
URL chuẩn SEO nên viết thế nào để dễ index và dễ click?
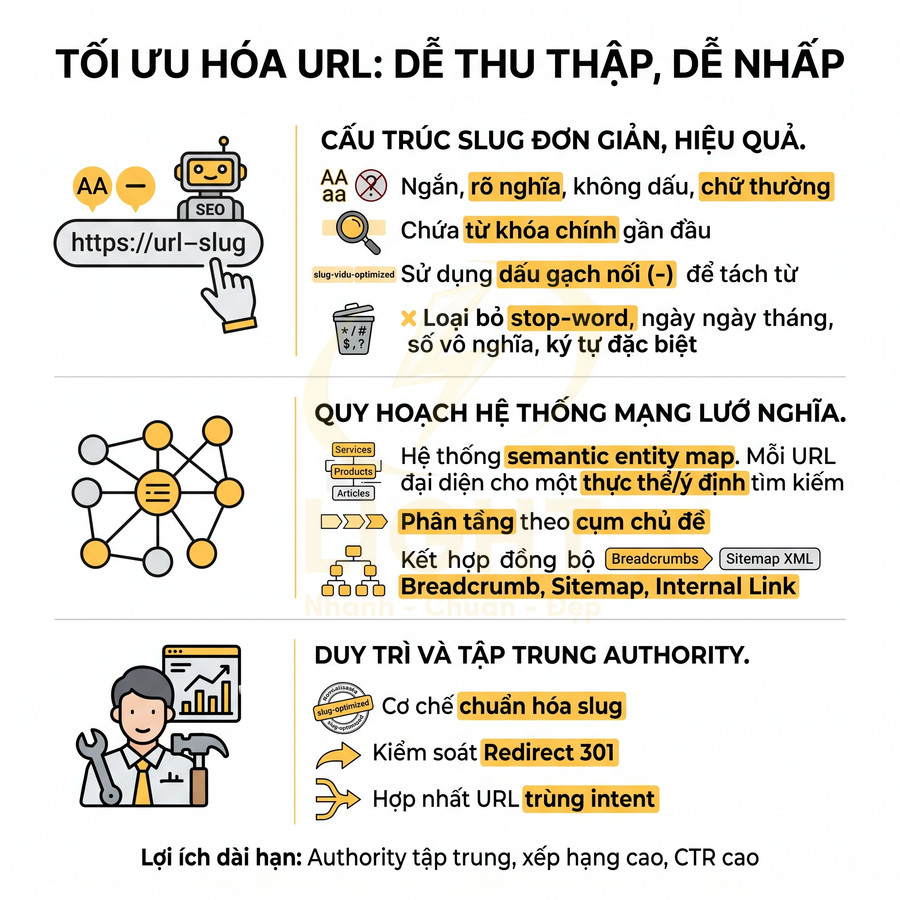
Muốn URL dễ được bot thu thập và người dùng sẵn sàng nhấp, hãy ưu tiên slug ngắn, rõ nghĩa, không dấu, chữ thường và chứa từ khóa chính ngay gần đầu. Cấu trúc tốt nhất là dùng dấu gạch nối để tách từ, loại bỏ ký tự đặc biệt, ngày tháng, số vô nghĩa và các stop-word dư thừa để đường dẫn tập trung vào đúng thực thể tìm kiếm. Một URL “sạch” như vậy giúp Google hiểu nhanh chủ đề trang, giảm rủi ro trùng lặp, đồng thời tạo cảm giác đáng tin và dễ đoán đúng thông tin khi hiển thị trên SERP.
Ở cấp độ toàn website, URL cần được quy hoạch như một hệ thống semantic entity map, nơi mỗi đường dẫn đại diện cho một thực thể hoặc một ý định tìm kiếm duy nhất: dịch vụ, sản phẩm, bài viết kiến thức, khu vực hoặc trang chuyển đổi. Từ lớp bản đồ này, cấu trúc thư mục được phân tầng theo cụm chủ đề để thể hiện rõ quan hệ cha–con giữa trang trụ cột, trang cluster, landing chuyển đổi và local page, giúp bot hiểu sâu ngữ cảnh và tăng topical authority. Khi đồng bộ thêm với breadcrumb, sitemap XML và internal link, toàn bộ hệ thống trở thành một mạng lưới ngữ nghĩa rõ ràng, hỗ trợ crawl budget và khả năng index ở quy mô lớn. Về dài hạn, cần duy trì cơ chế chuẩn hóa slug, kiểm soát redirect 301 và hợp nhất các URL trùng intent để tập trung authority vào một trang đại diện mạnh nhất, từ đó cải thiện cả khả năng xếp hạng lẫn tỷ lệ nhấp tự nhiên. URL sạch cần đi cùng cấu trúc website rõ ràng để Google hiểu đúng vị trí và vai trò của từng trang. Một nền tảng thiết kế web chuẩn SEO giúp đồng bộ slug, thư mục, breadcrumb và internal link, từ đó hạn chế URL rác và tăng khả năng crawl những trang quan trọng.
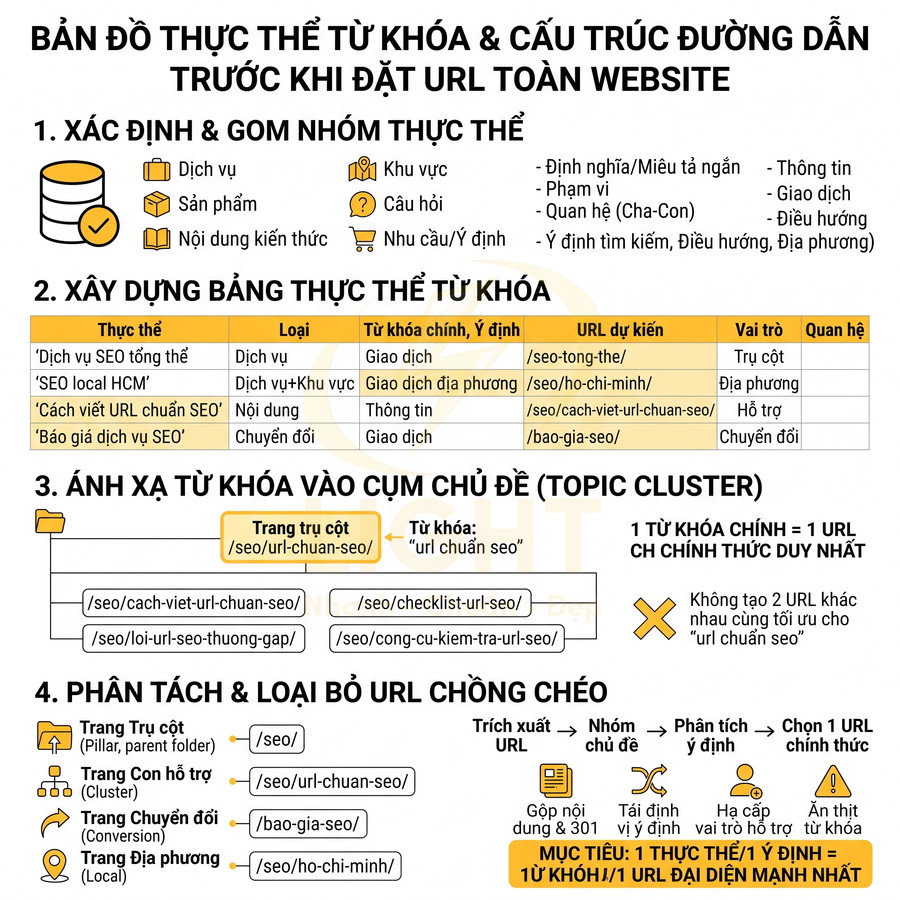
Bản đồ thực thể từ khóa và cấu trúc đường dẫn trước khi đặt URL toàn website
Toàn bộ website cần được quy hoạch như một hệ thống thực thể, trong đó mỗi URL đại diện cho một thực thể hoặc tổ hợp thực thể rõ ràng, có thuộc tính, phạm vi, quan hệ và ý định tìm kiếm cụ thể. Thực thể được gom thành các nhóm: dịch vụ, sản phẩm, nội dung kiến thức, khu vực, câu hỏi, nhu cầu; sau đó chuẩn hóa trong một bảng thực thể từ khóa với các cột: loại thực thể, từ khóa chính – phụ, ý định, URL dự kiến, vai trò trong cụm chủ đề và quan hệ cha – con. Từ bản đồ này, cấu trúc thư mục URL được chia tầng (dịch vụ, sản phẩm, blog, khu vực, chuyển đổi), ánh xạ với topic cluster, tách bạch trang trụ cột – trang con – trang chuyển đổi – trang địa phương và loại bỏ URL chồng chéo để tránh ăn thịt từ khóa. Cách tiếp cận này phù hợp với bản chất của URI/URL trong kiến trúc Web: một URI là chuỗi định danh cho một tài nguyên trừu tượng hoặc vật lý, không chỉ là “đường dẫn kỹ thuật” (Berners-Lee, Fielding & Masinter, RFC 3986). Vì vậy, khi thiết kế URL, cần xem mỗi URL như một định danh bền vững cho một thực thể nội dung, thay vì một slug tùy ý theo cảm tính. Nếu URL đại diện cho “dịch vụ SEO tổng thể”, nó phải giữ vai trò đó ổn định trong sitemap, breadcrumb, internal link và canonical. URL càng phản ánh đúng thực thể, toàn bộ hệ thống càng dễ crawl, dễ quản trị và ít phát sinh trùng lặp.
Xác định thực thể chính: dịch vụ, sản phẩm, bài viết, khu vực, câu hỏi tìm kiếm
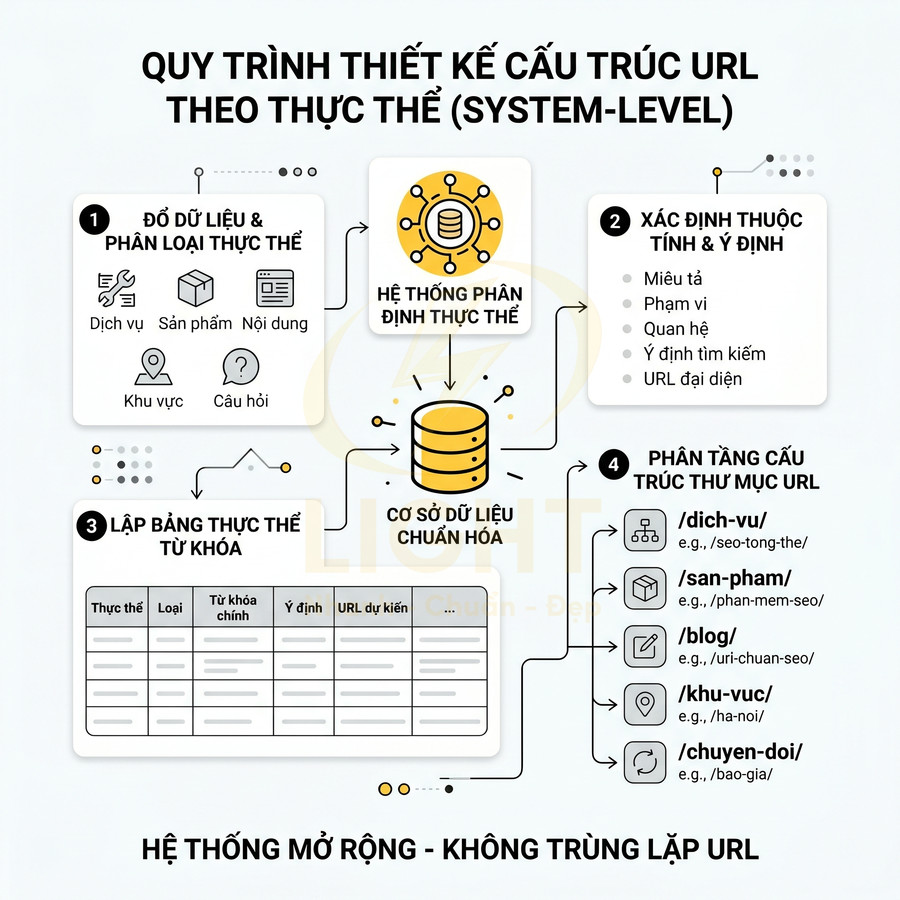
Để thiết kế URL chuẩn SEO ở cấp độ hệ thống, cần coi toàn bộ website như một “cơ sở dữ liệu thực thể” thay vì một tập hợp bài viết rời rạc. Thực thể (entity) là bất kỳ đối tượng nào có thể được người dùng tìm kiếm và Google nhận diện, có thuộc tính, có ngữ cảnh và có mối quan hệ với thực thể khác. Trong SEO thực thể, mỗi URL lý tưởng nên đại diện cho một thực thể hoặc một tổ hợp thực thể đủ rõ ràng, thay vì chỉ đại diện cho một chuỗi từ khóa. Khi xác định thực thể chính cho từng URL, cấu trúc website cần được tổ chức theo logic rõ ràng giữa dịch vụ, sản phẩm, bài viết, khu vực và câu hỏi tìm kiếm. Một nền tảng thiết kế website hợp lý giúp mỗi trang có vai trò riêng, tránh nội dung chồng chéo hoặc khó phân loại.
Các nhóm thực thể cốt lõi thường gặp trong website dịch vụ – nội dung gồm:
- Thực thể dịch vụ: dịch vụ tổng thể, gói dịch vụ, dịch vụ chuyên sâu, dịch vụ bổ trợ.
- Thực thể sản phẩm: sản phẩm đơn lẻ, dòng sản phẩm, bộ sản phẩm, phiên bản (size, dung lượng, gói).
- Thực thể nội dung: chủ đề kiến thức, hướng dẫn, quy trình, checklist, case study, review, so sánh.
- Thực thể khu vực: quốc gia, thành phố, quận/huyện, khu vực phục vụ, chi nhánh.
- Thực thể câu hỏi tìm kiếm: câu hỏi định nghĩa, cách làm, so sánh, chi phí, rủi ro, kinh nghiệm.
- Thực thể nhu cầu/ý định: tìm hiểu thông tin, so sánh lựa chọn, xem báo giá, đặt lịch, liên hệ, đăng ký demo.
Mỗi thực thể cần được mô tả bằng các thuộc tính tối thiểu:
- Định nghĩa/miêu tả ngắn: thực thể này là gì, giải quyết vấn đề nào.
- Phạm vi: mức độ rộng – hẹp, có bao trùm các thực thể con hay không.
- Quan hệ: cha – con, tương đương, bổ trợ, thay thế, liên quan gần.
- Ý định tìm kiếm chính: thông tin, giao dịch, điều hướng, so sánh, địa phương.
- URL đại diện: một hoặc một nhóm URL duy nhất, không chồng chéo.
Trong giai đoạn lập kế hoạch, nên bắt đầu bằng việc “đổ” toàn bộ dữ liệu kinh doanh và nội dung ra một file tổng hợp:
- Danh mục dịch vụ chính, dịch vụ con, gói dịch vụ, add-on.
- Danh mục sản phẩm, ngành hàng, nhóm sản phẩm, phiên bản.
- Khu vực phục vụ: quốc gia, thành phố, quận/huyện, chi nhánh.
- Nhóm câu hỏi thường gặp từ sales, support, khách hàng.
- Các dạng nội dung dự kiến: hướng dẫn, checklist, so sánh, review, case study, báo giá, landing page chuyển đổi, FAQ.
Sau đó, tiến hành chuẩn hóa và gom nhóm thành các nhóm thực thể cốt lõi. Mỗi nhóm thực thể sẽ tương ứng với một tầng trong cấu trúc thư mục URL:
- Tầng dịch vụ: /seo/, /thiet-ke-website/, /quang-cao-google/.
- Tầng sản phẩm: /san-pham/phan-mem-seo/, /san-pham/crm/.
- Tầng nội dung kiến thức: /blog/seo/, /blog/content-marketing/.
- Tầng khu vực: /seo/ho-chi-minh/, /seo/ha-noi/.
- Tầng chuyển đổi: /bao-gia-seo/, /dang-ky-demo-seo/, /lien-he/.
Để đảm bảo tính hệ thống, nên xây dựng một bảng thực thể từ khóa chi tiết hơn với các cột mở rộng:
- Thực thể: tên thực thể chuẩn hóa (ví dụ: “Dịch vụ SEO tổng thể”).
- Loại thực thể: dịch vụ, sản phẩm, khu vực, câu hỏi, nội dung kiến thức, chuyển đổi.
- Từ khóa chính: cụm từ khóa đại diện cho thực thể, có volume và ý định rõ ràng.
- Từ khóa phụ: biến thể dài, từ đồng nghĩa, cách diễn đạt khác.
- Ý định tìm kiếm: thông tin, giao dịch, điều hướng, so sánh, giao dịch địa phương.
- URL dự kiến: slug và cấu trúc thư mục tương ứng.
- Vai trò trong cụm chủ đề: trụ cột, hỗ trợ, chuyển đổi, địa phương.
- Quan hệ thực thể: thực thể cha, thực thể con, thực thể liên quan.
Bảng thực thể không chỉ giúp tránh trùng lặp URL, mà còn là “bản thiết kế” để:
- Tránh ăn thịt từ khóa khi mở rộng nội dung theo thời gian.
- Đảm bảo mỗi truy vấn quan trọng chỉ dẫn về một trang chính thức.
- Định hướng cấu trúc internal link theo cụm chủ đề và thực thể.
- Chuẩn bị dữ liệu cho schema, breadcrumb, sitemap theo thực thể.
| Thực thể | Loại thực thể | Từ khóa chính | Ý định tìm kiếm | Vai trò URL |
|---|---|---|---|---|
| Dịch vụ SEO tổng thể | Dịch vụ | dịch vụ seo tổng thể | Giao dịch | Trang trụ cột dịch vụ |
| SEO local Hồ Chí Minh | Dịch vụ + Khu vực | seo local hcm | Giao dịch địa phương | Trang địa phương |
| Cách viết URL chuẩn SEO | Bài viết kiến thức | url chuẩn seo | Thông tin | Trang nội dung chuyên sâu |
| Báo giá dịch vụ SEO | Trang chuyển đổi | báo giá seo | Giao dịch | Trang báo giá |
| SEO là gì | Câu hỏi tìm kiếm | seo là gì | Thông tin | Trang giải thích khái niệm |
Khi bản đồ thực thể được xây dựng kỹ, việc đặt URL trở thành một quy trình có chuẩn, có logic, có khả năng mở rộng. Mỗi khi thêm dịch vụ mới, khu vực mới hoặc chủ đề nội dung mới, chỉ cần tra lại bảng thực thể để xác định vị trí trong cấu trúc thư mục, slug phù hợp và mối quan hệ với các URL hiện có.
Ánh xạ từ khóa chính vào từng nhóm URL theo cụm chủ đề
Sau khi xác định thực thể, bước tiếp theo là ánh xạ từ khóa chính vào từng nhóm URL trong từng cụm chủ đề (topic cluster). Ở cấp độ chuyên sâu, cụm chủ đề không chỉ là nhóm bài viết xoay quanh một chủ đề, mà là một “mạng lưới thực thể” xoay quanh một thực thể trung tâm (pillar entity). Mỗi URL trong cụm phải có:
- Một thực thể chính rõ ràng.
- Một từ khóa chính duy nhất tương ứng với thực thể đó.
- Vai trò cụ thể trong cụm: trụ cột, giải thích, hướng dẫn, so sánh, chuyển đổi.
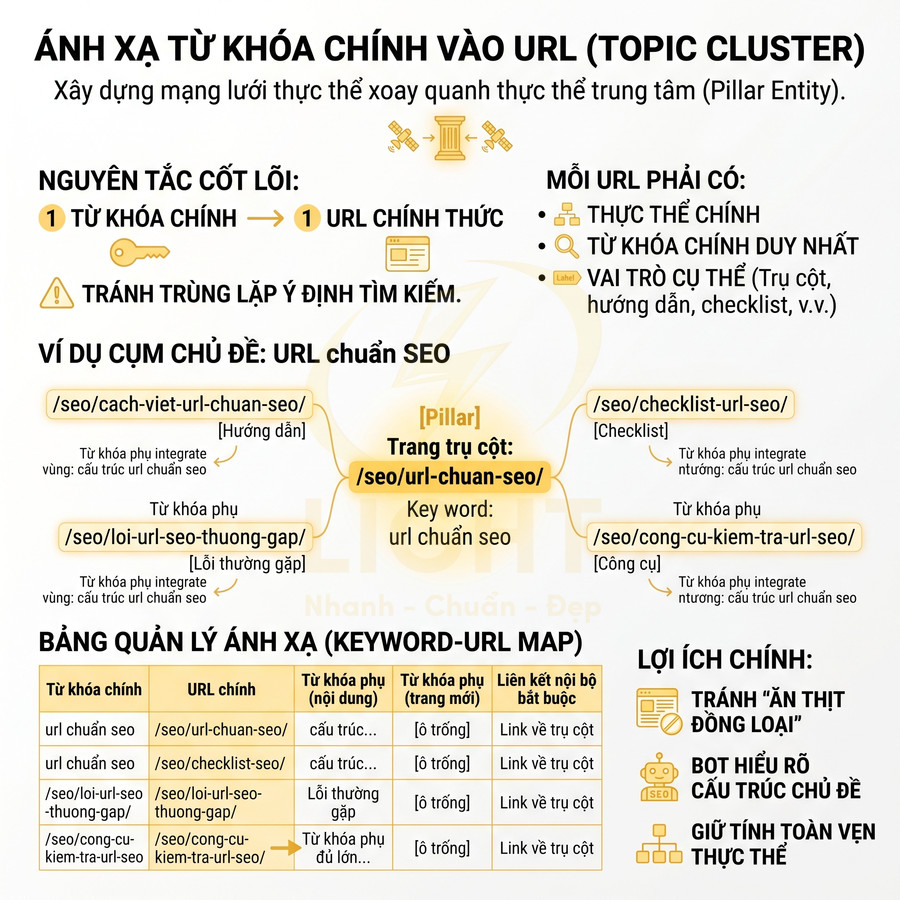
Nguyên tắc cốt lõi: một từ khóa chính tương ứng với một URL chính thức. Điều này có nghĩa là:
- Không tạo hai URL khác nhau cùng tối ưu cho “url chuẩn seo”.
- Không để nhiều bài viết cùng nhắm vào một ý định tìm kiếm như “cách viết url chuẩn seo”.
- Các biến thể dài hơn như “cách viết url chuẩn seo cho blog”, “cách tối ưu url chuẩn seo cho ecommerce” có thể trở thành trang con nếu đủ volume và ý định khác biệt.
Ví dụ cụm chủ đề “URL chuẩn SEO” có thể được thiết kế như sau:
- Trang trụ cột: /seo/url-chuan-seo/ – từ khóa chính: “url chuẩn seo”.
- Trang hướng dẫn chi tiết: /seo/cach-viet-url-chuan-seo/ – từ khóa chính: “cách viết url chuẩn seo”.
- Trang checklist: /seo/checklist-url-seo/ – từ khóa chính: “checklist url seo”.
- Trang lỗi thường gặp: /seo/loi-url-seo-thuong-gap/ – từ khóa chính: “lỗi url seo thường gặp”.
- Trang công cụ: /seo/cong-cu-kiem-tra-url-seo/ – từ khóa chính: “công cụ kiểm tra url seo”.
Nguyên tắc này có cơ sở từ nghiên cứu về search intent. Broder (2002) chỉ ra rằng truy vấn Web không chỉ mang nhu cầu thông tin, mà có thể là navigational, informational hoặc transactional. Vì vậy, khi ánh xạ keyword vào URL, điểm quan trọng không phải là “mỗi biến thể keyword tạo một trang”, mà là mỗi nhóm truy vấn cùng intent chỉ nên có một URL đại diện. Ví dụ “url chuẩn seo”, “cấu trúc url chuẩn seo” và “url seo là gì” có thể cùng nằm trong một trang trụ cột nếu đều phục vụ intent tìm hiểu. Ngược lại, “cách viết URL chuẩn SEO” có thể tách riêng nếu SERP và độ sâu nội dung cho thấy đây là intent hướng dẫn cụ thể.
Các từ khóa phụ như “cấu trúc url chuẩn seo”, “bao nhiêu ký tự cho url seo”, “có nên dùng ngày tháng trong url” sẽ được phân bổ vào nội dung của các trang trên, nhưng không nhất thiết tạo URL riêng nếu không đủ lớn hoặc trùng ý định.
Để quản lý ở quy mô lớn, nên lập bảng ánh xạ từ khóa – URL cho từng cụm chủ đề với các trường:
- Từ khóa chính: cụm từ khóa mục tiêu.
- URL chính: URL duy nhất được phép tối ưu trực tiếp cho từ khóa này.
- Từ khóa phụ dùng trong nội dung: được phép xuất hiện trong H2, H3, nội dung nhưng không tạo URL riêng.
- Từ khóa phụ đủ lớn để tạo trang mới: sẽ trở thành URL cluster mới trong cùng cụm.
- Liên kết nội bộ bắt buộc: URL nào phải link về trang trụ cột, URL nào cần link chéo với nhau.
Cách làm này giúp:
- Đội nội dung không vô tình tạo thêm trang mới cho cùng một ý định tìm kiếm.
- Bot hiểu rõ cấu trúc chủ đề thông qua đường dẫn, anchor text và internal link.
- Giữ được “tính toàn vẹn thực thể”: mỗi thực thể – mỗi ý định tìm kiếm quan trọng có một URL đại diện mạnh nhất.
Tách riêng URL cho trang trụ cột, trang con, trang chuyển đổi và trang địa phương
Một website tối ưu SEO tốt thường phân biệt rõ bốn loại trang: trang trụ cột (pillar), trang con hỗ trợ (cluster), trang chuyển đổi (conversion) và trang địa phương (local). Ở cấp độ cấu trúc URL, mỗi loại trang cần một quy tắc riêng để:
- Giúp bot nhận diện nhanh vai trò của trang.
- Giúp người dùng hiểu ngữ cảnh chỉ qua đường dẫn.
- Giúp đội marketing – phân tích dữ liệu dễ segment theo loại trang.
Việc tách URL theo vai trò trang giúp giảm xung đột intent. Broder (2002) cho thấy người dùng tìm kiếm với các mục tiêu khác nhau: có người muốn học thông tin, có người muốn đi tới một site, có người muốn thực hiện hành động. Do đó, trang pillar như /url-chuan-seo/ nên phục vụ intent tổng quan; trang cluster như /cach-viet-url-chuan-seo/ phục vụ intent hướng dẫn; trang conversion như /bao-gia-dich-vu-seo/ phục vụ intent giao dịch. Khi URL thể hiện đúng vai trò, Google và người dùng dễ hiểu trang đó dùng để làm gì, giảm rủi ro một trang phải gánh quá nhiều mục tiêu cùng lúc.
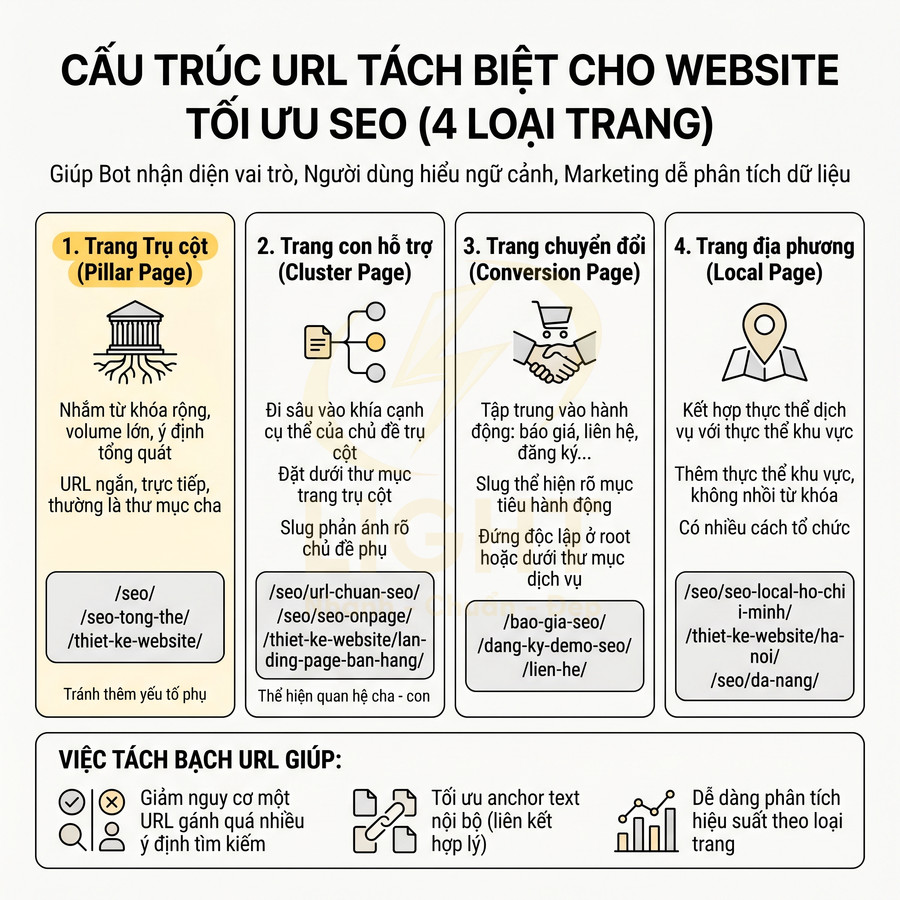
Trang trụ cột (pillar):
- Nhắm vào từ khóa rộng, volume lớn, ý định tổng quát.
- URL nên ngắn, trực tiếp, không thêm yếu tố phụ: /seo/, /seo-tong-the/, /thiet-ke-website/.
- Thường là thư mục cha cho các trang cluster: /seo/url-chuan-seo/, /seo/seo-onpage/.
Trang con hỗ trợ (cluster):
- Đi sâu vào một khía cạnh cụ thể của chủ đề trụ cột.
- Nên đặt dưới thư mục của trang trụ cột để thể hiện quan hệ cha – con: /seo/url-chuan-seo/, /seo/seo-onpage/, /thiet-ke-website/landing-page-ban-hang/.
- Slug nên phản ánh rõ chủ đề phụ, tránh lặp lại toàn bộ từ khóa của trang trụ cột nếu không cần thiết.
Trang chuyển đổi (conversion):
- Tập trung vào hành động: báo giá, liên hệ, đăng ký, đặt lịch.
- Slug thể hiện rõ mục tiêu hành động: /bao-gia-seo/, /dang-ky-demo-seo/, /lien-he/.
- Có thể đứng độc lập ở root hoặc dưới thư mục dịch vụ nếu là báo giá riêng cho dịch vụ đó.
Trang địa phương (local):
- Kết hợp thực thể dịch vụ với thực thể khu vực.
- Slug thêm thực thể khu vực nhưng không nhồi từ khóa: /seo/seo-local-ho-chi-minh/, /thiet-ke-website/ha-noi/.
- Có thể tổ chức theo dạng: /seo/ho-chi-minh/, /seo/da-nang/ nếu chiến lược local mạnh.
Việc tách bạch này giúp:
- Giảm nguy cơ một URL phải gánh quá nhiều ý định tìm kiếm (vừa thông tin, vừa giao dịch, vừa địa phương).
- Tối ưu anchor text nội bộ: link từ nội dung kiến thức về trang chuyển đổi, từ trang địa phương về trang trụ cột dịch vụ.
- Dễ dàng phân tích hiệu suất theo loại trang trong công cụ analytics.
Loại bỏ URL chồng chéo cùng nhắm một thực thể tìm kiếm
URL chồng chéo là nguyên nhân phổ biến gây ăn thịt từ khóa (keyword cannibalization) và làm loãng tín hiệu xếp hạng. Ở góc độ thực thể, đây là tình trạng nhiều URL cùng cố gắng đại diện cho một thực thể hoặc một ý định tìm kiếm giống nhau. Kết quả là:
- Google khó xác định URL nào là “đại diện chính thức”.
- Backlink, tín hiệu tương tác, CTR bị chia nhỏ cho nhiều trang.
- Thứ hạng tổng thể cho thực thể đó bị suy yếu.
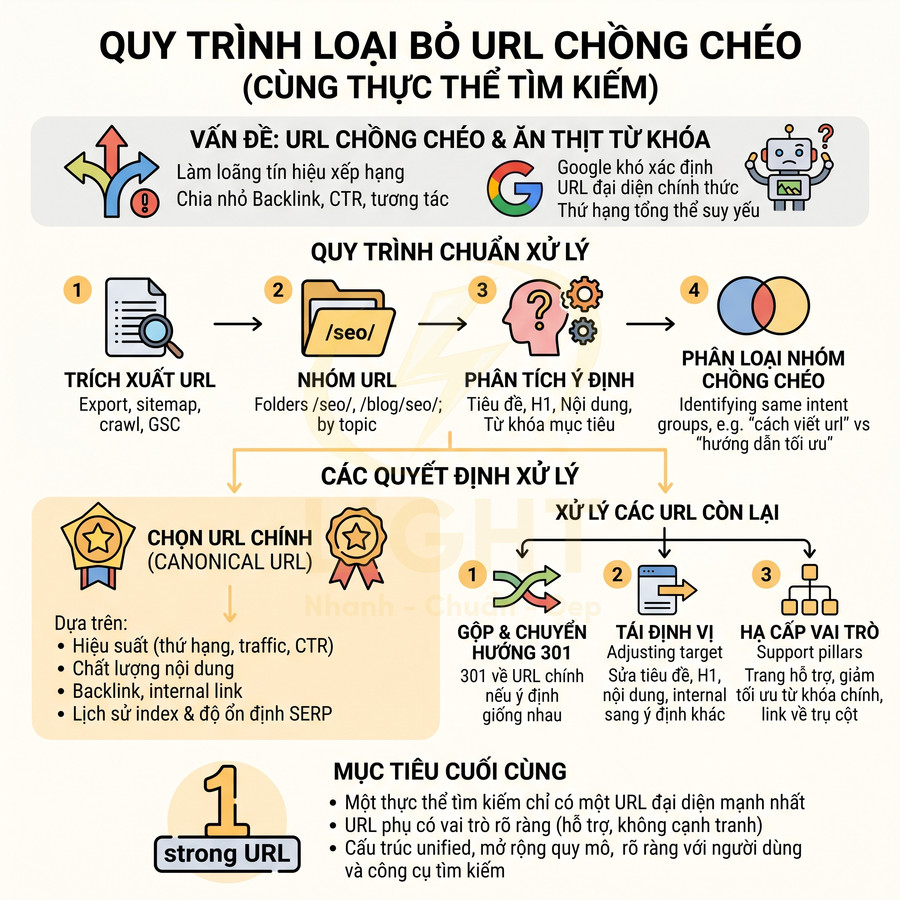
Quy trình chuẩn để xử lý URL chồng chéo nên bao gồm:
- Trích xuất toàn bộ URL từ sitemap, crawl, GSC.
- Nhóm theo thư mục và chủ đề: ví dụ nhóm toàn bộ URL trong thư mục /seo/, /blog/seo/.
- Phân tích tiêu đề SEO, H1, nội dung, từ khóa mục tiêu để xác định ý định tìm kiếm thực tế của từng trang.
- Đánh dấu các nhóm URL có ý định giống nhau, không chỉ trùng từ khóa. Ví dụ:
- “cách viết url chuẩn seo” và “hướng dẫn tối ưu url chuẩn seo” có thể cùng một ý định.
- “báo giá dịch vụ seo” và “chi phí dịch vụ seo” có thể là hai ý định gần nhau nhưng vẫn tách được nếu cấu trúc nội dung khác biệt.
Với mỗi nhóm chồng chéo, cần chọn một URL chính thức (canonical URL) dựa trên:
- Hiệu suất hiện tại: thứ hạng, traffic, CTR.
- Chất lượng và độ sâu nội dung.
- Backlink, internal link trỏ về.
- Lịch sử index, độ ổn định trên SERP.
Các URL còn lại sẽ được xử lý theo một trong ba hướng:
- Gộp nội dung và chuyển hướng 301 về URL chính nếu nội dung tương đồng, ý định giống nhau.
- Tái định vị sang một ý định tìm kiếm khác (sửa tiêu đề, H1, nội dung, internal link) nếu có thể tách được thực thể/ý định.
- Hạ cấp vai trò thành trang hỗ trợ, giảm tối ưu từ khóa chính, tăng internal link về URL trụ cột.
Mục tiêu cuối cùng là đảm bảo mỗi thực thể tìm kiếm quan trọng chỉ có một URL đại diện mạnh nhất, được hỗ trợ bởi các URL phụ rõ vai trò, không cạnh tranh trực tiếp. Khi đó, cấu trúc URL, bản đồ thực thể và cụm chủ đề sẽ vận hành thống nhất, giúp website mở rộng quy mô mà không đánh mất độ rõ ràng trong mắt cả người dùng lẫn công cụ tìm kiếm.
Nguyên tắc viết URL chuẩn SEO ngắn gọn, rõ nghĩa và tăng tỷ lệ nhấp
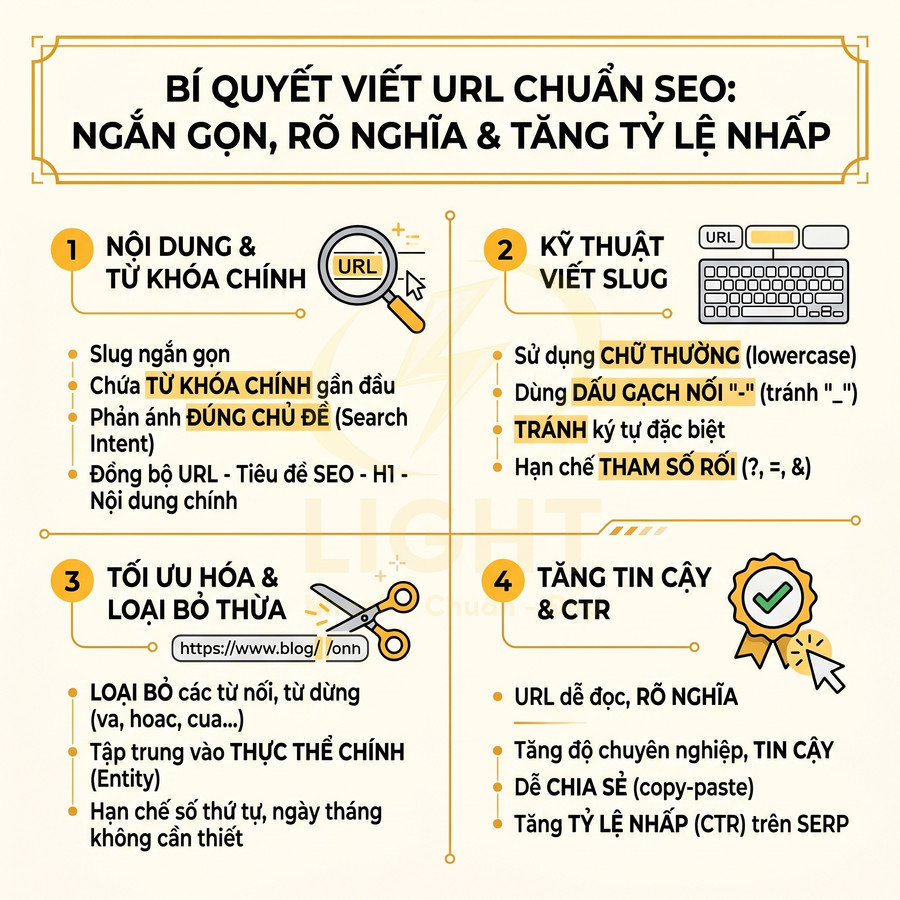
URL chuẩn SEO cần được tối ưu để vừa thân thiện với công cụ tìm kiếm, vừa dễ hiểu với người dùng. Slug nên ngắn gọn, chứa từ khóa chính ở gần đầu và phản ánh đúng chủ đề nội dung, đồng bộ với tiêu đề SEO, H1 và nội dung chính để tránh tình trạng “mồi một đằng, nội dung một nẻo” gây tăng bounce rate. Về kỹ thuật, nên dùng chữ thường, dấu gạch nối “-”, tránh ký tự đặc biệt, khoảng trắng, tham số rối và cấu trúc thư mục quá sâu. Hạn chế số thứ tự, ngày tháng và các từ nối dư thừa để URL tập trung vào thực thể chính, dễ đọc, dễ nhớ, dễ chia sẻ, từ đó tăng độ tin cậy và tỷ lệ nhấp trên SERP.
URL chứa từ khóa chính gần đầu và phản ánh đúng nội dung trang
URL chuẩn SEO không chỉ đơn thuần là “có chứa từ khóa”, mà phải là một chuỗi slug mô tả chính xác chủ đề nội dung và phù hợp với cách người dùng tìm kiếm. Về mặt kỹ thuật lẫn trải nghiệm, từ khóa chính nên xuất hiện càng gần đầu slug càng tốt, vì:
- Giúp người dùng lướt nhanh vẫn nhận diện được chủ đề chính.
- Giúp bot tìm kiếm phân loại chủ đề nhanh hơn, đặc biệt trong các hệ thống có nhiều thư mục con.
- Tăng khả năng trùng khớp với truy vấn tìm kiếm (query) về mặt ngữ nghĩa.
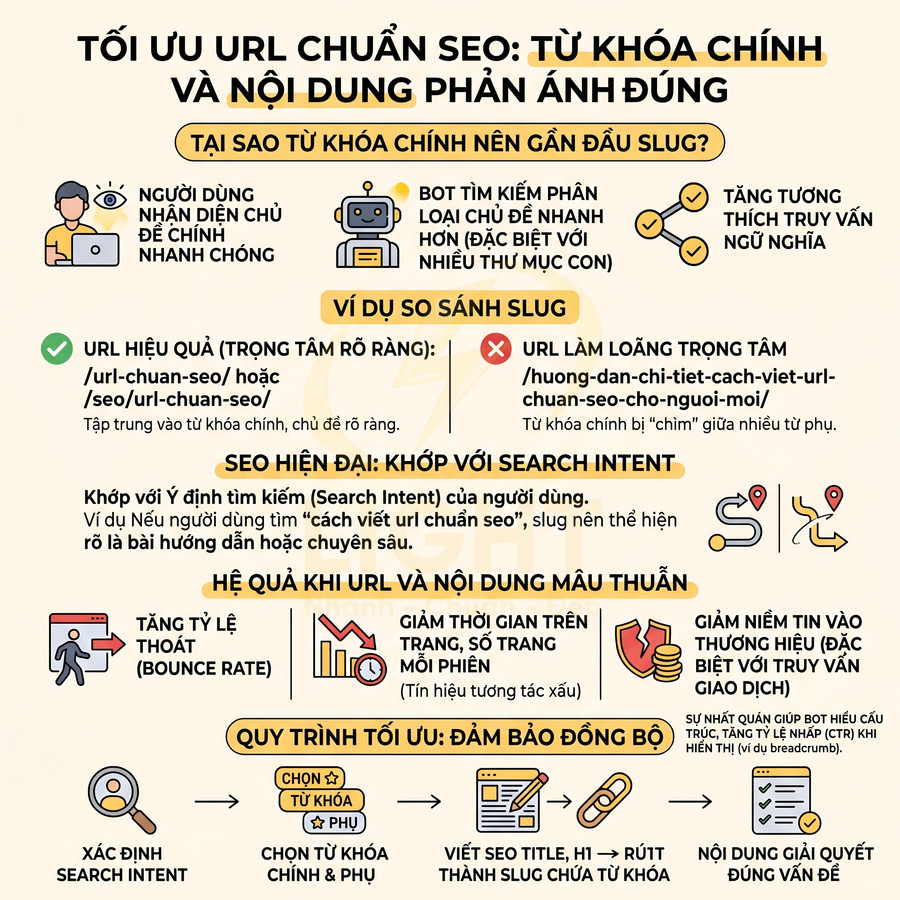
Ví dụ, với từ khóa “url chuẩn seo”, các slug như /url-chuan-seo/ hoặc /seo/url-chuan-seo/ thể hiện rõ chủ đề, trong khi dạng /huong-dan-chi-tiet-cach-viet-url-chuan-seo-cho-nguoi-moi/ khiến trọng tâm bị loãng, từ khóa chính bị “chìm” giữa nhiều từ phụ.
Ở góc độ SEO hiện đại, URL cần khớp với search intent (ý định tìm kiếm). Nếu người dùng tìm “cách viết url chuẩn seo” thì slug nên thể hiện rõ đây là một bài hướng dẫn hoặc bài phân tích chuyên sâu về chủ đề đó, không nên dùng slug chung chung như /blog/seo-2023/. Khi URL gợi ý một chủ đề nhưng nội dung lại nói về chủ đề khác (mồi một đằng, nội dung một nẻo), các hệ quả tiêu cực thường gặp là:
- Tỷ lệ thoát (bounce rate) tăng do người dùng quay lại SERP ngay.
- Thời gian trên trang thấp, số trang mỗi phiên thấp, tín hiệu tương tác xấu.
- Giảm niềm tin vào thương hiệu, đặc biệt với các truy vấn mang tính giao dịch.
Vì vậy, khi tối ưu, cần kiểm tra sự đồng bộ giữa URL – tiêu đề SEO – H1 – nội dung chính. Một quy trình thực tế có thể áp dụng:
- Xác định rõ search intent (informational, transactional, commercial, navigational).
- Chọn từ khóa chính và 1–2 từ khóa phụ có liên quan chặt chẽ.
- Viết tiêu đề SEO, H1 trước, sau đó rút gọn thành slug chứa từ khóa chính.
- Đảm bảo nội dung thực tế giải quyết đúng vấn đề mà URL và tiêu đề đã “hứa hẹn”.
Sự nhất quán này không chỉ hỗ trợ bot hiểu cấu trúc nội dung, mà còn tăng khả năng người dùng nhấp khi thấy URL trên SERP, đặc biệt khi URL được hiển thị dưới dạng breadcrumb.
Dùng chữ thường, dấu gạch nối, không ký tự thừa và không tham số rối
Về mặt kỹ thuật, một URL chuẩn SEO cần tuân thủ các nguyên tắc cơ bản để đảm bảo tính ổn định, khả năng thu thập dữ liệu (crawlability) và khả năng chia sẻ:
- Chỉ dùng chữ thường (lowercase): tránh rủi ro trùng lặp nội dung trên các hệ thống phân biệt hoa – thường, ví dụ /Url-Chuan-Seo/ và /url-chuan-seo/ có thể được coi là hai URL khác nhau.
- Dùng dấu gạch nối “-” để ngăn cách từ: Google và hầu hết các công cụ tìm kiếm hiểu “-” là dấu tách từ, trong khi “” thường bị coi là một ký tự nối, làm giảm khả năng phân tách từ khóa.
- Không dùng ký tự đặc biệt như “&”, “%”, “+”, “#”, “@” trừ khi bắt buộc về mặt kỹ thuật, vì chúng dễ gây lỗi mã hóa, khó đọc và khó chia sẻ.
- Không dùng khoảng trắng: khoảng trắng sẽ bị mã hóa thành %20 hoặc các dạng tương đương, khiến URL dài và khó nhìn.
- Hạn chế tối đa tham số (query string) như ?utmsource=..., ?sort=... trên các trang nội dung chính; chỉ nên dùng cho lọc, phân trang, tracking khi không thể tránh.
RFC 3986 quy định URI có các nhóm ký tự reserved, unreserved và percent-encoding; ký tự ngoài phạm vi an toàn thường phải được mã hóa, dẫn đến URL dài và khó đọc hơn. Google cũng khuyến nghị dùng hyphen - để tách từ, tránh underscore, tránh nối liền từ và dùng càng ít tham số càng tốt. Vì vậy, chuẩn slug nên là chữ thường, không dấu, không khoảng trắng, không ký tự đặc biệt ngoài dấu gạch nối. Ví dụ /cach-viet-url-chuan-seo/ dễ đọc, dễ crawl và dễ chia sẻ hơn /Cách%20Viết_URL_Seo?id=123. Sự sạch sẽ của URL là nền tảng cho canonical, redirect, sitemap và log analysis.
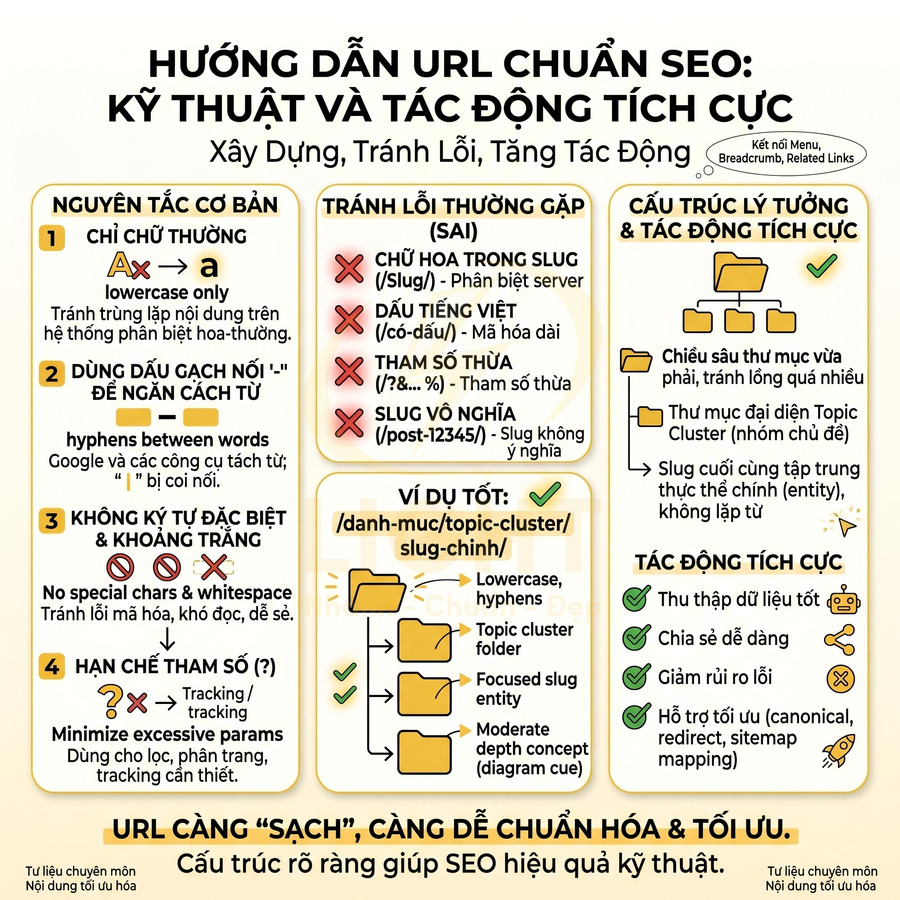
Những lỗi thường gặp cần tránh gồm:
- Dùng chữ hoa trong slug, ví dụ /Cach-Viet-URL-Chuan-SEO/, dễ gây ra hai phiên bản URL khác nhau nếu server phân biệt hoa – thường.
- Dùng dấu tiếng Việt: /cách-viết-url-chuẩn-seo/ sẽ bị mã hóa thành chuỗi ký tự dài, khó đọc khi chia sẻ, và có thể gây lỗi trên một số hệ thống cũ.
- Thêm ký tự như “&”, “%”, “+”, “?” không cần thiết, làm URL trông giống link kỹ thuật hơn là link nội dung.
- Để hệ thống tự sinh slug dạng /post-12345/, /bai-viet-xyz/ không mang ý nghĩa ngữ nghĩa, gây khó khăn cho cả người dùng lẫn bot.
Một URL chuẩn SEO nên có dạng /danh-muc/chu-de-chinh/, với cấu trúc thư mục rõ ràng, không tham số rối mắt. Về mặt kiến trúc thông tin, có thể áp dụng một số nguyên tắc:
- Chiều sâu thư mục (folder depth) nên vừa phải, tránh lồng quá nhiều cấp như /blog/seo/onpage/url/huong-dan/chi-tiet/....
- Thư mục nên đại diện cho nhóm chủ đề (topic cluster), giúp bot hiểu mối quan hệ giữa các bài viết.
- Slug cuối cùng tập trung vào thực thể chính (entity) của trang, không lặp lại từ đã có trong thư mục nếu không cần thiết.
URL càng “sạch” thì càng dễ chuẩn hóa trong các thao tác kỹ thuật như canonical, redirect 301, mapping sitemap, và càng ít rủi ro phát sinh lỗi khi thay đổi hệ thống hoặc di chuyển dữ liệu.
Loại bỏ số vô nghĩa, ngày tháng không cần thiết và từ nối dư thừa
Nhiều website cũ hoặc các CMS mặc định thường thêm ngày tháng hoặc số thứ tự vào URL bài viết, ví dụ: /2023/08/15/cach-viet-url-chuan-seo/ hoặc /bai-viet-123/. Về mặt SEO onpage hiện đại, các thành phần này thường không mang thêm giá trị xếp hạng, trong khi lại tạo ra nhiều bất lợi:
- Làm URL dài hơn, khó nhớ, khó gõ trực tiếp.
- Tạo cảm giác nội dung “cũ” khi người dùng nhìn thấy năm/tháng trong URL, đặc biệt với các truy vấn cần tính cập nhật.
- Gây khó khăn khi muốn cập nhật, tái tối ưu nội dung evergreen mà không muốn thay đổi URL (vì đổi URL sẽ kéo theo redirect, cập nhật internal link, cập nhật backlink…).

