
Cách thêm schema Organization, Article, Product cho website chuẩn SEO
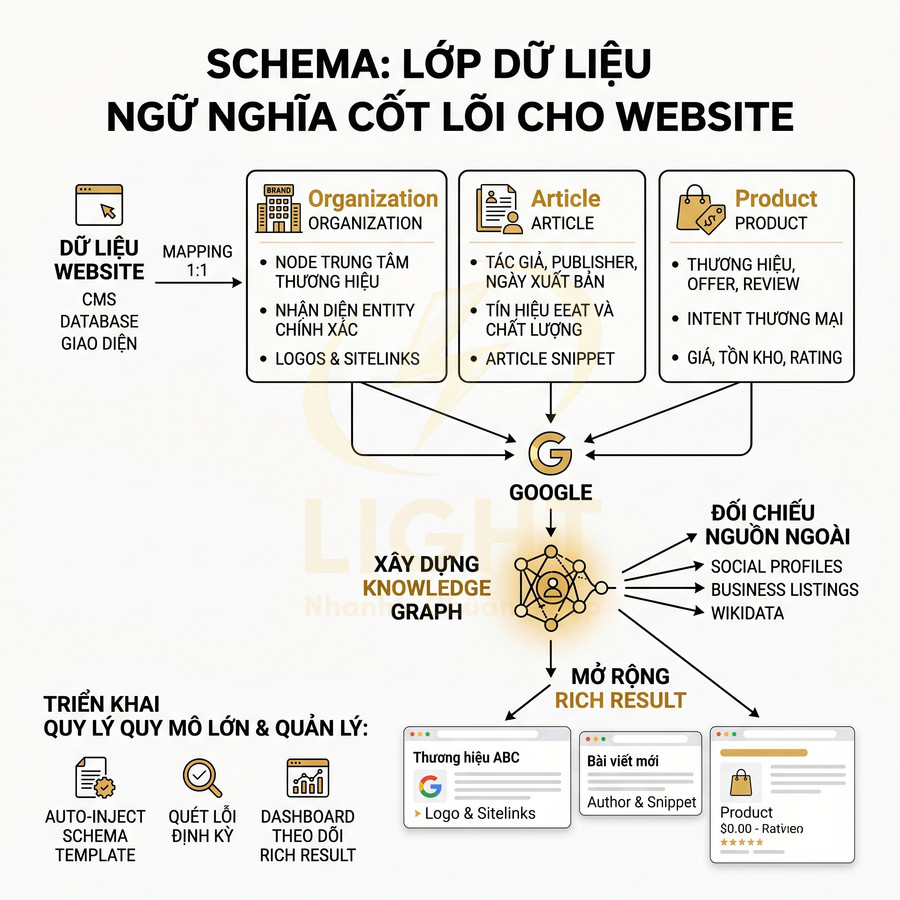
Schema Organization, Article và Product là lớp dữ liệu ngữ nghĩa cốt lõi giúp Google hiểu rõ website là ai, nội dung nói về gì và đang phục vụ mục đích nào. Khi được triển khai đúng bằng JSON-LD, Google không còn phải tự suy đoán thương hiệu, tác giả hay sản phẩm từ HTML thuần, mà có thể nhận diện trực tiếp các entity, đối chiếu với social profile, business listing, Wikidata và các nguồn ngoài để xây dựng Knowledge Graph xoay quanh brand. Nhờ đó, website có cơ hội mở rộng rich result như logo, sitelinks, article snippet, giá, tồn kho, rating hay review trên SERP.
Về triển khai, ba schema này cần được mapping chặt với CMS, database và giao diện hiển thị để bảo đảm dữ liệu trong schema khớp 1:1 với nội dung thật trên trang. Organization nên đóng vai trò node trung tâm của brand; Article gắn với author, publisher, ngày xuất bản và tín hiệu EEAT; Product liên kết với brand, offer, review và intent thương mại. Giá, tồn kho, author, dateModified hay logo đều nên được đồng bộ tự động từ cùng một nguồn dữ liệu để tránh sai lệch.
Ở quy mô lớn, website nên có hệ thống auto-inject schema theo từng template, cơ chế quét lỗi định kỳ và dashboard theo dõi rich result sau mỗi lần publish hay deploy. Quan trọng nhất, schema không chỉ cần đúng cú pháp mà còn phải đúng ngữ cảnh, nhất quán entity và phản ánh trung thực nội dung hiển thị để giữ eligibility rich result và củng cố độ tin cậy SEO lâu dài. Organization, Article và Product schema chỉ hiệu quả khi website có kiến trúc nội dung rõ ràng, mỗi template phục vụ đúng một loại thực thể. Khi Organization schema được dùng làm node trung tâm, Google dễ nhận diện thương hiệu và liên kết với các hồ sơ bên ngoài hơn. Quy trình thiết kế web chuẩn SEO tốt sẽ chuẩn hóa logo, thông tin liên hệ, social profile, địa chỉ và dữ liệu doanh nghiệp trên toàn bộ website.
Schema Organization, Article, Product giúp Google hiểu entity website và rich result như thế nào
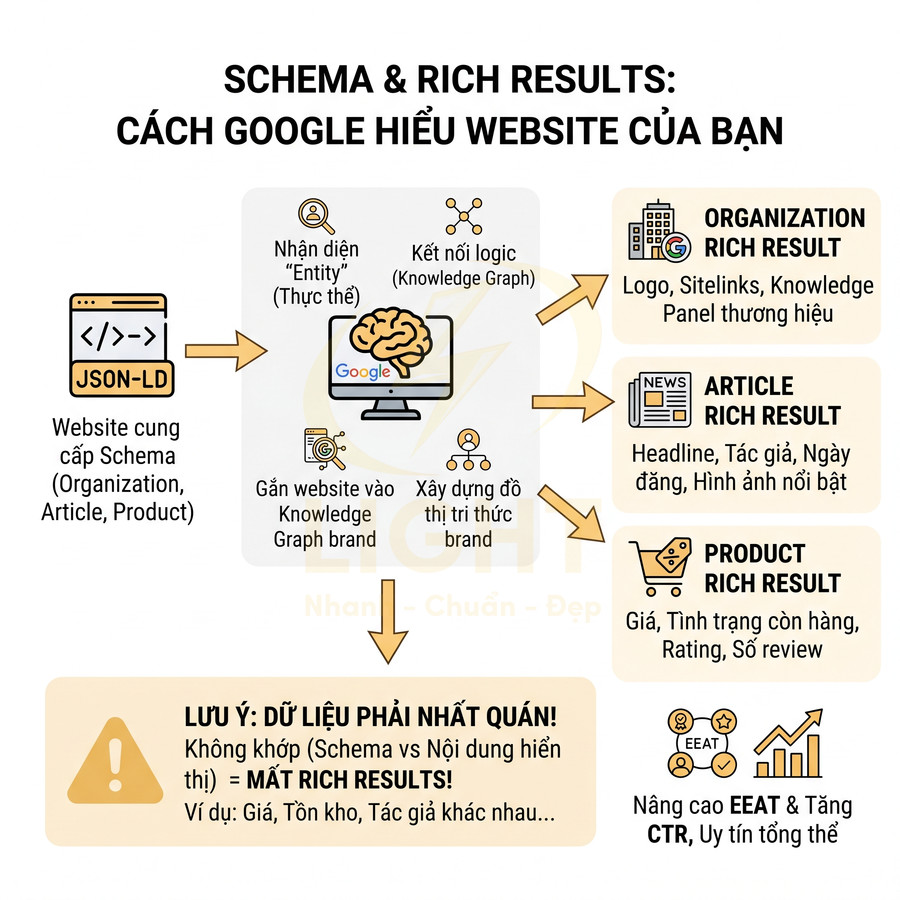
Schema Organization, Article và Product tạo thành lớp dữ liệu ngữ nghĩa giúp Google nhận diện rõ ai, cái gì và mục đích nội dung trên website. Thông qua JSON-LD, Google không phải đoán thương hiệu, tác giả hay sản phẩm, mà nhận được các node entity được định nghĩa chuẩn, liên kết logic với nhau và với nguồn ngoài (Wikidata, social, business listing…). Từ đó, hệ thống dễ dàng chuẩn hóa, đối chiếu và gắn website vào Knowledge Graph, xây dựng một đồ thị tri thức xoay quanh brand. Khi dữ liệu đủ tin cậy và nhất quán với nội dung hiển thị, Google có thể kích hoạt nhiều dạng rich result: logo, sitelinks, article rich result, product snippet với giá, tồn kho, rating…, đồng thời dùng chúng làm tín hiệu đánh giá EEAT và độ uy tín tổng thể. Đối với Product schema, dữ liệu về giá, tồn kho, đánh giá và mô tả sản phẩm phải khớp với nội dung hiển thị trên trang. Một hệ thống thiết kế website chuẩn giúp hạn chế lỗi dữ liệu, tránh tình trạng schema báo một kiểu nhưng giao diện lại thể hiện một kiểu khác.
Google dùng structured data để entity reconciliation, knowledge graph và rich snippets
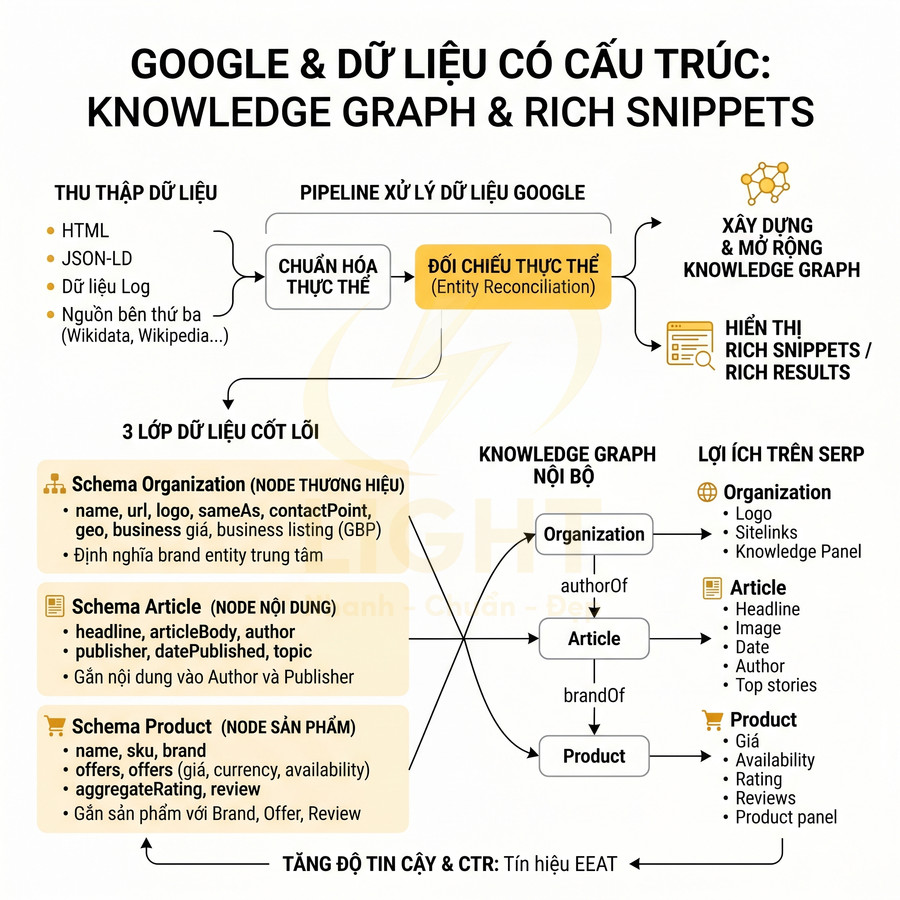
Schema Organization, Article và Product không chỉ là “3 loại schema cơ bản” mà thực tế là 3 lớp dữ liệu cốt lõi trong mô hình hiểu biết thực thể (entity understanding) của Google. Ở tầng kỹ thuật, Google thu thập dữ liệu từ HTML, từ JSON-LD, từ dữ liệu log, từ nguồn bên thứ ba (Wikidata, Wikipedia, business listing, social network…) rồi đưa vào pipeline xử lý để:
- Chuẩn hóa thực thể (entity normalization)
- Đối chiếu thực thể (entity reconciliation / entity resolution)
- Xây dựng và mở rộng Knowledge Graph
- Render rich snippets / rich results trên SERP
Luận điểm này phù hợp với nền tảng nghiên cứu về Knowledge Graph. Theo Hogan và cộng sự, đồ thị tri thức không chỉ lưu trữ dữ liệu rời rạc, mà tổ chức dữ liệu thành thực thể, thuộc tính và quan hệ để hỗ trợ truy vấn, suy luận và tích hợp thông tin ở quy mô lớn (Hogan et al., 2021). Khi website dùng Organization, Article và Product schema, Google có thêm lớp dữ liệu máy đọc được để hiểu “ai là thương hiệu”, “nội dung do ai tạo” và “sản phẩm nào đang được bán”. Vì vậy, schema nên được xem là hạ tầng nhận diện thực thể, không chỉ là đoạn mã tạo rich result.
Khi website chỉ có HTML thuần, Google phải tự suy luận: đoạn text nào là tên thương hiệu, đoạn nào là mô tả sản phẩm, đoạn nào là tác giả, đoạn nào là nội dung chính. Khi có JSON-LD chuẩn, Google nhận được một lớp “annotation ngữ nghĩa” rõ ràng:
- Organization định nghĩa node thương hiệu: name, legalName, url, logo, sameAs, contactPoint…
- Article / BlogPosting / NewsArticle định nghĩa node nội dung: headline, articleBody, author, datePublished, mainEntityOfPage…
- Product định nghĩa node sản phẩm: name, sku, brand, offers, aggregateRating, review…
Điểm này có thể củng cố bằng nghiên cứu về Schema.org của Guha, Brickley và Macbeth. Các tác giả mô tả Schema.org là bộ từ vựng được thiết kế để giúp website nhúng dữ liệu có cấu trúc cho công cụ tìm kiếm và các hệ thống tiêu thụ dữ liệu (Guha et al., 2016). Điều quan trọng là Schema.org không chỉ “đặt tên” cho đối tượng, mà còn chuẩn hóa cách mô tả người, tổ chức, bài viết, sản phẩm, địa điểm và quan hệ giữa chúng. Vì vậy, JSON-LD giúp giảm phụ thuộc vào suy luận từ HTML thuần. Bot không phải đoán ngữ nghĩa; website chủ động khai báo ngữ nghĩa.
Trong quá trình entity reconciliation, hệ thống sẽ cố gắng trả lời các câu hỏi:
- “Organization này có trùng với brand đã tồn tại trong Knowledge Graph không?”
- “Author này có phải cùng một người với profile trên LinkedIn, Wikipedia, hay các site báo chí không?”
- “Product này có phải là một biến thể (variant) của một sản phẩm đã biết, hay là một entity hoàn toàn mới?”
Schema Organization giúp Google xác định brand entity như một node trung tâm trong Knowledge Graph, với các thuộc tính và quan hệ:
- Quan hệ với domain chính (url, sameAs, sameAs đến social)
- Quan hệ với địa điểm (address, geo, hasMap, Google Business Profile)
- Quan hệ với sản phẩm (brand trong Product, manufacturer, provider)
- Quan hệ với người (founder, employee, contactPoint)
Nghiên cứu về dữ liệu liên kết cho thấy một thực thể chỉ thật sự hữu ích khi có định danh ổn định và có thể liên kết với các thực thể khác. Bizer, Heath và Berners-Lee nhấn mạnh nguyên tắc dùng định danh rõ ràng để dữ liệu trên web có thể được kết nối, truy vấn và tái sử dụng (Bizer et al., 2009). Áp dụng vào schema Organization, website nên dùng một @id cố định cho thương hiệu, ví dụ https://domain.com/#organization, rồi để Article dùng publisher, Product dùng brand, Service dùng provider trỏ về cùng thực thể đó. Đây là cách giảm phân mảnh brand entity trong hệ thống dữ liệu.
Schema Article giúp gắn các bài viết vào:
- Author entity (Person hoặc Organization)
- Brand entity (publisher, isPartOf, mainEntityOfPage)
- Topic entity (about, mentions, keywords, inLanguage)
Schema Product giúp gắn sản phẩm với:
- Brand entity (brand, manufacturer)
- Offer entity (Offer, AggregateOffer: price, priceCurrency, availability, priceValidUntil)
- Review / Rating entity (Review, Rating, AggregateRating: ratingValue, reviewCount)
- User intent (commercial / transactional thông qua offers, availability, price)
Khi các schema này được liên kết logic, Google có thể xây dựng một đồ thị tri thức nội bộ cho website:
- Node trung tâm: Organization (brand)
- Các node con: Product, Article, Person (author), Service, Place…
- Các cạnh (edges): publisherOf, authorOf, brandOf, reviewedBy, locatedIn, sameAs…
Rich snippets và rich results là lớp hiển thị của structured data trên SERP, nhưng phía sau là cả một quá trình đánh giá độ tin cậy (trustworthiness) của dữ liệu. Với Organization, website có thể hiển thị:
- Logo, tên thương hiệu, sitelinks, contact trong kết quả brand search
- Knowledge panel với thông tin tóm tắt về doanh nghiệp (nếu đủ tín hiệu)
Meusel, Bizer và Paulheim đã phân tích sự phát triển và mức độ chấp nhận Schema.org ở quy mô web, cho thấy dữ liệu có cấu trúc đã trở thành một tiêu chuẩn quan trọng trong cách website cung cấp metadata cho công cụ tìm kiếm (Meusel et al., 2015). Tuy nhiên, việc triển khai rộng không đồng nghĩa với chất lượng dữ liệu cao. Với SEO, điều đó có nghĩa là rich result không chỉ phụ thuộc vào việc có schema, mà còn phụ thuộc vào độ đúng, độ đầy đủ và tính nhất quán của dữ liệu. Schema sai, thiếu hoặc mâu thuẫn có thể làm mất cơ hội hiển thị nâng cao.
Với Article, website có thể hiển thị:
- Headline, image, datePublished, author trong rich result dạng article
- Top stories (với NewsArticle, nếu đủ điều kiện)
Với Product, website có thể hiển thị:
- Giá, tình trạng còn hàng, rating, số review ngay dưới snippet
- Product knowledge panel hoặc product listing trong Google Shopping (khi kết hợp với Merchant Center)
Các tín hiệu này không chỉ tăng CTR mà còn là input cho hệ thống đánh giá EEAT: một brand có schema rõ ràng, author có profile nhất quán, product có review thật, giá minh bạch… thường được coi là đáng tin cậy hơn trong bối cảnh cạnh tranh SERP.
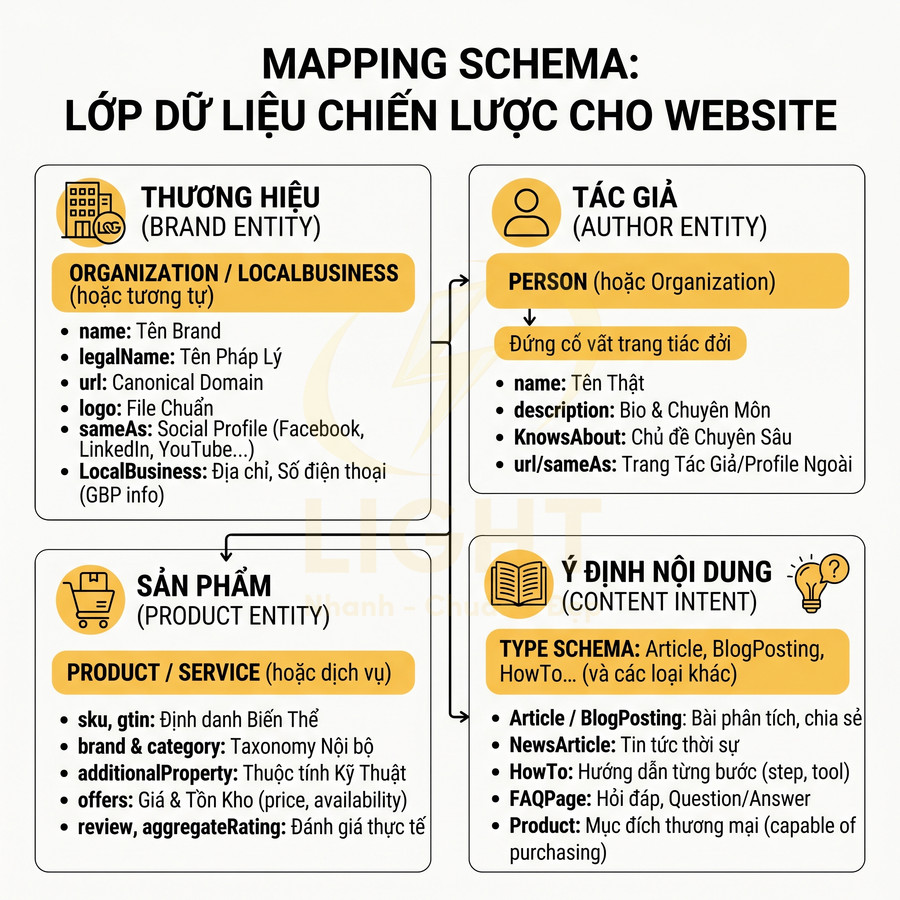
Mapping schema với brand entity, author entity, product entity và content intent
Để schema thực sự trở thành “lớp dữ liệu chiến lược” chứ không chỉ là vài đoạn JSON-LD rời rạc, cần thiết kế mapping ngay từ tầng kiến trúc thông tin (information architecture) và mô hình dữ liệu (data model) của CMS. Mỗi loại entity trong chiến lược SEO phải có một representation rõ ràng trong schema:
- Brand entity → Organization (hoặc LocalBusiness, Corporation… tùy loại hình)
- Author entity → Person (hoặc Organization nếu là brand author)
- Product entity → Product (hoặc Service, nếu là dịch vụ)
- Content intent → type schema: Article, BlogPosting, NewsArticle, Product, HowTo, FAQPage, WebPage…
Cần nhấn mạnh rằng mapping schema là vấn đề mô hình dữ liệu, không chỉ là vấn đề SEO kỹ thuật. Guha, Brickley và Macbeth cho thấy Schema.org thành công một phần vì cung cấp hệ thống từ vựng đủ đơn giản để triển khai rộng, nhưng vẫn đủ linh hoạt để mô tả nhiều loại thực thể (Guha et al., 2016). Vì vậy, CMS nên có các entity riêng như Brand, Author, Product, Article, Review, FAQ thay vì để toàn bộ thông tin nằm trong rich text. Khi dữ liệu được lưu có cấu trúc, hệ thống có thể sinh JSON-LD tự động, giảm lỗi nhập tay và duy trì nhất quán trên toàn website.
Với brand entity, Organization schema cần được chuẩn hóa và đồng bộ với toàn bộ hệ sinh thái thương hiệu:
- Tên pháp lý vs tên thương hiệu: dùng legalName cho tên pháp lý, name cho tên brand thường dùng
- Domain chính: url phải là canonical domain, nhất quán với rel="canonical" và hreflang
- Logo chuẩn: logo trỏ đến một file ổn định, kích thước và tỉ lệ phù hợp guideline của Google
- Social profile: sameAs trỏ đến các profile chính thức (Facebook, LinkedIn, YouTube…)
- Google Business Profile: thông tin địa chỉ, số điện thoại, giờ mở cửa phải khớp với LocalBusiness schema (nếu có)
Với author entity, Person schema cần thể hiện rõ chuyên môn và danh tính thực:
- Tên thật: name, givenName, familyName khớp với tên hiển thị trên trang
- Bio và chuyên môn: description, jobTitle, affiliation, knowsAbout (chủ đề chuyên sâu)
- Profile chuyên gia: link đến trang tác giả nội bộ (sameAs hoặc url)
- Social / professional profile: LinkedIn, profile trên các tạp chí, hiệp hội nghề nghiệp
Với product entity, Product schema phải được mapping chặt chẽ với hệ thống quản lý sản phẩm (PIM / ERP / eCommerce):
- Định danh sản phẩm: sku, gtin, mpn… để phân biệt các biến thể
- Brand và category: brand trỏ về Organization, category khớp với taxonomy nội bộ
- Thuộc tính kỹ thuật: additionalProperty cho các spec quan trọng (kích thước, chất liệu, công suất…)
- Giá và tồn kho: offers với price, priceCurrency, availability, itemCondition
- Review: review, aggregateRating mapping với hệ thống đánh giá thực tế
Với dữ liệu sản phẩm, độ chính xác của schema đặc biệt quan trọng vì các trường như giá, tồn kho, mã SKU và đánh giá có thể ảnh hưởng trực tiếp đến rich result và quyết định mua hàng. Selvam, Kejriwal và Miranker nghiên cứu dữ liệu Product-specific Schema.org từ Web Data Commons và chỉ ra rằng dữ liệu sản phẩm trên web rất đa dạng, thường cần thực hành chuẩn hóa để sử dụng hiệu quả (Selvam et al., 2020). Áp dụng vào ecommerce, Product schema nên lấy dữ liệu từ nguồn quản lý sản phẩm chính thức như PIM, ERP hoặc database bán hàng, không nhập tay trong template. Giá và tồn kho sai là lỗi EEAT ở cấp thương mại.
Content intent được phản ánh trực tiếp qua type schema và một số thuộc tính bổ sung:
- Article / BlogPosting: phù hợp cho bài phân tích, chia sẻ chuyên sâu, pillar content
- NewsArticle: dùng cho tin tức thời sự, cập nhật, có tính thời điểm
- HowTo: dùng cho hướng dẫn từng bước, có step, tool, supply rõ ràng
- FAQPage: dùng cho trang hỏi đáp, mỗi câu hỏi là một node Question/Answer
- Product: dùng cho trang có mục đích thương mại, có khả năng mua hàng
Khi mapping chuẩn, Google có thể hiểu ở cấp độ entity graph:
- Bài viết này thuộc về thương hiệu nào (publisher, isPartOf → Organization)
- Do chuyên gia nào viết (author → Person, sameAs → profile ngoài site)
- Liên quan đến sản phẩm / dịch vụ nào (mentions, about, reviewOf → Product / Service)
- Phục vụ mục đích thông tin, hướng dẫn hay thương mại (type schema + presence of offers, price…)
Điều này hỗ trợ mạnh cho EEAT vì mỗi entity đều có ngữ cảnh, lịch sử và mối quan hệ rõ ràng trong Knowledge Graph: brand có track record, author có chuyên môn, product có feedback từ người dùng, nội dung có intent rõ ràng.
Khi schema đúng nhưng nội dung trang không khớp gây mất rich result eligibility
Một vấn đề thường gặp ở các website lớn là “schema technically valid nhưng semantically inconsistent”. Google không chỉ chạy validator để kiểm tra cú pháp JSON-LD mà còn đối chiếu với:
- DOM và nội dung hiển thị thực tế
- Meta data (title, meta description, Open Graph, Twitter Card)
- Dữ liệu log và hành vi người dùng
- Dữ liệu từ các nguồn bên ngoài (Merchant Center, Business Profile, review platform…)
Vấn đề này được hỗ trợ bởi nghiên cứu của Meusel và Paulheim về lỗi phổ biến trong Schema.org Microdata. Các tác giả phân tích dữ liệu Microdata từ hơn 250 triệu trang và cho thấy dữ liệu có cấu trúc triển khai thực tế thường có lỗi, làm hạn chế khả năng sử dụng của dữ liệu (Meusel & Paulheim, 2015). Trong SEO, lỗi “valid về cú pháp nhưng sai về nghĩa” còn nguy hiểm hơn vì công cụ kiểm tra có thể không báo lỗi, nhưng Google vẫn có thể đánh giá dữ liệu không đáng tin cậy. Schema phải khớp với DOM, nội dung hiển thị, canonical URL và dữ liệu backend, đặc biệt với giá, tác giả, đánh giá và tồn kho.

