp, Googlebot thường không kích hoạt các event này. DOM mà bot thấy sẽ chỉ là trạng thái “trước tương tác”.
- Điều kiện logic phức tạp: Render phụ thuộc cookie, localStorage, geolocation, hoặc các điều kiện mà Googlebot không đáp ứng, dẫn đến việc bot nhận phiên bản DOM khác hẳn người dùng.
Để giảm rủi ro:
- Đảm bảo nội dung quan trọng được render ngay trong lần load đầu, không phụ thuộc event.
- Tối ưu bundle JS (code-splitting, tree-shaking, giảm dependency nặng).
- Giảm số lượng request API nối tiếp, ưu tiên fetch song song và cache hợp lý.
- Đảm bảo JS không throw error trong môi trường không có một số API trình duyệt (ví dụ: window, document, localStorage) khi render trên server hoặc WRS.
HTML server trả về vẫn là tín hiệu quan trọng cho crawl, index và preview SERP
Mặc dù Google có thể render JavaScript, HTML ban đầu vẫn là lớp tín hiệu nền tảng cho cả quá trình crawl, index và cách hiển thị snippet trên SERP. Nhiều quyết định xếp hạng và hiển thị được đưa ra trước khi bước render JS hoàn tất, đặc biệt với các URL mới hoặc site có crawl budget hạn chế. HTML ban đầu nên được xem là “bản tóm tắt đáng tin cậy” của URL. Dù trang có dùng animation, biểu đồ tương tác, bộ lọc động hoặc cá nhân hóa, response đầu tiên vẫn cần cho bot và người dùng biết trang đang nói về gì, có nội dung nào chính và có thể đi tiếp đến đâu. Điều này đặc biệt quan trọng với các liên kết nội bộ vì crawler thường dựa vào cấu trúc liên kết để khám phá URL mới và xác định quan hệ giữa các trang. Menu, breadcrumb, liên kết danh mục, liên kết bài viết liên quan và liên kết sản phẩm liên quan cần tồn tại dưới dạng thẻ <a> có href hợp lệ. Không nên để toàn bộ cấu trúc website chỉ hoạt động sau thao tác onClick hoặc sau khi tải dữ liệu phía client. (Brin & Page, 1998; Mavridis & Symeonidis, 2015).
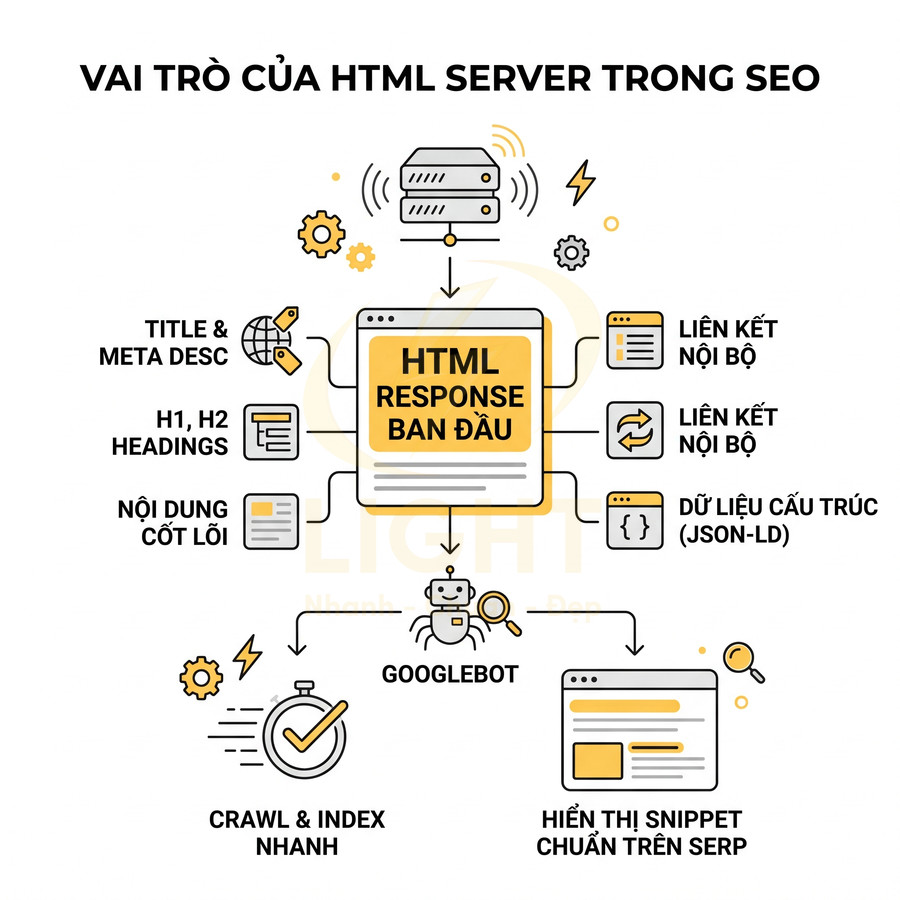
Các yếu tố nên có trong HTML response đầu tiên (không phụ thuộc JS):
- Title, meta description, robots, canonical:
- Thẻ
<title>chứa từ khóa chính, mô tả rõ chủ đề. <meta name="description">tóm tắt nội dung, hỗ trợ snippet.<meta name="robots">hoặc<meta name="googlebot">nếu cần kiểm soát index, snippet, image preview.<link rel="canonical">ổn định, không thay đổi tùy theo JS để tránh tín hiệu mâu thuẫn.
- Thẻ
- Heading H1, H2:
- H1 phản ánh chủ đề chính của trang.
- H2 phân chia các phần nội dung, chứa từ khóa liên quan, giúp Google hiểu cấu trúc chủ đề.
- Nội dung văn bản cốt lõi:
- Ít nhất phần mở đầu hoặc tóm tắt nội dung chính nên có sẵn trong HTML.
- Với trang sản phẩm, nên có tên sản phẩm, mô tả ngắn, giá cơ bản (nếu có thể) ngay trong HTML.
- Với bài viết, nên có tiêu đề, đoạn mở bài, và một phần nội dung thân bài.
- Internal link:
- Menu chính, breadcrumb, link đến category quan trọng nên xuất hiện trong HTML.
- Không nên để toàn bộ navigation phụ thuộc vào JS mới render.
- Structured data JSON-LD:
- Schema cho Article, Product, Breadcrumb, FAQ, Organization… nên được nhúng trực tiếp trong HTML.
- Tránh hoàn toàn phụ thuộc vào JS để inject JSON-LD, trừ khi đã kiểm tra kỹ khả năng render của Googlebot.
Khi các yếu tố này có sẵn trong HTML, Google có thể:
- Hiểu chủ đề trang và mối quan hệ nội bộ ngay cả khi JS chưa được render.
- Index nhanh hơn, đặc biệt với trang mới hoặc trang quan trọng.
- Hiển thị snippet ổn định trên SERP, giảm rủi ro snippet “trống” hoặc không liên quan.
Với Next.js, việc cấu hình đúng <Head> (hoặc metadata API trong app router), render H1/H2 và phần nội dung chính trên server là bước bắt buộc cho SEO kỹ thuật. Với React/Vue SPA, có thể cần dùng pre-rendering hoặc SSR để đảm bảo HTML response không rỗng.
Kiểm tra rendered HTML giúp phát hiện khác biệt giữa người dùng và bot
Để đảm bảo website React, Vue, Next.js thân thiện với Googlebot, cần thường xuyên so sánh HTML view-source, DOM sau render trên trình duyệt và HTML mà Googlebot thực sự thấy trong URL Inspection của Google Search Console. Sự khác biệt lớn giữa ba trạng thái này thường là dấu hiệu của vấn đề SEO kỹ thuật, cloaking vô tình, hoặc phụ thuộc quá mức vào JS. Kiểm tra SEO cho website JavaScript cần dựa trên bằng chứng từ nhiều lớp hiển thị khác nhau. View Source phản ánh response mà server gửi đi; tab Elements phản ánh DOM sau khi trình duyệt chạy JavaScript; còn dữ liệu kiểm tra URL từ công cụ tìm kiếm phản ánh cách bot thực sự thu thập và render trang. Nếu ba phiên bản này khác nhau quá lớn, website có nguy cơ xảy ra sai lệch nội dung, metadata thay đổi không ổn định hoặc điều kiện hiển thị ngoài ý muốn. Các nghiên cứu về cloaking cho thấy việc cung cấp nội dung khác nhau giữa bot và người dùng có thể xuất hiện từ cả hành vi cố ý lẫn cấu hình kỹ thuật không chủ đích. Mọi khác biệt về nội dung chính phải được điều tra như một rủi ro SEO nghiêm trọng. (Wang et al., 2011).
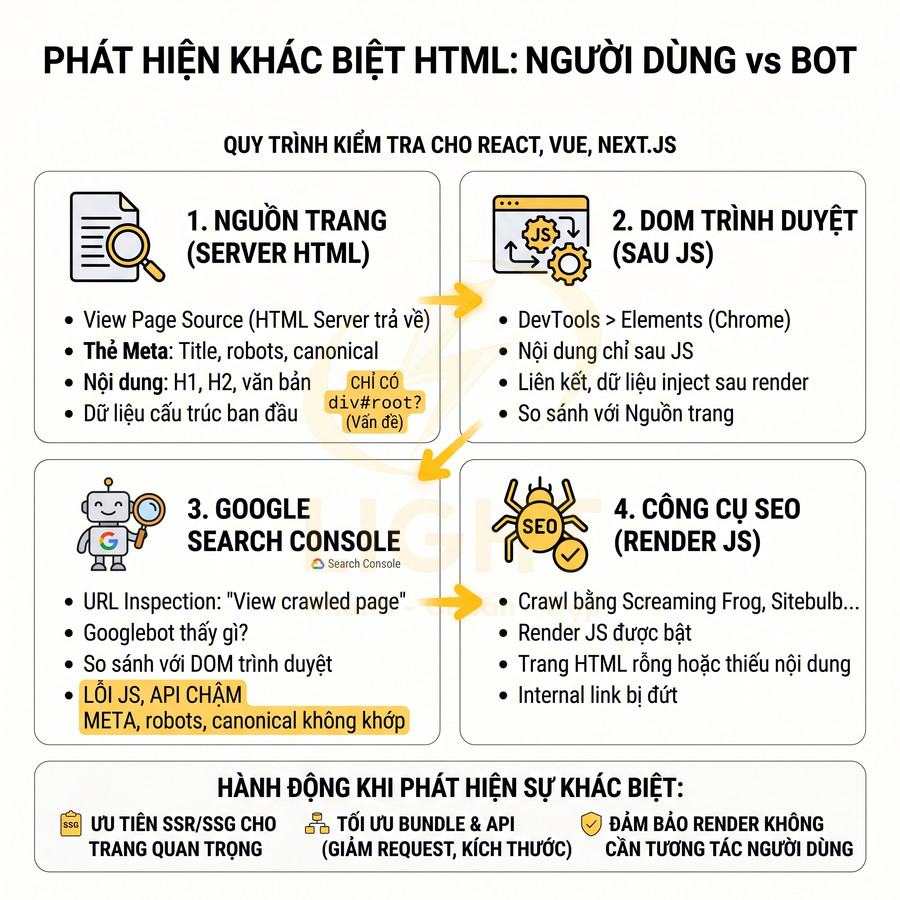
Các bước kiểm tra hữu ích:
- View Page Source:
- Kiểm tra HTML server trả về có chứa:
- Title, meta description, canonical, robots.
- H1, H2 và một phần nội dung văn bản.
- Internal link quan trọng (menu, breadcrumb).
- Structured data JSON-LD nếu có.
- Nếu view-source gần như chỉ có một div#root hoặc div#app, cần xem lại chiến lược render.
- Kiểm tra HTML server trả về có chứa:
- DevTools > Elements:
- Mở trang trong Chrome, vào tab Elements để xem DOM sau khi JS chạy.
- So sánh DOM này với view-source:
- Nội dung nào chỉ xuất hiện sau JS?
- Internal link nào chỉ có trong DOM render, không có trong HTML ban đầu?
- Structured data có được inject bằng JS hay có sẵn?
- URL Inspection trong Google Search Console:
- Dùng chức năng “View crawled page” hoặc “HTML” để xem phiên bản mà Googlebot render.
- So sánh với DOM trên trình duyệt:
- Nếu Googlebot không thấy một phần nội dung mà người dùng thấy, có thể do JS lỗi, API chậm, hoặc điều kiện render khác nhau.
- Kiểm tra xem structured data, canonical, meta robots có khớp không.
- Crawl bằng công cụ hỗ trợ JavaScript:
- Sử dụng Screaming Frog, Sitebulb, JetOctopus… ở chế độ render JS.
- Phân tích:
- Trang nào có HTML rỗng hoặc rất ít nội dung.
- Trang nào sau render vẫn thiếu H1, nội dung chính, hoặc structured data.
- Chuỗi internal link có bị đứt đoạn do navigation phụ thuộc JS không.
Khi phát hiện nội dung chỉ xuất hiện sau JavaScript hoặc khác biệt lớn giữa người dùng và bot, cần xem lại:
- Chiến lược render:
- Ưu tiên SSR/SSG/ISR cho trang quan trọng (Next.js, Nuxt…).
- Cân nhắc pre-render cho SPA nếu không thể chuyển sang SSR.
- Tối ưu bundle và API:
- Giảm kích thước bundle, loại bỏ code không cần thiết.
- Giảm số request API, tối ưu thời gian phản hồi.
- Logic điều kiện:
- Tránh phụ thuộc vào event người dùng để hiển thị nội dung chính.
- Đảm bảo nội dung quan trọng luôn render được trong môi trường không có tương tác.
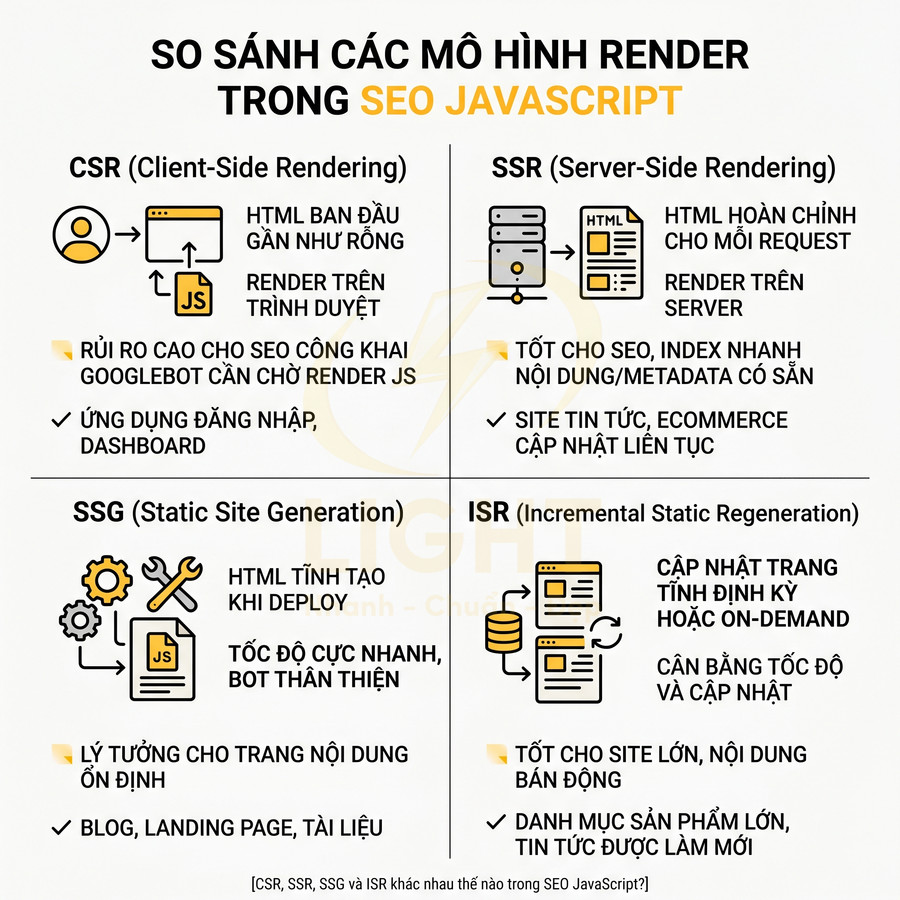
CSR, SSR, SSG và ISR khác nhau thế nào trong SEO JavaScript?
CSR, SSR, SSG và ISR là bốn mô hình render quan trọng trong SEO JavaScript, khác nhau chủ yếu ở thời điểm và nơi tạo HTML. Với CSR, HTML ban đầu gần như rỗng, nội dung phụ thuộc vào JavaScript phía client, phù hợp ứng dụng đăng nhập, nhưng rủi ro cho trang SEO công khai do bot phải chờ render JS, dễ mất nội dung, metadata và internal link. SSR tạo HTML đầy đủ trên server cho mỗi request, giúp nội dung, structured data và canonical sẵn sàng ngay trong response đầu tiên, hỗ trợ index nhanh cho trang tin tức, ecommerce, marketing. SSG build HTML tĩnh tại thời điểm deploy, cực nhanh và thân thiện với bot, lý tưởng cho blog, landing page, tài liệu ổn định. ISR mở rộng SSG bằng cơ chế regenerate theo chu kỳ hoặc on-demand, cân bằng giữa tốc độ site tĩnh và nhu cầu cập nhật nội dung thường xuyên. Việc lựa chọn mô hình render nên xuất phát từ đặc tính dữ liệu, không nên áp dụng một công thức duy nhất cho toàn bộ website. CSR phù hợp với khu vực riêng tư, dashboard hoặc luồng nghiệp vụ cần trạng thái người dùng; SSR phù hợp khi dữ liệu thay đổi liên tục và cần phản hồi mới ở mỗi request; SSG phù hợp với nội dung ổn định cần tốc độ cao; còn ISR phù hợp với lượng URL lớn cần cân bằng giữa cache và tần suất cập nhật. Một website có thể dùng đồng thời nhiều mô hình render, miễn là mỗi route được gán chiến lược rõ ràng theo giá trị SEO, tốc độ thay đổi dữ liệu và yêu cầu trải nghiệm. Việc tách dashboard khỏi các trang công khai cũng giúp giảm đáng kể chi phí kỹ thuật không cần thiết. (Pati & Zaki, 2025; Butkiewicz et al., 2011).
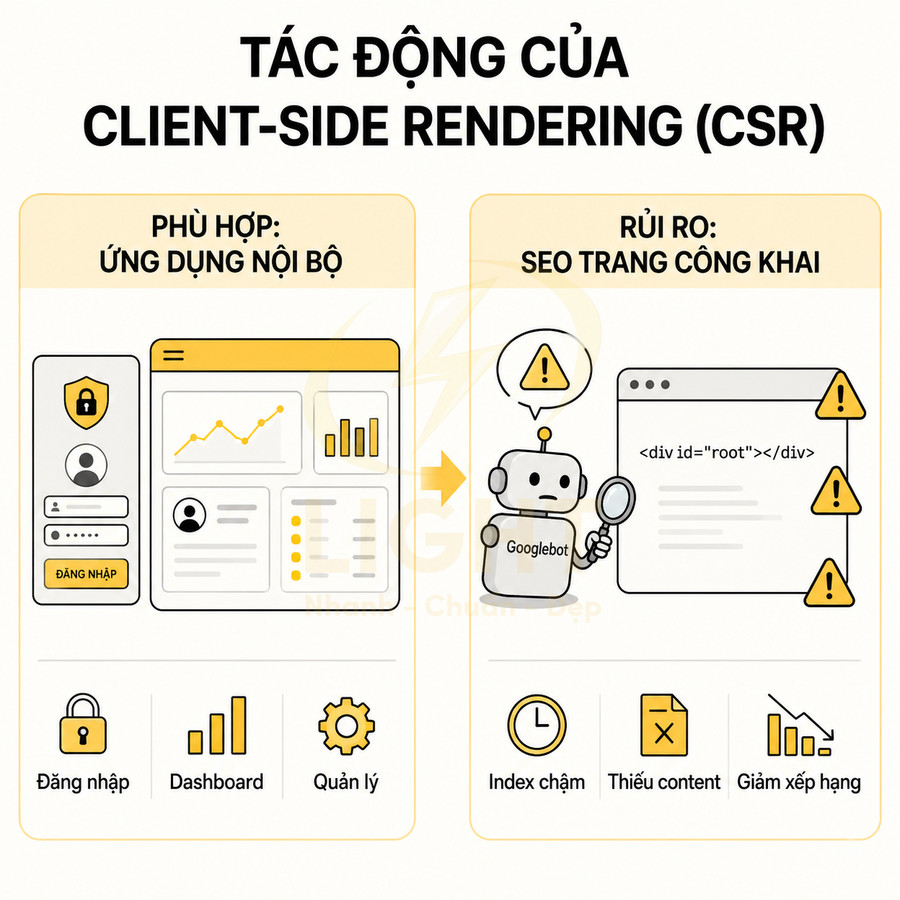
Client-side rendering phù hợp app đăng nhập nhưng rủi ro cho trang SEO công khai
Client-side rendering (CSR) là mô hình phổ biến của SPA: server trả về một file HTML gần như rỗng (thường chỉ có một <div id="root"> hoặc <div id="app">) cùng với bundle JavaScript. Sau khi JS được tải và thực thi, ứng dụng mới render giao diện, xử lý routing, state và logic phía client. Với trang công khai, CSR thuần có thể tạo khoảng cách giữa “trang người dùng nhìn thấy sau khi chờ” và “trang hệ thống thu thập có thể hiểu ngay”. Khoảng cách này đặc biệt lớn ở website thương mại điện tử, SaaS và nội dung chuyên sâu vì các trang thường chứa nhiều mô tả, bảng giá, FAQ, breadcrumb, danh sách liên quan và dữ liệu có cấu trúc. Nếu toàn bộ các phần đó được lấy sau khi trang tải xong, website vừa tăng áp lực lên thiết bị người dùng vừa tăng khả năng nội dung không được hiển thị ổn định. CSR không phải là lựa chọn sai, nhưng nên được dành cho phần không cần index hoặc cho tương tác sau khi HTML cốt lõi đã được cung cấp. (Arapakis et al., 2021; Pati & Zaki, 2025).
Ở góc độ kiến trúc, CSR thường đi kèm:
- Routing phía client (React Router, Vue Router) với URL được xử lý trong trình duyệt.
- State management phức tạp (Redux, Zustand, Pinia, Vuex) để điều khiển UI.
- API layer giao tiếp với backend (REST, GraphQL) để lấy dữ liệu động.
Mô hình này đặc biệt phù hợp với:
- Ứng dụng nội bộ, dashboard, admin panel cần nhiều tương tác real-time, biểu đồ, filter phức tạp.
- Web app yêu cầu đăng nhập (SaaS nội bộ, CRM, hệ thống quản lý), nơi nội dung không cần index công khai.
- Ứng dụng có luồng nghiệp vụ phức tạp, nhiều bước, nhiều trạng thái, phụ thuộc session của user hơn là organic traffic.
Tuy nhiên, với trang SEO công khai như blog, landing page, danh mục, sản phẩm, CSR thuần mang nhiều rủi ro kỹ thuật cho SEO:
- HTML ban đầu gần như rỗng, Googlebot phải đưa trang vào hàng đợi render JavaScript (rendering queue) mới thấy nội dung. Điều này tạo ra hai pha:
- Pha crawl HTML: Google chỉ thấy skeleton, rất ít nội dung.
- Pha render JS: Google mới thấy nội dung thực, nhưng có thể bị trễ hoặc bị bỏ qua nếu tài nguyên JS quá nặng hoặc lỗi.
- Nếu quá trình render chậm, timeout hoặc lỗi JS:
- Nội dung chính không được index hoặc index không đầy đủ.
- Các section quan trọng (mô tả sản phẩm, review, FAQ) có thể không xuất hiện trong snapshot mà Google lưu.
- Metadata SEO (title, meta description, og tags), canonical, structured data (JSON-LD) nếu được inject bằng JS sau khi load có thể:
- Không xuất hiện trong HTML response ban đầu.
- Không được Googlebot ghi nhận nếu script bị chặn, bị lỗi, hoặc bị trì hoãn.
- Internal link sinh động (tạo bằng event click, onChange, hoặc chỉ xuất hiện sau khi user tương tác) gây khó khăn cho bot:
- Nếu bot không render hoặc không kích hoạt event, nhiều URL quan trọng sẽ không được crawl.
- Cấu trúc internal linking bị “ẩn” sau JS, làm suy yếu khả năng phân phối PageRank nội bộ.
Về mặt đo lường, các vấn đề thường thấy ở site CSR thuần:
- Coverage trong Google Search Console có nhiều URL “Crawled – currently not indexed” hoặc “Discovered – currently not indexed”.
- Snapshot HTML trong công cụ “URL Inspection” không chứa nội dung mà user nhìn thấy.
- Structured data test không phát hiện schema vì schema chỉ được render sau khi JS chạy.
Do đó, CSR nên được dùng chủ yếu cho phần ứng dụng không cần SEO, hoặc cho các khu vực sau đăng nhập. Với các trang cần organic traffic, nên ưu tiên SSR, SSG hoặc ISR để:
- Đảm bảo nội dung, metadata, structured data có mặt trong HTML response đầu tiên.
- Giảm phụ thuộc vào khả năng render JS của Google và các bot khác (Bing, social crawler, tool SEO).
- Cải thiện tốc độ hiển thị nội dung đầu tiên (FCP, LCP), từ đó hỗ trợ Core Web Vitals.
Server-side rendering phù hợp trang cần nội dung cập nhật và index nhanh
Server-side rendering (SSR) tạo HTML hoàn chỉnh trên server cho mỗi request, sau đó gửi về trình duyệt. Ứng dụng React, Vue, Next.js, Nuxt có thể render cùng một component tree trên server, trả về HTML đã “hydrate” sẵn nội dung, rồi client-side JS tiếp quản để thêm tương tác.
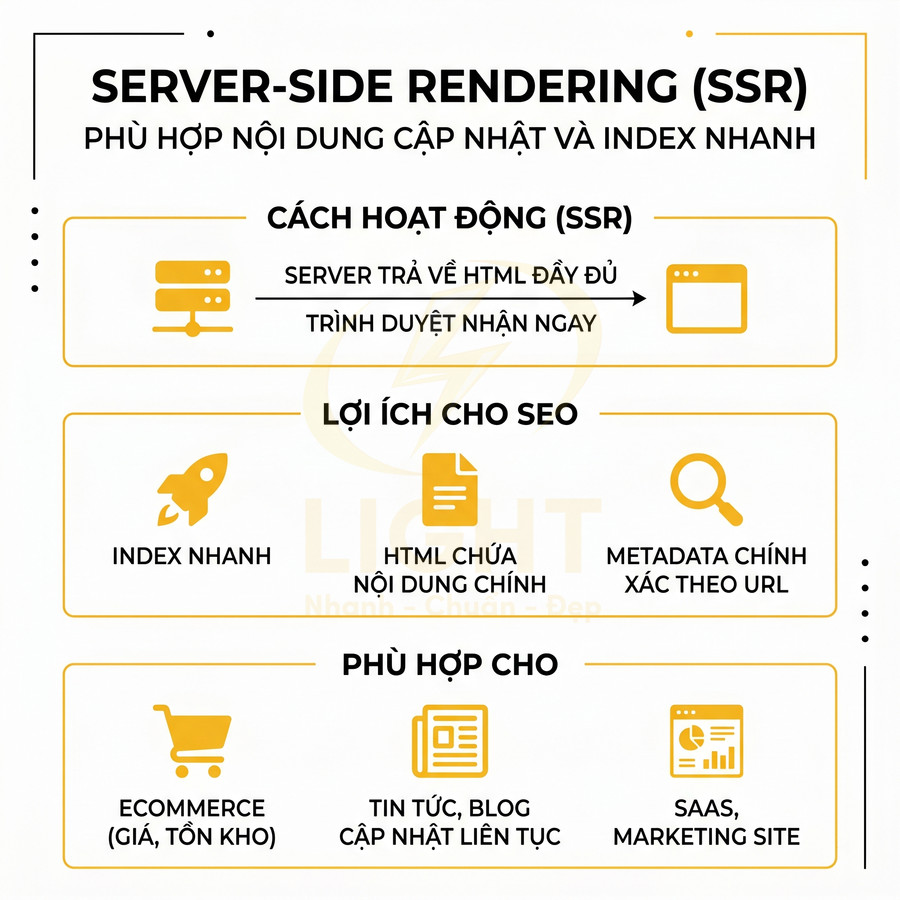
Về SEO, SSR mang lại nhiều lợi ích quan trọng:
- HTML có nội dung đầy đủ ngay từ response đầu tiên:
- Googlebot và các crawler khác có thể đọc text, link, heading, schema mà không cần chờ render JS.
- Giảm rủi ro mất nội dung do lỗi JS hoặc giới hạn tài nguyên render.
- Metadata, canonical, structured data được render theo từng URL:
- Title, meta description, og:title, og:image, canonical, hreflang… được gắn chính xác cho mỗi route.
- JSON-LD schema (Product, Article, Breadcrumb, FAQ…) có thể được render server-side, tăng khả năng rich results.
- Googlebot không phải chờ render JS để thấy nội dung chính:
- Index nhanh hơn, đặc biệt với site tin tức, landing page chiến dịch.
- Giảm độ trễ giữa thời điểm publish và thời điểm nội dung xuất hiện trên SERP.
- Phù hợp với nội dung thay đổi thường xuyên:
- Giá, tồn kho, khuyến mãi có thể được render mới trên mỗi request.
- Có thể áp dụng caching thông minh (per-route, per-user segment) để cân bằng giữa tươi mới và hiệu suất.
SSR đặc biệt phù hợp cho:
- Trang danh mục, sản phẩm ecommerce:
- Giá, tồn kho, badge khuyến mãi, label “out of stock” cần cập nhật liên tục.
- Filter, sort có thể kết hợp SSR cho lần load đầu và CSR cho tương tác tiếp theo.
- Trang tin tức, blog cập nhật liên tục:
- Bài viết mới cần được index nhanh để cạnh tranh trên SERP thời gian thực.
- Trang category, tag, topic page có nội dung động (bài mới nhất, trending) vẫn có HTML đầy đủ.
- Trang SaaS, marketing site:
- Nội dung marketing thay đổi theo chiến dịch, A/B testing, personalization nhẹ (theo geo, theo segment).
- Cần đảm bảo mỗi biến thể URL có metadata và nội dung rõ ràng cho SEO.
Nhược điểm của SSR là tăng tải server và độ phức tạp triển khai:
- Mỗi request cần render HTML trên server, tốn CPU và memory hơn so với phục vụ file tĩnh.
- Cần hạ tầng ổn định (Node server, edge functions, load balancer) và chiến lược cache:
- Cache toàn trang (full-page caching) cho các route ít thay đổi.
- Cache theo key (theo user segment, theo locale) để tránh render lại không cần thiết.
- Debug phức tạp hơn: phải xử lý code chạy cả server và client, tránh dùng API chỉ có trên browser khi render server.
Tuy vậy, với caching, CDN và kiến trúc hợp lý, SSR vẫn là lựa chọn cân bằng tốt giữa SEO, hiệu suất và khả năng mở rộng, đặc biệt khi kết hợp:
- SSR cho lần truy cập đầu tiên (initial request) để tối ưu SEO và FCP.
- CSR cho các tương tác tiếp theo (filter, sort, pagination) để tối ưu UX.
Static site generation phù hợp blog, landing page, tài liệu và trang danh mục ổn định
Static site generation (SSG) tạo HTML tĩnh tại thời điểm build, sau đó phục vụ qua CDN. Framework như Next.js, Nuxt, Gatsby sẽ chạy code render một lần trong quá trình build, tạo ra file HTML cho từng route, kèm theo assets tĩnh.
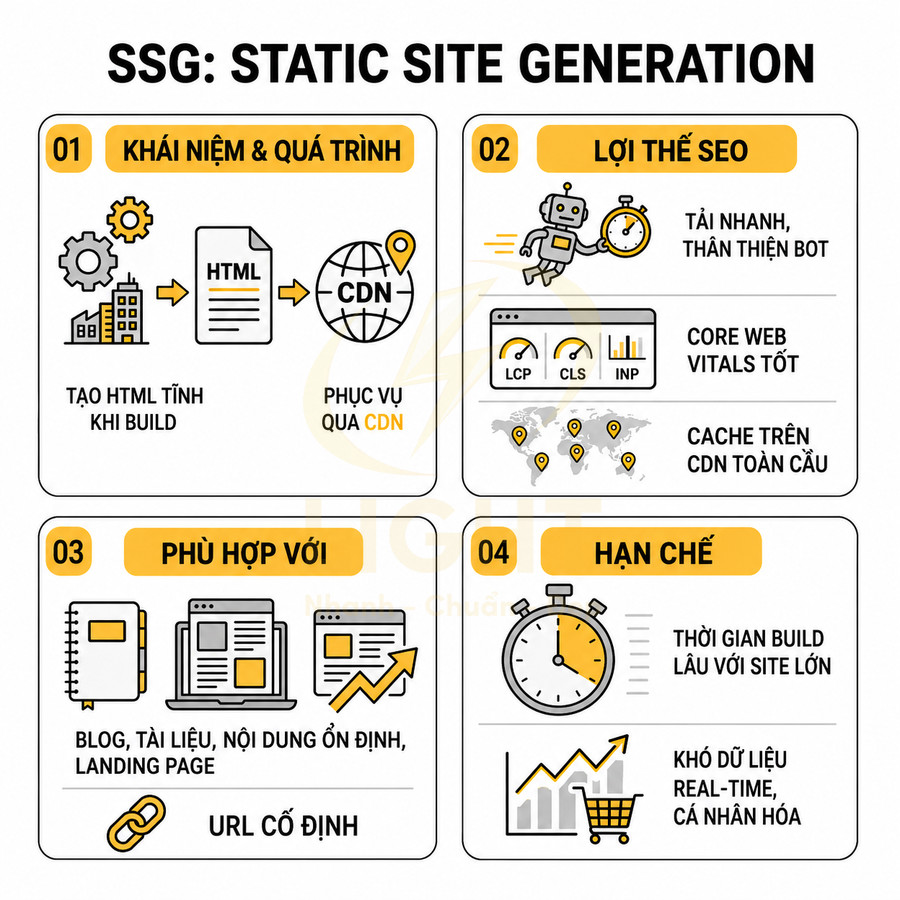
Về SEO, SSG mang lại các lợi thế nổi bật:
- HTML tĩnh, nhẹ, tải nhanh, rất thân thiện với Googlebot:
- Không cần render server-side trên mỗi request, không phụ thuộc vào JS để hiển thị nội dung chính.
- Bot có thể crawl số lượng lớn URL với chi phí tài nguyên thấp.
- Core Web Vitals tốt:
- LCP cải thiện do server chỉ trả về file tĩnh từ CDN gần user.
- CLS thấp vì layout ít phụ thuộc vào render động.
- FID/INP tốt nếu bundle JS được tối ưu (code splitting, lazy load).
- Khả năng cache mạnh trên CDN:
- Toàn bộ HTML có thể được cache lâu dài với cache-control phù hợp.
- Latency toàn cầu thấp, hỗ trợ SEO quốc tế và trải nghiệm người dùng đa khu vực.
SSG phù hợp với:
- Blog, tài liệu, knowledge base ít thay đổi theo từng request:
- Nội dung chủ yếu là text, hình ảnh, code snippet, không phụ thuộc dữ liệu real-time.
- URL ổn định, dễ tạo sitemap, dễ internal linking.
- Landing page chiến dịch marketing:
- Nội dung tương đối ổn định trong thời gian chạy campaign.
- Cần tốc độ tải nhanh để tối ưu conversion và điểm chất lượng quảng cáo.
- Trang danh mục có số lượng sản phẩm vừa phải, không thay đổi liên tục:
- Danh sách sản phẩm, bài viết có thể build sẵn theo batch.
- Các filter cơ bản có thể xử lý client-side mà không ảnh hưởng SEO.
Hạn chế của SSG:
- Thời gian build tăng theo số lượng trang:
- Site có hàng chục nghìn URL có thể mất rất lâu để build lại toàn bộ.
- Mỗi lần deploy nội dung mới phải chờ build xong, ảnh hưởng tốc độ cập nhật.
- Khó xử lý nội dung thay đổi real-time:
- Giá, tồn kho, dữ liệu cá nhân hóa theo user không phù hợp để render tĩnh hoàn toàn.
- Cần kết hợp với client-side fetch hoặc SSR cho một số phần động.
Với các website nội dung lớn, chiến lược thường dùng là kết hợp SSG với ISR hoặc SSR chọn lọc:
- SSG cho phần nội dung “evergreen” (bài viết, trang tĩnh, tài liệu).
- ISR cho trang cần cập nhật định kỳ nhưng không real-time.
- SSR cho phần cần dữ liệu mới mỗi request hoặc cá nhân hóa.
Incremental static regeneration cân bằng tốc độ, cập nhật nội dung và khả năng mở rộng
Incremental Static Regeneration (ISR) là cơ chế của Next.js cho phép cập nhật trang tĩnh sau khi deploy mà không cần rebuild toàn bộ site. Mỗi trang được build tĩnh lần đầu, sau đó khi có request mới vượt quá thời gian revalidate, server sẽ tạo lại HTML và cập nhật cache, trong khi vẫn phục vụ phiên bản cũ cho user hiện tại.
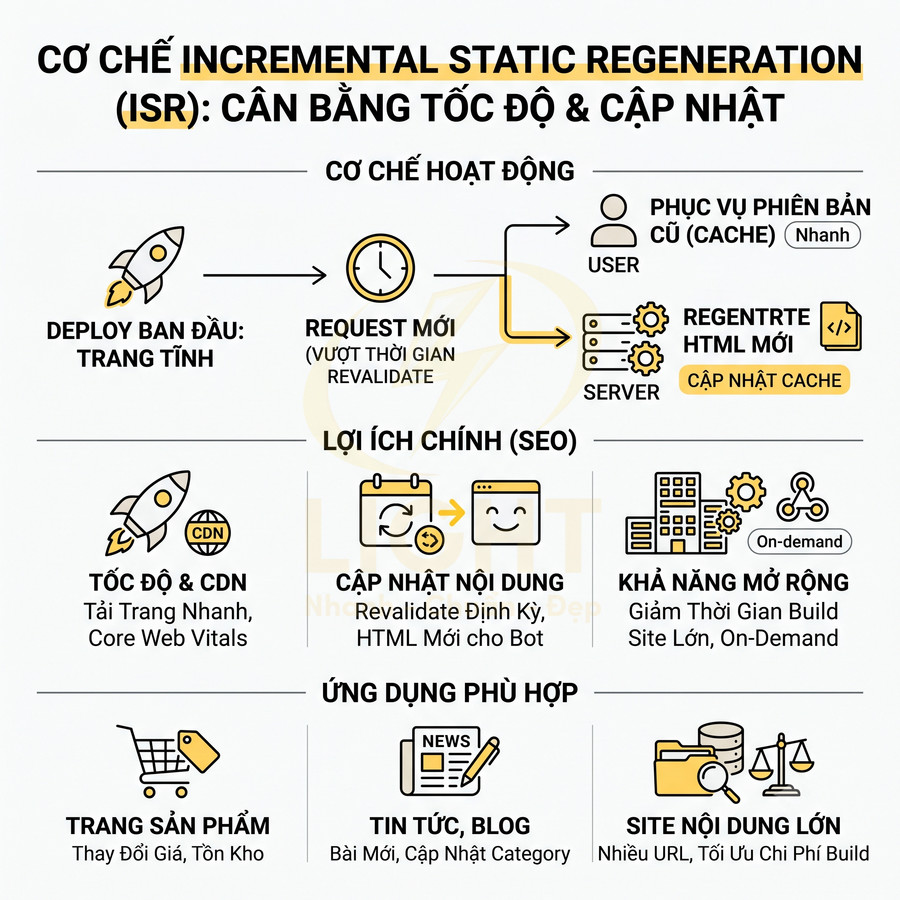
Về SEO, ISR mang lại sự kết hợp giữa ưu điểm của SSG và khả năng cập nhật:
- Giữ được lợi ích của SSG:
- HTML tĩnh, tải nhanh, thân thiện với bot.
- Có thể phân phối qua CDN, tối ưu Core Web Vitals.
- Cho phép cập nhật nội dung định kỳ:
- Cấu hình
revalidatetheo phút, giờ, ngày tùy loại nội dung. - Googlebot khi crawl lại sau một khoảng thời gian sẽ nhận được phiên bản HTML đã được regenerate.
- Cấu hình
- Giảm thời gian build cho site lớn:
- Không cần build trước tất cả trang hiếm khi được truy cập.
- Có thể sử dụng “on-demand ISR” (trigger từ webhook) để regenerate trang khi có sự kiện (cập nhật sản phẩm, publish bài viết).
ISR phù hợp cho:
- Trang sản phẩm, danh mục có thay đổi giá, tồn kho nhưng không cần real-time từng giây:
- Ví dụ: cập nhật mỗi 5–15 phút là đủ cho SEO và trải nghiệm người dùng.
- Giảm áp lực lên backend so với SSR full cho mọi request.
- Trang tin tức, blog:
- Bài viết mới có thể được build on-demand khi publish.
- Trang category, homepage có block “bài mới nhất” được regenerate định kỳ.
- Website nội dung lớn:
- Hàng chục nghìn hoặc hàng trăm nghìn URL, trong đó nhiều trang có traffic thấp.
- Chỉ regenerate những trang có truy cập hoặc có thay đổi nội dung, tối ưu chi phí build.
Với ISR, website React/Next.js có thể đạt hiệu suất gần như site tĩnh, đồng thời vẫn đảm bảo nội dung đủ mới cho SEO. Khi kết hợp với chiến lược caching, prefetch và routing hợp lý:
- Người dùng luôn nhận được HTML nhanh từ edge/CDN.
- Googlebot thấy nội dung cập nhật mà không cần phụ thuộc vào render JS.
- Đội ngũ marketing/biên tập có thể cập nhật nội dung thường xuyên mà không lo thời gian build kéo dài.
SEO technical bắt buộc cho website React, Vue, Next.js
Triển khai SEO technical cho website React, Vue, Next.js cần tập trung vào khả năng crawl và index của Google trong bối cảnh HTML được render động. Mỗi URL phải có bộ metadata đầy đủ, heading và nội dung chính hiển thị trong HTML response, cùng hệ thống routing, sitemap, robots.txt và status code đồng bộ với trạng thái index mong muốn. Ưu tiên SSR/SSG/ISR hoặc prerender cho các trang quan trọng, hạn chế phụ thuộc hoàn toàn vào JS và tương tác người dùng để hiển thị nội dung. URL cần sạch, ổn định, tránh hash routing và kiểm soát chặt chẽ các tham số filter, sort, pagination. Toàn bộ cấu hình phải được tự động hóa từ CMS/database, đảm bảo tính nhất quán giữa canonical, internal link và cấu trúc route thực tế.
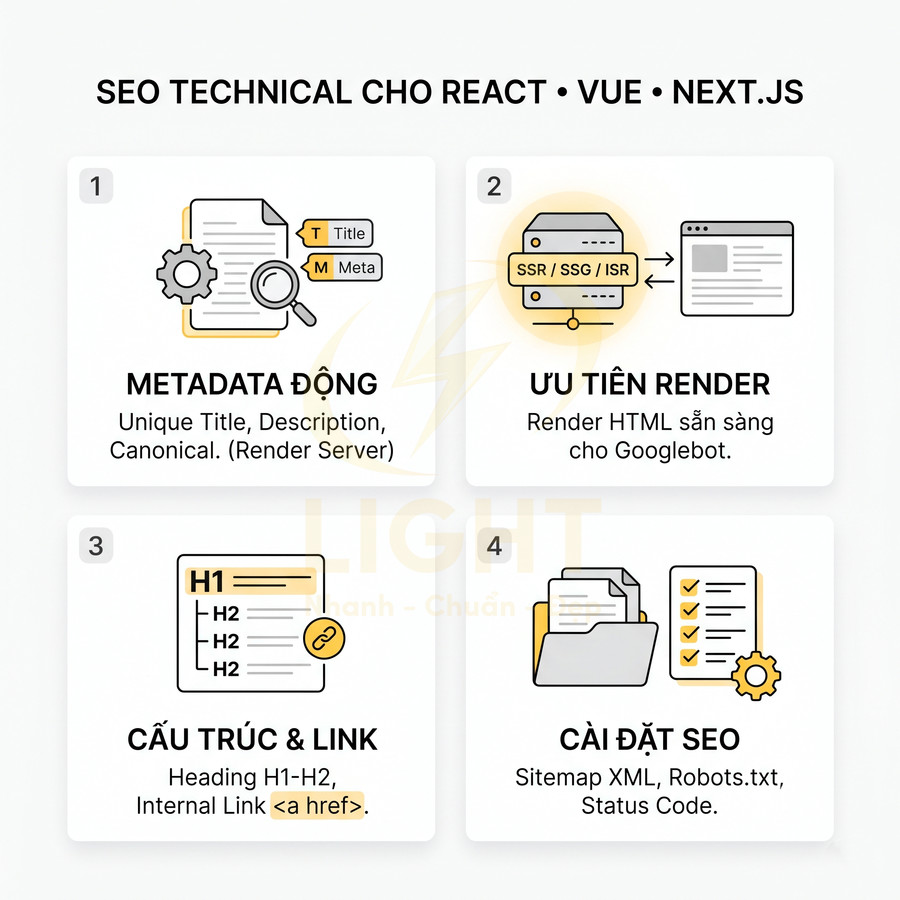
Title, meta description, canonical và robots meta phải xuất hiện đúng theo từng URL
Với các website xây dựng trên React, Vue, Next.js, toàn bộ phần HTML thường được sinh ra động dựa trên routing và state. Điều này khiến việc quản lý metadata trở nên phức tạp hơn nhiều so với HTML tĩnh, nhưng các nguyên tắc SEO cốt lõi vẫn giữ nguyên: mỗi URL có thể index phải có bộ metadata đầy đủ, chính xác và nhất quán, được render đúng thời điểm Googlebot crawl. Metadata chỉ có giá trị khi phản ánh đúng một thực thể nội dung cụ thể. Nếu nhiều route động dùng chung title, canonical hoặc meta description, công cụ tìm kiếm có thể khó phân biệt mục đích từng URL, trong khi người dùng cũng khó nhận ra trang nào phù hợp nhất trên kết quả tìm kiếm. Điều này đặc biệt quan trọng với product detail, bài viết, category, trang tác giả và landing page theo nhu cầu. Bên cạnh metadata, canonical cần thống nhất với URL thực tế, sitemap, internal link và trạng thái HTTP để tránh tạo tín hiệu mâu thuẫn. Mỗi URL indexable nên có một “hồ sơ SEO” riêng gồm tiêu đề, mô tả, canonical, robots, dữ liệu có cấu trúc và trạng thái phản hồi chính xác. (Mavridis & Symeonidis, 2015; Henzinger, 2006).