Với các nội dung evergreen (bền vững theo thời gian), nên loại bỏ ngày tháng khỏi slug và chỉ thể hiện yếu tố thời gian trong nội dung hoặc meta nếu cần. Ngược lại, với một số loại nội dung tin tức, việc giữ ngày tháng trong cấu trúc thư mục có thể chấp nhận được về mặt tổ chức, nhưng vẫn nên cân nhắc tác động dài hạn.
Bên cạnh đó, các từ nối dư thừa như “va”, “hoac”, “nhung”, “cua”, “la”, “mot”, “nhung-cach-de”, “huong-dan-chi-tiet-ve” thường không đóng góp thêm giá trị ngữ nghĩa đáng kể cho slug. Chúng làm URL dài hơn, khó scan nhanh, và làm giảm mật độ tập trung vào từ khóa chính. Thay vì /huong-dan-chi-tiet-cach-viet-url-chuan-seo-cho-nguoi-moi-bat-dau/, có thể rút gọn thành /cach-viet-url-chuan-seo/ hoặc /url-chuan-seo/ tùy chiến lược.
Một quy tắc thực hành tốt là:
- Giữ lại các từ mang tính thực thể, khái niệm chính: “url”, “chuan-seo”, “cach-viet”, “audit”, “checklist”, “bao-gia”, “dich-vu”.
- Loại bỏ các từ dừng (stop words) không cần thiết trong ngữ cảnh tiếng Việt: “la”, “cua”, “va”, “hoac”, “nhung”, “mot-so”, “nhung-cach-de”, “huong-dan-chi-tiet-ve”…
- Ưu tiên cấu trúc ngắn gọn, dễ đọc, nhưng vẫn đủ thông tin để phân biệt với các bài khác trong cùng nhóm chủ đề.
Việc loại bỏ số vô nghĩa, ngày tháng không cần thiết và từ nối dư thừa giúp slug:
- Ngắn gọn, tập trung vào thực thể chính.
- Dễ đọc, dễ nhớ, dễ gõ lại.
- Dễ tái sử dụng khi cập nhật nội dung, không bị “khóa cứng” bởi thời gian hoặc thứ tự.
Giữ URL dễ đọc để tăng độ tin cậy khi hiển thị trên kết quả tìm kiếm
Trên trang kết quả tìm kiếm, người dùng không chỉ nhìn tiêu đề (title) và mô tả (meta description), mà còn chú ý đến đường dẫn (breadcrumb/URL). Một URL dễ đọc, rõ nghĩa, chứa thực thể liên quan sẽ tạo cảm giác tin cậy và chuyên nghiệp hơn so với một chuỗi ký tự khó hiểu, đặc biệt trong bối cảnh cạnh tranh cao trên SERP.
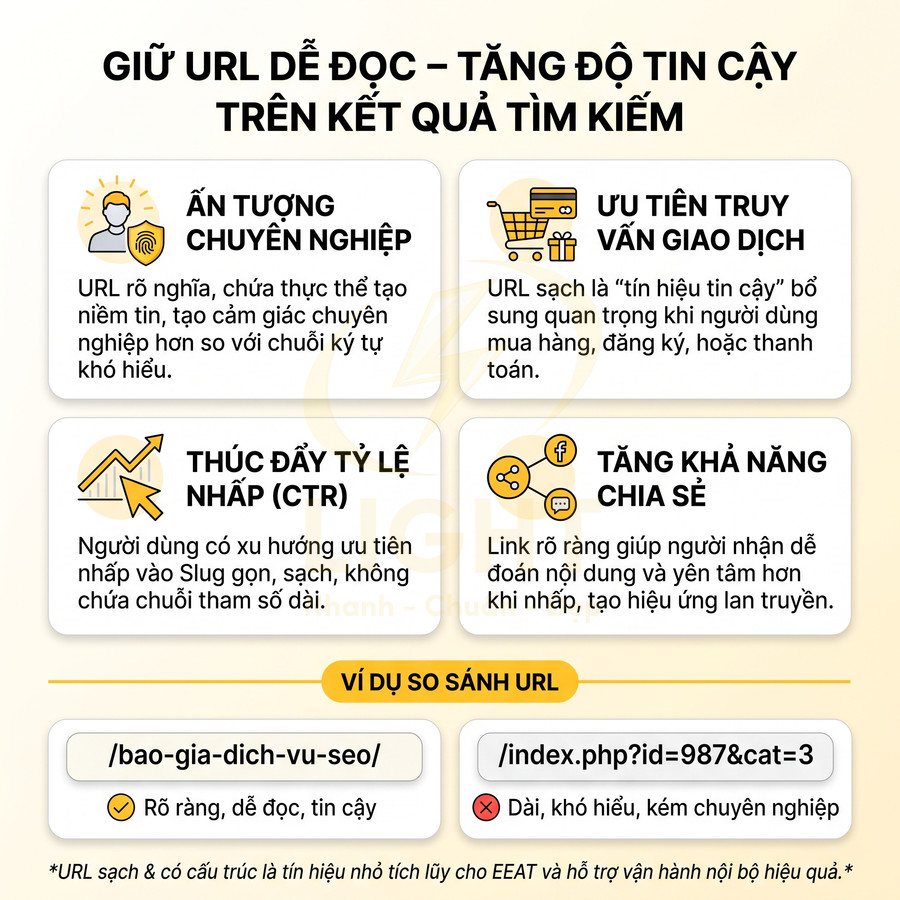
Với các truy vấn thương mại hoặc có liên quan đến giao dịch (mua hàng, đăng ký, thanh toán), URL đóng vai trò như một “tín hiệu tin cậy” bổ sung. Người dùng có xu hướng ưu tiên nhấp vào các kết quả có:
- Domain rõ ràng, thương hiệu quen thuộc.
- Breadcrumb/URL thể hiện đúng chủ đề họ đang tìm.
- Slug gọn, không chứa chuỗi tham số dài hoặc ký tự lạ.
Ví dụ, khi so sánh /bao-gia-dich-vu-seo/ với một URL dạng /index.php?id=987&cat=3, đa số người dùng sẽ cảm thấy yên tâm hơn với URL có cấu trúc rõ ràng, vì họ có thể đoán được nội dung trước khi nhấp.
URL dễ đọc cũng giúp tăng khả năng chia sẻ tự nhiên. Khi người dùng copy link gửi qua email, chat, mạng xã hội, một slug rõ ràng như /bao-gia-dich-vu-seo/, /audit-seo-website/, /checklist-seo-onpage/ sẽ khiến người nhận dễ đoán nội dung và sẵn sàng click hơn so với một URL dài, chứa tham số hoặc mã hóa. Điều này đặc biệt hữu ích trong các chiến dịch marketing lan truyền (viral) hoặc khi nội dung được trích dẫn lại trên các nền tảng khác.
Ở góc độ EEAT, URL sạch và có cấu trúc là một trong những tín hiệu nhỏ nhưng tích lũy, góp phần xây dựng hình ảnh một website được quản trị chuyên nghiệp. Một hệ thống URL được thiết kế tốt thường đi kèm với:
- Kiến trúc thông tin rõ ràng, phân cấp chủ đề hợp lý.
- Chiến lược nội dung theo cụm chủ đề (topic cluster) và trang trụ cột (pillar page).
- Quy trình quản lý redirect, canonical, sitemap bài bản, hạn chế lỗi 404 và trùng lặp nội dung.
Về mặt vận hành, việc giữ URL dễ đọc còn giúp đội ngũ nội bộ (SEO, content, dev, marketing) làm việc hiệu quả hơn: dễ trao đổi, dễ tìm kiếm nội bộ, dễ mapping khi audit, và giảm nhầm lẫn khi triển khai các chiến dịch quảng cáo hoặc tracking.
Cấu trúc URL theo cụm chủ đề giúp bot dễ thu thập và hiểu ngữ cảnh trang
Cấu trúc URL theo cụm chủ đề cần được thiết kế như một lớp ngữ nghĩa bổ sung, trong đó mỗi segment phản ánh quan hệ cha – con và mức độ cụ thể của truy vấn. Khi URL đồng bộ với cấu trúc silo và chiến lược liên kết nội bộ, bot có thể nhận diện nhanh cụm chủ đề, đánh giá topical authority và tối ưu crawl budget hiệu quả hơn. Song song, việc tách riêng namespace cho dịch vụ, blog, dự án, khu vực giúp quản trị nội dung, phân tích dữ liệu và tối ưu SEO theo nhóm rõ ràng, hạn chế xung đột slug. Cuối cùng, cần chuẩn hóa và thống nhất URL, đảm bảo mỗi nội dung chỉ có một địa chỉ chuẩn, các biến thể khác được xử lý bằng redirect 301, canonical hoặc noindex để tránh trùng lặp và phân tán tín hiệu.
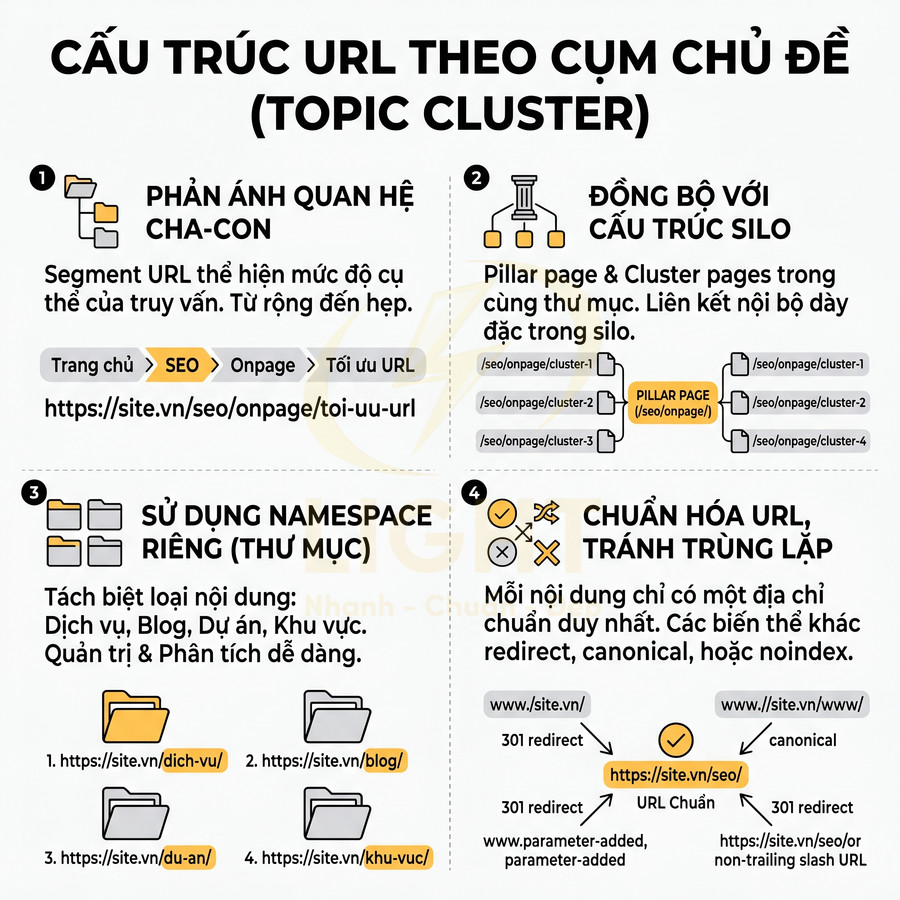
Đường dẫn phản ánh quan hệ chủ đề cha – con – truy vấn cụ thể
Cấu trúc URL theo cụm chủ đề không chỉ là việc chia thư mục cho “gọn mắt”, mà là một lớp ngữ nghĩa bổ sung giúp bot hiểu được bối cảnh nội dung trước cả khi phân tích HTML. Mỗi segment trong URL tương ứng với một tầng chủ đề, từ rộng đến hẹp, tạo thành một “đường dẫn ngữ nghĩa” (semantic path) dẫn bot đi từ chủ đề tổng quát đến truy vấn cụ thể.
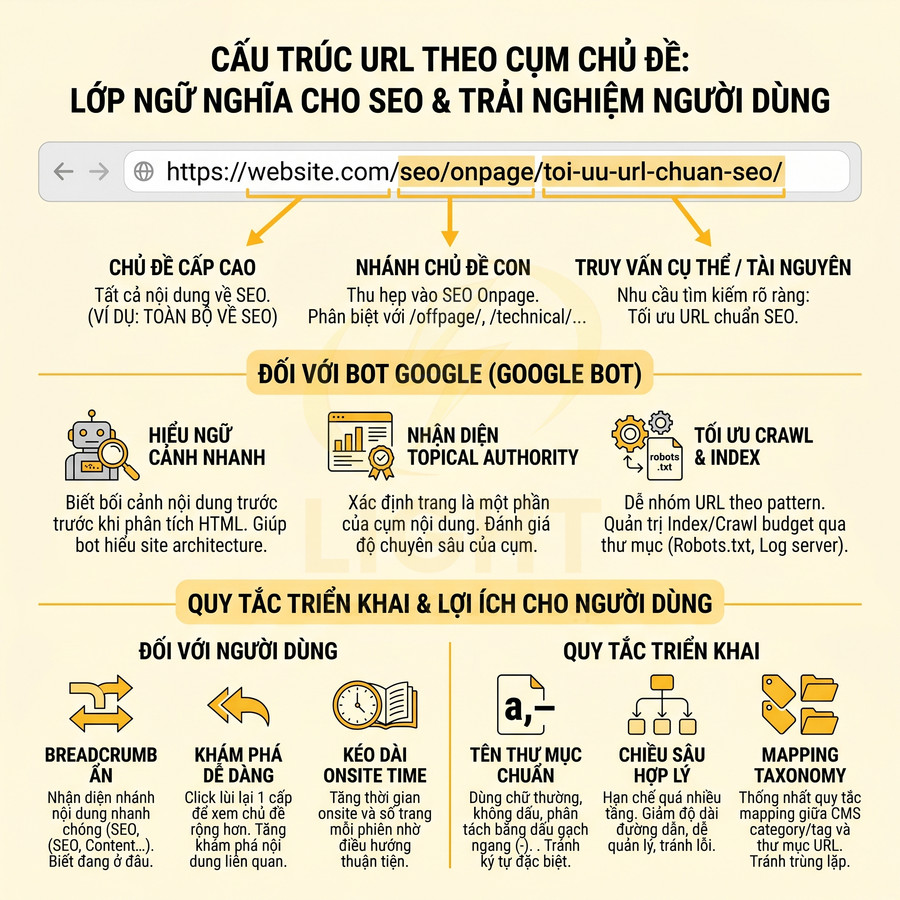
Với ví dụ: /seo/onpage/toi-uu-url-chuan-seo/:
- /seo/ thể hiện chủ đề cấp cao: toàn bộ nội dung liên quan đến SEO.
- /seo/onpage/ thu hẹp vào nhánh SEO Onpage, phân tách rõ với các nhánh khác như /seo/offpage/ hoặc /seo/technical/.
- /seo/onpage/toi-uu-url-chuan-seo/ là tài nguyên cụ thể, giải quyết một nhu cầu tìm kiếm rõ ràng: tối ưu URL chuẩn SEO.
Cách tổ chức này giúp bot:
- Hiểu được ngữ cảnh chủ đề của trang mà không cần crawl toàn bộ site.
- Nhận diện trang nào là một phần của cụm nội dung SEO Onpage, từ đó đánh giá độ chuyên sâu (topical authority) của toàn cụm.
- Dễ dàng nhóm các URL theo pattern để phục vụ cho việc lập chỉ mục, crawl budget và đánh giá chất lượng theo cụm.
Về mặt kỹ thuật, quan hệ cha – con trong URL hỗ trợ mạnh cho phân quyền nội dung và quản trị index:
- Ở cấp máy chủ hoặc CDN, có thể áp dụng quy tắc chặn index, chặn crawl, hoặc giới hạn truy cập theo từng thư mục, ví dụ: chặn /test/, /staging/, hoặc /seo/experiment/.
- Trong file robots.txt, có thể dùng pattern thư mục để điều khiển bot: Disallow: /private/ hoặc Disallow: /seo/internal-report/.
- Trong các công cụ phân tích log server, có thể lọc request theo thư mục để xem bot crawl cụm nào nhiều, cụm nào ít, từ đó tối ưu crawl budget.
Đối với người dùng, đường dẫn dạng thư mục tạo ra một “breadcrumb ẩn” ngay trên thanh địa chỉ. Khi nhìn vào URL, họ có thể:
- Nhận diện nhanh mình đang ở nhánh nội dung nào (SEO, Content, Ads…).
- Click “lùi lại” một cấp để xem chủ đề rộng hơn, ví dụ từ /seo/onpage/toi-uu-url-chuan-seo/ quay về /seo/onpage/ để xem toàn bộ bài viết về Onpage.
- Tăng khả năng khám phá nội dung liên quan, kéo dài thời gian onsite và tăng số trang mỗi phiên.
Ở mức triển khai, cần thống nhất rõ:
- Quy tắc đặt tên thư mục: dùng chữ thường, không dấu, phân tách bằng dấu gạch ngang, tránh ký tự đặc biệt.
- Chiều sâu tối đa của URL: hạn chế quá nhiều tầng khiến đường dẫn dài, khó quản lý và dễ gây lỗi khi refactor.
- Quy tắc mapping giữa taxonomy (category, tag) trong CMS và thư mục vật lý/ảo trong URL để tránh trùng lặp.
Danh mục URL đồng bộ với cấu trúc silo và liên kết nội bộ
Cấu trúc URL chỉ phát huy tối đa hiệu quả khi được thiết kế đồng bộ với cấu trúc silo và chiến lược liên kết nội bộ. Một silo chủ đề chuẩn thường bao gồm:
- Trang trụ cột (pillar page) ở tầng trên cùng, bao quát toàn bộ chủ đề.
- Các trang cluster (bài viết chuyên sâu) ở tầng dưới, mỗi trang xử lý một khía cạnh cụ thể của chủ đề.
- Liên kết nội bộ dày đặc trong cùng silo, tạo thành một “khối” nội dung chặt chẽ về mặt chủ đề.
- Hạn chế liên kết chéo không cần thiết sang silo khác để tránh loãng tín hiệu chủ đề.
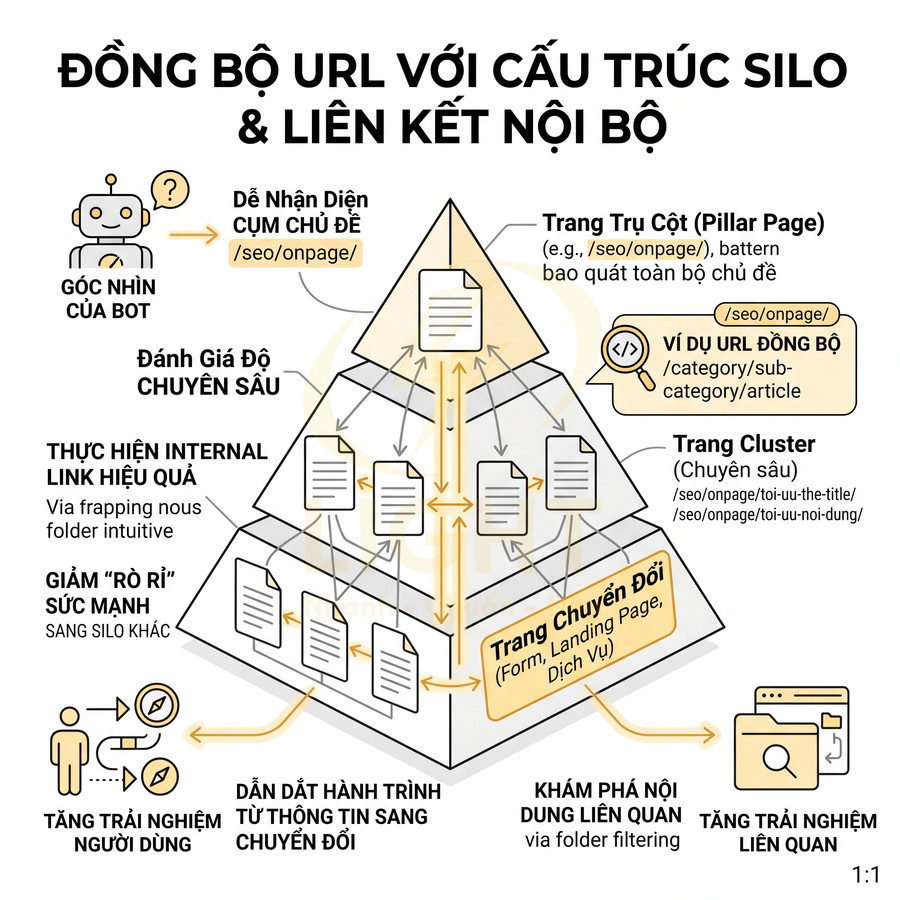
URL cần phản ánh chính xác cấu trúc silo này. Ví dụ với silo SEO Onpage:
- Trang trụ cột: /seo/onpage/
- Trang cluster: /seo/onpage/toi-uu-url-chuan-seo/, /seo/onpage/toi-uu-the-title/, /seo/onpage/toi-uu-noi-dung/…
Khi danh mục URL đồng bộ với silo:
- Bot dễ nhận diện cụm chủ đề: chỉ cần phân tích pattern /seo/onpage/ là có thể gom toàn bộ nội dung liên quan.
- Độ chuyên sâu của silo được thể hiện rõ qua số lượng và chất lượng trang con trong cùng thư mục.
- Việc xây dựng internal link trở nên trực quan: trang trong cùng thư mục ưu tiên liên kết cho nhau, giảm rủi ro “rò rỉ” sức mạnh sang silo không liên quan.
Về mặt triển khai liên kết nội bộ trong silo:
- Trang trụ cột liên kết xuống tất cả trang cluster quan trọng, sử dụng anchor text giàu ngữ nghĩa, bám sát chủ đề của từng trang con.
- Trang cluster liên kết ngược lên trang trụ cột, khẳng định mối quan hệ cha – con và giúp bot hiểu trang nào là trung tâm của silo.
- Các trang cluster liên kết ngang với nhau khi có liên quan nội dung, tạo thành mạng lưới dày đặc trong silo.
- Các trang chuyển đổi (form, landing page, trang dịch vụ) trong silo được gắn ở những vị trí chiến lược: cuối bài, giữa bài, hoặc trong các block đề xuất nội dung.
Về trải nghiệm người dùng, cấu trúc URL đồng bộ với silo giúp:
- Dẫn dắt hành trình từ nội dung thông tin (informational) sang nội dung chuyển đổi (transactional) một cách tự nhiên.
- Giảm cảm giác “bị đẩy sang trang lạ” vì URL vẫn nằm trong cùng nhánh chủ đề.
- Tăng khả năng người dùng khám phá thêm nội dung trong cùng silo nhờ các block “bài viết liên quan” được filter theo thư mục.
Trang dịch vụ, bài viết, dự án và khu vực dùng quy tắc thư mục riêng
Để website dễ mở rộng, dễ bảo trì và dễ phân tích dữ liệu, cần định nghĩa quy tắc thư mục riêng cho từng loại nội dung chính. Mỗi loại nội dung nên có một “namespace” rõ ràng trong URL, giúp phân tách logic giữa các nhóm:
- /dich-vu/ten-dich-vu/ cho trang dịch vụ, thường mang mục tiêu chuyển đổi (lead, đơn hàng, đăng ký).
- /blog/chu-de-bai-viet/ hoặc /kien-thuc/chu-de/ cho bài viết kiến thức, chủ yếu phục vụ nhu cầu tìm hiểu, giáo dục thị trường.
- /du-an/ten-du-an/ cho case study, portfolio, thể hiện năng lực thực thi.
- /khu-vuc/ten-khu-vuc/ hoặc /dich-vu/ten-dich-vu/ten-khu-vuc/ cho trang địa phương, phục vụ SEO local và truy vấn có yếu tố vị trí.
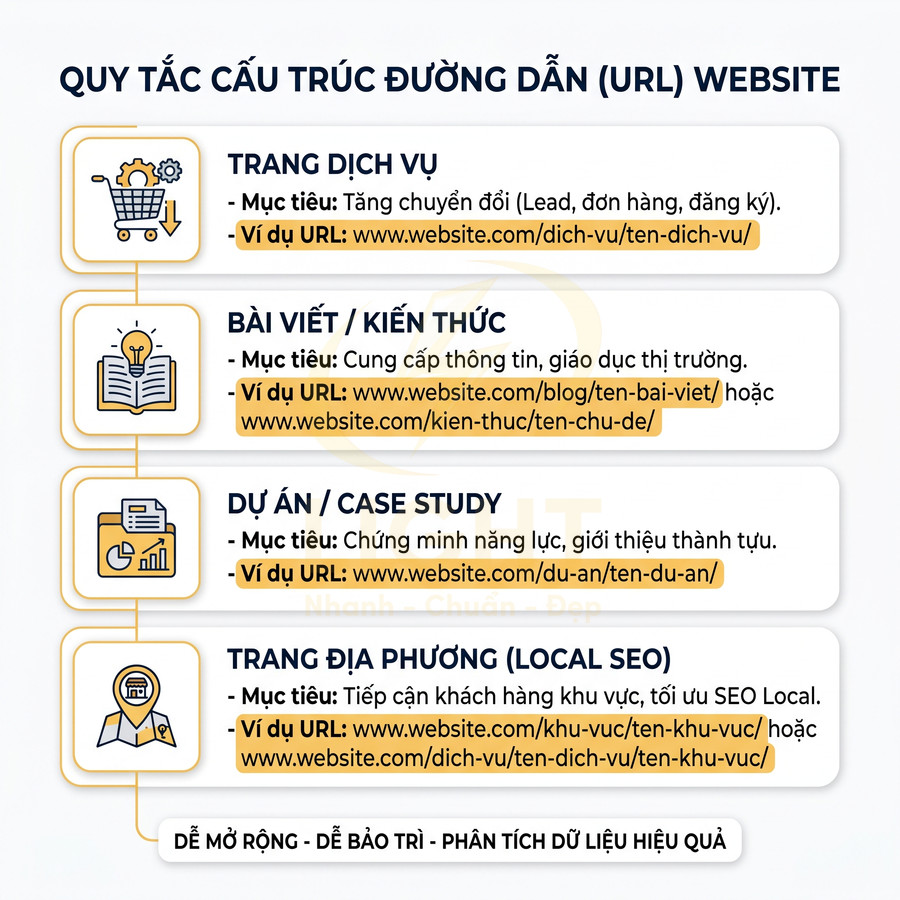
Cách phân tách này mang lại nhiều lợi ích:
- Quản trị nội dung: đội content, marketing, sales dễ nhận biết loại trang chỉ bằng cách nhìn URL; quy trình review, cập nhật, A/B test cũng rõ ràng hơn.
- Phân tích dữ liệu: trong Google Analytics, Search Console hoặc BI, có thể tạo segment theo pattern URL để xem hiệu suất riêng của từng nhóm:
- Nhóm dịch vụ: /dich-vu/…
- Nhóm blog: /blog/… hoặc /kien-thuc/…
- Nhóm dự án: /du-an/…
- Nhóm địa phương: /khu-vuc/… hoặc /dich-vu/ten-dich-vu/ten-khu-vuc/
- Tối ưu SEO theo nhóm: khi cần đẩy mạnh index hoặc cải thiện CTR cho một nhóm cụ thể (ví dụ: trang địa phương), có thể thao tác theo pattern URL mà không ảnh hưởng nhóm khác.
Ở góc độ kiến trúc thông tin, việc tách rõ các loại nội dung trong URL giúp:
- Tránh xung đột slug giữa bài viết và dịch vụ (ví dụ: /dich-vu/seo/ và /blog/seo/ có thể cùng tồn tại mà không gây nhầm lẫn).
- Định nghĩa rõ luồng internal link: bài viết kiến thức dẫn về trang dịch vụ tương ứng, case study dẫn về cả dịch vụ và khu vực liên quan.
- Dễ dàng mở rộng sang các ngôn ngữ hoặc thị trường khác bằng cách thêm tầng /en/, /jp/… mà vẫn giữ logic thư mục bên trong.
Khi triển khai trang địa phương, có hai mô hình URL phổ biến:
- /khu-vuc/ten-khu-vuc/: phù hợp khi muốn xây cụm nội dung xoay quanh khu vực (tin tức, hướng dẫn, danh sách chi nhánh…).
- /dich-vu/ten-dich-vu/ten-khu-vuc/: phù hợp khi trọng tâm là dịch vụ tại từng khu vực, tối ưu cho truy vấn kiểu “dịch vụ + khu vực”.
Quan trọng là phải thống nhất mô hình ngay từ đầu, tránh việc cùng một loại trang địa phương lại xuất hiện ở nhiều pattern khác nhau, gây khó khăn cho cả bot lẫn người dùng.
Không để một nội dung xuất hiện ở nhiều biến thể URL khác nhau
Một trong những lỗi kỹ thuật nghiêm trọng nhưng thường bị bỏ qua là để cùng một nội dung có thể truy cập qua nhiều biến thể URL. Các biến thể phổ biến gồm:
- Có hoặc không “www”: https://example.com/ và https://www.example.com/.
- Có hoặc không “/” ở cuối: /seo/onpage/ và /seo/onpage.
- Có hoặc không tham số tracking: /seo/onpage/?utm_source=… so với URL gốc.
- Có hoặc không chữ hoa: /SEO/Onpage/ so với /seo/onpage/.
- Cùng một bài viết xuất hiện ở nhiều đường dẫn danh mục khác nhau, ví dụ:
- /blog/seo/toi-uu-url-chuan-seo/
- /kien-thuc/seo-onpage/toi-uu-url-chuan-seo/
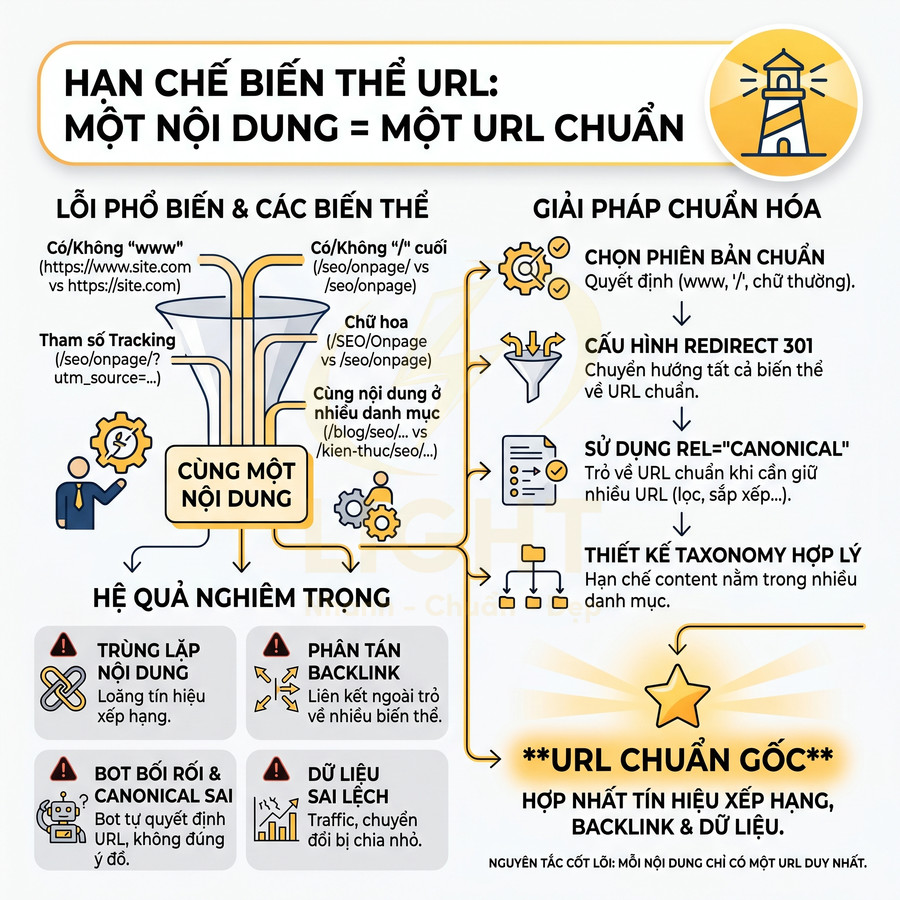
Hệ quả là:
- Trùng lặp nội dung (duplicate content) trong mắt bot, làm loãng tín hiệu xếp hạng.
- Phân tán backlink: liên kết ngoài trỏ về nhiều biến thể khác nhau, thay vì dồn về một URL chuẩn.
- Khó chọn phiên bản chuẩn: bot phải tự quyết định URL nào là canonical, đôi khi không trùng với ý đồ của bạn.
- Khó phân tích dữ liệu: traffic và chuyển đổi bị chia nhỏ theo từng biến thể, làm sai lệch báo cáo.
Để tránh tình trạng này, cần thiết lập quy tắc chuẩn hóa URL ở cả mức kỹ thuật và quy trình:
- Chọn một phiên bản duy nhất cho toàn site:
- Quyết định dùng hoặc không dùng “www” (thường là không “www”).
- Quyết định có hoặc không có “/” ở cuối (trang HTML thường thống nhất một kiểu; API có thể khác).
- Chuẩn hóa dùng chữ thường, không dấu tiếng Việt, không khoảng trắng, không ký tự đặc biệt.
- Cấu hình redirect 301:
- Redirect tất cả biến thể “www” về non-www hoặc ngược lại.
- Redirect phiên bản HTTP về HTTPS.
- Redirect các URL có chữ hoa về phiên bản chữ thường.
- Redirect các URL cũ (khi thay đổi cấu trúc) về URL mới tương ứng, tránh tạo chuỗi redirect.
- Sử dụng thẻ rel="canonical":
- Áp dụng cho các trường hợp cần giữ nhiều URL vì lý do kỹ thuật (lọc, sắp xếp, phân trang…), nhưng chỉ muốn index một phiên bản chuẩn.
- Đảm bảo canonical luôn trỏ về URL chuẩn, không trỏ chéo hoặc tự tham chiếu sai.
- Thiết kế taxonomy và slug hợp lý:
- Hạn chế để một nội dung nằm trong nhiều danh mục tạo ra nhiều slug khác nhau.
- Nếu CMS bắt buộc tạo nhiều đường dẫn, cần chọn một URL chính để index, các URL còn lại noindex + canonical về URL chính hoặc redirect 301.
Nguyên tắc cốt lõi: mỗi nội dung chỉ nên có một URL duy nhất được index. Mọi biến thể khác phải được xử lý bằng redirect 301, canonical hoặc noindex tùy trường hợp, nhằm đảm bảo tín hiệu xếp hạng, backlink và dữ liệu hành vi đều tập trung về một địa chỉ chuẩn.
Cách viết URL cho trang dịch vụ, bài viết kiến thức và trang chuyển đổi
URL cho từng loại trang cần bám sát mục đích sử dụng, vừa thân thiện với người dùng vừa hỗ trợ SEO và quản trị dài hạn. Với trang dịch vụ, slug nên phản ánh đúng tên dịch vụ và nhu cầu tìm kiếm, ưu tiên cấu trúc phân cấp rõ ràng theo nhóm dịch vụ, tránh tính từ tiếp thị và giữ ổn định để không phải redirect nhiều lần. Với bài viết kiến thức, slug bám theo câu hỏi hoặc vấn đề người dùng gõ vào, thể hiện dạng nội dung (cách, hướng dẫn, so sánh, checklist), tập trung vào thực thể chính, ngắn gọn và không lạm dụng năm hoặc tính từ “nhất”. Trang chuyển đổi cần slug thể hiện hành động (bao-gia, dang-ky-demo, dat-lich-tu-van), dễ phân tích dữ liệu và đồng bộ với anchor text. Trang địa phương kết hợp thực thể dịch vụ và khu vực, cấu trúc hệ thống, tránh nhồi từ khóa và phải đi kèm nội dung bản địa hóa thực sự.
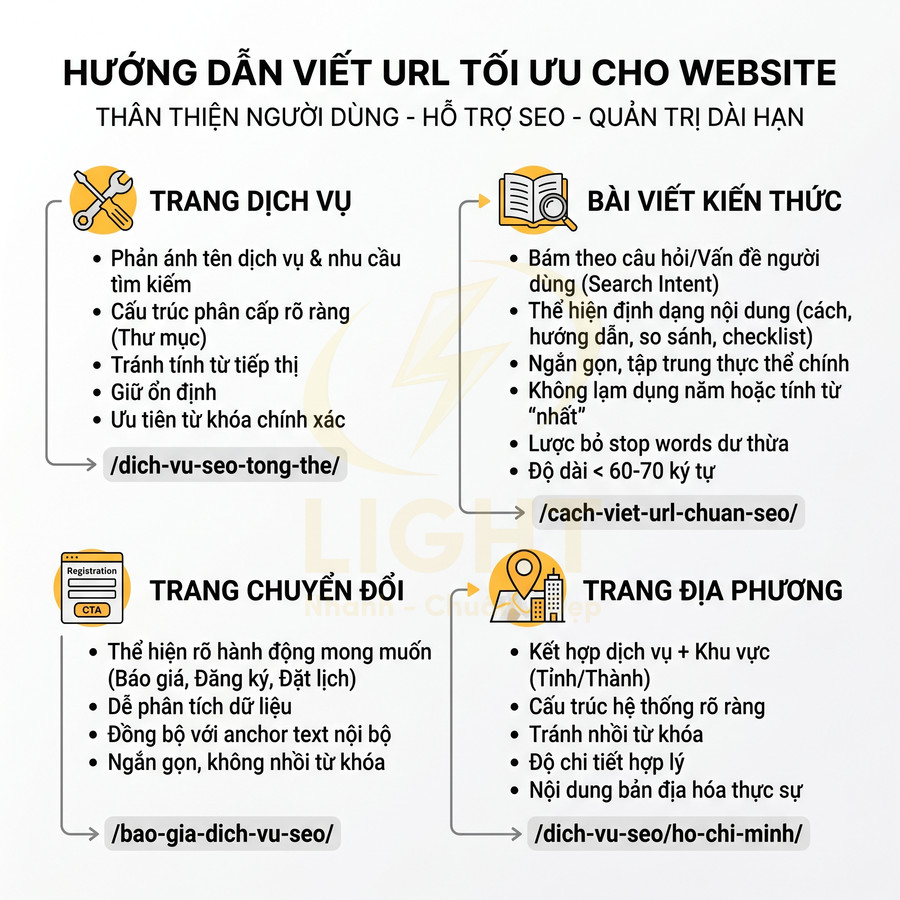
URL trang dịch vụ bám theo tên dịch vụ và nhu cầu khách hàng
Trang dịch vụ là nhóm URL có tác động trực tiếp đến doanh thu, nên cách đặt slug cần đáp ứng đồng thời ba tiêu chí: rõ ràng với người dùng, tối ưu cho SEO và dễ quản trị về lâu dài. Thay vì sử dụng tên gói nội bộ, hãy ưu tiên chính xác cụm từ mà khách hàng gõ vào Google. Ví dụ, nếu phần lớn truy vấn xoay quanh “dịch vụ seo tổng thể”, slug hợp lý sẽ là /dich-vu-seo-tong-the/, trong khi /goi-seo-premium/ chỉ có ý nghĩa với đội ngũ nội bộ và không phản ánh đúng ngôn ngữ tìm kiếm của thị trường.
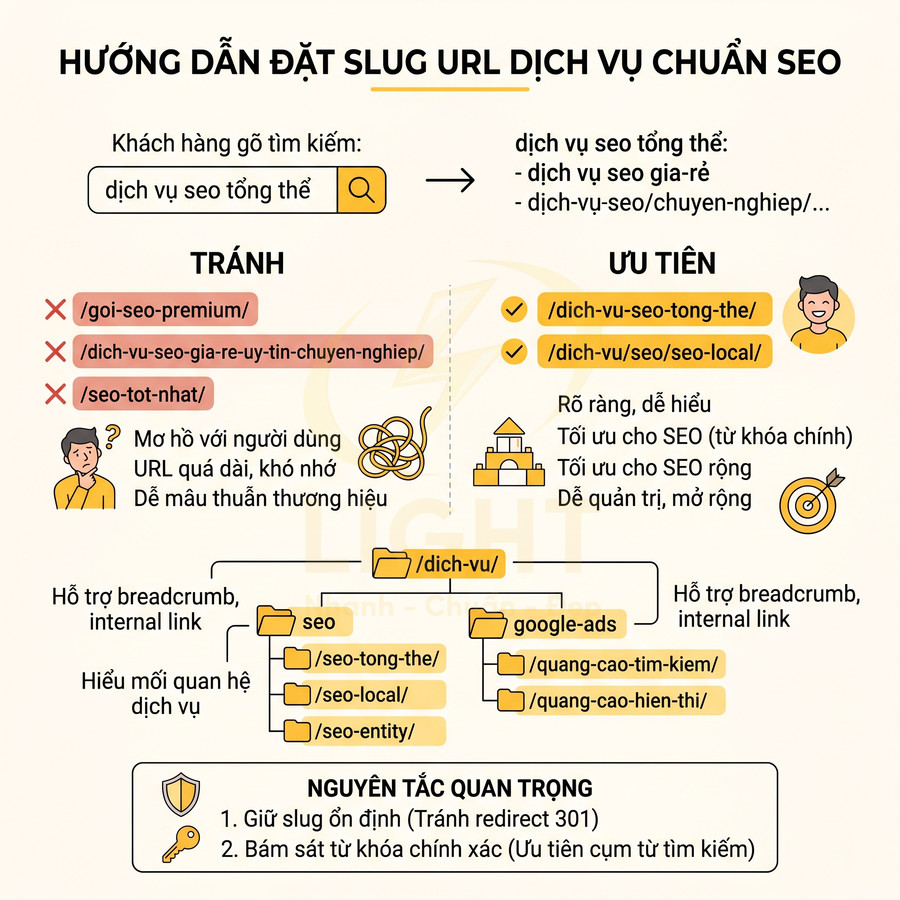
Với các dịch vụ có nhiều biến thể, nên thiết kế cấu trúc thư mục mang tính phân cấp, giúp Google hiểu mối quan hệ giữa các dịch vụ và giúp người dùng dễ định vị:
- /dich-vu/seo/seo-tong-the/
- /dich-vu/seo/seo-local/
- /dich-vu/seo/seo-entity/
Mỗi slug nên thể hiện một thực thể dịch vụ rõ ràng, không chồng chéo, không mơ hồ. Cấu trúc dạng thư mục cũng hỗ trợ tốt cho breadcrumb, internal link và việc mở rộng thêm dịch vụ mới trong tương lai mà không phá vỡ logic tổng thể.
Khi tối ưu slug cho trang dịch vụ, cần lưu ý một số nguyên tắc chuyên sâu:
- Không lạm dụng tính từ tiếp thị như “chuyen-nghiep”, “gia-re”, “tot-nhat”, “uy-tin”, vì:
- Không tạo ra khác biệt đáng kể về SEO so với từ khóa chính.
- Làm URL dài, khó đọc, khó nhớ và khó chia sẻ.
- Dễ mâu thuẫn với chiến lược định vị thương hiệu trong tương lai (ví dụ chuyển từ “giá rẻ” sang “cao cấp”).
- Giữ slug ổn định: thay đổi slug dịch vụ sẽ kéo theo redirect 301, nguy cơ mất một phần tín hiệu SEO và gây gián đoạn tracking chiến dịch.
- Ưu tiên từ khóa chính xác thay vì biến thể sáng tạo: “/dich-vu-seo-tong-the/” thường tốt hơn “/giai-phap-marketing-seo-tong-the/” vì bám sát cách người dùng tìm kiếm.
Với các dịch vụ phức tạp, có nhiều tầng, có thể áp dụng cấu trúc phân nhóm theo ngành hoặc mục tiêu, miễn là vẫn giữ được sự ngắn gọn và tính nhất quán:
- /dich-vu/seo/
- /dich-vu/google-ads/
- /dich-vu/social-media/
Bên trong mỗi nhóm, slug con nên phản ánh đúng “job to be done” của khách hàng, ví dụ: /dich-vu/google-ads/quang-cao-tim-kiem/, /dich-vu/google-ads/quang-cao-hien-thi/. Cách đặt này giúp cả bot lẫn người dùng hiểu được bức tranh tổng thể dịch vụ chỉ bằng cách nhìn vào URL.
URL bài viết bám theo câu hỏi hoặc vấn đề người dùng tìm kiếm
Với bài viết kiến thức, mục tiêu chính là đáp ứng ý định tìm kiếm (search intent), nên slug cần bám sát câu hỏi hoặc vấn đề mà người dùng thực sự gõ vào ô tìm kiếm. Nếu truy vấn phổ biến là “url chuẩn seo là gì”, slug nên là /url-chuan-seo-la-gi/. Nếu truy vấn là “cách viết url chuẩn seo”, slug nên là /cach-viet-url-chuan-seo/. Khi người dùng nhìn thấy URL trong SERP, cảm giác “đúng cái mình đang hỏi” sẽ tăng CTR và hỗ trợ thêm cho tín hiệu liên quan.
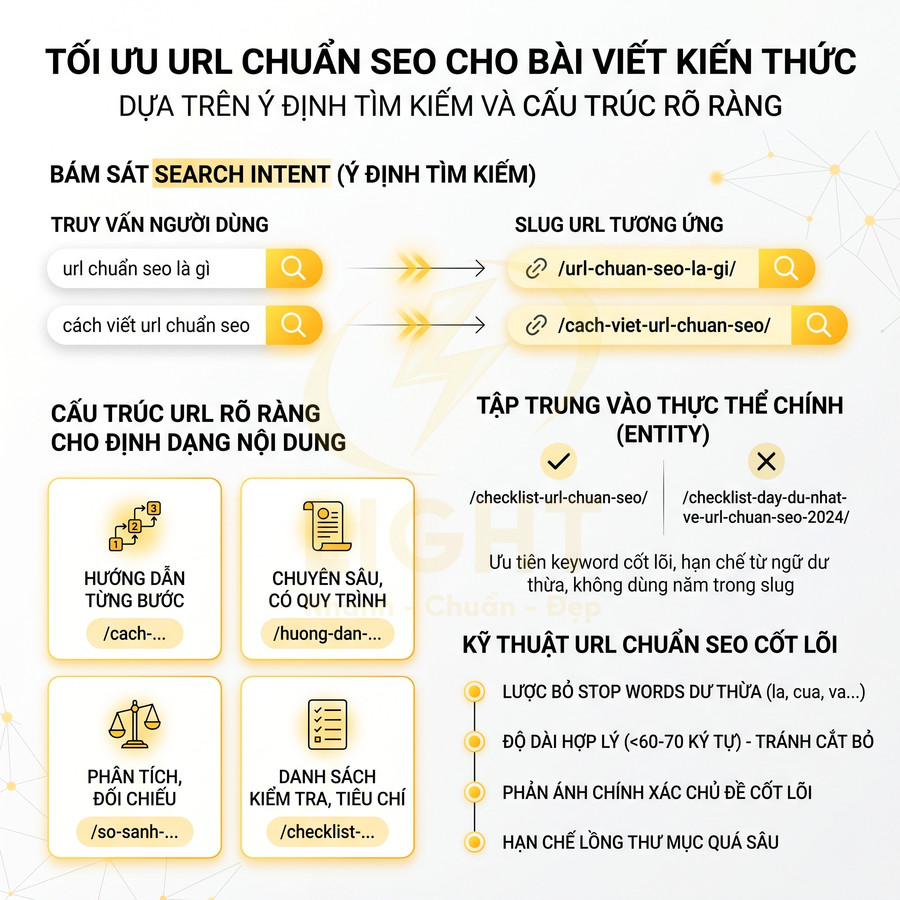
Đối với các bài viết dạng hướng dẫn, checklist, so sánh, nên ưu tiên các mẫu slug có cấu trúc rõ ràng, thể hiện ngay định dạng nội dung:
- /cach-…/ – phù hợp với bài hướng dẫn từng bước.
- /huong-dan-…/ – dùng cho nội dung chuyên sâu, có quy trình.
- /so-sanh-…/ – dùng cho bài phân tích, đối chiếu nhiều lựa chọn.
- /checklist-…/ – dùng cho bài dạng danh sách kiểm tra, tiêu chí.
Điểm quan trọng là slug vẫn phải xoay quanh thực thể chính (entity) của bài viết. Ví dụ, với chủ đề “URL chuẩn SEO”, slug /checklist-url-chuan-seo/ sẽ rõ ràng và tập trung hơn so với /checklist-day-du-nhat-ve-url-chuan-seo-2024/.
Các yếu tố như “day-du-nhat”, “chi-tiet-nhat”, “moi-nhat-2024” thường nên đặt trong title và H1 thay vì slug, vì:
- Không mang lại nhiều giá trị SEO bổ sung so với từ khóa chính.
- Làm slug dài, khó đọc, khó tối ưu khi cập nhật nội dung theo năm.
- Mỗi lần đổi năm (2023 → 2024) sẽ phải đổi slug nếu có năm trong URL, kéo theo redirect và rủi ro mất tín hiệu.
Về mặt kỹ thuật, slug bài viết kiến thức nên:
- Không chứa stop words dư thừa nếu không cần thiết cho ngữ nghĩa (ví dụ có thể lược bỏ “la”, “cua”, “va” nếu không làm mất nghĩa).
- Giữ độ dài hợp lý, thường dưới 60–70 ký tự, để tránh bị cắt trong một số giao diện và đảm bảo dễ chia sẻ.
- Phản ánh chính xác chủ đề: nếu bài viết mở rộng sang nhiều chủ đề phụ, vẫn nên chọn slug theo chủ đề cốt lõi có volume và giá trị cao nhất.
Với các series bài viết, có thể dùng cấu trúc thư mục nhẹ để nhóm nội dung, ví dụ: /kien-thuc-seo/url-chuan-seo-la-gi/, /kien-thuc-seo/cach-viet-url-chuan-seo/. Tuy nhiên, không nên lồng quá nhiều cấp như /blog/kien-thuc/seo/onpage/url-chuan-seo-la-gi/ vì sẽ làm URL rườm rà, khó quản trị khi tái cấu trúc chuyên mục.
URL trang báo giá, liên hệ, demo ưu tiên rõ mục tiêu chuyển đổi
Các trang chuyển đổi như báo giá, liên hệ, đăng ký demo, đặt lịch tư vấn đóng vai trò là điểm kết thúc hoặc điểm then chốt trong phễu bán hàng. Slug của nhóm trang này cần thể hiện rõ ràng hành động mà doanh nghiệp mong muốn người dùng thực hiện. Ví dụ:
- /bao-gia-dich-vu-seo/
- /dang-ky-demo-phan-mem-seo/
- /dat-lich-tu-van-seo/
- /lien-he/
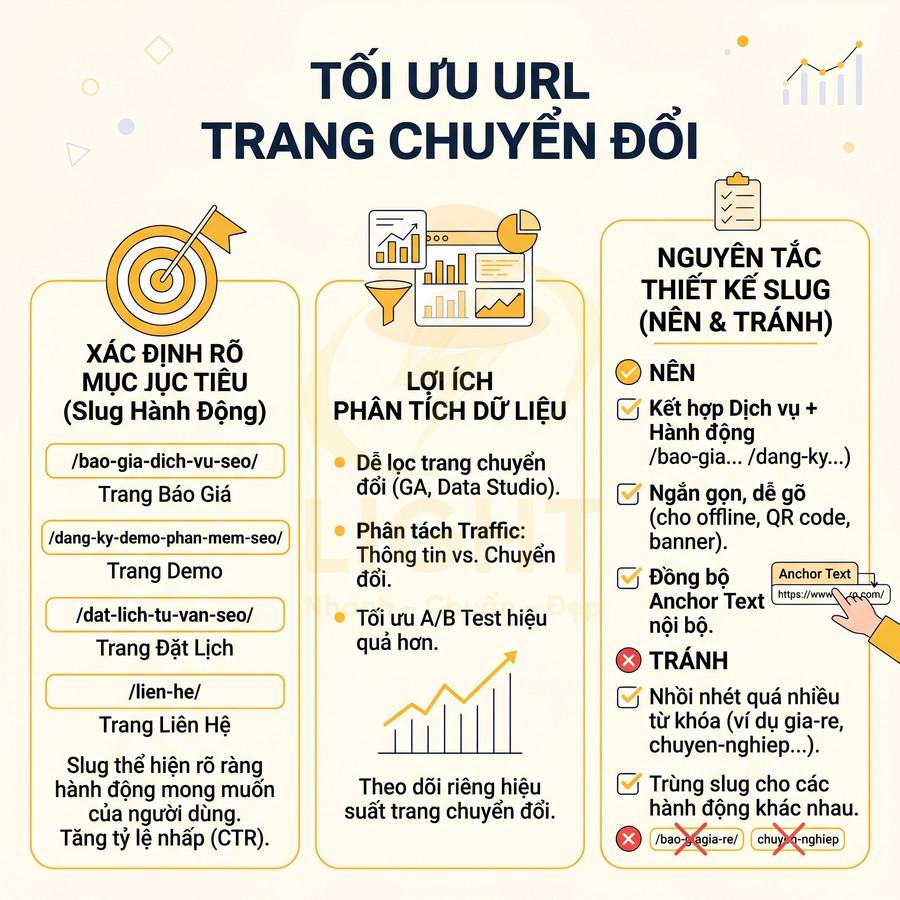
URL rõ ràng giúp người dùng ngay lập tức hiểu họ sẽ đến đâu khi click, giảm cảm giác rủi ro (ví dụ sợ bị chuyển sang trang không liên quan hoặc bị ép mua hàng) và từ đó tăng tỷ lệ nhấp. Về mặt phân tích dữ liệu, slug có cấu trúc nhất quán theo hành động cũng giúp:
- Dễ dàng tạo bộ lọc trong Google Analytics, Data Studio, hoặc các công cụ BI để theo dõi riêng hiệu suất trang chuyển đổi.
- Phân tách rõ traffic mang tính thông tin (informational) và traffic mang tính chuyển đổi (transactional).
- Tối ưu A/B test nội dung, form, CTA dựa trên từng nhóm URL chuyển đổi.
Với các trang này, không cần (và không nên) nhồi nhét quá nhiều từ khóa. Chỉ cần kết hợp thực thể dịch vụ + hành động là đủ, ví dụ: /bao-gia-dich-vu-seo/, /dang-ky-demo-phan-mem-seo/. Việc cố gắng thêm các cụm như “gia-re”, “chuyen-nghiep”, “tot-nhat” vào slug chuyển đổi thường không mang lại thêm giá trị, trong khi lại làm URL kém tin cậy hơn trong mắt người dùng có kinh nghiệm.
Ngoài ra, nên đảm bảo:
- Không trùng slug giữa các loại hành động khác nhau. Ví dụ, không nên dùng chung “/lien-he/” cho cả form liên hệ chung và form đặt lịch tư vấn chuyên sâu.
- Giữ slug ngắn và dễ gõ để có thể sử dụng trên ấn phẩm offline, QR code, banner, hoặc trong các chiến dịch remarketing.
- Đồng bộ với anchor text nội bộ: nếu slug là “/dat-lich-tu-van-seo/”, anchor text nội bộ nên ưu tiên các cụm như “đặt lịch tư vấn SEO”, “đăng ký tư vấn SEO” để tăng tính nhất quán ngữ nghĩa.
URL trang địa phương thêm thực thể khu vực nhưng không nhồi từ khóa
Trang địa phương (local landing page) là nơi kết hợp giữa thực thể dịch vụ và thực thể khu vực. Mục tiêu là giúp Google hiểu doanh nghiệp cung cấp dịch vụ gì, tại khu vực nào, đồng thời tránh bị đánh giá là nhồi từ khóa hoặc tạo nội dung trùng lặp. Thay vì sử dụng cấu trúc lặp lại như /dich-vu-seo-ho-chi-minh-seo-ho-chi-minh/, nên tối ưu thành:
- /dich-vu-seo/ho-chi-minh/
- /seo-local-ho-chi-minh/
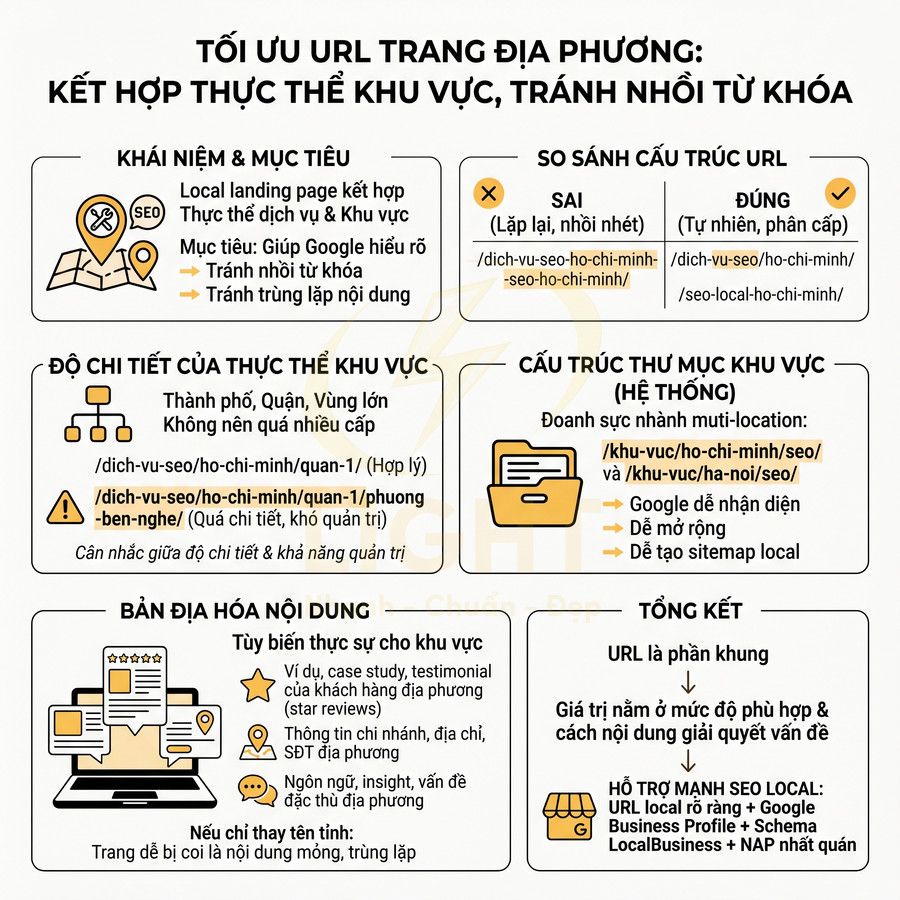
Thực thể khu vực có thể là tên thành phố, quận, hoặc vùng lớn, nhưng không nên liệt kê quá nhiều cấp trong một slug, ví dụ: /dich-vu-seo/ho-chi-minh/quan-1/ là hợp lý, trong khi /dich-vu-seo/ho-chi-minh/quan-1/phuong-ben-nghe/ thường là quá chi tiết và khó mở rộng. Cần cân nhắc giữa độ chi tiết và khả năng quản trị nội dung.
Với doanh nghiệp phục vụ nhiều tỉnh thành, nên xây dựng một cấu trúc thư mục khu vực rõ ràng, có tính hệ thống:
- /khu-vuc/ho-chi-minh/seo/
- /khu-vuc/ha-noi/seo/
Cách tổ chức này giúp:
- Google dễ nhận diện cụm nội dung local theo từng khu vực.
- Đội ngũ nội dung dễ mở rộng thêm tỉnh thành mới mà không phá vỡ cấu trúc cũ.
- Dễ tạo sitemap riêng cho local landing page nếu cần.
Mỗi URL địa phương cần có nội dung được tùy biến thực sự cho khu vực đó, không chỉ copy-paste rồi thay tên tỉnh. Các yếu tố nên được bản địa hóa gồm:
- Ví dụ, case study, testimonial của khách hàng tại khu vực đó.
- Thông tin chi nhánh, địa chỉ, số điện thoại địa phương.
- Ngôn ngữ, insight, vấn đề đặc thù của thị trường địa phương.
Nếu chỉ thay tên tỉnh trong nội dung, trang rất dễ bị coi là nội dung mỏng hoặc trùng lặp, làm giảm hiệu quả SEO local. URL chỉ là phần khung; giá trị thực nằm ở mức độ phù hợp với người dùng địa phương và cách nội dung giải quyết vấn đề của họ. Khi kết hợp với các tín hiệu khác như Google Business Profile, schema LocalBusiness, NAP nhất quán, cấu trúc URL local rõ ràng sẽ hỗ trợ mạnh cho chiến lược SEO địa phương.
Quy tắc URL giúp dễ index khi website mở rộng nhiều chuyên mục
Cấu trúc URL trong giai đoạn website mở rộng cần được thiết kế như một hệ thống phân luồng crawl hiệu quả, thay vì chỉ tập trung vào yếu tố “đẹp” hay chứa từ khóa. Mục tiêu là giữ URL ngắn, ổn định, dễ chuẩn hóa, đồng thời phản ánh rõ các nhóm nội dung quan trọng nhất. Độ sâu thư mục nên được kiểm soát ở mức hợp lý để hạn chế tạo ra các tầng nội dung khó tiếp cận, tránh hình thành những khu vực ít được bot ghé thăm. Slug cần được xem như một định danh bền vững, ưu tiên chủ đề cốt lõi, hạn chế tối đa việc thay đổi khi chỉ chỉnh sửa nội dung nhỏ. Các nhóm URL phân trang, lọc, tìm kiếm nội bộ phải có quy tắc rõ ràng, kết hợp với thẻ canonical để hợp nhất tín hiệu SEO, giảm trùng lặp và tối ưu ngân sách crawl.
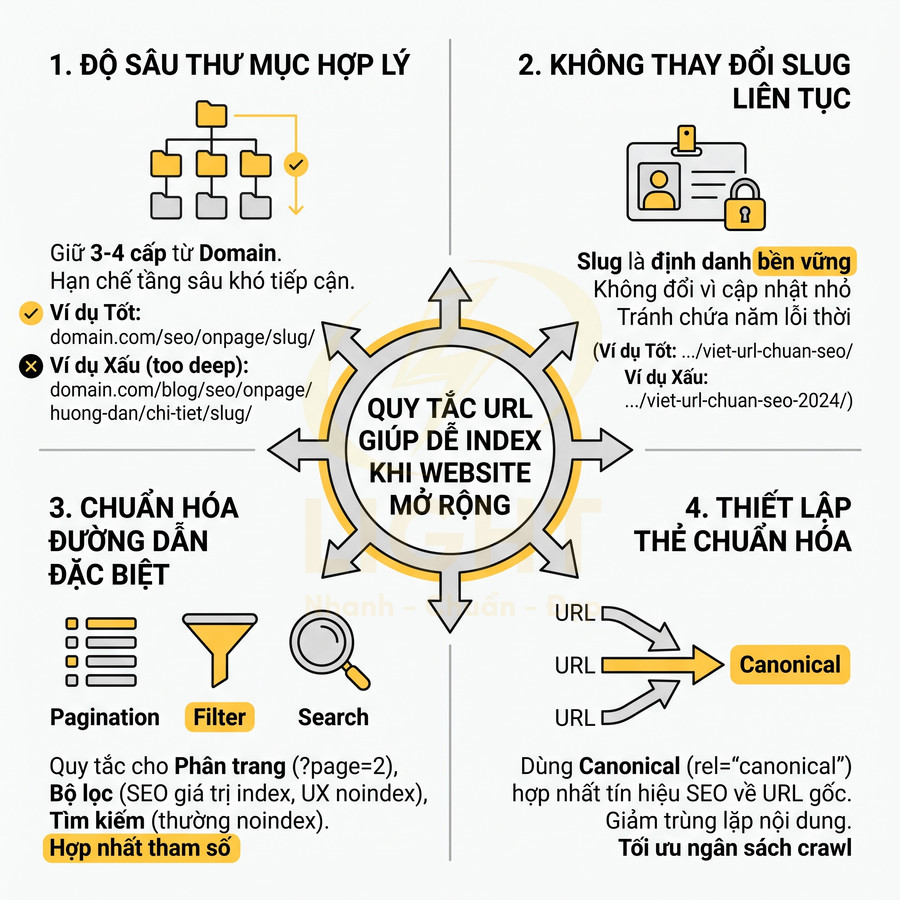
Giữ độ sâu thư mục hợp lý để bot truy cập nhanh
Khi website phát triển thành một hệ thống lớn với nhiều chuyên mục, tag, landing page và trang lọc, cấu trúc URL không chỉ là vấn đề “đẹp” hay “chuẩn SEO” mà còn liên quan trực tiếp đến khả năng crawl và index của bot. Mỗi cấp thư mục bổ sung là một “bước nhảy” xa hơn khỏi trang chủ trong đồ thị liên kết nội bộ, khiến các trang ở tầng sâu dễ bị giảm tần suất thu thập, đặc biệt trên những site có hàng chục nghìn URL.