Với Product schema, các mismatch phổ biến:
- Schema khai báo price = 1.000.000 nhưng trên trang hiển thị 1.200.000
- Schema khai báo availability = InStock nhưng UI hiển thị “Hết hàng” hoặc không có nút mua
- Schema khai báo aggregateRating và reviewCount nhưng trên trang không có bất kỳ review nào hiển thị
- Schema khai báo brand là A nhưng nội dung trang, hình ảnh, logo lại thể hiện brand B
Với Article schema, các mismatch thường gặp:
- Schema khai báo author = Chuyên gia A nhưng trên trang hiển thị tên B, hoặc không hiển thị author
- Schema khai báo datePublished nhưng không có timestamp rõ ràng trên trang (hoặc khác ngày)
- Schema khai báo headline khác đáng kể so với H1 / title hiển thị
- Schema khai báo reviewRating hoặc commentCount nhưng không có phần review / comment trên trang
Những mismatch này khiến hệ thống đánh giá structured data là “không đáng tin cậy”, từ đó:
- Giảm hoặc loại bỏ eligibility cho rich result (dù schema vẫn “valid” trong tool)
- Giảm mức độ ưu tiên crawl / index cho một số loại trang (đặc biệt là product)
- Ảnh hưởng gián tiếp đến perception về độ tin cậy của website trong các hệ thống ranking
Để hạn chế rủi ro, cần thiết kế một cơ chế auto-sync schema với nội dung thực ở tầng hệ thống:
- Không hard-code JSON-LD tĩnh trong template nếu dữ liệu có thể thay đổi (giá, tồn kho, rating…)
- Sử dụng cùng một nguồn dữ liệu (database, API) để render cả HTML và JSON-LD
- Thiết lập rule: bất kỳ thay đổi nào ở giá, availability, author, datePublished… phải trigger update schema
Song song, nên có công cụ hoặc script quét định kỳ để phát hiện entity mismatch:
- So sánh giá trong schema với giá hiển thị trên trang cho các URL product quan trọng
- So sánh author, headline, datePublished trong schema với nội dung DOM
- Kiểm tra sự tồn tại của review / rating trên UI khi schema có khai báo
- Log và cảnh báo cho team SEO / dev khi phát hiện chênh lệch vượt ngưỡng cho phép
Đặc biệt, cần ưu tiên kiểm soát chặt chẽ trên:
- Các trang sản phẩm mang lại nhiều doanh thu
- Các landing page chuyển đổi cao (PPC + SEO)
- Các bài viết trụ cột (pillar content) và trang thể hiện chuyên môn của chuyên gia
Khi structured data, nội dung hiển thị và dữ liệu backend được đồng bộ, website không chỉ giữ được eligibility cho rich result mà còn xây dựng được một lớp entity data đáng tin cậy, hỗ trợ lâu dài cho chiến lược EEAT và entity-based SEO.
Kiến trúc hệ thống tự động thêm schema theo từng loại template website chuẩn SEO
Kiến trúc hệ thống tập trung vào cơ chế auto-inject schema theo từng page type, giúp triển khai JSON-LD ở quy mô lớn mà không cần gắn tay cho từng URL. Lớp Routing/Page Resolver nhận diện loại trang, map sang Template Layer, từ đó kích hoạt Schema Module/Factory để sinh object schema và chuyển cho Renderer inject vào HTML. Toàn bộ hoạt động được điều khiển bằng config, feature flag, validation và cache để dễ mở rộng, kiểm soát lỗi và tối ưu hiệu năng. Khi thêm template mới, chỉ cần khai báo page type, tạo module schema, mapping field CMS và cập nhật config, toàn bộ URL thuộc template đó sẽ tự động có schema chuẩn, nhất quán với entity graph chung.
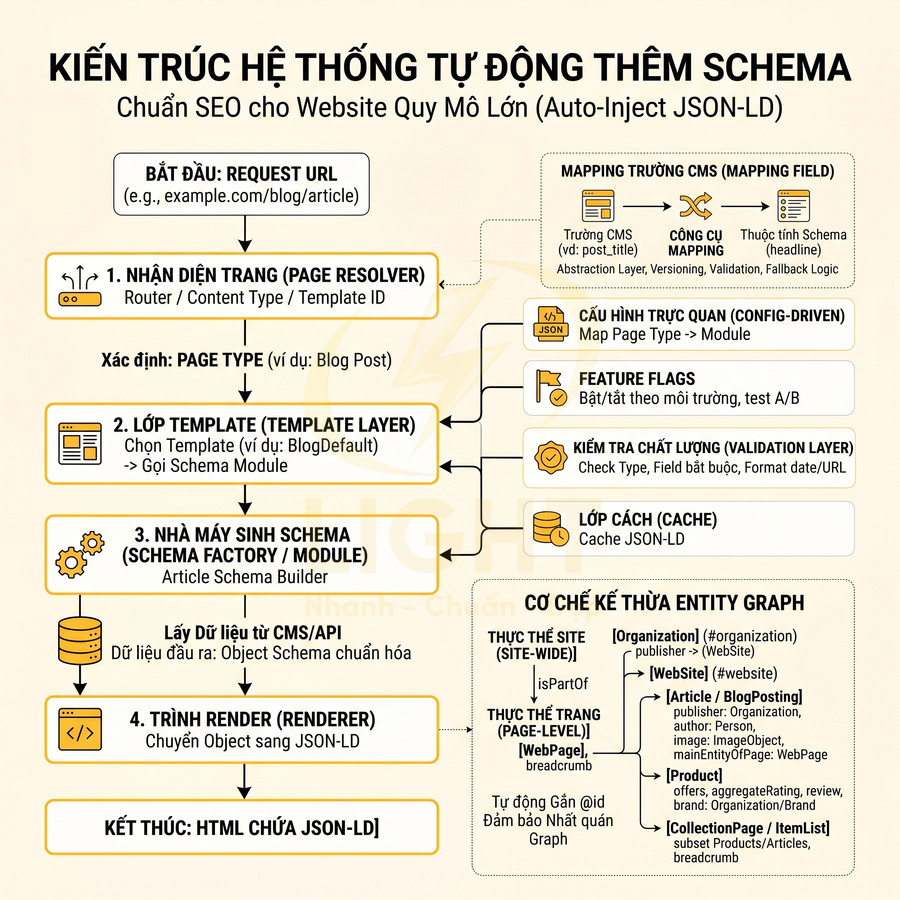
Auto-inject schema theo page type: homepage, blog post, product page, category page
Để triển khai schema ở quy mô lớn, cần thiết kế một kiến trúc auto-inject schema mang tính hệ thống, tách biệt rõ giữa page type, template và business logic. Thay vì gắn schema thủ công cho từng URL, hệ thống nên hoạt động dựa trên cơ chế nhận diện loại trang (route, content type, template ID) và áp dụng module schema tương ứng. Điều này đặc biệt quan trọng với các website có hàng chục nghìn URL, nhiều ngôn ngữ hoặc nhiều brand con. Triển khai theo page type giúp giảm lỗi ở quy mô lớn vì schema được kiểm soát ở cấp template thay vì từng URL riêng lẻ. Meusel, Bizer và Paulheim cho thấy Schema.org được áp dụng rộng rãi trên web, nhưng khi số lượng trang lớn, lỗi và biến thể triển khai cũng tăng theo (Meusel et al., 2015). Vì vậy, website nên dùng schema module theo từng mẫu trang: homepage sinh Organization và WebSite; blog post sinh Article; product page sinh Product; category sinh CollectionPage hoặc ItemList. Mỗi template cần một “hợp đồng dữ liệu” rõ ràng, gồm trường bắt buộc, trường khuyến nghị, nguồn dữ liệu và rule fallback.
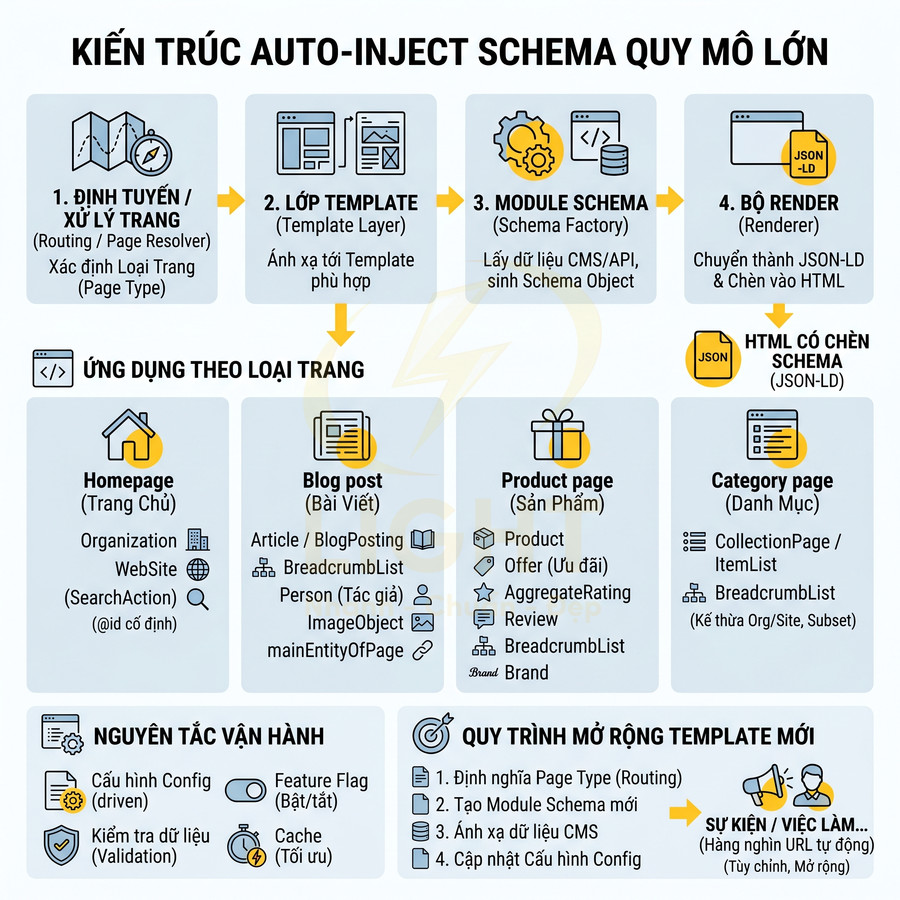
Một kiến trúc điển hình thường gồm các lớp:
- Routing / Page Resolver: xác định page type từ URL, route name, hoặc content type trong CMS (vd: homepage, blogpost, productdetail, categorylisting, landingpage, aboutpage, contactpage).
- Template Layer: mỗi page type map tới một template hoặc một nhóm template (vd: productdetaildefault, productdetailvariant), từ đó kích hoạt module schema tương ứng.
- Schema Module / Schema Factory: mỗi page type có một lớp hoặc service chuyên sinh JSON-LD, nhận data từ CMS/API và trả về object schema đã chuẩn hóa.
- Renderer: chuyển object schema sang JSON-LD string và inject vào <head> hoặc cuối <body> của HTML.
Với từng loại page type, logic auto-inject có thể chi tiết như sau:
- Homepage:
- Tự động inject Organization + WebSite (và có thể thêm WebPage nếu cần).
- Thêm SearchAction trong WebSite nếu website có chức năng search nội bộ, mapping query parameter từ route search (vd: https://example.com/search?q={searchtermstring}).
- Đảm bảo @id của Organization và WebSite là cố định, dùng lại trên toàn site để tạo entity graph nhất quán.
- Blog post:
- Inject Article hoặc BlogPosting tùy theo nature của nội dung.
- Luôn kèm BreadcrumbList để thể hiện cấu trúc chuyên mục, category, tag.
- Inject Person cho author, có thể link tới một entity Person site-wide (tác giả cố định) hoặc dynamic (nhiều tác giả).
- Có thể bổ sung ImageObject cho featured image, mainEntityOfPage trỏ về URL của bài viết.
- Product page:
- Inject Product làm node chính, kèm theo Offer, AggregateRating, Review (nếu có dữ liệu review thực).
- Thêm BreadcrumbList để thể hiện vị trí sản phẩm trong category tree.
- Mapping brand tới Organization hoặc Brand tùy cấu trúc dữ liệu.
- Hỗ trợ nhiều Offer (đa currency, đa seller) nếu là marketplace, hoặc một Offer nếu là single-vendor.
- Category page:
- Dùng CollectionPage hoặc ItemList để mô tả danh sách sản phẩm/bài viết.
- Kết hợp BreadcrumbList để thể hiện hierarchy category.
- Kế thừa Organization và WebSite từ cấp site-wide, tránh lặp lại thông tin brand trên từng category.
- Có thể liệt kê một subset sản phẩm nổi bật trong ItemList (top N sản phẩm) thay vì toàn bộ để tránh payload quá lớn.
Để kiến trúc này vận hành ổn định, nên áp dụng một số nguyên tắc kỹ thuật:
- Config-driven: mapping page type → schema module nên được cấu hình (file JSON/YAML hoặc trong CMS) thay vì hard-code, giúp dễ mở rộng khi thêm template mới.
- Feature flag: cho phép bật/tắt từng loại schema theo môi trường (staging/production) để test A/B hoặc rollback nhanh khi có lỗi.
- Validation layer: trước khi render JSON-LD, chạy qua một lớp validate (schema type, field bắt buộc, format date, URL) để tránh sinh ra markup lỗi.
- Cache: với các trang ít thay đổi (homepage, about, category), có thể cache JSON-LD theo URL để giảm chi phí render.
Khi thêm template mới (ví dụ: landing page cho campaign, microsite, hoặc page type đặc thù như event, job posting), chỉ cần:
- Định nghĩa page type mới trong routing.
- Tạo module schema tương ứng (vd: EventSchemaBuilder, JobPostingSchemaBuilder).
- Mapping field từ CMS vào module đó.
- Cập nhật config để route/template mới sử dụng module schema tương ứng.
Nhờ vậy, toàn bộ URL thuộc template mới sẽ tự động được gắn schema chuẩn mà không cần thao tác thủ công từ team content, đồng thời vẫn đảm bảo tính nhất quán với entity graph chung của website.
Mapping field CMS vào JSON-LD: title, author, brand, price, stock, review, publish date
Trọng tâm của hệ thống auto-schema là lớp mapping giữa field trong CMS và property trong JSON-LD. Lớp này đóng vai trò như một “bản hợp đồng” giữa team dev, SEO và content. Nếu không có mapping rõ ràng, rất dễ xảy ra các lỗi như:
- Thiếu field bắt buộc (vd: datePublished cho Article, price cho Offer).
- Mapping sai ngữ cảnh (vd: dùng posttitle cho name của Product).
- Không đồng bộ khi đổi tên cột database hoặc thay đổi cấu trúc content type.
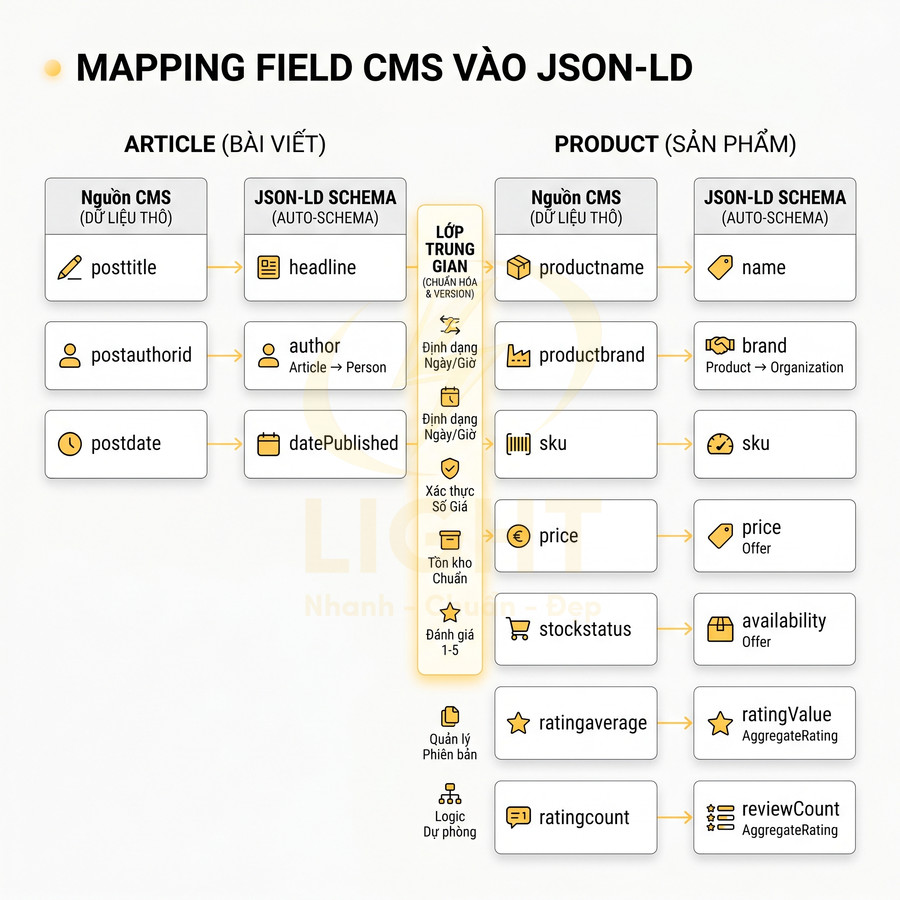
Mỗi content type (Article, Product, Category, Landing page…) nên có một bảng mapping riêng, được version control trong codebase hoặc trong cấu hình CMS. Bảng dưới là ví dụ cho Article và Product:
| Field CMS | Schema Property | Schema Type | Ghi chú |
|---|---|---|---|
| posttitle | headline | Article | Tiêu đề chính bài viết |
| postauthorid | author | Article → Person | Tham chiếu đến entity tác giả |
| postdate | datePublished | Article | Ngày xuất bản đầu tiên |
| postmodified | dateModified | Article | Ngày chỉnh sửa gần nhất |
| productname | name | Product | Tên sản phẩm |
| productbrand | brand | Product → Organization | Thương hiệu sản phẩm |
| sku | sku | Product | Mã SKU duy nhất |
| price | price | Offer | Giá hiện tại |
| stockstatus | availability | Offer | InStock, OutOfStock… |
| ratingaverage | ratingValue | AggregateRating | Điểm trung bình |
| ratingcount | reviewCount | AggregateRating | Số lượng đánh giá |
Để mapping hoạt động ổn định trong môi trường phức tạp, nên áp dụng một số kỹ thuật:
- Abstraction layer: thay vì mapping trực tiếp field CMS → JSON-LD, tạo một lớp model hoặc API trung gian (vd: ArticleModel.title, ProductModel.brand). Lớp này chịu trách nhiệm đọc dữ liệu từ CMS/database, chuẩn hóa format (date, currency, URL) rồi mới mapping sang schema property.
- Versioning: mỗi thay đổi lớn trong cấu trúc field (thêm field, đổi tên, thay đổi kiểu dữ liệu) nên được gắn version. Module schema có thể đọc version để xử lý backward compatibility, tránh làm hỏng schema của các trang cũ.
- Type & format validation:
- datePublished, dateModified: chuẩn ISO 8601 (vd: 2024-03-10T10:30:00+07:00).
- price: kiểu số, không kèm đơn vị tiền tệ (currency để trong priceCurrency).
- availability: dùng các giá trị chuẩn của schema.org (InStock, OutOfStock, PreOrder…).
- ratingValue: nằm trong khoảng min-max hợp lệ (vd: 1–5).
- Fallback logic: khi thiếu field, có thể áp dụng fallback có kiểm soát (vd: nếu không có post_modified thì dùng postdate cho dateModified), nhưng cần được document rõ để team SEO nắm được.
- Environment-specific config: một số field có thể khác nhau giữa staging và production (vd: base URL, brand name test), nên mapping cần hỗ trợ config theo môi trường.
Với hệ thống lớn, việc mapping không nên phụ thuộc trực tiếp vào tên cột database. Thay vào đó, nên:
- Dùng domain model (Article, Product, Category) với các property chuẩn hóa.
- Để lớp repository hoặc data source chịu trách nhiệm map từ database/CMS sang domain model.
- Để lớp schema builder chỉ làm nhiệm vụ map domain model → JSON-LD, giúp code sạch, dễ test và ít bị ảnh hưởng khi thay đổi cấu trúc dữ liệu bên dưới.
Kế thừa entity graph giữa Organization → WebSite → Article → Product
Website chuẩn SEO không chỉ dừng ở việc gắn các schema rời rạc, mà cần xây dựng một entity graph thống nhất, giúp Google và các công cụ tìm kiếm hiểu rõ mối quan hệ giữa các thực thể trên toàn site. Cấu trúc cơ bản thường là: Organization → WebSite → WebPage → Article/Product. Khái niệm entity graph thống nhất phù hợp với cách Knowledge Graph tổ chức tri thức. Hogan và cộng sự mô tả vai trò của schema, identity và context trong đồ thị tri thức: thực thể cần được định danh, đặt trong ngữ cảnh và liên kết bằng quan hệ rõ ràng (Hogan et al., 2021). Với website, điều này có nghĩa là Organization, WebSite, WebPage, Article và Product không nên tồn tại như các block JSON-LD rời rạc. Chúng nên được kết nối bằng @id, isPartOf, publisher, brand, mainEntityOfPage. Một graph nhất quán giúp Google hợp nhất tín hiệu thay vì xử lý từng schema như dữ liệu cô lập.
.jpg)
Các node chính trong graph và mối quan hệ điển hình:
- Organization:
- Đại diện cho thương hiệu hoặc công ty.
- Có property url trỏ đến homepage.
- Có thể có logo, contactPoint, sameAs (link mạng xã hội).
- WebSite:
- Đại diện cho toàn bộ website.
- Có property publisher trỏ đến Organization.
- Có thể có potentialAction là SearchAction.
- Thường có @id cố định (vd: https://example.com/#website).
- WebPage:
- Đại diện cho từng trang cụ thể (homepage, category page, landing page…).
- Có property isPartOf trỏ đến WebSite.
- Có thể có breadcrumb trỏ đến BreadcrumbList.
- Thường dùng cho các page không phải Article/Product, hoặc làm lớp trung gian cho Article/Product.
- Article / Product:
- Đại diện cho nội dung hoặc sản phẩm cụ thể.
- Article có publisher trỏ đến Organization, author trỏ đến Person.
- Product có brand trỏ đến Organization hoặc Brand, offers trỏ đến Offer, aggregateRating trỏ đến AggregateRating.
- Có thể dùng mainEntityOfPage trỏ đến WebPage hoặc URL của chính nó.
Để entity graph hoạt động hiệu quả, cần sử dụng @id hoặc URL nhất quán cho từng node. Ví dụ:
- Organization: https://example.com/#organization
- WebSite: https://example.com/#website
- WebPage (mỗi URL): https://example.com/some-page/#webpage
- Article: https://example.com/blog/some-post/#article
- Product: https://example.com/product/sku-123/#product
Kiến trúc hệ thống nên hỗ trợ cơ chế kế thừa entity theo tầng:
- Site-wide layer:
- Inject Organization và WebSite cho toàn bộ website (thường ở layout gốc hoặc middleware).
- Các thông tin như tên brand, logo, URL, social profile được quản lý tập trung (vd: trong CMS hoặc file config).
- Template layer:
- Mỗi template (homepage, category, product, blog post) inject WebPage và các schema đặc thù (Article, Product…).
- WebPage luôn isPartOf WebSite (thông qua @id).
- Content layer:
- Article kế thừa publisher từ Organization, không lặp lại thông tin brand trên từng bài viết.
- Product kế thừa brand từ Organization hoặc từ entity Brand được link với Organization.
- Các entity Person (author), Review (reviewer) có thể được quản lý như entity riêng, tái sử dụng trên nhiều trang.
Cách triển khai kỹ thuật có thể theo hướng:
- Tạo một GlobalSchemaContext chứa Organization và WebSite, được khởi tạo ở cấp application hoặc layout.
- Các module schema cho WebPage, Article, Product nhận GlobalSchemaContext làm input, từ đó tự động gắn @id của Organization/WebSite vào các property liên quan (publisher, isPartOf, brand…).
- Khi thông tin thương hiệu thay đổi (tên, logo, URL), chỉ cần cập nhật GlobalSchemaContext, toàn bộ schema trên site sẽ tự động đồng bộ.
Việc xây dựng entity graph thống nhất không chỉ giúp Google hiểu rõ cấu trúc website, mà còn giảm trùng lặp dữ liệu, hạn chế sai lệch giữa các trang và đơn giản hóa quá trình bảo trì, mở rộng trong dài hạn.
Cách thêm schema Organization chuẩn SEO cho homepage, about page và brand entity hub
Schema Organization cần được triển khai như lớp dữ liệu trung tâm để định nghĩa brand entity nhất quán trên toàn bộ hệ sinh thái digital. Trọng tâm là nhóm thuộc tính cốt lõi name, url, logo, sameAs, contactPoint, foundingDate, kết hợp với address, legalName, description… nhằm tạo một hồ sơ thương hiệu có thể kiểm chứng với social, directory, hồ sơ pháp lý và Google Business Profile. Homepage thường giữ vai trò node chính, about page và brand hub mở rộng thêm các thuộc tính như founder, award, areaServed nhưng vẫn tham chiếu cùng một @id để tránh phân mảnh entity. Việc quản lý nên thông qua một brand config layer tập trung, cho phép tự động đồng bộ logo, hotline, địa chỉ, social URL và schema trên mọi template khi thương hiệu thay đổi.
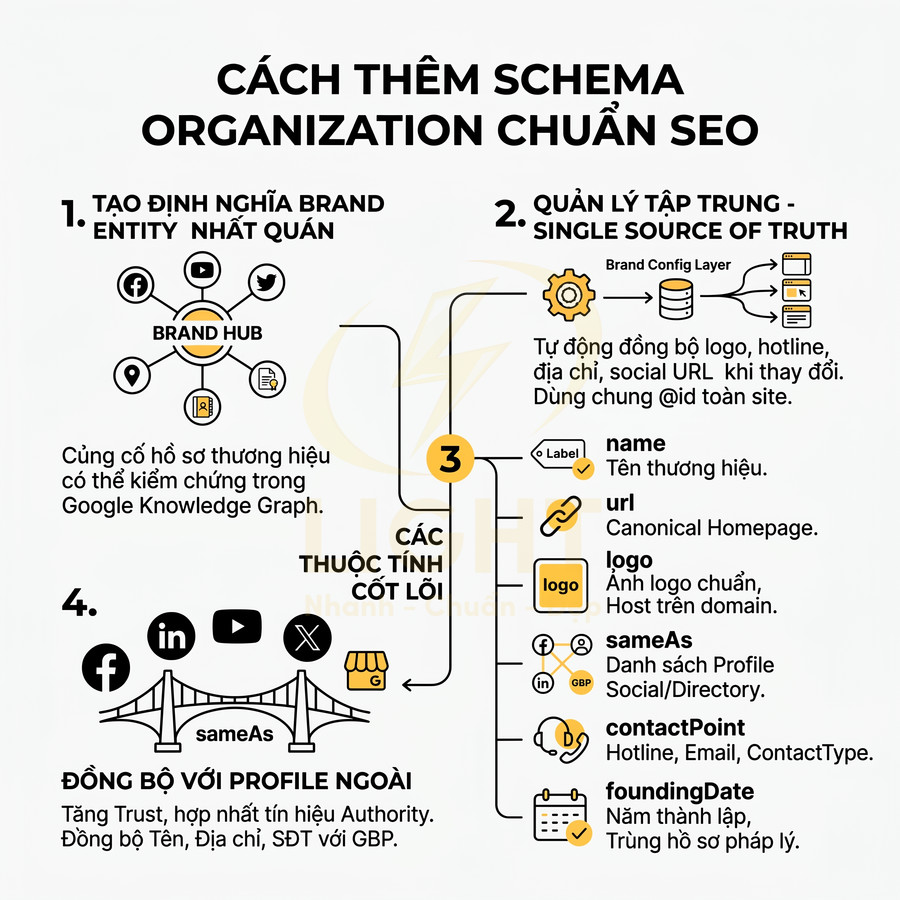
Thuộc tính bắt buộc: name, url, logo, sameAs, contactPoint, foundingDate
Schema Organization là lớp dữ liệu nền tảng để Google xây dựng và củng cố brand entity trong Knowledge Graph. Khi triển khai cho homepage, about page và các trang brand hub, mục tiêu không chỉ là “có schema” mà là tạo một định nghĩa thương hiệu nhất quán, có thể kiểm chứng qua nhiều nguồn bên ngoài (social, business listing, hồ sơ pháp lý, báo chí, directory…).
Với các website định hướng xây dựng thương hiệu dài hạn, Organization schema nên được thiết kế như một “single source of truth” cho toàn bộ hệ sinh thái digital. Những thuộc tính quan trọng gồm: name, url, logo, sameAs, contactPoint, foundingDate, cùng với address, legalName, description khi phù hợp. Mỗi thuộc tính không chỉ là dữ liệu hiển thị mà còn là tín hiệu nhận diện để hệ thống entity reconciliation của Google so khớp với các nguồn dữ liệu khác.
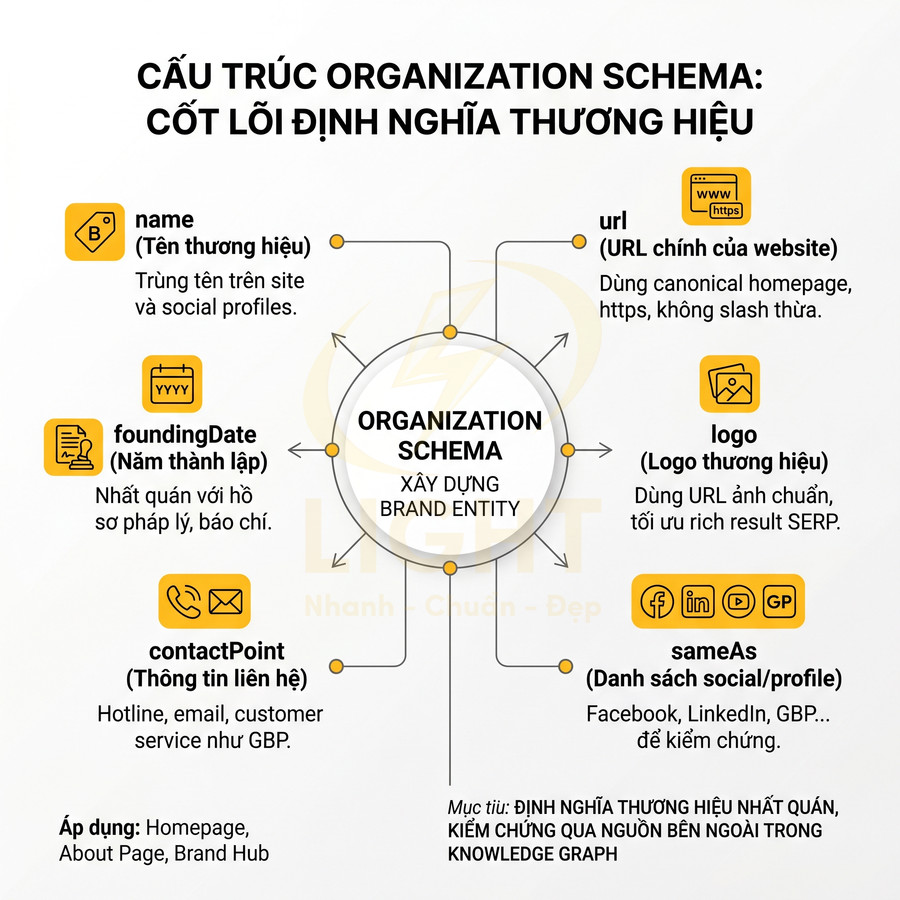
| Thuộc tính | Bắt buộc/Khuyến nghị | Ý nghĩa | Lưu ý SEO |
|---|---|---|---|
| name | Bắt buộc | Tên thương hiệu | Trùng với tên hiển thị trên site và social |
| url | Bắt buộc | URL chính của website | Dùng canonical homepage, https, không slash thừa |
| logo | Bắt buộc | Logo thương hiệu | Dùng URL ảnh chuẩn, kích thước tối ưu cho SERP |
| sameAs | Bắt buộc | Danh sách social/profile | Facebook, LinkedIn, YouTube, Wikipedia, GBP… |
| contactPoint | Khuyến nghị mạnh | Thông tin liên hệ | Hotline, email, type như customer service, sales |
| foundingDate | Khuyến nghị | Năm thành lập | Nhất quán với hồ sơ pháp lý, profile báo chí |
name cần phản ánh chính xác brand name được dùng trên logo, header site, social profile và Google Business Profile. Tránh dùng biến thể khác nhau (viết tắt, thêm từ khóa SEO, thêm địa điểm) giữa các kênh, vì mỗi biến thể có thể bị Google coi là một candidate entity khác nhau.
url phải là canonical homepage, dùng https, không có tham số tracking, không thêm slash thừa hoặc subdomain phụ. Trong schema, url này thường được dùng làm global identifier của brand trên website, nên mọi trang khác khi tham chiếu Organization đều nên dùng cùng một @id hoặc cùng một url.
logo nên là một file ảnh tĩnh, kích thước tối ưu cho rich result (thường tối thiểu 112x112, tỉ lệ gần vuông, nền trong suốt hoặc nền đồng nhất). Logo nên được host trên cùng domain với website chính, có URL ổn định, không đổi theo phiên bản build. Khi thay logo, nên cập nhật file mới trên cùng URL hoặc cập nhật đồng bộ trong brand config layer.
sameAs là danh sách URL profile chính thức của thương hiệu trên các nền tảng bên ngoài. Nên ưu tiên:
- Facebook Page, LinkedIn Company, YouTube Channel, Twitter/X, Instagram
- Wikipedia, Wikidata, Crunchbase, các directory uy tín nếu có
- Google Business Profile URL (nếu có dạng URL public ổn định)
Mỗi URL trong sameAs phải là URL public, không có tham số tracking, không redirect qua nhiều bước. Nếu một profile bị đổi URL hoặc bị xóa, cần cập nhật ngay trong hệ thống để tránh trỏ tới 404 hoặc redirect chain dài.
contactPoint nên được cấu trúc theo dạng danh sách, mỗi phần tử là một ContactPoint với các thuộc tính như telephone, contactType, email, areaServed, availableLanguage. Tối thiểu nên có một contactPoint cho customer service hoặc sales, trùng với hotline và email hiển thị trên site. Với các brand lớn, có thể tách contactPoint theo khu vực địa lý hoặc theo loại dịch vụ, nhưng vẫn phải đảm bảo tính nhất quán với thông tin trên Google Business Profile và các directory khác.
foundingDate nên dùng định dạng ISO (YYYY-MM-DD hoặc ít nhất YYYY), và phải trùng với thông tin trong hồ sơ pháp lý, bài báo giới thiệu doanh nghiệp, profile trên Wikipedia hoặc các nguồn có độ tin cậy cao. Nếu có sự khác biệt về năm thành lập giữa các nguồn, nên chuẩn hóa lại và cập nhật đồng bộ, vì đây là một trong những tín hiệu lịch sử giúp Google xác định độ lâu đời và uy tín của brand.
Homepage thường là nơi đặt Organization schema chính, about page và brand entity hub có thể kế thừa hoặc mở rộng thêm thông tin như foundingMember, founder, award, knowsAbout, areaServed. Về mặt kỹ thuật, nên:
- Dùng cùng một @id (ví dụ: "https://example.com/#organization") cho Organization trên toàn site
- Trên homepage: khai báo đầy đủ các thuộc tính cốt lõi (name, url, logo, sameAs, contactPoint, foundingDate, address, legalName… nếu có)
- Trên about page và brand hub: tham chiếu lại cùng @id và bổ sung các thuộc tính mở rộng (founder, foundingMember, award, brand, knowsAbout, memberOf…)
- Tránh tạo nhiều Organization khác nhau với @id khác nhau cho cùng một brand, vì có thể khiến Knowledge Graph tạo nhiều node entity trùng lặp
Đồng bộ Organization schema với social profile và Google Business Profile entity
Thuộc tính sameAs trong Organization schema là cầu nối kỹ thuật giữa website và các profile bên ngoài như Facebook Page, LinkedIn Company, YouTube Channel, Twitter/X, Instagram, Wikipedia, Crunchbase, Google Business Profile. Khi các URL này được khai báo đầy đủ và chính xác, hệ thống entity matching của Google có thể:
- Nhận diện rằng tất cả các profile đó thuộc cùng một thương hiệu
- Hợp nhất tín hiệu authority, review, mention, backlink về một brand entity duy nhất
- Giảm khả năng nhầm lẫn với các thương hiệu trùng tên hoặc gần giống
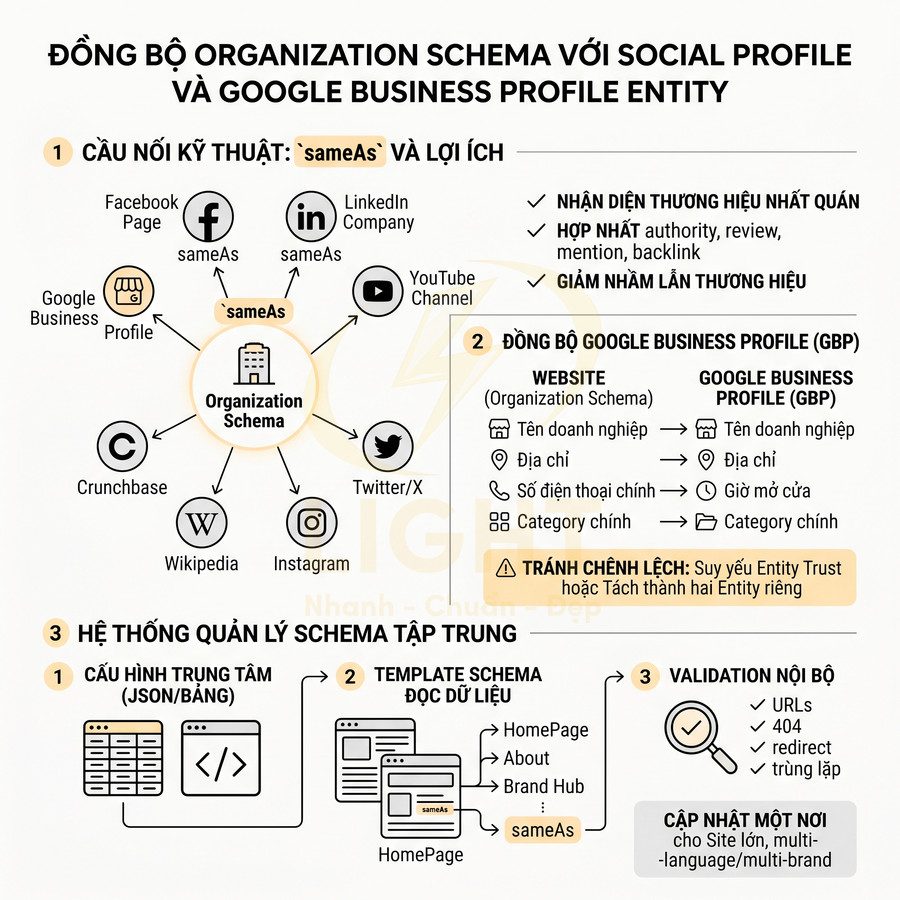
Google Business Profile (GBP) là một entity quan trọng trong local SEO, đặc biệt với các doanh nghiệp có địa điểm vật lý hoặc phục vụ theo khu vực. Dù GBP không dùng schema trực tiếp, nhưng Organization schema trên website nên đồng bộ với thông tin trên GBP về:
- Tên doanh nghiệp (business name)
- Địa chỉ (address, geo, areaServed nếu có)
- Số điện thoại chính (primary phone)
- Giờ mở cửa (openingHoursSpecification nếu khai báo)
- Category chính (có thể phản ánh gián tiếp qua description, knowsAbout, service schema…)
Nếu có chênh lệch lớn (ví dụ tên thương hiệu khác nhau, số điện thoại khác, địa chỉ khác), hệ thống entity reconciliation có thể đánh giá thấp độ tin cậy của brand entity, hoặc tệ hơn là tách thành hai entity riêng biệt: một từ website, một từ GBP. Điều này làm suy yếu hiệu ứng cộng hưởng giữa organic SEO và local SEO.
Hệ thống quản lý schema nên có module cấu hình social profile và GBP tập trung, từ đó tự động cập nhật vào Organization schema trên toàn site. Cách tiếp cận hiệu quả thường gồm:
- Một bảng cấu hình hoặc JSON lưu danh sách social URL, GBP URL, cùng metadata (loại kênh, trạng thái active/inactive)
- Các template schema (homepage, about, brand hub, footer) đọc dữ liệu từ cấu hình này để build thuộc tính sameAs và các field liên quan
- Cơ chế validation nội bộ để phát hiện URL 404, redirect bất thường hoặc trùng lặp
Khi thêm kênh social mới hoặc đổi URL, chỉ cần cập nhật một nơi, tránh tình trạng mỗi trang một phiên bản khác nhau. Điều này đặc biệt quan trọng với các site lớn, multi-language hoặc multi-brand, nơi việc cập nhật thủ công rất dễ gây sai lệch giữa các phiên bản.
Tự động cập nhật logo, hotline, địa chỉ và social URL khi brand thay đổi
Trong vòng đời thương hiệu, việc thay đổi logo, hotline, địa chỉ văn phòng, URL social là điều thường gặp: rebranding, mở rộng chi nhánh, hợp nhất công ty, đổi domain, đổi chiến lược kênh social. Nếu không có cơ chế tự động, schema rất dễ bị lỗi thời, gây mismatch giữa dữ liệu cấu trúc và nội dung hiển thị, cũng như giữa website và các nguồn bên ngoài.
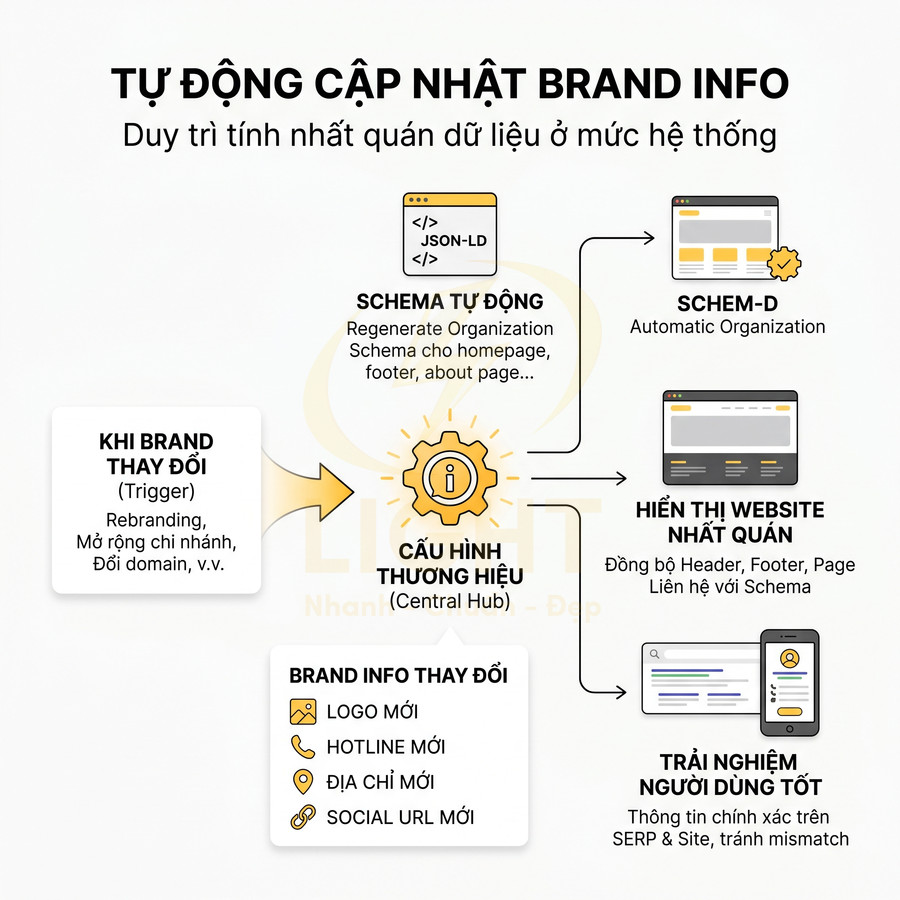
Mismatch này không chỉ làm giảm độ tin cậy của brand entity trong mắt Google mà còn tạo trải nghiệm không nhất quán cho người dùng (ví dụ click vào số điện thoại trong SERP khác với số hiển thị trên site). Để tránh tình trạng đó, giải pháp là xây dựng một brand config layer trong CMS hoặc trong file cấu hình (database, JSON, environment variable) chứa các thông tin:
- logo URL (phiên bản chuẩn dùng cho schema và cho SERP)
- hotline chính và các số liên hệ quan trọng khác
- địa chỉ chuẩn (định dạng thống nhất, có thể kèm geo nếu dùng cho LocalBusiness)
- danh sách social URL, GBP URL
- foundingDate, legalName, tax ID nếu cần cho các use case nâng cao
Organization schema trên mọi template sẽ đọc dữ liệu từ layer này, không hard-code trong từng file. Về mặt kỹ thuật, có thể triển khai:
- Một service hoặc helper function trong code backend trả về object brandConfig
- Các component schema (JSON-LD generator) nhận brandConfig làm input và render Organization schema tương ứng
- Các phần tử UI như header, footer, contact page cũng đọc từ cùng brandConfig để đảm bảo nội dung hiển thị và schema luôn trùng khớp
Khi brand thay đổi, team marketing chỉ cần cập nhật brand config qua CMS hoặc qua một file cấu hình trung tâm, hệ thống sẽ tự động regenerate schema cho homepage, about page, footer, header, Article, Product… đảm bảo mọi nơi đều dùng logo mới, hotline mới, địa chỉ mới. Với hệ thống lớn, có thể kết hợp thêm job background để re-render hoặc re-deploy các trang tĩnh sau khi brand config thay đổi, đồng thời:
- Trigger build lại static site (Jamstack) hoặc invalidate cache trên CDN
- Chạy batch job kiểm tra lại structured data bằng API của Google Rich Results Test hoặc các tool nội bộ
- Log version của brandConfig để có thể audit lại khi cần (ví dụ khi Google cập nhật Knowledge Panel, có thể đối chiếu với phiên bản brandConfig tại thời điểm đó)
Cách tiếp cận này biến Organization schema từ một đoạn code tĩnh thành một phần của brand infrastructure, giúp duy trì tính nhất quán dữ liệu ở mức hệ thống, giảm rủi ro sai lệch khi brand phát triển và thay đổi theo thời gian.
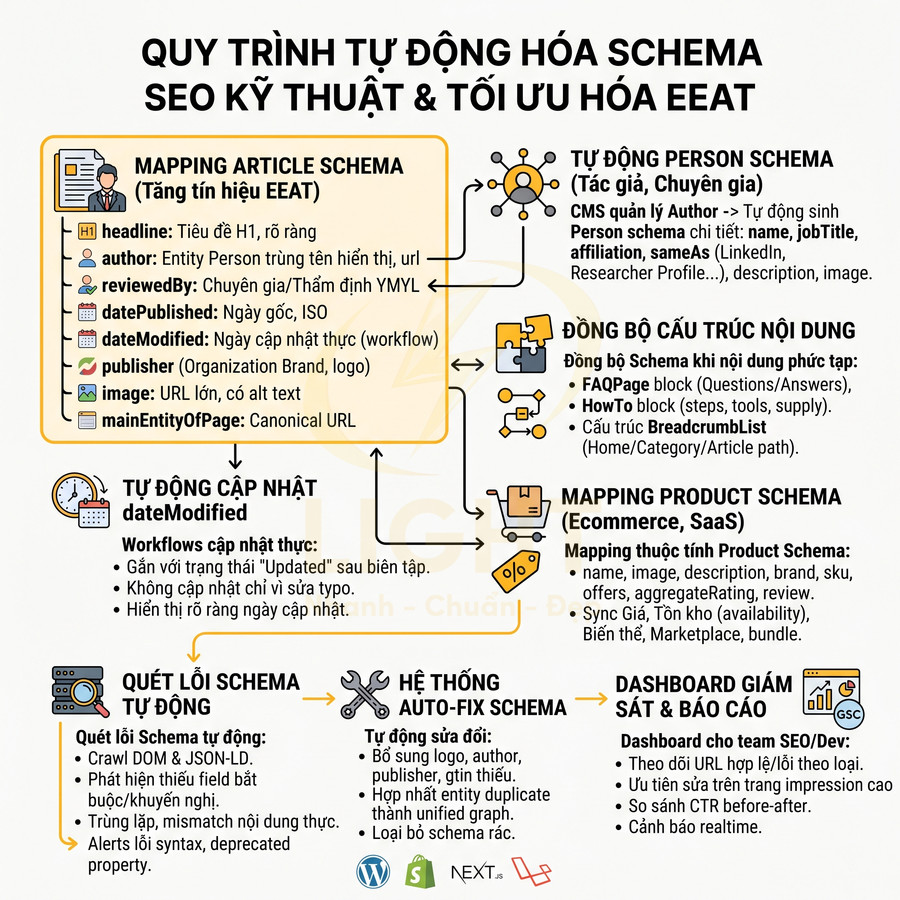
Cách thêm schema Article cho blog, news, guide và content hub theo EEAT
Schema Article cần được triển khai như một lớp dữ liệu kỹ thuật song song với nội dung, đảm bảo mọi thuộc tính quan trọng đều được lấy trực tiếp từ CMS và khớp 1:1 với giao diện. Các field như headline, author, reviewedBy, datePublished, dateModified, image, mainEntityOfPage, publisher phải được mapping rõ ràng, ưu tiên tự động hóa theo workflow biên tập để tránh hard-code trong template. Person schema cho author, reviewer, expert contributor nên được quản lý như entity riêng, liên kết với Article qua author, reviewedBy, contributor, phản ánh đúng chuyên môn, affiliation và hồ sơ công khai. Với nội dung chuyên sâu, có thể kết hợp Article với FAQPage, HowTo, BreadcrumbList, miễn là các block tương ứng thực sự tồn tại trên trang và được mapping chính xác. Với Article schema, tính nhất quán giữa nội dung hiển thị và dữ liệu có cấu trúc là yếu tố cốt lõi để củng cố EEAT. Nghiên cứu về lỗi Schema.org cho thấy dữ liệu triển khai trên web thường gặp sai lệch về kiểu dữ liệu, thuộc tính và cấu trúc, làm giảm khả năng được hệ thống tiêu thụ dữ liệu xử lý chính xác (Meusel & Paulheim, 2015). Vì vậy, các trường headline, author, datePublished, dateModified, image, publisher nên được sinh từ CMS, không nhập tay trong JSON-LD. Nếu giao diện hiển thị tác giả A nhưng schema khai báo tác giả B, tín hiệu tin cậy bị suy yếu ngay cả khi schema vẫn hợp lệ về cú pháp.
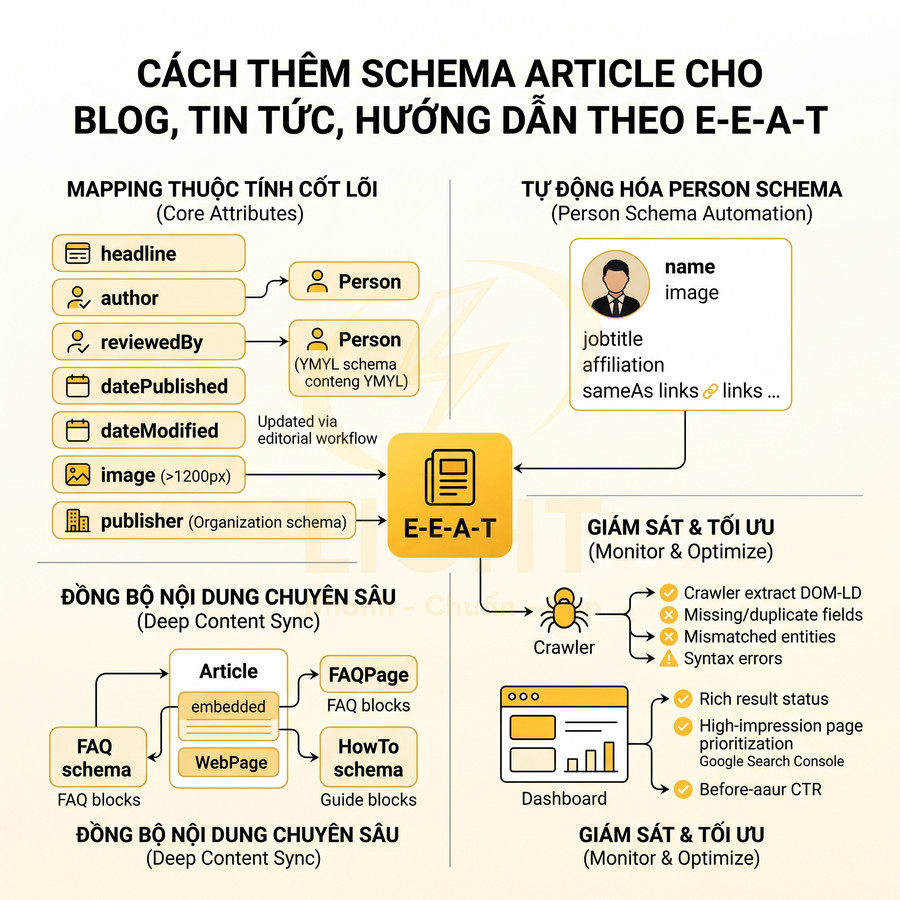
Mapping headline, author, reviewedBy, datePublished, dateModified, image, mainEntityOfPage
Schema Article là công cụ quan trọng để thể hiện chuyên môn (Expertise) và tính cập nhật (Experience/Trust) của nội dung. Để tối ưu theo EEAT ở mức kỹ thuật, cần mapping đầy đủ và chính xác các thuộc tính: headline, author, reviewedBy, datePublished, dateModified, image, mainEntityOfPage, publisher. Mỗi thuộc tính phải khớp 1:1 với nội dung hiển thị trên giao diện, được cập nhật tự động theo workflow biên tập và không bị “cứng mã” trong template.
| Thuộc tính | Ý nghĩa | Nguồn dữ liệu | Lưu ý EEAT |
|---|---|---|---|
| headline | Tiêu đề bài viết | posttitle | Rõ ràng, không nhồi nhét từ khóa |
| author | Tác giả | authorid → Person | Hiển thị tên thật, link đến trang tác giả |
| reviewedBy | Người review/chuyên gia | reviewerid → Person | Quan trọng với nội dung YMYL |
| datePublished | Ngày xuất bản | postdate | Không thay đổi tùy tiện để câu view |
| dateModified | Ngày cập nhật | postmodified | Cập nhật khi có chỉnh sửa nội dung thực |
| image | Ảnh đại diện | featuredimage | Độ phân giải đủ lớn, liên quan nội dung |
| mainEntityOfPage | Entity chính của trang | URL bài viết | Giúp Google hiểu nội dung chính |
Ở mức triển khai, mỗi thuộc tính nên được mapping theo nguyên tắc:
- headline: lấy trực tiếp từ posttitle, giới hạn độ dài hợp lý (thường < 110 ký tự) để tránh bị cắt trong SERP; không tự động chèn thêm brand name nếu đã có trong title HTML để tránh trùng lặp.
- author: mapping từ authorid sang entity Person, đảm bảo:
- Tên hiển thị (displayname) trùng với name trong Person schema.
- URL trang tác giả (author archive hoặc custom author page) trùng với sameAs hoặc url trong Person.
- reviewedBy: dùng cho bài có quy trình thẩm định; mapping từ trường reviewerid trong CMS sang Person, chỉ hiển thị khi thực sự có quy trình review (có log, có ngày review).
- datePublished: lấy từ postdate gốc, không ghi đè khi update; nếu migrate dữ liệu, cần giữ lại ngày xuất bản ban đầu để không làm sai lịch sử nội dung.
- dateModified: lấy từ postmodified, nhưng nên gắn với workflow (trạng thái “Updated/Republished”) thay vì mọi lần autosave; tránh cập nhật chỉ vì sửa typo nhỏ.
- image: mapping từ featuredimage với đầy đủ:
- URL ảnh kích thước lớn (thường >= 1200px chiều ngang).
- Thuộc tính width, height và caption/alt nếu có.
- mainEntityOfPage: trỏ đến URL canonical của bài viết; nếu có tham số tracking (UTM), cần loại bỏ để tránh tạo nhiều entity khác nhau cho cùng một nội dung.
Với blog, news, guide, content hub, nên chọn type phù hợp: BlogPosting cho blog, NewsArticle cho tin tức, Article chung cho bài phân tích, MedicalWebPage hoặc TechArticle cho nội dung chuyên ngành khi phù hợp. Khi chọn type, cần nhất quán theo template hoặc theo taxonomy, tránh một URL lúc là BlogPosting, lúc là NewsArticle. mainEntityOfPage nên trỏ đến chính URL bài viết, giúp Google hiểu đây là nội dung chính chứ không phải phần phụ như widget, sidebar hay block liên quan.
Về publisher, nên mapping đến Organization schema của brand:
- name: tên thương hiệu chính thức.
- logo: URL logo chuẩn, kích thước theo guideline Google (thường 112x112 hoặc lớn hơn, hình vuông).
- url: domain chính, trùng với canonical homepage.
Tự động thêm Person schema cho author, reviewer và expert contributor
Để tăng độ tin cậy, mỗi author, reviewer, expert contributor nên có Person schema riêng, liên kết với Article thông qua property author, reviewedBy, contributor. Person schema không chỉ là tên và ảnh, mà cần phản ánh rõ chuyên môn và bối cảnh nghề nghiệp của cá nhân đó.
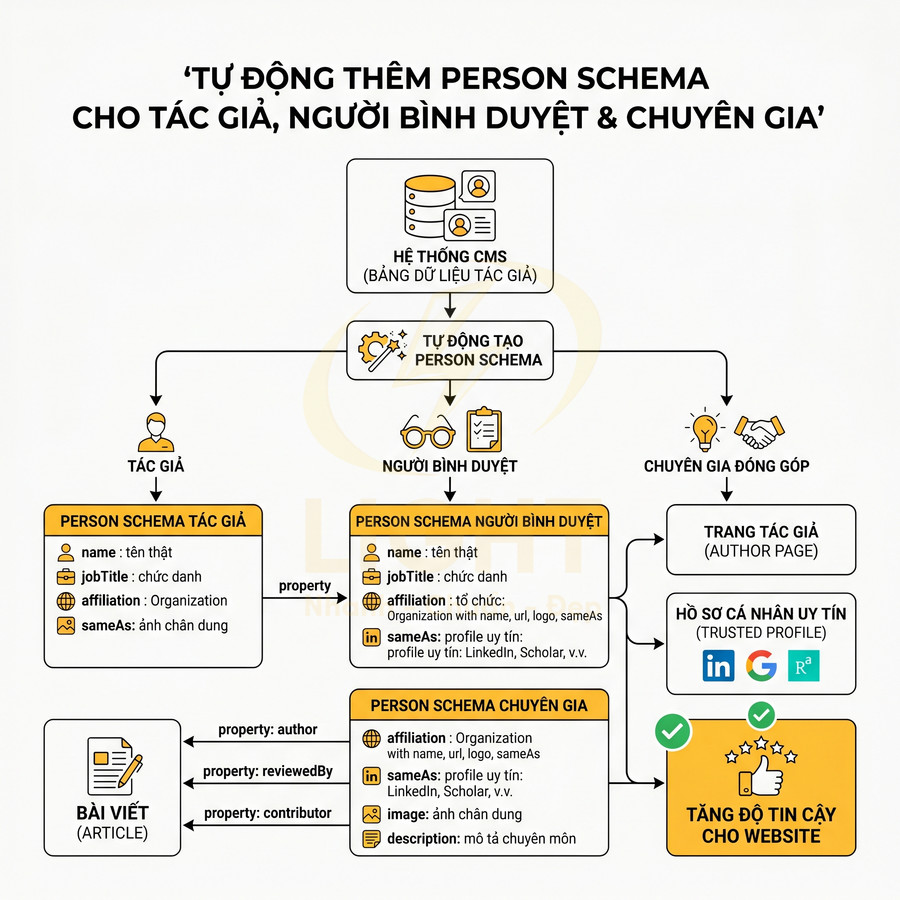
Các thuộc tính nên có trong Person schema:
- name: tên thật, trùng với tên hiển thị trên trang; tránh dùng nickname hoặc bút danh không có hồ sơ công khai.
- jobTitle: chức danh chuyên môn hiện tại (ví dụ: “Bác sĩ Nội tổng quát”, “Chuyên gia Tài chính cá nhân”).
- affiliation (Organization): tổ chức đang làm việc hoặc cộng tác; nên mapping tới một Organization schema có:
- name, url, logo.
- sameAs nếu có (LinkedIn company page, trang giới thiệu chính thức).
- sameAs: liên kết tới các profile uy tín:
- LinkedIn, ResearchGate, Google Scholar, trang profile tại bệnh viện/trường đại học.
- Trang tác giả trên chính website (author page) nếu có nội dung giới thiệu chi tiết.
- image: ảnh chân dung rõ mặt, chuyên nghiệp, trùng với ảnh hiển thị trên trang tác giả.
- description: đoạn mô tả ngắn về chuyên môn, kinh nghiệm, lĩnh vực nghiên cứu hoặc hành nghề.
Hệ thống CMS nên quản lý author như một entity riêng (bảng user hoặc author profile), từ đó tự động generate Person schema cho trang tác giả và embed vào mọi Article liên quan. Cấu trúc đề xuất:
- Mỗi author có một record với:
- authorid (khóa chính).
- name, slug, avatar, bio, jobtitle, organizationid.
- sociallinks (LinkedIn, profile chuyên gia, v.v.).
- Mỗi Organization (affiliation) là một entity riêng để tái sử dụng cho nhiều author.
- Template Article đọc authorid, reviewerid, contributorid và tự động embed Person schema tương ứng.
Với reviewer hoặc expert contributor, có thể dùng field custom trong bài viết để chọn chuyên gia, sau đó mapping sang Person schema. Đặc biệt với nội dung YMYL (Your Money Your Life) như tài chính, sức khỏe, pháp lý, nên:
- Luôn hiển thị rõ “Được kiểm chứng bởi…” hoặc “Được review bởi…” trên giao diện.
- Đảm bảo reviewer có Person schema với jobTitle và affiliation phù hợp lĩnh vực.
- Log lại lịch sử review (ngày, người review) để có thể mapping thêm thuộc tính reviewedBy và liên hệ với dateModified khi cập nhật.
Việc tự động hóa giúp đảm bảo mọi bài viết đều có author rõ ràng, tránh tình trạng bài không có tác giả hoặc dùng tên bút danh không liên kết với bất kỳ entity nào. Khi chuyên gia thay đổi chức danh, nơi làm việc, chỉ cần cập nhật trong profile, Person schema trên toàn site sẽ được cập nhật tương ứng, giữ tính nhất quán và giảm rủi ro sai lệch thông tin chuyên môn.
Đồng bộ Article schema với FAQ, Breadcrumb và HowTo khi nội dung chuyên sâu
Nhiều bài viết chuyên sâu có cấu trúc nội dung phức tạp: phần hướng dẫn từng bước, phần hỏi đáp, phần danh sách tài nguyên. Để tận dụng tối đa rich result, có thể kết hợp Article schema với FAQPage, HowTo và BreadcrumbList trong cùng một trang, miễn là nội dung thực sự chứa các phần tương ứng và được trình bày rõ ràng cho người dùng.
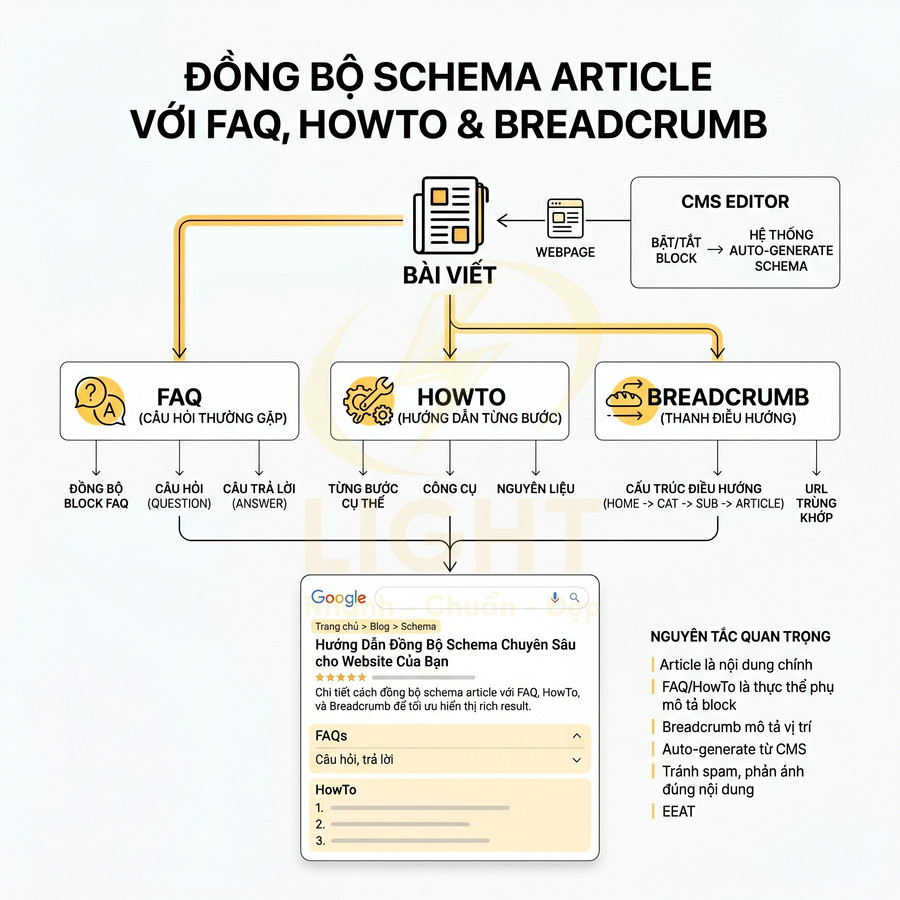
Nguyên tắc quan trọng:
- Article là entity nội dung chính, gắn với WebPage.
- FAQPage và HowTo là các entity phụ, mô tả các block nội dung cụ thể trong cùng WebPage.
- BreadcrumbList mô tả cấu trúc điều hướng, giúp Google hiểu vị trí của Article trong site architecture.
FAQPage schema nên mapping với block FAQ trong CMS:
- Mỗi câu hỏi là một Question:
- name: nội dung câu hỏi hiển thị.
- acceptedAnswer.text: nội dung câu trả lời, không được khác với phần hiển thị cho người dùng.
- Không tạo FAQ schema cho các câu hỏi không hiển thị trên trang.
- Tránh lặp lại cùng một câu hỏi ở nhiều trang với cùng câu trả lời nếu không thực sự cần thiết.
HowTo schema nên mapping với block hướng dẫn:
- step: từng bước cụ thể, trùng với heading hoặc list step trong nội dung.
- tool, supply: nếu bài hướng dẫn có phần liệt kê công cụ, nguyên liệu, cần mapping đúng tên và số lượng.
- estimatedCost, totalTime: chỉ thêm khi có thông tin rõ ràng trong bài, tránh ước lượng tùy tiện.
BreadcrumbList nên mapping với cấu trúc điều hướng: Home → Category → Subcategory → Article, trong đó:
- Mỗi item có position, name, item (URL).
- URL phải trùng với đường dẫn điều hướng thực tế trên site.
- Category và Subcategory nên là taxonomy ổn định, không thay đổi thường xuyên để tránh thay đổi breadcrumb liên tục.
Hệ thống nên cho phép content editor bật/tắt block FAQ, HowTo trong editor, và khi bật thì schema tương ứng được auto-generate. Cách làm này đảm bảo schema luôn phản ánh đúng cấu trúc nội dung, tránh tình trạng thêm FAQ schema nhưng trang không có phần hỏi đáp hiển thị, vốn có thể bị xem là spam structured data và ảnh hưởng tiêu cực đến EEAT.
Tự động cập nhật dateModified theo content refresh và editorial workflow
dateModified là tín hiệu quan trọng thể hiện nội dung được cập nhật, nhưng nếu lạm dụng hoặc cập nhật sai thực tế, có thể làm giảm độ tin cậy. Hệ thống nên gắn dateModified với editorial workflow thực sự: chỉ cập nhật khi có thay đổi nội dung đáng kể (text, hình ảnh, dữ liệu), không cập nhật khi chỉ sửa lỗi chính tả nhỏ hoặc thay đổi không ảnh hưởng đến người đọc.
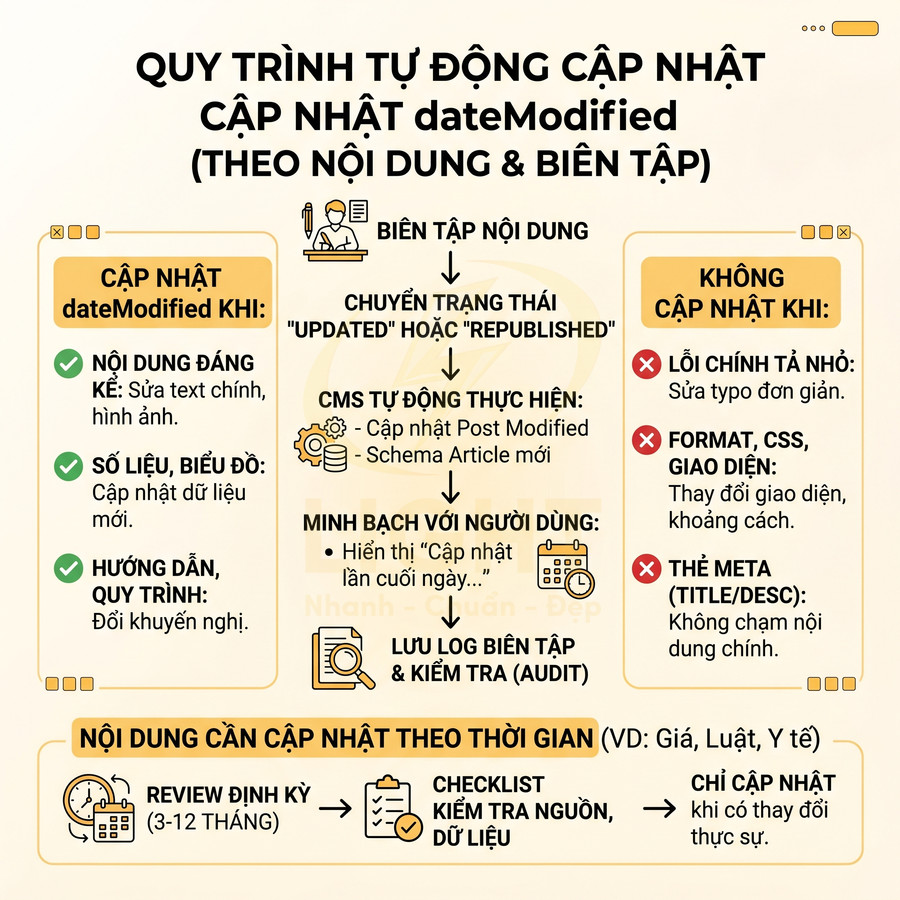
Một số nguyên tắc kỹ thuật và biên tập:
- Chỉ cập nhật dateModified khi:
- Thêm, xóa, chỉnh sửa đoạn nội dung có ý nghĩa.
- Cập nhật số liệu, biểu đồ, bảng dữ liệu.
- Thay đổi khuyến nghị, quy trình, hướng dẫn.
- Không cập nhật dateModified khi:
- Sửa typo nhỏ, lỗi chính tả đơn lẻ.
- Thay đổi format, spacing, hoặc chỉnh CSS.
- Thay đổi meta description, thẻ title mà không chạm vào nội dung chính.
Trong CMS, có thể thiết kế cơ chế:
- Khi bài viết được chuyển sang trạng thái “Updated” hoặc “Republished” sau khi biên tập, hệ thống tự động cập nhật post_modified và regenerate Article schema với dateModified mới.
- Log lại người chỉnh sửa, lý do chỉnh sửa để team SEO và content có thể audit khi cần.
- Hiển thị rõ ràng “Cập nhật lần cuối ngày…” trên trang để người dùng thấy sự minh bạch, đồng bộ với giá trị dateModified trong schema.
Với nội dung cần tính thời sự hoặc dữ liệu thay đổi theo thời gian (giá, lãi suất, quy định pháp luật, phác đồ điều trị), nên xây dựng quy trình content refresh định kỳ, gắn với:
- Lịch review nội dung (ví dụ: 6 tháng/lần cho bài sức khỏe, 3 tháng/lần cho bài tài chính).
- Checklist kiểm tra: dữ liệu, nguồn tham khảo, guideline mới, thay đổi pháp lý.
- Cập nhật dateModified chỉ khi có thay đổi thực sự sau review.
Cách làm này phù hợp với nguyên tắc EEAT, giúp Google và người dùng hiểu rằng nội dung không chỉ được xuất bản một lần rồi bỏ đó, mà được duy trì, kiểm chứng và cập nhật có hệ thống, phản ánh đúng chuyên môn và trách nhiệm của publisher.
Cách thêm schema Product cho ecommerce, SaaS pricing và landing page chuyển đổi
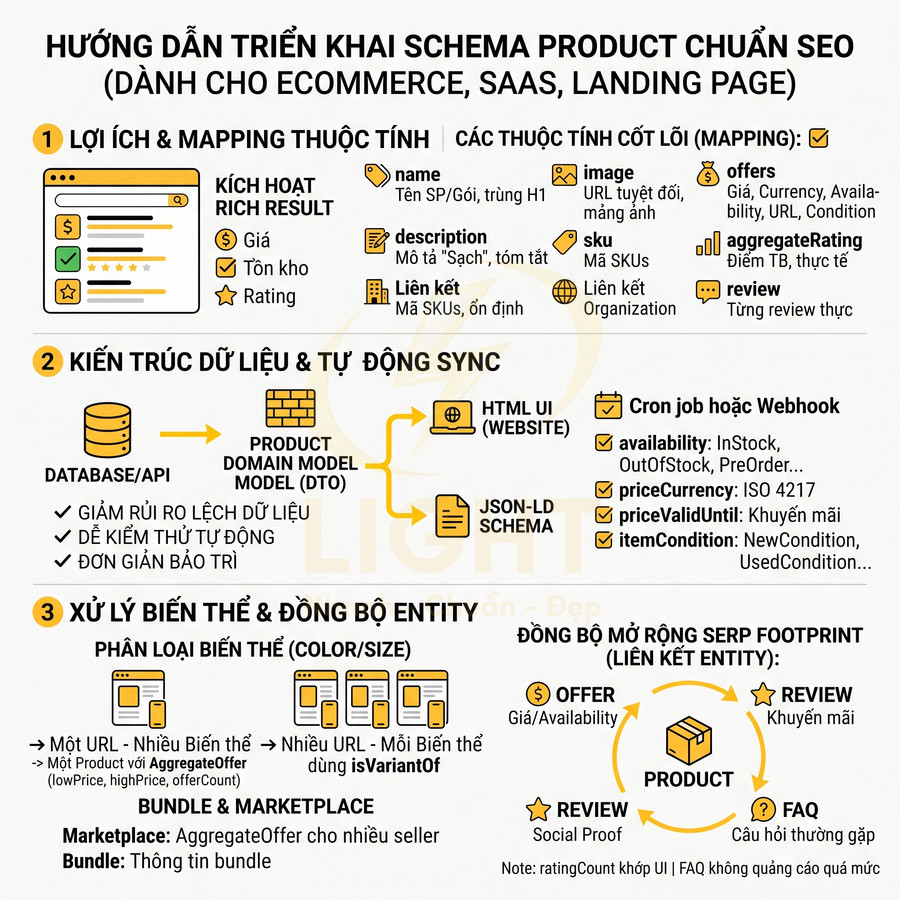
Mapping name, image, description, brand, sku, offers, aggregateRating, review
Schema Product là chìa khóa để kích hoạt rich result về giá, tồn kho, rating trên SERP. Để triển khai chuẩn SEO, cần mapping đầy đủ các thuộc tính: name, image, description, brand, sku, gtin, offers, aggregateRating, review. Mỗi thuộc tính nên lấy từ cùng nguồn dữ liệu với nội dung hiển thị để tránh mismatch giữa giao diện và JSON-LD, đặc biệt trong bối cảnh site dùng cache, CDN hoặc static generation.