Các thành phần metadata quan trọng cần kiểm soát chặt chẽ:
- Title phải là duy nhất cho từng URL, chứa từ khóa chính và biến thể hợp lý, tránh trùng lặp giữa các trang danh mục, chi tiết, filter, sort. Nên giới hạn độ dài khoảng 50–60 ký tự (theo pixel width) để hạn chế bị cắt trên SERP.
- Meta description cần mô tả rõ ràng nội dung trang, phản ánh đúng intent của người dùng, có call-to-action nhẹ để tăng CTR. Độ dài nên trong khoảng 120–155 ký tự, ưu tiên hiển thị tốt trên cả desktop và mobile. Tránh auto-generate quá chung chung cho toàn site.
- Canonical phải trỏ về URL chuẩn duy nhất cho cùng một nội dung. Với các trang có tham số filter, sort, pagination, cần xác định rõ:
- Trang nào là URL chuẩn (ví dụ: không có tham số, hoặc chỉ giữ tham số quan trọng).
- Trang phân trang có canonical trỏ về chính nó hay về trang đầu (tùy chiến lược, nhưng phải nhất quán).
- Tránh canonical vòng lặp hoặc canonical chéo giữa các route động.
- Robots meta (index, noindex, follow, nofollow) phải phản ánh chính xác trạng thái index mong muốn:
- Các trang nội dung chính: index, follow.
- Các trang filter vô hạn, kết quả tìm kiếm nội bộ, trang test: noindex, follow để không index nhưng vẫn truyền PageRank qua link.
- Không lạm dụng nofollow nội bộ, tránh làm đứt mạch internal link.
Về mặt triển khai kỹ thuật:
- Trong Next.js, nên cấu hình metadata ở cấp
pagehoặc route:- Với App Router (Next 13+), sử dụng
generateMetadata()hoặc exportmetadatacho từng file trongapp/, đảm bảo metadata phụ thuộc vàoparamsvàsearchParamsđược tính toán server-side. - Với Pages Router, dùng
next/headtrong từng page, tránh nhúng một template head cố định cho toàn bộ site.
- Với App Router (Next 13+), sử dụng
- Trong Nuxt, cấu hình metadata ở cấp page thông qua
head()hoặcuseHead(), có thể lấy dữ liệu từ async data/fetch để tạo title, description, canonical động theo slug, id, params. - Với SPA React/Vue thuần:
- Dùng thư viện như react-helmet, react-helmet-async hoặc vue-meta, @vueuse/head để quản lý metadata theo route.
- Quan trọng: metadata phải được render server-side (SSR) hoặc prerender. Nếu chỉ thay đổi client-side sau khi load JS, Google có thể không luôn cập nhật đúng title, description, canonical, đặc biệt với các trang crawl ít thường xuyên.
- Kiểm tra bằng cách xem HTML source từ response server (không phải DOM sau render) để chắc chắn metadata đã có sẵn.
Cần xây dựng quy ước đặt metadata theo loại trang (category, product, blog, landing) nhưng vẫn cho phép override ở từng URL cụ thể. Tránh dùng một template cứng cho toàn site như “Brand – Slogan” cho mọi trang, vì sẽ gây trùng lặp và giảm khả năng phân biệt nội dung trên SERP.
Heading, nội dung chính và internal link cần có trong HTML render được
Cấu trúc nội dung là tín hiệu quan trọng để Google hiểu chủ đề và mức độ ưu tiên thông tin trên mỗi trang. Với React, Vue, Next.js, việc render động dễ dẫn đến tình trạng heading và nội dung chính chỉ xuất hiện sau các tương tác hoặc sau khi JS chạy xong, khiến bot khó crawl đầy đủ.
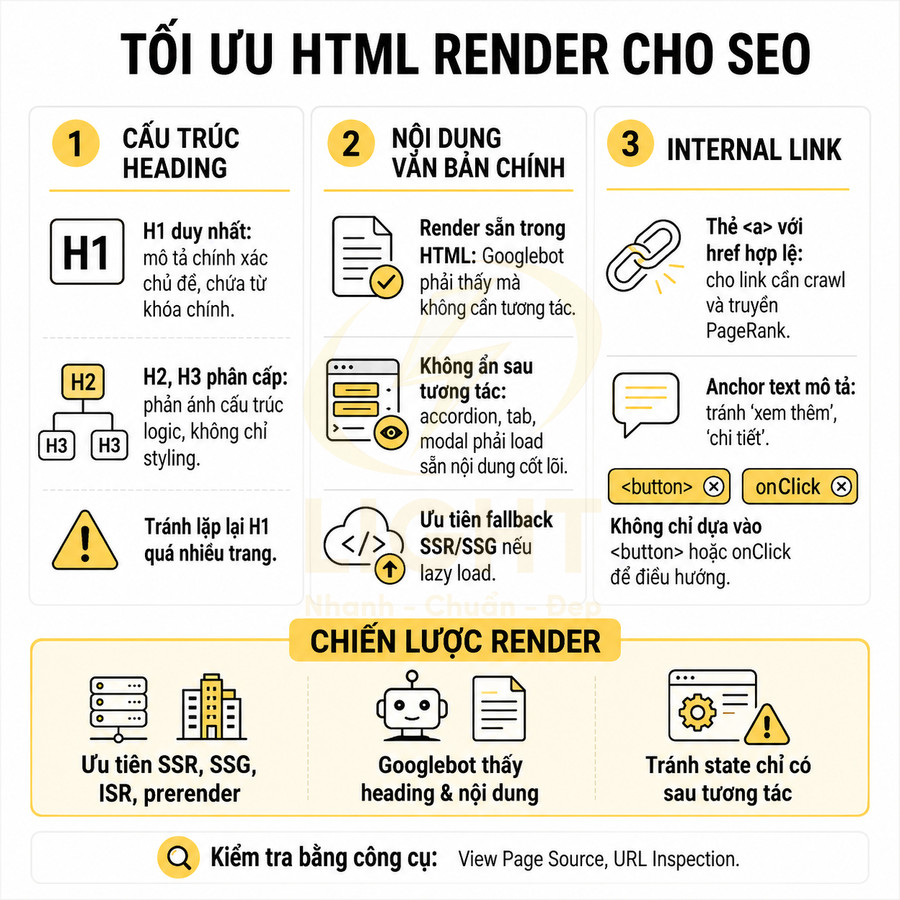
Các nguyên tắc cần đảm bảo:
- H1 duy nhất cho mỗi URL, mô tả chính xác chủ đề trang. H1 nên:
- Chứa từ khóa chính hoặc cụm từ khóa gần nghĩa.
- Không bị lặp lại y hệt trên quá nhiều trang (trừ các trường hợp listing có cấu trúc giống nhau nhưng khác filter rất nhẹ).
- Được render trực tiếp trong HTML response hoặc sau bước render JS đơn giản, không phụ thuộc event click, scroll.
- H2, H3 dùng để phân cấp nội dung:
- H2 cho các phần nội dung lớn (section chính).
- H3 cho các mục con bên trong từng H2.
- Tránh lạm dụng heading cho mục đích styling; heading nên phản ánh cấu trúc logic của nội dung.
- Nội dung văn bản chính:
- Phải xuất hiện trong HTML render được, không ẩn hoàn toàn sau các component chỉ load khi người dùng tương tác (accordion bắt buộc click, tab không load trước, modal, v.v.).
- Lazy load nội dung dài là được, nhưng phần nội dung cốt lõi cần có sẵn hoặc được render sau một vòng render JS đơn giản mà Googlebot có thể thực thi.
- Tránh render nội dung quan trọng hoàn toàn bằng client-side fetch sau khi trang đã load, nếu không có fallback SSR/SSG.
- Internal link:
- Sử dụng thẻ
<a>với thuộc tínhhrefhợp lệ cho các link cần crawl và truyền PageRank. - Anchor text nên mô tả nội dung trang đích, tránh dùng quá nhiều “xem thêm”, “chi tiết” mà không có ngữ cảnh.
- Không chỉ dựa vào
<button>,onClickhoặc event JS để điều hướng, vì Googlebot có thể không kích hoạt các event này. - Với Next.js/Nuxt, có thể dùng
<Link>hoặc<NuxtLink>, nhưng vẫn phải đảm bảo chúng render thành<a href="...">trong HTML.
- Sử dụng thẻ
Về chiến lược render:
- Ưu tiên SSR/SSG/ISR hoặc prerender cho các trang quan trọng với SEO (category, product, blog, landing). Heading và nội dung chính nên có mặt trong HTML response ban đầu.
- Tránh tạo heading hoặc nội dung chính dựa trên state chỉ có sau khi người dùng tương tác (ví dụ: sau khi chọn filter, click tab, mở dropdown). Nếu cần, hãy:
- Render phiên bản mặc định có nội dung cơ bản ngay từ đầu.
- Cập nhật nội dung bằng JS sau tương tác, nhưng không phụ thuộc hoàn toàn vào tương tác để hiển thị nội dung.
- Kiểm tra bằng công cụ như “View Page Source”, “Inspect HTML response” trong DevTools hoặc “URL Inspection” của Google Search Console để chắc chắn Googlebot có thể thấy heading và nội dung mà không cần tương tác.
Sitemap XML, robots.txt và status code phải phản ánh đúng trạng thái index
Hệ thống routing động, nested route, dynamic segment, fallback… trong React, Vue, Next.js khiến việc đồng bộ giữa URL thực tế, sitemap, robots.txt và status code trở nên khó khăn. Bất kỳ sai lệch nào cũng có thể dẫn đến index nhầm trang, bỏ sót trang quan trọng hoặc tạo ra nhiều URL rác.
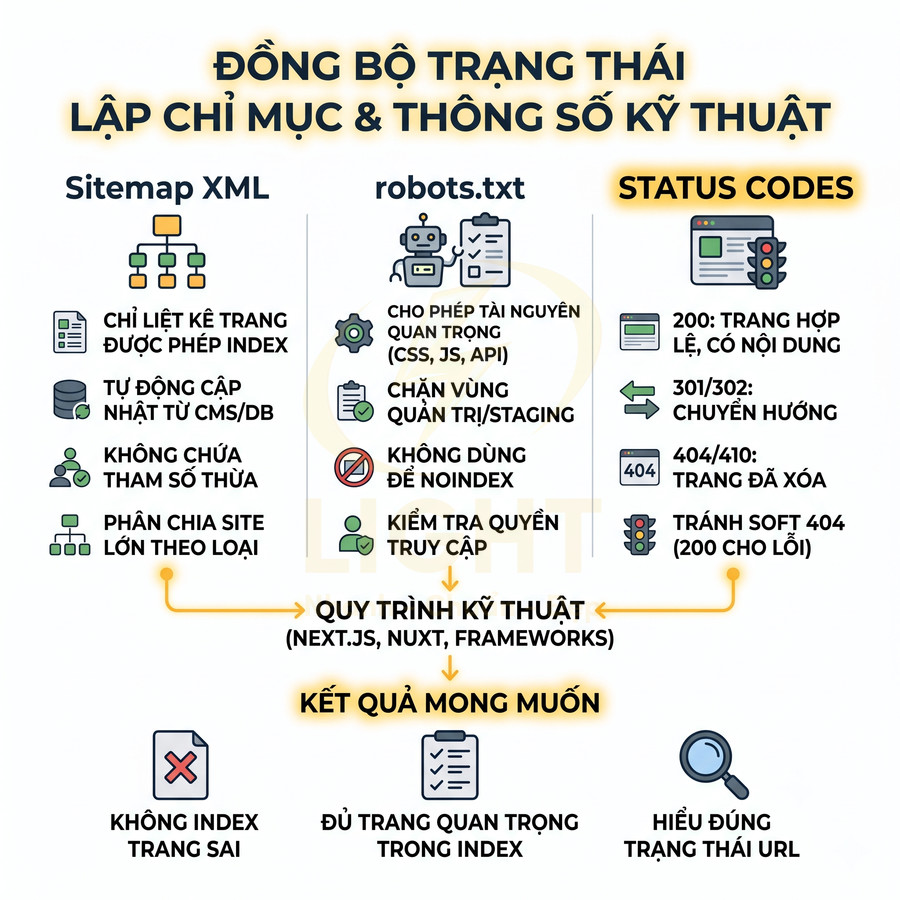
Các yêu cầu kỹ thuật cần tuân thủ:
- Sitemap XML:
- Chỉ liệt kê các URL indexable (trạng thái mong muốn là index, follow, status code 200, không bị chặn robots.txt).
- Được cập nhật tự động khi thêm, sửa, xóa nội dung từ CMS hoặc database. Tránh generate thủ công rồi quên cập nhật.
- Với site lớn, nên chia sitemap theo loại nội dung (product, category, blog, v.v.) và dùng sitemap index để quản lý.
- Đảm bảo URL trong sitemap trùng khớp với canonical và không chứa tham số filter, sort, tracking không cần thiết.
- Robots.txt:
- Không chặn các route, asset, API quan trọng cho quá trình render (CSS, JS, API trả về HTML fragment hoặc JSON cần thiết cho SSR/CSR).
- Chỉ dùng
Disallowcho các khu vực thực sự không muốn crawl (admin, staging, endpoint kỹ thuật, v.v.). - Không dùng robots.txt để “noindex” trang; dùng robots meta hoặc status code phù hợp.
- Status code:
- 200 cho trang hợp lệ, có nội dung thực sự.
- 301/302 cho redirect, với ưu tiên 301 cho chuyển hướng vĩnh viễn (thay đổi URL, hợp nhất nội dung).
- 404 hoặc 410 cho trang không tồn tại, đã xóa và không có URL thay thế.
- Tránh trả về 200 cho trang lỗi, trang rỗng, trang chỉ có thông báo “không tìm thấy” nhưng vẫn là 200, vì sẽ tạo soft 404 và làm loãng index.
Trong Next.js, Nuxt và các framework tương tự:
- Cần cấu hình route động, fallback, middleware và API route sao cho status code phản ánh đúng trạng thái trang:
- Với dynamic route (ví dụ:
[slug].tsxhoặc[id].vue), nếu dữ liệu không tồn tại, phải trả về 404 thực sự, không render trang trống với 200. - Với fallback (ISR, SSG), đảm bảo khi không tìm thấy dữ liệu, logic server trả về 404 thay vì render một skeleton vô hạn.
- Middleware hoặc server handler không nên “nuốt” lỗi và luôn trả 200 cho mọi path.
- Với dynamic route (ví dụ:
- Sitemap nên được generate tự động từ nguồn dữ liệu (CMS, database, API):
- Tránh hard-code danh sách URL trong file tĩnh.
- Đảm bảo loại bỏ các URL đã redirect, đã noindex hoặc đã xóa.
- Đồng bộ với canonical và routing thực tế để không tạo URL ảo.
URL sạch, routing ổn định và không phụ thuộc hash fragment cho trang cần SEO
URL là một trong những tín hiệu quan trọng cho cả SEO lẫn trải nghiệm người dùng. Với các SPA và framework hiện đại, việc cấu hình routing sai có thể tạo ra URL khó crawl, khó hiểu hoặc không được Google coi là path thực sự.
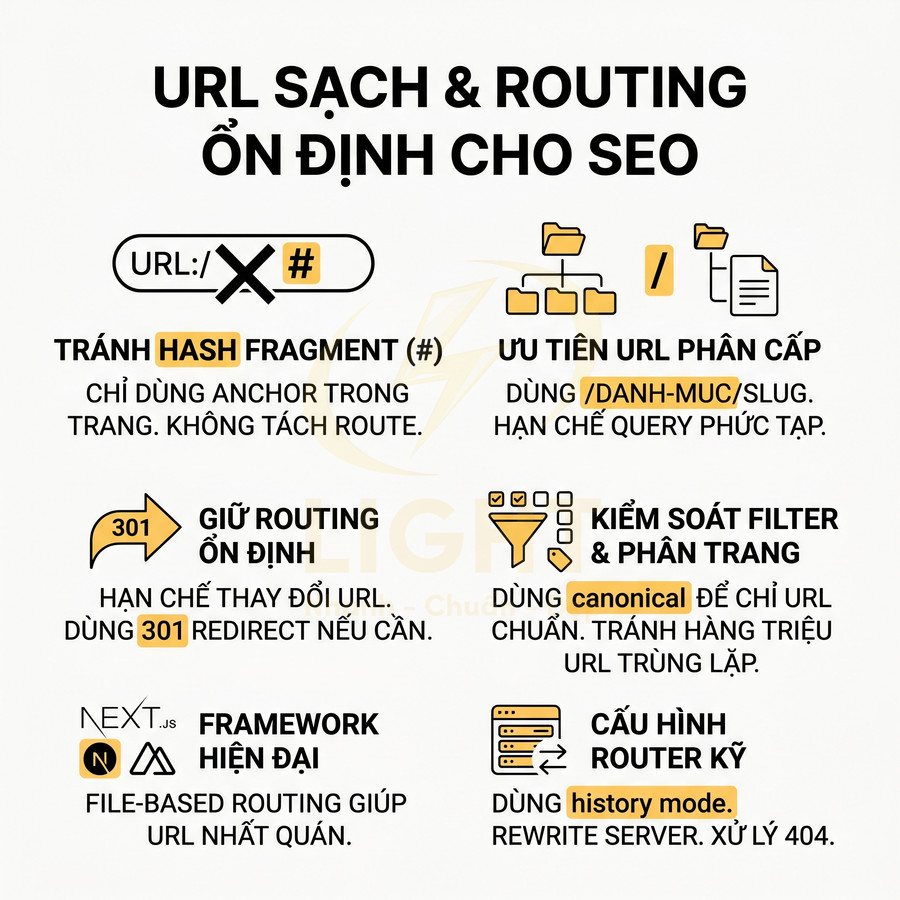
Các nguyên tắc chính khi thiết kế URL và routing:
- Không dùng hash fragment (#) cho routing các trang cần SEO:
- Google coi phần sau
#là anchor trong trang, không phải path riêng biệt. - Các URL dạng
/page#sectionkhông được xem là URL khác so với/pagevề mặt index. - Hash chỉ nên dùng để cuộn đến anchor trong cùng trang, không dùng để phân tách route chính.
- Google coi phần sau
- Ưu tiên URL dạng /danh-muc/san-pham thay vì query phức tạp:
- URL nên ngắn gọn, có cấu trúc, chứa từ khóa mô tả nội dung.
- Hạn chế lạm dụng query string cho các thông tin cốt lõi (ví dụ:
?category=abc&id=123), trừ khi đó là filter phụ. - Với filter, sort, pagination, cần kiểm soát:
- Tham số nào được phép index (ví dụ: filter quan trọng).
- Tham số nào nên noindex hoặc canonical về URL chuẩn.
- Giữ routing ổn định:
- Hạn chế thay đổi cấu trúc URL nếu không thực sự cần thiết, vì sẽ mất lịch sử tín hiệu SEO, backlink, và gây ra nhiều redirect.
- Nếu bắt buộc thay đổi, cần thiết lập 301 redirect chuẩn, cập nhật canonical, sitemap và internal link.
- Tránh tạo vô số URL từ filter, sort, pagination mà không kiểm soát canonical và index:
- Các tổ hợp filter vô hạn (màu, size, giá, brand, v.v.) có thể tạo ra hàng triệu URL gần như trùng nội dung.
- Cần xác định tập URL filter chiến lược được phép index, còn lại nên:
- Dùng noindex, follow hoặc
- Canonical về URL gốc hoặc URL filter chính.
- Pagination nên có cấu trúc rõ ràng (
?page=2hoặc/page/2) và nhất quán.
Về mặt triển khai routing:
- File-based routing của Next.js, Nuxt giúp tạo URL sạch và nhất quán:
- Cấu trúc thư mục phản ánh trực tiếp cấu trúc URL, giúp dễ kiểm soát và tránh tạo route “ngẫu hứng”.
- Dynamic segment (
[slug],[id]) nên được đặt tên có ý nghĩa, gắn với loại nội dung.
- Với React Router hoặc Vue Router:
- Cần cấu hình chế độ history thay vì hash, để URL có dạng chuẩn (không có
#). - Server phải hỗ trợ rewrite đúng:
- Mọi request đến URL hợp lệ (ví dụ:
/category/product) phải được map về entry HTML của app mà không trả 404. - Đồng thời, các URL không tồn tại thực sự phải trả 404, không rewrite mù quáng mọi thứ về index.html.
- Mọi request đến URL hợp lệ (ví dụ:
- Kiểm tra kỹ behavior khi người dùng truy cập trực tiếp một URL sâu (deep link) hoặc refresh trang, đảm bảo không lỗi 404 server-side.
- Cần cấu hình chế độ history thay vì hash, để URL có dạng chuẩn (không có
Next.js hỗ trợ SEO như thế nào so với React SPA thuần?
Next.js mang lại lợi thế SEO rõ rệt so với React SPA thuần nhờ khả năng kết hợp routing, render phía server và quản lý metadata một cách có cấu trúc. Thay vì gom toàn bộ nội dung vào một entry point, mỗi route trong Next.js có thể sở hữu bộ metadata, canonical và structured data riêng, được render sẵn trong HTML. Cơ chế SSR, SSG và ISR giúp nội dung, heading, internal link, JSON-LD xuất hiện ngay từ response đầu tiên, giảm phụ thuộc vào việc bot phải thực thi JavaScript. Với dynamic routes, metadata động gắn chặt với dữ liệu từ CMS/API, hạn chế trùng lặp và sai lệch snippet. Đồng thời, middleware, redirects và headers nếu cấu hình chuẩn sẽ hỗ trợ chuẩn hóa URL, kiểm soát noindex, cache và bảo mật mà vẫn giữ trải nghiệm crawl ổn định.
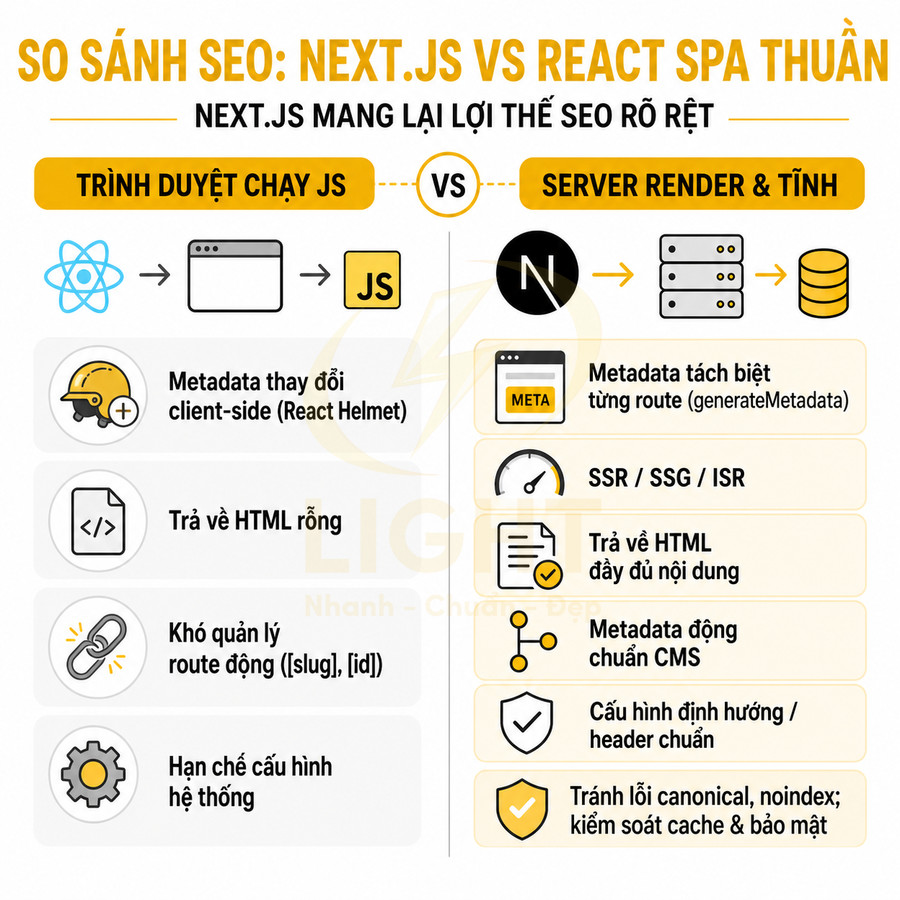
App Router và Pages Router cho phép tạo metadata theo từng route
Next.js cung cấp hai cơ chế routing chính: Pages Router (truyền thống) và App Router (mới hơn). Cả hai đều hỗ trợ định nghĩa metadata theo từng route, giúp kiểm soát SEO chi tiết hơn so với React SPA thuần, nơi mọi thứ thường bị gom vào một entry point duy nhất.
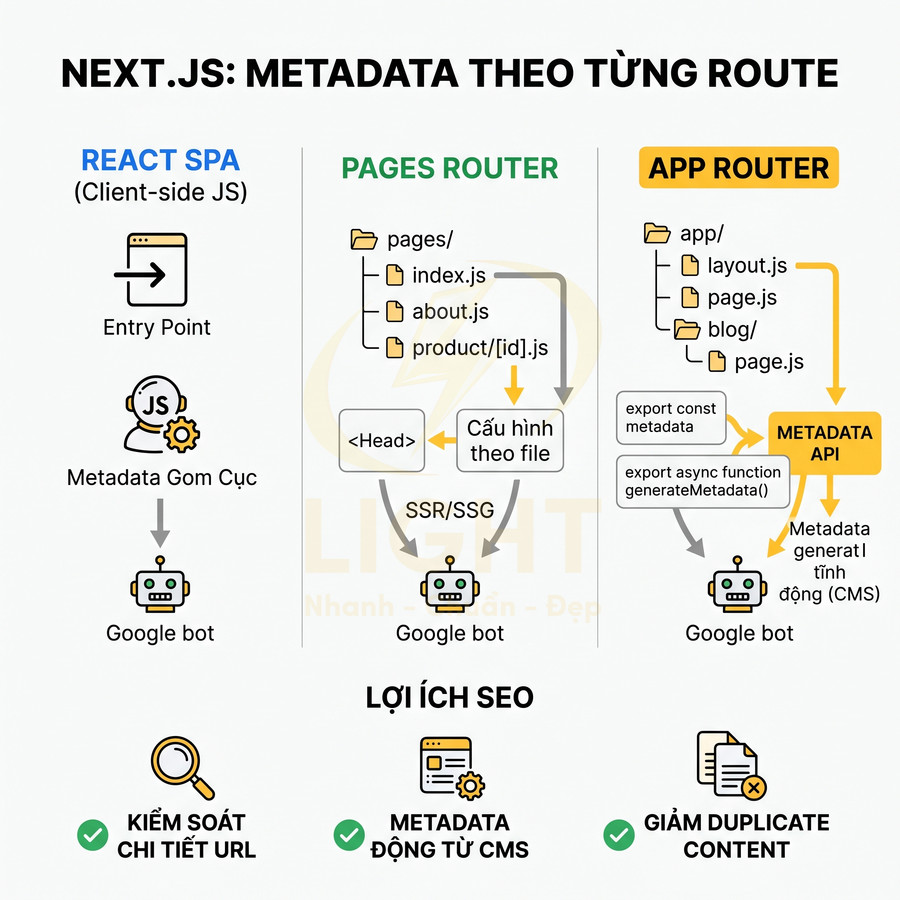
Với Pages Router, mỗi file trong thư mục pages/ tương ứng với một route. Metadata thường được cấu hình trực tiếp trong từng file page, kết hợp với next/head hoặc các helper tự xây dựng:
- Sử dụng
<Head>để set<title>,<meta name="description">, thẻog:,twitter:… - Có thể tạo các component Head dùng lại cho nhóm trang (category, blog, product) nhưng vẫn cho phép override theo từng page.
- Hỗ trợ render metadata ngay trong giai đoạn SSR/SSG, đảm bảo bot thấy nội dung meta đầy đủ trong HTML ban đầu.
Với App Router (thư mục app/), Next.js giới thiệu Metadata API mạnh hơn, mang tính cấu trúc và type-safe:
- Định nghĩa metadata tĩnh bằng export
export const metadata = { ... }trong từng segment route. - Generate metadata động bằng
export async function generateMetadata(), có thể fetch dữ liệu từ CMS, API, database trước khi render. - Hỗ trợ các field chuyên sâu: title (template, default), description, openGraph, twitter, robots, alternates, canonical, icons, appLinks…
Các lợi ích SEO chuyên sâu:
- Granular control theo từng URL: mỗi segment route có metadata riêng, có thể kế thừa từ layout cha nhưng vẫn tùy biến cho từng page con, tránh việc dùng chung template metadata cho toàn bộ site.
- Metadata động gắn với nội dung thực: dễ dàng generate title, description, og:image dựa trên dữ liệu bài viết, sản phẩm, tác giả, category… lấy từ CMS; giảm nguy cơ sai lệch giữa nội dung hiển thị và snippet trên SERP.
- Giảm trùng lặp SEO: metadata API giúp chuẩn hóa cách set canonical, alternates (hreflang, language, region), từ đó hạn chế duplicate content và vấn đề index sai phiên bản.
So với React SPA thuần, nơi metadata thường chỉ thay đổi client-side bằng react-helmet hoặc tương tự, Next.js có ưu thế:
- Metadata xuất hiện ngay trong HTML server render, không phụ thuộc vào việc bot phải thực thi JavaScript.
- Giảm rủi ro bot không render hoặc render không đầy đủ JS, đặc biệt với các bot non-Google hoặc công cụ social preview.
- Cải thiện độ tin cậy của dữ liệu Open Graph, Twitter Card, robots, giúp share trên mạng xã hội và index ổn định hơn.
SSR và SSG giúp trả về HTML có nội dung trước khi trình duyệt chạy JavaScript
Khác với React SPA thuần thường gửi một HTML gần như rỗng và tải toàn bộ nội dung qua bundle JS, Next.js tích hợp sâu SSR (Server-Side Rendering) và SSG (Static Site Generation), cho phép trả về HTML đã render sẵn nội dung.
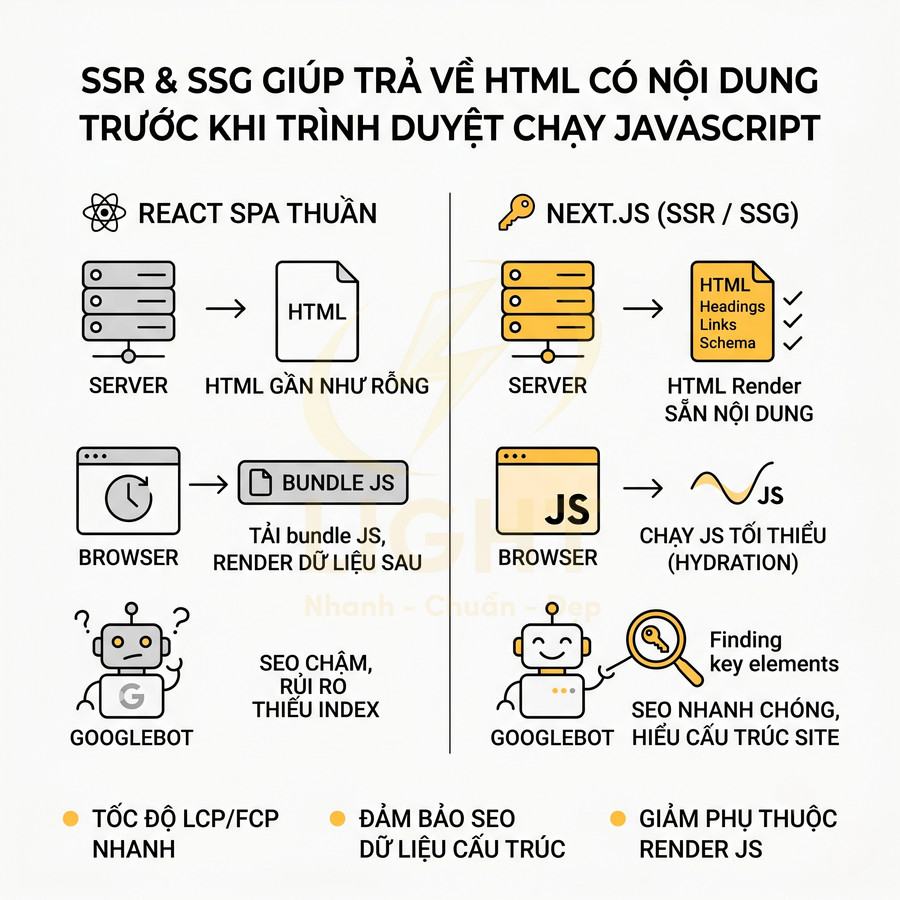
- SSR: mỗi request được render trên server, dữ liệu được fetch trước, HTML hoàn chỉnh (bao gồm nội dung, internal link, heading, structured data) được gửi về client.
- SSG: HTML được generate tại build time cho các trang ít thay đổi; file tĩnh này được phục vụ trực tiếp từ CDN, tốc độ rất cao, vẫn chứa đầy đủ nội dung SEO-critical.
Ý nghĩa SEO chuyên sâu:
- Googlebot nhận HTML có nội dung ngay lập tức: bot không cần chờ giai đoạn render JS thứ hai (rendering queue), giảm nguy cơ bị index phiên bản thiếu nội dung hoặc chậm index.
- Structured data, internal link, heading hierarchy (H1–H6), breadcrumb, content chính đều có trong HTML ban đầu, giúp bot hiểu cấu trúc site và ngữ cảnh nội dung tốt hơn.
- Giảm phụ thuộc vào khả năng render JS của từng bot: nhiều crawler, social bot, tool SEO không render JS đầy đủ; SSR/SSG đảm bảo chúng vẫn thấy nội dung quan trọng.
SSR và SSG cũng tác động trực tiếp đến Core Web Vitals và trải nghiệm người dùng:
- FCP (First Contentful Paint) và LCP (Largest Contentful Paint) được cải thiện vì nội dung chính đã có sẵn trong HTML, trình duyệt chỉ cần paint thay vì chờ JS fetch và render.
- TTI (Time to Interactive) tốt hơn khi kết hợp với kỹ thuật streaming, partial hydration, code-splitting; người dùng cảm nhận site nhanh và mượt hơn, giảm bounce rate.
- Trên mobile, nơi băng thông và CPU hạn chế, việc giảm khối lượng JS phải thực thi giúp tăng khả năng tương tác, gián tiếp hỗ trợ ranking.
So với React SPA thuần:
- SPA thường phải dựa vào prerendering hoặc dynamic rendering phức tạp để đạt hiệu quả tương tự, dễ phát sinh lỗi không đồng bộ giữa bản prerender và bản client.
- Next.js cung cấp mô hình SSR/SSG/ISR tích hợp, có chiến lược revalidate rõ ràng, giúp cân bằng giữa SEO, performance và tính cập nhật nội dung.
Dynamic routes cần generate metadata, canonical và structured data riêng
Next.js hỗ trợ dynamic routes như /blog/[slug], /product/[id], /category/[...segments], rất phù hợp cho website nội dung lớn và ecommerce. Tuy nhiên, mỗi route động vẫn là một URL độc lập trong mắt Google, nên cần tối ưu SEO chi tiết cho từng trang.
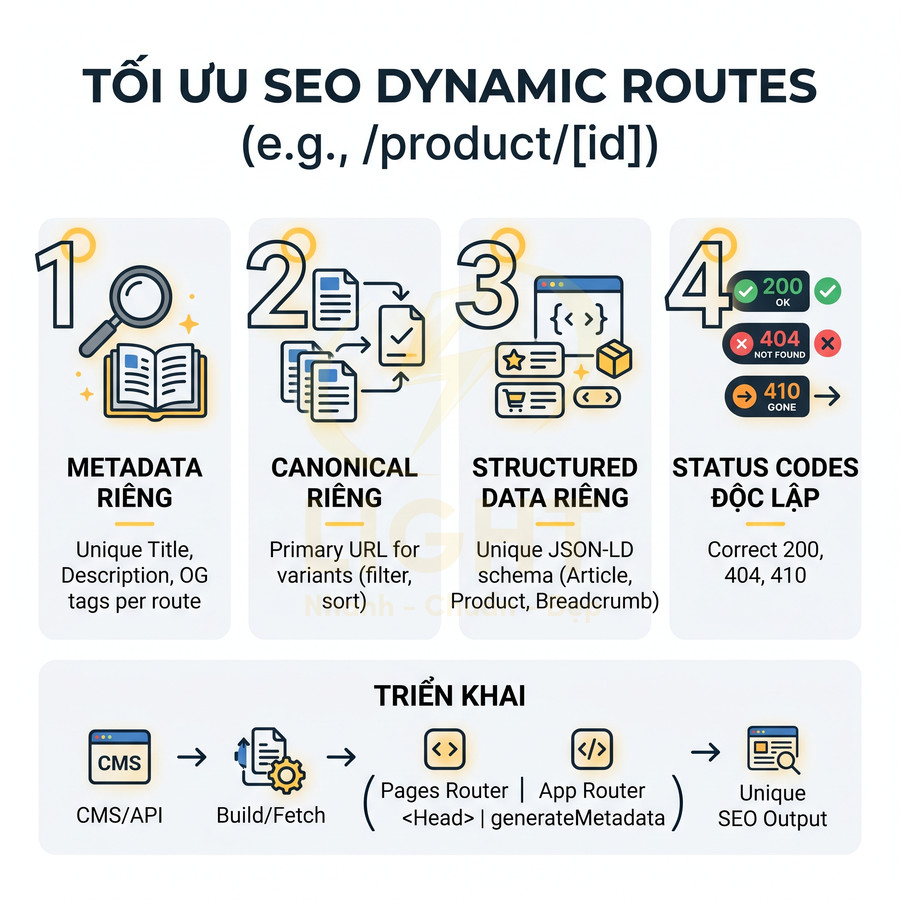
- Metadata theo nội dung: title, description, og:title, og:description, og:image nên được generate dựa trên dữ liệu bài viết, sản phẩm, danh mục, tác giả, brand… để tăng CTR và độ liên quan.
- Canonical chính xác: với các biến thể URL (filter, sort, pagination, tracking param), cần set canonical về phiên bản chuẩn để tránh duplicate content và phân tán tín hiệu link equity.
- Structured data JSON-LD riêng: mỗi trang nên inject schema phù hợp (Article, BlogPosting, Product, BreadcrumbList, FAQPage…) với dữ liệu cụ thể: name, description, price, availability, rating, author, datePublished…
- Status code chuẩn: 200 cho trang tồn tại, 404 cho slug không hợp lệ, 410 cho nội dung đã gỡ vĩnh viễn; tránh trả 200 cho trang rỗng hoặc trang báo lỗi hiển thị trong HTML.
Trong Next.js, việc generate metadata và schema nên được thực hiện trong quá trình SSR/SSG/ISR:
- Với Pages Router, dùng
getStaticProps,getStaticPaths,getServerSidePropsđể fetch dữ liệu, sau đó render metadata và JSON-LD trong<Head>. - Với App Router, dùng
generateMetadatađể tạo metadata dựa trên params và dữ liệu fetch từ CMS/API, đồng thời render JSON-LD trực tiếp trong component server. - Tránh chỉ inject structured data client-side sau khi hydrate, vì bot có thể index trước khi JS chạy xong.
Kết nối chặt chẽ giữa Next.js và CMS/API là yếu tố then chốt:
- Dữ liệu SEO (title SEO, meta description, canonical, schema fields) nên được lưu trong CMS cùng với nội dung, không hard-code trong codebase.
- Pipeline build/ISR cần đảm bảo khi nội dung thay đổi, metadata và structured data cũng được cập nhật tương ứng.
- Các trường như slug, primary category, language, region nên được chuẩn hóa để mapping chính xác sang URL, canonical và hreflang.
Middleware, redirects và headers cần cấu hình tránh lỗi canonical, noindex và cache
Next.js cung cấp middleware, redirects và cấu hình headers rất linh hoạt, cho phép xử lý logic phức tạp ở edge (A/B testing, geo routing, auth, feature flag…). Tuy nhiên, nếu cấu hình không cẩn thận, các tính năng này có thể gây ra lỗi SEO khó phát hiện.
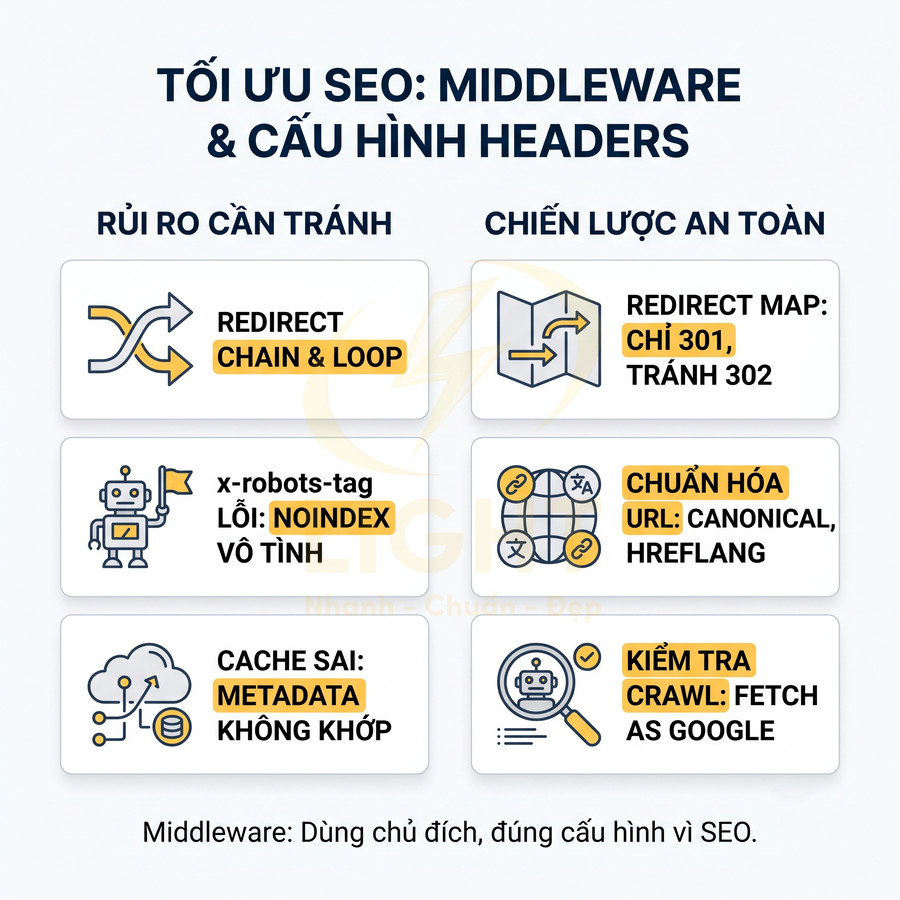
Một số rủi ro thường gặp:
- Redirect chain hoặc loop: nhiều bước redirect (301 → 302 → 301…) làm chậm crawl, giảm PageRank truyền qua link, lãng phí crawl budget và gây trải nghiệm kém cho người dùng.
- x-robots-tag noindex ngoài ý muốn: cấu hình header chung cho toàn bộ domain hoặc environment staging nhưng quên tắt khi lên production, khiến toàn site bị noindex.
- Cache header không đồng bộ: nội dung đã cập nhật nhưng cache (CDN, browser, ISR) vẫn phục vụ phiên bản cũ, dẫn đến Googlebot thấy metadata, canonical, structured data không khớp với nội dung thực.
- Middleware phân biệt bot và người dùng: trả về nội dung khác nhau cho Googlebot và user (dù vô tình) có thể bị xem là cloaking, ảnh hưởng nghiêm trọng đến trust.
Chiến lược cấu hình an toàn hơn:
- Redirect map rõ ràng: quản lý redirect trong file cấu hình (ví dụ
next.config.js) hoặc trong hệ thống riêng, đảm bảo mỗi URL cũ chỉ redirect một bước đến URL mới, ưu tiên 301 ổn định, hạn chế 302 trừ khi thực sự tạm thời. - Kiểm soát x-robots-tag và meta robots theo môi trường: dùng biến môi trường để bật noindex trên dev/staging, nhưng có cơ chế kiểm tra tự động (CI/CD) để tránh deploy nhầm noindex lên production.
- Đồng bộ cache với ISR/SSR/SSG: thiết kế chiến lược revalidate, cache-control, ETag sao cho khi nội dung hoặc metadata thay đổi, phiên bản cũ được invalidated kịp thời; tránh cache HTML quá lâu trong khi API đã đổi.
- Test với user agent Googlebot: dùng công cụ như URL Inspection, Fetch as Google, hoặc curl với UA Googlebot để so sánh response giữa bot và user; đảm bảo không có khác biệt bất thường về nội dung, metadata, structured data.
Middleware nên được dùng một cách có chủ đích cho SEO:
- Chuẩn hóa URL (thêm/bỏ slash cuối, force HTTPS, force lowercase) để giảm duplicate URL và thống nhất canonical.
- Áp dụng logic geo/language nhưng vẫn đảm bảo mỗi phiên bản ngôn ngữ có URL riêng, canonical và hreflang rõ ràng, tránh auto-redirect cứng dựa trên IP gây khó cho bot.
- Thiết lập header bảo mật (HSTS, X-Frame-Options, CSP) mà không ảnh hưởng đến khả năng crawl và render của bot.
Vue và Nuxt có làm SEO tốt cho website nội dung, ecommerce, SaaS không?
Vue và Nuxt hoàn toàn có thể hỗ trợ SEO tốt cho website nội dung, ecommerce và SaaS nếu được triển khai đúng cách với SSR, SSG hoặc prerender. Vấn đề không nằm ở framework mà ở cách render HTML, tổ chức dữ liệu và kiểm soát metadata. Với Vue SPA thuần, cần bổ sung prerender hoặc SSR để đảm bảo HTML ban đầu đã chứa nội dung chính, metadata và structured data, đặc biệt cho các trang category, product, article, landing page. Nuxt mang lại lợi thế lớn nhờ cơ chế SSR/SSG linh hoạt, route meta theo trang, khả năng inject JSON-LD và kiến trúc data layer trung tâm, giúp scale lên hàng nghìn URL mà vẫn giữ được tính nhất quán nội dung và tín hiệu SEO.