Về mặt thực tiễn, nên giữ độ sâu URL ở mức không quá 3–4 cấp tính từ domain, tính cả thư mục chuyên mục lẫn slug bài viết. Điều này giúp:
- Giảm số bước bot phải đi qua từ trang chủ đến trang đích.
- Giữ cấu trúc site phẳng hơn, dễ phân bổ internal link và PageRank.
- Hạn chế việc tạo ra các “vùng mồ SEO” – nơi bot ít khi quay lại crawl.
Ví dụ, cấu trúc như /seo/onpage/url-chuan-seo/ là hợp lý: một thư mục chính (seo), một thư mục con (onpage) và slug bài viết. Ngược lại, dạng /blog/seo/onpage/huong-dan/chi-tiet/url-chuan-seo/ thể hiện quá nhiều tầng phân cấp, thường là kết quả của việc bê nguyên cây danh mục trong CMS vào URL. Cách làm này khiến URL dài, khó nhớ, khó chia sẻ và làm loãng tín hiệu liên quan chủ đề.
Nguyên tắc quan trọng là: cấu trúc thư mục nên phản ánh chủ đề chính, không phản ánh toàn bộ cây danh mục kỹ thuật. Nếu hệ thống danh mục phức tạp (ví dụ: SEO > Onpage > URL > Hướng dẫn chi tiết), có thể:
- Chọn một danh mục chính (ví dụ: seo) đưa vào URL.
- Các danh mục phụ (onpage, hướng dẫn, chi tiết) chỉ dùng cho phân loại nội bộ, breadcrumb, điều hướng, không nhất thiết xuất hiện trong URL.
- Dùng internal link, breadcrumb và schema (BreadcrumbList) để thể hiện mối quan hệ phân cấp thay vì “nhồi” hết vào đường dẫn.
Với site thương mại điện tử hoặc site nội dung lớn, có thể áp dụng mô hình:
- /danh-muc-chinh/slug-san-pham/ cho sản phẩm.
- /chu-de-chinh/slug-bai-viet/ cho bài viết.
- Hạn chế các tầng như /shop/category/sub-category/sub-sub-category/slug/ trừ khi thực sự cần cho trải nghiệm người dùng.
Cũng cần phân biệt giữa “độ sâu URL” và “độ sâu click”. Một URL có 3 cấp nhưng được liên kết trực tiếp từ trang chủ vẫn dễ crawl hơn một URL 2 cấp nhưng bị chôn sâu trong nhiều lớp điều hướng. Tuy vậy, việc giữ URL ngắn, ít thư mục vẫn là một tín hiệu kỹ thuật tốt, hỗ trợ cả bot lẫn người dùng.
Không thay đổi slug liên tục khi cập nhật nội dung nhỏ
Slug là phần định danh duy nhất của trang trong URL, vì vậy nên được xem như một identifier ổn định thay vì một trường có thể thay đổi tùy hứng. Mỗi lần đổi slug, bạn buộc phải:
- Thiết lập chuyển hướng 301 từ URL cũ sang URL mới.
- Cập nhật toàn bộ liên kết nội bộ trỏ đến URL cũ (menu, breadcrumb, bài viết liên quan, anchor text trong nội dung).
- Cập nhật sitemap XML, sitemap HTML (nếu có), file dữ liệu cho quảng cáo (nếu dùng URL trong feed).
- Chấp nhận rủi ro mất một phần tín hiệu xếp hạng trong ngắn hạn do Google cần thời gian hợp nhất tín hiệu qua 301.
Quan điểm này trùng với nguyên tắc kinh điển của Tim Berners-Lee: “Cool URIs don’t change.” W3C nhấn mạnh rằng URI tốt là URI ổn định, vì khi URI thay đổi, liên kết cũ, tài liệu tham chiếu, bookmark, trích dẫn và hệ thống liên kết bên ngoài đều có thể bị ảnh hưởng. Trong SEO, mỗi lần đổi slug dù có 301 vẫn khiến Google phải xử lý lại quan hệ URL cũ – URL mới, đồng thời đội kỹ thuật phải cập nhật internal link, sitemap và canonical. Vì vậy, chỉ nên đổi URL khi có lý do chiến lược rõ ràng, không đổi chỉ vì sửa title, thêm số liệu hoặc cập nhật một vài đoạn nội dung.
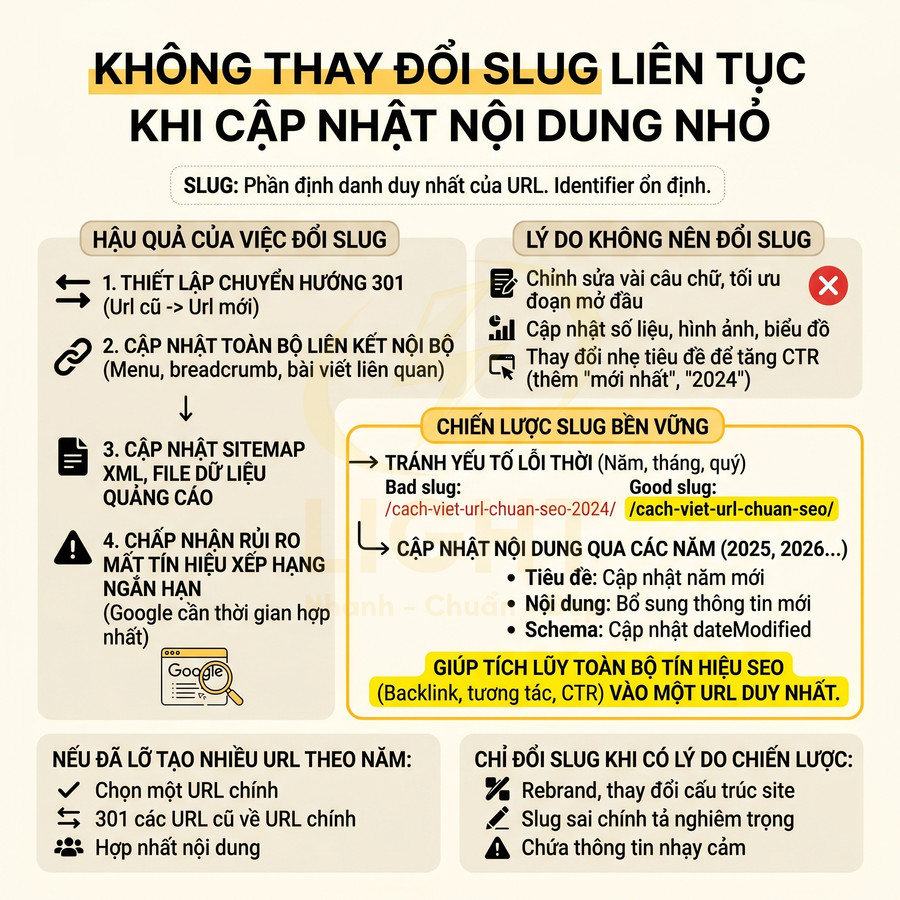
Vì vậy, không nên đổi URL chỉ vì:
- Chỉnh sửa vài câu chữ, tối ưu lại đoạn mở bài, thêm ví dụ.
- Cập nhật số liệu, hình ảnh, biểu đồ.
- Thay đổi nhẹ tiêu đề để tăng CTR (ví dụ thêm “chi tiết”, “mới nhất”, “cập nhật”).
Slug nên được thiết kế ngay từ đầu theo hướng bền vững theo thời gian, tập trung vào chủ đề cốt lõi, tránh các yếu tố dễ lỗi thời như năm, tháng, quý. Ví dụ, thay vì:
- /cach-viet-url-chuan-seo-2024/
nên dùng:
- /cach-viet-url-chuan-seo/
Khi đến năm 2025, 2026, chỉ cần cập nhật:
- Tiêu đề: “Cách viết URL chuẩn SEO 2024” → “Cách viết URL chuẩn SEO 2025 (cập nhật)”
- Nội dung: bổ sung phần thay đổi thuật toán, best practice mới.
- Schema: cập nhật dateModified, có thể thêm year trong headline.
Cách làm này giúp toàn bộ tín hiệu SEO (backlink, lịch sử tương tác, CTR, dữ liệu hành vi) được tích lũy vào một URL duy nhất, thay vì phân tán qua nhiều phiên bản theo năm. Nếu trước đây đã lỡ tạo nhiều URL theo năm, có thể:
- Chọn một URL chính (thường là URL mới nhất, nội dung đầy đủ nhất).
- 301 các URL cũ về URL chính.
- Hợp nhất nội dung giá trị từ các bài cũ vào bài chính, tránh trùng lặp.
Chỉ nên cân nhắc đổi slug khi có lý do chiến lược rõ ràng, ví dụ:
- Rebrand, thay đổi toàn bộ cấu trúc site, cần đồng bộ URL với brand mới.
- Slug cũ sai chính tả nghiêm trọng, gây hiểu nhầm chủ đề.
- Slug chứa thông tin nhạy cảm, thông tin cá nhân cần loại bỏ.
Chuẩn hóa đường dẫn phân trang, lọc và tìm kiếm nội bộ
Các nhóm URL phân trang, lọc và tìm kiếm nội bộ thường là nguồn phát sinh hàng loạt URL có tham số, dễ gây:
- Trùng lặp nội dung (nhiều URL khác nhau nhưng nội dung gần như giống nhau).
- Lãng phí ngân sách crawl khi bot phải thu thập vô số biến thể không có giá trị SEO.
- Làm rối cấu trúc site, khó kiểm soát index và canonical.
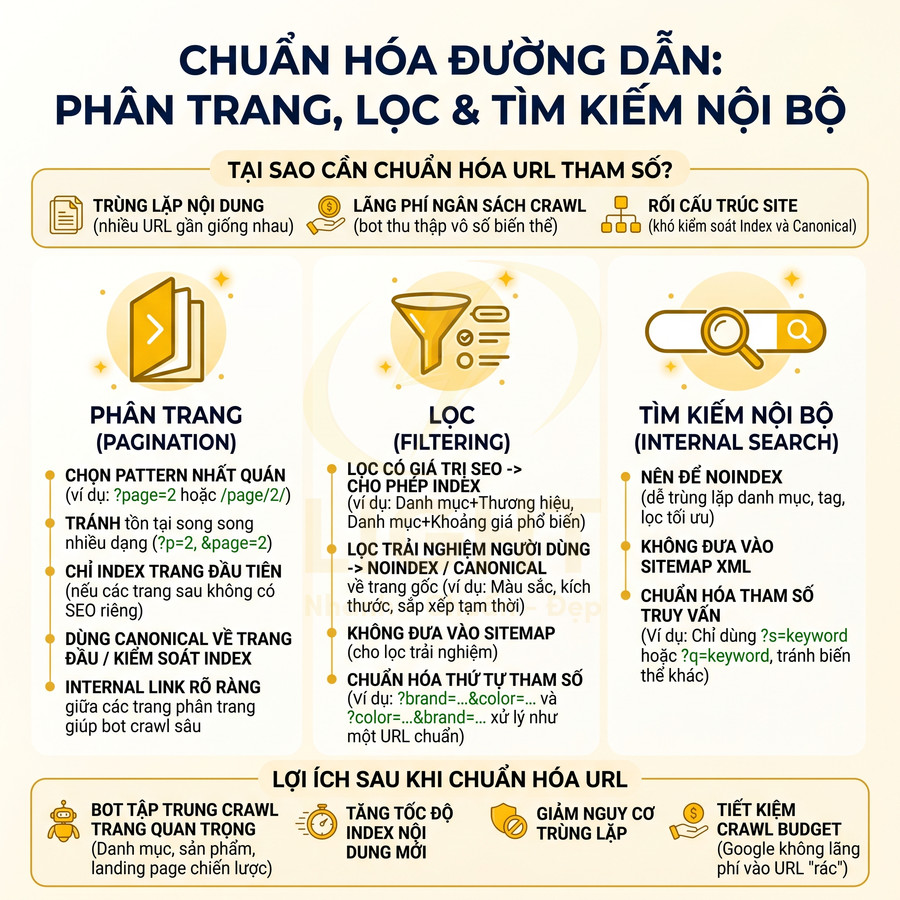
Cần định nghĩa rõ quy tắc cho từng loại:
Phân trang
- Chọn một pattern nhất quán, ví dụ ?page=2 hoặc /page/2/, tránh tồn tại song song nhiều dạng như ?page=2, &page=2, ?p=2.
- Nếu các trang sau chỉ là danh sách tiếp nối, không có nội dung SEO riêng, thường chỉ nên index trang đầu tiên, các trang sau có thể:
- Dùng canonical trỏ về trang đầu (trong một số chiến lược).
- Hoặc cho phép index có kiểm soát nếu cần để bot hiểu đầy đủ danh sách sản phẩm/bài viết.
- Có thể sử dụng cấu trúc internal link rõ ràng giữa các trang phân trang để bot dễ crawl sâu hơn.
Lọc
- Xác định rõ bộ lọc nào có giá trị SEO (ví dụ: danh mục + thương hiệu, danh mục + khoảng giá phổ biến) và cho phép index.
- Các bộ lọc chỉ phục vụ trải nghiệm người dùng (màu sắc, kích thước, sắp xếp tạm thời) nên:
- Đặt noindex hoặc canonical về trang danh mục gốc.
- Không đưa vào sitemap.
- Chuẩn hóa thứ tự tham số lọc (ví dụ: ?brand=nike&color=red và ?color=red&brand=nike nên được xử lý như một URL chuẩn duy nhất).
Tìm kiếm nội bộ
- Thường nên để noindex vì kết quả tìm kiếm nội bộ dễ trùng lặp với danh mục, tag, hoặc các trang lọc đã được tối ưu.
- Không đưa URL tìm kiếm nội bộ vào sitemap XML.
- Chuẩn hóa tham số truy vấn, ví dụ chỉ dùng ?s=keyword hoặc ?q=keyword, tránh nhiều biến thể khác nhau.
Việc chuẩn hóa các loại URL này giúp bot tập trung crawl vào những trang thực sự quan trọng: trang danh mục chính, trang sản phẩm/bài viết, landing page chiến lược. Từ đó, tốc độ index nội dung mới được cải thiện, giảm nguy cơ trùng lặp và hạn chế việc Google lãng phí crawl budget vào các URL “rác” hoặc ít giá trị.
Thiết lập thẻ chuẩn hóa cho URL gần giống nhau
Ngay cả khi đã chuẩn hóa cấu trúc URL, vẫn khó tránh khỏi việc tồn tại nhiều phiên bản URL gần giống nhau về nội dung: phiên bản có và không tham số, phiên bản sắp xếp khác nhau, phiên bản lọc nhẹ. Trong những trường hợp này, thẻ canonical là công cụ quan trọng để:
- Chỉ định phiên bản chuẩn mà bot nên ưu tiên index và xếp hạng.
- Hợp nhất tín hiệu SEO (backlink, tín hiệu người dùng) về một URL duy nhất.
- Giảm nguy cơ Google tự chọn nhầm phiên bản ít tối ưu hơn làm trang đại diện.
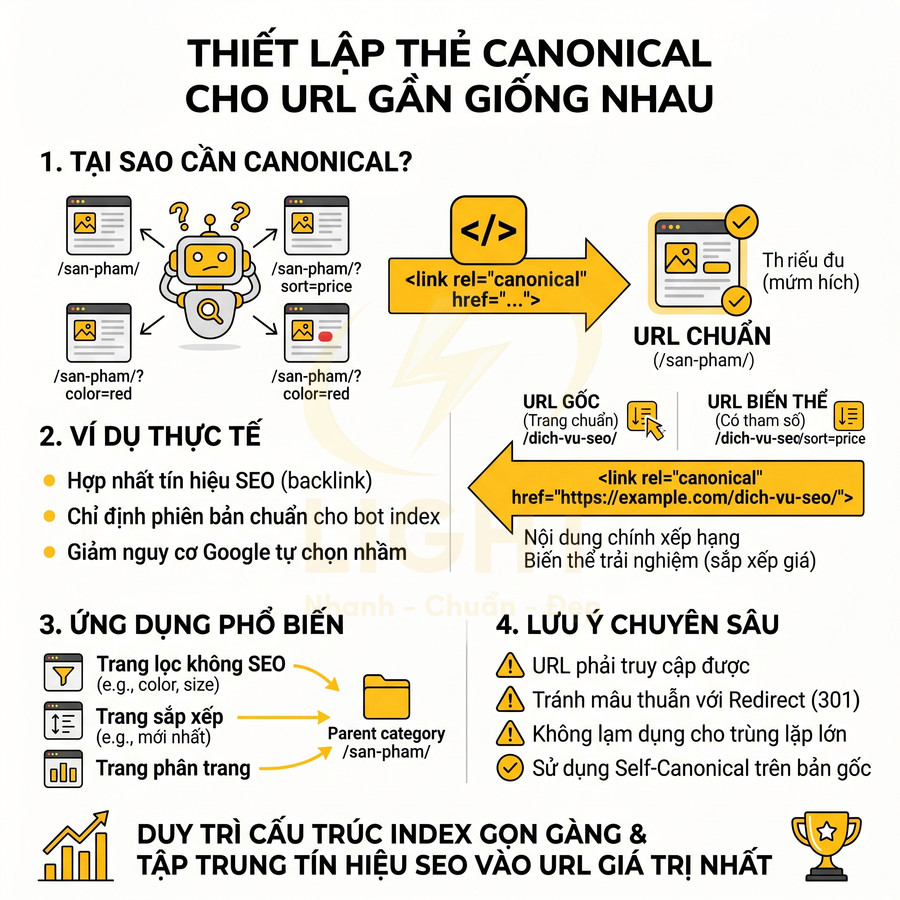
Canonical không phải là chuyển hướng, người dùng vẫn ở lại URL hiện tại, nhưng nó là một tín hiệu mạnh gửi tới công cụ tìm kiếm. Ví dụ, nếu tồn tại:
- /dich-vu-seo/
- /dich-vu-seo/?sort=price
thì trang có tham số ?sort=price nên đặt canonical trỏ về /dich-vu-seo/. Điều này cho Google biết rằng nội dung chính cần xếp hạng là phiên bản không tham số, còn phiên bản có tham số chỉ là biến thể phục vụ trải nghiệm người dùng (sắp xếp theo giá).
Tương tự, với các trang lọc không mang giá trị SEO riêng (ví dụ: lọc theo màu, size, sắp xếp theo “mới nhất”), canonical nên trỏ về trang danh mục gốc. Một số lưu ý chuyên sâu khi dùng canonical:
- Canonical phải trỏ đến URL có thể truy cập, không bị chặn bởi robots.txt, không noindex.
- Tránh mâu thuẫn giữa canonical và redirect: nếu đã 301 về URL A, không nên canonical sang URL B khác.
- Không lạm dụng canonical để “che” nội dung trùng lặp lớn; với nội dung gần như giống hệt, nên cân nhắc hợp nhất nội dung thực sự.
- Đảm bảo canonical tự tham chiếu (self-canonical) trên phiên bản chuẩn để Google hiểu rõ trang nào là bản gốc.
Việc sử dụng canonical đúng cách cho phép bạn vừa giữ được trải nghiệm người dùng phong phú (lọc, sắp xếp, phân trang linh hoạt), vừa tránh phân tán tín hiệu SEO. Khi website mở rộng nhiều chuyên mục, nhiều lớp lọc, canonical trở thành một phần không thể thiếu trong chiến lược quản trị URL, giúp duy trì cấu trúc index gọn, rõ ràng và tập trung vào những URL có giá trị cao nhất.
Hệ thống tự động quét URL chuẩn SEO và sửa hàng loạt toàn website
Hệ thống cần vận hành như một chuỗi pipeline khép kín, từ khâu quét – phân tích – sửa – chuyển hướng. Trước hết, công cụ crawl và các script tích hợp CMS sẽ thu thập toàn bộ URL, chuẩn hóa và đối chiếu với bộ rule SEO chi tiết để phát hiện slug quá dài, trùng lặp, thiếu từ khóa, sai thư mục hoặc chứa ký tự, tham số không chuẩn. Từ dữ liệu này, đội SEO xây dựng ma trận ưu tiên và thiết lập rule sửa hàng loạt theo chuyên mục, loại trang, cụm chủ đề, kèm cơ chế preview, kiểm tra xung đột, phê duyệt và rollback. Mọi thay đổi slug phải tự động tạo chuyển hướng 301, kiểm soát redirect chain, cập nhật sitemap và được giám sát qua crawl, log server để vừa chuẩn hóa URL diện rộng vừa giữ vững thứ hạng.
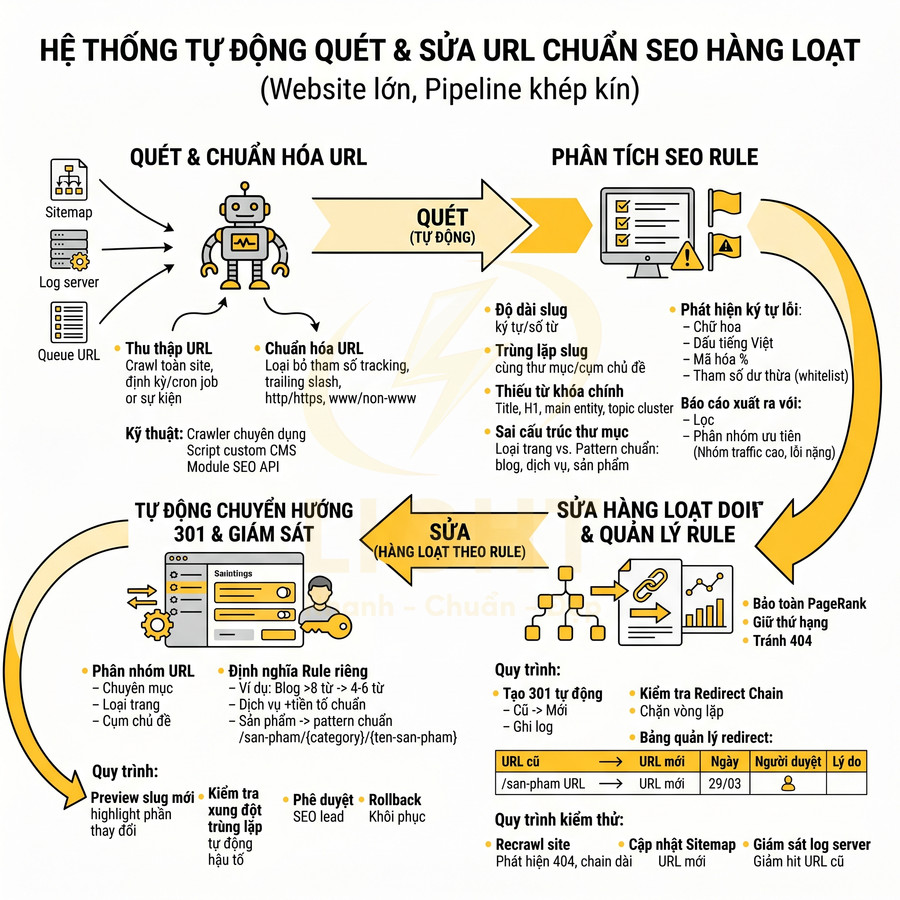
Quét tự động slug quá dài, trùng lặp, thiếu từ khóa hoặc sai cấu trúc thư mục
Với các website lớn (hàng chục nghìn đến hàng triệu URL), việc kiểm tra thủ công từng đường dẫn là không khả thi về mặt chi phí và thời gian. Cần thiết kế một pipeline quét URL tự động hoạt động định kỳ (cron job) hoặc theo sự kiện (khi tạo/sửa nội dung), có khả năng:
- Crawl toàn bộ website dựa trên sitemap, log server, hoặc queue URL nội bộ.
- Chuẩn hóa URL trước khi phân tích (loại bỏ tham số tracking, chuẩn hóa trailing slash, http/https, www/non-www).
- Phân tích slug theo từng rule SEO đã định nghĩa trước.
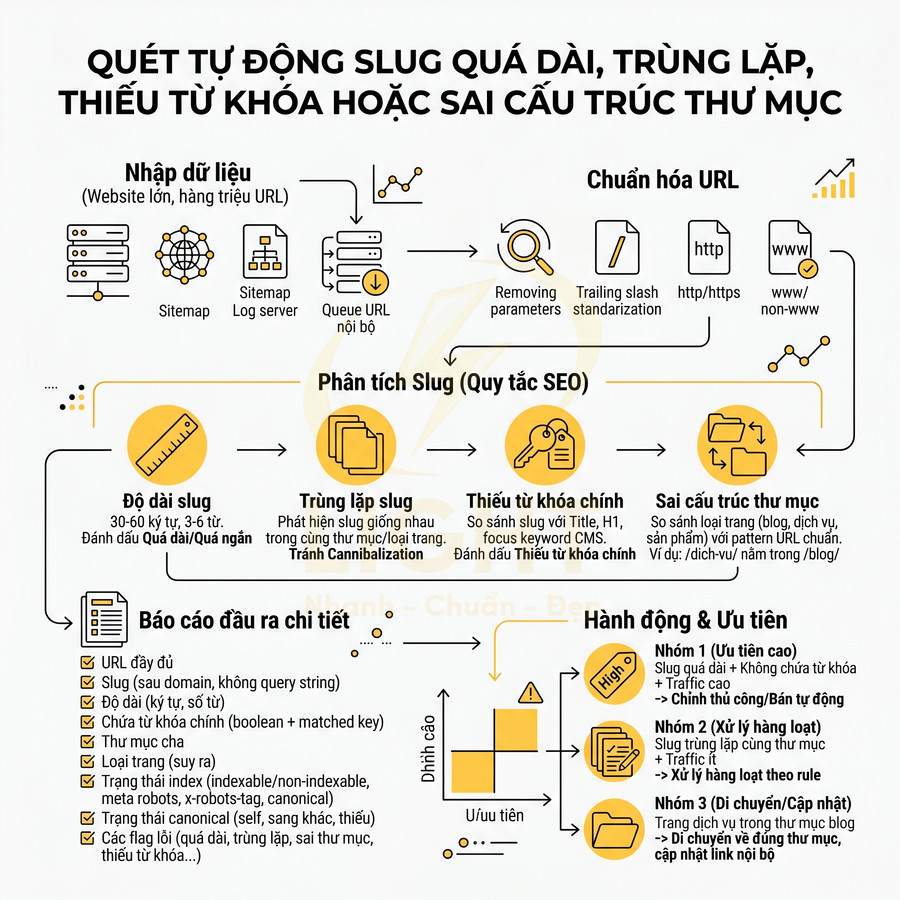
Về mặt kỹ thuật, hệ thống có thể được xây dựng bằng:
- Crawler chuyên dụng (Screaming Frog, Sitebulb, custom crawler dùng Python/Node) kết nối với database để lưu kết quả phân tích.
- Script tùy chỉnh chạy trực tiếp trên database CMS (WordPress, Laravel, Magento…) để quét bảng chứa URL/slug.
- Module tích hợp trong SEO platform (in-house hoặc SaaS) có API để đồng bộ dữ liệu và trigger sửa hàng loạt.
Hệ thống cần áp dụng các rule phân tích slug ở mức chi tiết:
- Độ dài slug: tính theo số ký tự và số từ, so sánh với ngưỡng tối ưu (ví dụ 30–60 ký tự, 3–6 từ). Slug vượt ngưỡng được gắn nhãn “quá dài” hoặc “quá ngắn”.
- Trùng lặp slug: phát hiện slug giống nhau trong cùng thư mục hoặc cùng loại trang. Cần phân biệt:
- Trùng slug nhưng khác thư mục (có thể chấp nhận được trong một số cấu trúc).
- Trùng slug trong cùng thư mục hoặc cùng cụm chủ đề (rủi ro cao về cannibalization và nhầm lẫn người dùng).
- Thiếu thực thể chính/từ khóa chính: so sánh slug với:
- Title, H1, hoặc trường “main entity”/“focus keyword” trong CMS.
- Nhóm từ khóa đã được gán cho cụm chủ đề (topic cluster).
Nếu slug không chứa bất kỳ biến thể nào của thực thể chính, đánh dấu là “thiếu từ khóa chính”.
- Sai cấu trúc thư mục: dựa trên rule mapping giữa:
- Loại trang (blog, dịch vụ, sản phẩm, category, tag, landing page, trang hệ thống).
- Pattern URL chuẩn (ví dụ: /blog/{slug}, /dich-vu/{slug}, /san-pham/{category}/{slug}).
Hệ thống so sánh loại trang (xác định từ template, post type, schema, hoặc pattern nội dung) với thư mục hiện tại để phát hiện các URL như: trang dịch vụ nhưng nằm trong /blog/, trang sản phẩm nhưng nằm trong /tin-tuc/.
Báo cáo xuất ra nên có cấu trúc chi tiết, phục vụ cho việc lọc và ưu tiên:
- URL đầy đủ (absolute URL).
- Slug (phần sau domain, loại bỏ query string).
- Độ dài slug (ký tự, số từ).
- Có chứa từ khóa chính (boolean + từ khóa được match).
- Thư mục cha (ví dụ: /blog/, /dich-vu/, /san-pham/…).
- Loại trang (suy ra từ post type, template, schema, hoặc rule pattern).
- Trạng thái index (indexable/non-indexable, dựa trên meta robots, x-robots-tag, canonical).
- Trạng thái canonical (self-canonical, canonical sang URL khác, thiếu canonical).
- Các flag lỗi: slug quá dài, slug trùng lặp, sai thư mục, thiếu từ khóa, v.v.
Từ báo cáo này, đội SEO có thể xây dựng ma trận ưu tiên, ví dụ:
- Nhóm 1: slug quá dài + không chứa từ khóa + là trang đang có traffic cao → ưu tiên cao, cần chỉnh thủ công hoặc bán tự động.
- Nhóm 2: slug trùng lặp trong cùng thư mục nhưng trang ít traffic → có thể xử lý hàng loạt theo rule.
- Nhóm 3: trang dịch vụ nằm trong thư mục blog → cần di chuyển về đúng thư mục và cập nhật internal link.
Phát hiện URL có ký tự lỗi, chữ hoa, dấu tiếng Việt hoặc tham số dư thừa
Một lớp kiểm tra quan trọng khác là chuẩn hóa ký tự URL. Về nguyên tắc kỹ thuật và SEO, slug nên:
- Chỉ dùng chữ thường (lowercase).
- Không dấu, không ký tự đặc biệt ngoài dấu gạch ngang
-và một số ký tự an toàn. - Hạn chế tối đa query string, chỉ giữ các tham số nằm trong whitelist (ví dụ: utm_* có thể được strip khi phân tích).