Về mặt kỹ thuật, nên chuẩn hóa một lớp product domain model (hoặc DTO) làm nguồn dữ liệu duy nhất cho cả HTML và JSON-LD. Lớp này được build từ database hoặc API nội bộ, sau đó được render song song: một nhánh cho UI, một nhánh cho schema. Cách làm này giúp:
- Giảm rủi ro sai lệch giá, tồn kho, tên sản phẩm giữa UI và schema.
- Dễ kiểm thử tự động (so sánh snapshot UI vs JSON-LD).
- Đơn giản hóa việc bảo trì khi thêm thuộc tính mới (gtin, mpn, itemCondition…).
Chi tiết mapping cho từng thuộc tính quan trọng:
- name: bắt buộc, nên trùng với H1 và title logic của sản phẩm. Nếu có tiền tố/ hậu tố marketing (VD: “Giảm 50%”), không nên đưa vào name trong schema để tránh spam.
- image: nên dùng URL tuyệt đối, có thể là mảng nhiều ảnh. Ưu tiên ảnh có kích thước tối thiểu 1200px chiều rộng, định dạng web-friendly (WebP, JPEG). Nếu có nhiều ảnh, nên đặt ảnh chính ở vị trí đầu tiên trong mảng.
- description: nên là mô tả “clean” đã loại bỏ HTML không cần thiết, không nhồi nhét từ khóa, không copy nguyên meta description nếu meta quá ngắn. Có thể dùng bản tóm tắt 1–2 đoạn đầu của mô tả chi tiết.
- brand: nên liên kết với một entity Organization hoặc Brand riêng (có @id cố định). Điều này giúp Google hiểu mối quan hệ giữa nhiều sản phẩm cùng thương hiệu và hỗ trợ xây dựng knowledge graph.
- sku: dùng làm định danh nội bộ, phải ổn định theo thời gian. Với sản phẩm có nhiều biến thể, mỗi biến thể nên có sku riêng, tránh dùng chung một sku cho nhiều size/màu.
- gtin (gtin8, gtin12, gtin13, gtin14): nếu có, nên mapping chính xác theo chuẩn mã vạch. Không nên “bịa” gtin chỉ để đủ field, vì có thể gây lỗi validation.
- offers: chứa thông tin bán hàng (giá, currency, availability, url, itemCondition…). Có thể là Offer (một giá) hoặc AggregateOffer (nhiều mức giá/ nhiều seller).
- aggregateRating: phản ánh điểm trung bình thực tế, tính từ dữ liệu review thật. Không nên hard-code 5.0/5 cho mọi sản phẩm.
- review: nên mapping từng review thực, có author, rating, nội dung, ngày đăng. Không nên tạo review giả chỉ tồn tại trong JSON-LD.
| Thuộc tính | Ý nghĩa | Nguồn dữ liệu | Lưu ý |
|---|---|---|---|
| name | Tên sản phẩm | productname | Trùng với H1 trên trang |
| image | Ảnh sản phẩm | gallerymain | Có thể là mảng nhiều ảnh |
| description | Mô tả sản phẩm | productdescription | Không nhồi nhét từ khóa |
| brand | Thương hiệu | brandid → Organization | Liên kết với brand entity |
| sku | Mã SKU | sku | Độc nhất cho mỗi sản phẩm/biến thể |
| offers | Thông tin bán hàng | price, currency, stock | Dùng Offer hoặc AggregateOffer |
| aggregateRating | Điểm trung bình | ratingaverage, ratingcount | Chỉ dùng khi có review thực |
| review | Danh sách review | review table | Review schema lồng trong Product |
Với SaaS pricing hoặc landing page, Product schema vẫn áp dụng được: name là tên gói, description là mô tả gói, offers chứa price, priceCurrency, availability (InStock cho gói đang bán), url là URL landing page. Nếu có testimonial hoặc review, có thể mapping sang Review schema, nhưng cần đảm bảo review hiển thị rõ ràng trên trang.
Đối với SaaS, một số thực hành chuyên sâu:
- Dùng Product cho từng gói (Basic, Pro, Enterprise) nếu mỗi gói có URL riêng; nếu tất cả gói trên một URL, có thể dùng một Product với AggregateOffer hoặc nhiều Offer.
- Tránh dùng schema Service song song với Product cho cùng một gói để không gây nhiễu; chọn một loại chính và dùng additionalType nếu cần.
- Nếu có free trial, có thể biểu diễn bằng Offer với price = 0 và mô tả rõ trong description, nhưng vẫn cần Offer trả phí là chính.
Tự động sync giá, tồn kho, biến thể và khuyến mãi từ database sản phẩm
Giá, tồn kho, biến thể và khuyến mãi thường thay đổi liên tục, nên Product schema phải được tự động sync từ database sản phẩm hoặc hệ thống ERP, không nên nhập tay. Offers trong schema cần phản ánh chính xác giá hiện tại, currency, availability, priceValidUntil (nếu có khuyến mãi theo thời gian), itemCondition, url.
Kiến trúc tốt là để layer schema đọc trực tiếp từ API sản phẩm hoặc từ model đã được chuẩn hóa, giống như layer render HTML. Khi giá thay đổi trong database, cả giao diện và JSON-LD đều cập nhật cùng lúc. Với hệ thống có cache hoặc static generation, cần thiết kế cơ chế revalidate hoặc re-render khi có thay đổi giá/tồn kho, tránh tình trạng schema cũ trong khi giao diện mới.
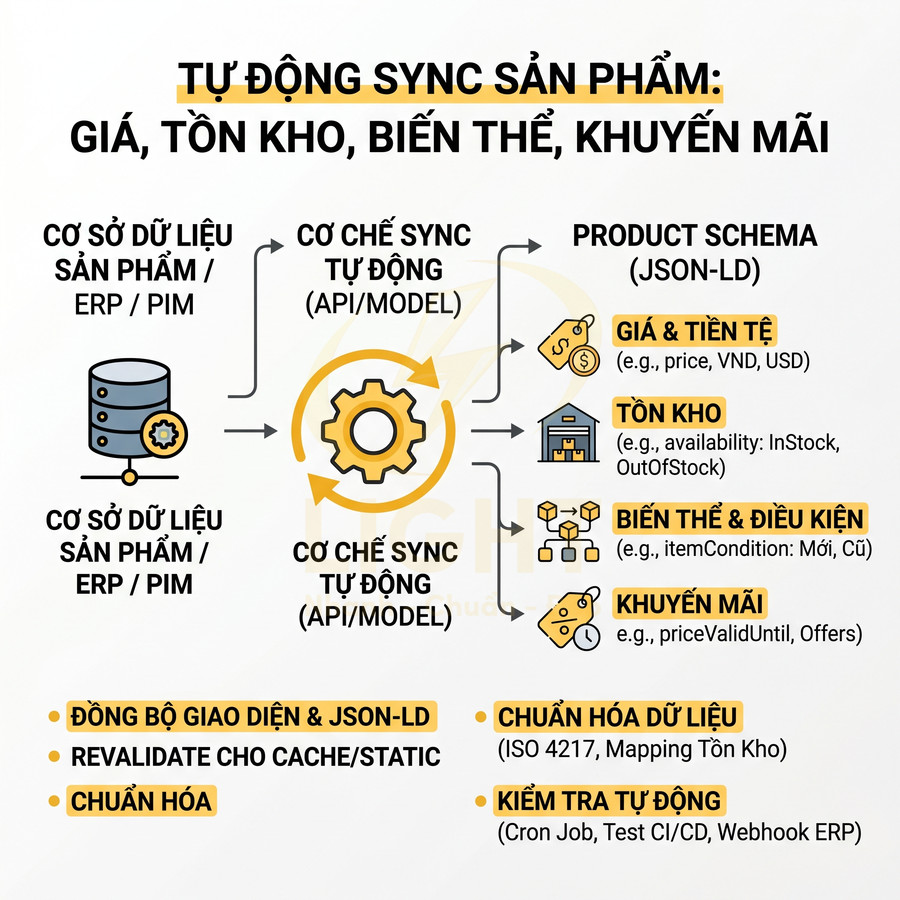
Một số điểm kỹ thuật chuyên sâu cần lưu ý khi sync tự động:
- availability: mapping chuẩn các trạng thái như InStock, OutOfStock, PreOrder, BackOrder. Không dùng chuỗi tùy ý (VD: “Còn hàng ít”) trong schema.
- priceCurrency: luôn dùng mã ISO 4217 (USD, VND, EUR…). Nếu site đa tiền tệ, schema nên phản ánh đúng currency đang hiển thị cho user (theo geo hoặc setting).
- priceValidUntil: chỉ nên set khi có khuyến mãi có ngày kết thúc rõ ràng. Khi hết hạn, job tự động phải xóa hoặc cập nhật field này.
- itemCondition: dùng các giá trị chuẩn như NewCondition, UsedCondition, RefurbishedCondition, tránh để trống với sản phẩm second-hand.
- url: nên là canonical URL của sản phẩm/gói, trùng với thẻ link rel="canonical".
Với khuyến mãi, có thể dùng priceSpecification hoặc thêm priceValidUntil trong Offer. Nếu có nhiều mức giá (giá gốc, giá khuyến mãi), cần mapping rõ ràng: price là giá hiện tại, highPrice/lowPrice trong AggregateOffer phản ánh khoảng giá cho nhiều biến thể.
Để đảm bảo tính nhất quán, nên triển khai:
- Job kiểm tra định kỳ (cron) so sánh giá/tồn kho trong schema với database, log chênh lệch.
- Test tự động dùng Google Rich Results Test hoặc Schema Validator trong pipeline CI/CD.
- Cơ chế webhook từ ERP/PIM để trigger re-render hoặc cache purge khi có thay đổi lớn (flash sale, thay đổi bảng giá).
Product schema cho biến thể màu, size, bundle và multi-seller marketplace
Website ecommerce thường có sản phẩm với nhiều biến thể: màu, size, dung lượng, bundle, hoặc nhiều người bán (marketplace). Schema Product cần phản ánh cấu trúc này một cách hợp lý, tránh trùng lặp và vẫn đảm bảo Google hiểu được giá và availability chính.
Với biến thể màu/size, có thể chọn một trong hai hướng: dùng một Product chính với AggregateOffer cho nhiều biến thể, hoặc dùng Product cho từng biến thể với thuộc tính additionalProperty (color, size). Lựa chọn phụ thuộc vào cách website tổ chức URL: nếu mỗi biến thể có URL riêng, có thể dùng Product riêng; nếu tất cả biến thể trên một URL, nên dùng một Product với AggregateOffer.
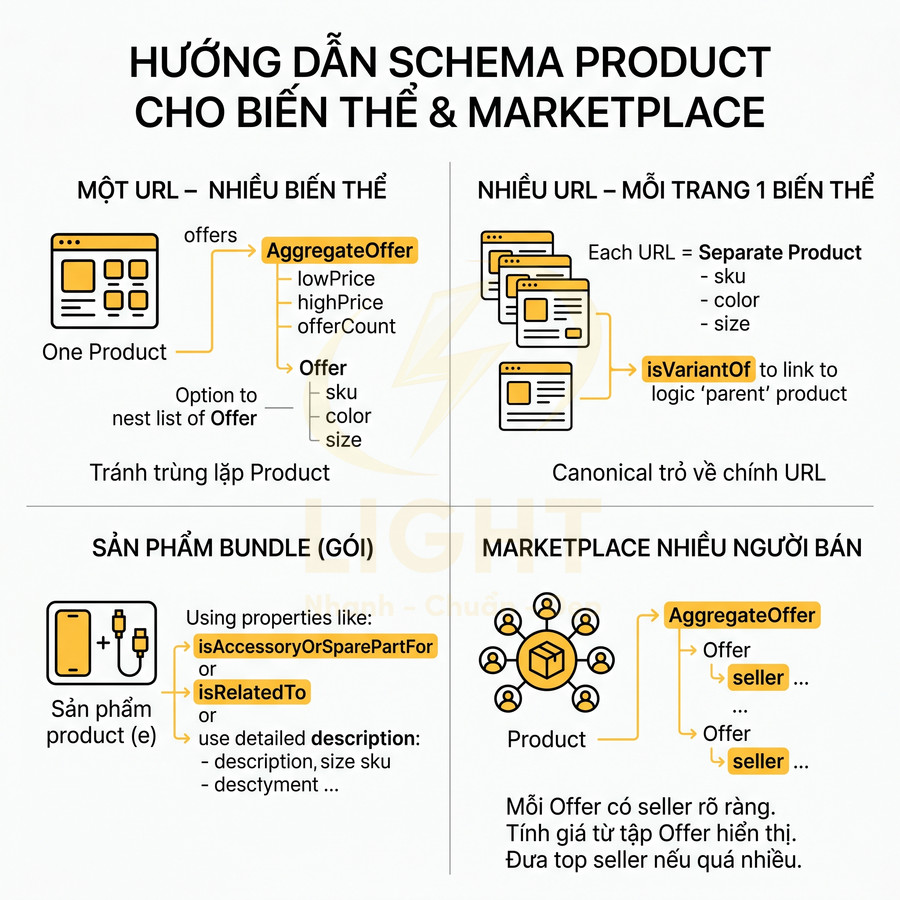
Chi tiết chuyên sâu cho từng mô hình:
- Một URL – nhiều biến thể:
- Dùng một Product duy nhất, trong đó:
- offers là AggregateOffer, chứa lowPrice, highPrice, offerCount.
- Có thể lồng danh sách Offer cho từng biến thể nếu cần chi tiết (mỗi Offer có sku, color, size trong additionalProperty).
- Không nên tạo nhiều Product lặp lại cùng @id trên cùng URL cho từng màu/size, dễ gây trùng lặp.
- Dùng một Product duy nhất, trong đó:
- Nhiều URL – mỗi biến thể một trang:
- Mỗi URL là một Product riêng, với sku, color, size cụ thể.
- Có thể dùng isVariantOf để liên kết các biến thể với một Product “cha” logic.
- Canonical mỗi trang trỏ về chính URL biến thể tương ứng để tránh self-canonical sai.
Với bundle, có thể dùng isAccessoryOrSparePartFor, isRelatedTo, hoặc thêm description chi tiết về bundle. Với marketplace nhiều người bán, nên dùng AggregateOffer với lowPrice, highPrice, offerCount, và Offer riêng cho từng seller nếu cần. Quan trọng là không tạo quá nhiều Product trùng lặp cho cùng một item, tránh gây nhiễu cho Google.
Một số lưu ý nâng cao cho marketplace:
- Mỗi Offer nên có seller (Organization hoặc Person) với tên seller rõ ràng.
- Nếu có hàng chục seller, có thể chỉ đưa một phần (VD: top 5 seller) vào schema để tránh JSON-LD quá lớn.
- lowPrice và highPrice phải tính từ tập Offer đang hiển thị cho user (đã loại bỏ seller bị ẩn hoặc không hoạt động).
Đồng bộ Product với Offer, Review và FAQ để mở rộng SERP footprint
Để mở rộng footprint trên SERP, Product schema nên được liên kết chặt chẽ với Offer, Review và FAQ. Offer cung cấp thông tin giá và availability, Review cung cấp tín hiệu social proof, FAQ cung cấp câu trả lời cho các câu hỏi thường gặp về sản phẩm. Khi kết hợp, kết quả tìm kiếm có thể hiển thị giá, rating, số review, và đôi khi cả FAQ snippet.
Hệ thống nên mapping review từ bảng review thực tế: mỗi review có author, reviewRating, reviewBody, datePublished. AggregateRating nên tính toán từ dữ liệu thực, không hard-code. FAQ nên mapping từ block FAQ trong trang sản phẩm, với câu hỏi về bảo hành, vận chuyển, đổi trả, hướng dẫn sử dụng. Tất cả phải hiển thị rõ ràng cho người dùng, không chỉ tồn tại trong JSON-LD.
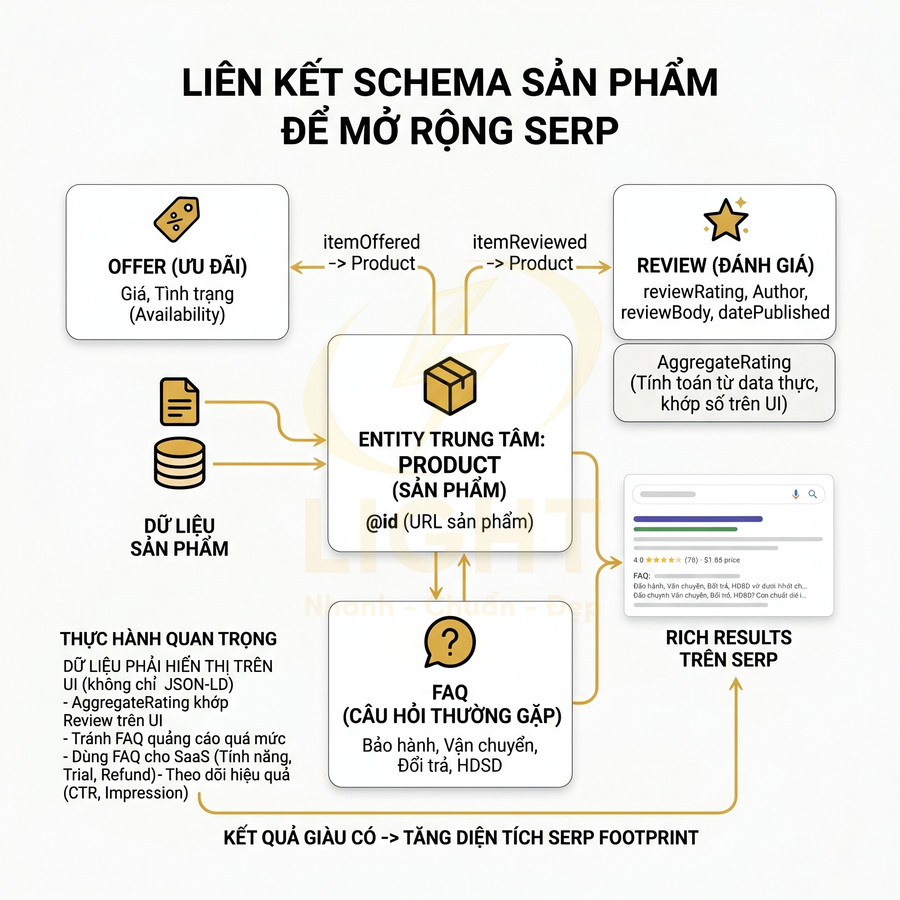
Cách tổ chức dữ liệu schema theo hướng “liên kết entity”:
- Product là entity trung tâm, có @id cố định (thường là URL sản phẩm).
- Offer tham chiếu về Product qua itemOffered hoặc nằm lồng trong Product.
- Review tham chiếu về Product qua itemReviewed, đồng thời lồng trong Product để Google dễ crawl.
- FAQPage (hoặc FAQ block) có thể tách thành schema riêng nhưng vẫn nằm trên cùng URL, song song với Product.
Một số thực hành chuyên sâu để tối ưu SERP footprint:
- Đảm bảo số review trong aggregateRating (ratingCount) khớp với số review hiển thị trên UI, tránh bị coi là thao túng.
- Không dùng FAQ schema cho các câu hỏi mang tính quảng cáo quá mức; tập trung vào câu hỏi thực tế của người dùng.
- Đối với SaaS, có thể dùng FAQ để giải thích tính năng, điều khoản thanh toán, trial, refund… và liên kết logic với Product schema của gói.
- Thiết lập tracking để đo lường tác động của rich result (CTR, impression) sau khi triển khai Product + Review + FAQ, từ đó tối ưu nội dung câu hỏi/đáp.
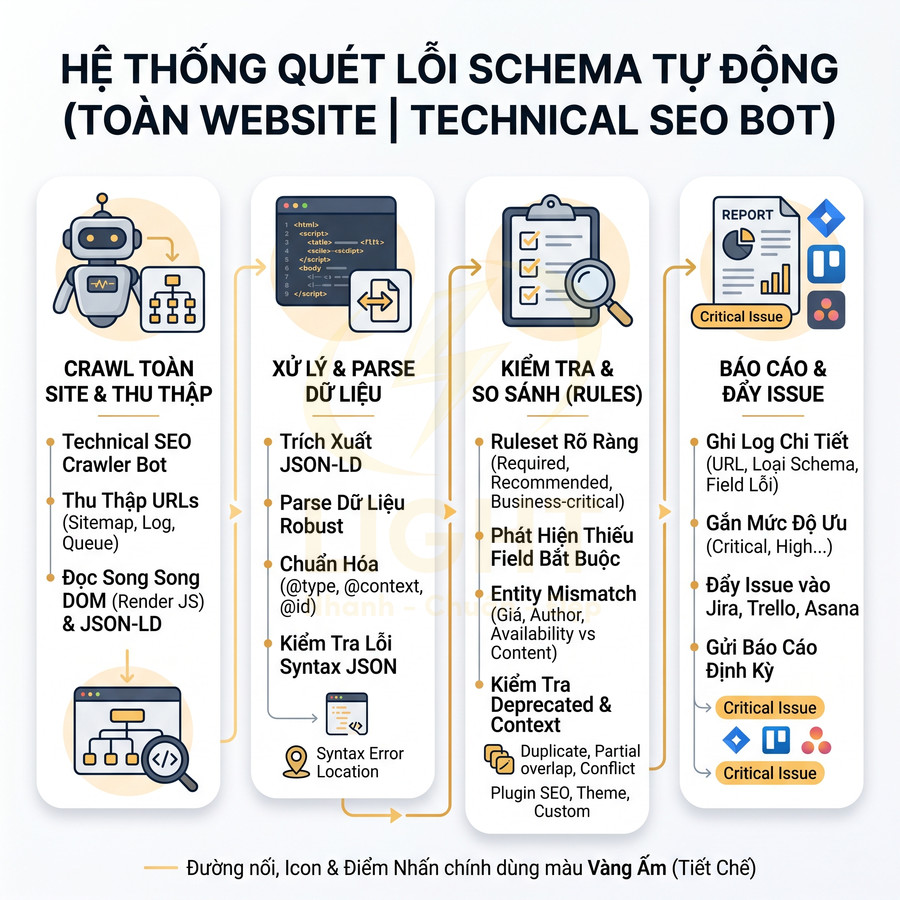
Tính năng quét lỗi schema tự động toàn website theo chuẩn technical SEO
Crawl DOM và JSON-LD để phát hiện schema thiếu field bắt buộc
Để duy trì chất lượng schema trên toàn site ở mức enterprise, cần xây dựng một hệ thống schema crawler hoạt động như một technical SEO bot chuyên dụng, có khả năng đọc song song cả DOM (HTML đã render) và JSON-LD (dạng script). Thay vì chỉ dựa vào API kiểm tra từng URL đơn lẻ, crawler phải có khả năng:
- Thu thập sitemap, log server hoặc queue từ hệ thống để lấy danh sách URL đầy đủ.
- Render trang (headless browser nếu cần) để lấy DOM cuối cùng sau khi JavaScript chạy.
- Trích xuất tất cả thẻ
<script type="application/ld+json">trên mỗi trang. - Parse JSON-LD, chuẩn hóa dữ liệu (normalize @type, @context, @id, mainEntityOfPage…).
- Ánh xạ từng schema với template hoặc loại trang (product page, article page, homepage…).
Cách tiếp cận này nên được xem như một hình thức kiểm thử chất lượng dữ liệu, không chỉ kiểm thử SEO. Trong nghiên cứu về lỗi Schema.org, Meusel và Paulheim nhấn mạnh rằng dữ liệu có cấu trúc trên web thường không sạch và cần heuristic để phát hiện, sửa hoặc chuẩn hóa lỗi (Meusel & Paulheim, 2015). Với website doanh nghiệp, crawler nên kiểm tra ba lớp: cú pháp JSON-LD, tính hợp lệ của thuộc tính theo schema type và tính nhất quán với DOM. Ví dụ, Product thiếu offers.price là lỗi field; Article thiếu author là lỗi EEAT; giá trong schema khác giá hiển thị là lỗi semantic consistency.
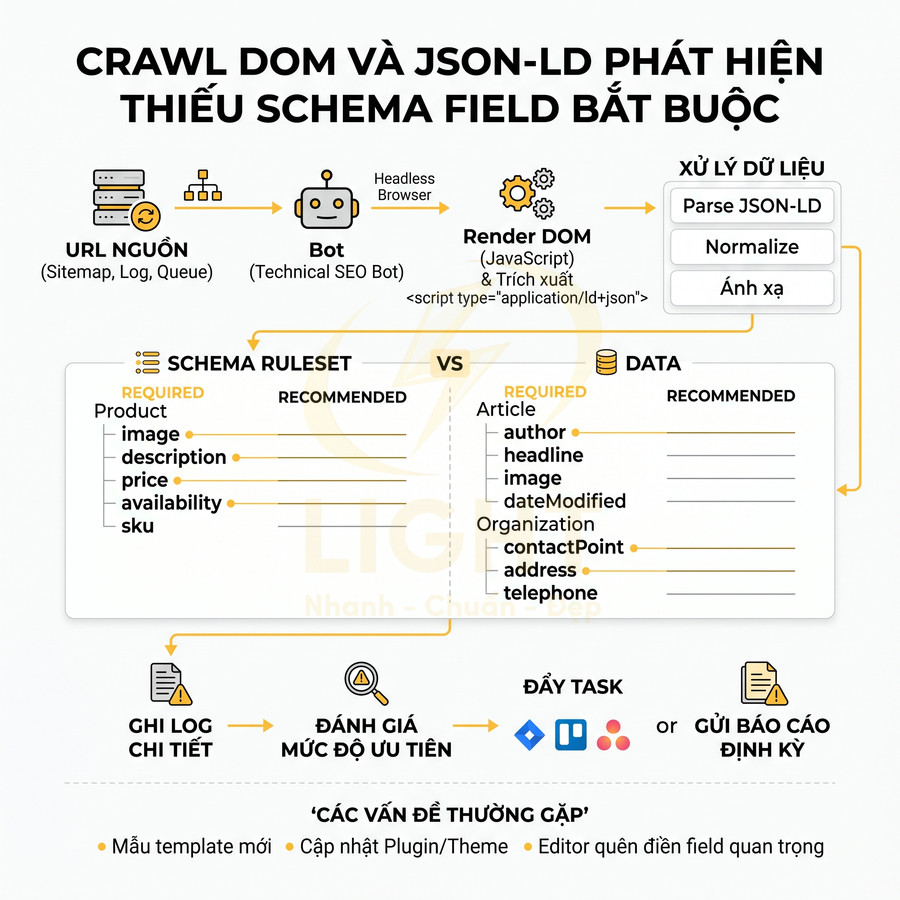
Sau khi parse, hệ thống cần có một schema ruleset được định nghĩa rõ ràng cho từng type quan trọng (Organization, Article, Product, BreadcrumbList, FAQPage, Event…). Ruleset này nên tách thành:
- Required fields (bắt buộc): nếu thiếu, có thể làm mất rich result hoặc khiến Google bỏ qua schema.
- Recommended fields (khuyến nghị quan trọng): nếu thiếu, không gây lỗi nặng nhưng làm giảm độ phong phú của rich result.
- Business-critical fields: các field quan trọng với KPI của doanh nghiệp (giá, tình trạng hàng, rating…).
Ví dụ, với Product, ngoài các field cơ bản như name, image, description, hệ thống nên kiểm tra sâu hơn:
offers.price,offers.priceCurrency,offers.availability,offers.url.aggregateRating.ratingValue,aggregateRating.reviewCountnếu site có review.sku,gtin8,gtin13,brandnếu ngành hàng yêu cầu.
Với Article, ngoài headline, datePublished, author, image, crawler nên kiểm tra thêm:
dateModified,mainEntityOfPage,articleSection,publisher.author.@type(Person hay Organization) có phù hợp với thực tế hay không.
Với Organization, ngoài name, url, logo, sameAs, hệ thống có thể kiểm tra:
contactPoint(support, sales, customer service) nếu doanh nghiệp có nhiều kênh liên hệ.foundingDate,address,telephonecho các use case local/brand.
Mỗi lần crawler phát hiện thiếu field bắt buộc hoặc khuyến nghị quan trọng, hệ thống cần:
- Ghi log chi tiết: URL, loại schema, field thiếu, giá trị mong đợi, timestamp crawl.
- Gắn mức độ ưu tiên (critical, high, medium, low) dựa trên loại trang và impact SEO.
- Đẩy issue vào hệ thống quản lý task (Jira, Trello, Asana…) hoặc gửi báo cáo định kỳ cho team SEO/dev.
Cách tiếp cận này giúp phát hiện sớm các lỗi phát sinh khi:
- Thêm template mới mà quên mapping schema.
- Cập nhật plugin/theme làm thay đổi cấu trúc JSON-LD.
- Content editor quên điền field quan trọng (giá, author, image featured…).
Kiểm tra schema trùng lặp giữa plugin SEO, theme và module custom
Trong môi trường CMS như WordPress, Magento, Shopify…, việc kết hợp nhiều nguồn schema là rất phổ biến: plugin SEO (Yoast, Rank Math, SEOPress…), theme tự sinh schema, và các module custom do dev viết. Điều này dễ dẫn đến schema trùng lặp hoặc mâu thuẫn, gây nhiễu cho Google và làm giảm độ tin cậy của dữ liệu có cấu trúc.
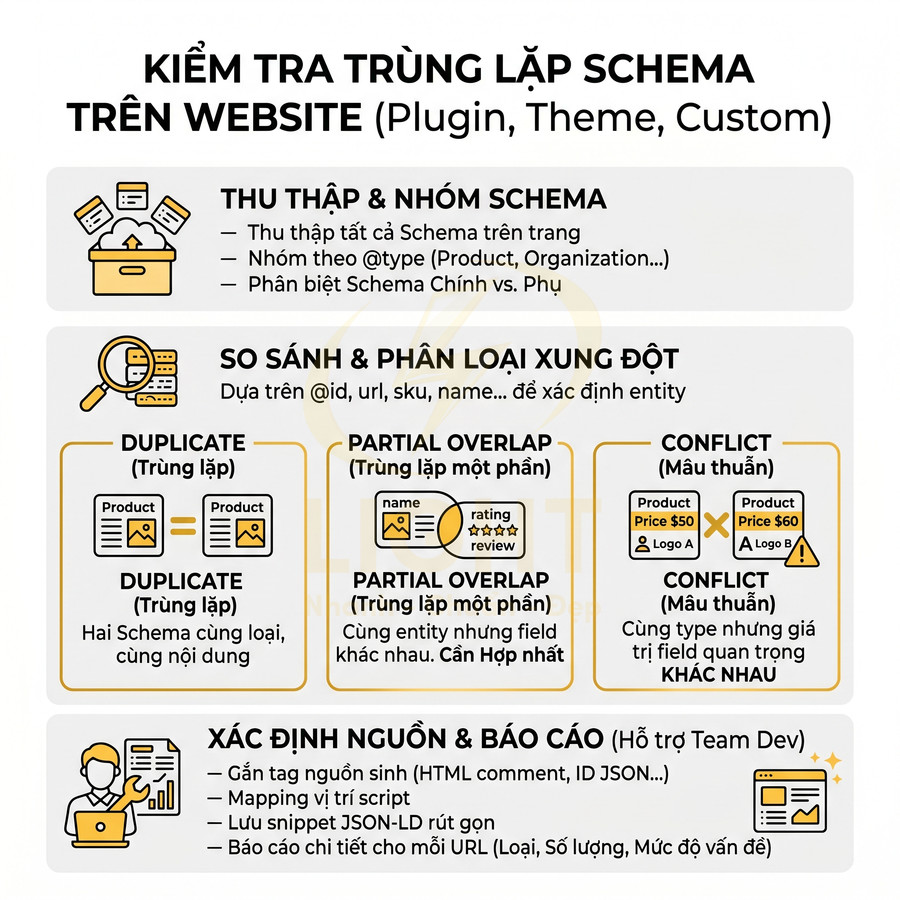
Schema crawler cần một lớp deduplication & conflict detection với các bước:
- Nhóm tất cả schema trên trang theo
@type(Product, Article, Organization…). - Phân biệt schema chính (main entity) và schema phụ (breadcrumb, logo, sitelinks…).
- So sánh các schema cùng type dựa trên:
mainEntityOfPage,@id,urlđể xác định cùng một entity hay khác entity.- Các field nhận diện như
name,headline,sku,brand.
Hệ thống nên phân loại rõ:
- Duplicate (trùng lặp hoàn toàn): hai Product schema có cùng
name,sku,offers,url, chỉ khác nguồn sinh (plugin vs theme). Trường hợp này nên tắt bớt một nguồn. - Partial overlap (trùng lặp một phần): hai schema mô tả cùng một entity nhưng mỗi bên có một số field riêng. Ví dụ, plugin SEO sinh Product với
name,image,offers, còn module custom thêmaggregateRating,review. Nên hợp nhất để tránh phân mảnh dữ liệu. - Conflict (mâu thuẫn): hai schema cùng type nhưng có giá trị khác nhau ở các field quan trọng, ví dụ:
- Hai Organization schema với
logokhác nhau. - Hai Article schema với
authorhoặcdatePublishedkhác nhau. - Hai Product schema với
pricehoặcavailabilitykhác nhau.
- Hai Organization schema với
Để hỗ trợ team dev xử lý nhanh, crawler nên cố gắng xác định nguồn gốc schema bằng cách:
- Gắn tag theo pattern: comment HTML, class, id, hoặc cấu trúc JSON đặc trưng của từng plugin/theme.
- Mapping vị trí script trong DOM (trong
<head>, cuối<body>, trong block cụ thể…). - Lưu lại snippet JSON-LD rút gọn để dev dễ nhận diện.
Báo cáo nên thể hiện cho mỗi URL:
- Danh sách type bị trùng lặp (Product, Article, Organization…).
- Số lượng schema mỗi type, nguồn sinh (plugin A, theme B, custom C).
- Mức độ vấn đề: duplicate, partial overlap, conflict.
Phát hiện entity mismatch giữa schema và nội dung hiển thị trên trang
Ngoài việc đảm bảo schema đầy đủ field, một yêu cầu technical SEO nâng cao là phát hiện entity mismatch giữa dữ liệu có cấu trúc và nội dung thực tế trên trang. Google ngày càng ưu tiên tính nhất quán giữa schema và UI, nên các sai lệch về giá, author, rating, availability… có thể làm giảm độ tin cậy hoặc khiến rich result bị hạn chế.
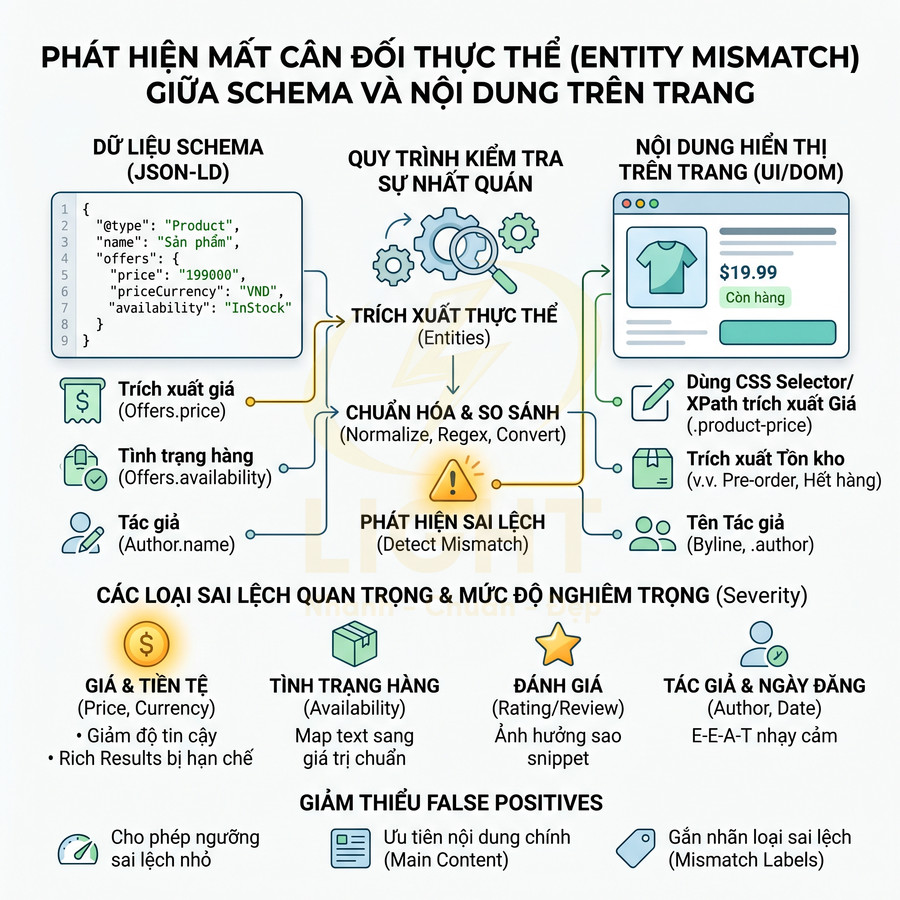
Schema crawler có thể triển khai một lớp content-schema consistency check theo hướng rule-based kết hợp heuristic:
- Đối với giá sản phẩm:
- Dùng CSS selector hoặc XPath để trích xuất giá từ DOM (ví dụ:
.product-price,[itemprop="price"]). - Dùng regex để chuẩn hóa giá (loại bỏ ký tự tiền tệ, dấu chấm, dấu phẩy, khoảng trắng).
- So sánh với
offers.pricetrong JSON-LD sau khi convert về cùng format và currency.
- Dùng CSS selector hoặc XPath để trích xuất giá từ DOM (ví dụ:
- Đối với author bài viết:
- Trích xuất tên author từ block byline (ví dụ:
.post-author,.byline). - So sánh với
author.nametrong Article schema (hoặcPerson.nameliên kết).
- Trích xuất tên author từ block byline (ví dụ:
- Đối với availability:
- Trích xuất text trạng thái tồn kho (ví dụ: “Còn hàng”, “Hết hàng”, “Pre-order”).
- Map text sang các giá trị chuẩn của schema.org (
InStock,OutOfStock,PreOrder…). - So sánh với
offers.availabilitytrong JSON-LD.
Hệ thống nên gắn mức độ nghiêm trọng cao cho các mismatch liên quan đến:
- Giá (price) và currency.
- Tình trạng hàng (availability).
- Rating, review count nếu ảnh hưởng đến rich snippet sao.
- Author, datePublished đối với nội dung E-E-A-T nhạy cảm.
Để giảm false positive, crawler có thể áp dụng một số kỹ thuật:
- Cho phép một ngưỡng sai lệch nhỏ (ví dụ: giá hiển thị đã bao gồm khuyến mãi tạm thời, trong khi schema là giá gốc).
- Ưu tiên so sánh với block nội dung chính (main content) thay vì các block phụ (related products, upsell…).
- Gắn nhãn loại mismatch (price mismatch, author mismatch, availability mismatch…) để team SEO phân loại nhanh.
Cảnh báo lỗi syntax JSON, property deprecated và type sai ngữ cảnh
Một lớp lỗi phổ biến khác đến từ syntax JSON sai, sử dụng property đã deprecated hoặc dùng type sai ngữ cảnh. Những lỗi này thường không được phát hiện nếu chỉ test thủ công vài URL trên Rich Results Test, nhưng khi scale lên hàng nghìn trang, tỷ lệ lỗi có thể rất lớn.
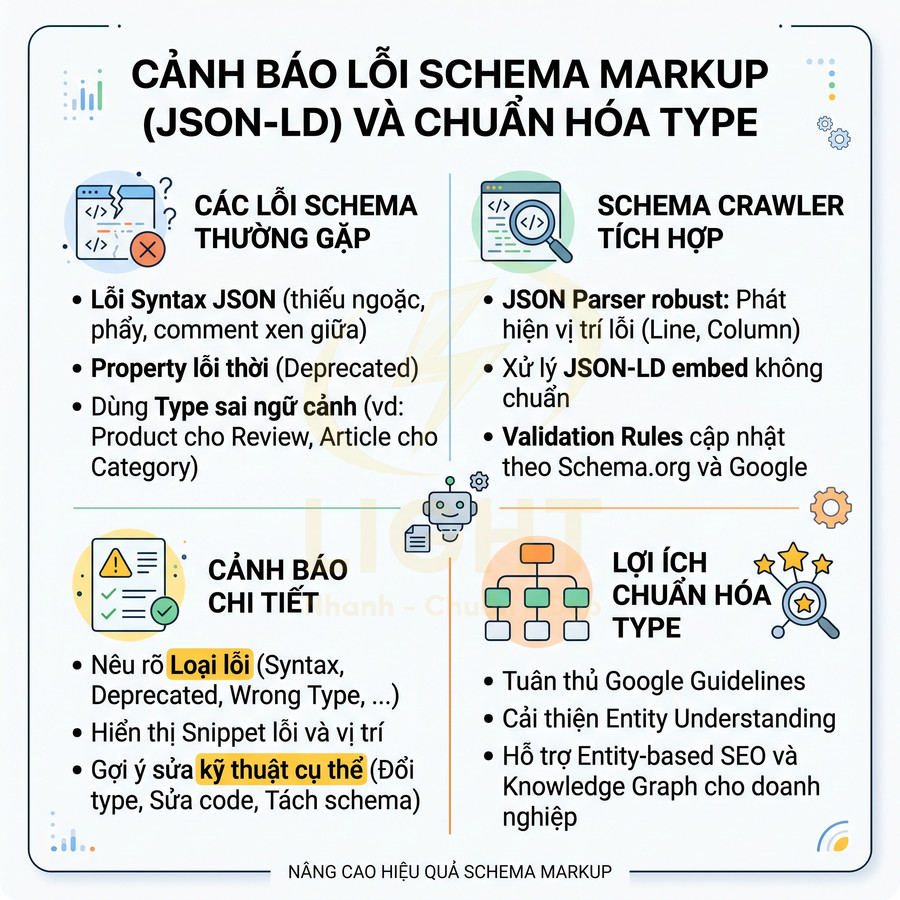
Schema crawler nên tích hợp:
- Một JSON parser robust có khả năng:
- Phát hiện lỗi thiếu dấu ngoặc, dấu phẩy, dấu nháy.
- Xử lý các trường hợp JSON-LD được embed không chuẩn (comment xen giữa, ký tự lạ…).
- Trả về vị trí lỗi (line, column) để dev dễ debug.
- Một bộ validation rules cập nhật theo schema.org và guideline của Google:
- Kiểm tra property có thuộc type tương ứng hay không (ví dụ:
pricekhông thuộc Article). - Kiểm tra type có được Google hỗ trợ rich result hay không (FAQPage, HowTo, Product, Review…).
- Phát hiện property deprecated hoặc bị thay thế (ví dụ: một số property cũ của VideoObject, ImageObject…).
- Kiểm tra kiểu dữ liệu: string vs number, object vs array, URL vs Text.
- Kiểm tra property có thuộc type tương ứng hay không (ví dụ:
Khi phát hiện lỗi, hệ thống cần sinh cảnh báo chi tiết cho từng URL:
- Loại lỗi: syntax error, invalid property, deprecated property, wrong type, unsupported type.
- Đoạn JSON-LD liên quan (snippet rút gọn), vị trí lỗi (line/column hoặc index trong script).
- Gợi ý sửa ở mức kỹ thuật: đổi type, đổi property, sửa kiểu dữ liệu, tách schema theo đúng ngữ cảnh.
Đặc biệt, việc dùng type sai ngữ cảnh cần được flag rõ ràng. Một số ví dụ điển hình:
- Dùng
Productcho bài review tổng hợp, trong khi phù hợp hơn làReviewhoặcProduct + Reviewlồng nhau. - Dùng
Articlecho trang category hoặc landing page không phải bài viết. - Dùng
Organizationcho local business mà không bổ sungLocalBusinesshoặc subtype phù hợp.
Việc chuẩn hóa type theo đúng ngữ cảnh không chỉ giúp tuân thủ guideline của Google mà còn cải thiện khả năng hiểu entity, từ đó hỗ trợ tốt hơn cho chiến lược entity-based SEO và knowledge graph của doanh nghiệp.
Hệ thống auto-fix schema cho website chuẩn SEO sau khi phát hiện lỗi
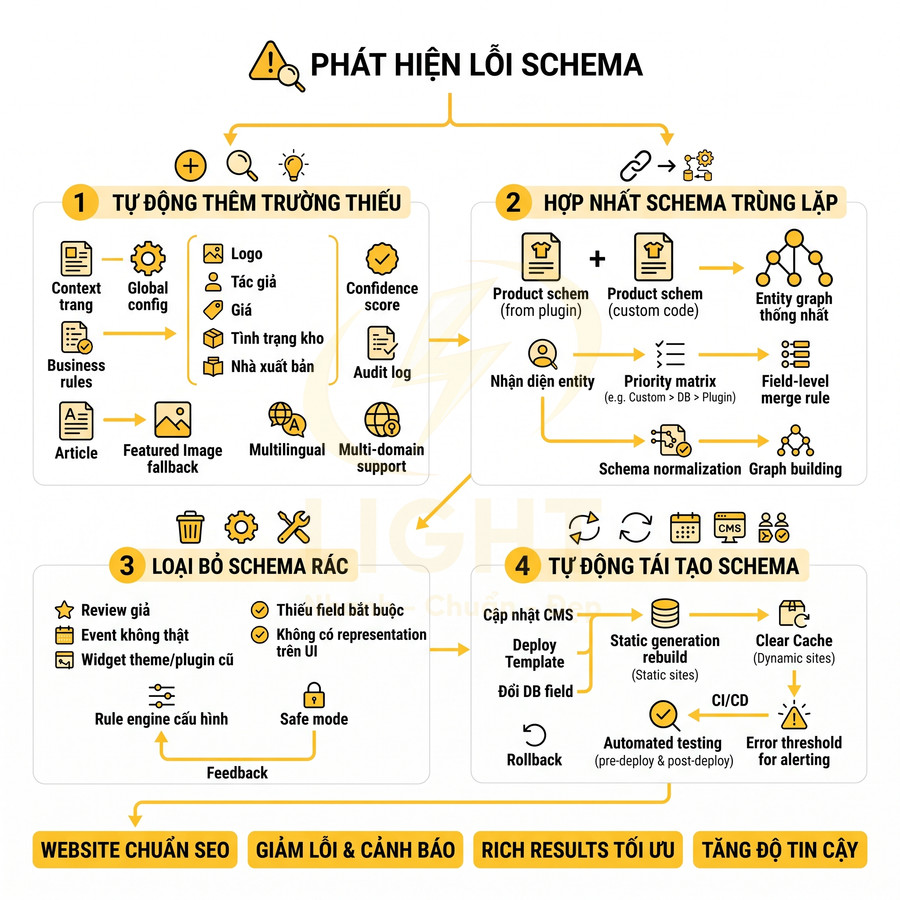
Tự động thêm field thiếu như logo, author, price, availability, publisher
Sau khi phát hiện lỗi, bước tiếp theo là auto-fix trong phạm vi an toàn. Với những field có thể suy ra từ context hoặc từ config chung, hệ thống có thể tự động bổ sung mà không cần can thiệp thủ công. Ví dụ: nếu Organization thiếu logo nhưng brand config có logo, hệ thống tự thêm; nếu Article thiếu publisher nhưng site đã có Organization, hệ thống tự gán publisher.
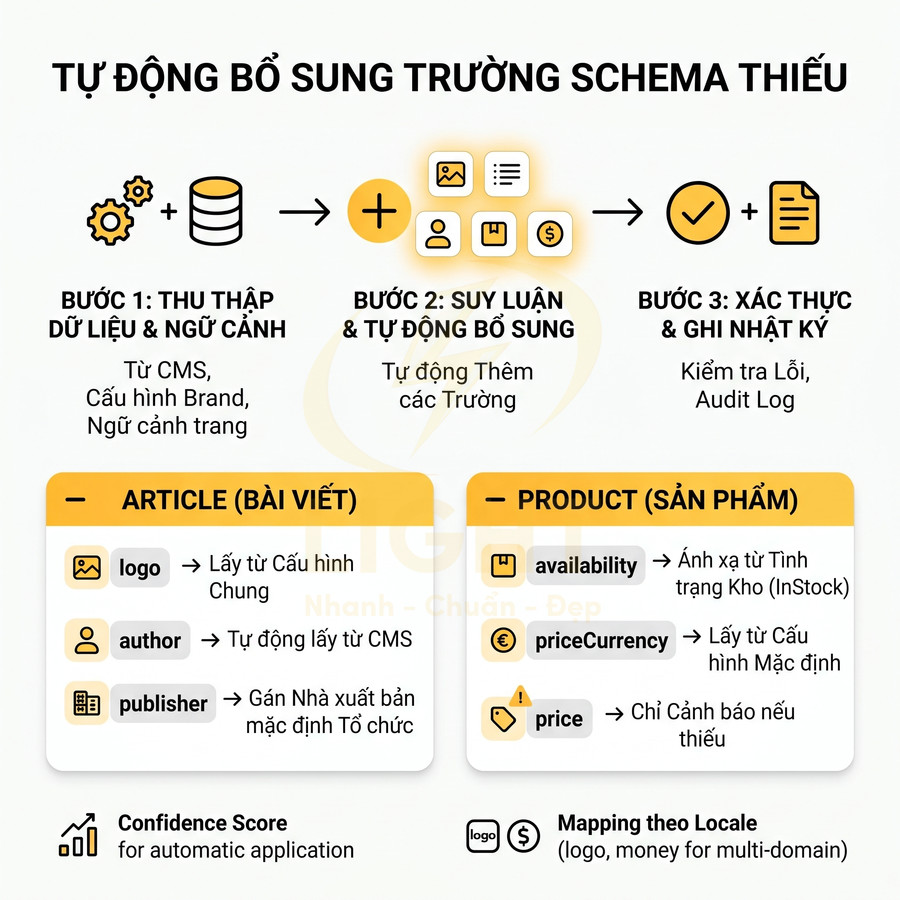
Ở mức triển khai chuyên sâu, hệ thống nên có một schema inference layer hoạt động dựa trên:
- Global config: brand name, logo, default publisher, default priceCurrency, default inStock threshold.
- Context trang: loại template (Product, Article, Category), taxonomy, post type, layout.
- Business rule: ưu tiên dữ liệu từ database so với dữ liệu hard-code trong theme, ưu tiên dữ liệu mới hơn, có timestamp cập nhật.
Với Article, hệ thống có thể:
- Tự động thêm author từ trường postauthor trong CMS hoặc từ custom field mapping.
- Suy ra datePublished, dateModified từ createdat, updated_at trong database.
- Gán publisher là Organization mặc định nếu không có publisher riêng cho từng brand con.
Với Product, nếu thiếu availability nhưng database có stockstatus, hệ thống tự map InStock/OutOfStock. Nếu thiếu priceCurrency nhưng site chỉ dùng một currency, có thể lấy từ config. Tuy nhiên, với field nhạy cảm như price, nếu không chắc chắn, hệ thống nên chỉ cảnh báo, không tự điền để tránh sai lệch.
Để đảm bảo an toàn dữ liệu, hệ thống auto-fix nên áp dụng các cơ chế:
- Validation rule cho từng field: kiểu dữ liệu, pattern (ISO 4217 cho currency, ISO 8601 cho date), range hợp lệ.
- Confidence score cho mỗi giá trị suy luận: chỉ auto-apply khi vượt ngưỡng, còn lại chuyển sang trạng thái “needs review”.
- Audit log ghi lại mọi thay đổi auto-fix: field cũ, field mới, nguồn dữ liệu, thời gian, môi trường (staging/production).
Với các field như logo, image, thumbnailUrl, hệ thống có thể áp dụng rule ưu tiên:
- Nếu post có featured image, dùng làm image chính cho Article/Product.
- Nếu không có, fallback sang default image theo category hoặc brand.
- Nếu vẫn không có, chỉ cảnh báo thay vì tự chèn một URL không được hiển thị trên giao diện.
Đối với các site đa ngôn ngữ hoặc đa domain, layer auto-fix cần hỗ trợ mapping theo locale:
- Logo, name, description của Organization có thể khác nhau theo market.
- Currency, price, availability có thể phụ thuộc vào warehouse hoặc region.
- Hệ thống nên lưu config theo cặp domain/locale để tránh auto-fix sai thị trường.
Tự động hợp nhất schema duplicate thành entity graph thống nhất
Khi phát hiện nhiều schema trùng lặp trên cùng một trang, hệ thống có thể đề xuất hoặc tự động hợp nhất thành một entity graph thống nhất. Ví dụ: hai Product schema từ plugin và custom có thể được merge: giữ name, image từ custom, giữ aggregateRating từ plugin, giữ offers từ database. Kết quả là một Product duy nhất, đầy đủ và nhất quán.
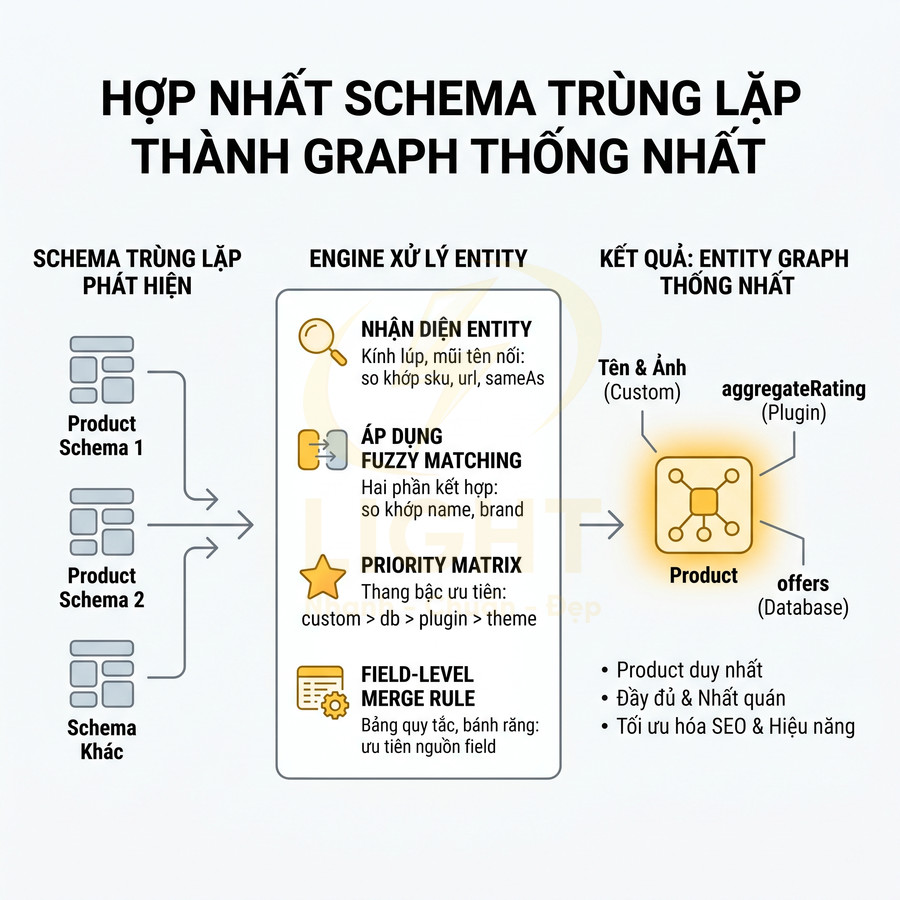
Để làm được điều này ở mức chuyên sâu, hệ thống cần một entity resolution engine với các bước:
- Nhận diện entity trùng:
- So khớp theo sku, productID, url, sameAs, hoặc canonical URL.
- Áp dụng fuzzy matching cho name kết hợp với brand để phát hiện Product tương đương.
- Xây dựng priority matrix:
- Ví dụ: custom schema > database > plugin > theme.
- Ưu tiên nguồn có version mới hơn hoặc được đánh dấu “trusted source”.
- Field-level merge rule:
- Field định danh (sku, gtin, url) chỉ lấy từ nguồn có độ tin cậy cao nhất.
- Field bổ sung (aggregateRating, review, offers) có thể merge theo dạng union.
Việc hợp nhất nên dựa trên rule rõ ràng: ưu tiên nguồn nào cho field nào, tránh ghi đè dữ liệu chính xác bằng dữ liệu kém tin cậy. Với Organization, nên chọn một nguồn làm “source of truth” (thường là brand config), các nguồn khác chỉ bổ sung nếu thiếu. Hệ thống cũng nên cập nhật code hoặc config để ngăn trùng lặp tái diễn, không chỉ fix tạm thời trên output.
Ở tầng triển khai, có thể áp dụng:
- Schema normalization: convert mọi schema (JSON-LD, Microdata, RDFa) về một internal model thống nhất trước khi merge.
- Graph builder: thay vì xuất nhiều block JSON-LD rời rạc, xây dựng một graph duy nhất với @id rõ ràng cho từng entity (Product, Organization, WebPage, BreadcrumbList…).
- Conflict detector: nếu hai nguồn cùng cung cấp giá trị khác nhau cho một field critical (price, availability, brand), hệ thống có thể:
- Chọn theo priority rule.
- Hoặc chuyển sang chế độ “manual review required” và không auto-fix trên production.
Đối với các trang phức tạp (Product + FAQ + HowTo + Review), entity graph thống nhất giúp:
- Liên kết Review với đúng Product thông qua @id.
- Liên kết FAQPage, HowTo với WebPage chính, tránh tạo các entity rời rạc khó crawl.
- Giảm kích thước JSON-LD trùng lặp, tối ưu performance và bandwidth.
Loại bỏ schema rác từ widget theme, plugin cũ hoặc page builder
Nhiều theme, widget, page builder cũ tự động chèn schema không còn phù hợp: Review giả, Event không có thật, Product cho mọi bài viết, Organization trùng lặp. Những schema rác này không chỉ không giúp SEO mà còn làm giảm độ tin cậy. Hệ thống auto-fix nên có khả năng lọc và loại bỏ schema rác dựa trên rule.