Vue SPA cần prerender hoặc SSR nếu trang công khai phụ thuộc organic traffic
Vue SPA thuần, tương tự React SPA, thường dùng CSR, khiến HTML ban đầu rỗng và nội dung phụ thuộc JavaScript. Với các trang công khai cần organic traffic, mô hình này mang nhiều rủi ro SEO, đặc biệt với website nội dung lớn, ecommerce nhiều danh mục/sản phẩm, hoặc SaaS có nhiều landing page theo ngách. Vấn đề cốt lõi nằm ở:
- HTML ban đầu không chứa nội dung chính (title, mô tả, danh sách sản phẩm, nội dung bài viết).
- Googlebot phải render JavaScript để thấy nội dung, dễ bị lỗi nếu script chậm, bị chặn, hoặc phụ thuộc nhiều request API.
- Khó kiểm soát chính xác metadata, canonical, structured data theo từng URL nếu mọi thứ chỉ được gắn client-side.
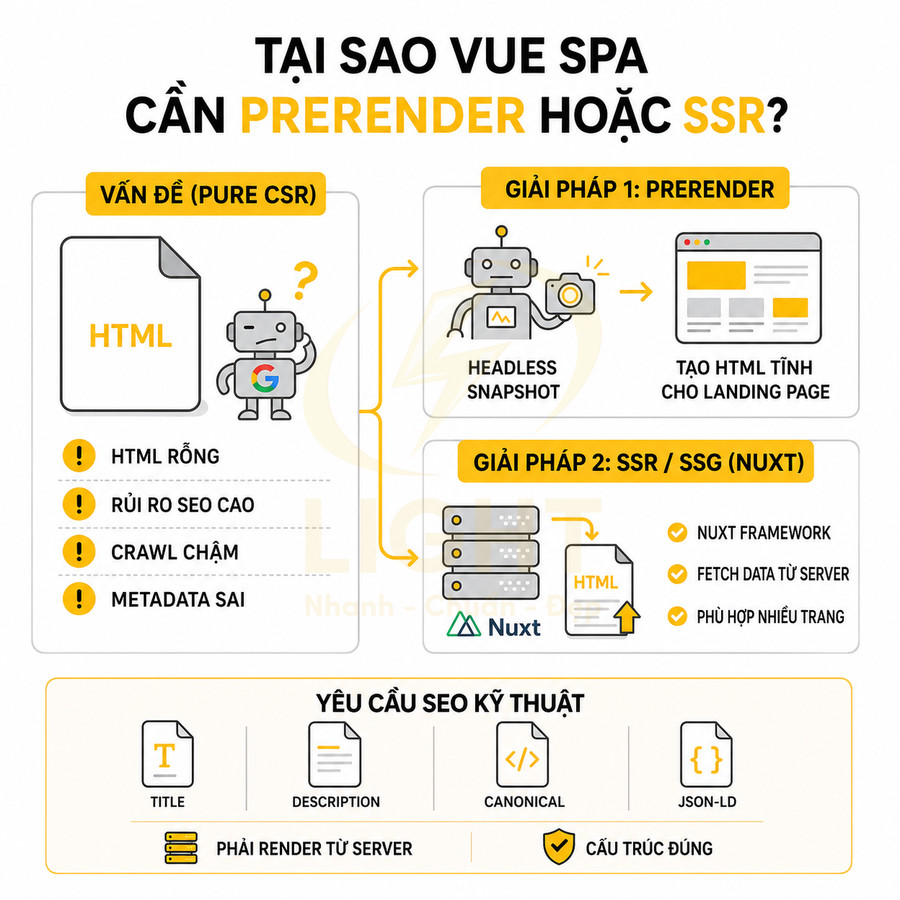
Để khắc phục, có thể:
- Dùng prerender cho một số route quan trọng (home, danh mục chính, landing page). Công cụ prerender sẽ:
- Chạy ứng dụng Vue ở chế độ headless browser trên server build.
- Snapshot HTML đã render đầy đủ nội dung và lưu thành file tĩnh.
- Trả về HTML này cho bot và người dùng ngay từ request đầu tiên.
- Tích hợp SSR thủ công hoặc chuyển sang Nuxt để tận dụng SSR/SSG:
- SSR giúp server chạy Vue, fetch dữ liệu, render HTML hoàn chỉnh rồi gửi cho client.
- Client sau đó hydrate, gắn event listener để SPA hoạt động bình thường.
- SSG build trước HTML cho các route tĩnh, giảm tải server và tăng tốc độ.
- Đảm bảo metadata, canonical, structured data được render server-side hoặc prerender:
- Title, meta description, og tags, twitter cards phải có trong HTML trả về.
- Thẻ link rel="canonical" cần được xác định rõ cho từng loại trang (category, product, article).
- Structured data JSON-LD nên được inject từ server dựa trên dữ liệu thực tế (giá, tồn kho, tác giả, ngày xuất bản).
Prerender phù hợp với số lượng trang hạn chế, ít thay đổi (landing page, vài trang marketing). Với website nội dung lớn, ecommerce, SaaS có nhiều trang và dữ liệu thay đổi thường xuyên, SSR hoặc SSG qua Nuxt thường là lựa chọn bền vững hơn cho SEO vì:
- Có thể scale lên hàng nghìn, hàng chục nghìn URL mà không phải cấu hình prerender thủ công.
- Dễ tích hợp với CMS, API, search engine nội bộ để generate nội dung động.
- Cho phép kết hợp caching, incremental regeneration, revalidate theo thời gian hoặc theo event (webhook từ CMS).
Nuxt hỗ trợ SSR, SSG, route meta và structured data theo từng trang
Nuxt là meta-framework cho Vue, tương tự Next.js cho React, cung cấp các cơ chế render khác nhau để tối ưu SEO và hiệu suất:
- SSR cho nội dung động, cần cập nhật thường xuyên:
- Phù hợp với trang sản phẩm có giá, tồn kho thay đổi liên tục.
- Phù hợp với dashboard public, trang listing có filter server-side.
- Cho phép áp dụng caching theo URL, theo user segment, hoặc theo header.
- SSG cho trang tĩnh, blog, landing page, tài liệu:
- Build trước HTML cho từng route dựa trên dữ liệu từ CMS/API.
- Giảm TTFB, tăng Core Web Vitals, có lợi cho SEO.
- Thích hợp cho blog, docs, knowledge base, case study.
- Route meta để định nghĩa title, description, robots, canonical theo từng trang:
- Mỗi page có thể export cấu hình meta riêng dựa trên props hoặc dữ liệu fetch từ API.
- Có thể set noindex cho các trang filter, search nội bộ, trang test.
- Có thể tùy biến canonical cho các biến thể URL (sort, filter, pagination).
- Khả năng inject structured data JSON-LD dựa trên dữ liệu từ CMS, API:
- Trang sản phẩm: schema Product với name, image, description, offers, aggregateRating.
- Trang bài viết: schema Article hoặc BlogPosting với headline, author, datePublished.
- Breadcrumb: schema BreadcrumbList phản ánh đúng cấu trúc category > subcategory > product.
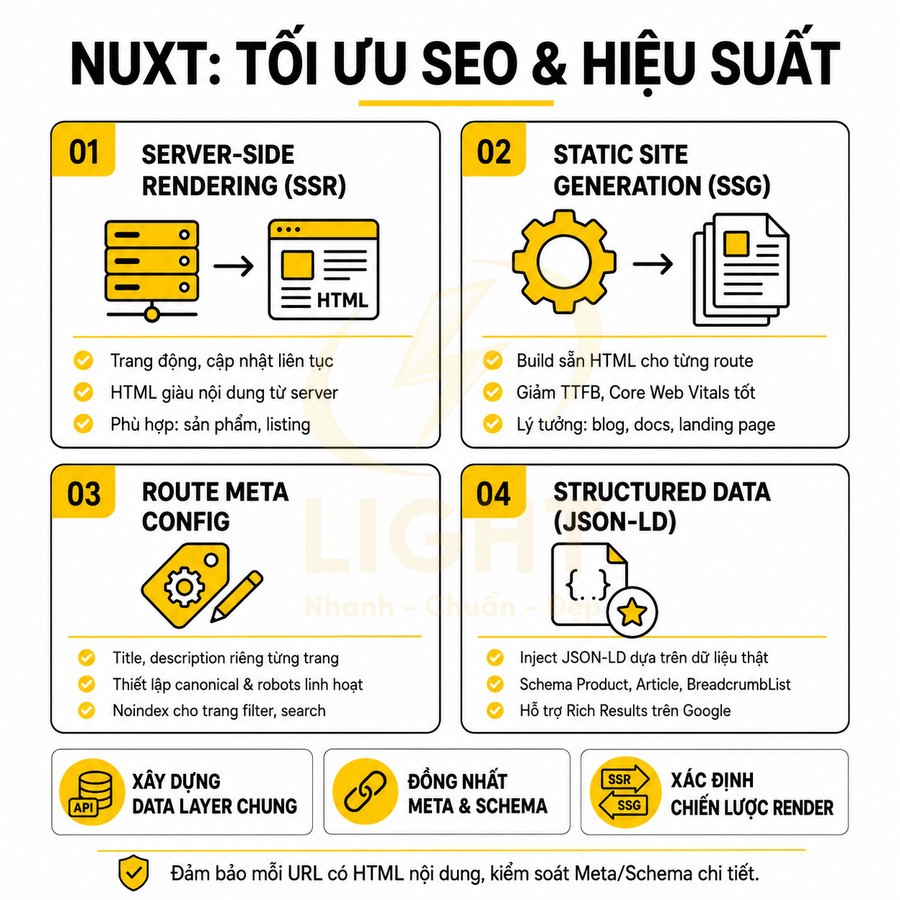
Với Nuxt, website nội dung, ecommerce, SaaS có thể:
- Đảm bảo mỗi URL có HTML giàu nội dung ngay từ server:
- Danh sách sản phẩm, mô tả, thông số kỹ thuật, review được render sẵn.
- Nội dung bài viết, mục lục, block liên quan xuất hiện trong HTML trước khi JavaScript chạy.
- Giảm phụ thuộc vào client-side fetch cho nội dung chính.
- Kiểm soát metadata và schema chi tiết cho từng loại trang:
- Template meta riêng cho category, product, article, landing page.
- Dynamic title/description dựa trên thuộc tính sản phẩm (brand, model, feature chính).
- Structured data được generate từ cùng một nguồn dữ liệu với UI, đảm bảo tính nhất quán.
- Kết hợp SSR/SSG để tối ưu hiệu suất và khả năng index:
- SSG cho trang ít thay đổi (blog cũ, docs, trang giới thiệu).
- SSR hoặc ISR cho trang thay đổi thường xuyên (product, category có tồn kho, giá).
- Có thể áp dụng chiến lược revalidate theo thời gian (ví dụ mỗi 5 phút) cho dữ liệu bán chạy.
Điều quan trọng là thiết kế kiến trúc dữ liệu và routing sao cho Nuxt có thể generate trang dựa trên nguồn dữ liệu trung tâm, tránh trùng lặp và đảm bảo tính nhất quán giữa nội dung hiển thị và dữ liệu SEO. Một số nguyên tắc kiến trúc:
- Xây dựng data layer chung (CMS, API gateway) cung cấp:
- Thông tin nội dung (title, body, excerpt, thumbnail).
- Thông tin SEO (slug, meta title, meta description, canonical, indexability).
- Thông tin schema (type, thuộc tính chính, quan hệ với entity khác).
- Routing trong Nuxt map trực tiếp với cấu trúc URL SEO:
- /blog/[slug], /category/[slug], /product/[slug] hoặc /[category]/[product].
- Tránh tạo nhiều route khác nhau cho cùng một nội dung nếu không có canonical rõ ràng.
- Quy ước rõ ràng về trailing slash, lowercase, ký tự đặc biệt trong slug.
- Page-level config chịu trách nhiệm:
- Lấy dữ liệu từ data layer theo slug/ID.
- Render nội dung chính và structured data từ cùng một object.
- Thiết lập meta, canonical, robots dựa trên field SEO trong dữ liệu.
Trang danh mục, sản phẩm và bài viết cần HTML indexable ngay từ lần tải đầu
Với website nội dung, ecommerce, SaaS, các trang mang lại nhiều organic traffic thường là:
- Trang danh mục (category, collection).
- Trang sản phẩm (product detail).
- Trang bài viết (blog, tài liệu, case study).
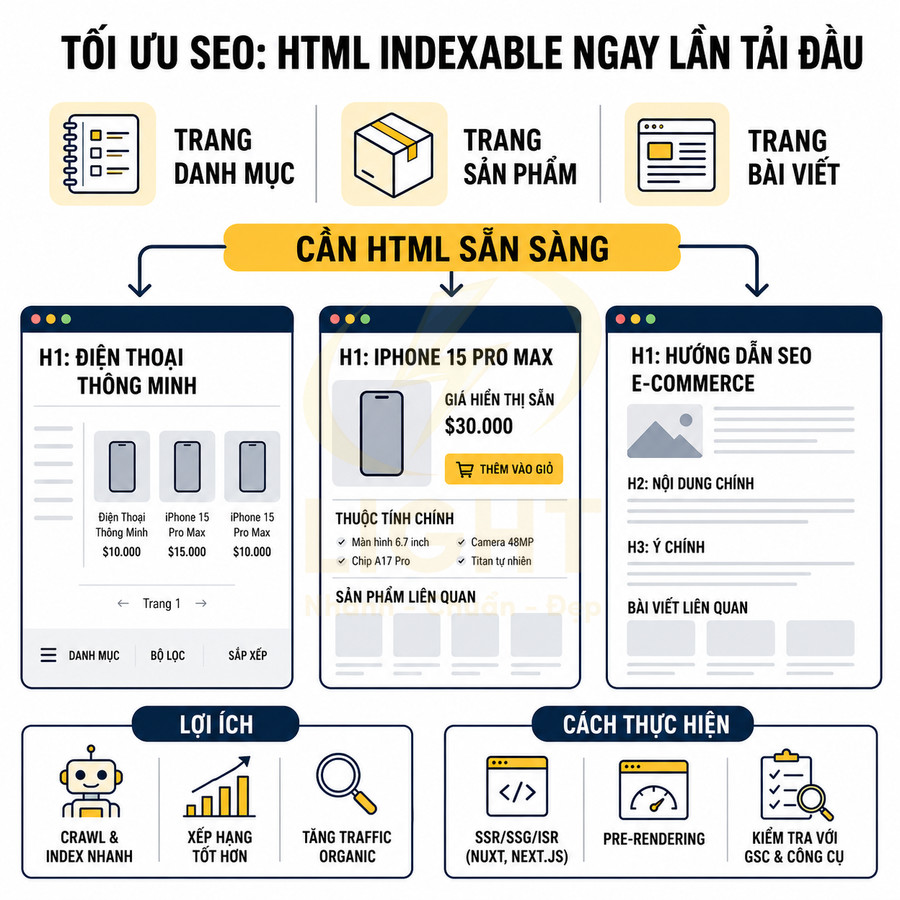
Các trang này cần HTML indexable ngay từ lần tải đầu, nghĩa là:
- Tiêu đề, mô tả, giá, thuộc tính chính, nội dung bài viết có trong HTML server render:
- H1, đoạn mở đầu, section nội dung chính phải xuất hiện trong source HTML.
- Giá, khuyến mãi, tình trạng còn hàng của sản phẩm nên có trong HTML, không chỉ trong JSON trả về API.
- Đối với SaaS, các section mô tả tính năng, lợi ích, pricing tier nên render server-side.
- Internal link đến sản phẩm liên quan, bài viết liên quan, danh mục cha/con:
- Block “Sản phẩm liên quan”, “Bài viết liên quan” nên là anchor HTML thực, không phải chỉ là event click gọi API.
- Breadcrumb nên là danh sách link HTML, đồng bộ với schema BreadcrumbList.
- Menu điều hướng chính và footer link cũng nên có trong HTML để bot crawl sâu hơn.
- Structured data phù hợp (Product, Article, Breadcrumb) gắn với nội dung thực tế:
- Giá trong schema Product phải trùng với giá hiển thị, tránh mismatch gây lỗi rich result.
- Ngày xuất bản, cập nhật trong Article schema nên khớp với thông tin hiển thị cho người dùng.
- BreadcrumbList phản ánh đúng cấu trúc URL và hierarchy thực tế.
Nếu danh sách sản phẩm hoặc nội dung bài viết chỉ xuất hiện sau khi gọi API client-side, Googlebot có thể không thấy hoặc thấy không đầy đủ, làm giảm khả năng xếp hạng. Điều này đặc biệt rủi ro với:
- Trang category có pagination, filter phức tạp, nếu mọi thứ chỉ load sau khi user tương tác.
- Trang product dùng tab nội dung (mô tả, thông số, review) nhưng chỉ load tab khi click.
- Trang blog dài, chia section, nếu phần lớn nội dung được lazy-load bằng JS.
SSR/SSG/ISR của Nuxt hoặc giải pháp prerender là cách đảm bảo các trang này luôn indexable. Khi triển khai, cần chú ý:
- Đảm bảo critical content luôn nằm trong batch render đầu tiên:
- Không trì hoãn nội dung chính bằng lazy-load nếu không thực sự cần thiết.
- Ưu tiên lazy-load cho phần ít quan trọng (carousel, review dài, gallery phụ).
- Kiểm tra HTML thực tế bằng:
- View Source để xem nội dung server render.
- Google Search Console URL Inspection > View Crawled Page > HTML.
- Công cụ như Screaming Frog, Sitebulb để kiểm tra khả năng index hàng loạt URL.
- Thiết lập caching và revalidation hợp lý:
- Tránh để nội dung cũ quá lâu trên trang product (giá, tồn kho) gây trải nghiệm xấu.
- Đối với blog/docs, có thể cache lâu hơn vì nội dung ít thay đổi.
Component tái sử dụng cần tránh tạo heading, schema và meta trùng lặp
Vue và Nuxt khuyến khích component hóa, nhưng điều này cũng dễ dẫn đến trùng lặp heading, structured data và metadata nếu không kiểm soát. Một số lỗi phổ biến:
- Component section tự tạo H1, dẫn đến nhiều H1 trên một trang:
- Ví dụ: component “HeroSection” luôn render H1, nhưng page cũng có H1 riêng.
- Hoặc nhiều block nội dung (FAQ, feature, testimonial) đều dùng H1 thay vì H2/H3.
- Component sản phẩm liên quan inject Product schema cho từng item, gây trùng lặp schema không cần thiết:
- Trang product chính đã có Product schema, block “Sản phẩm liên quan” không cần thêm Product schema cho từng item.
- Google có thể coi đó là spammy structured data hoặc khó xác định entity chính.
- Component layout thêm meta robots hoặc canonical chung cho mọi trang:
- Meta robots “noindex” vô tình áp dụng cho toàn site nếu đặt ở layout.
- Canonical trỏ về homepage cho mọi URL, làm mất tín hiệu cho từng trang cụ thể.
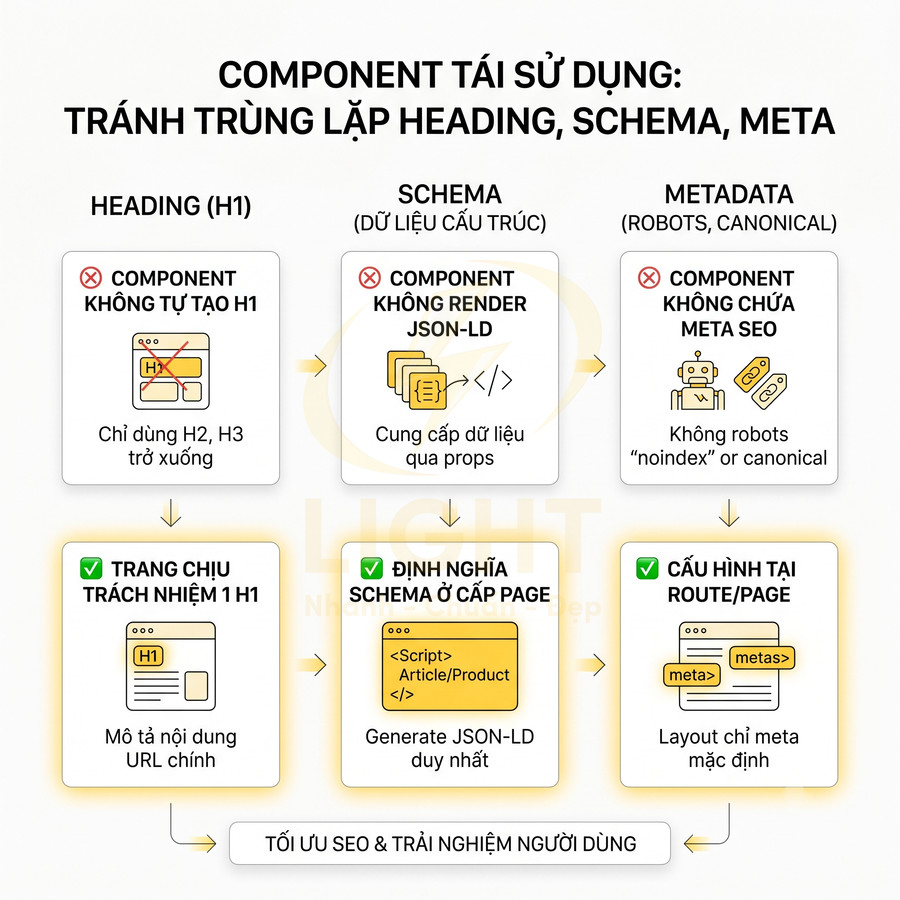
Để tránh lỗi này, cần:
- Quy định rõ H1 chỉ được tạo ở cấp page, component chỉ dùng H2, H3 trở xuống:
- Page-level template chịu trách nhiệm render H1 duy nhất, mô tả nội dung chính của URL.
- Component nhận prop để biết heading level (ví dụ: headingTag="h2") thay vì tự cố định là H1.
- Kiểm tra tự động bằng lint rule hoặc test để phát hiện nhiều H1 trên một trang.
- Structured data chính (Article, Product) được define ở cấp page, component chỉ cung cấp dữ liệu:
- Page thu thập dữ liệu từ các component (product info, author info, rating) rồi generate JSON-LD duy nhất.
- Component không tự render script JSON-LD, mà expose data qua props/event.
- Đối với listing (category), có thể dùng schema ItemList cho danh sách, nhưng vẫn nên define ở page.
- Metadata quan trọng (title, description, canonical, robots) được cấu hình ở route/page, không nằm trong component dùng chung:
- Layout chỉ nên chứa meta mặc định (charset, viewport, favicon), không chứa meta SEO động.
- Page-level config sử dụng dữ liệu từ CMS/API để set meta chính xác cho từng URL.
- Tránh để component marketing (popup, banner) tự thêm meta robots hoặc canonical.
Bên cạnh đó, cần chú ý thêm:
- Tránh trùng lặp nội dung giữa các component tái sử dụng:
- Không copy nguyên block nội dung dài cho nhiều page nếu không có canonical hoặc biến thể rõ ràng.
- Ưu tiên cấu hình nội dung động theo context page (ví dụ: testimonial, FAQ theo category).
- Đảm bảo performance của component không làm hại Core Web Vitals:
- Lazy-load hình ảnh, video, carousel trong component nhưng không trì hoãn nội dung text chính.
- Giảm JavaScript không cần thiết trong component dùng chung để tránh tăng TBT, INP.
Lỗi SEO phổ biến trên website React, Vue, Next.js
Các framework React, Vue, Next.js thường gặp nhiều lỗi SEO do đặc thù render bằng JavaScript. Vấn đề cốt lõi là Google cần HTML có nội dung, metadata và link nội bộ rõ ràng, trong khi nhiều ứng dụng lại để mọi thứ phụ thuộc vào CSR, API client-side hoặc component layout dùng chung. Điều này dễ dẫn đến trang rỗng, metadata trùng lặp, canonical sai và internal link không crawl được. Bên cạnh đó, Core Web Vitals bị ảnh hưởng mạnh bởi bundle JS lớn, hydration nặng và tài nguyên chưa tối ưu. Để khắc phục, cần ưu tiên SSR/SSG/ISR cho các URL có traffic organic, tối ưu bundle, ảnh, font, đồng thời triển khai structured data, log, crawl test và audit SEO tự động trong CI/CD để đảm bảo mỗi trang indexable đều đầy đủ nội dung, metadata và hiệu suất tốt.

Nội dung chính chỉ xuất hiện sau API call chậm hoặc lỗi render phía client
Một trong những lỗi SEO nghiêm trọng nhất trên các ứng dụng SPA/CSR là để toàn bộ nội dung chính, cấu trúc heading và internal link phụ thuộc 100% vào API call phía client. Khi đó, HTML ban đầu trả về từ server chỉ là một khung rỗng với một root div và vài đoạn skeleton/loading. Nếu API chậm, lỗi, hoặc bị chặn với Googlebot, các vấn đề sau thường xảy ra:
- Trang chỉ hiển thị skeleton hoặc loading vô hạn, không có nội dung thực sự trong DOM khi Googlebot render.
- DOM cuối cùng không chứa văn bản có ý nghĩa (body text, heading, list, bảng…), khiến trang bị coi là thin content hoặc nội dung gần như trống.
- Không có internal link đến các trang khác, làm đứt gãy cấu trúc crawl và giảm khả năng phân bổ PageRank nội bộ.
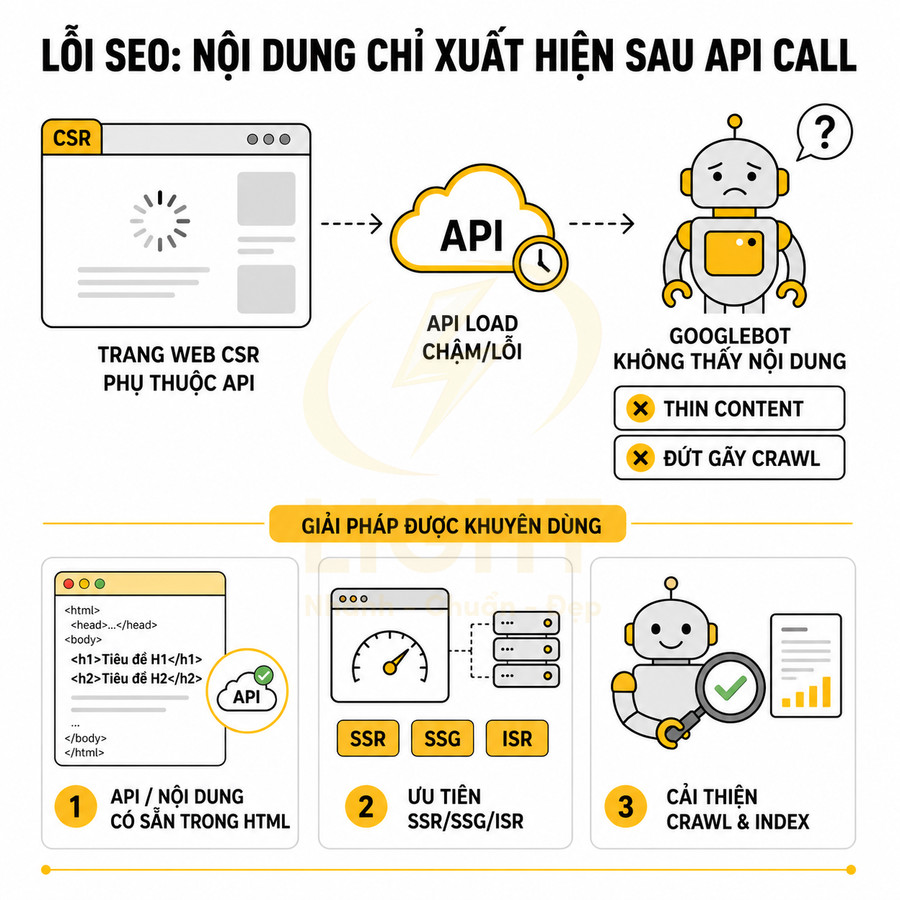
Về mặt kỹ thuật, Google sử dụng hai bước: crawl HTML ban đầu, sau đó mới render JavaScript. Nếu HTML ban đầu không có nội dung, còn quá trình render JS phụ thuộc vào API chậm hoặc bị chặn, Google có thể:
- Không chờ đủ lâu để nội dung load xong, đặc biệt với các trang có thời gian TTFB và TTI cao.
- Không thể gọi được API nếu API bị chặn bởi firewall, rate limit, hoặc yêu cầu header/cookie đặc biệt mà Googlebot không gửi.
- Gặp lỗi JavaScript (runtime error) khiến quá trình hydrate/render bị dừng trước khi nội dung được gắn vào DOM.
Để tránh tình trạng này, cần thiết kế kiến trúc render ưu tiên SSR/SSG/ISR cho các phần nội dung quan trọng:
- Đưa các API call quan trọng (nội dung bài viết, danh sách sản phẩm, category listing, nội dung landing page…) vào quá trình render phía server (SSR) hoặc build-time (SSG/ISR), để dữ liệu đã có sẵn trong HTML server render trước khi gửi cho client.
- Chỉ để các API call client-side cho những phần không quan trọng với SEO (ví dụ: widget cá nhân hóa, dữ liệu realtime, module tương tác phức tạp) và không ảnh hưởng đến khả năng hiểu nội dung chính của trang.
- Thiết kế fallback nội dung hợp lý nếu API lỗi: hiển thị thông báo, một phần nội dung tĩnh, hoặc phiên bản cached gần nhất, thay vì để trang rỗng hoặc chỉ có loading spinner.
- Đảm bảo các heading chính (h1, h2), đoạn văn mô tả, danh sách sản phẩm/bài viết chính và internal link quan trọng đều có mặt trong HTML server render, không phụ thuộc hoàn toàn vào client-side rendering.
Về mặt kiểm thử và giám sát, cần:
- Kiểm tra với user agent Googlebot (hoặc dùng công cụ “URL Inspection” trong Google Search Console) để đảm bảo API không bị chặn bởi firewall, WAF, hoặc các rule bảo mật chỉ cho phép browser thông thường.
- Dùng các công cụ như “View Rendered Source”, “Mobile-Friendly Test”, hoặc crawler hỗ trợ JavaScript để so sánh HTML ban đầu và HTML sau render, xác định xem nội dung chính có thực sự xuất hiện khi Google render hay không.
- Giám sát log server để phát hiện các lỗi 4xx/5xx từ API khi user agent là Googlebot, từ đó điều chỉnh rule bảo mật hoặc tối ưu hiệu năng API.
Trong các framework như Next.js, Nuxt, cần ưu tiên sử dụng các phương thức lấy dữ liệu server-side (ví dụ: getServerSideProps, getStaticProps, asyncData, serverPrefetch) cho các route quan trọng với SEO, thay vì chỉ gọi API trong useEffect hoặc lifecycle hook phía client.
Mỗi trang dùng chung title, meta description, canonical hoặc Open Graph
Do sử dụng layout và component chung, nhiều website React, Vue, Next.js mắc lỗi dùng chung metadata cho nhiều trang hoặc thậm chí toàn bộ site. Điều này thường xuất phát từ việc:
- Đặt thẻ
<title>,<meta name="description">,<link rel="canonical">,og:title,og:description,og:urlcố định trong layout gốc. - Không cập nhật metadata theo route khi điều hướng client-side (SPA), dẫn đến Google chỉ thấy metadata của lần load đầu tiên.
- Không đồng bộ metadata với dữ liệu từ CMS hoặc API, khiến mọi trang cùng dùng một bộ thông tin mặc định.
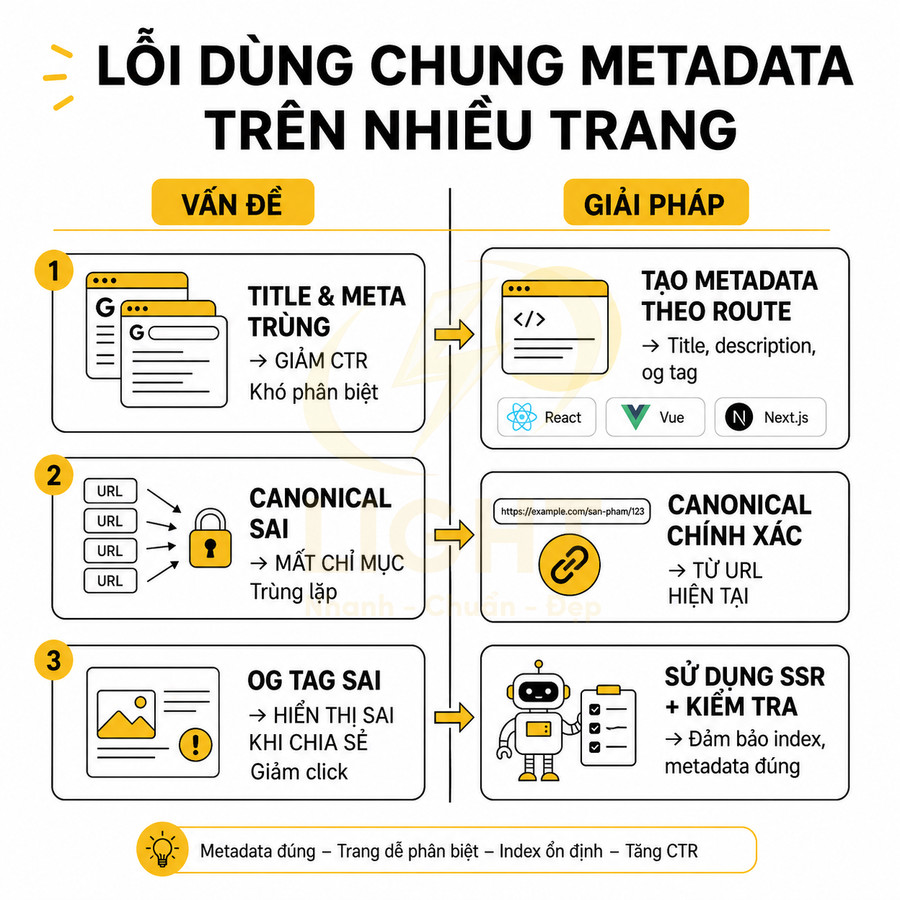
Hậu quả trực tiếp đối với SEO và trải nghiệm người dùng:
- Title và meta description trùng lặp trên nhiều URL, làm giảm khả năng phân biệt trang trên SERP, giảm CTR và khiến Google khó hiểu mục đích riêng của từng trang.
- Canonical trỏ về một URL duy nhất (thường là trang chủ hoặc một route mặc định), khiến các trang khác bị coi là bản sao (duplicate) và có thể bị loại khỏi chỉ mục hoặc bị hợp nhất tín hiệu về một URL.
- Open Graph không phản ánh đúng nội dung từng trang, làm cho khi chia sẻ lên mạng xã hội (Facebook, Zalo, LinkedIn…) hiển thị sai tiêu đề, mô tả, hình ảnh, giảm khả năng thu hút click.
Giải pháp kỹ thuật cần tập trung vào việc generate metadata theo từng route và đảm bảo metadata được cập nhật đúng khi render server-side lẫn client-side:
- Trong Next.js, sử dụng
generateMetadata(App Router) hoặcnext/head(Pages Router) để tạo metadata dựa trên params và dữ liệu trang, thay vì hard-code trong layout. - Trong Vue/Nuxt, dùng
useHead,head()hoặc plugin meta để set title, description, canonical, OG tag theo từng route và dữ liệu fetch từ API/CMS. - Tránh hard-code canonical trong layout. Thay vào đó, tính toán canonical từ URL hiện tại (server-side) hoặc từ dữ liệu CMS, đảm bảo mỗi trang có canonical chính xác, nhất quán với URL được index.
- Đối với SPA thuần (React Router, Vue Router), sử dụng thư viện quản lý head (như react-helmet, vue-meta) kết hợp với SSR để Google nhận được metadata đúng ngay trong HTML ban đầu.
Về kiểm tra và giám sát:
- Sử dụng crawl tool (Screaming Frog, Sitebulb, hoặc crawler tương đương) để quét toàn bộ site, phát hiện các trang có title, description, canonical, OG tag trùng lặp hoặc thiếu.
- Kiểm tra thủ công một số URL đại diện bằng cách xem source HTML thực tế mà server trả về (không chỉ DOM sau render) để đảm bảo metadata đã được render server-side.
- Đảm bảo canonical không trỏ nhầm sang phiên bản có tham số tracking, phiên bản HTTP/HTTPS khác, hoặc subdomain khác, tránh gây tín hiệu mâu thuẫn cho Google.
Link nội bộ dùng button, onclick hoặc route không có thẻ anchor hợp lệ
React Router, Vue Router và các router SPA khác cho phép điều hướng bằng component hoặc hàm JavaScript. Tuy nhiên, nếu các component này không render ra thẻ <a> với thuộc tính href hợp lệ, Googlebot có thể không nhận diện được đó là link nội bộ. Các lỗi thường gặp bao gồm:
- Dùng
<button onClick=...>để điều hướng sang trang khác, thay vì sử dụng anchor hoặc component link chuẩn. - Dùng
router.push(),navigate()trong event handler (onClick, onSubmit…) mà không có bất kỳ thẻ<a>nào trỏ đến URL đích. - Component link custom chỉ dùng onClick để gọi router, không render
href, hoặc render<span>,<div>thay vì<a>.
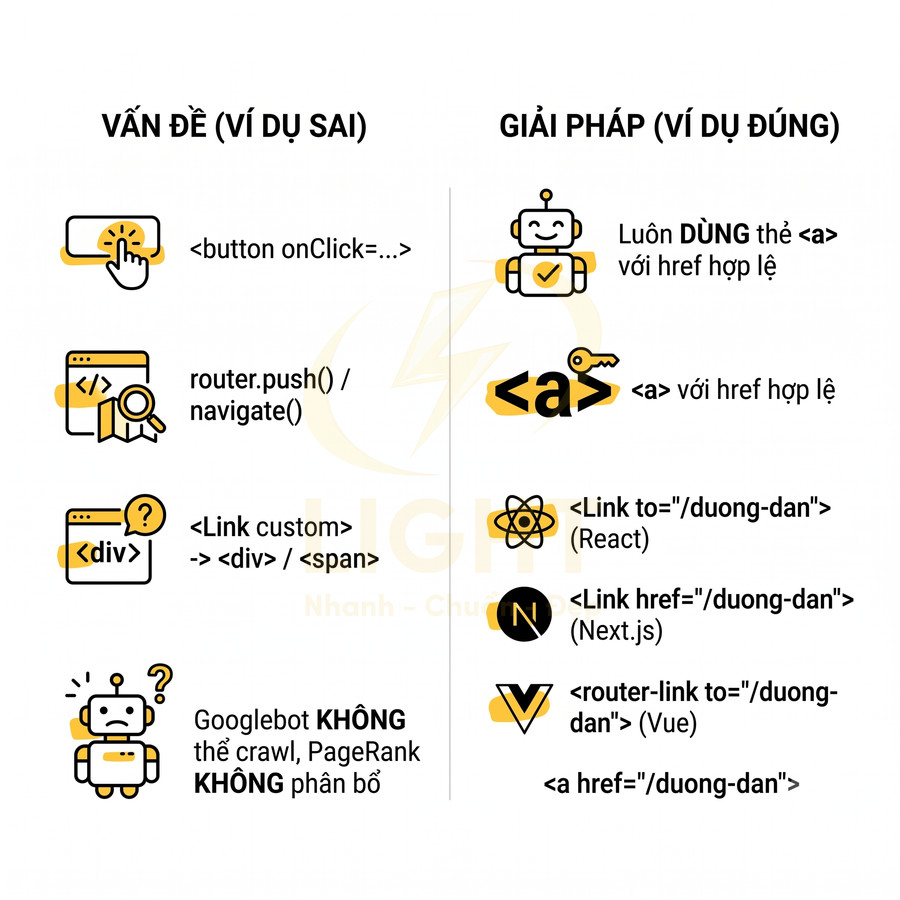
Hậu quả đối với crawl và phân bổ sức mạnh internal link:
- Googlebot không crawl được sâu vào site vì không “thấy” các đường dẫn điều hướng quan trọng, đặc biệt là các trang nằm sâu trong cấu trúc điều hướng.
- Internal link equity (PageRank nội bộ) không được phân bổ đúng, khiến các trang quan trọng không nhận đủ tín hiệu liên kết.
- Các trang quan trọng có thể trở thành trang mồ côi (orphan pages) trong mắt Google, dù người dùng vẫn truy cập được thông qua tương tác JavaScript.
Giải pháp chuẩn là luôn sử dụng thẻ <a> với href hợp lệ cho link nội bộ, kể cả khi kết hợp với router SPA:
- Trong React Router, sử dụng component
<Link to="/duong-dan">đảm bảo nó render ra<a href="/duong-dan">, không override bằng cách đổi sang<button>hoặc<div>. - Trong Next.js, dùng
<Link href="/duong-dan"><a>... (hoặc API mới cho phép bỏ thẻ<a>nhưng vẫn render href) để Google có thể nhận diện link. - Trong Vue Router, dùng
<router-link to="/duong-dan">và đảm bảo nó render thành anchor với href, không bị custom lại thành element khác. - Với component link custom, luôn đảm bảo output cuối cùng là
<a href="...">, có thể kết hợp onClick để gọi router.push nhưng không được bỏ thuộc tính href.
Để kiểm tra, có thể:
- Xem HTML render cuối cùng (sau SSR hoặc sau hydrate) để đảm bảo các link điều hướng chính (menu, breadcrumb, link trong nội dung) đều là anchor với href.
- Dùng crawler để xem số lượng internal link trỏ đến từng URL; nếu nhiều trang quan trọng có rất ít hoặc không có internal link, cần rà soát lại cách implement link.
- Tránh sử dụng JavaScript-only navigation cho các đường dẫn quan trọng với SEO; nếu cần tương tác phức tạp, vẫn nên có một anchor fallback để Google có thể crawl.
Trang lỗi trả về HTTP 200 khiến Google index soft 404
Nhiều website React, Vue, Next.js xử lý 404 bằng cách render một component lỗi (ví dụ: “Page not found”) nhưng vẫn trả về HTTP 200 từ server. Với Google, đây là dấu hiệu của soft 404: giao diện trông như trang lỗi hoặc nội dung rất mỏng, nhưng status code lại báo thành công. Điều này thường xảy ra khi:
- Server luôn trả về index.html (SPA) với status 200 cho mọi URL, còn logic 404 được xử lý hoàn toàn phía client bằng router.
- Trong Next.js/Nuxt hoặc framework SSR khác, route 404 không được cấu hình đúng, hoặc middleware luôn trả về 200 dù route không tồn tại.
- Các URL lỗi bị redirect về trang chủ (home) với status 200, trong khi nội dung không liên quan đến URL gốc.
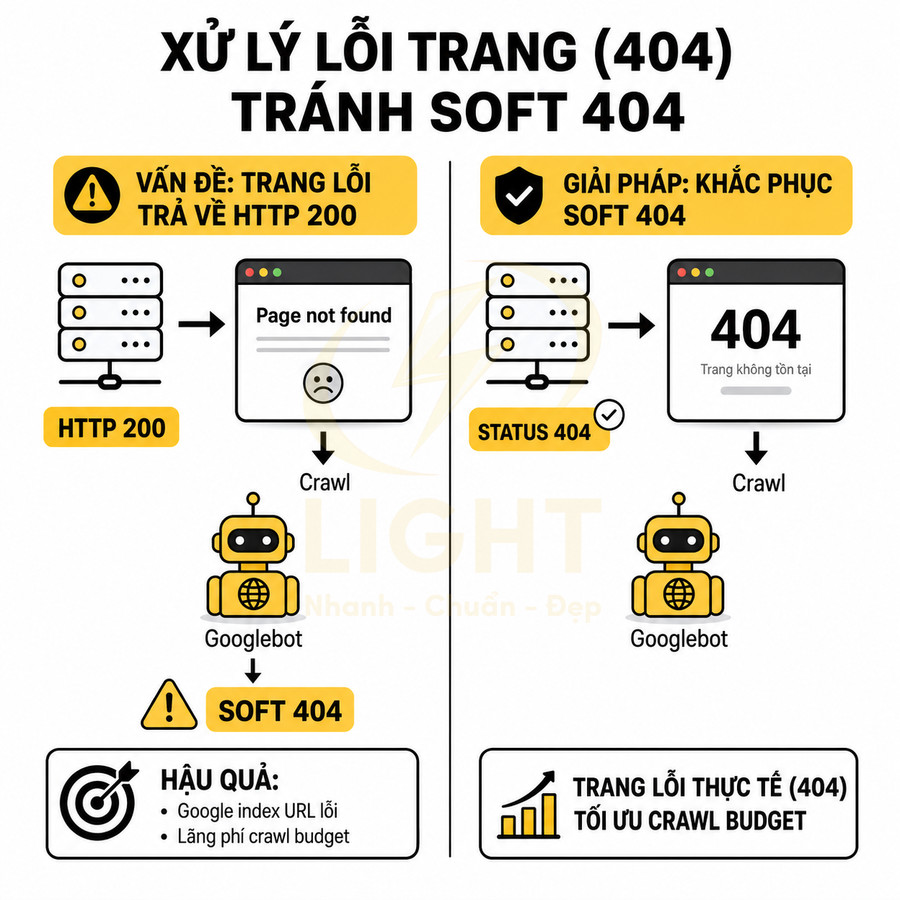
Hậu quả đối với SEO và crawl budget:
- Google index các URL không tồn tại như trang hợp lệ, nhưng sau đó đánh giá là soft 404, gây nhiễu chỉ mục và báo cáo trong Google Search Console.
- Crawl budget bị lãng phí vào các trang vô giá trị, trong khi những URL quan trọng có thể không được crawl đủ thường xuyên.
- Báo cáo Coverage trong GSC xuất hiện nhiều soft 404, khiến việc phân tích lỗi index trở nên phức tạp và khó phát hiện các vấn đề thực sự.
Để khắc phục, cần đảm bảo tầng server và router framework xử lý đúng status code:
- Đảm bảo route 404 thực sự trả về status code 404 từ server. Với SSR, khi không tìm thấy dữ liệu hoặc route, cần set status 404 trước khi render component lỗi.
- Trong Next.js, cấu hình đúng trang 404 (ví dụ:
app/not-found.tsxhoặcpages/404.tsx) và đảm bảo dynamic routes (catch-all, optional catch-all) trả về 404 khi không có dữ liệu, không trả về 200 với nội dung “không tìm thấy”. - Trong Nuxt hoặc các framework tương tự, sử dụng cơ chế error/404 built-in và set
res.statusCode = 404khi cần, thay vì chỉ render component lỗi. - Không redirect tất cả lỗi về home với 200. Nếu cần redirect, nên dùng 301/302 đến trang thay thế phù hợp về mặt nội dung, hoặc trả về 404/410 nếu URL thực sự không còn giá trị.
Về kiểm tra và giám sát:
- Dùng công cụ như
curl -I, DevTools Network, hoặc HTTP client để kiểm tra status code thực tế của các URL không tồn tại, đảm bảo trả về 404/410 chứ không phải 200. - Theo dõi báo cáo Coverage trong Google Search Console, đặc biệt là nhóm “Soft 404”, để xác định pattern URL và loại lỗi cấu hình đang xảy ra.
- Kiểm tra cấu hình server (Nginx, Apache, CDN, serverless function) để đảm bảo không có rule catch-all trả về 200 cho mọi request mà không phân biệt tồn tại route.
Core Web Vitals và hiệu suất SEO cho JavaScript framework
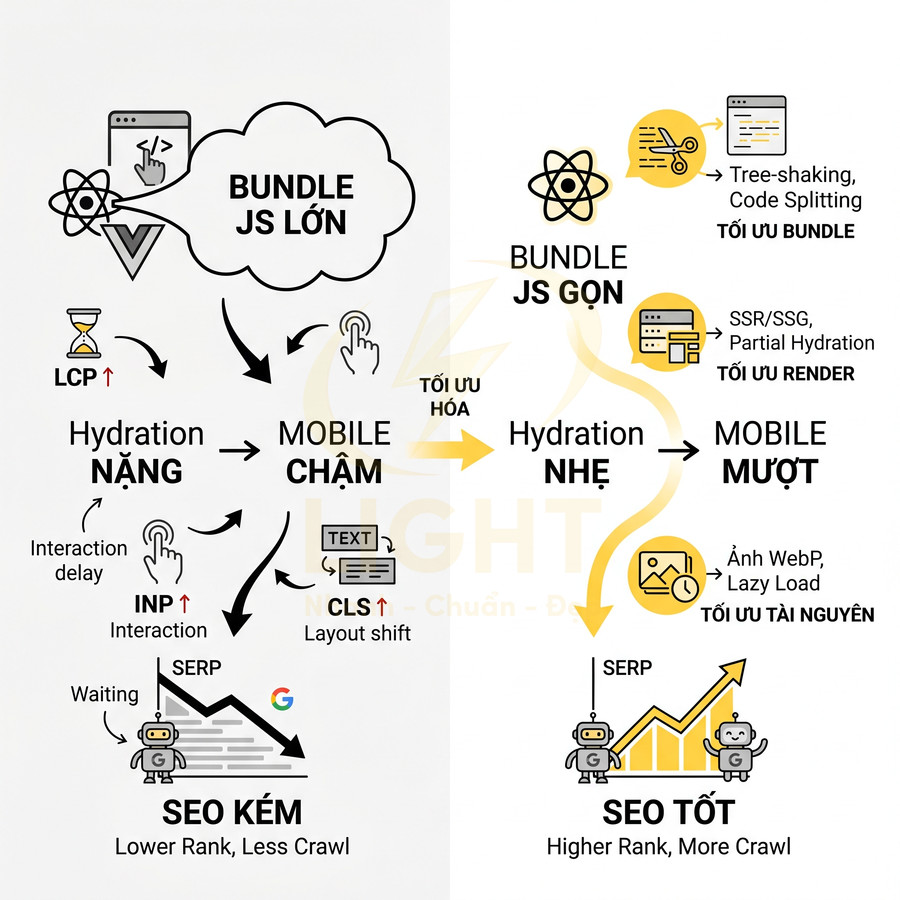
JavaScript bundle lớn làm tăng LCP, INP và thời gian tương tác
Trong các ứng dụng sử dụng React, Vue, Next.js hoặc Nuxt, kích thước JavaScript bundle thường phình to do:
- Sử dụng nhiều thư viện UI (component library, design system) như MUI, Ant Design, Vuetify.
- Thư viện animation (Framer Motion, GSAP, anime.js) được import toàn cục.
- Thư viện state management (Redux, MobX, Zustand, Pinia, Vuex) với nhiều slice/module không dùng cho mọi route.
- Polyfill, helper, utility được bundle chung thay vì tách theo môi trường.