Hệ thống quét cần có module phân tích ký tự, thực hiện:
- Phát hiện chữ hoa trong path:
- So sánh URL gốc với phiên bản lowercase.
- Nếu khác nhau, gắn nhãn “chứa chữ hoa”.
- Phát hiện dấu tiếng Việt:
- Kiểm tra sự xuất hiện của ký tự Unicode có dấu (á, à, ă, â, ê, ô, ơ, ư, đ…).
- Đánh dấu “chứa dấu tiếng Việt” để đưa vào danh sách cần chuyển đổi sang không dấu.
- Phát hiện ký tự mã hóa:
- Tìm các chuỗi
%xx(URL encoded) trong path, ví dụ%20cho khoảng trắng,%C3%A1cho ký tự có dấu. - Gắn nhãn “chứa ký tự mã hóa %” vì đây thường là dấu hiệu của việc nhập slug không chuẩn hoặc hệ thống encode không đúng.
- Tìm các chuỗi
- Phát hiện khoảng trắng (trước khi encode) nếu quét trực tiếp từ database CMS.
- Phân tích tham số dư thừa:
- Xác định danh sách tham số hợp lệ (whitelist) như page, sort, filter…
- Mọi tham số ngoài whitelist được đánh dấu “tham số không nằm trong whitelist”.
- Đặc biệt chú ý các tham số tạo ra vô hạn biến thể URL (session id, tracking nội bộ, filter không canonical…).
Báo cáo nên thể hiện rõ từng URL vi phạm cùng loại lỗi tương ứng, ví dụ:
- /Blog/Dich-Vu-SEO/ → chứa chữ hoa.
- /dich-vu/tư-vấn-seo/ → chứa dấu tiếng Việt.
- /san-pham/ao%20thun-nam/ → chứa ký tự mã hóa %.
- /blog/huong-dan-seo?ref=abc&sessionid=123 → chứa tham số không nằm trong whitelist.
Từ danh sách này, có thể thiết lập rule chuyển đổi tự động hoặc bán tự động:
- Chuyển toàn bộ path sang lowercase.
- Loại bỏ dấu tiếng Việt, thay khoảng trắng bằng dấu gạch ngang, loại bỏ ký tự đặc biệt.
- Strip hoặc canonicalize các tham số không cần thiết, đồng thời tạo 301 về phiên bản sạch.
Thiết lập quy tắc sửa hàng loạt slug theo chuyên mục, loại trang và cụm chủ đề
Sau khi đã có danh sách URL cần tối ưu, thay vì thao tác thủ công từng trang, cần xây dựng bộ rule sửa slug hàng loạt dựa trên taxonomy và logic nội dung. Cách tiếp cận hiệu quả là:
- Nhóm URL theo:
- Chuyên mục (category, folder: /blog/, /dich-vu/, /san-pham/…).
- Loại trang (post, page, product, category page, tag page, landing page).
- Cụm chủ đề (topic cluster, dựa trên mapping từ khóa hoặc internal link hub).
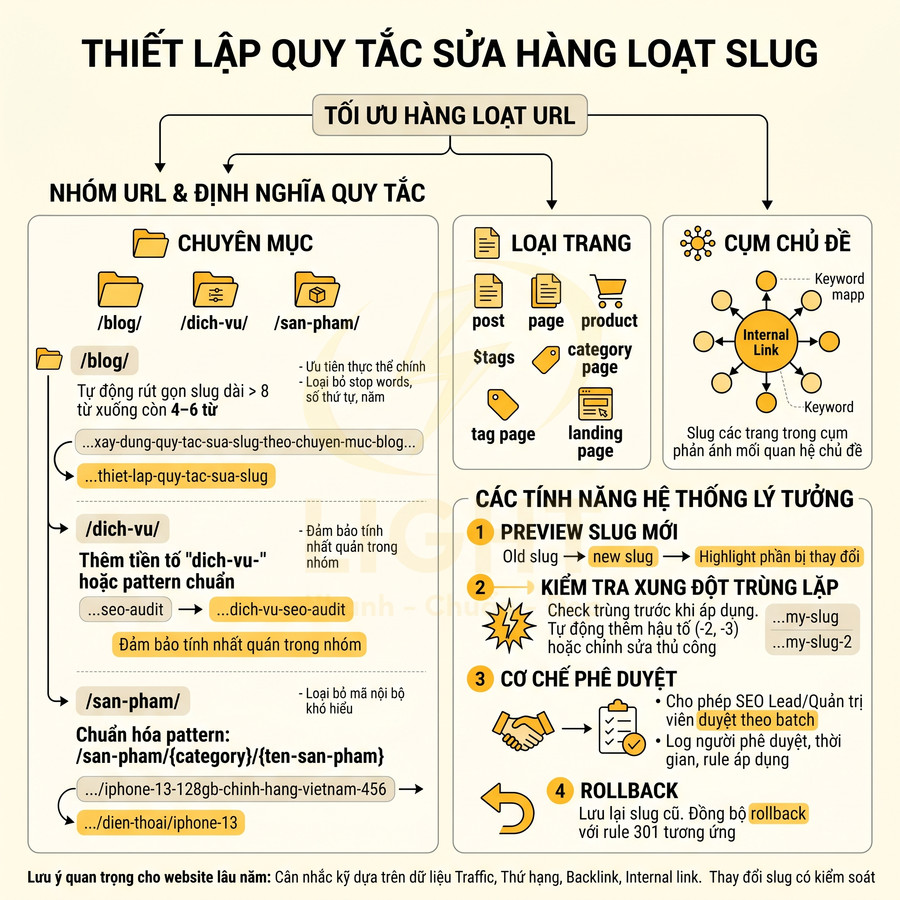
- Định nghĩa rule riêng cho từng nhóm, ví dụ:
- Với tất cả URL trong thư mục /blog/ có slug dài hơn 8 từ:
- Tự động đề xuất rút gọn còn 4–6 từ.
- Ưu tiên giữ lại thực thể chính (brand, sản phẩm, dịch vụ, chủ đề chính).
- Loại bỏ stop words, số thứ tự, năm nếu không cần thiết (trừ khi năm là yếu tố chính của nội dung).
- Với tất cả URL trong thư mục /dich-vu/ không chứa từ “dich-vu”:
- Tự động thêm tiền tố “dich-vu-” hoặc pattern chuẩn như “dich-vu-{thuc-the-chinh}”.
- Đảm bảo tính nhất quán giữa các dịch vụ cùng nhóm (ví dụ: /dich-vu-seo-tong-the/, /dich-vu-seo-audit/).
- Với sản phẩm trong cùng category:
- Chuẩn hóa pattern: /san-pham/{category}/{ten-san-pham}.
- Loại bỏ mã nội bộ khó hiểu khỏi slug, chỉ giữ phần tên sản phẩm thân thiện.
- Với tất cả URL trong thư mục /blog/ có slug dài hơn 8 từ:
Về mặt triển khai, hệ thống lý tưởng cần có các tính năng:
- Preview slug mới:
- Hiển thị song song slug cũ và slug đề xuất mới.
- Highlight phần bị thay đổi để người duyệt dễ đánh giá.
- Kiểm tra xung đột trùng lặp:
- Trước khi áp dụng, hệ thống phải check xem slug mới có trùng với slug hiện có hay không.
- Nếu trùng, tự động thêm hậu tố (ví dụ:
-2,-3) hoặc yêu cầu chỉnh sửa thủ công.
- Cơ chế phê duyệt:
- Cho phép SEO lead hoặc quản trị viên duyệt theo batch.
- Có log người phê duyệt, thời gian, rule áp dụng.
- Rollback:
- Lưu lại slug cũ để có thể khôi phục nếu phát sinh sự cố.
- Đồng bộ rollback với rule 301 tương ứng.
Cách làm này giúp chuẩn hóa URL trên diện rộng nhưng vẫn giữ được mức độ kiểm soát cần thiết, đặc biệt quan trọng với website lâu năm, có nhiều backlink, nhiều trang đang xếp hạng cao. Bất kỳ thay đổi slug nào cũng phải được cân nhắc dựa trên dữ liệu: traffic, thứ hạng, số lượng backlink, vai trò trong cấu trúc internal link.
Tự động tạo chuyển hướng 301 khi thay đổi URL để giữ thứ hạng
Mỗi lần thay đổi slug hoặc di chuyển trang sang thư mục khác, cần đảm bảo chuyển hướng 301 từ URL cũ sang URL mới để:
- Bảo toàn tối đa PageRank và tín hiệu liên kết từ backlink cũ.
- Tránh phát sinh lỗi 404, giảm tỷ lệ thoát và cải thiện trải nghiệm người dùng.
- Giữ ổn định thứ hạng từ khóa đã đạt được trước khi tái cấu trúc URL.
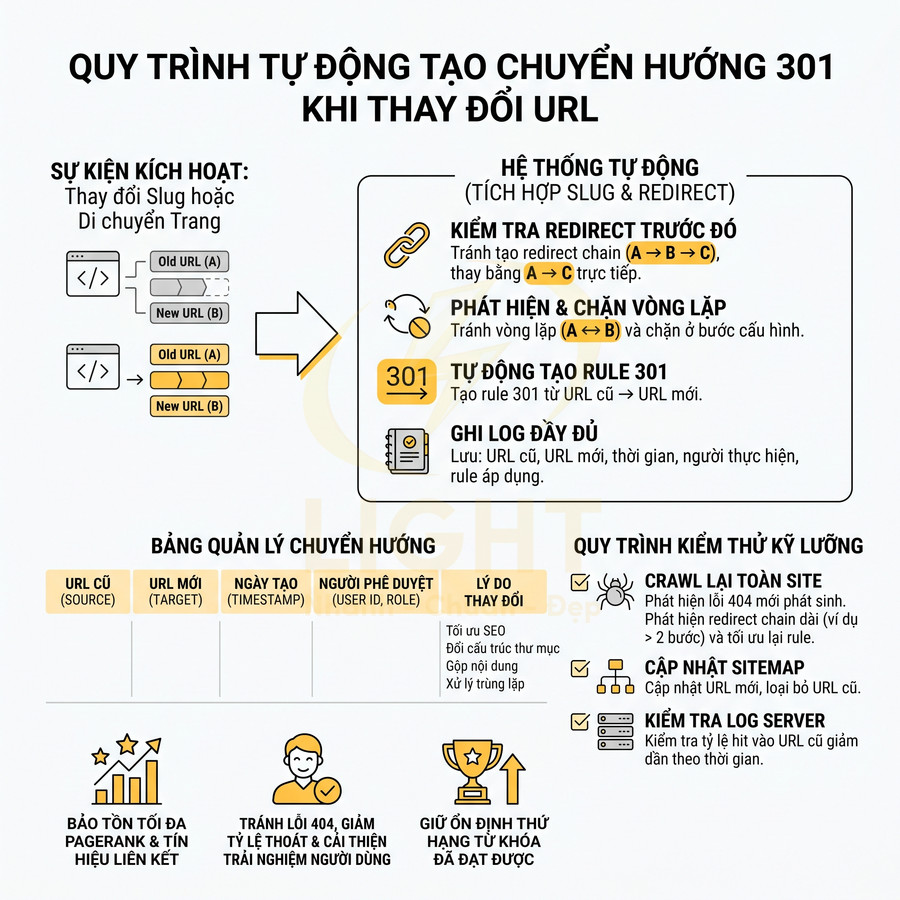
Hệ thống tối ưu nên tích hợp chặt chẽ giữa module sửa slug và module redirect:
- Mỗi khi slug được cập nhật (thủ công hoặc hàng loạt), hệ thống:
- Tự động tạo rule 301 từ URL cũ → URL mới.
- Ghi log đầy đủ: URL cũ, URL mới, thời gian, người thực hiện, rule áp dụng.
- Trước khi ghi rule mới, cần:
- Kiểm tra xem URL cũ đã từng được redirect trước đó chưa.
- Nếu có, cập nhật rule để tránh tạo redirect chain (A → B → C), thay bằng A → C trực tiếp.
- Phát hiện vòng lặp (A → B, B → A) và chặn ngay ở bước cấu hình.
Bảng quản lý chuyển hướng nên lưu các trường:
- URL cũ (source).
- URL mới (target).
- Ngày tạo (timestamp).
- Người phê duyệt (user id, role).
- Lý do thay đổi (tối ưu SEO, đổi cấu trúc thư mục, gộp nội dung, xử lý trùng lặp…).
Khi triển khai thay đổi hàng loạt, cần có quy trình kiểm thử kỹ lưỡng:
- Chạy crawl lại toàn site sau khi áp dụng rule để:
- Phát hiện lỗi 404 mới phát sinh.
- Phát hiện redirect chain dài (ví dụ > 2 bước) và tối ưu lại rule.
- Cập nhật sitemap với URL mới, loại bỏ URL cũ khỏi sitemap để tránh Google tiếp tục crawl phiên bản cũ.
- Kiểm tra log server để xem tỷ lệ hit vào URL cũ giảm dần theo thời gian, đảm bảo người dùng và bot đã chuyển sang dùng URL mới.
Việc quản trị chuyển hướng bài bản, có hệ thống, là điều kiện tiên quyết để tái cấu trúc URL toàn site mà không đánh mất thành quả SEO tích lũy trong nhiều năm, đồng thời tạo nền tảng sạch cho các chiến lược nội dung và technical SEO về sau.
Cách tránh trùng URL và ăn thịt từ khóa giữa các trang cùng chủ đề
Nguyên tắc cốt lõi để tránh trùng URL và ăn thịt từ khóa là quản trị truy vấn, intent và slug ở cấp hệ thống, không chỉ ở từng bài viết. Mỗi nhóm truy vấn được định nghĩa rõ theo topic – intent – scope và ánh xạ về một URL chính thức, được lưu trong bảng “truy vấn – URL” để biên tập viên tra cứu trước khi tạo nội dung mới. Với cùng intent, nên gom vào một trang trụ cột sâu, có cấu trúc heading, schema và internal link rõ ràng, thay vì tách nhiều URL mỏng. Ở lớp kỹ thuật, dùng slug blacklist và cơ chế cảnh báo tương đồng URL dựa trên dữ liệu Search Console để chặn hoặc cảnh báo khi slug mới gần trùng các URL đang xếp hạng, từ đó tập trung authority và tối ưu trải nghiệm người dùng.
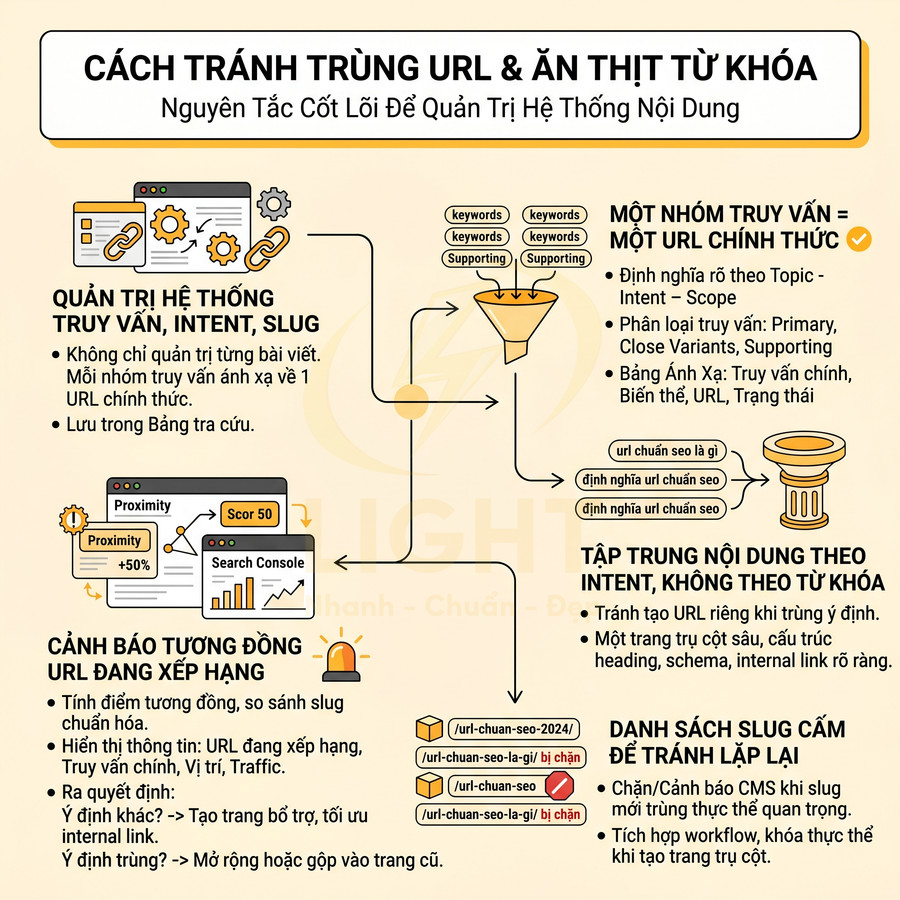
Mỗi nhóm truy vấn chỉ ánh xạ về một URL chính thức
Nguyên tắc một nhóm truy vấn = một URL chính thức thực chất là một quy trình quản trị thông tin ở cấp hệ thống, chứ không chỉ là mẹo SEO. Mỗi nhóm truy vấn phải được định nghĩa rõ ràng theo ba trục: (1) chủ đề trung tâm (topic), (2) ý định tìm kiếm (intent), (3) mức độ sâu – rộng của nội dung (scope). Khi ba yếu tố này trùng nhau ở mức cao, các truy vấn đó nên được gom về cùng một URL trụ cột.
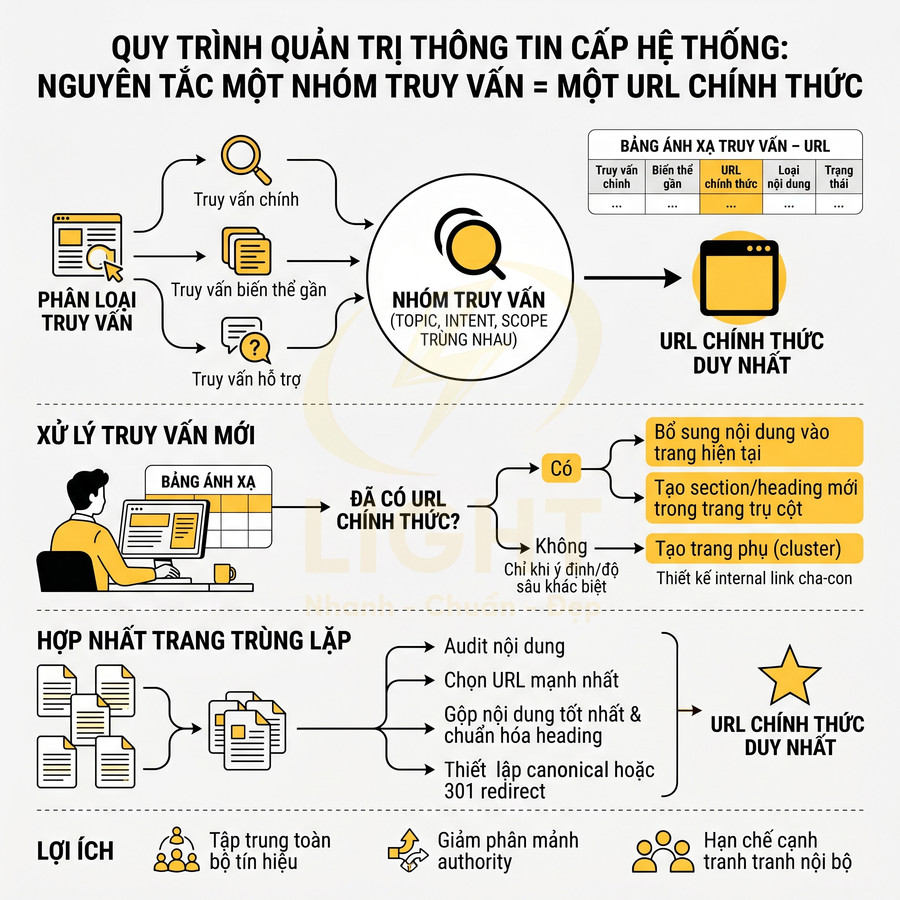
Về mặt thực thi, cần phân loại truy vấn thành các nhóm:
- Truy vấn chính (primary keyword): từ khóa có volume cao, thể hiện rõ chủ đề cốt lõi, thường là tiêu đề chính của trang.
- Truy vấn biến thể gần (close variants): khác nhau về hình thức (thêm bớt từ, đảo vị trí, dùng từ đồng nghĩa) nhưng cùng ý định và cùng mức độ thông tin mong đợi.
- Truy vấn hỗ trợ (supporting queries): là các câu hỏi phụ, khía cạnh nhỏ hơn nhưng vẫn thuộc phạm vi xử lý của một bài trụ cột duy nhất.
Khi đã gom nhóm, mỗi nhóm phải được gán cho một URL chính thức duy nhất. Để đảm bảo tính nhất quán, nên xây dựng một bảng ánh xạ truy vấn – URL ở dạng có thể tra cứu và cập nhật thường xuyên. Bảng này tối thiểu cần có các cột:
- Truy vấn chính
- Các biến thể gần
- URL chính thức
- Loại nội dung (trụ cột, cluster, landing, blog, tài liệu…)
- Trạng thái (đang hoạt động, cần tối ưu, dự kiến gộp…)
Khi tạo nội dung mới, biên tập viên phải kiểm tra bảng này trước. Nếu truy vấn mục tiêu đã được gán cho một URL khác, có ba lựa chọn:
- Bổ sung nội dung vào trang hiện tại nếu ý định trùng hoàn toàn.
- Tạo section hoặc heading mới trong trang trụ cột để xử lý thêm khía cạnh mới.
- Tạo trang phụ (cluster) chỉ khi ý định hoặc độ sâu thông tin khác biệt rõ ràng, và phải thiết kế internal link để thể hiện quan hệ cha – con.
Nếu phát hiện nhiều trang đang nhắm cùng một nhóm truy vấn, cần lập kế hoạch hợp nhất:
- Audit nội dung từng trang: chất lượng, backlink, traffic, thứ hạng, CTR.
- Chọn URL mạnh nhất (thường là URL cũ hơn, nhiều backlink hơn, đang có thứ hạng tốt hơn) làm URL chính thức.
- Gộp nội dung tốt nhất từ các trang còn lại vào URL chính thức, loại bỏ phần trùng lặp, chuẩn hóa cấu trúc heading.
- Thiết lập canonical trỏ về URL chính thức (nếu vẫn cần giữ trang phụ vì lý do UX hoặc business).
- Hoặc chuyển hướng 301 các URL còn lại về URL chính thức nếu không còn lý do tồn tại độc lập.
Cách làm này giúp tập trung toàn bộ tín hiệu (backlink, engagement, lịch sử tương tác) về một URL, giảm phân mảnh authority và hạn chế tình trạng nhiều trang cùng domain cạnh tranh nhau cho cùng một truy vấn.
Không tạo nhiều URL khác nhau cho cùng một ý định tìm kiếm
Search intent là lớp trừu tượng cao hơn từ khóa, phản ánh “người dùng thực sự muốn gì” khi gõ truy vấn. Về mặt SEO chuyên sâu, có thể phân tách intent theo các chiều:
- Loại intent: thông tin (informational), giao dịch (transactional), điều hướng (navigational), so sánh/đánh giá (commercial investigation).
- Độ khẩn cấp: cần giải pháp ngay (problem-solving), nghiên cứu dài hạn, tham khảo.
- Độ sâu kiến thức: cơ bản, trung cấp, chuyên sâu, tài liệu kỹ thuật.
Nếu hai truy vấn khác nhau về câu chữ nhưng trùng nhau ở ba chiều trên, việc tách thành hai URL riêng thường gây hại nhiều hơn lợi. Ví dụ, “url chuẩn seo là gì” và “định nghĩa url chuẩn seo” đều là informational, mức độ cơ bản, mục tiêu là hiểu khái niệm. Một bài viết giải thích khái niệm, kèm ví dụ, best practice, FAQ là đủ để bao phủ cả hai truy vấn.
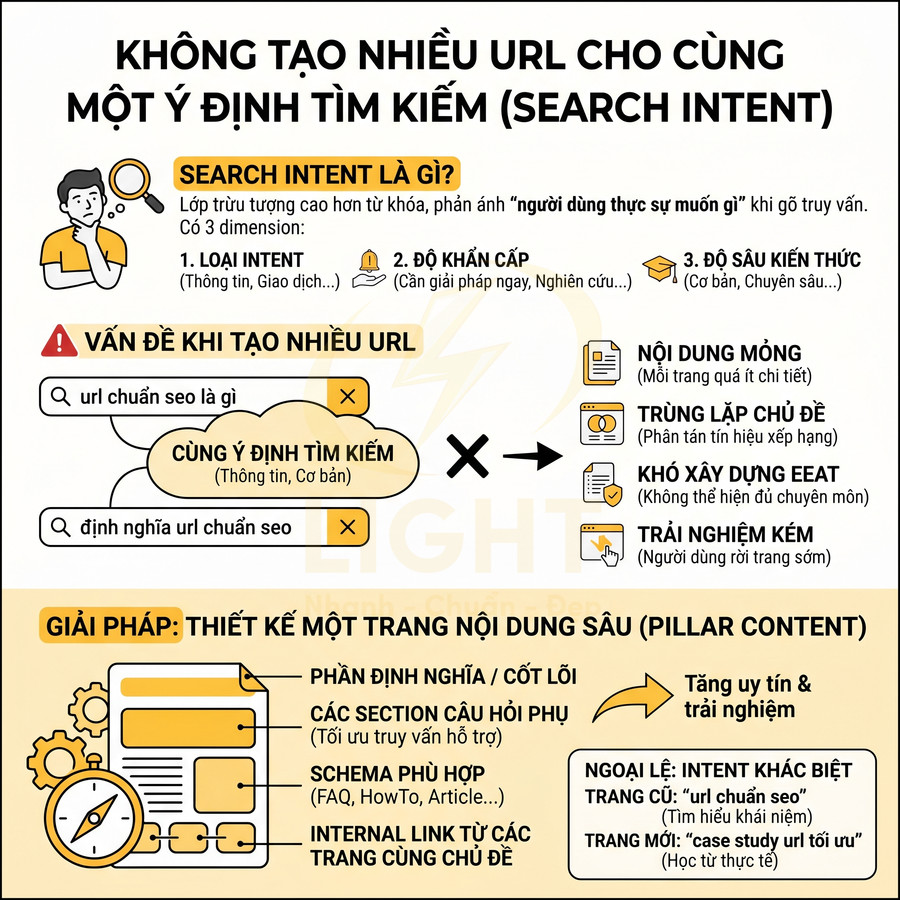
Hậu quả khi cố tình tạo nhiều URL cho cùng một intent:
- Nội dung mỏng (thin content): mỗi trang chỉ có vài đoạn, không đủ chiều sâu để cạnh tranh với đối thủ có bài trụ cột mạnh.
- Trùng lặp chủ đề: Google khó phân biệt trang nào là đại diện tốt nhất, dẫn đến phân tán tín hiệu xếp hạng.
- Khó xây dựng EEAT: mỗi trang quá nhỏ, không thể hiện được chuyên môn, kinh nghiệm, độ tin cậy; trong khi một bài dài, có cấu trúc, trích dẫn, case study sẽ mạnh hơn nhiều.
- Trải nghiệm người dùng kém: người dùng có thể đi vào một trang phụ sơ sài thay vì trang trụ cột, tăng bounce rate, giảm time on page.
Giải pháp là thiết kế một trang nội dung sâu cho mỗi intent chính, với cấu trúc rõ ràng:
- Phần định nghĩa/giải thích cốt lõi cho truy vấn chính.
- Các section xử lý từng câu hỏi phụ (có thể tối ưu cho các truy vấn hỗ trợ).
- Schema phù hợp (FAQ, HowTo, Article…) để tăng khả năng hiển thị rich result.
- Internal link từ các trang liên quan trong cùng cụm chủ đề, thể hiện rõ vai trò “điểm đến chính”.
Khi bắt buộc phải tạo trang mới trong cùng chủ đề, cần xác định rõ intent khác biệt. Ví dụ: trang cũ là hướng dẫn tổng quan “url chuẩn seo”, trang mới có thể là “case study tối ưu url chuẩn seo cho website thương mại điện tử”. Intent lúc này chuyển từ “tìm hiểu khái niệm” sang “xem ví dụ thực tế, học từ case study”, do đó hai URL có thể cùng tồn tại mà không ăn thịt nhau nếu được liên kết nội bộ hợp lý.
Danh sách slug cấm để tránh lặp lại thực thể đã dùng
Danh sách slug cấm (slug blacklist) là một lớp kiểm soát kỹ thuật giúp enforce nguyên tắc “một nhóm truy vấn = một URL chính thức” ở cấp CMS. Thay vì chỉ dựa vào quy ước nội bộ, hệ thống sẽ chủ động chặn hoặc cảnh báo khi biên tập viên cố gắng tạo slug trùng hoặc gần trùng với slug đã được gán cho một thực thể quan trọng.
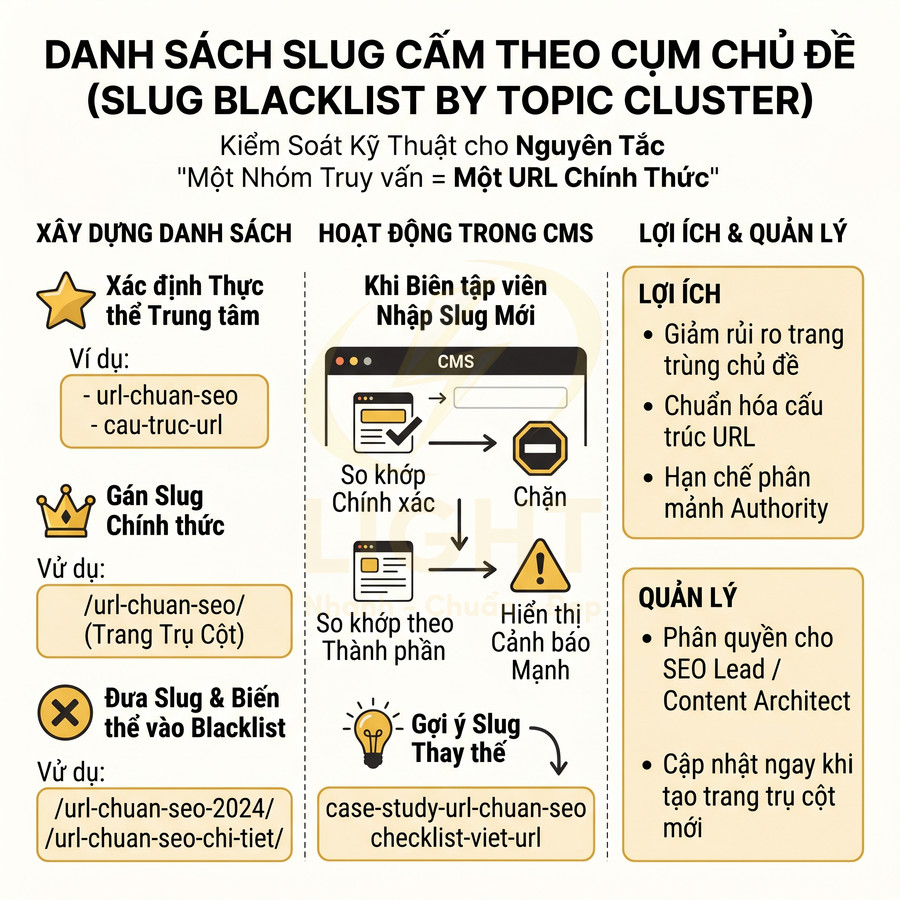
Cách thiết kế danh sách slug cấm theo cụm chủ đề:
- Xác định thực thể trung tâm của từng cụm (ví dụ: “url-chuan-seo”, “cau-truc-url”, “tham-so-url”).
- Gán slug chính thức cho từng thực thể (ví dụ: /url-chuan-seo/ là trang trụ cột).
- Đưa slug này và các biến thể cần chặn vào blacklist cho cụm đó:
- /url-chuan-seo-2024/
- /url-chuan-seo-chi-tiet/
- /url-chuan-seo-la-gi/
Trong CMS, khi biên tập viên nhập slug mới, hệ thống cần thực hiện:
- So khớp chính xác với danh sách slug cấm.
- So khớp theo thành phần: nếu slug chứa thực thể đã được đánh dấu là “độc quyền” cho một URL (ví dụ: “url-chuan-seo”), hệ thống hiển thị cảnh báo mạnh.
- Gợi ý slug thay thế nếu trang mới thực sự có intent khác (ví dụ: “case-study-url-chuan-seo”, “checklist-viet-url”).
Việc tích hợp blacklist vào workflow giúp:
- Giảm rủi ro tạo trang trùng chủ đề do thiếu thông tin hoặc do nhân sự mới chưa nắm hệ thống.
- Chuẩn hóa cấu trúc URL theo từng cụm, tránh tình trạng mỗi người đặt một kiểu.
- Hạn chế việc “chạy theo trend” bằng cách thêm năm, thêm tính từ vào slug cho cùng một chủ đề, gây phân mảnh authority.
Trong các đội nội dung lớn, nên phân quyền quản lý blacklist cho SEO lead hoặc content architect, không để mọi biên tập viên tự ý sửa. Mỗi khi tạo trang trụ cột mới, cần cập nhật ngay slug vào danh sách cấm của cụm tương ứng để khóa lại thực thể đó cho một URL duy nhất.
Cảnh báo trang mới có URL gần giống trang đang xếp hạng
Bên cạnh blacklist tĩnh, một cơ chế cảnh báo tương đồng URL động giúp phát hiện sớm nguy cơ ăn thịt từ khóa ở giai đoạn lên kế hoạch nội dung. Thay vì chỉ kiểm tra trùng slug, hệ thống nên đánh giá mức độ tương đồng giữa slug mới và các slug đang có thứ hạng tốt trên SERP cho cùng domain.
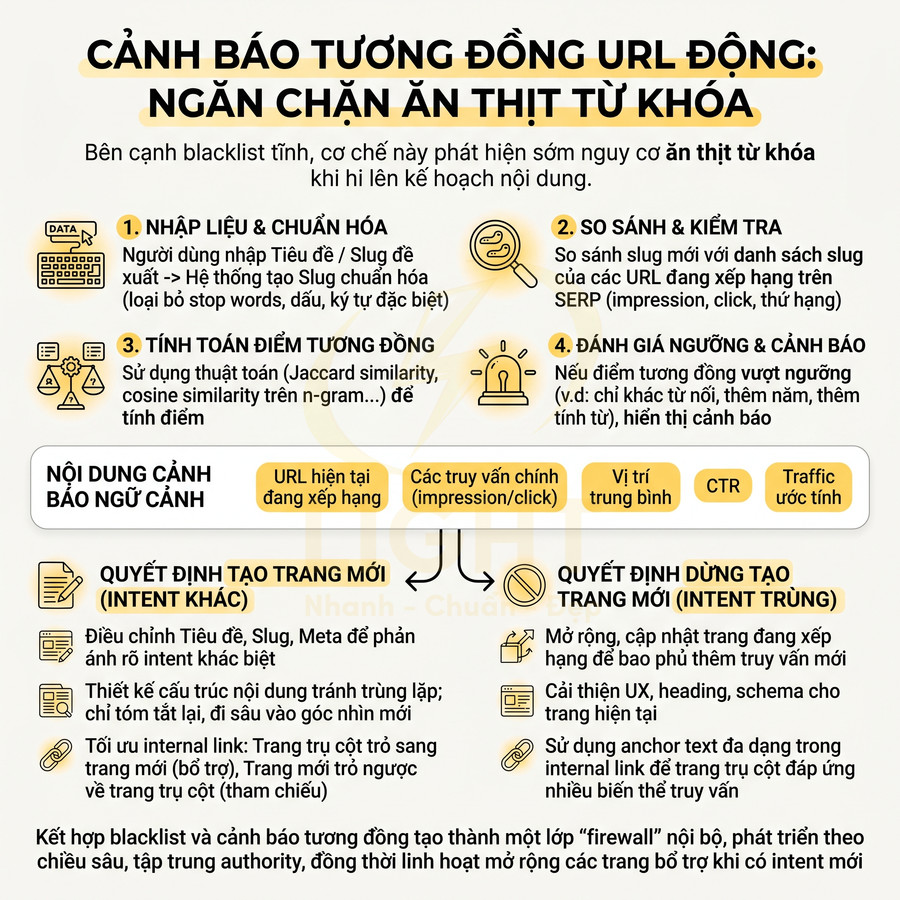
Các bước kỹ thuật cơ bản:
- Khi người dùng nhập tiêu đề hoặc slug đề xuất, hệ thống sinh ra một slug chuẩn hóa (loại bỏ stop words, chuẩn hóa dấu, ký tự đặc biệt).
- So sánh slug này với danh sách slug của các URL đang có impression, click hoặc thứ hạng trong Search Console.
- Tính điểm tương đồng (ví dụ: dựa trên Jaccard similarity, cosine similarity trên n-gram, hoặc đơn giản là số token trùng nhau).
- Nếu điểm tương đồng vượt ngưỡng (ví dụ: chỉ khác một từ nối, thêm năm, thêm tính từ), hiển thị cảnh báo.
Cảnh báo nên kèm theo thông tin ngữ cảnh để biên tập viên đánh giá rủi ro:
- URL hiện tại đang xếp hạng.
- Các truy vấn chính mà URL đó đang nhận impression/click.
- Vị trí trung bình, CTR, traffic ước tính.
Khi nhận cảnh báo, đội nội dung cần trả lời rõ ràng hai câu hỏi:
- Intent của trang mới có thực sự khác intent của trang đang xếp hạng không?
- Nếu khác, mối quan hệ giữa hai trang là gì: trụ cột – cluster, hướng dẫn – case study, lý thuyết – tài liệu tham khảo…?
Nếu quyết định vẫn tạo trang mới, cần:
- Điều chỉnh tiêu đề, slug, meta để phản ánh rõ intent khác biệt (ví dụ: thêm “case study”, “template”, “checklist”, “advanced”… khi nội dung thực sự tương ứng).
- Thiết kế cấu trúc nội dung tránh trùng lặp dài dòng với trang cũ; chỉ tóm tắt lại những phần bắt buộc, sau đó đi sâu vào góc nhìn mới.
- Tối ưu internal link: từ trang trụ cột trỏ sang trang mới như một tài nguyên bổ trợ, và từ trang mới trỏ ngược về trang trụ cột như nguồn tham chiếu nền tảng.
Ngược lại, nếu nhận thấy intent trùng, nên dừng việc tạo trang mới và chuyển sang:
- Mở rộng, cập nhật trang đang xếp hạng để bao phủ thêm truy vấn mới.
- Cải thiện UX, cấu trúc heading, schema cho trang hiện tại thay vì nhân bản nội dung.
- Sử dụng các anchor text đa dạng trong internal link để trang trụ cột có thể đồng thời đáp ứng nhiều biến thể truy vấn mà không cần thêm URL.
Kết hợp slug blacklist và cảnh báo tương đồng URL tạo thành một lớp “firewall” nội bộ chống ăn thịt từ khóa, giúp hệ thống nội dung phát triển theo chiều sâu, tập trung authority cho các URL trụ cột, đồng thời vẫn linh hoạt mở rộng các trang bổ trợ khi có intent mới thực sự khác biệt.
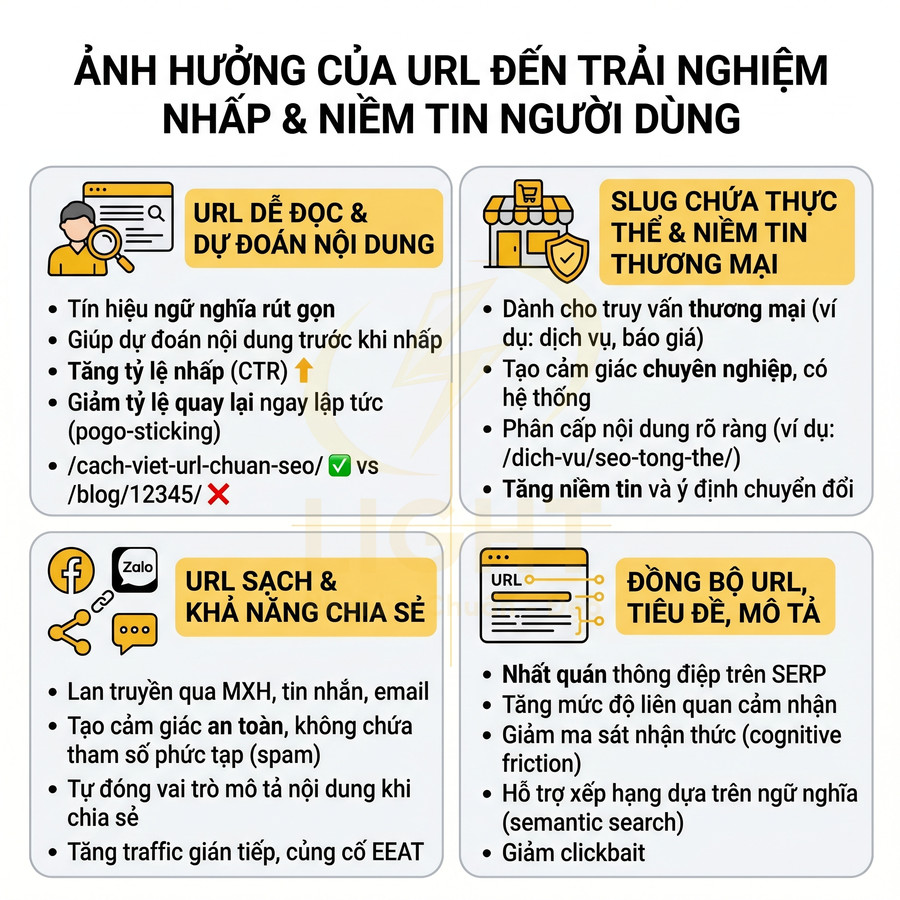
Ảnh hưởng của URL đến trải nghiệm nhấp và niềm tin người dùng trên trang tìm kiếm
URL tác động trực tiếp đến cách người dùng nhận diện, đánh giá và ra quyết định nhấp trên trang kết quả tìm kiếm. Khi được thiết kế dễ đọc, có cấu trúc logic và chứa thực thể rõ ràng, URL hoạt động như một lớp ngữ nghĩa cô đọng, giúp người dùng dự đoán nội dung, mức độ liên quan và độ tin cậy của trang trước khi click. Điều này không chỉ cải thiện CTR, giảm pogo-sticking mà còn củng cố cảm giác chuyên nghiệp, có hệ thống, đặc biệt với truy vấn thương mại. Ngược lại, URL rối, nhiều tham số, thiếu ngữ cảnh làm suy giảm niềm tin, hạn chế khả năng chia sẻ và trích dẫn. Sự đồng bộ giữa URL, tiêu đề và mô tả tạo nên một thông điệp nhất quán, nâng cao cả trải nghiệm nhấp lẫn tín hiệu SEO.
URL dễ đọc giúp người dùng đoán đúng nội dung trước khi nhấp
Khi người dùng nhìn vào kết quả tìm kiếm, họ thường lướt rất nhanh qua ba thành phần chính: tiêu đề, mô tả (snippet) và đường dẫn URL. Trong bối cảnh đó, URL đóng vai trò như một “tín hiệu ngữ nghĩa rút gọn”, giúp người dùng hình dung sơ bộ cấu trúc nội dung bên trong trước khi quyết định nhấp. Một URL dễ đọc, có cấu trúc logic, chứa thực thể và từ khóa liên quan, cho phép người dùng dự đoán khá chính xác xem trang có giải quyết đúng nhu cầu tìm kiếm hay không.
Ngược lại, các URL mơ hồ, chứa chuỗi ký tự, mã số, tham số động (query string) hoặc thư mục không mang ý nghĩa ngữ nghĩa sẽ làm giảm khả năng “đọc hiểu” của người dùng. Dù tiêu đề có hấp dẫn, người dùng vẫn có xu hướng nghi ngờ và bỏ qua nếu URL trông giống một đường dẫn kỹ thuật, thiếu ngữ cảnh. Điều này đặc biệt rõ với những truy vấn mang tính thông tin chuyên sâu, nơi người dùng cần cảm giác rằng nội dung được tổ chức bài bản và có chủ đích. Nội dung này có thể gia cố bằng Information Foraging Theory của Pirolli và Card. Lý thuyết này cho rằng người dùng đánh giá giá trị của nguồn thông tin dựa trên các tín hiệu gần, gọi là information scent, như link, biểu tượng, nhãn và ngữ cảnh xung quanh. URL dễ đọc chính là một dạng information scent: nó giúp người dùng ước lượng trang có đáng nhấp hay không trước khi tiêu tốn thời gian. Ví dụ /bao-gia-dich-vu-seo/ phát tín hiệu rõ hơn nhiều so với /index.php?id=987. URL càng rõ, chi phí nhận thức càng thấp, khả năng nhấp đúng kỳ vọng càng cao.
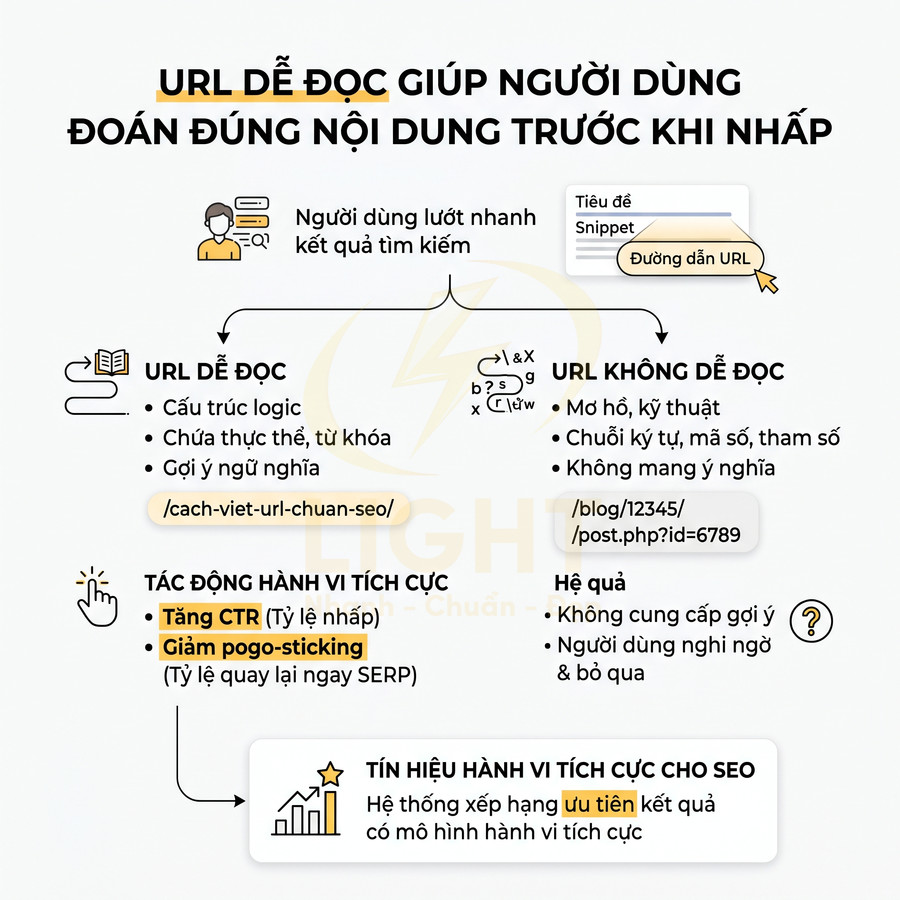
Ví dụ, với truy vấn “cách viết url chuẩn seo”, URL /cach-viet-url-chuan-seo/ thể hiện rõ chủ đề, phạm vi nội dung và mức độ liên quan đến truy vấn. Người dùng có thể suy luận rằng trang sẽ nói về quy tắc, best practice, ví dụ thực tế liên quan đến URL chuẩn SEO. Trong khi đó, các URL như /blog/12345/ hoặc /post.php?id=6789 không cung cấp bất kỳ gợi ý ngữ nghĩa nào, khiến người dùng phải “đánh cược” khi nhấp.
Về mặt hành vi, một URL dễ đọc góp phần cải thiện trải nghiệm nhấp (click experience) theo hai chiều:
- Tăng tỷ lệ nhấp (CTR) vì người dùng cảm thấy kết quả “khớp” với kỳ vọng ngay từ SERP.
- Giảm tỷ lệ quay lại SERP ngay lập tức (pogo-sticking) do nội dung bên trong thường bám sát chủ đề mà URL đã “hứa hẹn”.
Đây là những tín hiệu hành vi gián tiếp cho thấy mức độ phù hợp giữa truy vấn – kết quả – trải nghiệm sau nhấp. Dù Google không công bố chi tiết từng tín hiệu, nhưng về mặt logic, một hệ thống xếp hạng dựa trên mức độ hài lòng người dùng sẽ ưu tiên các kết quả có mô hình hành vi tích cực, trong đó URL dễ đọc là một thành phần quan trọng.
Slug chứa thực thể rõ ràng tăng mức độ tin cậy với truy vấn thương mại
Với các truy vấn thương mại như “dịch vụ seo”, “báo giá seo”, “thiết kế website bán hàng”, người dùng không chỉ tìm thông tin mà còn đánh giá mức độ tin cậy và chuyên môn của nhà cung cấp. Ở nhóm truy vấn này, slug – phần cuối của URL – nếu chứa thực thể dịch vụ rõ ràng, được đặt trong một cấu trúc thư mục hợp lý, sẽ tạo cảm giác website được xây dựng có chiến lược, có phân loại nội dung rõ ràng.
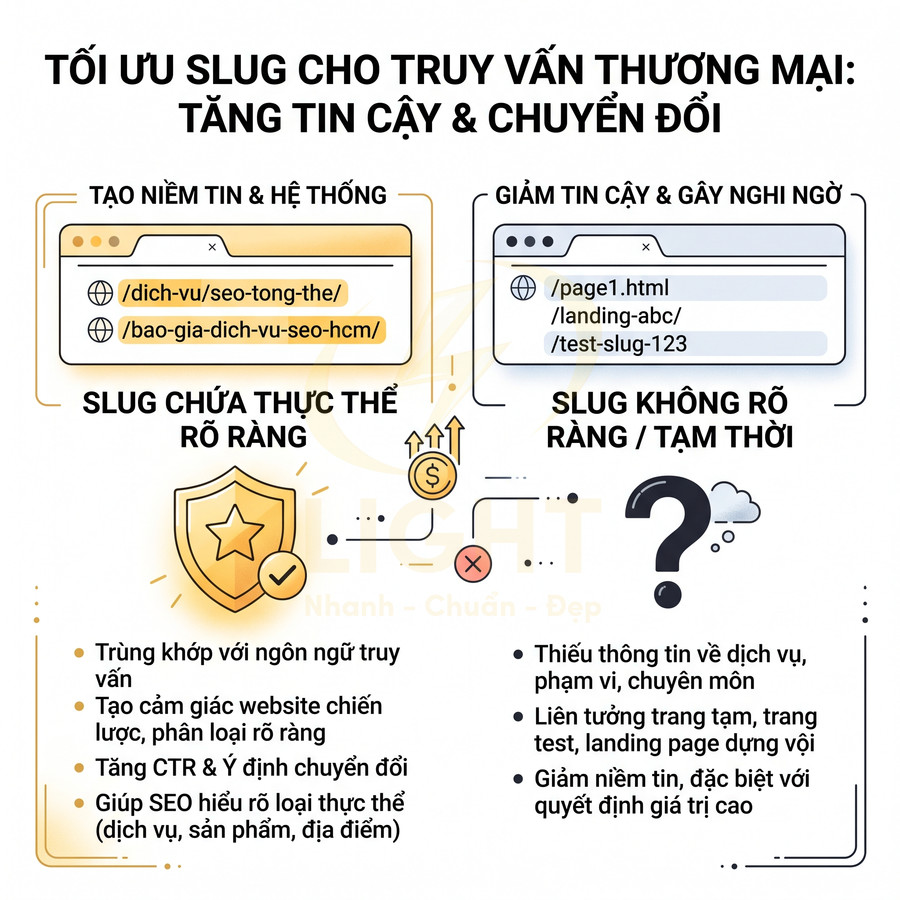
Ví dụ, các cấu trúc như /dich-vu/seo-tong-the/ hoặc /bao-gia-dich-vu-seo/ thể hiện:
- Thực thể chính: “dịch vụ”, “báo giá dịch vụ seo”.
- Phân cấp nội dung: thư mục “dich-vu” chứa các trang dịch vụ, tạo cảm giác về một hệ thống dịch vụ hoàn chỉnh.
- Sự trùng khớp với ngôn ngữ truy vấn: người dùng dễ dàng nhận ra từ khóa họ vừa tìm xuất hiện trực tiếp trong slug.
Trong khi đó, các URL như /page1.html hoặc /landing-abc/ không truyền tải được bất kỳ thông tin nào về loại dịch vụ, phạm vi, hay mức độ chuyên môn. Ở góc độ tâm lý, người dùng có thể liên tưởng đây là trang tạm, trang test, hoặc một landing page được dựng vội cho quảng cáo, thiếu tính hệ thống. Điều này làm giảm niềm tin, đặc biệt với các quyết định có giá trị cao như thuê dịch vụ SEO, thiết kế website, chạy quảng cáo.
Trong môi trường cạnh tranh cao trên SERP, nơi nhiều website có tiêu đề và mô tả tương tự nhau, những chi tiết nhỏ như slug có thể tạo ra sự khác biệt đáng kể về CTR giữa các kết quả có vị trí gần nhau. Khi người dùng thấy slug trùng khớp với mô hình nhu cầu của họ (ví dụ: “dịch vụ + khu vực + hành động” như /dich-vu/seo-tong-the-ha-noi/, /bao-gia-dich-vu-seo-hcm/), họ có xu hướng tin rằng trang được thiết kế riêng cho bối cảnh của mình.
Điều này không chỉ tăng khả năng nhấp mà còn nâng cao ý định chuyển đổi sau khi vào trang, vì người dùng bước vào với kỳ vọng rằng nội dung sẽ giải quyết đúng nhu cầu thương mại cụ thể. Từ góc độ SEO, slug chứa thực thể rõ ràng còn giúp hệ thống xếp hạng hiểu rõ hơn về loại thực thể (dịch vụ, sản phẩm, khu vực, loại báo giá), hỗ trợ việc ánh xạ truy vấn – tài nguyên một cách chính xác hơn.
URL sạch giúp tăng khả năng chia sẻ trên mạng xã hội và tin nhắn
URL không chỉ xuất hiện trên Google mà còn lan truyền qua nhiều kênh khác như Facebook, Zalo, email, chat nội bộ, diễn đàn. Trong các ngữ cảnh này, người dùng thường nhìn thấy đường dẫn trước khi đọc nội dung, đặc biệt khi link được chia sẻ kèm rất ít lời giới thiệu. Một URL sạch, ngắn, dễ đọc, không chứa chuỗi tham số phức tạp sẽ tạo cảm giác an toàn, chuyên nghiệp và đáng tin hơn.
Các URL dài, chứa nhiều tham số (utm, session id, filter, sort, ref, v.v.) hoặc ký tự lạ dễ bị người nhận nghi ngờ là spam, link lừa đảo, hoặc trang quảng cáo ẩn. Điều này làm giảm tỷ lệ click tự nhiên, ngay cả khi nội dung thực sự hữu ích. Về mặt bảo mật, người dùng ngày càng có xu hướng kiểm tra nhanh domain và slug trước khi nhấp, nên một URL sạch là lợi thế cạnh tranh về niềm tin.
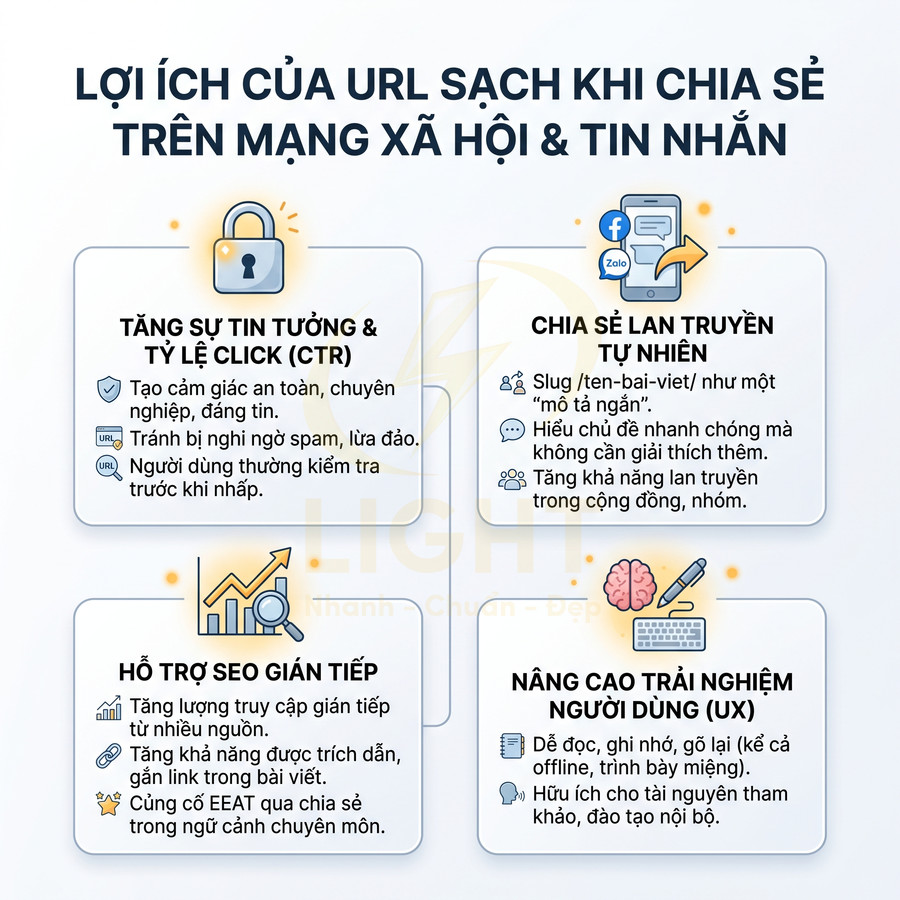
Khi người dùng copy link và dán vào tin nhắn, slug như /url-chuan-seo/ tự nó đã đóng vai trò như một “mô tả ngắn” về nội dung. Người nhận chỉ cần nhìn vào slug là có thể hiểu sơ bộ chủ đề: bài viết nói về cách tối ưu URL chuẩn SEO. Điều này giảm nhu cầu phải giải thích thêm, giúp quá trình chia sẻ diễn ra tự nhiên hơn, tăng khả năng lan truyền trong các nhóm chuyên môn, cộng đồng nội bộ doanh nghiệp hoặc nhóm khách hàng tiềm năng.
Về mặt tín hiệu SEO, dù các “tín hiệu xã hội” không phải là yếu tố xếp hạng trực tiếp, nhưng một URL dễ chia sẻ sẽ:
- Tăng lượng truy cập gián tiếp từ nhiều nguồn khác nhau.
- Tăng khả năng được trích dẫn, gắn link trong bài viết, tài liệu, slide, tài nguyên nội bộ.
- Góp phần củng cố EEAT (Experience, Expertise, Authoritativeness, Trustworthiness) thông qua việc nội dung được chia sẻ trong các ngữ cảnh chuyên môn.
Ở góc độ trải nghiệm người dùng, URL sạch còn giúp việc đọc, ghi nhớ và gõ lại (trong trường hợp offline hoặc trình bày miệng) trở nên dễ dàng hơn. Điều này đặc biệt hữu ích với các tài nguyên mang tính “reference” như tài liệu hướng dẫn, checklist, tài nguyên đào tạo nội bộ, nơi người dùng có thể cần truy cập lặp lại nhiều lần.
Đồng bộ URL với tiêu đề SEO để tăng mức liên quan cảm nhận
Sự đồng bộ giữa URL – tiêu đề SEO – mô tả tạo nên một thông điệp nhất quán trên trang kết quả tìm kiếm. Khi người dùng thấy từ khóa hoặc thực thể chính xuất hiện trong cả ba thành phần, họ hình thành cảm nhận rằng trang được tối ưu xoay quanh đúng chủ đề họ đang tìm. Mức độ “liên quan cảm nhận” này thường có tác động trực tiếp đến quyết định nhấp, đôi khi còn mạnh hơn cả vị trí xếp hạng.
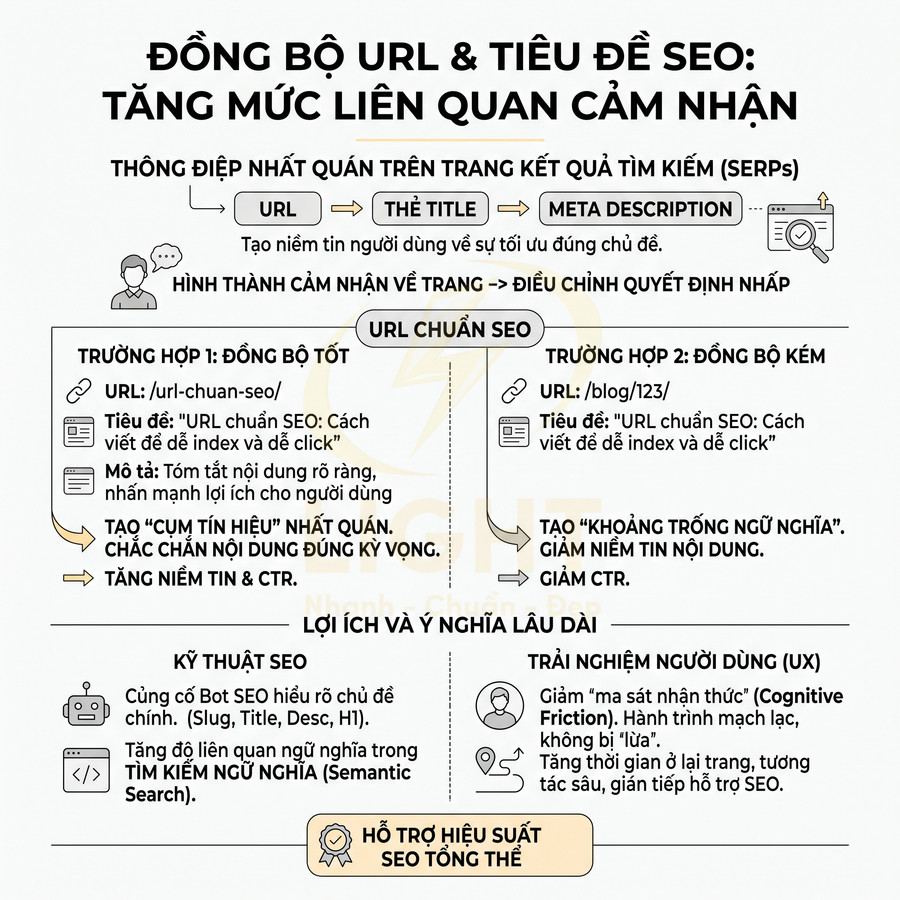
Ví dụ, với truy vấn “url chuẩn seo”, một kết quả có:
- URL: /url-chuan-seo/
- Tiêu đề: “URL chuẩn SEO: Cách viết để dễ index và dễ click”
- Mô tả: tóm tắt rõ ràng nội dung, nhấn mạnh lợi ích cho người dùng
sẽ tạo ra một “cụm tín hiệu” nhất quán, khiến người dùng gần như chắc chắn rằng khi nhấp vào, họ sẽ nhận được nội dung đúng như kỳ vọng. Trong khi đó, một kết quả khác có tiêu đề tương tự nhưng URL là /blog/123/ sẽ tạo ra một “khoảng trống ngữ nghĩa” giữa URL và phần còn lại, làm giảm niềm tin và CTR.
Về mặt kỹ thuật SEO, sự đồng bộ này còn giúp bot củng cố hiểu biết về chủ đề trang. Khi thực thể chính (ví dụ: “url chuẩn seo”, “dịch vụ seo”, “báo giá seo”) xuất hiện nhất quán trong:
- Slug URL
- Thẻ title
- Meta description
- Heading chính trong nội dung
hệ thống xếp hạng có thêm cơ sở để xác định chủ đề trung tâm của trang, tăng độ liên quan ngữ nghĩa trong quá trình lập chỉ mục và xếp hạng. Điều này đặc biệt quan trọng trong bối cảnh tìm kiếm ngữ nghĩa (semantic search), nơi công cụ tìm kiếm không chỉ so khớp từ khóa mà còn cố gắng hiểu ý định và thực thể.
Ở góc độ UX, sự đồng bộ còn giúp giảm “ma sát nhận thức” (cognitive friction). Khi người dùng nhấp vào một kết quả mà URL, tiêu đề, mô tả và nội dung bên trong đều xoay quanh cùng một chủ đề, họ cảm thấy hành trình tìm kiếm của mình mạch lạc, không bị “lừa” bởi clickbait hoặc tối ưu sai hướng. Điều này góp phần tăng thời gian ở lại trang, tăng khả năng tương tác sâu (scroll, click nội bộ, đăng ký, liên hệ), từ đó gián tiếp hỗ trợ hiệu suất SEO tổng thể.
Chuẩn chuyên môn và độ tin cậy khi quản trị URL lâu dài
Quản trị URL lâu dài đòi hỏi mức chuẩn chuyên môn tương đương một lớp hạ tầng kỹ thuật: vừa phục vụ SEO, vừa đảm bảo tính ổn định cho dữ liệu và khả năng mở rộng hệ thống. Cốt lõi là xây dựng bộ quy chuẩn slug thống nhất, có tài liệu rõ ràng, được tự động hóa trong CMS và tuân thủ bởi nội dung, SEO, kỹ thuật, data. Mỗi thay đổi URL phải được xem như thay đổi kiến trúc thông tin, có quy trình phê duyệt, kế hoạch redirect, cập nhật internal link, sitemap và cơ chế giám sát sau triển khai. Song song, cần duy trì audit log lịch sử URL, hệ thống nhật ký quét lỗi để phát hiện sớm trang mất index, và thiết kế pattern URL đủ linh hoạt để mở rộng dịch vụ, khu vực mới mà vẫn giữ cấu trúc nhất quán, tin cậy.
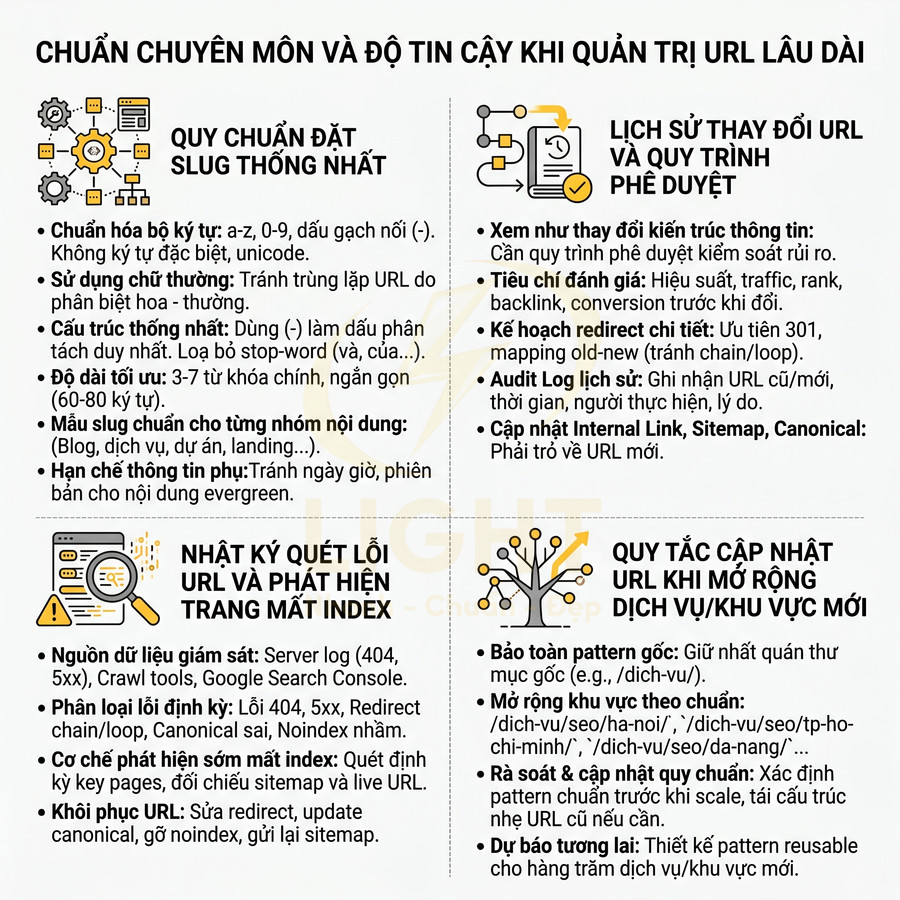
Quy chuẩn đặt slug thống nhất cho đội nội dung và kỹ thuật
Quản trị URL bền vững không chỉ là vấn đề “đặt tên cho đẹp”, mà là một lớp hạ tầng thông tin có tính kỹ thuật cao, ảnh hưởng trực tiếp đến SEO, khả năng mở rộng hệ thống và độ tin cậy dữ liệu. Vì vậy, cần xây dựng một bộ quy chuẩn slug mang tính “spec kỹ thuật” rõ ràng, được áp dụng thống nhất cho cả đội nội dung, SEO, kỹ thuật và data.
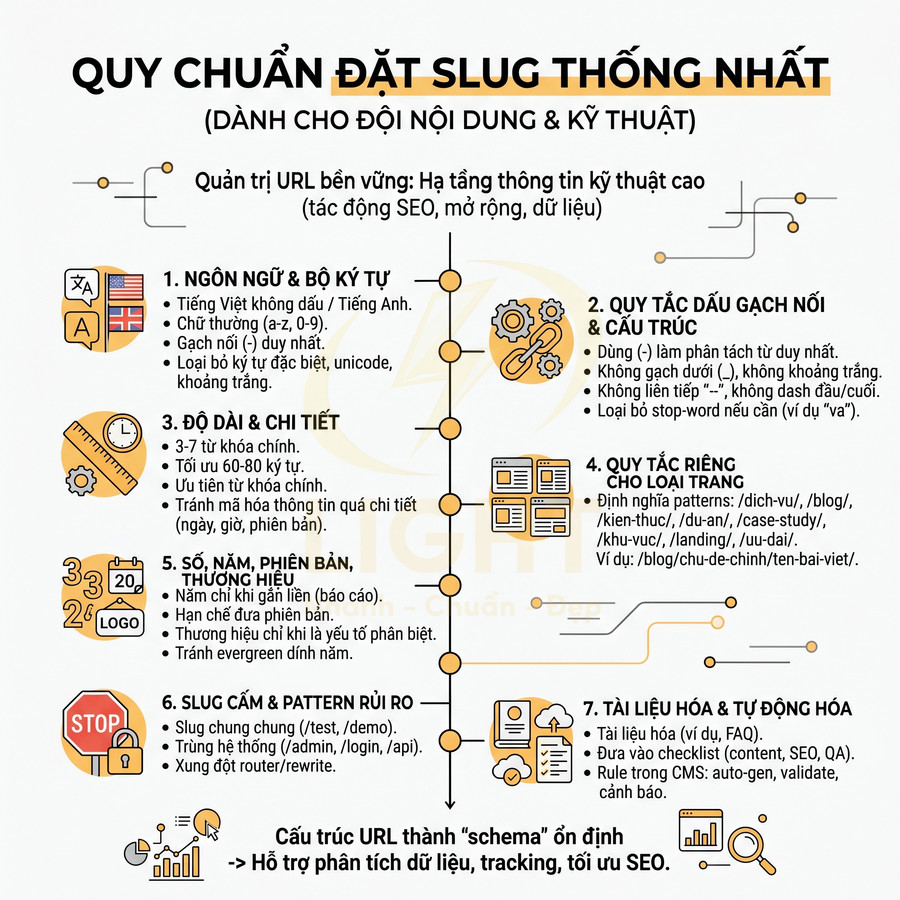
Khi thiết kế quy chuẩn, nên xác định rõ các trục quyết định sau:
1. Ngôn ngữ và bộ ký tự sử dụng
Quy định nhất quán về:
- Ngôn ngữ slug: tiếng Việt không dấu, tiếng Anh, hay kết hợp (ví dụ: ưu tiên tiếng Việt không dấu cho content local, tiếng Anh cho tài liệu kỹ thuật).
- Bộ ký tự cho phép: a–z, 0–9, dấu gạch nối (-); loại bỏ ký tự đặc biệt, ký tự có dấu, khoảng trắng, ký tự Unicode khó chuẩn hóa.
- Chuẩn hóa chữ thường: toàn bộ slug phải là chữ thường để tránh trùng lặp URL do phân biệt hoa – thường trên một số hệ thống.
2. Quy tắc dùng dấu gạch nối và cấu trúc từ
Slug nên được chuẩn hóa theo các quy tắc:
- Dùng dấu gạch nối (-) làm dấu phân tách từ duy nhất; không dùng gạch dưới (_), không dùng khoảng trắng được encode.
- Không để 2 dấu gạch nối liên tiếp, không để gạch nối ở đầu hoặc cuối slug.
- Chuẩn hóa loại bỏ stop-word nếu cần (như “va”, “và”, “của”, “the”, “a”) để slug ngắn gọn hơn, nhưng phải được quy định rõ ràng để tránh mỗi người làm một kiểu.
3. Độ dài tối ưu và mức độ chi tiết
Slug quá dài gây khó đọc, khó chia sẻ, và tăng rủi ro phải đổi sau này. Nên định nghĩa:
- Độ dài khuyến nghị: ví dụ 3–7 từ khóa chính, tối đa khoảng 60–80 ký tự.
- Ưu tiên từ khóa chính, loại bỏ các từ thừa không mang giá trị phân biệt.
- Không encode thông tin quá chi tiết (như ngày, giờ, phiên bản) vào slug nếu nội dung có thể thay đổi hoặc cập nhật định kỳ.
4. Quy tắc riêng cho từng loại trang
Cần định nghĩa pattern slug chuẩn cho từng nhóm nội dung để đảm bảo tính hệ thống:
- Trang dịch vụ: /dich-vu/ten-dich-vu/ (có thể thêm ngành hoặc khu vực nếu là trục phân loại chính).
- Trang blog / bài viết kiến thức: /blog/chu-de-chinh/ten-bai-viet/ hoặc /kien-thuc/ten-bai-viet/ với quy tắc rõ ràng về “chu-de-chinh”.
- Trang dự án / case study: /du-an/ten-du-an/ hoặc /case-study/ten-khach-hang/ten-du-an/ nếu cần phân nhóm theo khách hàng.
- Trang khu vực: /khu-vuc/ten-khu-vuc/ hoặc gắn với dịch vụ: /dich-vu/ten-dich-vu/ten-khu-vuc/.
- Trang chuyển đổi (landing page, form, campaign): /landing/ten-chien-dich/ hoặc /uu-dai/ten-chien-dich/, tách biệt với content evergreen.
5. Cách xử lý số, năm, phiên bản, thương hiệu
Đây là nhóm yếu tố dễ gây lỗi khi nội dung thay đổi theo thời gian:
- Năm: chỉ nên đưa năm vào slug nếu nội dung thực sự gắn với năm đó (báo cáo 2023, thống kê 2022). Với nội dung evergreen, nên tránh gắn năm để không phải đổi slug mỗi năm.
- Số thứ tự / phiên bản: hạn chế đưa vào slug nếu có khả năng cập nhật; thay vào đó quản lý phiên bản trong nội dung hoặc tham số.
- Thương hiệu: chỉ đưa brand vào slug khi đó là yếu tố phân biệt chính (ví dụ so sánh sản phẩm, review), tránh lặp lại brand ở mọi slug gây dài dòng.
6. Danh sách slug cấm và pattern rủi ro
Nên duy trì một danh sách slug hoặc pattern không được phép sử dụng, ví dụ:
- Các slug quá chung chung: /test/, /demo/, /new/, /temp/.
- Các slug dễ trùng lặp hoặc gây nhầm lẫn với hệ thống: /admin/, /login/, /api/.
- Các slug có thể gây xung đột với rule rewrite hoặc router của hệ thống.
7. Tài liệu hóa và tự động hóa trong CMS
Quy chuẩn slug cần được:
- Tài liệu hóa chi tiết, có ví dụ đúng – sai, case đặc biệt, và FAQ cho đội nội dung.
- Đưa vào checklist khi tạo nội dung mới, review SEO onpage, và quy trình QA.
- Mã hóa thành rule trong CMS: auto-generate slug theo chuẩn, validate ký tự, cảnh báo trùng slug, cảnh báo độ dài, cảnh báo dùng từ cấm.
Khi mọi người cùng tuân thủ một chuẩn, cấu trúc URL trở thành một “schema” ổn định, hỗ trợ mạnh cho việc phân tích dữ liệu, xây dựng dashboard, tracking theo thư mục, và tối ưu SEO dựa trên performance của từng cụm URL.
Lịch sử thay đổi URL và quy trình phê duyệt chuyển hướng
Mỗi lần thay đổi URL là một thay đổi kiến trúc thông tin, có thể làm mất traffic, mất backlink hoặc tạo lỗi trải nghiệm nếu không được kiểm soát. Do đó, cần một quy trình phê duyệt có tính kiểm soát rủi ro, tương tự như quy trình deploy code.