Để phân loại “schema rác”, hệ thống có thể áp dụng các tiêu chí:
- Thiếu field bắt buộc theo guideline của search engine:
- Review không có reviewBody, không có author, không có ratingValue.
- Event không có startDate, location, name.
- Product không có offers, price, hoặc không có bất kỳ signal mua hàng nào.
- Không có representation trên UI:
- Schema Review không có block review hiển thị trên trang.
- Schema Event không có section event nào trong nội dung.
- Nguồn không đáng tin cậy:
- Plugin đã deprecated, không còn được maintain.
- Widget theme cũ, hard-code rating 5/5 cho mọi bài viết.
Ví dụ: nếu một schema Review không có reviewBody, không có author, không hiển thị trên trang, có thể coi là rác và loại bỏ. Nếu một Product không có price, không có offer, không có nút mua trên trang, có thể là schema thừa từ theme. Việc loại bỏ nên được log lại để dev có thể chỉnh sửa tận gốc (tắt tính năng trong plugin, sửa template).
Hệ thống nên hỗ trợ:
- Rule engine cấu hình được:
- Cho phép SEO/Dev định nghĩa rule theo loại schema, theo path URL, theo post type.
- Ví dụ: chặn mọi Product schema trên post type “blog”, chỉ cho phép trên “product”.
- Safe mode:
- Ban đầu chỉ flag schema rác và ghi log, không xóa ngay trên production.
- Sau khi review, chuyển sang chế độ auto-remove.
- Feedback loop:
- Khi dev tắt một plugin hoặc sửa template, hệ thống cập nhật lại rule để tránh false positive.
- Có dashboard thống kê số lượng schema bị loại bỏ theo loại, theo plugin, giúp ưu tiên refactor.
Ở mức nâng cao, có thể kết hợp log từ Search Console (warning, manual action liên quan đến spammy structured data) để tinh chỉnh rule loại bỏ schema rác, đảm bảo tuân thủ guideline và giảm rủi ro penalty.
Regenerate schema sau khi cập nhật CMS, deploy template hoặc đổi database field
Mỗi lần cập nhật CMS, deploy template mới, đổi cấu trúc database, nguy cơ schema bị lỗi tăng cao. Hệ thống nên có cơ chế regenerate schema cho các trang bị ảnh hưởng, kết hợp với quét lỗi sau deploy. Với site dùng static generation (Next.js, Gatsby…), cần trigger build lại các trang liên quan; với site dynamic, cần clear cache schema hoặc rebuild fragment.
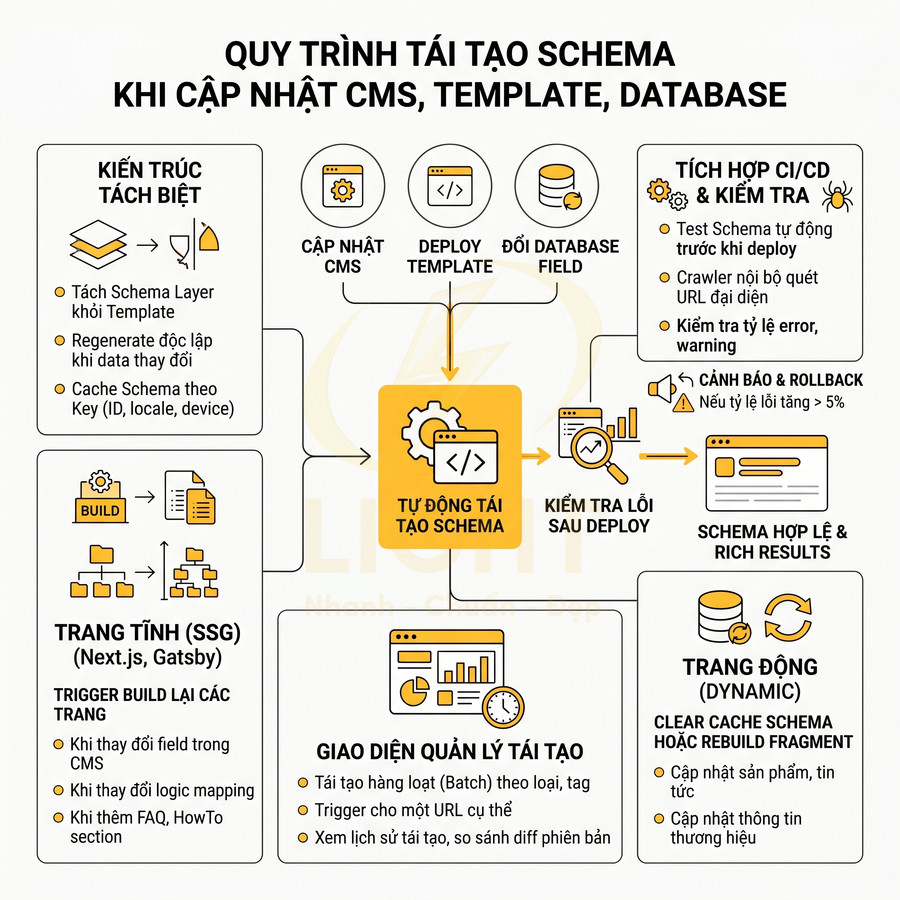
Ở tầng kiến trúc, nên tách schema generation layer khỏi template để có thể:
- Regenerate schema độc lập với HTML khi data thay đổi.
- Cache schema theo key (entity ID, locale, device) và invalidation theo event (product updated, price changed).
- Hỗ trợ rollback nhanh nếu deploy mới làm tăng error rate.
Quy trình CI/CD nên tích hợp bước test schema tự động: chạy crawler trên một tập URL đại diện, kiểm tra error rate, nếu vượt ngưỡng thì chặn deploy hoặc cảnh báo. Điều này giúp đảm bảo mỗi lần release không làm giảm số lượng schema valid hoặc mất rich result quan trọng.
Một pipeline chuyên sâu có thể bao gồm:
- Pre-deploy validation:
- Chạy unit test cho schema builder (mapping field, type, required property).
- Snapshot test JSON-LD cho một số URL quan trọng để phát hiện thay đổi ngoài ý muốn.
- Post-deploy crawl:
- Crawler nội bộ quét một sample URL theo từng template (home, category, product, article, landing page…).
- Gọi API validator (nếu có) hoặc dùng validator nội bộ để đo:
- Tỷ lệ trang có schema.
- Tỷ lệ error, warning theo loại schema.
- Threshold & guardrail:
- Nếu error rate tăng vượt ngưỡng cấu hình (ví dụ >5%), tự động:
- Rollback phiên bản schema builder trước đó.
- Hoặc gửi alert tới team SEO/Dev để can thiệp.
- Nếu error rate tăng vượt ngưỡng cấu hình (ví dụ >5%), tự động:
Với site dùng static generation (Next.js, Gatsby…), cần trigger build lại các trang liên quan khi:
- Thay đổi field trong CMS (ví dụ đổi slug, đổi cấu trúc price, thêm field rating).
- Thay đổi logic mapping trong schema builder (ví dụ đổi cách map availability, đổi default currency).
- Thay đổi template ảnh hưởng đến loại schema (ví dụ thêm FAQ block, thêm HowTo section).
Với site dynamic, cần clear cache schema hoặc rebuild fragment khi:
- Product update (price, stock, promotion) để tránh schema lệch so với UI.
- Article update (title, description, author) để đồng bộ với meta và nội dung.
- Brand/Organization update (logo, name, contactPoint) để tránh thông tin cũ tồn tại lâu trong cache.
Hệ thống cũng nên cung cấp giao diện cho phép:
- Regenerate schema theo batch (theo category, theo tag, theo post type).
- Trigger regenerate cho một URL cụ thể khi SEO/Content chỉnh sửa nội dung quan trọng.
- Xem lịch sử regenerate, so sánh diff giữa các phiên bản schema để debug khi mất rich result.
Dashboard giám sát rich result và lỗi schema cho team SEO, dev, content

Theo dõi số URL hợp lệ cho Organization, Article, Product rich result
Một dashboard giám sát schema ở mức chuyên sâu cần được thiết kế như một “control center” cho toàn bộ hệ sinh thái SEO, dev, content, không chỉ dừng ở việc đếm số URL hợp lệ. Về mặt kỹ thuật, hệ thống nên:
- Thu thập dữ liệu từ Google Search Console (Search Appearance, Search Results, URL Inspection API) để biết:
- Số URL đang đủ điều kiện hiển thị rich result theo từng loại: Organization, Article, Product, FAQ, Breadcrumb, HowTo.
- Loại rich result thực tế đã hiển thị trong SERP (không chỉ “eligible” mà là “shown”).
- Impression, click, CTR, position cho từng nhóm schema.
- Kết hợp với dữ liệu từ crawler nội bộ (Screaming Frog, custom crawler, headless browser):
- Phát hiện loại schema hiện diện trên từng URL (JSON-LD, Microdata, RDFa).
- Kiểm tra tính hợp lệ sơ bộ dựa trên schema.org + rule nội bộ (field bắt buộc, field khuyến nghị, logic giá, stock, datePublished…).
- Gắn tag theo template (product detail, category, blog article, landing page) để dễ phân tích theo loại trang.
Dashboard schema nên theo dõi cả chất lượng dữ liệu và tác động tìm kiếm. Nghiên cứu về mức độ chấp nhận Schema.org cho thấy dữ liệu có cấu trúc là hiện tượng triển khai rộng trên web (Meusel et al., 2015), nhưng nghiên cứu về lỗi triển khai lại cho thấy chất lượng dữ liệu không tự bảo đảm (Meusel & Paulheim, 2015). Do đó, dashboard cần kết hợp crawler nội bộ với dữ liệu Google Search Console: số URL có schema, số URL hợp lệ, lỗi theo template, rich result impression, CTR trước–sau khi sửa schema. Cách này giúp team không chỉ biết “schema có lỗi không”, mà còn biết lỗi nào ảnh hưởng nhiều nhất đến traffic, CTR và doanh thu.

Dashboard nên có các khối dữ liệu chính:
- Overview toàn site:
- Tổng số URL có schema.
- Tổng số URL valid / warning / error cho từng loại rich result: Organization, Article, Product, FAQ, Breadcrumb, HowTo.
- Tỷ lệ % URL có khả năng hiển thị rich result trên tổng số URL indexable.
- Breakdown theo loại schema:
- Organization: số URL (thường 1–vài URL), trạng thái logo, contactPoint, sameAs, social profile.
- Article: số bài viết có author, datePublished, headline, image, publisher; tỷ lệ bài có structured data so với tổng số bài.
- Product: số trang sản phẩm có price, priceCurrency, availability, review, aggregateRating; tỷ lệ sản phẩm đủ điều kiện rich result.
- FAQ, HowTo, Breadcrumb: số URL có schema, số URL valid, số URL bị Google bỏ qua (có schema nhưng không hiển thị).
Biểu đồ theo thời gian nên được xây dựng ở mức time series ngày hoặc tuần, cho phép:
- Theo dõi xu hướng số URL Product có rich result: tăng đều sau khi rollout schema tự động, hay giảm đột ngột sau một lần refactor template.
- Quan sát số Article hiển thị rich snippet (author/date/image) trước và sau khi thay đổi cấu trúc bài viết, thay theme, hoặc đổi plugin SEO.
- So sánh đường biểu diễn:
- “URL có schema” vs “URL valid rich result” vs “URL thực sự hiển thị rich result trong SERP”.
- Giúp phát hiện trường hợp schema hợp lệ nhưng Google không hiển thị (do chất lượng nội dung, intent, hoặc update thuật toán).
Khi có biến động bất thường, dashboard nên hỗ trợ drill-down:
- Click vào điểm rơi trên biểu đồ để xem:
- Loại schema bị ảnh hưởng (Product, Article, FAQ…).
- Nhóm template hoặc thư mục URL (ví dụ: /product/, /blog/, /category/).
- Danh sách URL cụ thể, trạng thái trước và sau (valid → error, valid → warning).
- Hiển thị mốc thời gian release (deployment marker) trên biểu đồ để team dev dễ đối chiếu:
- Release version, branch, người deploy.
- Loại thay đổi: template, plugin, CMS core, tracking script.
Với cách tổ chức này, dashboard không chỉ là báo cáo mà là công cụ vận hành: team SEO, dev, content có thể cùng nhìn một nguồn dữ liệu, nói chung một “ngôn ngữ” khi phân tích sự cố schema và rich result.
Ưu tiên sửa schema trên trang có impression cao trong Google Search Console
Trong thực tế, tài nguyên dev luôn giới hạn, nên cần một cơ chế prioritization rõ ràng dựa trên dữ liệu. Dashboard nên kết hợp dữ liệu lỗi schema với impression và click từ Google Search Console để tính toán mức độ ưu tiên cho từng URL hoặc nhóm URL.

Các bước xử lý dữ liệu nên bao gồm:
- Join dữ liệu:
- GSC Search Results: impression, click, CTR, position theo URL.
- GSC Search Appearance: loại rich result đã hiển thị hoặc đủ điều kiện.
- Internal crawler: loại schema, trạng thái valid/error/warning, chi tiết lỗi (missing field, invalid type, mismatch).
- Phân loại mức độ lỗi:
- Lỗi nghiêm trọng (blocking rich result): thiếu field bắt buộc (required), sai định dạng (date, price), mismatch giá giữa schema và HTML, dùng property sai type.
- Lỗi trung bình: thiếu field recommended, thiếu review nhưng vẫn đủ điều kiện rich result cơ bản.
- Lỗi nhẹ: warning không ảnh hưởng trực tiếp đến eligibility nhưng ảnh hưởng chất lượng hiển thị.
- Tính điểm ưu tiên (priority score) cho từng URL:
- Có thể dùng công thức đơn giản: Priority = f(impression, click, severity, type).
- Ví dụ:
- Impression cao + lỗi nghiêm trọng + loại schema Product/Article = ưu tiên rất cao.
- Impression thấp + lỗi warning + loại schema ít ảnh hưởng (Breadcrumb) = ưu tiên thấp.
Dashboard nên hiển thị một danh sách ưu tiên có thể filter và export:
- Các cột quan trọng:
- URL, loại trang (product, article, category…).
- Loại schema bị lỗi (Product, Article, FAQ…).
- Impression 28 ngày gần nhất, click, CTR, position.
- Loại lỗi (missing required field, price mismatch, invalid value…).
- Priority score, owner (SEO, dev, content), status (open, in progress, fixed, verified).
- Các filter hữu ích:
- Impression > X, CTR < Y, position trong top 10 nhưng không có rich result.
- Chỉ hiển thị Product schema error trên các trang có doanh thu cao (nếu có dữ liệu revenue).
- Chỉ hiển thị lỗi phát sinh sau một mốc thời gian (sau release gần nhất).
Với cách tiếp cận này, team SEO và dev có thể tập trung vào nhóm URL “high impact”:
- Trang sản phẩm có 100.000 impression/tháng nhưng mất rich result do lỗi schema sẽ được đẩy lên đầu backlog.
- Trang blog có traffic thấp, lỗi warning nhẹ có thể gom lại xử lý sau hoặc tự động hóa bằng rule.
Điều này giúp tối ưu ROI cho thời gian và nguồn lực, đồng thời tạo cơ sở dữ liệu rõ ràng để trao đổi với stakeholder: mỗi bug fix schema đều gắn với một cơ hội traffic và doanh thu cụ thể.
So sánh before–after CTR sau khi thêm schema đúng chuẩn
Để đánh giá hiệu quả thực sự của việc triển khai schema, dashboard cần có module experiment / impact analysis cho phép so sánh hiệu suất trước và sau khi thêm hoặc sửa schema trên cùng một nhóm URL.