Bundle lớn ảnh hưởng trực tiếp đến các chỉ số Core Web Vitals và các chỉ số hiệu suất liên quan:
- LCP (Largest Contentful Paint):
- Trình duyệt phải tải, parse và compile một lượng lớn JavaScript trước khi có thể render phần nội dung chính.
- Nếu LCP element (hero image, heading lớn, section đầu trang) phụ thuộc vào JavaScript để hiển thị hoặc layout, LCP sẽ bị trì hoãn đáng kể.
- Trên mobile, CPU yếu khiến thời gian parse/compile JS tăng, kéo dài LCP ngay cả khi network không quá chậm.
- INP (Interaction to Next Paint):
- Bundle lớn thường đi kèm với nhiều logic chạy trên main thread (event handler phức tạp, re-render nhiều, effect nặng).
- Khi người dùng click, scroll, input, main thread đang bận xử lý JS hoặc layout, dẫn đến input delay và processing delay cao.
- INP xấu thường xuất hiện ở các trang có nhiều component interactive được hydrate cùng lúc.
- Time to Interactive (TTI):
- TTI đo thời gian từ lúc load đến khi trang có thể phản hồi tương tác một cách ổn định.
- Bundle JS lớn + nhiều script blocking (không dùng
deferhoặcasync) làm TTI tăng mạnh. - TTI cao khiến người dùng thấy giao diện nhưng không thể tương tác mượt, làm giảm trải nghiệm và tăng bounce rate.
Google sử dụng Core Web Vitals như một tín hiệu xếp hạng, đặc biệt quan trọng trên mobile. Khi LCP, INP và TTI kém, trang có thể:
- Giảm khả năng cạnh tranh trên SERP so với đối thủ có hiệu suất tốt hơn.
- Bị giảm crawl budget do thời gian phản hồi chậm, Googlebot phải chờ lâu hơn để tải và render.
- Giảm tỷ lệ chuyển đổi vì người dùng rời trang trước khi nội dung chính sẵn sàng.
Để tối ưu kích thước bundle và tác động đến Core Web Vitals, cần áp dụng các kỹ thuật chuyên sâu hơn:
- Tree-shaking và loại bỏ code không dùng:
- Đảm bảo sử dụng ES modules (import/export) để bundler (Webpack, Rollup, Vite) có thể loại bỏ code dead.
- Tránh import toàn bộ thư viện khi chỉ dùng một phần, ví dụ:
import { Button } from 'library'thay vìimport * as UI from 'library'.
- Loại bỏ polyfill không cần thiết bằng cách cấu hình browserslist và sử dụng polyfill on-demand.
- Dùng plugin phân tích bundle (Webpack Bundle Analyzer, Rollup Visualizer) để phát hiện module nặng, trùng lặp.
- Code splitting và dynamic import:
- Chia nhỏ bundle theo route (route-based splitting) hoặc theo feature (component-level splitting).
- Sử dụng
import()dynamic trong React/Vue để tải component khi cần:- React:
const Chart = React.lazy(() => import('./Chart')); - Vue:
const Chart = defineAsyncComponent(() => import('./Chart.vue'));
- React:
- Trong Next.js, sử dụng
next/dynamicđể tách các component nặng (chart, map, editor) khỏi bundle chính. - Đảm bảo prefetch/preload hợp lý cho các route quan trọng để không làm chậm điều hướng lần đầu.
- Tránh load thư viện nặng trên mọi trang:
- Chỉ import các thư viện như charting, map, rich text editor ở những route thực sự cần.
- Tách các phần admin, dashboard, tool nội bộ thành bundle riêng, không gộp chung với phần public site.
- Dùng conditional import dựa trên điều kiện runtime (ví dụ: chỉ load editor khi user đã login và vào trang soạn thảo).
Hydration nặng khiến mobile chậm dù giao diện đã hiển thị
SSR (Server-Side Rendering) và SSG (Static Site Generation) giúp HTML được render sẵn trên server, nên người dùng thấy giao diện rất nhanh, cải thiện FCP và LCP. Tuy nhiên, sau khi HTML được tải, framework như React/Vue phải thực hiện hydration:
- So khớp (reconcile) DOM đã render sẵn với virtual DOM.
- Gắn event listener cho các component interactive.
- Khởi tạo state, effect, context, router, store.
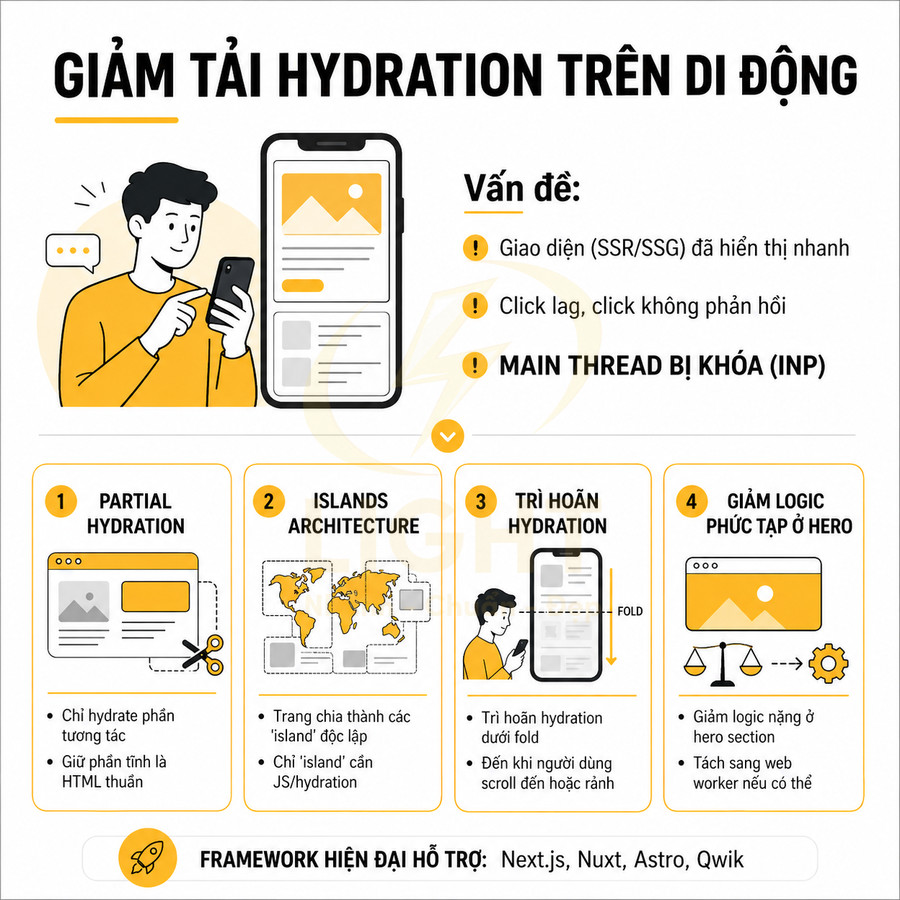
Khi hydration nặng, đặc biệt trên mobile cấu hình thấp, các vấn đề thường gặp:
- Người dùng thấy giao diện nhưng click không phản hồi ngay, gây cảm giác “lag”.
- INP tăng do main thread bị khóa bởi quá trình hydration.
- Scroll, input, animation bị giật do JS chạy liên tục sau khi load.
Để giảm tải hydration và cải thiện trải nghiệm, có thể áp dụng:
- Partial hydration:
- Chỉ hydrate những phần thực sự cần tương tác, giữ các phần tĩnh ở dạng HTML thuần.
- Giảm số lượng component phải chạy lifecycle/hook trên client.
- Phù hợp cho các trang content-heavy (blog, landing page) với ít khu vực interactive.
- Islands architecture:
- Trang được chia thành nhiều “island” interactive nhỏ, mỗi island là một ứng dụng JS độc lập.
- Các phần tĩnh không cần hydration, chỉ các island (form, search box, slider, cart) mới cần JS.
- Giảm đáng kể JS phải tải và hydrate cho mỗi trang, cải thiện INP và TTI.
- Trì hoãn hydration cho component không quan trọng:
- Hydrate ưu tiên các component above-the-fold và critical interaction (menu, search, CTA).
- Component dưới fold hoặc ít quan trọng có thể hydrate khi:
- Người dùng scroll đến vùng đó (dùng Intersection Observer).
- Idle time của main thread (dùng
requestIdleCallbackhoặc scheduler).
- Giảm logic phức tạp trong component above-the-fold:
- Tránh đặt logic nặng (data transformation lớn, complex layout calculation) trong hero section.
- Tách logic tính toán ra web worker nếu có thể, để không chặn main thread.
- Giảm số lượng hook, effect, re-render trong các component xuất hiện ngay khi load.
Next.js, Nuxt và các framework mới đang dần hỗ trợ mô hình partial hydration và islands architecture:
- Next.js với React Server Components và app router cho phép render nhiều logic trên server, giảm JS client.
- Nuxt hỗ trợ hybrid rendering, cho phép tắt/hạn chế hydration ở một số component.
- Các framework như Astro, Qwik tập trung mạnh vào islands/partial hydration, là nguồn tham khảo tốt cho kiến trúc tối ưu.
Image optimization, code splitting và lazy loading giúp giảm tải tài nguyên
Hình ảnh và JavaScript là hai nguồn tài nguyên nặng nhất trên website React, Vue, Next.js. Việc tối ưu chúng mang lại tác động trực tiếp đến LCP, INP, CLS và thời gian tải tổng thể.
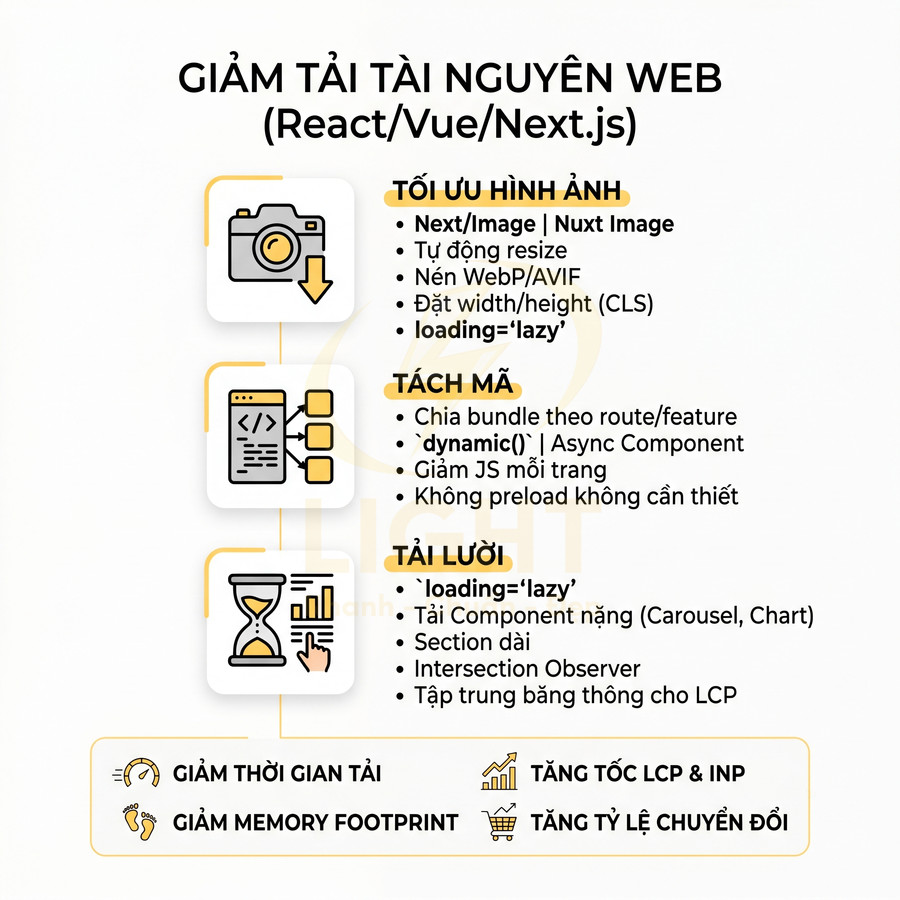
- Component image tối ưu:
- Sử dụng Next/Image, Nuxt Image hoặc component image tương đương để:
- Tự động resize ảnh theo kích thước viewport và breakpoint.
- Nén ảnh với chất lượng phù hợp, dùng định dạng hiện đại như WebP, AVIF.
- Thiết lập
srcsetvàsizesđể trình duyệt chọn phiên bản ảnh tối ưu.
- Đảm bảo khai báo
widthvàheighthoặc aspect-ratio để tránh layout shift, cải thiện CLS.
- Sử dụng Next/Image, Nuxt Image hoặc component image tương đương để:
- Lazy loading cho ảnh và component:
- Áp dụng
loading="lazy"cho ảnh dưới fold hoặc dùng cơ chế lazy của component image. - Dùng Intersection Observer để lazy load:
- Component nặng như carousel, map, chart.
- Section nội dung dài phía dưới trang.
- Giảm lượng tài nguyên tải ngay lập tức, giúp:
- Cải thiện LCP vì băng thông tập trung cho nội dung quan trọng.
- Giảm memory footprint trên mobile.
- Áp dụng
- Code splitting cho JavaScript:
- Chia nhỏ bundle theo route, feature, hoặc theo nhóm dependency.
- Trong Next.js, mỗi page là một entry riêng, kết hợp với
dynamic()để tách component nặng. - Trong Vue/Nuxt, sử dụng async component và lazy route để giảm JS cho mỗi trang.
- Đảm bảo không preload quá nhiều chunk không cần thiết, tránh làm nghẽn network.
Khi kết hợp với caching và CDN, các kỹ thuật trên giúp:
- Giảm thời gian tải tài nguyên tĩnh (ảnh, JS, CSS).
- Cải thiện LCP nhờ ảnh hero và nội dung chính được phục vụ nhanh hơn.
- Giảm INP do main thread ít bị block bởi JS không cần thiết.
- Tăng tỷ lệ chuyển đổi nhờ trải nghiệm mượt, đặc biệt trên mobile và mạng yếu.
Server rendering, caching và edge delivery cải thiện tốc độ cho bot và người dùng
Hiệu suất SEO không chỉ phụ thuộc vào front-end mà còn gắn chặt với kiến trúc server và hạ tầng phân phối nội dung. Với website React, Vue, Next.js, các yếu tố quan trọng gồm:
- SSR/SSG/ISR:
- SSR (Server-Side Rendering):
- HTML được render trên server cho mỗi request.
- Giúp Googlebot và người dùng nhận HTML đầy đủ nhanh hơn, không phụ thuộc vào JS client để render nội dung chính.
- SSG (Static Site Generation):
- HTML được build sẵn tại build time, phục vụ như file tĩnh.
- Rất phù hợp cho content ít thay đổi, landing page, blog, docs.
- ISR (Incremental Static Regeneration):
- Kết hợp ưu điểm của SSG và SSR: trang được build tĩnh nhưng có thể re-generate theo chu kỳ hoặc on-demand.
- Giúp giữ hiệu suất cao mà vẫn đảm bảo nội dung tương đối mới.
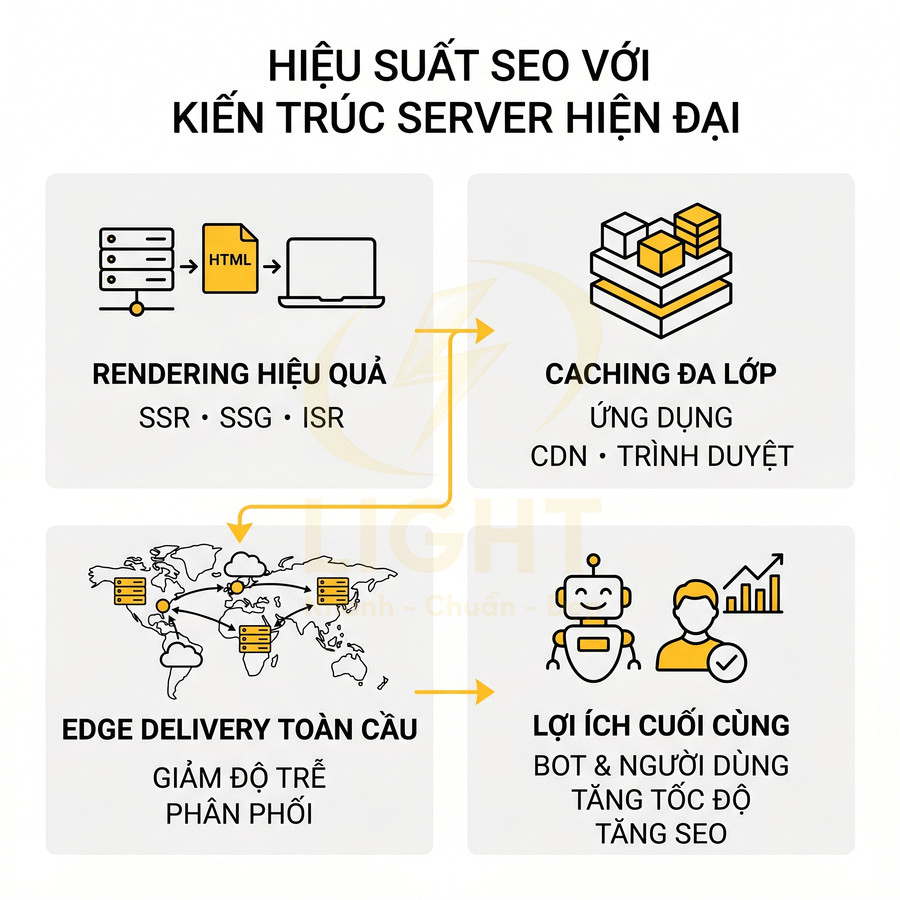
- Caching nhiều lớp:
- Application cache:
- Cache kết quả query database, API response, template render.
- Giảm thời gian server xử lý cho các request lặp lại.
- CDN cache:
- Cache HTML, JS, CSS, image tại edge node gần người dùng.
- Cấu hình
Cache-Control,ETag,Last-Modifiedhợp lý để tối ưu hit rate.
- Browser cache:
- Thiết lập cache dài hạn cho asset có fingerprint (hash) trong tên file.
- Giảm tải cho server và CDN cho các lần truy cập sau.
- Application cache:
- Edge delivery:
- Phục vụ nội dung từ server gần người dùng và bot nhất để giảm latency.
- Sử dụng edge function/middleware để:
- Thực hiện redirect, rewrite, A/B testing ngay tại edge.
- Áp dụng logic personalization nhẹ mà không cần round-trip về origin.
- Giúp Googlebot crawl nhanh hơn, giảm thời gian chờ response cho mỗi URL.
Next.js và Nuxt tích hợp tốt với các nền tảng như Vercel, Netlify, Cloudflare Pages, cho phép:
- Triển khai SSR/SSG/ISR với cấu hình tối thiểu.
- Tự động bật edge caching cho HTML và asset tĩnh.
- Kết hợp routing, middleware, function serverless ngay trên edge network.
Khi cấu hình đúng, Googlebot và người dùng sẽ nhận được HTML và tài nguyên nhanh hơn, giảm độ trễ, tăng khả năng crawl sâu và cải thiện hiệu suất SEO tổng thể cho các website xây dựng bằng JavaScript framework.
Structured data và entity SEO trên website React, Vue, Next.js
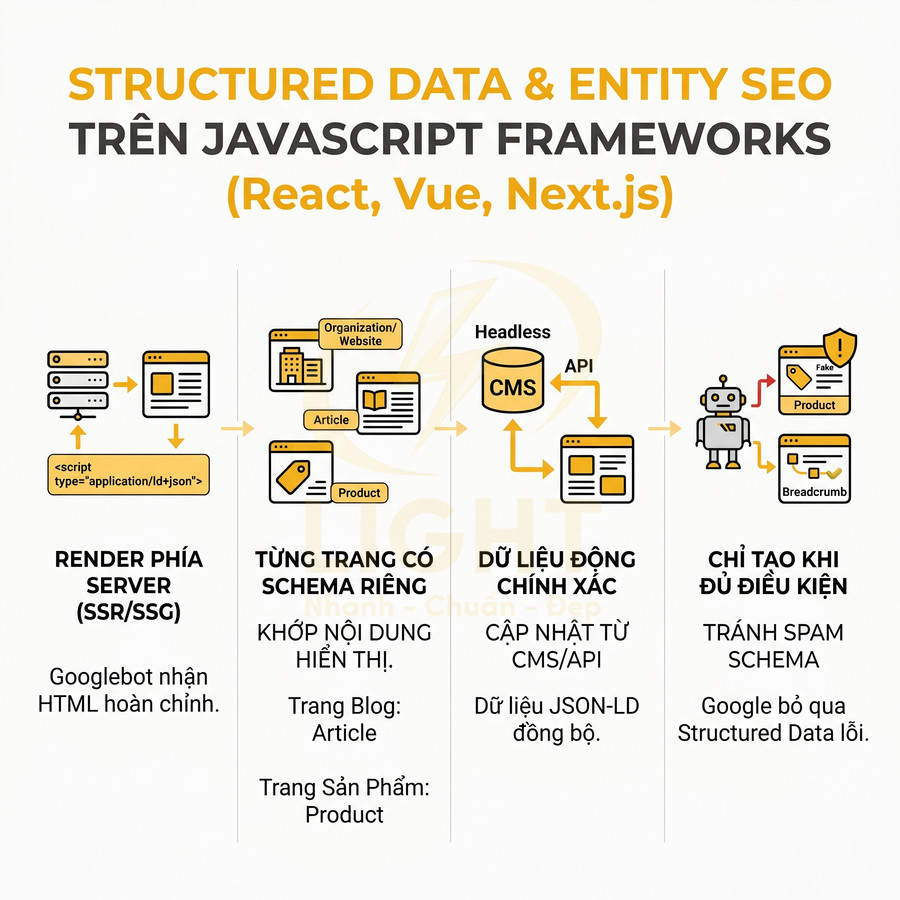
JSON-LD cần render đúng theo từng trang và không bị ghi đè khi chuyển route
Structured data JSON-LD trong môi trường SPA/MPA hiện đại (React, Vue, Next.js, Nuxt, Remix…) không chỉ là việc “thêm một script” vào DOM, mà là một phần của kiến trúc SEO kỹ thuật. Googlebot cần nhìn thấy JSON-LD trong HTML đã render (SSR/SSG/ISR hoặc prerender) và cần hiểu rõ mối quan hệ giữa các entity (Organization, WebSite, Article, Product…). Vì vậy, cách triển khai phải chú ý cả về kỹ thuật lẫn logic dữ liệu.
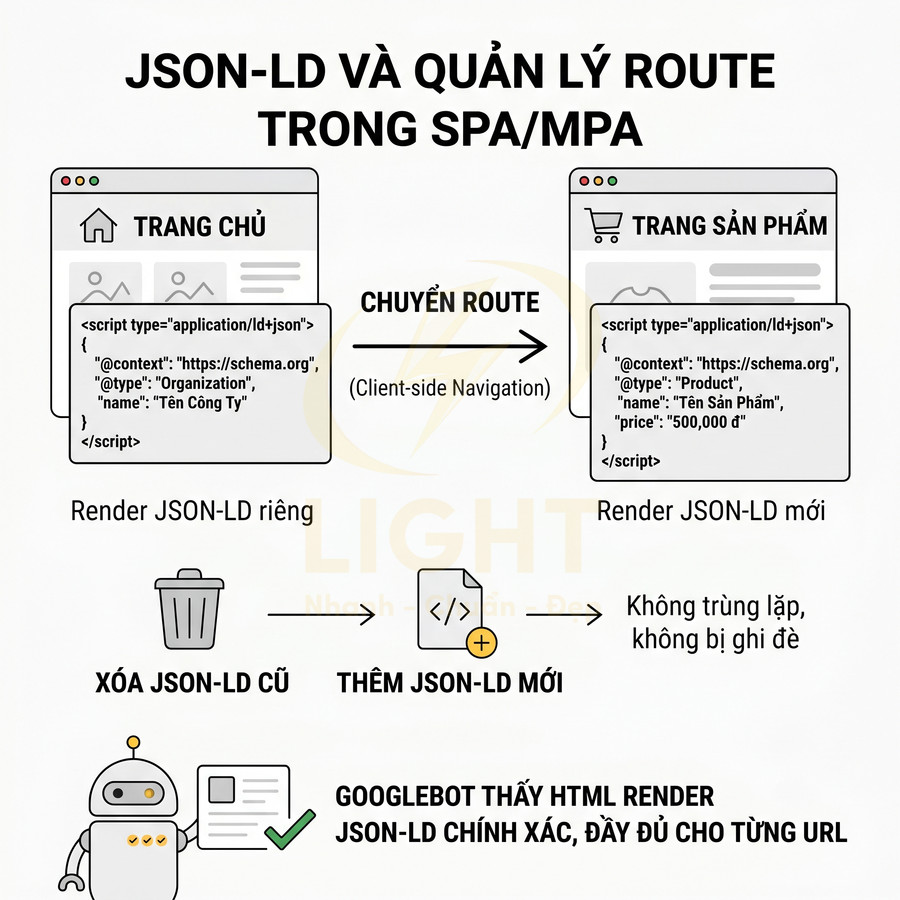
- Mỗi route/page phải có JSON-LD riêng biệt, gắn với intent và loại nội dung của trang: trang blog dùng Article, trang sản phẩm dùng Product, trang category có thể dùng CollectionPage kết hợp BreadcrumbList, trang chủ dùng WebSite + Organization.
- JSON-LD nên được render trong HTML trả về từ server (SSR/SSG/ISR) hoặc từ quá trình prerender, để:
- Googlebot không phải phụ thuộc vào JavaScript để inject script.
- Tránh rủi ro structured data không được crawl đầy đủ khi JS bị giới hạn.
- Đảm bảo tính ổn định khi Google snapshot HTML lần đầu.
- Trong SPA navigation (client-side routing), mỗi lần chuyển route cần:
- Loại bỏ script JSON-LD cũ khỏi DOM.
- Thêm script JSON-LD mới tương ứng với route hiện tại.
- Đảm bảo không tồn tại nhiều script cùng loại mô tả các entity khác nhau cho cùng một URL canonical.
Về mặt kỹ thuật, có thể áp dụng các pattern sau:
- Với Next.js: tạo component
<Script type="application/ld+json">trong<Head>của từng page, dữ liệu được build từgetStaticProps,getServerSidePropshoặcgenerateMetadata. Khi route thay đổi, Next.js tự thay thế phần<head>, giúp tránh trùng lặp. - Với Nuxt/Vue: sử dụng
useHeadhoặchead()để inject script JSON-LD, gắn key duy nhất cho mỗi script để framework quản lý lifecycle khi route thay đổi. - Với React SPA thuần: dùng thư viện quản lý head (như
react-helmet-async) hoặc tự quản lý DOM:- Trước khi thêm script mới, tìm và xóa các script
type="application/ld+json"cũ thuộc page trước. - Đảm bảo mỗi script có
idhoặc marker để tránh xóa nhầm script global (ví dụ Organization cố định).
- Trước khi thêm script mới, tìm và xóa các script
Nếu JSON-LD bị ghi đè sai (ví dụ: trang sản phẩm vẫn giữ Article schema của blog trước đó) hoặc bị trùng lặp (nhiều Product schema cho các sản phẩm khác nhau trên cùng một URL), Google có thể:
- Bỏ qua structured data vì tín hiệu không nhất quán.
- Hiểu nhầm loại nội dung, dẫn đến không hiển thị rich result phù hợp.
- Giảm mức độ tin cậy của site về mặt structured data, làm mất cơ hội hiển thị rich snippet, FAQ, breadcrumb, product rich result.
Organization, WebSite, Breadcrumb, Article và Product schema phải khớp nội dung hiển thị
Structured data chỉ mang lại giá trị SEO khi phản ánh trung thực và chi tiết nội dung đang hiển thị cho người dùng. Trong kiến trúc React, Vue, Next.js, mỗi loại schema nên được thiết kế như một “layer dữ liệu” gắn với component/page tương ứng, tránh hard-code và tránh dùng chung một schema cho nhiều loại trang.
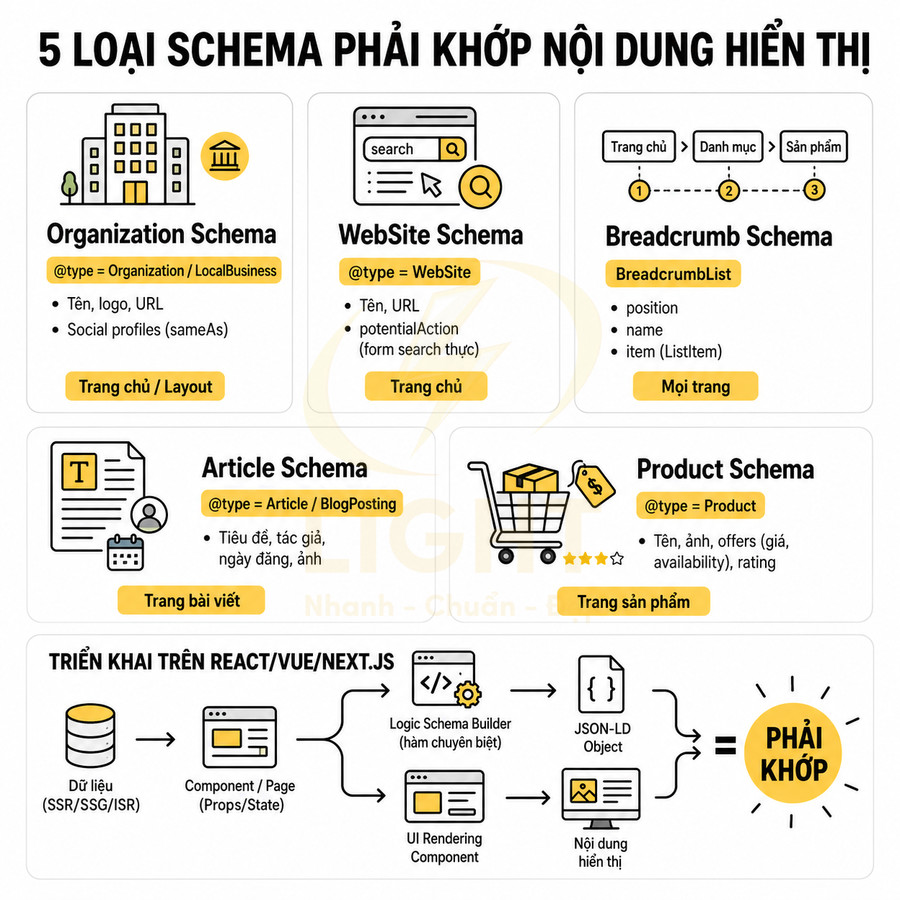
- Organization:
- Dùng cho entity doanh nghiệp/brand:
@type=OrganizationhoặcLocalBusinessnếu có địa điểm cụ thể. - Các thuộc tính quan trọng:
name,url,logo,sameAs(social profiles),contactPointnếu có. - Nên đặt ở các trang global (thường là trang chủ, hoặc inject global trong layout) nhưng phải khớp với brand hiển thị: logo, tên, URL, social link phải tồn tại trên UI.
- Dùng cho entity doanh nghiệp/brand:
- WebSite:
- Mô tả toàn bộ website:
@type=WebSite,url,name,potentialActioncho sitelinks search box. - Form search trên site phải thực sự tồn tại và hoạt động giống như
targettrong JSON-LD. - Thường chỉ cần một schema WebSite cho toàn site, render ở trang chủ hoặc layout gốc.
- Mô tả toàn bộ website:
- Breadcrumb:
- Dùng
BreadcrumbListvớiitemListElementlà cácListItemcóposition,name,item. - Chuỗi breadcrumb trong JSON-LD phải trùng với breadcrumb hiển thị trên UI (thứ tự, label, URL).
- Trong SPA, khi route thay đổi, breadcrumb schema phải được cập nhật đồng bộ với component breadcrumb.
- Dùng
- Article:
- Dùng cho blog, news, knowledge base:
@type=Article,BlogPostinghoặcNewsArticletùy loại. - Các field quan trọng:
headline,author,datePublished,dateModified,image,articleBodyhoặcdescription. - Giá trị phải khớp với nội dung: tiêu đề, tác giả, ngày xuất bản, thumbnail… đều phải hiển thị trên trang.
- Dùng cho blog, news, knowledge base:
- Product:
- Dùng cho trang chi tiết sản phẩm:
@type=Product. - Field quan trọng:
name,image,description,sku,brand,offers(giá, currency, availability),aggregateRating,reviewnếu có. - Giá, tình trạng còn hàng, rating, số review trong JSON-LD phải trùng với UI; nếu UI không hiển thị rating mà schema có rating, rất dễ bị coi là spam.
- Dùng cho trang chi tiết sản phẩm:
Khi triển khai trên React/Vue/Next.js, nên tách logic schema thành các hàm builder chuyên biệt, ví dụ:
buildOrganizationSchema(brandConfig)buildWebsiteSchema(siteConfig)buildBreadcrumbSchema(breadcrumbItems)buildArticleSchema(articleData)buildProductSchema(productData)
Các hàm này nhận dữ liệu từ props hoặc từ layer data-fetching (SSR/SSG/ISR) và trả về object JSON-LD đã chuẩn hóa. Cách làm này giúp:
- Đảm bảo schema luôn bám sát dữ liệu thực tế.
- Dễ kiểm thử (unit test) để tránh sai field, sai format.
- Dễ tái sử dụng giữa các framework (React, Vue, Next.js, Nuxt) vì logic schema tách biệt với UI.
Schema cho trang động cần lấy dữ liệu chính xác từ CMS, API hoặc database
Với dynamic routes trong Next.js, Nuxt hoặc bất kỳ framework SSR/SSG nào, structured data nên được generate từ cùng một nguồn dữ liệu với nội dung hiển thị. Điều này đảm bảo tính nhất quán dữ liệu và khả năng mở rộng khi số lượng trang tăng lớn.
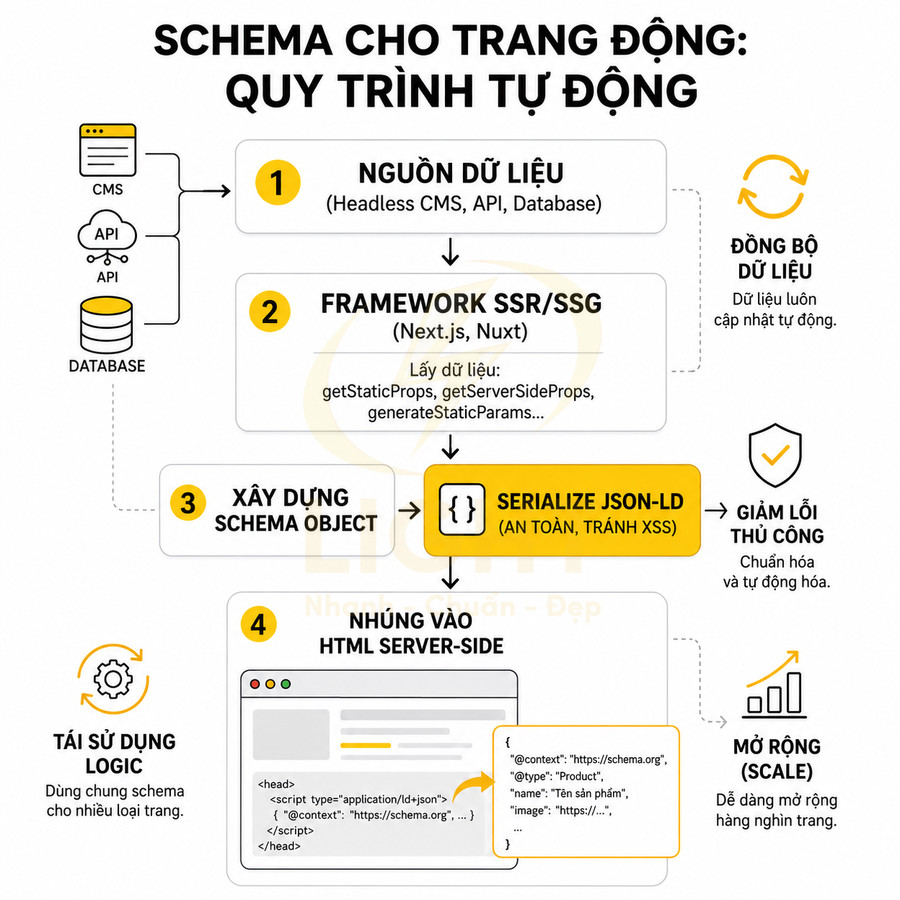
- Nguồn dữ liệu:
- Headless CMS (Contentful, Strapi, Sanity, WordPress headless…): lưu trữ bài viết, sản phẩm, category.
- API nội bộ hoặc microservice: trả về thông tin giá, tồn kho, rating, metadata.
- Database trực tiếp (qua ORM): dùng cho hệ thống custom.
- Quy trình chuẩn:
- Lấy dữ liệu trong quá trình SSR/SSG/ISR:
- Next.js:
getStaticProps,getServerSideProps,generateStaticParams. - Nuxt:
asyncData,useAsyncData, hoặc server routes.
- Next.js:
- Từ dữ liệu đó, build object schema bằng các hàm builder đã chuẩn hóa.
- Serialize object thành JSON string an toàn (tránh XSS) và inject vào
<script type="application/ld+json">trong HTML server-side.
- Lấy dữ liệu trong quá trình SSR/SSG/ISR:
Cách làm này mang lại nhiều lợi ích:
- Đồng bộ tuyệt đối giữa UI và schema: khi giá sản phẩm thay đổi trong CMS/API, cả UI và JSON-LD đều cập nhật từ cùng một nguồn.
- Giảm lỗi thủ công: không cần sửa JSON-LD bằng tay khi chỉnh nội dung, tránh sai ngày, sai giá, sai rating.
- Khả năng scale: có thể generate schema cho hàng nghìn, hàng chục nghìn trang sản phẩm/bài viết mà không tăng chi phí bảo trì.
Trong môi trường ISR (Incremental Static Regeneration) hoặc revalidation, khi dữ liệu trong CMS thay đổi, trang được rebuild, JSON-LD cũng được regenerate theo dữ liệu mới. Điều này đặc biệt quan trọng với:
- Trang sản phẩm có giá và tồn kho thay đổi thường xuyên.
- Trang bài viết được cập nhật nội dung, cần update
dateModified. - Trang listing có breadcrumb hoặc context thay đổi.
Lưu ý kỹ thuật: khi serialize JSON-LD, cần đảm bảo:
- Không escape sai (ví dụ double-encode) khiến JSON không hợp lệ.
- Không inject dữ liệu chưa được sanitize từ user input vào JSON-LD để tránh XSS.
- Giữ đúng
@context("https://schema.org") và@typeđể Google hiểu đúng entity.
Không tạo structured data tự động hàng loạt khi nội dung trang không đủ điều kiện
Một trong những lỗi phổ biến khi làm SEO cho SPA/SSR app là “tự động hóa quá mức”: tạo structured data cho mọi route chỉ vì “có template sẵn”. Điều này dễ dẫn đến spam structured data trong mắt Google, đặc biệt khi schema mô tả những yếu tố không tồn tại trên trang.