1. Tiêu chí đánh giá trước khi đổi slug
Trước khi quyết định đổi URL, cần phân tích tối thiểu các yếu tố:
- Hiệu suất hiện tại: organic traffic, thứ hạng từ khóa chính, số lượng và chất lượng backlink, tỷ lệ chuyển đổi.
- Lý do thay đổi: tái cấu trúc site, chuẩn hóa slug, gộp nội dung trùng lặp, đổi ngôn ngữ, đổi taxonomy.
- Rủi ro SEO: trang đang top đầu, có nhiều backlink, hoặc là landing chính cho chiến dịch thì cần cân nhắc kỹ, có thể trì hoãn hoặc tìm giải pháp khác.
2. Kế hoạch chuyển hướng và cập nhật liên quan
Một thay đổi URL chuẩn phải đi kèm kế hoạch kỹ thuật chi tiết:
- Loại redirect: ưu tiên 301 (mãi mãi) cho thay đổi cấu trúc; tránh 302 kéo dài.
- Mapping URL cũ – mới: bảng mapping đầy đủ, không bỏ sót, không để redirect chain (A → B → C) hoặc loop.
- Cập nhật internal link: sửa toàn bộ link nội bộ trỏ về URL mới, tránh để link nội bộ đi qua redirect.
- Cập nhật sitemap: thay URL cũ bằng URL mới, đảm bảo sitemap không chứa URL đã redirect hoặc 404.
- Kiểm tra canonical: canonical phải trỏ về URL mới, không trỏ về URL cũ đã redirect.
3. Lịch sử thay đổi URL như một “audit log”
Hệ thống nên lưu lịch sử thay đổi URL với các trường thông tin tối thiểu:
- URL cũ, URL mới.
- Ngày giờ thay đổi.
- Người đề xuất, người thực hiện, người phê duyệt.
- Lý do thay đổi, ghi chú về rủi ro và biện pháp giảm thiểu.
Audit log này giúp:
- Truy vết khi thứ hạng hoặc traffic biến động bất thường sau một đợt đổi URL.
- Tránh lặp lại các pattern sai (ví dụ: từng redirect một cụm thư mục gây mất index).
- Hỗ trợ rollback: nếu cần khôi phục cấu trúc cũ, có đủ thông tin để đảo ngược.
4. Quy trình nhiều bước cho website lớn
Với hệ thống lớn, nên áp dụng quy trình nhiều bước:
- Đề xuất: đội nội dung hoặc product đề xuất thay đổi, kèm lý do và danh sách URL.
- Review SEO: chuyên gia SEO đánh giá rủi ro, đề xuất phương án redirect, ưu tiên, thời điểm triển khai.
- Review kỹ thuật: đội dev/infra kiểm tra khả năng triển khai, xung đột rule rewrite, ảnh hưởng đến hệ thống khác (tracking, API, app).
- Phê duyệt: người chịu trách nhiệm business/SEO chấp thuận, có thể chia nhỏ thành nhiều đợt rollout.
- Triển khai: áp dụng redirect, cập nhật CMS, sitemap, internal link.
- Kiểm thử và giám sát: crawl lại, kiểm tra lỗi 404, redirect chain, theo dõi Search Console và log server trong vài tuần sau triển khai.
Nhật ký quét lỗi URL để phát hiện trang mất index
Quản trị URL chuyên nghiệp luôn gắn với một cơ chế giám sát liên tục. Nhật ký quét lỗi URL đóng vai trò như hệ thống cảnh báo sớm cho các vấn đề index và crawl.
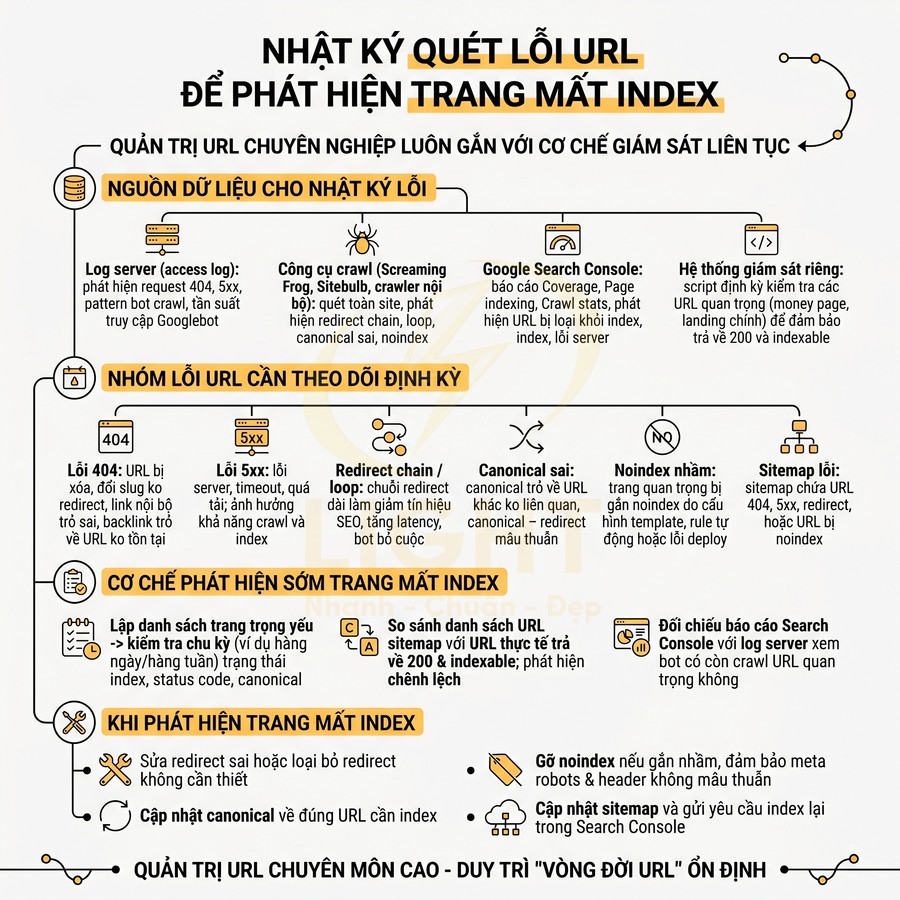
1. Nguồn dữ liệu cho nhật ký lỗi
Có thể kết hợp nhiều nguồn để có bức tranh đầy đủ:
- Log server (access log): phát hiện request 404, 5xx, pattern bot crawl, tần suất truy cập của Googlebot.
- Công cụ crawl (Screaming Frog, Sitebulb, crawler nội bộ): quét toàn site để phát hiện redirect chain, loop, canonical sai, noindex.
- Google Search Console: báo cáo Coverage, Page indexing, Crawl stats, giúp phát hiện URL bị loại khỏi index hoặc gặp lỗi server.
- Hệ thống giám sát riêng: script định kỳ kiểm tra các URL quan trọng (money page, landing chính) để đảm bảo luôn trả về 200 và indexable.
2. Nhóm lỗi URL cần theo dõi định kỳ
Nhật ký nên phân loại lỗi theo nhóm để dễ ưu tiên xử lý:
- Lỗi 404: URL bị xóa, đổi slug nhưng không redirect, link nội bộ trỏ sai, backlink trỏ về URL không tồn tại.
- Lỗi 5xx: lỗi server, timeout, quá tải; ảnh hưởng trực tiếp đến khả năng crawl và index.
- Redirect chain / loop: chuỗi redirect dài làm giảm tín hiệu SEO, tăng latency, có thể khiến bot bỏ cuộc.
- Canonical sai: canonical trỏ về URL khác không liên quan, hoặc canonical – redirect mâu thuẫn.
- Noindex nhầm: trang quan trọng bị gắn noindex do cấu hình template, rule tự động hoặc lỗi deploy.
- Sitemap lỗi: sitemap chứa URL 404, 5xx, redirect, hoặc URL bị noindex.
3. Cơ chế phát hiện sớm trang mất index
Để không bị động, nên thiết kế quy trình:
- Thiết lập danh sách “trang trọng yếu” (key pages) và kiểm tra trạng thái index, status code, canonical của chúng theo chu kỳ (ví dụ hàng ngày hoặc hàng tuần).
- So sánh danh sách URL trong sitemap với danh sách URL thực tế trả về 200 và indexable; phát hiện chênh lệch.
- Đối chiếu báo cáo Search Console với log server để xem bot có còn crawl các URL quan trọng hay không.
Khi phát hiện trang quan trọng bị mất index, có thể khôi phục bằng cách:
- Sửa redirect sai hoặc loại bỏ redirect không cần thiết.
- Cập nhật canonical về đúng URL cần index.
- Gỡ noindex nếu gắn nhầm, đảm bảo meta robots và header không mâu thuẫn.
- Cập nhật lại sitemap và gửi yêu cầu index lại trong Search Console.
Quản trị URL ở mức chuyên môn cao không dừng ở việc tạo slug chuẩn, mà là duy trì một “vòng đời URL” ổn định: từ lúc tạo, vận hành, thay đổi, đến khi ngừng sử dụng, luôn được giám sát và ghi nhận.
Quy tắc cập nhật URL khi mở rộng dịch vụ hoặc khu vực mới
Khi doanh nghiệp mở rộng danh mục dịch vụ hoặc khu vực phục vụ, cấu trúc URL phải được xem như một “schema dữ liệu” cần giữ tính nhất quán. Mỗi quyết định đặt URL mới sẽ ảnh hưởng đến khả năng scale, phân tích và tối ưu trong tương lai.
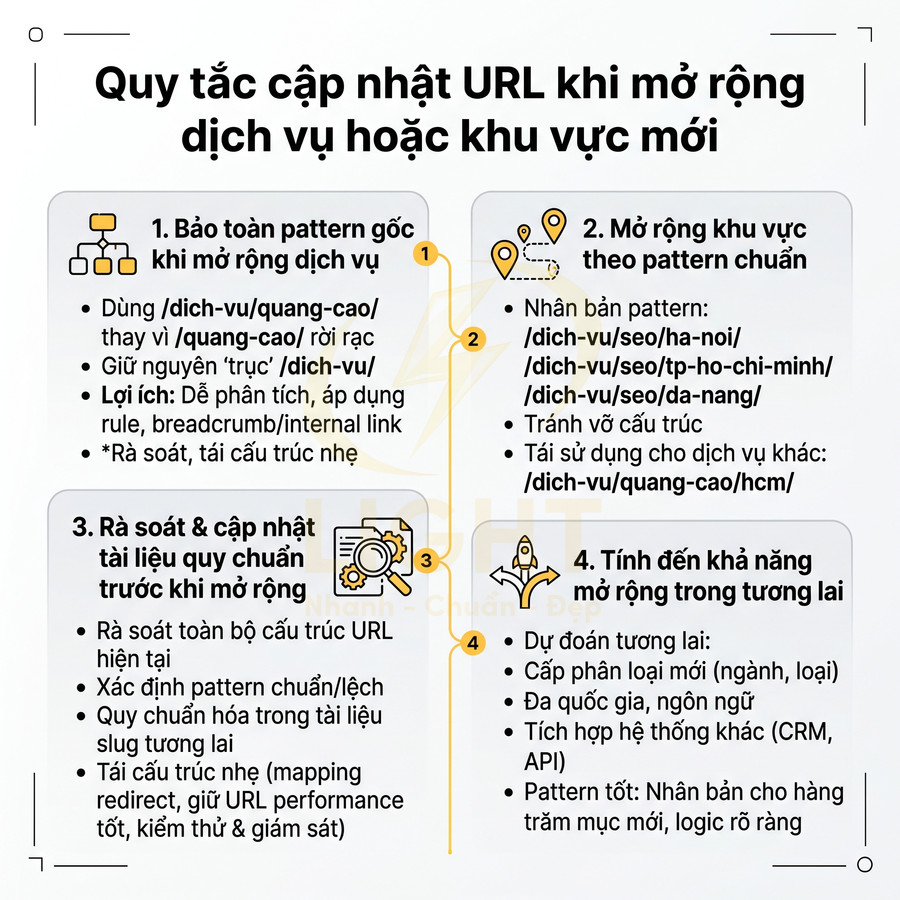
1. Bảo toàn pattern gốc khi mở rộng dịch vụ
Nếu trước đây đã dùng pattern /dich-vu/seo/, khi thêm dịch vụ quảng cáo, nên tuân thủ:
- Dùng /dich-vu/quang-cao/ thay vì /quang-cao/ rời rạc để giữ nguyên “trục” /dich-vu/.
- Đảm bảo mọi dịch vụ mới đều nằm dưới cùng một thư mục gốc, giúp:
- Dễ phân tích performance theo thư mục /dich-vu/ trong analytics.
- Dễ áp dụng rule bảo mật, caching, hoặc tracking riêng cho nhóm dịch vụ.
- Dễ triển khai breadcrumb, internal link theo cấu trúc thư mục.
Trước khi thêm dịch vụ mới, nên rà soát:
- Các pattern hiện có: có dịch vụ nào đang “lạc” ngoài thư mục chuẩn không.
- Khả năng cần tái cấu trúc nhẹ: đưa các dịch vụ cũ về pattern chuẩn, kèm kế hoạch redirect.
2. Mở rộng khu vực theo pattern chuẩn
Nếu đã dùng pattern /dich-vu/ten-dich-vu/ten-khu-vuc/, khi mở thêm tỉnh mới, chỉ cần nhân bản pattern:
- /dich-vu/seo/ha-noi/, /dich-vu/seo/tp-ho-chi-minh/, /dich-vu/seo/da-nang/…
- Không tạo nhánh mới kiểu /seo-ha-noi/, /seo-hcm/ nếu trước đó không dùng pattern này, để tránh “vỡ” cấu trúc.
Với các dịch vụ khác, có thể tái sử dụng cùng pattern:
- /dich-vu/quang-cao/ha-noi/, /dich-vu/quang-cao/hcm/…
3. Rà soát và cập nhật tài liệu quy chuẩn trước khi mở rộng
Trước mỗi đợt mở rộng lớn (thêm nhiều dịch vụ hoặc nhiều khu vực), nên:
- Rà soát toàn bộ cấu trúc URL hiện tại, xác định pattern chuẩn và pattern “lệch chuẩn”.
- Quyết định pattern chính thức sẽ dùng cho tương lai, ghi rõ trong tài liệu quy chuẩn slug.
- Nếu cần, thực hiện tái cấu trúc nhẹ các URL cũ để đồng bộ, nhưng phải:
- Lập mapping redirect chi tiết.
- Ưu tiên giữ nguyên URL cho các trang đang có performance tốt, chỉ đổi khi thực sự cần.
- Triển khai và kiểm thử cẩn thận, kết hợp giám sát sau khi đổi.
4. Tính đến khả năng mở rộng trong tương lai
Khi thiết kế pattern URL cho dịch vụ và khu vực, nên dự đoán trước:
- Khả năng thêm cấp phân loại mới (ngành, phân khúc khách hàng, loại dịch vụ con).
- Khả năng mở rộng ra nhiều quốc gia, nhiều ngôn ngữ (có cần /vi/, /en/, hay subdomain riêng).
- Khả năng tích hợp với hệ thống khác (app, API, CRM) đang dùng URL làm key.
Một pattern tốt là pattern có thể “nhân bản” cho hàng trăm dịch vụ và khu vực mới mà không cần nghĩ lại từ đầu, không phải đổi URL cũ, và vẫn giữ được logic phân cấp rõ ràng cho cả người dùng lẫn bot.
Kiểm thử URL trước khi chạy chính thức để tránh lỗi index
Kiểm thử URL trên môi trường staging giúp mô phỏng gần như đầy đủ production, từ đó phát hiện sớm các vấn đề về slug, cấu trúc thư mục, trùng lặp URL, canonical, meta robots và hệ thống redirect. Bằng cách dùng crawler chuyên dụng, cấu hình user-agent giống Googlebot và xuất đầy đủ trường dữ liệu SEO, có thể phân loại lỗi theo mức độ nghiêm trọng, hiệu suất và tối ưu nâng cao để xử lý dứt điểm trước khi deploy.
Song song, cần kiểm tra chuỗi chuyển hướng, lỗi 404, loop, URL mồ côi, đối chiếu với breadcrumb, sitemap XML, internal link và bảng mapping từ khóa – URL. Mục tiêu là đảm bảo mỗi URL quan trọng đều có vai trò rõ trong cụm chủ đề, được index đúng phiên bản và không gây lãng phí crawl budget hay mất tín hiệu xếp hạng.