Các thành phần kỹ thuật quan trọng:
- Đánh dấu thời điểm triển khai:
- Lưu lại mốc thời gian (deployment timestamp) khi:
- Rollout Product schema cho một nhóm product template.
- Thêm Article schema cho toàn bộ blog.
- Sửa lỗi price mismatch hoặc thêm review schema.
- Gắn tag cho nhóm URL chịu ảnh hưởng (cohort): ví dụ “Product-Schema-Rollout-2026-03-01”.
- Lưu lại mốc thời gian (deployment timestamp) khi:
- Chọn khoảng thời gian so sánh:
- Mặc định: 28 ngày trước vs 28 ngày sau.
- Có thể tùy chỉnh: 14/30/60 ngày tùy theo seasonality và volume traffic.
- Loại trừ các ngày có sự kiện bất thường (sale lớn, downtime, core update) nếu có thể.
- Chỉ số cần so sánh:
- CTR trung bình (click / impression).
- Impression tổng và trung bình mỗi URL.
- Position trung bình.
- Tỷ lệ URL thực sự hiển thị rich result trong SERP.
Dashboard nên hiển thị kết quả theo hai lớp:
- Mức aggregate (toàn bộ cohort):
- CTR trung bình trước vs sau, % thay đổi.
- Position trung bình trước vs sau, % thay đổi.
- Biểu đồ line hoặc bar thể hiện xu hướng theo ngày.
- Mức URL:
- Danh sách URL trong cohort, với:
- CTR before, CTR after, delta CTR.
- Impression before/after để tránh hiểu nhầm do biến động volume.
- Flag URL có rich result hiển thị ổn định vs không ổn định.
- Filter URL có improvement rõ rệt (ví dụ CTR tăng > 20%) để phân tích pattern:
- Loại nội dung, độ dài, chất lượng review, giá, hình ảnh.
- Danh sách URL trong cohort, với:
Ví dụ: nhóm 500 trang sản phẩm được thêm Product schema chuẩn vào ngày X. Dashboard sẽ:
- Tự động gom 500 URL vào một cohort.
- Lấy dữ liệu GSC 28 ngày trước và 28 ngày sau ngày X.
- Tính toán:
- CTR trung bình tăng từ 3,2% lên 4,5% (+40,6%).
- Position giữ gần như không đổi (chênh lệch < 0,2), cho thấy cải thiện chủ yếu đến từ rich result.
- Tỷ lệ URL có rich result hiển thị tăng từ 10% lên 70%.
Kết quả này là bằng chứng định lượng giúp thuyết phục stakeholder đầu tư thêm vào technical SEO, tự động hóa schema trong CMS, hoặc mở rộng sang các loại schema khác (FAQ, HowTo, Video…). Đồng thời, module này cũng giúp phát hiện trường hợp schema không mang lại hiệu quả như kỳ vọng, từ đó điều chỉnh chiến lược (ví dụ: nội dung không phù hợp intent, markup chưa đủ phong phú, hoặc bị giới hạn bởi guideline của Google).
Cảnh báo realtime khi số lượng schema valid giảm sau release
Để tránh sự cố kéo dài và mất traffic không cần thiết, hệ thống nên có cơ chế cảnh báo realtime hoặc near-realtime khi số lượng schema valid hoặc số URL có rich result giảm đột ngột sau một release hoặc thay đổi lớn.
Các thành phần chính của hệ thống cảnh báo:
- Job giám sát định kỳ:
- Pull dữ liệu từ:
- GSC (Search Appearance, URL Inspection API nếu khả thi).
- Crawler nội bộ chạy incremental (chỉ crawl các URL mới hoặc có thay đổi gần đây).
- Tần suất: 1–4 giờ/lần tùy quy mô site và giới hạn API.
- Pull dữ liệu từ:
- Rule phát hiện bất thường:
- So sánh số URL valid / số URL có rich result hiện tại với:
- Trung bình 24–72 giờ trước.
- Hoặc baseline theo ngày trong tuần (để tránh noise do seasonality).
- Kích hoạt alert khi:
- Số URL Product có rich result giảm >= 30% trong 24–48 giờ.
- Số lỗi schema (error) tăng gấp đôi so với baseline.
- Một loại schema quan trọng (Organization, Product, Article) gần như biến mất khỏi site.
- So sánh số URL valid / số URL có rich result hiện tại với:
- Tích hợp với hệ thống release:
- Gắn log release (version, thời gian, phạm vi thay đổi) vào dashboard.
- Khi alert xảy ra gần một mốc release, ưu tiên xem xét release đó đầu tiên.
Thông tin trong cảnh báo nên đủ chi tiết để team dev có thể hành động ngay, không phải truy vấn thêm quá nhiều:
- Loại schema bị ảnh hưởng (Product, Article, FAQ, Breadcrumb, HowTo, Organization).
- Số URL valid trước và sau, % thay đổi.
- Ví dụ một số URL cụ thể bị chuyển từ valid → error/warning.
- Thời điểm bắt đầu giảm, so với thời điểm release gần nhất.
- Link trực tiếp đến view chi tiết trong dashboard để điều tra sâu hơn.
Kênh gửi alert có thể là email, Slack, hoặc tích hợp với công cụ quản lý dự án (Jira, Asana, Trello) để tự động tạo ticket cho team dev/SEO. Trong trường hợp nghiêm trọng (ví dụ: toàn bộ Product schema biến mất sau khi deploy template mới), quy trình có thể bao gồm:
- Tự động gắn tag “critical” cho alert.
- Ping trực tiếp channel on-call của dev/ops.
- Đề xuất rollback release hoặc triển khai hotfix nếu xác nhận nguyên nhân đến từ thay đổi code.
Với cơ chế cảnh báo realtime như vậy, tổn thất traffic và doanh thu do lỗi schema sẽ được giới hạn trong vài giờ hoặc vài ngày, thay vì kéo dài hàng tuần vì không ai phát hiện ra sự cố cho đến khi nhìn thấy drop trong báo cáo SEO tổng quan.
Tích hợp auto schema cho WordPress, Shopify, Next.js, Laravel và custom CMS
WordPress với Yoast SEO, Rank Math và schema graph tùy biến
Trên WordPress, các plugin SEO như Yoast SEO, Rank Math, SEOPress… thường auto-generate schema cơ bản cho Organization, WebSite, WebPage, Article, Product. Tuy nhiên, để đạt chuẩn EEAT, entity-based SEO và xây được một schema graph phức tạp, cần can thiệp sâu hơn vào JSON-LD mặc định, đảm bảo:
- Không trùng lặp schema giữa theme, plugin SEO và plugin schema riêng.
- Các entity chính (Organization, Person, WebSite, WebPage, Article, Product, FAQPage, HowTo…) được liên kết bằng thuộc tính
@idrõ ràng. - Mapping đầy đủ các field quan trọng: author, reviewedBy, publisher, brand, gtin, mpn, sameAs, aggregateRating…
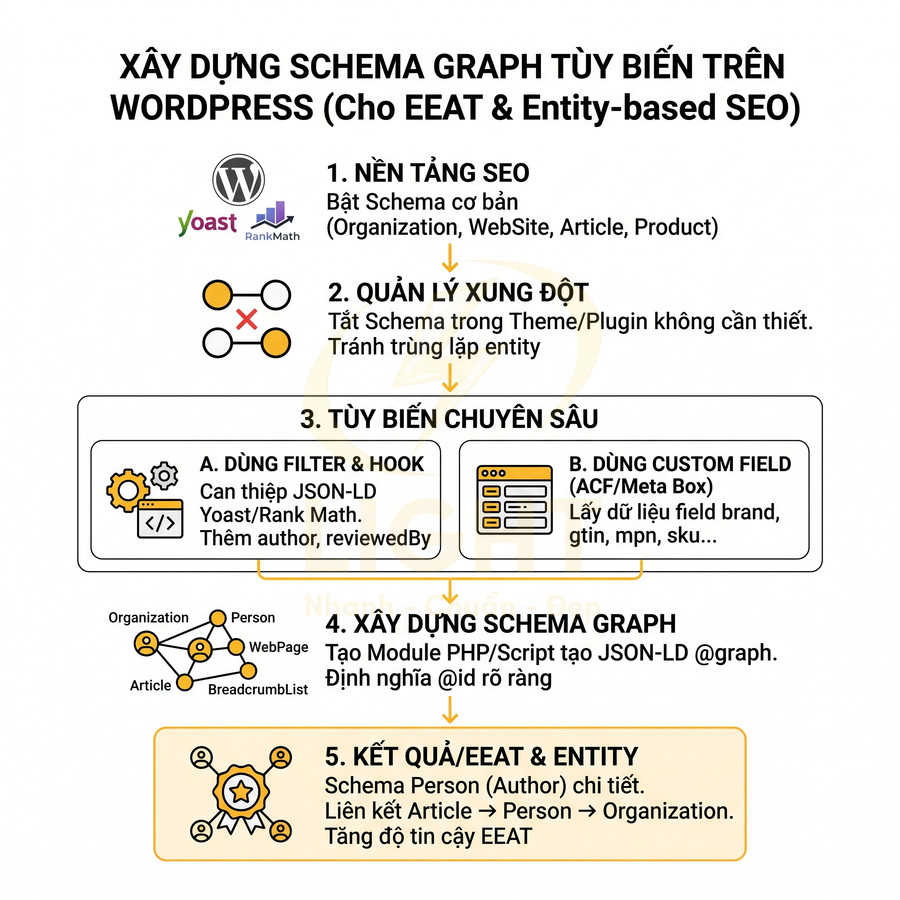
Chiến lược kỹ thuật hiệu quả cho WordPress:
- Dùng plugin SEO làm nền tảng: bật schema core trong Yoast/Rank Math cho:
- Organization/WebSite (logo, social profile, contact).
- Article/BlogPosting cho post.
- Product cho WooCommerce product.
- Override/mở rộng bằng hook & filter:
- Với Yoast: sử dụng filter như
wpseoschemagraphpieces,wpseoschemaorganization,wpseoschemaarticleđể:- Thêm
Personcho author vớisameAs(LinkedIn, Twitter, personal site). - Thêm
reviewedBy(Person/Organization) cho Article để tăng EEAT. - Liên kết Article với Organization qua
publishervàisPartOf.
- Thêm
- Với Rank Math: dùng filter
rankmath/jsonldđể:- Inject thêm
FAQPage,HowTodựa trên custom field hoặc block. - Custom Product schema (brand, gtin, mpn, sku, review, aggregateRating).
- Inject thêm
- Với Yoast: sử dụng filter như
- Schema graph tùy biến:
- Tạo một module PHP (plugin riêng hoặc trong
functions.php) đóng vai trò schema graph builder. - Module này:
- Định nghĩa các
@idcố định cho Organization, WebSite, mainEntity. - Generate JSON-LD dạng
@graphgồm nhiều node: Organization, WebSite, WebPage, Article/Product, BreadcrumbList, FAQPage… - Hook vào
wpheadđể in ra<script type="application/ld+json">.
- Định nghĩa các
- Tạo một module PHP (plugin riêng hoặc trong
- Quản lý xung đột schema:
- Tắt schema trong theme (nếu theme tự generate) hoặc trong plugin không cần thiết.
- Ưu tiên chỉ một nguồn chính cho mỗi loại entity (ví dụ: Product schema chỉ từ Rank Math + custom, không từ theme).
- WooCommerce & Product schema nâng cao:
- Tạo custom field (ACF, Meta Box, hoặc native custom field) cho:
brand(text hoặc taxonomy).gtin(gtin8/gtin12/gtin13/gtin14 tùy thị trường).mpn,sku,manufacturer.
- Mapping các field này vào Product schema:
brand:{"@type": "Brand", "name": "..."}.gtin13hoặcgtin14tùy chuẩn.mpn,skulà string.
- Nếu có review/rating: build
aggregateRatingvàreviewtừ WooCommerce review data.
- Tạo custom field (ACF, Meta Box, hoặc native custom field) cho:
Đối với EEAT, nên bổ sung:
- Schema Person cho tác giả với:
jobTitle,affiliation(Organization),sameAs(profile chuyên môn).- Liên kết Article →
author→ Person, Article →reviewedBy→ Person/Organization.
- Trang About/Author page có schema Person chi tiết, dùng
@idtrùng với author trong Article.
Shopify auto Product schema theo product template và metafield
Shopify core đã auto-generate Product schema cho product page dựa trên product object (title, price, availability, image…). Tuy nhiên, schema mặc định thường thiếu các field nâng cao như brand, gtin, mpn, FAQ, HowTo, review. Để xây auto schema chuyên sâu, cần tận dụng metafield và Liquid template.
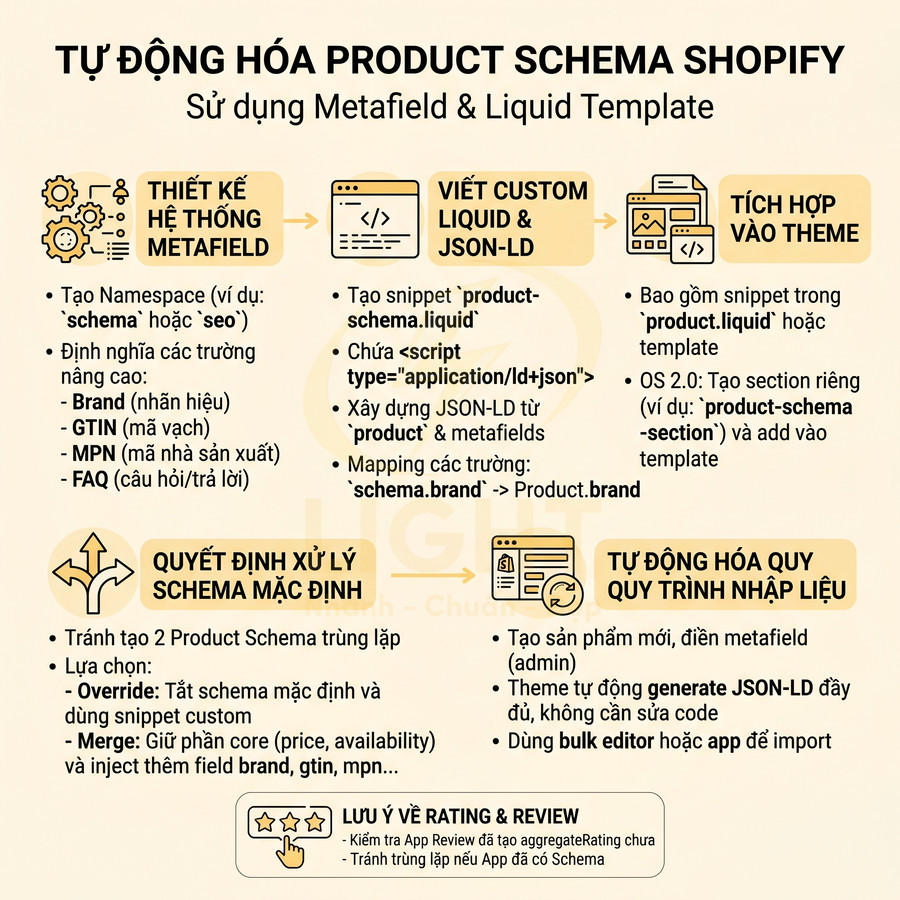
Quy trình kỹ thuật tối ưu:
- Thiết kế hệ thống metafield:
- Tạo metafield namespace riêng, ví dụ:
seohoặcschema. - Định nghĩa metafield cho product:
schema.brand(single line text hoặc reference Brand).schema.gtin(text/number, chuẩn hóa độ dài theo thị trường).schema.mpn,schema.manufacturer.schema.faq(list of objects: question/answer) nếu dùng metafield dạng JSON hoặc metaobject.schema.ratingvalue,schema.ratingcountnếu không dùng app review.
- Tạo metafield namespace riêng, ví dụ:
- Custom JSON-LD trong theme Liquid:
- Tạo một snippet, ví dụ:
product-schema.liquid, chứa:- Đoạn
<script type="application/ld+json">với JSON-LD build từproduct+product.metafields. - Mapping:
product.metafields.schema.brand→Product.brand.product.metafields.schema.gtin→Product.gtin13hoặcgtin14.product.metafields.schema.mpn→Product.mpn.product.metafields.schema.faq→FAQPagehoặcmainEntitylà listQuestion.
- Đoạn
- Include snippet này trong
product.liquidhoặc product template JSON:- Với Online Store 2.0: tạo section riêng (ví dụ
product-schema-section) và add vào template.
- Với Online Store 2.0: tạo section riêng (ví dụ
- Tạo một snippet, ví dụ:
- Quyết định override hay merge với schema mặc định:
- Nếu theme đã có Product schema:
- Hoặc tắt schema mặc định (nếu theme cho phép) và dùng snippet custom làm nguồn duy nhất.
- Hoặc merge: giữ phần core (price, availability) và chỉ inject thêm field brand, gtin, mpn, review.
- Đảm bảo không tạo hai Product schema độc lập cho cùng một URL.
- Nếu theme đã có Product schema:
- Auto hóa quy trình nhập liệu:
- Khi tạo sản phẩm mới, chỉ cần:
- Điền metafield brand, gtin, mpn, faq… trong admin.
- Theme tự động generate JSON-LD đầy đủ, không cần chỉnh code.
- Có thể dùng bulk editor hoặc app để import metafield từ file CSV/ERP.
- Khi tạo sản phẩm mới, chỉ cần:
- Rating & review:
- Nếu dùng app review (Judge.me, Loox, Yotpo…):
- Kiểm tra app đã generate
aggregateRatingchưa. - Nếu app đã có schema, tránh trùng lặp bằng cách không tự build rating trong snippet.
- Kiểm tra app đã generate
- Nếu dùng app review (Judge.me, Loox, Yotpo…):
Next.js render JSON-LD động theo SSR, ISR và route segment
Trong Next.js, schema nên được render server-side để Google bot thấy ngay trong HTML ban đầu. Cách tiếp cận tốt là xây một schema builder layer tách biệt với UI, hoạt động thống nhất cho SSR, SSG, ISR.

Kiến trúc đề xuất:
- Schema builder theo page type:
- Tạo một thư mục, ví dụ:
/lib/schemahoặc/services/schema. - Định nghĩa các hàm:
buildHomePageSchema(data)cho homepage.buildArticleSchema(article, site, author)cho blog.buildProductSchema(product, brand, reviews)cho product page.buildCategorySchema(category, products)cho category/collection.
- Mỗi builder trả về object JSON-LD (có thể là
@graph).
- Tạo một thư mục, ví dụ:
- Tích hợp với SSR/SSG/ISR:
- Trong
getServerSidePropshoặcgetStaticProps:- Fetch data từ API/CMS (article, product, author, organization…).
- Gọi builder tương ứng để tạo schema object.
- Pass schema object vào props của page component.
- Trong component:
- Render:
<script type="application/ld+json" dangerouslySetInnerHTML={{ _html: JSON.stringify(schema) }} />
- Render:
- Với ISR:
- Dùng
revalidateđể khi dữ liệu thay đổi, schema cũng được regenerate.
- Dùng
- Trong
- Route segment & dynamic routing:
- Với Next.js App Router (app directory):
- Sử dụng
generateMetadatahoặc layout để inject schema cho từng segment. - Phân loại route:
/blog/[slug]→ Article,/product/[slug]→ Product,/category/[slug]→ CollectionPage.
- Sử dụng
- Builder có thể được gọi trong server component, đảm bảo schema render server-side.
- Với Next.js App Router (app directory):
- Tránh render schema trên client:
- Không nên dùng
useEffectđể inject schema sau khi hydrate. - Google ưu tiên nội dung có sẵn trong HTML ban đầu; schema client-side có thể bị bỏ qua hoặc xử lý không ổn định.
- Không nên dùng
- Entity graph & EEAT:
- Định nghĩa
@idcố định cho:- Organization:
https://example.com/#organization. - WebSite:
https://example.com/#website. - Author Person:
https://example.com/author/[slug]#person.
- Organization:
- Trong Article/Product schema:
- Tham chiếu đến các
@idnày quapublisher,author,brand,isPartOf.
- Tham chiếu đến các
- Định nghĩa
Laravel hoặc headless CMS inject schema từ API layer và template engine
Trong Laravel hoặc kiến trúc headless CMS, mục tiêu là tách biệt schema logic khỏi layer giao diện, để có thể tái sử dụng cho nhiều frontend (Blade, React, Vue, Next.js, mobile app…). Cách tiếp cận chuyên nghiệp là xây một schema service layer ở backend.
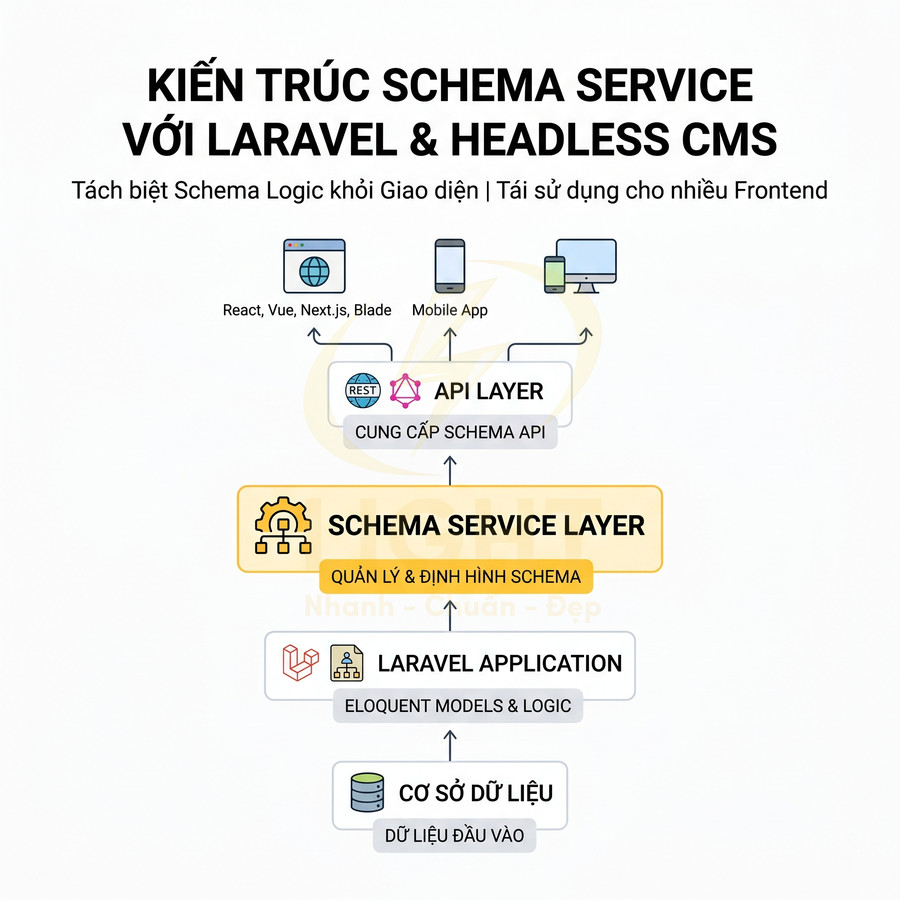
Mô hình triển khai với Laravel:
- Schema service trong backend:
- Tạo một service class, ví dụ:
App\Services\SchemaService. - Service này có các method:
organization(),website(),webPage($model).article($articleModel),product($productModel),faq($faqCollection).
- Các method trả về array PHP tương ứng với JSON-LD, có thể combine thành
@graph.
- Tạo một service class, ví dụ:
- Inject schema vào Blade hoặc API:
- Với Blade:
- Controller gọi
SchemaServiceđể build schema array. - Pass schema sang view, trong Blade:
<script type="application/ld+json">{!! jsonencode($schema, JSONUNESCAPEDUNICODE|JSONUNESCAPEDSLASHES) !!}</script>
- Controller gọi
- Với API (headless):
- Endpoint trả về:
- Data chính (article, product…).
- Field
schemachứa JSON-LD hoặc object để frontend render.
- Endpoint trả về:
- Với Blade:
- Headless CMS (Strapi, Contentful, Sanity…):
Trong headless CMS, schema nên được điều khiển bởi content model:
- Thiết kế content model có field schema-specific:
- Article:
- author (relation đến Author content type).
- reviewer (optional, relation đến Expert/Reviewer).
- faq (repeatable component: question/answer).
- Product:
- brand (relation hoặc text).
- gtin, mpn, sku, manufacturer.
- ratingvalue, ratingcount (hoặc relation đến Review type).
- Organization:
- legalName, logo, sameAs, contactPoint.
- Article:
- API trả về dữ liệu đã chuẩn hóa:
- Trong Strapi: có thể dùng lifecycle hook hoặc custom controller để:
- Build sẵn schema object cho mỗi entry.
- Đính kèm vào response JSON (field
schema).
- Trong Contentful/Sanity:
- Dùng GROQ/GraphQL để query đầy đủ field cần cho schema.
- Frontend mapping sang JSON-LD theo builder riêng.
- Trong Strapi: có thể dùng lifecycle hook hoặc custom controller để:
- Tách biệt logic schema khỏi giao diện:
- Backend chịu trách nhiệm:
- Định nghĩa entity, quan hệ, chuẩn hóa field.
- Đảm bảo consistency của
@id,sameAs,publisher,author.
- Frontend chỉ:
- Nhận schema object từ API.
- Render vào HTML dưới dạng
<script type="application/ld+json">.
- Backend chịu trách nhiệm:
- Hỗ trợ đa frontend (web, AMP, PWA):
- Cùng một API/schema service có thể phục vụ:
- Website chính (Next.js, Nuxt, Laravel Blade…).
- AMP page (schema thường yêu cầu chặt chẽ hơn cho Article, NewsArticle).
- PWA hoặc mobile app (nếu cần embed schema trong webview).
- Việc centralize schema logic giúp:
- Dễ bảo trì khi Google cập nhật guideline.
- Giảm rủi ro sai lệch schema giữa các kênh.
- Cùng một API/schema service có thể phục vụ:
Checklist schema Organization, Article, Product cần có trước khi publish

Kiểm tra field required, entity consistency và rich result eligibility
Trước khi publish bài viết hoặc sản phẩm mới, team SEO, content và dev nên có một checklist schema chi tiết, mang tính kỹ thuật cao để đảm bảo dữ liệu có cấu trúc không chỉ hợp lệ mà còn tối ưu cho rich result, crawl, index và entity recognition. Checklist nên được chuẩn hóa thành tài liệu nội bộ, gắn với từng loại template (homepage, category, product, blog, landing page) và được review định kỳ.
Ở mức kỹ thuật, checklist nên chia thành ba lớp kiểm tra: field required (bắt buộc và khuyến nghị), entity consistency (nhất quán thực thể trên toàn hệ thống) và rich result eligibility (đủ điều kiện hiển thị dạng nâng cao trên SERP).

- Field required: ngoài các field cơ bản, nên phân biệt rõ:
- Organization:
- name: trùng với brand chính thức, không thêm từ khóa spam; nên cố định trong config, không để content tự sửa.
- url: dùng canonical root (https, không slash thừa), đồng bộ với cấu hình trong Search Console.
- logo: dùng URL tuyệt đối, kích thước tối thiểu theo guideline Google; nên dùng định dạng nhẹ (WebP/PNG) và đảm bảo logo có thể crawl (không chặn bằng robots.txt).
- sameAs: trỏ đến các profile chính thức (Facebook, LinkedIn, YouTube, Wikipedia, Crunchbase, v.v.); tránh trỏ đến trang không còn tồn tại hoặc profile không chính chủ.
- Khuyến nghị thêm: contactPoint (support, sales), foundingDate, address (nếu là local business) để hỗ trợ entity building.
- Article:
- headline: độ dài hợp lý (<110 ký tự), không nhồi nhét từ khóa; nên khớp hoặc gần với <title> và H1.
- author: dùng kiểu
PersonhoặcOrganization; nếu là Person, nên cónamevà nếu có thể thêmsameAs(LinkedIn, author page) để tăng độ tin cậy. - datePublished và dateModified: dùng ISO 8601 (YYYY-MM-DDThh:mm:ss+timezone); đảm bảo đồng bộ với timestamp hiển thị trên trang và trong CMS.
- image: dùng ảnh chất lượng cao, tỷ lệ phù hợp (thường >= 1200px chiều rộng); nên khai báo dạng mảng nếu có nhiều ảnh.
- Khuyến nghị thêm: mainEntityOfPage, description, articleSection, publisher (Organization + logo) để tăng khả năng hiểu ngữ cảnh.
- Product:
- name: trùng với tên sản phẩm trên UI; tránh thêm thông tin khuyến mãi, giảm giá vào name.
- image: nên có nhiều góc chụp, khai báo dạng mảng; đảm bảo ảnh có thể crawl và không bị chặn bởi watermark quá nặng.
- offers.price: dùng số, không kèm đơn vị; đồng bộ với giá hiển thị, không để lệch do cache hoặc multi-currency.
- offers.priceCurrency: dùng mã ISO 4217 (VD: VND, USD); không dùng ký hiệu tiền tệ.
- offers.availability: dùng giá trị chuẩn schema.org (VD:
https://schema.org/InStock,OutOfStock,PreOrder); không dùng text tự do. - Khuyến nghị thêm: sku, brand, gtin8/gtin13/gtin14, review, aggregateRating (nếu có dữ liệu thật) để tối ưu rich result.
- Organization:
- Entity consistency: đảm bảo schema phản ánh chính xác dữ liệu business và nội dung hiển thị, tránh tạo “shadow data” chỉ tồn tại trong markup.
- Tên brand, author, giá, tồn kho trong schema phải:
- Trùng với nội dung trên UI (H1, block giá, block stock).
- Trùng với dữ liệu trong database hoặc API nguồn; nên có cơ chế generate schema trực tiếp từ source of truth thay vì nhập tay.
- URL trong mainEntityOfPage:
- Phải trùng với canonical URL (bao gồm protocol, trailing slash).
- Không dùng URL có tham số tracking (utm, gclid, fbclid).
- sameAs:
- Chỉ trỏ đến profile chính thức, có nội dung tương ứng với entity.
- Định kỳ kiểm tra link chết, redirect 404/410 hoặc đổi brand.
- Với author:
- Schema
Personnên trỏ đến trang hồ sơ tác giả nội bộ (author page) và các profile chuyên môn (LinkedIn, chuyên trang). - Tên tác giả trong schema phải trùng với byline hiển thị.
- Schema
- Với Product:
- Giá, khuyến mãi, tình trạng còn hàng phải được cập nhật tự động từ hệ thống bán hàng để tránh mismatch.
- Nếu sản phẩm ngừng bán, cần cập nhật
availabilityvà cân nhắc noindex hoặc chuyển hướng.
- Tên brand, author, giá, tồn kho trong schema phải:
- Rich result eligibility: tập trung vào việc đáp ứng guideline của Google, tránh lạm dụng schema.
- Dùng đúng type được Google hỗ trợ cho rich result:
- Article/NewsArticle/BlogPosting cho nội dung tin tức, blog.
- Product cho trang chi tiết sản phẩm, không dùng cho category.
- Organization/LocalBusiness cho trang brand, contact, store.
- Không dùng review giả:
- Chỉ markup review và aggregateRating nếu có dữ liệu thật, hiển thị trên trang.
- Không tự tạo rating 5.0/5.0 nếu không có hệ thống thu thập đánh giá minh bạch.
- Không nhồi nhét schema không phản ánh nội dung thực:
- Không gắn Product schema cho bài blog chỉ nhắc đến sản phẩm.
- Không gắn FAQPage nếu không có block FAQ rõ ràng trên UI.
- Không gắn HowTo nếu nội dung không phải hướng dẫn từng bước.
- Đảm bảo tuân thủ Google Search Central guidelines:
- Không dùng schema để che giấu nội dung spam, nội dung không hiển thị.
- Không lặp nhiều block schema trùng nhau trên cùng một trang nếu không cần thiết.
- Dùng đúng type được Google hỗ trợ cho rich result:
Test bằng Google Rich Results Test và Schema Markup Validator
Sau khi hoàn thiện schema, bước bắt buộc là test bằng Google Rich Results Test và Schema Markup Validator để đảm bảo cả hai lớp: tính hợp lệ theo schema.org và khả năng đủ điều kiện rich result theo chuẩn Google. Việc test nên được chuẩn hóa thành một bước trong quy trình release, không chỉ là thao tác thủ công ad-hoc.
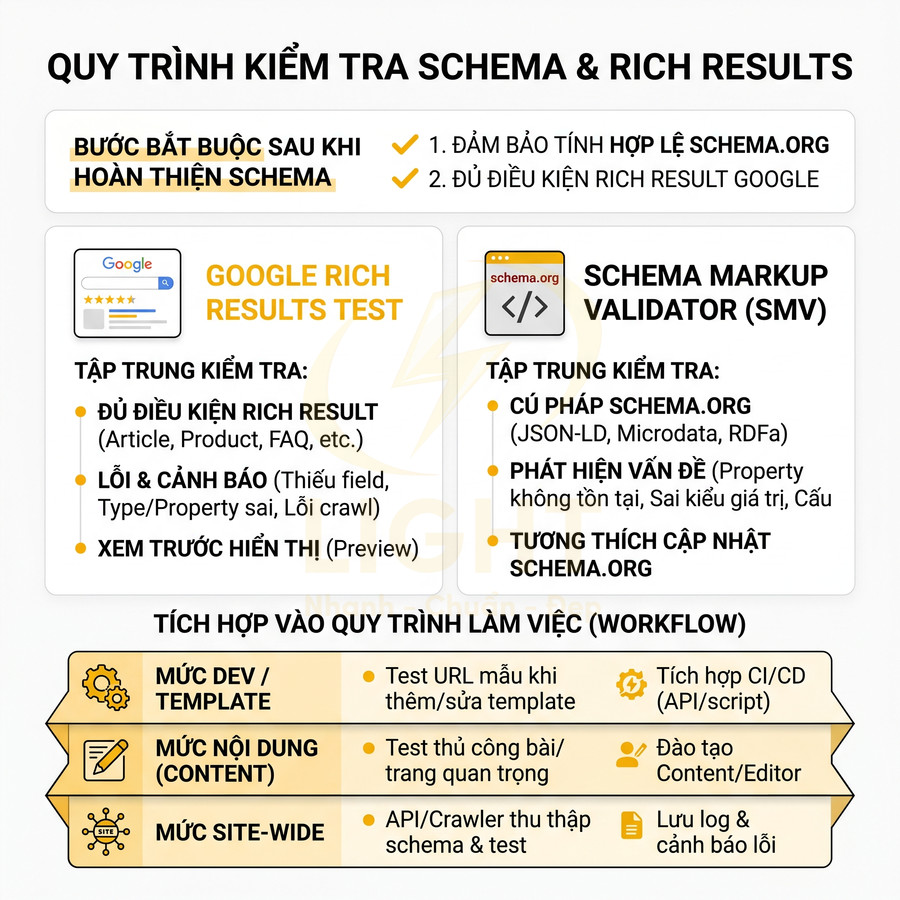
Google Rich Results Test tập trung vào việc kiểm tra:
- Trang có đủ điều kiện hiển thị rich result cho các loại schema được hỗ trợ (Article, Product, FAQ, HowTo, Breadcrumb, Organization, v.v.).
- Các lỗi và cảnh báo liên quan đến rich result:
- Thiếu field bắt buộc hoặc khuyến nghị cho từng loại rich result.
- Type không được hỗ trợ hoặc property không được Google dùng cho rich result.
- Vấn đề về URL, hình ảnh, hoặc dữ liệu không thể crawl.
- Hiển thị preview dạng rich result (nếu có) để so sánh với kỳ vọng.
Schema Markup Validator (SMV) tập trung vào:
- Kiểm tra cú pháp JSON-LD/Microdata/RDFa theo chuẩn schema.org.
- Phát hiện:
- Property không tồn tại cho type tương ứng.
- Giá trị sai kiểu (VD: dùng text cho field yêu cầu URL hoặc number).
- Type lồng nhau sai cấu trúc (VD: dùng Thing thay vì Product/Organization cụ thể).
- Đảm bảo schema không bị lỗi khi schema.org cập nhật version mới.
Quy trình tốt là tích hợp test vào workflow ở nhiều lớp:
- Ở mức dev/template:
- Khi dev thêm template mới hoặc refactor schema, chạy test trên một bộ URL mẫu đại diện cho từng loại trang.
- Thêm bước kiểm tra schema vào CI/CD (nếu có thể) bằng cách gọi API hoặc script tự động.
- Ở mức content:
- Khi publish bài trụ cột, landing page quan trọng hoặc sản phẩm chủ lực, test thủ công ít nhất một lần.
- Đào tạo content/editor hiểu các cảnh báo phổ biến để có thể tự phát hiện vấn đề đơn giản.
- Ở mức site-wide:
- Với site lớn, có thể dùng API hoặc crawler nội bộ để:
- Thu thập schema từ toàn bộ URL.
- Gửi mẫu URL đại diện lên công cụ test hoặc dùng thư viện validate schema.org.
- Lưu log lỗi theo thời gian để phân tích xu hướng.
- Tích hợp cảnh báo (alert) khi tỷ lệ URL lỗi vượt ngưỡng cho phép.
- Với site lớn, có thể dùng API hoặc crawler nội bộ để:
Chạy quét lỗi schema định kỳ sau content update, product update và redesign
Schema không phải cấu hình một lần rồi bỏ đó. Mỗi lần update nội dung, thêm sản phẩm, đổi giá, thay đổi cấu trúc URL hoặc redesign giao diện, nguy cơ lỗi schema lại xuất hiện do thay đổi template, logic render hoặc nguồn dữ liệu. Vì vậy, cần xây dựng một quy trình quét lỗi schema định kỳ có hệ thống, gắn với lịch release và tần suất cập nhật nội dung.
Với site vừa, tần suất hợp lý là hàng tuần; với site lớn hoặc ecommerce có biến động giá và tồn kho liên tục, nên quét hàng ngày hoặc gần real-time cho nhóm URL quan trọng (top traffic, top revenue). Mục tiêu không chỉ là sửa lỗi mà còn là phát hiện pattern lỗi để cải thiện template và quy trình.

- Chiến lược chọn URL để quét:
- Tập trung vào nhóm URL thay đổi gần đây:
- Dựa trên log server (last access, last update).
- Dựa trên
lastmodtrong sitemap. - Dựa trên timestamp trong database (last content update, last price change).
- Kết hợp với quét toàn site theo chu kỳ dài hơn (VD: 1–2 tuần/lần) để bắt lỗi trên các trang ít thay đổi nhưng có thể bị ảnh hưởng bởi update global (header, footer, script chung).
- Ưu tiên:
- Trang có traffic cao, mang lại nhiều chuyển đổi.
- Template mới triển khai hoặc vừa được chỉnh sửa.
- Tập trung vào nhóm URL thay đổi gần đây:
- Cách thức quét và kiểm tra:
- Dùng crawler nội bộ hoặc tool bên thứ ba để:
- Thu thập toàn bộ block JSON-LD/Microdata trên trang.
- Parse và validate theo schema.org (dùng thư viện JSON Schema hoặc validator chuyên dụng).
- Gắn nhãn từng URL theo loại template (Article, Product, Category, v.v.).
- Kiểm tra các nhóm lỗi:
- Lỗi cú pháp (JSON không hợp lệ, thiếu dấu ngoặc, ký tự đặc biệt không escape).
- Lỗi logic (thiếu field bắt buộc, type sai, property không hỗ trợ).
- Lỗi nhất quán (giá trong schema khác giá hiển thị, URL sai canonical, author không tồn tại).
- Tự động phân loại lỗi theo mức độ ưu tiên:
- Critical: làm mất rich result hoặc gây hiểu sai entity (VD: thiếu price, type Product sai, URL sai).
- Major: không làm mất rich result ngay nhưng ảnh hưởng chất lượng dữ liệu (VD: thiếu recommended field, thiếu sameAs quan trọng).
- Minor: cảnh báo nhỏ, có thể xử lý sau (VD: thiếu description, thiếu articleSection).
- Dùng crawler nội bộ hoặc tool bên thứ ba để:
- Báo cáo và cải thiện quy trình:
- Báo cáo định kỳ nên bao gồm:
- Tỷ lệ URL có schema hợp lệ vs lỗi theo thời gian.
- Top loại lỗi phổ biến (missing field, type mismatch, URL mismatch).
- Template hoặc module nào gây lỗi nhiều nhất.
- Dựa trên báo cáo để:
- Ưu tiên fix ở cấp template thay vì sửa tay từng URL.
- Cập nhật guideline cho content/editor (VD: luôn nhập author chuẩn, luôn cập nhật giá đúng field).
- Thêm test tự động vào pipeline dev khi chạm vào phần render schema.
- Với ecommerce:
- Đặc biệt theo dõi lỗi liên quan đến offers (price, availability, priceCurrency) vì ảnh hưởng trực tiếp đến rich result Product.
- Đảm bảo khi sản phẩm hết hàng hoặc ngừng bán, schema được cập nhật tương ứng để tránh hiển thị thông tin sai trên SERP.
- Báo cáo định kỳ nên bao gồm:
FAQ về tự động thêm schema và quét lỗi schema website chuẩn SEO