- Các ví dụ sai thường gặp:
- Gắn Product schema cho mọi trang có mention tên sản phẩm, dù không phải trang chi tiết sản phẩm (không có giá, không có CTA mua hàng).
- Gắn Article schema cho trang chỉ có vài dòng giới thiệu hoặc landing page marketing không có cấu trúc bài viết rõ ràng.
- Gắn Review/AggregateRating khi không có review thực tế hiển thị cho người dùng.
Hệ quả có thể xảy ra:
- Google bỏ qua structured data của toàn bộ site hoặc của một loại schema cụ thể.
- Search Console gửi cảnh báo về “Misleading structured data” hoặc “Spammy structured data”.
- Giảm độ tin cậy của website, làm chậm hoặc hạn chế khả năng xuất hiện rich result trong tương lai.
Để tránh rủi ro này, cần thiết kế logic điều kiện khi generate schema trong code:
- Chỉ tạo Product schema khi:
- Route là trang chi tiết sản phẩm (ví dụ:
/product/[slug]). - Dữ liệu từ CMS/API có đủ field: name, price, availability, image…
- UI thực sự hiển thị các thông tin đó cho người dùng.
- Route là trang chi tiết sản phẩm (ví dụ:
- Chỉ tạo Article schema khi:
- Trang có nội dung dạng bài viết với cấu trúc rõ ràng (title, body, author, date).
- Độ dài nội dung đủ để được coi là article, không phải chỉ vài dòng text.
- Trang được index (không phải trang noindex, không phải trang internal-only).
- Chỉ tạo Review/AggregateRating khi:
- Trang hiển thị rating hoặc review thực tế (số sao, số lượng review, nội dung review).
- Dữ liệu rating lấy từ hệ thống review thật, không phải giá trị giả lập.
Trong code React/Vue/Next.js, có thể triển khai bằng các guard logic:
- Kiểm tra dữ liệu từ CMS/API trước khi build schema:
- Nếu thiếu field bắt buộc hoặc UI không render phần đó, không generate schema tương ứng.
- Nếu trang bị đánh dấu là “noindex” hoặc “draft”, không render JSON-LD.
- Tách rõ schema global (Organization, WebSite) và schema theo page (Article, Product, Breadcrumb), tránh nhồi nhét tất cả schema vào mọi trang.
Cách tiếp cận an toàn là ưu tiên chất lượng và độ chính xác của structured data hơn là số lượng. Một số ít schema được triển khai đúng, khớp nội dung, và được Google tin tưởng sẽ mang lại hiệu quả SEO tốt hơn nhiều so với việc gắn schema hàng loạt nhưng không đủ điều kiện.
Quy trình kiểm tra SEO cho website dùng React, Vue, Next.js
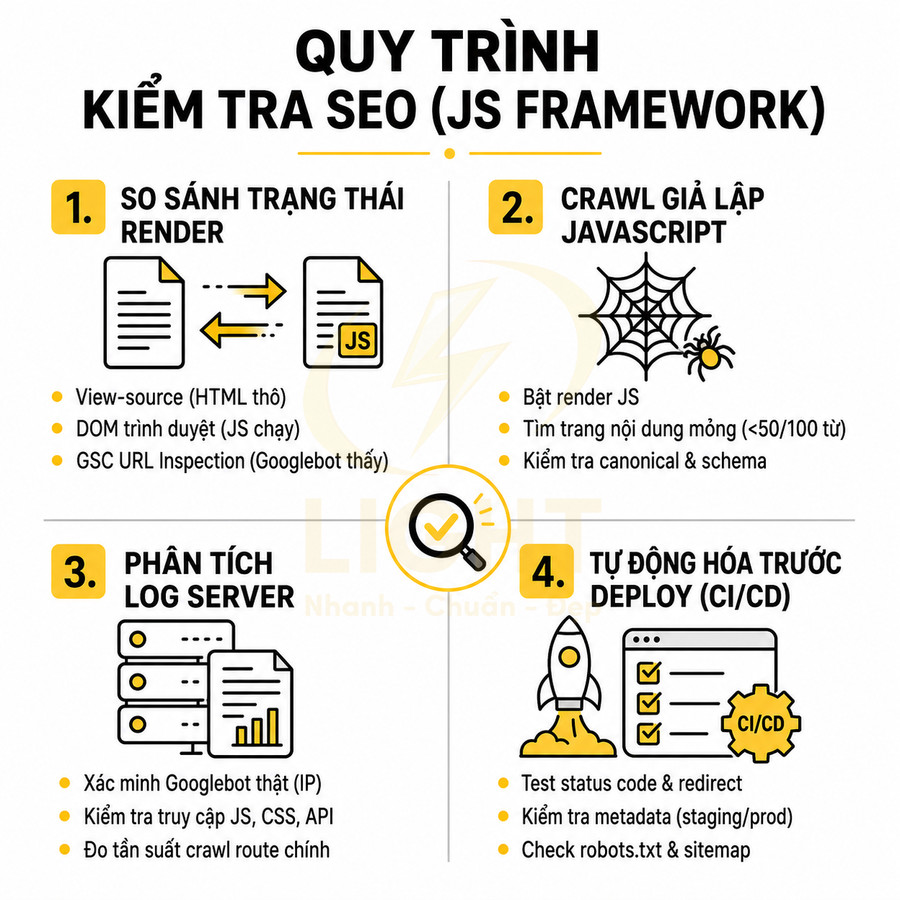
So sánh view-source, rendered DOM và URL Inspection trong Google Search Console
Một quy trình kiểm tra SEO hiệu quả cho website JavaScript framework nên bắt đầu từ việc so sánh ba trạng thái, nhưng cần đi sâu hơn vào từng lớp để hiểu rõ cách Google thực sự nhìn thấy và xử lý nội dung:
- View-source (HTML thô từ server):
- Kiểm tra xem HTML trả về có chứa nội dung chính (main content) hay chỉ là một div root (ví dụ:
<div id="root"></div>). - Đảm bảo có đầy đủ thẻ heading (H1, H2, H3) ở mức tối thiểu trong HTML server-side, đặc biệt với các trang quan trọng (category, product, landing).
- Kiểm tra metadata:
<title>có động và đúng theo từng URL hay không.<meta name="description">có được render server-side hay chỉ xuất hiện sau khi JS chạy.- Các thẻ
og:,twitter:có xuất hiện trong view-source hay không (ảnh hưởng social share nhưng cũng phản ánh mức độ SSR).
- Kiểm tra JSON-LD:
- Xác định có
<script type="application/ld+json">trong view-source không. - Đảm bảo JSON-LD không bị render trễ hoặc phụ thuộc vào event client-side (onClick, onLoad).
- Xác định có
- Ghi nhận pattern: nếu phần lớn trang có view-source gần như rỗng, site đang phụ thuộc mạnh vào client-side rendering (CSR) và cần đánh giá rủi ro index.
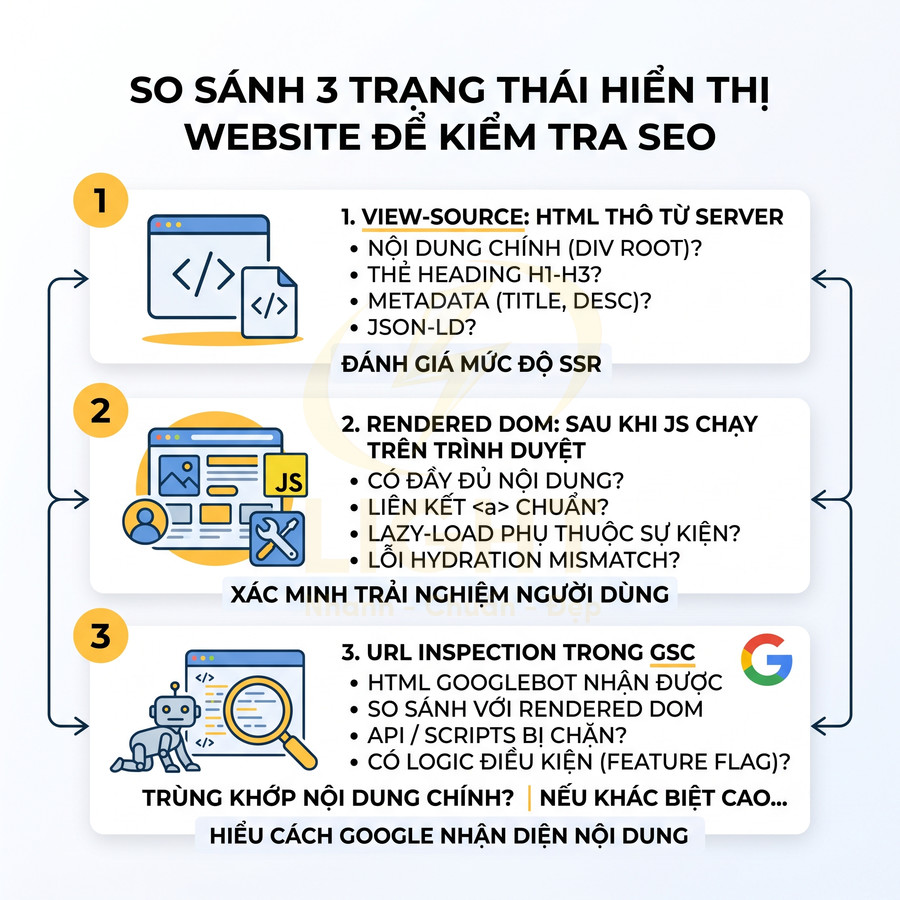
- Rendered DOM (sau khi JavaScript chạy trên trình duyệt):
- Sử dụng DevTools (tab Elements) để xem DOM sau render, so sánh với view-source:
- Nội dung text, heading, internal link có xuất hiện đầy đủ không.
- Các block quan trọng (product list, article body, navigation) có bị lazy-load phụ thuộc vào event scroll/click không.
- Kiểm tra link structure:
- Internal link có dùng
<a href="...">chuẩn hay chỉ là event onClick trên<div>/<button>. - Đảm bảo router (React Router, Vue Router, Next.js Link) vẫn render ra thẻ
<a>với href tĩnh, không che giấu URL bằng JS.
- Internal link có dùng
- Đánh giá hydration:
- Xem console có lỗi hydration mismatch không (đặc biệt với Next.js, Nuxt, Remix).
- Nếu có lỗi, DOM mà Googlebot thấy sau render có thể khác DOM người dùng, gây mất nội dung hoặc structured data.
- Sử dụng DevTools (tab Elements) để xem DOM sau render, so sánh với view-source:
- URL Inspection trong Google Search Console (HTML Googlebot thấy):
- Dùng chức năng Inspect URL > View crawled page > HTML:
- So sánh HTML này với rendered DOM trên trình duyệt (Chrome) cùng URL.
- Kiểm tra xem nội dung chính, heading, internal link, structured data có trùng khớp không.
- Nếu view-source rỗng nhưng rendered DOM và GSC giống nhau:
- Website đang phụ thuộc vào render JS, nhưng Google vẫn xử lý được trong điều kiện hiện tại.
- Tuy nhiên, vẫn có rủi ro về delayed indexing hoặc resource limit nếu site lớn, nên cân nhắc SSR/SSG cho các template quan trọng.
- Nếu HTML trong GSC khác nhiều so với DOM trên trình duyệt:
- Có thể có vấn đề với hydration (SSR khác CSR), API trả dữ liệu khác khi user agent là Googlebot, hoặc logic điều kiện (feature flag, A/B testing).
- Cần kiểm tra:
- API có chặn Googlebot (theo IP, user agent, token) không.
- Có code phân nhánh theo user agent (ví dụ: nếu không phải browser thật thì không trả nội dung) không.
- Các script quan trọng có bị chặn bởi robots.txt hoặc CSP (Content Security Policy) không.
- Dùng chức năng Inspect URL > View crawled page > HTML:
Crawl website bằng công cụ hỗ trợ JavaScript rendering để phát hiện trang rỗng
Các công cụ crawl như Screaming Frog, Sitebulb, JetOctopus hỗ trợ render JavaScript, rất hữu ích cho website React, Vue, Next.js. Để khai thác tối đa, cần cấu hình và phân tích sâu hơn:
- Crawl site với chế độ render JS bật:
- Chọn chế độ JavaScript Rendering (Chromium-based) thay vì chỉ HTML.
- Thiết lập user agent giống Googlebot Smartphone để mô phỏng gần với thực tế.
- Giới hạn tốc độ crawl để tránh bị firewall/CDN chặn, nhưng vẫn đủ sâu để bao phủ toàn bộ cấu trúc site.
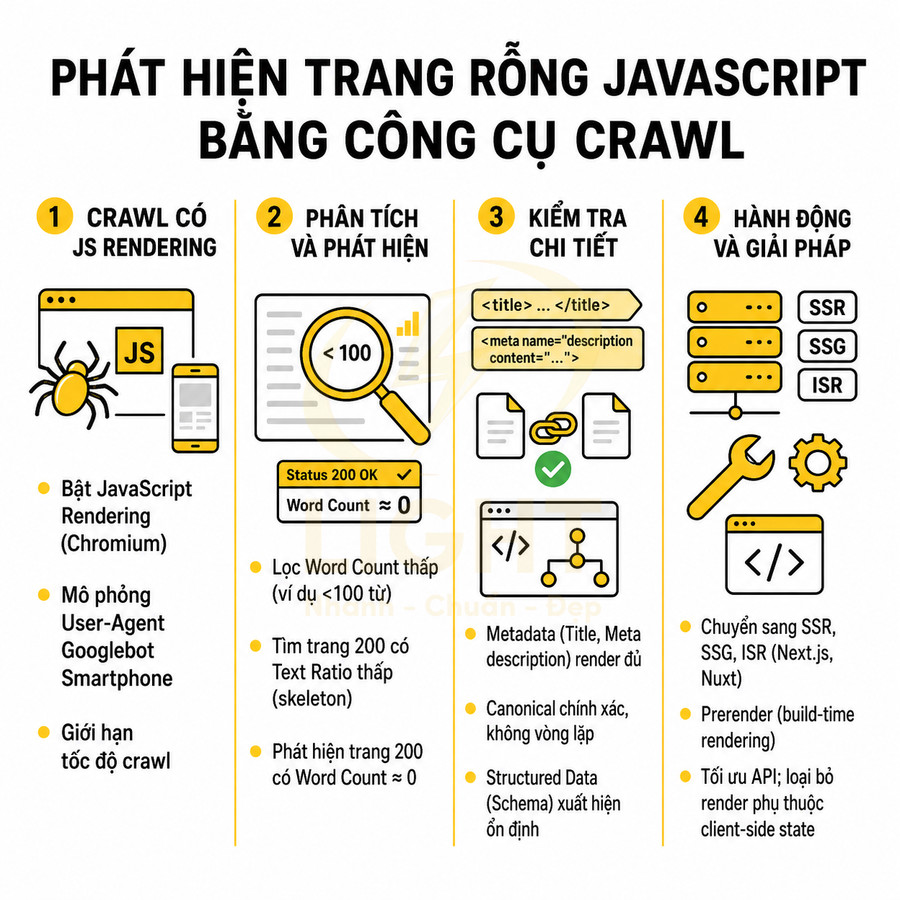
- Kiểm tra các trang có word count thấp hoặc không có nội dung chính:
- Lọc theo:
- Word Count < một ngưỡng nhất định (ví dụ < 50 hoặc < 100 từ) cho các template lẽ ra phải có nội dung dài (product detail, article).
- Trang có Text Ratio thấp (tỷ lệ text/HTML nhỏ), thường là dấu hiệu skeleton hoặc layout trống.
- Kiểm tra thủ công một mẫu URL trong nhóm này:
- Nếu chỉ thấy skeleton loading hoặc spinner, nghĩa là nội dung phụ thuộc vào API chưa trả về hoặc bị chặn.
- Nếu nội dung chỉ xuất hiện sau khi scroll hoặc tương tác, cần điều chỉnh để phần quan trọng được render ngay khi load.
- Lọc theo:
- Phân tích metadata, canonical, structured data trên từng URL:
- Đảm bảo title, meta description được render đầy đủ sau JS, không bị trùng lặp hàng loạt do logic client-side.
- Kiểm tra canonical:
- Không để canonical trỏ về một URL khác domain hoặc về homepage cho toàn bộ trang.
- Không tạo canonical loop (A canonical B, B canonical A).
- Đối với structured data:
- Kiểm tra loại schema (Product, Article, Breadcrumb, FAQ) có xuất hiện ổn định trên tất cả template liên quan.
- Đảm bảo không có nhiều block JSON-LD trùng loại nhưng mâu thuẫn dữ liệu trên cùng một trang.
- Phát hiện trang trả về 200 nhưng nội dung rỗng hoặc chỉ có skeleton:
- Lọc các URL:
- Status code 200.
- Word count ≈ 0 hoặc chỉ chứa text kỹ thuật (Loading..., No data...).
- Đây là nhóm trang có nguy cơ bị index nội dung rỗng, gây soft 404 hoặc giảm chất lượng toàn site.
- Cần phân loại:
- Trang cần chuyển sang SSR/SSG/ISR (Next.js, Nuxt, Remix) để đảm bảo nội dung có sẵn trong HTML.
- Trang cần prerender (dùng dịch vụ prerender hoặc build-time rendering) nếu không thể SSR toàn bộ.
- Trang cần tối ưu API và logic render:
- Đảm bảo API trả dữ liệu cho Googlebot giống người dùng thật.
- Loại bỏ điều kiện render phụ thuộc localStorage, cookie, hoặc event mà Googlebot không kích hoạt.
- Lọc các URL:
Kết quả crawl chi tiết giúp xác định rõ nhóm template hoặc route cần ưu tiên tối ưu, tránh tình trạng chỉ một phần nhỏ site thực sự indexable trong khi phần còn lại bị Google coi là mỏng nội dung.
Kiểm tra log server để biết Googlebot có truy cập asset, API và route quan trọng không
Log server là nguồn dữ liệu quan trọng để hiểu cách Googlebot tương tác với website React, Vue, Next.js, đặc biệt khi có nhiều lớp CDN, WAF, và microservice. Phân tích log nên đi theo các bước chuyên sâu:
- Xác định request của Googlebot thật:
- Lọc theo user agent chứa
Googlebot, nhưng cần xác minh IP bằng reverse DNS để tránh bot giả. - Phân biệt:
- Googlebot Smartphone (ưu tiên cho indexing hiện nay).
- Các bot khác như Googlebot-Image, AdsBot nếu có.
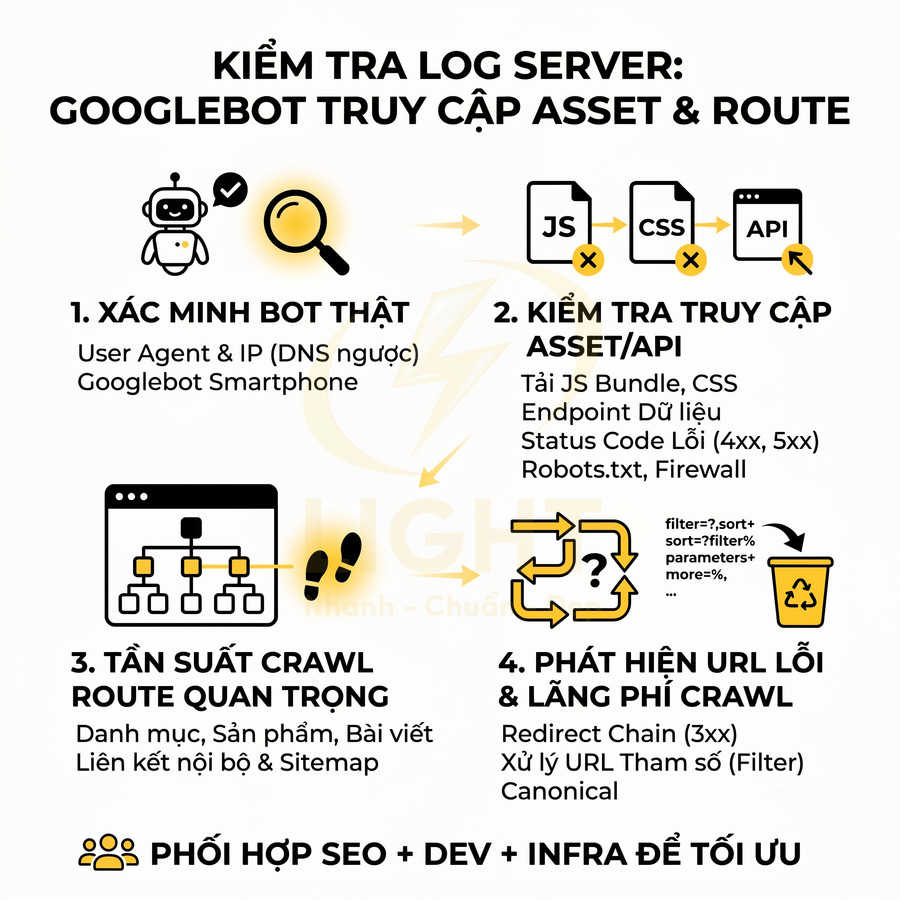
- Googlebot có truy cập JS bundle, CSS, API cần thiết cho render không:
- Kiểm tra log cho:
- Các file JS chính (bundle, chunk, vendor) được gọi từ HTML.
- Các file CSS quan trọng ảnh hưởng layout và CLS.
- Các endpoint API cung cấp dữ liệu cho product list, article content, navigation.
- Nếu thấy nhiều status 403, 404, 5xx cho các asset/API này:
- Kiểm tra robots.txt có chặn
/static/,/_next/,/api/hoặc thư mục build không. - Kiểm tra firewall/WAF có rule chặn Googlebot hoặc request không có cookie/session không.
- Đảm bảo header CORS, auth token không ngăn Googlebot gọi API cần thiết.
- Kiểm tra robots.txt có chặn
- Kiểm tra log cho:
- Các route quan trọng có được crawl thường xuyên không:
- Xác định nhóm URL quan trọng:
- Danh mục (category, collection).
- Trang sản phẩm, bài viết, landing page.
- Trang hub nội dung (tag, topic).
- Phân tích tần suất crawl:
- Nếu chỉ một phần nhỏ URL trong nhóm này được Googlebot truy cập, có thể internal link hoặc sitemap chưa tốt.
- Nếu Googlebot chỉ crawl sâu 2–3 level click, cần tối ưu cấu trúc link và pagination.
- Xác định nhóm URL quan trọng:
- Phát hiện request đến URL lỗi, redirect chain, tham số không cần thiết:
- Lọc log theo:
- Status 3xx nhiều lần liên tiếp cho cùng một URL (redirect chain).
- Status 404/410 cho pattern URL cụ thể (tham số filter, sort, tracking).
- Nếu thấy Googlebot tiêu tốn nhiều crawl budget vào URL có tham số không cần thiết:
- Cân nhắc dùng canonical về URL sạch.
- Cấu hình URL Parameters trong GSC (nếu phù hợp) hoặc xử lý redirect/normalize URL ở level app/router.
- Lọc log theo:
Nếu log cho thấy Googlebot không truy cập được asset hoặc API quan trọng, cần phối hợp giữa team SEO, dev và infra để rà soát robots.txt, header, firewall, CDN rule, cũng như kiến trúc route của ứng dụng.
Test status code, redirect, canonical, noindex, sitemap và robots trước khi deploy
Với pipeline CI/CD hiện đại, website React, Vue, Next.js thường được deploy liên tục. Để tránh lỗi SEO nghiêm trọng lan ra production, nên thiết kế một lớp audit SEO tự động trong pipeline với mức độ chi tiết cao:
- Kiểm tra status code cho các route chính:
- Xây dựng danh sách URL đại diện cho từng template:
- Homepage, category, product, article, search, 404 page.
- Dùng script (Node.js, Python) hoặc tool để:
- Gửi request HEAD/GET và xác nhận status code đúng (200 cho trang tồn tại, 404 cho trang không tồn tại, 301/302 cho redirect hợp lệ).
- Đảm bảo không có trang quan trọng trả về 500/503 hoặc 200 nhưng nội dung là error message.
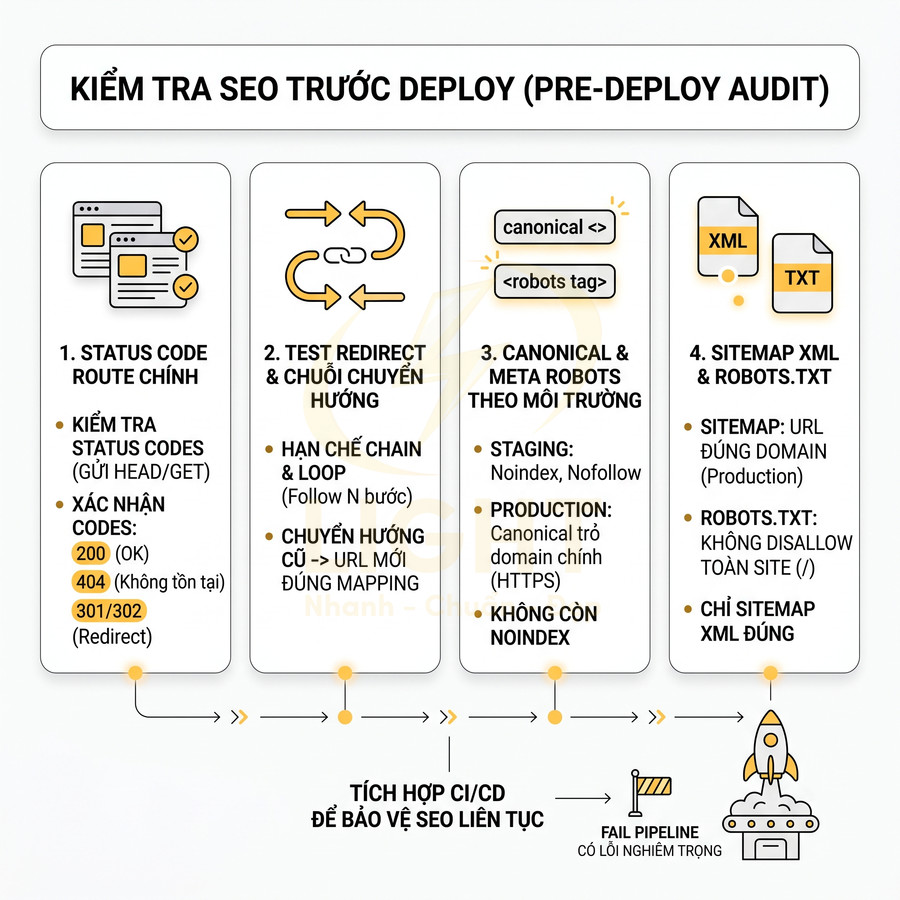
- Test redirect không tạo chain, loop, hoặc redirect sai hướng:
- Kiểm tra:
- HTTP to HTTPS, non-www to www (hoặc ngược lại) chỉ có một bước redirect.
- Các redirect cũ (legacy URL) đến URL mới đúng mapping, không vòng lặp.
- Tự động phát hiện chain:
- Script follow redirect tối đa N bước (ví dụ 5), nếu vượt quá thì flag lỗi.
- Ghi lại toàn bộ chuỗi URL để dev chỉnh sửa rule (Nginx, CDN, app router).
- Kiểm tra:
- Đảm bảo canonical và noindex đúng theo môi trường (staging vs production):
- Trên staging:
- Có thể dùng
<meta name="robots" content="noindex, nofollow">hoặc chặn bằng auth/robots.txt. - Canonical không được trỏ về domain production nếu staging có thể bị crawl.
- Có thể dùng
- Trên production:
- Đảm bảo không còn thẻ
noindexsót lại từ staging. - Canonical trỏ đúng phiên bản chuẩn (HTTPS, đúng subdomain, không có tham số thừa).
- Đảm bảo không còn thẻ
- Có thể viết test tự động:
- Fetch HTML, parse DOM, kiểm tra giá trị canonical và meta robots theo môi trường.
- Trên staging:
- Kiểm tra sitemap XML và robots.txt trỏ đúng domain, không chặn nhầm:
- Đối với sitemap XML:
- Đảm bảo
<loc>trong sitemap dùng đúng domain (production), không còn URL staging hoặc localhost. - Kiểm tra số lượng URL, tần suất update, và status code của một mẫu URL trong sitemap.
- Đảm bảo
- Đối với robots.txt:
- Đảm bảo không có rule
Disallow: /hoặc chặn thư mục quan trọng trên production. - Kiểm tra đường dẫn
Sitemap:trong robots.txt trỏ đúng file sitemap trên production.
- Đảm bảo không có rule
- Tích hợp vào CI/CD:
- Chạy test sau mỗi build, trước bước deploy chính thức.
- Nếu phát hiện noindex, canonical sai domain, hoặc robots.txt chặn toàn site, pipeline phải fail để tránh mất organic traffic.
- Đối với sitemap XML:
Các test này khi được tự động hóa bằng script hoặc công cụ chuyên dụng sẽ trở thành một lớp bảo vệ liên tục, giúp team dev triển khai nhanh mà vẫn giữ được tính ổn định và an toàn cho SEO của toàn bộ hệ thống.
Checklist triển khai website JavaScript framework chuẩn SEO
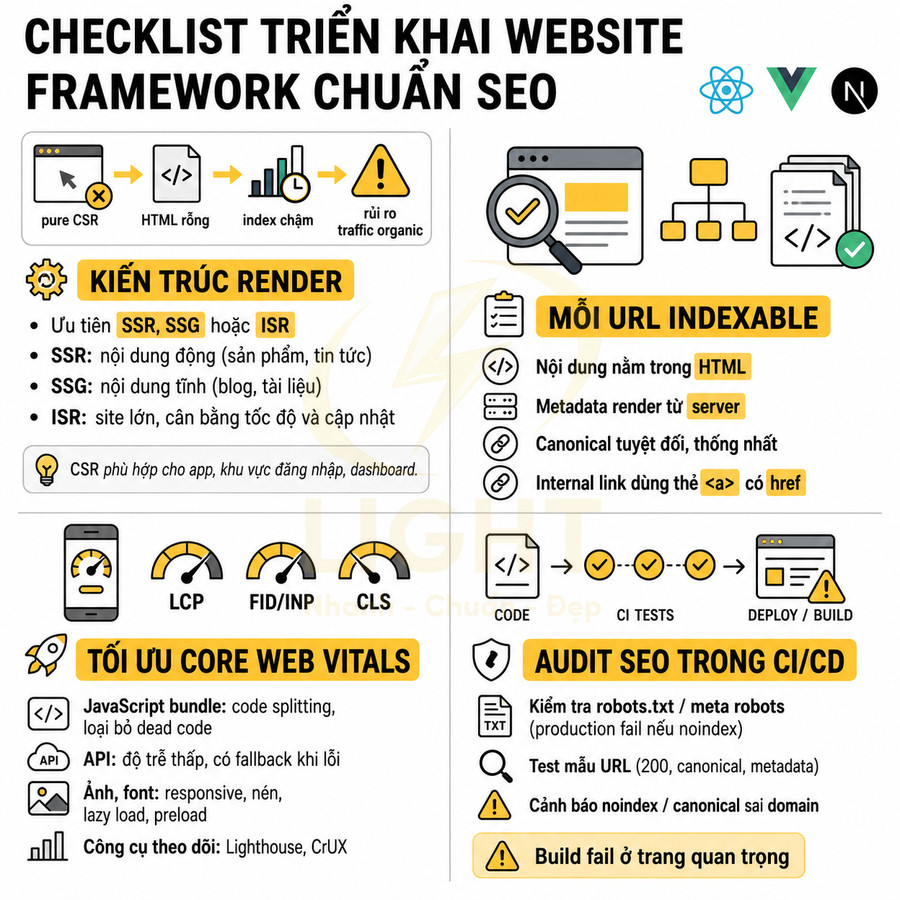
Chọn SSR, SSG hoặc ISR cho trang cần organic traffic thay vì CSR thuần
Khi thiết kế kiến trúc SEO cho website dùng React, Vue, Next.js hoặc bất kỳ JavaScript framework hiện đại nào, nguyên tắc cốt lõi là không dùng CSR thuần cho các trang cần organic traffic. CSR thuần (client-side rendering) khiến HTML ban đầu gần như rỗng, nội dung chính chỉ xuất hiện sau khi JavaScript chạy, dẫn đến:
- Googlebot phải render JavaScript, tốn thêm một bước trong quy trình index.
- Nguy cơ rendering queue chậm, nội dung được index trễ hoặc không đầy đủ.
- Khó kiểm soát trạng thái khi JS lỗi, API timeout, hoặc bundle bị block.

Thay vào đó, kiến trúc nên ưu tiên:
- SSR (Server-Side Rendering) cho các trang nội dung động, cần cập nhật nhanh:
- Trang listing sản phẩm, trang chi tiết sản phẩm có giá, tồn kho thay đổi liên tục.
- Trang tin tức, bài viết có block nội dung cá nhân hóa nhẹ nhưng vẫn cần HTML đầy đủ.
- SSR giúp Google nhận được HTML đã render sẵn, giảm phụ thuộc vào JS runtime.
- SSG (Static Site Generation) cho trang tĩnh, blog, landing page, tài liệu:
- Build trước toàn bộ HTML ở build time, deploy lên CDN, tốc độ tải cực nhanh.
- Rất phù hợp cho content evergreen, tài liệu, blog, category ít thay đổi.
- Giảm tải server, tối ưu chi phí, đồng thời đảm bảo HTML luôn sẵn sàng cho bot.
- ISR (Incremental Static Regeneration) cho trang cần cân bằng giữa cập nhật và hiệu suất:
- Phù hợp với site có hàng chục nghìn đến hàng triệu URL, nội dung thay đổi định kỳ.
- Cho phép tái sinh (re-generate) HTML theo chu kỳ hoặc on-demand mà không rebuild toàn site.
- Đảm bảo người dùng và bot luôn nhận được HTML gần như mới nhất với chi phí hợp lý.
CSR vẫn có thể dùng hiệu quả cho phần ứng dụng sau đăng nhập, dashboard, hoặc các tính năng không cần index:
- Khu vực tài khoản, quản lý đơn hàng, báo cáo nội bộ, admin panel.
- Các widget tương tác cao nhưng không phải là nội dung chính để SEO.
Chiến lược tốt là phân tách rõ phần cần SEO và phần app:
- Layer public (SEO) dùng SSR/SSG/ISR, đảm bảo mỗi URL quan trọng có HTML đầy đủ.
- Layer app (SPA) dùng CSR, tập trung vào UX, state management, logic nghiệp vụ.
- Routing nên được thiết kế sao cho bot chỉ crawl khu vực public, tránh lẫn route nội bộ.
Mỗi URL indexable có nội dung chính, metadata, canonical và internal link render được
Mỗi URL mà bạn muốn Google index cần được xem như một “đơn vị SEO” hoàn chỉnh. Về mặt kỹ thuật, mỗi URL indexable phải đáp ứng các tiêu chí sau:
- Nội dung chính xuất hiện trong HTML render được:
- Nội dung quan trọng (heading, đoạn text, danh sách, bảng, schema) phải có trong HTML trả về từ server (SSR/SSG/ISR hoặc prerender).
- Tránh pattern “shell rỗng” chỉ có skeleton, nội dung chính load qua JS sau khi bot đã snapshot HTML.
- Đảm bảo các thành phần quan trọng như H1, H2, breadcrumb, main content không phụ thuộc hoàn toàn vào client-side rendering.