Quét toàn bộ website thử nghiệm để phát hiện URL lỗi chuẩn SEO
Trên môi trường staging, cần mô phỏng gần như 100% cấu hình của production (web server, CMS, plugin, rewrite rule, CDN, cache, bảo mật) để kết quả crawl phản ánh đúng thực tế. Sau đó sử dụng các công cụ crawler chuyên dụng (Screaming Frog, Sitebulb, JetOctopus,…) để quét toàn bộ website thử nghiệm với user-agent giống Googlebot, giới hạn tốc độ crawl tương đương hoặc thấp hơn môi trường thật để tránh quá tải.
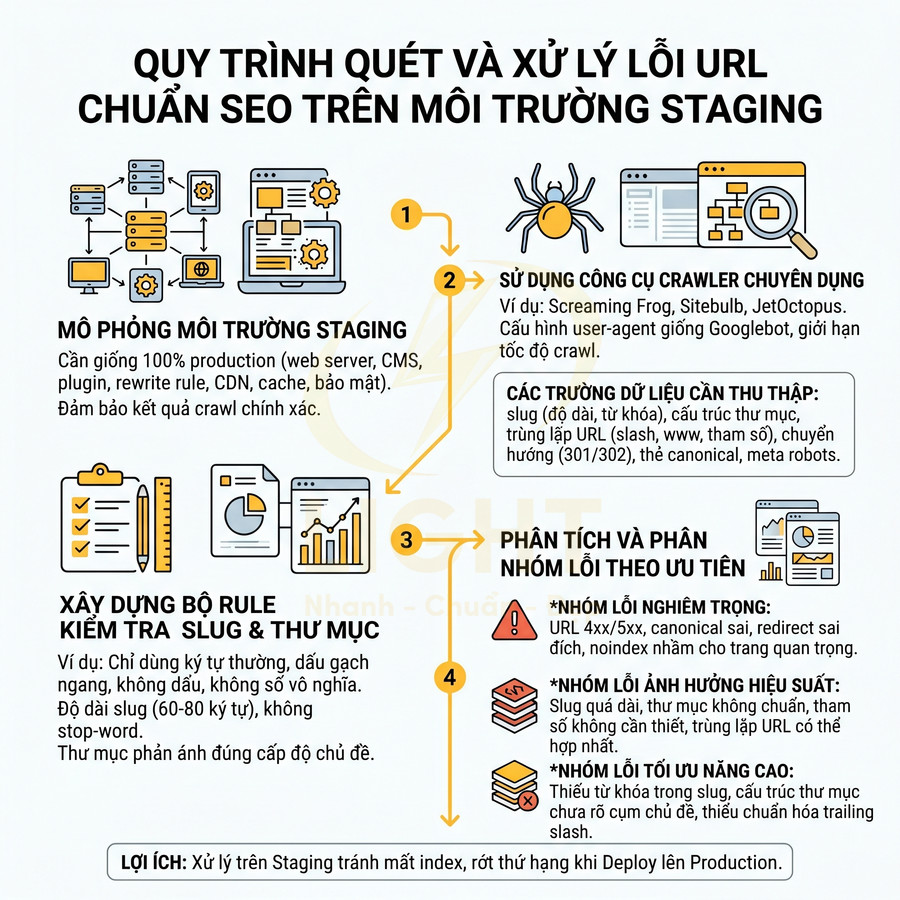
Khi crawl, nên cấu hình xuất đầy đủ các trường dữ liệu liên quan đến chuẩn SEO của URL, bao gồm:
- Độ dài slug, có chứa từ khóa chính hay không, có ký tự đặc biệt, ký tự tiếng Việt có dấu, khoảng trắng, ký tự in hoa.
- Cấu trúc thư mục: có tuân theo phân cấp chuyên mục, có thư mục “mồ côi” không nằm trong hệ thống category, có thư mục trùng lặp chủ đề.
- Trùng lặp URL: cùng một nội dung nhưng nhiều đường dẫn khác nhau (có/không có slash cuối, có/không có www, http/https, có tham số UTM, filter, sort,…).
- Trạng thái chuyển hướng: có redirect 301/302 từ URL cũ sang URL mới, có thiếu redirect, redirect sai đích, hoặc redirect về URL không chuẩn canonical.
- Thẻ canonical: có canonical tự tham chiếu, canonical trỏ nhầm sang URL khác chủ đề, canonical trỏ sang URL noindex, hoặc canonical bị bỏ trống.
- Meta robots: phát hiện các trường hợp noindex, nofollow, noarchive bị gắn nhầm cho các trang quan trọng.
Để kiểm soát tốt, nên xây dựng một bộ rule kiểm tra cho slug và thư mục, ví dụ:
- Slug chỉ dùng ký tự thường, dấu gạch ngang, không dấu, không số vô nghĩa.
- Không vượt quá X ký tự (tùy ngành, thường 60–80 ký tự).
- Không chứa stop-word thừa (và, là, của, những,… nếu không cần thiết).
- Thư mục phản ánh đúng cấp độ chủ đề: /danh-muc-chinh/danh-muc-phu/slug-bai-viet.
Sau khi crawler hoàn tất, xuất báo cáo và phân nhóm lỗi theo mức độ ưu tiên:
- Nhóm lỗi nghiêm trọng: URL trả về 4xx/5xx, canonical sai, redirect sai đích, noindex nhầm cho trang quan trọng.
- Nhóm lỗi ảnh hưởng hiệu suất: slug quá dài, thư mục không chuẩn, tham số không cần thiết, trùng lặp URL có thể hợp nhất.
- Nhóm lỗi tối ưu nâng cao: thiếu từ khóa trong slug, cấu trúc thư mục chưa phản ánh rõ cụm chủ đề, thiếu chuẩn hóa trailing slash.
Việc xử lý các lỗi này trên staging giúp tránh tình trạng khi deploy lên production mới phát hiện hàng loạt URL không đạt chuẩn SEO, gây mất index, rớt thứ hạng hoặc phân tán tín hiệu liên kết.
Kiểm tra chuỗi chuyển hướng, lỗi 404, lỗi vòng lặp và URL mồ côi
Sau khi thiết lập hệ thống redirect cho các URL cũ sang URL mới, cần kiểm tra kỹ bằng crawler và log server để đảm bảo:
- Mỗi URL cũ chỉ có một bước chuyển hướng (301 trực tiếp) đến URL đích chuẩn, không đi qua nhiều tầng trung gian.
- Không tồn tại redirect chain: A → B → C → D, đặc biệt với các trang có nhiều traffic hoặc nhiều backlink.
- Không có redirect loop: A → B → A hoặc A → B → C → A khiến bot và người dùng không thể truy cập nội dung.
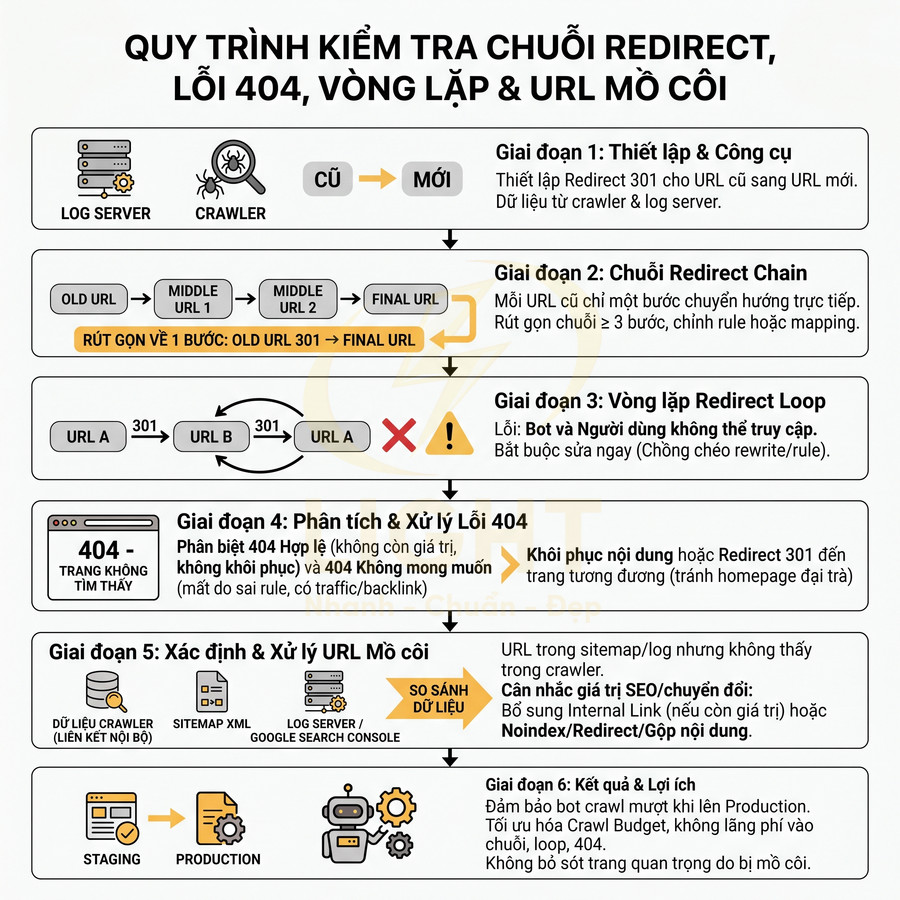
Các công cụ crawl thường cung cấp báo cáo riêng cho redirect chain và loop. Nên xuất danh sách và phân loại:
- Chuỗi 2 bước: có thể chấp nhận tạm thời nhưng vẫn nên rút gọn về 1 bước.
- Chuỗi >= 3 bước: cần ưu tiên xử lý, chỉnh lại rule hoặc mapping để A trỏ thẳng đến URL cuối cùng.
- Loop: bắt buộc sửa ngay, thường do cấu hình rewrite hoặc redirect rule chồng chéo.
Đối với lỗi 404, cần phân biệt:
- 404 hợp lệ: trang thực sự không còn giá trị, không có nhu cầu khôi phục, không có backlink quan trọng.
- 404 không mong muốn: trang vẫn có nhu cầu tìm kiếm, có traffic, có backlink, nhưng bị mất do sai mapping hoặc sai rule.
Với 404 không mong muốn, cần:
- Khôi phục nội dung nếu còn phù hợp chiến lược.
- Hoặc redirect 301 đến trang tương đương nhất về chủ đề, tránh redirect về homepage một cách đại trà.
Về URL mồ côi, nên kết hợp dữ liệu từ:
- Crawler (chỉ thấy URL có liên kết nội bộ).
- Sitemap XML (danh sách URL mà site chủ động khai báo).
- Log server hoặc Google Search Console (URL mà bot đã từng crawl hoặc người dùng đã truy cập).
URL xuất hiện trong sitemap hoặc log nhưng không xuất hiện trong kết quả crawl nội bộ thường là URL mồ côi. Với các URL này, cần đánh giá:
- Nếu còn giá trị SEO hoặc chuyển đổi: bổ sung liên kết nội bộ từ các trang liên quan, từ menu, breadcrumb, hoặc các hub page.
- Nếu không còn giá trị: loại khỏi sitemap, cân nhắc noindex hoặc redirect/gộp nội dung sang trang khác.
Kiểm thử kỹ các nhóm lỗi này trên staging giúp đảm bảo khi chuyển sang production, bot có thể crawl mượt, không bị lãng phí crawl budget vào chuỗi redirect, 404, loop, và không bỏ sót các trang quan trọng do bị mồ côi.
Đối chiếu URL với breadcrumb, sơ đồ trang XML và liên kết nội bộ
Cấu trúc URL chỉ thực sự “có nghĩa” với bot khi nó đồng bộ với các tín hiệu cấu trúc khác như breadcrumb, sitemap XML và internal link. Trên môi trường thử nghiệm, cần kiểm tra theo từng lớp:
- Breadcrumb: mỗi cấp breadcrumb phải phản ánh đúng cấp thư mục trong URL và đúng logic phân cấp nội dung.
- Sitemap XML: chỉ chứa các URL indexable, trả về 200, trùng khớp với canonical, không chứa URL test, URL staging, hoặc URL có tham số filter.
- Liên kết nội bộ: anchor text, cấu trúc liên kết, depth (số click từ trang chủ đến URL) phải hỗ trợ cho chiến lược cụm chủ đề.
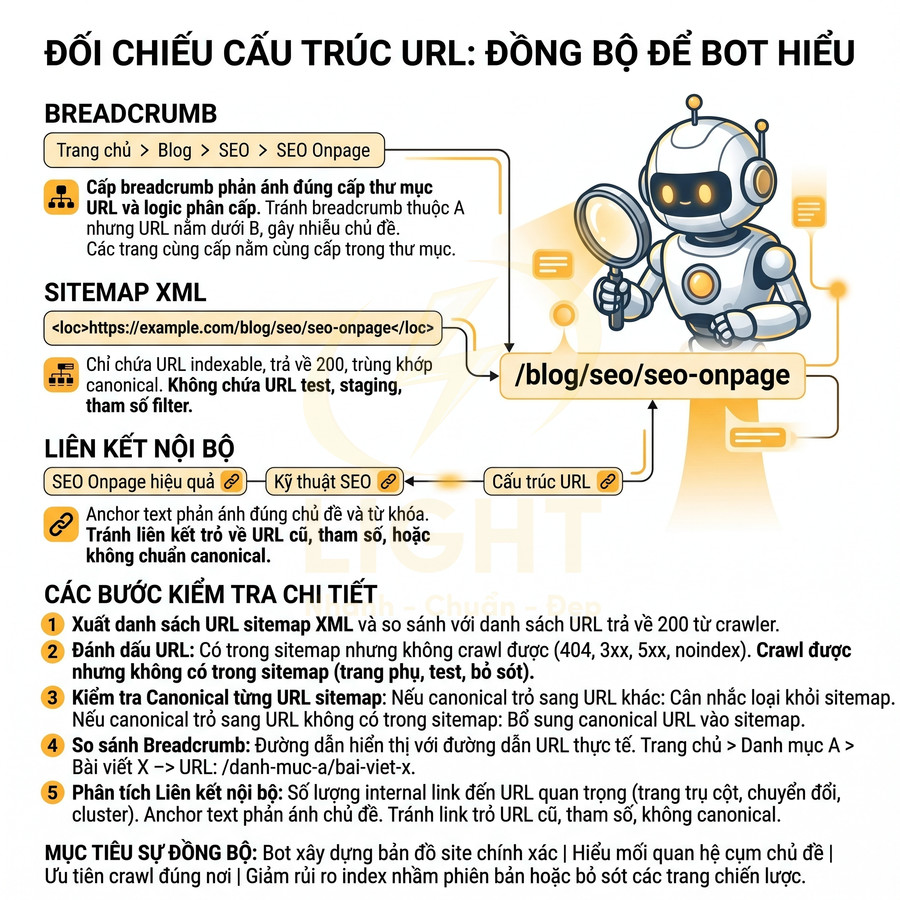
Các bước kiểm tra chi tiết:
- Xuất danh sách toàn bộ URL từ sitemap XML và so sánh với danh sách URL trả về 200 từ crawler.
- Đánh dấu các URL:
- Có trong sitemap nhưng không crawl được (404, 3xx, 5xx, noindex).
- Crawl được nhưng không có trong sitemap (có thể là trang phụ, trang test, hoặc bị bỏ sót).
- Kiểm tra canonical của từng URL trong sitemap:
- Nếu canonical trỏ sang URL khác: cân nhắc loại URL đó khỏi sitemap.
- Nếu canonical trỏ sang URL không có trong sitemap: bổ sung URL canonical vào sitemap.
Với breadcrumb, cần so sánh:
- Đường dẫn breadcrumb hiển thị với đường dẫn URL thực tế:
- Nếu breadcrumb: Trang chủ > Danh mục A > Bài viết X, thì URL nên có dạng /danh-muc-a/bai-viet-x.
- Tránh trường hợp breadcrumb thuộc danh mục A nhưng URL lại nằm dưới danh mục B, gây nhiễu chủ đề.
- Các trang cùng cấp trong breadcrumb phải nằm cùng cấp trong cấu trúc thư mục, tránh lẫn lộn cấp độ.
Về liên kết nội bộ, cần phân tích:
- Số lượng internal link trỏ đến mỗi URL quan trọng (trang trụ cột, trang chuyển đổi, trang cluster chính).
- Anchor text có phản ánh đúng chủ đề và từ khóa mục tiêu của URL không.
- Có liên kết nội bộ nào vẫn trỏ về URL cũ, URL có tham số, hoặc URL không chuẩn canonical hay không.
Mục tiêu là đảm bảo:
- Mỗi URL quan trọng:
- Có mặt trong sitemap XML.
- Được breadcrumb phản ánh đúng vị trí trong cấu trúc site.
- Nhận đủ liên kết nội bộ từ các trang liên quan, với anchor text phù hợp.
- Không có URL “ngoài luồng”:
- Breadcrumb một kiểu, URL một kiểu, sitemap lại một kiểu.
- Internal link trỏ lung tung sang phiên bản không chuẩn.
Sự đồng bộ này giúp bot xây dựng bản đồ site chính xác, hiểu rõ mối quan hệ giữa các cụm chủ đề, ưu tiên crawl đúng nơi, và giảm thiểu rủi ro index nhầm phiên bản hoặc bỏ sót các trang chiến lược.
Xác nhận mỗi URL đều có mục tiêu từ khóa và vai trò rõ trong cụm chủ đề
Trước khi đưa cấu trúc URL vào vận hành chính thức, cần quay lại bảng ánh xạ từ khóa – URL (keyword-to-URL mapping) đã xây dựng ở giai đoạn lập kế hoạch để kiểm tra tính nhất quán. Mỗi URL phải được gắn với:
- Từ khóa chính (primary keyword) và một nhóm từ khóa phụ (secondary, long-tail) rõ ràng.
- Ý định tìm kiếm (search intent): thông tin, giao dịch, điều hướng, so sánh, hỗ trợ.
- Vai trò trong cụm chủ đề:
- Trang trụ cột (pillar): bao quát chủ đề rộng, liên kết đến nhiều cluster.
- Trang cluster: đào sâu một khía cạnh cụ thể, liên kết ngược về pillar.
- Trang chuyển đổi: landing page, sản phẩm, dịch vụ, form đăng ký.
- Trang hỗ trợ: FAQ, hướng dẫn sử dụng, chính sách,…
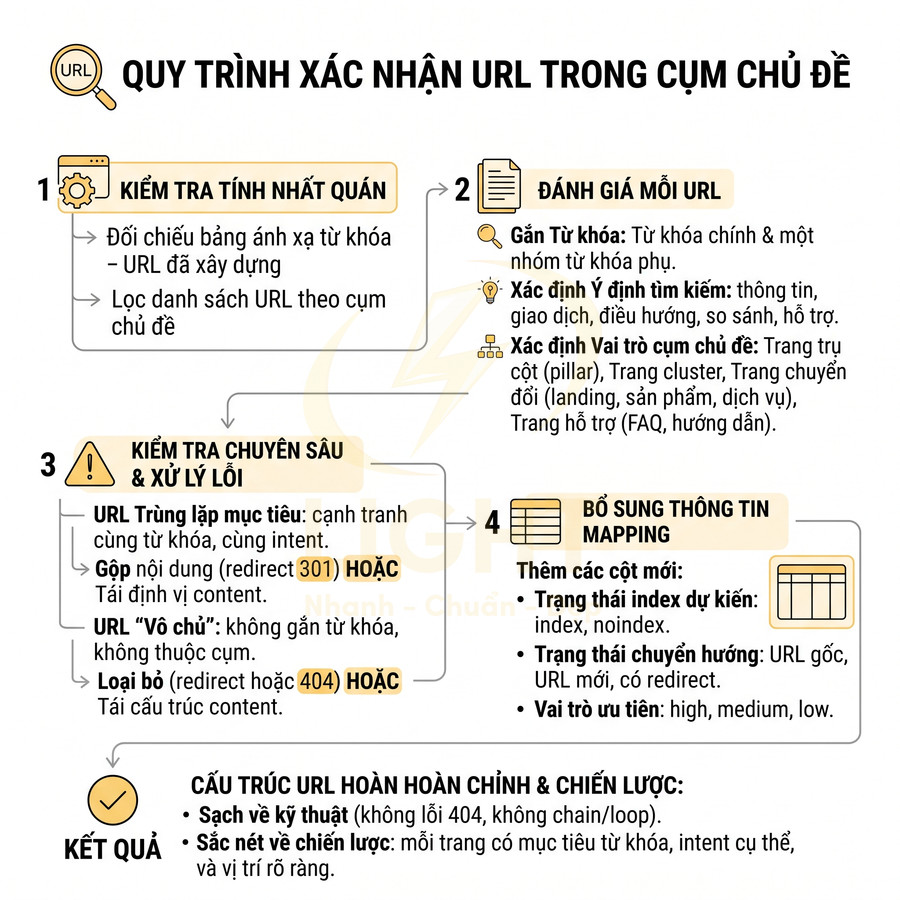
Các bước kiểm tra chuyên sâu:
- Lọc danh sách URL theo từng cụm chủ đề, đối chiếu:
- Có URL nào nhắm cùng một từ khóa chính và cùng intent với URL khác hay không.
- Có URL nào không được gắn từ khóa chính (chỉ có nội dung chung chung, không rõ mục tiêu) hay không.
- Đánh dấu các URL:
- Trùng lặp mục tiêu: hai hoặc nhiều URL cạnh tranh cùng một từ khóa, cùng intent.
- Vô chủ: không gắn với từ khóa nào, không thuộc cụm chủ đề nào, không có vai trò chuyển đổi.
Với URL trùng lặp mục tiêu, cần quyết định:
- Gộp nội dung về một URL duy nhất, dùng redirect 301 từ các URL còn lại.
- Hoặc tái định vị: điều chỉnh nội dung, từ khóa, intent để mỗi URL phục vụ một nhu cầu tìm kiếm khác nhau.
Với URL “vô chủ”, có thể:
- Loại bỏ nếu không còn giá trị SEO hoặc kinh doanh, đảm bảo xử lý redirect hoặc 404 hợp lệ.
- Hoặc tái cấu trúc nội dung, gắn vào một cụm chủ đề hiện có, bổ sung internal link và tối ưu lại từ khóa.
Nên bổ sung thêm một cột trong bảng mapping để ghi nhận:
- Trạng thái index dự kiến: index, noindex.
- Trạng thái chuyển hướng: URL gốc, URL mới, có redirect hay không.
- Vai trò ưu tiên: high, medium, low để phân bổ crawl budget và liên kết nội bộ.
Khi hoàn tất bước xác nhận này trên staging, cấu trúc URL không chỉ sạch về mặt kỹ thuật (không lỗi 404, không chain, không loop) mà còn sắc nét về mặt chiến lược: mỗi trang đều có lý do tồn tại rõ ràng, gắn với một mục tiêu từ khóa, một intent cụ thể, và một vị trí xác định trong hệ thống cụm chủ đề của toàn site.
Câu hỏi thường gặp về cách viết URL chuẩn SEO dễ index và dễ click
Phần FAQ này tập trung giải đáp các thắc mắc xoay quanh việc tối ưu URL cho SEO, nhấn mạnh rằng URL có dấu không gây hại trực tiếp đến khả năng index nhưng làm giảm trải nghiệm, khó chia sẻ và phức tạp khi quản trị kỹ thuật. Do đó, nên ưu tiên slug không dấu, chữ thường, ngắn gọn, dùng dấu gạch nối và loại bỏ ký tự đặc biệt. Với URL cũ đang có thứ hạng tốt, chỉ nên đổi khi có lý do chiến lược rõ ràng và phải triển khai quy trình redirect 301, cập nhật internal link, sitemap, theo dõi Search Console cẩn thận. Nội dung cũng đề cập cách xác định độ dài slug hợp lý, nguyên tắc giữ slug ổn định, quy trình đổi URL hàng loạt an toàn và nhóm công cụ (crawler, Search Console, plugin, script) hỗ trợ quét – sửa URL toàn site.
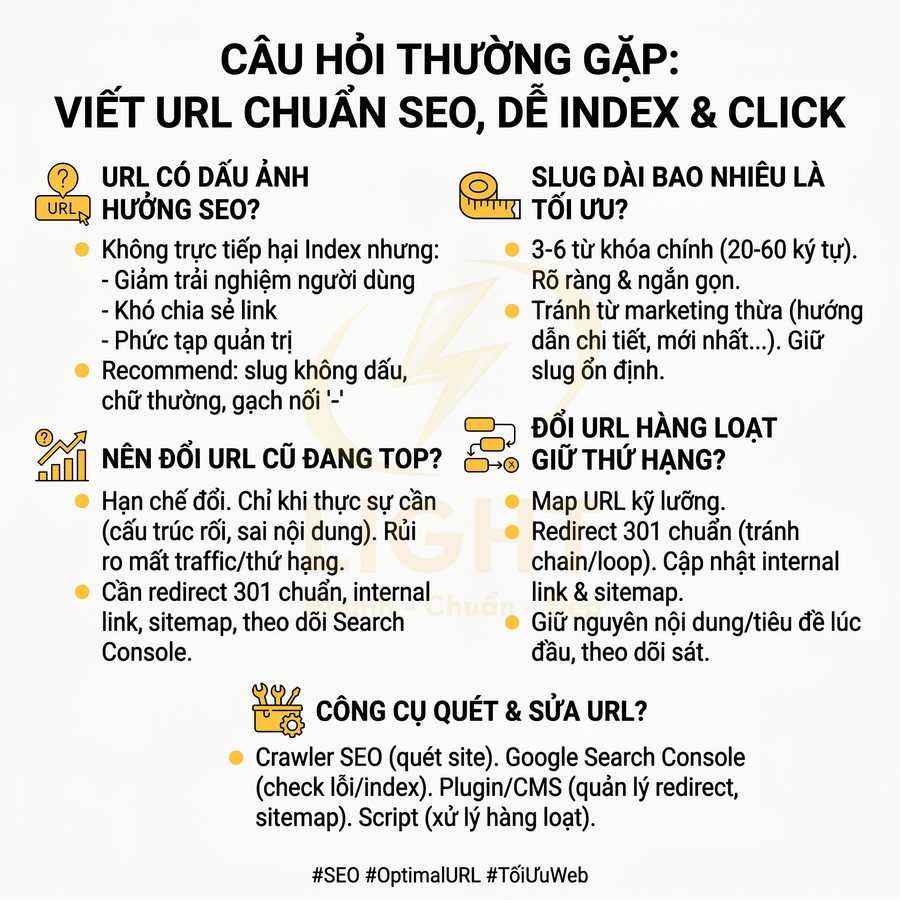
URL tiếng Việt có dấu có ảnh hưởng SEO không?
Về mặt kỹ thuật, các công cụ tìm kiếm hiện đại (Google, Bing…) có thể crawl, parse và index URL tiếng Việt có dấu nhờ cơ chế mã hóa theo chuẩn RFC 3986 (percent-encoding). Tuy nhiên, khi đi vào thực tế triển khai SEO và vận hành website, URL có dấu thường bị chuyển thành chuỗi ký tự đã mã hóa như %C3%A1, %C6%B0… khiến đường dẫn trở nên rất dài, khó đọc và khó thao tác.

Vấn đề không nằm ở khả năng index của Google mà nằm ở:
- Trải nghiệm người dùng: URL dài, lạ mắt, chứa nhiều ký tự “%” và số hexa làm người dùng cảm giác thiếu tin cậy, dễ nhầm với link spam hoặc link theo dõi.
- Khả năng chia sẻ: Khi copy – paste lên mạng xã hội, email, chat nội bộ, URL có dấu bị mã hóa khiến người nhận khó nhận diện nội dung, khó nhớ và khó gõ lại thủ công.
- Quản trị kỹ thuật: Làm việc với file log, cấu hình redirect, rewrite rule (Apache, Nginx), hoặc viết regex sẽ phức tạp hơn rất nhiều nếu slug chứa ký tự có dấu.
- Khả năng debug: Khi cần so sánh, đối chiếu URL trong báo cáo, trong code, trong database, chuỗi mã hóa gây khó khăn cho việc đọc nhanh và phát hiện lỗi.
Vì các lý do trên, phần lớn website chuyên nghiệp, đặc biệt là các site thương mại điện tử, báo điện tử, blog lớn, đều chọn dùng tiếng Việt không dấu, chữ thường trong slug. Cách làm này:
- Giữ được ngữ nghĩa chính xác của thực thể (sản phẩm, bài viết, danh mục).
- Dễ đọc, dễ gõ, dễ chia sẻ trên mọi kênh.
- Thân thiện với hệ thống log, rule rewrite, script xử lý hàng loạt.
- Hoàn toàn đáp ứng yêu cầu SEO, vì Google hiểu nội dung trang dựa trên tổng thể: nội dung, tiêu đề, heading, internal link, structured data… chứ không chỉ dựa vào dấu trong URL.
Về mặt tối ưu, nên chuẩn hóa slug theo các nguyên tắc:
- Dùng chữ thường toàn bộ để tránh trùng lặp URL do phân biệt hoa – thường.
- Dùng dấu gạch nối “-” để ngăn cách từ; tránh dùng “” vì Google coi “” như nối liền từ.
- Loại bỏ ký tự đặc biệt, ký tự có dấu, ký tự khoảng trắng thừa ở đầu – cuối.
- Giữ slug ngắn gọn nhưng vẫn thể hiện rõ thực thể chính (ví dụ:
/may-loc-khong-khi-sharp-fp-j40e-w/).
Do đó, URL tiếng Việt có dấu không gây hại trực tiếp cho SEO về mặt index, nhưng lại gây bất lợi lớn về trải nghiệm, quản trị và khả năng tối ưu kỹ thuật. Lựa chọn an toàn và bền vững vẫn là dùng URL không dấu, chữ thường, có cấu trúc rõ ràng.
Có nên thay đổi URL cũ đang có thứ hạng tốt không?
Với các URL cũ đang có thứ hạng và traffic tốt, bản thân URL đã tích lũy một lượng tín hiệu đáng kể: backlink, lịch sử tương tác người dùng, dữ liệu hành vi (CTR, dwell time), tín hiệu tin cậy theo thời gian. Việc thay đổi slug, kể cả khi dùng redirect 301 đúng chuẩn, luôn tiềm ẩn rủi ro mất một phần tín hiệu hoặc làm Google phải đánh giá lại trang.
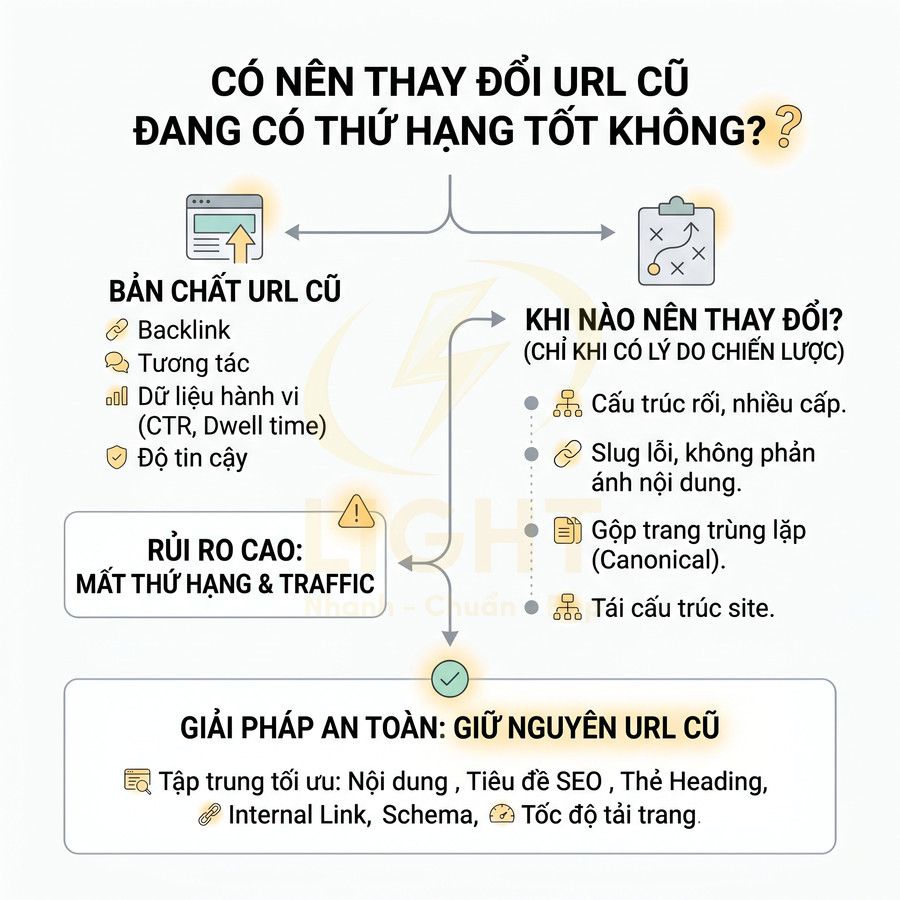
Chỉ nên cân nhắc đổi URL khi có lý do chiến lược rõ ràng như:
- Cấu trúc URL cũ quá rối, gây cản trở mở rộng site (ví dụ: chứa tham số động, ID khó hiểu, nhiều cấp thư mục không cần thiết).
- Slug hiện tại không mang ý nghĩa, chứa ký tự lỗi, ký tự đặc biệt, hoặc không phản ánh đúng nội dung (ví dụ:
/post-1234/cho một bài viết quan trọng). - Cần gộp nhiều trang trùng lặp hoặc gần trùng lặp về một URL chuẩn (canonical URL) để tránh cannibalization.
- Thực hiện tái cấu trúc toàn bộ site (replatform, đổi CMS, đổi taxonomy) và buộc phải thay đổi đường dẫn.
Nếu chỉ vì muốn “đẹp hơn”, “ngắn hơn” mà đổi slug cho các URL đang hoạt động tốt, lợi ích thường không bù được rủi ro. Trong nhiều case thực tế, việc đổi URL hàng loạt cho các bài top đã khiến thứ hạng giảm, traffic sụt trong nhiều tháng dù đã redirect 301 đầy đủ.
Khi buộc phải thay đổi URL, cần quy trình chặt chẽ:
- Phân tích hiệu suất hiện tại: Xác định URL nào mang lại nhiều traffic, nhiều chuyển đổi, nhiều backlink nhất để ưu tiên kiểm soát rủi ro.
- Lập kế hoạch chuyển hướng 301 chi tiết: Mỗi URL cũ phải map 1–1 với URL mới tương ứng, tránh redirect về trang chung chung (homepage, category lớn) vì dễ làm mất liên quan chủ đề.
- Cập nhật toàn bộ internal link: Sửa link trong menu, breadcrumb, nội dung bài viết, footer, module liên quan… để trỏ trực tiếp đến URL mới, không đi qua redirect.
- Cập nhật sitemap XML với URL mới, loại bỏ URL cũ đã redirect, gửi lại sitemap trong Google Search Console.
- Kiểm thử redirect: Dùng crawler (Screaming Frog, Sitebulb…) để kiểm tra không có redirect chain (301 → 301 → 200) hoặc redirect loop.
- Theo dõi biến động: Quan sát thứ hạng, CTR, traffic, lỗi 404, báo cáo Coverage trong Search Console trong ít nhất 4–8 tuần sau khi triển khai.
Trong nhiều trường hợp, giải pháp an toàn hơn là giữ nguyên URL cũ và tập trung tối ưu các yếu tố khác: nội dung, tiêu đề SEO, thẻ heading, internal link, schema, tốc độ tải trang… vẫn có thể cải thiện SEO đáng kể mà không đụng đến slug.
Slug dài bao nhiêu là tối ưu cho SEO và tỷ lệ nhấp?
Không tồn tại một con số “chuẩn tuyệt đối” cho mọi website, nhưng kinh nghiệm thực tế trên nhiều dự án cho thấy slug hiệu quả thường nằm trong khoảng 3–6 từ khóa chính, tương đương khoảng 20–60 ký tự tùy ngôn ngữ và lĩnh vực. Mục tiêu là cân bằng giữa:
- Độ rõ ràng ngữ nghĩa: Người dùng và công cụ tìm kiếm đều có thể hiểu ngay chủ đề chính của trang chỉ qua URL.
- Độ ngắn gọn: Tránh bị cắt trên SERP, tránh gây rối mắt khi hiển thị trên thiết bị di động, dễ đọc – dễ nhớ.

Cách xây dựng slug nên ưu tiên:
- Từ khóa chính (main keyword) thể hiện thực thể hoặc chủ đề cốt lõi.
- Thêm 1–2 từ bổ nghĩa nếu cần làm rõ phạm vi, loại, mục đích (ví dụ:
/seo-onpage-la-gi/,/cach-viet-url-chuan-seo/).
Nên tránh đưa vào slug các cụm từ mang tính marketing, không tạo thêm giá trị ngữ nghĩa cho URL như:
huong-dan-chi-tiet,day-du-nhat,moi-nhat-2024,top-1-google…
Những cụm này nếu cần nhấn mạnh, hãy đặt trong tiêu đề SEO (title) hoặc thẻ H1, vì đó là nơi tác động mạnh hơn đến CTR và nhận thức người dùng. Slug nên giữ vai trò “định danh” rõ ràng, ổn định theo thời gian, hạn chế phải thay đổi mỗi năm.
Về mặt tối ưu CTR, có thể áp dụng quy trình thử nghiệm:
- Trích xuất dữ liệu từ Search Console để tìm các trang có vị trí trung bình tốt nhưng CTR thấp.
- Đánh giá xem slug hiện tại có quá dài, chứa nhiều từ thừa, hoặc không phản ánh đúng ý định tìm kiếm hay không.
- Thử nghiệm rút gọn slug, loại bỏ từ không cần thiết, giữ lại từ khóa chính và 1–2 từ bổ nghĩa quan trọng.
- Theo dõi CTR, vị trí, traffic trong vài tuần để so sánh trước – sau thay đổi.
Điểm quan trọng là slug phải ổn định. Không nên thay đổi slug liên tục chỉ để “tối ưu CTR”, vì mỗi lần đổi là một lần Google phải xử lý lại redirect và đánh giá lại URL. Hãy chỉ thay đổi khi nhận thấy vấn đề rõ ràng và có kế hoạch đo lường cụ thể.
Khi đổi URL hàng loạt làm sao giữ nguyên thứ hạng?
Đổi URL hàng loạt (tái cấu trúc toàn site) là một dự án SEO mang tính kỹ thuật cao, thường diễn ra khi:
- Đổi nền tảng CMS hoặc framework (ví dụ: từ custom sang WordPress, từ Magento sang Shopify…).
- Thiết kế lại cấu trúc thông tin (information architecture), thay đổi taxonomy, danh mục, phân cấp thư mục.
- Chuẩn hóa URL từ dạng động (có nhiều tham số) sang dạng tĩnh, thân thiện SEO.
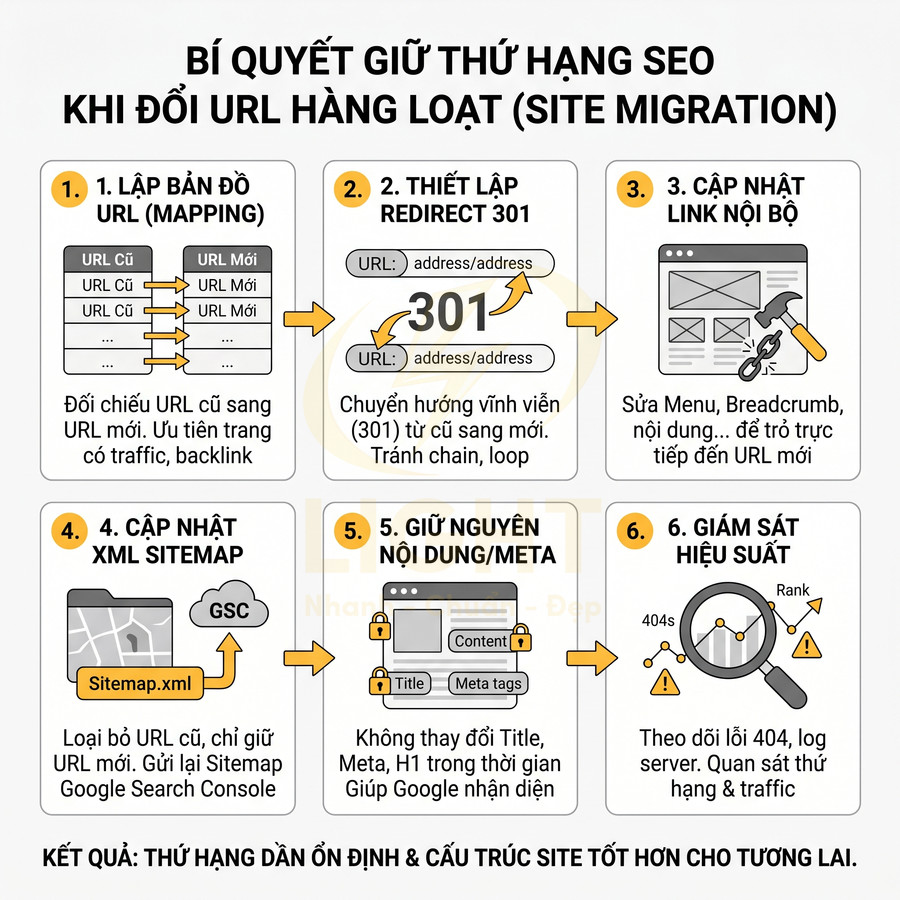
Để giảm thiểu rủi ro mất thứ hạng, cần tuân thủ các bước chính:
- Lập bản đồ URL cũ – URL mới cho toàn bộ site:
- Xuất toàn bộ URL hiện tại bằng crawler hoặc từ database.
- Xác định URL tương ứng trong cấu trúc mới, đảm bảo mỗi URL cũ có một đích mới phù hợp về chủ đề.
- Ưu tiên map chính xác cho các URL có nhiều traffic, nhiều backlink.
- Tạo và kiểm thử rule chuyển hướng 301:
- Thiết lập redirect 301 từ từng URL cũ sang URL mới tương ứng.
- Tránh tạo redirect chain (301 → 301 → 200) và redirect loop (vòng lặp).
- Dùng crawler để test toàn bộ redirect, đảm bảo mã trạng thái 301/308 đúng chuẩn.
- Cập nhật toàn bộ internal link:
- Sửa link trong menu, breadcrumb, nội dung, sidebar, footer… để trỏ trực tiếp đến URL mới.
- Không để internal link trỏ đến URL cũ rồi mới redirect, vì làm lãng phí crawl budget và giảm trải nghiệm.
- Cập nhật sitemap XML:
- Loại bỏ URL cũ đã redirect, chỉ giữ URL mới.
- Gửi lại sitemap trong Google Search Console để Google nắm được cấu trúc mới nhanh hơn.
- Giữ nguyên nội dung, tiêu đề, meta trong giai đoạn đầu:
- Hạn chế thay đổi quá nhiều yếu tố onpage cùng lúc với việc đổi URL.
- Giữ nội dung, title, H1, meta description càng giống càng tốt để Google dễ nhận diện “đây là cùng một trang, chỉ đổi địa chỉ”.
- Giám sát log crawl, lỗi 404, biến động thứ hạng:
- Theo dõi log server để xem bot truy cập URL cũ – mới ra sao, có lỗi bất thường không.
- Kiểm tra báo cáo Coverage, 404, Soft 404 trong Search Console.
- Quan sát thứ hạng và traffic theo nhóm URL quan trọng trong vài tuần – vài tháng đầu.
Nếu quy trình được thực hiện đúng, thứ hạng có thể dao động nhẹ trong ngắn hạn nhưng thường sẽ ổn định lại khi Google hoàn tất tái lập chỉ mục. Lợi ích lâu dài là cấu trúc URL mới logic, dễ mở rộng, dễ quản trị, giúp việc tối ưu SEO và phát triển nội dung về sau thuận lợi hơn.
Công cụ nào hỗ trợ tự động quét và sửa URL toàn website?
Quản trị URL ở quy mô lớn đòi hỏi kết hợp nhiều nhóm công cụ khác nhau để vừa phát hiện vấn đề, vừa triển khai sửa chữa hàng loạt một cách an toàn.