Một trang có thể dùng đồng thời Organization, Article và Product không
Một trang hoàn toàn có thể chứa nhiều loại schema khác nhau, miễn là các schema đó phản ánh đúng nội dung thực tế, có mối quan hệ logic và không gây hiểu nhầm cho công cụ tìm kiếm. Về mặt kỹ thuật, Google và các search engine có thể parse nhiều loại structured data trên cùng một URL, nhưng về mặt chiến lược SEO cần phân định rõ main entity và các entity phụ.
Organization thường là entity mang tính site-wide, đại diện cho doanh nghiệp hoặc tổ chức đứng sau toàn bộ website. Thông thường:
- Organization nên được khai báo ở cấp global (header, footer, template chung) với một
@idcố định. - Không nên gắn một Organization mới cho từng trang, trừ khi đó là:
- Trang brand hub, giới thiệu chi tiết về thương hiệu.
- Trang profile của một brand con trong hệ thống multi-brand.
- Các schema khác như WebSite, WebPage, Article, Product nên tham chiếu đến Organization qua
publisher,brand, hoặcproviderbằng@id.
Trên một trang sản phẩm (Product detail page), cấu trúc hợp lý thường gồm:
- Product: là
mainEntityOfPage, chứa các thuộc tính nhưname,image,description,sku,brand,offers,aggregateRating,review, v.v. - BreadcrumbList: phản ánh cấu trúc điều hướng, hỗ trợ rich result breadcrumb.
- FAQPage (nếu có phần FAQ thật trên trang): mỗi câu hỏi là một
QuestionvớiacceptedAnswer. - Review hoặc AggregateRating: gắn vào Product, không nên tách rời thành entity độc lập nếu chỉ phục vụ cho sản phẩm đó.
- Organization/WebSite: được kế thừa từ template, thường không cần khai báo lại riêng cho từng trang.
Trên một trang blog review sản phẩm, có thể kết hợp:
- Article (hoặc
BlogPosting): làmainEntityOfPage, mô tả nội dung bài review, vớiheadline,author,datePublished,dateModified,image,articleBody, v.v. - Product: là entity được review, có thể được tham chiếu từ Article qua thuộc tính như
abouthoặcmentions, hoặc dùngmainEntitynếu toàn bộ bài viết xoay quanh một sản phẩm duy nhất.
Cần tránh các sai lầm phổ biến:
- Gắn Product schema cho mọi bài viết chỉ để cố lấy rich snippet, trong khi:
- Trang không có chức năng mua hàng.
- Không có thông tin giá, tình trạng còn hàng, hoặc thông tin bán hàng rõ ràng.
- Dùng Organization như một “label” cho mọi trang mà không có mối quan hệ logic (ví dụ: gắn Organization riêng cho từng bài blog).
- Không phân biệt rõ
mainEntityOfPage(Article hay Product) khiến Google khó hiểu đâu là nội dung chính.
Chiến lược tốt là xây một entity graph rõ ràng:
- Organization là node trung tâm, có
@idcố định. - WebSite, WebPage, Article, Product… liên kết qua
@id,publisher,brand,about,mentions. - Mỗi trang xác định rõ 1 main entity, các entity khác là phụ, được tham chiếu chặt chẽ.
Schema đúng nhưng không có rich snippet do đâu
Ngay cả khi schema đúng cú pháp, pass mọi tool validate (Rich Results Test, Schema Markup Validator) và điền đầy đủ field, Google vẫn có thể không hiển thị rich snippet. Nguyên nhân thường nằm ở tầng chất lượng, tín hiệu tin cậy và chính sách hiển thị, không chỉ ở kỹ thuật.
Một số nhóm nguyên nhân chính:
- Chất lượng nội dung chưa đủ:
- Nội dung mỏng, trùng lặp, hoặc chỉ “bọc” schema quanh nội dung rất ít giá trị.
- Bài viết không thực sự giải quyết intent của người dùng, chỉ tối ưu kỹ thuật.
- Website thiếu độ tin cậy (EEAT yếu):
- Thiếu thông tin về tác giả, tổ chức, thông tin liên hệ, chính sách rõ ràng.
- Ít hoặc không có backlink chất lượng, brand chưa được nhận diện như một entity rõ ràng.
- Schema không phản ánh nội dung thực:
- Gắn FAQPage nhưng trên trang không có phần FAQ hiển thị cho người dùng.
- Gắn Review, Rating nhưng không có review thực, hoặc review không hiển thị.
- Gắn Product với giá, tình trạng còn hàng nhưng trang chỉ là bài giới thiệu, không có chức năng mua.
- Vi phạm guideline:
- Review giả, rating tự tạo, tự đánh giá chính mình mà không minh bạch.
- Dùng structured data để “thổi phồng” thông tin (ví dụ: rating 5.0 nhưng không có nguồn).
- Cạnh tranh cao trên SERP:
- Nhiều đối thủ cùng loại schema, Google chọn hiển thị một số ít domain có tín hiệu mạnh hơn.
- Google điều chỉnh layout SERP theo loại truy vấn, có thể giảm số lượng rich result hiển thị.
- Chính sách hiển thị của Google:
- Rich result luôn là không được đảm bảo, ngay cả khi mọi thứ đều đúng.
- Google có thể test A/B layout, tắt/bật một số loại rich result theo thời gian hoặc theo khu vực.
Để tăng khả năng hiển thị rich snippet, cần tiếp cận theo hướng tổng thể:
- Tối ưu EEAT: thông tin tác giả, trang giới thiệu, chính sách, tín hiệu chuyên môn.
- Xây dựng entity rõ ràng: Organization, Person, Product… có
@idnhất quán, liên kết với các nguồn ngoài (sameAs đến social, knowledge graph, v.v.). - Cải thiện backlink và brand mention từ các nguồn uy tín.
- Tối ưu UX: tốc độ, mobile-friendly, layout rõ ràng, nội dung dễ đọc.
- Đảm bảo schema luôn phản ánh trung thực nội dung hiển thị cho người dùng, tránh mọi dạng “tô vẽ”.
Bao lâu nên quét lỗi schema toàn site một lần
Tần suất quét lỗi schema phụ thuộc vào quy mô, tần suất cập nhật và độ phức tạp kỹ thuật của website. Mục tiêu là phát hiện sớm các lỗi phát sinh từ thay đổi template, plugin, dữ liệu hoặc logic render.
Gợi ý theo từng nhóm:
- Site nhỏ, ít thay đổi (blog cá nhân, site giới thiệu đơn giản):
- Quét toàn site khoảng 1 lần/tháng.
- Ưu tiên quét lại khi có thay đổi theme, plugin SEO, hoặc thêm loại nội dung mới.
- Site vừa (magazine, corporate site có nhiều landing page):
- Quét toàn site mỗi tuần để bắt kịp các thay đổi nội dung và template.
- Có thể chia theo nhóm URL (blog, landing, product) để tối ưu tài nguyên crawl.
- Ecommerce hoặc site tin tức lớn:
- Quét hàng ngày, hoặc nhiều lần mỗi ngày cho:
- Nhóm URL mới tạo.
- Nhóm URL vừa được cập nhật giá, tồn kho, nội dung.
- Định kỳ (tuần/tháng) quét sâu toàn bộ để phát hiện lỗi hệ thống.
- Quét hàng ngày, hoặc nhiều lần mỗi ngày cho:
Bên cạnh quét định kỳ, cần quét ngay sau các sự kiện lớn có nguy cơ làm hỏng schema:
- Deploy template mới hoặc refactor front-end.
- Update plugin/theme (đặc biệt là plugin SEO, page builder, ecommerce).
- Migrate dữ liệu, đổi CMS, đổi cấu trúc URL.
- Redesign giao diện, thay đổi cách render nội dung (SSR, CSR, hydration, v.v.).
Với website lớn, nên kết hợp:
- Quét định kỳ (scheduled crawl) cho toàn site hoặc từng segment.
- Cảnh báo realtime khi:
- Tỷ lệ URL có schema valid giảm đột ngột.
- Số lượng lỗi critical (missing required field, invalid type) tăng bất thường.
- Dashboard theo dõi:
- Tỷ lệ valid/warning/error theo từng loại schema (Product, Article, FAQPage…).
- Trend theo thời gian để phát hiện regression sau mỗi lần deploy.
Có nên auto-fix schema ngay sau mỗi lần publish bài viết hoặc sản phẩm mới không
Auto-fix là một cơ chế mạnh, giúp giảm khối lượng công việc thủ công, nhưng nếu không kiểm soát tốt có thể sửa sai trên diện rộng. Cần phân loại rõ loại lỗi nào được phép auto-fix, loại nào chỉ nên cảnh báo.
Nhóm lỗi có thể auto-fix an toàn, thường là lỗi thiếu thông tin có thể suy ra từ config chung:
- Thiếu
logohoặcpublishercho Article/WebPage:- Có thể tự động gán Organization mặc định với
@idvà logo từ cấu hình site.
- Có thể tự động gán Organization mặc định với
- Thiếu
priceCurrencycho Product:- Có thể lấy từ cấu hình store (ví dụ: “VND”, “USD”) và auto-fill.
- Thiếu
inLanguagecho Article/WebPage:- Có thể lấy từ setting ngôn ngữ của site hoặc folder.
Nhóm lỗi không nên auto-fix, vì cần quyết định của con người hoặc dữ liệu nguồn có thể sai:
- Giá sai (
pricekhông khớp với giá hiển thị, hoặc đơn vị không đúng). - Author sai (gán nhầm tác giả mặc định cho bài viết có nhiều contributor).
- Type sai (gắn Product cho trang không phải trang bán hàng, gắn FAQPage cho trang không có FAQ).
- Thông tin nhạy cảm như rating, review, medical/financial claim.
Chiến lược hợp lý:
- Sau khi publish, hệ thống chạy một vòng kiểm tra nhanh trên trang mới:
- Validate schema theo rule nội bộ + guideline của Google.
- Phân loại lỗi thành:
- Lỗi auto-fix được (low risk).
- Lỗi cần review (high risk).
- Với lỗi auto-fix:
- Thực hiện sửa ngay (bổ sung field từ config, chuẩn hóa format).
- Log lại thay đổi để có thể rollback nếu cần.
- Với lỗi cần quyết định của con người:
- Gửi cảnh báo cho editor, SEO hoặc merchandiser.
- Đính kèm chi tiết URL, loại schema, field lỗi, gợi ý sửa.
Cách tiếp cận này giúp cân bằng giữa tự động hóa và kiểm soát chất lượng, tránh việc một rule auto-fix sai làm hỏng schema trên hàng nghìn URL.
Website lớn nhiều ngôn ngữ cần quản lý schema entity ra sao
Với website đa ngôn ngữ, thách thức chính là giữ entity thống nhất trong khi nội dung, URL, thậm chí brand name hiển thị có thể khác nhau theo từng locale. Structured data cần phản ánh cả:
- Ngôn ngữ hiển thị cho người dùng.
- Identity cốt lõi của entity (Organization, Product, Person…) không thay đổi.
Một số nguyên tắc quan trọng:
- Organization thường là một entity chung cho toàn bộ site:
- Dùng một
@idduy nhất cho Organization trên mọi ngôn ngữ. - Có thể dùng
alternateNamecho các biến thể tên theo ngôn ngữ. - Thông tin như
url,logo,sameAs(social, Wikipedia, v.v.) nên nhất quán.
- Dùng một
- WebSite, WebPage, Article, Product có phiên bản theo từng ngôn ngữ:
- Dùng
inLanguageđể chỉ định ngôn ngữ (ví dụ:"vi","en"). - Liên kết giữa các phiên bản ngôn ngữ bằng:
urltương ứng với cặphreflangtrong HTML.sameAshoặc một@idchung nếu hệ thống phức tạp.
- Dùng
Ví dụ: một sản phẩm có phiên bản tiếng Việt và tiếng Anh:
- Trang tiếng Việt:
- Product schema với
name,descriptionbằng tiếng Việt. inLanguage: "vi".sku,gtin,brandgiống bản tiếng Anh.
- Product schema với
- Trang tiếng Anh:
- Product schema với
name,descriptionbằng tiếng Anh. inLanguage: "en".- Cùng
sku,gtin,brand.
- Product schema với
Có hai mô hình liên kết entity:
- Mô hình mỗi ngôn ngữ một Product riêng:
- Mỗi URL có một Product với
@idriêng (theo URL). - Dùng
sameAsđể liên kết các Product đa ngôn ngữ với nhau. - Ưu điểm: đơn giản, dễ debug, phù hợp với hầu hết CMS.
- Mỗi URL có một Product với
- Mô hình một Product chung, nhiều view ngôn ngữ:
- Dùng một
@idchung cho Product (theo SKU hoặc ID nội bộ). - Trong mỗi ngôn ngữ, WebPage/Article tham chiếu đến cùng
@idProduct. - Có thể dùng nhiều
descriptionvớiinLanguagekhác nhau trong hệ thống phức tạp. - Ưu điểm: entity graph rất rõ, nhưng yêu cầu hệ thống quản lý dữ liệu tốt.
- Dùng một
Điểm mấu chốt là giữ identifier nhất quán:
- Product:
sku,gtin,mpn, hoặc@idnội bộ. - Organization: một
@idduy nhất cho mọi locale. - Person (tác giả, chuyên gia):
@idcố định, dùngalternateNamenếu cần.
Khi entity được định danh rõ ràng và liên kết đúng giữa các ngôn ngữ, Google dễ hiểu rằng đây là cùng một entity được trình bày cho các thị trường khác nhau, từ đó hỗ trợ tốt hơn cho cả SEO quốc tế và hiển thị rich result đa ngôn ngữ.



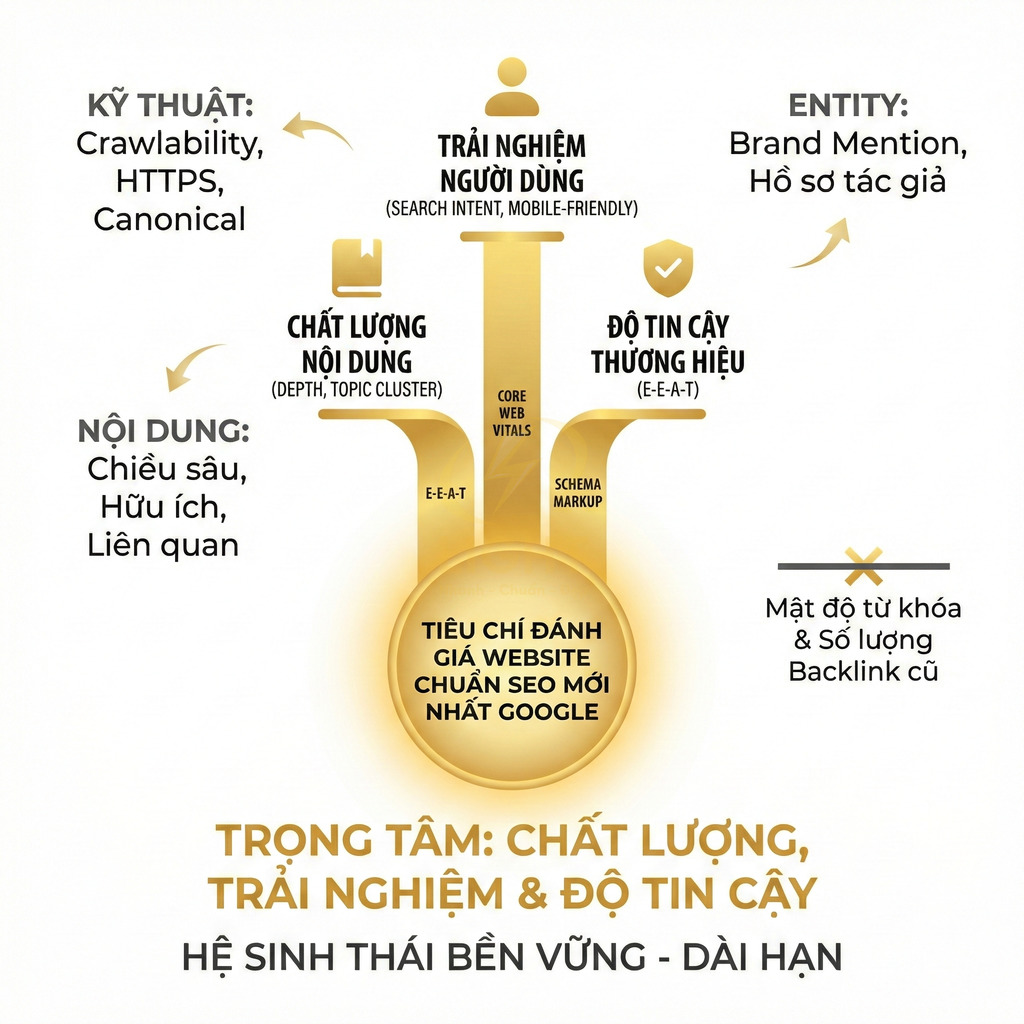

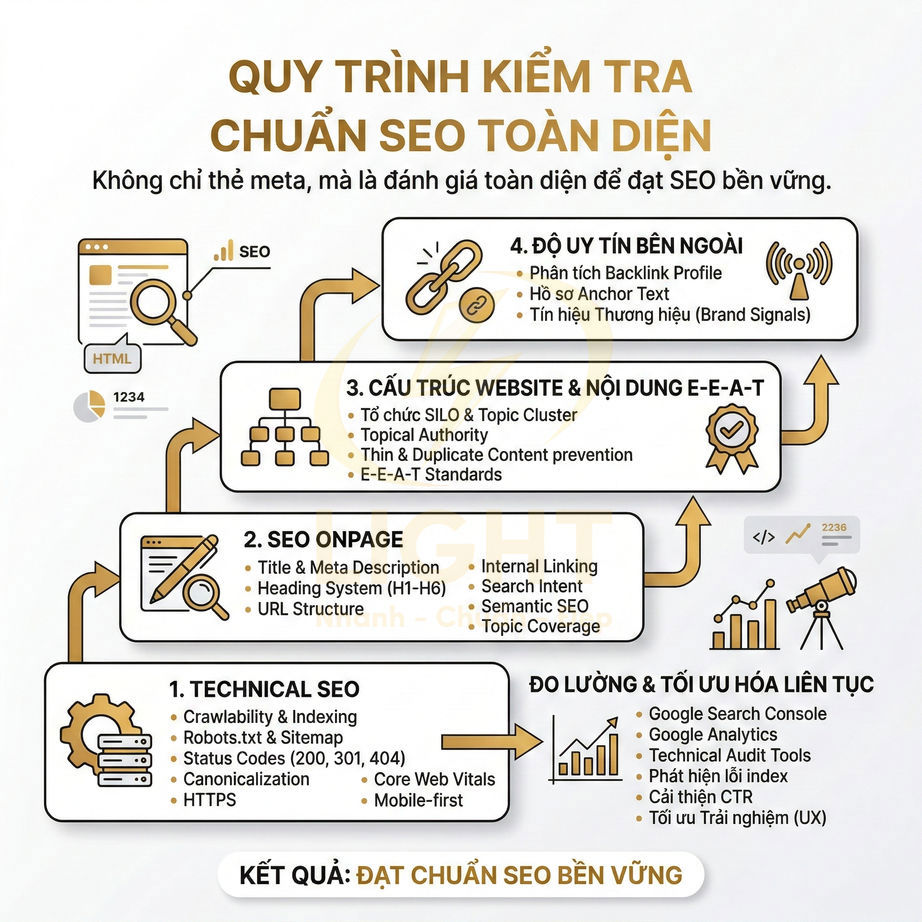
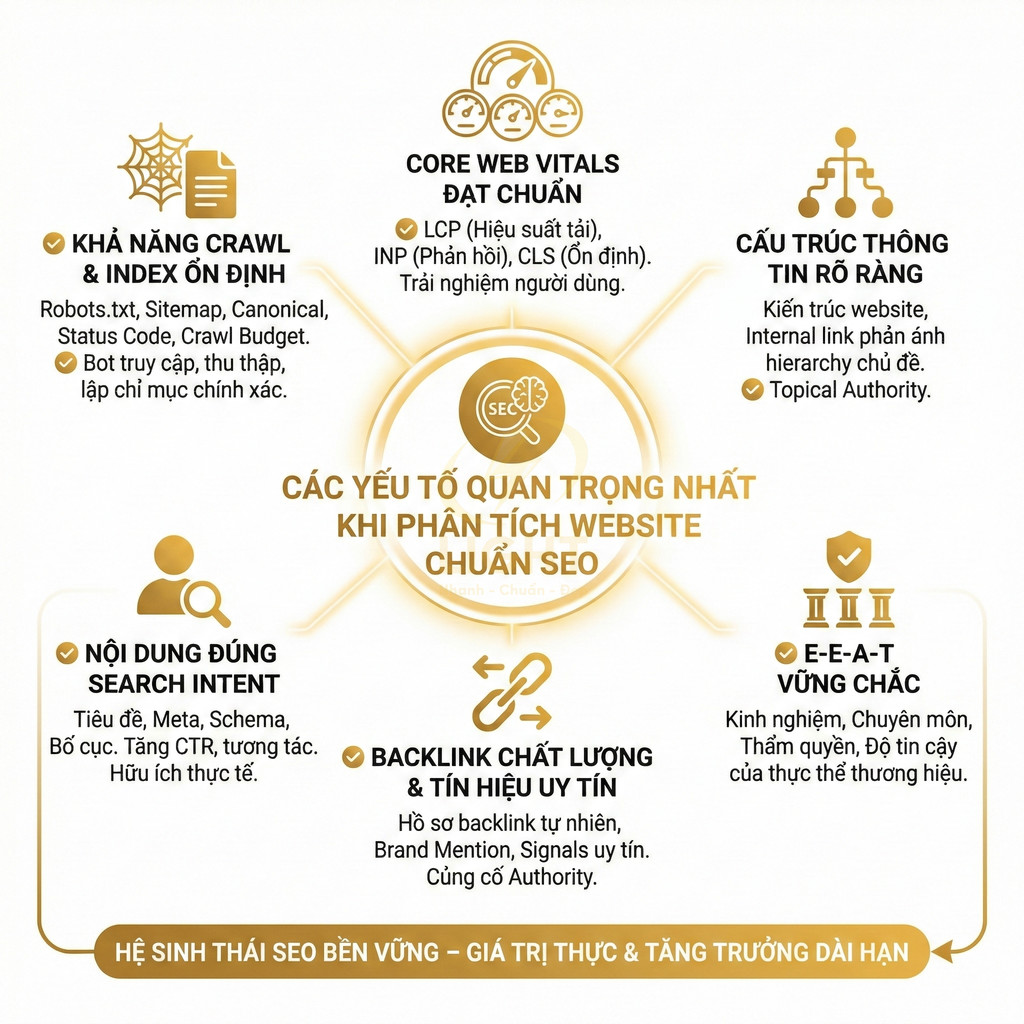

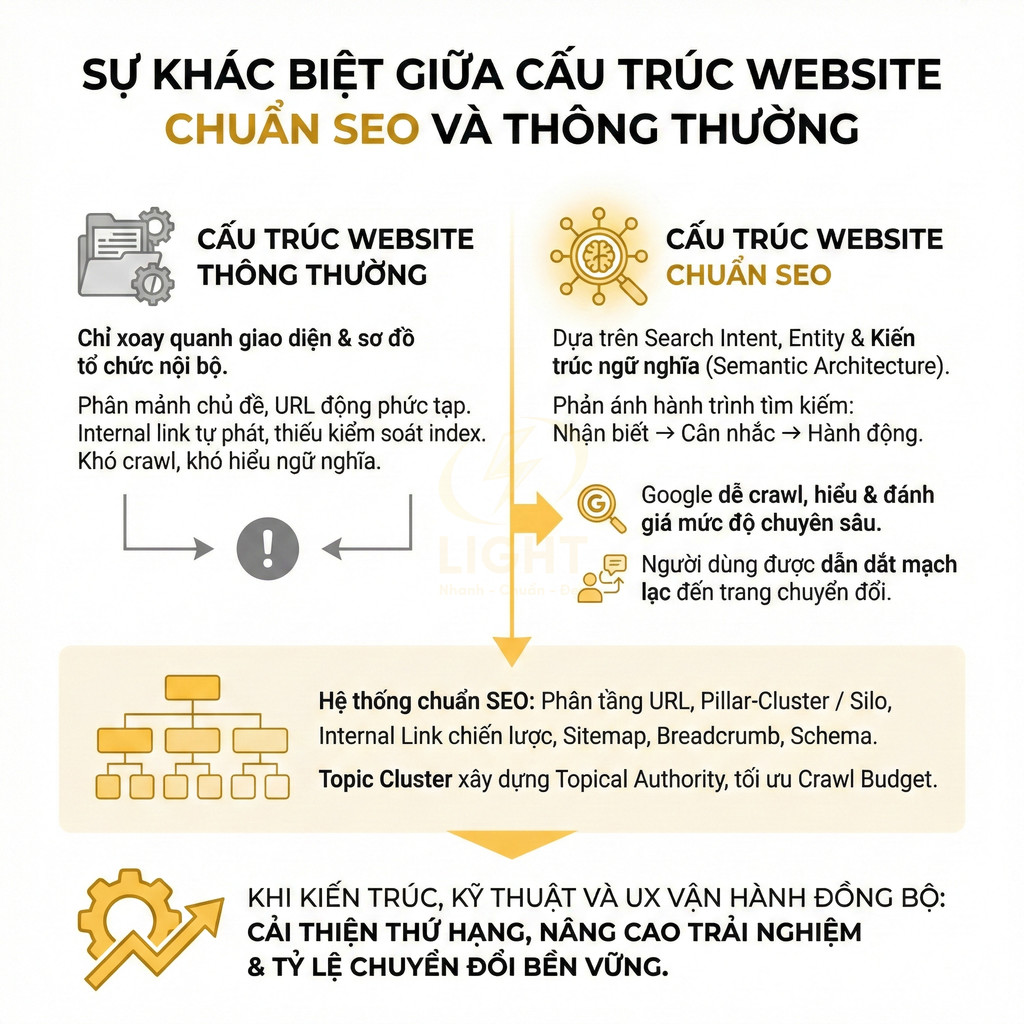

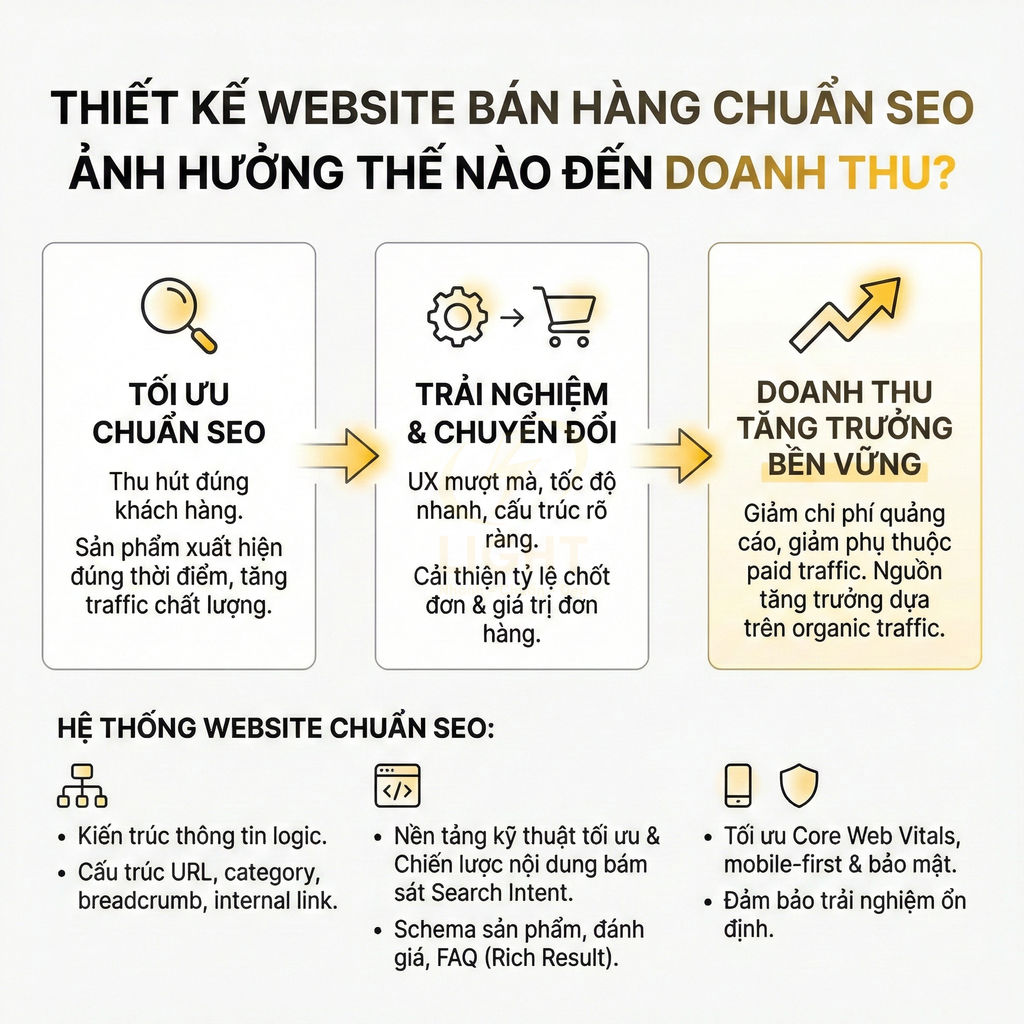


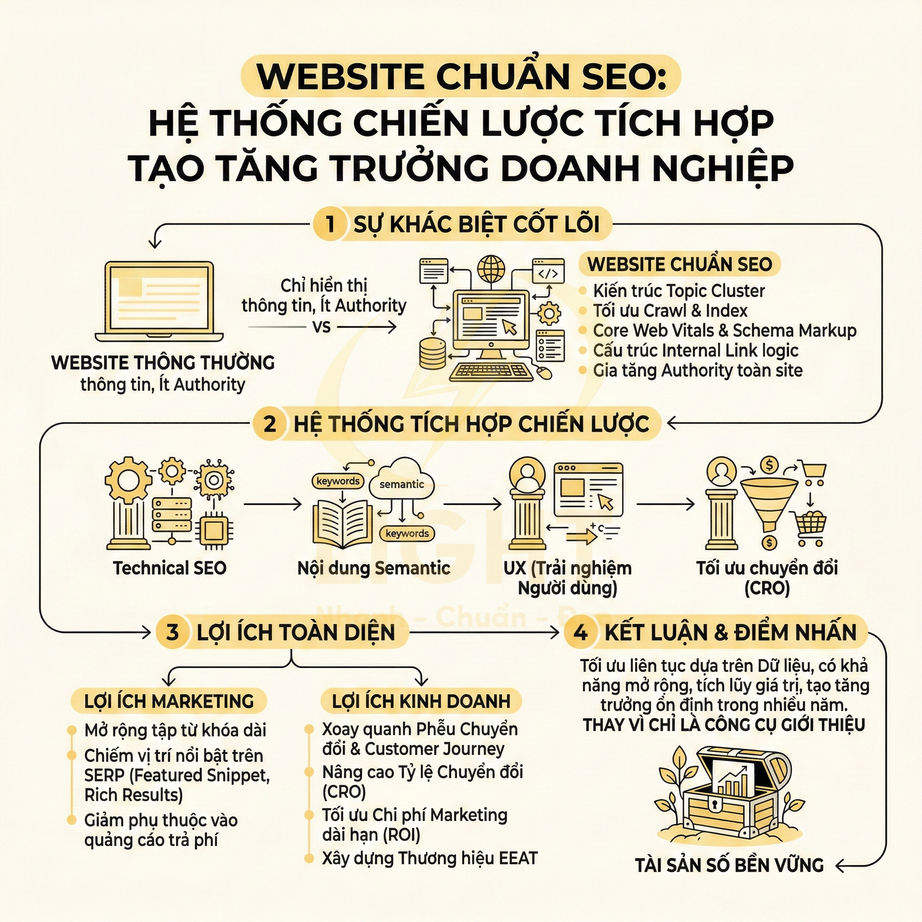
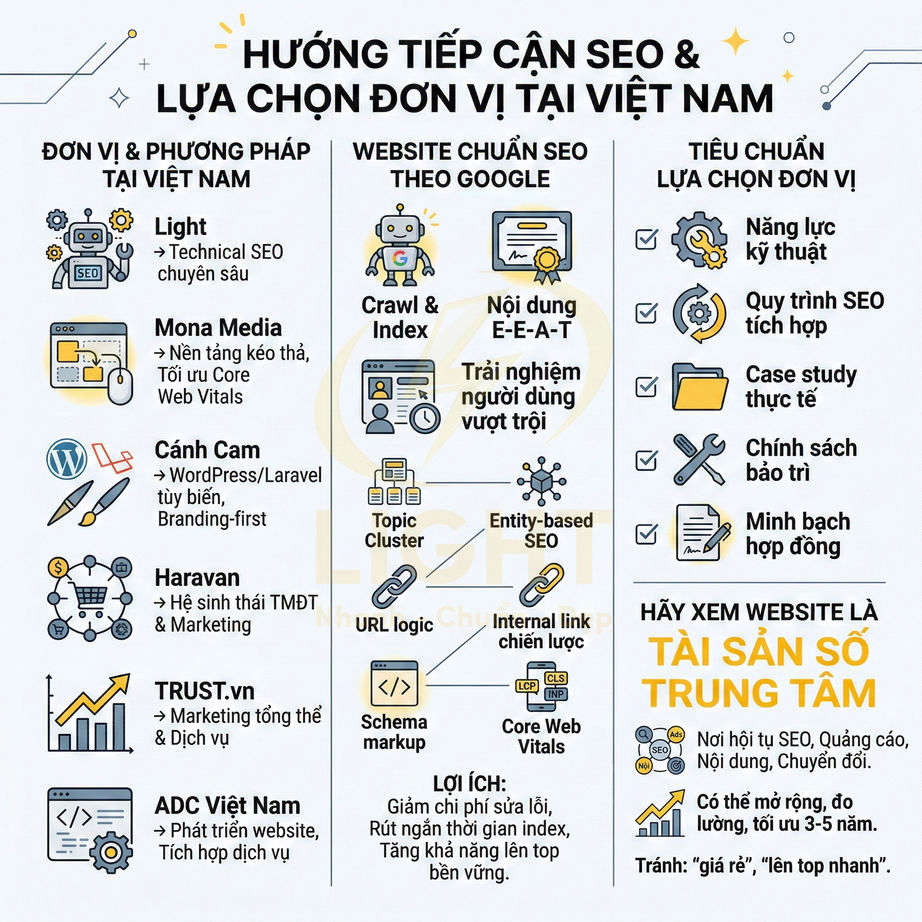
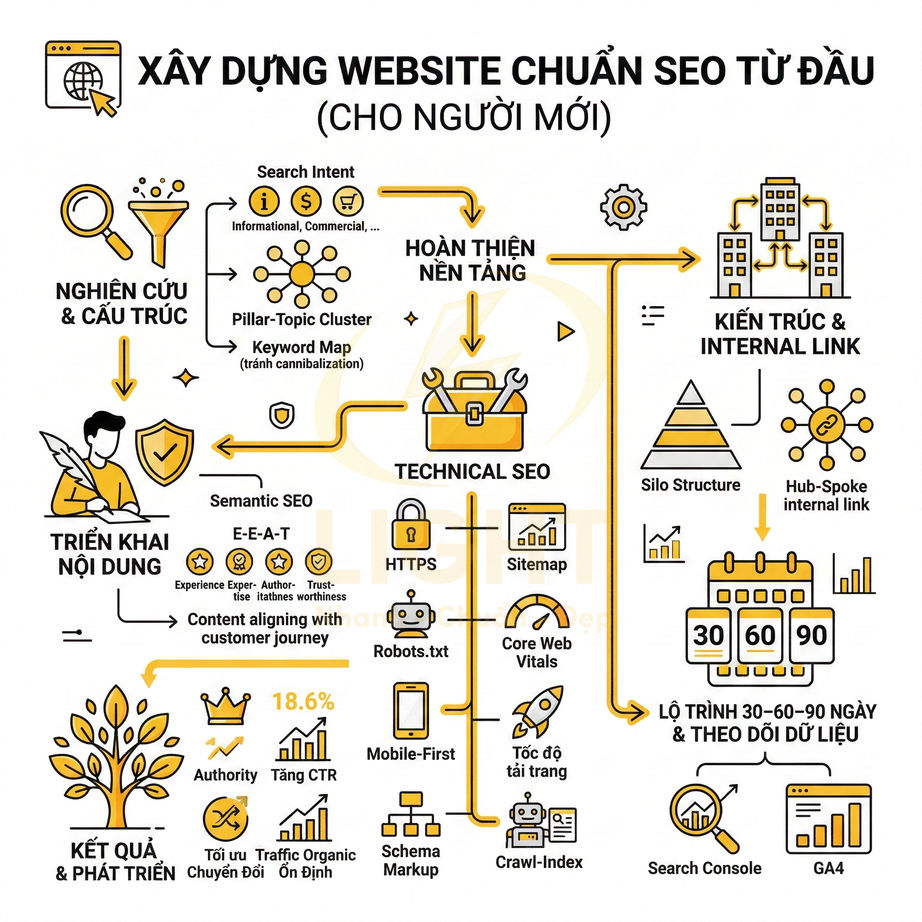
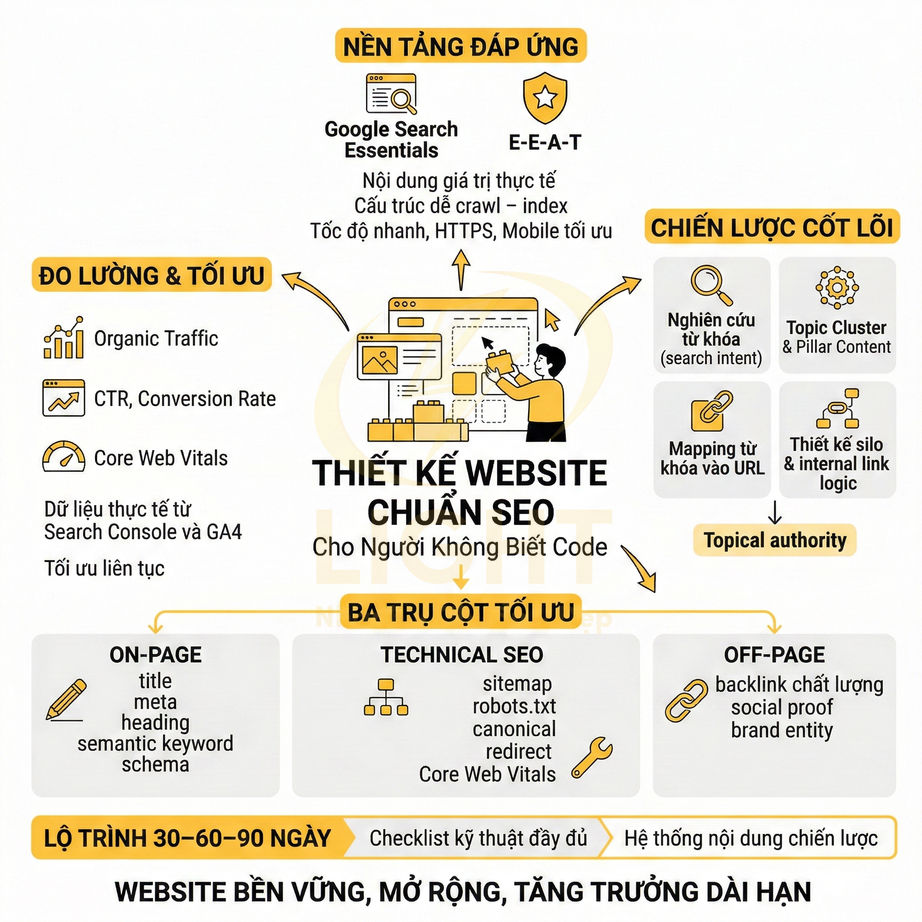



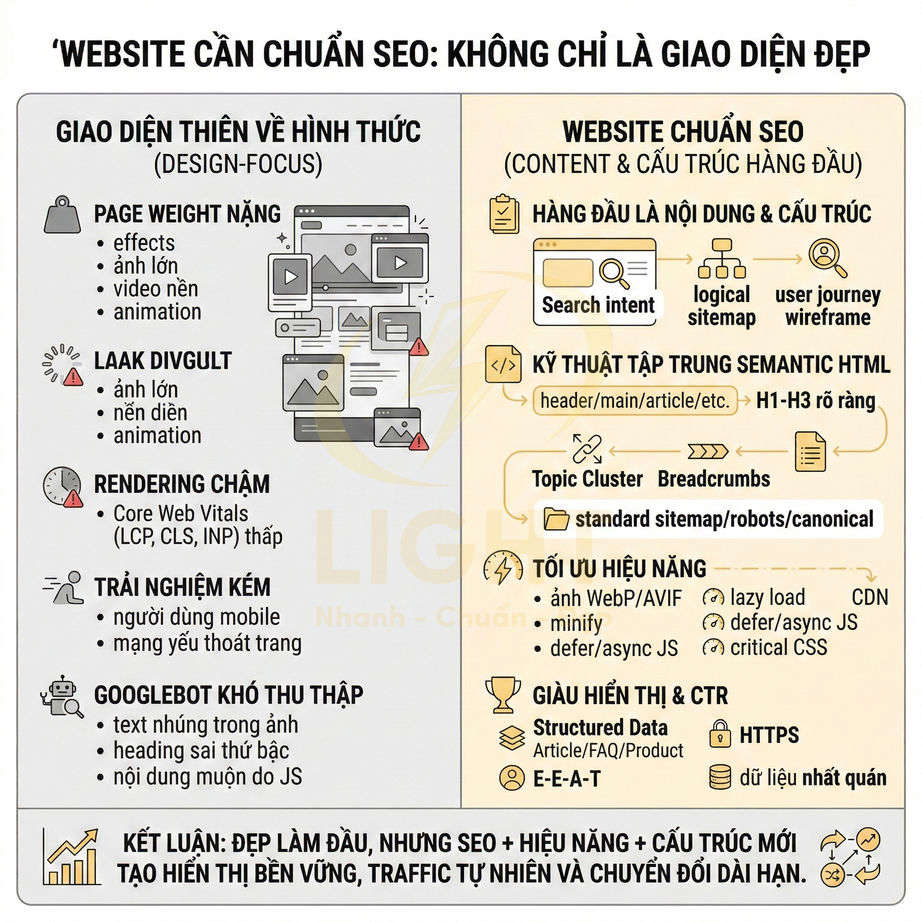
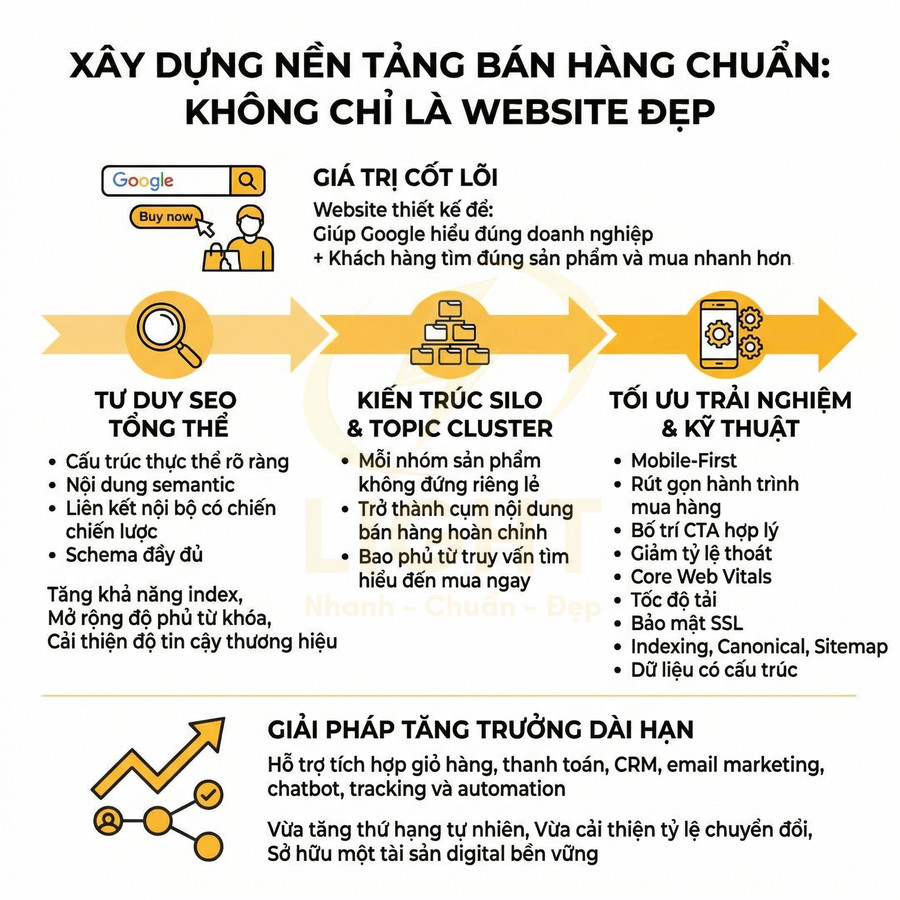