- Metadata (title, description, robots) chính xác, không trùng lặp:
- Title phải được render server-side, duy nhất cho từng URL, phản ánh đúng nội dung.
- Meta description nên được generate động theo nội dung, tránh dùng một template cho toàn site.
- Meta robots (index, noindex, follow, nofollow) phải được set đúng theo chiến lược index.
- Tránh để framework override metadata sau khi load, gây chênh lệch giữa HTML initial và state cuối.
- Canonical trỏ đúng URL chuẩn:
- Canonical phải là URL tuyệt đối, thống nhất về protocol (https) và hostname.
- Không canonical nhầm sang trang khác nội dung khác, tránh mất tín hiệu xếp hạng.
- Tránh canonical tự tham chiếu sai (ví dụ thiếu slash, sai query param quan trọng).
- Đối với trang có filter, sort, pagination, cần quy ước rõ URL canonical và giữ nhất quán.
- Internal link đến và từ các trang liên quan:
- Dùng thẻ
<a>với thuộc tínhhreflà URL thực, không chỉ rely vào event onClick. - Đảm bảo link tồn tại trong HTML server-rendered, không chỉ xuất hiện sau khi JS chạy.
- Anchor text nên mô tả nội dung đích, tránh “click here” hoặc text chung chung.
- Kiểm tra rằng các component router (như
Linkcủa Next.js,<router-link>của Vue) vẫn render thành thẻ<a>chuẩn trong HTML.
- Dùng thẻ
Checklist này nên được áp dụng xuyên suốt vòng đời phát triển:
- Trong giai đoạn thiết kế kiến trúc route và layout.
- Trong quá trình coding component, đặc biệt là layout, head, navigation.
- Trong giai đoạn QA, dùng các tool như “View Source”, “Fetch as Google”, hoặc headless browser để kiểm tra HTML thực tế.
Thực hiện sớm giúp tránh các lỗi khó sửa như:
- Hàng nghìn URL bị index với title/description trùng lặp.
- Canonical sai khiến mất tín hiệu ranking của cả cụm trang.
- Internal link không crawl được do chỉ tồn tại trong state client-side.
Bundle JavaScript, API, ảnh và font được tối ưu cho mobile và Core Web Vitals
Để website React, Vue, Next.js đạt chuẩn SEO hiện đại, tối ưu hiệu suất không chỉ là “nice to have” mà là yêu cầu bắt buộc. Core Web Vitals (LCP, FID/INP, CLS) ảnh hưởng trực tiếp đến trải nghiệm người dùng và là tín hiệu xếp hạng. Checklist hiệu suất nên bao gồm:
- Bundle JavaScript:
- Chia nhỏ bundle (code splitting, route-based splitting, component-level splitting) để giảm JS tải ban đầu.
- Loại bỏ code không dùng (tree-shaking, loại bỏ polyfill dư thừa, tách code admin khỏi bundle public).
- Nén (gzip, brotli) và cấu hình cache hợp lý (long-term caching với hash, cache-control).
- Hạn chế hydration không cần thiết, ưu tiên partial hydration hoặc islands architecture nếu framework hỗ trợ.
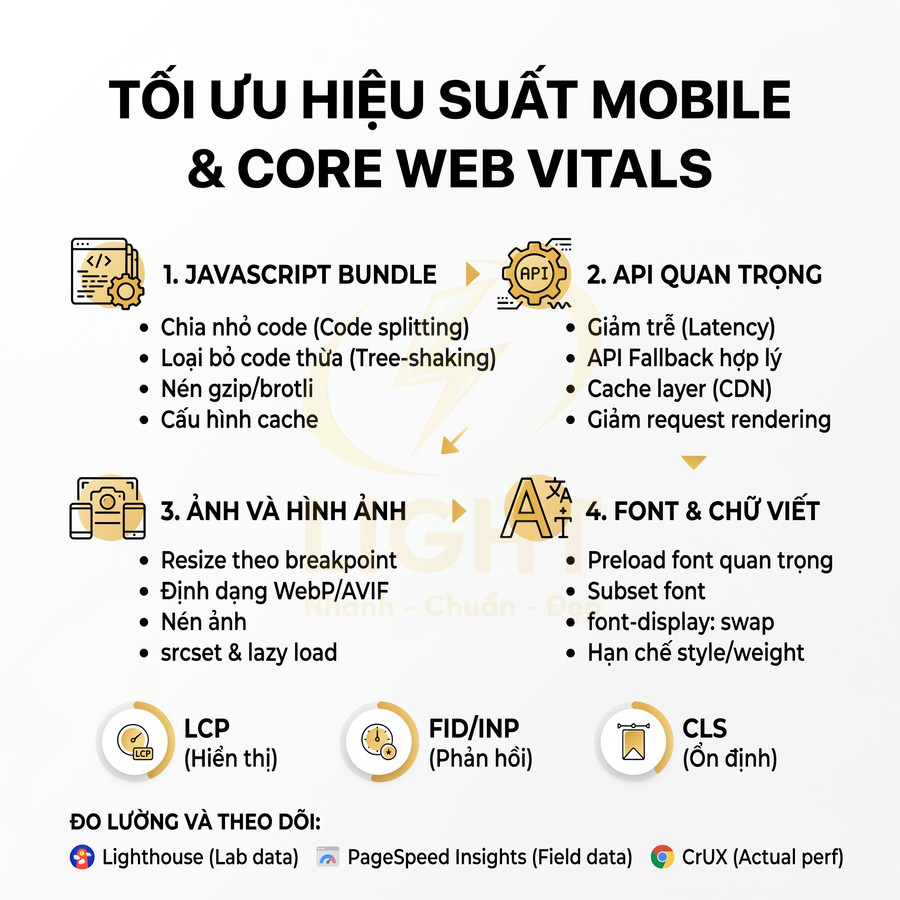
- API quan trọng:
- Tối ưu latency của API được gọi trong quá trình SSR/SSG/ISR để tránh server response chậm.
- Thiết kế fallback hợp lý khi API lỗi hoặc timeout, tránh trả về HTML rỗng hoặc skeleton không có nội dung.
- Cache layer (CDN, edge cache, application cache) cho các API đọc nhiều, ghi ít.
- Giảm số lượng request cần thiết để render above-the-fold content.
- Ảnh:
- Resize ảnh theo breakpoint, không dùng một ảnh lớn cho mọi kích thước màn hình.
- Nén ảnh (lossy/lossless) và dùng định dạng hiện đại như WebP, AVIF nếu phù hợp.
- Dùng
srcset,sizeshoặc component image của framework (nhưnext/image) để tối ưu responsive image. - Lazy load ảnh dưới màn hình đầu tiên, nhưng giữ LCP image load sớm và ổn định kích thước để tránh CLS.
- Font:
- Preload font quan trọng dùng cho text above-the-fold để giảm thời gian hiển thị.
- Subset font (chỉ giữ glyph cần thiết) để giảm kích thước file.
- Cấu hình font-display (ví dụ:
swap) để tránh text invisible quá lâu. - Hạn chế số lượng font family và weight, tránh làm tăng số request và dung lượng.
Đo lường và theo dõi liên tục bằng:
- Lighthouse: chạy trong DevTools hoặc CI để kiểm tra performance, accessibility, SEO.
- PageSpeed Insights: kết hợp dữ liệu lab và field, hiển thị Core Web Vitals từ người dùng thực.
- CrUX (Chrome User Experience Report): nguồn dữ liệu field-level để đánh giá hiệu suất thực tế theo quốc gia, thiết bị.
Việc tích hợp các công cụ này vào quy trình phát triển giúp phát hiện sớm regression về hiệu suất khi thêm tính năng mới, bundle mới hoặc thay đổi kiến trúc.
CI/CD có bước audit SEO để tránh deploy lỗi noindex, metadata hoặc route 404
Trong môi trường phát triển nhanh, nhiều branch, nhiều release mỗi ngày, các lỗi SEO nghiêm trọng như noindex toàn site, canonical sai domain, route 404 hàng loạt rất dễ xảy ra nếu không có guardrail tự động. Để giảm rủi ro, pipeline CI/CD nên được thiết kế có bước audit SEO cơ bản:
- Kiểm tra robots.txt và meta robots theo môi trường:
- Đảm bảo môi trường staging, dev có thể dùng
Disallow: /hoặc metanoindex, nhưng production thì không. - Thiết lập rule tự động: nếu branch là production, build phải fail nếu robots.txt chặn toàn bộ hoặc meta robots noindex xuất hiện trên trang quan trọng.
- So sánh robots.txt hiện tại với phiên bản chuẩn để phát hiện thay đổi ngoài ý muốn.
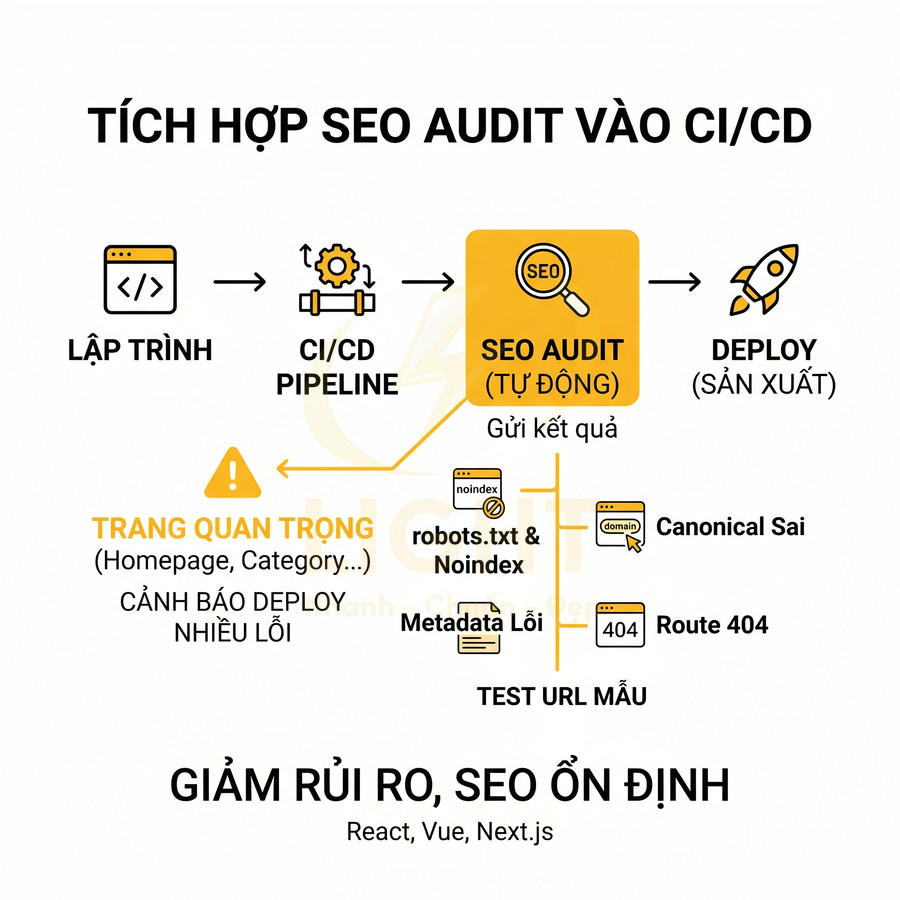
- Test một tập URL mẫu cho status code, canonical, title, description:
- Chọn tập URL đại diện: homepage, category, product, blog, landing page.
- Dùng headless browser hoặc HTTP client để fetch HTML và kiểm tra:
- Status code phải là 200 cho trang indexable, 301/302 cho redirect hợp lệ, 404/410 cho trang đã gỡ bỏ.
- Canonical phải trỏ đúng domain, đúng path, không trỏ sang môi trường staging hoặc domain test.
- Title và description không rỗng, không trùng lặp giữa các URL mẫu.
- Log kết quả vào CI để team dễ dàng review khi có thay đổi.
- Cảnh báo nếu phát hiện noindex trên trang quan trọng hoặc canonical trỏ sai:
- Định nghĩa danh sách URL “critical” (homepage, category chính, trang top traffic).
- Trong pipeline, nếu meta robots chứa
noindexhoặc header x-robots-tag chặn index trên các URL này, build phải fail hoặc raise alert. - Kiểm tra canonical không trỏ sang domain khác (ví dụ: staging.example.com, localhost) hoặc protocol http khi site dùng https.
Tích hợp audit SEO vào CI/CD giúp:
- Giảm phụ thuộc vào kiểm tra thủ công sau deploy, vốn dễ bỏ sót.
- Phát hiện sớm lỗi cấu hình khi merge code liên quan đến routing, head, layout.
- Đảm bảo website React, Vue, Next.js luôn duy trì trạng thái SEO ổn định, ngay cả khi team phát triển liên tục cập nhật tính năng mới, refactor component, hoặc thay đổi kiến trúc build.
Câu hỏi thường gặp về React, Vue, Next.js và SEO
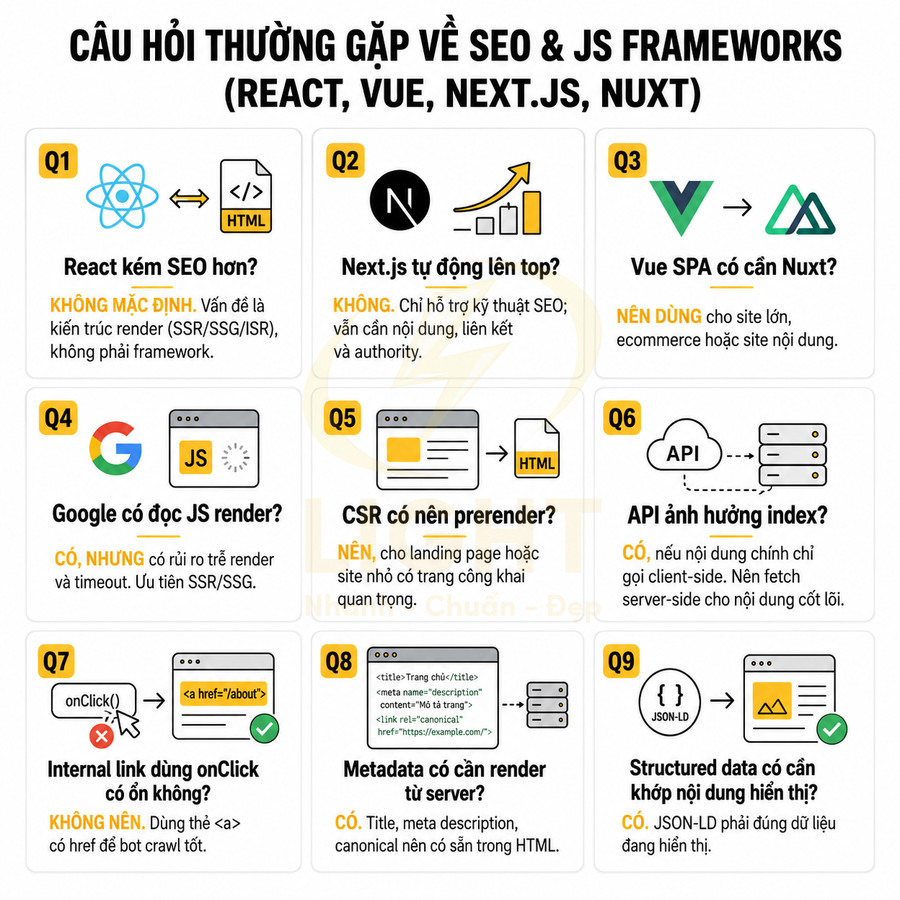
React có kém SEO hơn HTML tĩnh không?
React không mặc định kém SEO hơn HTML tĩnh; vấn đề nằm ở cách triển khai kiến trúc render. Về bản chất, Googlebot chỉ cần một tài liệu HTML có nội dung đầy đủ, cấu trúc rõ ràng và metadata chuẩn. Khi React được dùng với các kỹ thuật như SSR (Server-Side Rendering), SSG (Static Site Generation) hoặc prerender, server sẽ trả về HTML đã được render sẵn, trong đó:
- Phần nội dung chính (main content) đã xuất hiện đầy đủ trong HTML ban đầu.
- Các thẻ <title>, meta description, canonical, og:, twitter: được gắn đúng cho từng URL.
- Các đoạn structured data (JSON-LD) có thể được render server-side, giúp Google hiểu rõ loại trang (Article, Product, FAQ, Breadcrumb, Organization...).
Trong trường hợp này, React chỉ là view layer, còn về SEO, Google gần như nhìn thấy một trang HTML tĩnh hoàn chỉnh. Lợi thế của React so với HTML tĩnh nằm ở:
- Quản lý metadata động theo route, state, A/B testing, personalization.
- Tái sử dụng component cho schema, breadcrumbs, internal link blocks.
- Dễ tích hợp các logic phức tạp như phân trang, filter, sort mà vẫn giữ HTML indexable.
Vấn đề SEO thường xuất hiện khi React được dùng theo mô hình CSR (Client-Side Rendering) thuần:
- Server trả về HTML gần như rỗng, chỉ có một <div id="root"> và bundle JS.
- Nội dung chính, heading, danh sách sản phẩm/bài viết chỉ xuất hiện sau khi JS tải xong, API trả dữ liệu và React render.
- Nếu JS lỗi, API chậm, hoặc Googlebot không chờ đủ lâu, HTML mà bot thấy sẽ rất ít nội dung.
Trong bối cảnh đó, React trông có vẻ kém SEO hơn HTML tĩnh, nhưng nguyên nhân là do kiến trúc CSR, không phải do React. Để tối ưu sâu hơn cho SEO với React:
- Ưu tiên dùng Next.js, Remix hoặc framework hỗ trợ SSR/SSG thay vì tự build SSR từ đầu.
- Đảm bảo mỗi URL quan trọng có:
- HTML server-render chứa nội dung chính.
- Heading H1, H2, internal links, breadcrumbs rõ ràng.
- Metadata và canonical chính xác, không trùng lặp.
- Kiểm tra bằng:
- “View Source” để xem HTML ban đầu có nội dung hay không.
- Google Search Console > URL Inspection > View Crawled Page > HTML.
- “Mobile-Friendly Test” hoặc “Rich Results Test” để xem Google render gì.
Next.js có tự động giúp website lên top Google không?
Next.js cung cấp một hệ sinh thái rất mạnh cho SEO kỹ thuật, nhưng không phải là công cụ “auto top”. Nó giải quyết lớp “rendering & delivery”, còn thứ hạng tìm kiếm phụ thuộc vào nhiều lớp khác nhau:
- Lớp kỹ thuật (Technical SEO) – nơi Next.js hỗ trợ mạnh:
- SSR, SSG, ISR giúp tạo HTML giàu nội dung cho mỗi route.
- Routing file-based giúp tạo cấu trúc URL rõ ràng, thân thiện.
- Metadata API (trong App Router) cho phép:
- Thiết lập title, description, canonical, robots, open graph, twitter card.
- Tạo metadata động theo slug, locale, phân khúc user.
- Image Optimization, Script Strategy giúp tối ưu hiệu suất, LCP, CLS.
- ISR (Incremental Static Regeneration) cân bằng giữa nội dung động và HTML tĩnh.
- Lớp nội dung (Content & Intent):
- Chất lượng, độ sâu, tính hữu ích của nội dung so với đối thủ.
- Mức độ phù hợp với search intent (informational, transactional, commercial...).
- Cấu trúc nội dung: heading, mục lục, schema FAQ/HowTo/Article.
- Lớp authority & E-E-A-T:
- Backlink profile, mentions, brand search volume.
- Expertise, Experience, Author profile, trust signals (review, policy pages).
Next.js giúp giảm đáng kể rủi ro về:
- Trang bị Google index thiếu nội dung do CSR.
- Canonical sai, duplicate content giữa nhiều biến thể URL.
- Hiệu suất kém, ảnh hưởng Core Web Vitals.
Để tận dụng Next.js ở mức chuyên sâu cho SEO:
- Thiết kế kiến trúc URL ngay từ đầu (slug, category, locale, pagination).
- Dùng dynamic routes kết hợp SSG/ISR cho blog, category, product listing.
- Tạo sitemap.xml, robots.txt động dựa trên routes thực tế.
- Tích hợp structured data (Article, Product, Breadcrumb, FAQ) ở layer server.
Vue SPA có cần chuyển sang Nuxt để làm SEO không?
Vue SPA (Single Page Application) thuần, nếu chỉ render client-side, sẽ gặp các vấn đề tương tự React CSR về SEO. Vẫn có thể làm SEO bằng cách:
- Dùng prerender cho một số route quan trọng (home, category, landing).
- Tự tích hợp SSR thủ công với Node server, Vue server renderer.
Tuy nhiên, với các website nội dung lớn, ecommerce, SaaS nhiều trang, việc tự duy trì SSR, routing, metadata, schema sẽ nhanh chóng trở nên phức tạp. Trong bối cảnh đó, chuyển sang Nuxt thường hợp lý hơn vì:
- Hỗ trợ SSR, SSG, hybrid rendering ngay ở cấp framework.
- Routing tự động dựa trên cấu trúc thư mục, dễ mapping với sitemap và kiến trúc SEO.
- Quản lý head/meta (title, description, canonical, og, twitter) theo từng page component.
- Hỗ trợ middleware cho logic redirect, auth, locale – quan trọng cho SEO quốc tế.
- Dễ tổ chức structured data theo page type (blog, product, category).
Với Vue SPA nhỏ, landing page, dashboard nội bộ, có thể không cần Nuxt. Nhưng với:
- Blog/portal nội dung nhiều nghìn bài.
- Website thương mại điện tử với nhiều category, filter, pagination.
- SaaS có public docs, knowledge base, marketing site.
Nuxt giúp đảm bảo:
- Mỗi URL có HTML indexable, không phụ thuộc hoàn toàn vào JS client.
- Metadata, canonical, hreflang (nếu đa ngôn ngữ) được quản lý tập trung.
- Hiệu suất tốt hơn nhờ SSG/ISR, giảm TTFB và cải thiện Core Web Vitals.
Google có đọc được nội dung render bằng JavaScript không?
Google có khả năng render JavaScript, bao gồm các ứng dụng React, Vue, Next.js, Nuxt, nhưng quá trình này diễn ra theo hai bước:
- Crawl & index HTML ban đầu:
- Googlebot tải HTML, CSS, một phần JS cơ bản.
- Nếu HTML ban đầu đã có nội dung, Google có thể index ngay phần đó.
- Render JavaScript (Web Rendering Service):
- Google đưa trang vào hàng đợi để render JS đầy đủ.
- Sau khi render, nội dung bổ sung mới có thể được index.
- Quá trình này tốn tài nguyên và có thể bị trì hoãn.
Các rủi ro khi phụ thuộc quá nhiều vào JS phức tạp:
- API chậm hoặc lỗi khiến nội dung không xuất hiện kịp khi render.
- Hydration lỗi, exception JS làm React/Vue không mount được.
- Logic điều kiện (feature flag, AB test) ẩn nội dung với bot.
Vì vậy, dù Google hỗ trợ JS, vẫn nên ưu tiên:
- SSR, SSG, ISR hoặc prerender cho:
- Trang landing, category, product, blog post.
- Trang có search intent rõ ràng và mang lại traffic.
- Đảm bảo nội dung quan trọng (title, H1, đoạn mở đầu, danh sách item chính) có mặt trong HTML server-render.
- Tránh phụ thuộc vào event client-side (scroll, click) để load nội dung cốt lõi.
Website dùng CSR có nên prerender các trang quan trọng không?
Với website đang chạy CSR thuần (React/Vue SPA), việc refactor toàn bộ sang SSR/SSG có thể tốn kém. Trong trường hợp này, prerender các trang quan trọng là giải pháp thực tế để cải thiện SEO mà không thay đổi toàn bộ kiến trúc.
Prerender hoạt động bằng cách:
- Dùng một service hoặc tool (headless browser) để:
- Load ứng dụng SPA như trình duyệt thật.
- Chờ JS chạy xong, nội dung render đầy đủ.
- Snapshot HTML cuối cùng và lưu lại.
- Server cấu hình để:
- Trả HTML prerender cho bot (Googlebot, Bingbot) hoặc cho một số route.
- Trả SPA bình thường cho user.
Lợi ích:
- Các route quan trọng (home, category chính, landing page) có HTML giàu nội dung.
- Giảm rủi ro Google index trang rỗng do JS chưa chạy.
- Không cần viết lại toàn bộ app sang SSR framework.
Hạn chế:
- Khó mở rộng cho site rất lớn với hàng chục nghìn URL.
- Quản lý cache, invalidation phức tạp khi nội dung thay đổi thường xuyên.
- Có thể phát sinh vấn đề khi phân biệt bot và user (user-agent sniffing).
Với site lớn, nhiều trang và nội dung cập nhật thường xuyên, kiến trúc SSR/SSG/ISR qua Next.js, Nuxt thường bền vững hơn so với prerender thủ công, vì:
- Render diễn ra như một phần tự nhiên của build/deploy pipeline.
- Không cần duy trì thêm một lớp prerender service riêng.
- Dễ tích hợp với CDN, cache, revalidation.
Dùng API để tải nội dung có ảnh hưởng đến index không?
Dùng API để tải nội dung là mô hình phổ biến trong các ứng dụng hiện đại (headless CMS, microservices, backend for frontend). Về SEO, điểm mấu chốt không phải là “có dùng API hay không”, mà là API được gọi ở đâu trong pipeline render.
Trường hợp tốt cho SEO:
- API được gọi trong SSR/SSG/ISR:
- Next.js: gọi API trong
getServerSideProps,getStaticProps, hoặc server components. - Nuxt: gọi API trong
asyncData,fetch, hoặc server-side composables.
- Next.js: gọi API trong
- Server nhận dữ liệu từ API, render HTML hoàn chỉnh rồi trả về cho client.
- Googlebot thấy nội dung ngay trong HTML ban đầu, không cần chờ JS.
Trường hợp rủi ro cho SEO:
- API chỉ được gọi client-side (useEffect, mounted, onCreated...).
- HTML ban đầu không chứa nội dung chính, chỉ có skeleton/loading.
- Nếu JS bị chặn, lỗi, hoặc Google không render kịp, nội dung sẽ không được index đầy đủ.
Để tối ưu sâu hơn khi dùng API:
- Đối với nội dung quan trọng cho SEO (title, H1, đoạn mô tả, danh sách item chính):
- Ưu tiên gọi API ở server-side (SSR/SSG/ISR).
- Đảm bảo HTML trả về đã chứa dữ liệu này.
- Dùng client-side API call cho:
- Dữ liệu phụ, không quan trọng cho index (widget, personalization, recommendation).
- Phần tương tác sau khi trang đã được index (filter, sort, infinite scroll).
- Thiết kế API ổn định, nhanh, tránh timeout hoặc lỗi 5xx trong quá trình server render.



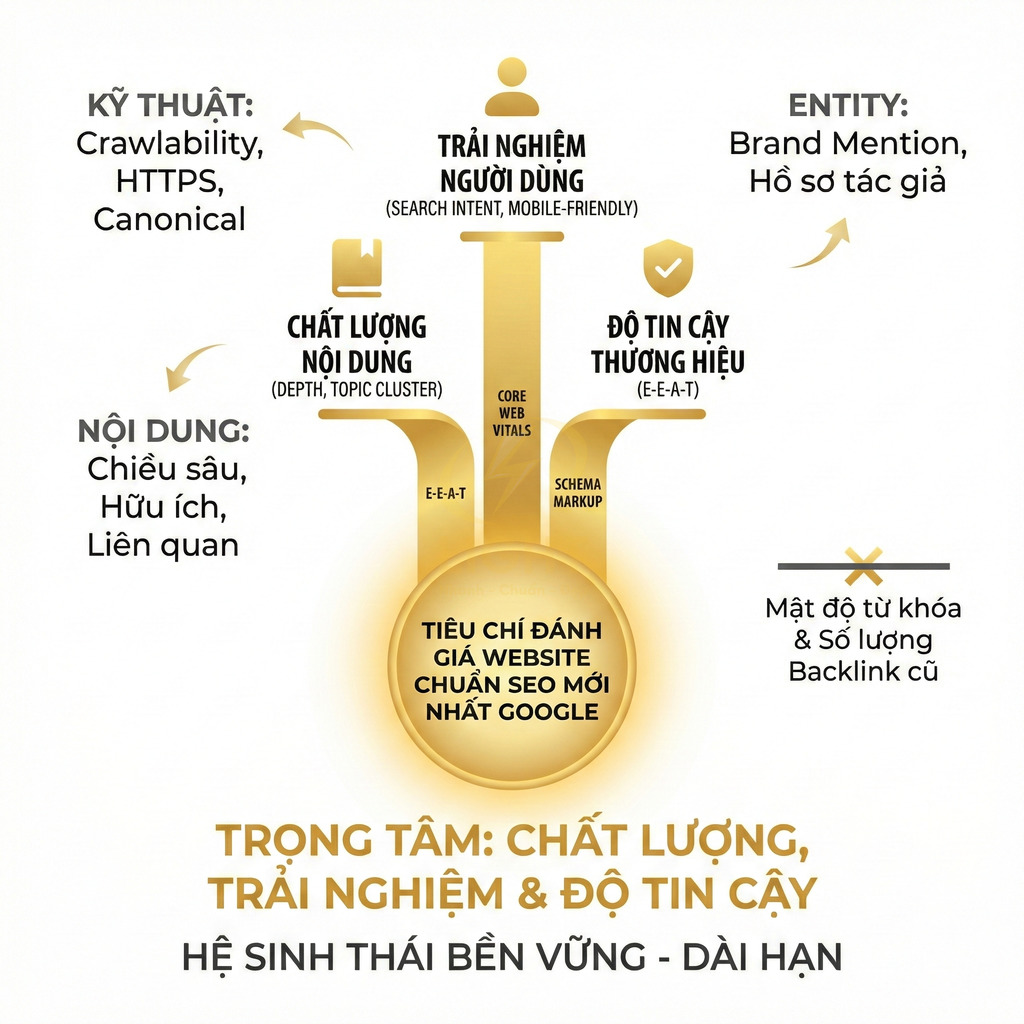

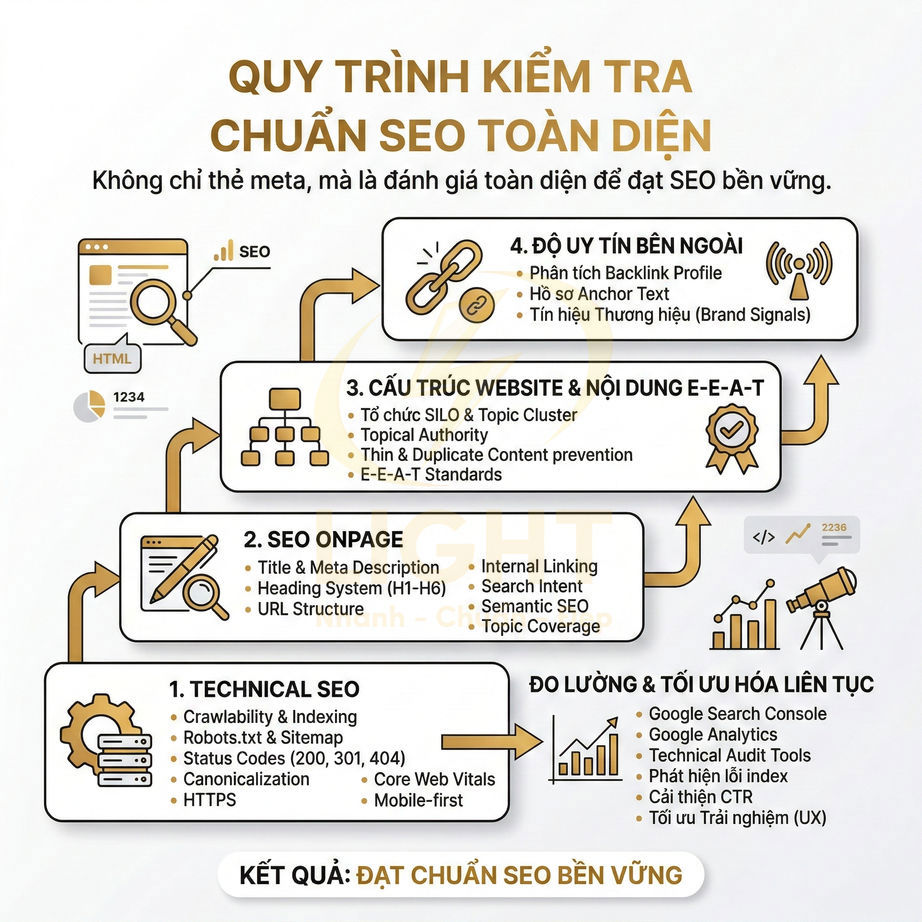
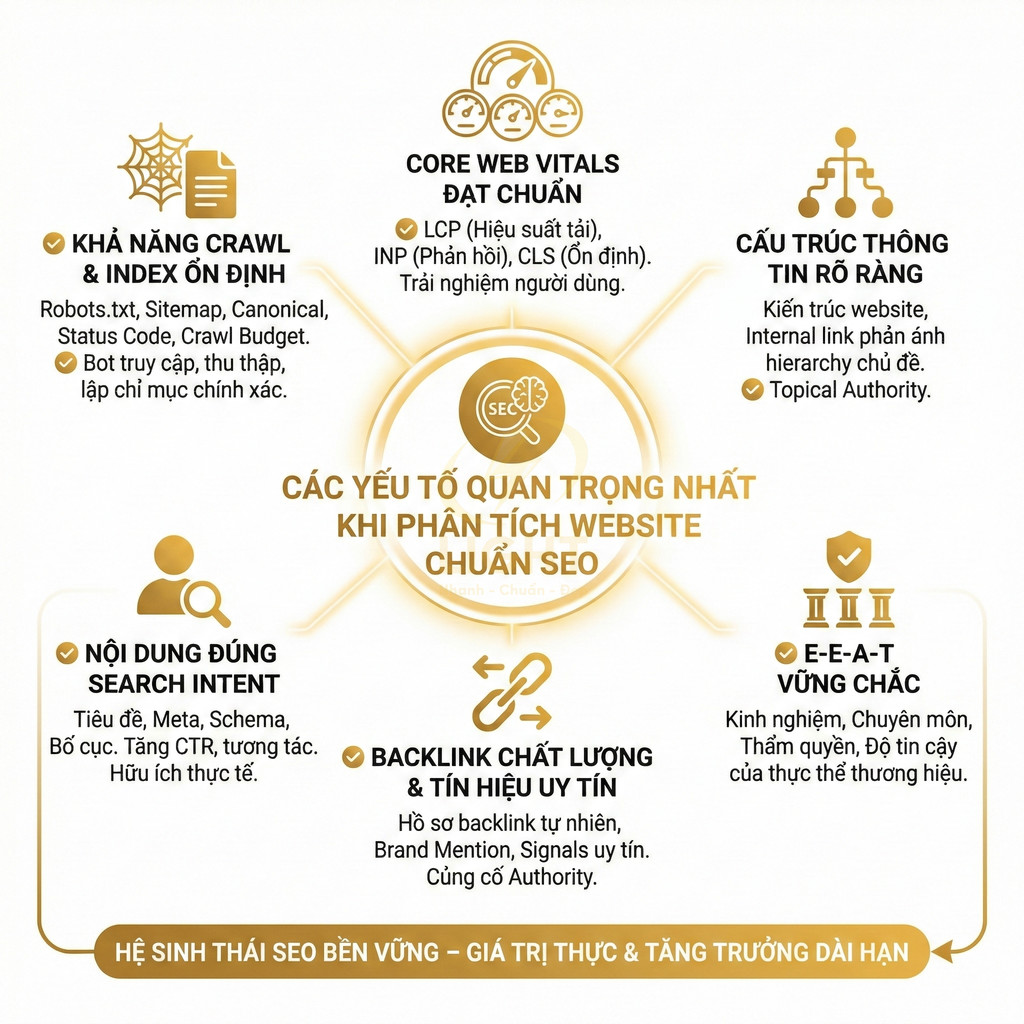

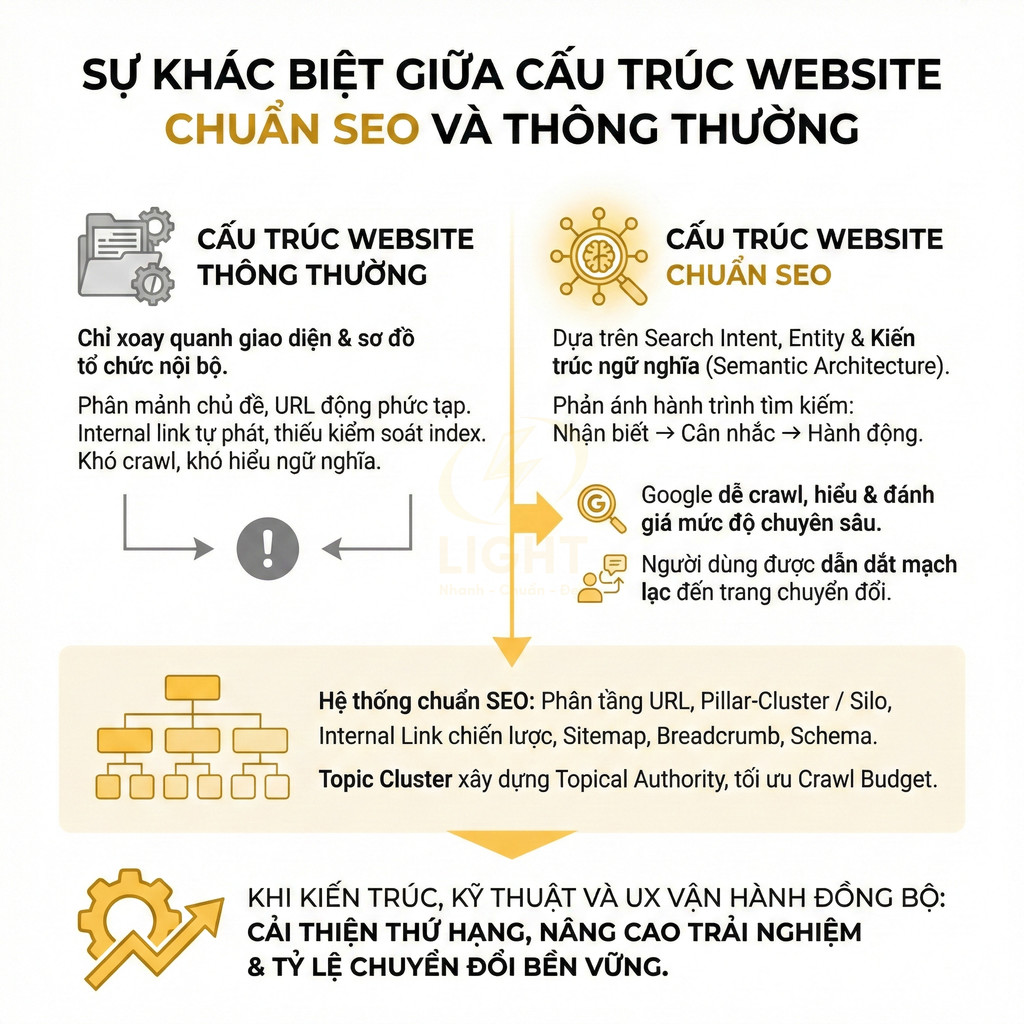

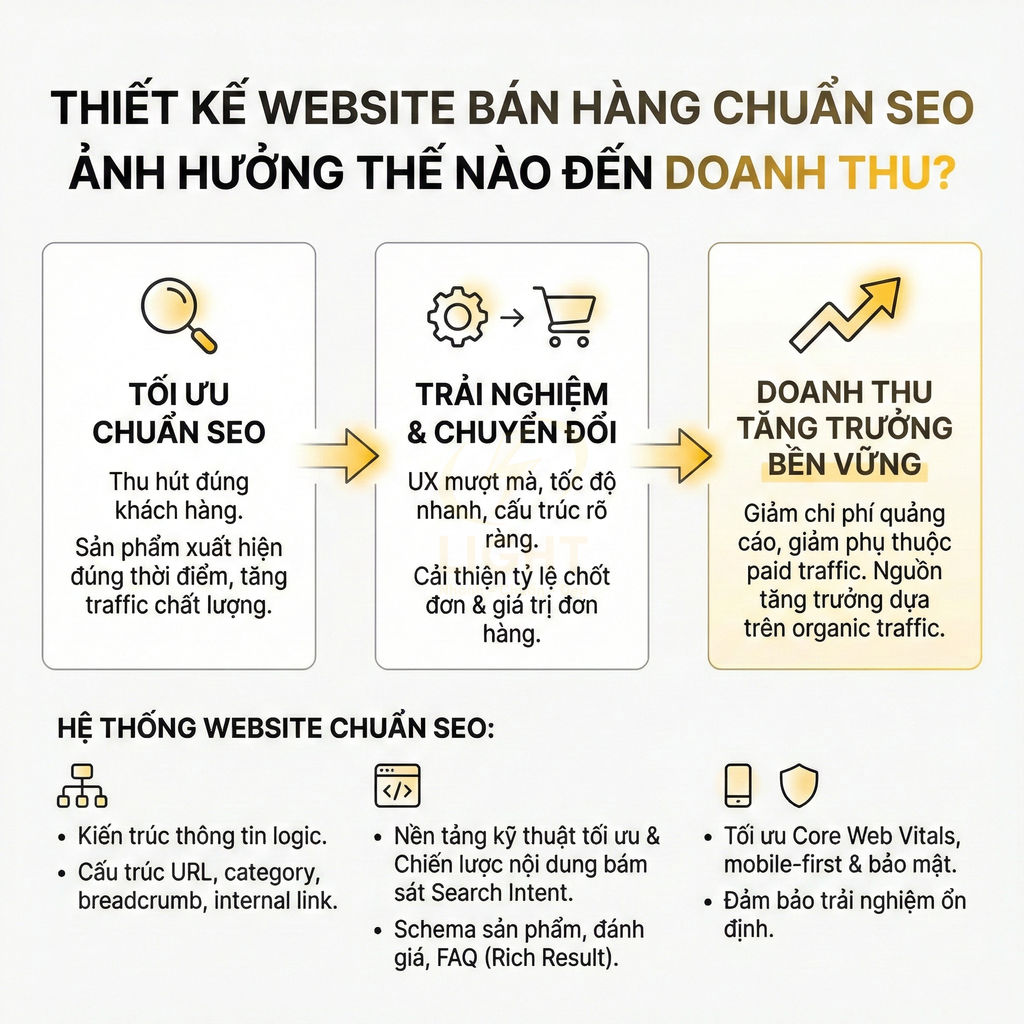


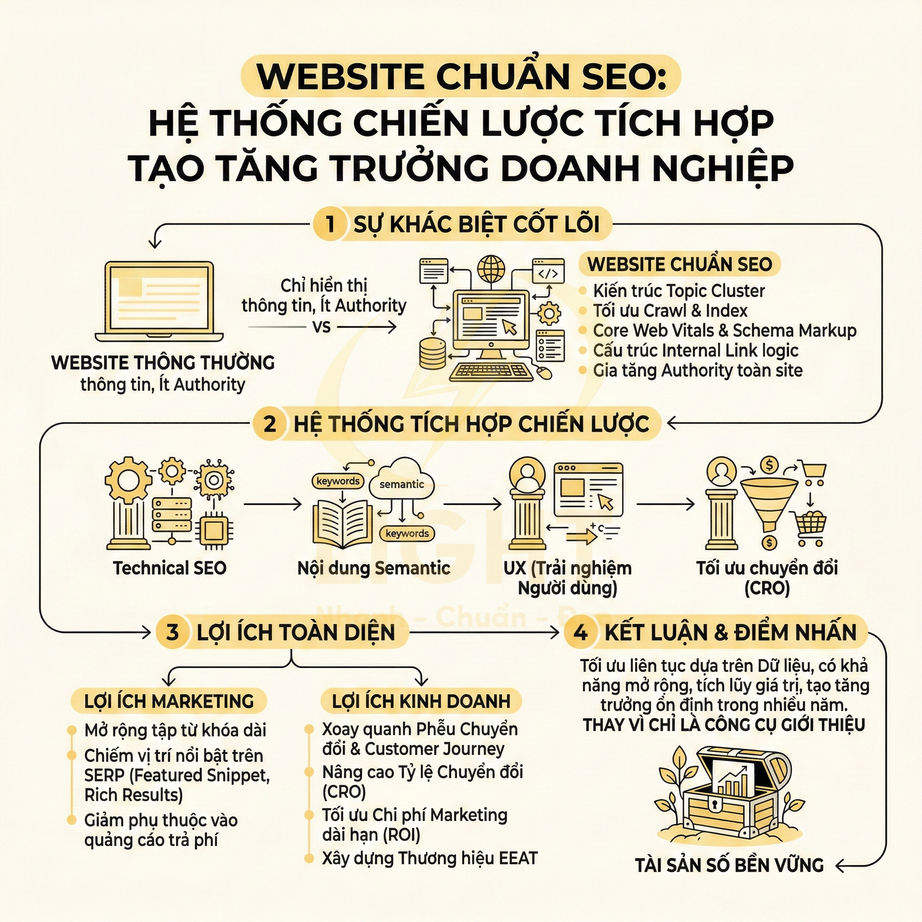
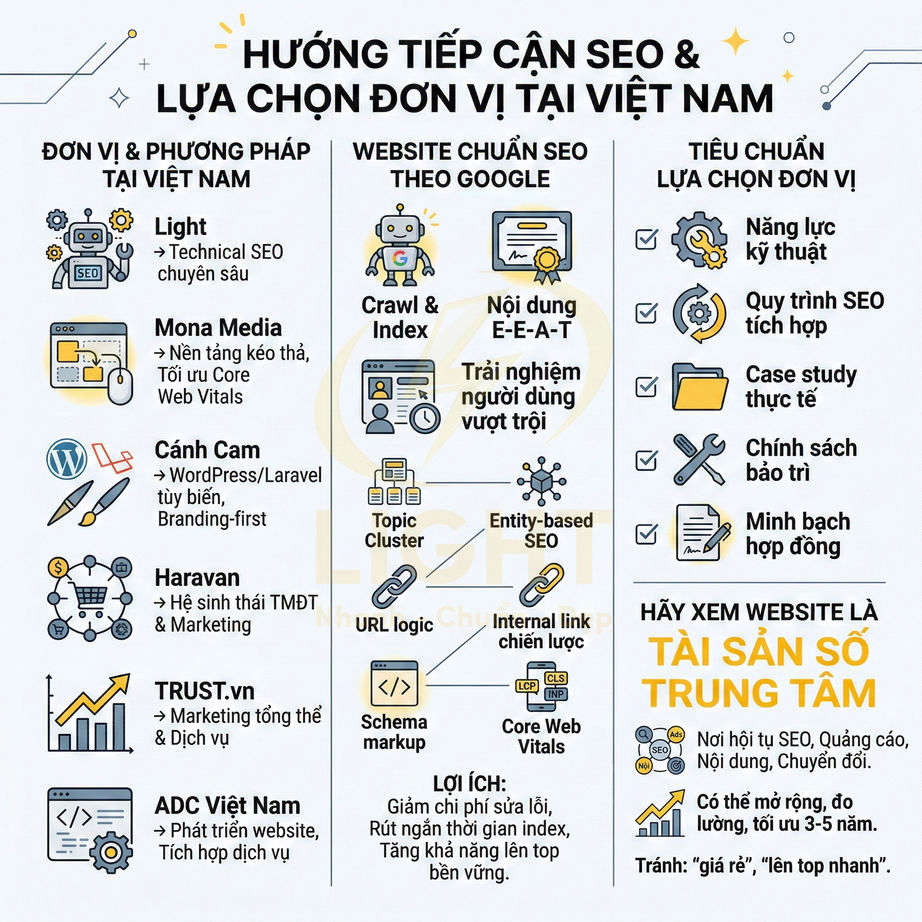
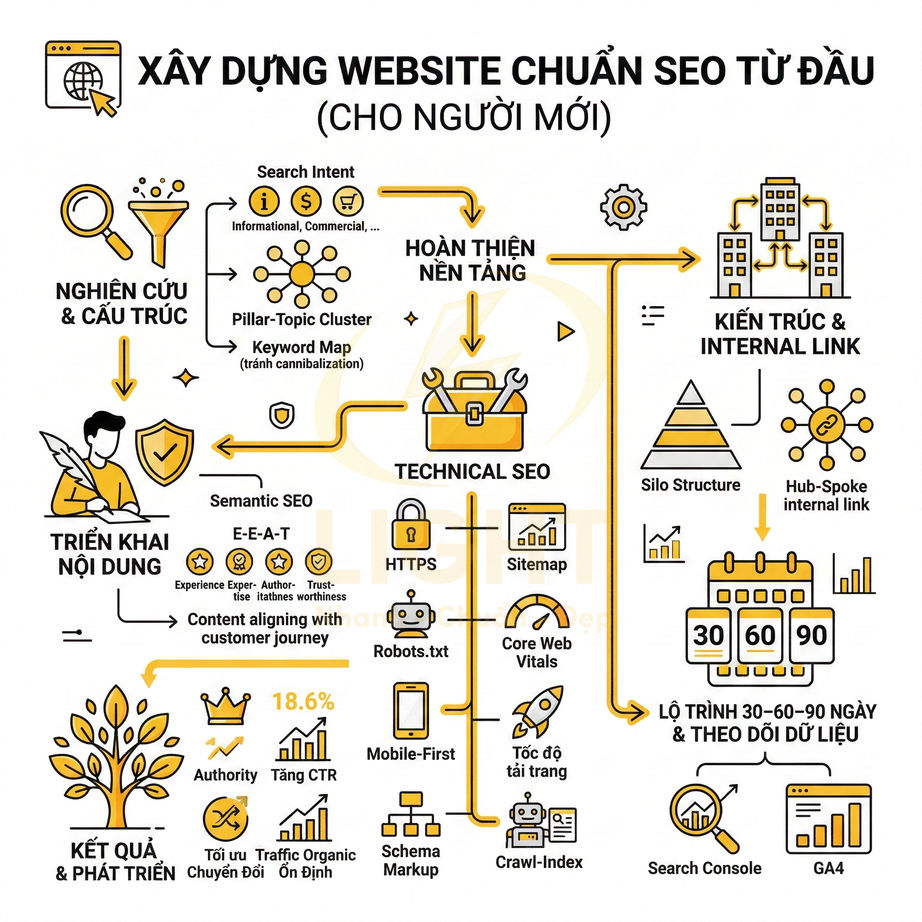
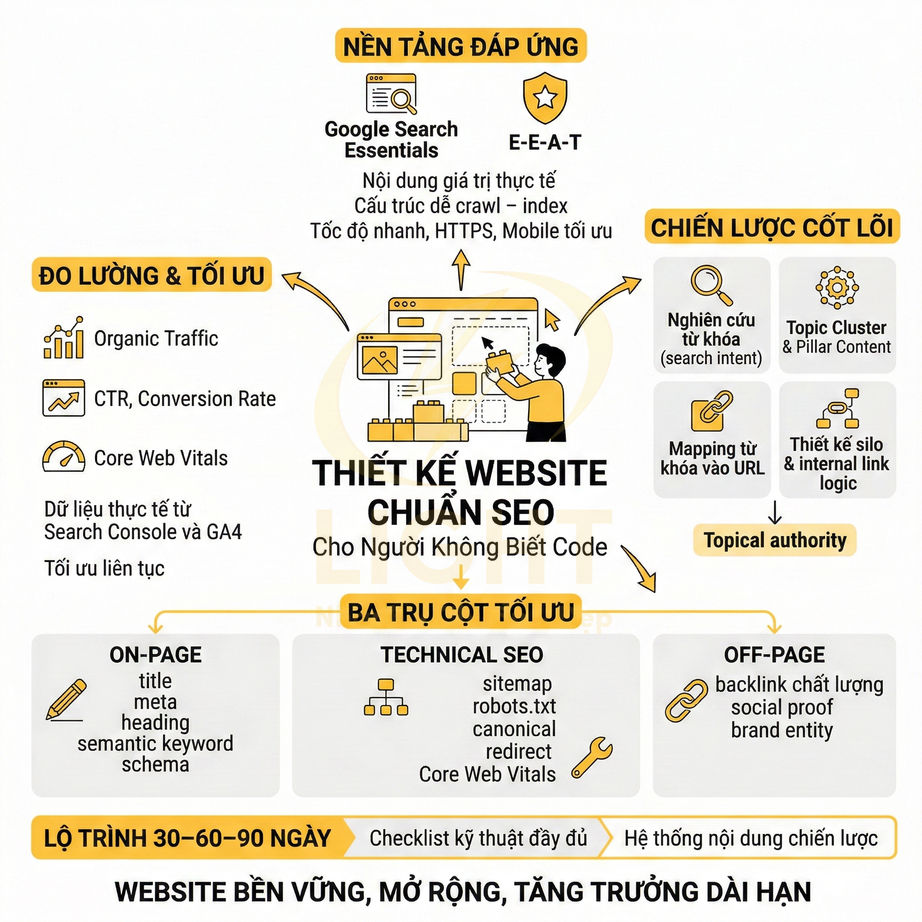