- Crawler SEO:
- Screaming Frog, Sitebulb, JetOctopus… cho phép quét toàn bộ site như cách bot tìm kiếm hoạt động.
- Giúp phát hiện:
- Lỗi URL: ký tự đặc biệt, độ dài quá mức, trùng lặp slug.
- Chuỗi redirect, redirect loop, redirect về trang không liên quan.
- Vấn đề canonical, thẻ noindex, hreflang, status code bất thường.
- Có thể xuất dữ liệu ra CSV/Excel để phân tích, lập bản đồ URL cũ – mới, và làm tài liệu cho đội dev.
- Công cụ của Google:
- Google Search Console cung cấp:
- Báo cáo Coverage: URL bị loại khỏi index, lỗi 404, Soft 404, redirect lỗi.
- Báo cáo hiệu suất theo trang: impression, click, CTR, vị trí trung bình cho từng URL.
- Công cụ kiểm tra URL (URL Inspection) để xem trạng thái index, canonical mà Google chọn, phiên bản đã cache.
- Giúp xác nhận xem sau khi đổi URL, Google đã nhận diện và index đúng URL mới hay chưa.
- Google Search Console cung cấp:
- Plugin/CMS:
- Yoast SEO, Rank Math trên WordPress; các module SEO trong Magento, Shopify; hoặc hệ thống tùy chỉnh đều có thể:
- Tự động tạo slug từ tiêu đề theo quy tắc (bỏ dấu, chuyển thường, thay khoảng trắng bằng “-”).
- Thiết lập canonical, meta robots, sitemap XML.
- Quản lý redirect 301/302 ngay trong giao diện quản trị, hỗ trợ import/export rule.
- Với CMS lớn, có thể xây dựng module riêng để chuẩn hóa slug theo bộ quy tắc thống nhất toàn hệ thống.
- Yoast SEO, Rank Math trên WordPress; các module SEO trong Magento, Shopify; hoặc hệ thống tùy chỉnh đều có thể:
- Script tùy chỉnh:
- Dùng API của CMS hoặc framework để:
- Xuất toàn bộ slug hiện tại, xử lý hàng loạt (chuẩn hóa, loại bỏ ký tự lỗi, rút gọn…).
- Nhập lại slug mới theo quy tắc đã định, đồng thời tạo bảng map URL cũ – mới.
- Script cũng có thể hỗ trợ:
- Tự động sinh rule redirect 301 từ bảng map.
- Kiểm tra nhanh các pattern URL để phát hiện ngoại lệ cần xử lý thủ công.
- Dùng API của CMS hoặc framework để:
Cách tiếp cận hiệu quả thường là kết hợp nhiều công cụ: dùng crawler để phát hiện vấn đề và lập bản đồ, dùng CMS/plugin hoặc script để sửa hàng loạt, và dùng Search Console để xác nhận kết quả index, hiệu suất sau tối ưu. Khi quy trình được thiết kế tốt, việc chuẩn hóa URL toàn site có thể thực hiện tương đối an toàn, kiểm soát được rủi ro SEO và tối ưu được chi phí vận hành lâu dài.
Lộ trình tối ưu URL dài hạn theo dữ liệu index và hành vi nhấp
Giai đoạn tối ưu URL dài hạn tập trung khai thác dữ liệu thực tế từ GSC, log server và hiệu suất organic để ra quyết định thay vì chỉnh sửa cảm tính. Trọng tâm là nhận diện các URL có vị trí tốt nhưng CTR thấp, phân tích intent, nội dung, title, description và yếu tố SERP trước khi cân nhắc làm mới slug như một tín hiệu bổ sung về mức độ liên quan. Song song, cần xử lý triệt để hiện tượng trùng chủ đề bằng cách gộp URL dựa trên dữ liệu hiệu suất, chọn một trang authority làm trụ cột, hợp nhất nội dung giá trị và triển khai chuyển hướng 301 chuẩn. Để mở rộng bền vững, doanh nghiệp nên xây dựng hệ thống tự động đề xuất slug và tích hợp quy tắc URL vào workflow page builder, đảm bảo cấu trúc nhất quán, dễ quản lý và chuẩn SEO ở quy mô lớn.
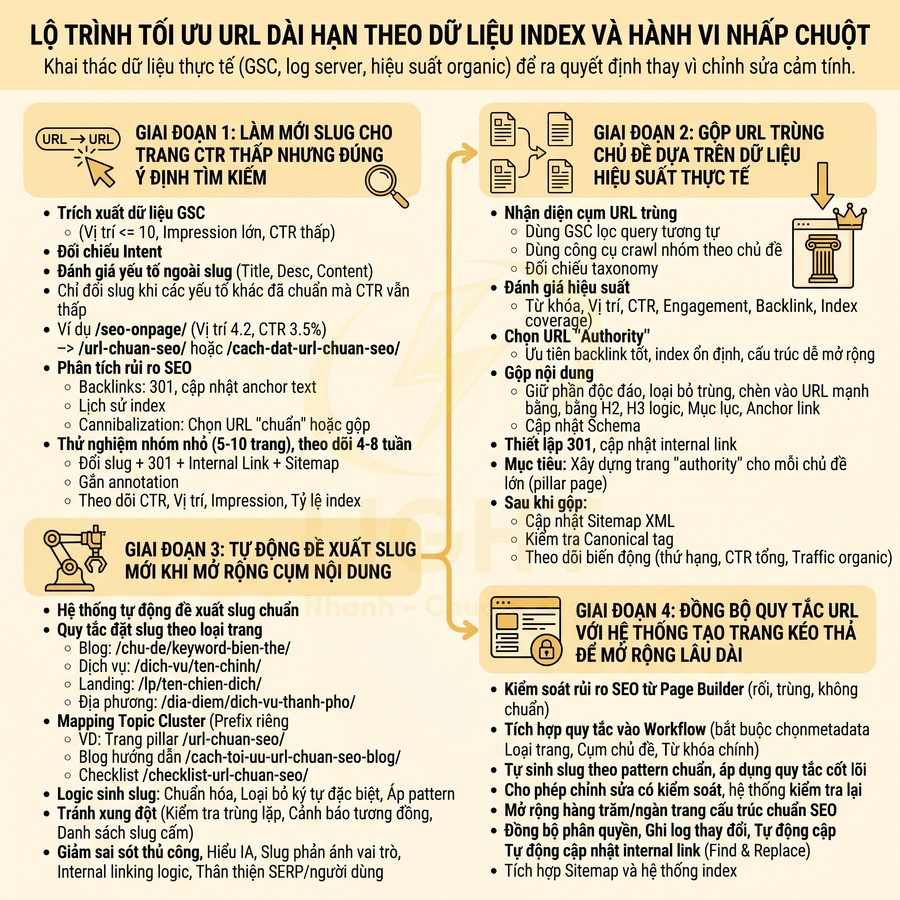
Làm mới slug cho trang CTR thấp nhưng đúng ý định tìm kiếm
Sau khi cấu trúc URL đã ổn định, giai đoạn tối ưu dài hạn nên dựa mạnh vào dữ liệu thực tế từ Google Search Console (GSC) và log server, thay vì chỉ dựa trên cảm tính. Trọng tâm là các trang có vị trí trung bình tốt (top 3–10) nhưng CTR thấp hơn đáng kể so với benchmark ngành. Đây là nhóm URL có tiềm năng tăng trưởng nhanh nếu cải thiện được mức độ liên quan cảm nhận (perceived relevance) trong kết quả tìm kiếm.
Quy trình chuyên sâu có thể triển khai theo các bước:
- Trích xuất dữ liệu GSC: Lọc theo:
- Vị trí trung bình <= 10
- Impression đủ lớn (ví dụ > 500–1.000 trong 28–90 ngày)
- CTR thấp hơn trung bình site hoặc thấp hơn CTR chuẩn theo vị trí (ví dụ vị trí 3 nhưng CTR < 10–12%)
- Đối chiếu với intent: Kiểm tra:
- Query chính mà URL đang nhận impression
- Loại intent (informational, commercial, transactional, navigational)
- Mức độ khớp giữa query & nội dung thực tế trên trang
- Đánh giá yếu tố ngoài slug:
- Title, meta description đã tối ưu theo intent chưa
- Rich result / schema có xuất hiện không
- Snippet có bị cắt, trùng lặp, hoặc hiển thị thông tin không liên quan không
Chỉ khi title, description, nội dung và intent đã tương đối chuẩn mà CTR vẫn thấp, mới cân nhắc đến việc làm mới slug. Lúc này, slug đóng vai trò như một tín hiệu bổ sung giúp người dùng nhanh chóng nhận diện mức độ phù hợp của kết quả với nhu cầu tìm kiếm.
Ví dụ chuyên sâu hơn với truy vấn “url chuẩn seo”:
- URL hiện tại: /seo-onpage/
- Vị trí trung bình: 4,2
- CTR: 3,5% (thấp hơn nhiều so với CTR trung bình vị trí 4 trong ngành, giả sử 8–10%)
- Query top: “url chuẩn seo”, “cách đặt url chuẩn seo”, “tối ưu url onpage”
- Đề xuất slug mới: /url-chuan-seo/ hoặc /cach-dat-url-chuan-seo/, tùy theo intent chính là hướng dẫn hay khái niệm.
Trước khi đổi slug, cần phân tích rủi ro SEO:
- Backlink profile: URL cũ có nhiều backlink chất lượng không? Nếu có, bắt buộc phải:
- Thiết lập chuyển hướng 301 vĩnh viễn từ URL cũ sang URL mới
- Cập nhật anchor text nội bộ để phản ánh chủ đề “url chuẩn seo” rõ hơn
- Lịch sử index: URL cũ đã được index lâu chưa, có từng gặp vấn đề soft 404, canonical, hoặc duplicate content không?
- Nguy cơ cannibalization: Có URL nào khác trong site cũng đang nhắm đến “url chuẩn seo” không? Nếu có, cần:
- Quyết định URL “chuẩn” sẽ giữ lại
- Gộp nội dung hoặc điều chỉnh từ khóa mục tiêu để tránh trùng lặp chủ đề
Chiến lược an toàn là thử nghiệm trên một nhóm nhỏ URL (ví dụ 5–10 trang) trong 4–8 tuần:
- Đổi slug + 301 + cập nhật internal link + cập nhật sitemap
- Gắn annotation trong công cụ theo dõi (GA, GSC) để đánh dấu thời điểm thay đổi
- Theo dõi:
- CTR theo query chính
- Vị trí trung bình
- Impression & click tổng
- Tỷ lệ index của URL mới (trạng thái trong Index Coverage)
Nếu sau giai đoạn thử nghiệm, CTR tăng mà vị trí không giảm đáng kể, có thể mở rộng phương pháp cho các nhóm URL tương tự. Ngược lại, nếu thứ hạng biến động mạnh hoặc CTR không cải thiện, cần xem lại giả định: có thể vấn đề nằm ở nội dung, intent, hoặc cạnh tranh SERP (feature snippet, video, People Also Ask) chứ không phải slug.
Gộp URL trùng chủ đề dựa trên dữ liệu hiệu suất thực tế
Trong các site đã hoạt động lâu năm, hiện tượng phổ biến là trùng chủ đề (topic overlap): nhiều bài viết hoặc landing page xoay quanh cùng một nhóm từ khóa, nhưng phân tán traffic và authority. Điều này dẫn đến:
- Cannibalization từ khóa: nhiều URL cùng cạnh tranh cho một query
- CTR thấp vì Google thử hiển thị luân phiên các URL khác nhau
- Backlink bị chia nhỏ, không tạo được trang “trụ cột” mạnh
Để xử lý, cần một quy trình gộp URL dựa trên dữ liệu thay vì cảm tính:
- Nhận diện cụm URL trùng chủ đề:
- Dùng GSC để lọc các URL cùng nhận impression cho một nhóm query tương tự
- Dùng công cụ crawl (Screaming Frog, Sitebulb,…) để nhóm URL theo chủ đề dựa trên title, H1, content similarity
- Đối chiếu với taxonomy nội bộ (category, tag, topic cluster) để phát hiện các cụm bị phân mảnh
- Đánh giá hiệu suất từng URL:
- Từ khóa xếp hạng: số lượng keyword, vị trí trung bình, độ liên quan với chủ đề chính
- CTR: URL nào đang có CTR tốt hơn cho query quan trọng
- Engagement: thời gian trên trang, scroll depth, bounce rate
- Backlink: số lượng, chất lượng, anchor text
- Index coverage: URL nào ổn định, không bị excluded, noindex, hoặc canonical sang nơi khác
- Chọn URL “authority” để giữ lại:
- Ưu tiên URL:
- Có backlink tốt
- Đã được index ổn định, có lịch sử lâu
- Có cấu trúc nội dung dễ mở rộng (có thể trở thành pillar page)
- Ưu tiên URL:
Sau khi chọn được URL chính, tiến hành gộp nội dung:
- Rà soát nội dung các URL yếu:
- Giữ lại phần nội dung độc đáo, có giá trị, không trùng lặp
- Loại bỏ đoạn mỏng, trùng, hoặc lỗi thời
- Chèn các phần nội dung giá trị vào URL mạnh:
- Cấu trúc lại bằng heading logic (H2, H3)
- Thêm mục lục, anchor link nội bộ nếu bài dài
- Cập nhật schema (FAQ, HowTo, Article) nếu phù hợp
- Thiết lập chuyển hướng 301 từ URL yếu về URL mạnh:
- Đảm bảo không tạo chuỗi redirect (chain) hoặc vòng lặp
- Cập nhật internal link trỏ về URL mới để tránh redirect hop
Mục tiêu cuối cùng là xây dựng một trang “authority” cho mỗi chủ đề quan trọng, đóng vai trò như pillar page trong mô hình topic cluster. Sau khi gộp, cần:
- Cập nhật sitemap XML để phản ánh URL mới
- Kiểm tra lại canonical tag trên trang authority
- Theo dõi biến động:
- Thứ hạng cho các từ khóa chính và phụ
- CTR tổng của cụm chủ đề
- Traffic organic trước và sau gộp (so sánh 28–90 ngày)
Nếu thứ hạng giảm mạnh hoặc mất hiển thị cho một số query phụ, có thể cần:
- Bổ sung thêm section nội dung để phục vụ query đó
- Điều chỉnh internal link từ các bài liên quan để nhấn mạnh chủ đề
- Xem lại mapping từ khóa để tránh bỏ sót intent phụ (ví dụ informational vs transactional)
Tự động đề xuất slug mới khi mở rộng cụm nội dung
Khi mở rộng cụm nội dung (content cluster) cho các chủ đề lớn, việc đặt slug thủ công dễ dẫn đến thiếu nhất quán, trùng lặp, hoặc phá vỡ pattern đã định. Một hệ thống hỗ trợ tự động đề xuất slug dựa trên quy tắc chuẩn sẽ giúp duy trì tính kỷ luật trong cấu trúc URL, đặc biệt với đội nội dung đông và tần suất xuất bản cao.
Các thành phần cốt lõi của hệ thống đề xuất slug:
- Quy tắc đặt slug theo loại trang:
- Blog: /chu-de-chinh/keyword-chinh-bien-the/
- Dịch vụ: /dich-vu/ten-dich-vu-chinh/
- Landing quảng cáo: /lp/ten-chien-dich/
- Địa phương: /dia-diem/ten-dich-vu-ten-thanh-pho/
- Mapping với cụm chủ đề:
- Mỗi topic cluster có một “prefix” hoặc pattern riêng
- Ví dụ cụm “url chuẩn seo”:
- Trang pillar: /url-chuan-seo/
- Trang hướng dẫn blog: /cach-toi-uu-url-chuan-seo-blog/
- Trang checklist: /checklist-url-chuan-seo/
- Logic sinh slug từ từ khóa mục tiêu:
- Chuẩn hóa:
- Chữ thường
- Không dấu
- Thay khoảng trắng bằng dấu gạch ngang
- Loại bỏ ký tự đặc biệt
- Áp pattern theo loại trang và cụm chủ đề
- Chuẩn hóa:
Ví dụ, khi biên tập viên nhập từ khóa “cách tối ưu url chuẩn seo cho blog”, hệ thống có thể:
- Nhận diện:
- Loại trang: blog
- Cụm chủ đề: “url chuẩn seo”
- Intent: hướng dẫn (how-to)
- Đề xuất slug: /cach-toi-uu-url-chuan-seo-blog/ theo pattern:
- /[dong-tu]-[chu-de-chinh]-[ngữ-cảnh]/
Để tránh xung đột, hệ thống cần:
- Kiểm tra trùng lặp slug với toàn bộ database URL hiện có
- Cảnh báo tương đồng cao:
- Nếu slug mới quá giống slug cũ (ví dụ chỉ khác 1–2 ký tự), yêu cầu biên tập viên xác nhận lại để tránh tạo trang trùng chủ đề
- Danh sách slug cấm:
- Các slug chung chung: /bai-viet-1/, /new-page/, /test/
- Các slug đã được dùng cho thực thể quan trọng (brand, category chính) để tránh nhầm lẫn
Tính năng đề xuất slug không chỉ giảm sai sót thủ công mà còn:
- Giúp đội nội dung hiểu rõ hơn về cấu trúc thông tin (information architecture) của site
- Đảm bảo mỗi slug mới đều:
- Phản ánh đúng vai trò trong cụm nội dung
- Hỗ trợ internal linking logic (từ pillar đến cluster content và ngược lại)
- Thân thiện với người dùng khi nhìn trên SERP hoặc khi chia sẻ link
Đồng bộ quy tắc URL với hệ thống tạo trang kéo thả để mở rộng lâu dài
Khi doanh nghiệp sử dụng page builder hoặc hệ thống tạo trang kéo thả (no-code/low-code), rủi ro lớn là mỗi marketer có thể tự đặt slug theo cách riêng, dẫn đến:
- Cấu trúc URL rối, khó quản lý
- Trùng lặp slug hoặc trùng chủ đề
- Không tuân thủ chuẩn SEO (ký tự đặc biệt, chữ hoa, slug quá dài, không phản ánh intent)
Để kiểm soát, cần tích hợp quy tắc đặt slug vào chính workflow của page builder, biến nó thành một phần bắt buộc trong quy trình tạo trang mới. Một số nguyên tắc triển khai:
- Bước tạo trang bắt buộc chọn metadata cấu trúc:
- Loại trang: dịch vụ, blog, landing quảng cáo, địa phương, tài nguyên (ebook, webinar)…
- Cụm chủ đề: chọn từ danh sách topic cluster đã được định nghĩa trước
- Từ khóa chính: nhập hoặc chọn từ gợi ý (dựa trên keyword research có sẵn)
- Hệ thống tự sinh slug theo pattern chuẩn:
- Dựa trên:
- Loại trang
- Cụm chủ đề
- Từ khóa chính
- Áp dụng các quy tắc cốt lõi:
- Chỉ dùng chữ thường
- Không dấu, không ký tự đặc biệt
- Không chứa tham số thừa (trừ khi có chủ đích tracking riêng)
- Không trùng với slug đã tồn tại hoặc slug được bảo vệ (reserved)
- Dựa trên:
- Cho phép chỉnh sửa trong phạm vi kiểm soát:
- Marketer có thể tinh chỉnh một số từ trong slug để phù hợp với thông điệp marketing
- Hệ thống kiểm tra lại:
- Độ dài slug (tránh quá dài, khó đọc)
- Tuân thủ quy tắc ký tự
- Không phá vỡ pattern chính (ví dụ không được xóa prefix /lp/ cho landing quảng cáo)
Để đảm bảo khả năng mở rộng hàng trăm, hàng nghìn trang mà vẫn giữ cấu trúc URL chuẩn SEO, cần thêm:
- Đồng bộ với hệ thống phân quyền:
- Chỉ cho phép một số vai trò (SEO lead, admin) override các quy tắc đặc biệt
- Ghi log mọi thay đổi slug để có thể rollback khi cần
- Tự động cập nhật internal link khi slug thay đổi:
- Page builder nên có cơ chế tìm & thay (find & replace) internal link trong nội dung
- Đảm bảo không để lại link cũ dẫn đến 404 hoặc redirect chain
- Tích hợp với sitemap và hệ thống index:
- Khi trang mới được publish, slug mới tự động được thêm vào sitemap XML
- Có thể gửi ping đến công cụ tìm kiếm (hoặc rely vào crawl tự nhiên) tùy chiến lược
Cách tiếp cận này biến quy tắc URL từ “tài liệu hướng dẫn” thành luật vận hành kỹ thuật được thực thi tự động, giúp giảm phụ thuộc vào ý thức cá nhân và đảm bảo tính nhất quán khi website phát triển quy mô lớn.



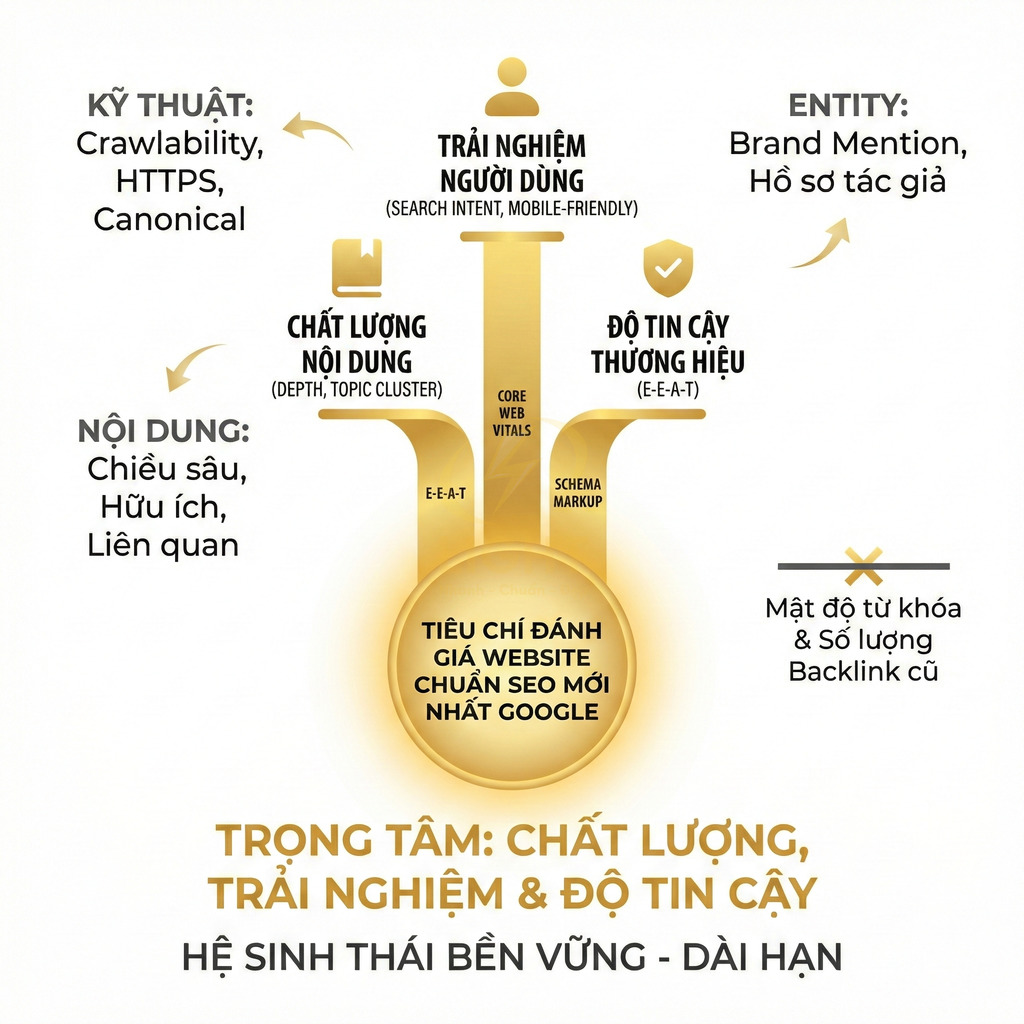

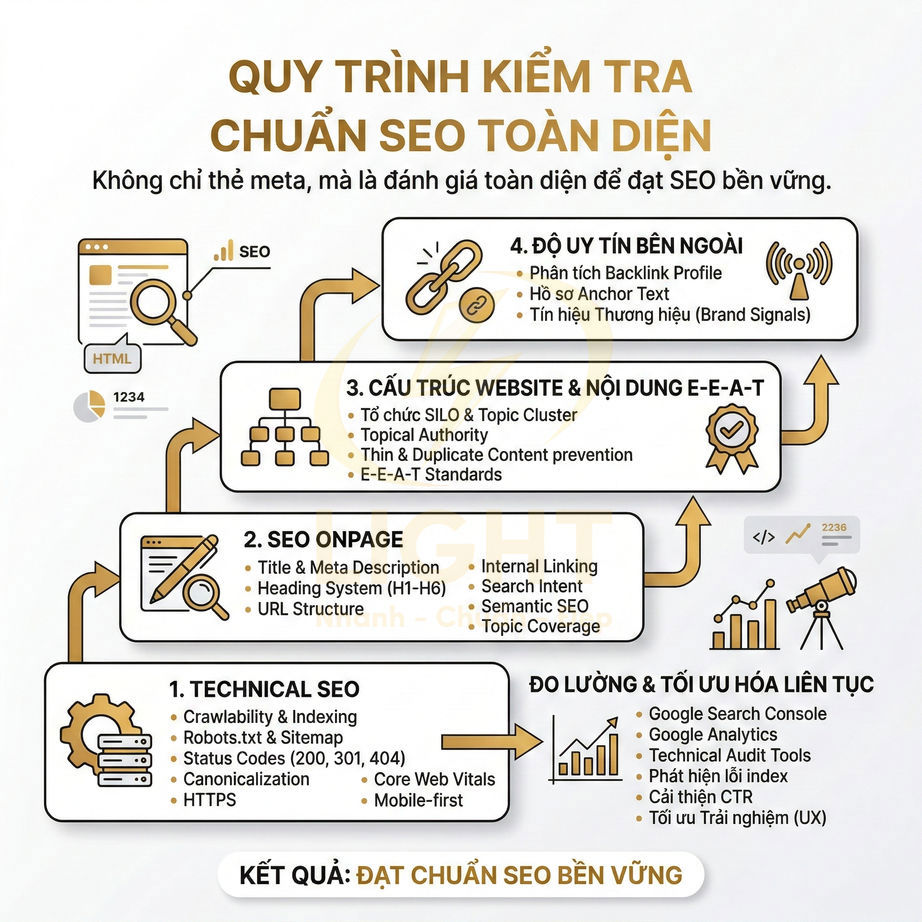
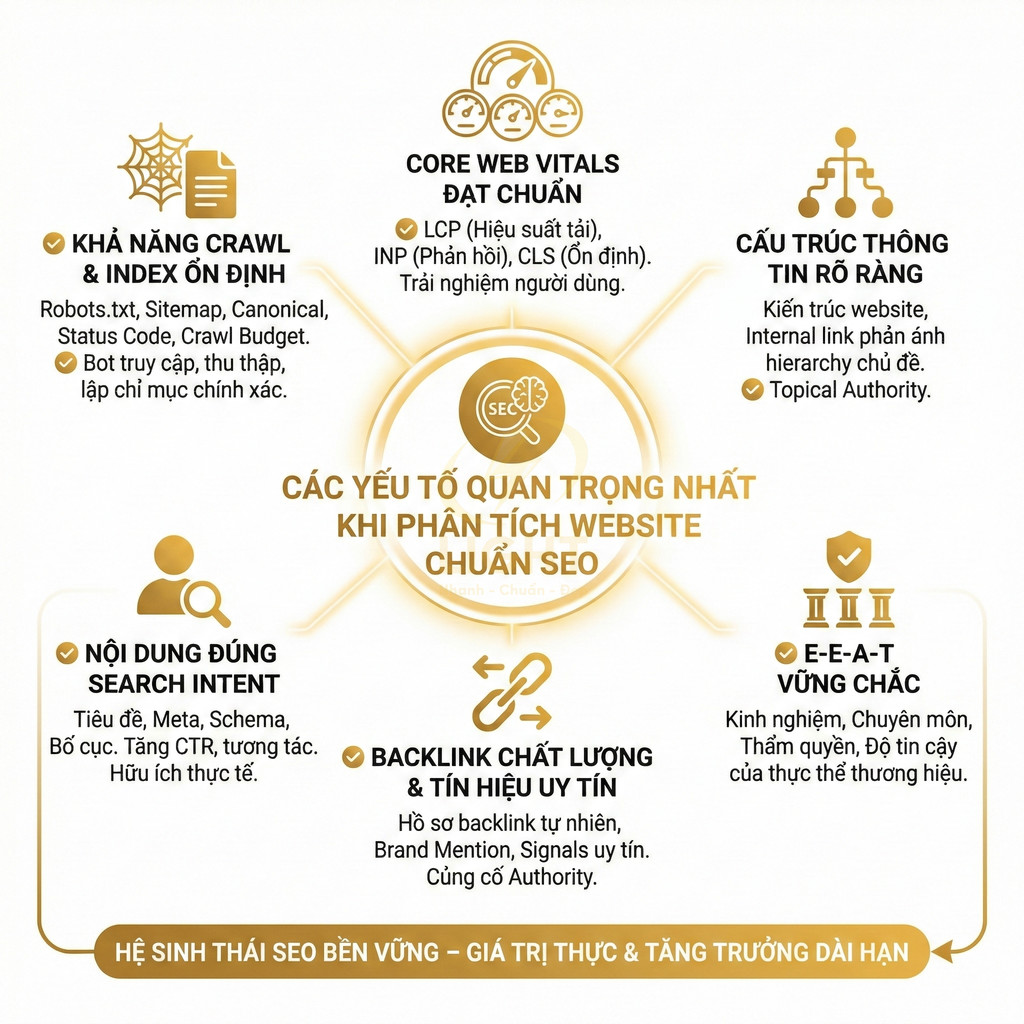

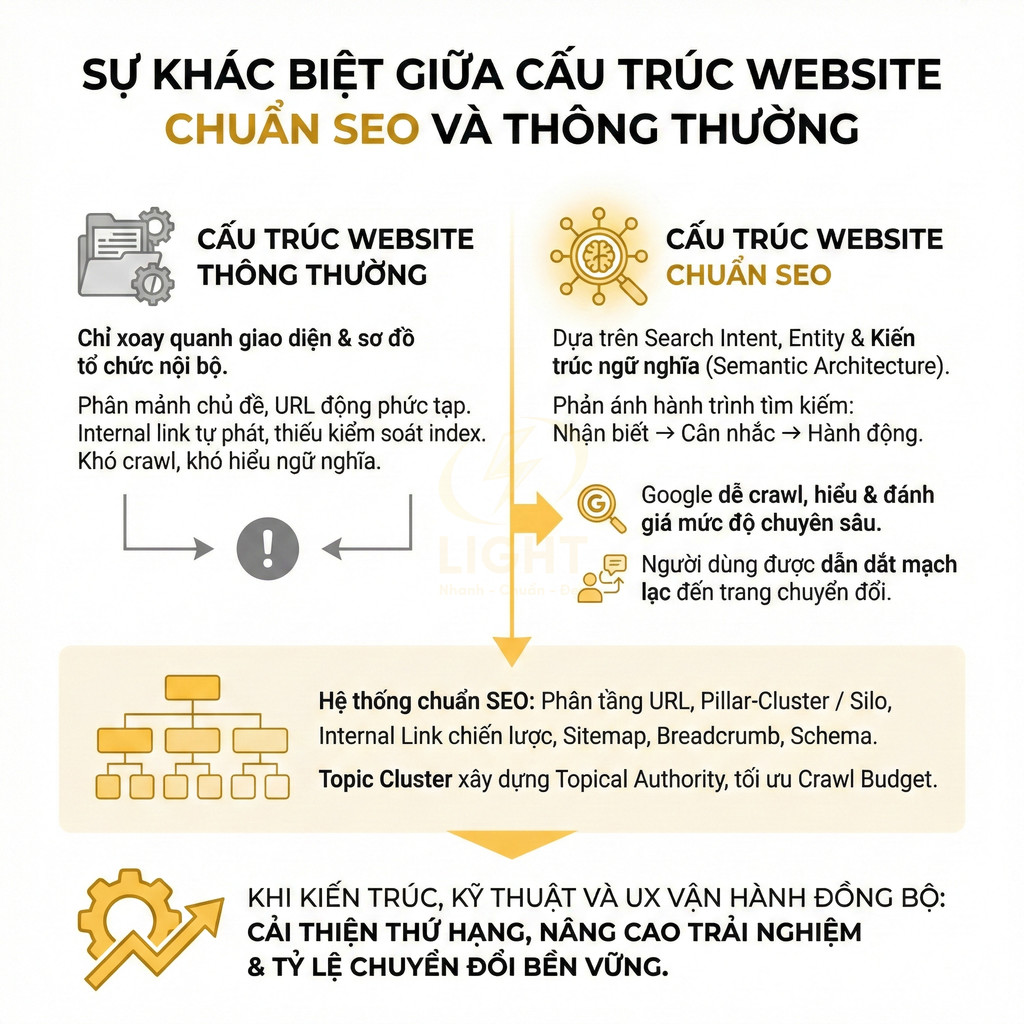

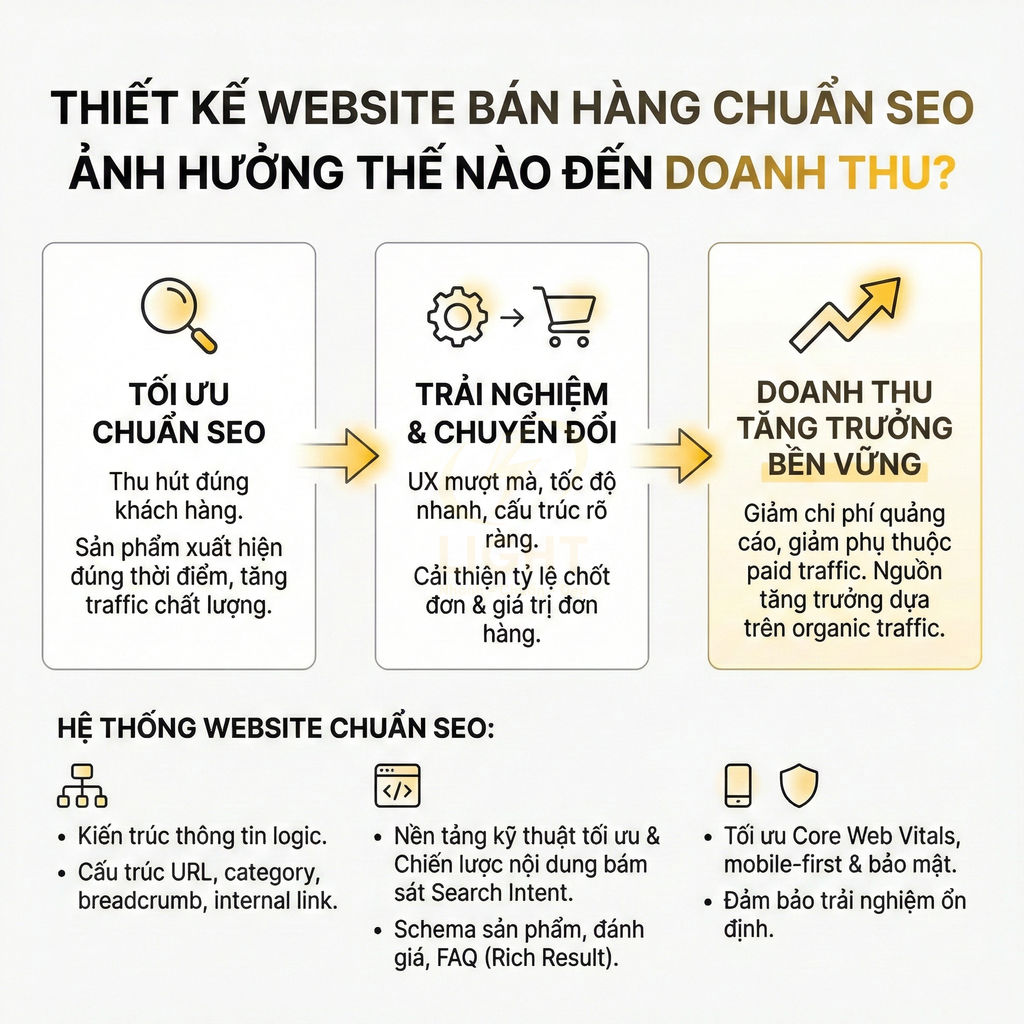


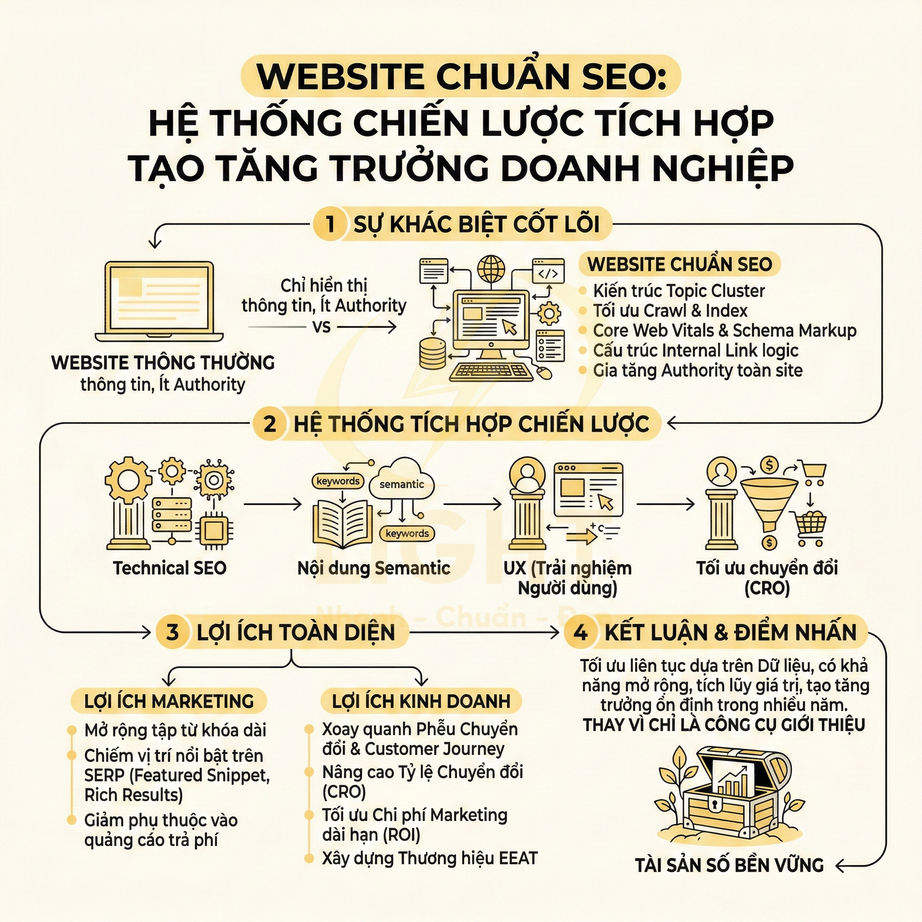
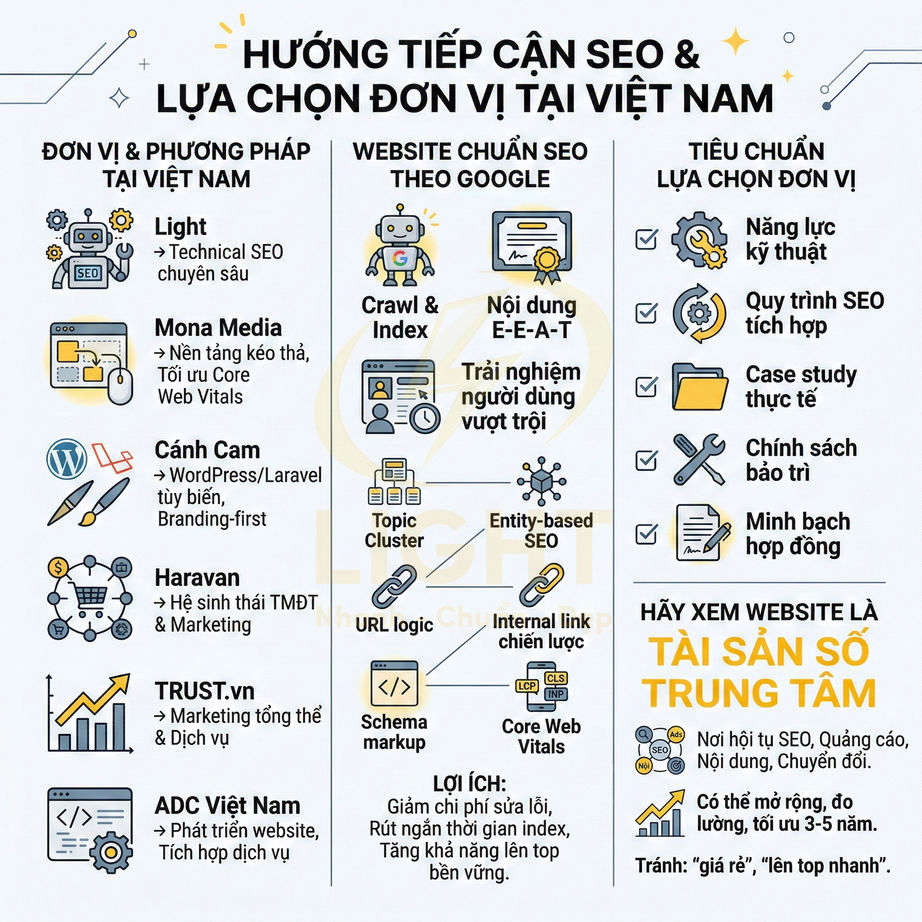
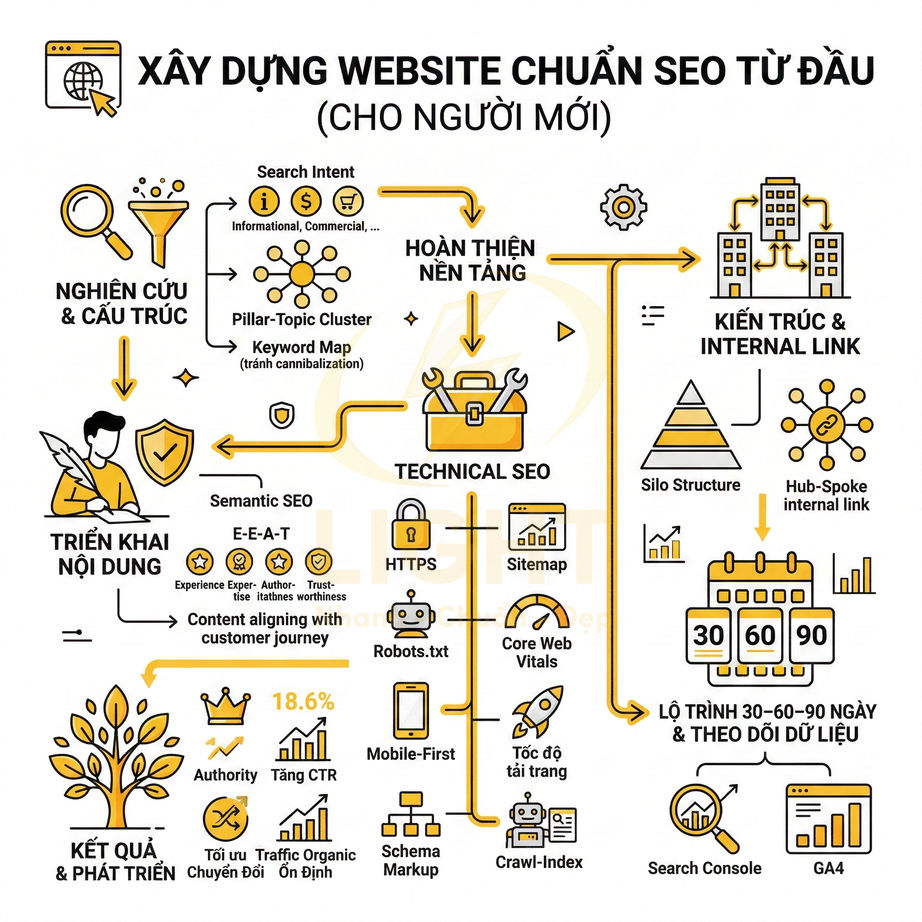
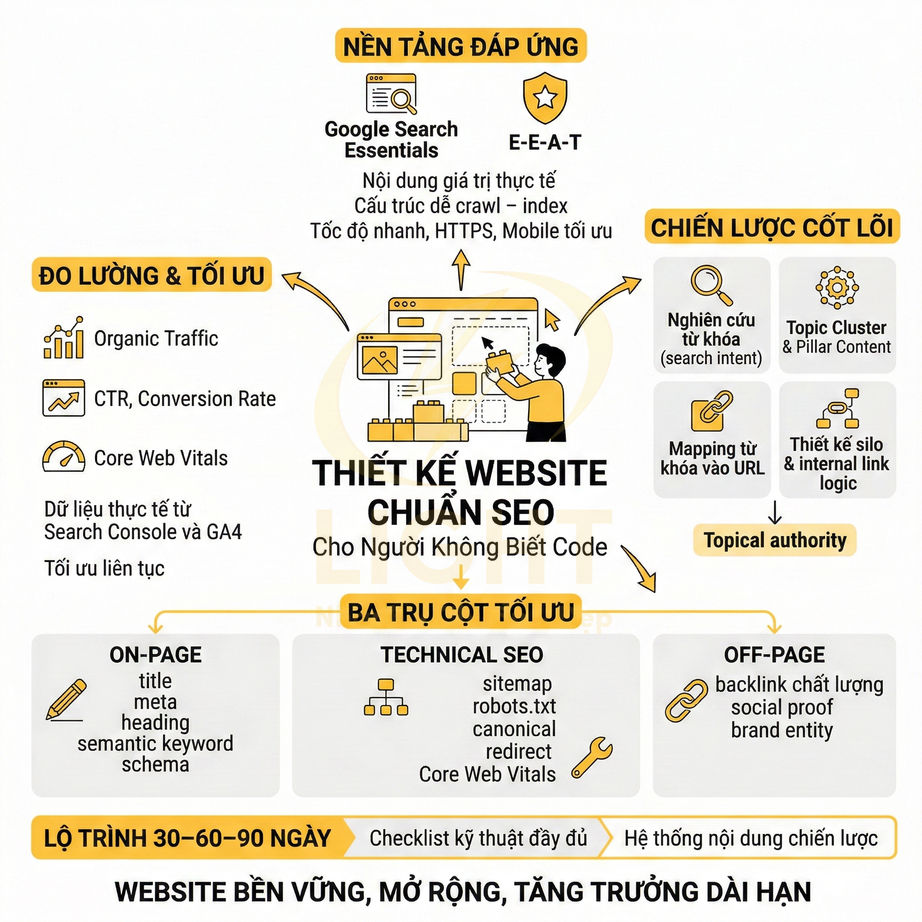



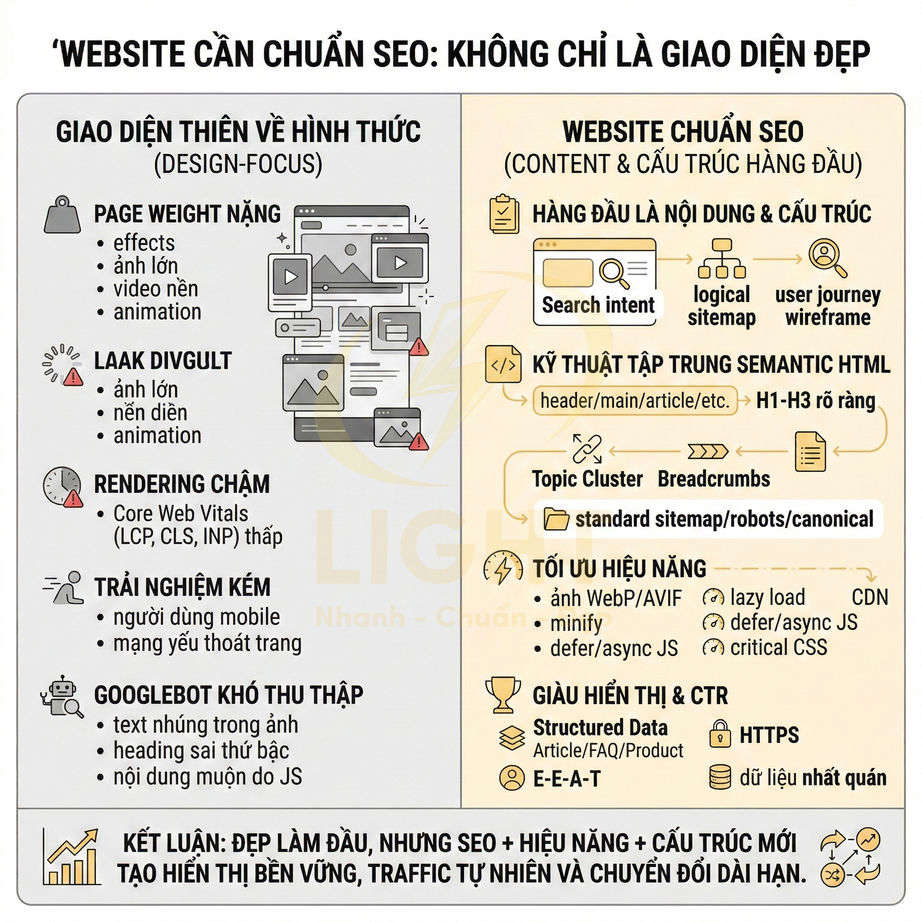
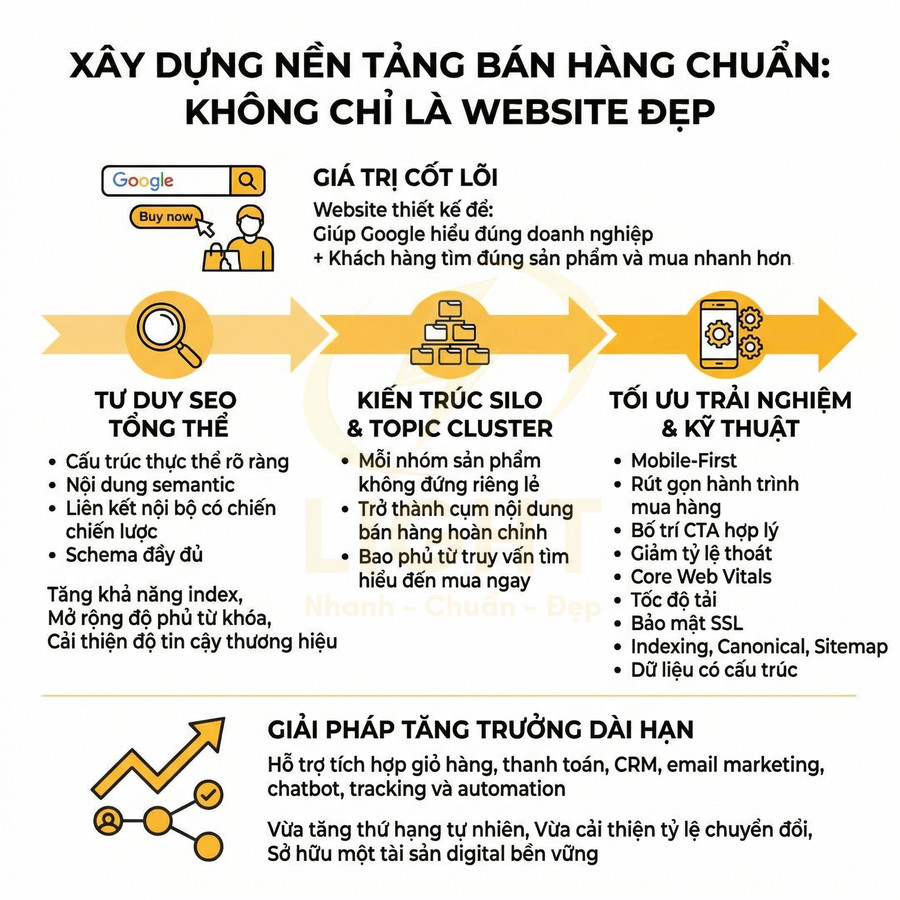