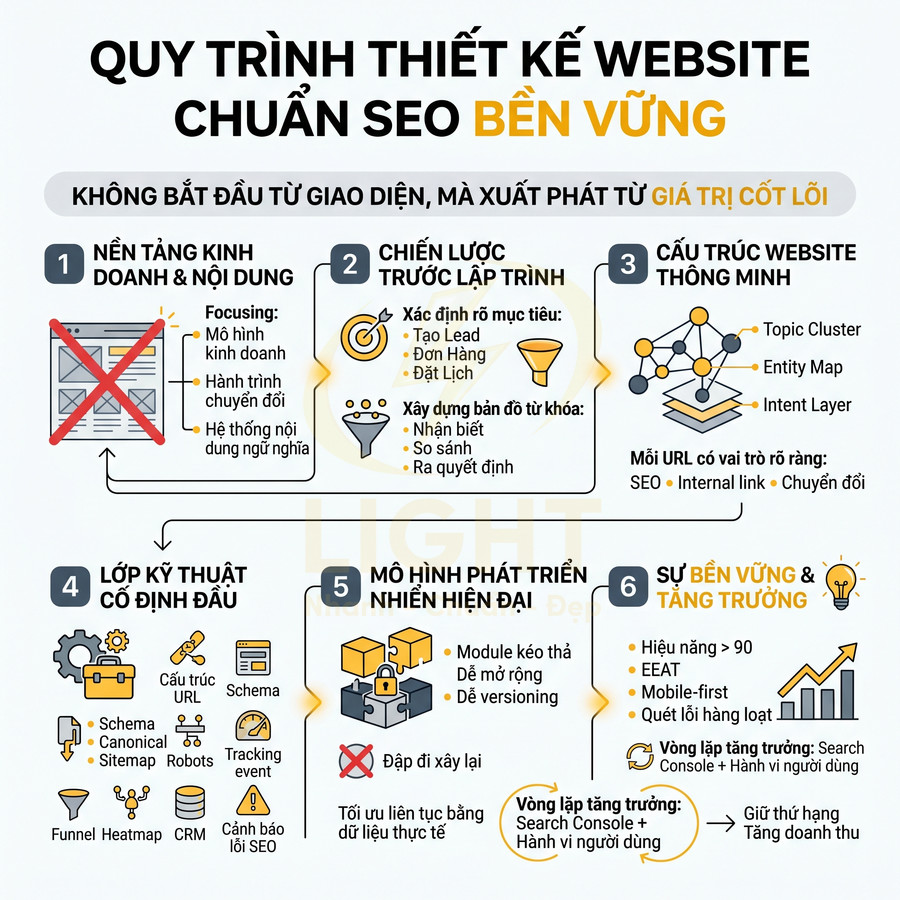
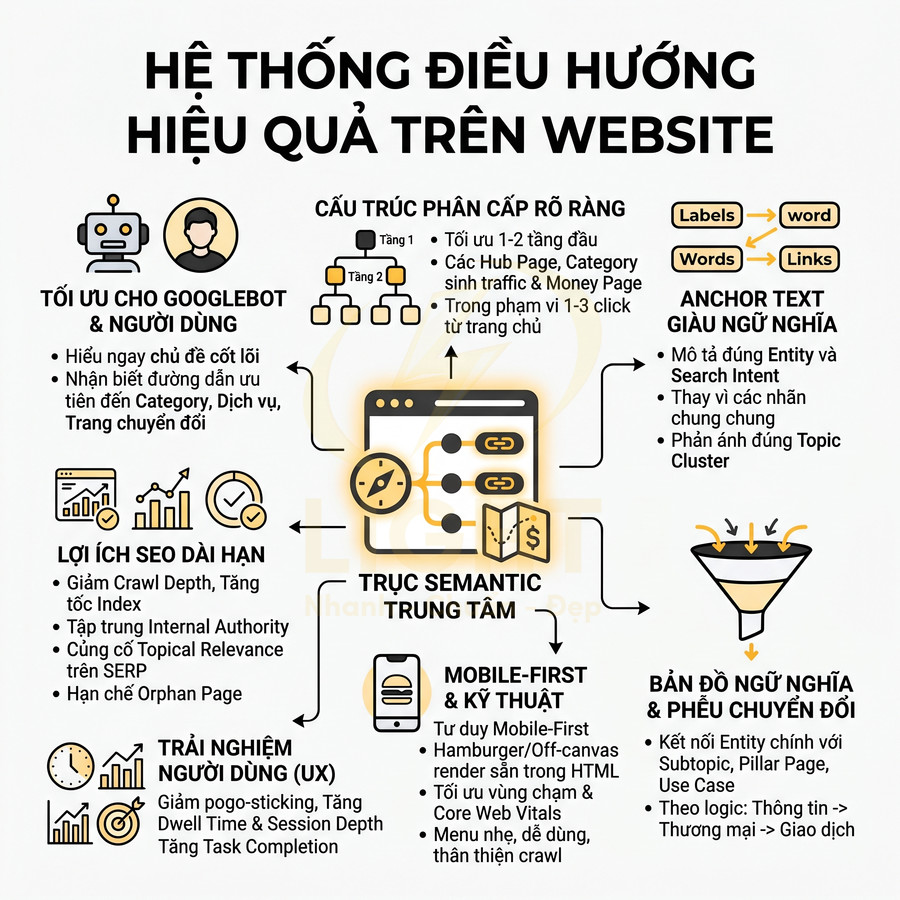
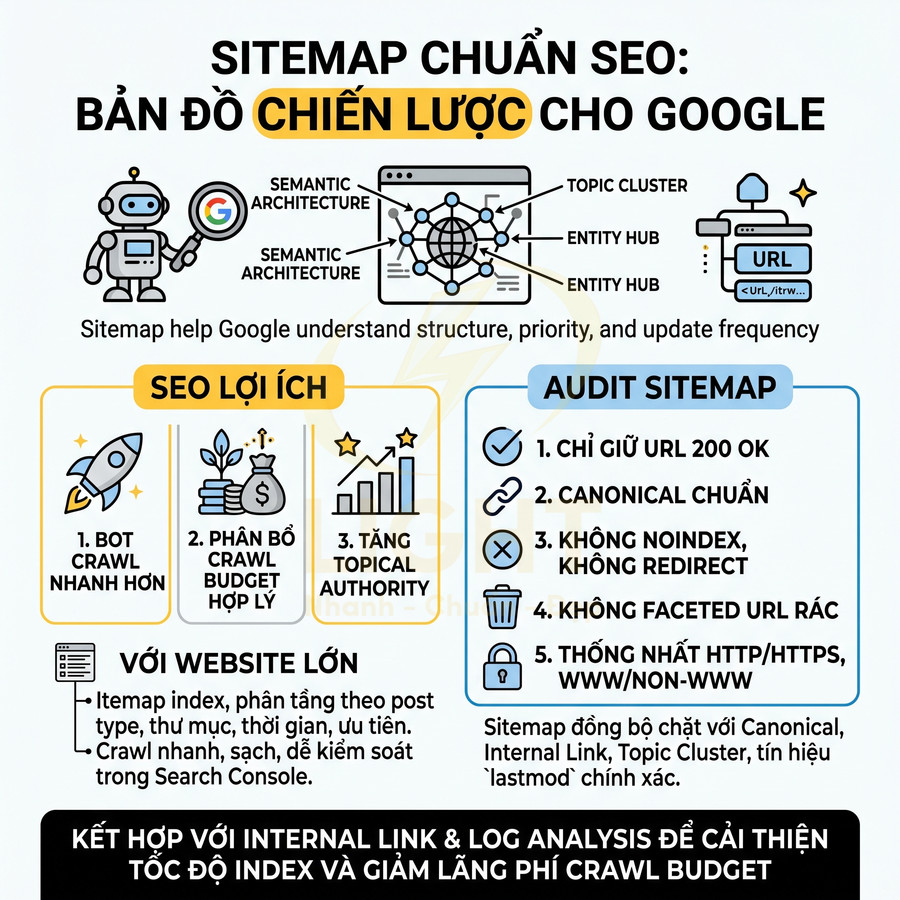
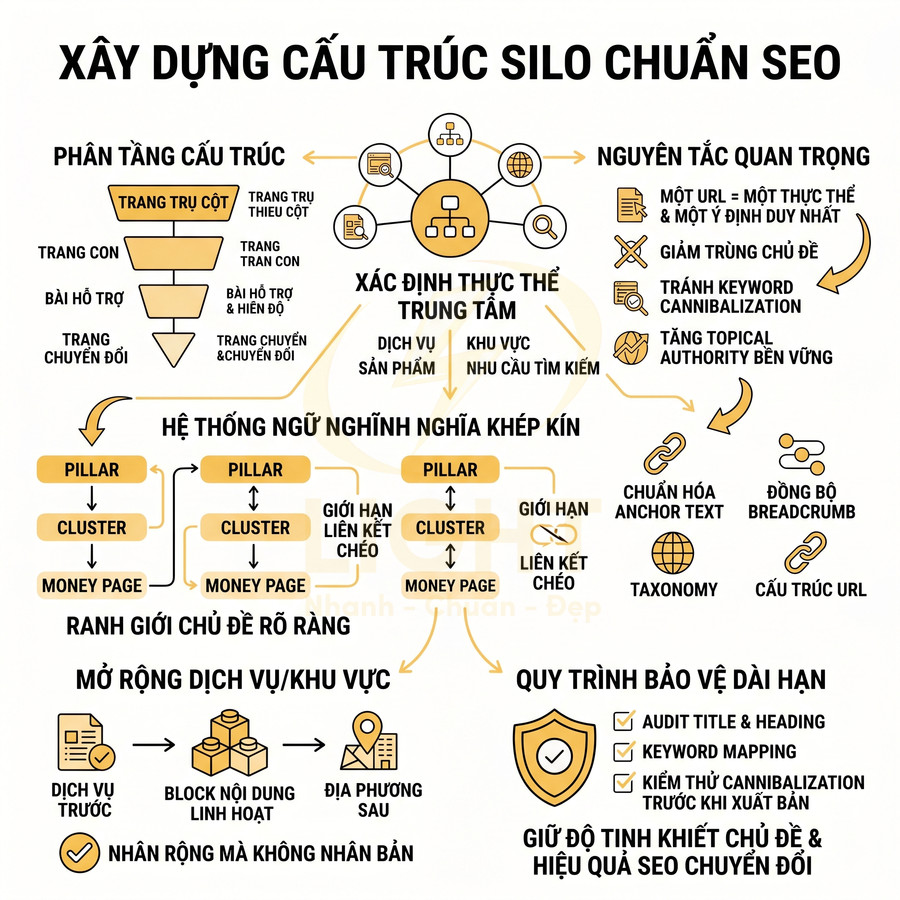
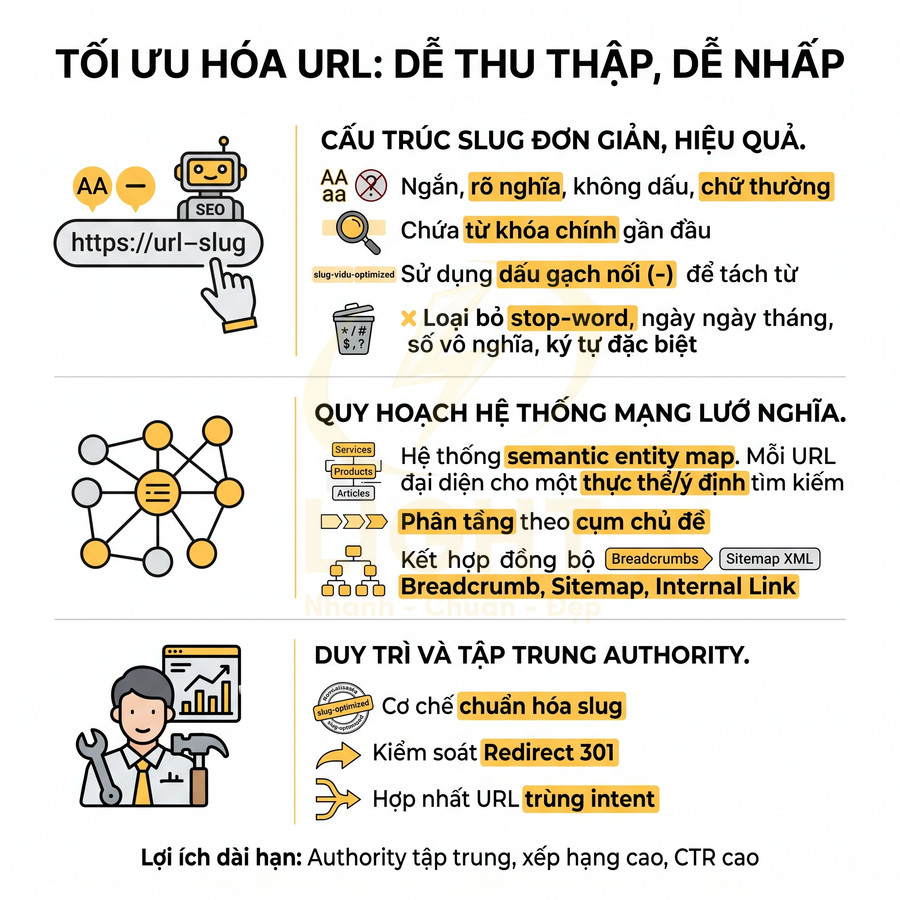
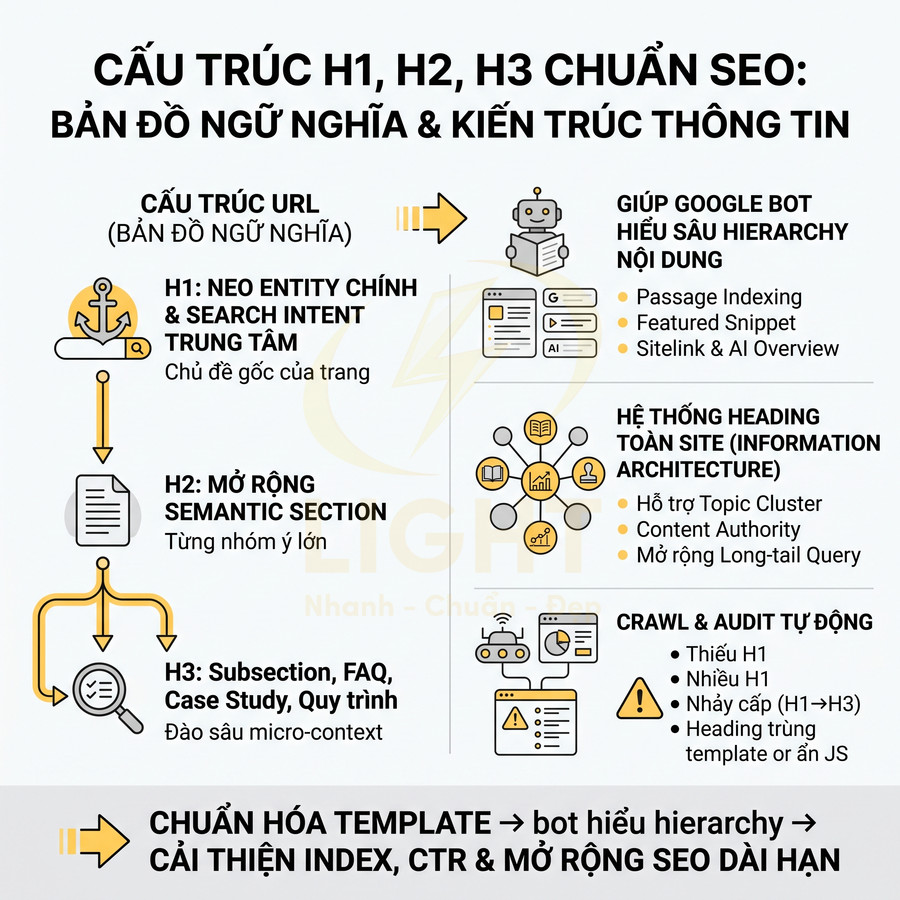
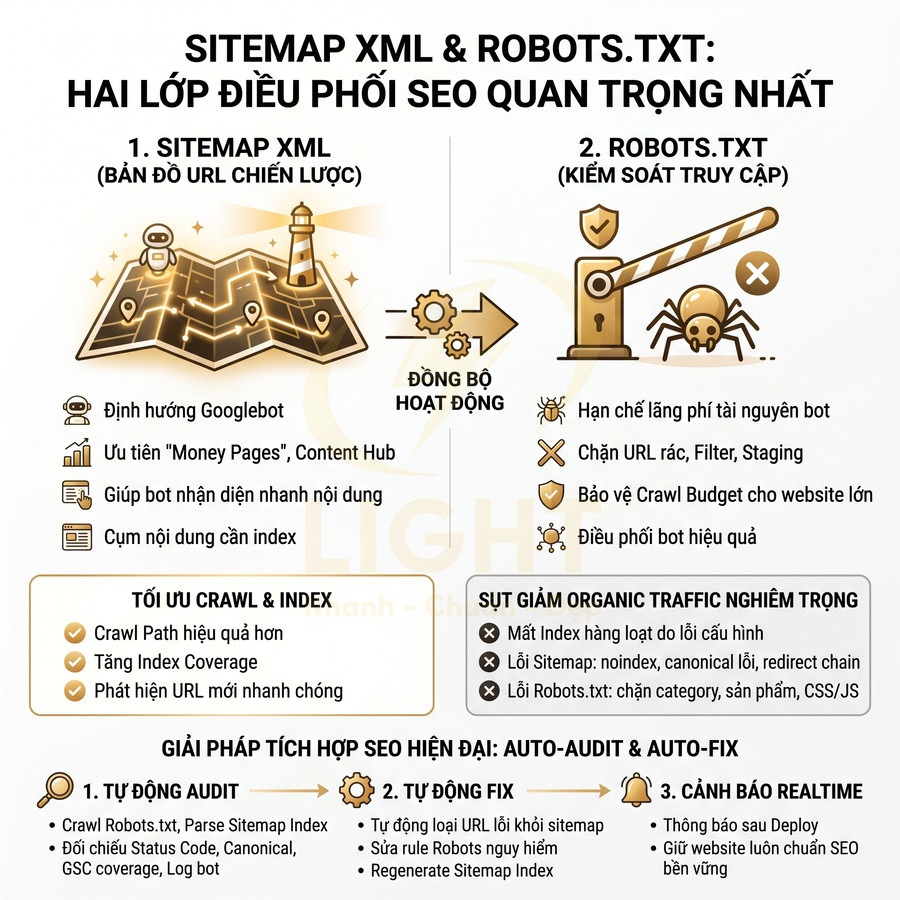
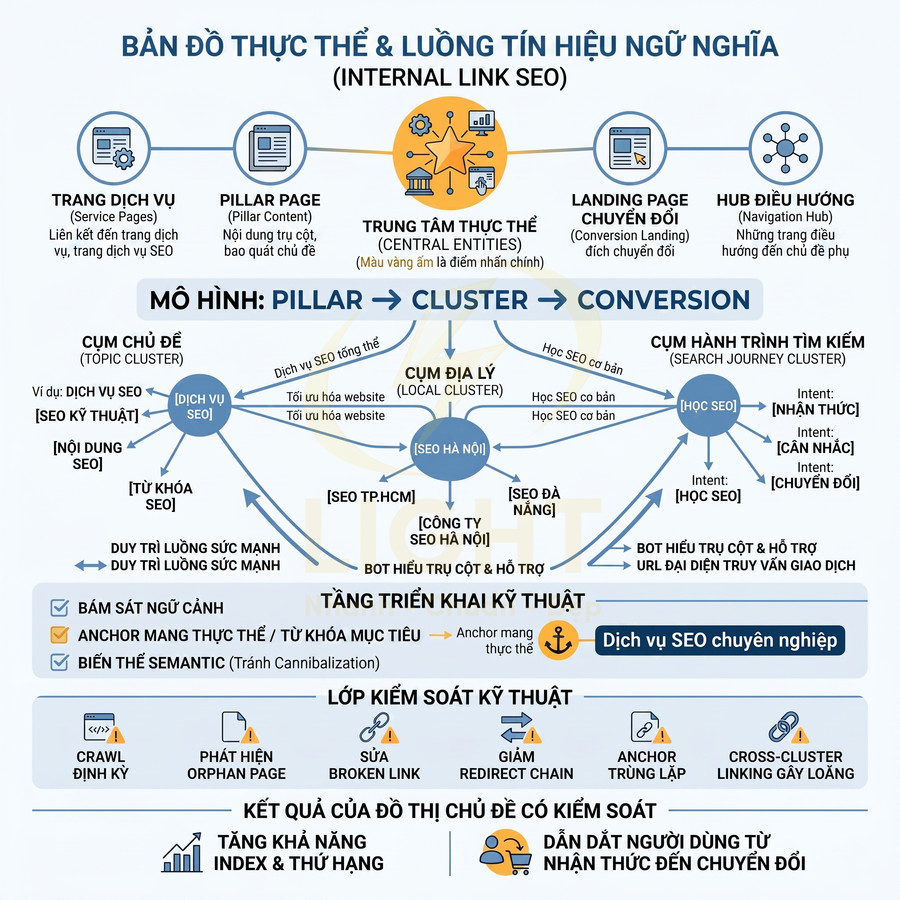
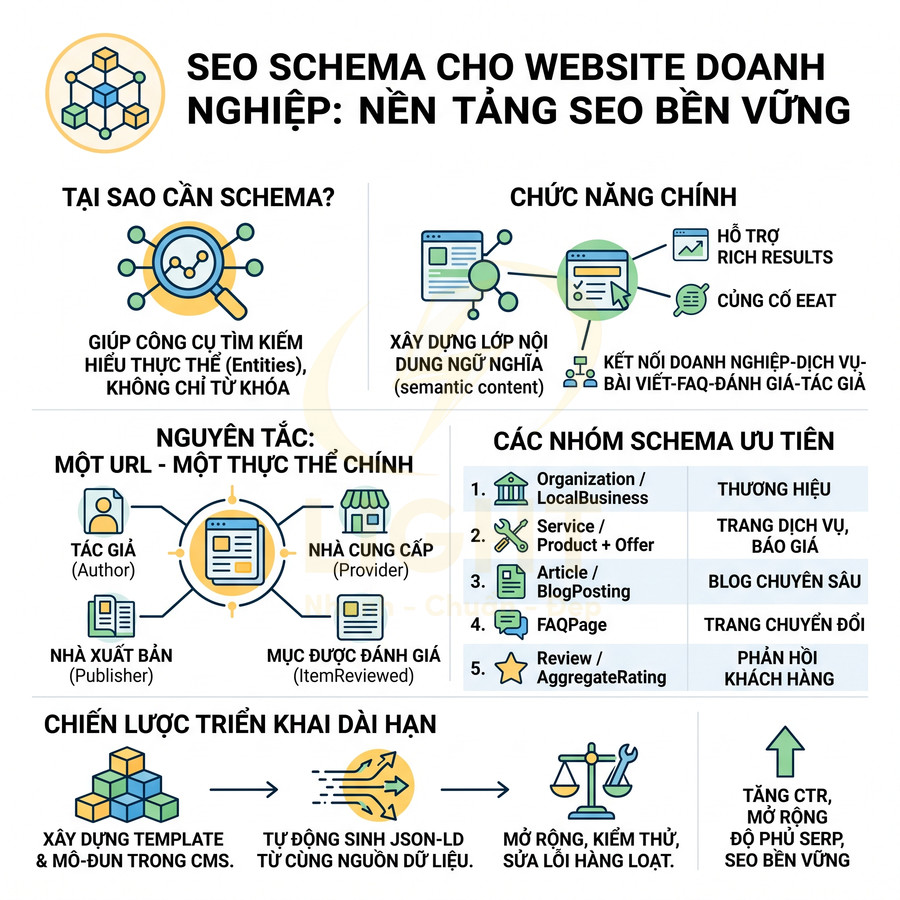


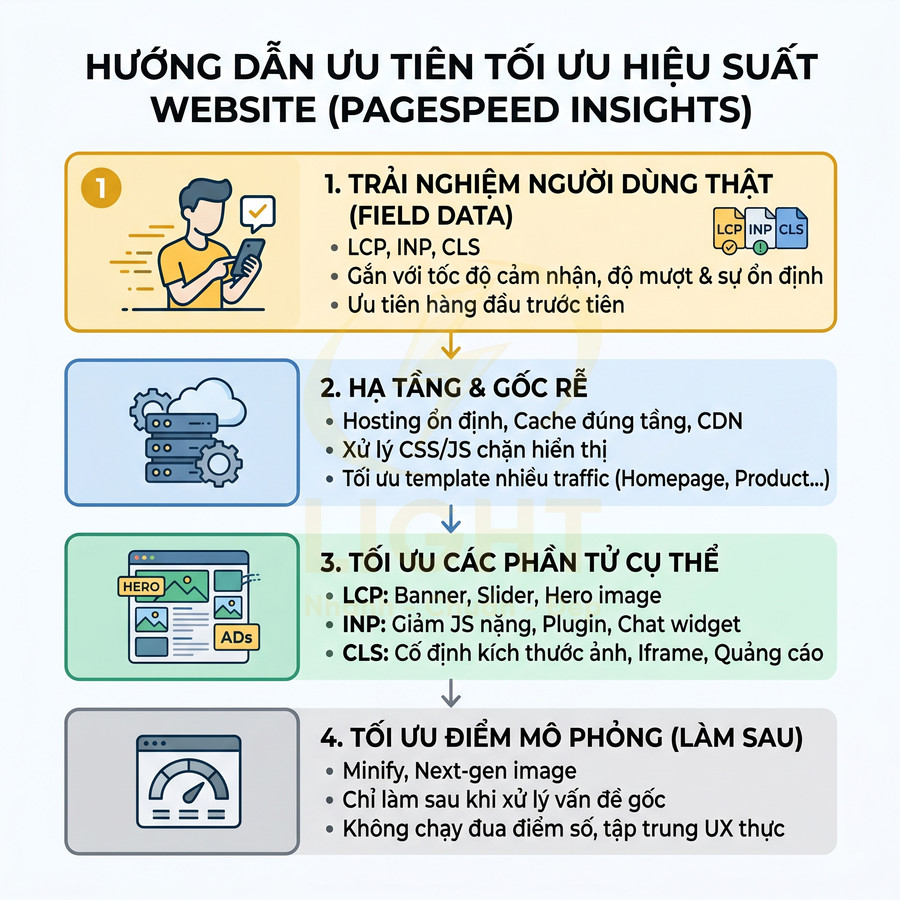
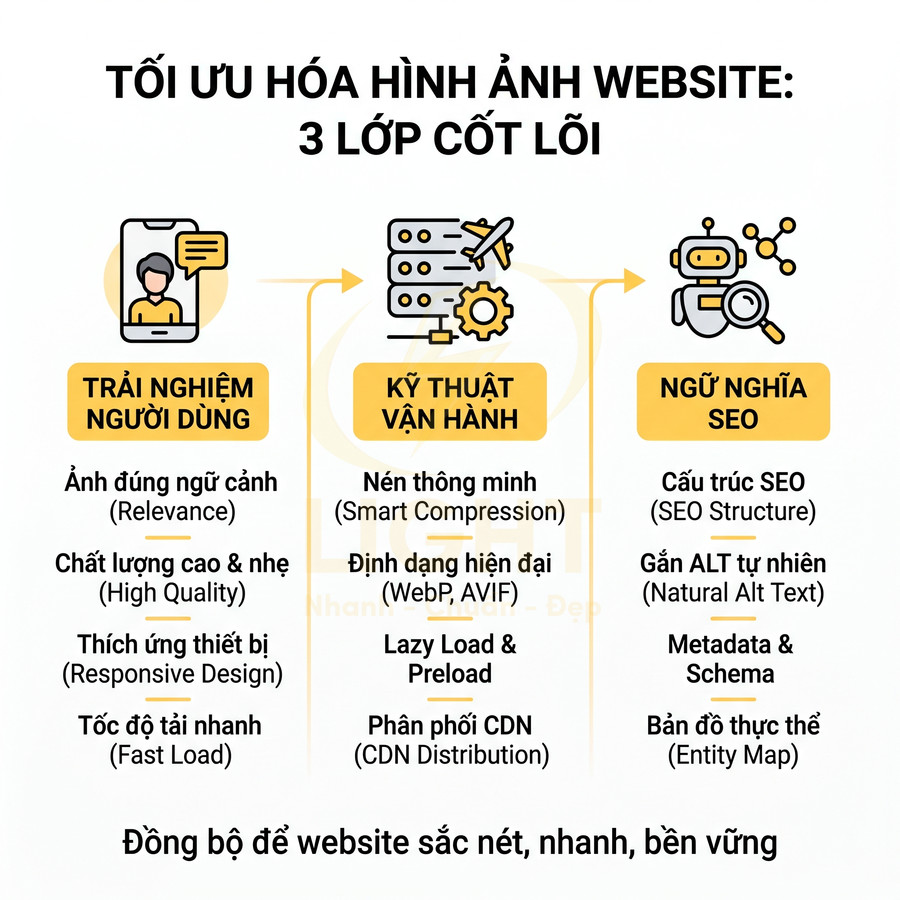

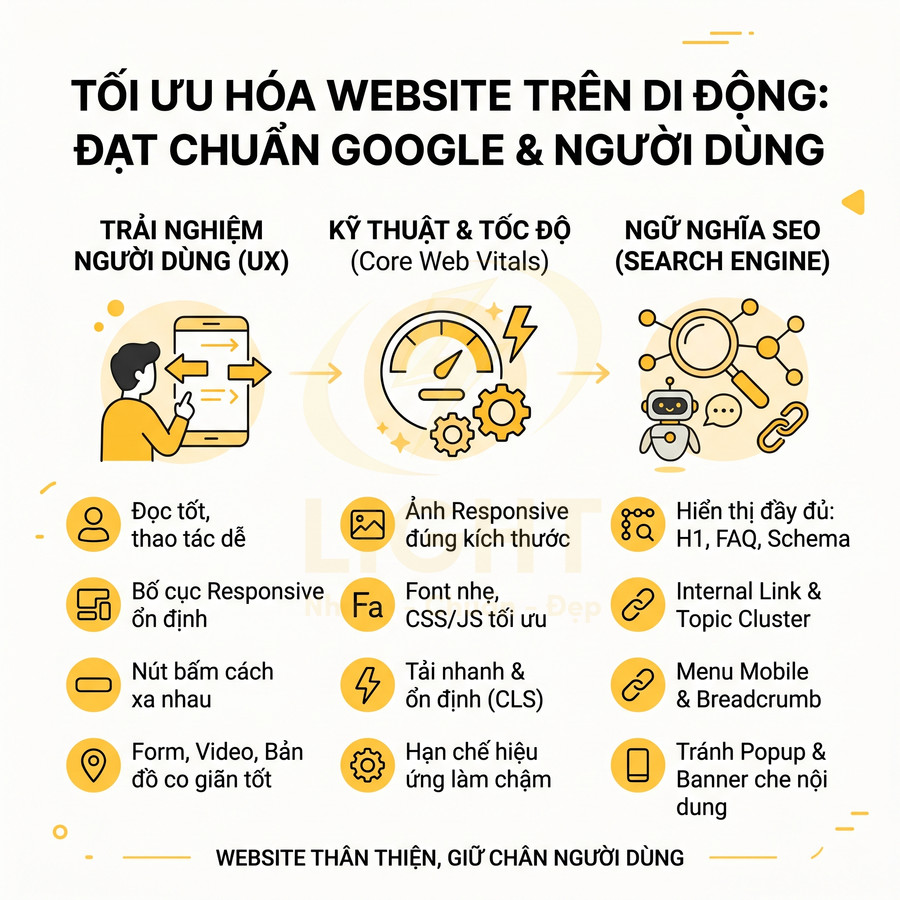
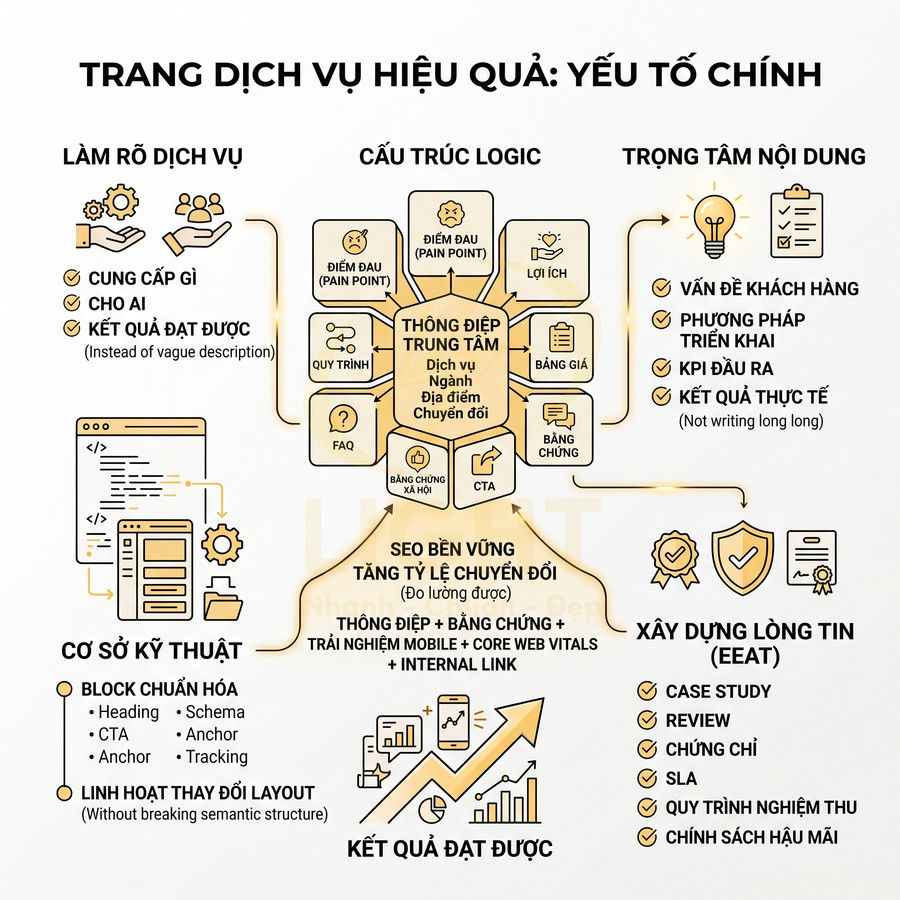
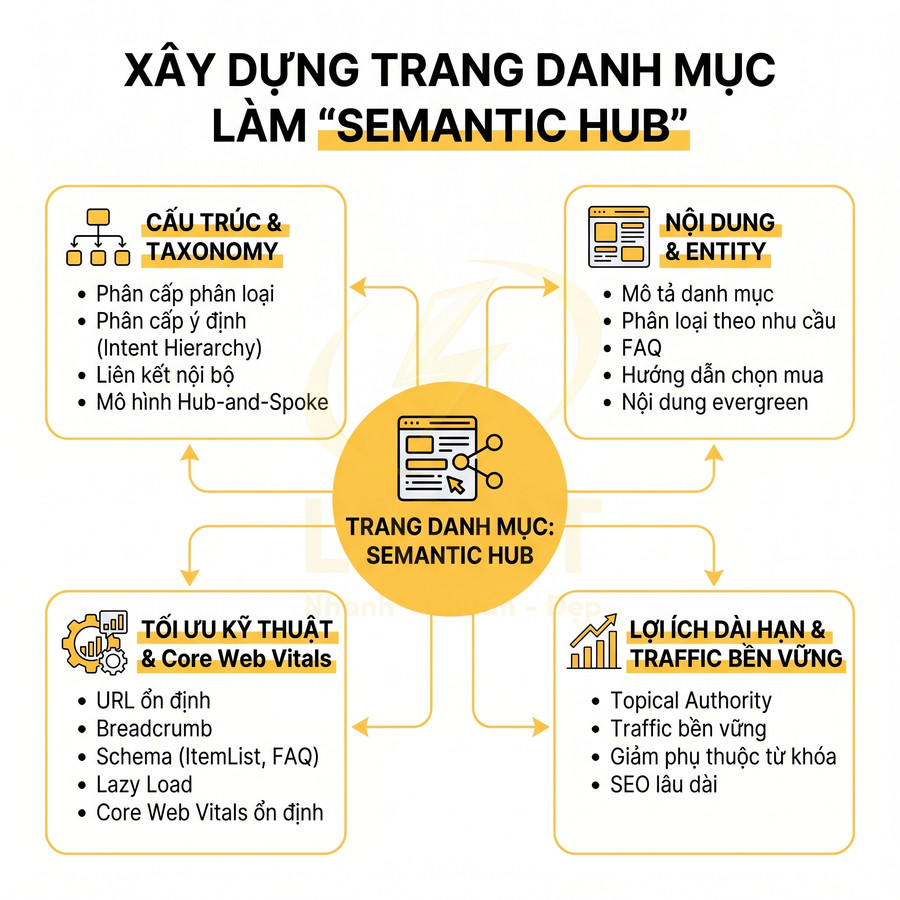

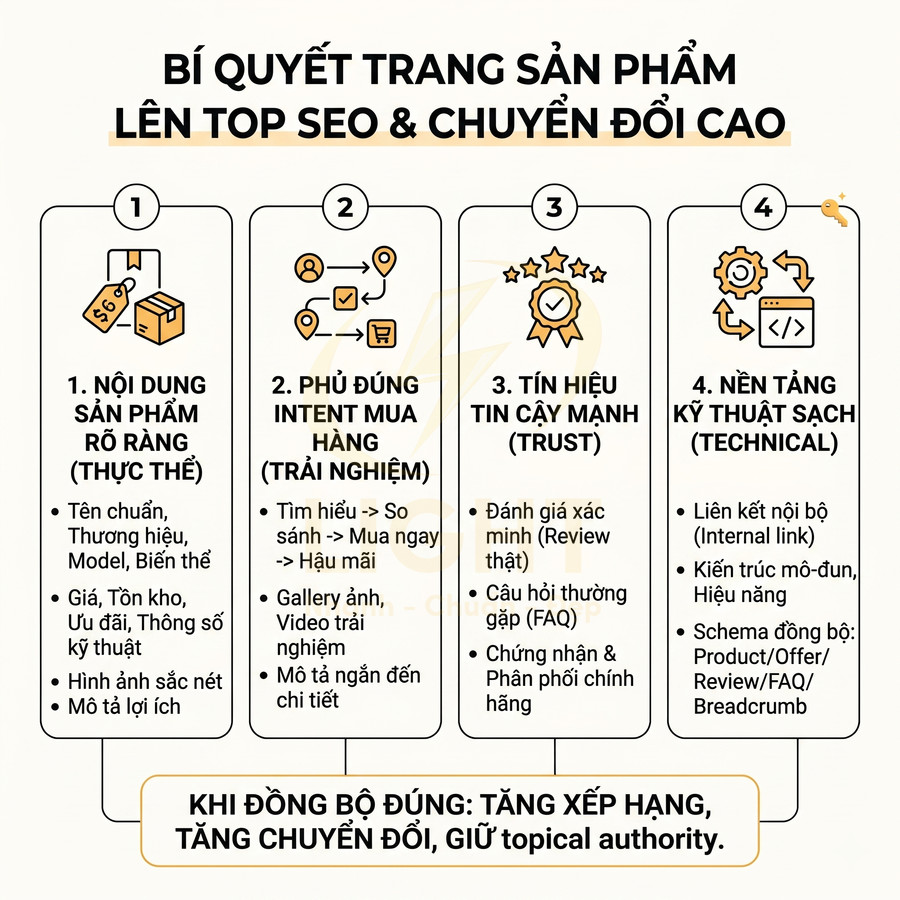


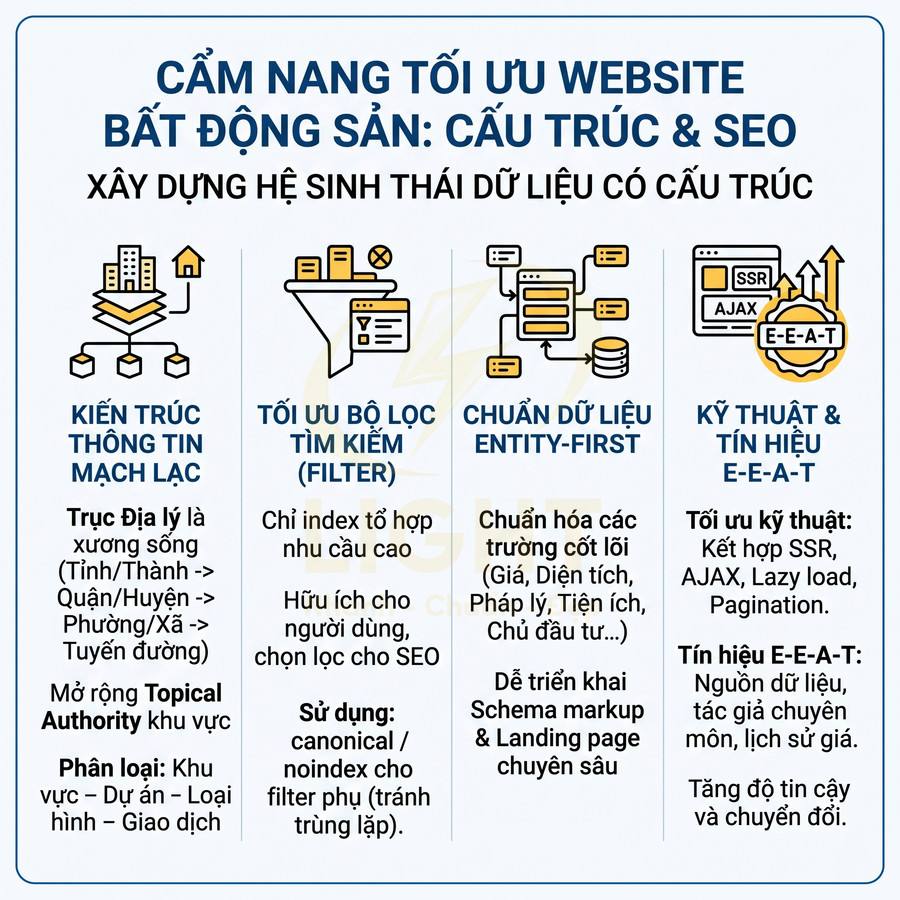


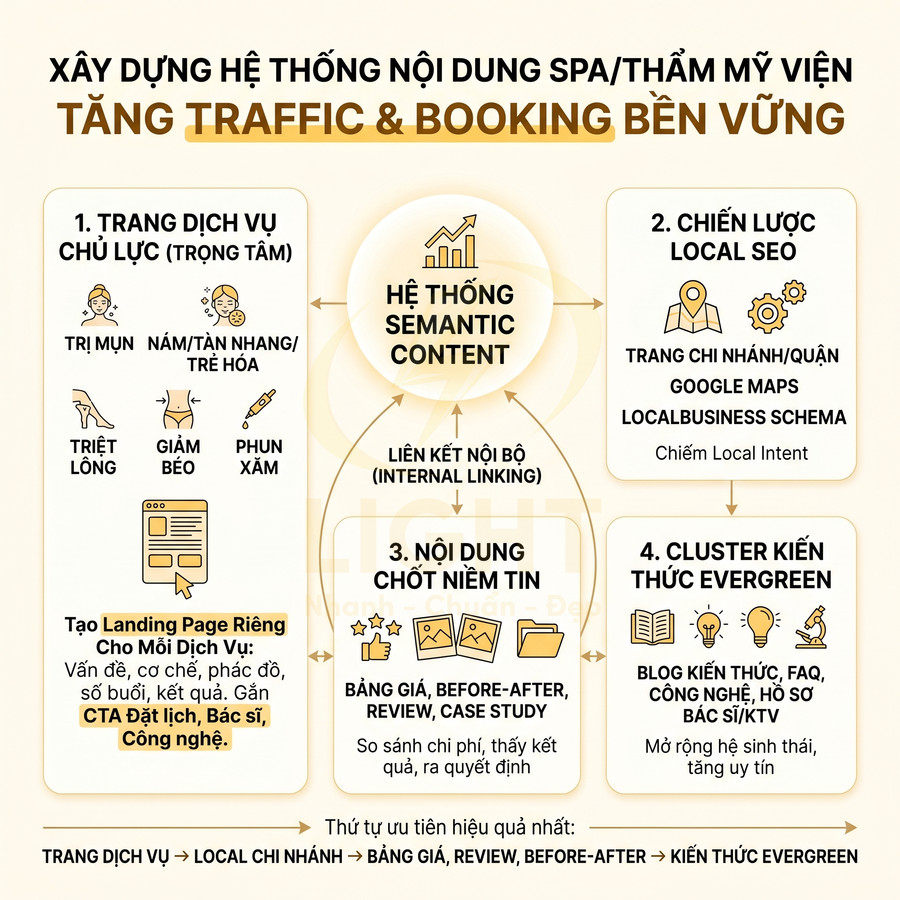
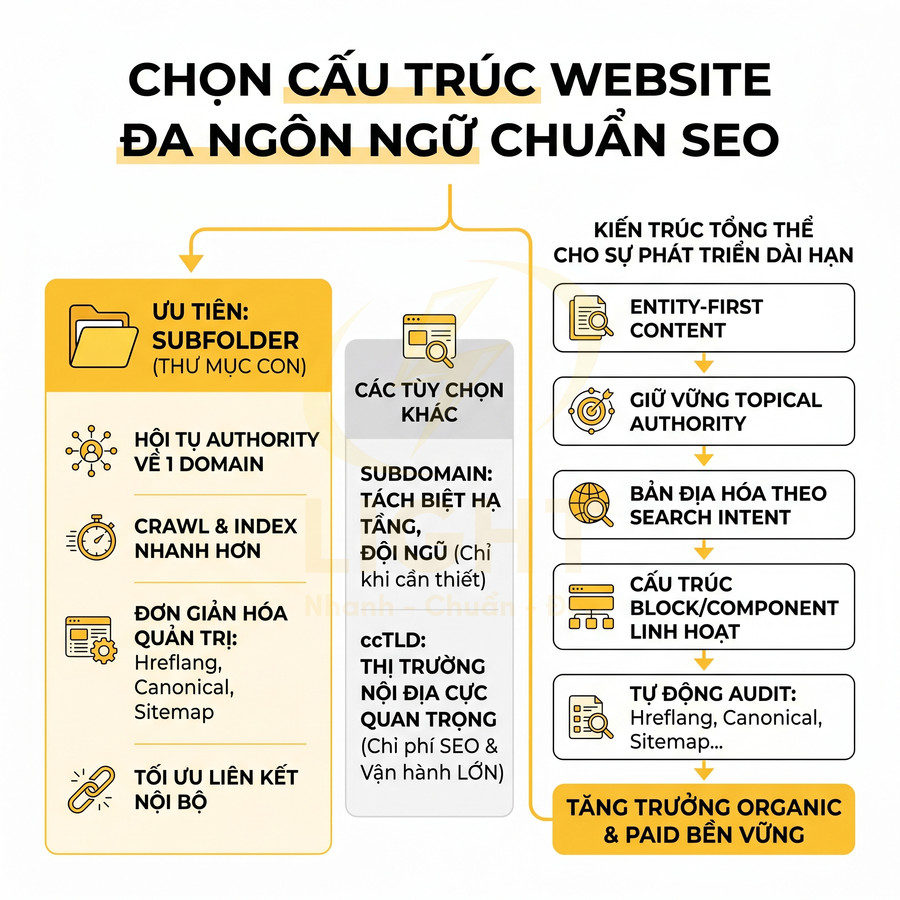
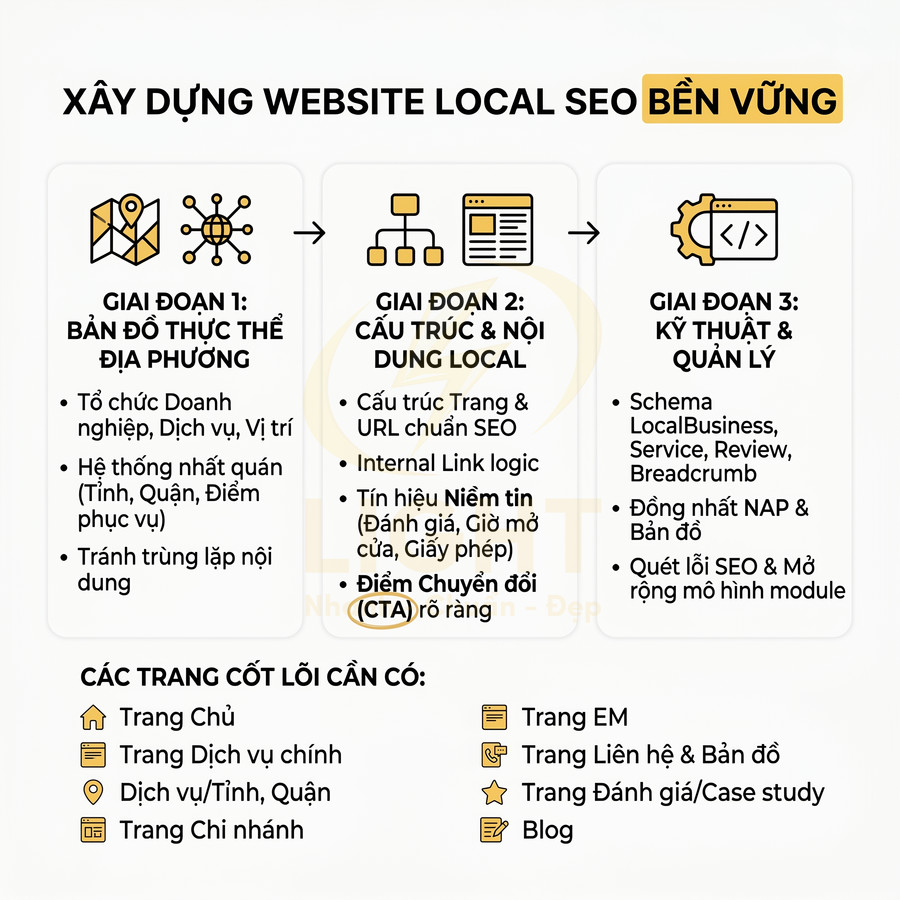