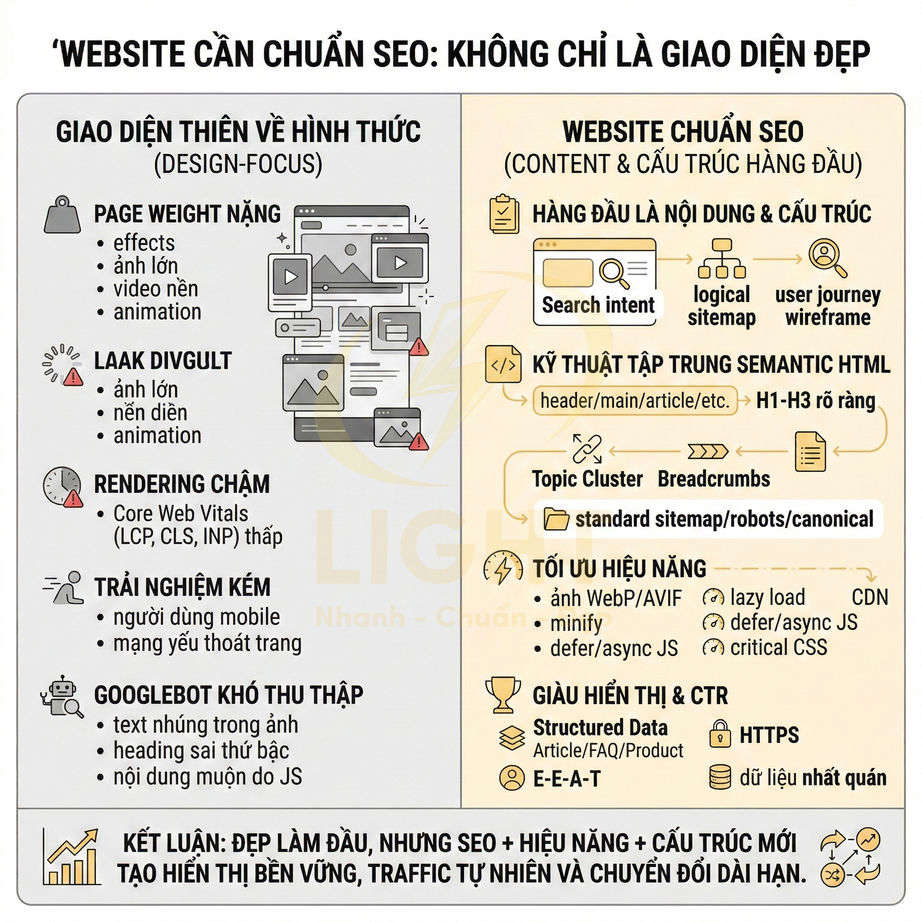

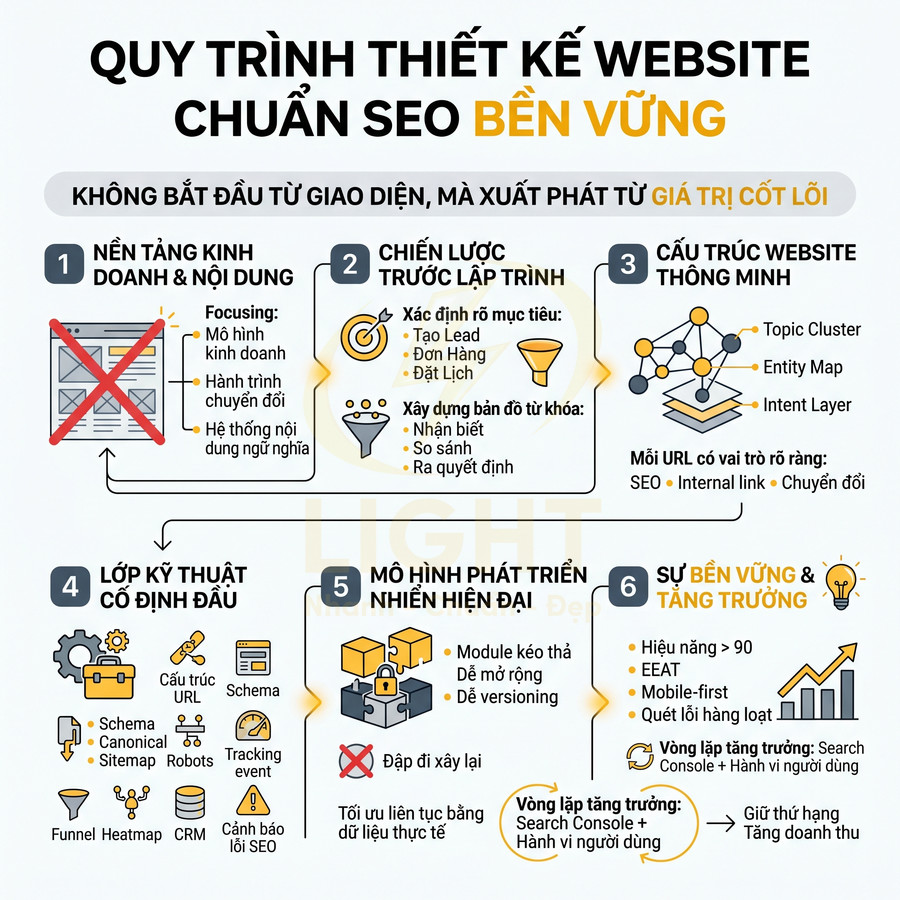
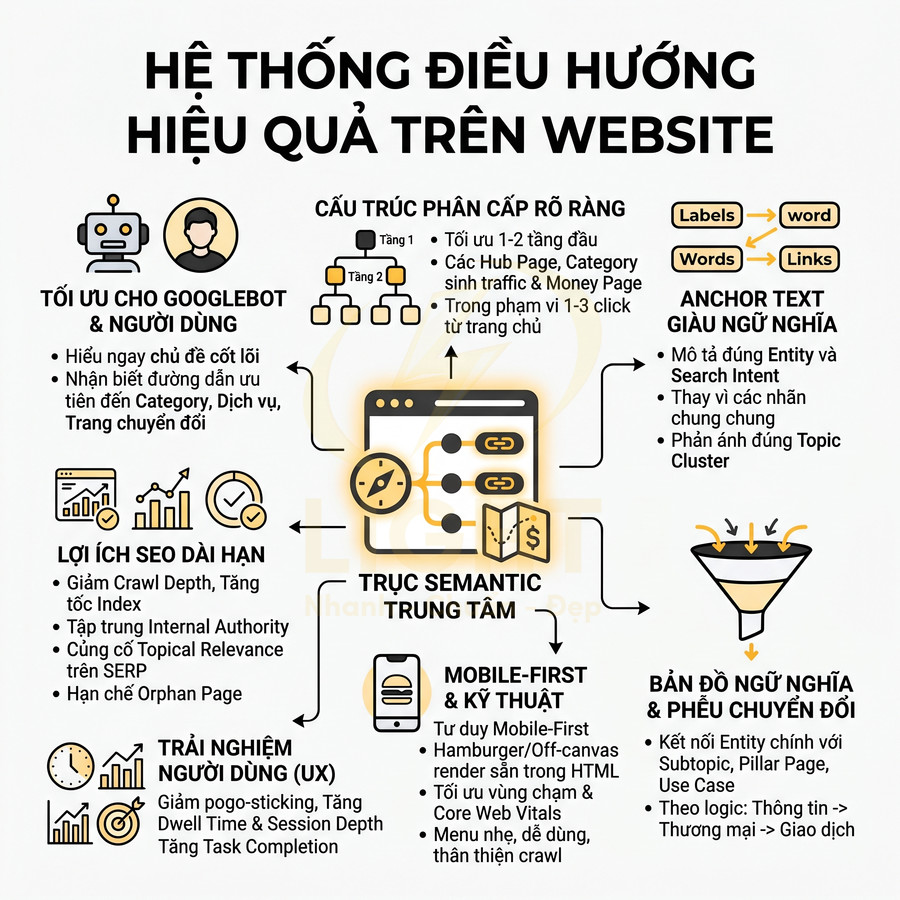
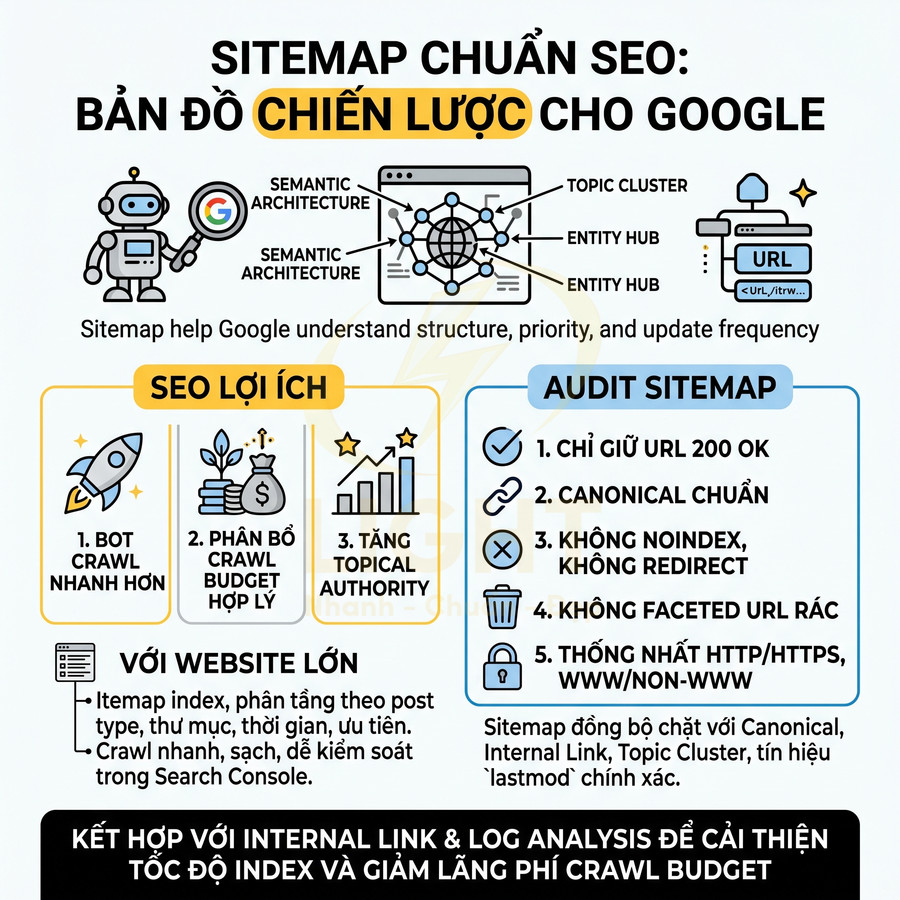
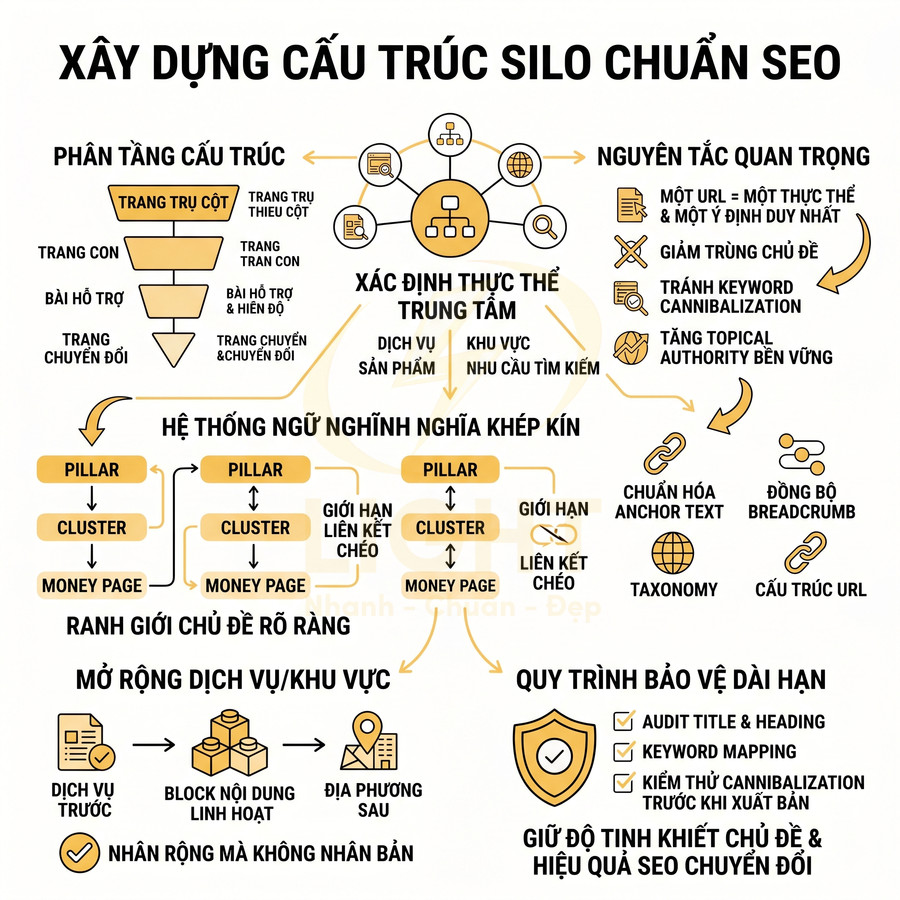
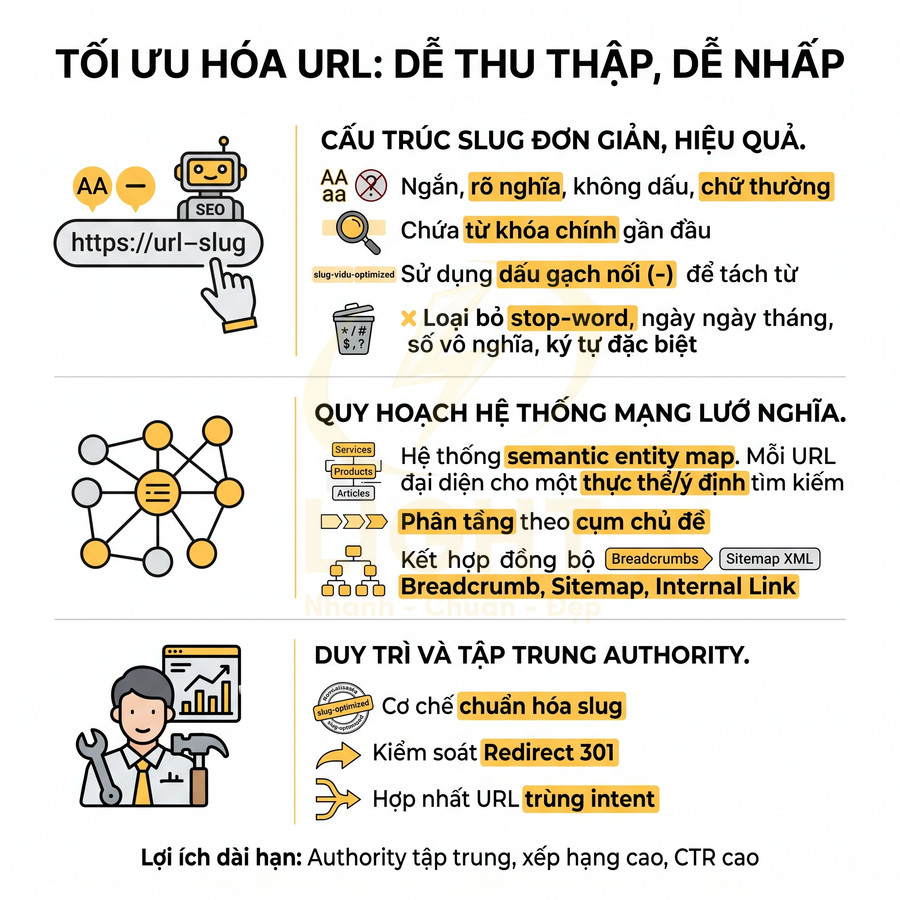
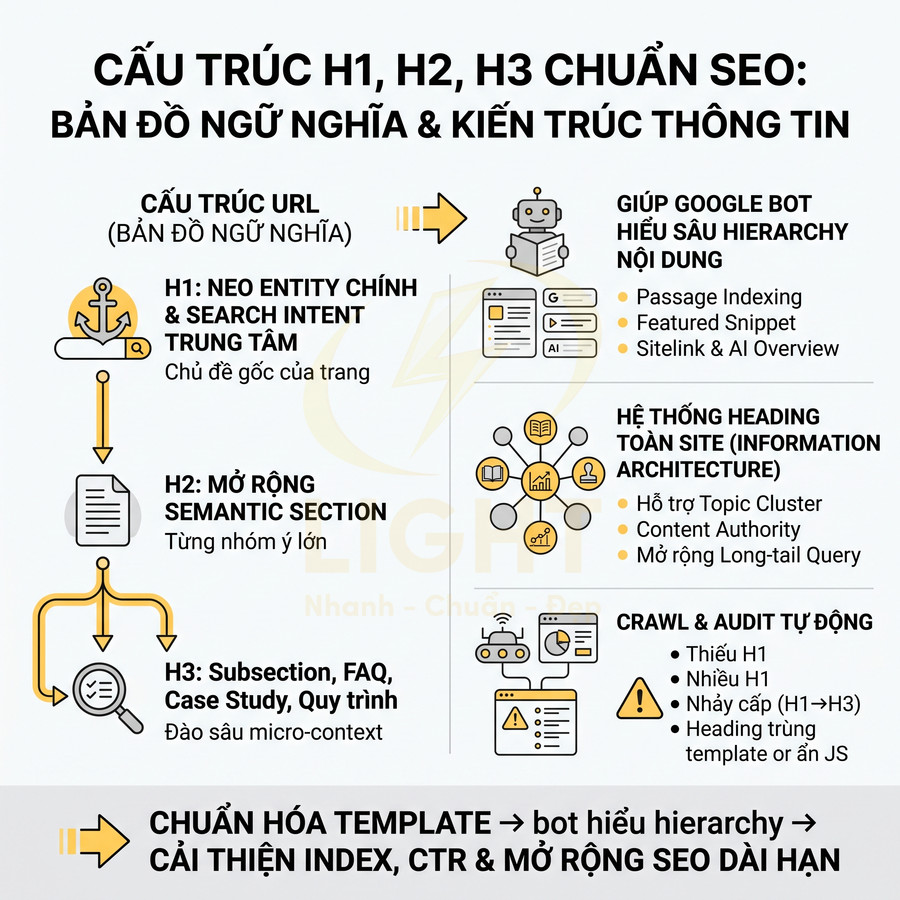
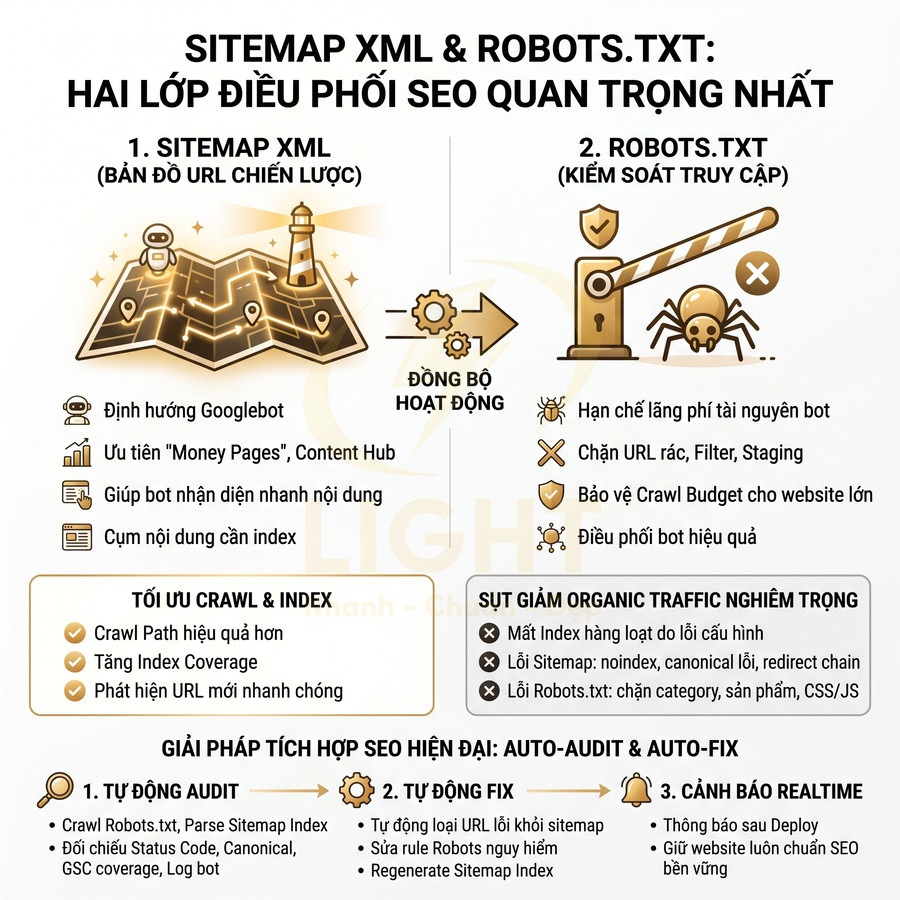
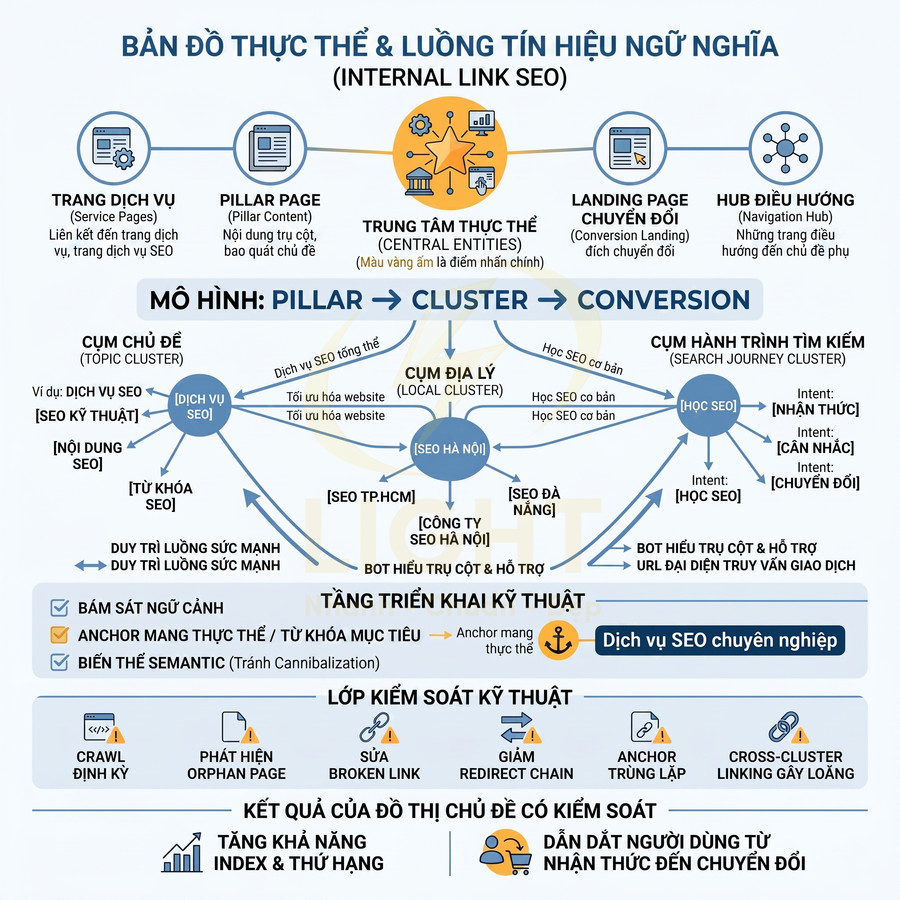
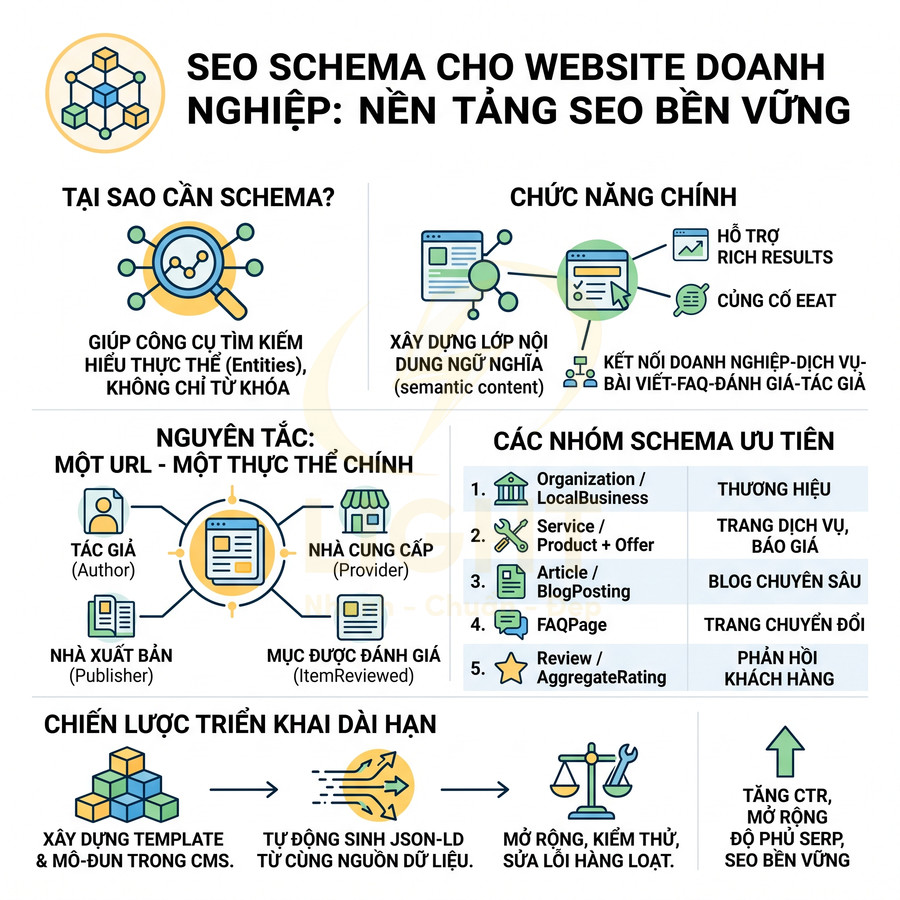
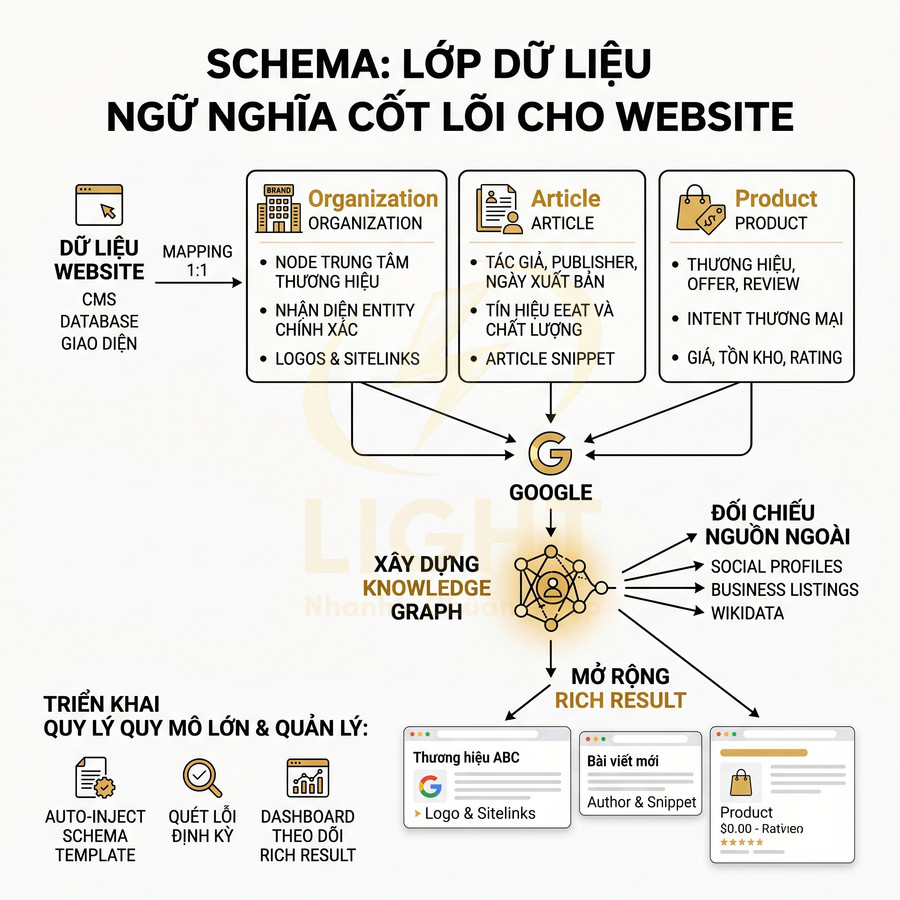

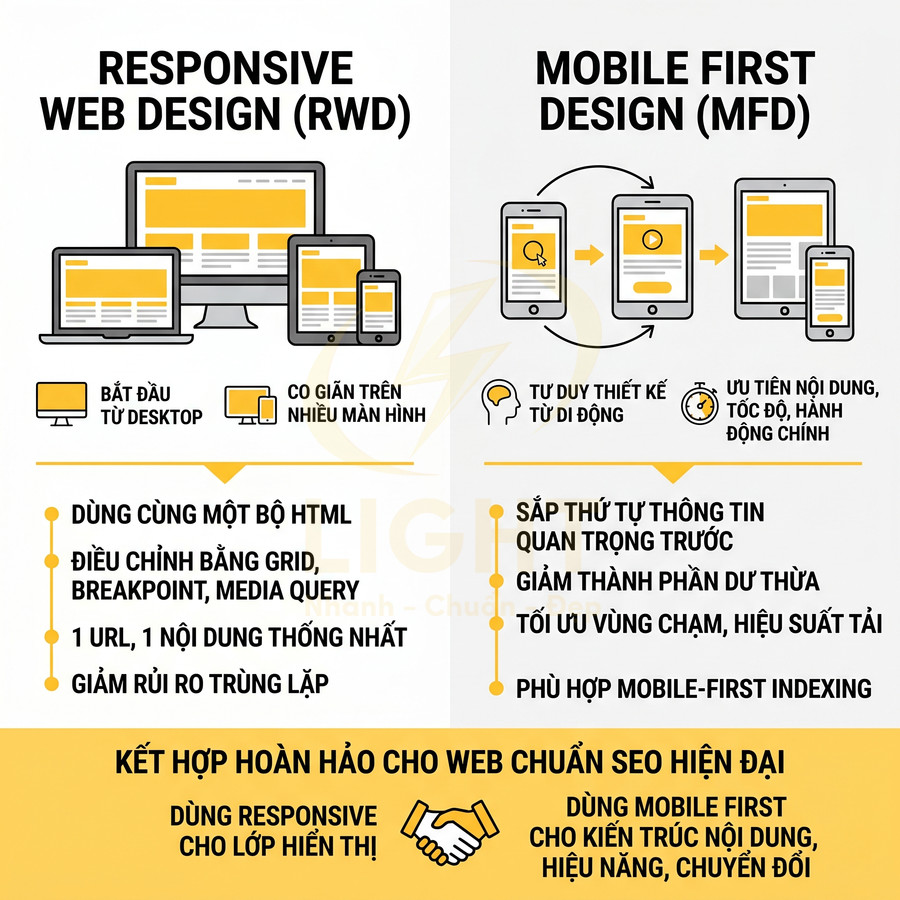

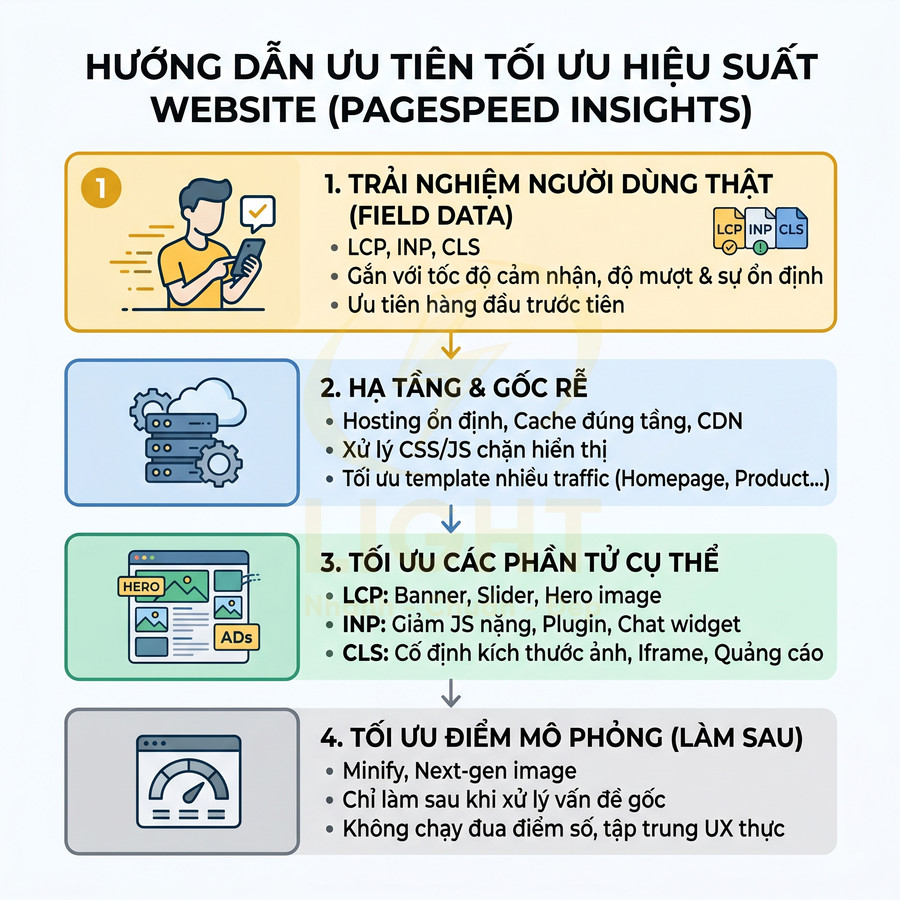
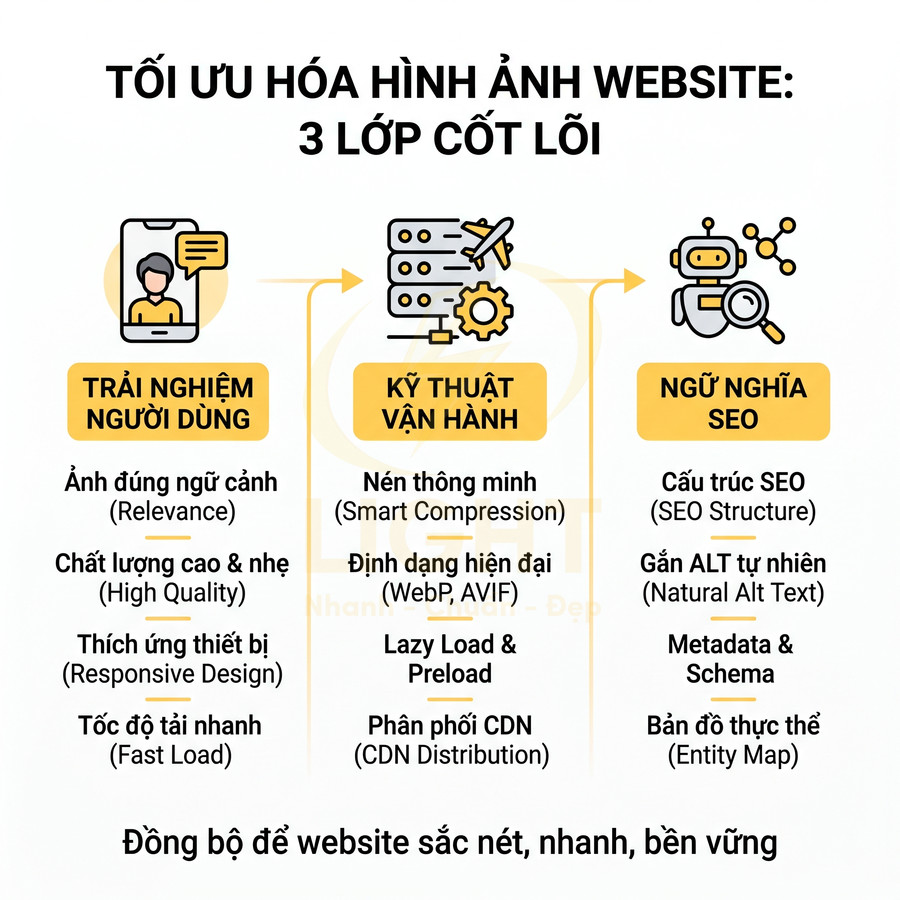

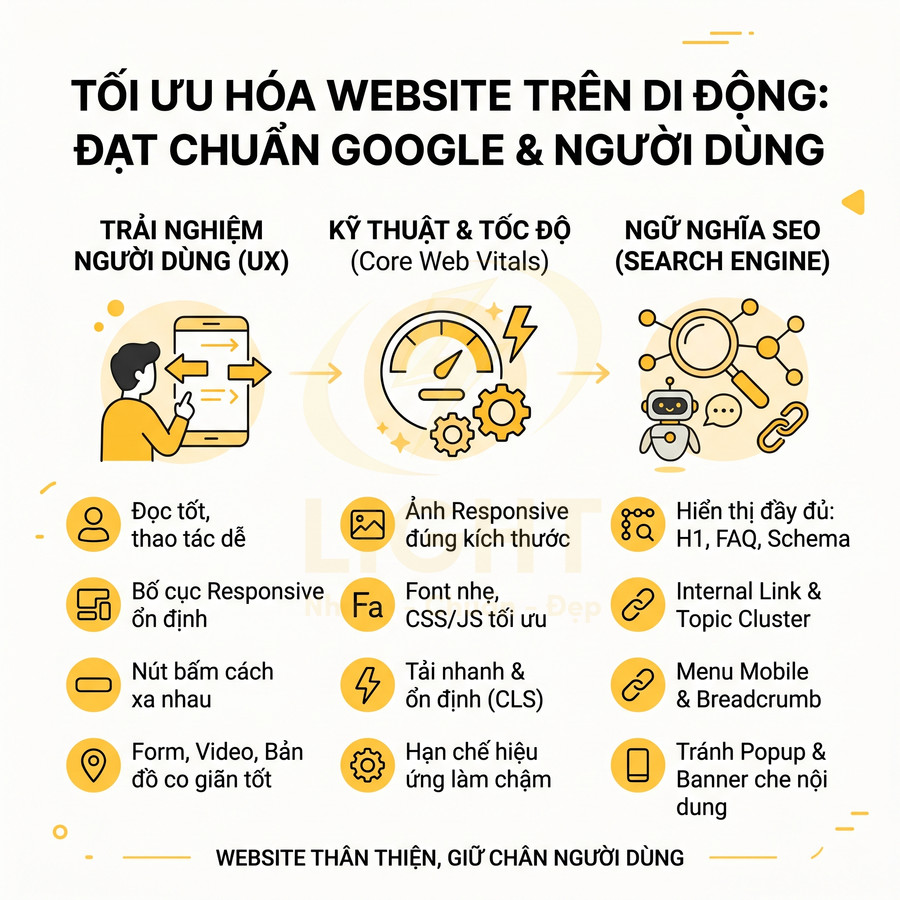
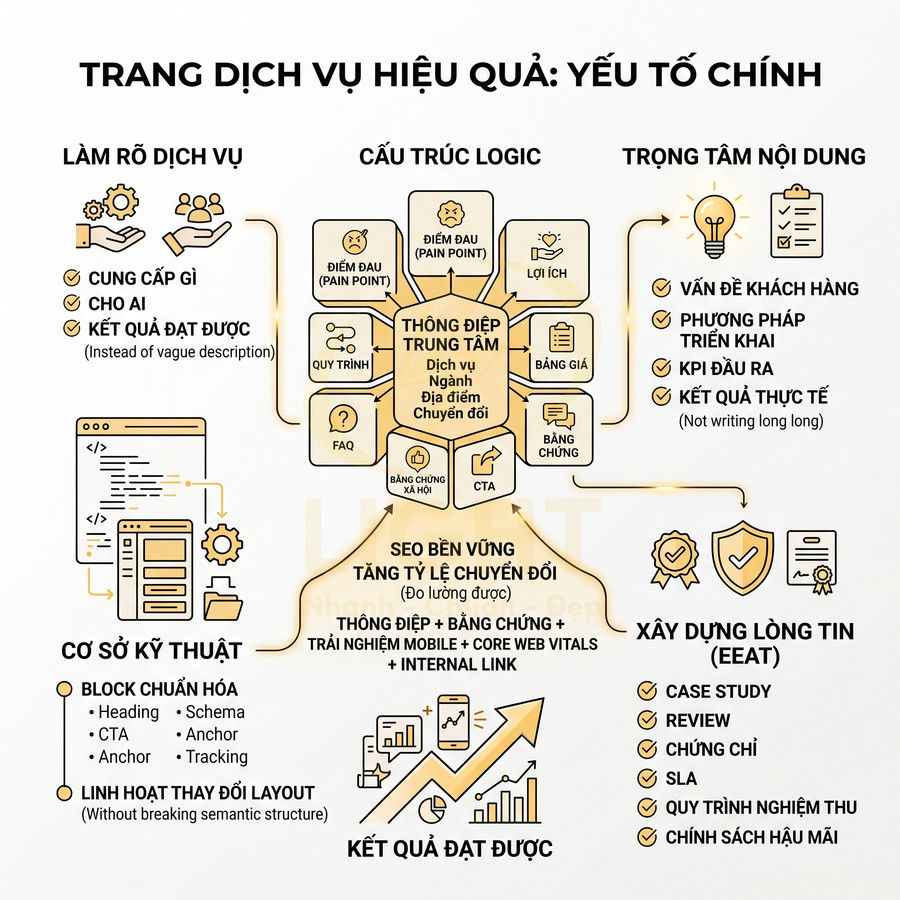
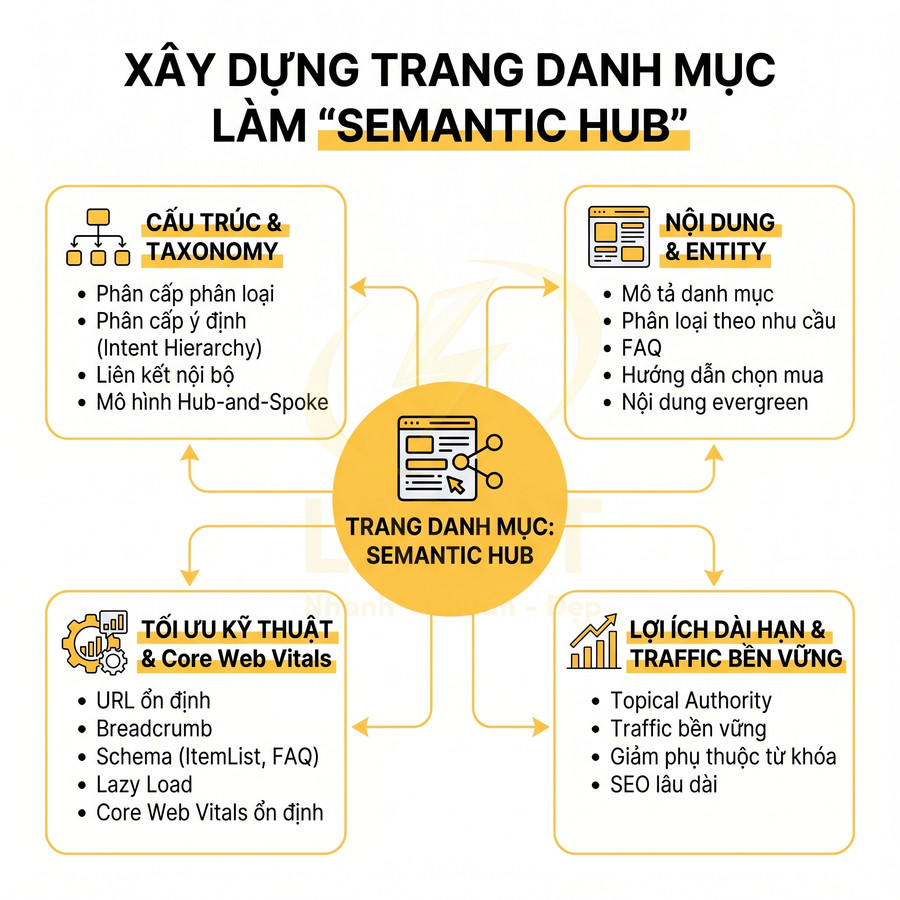

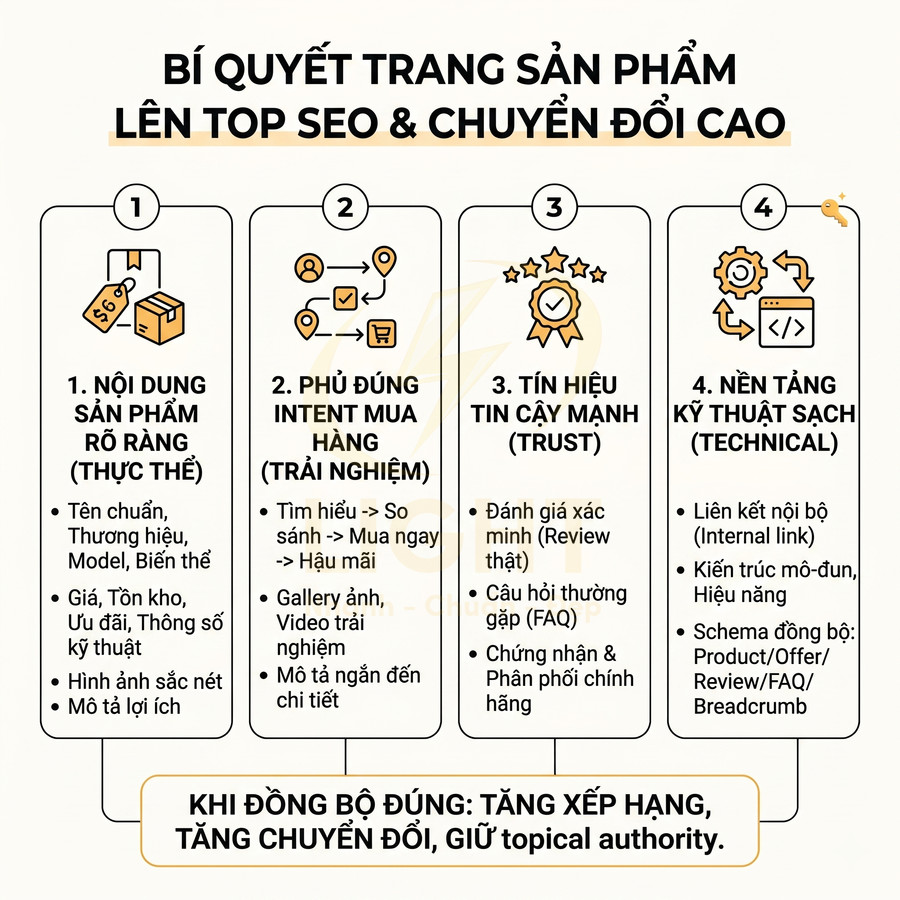


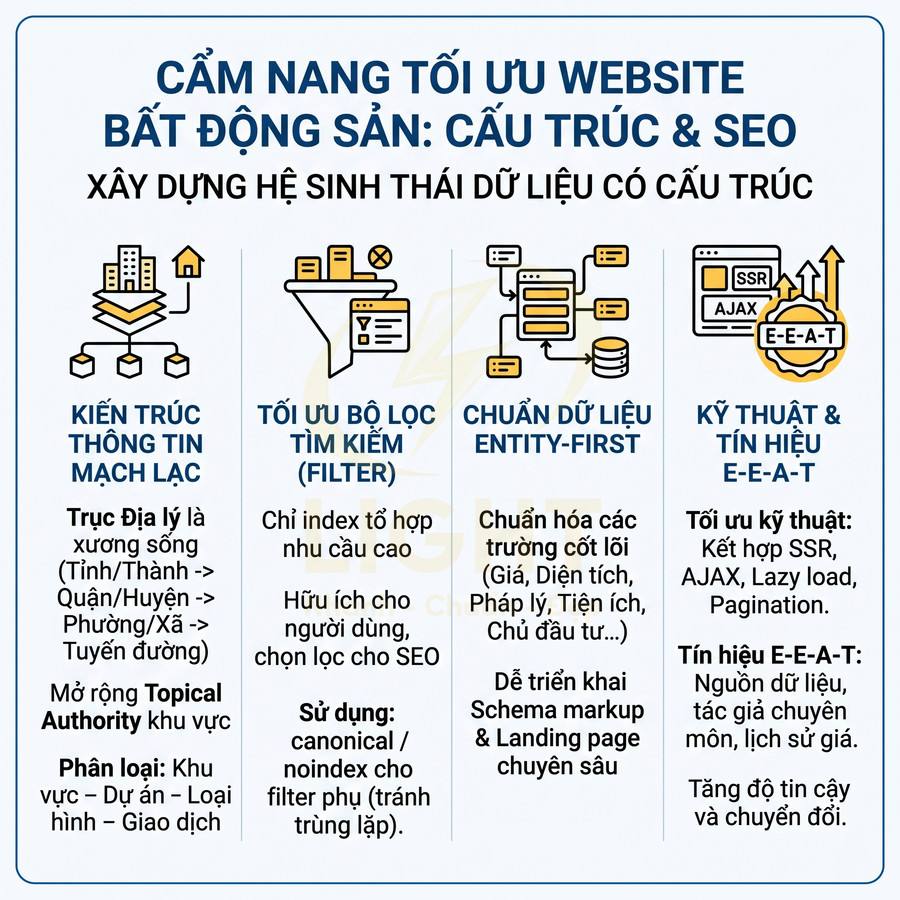


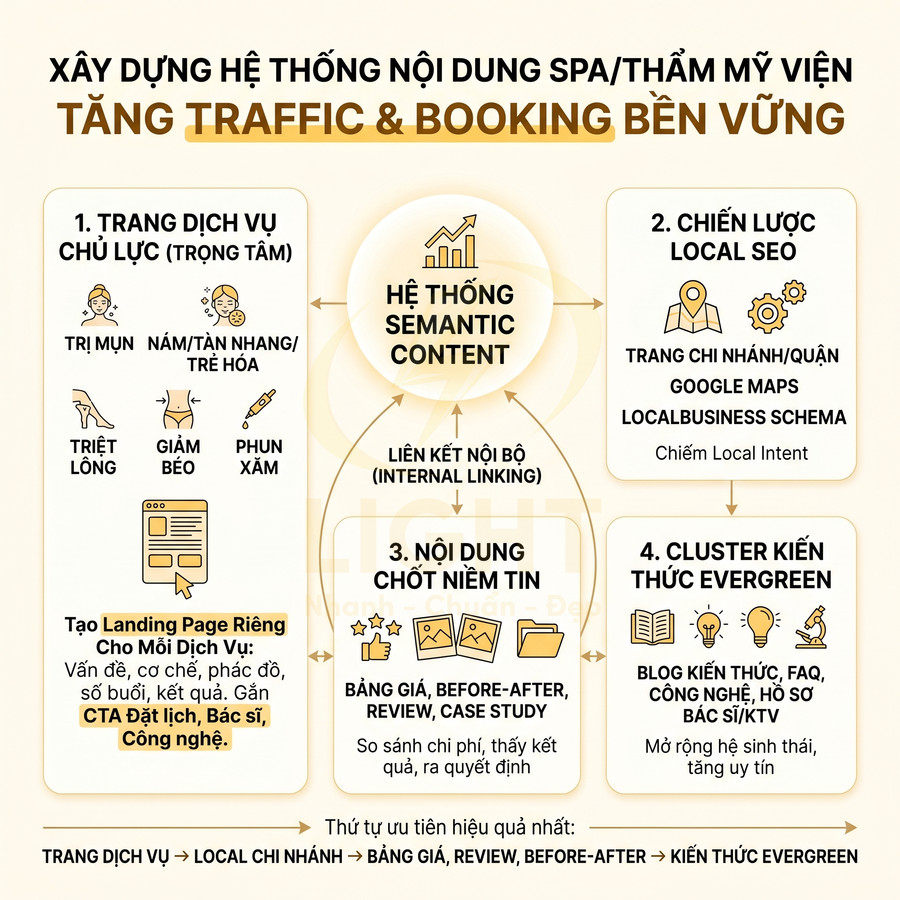
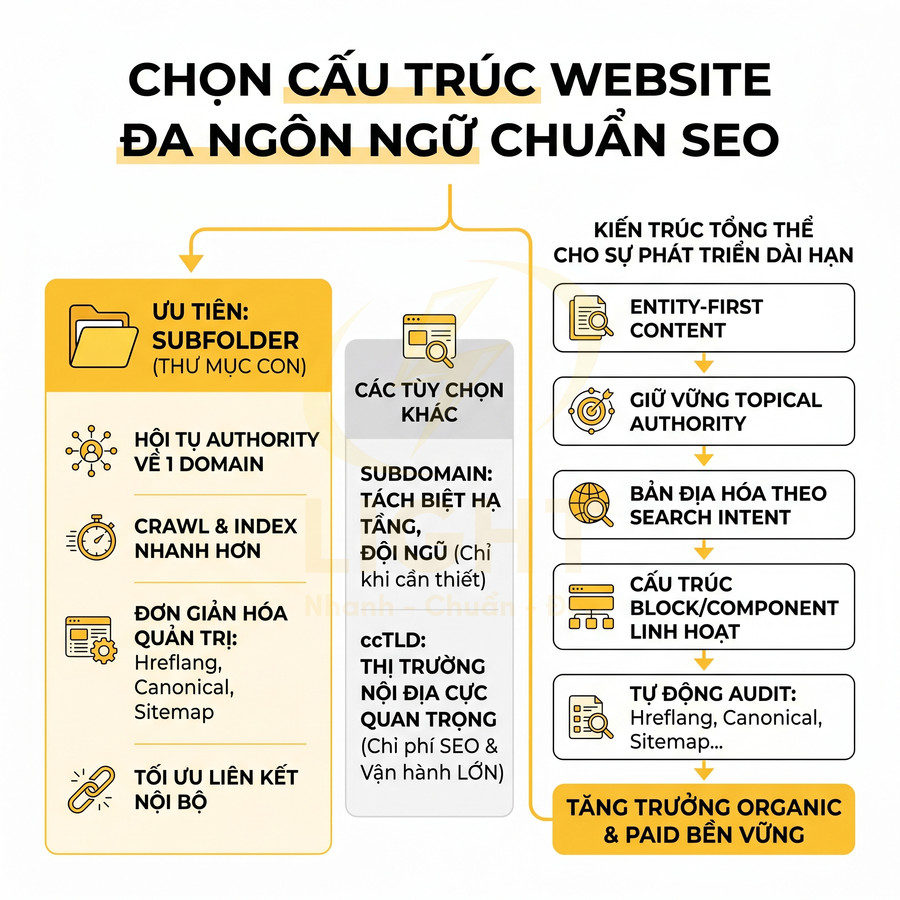
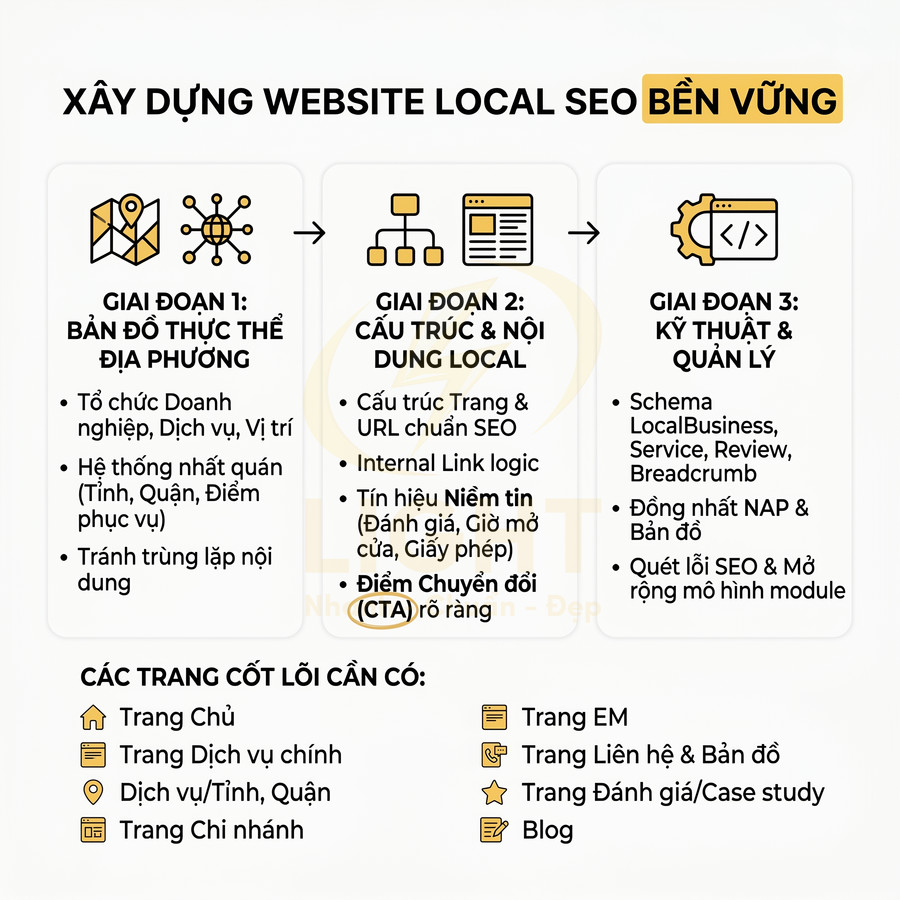

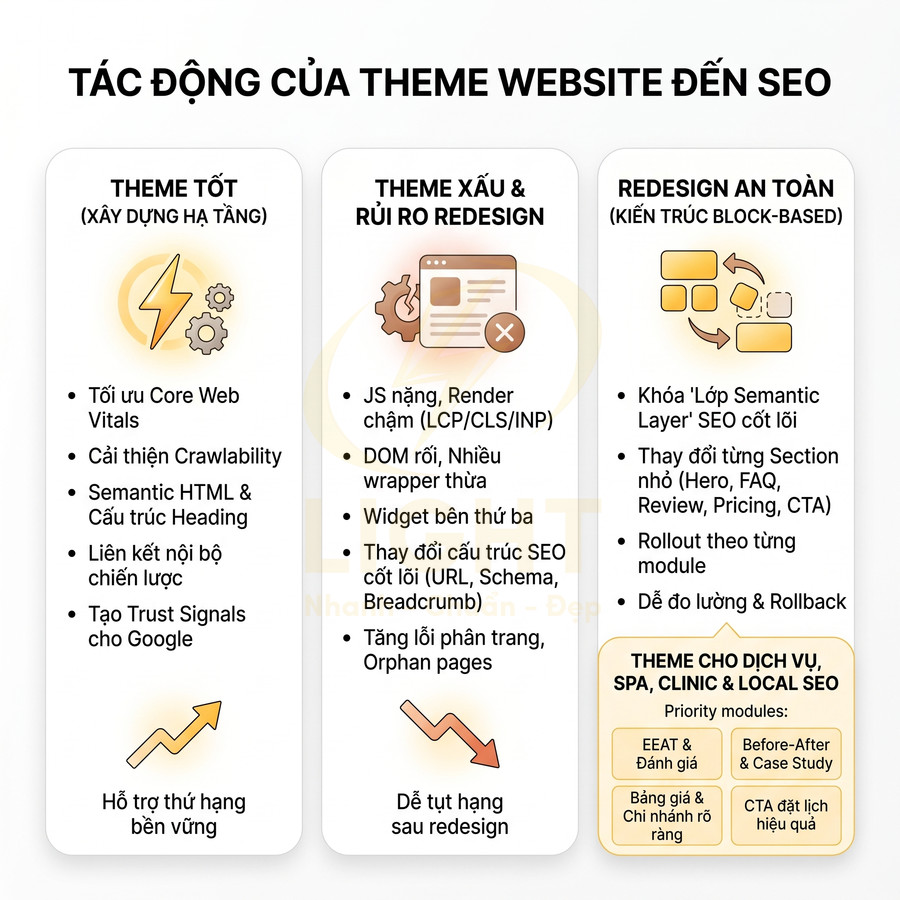
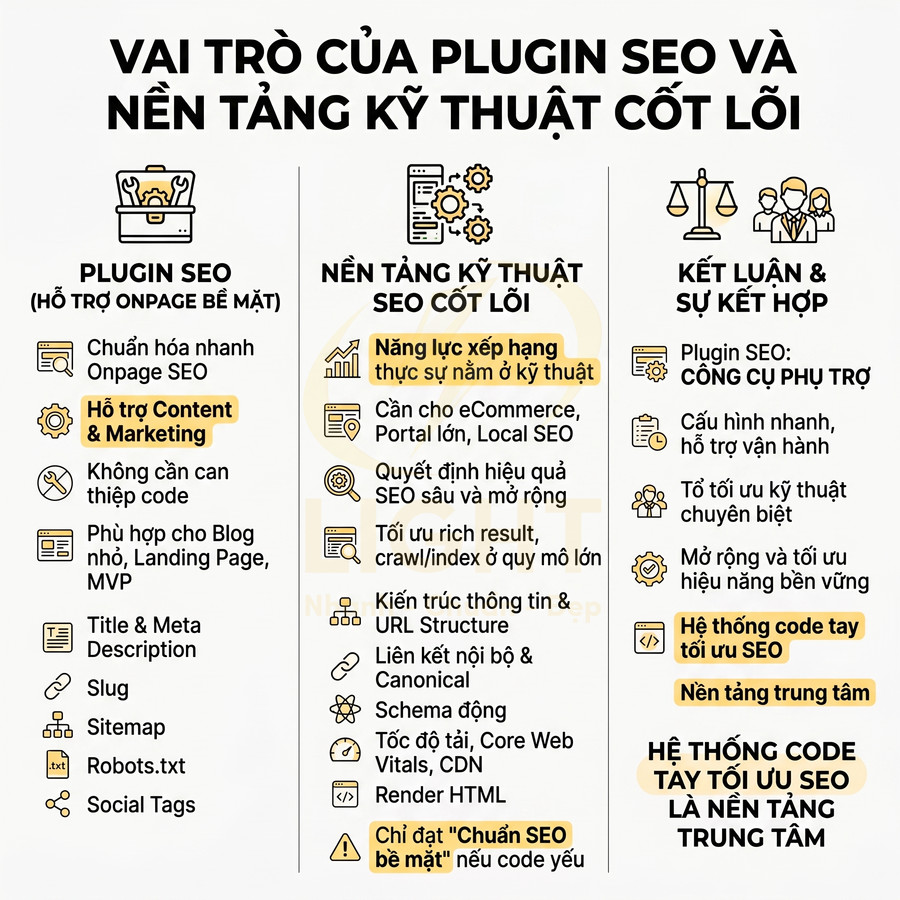


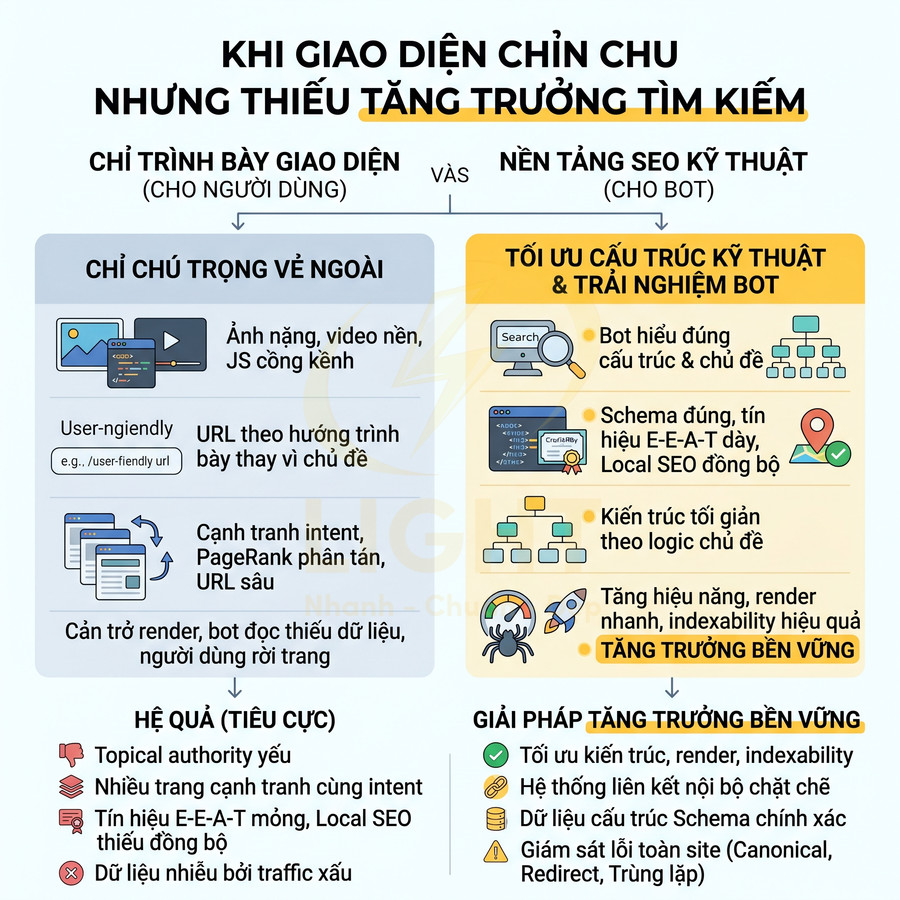

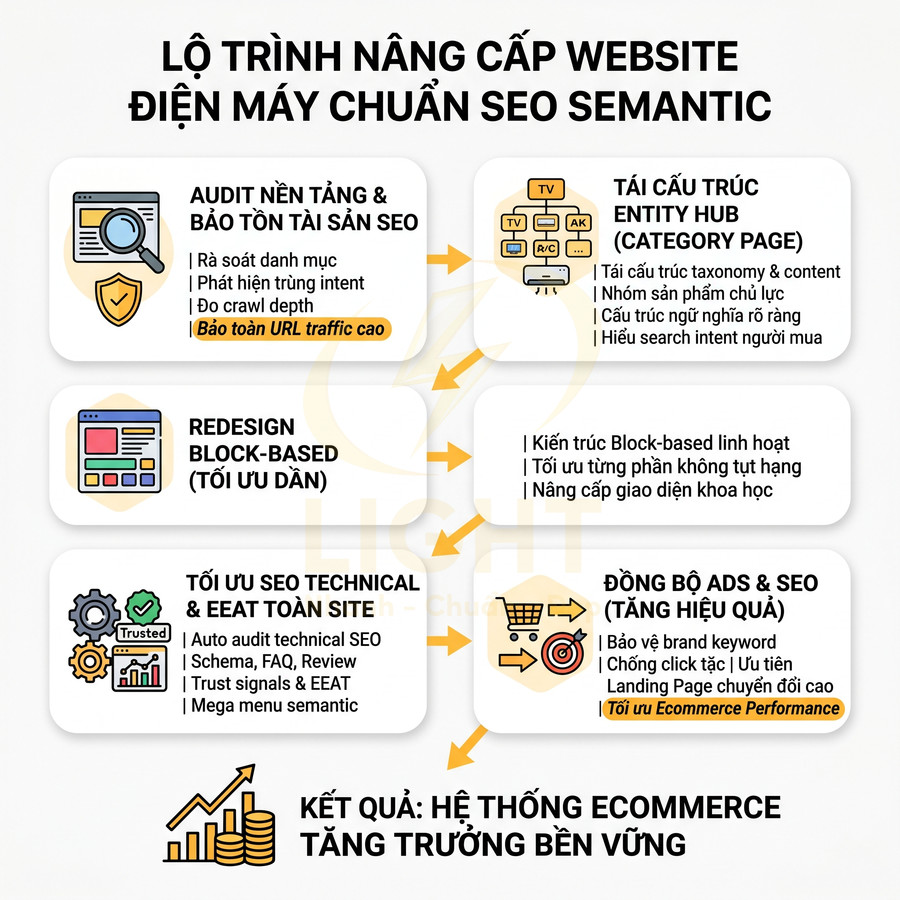
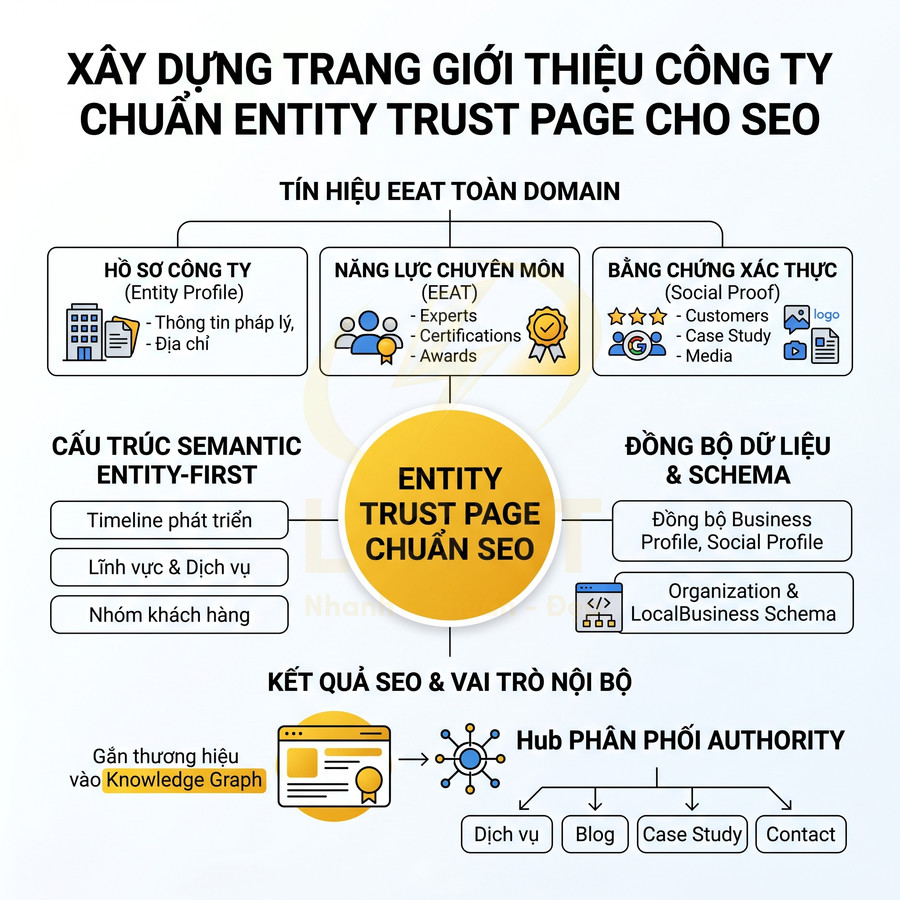
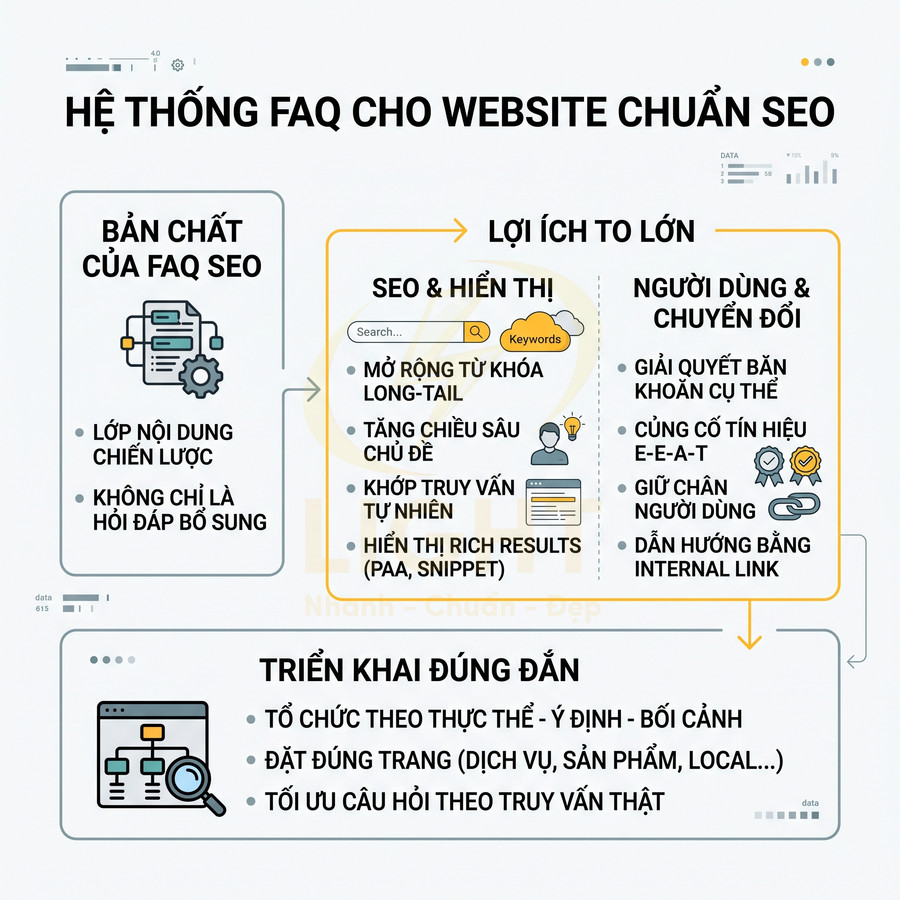
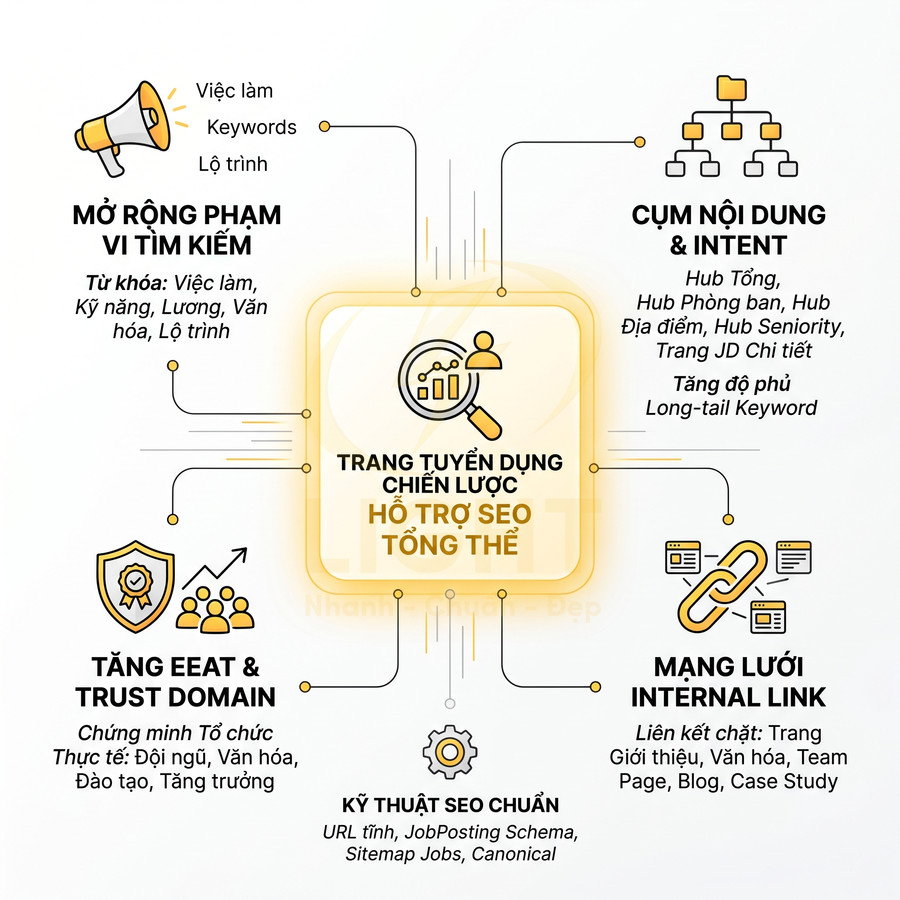


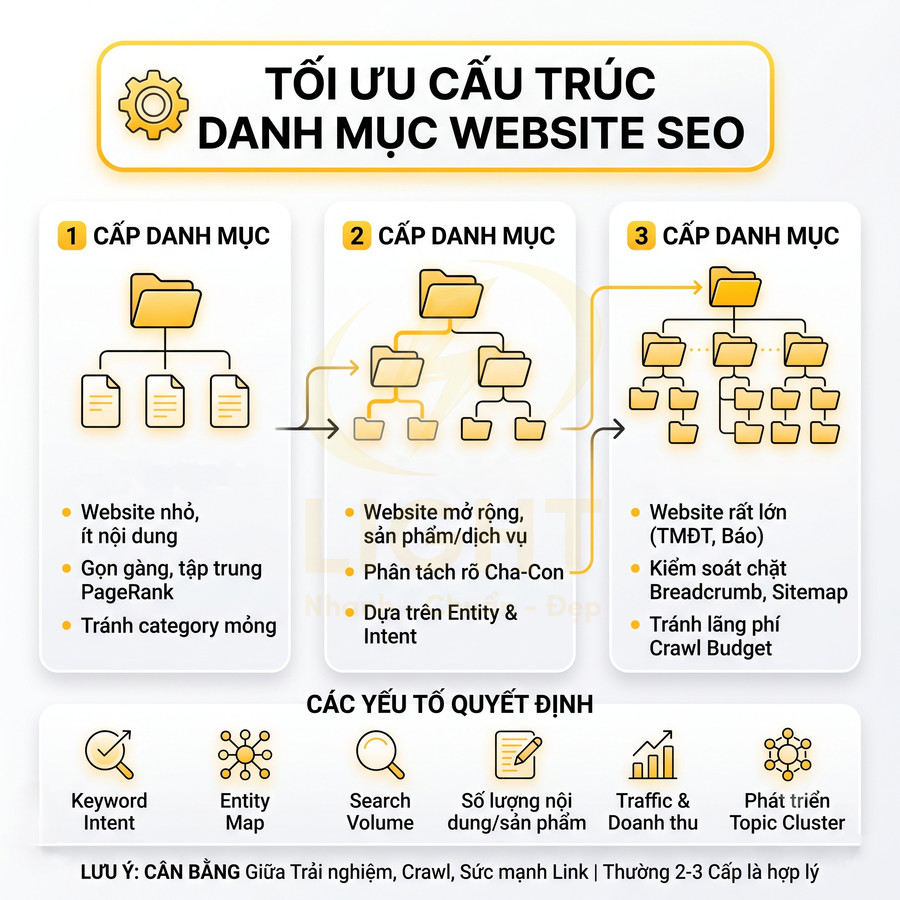




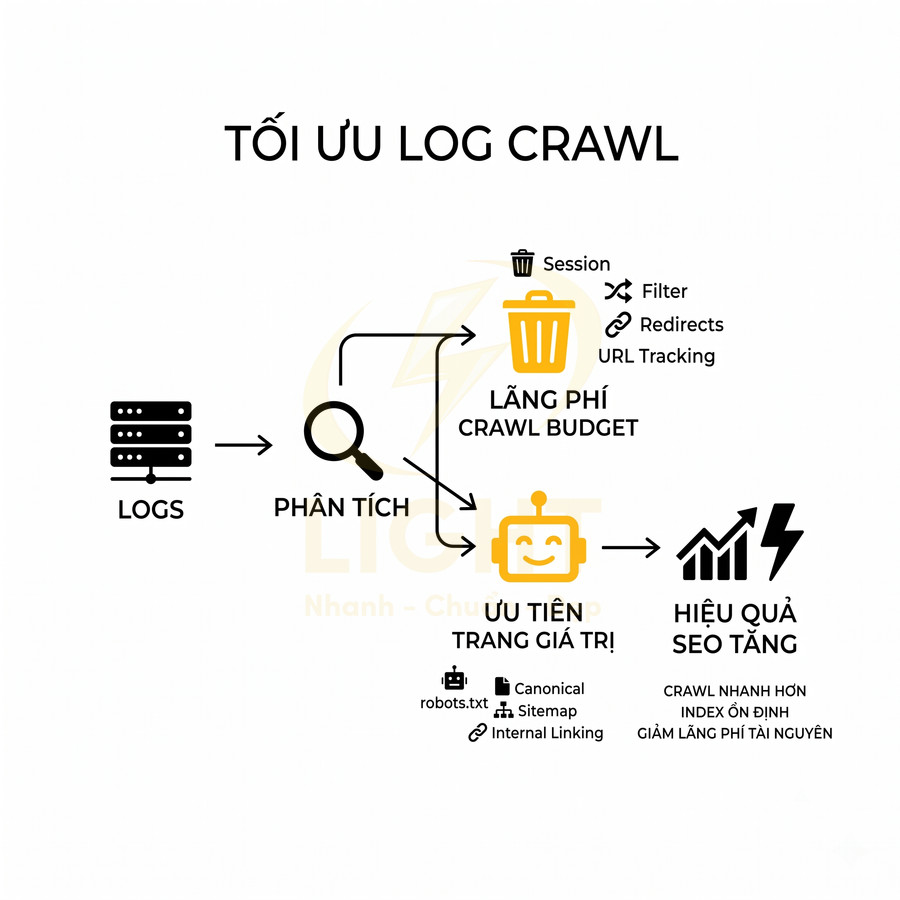




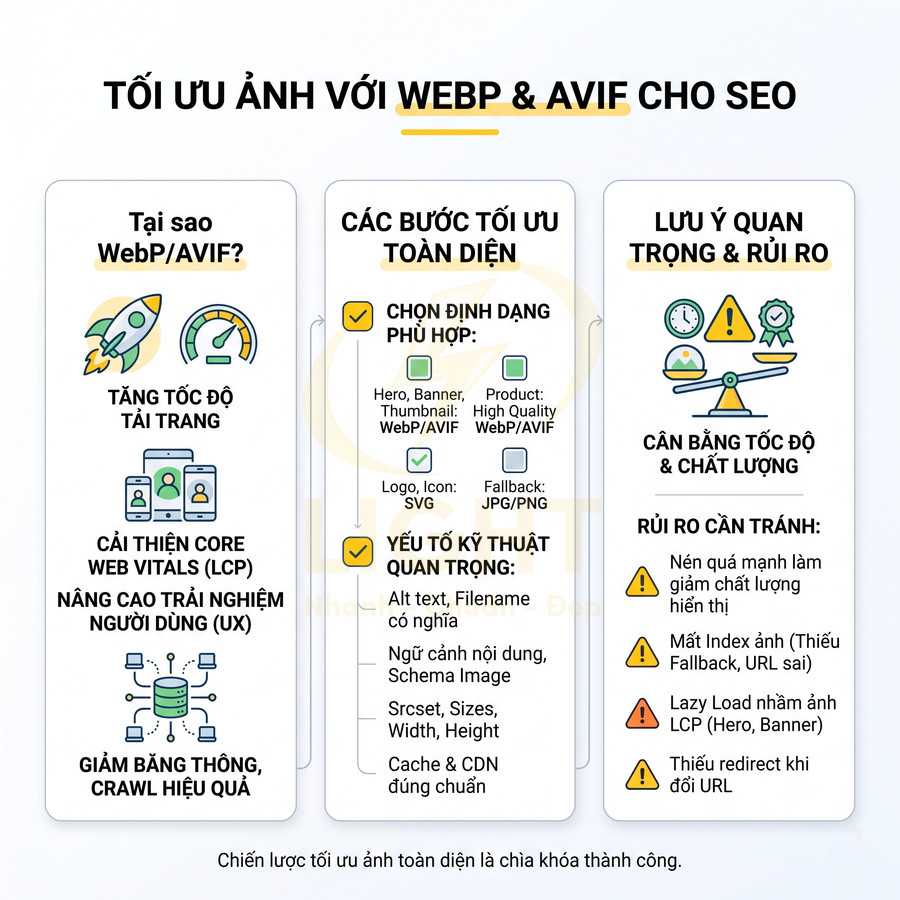



Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