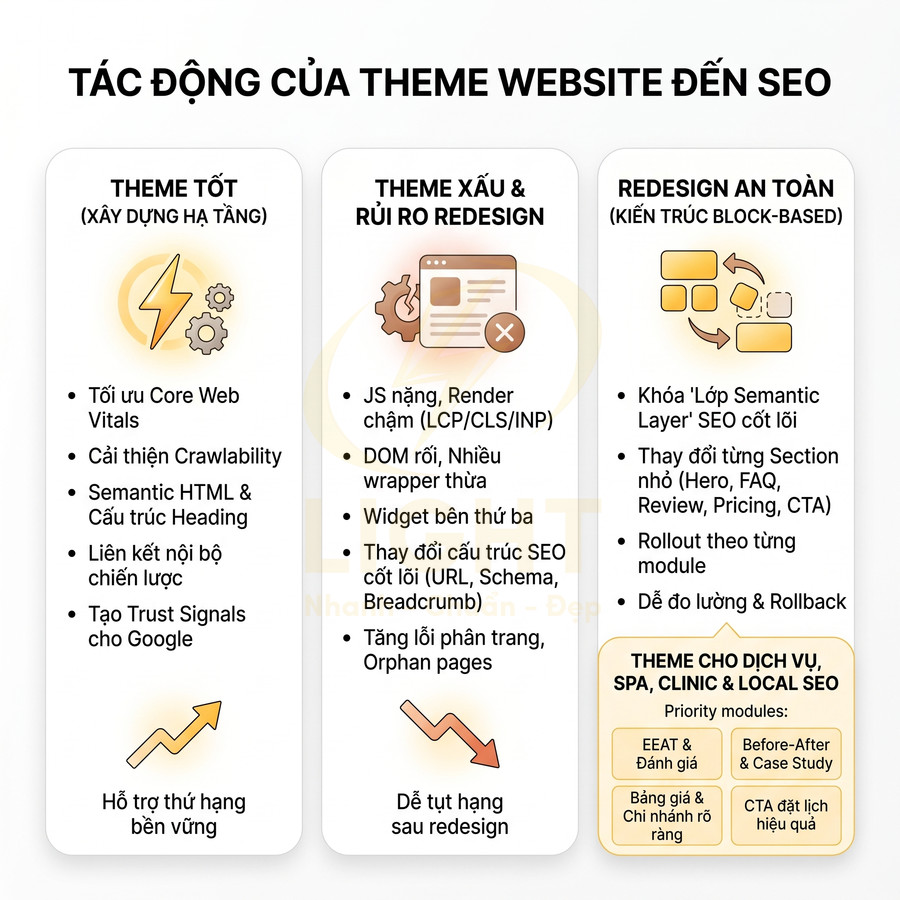
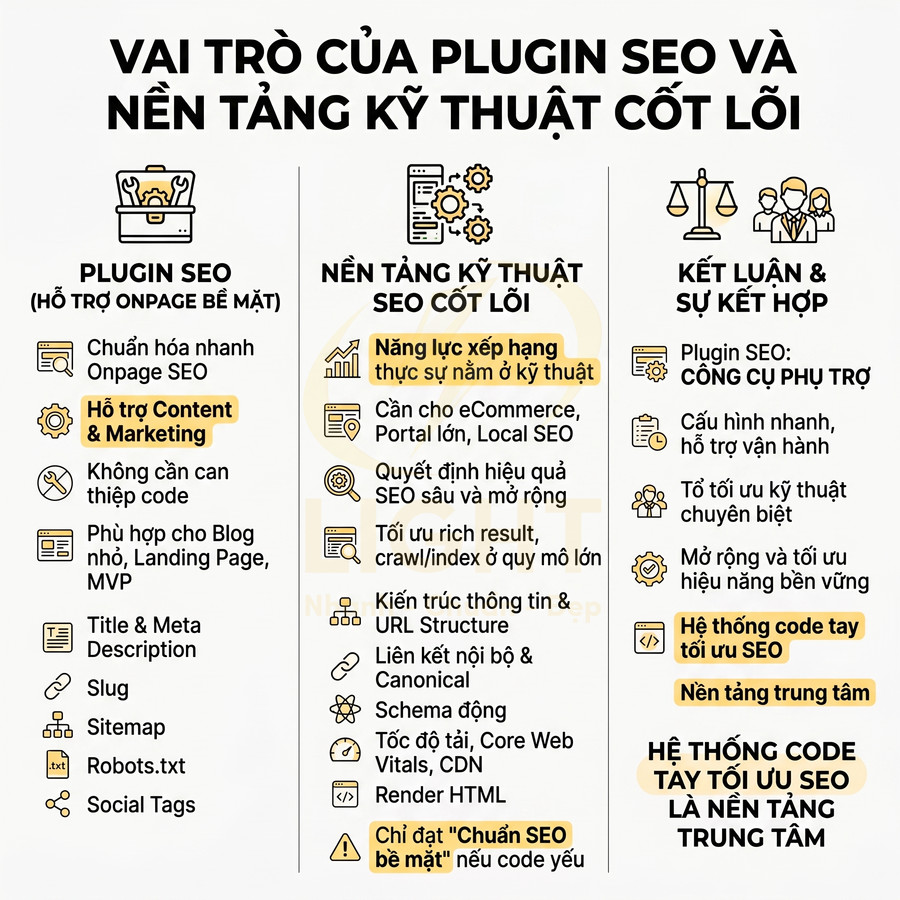

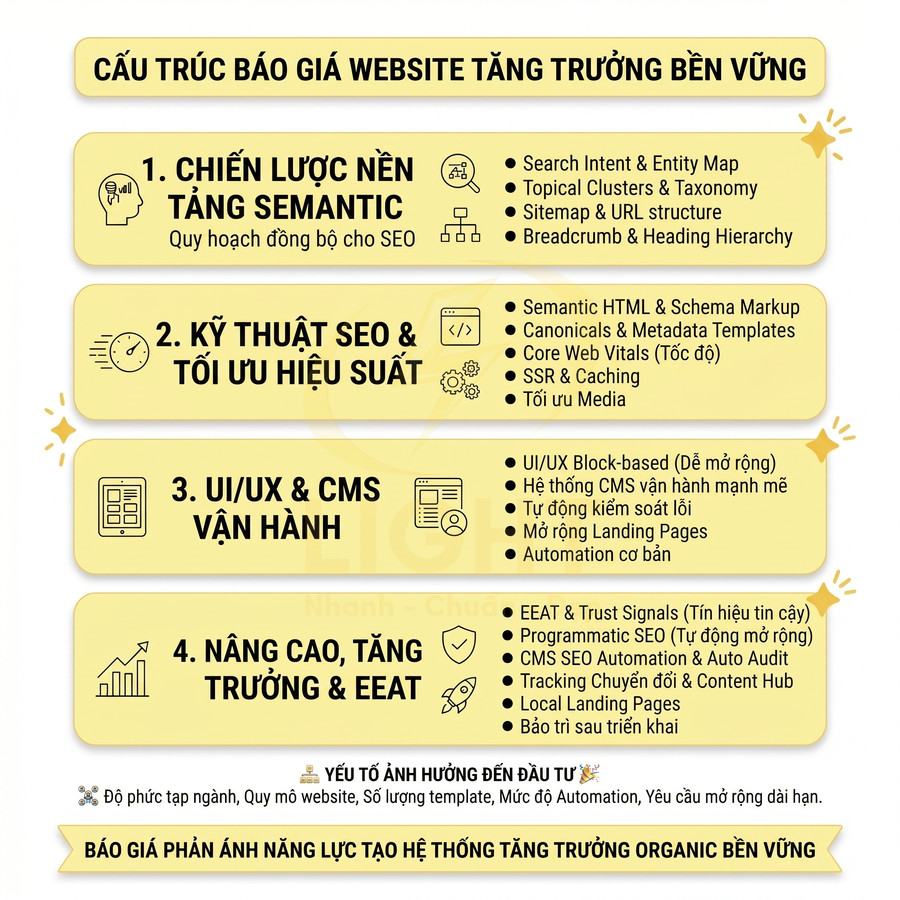

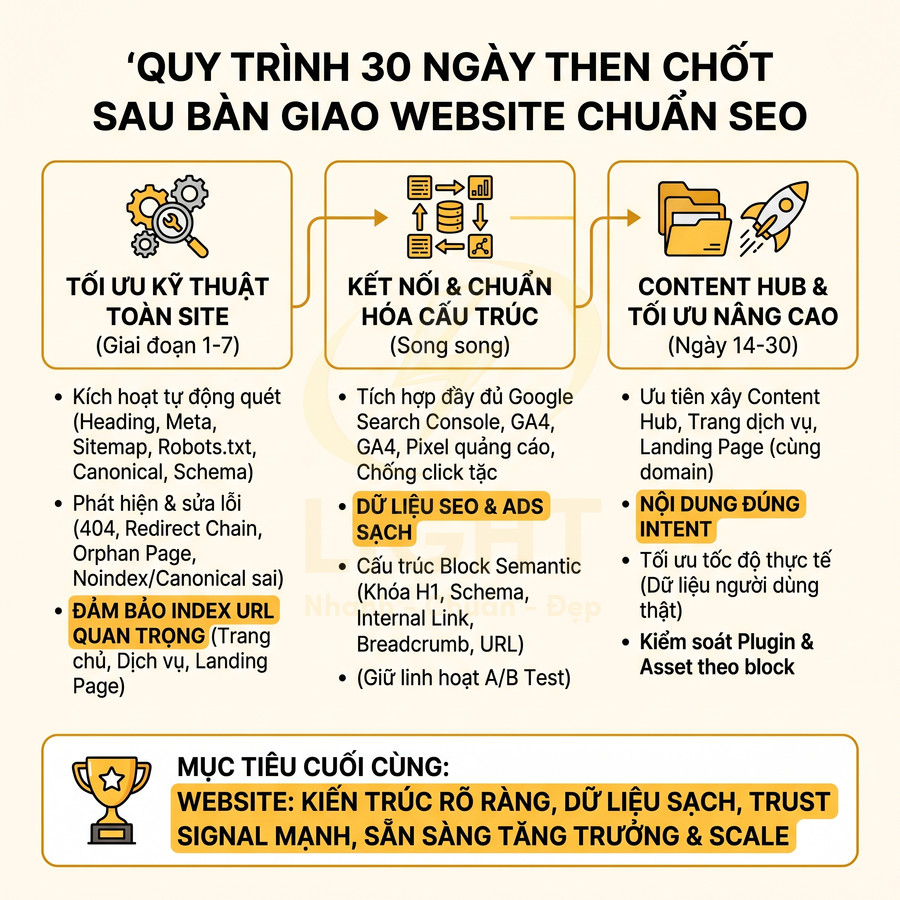
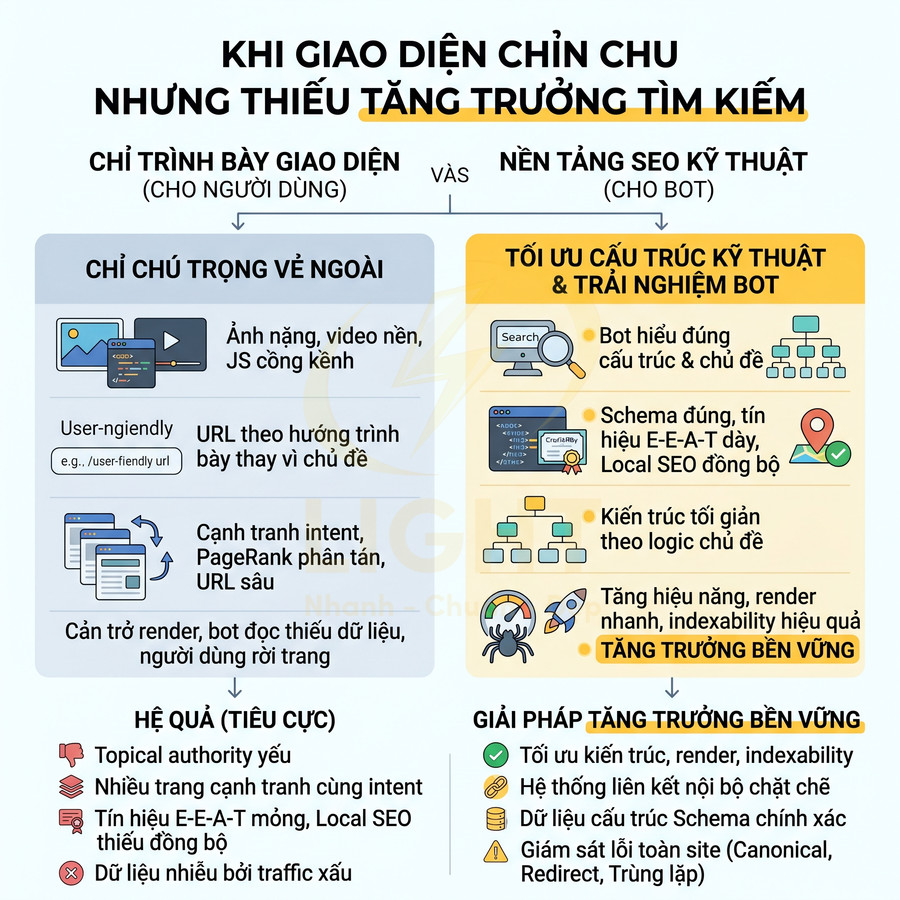

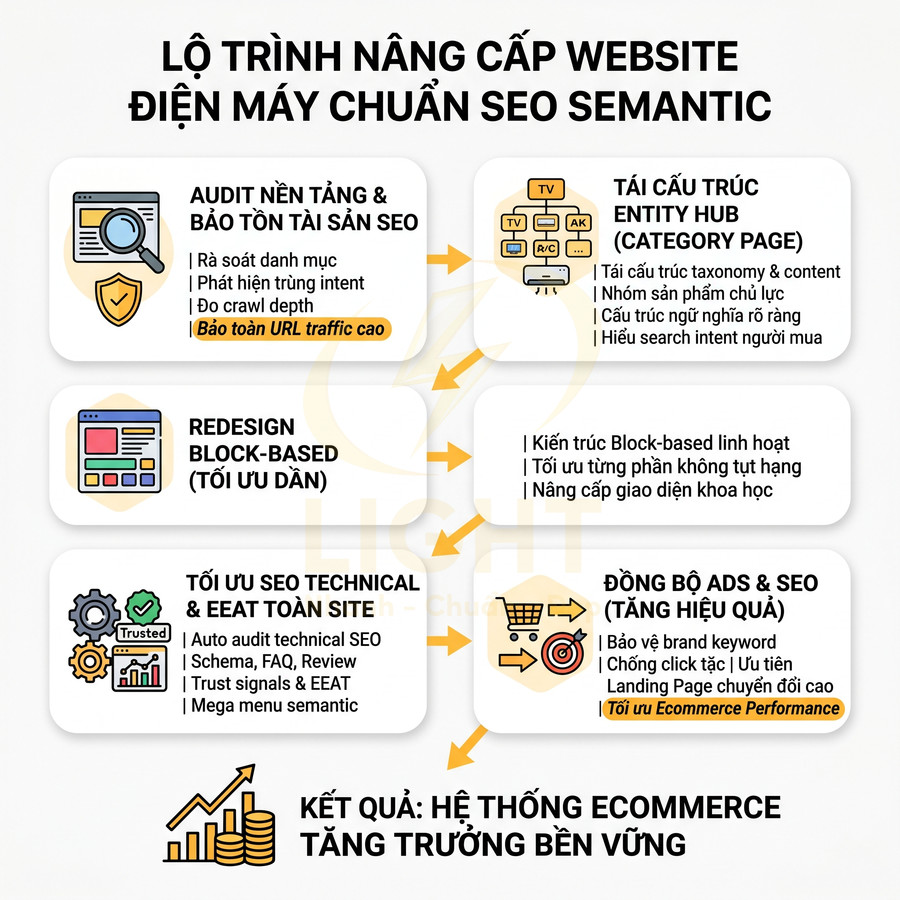
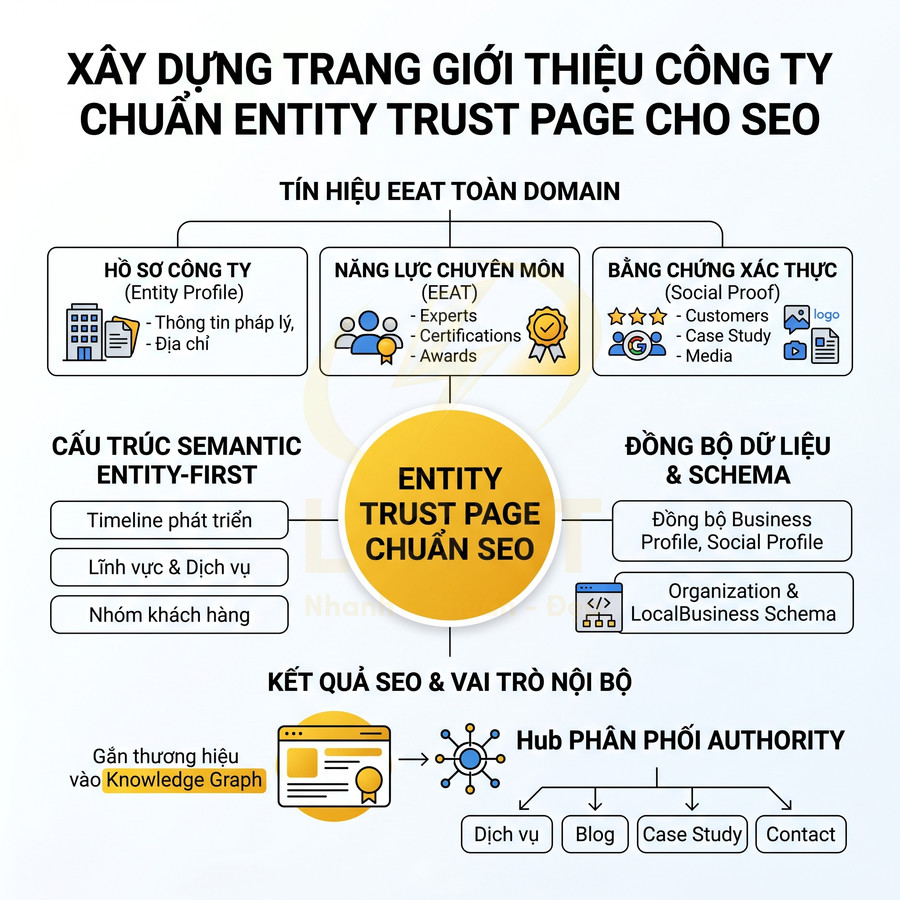

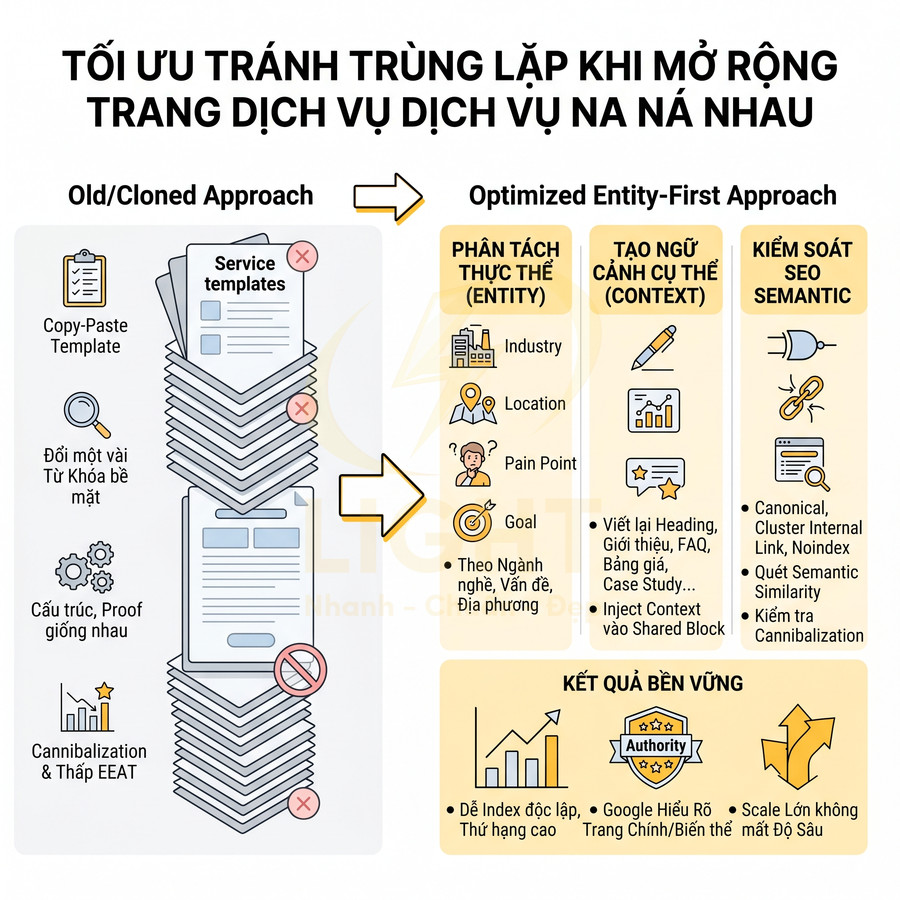

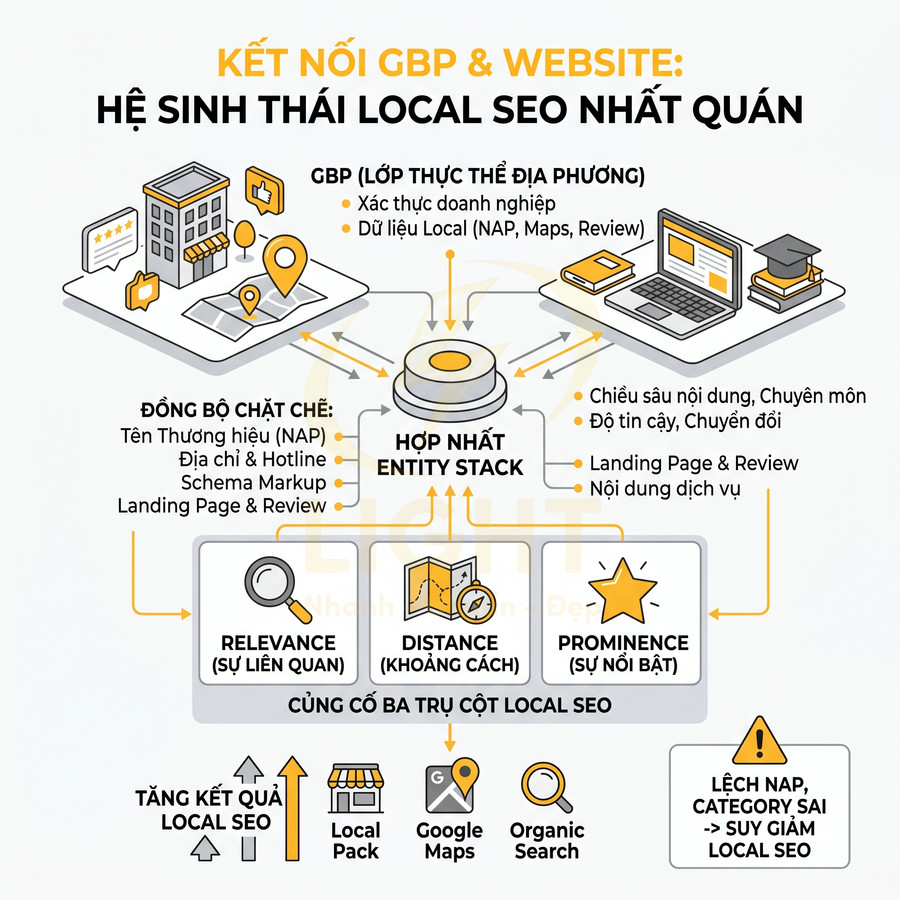
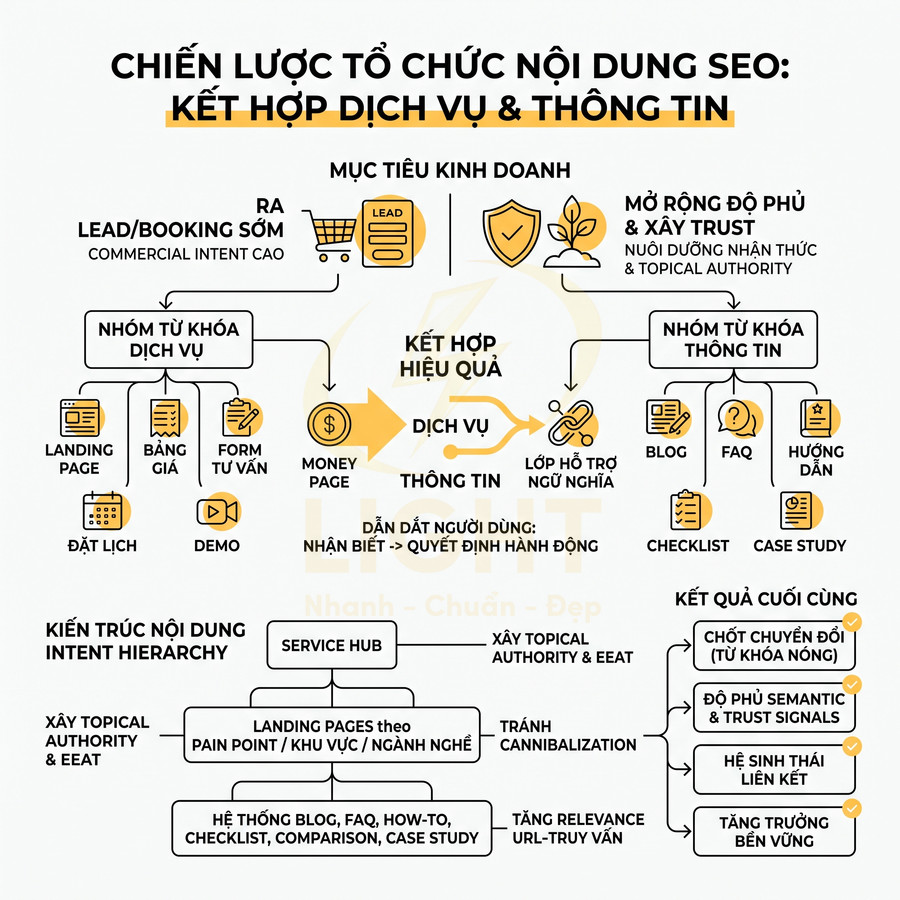
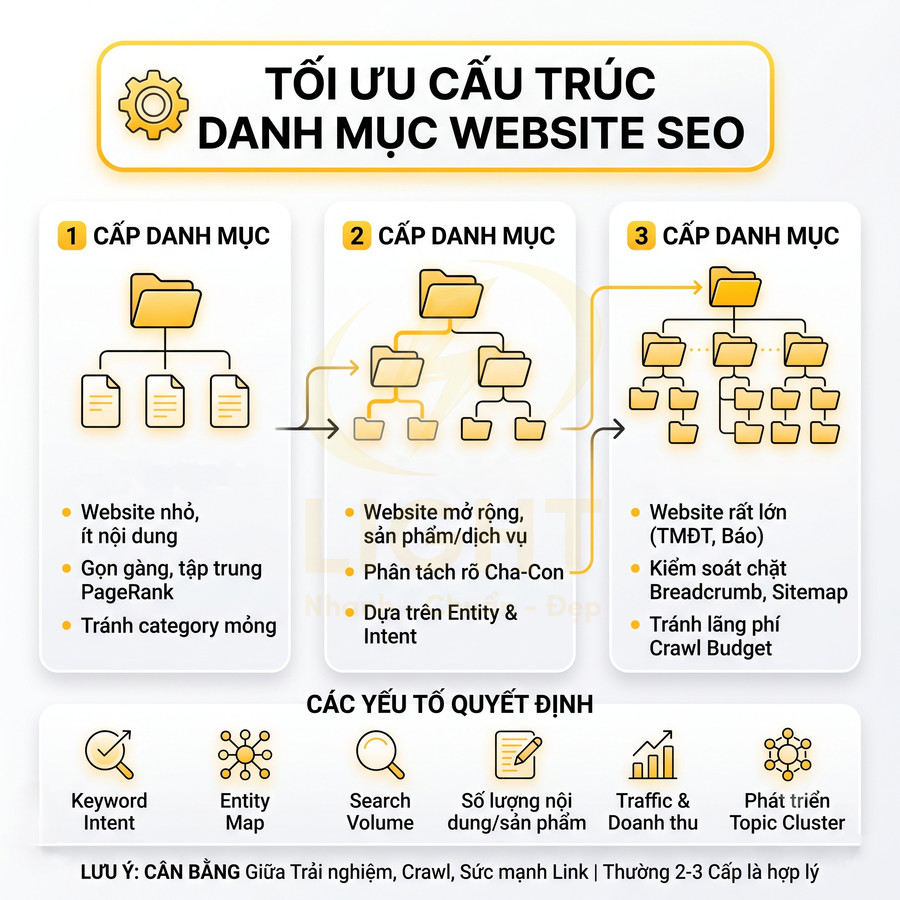








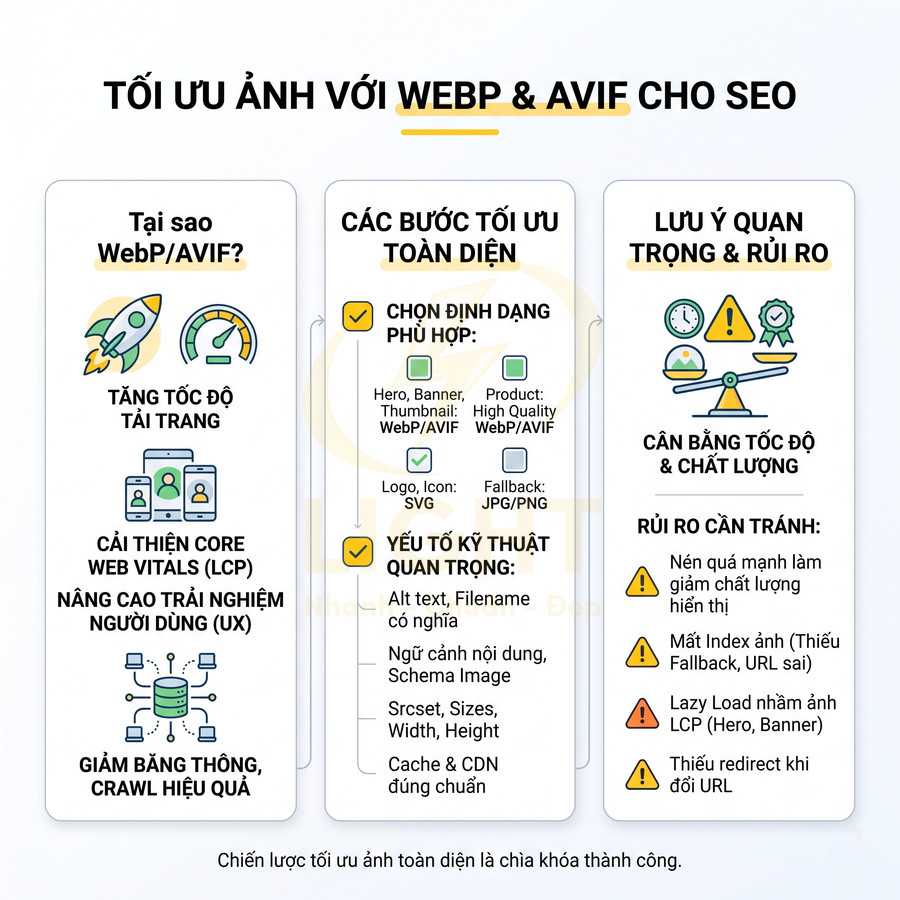
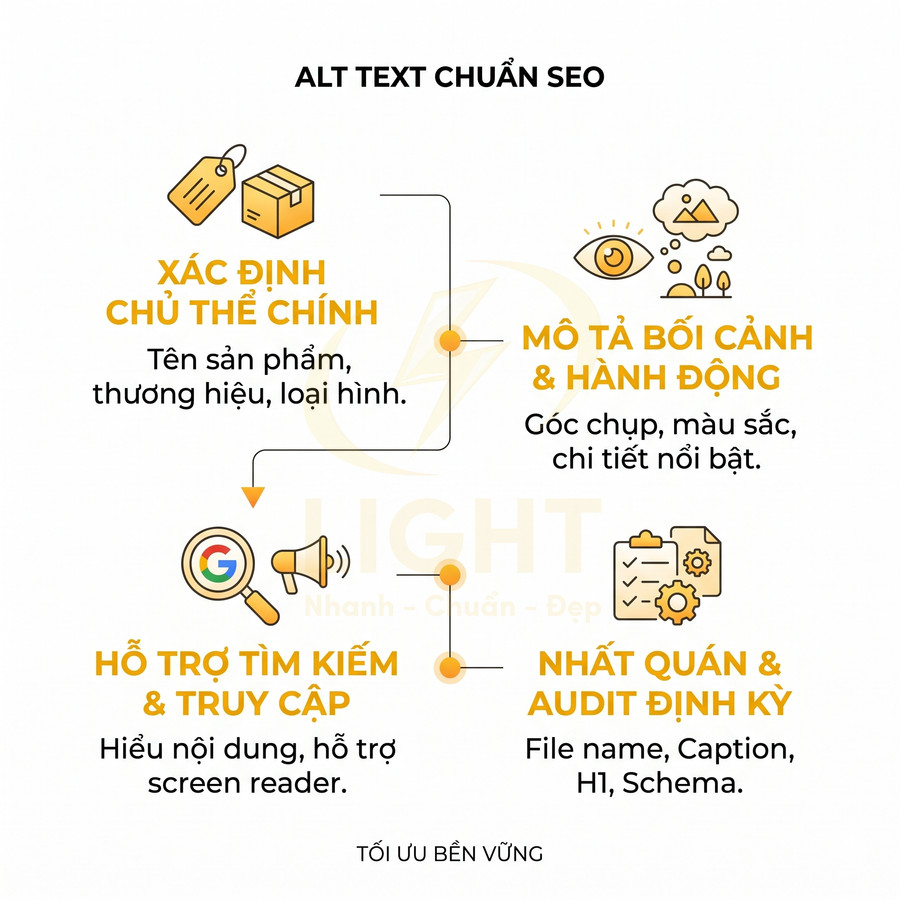

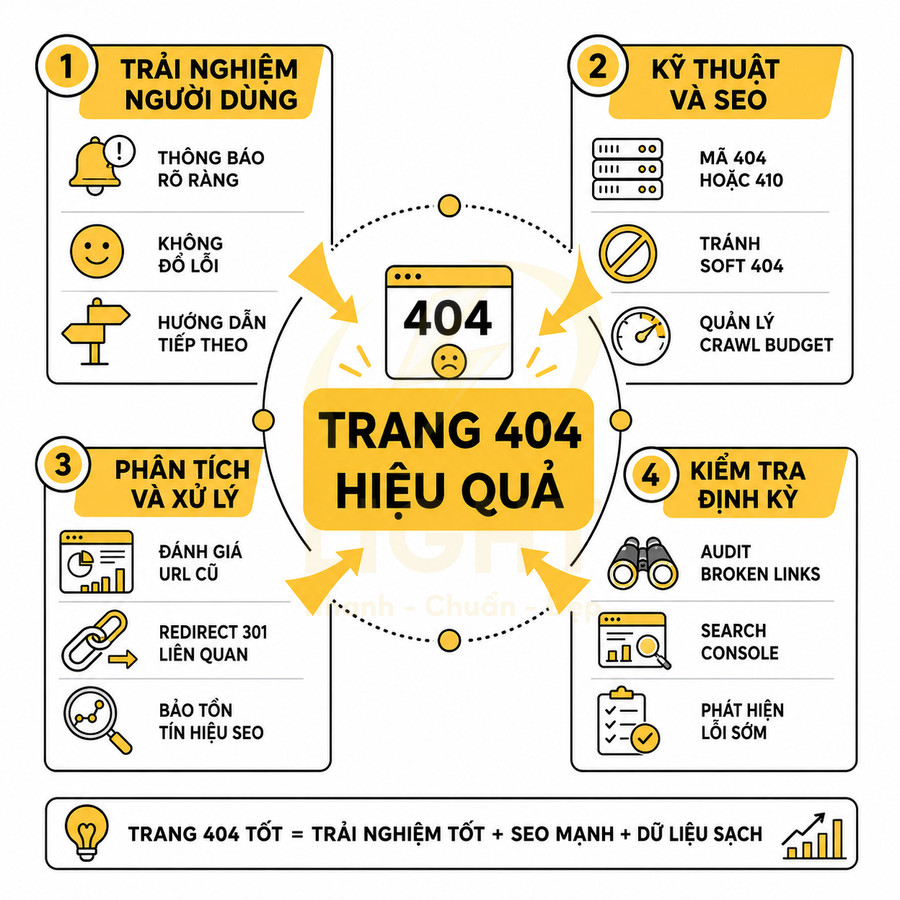

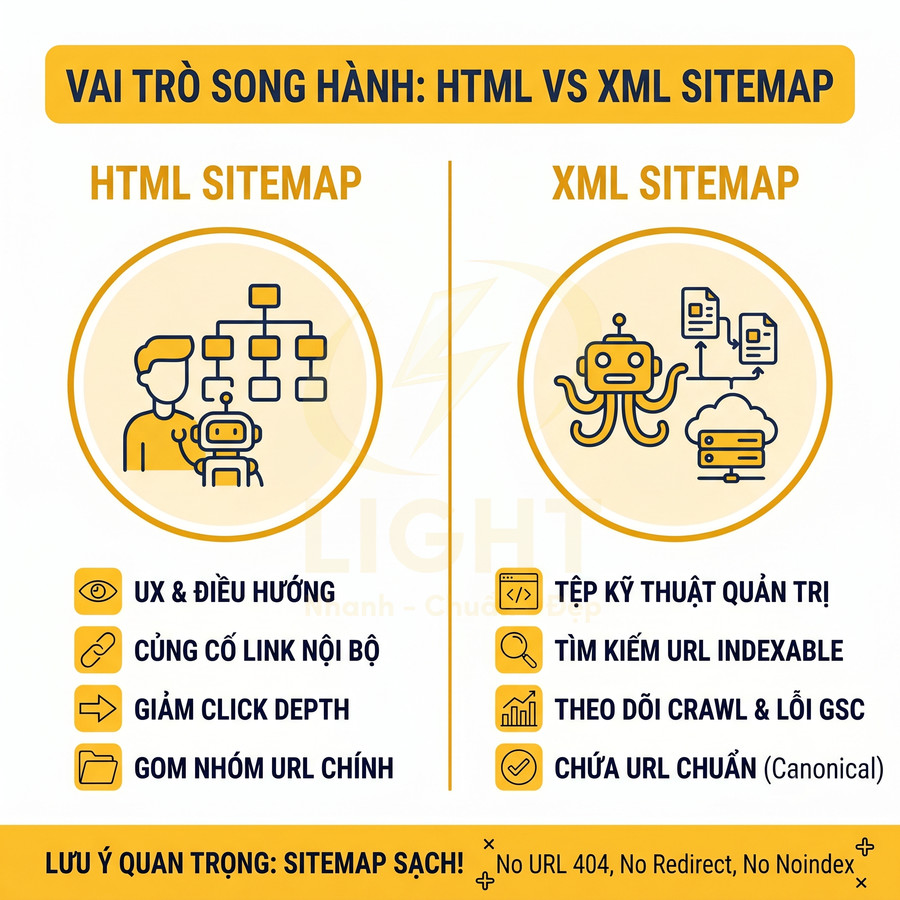
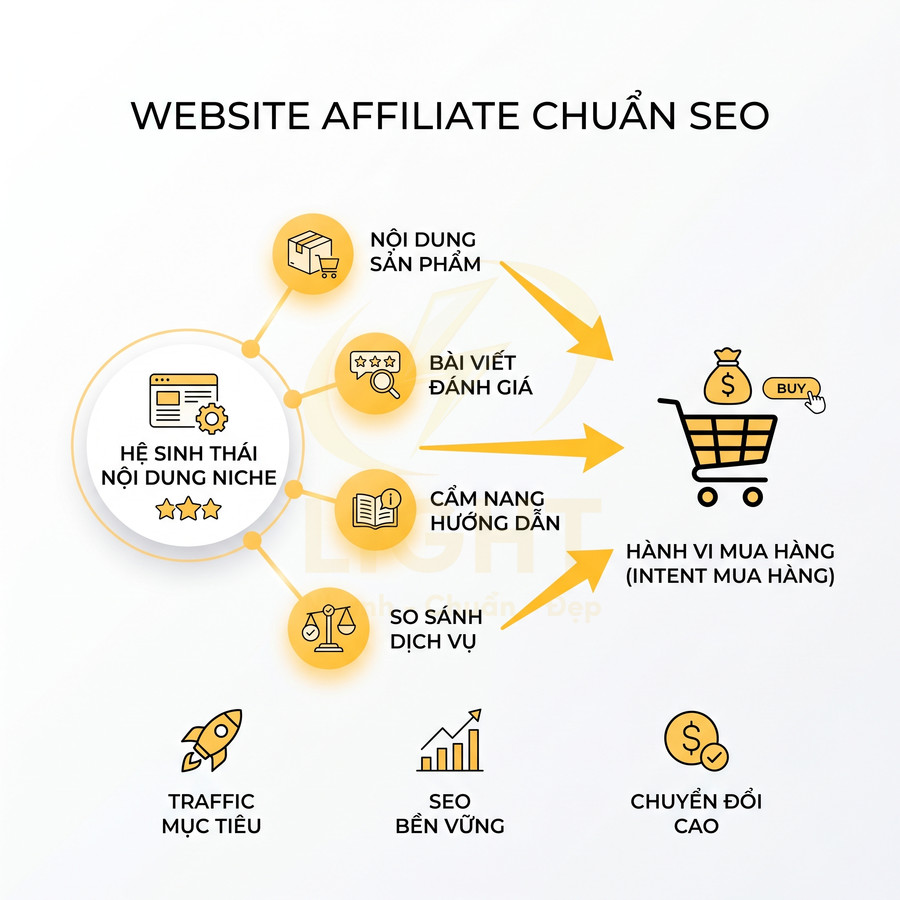

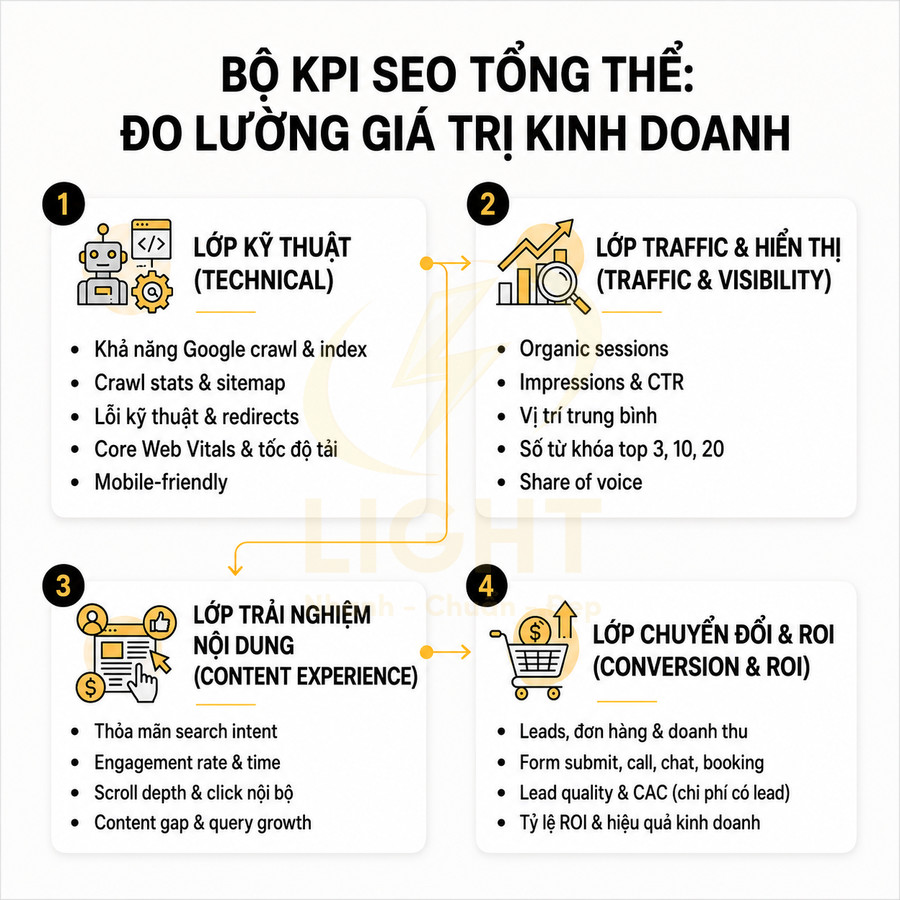



Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