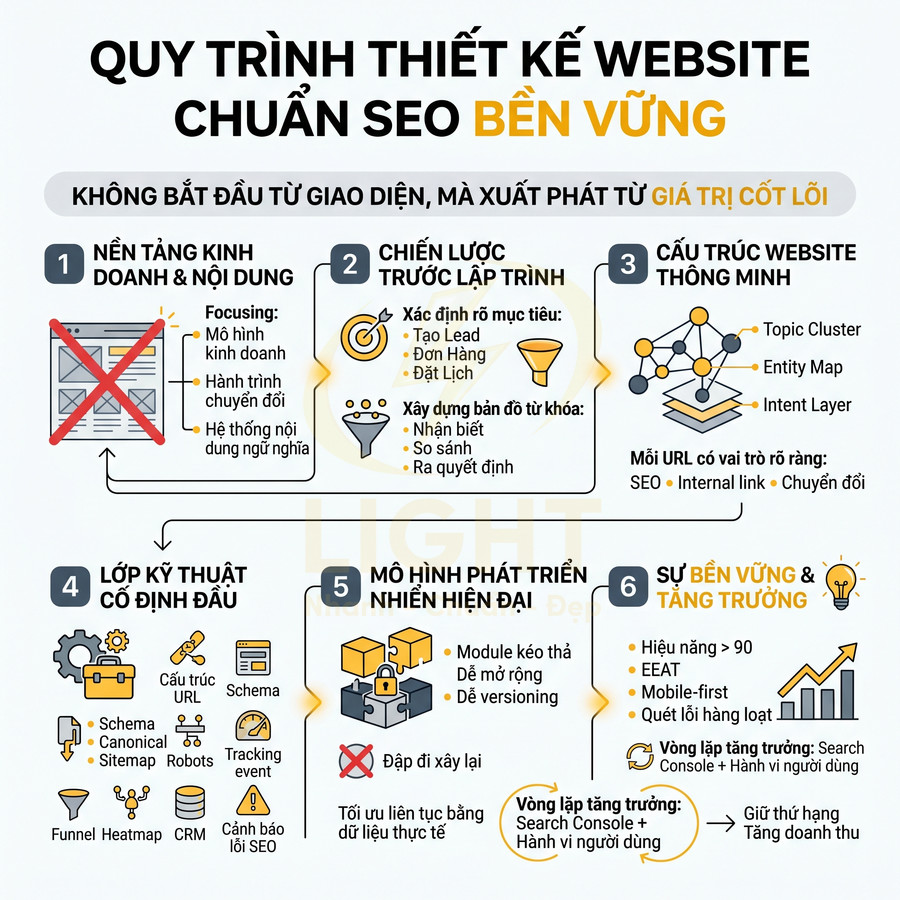
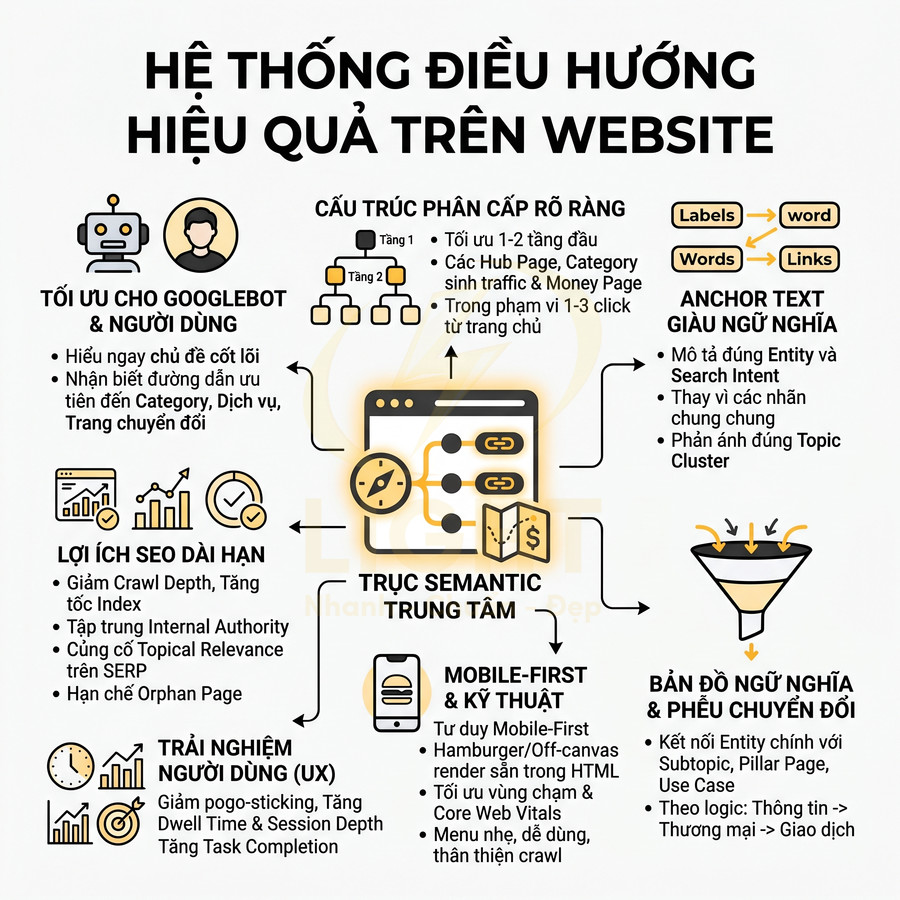
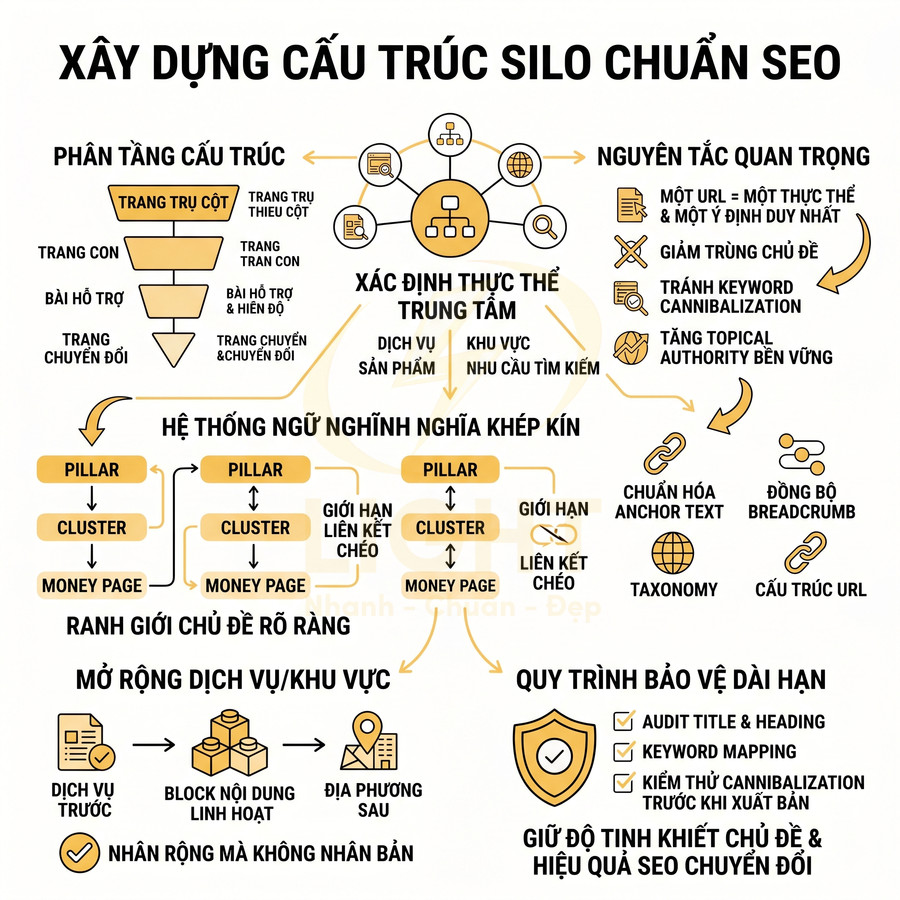
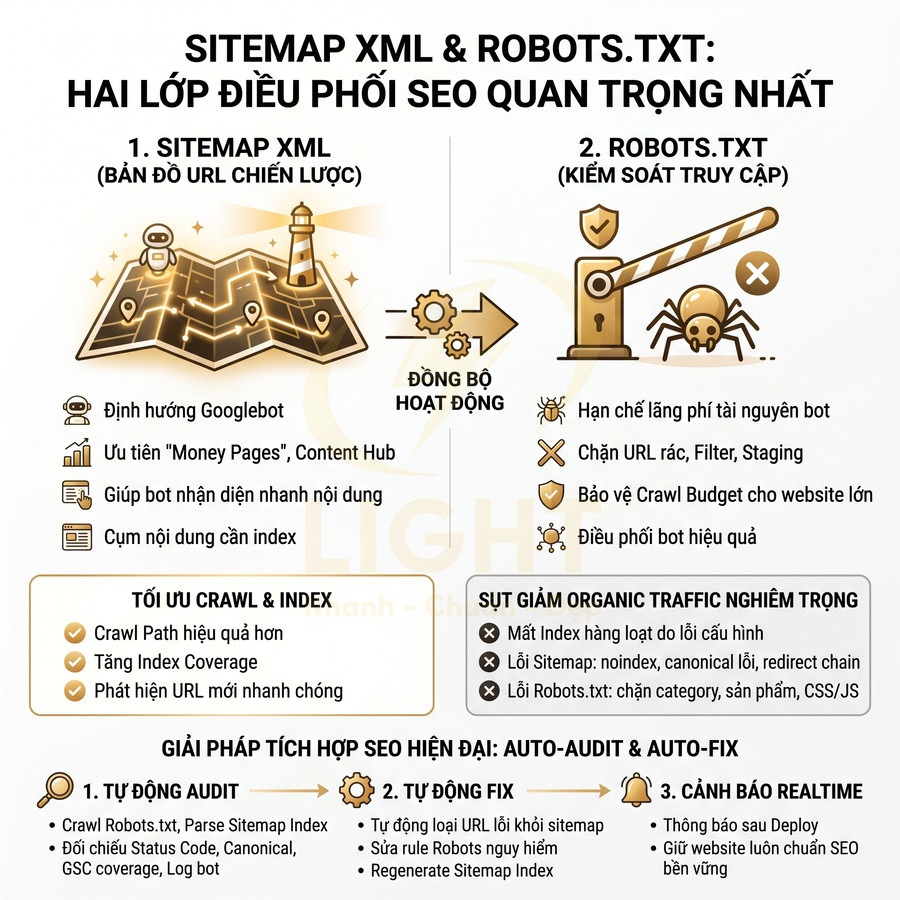
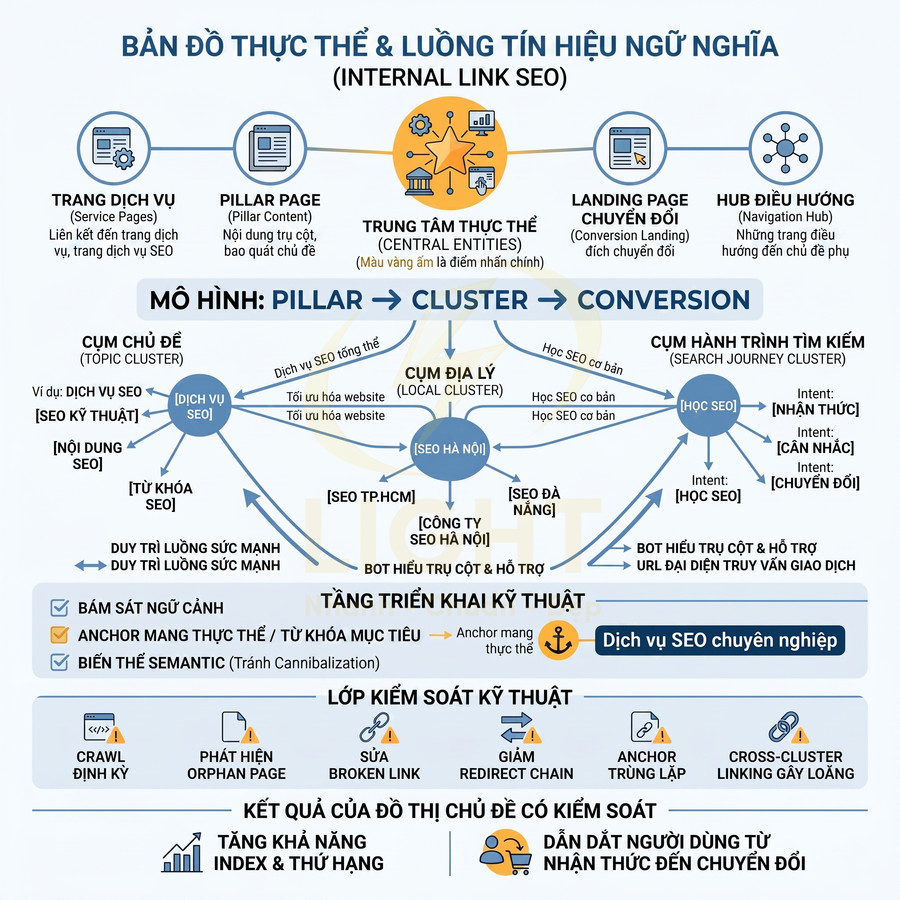
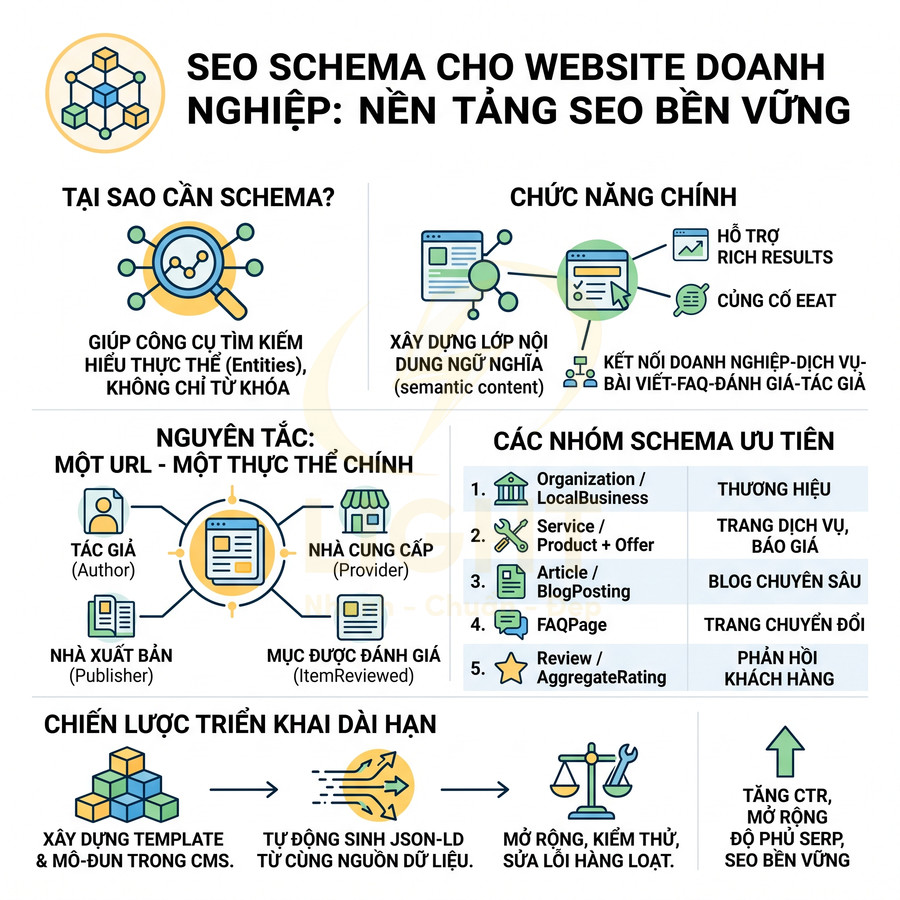
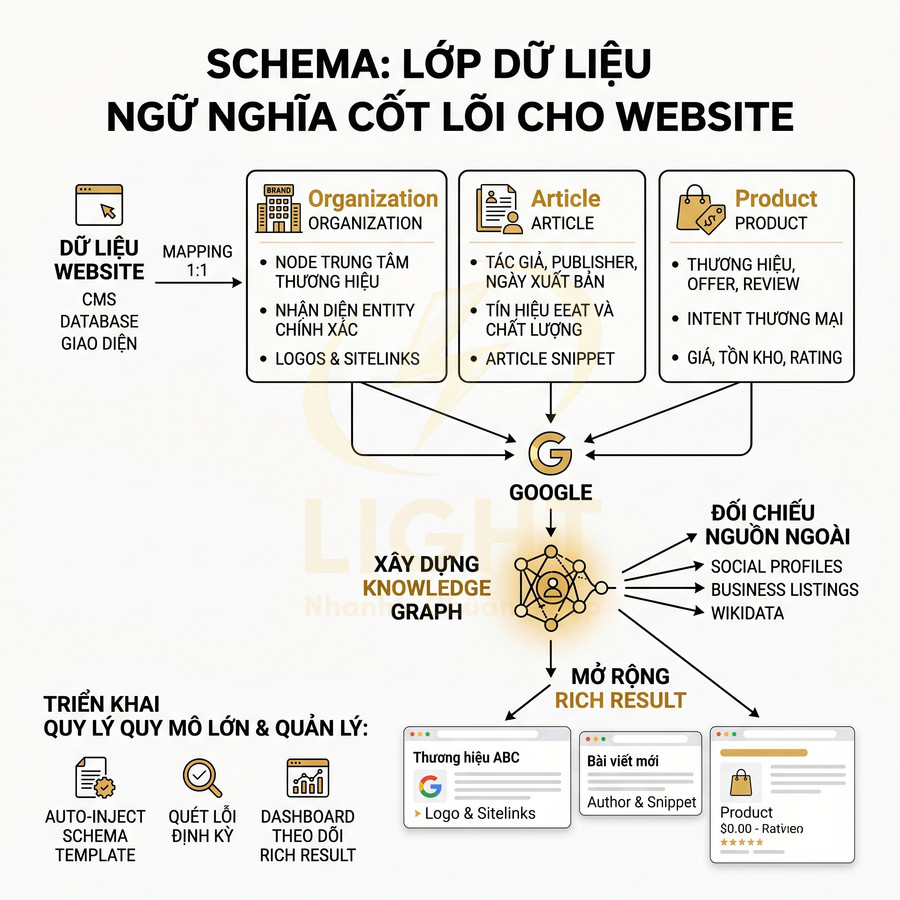

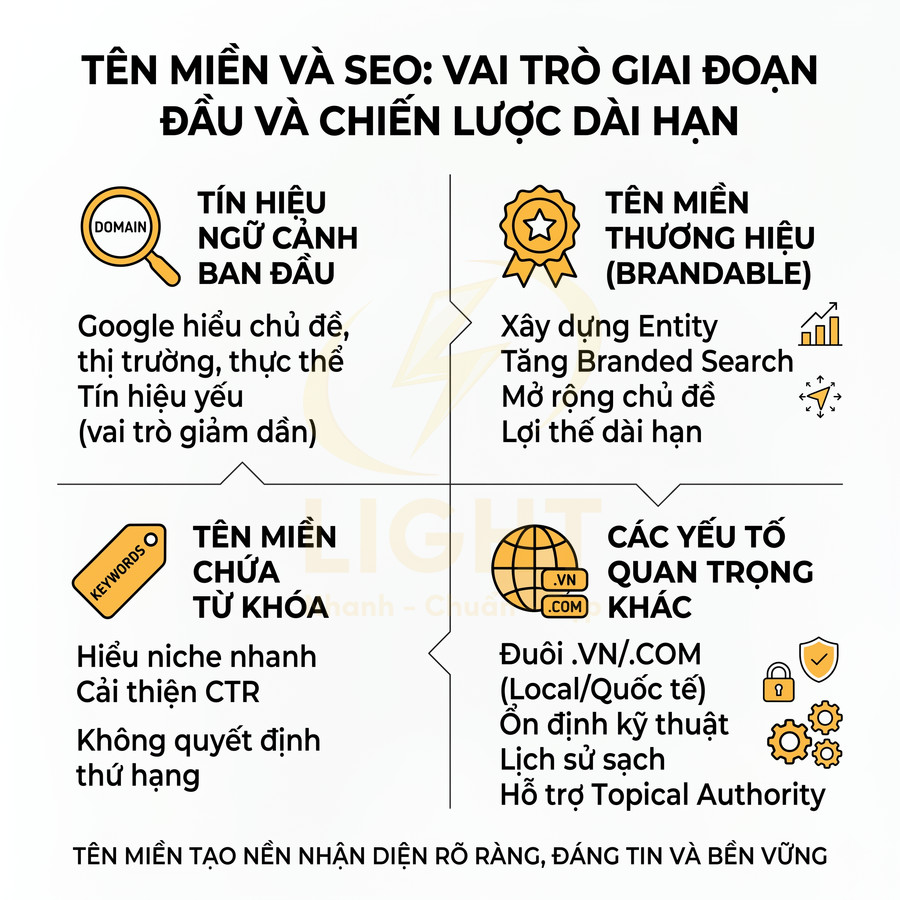

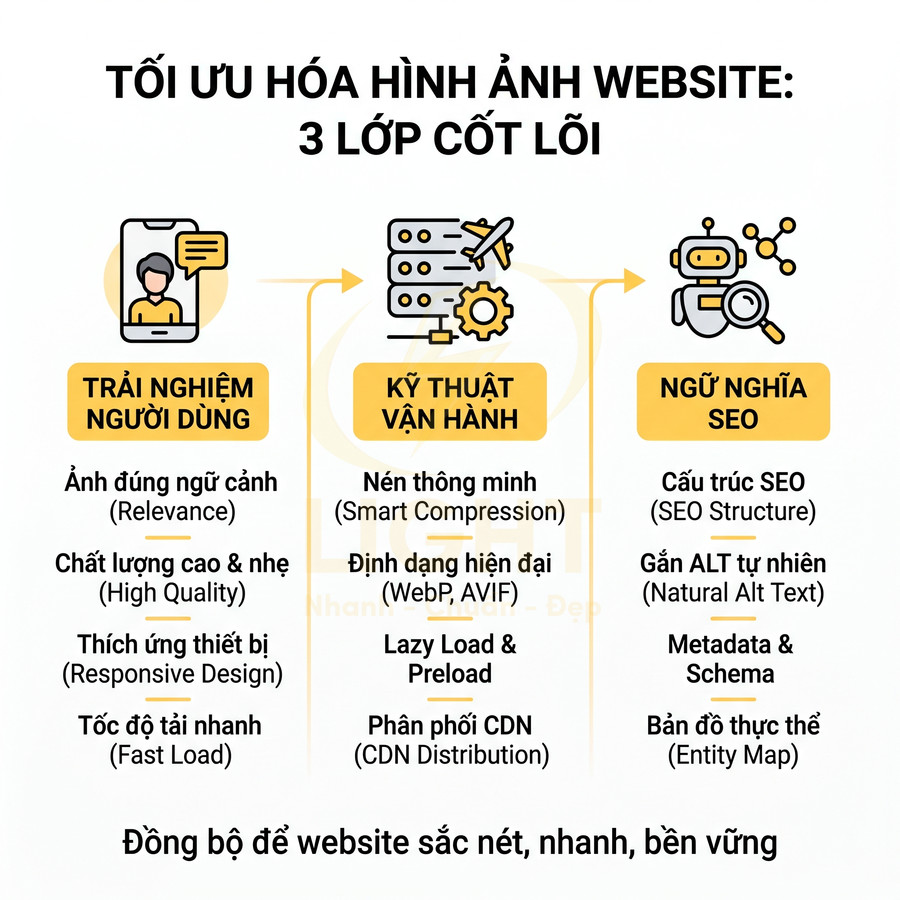

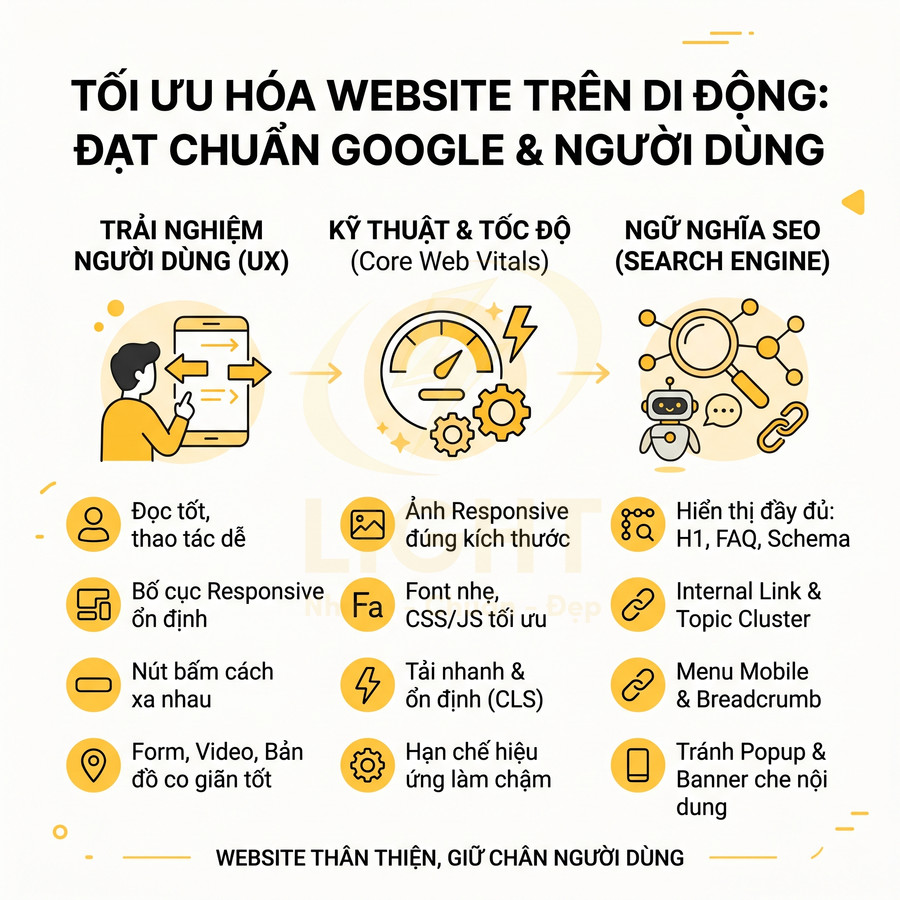
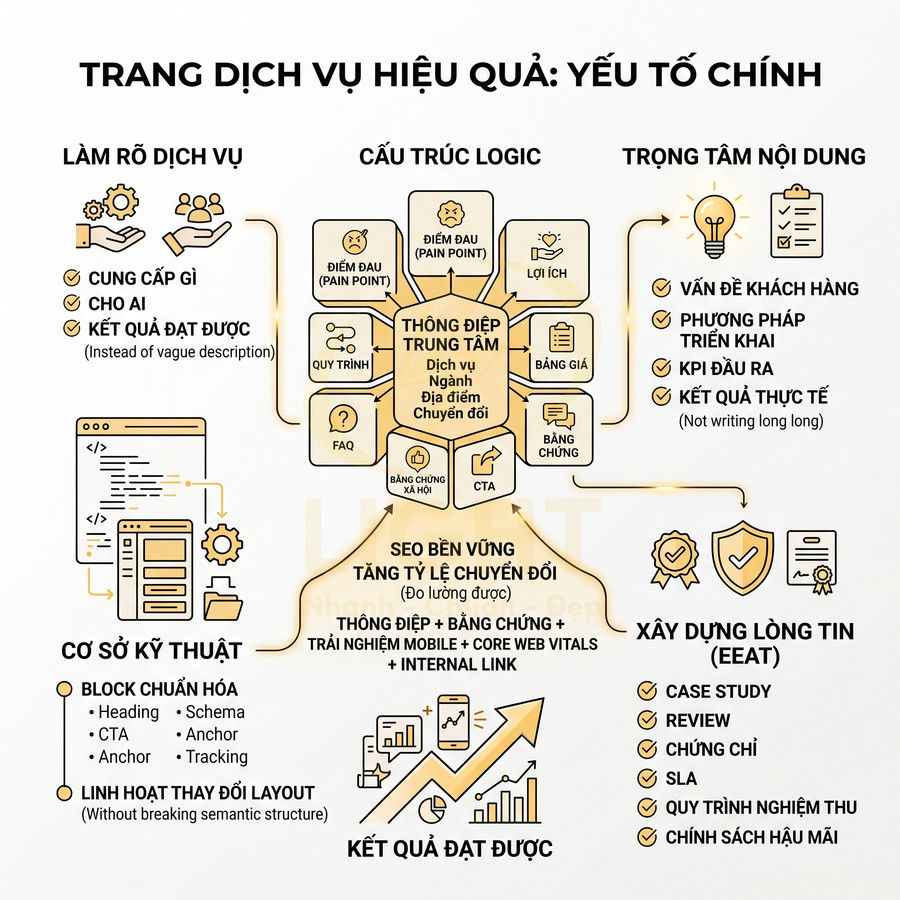
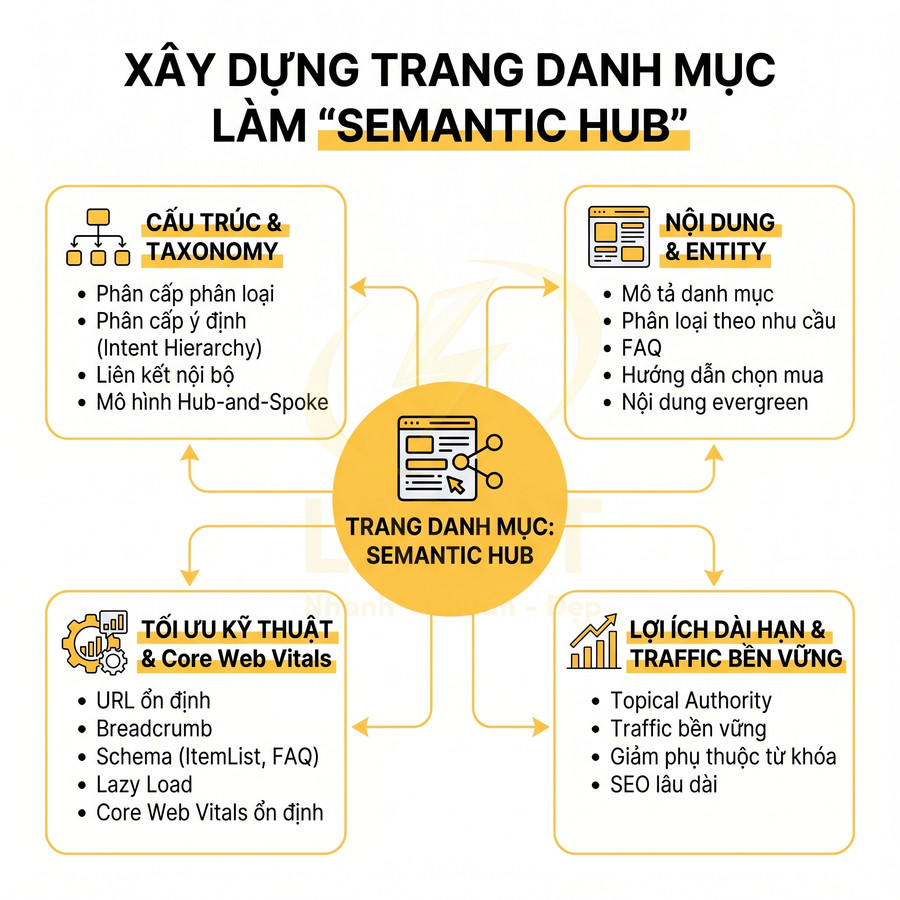

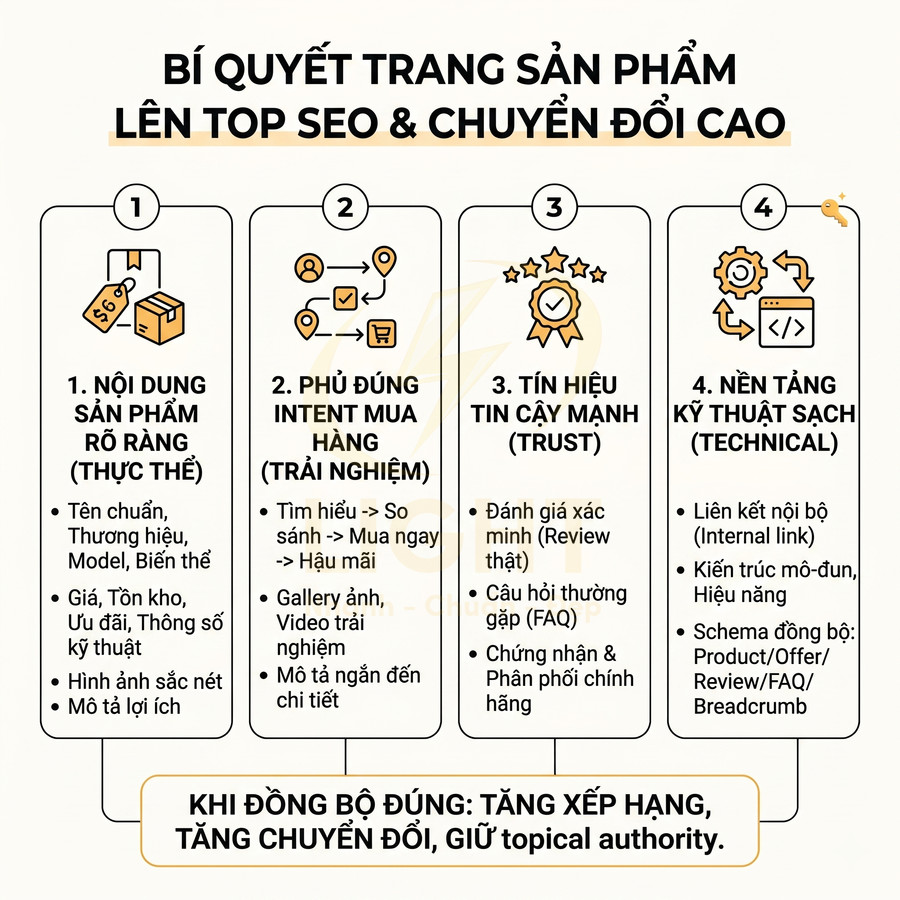


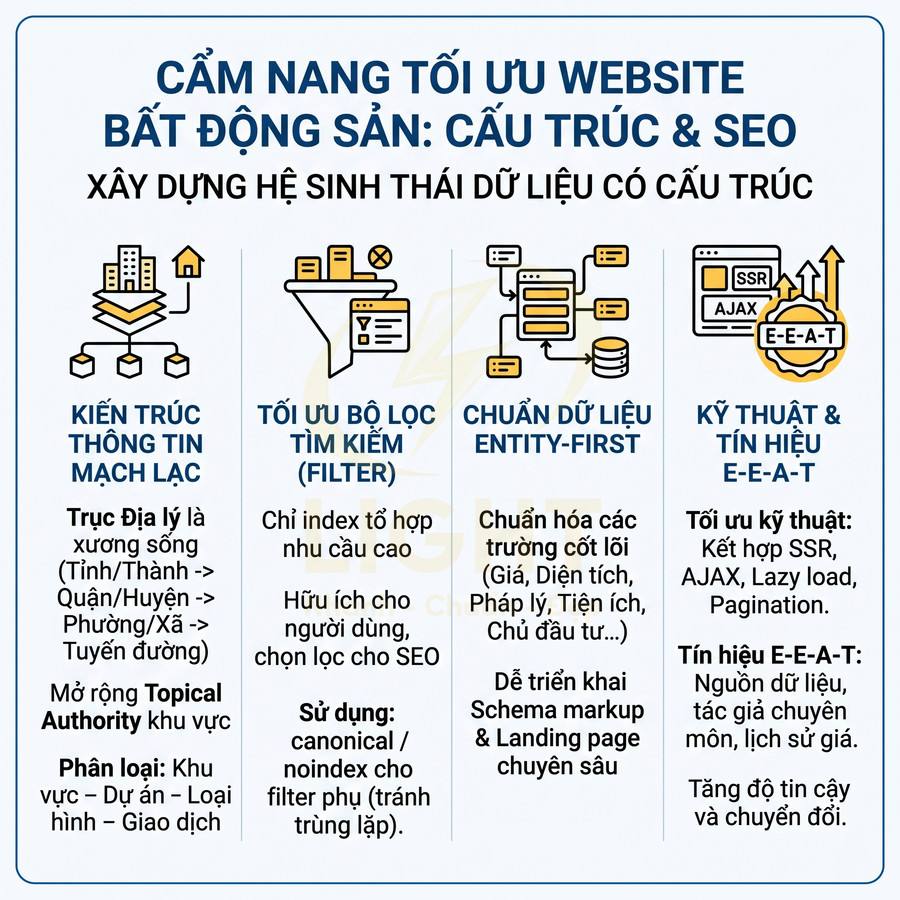


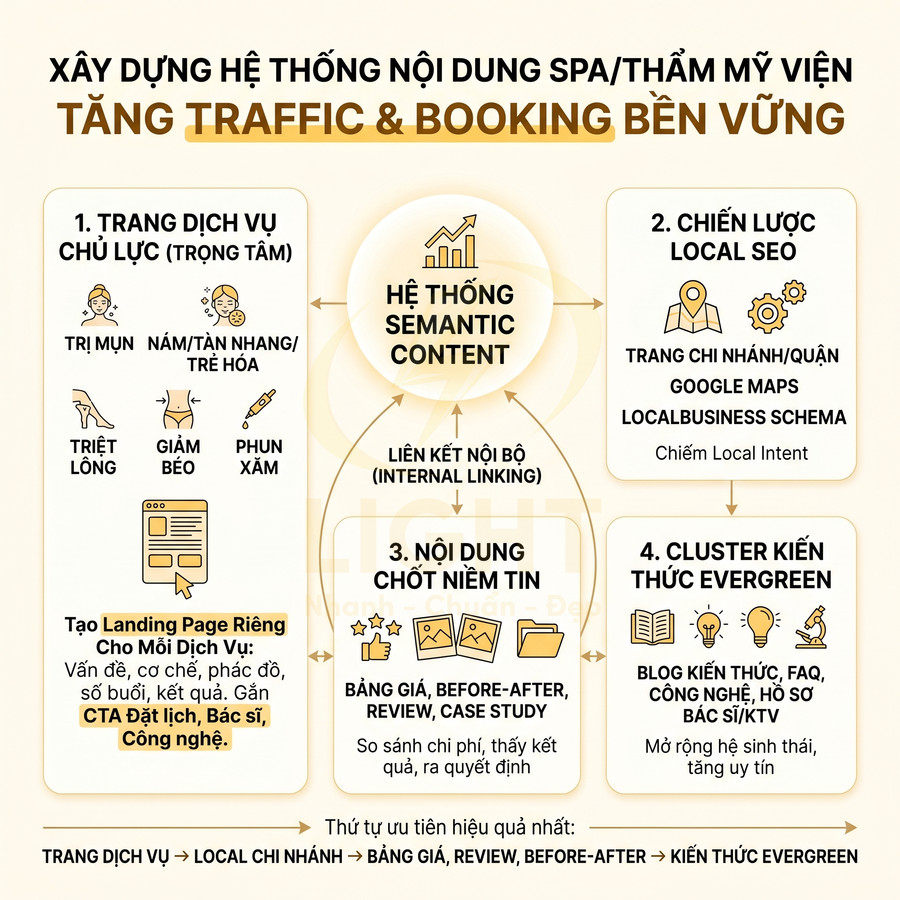
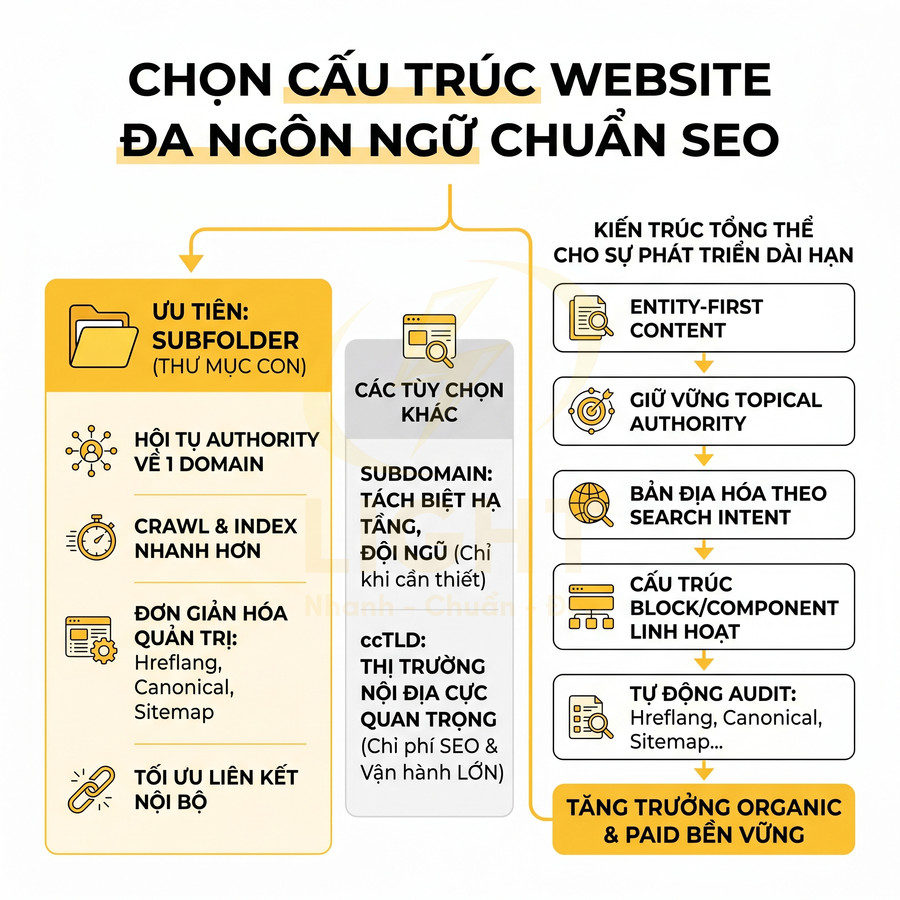
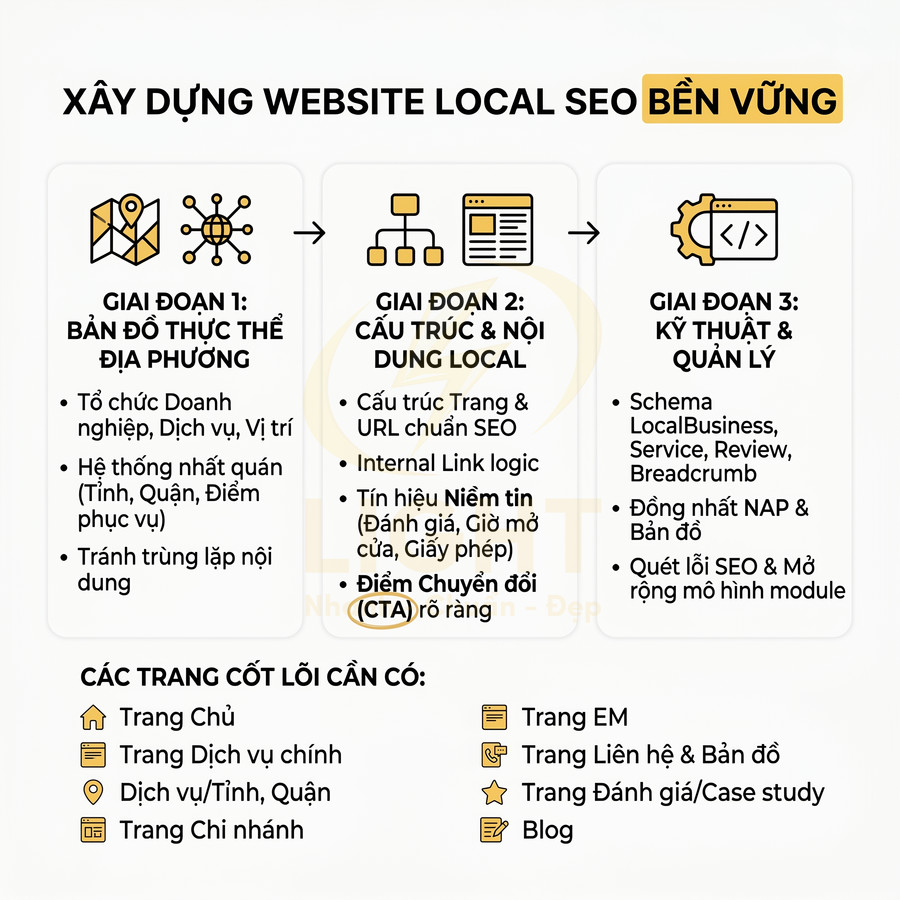



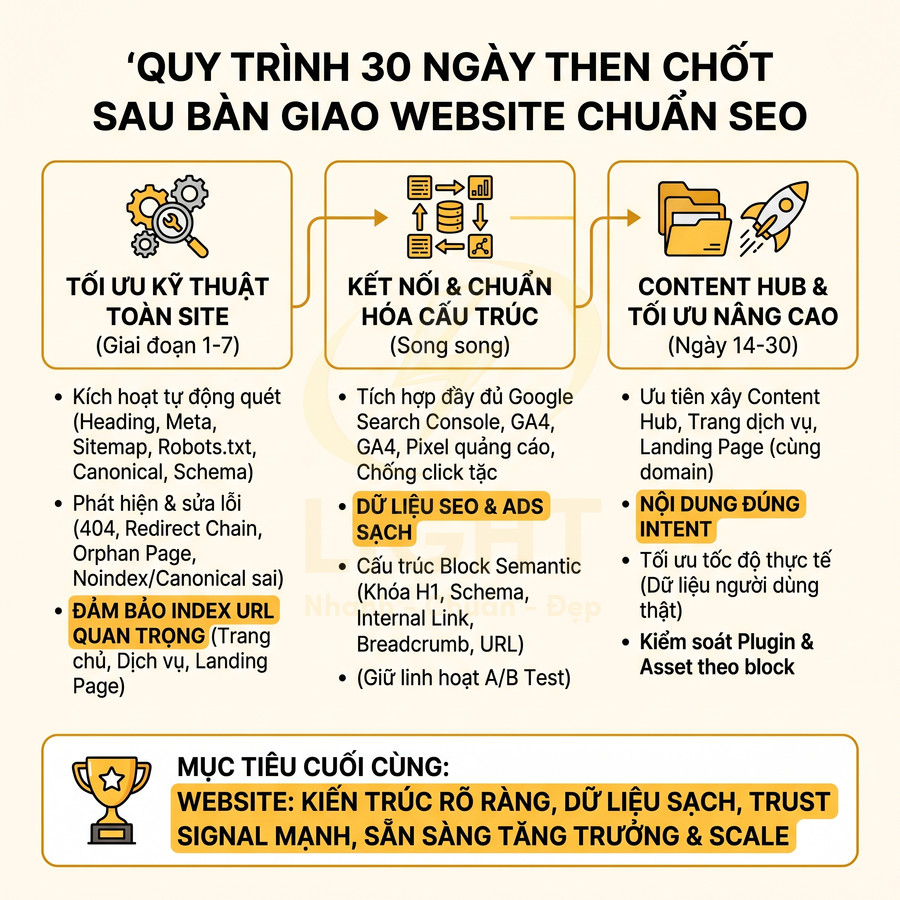
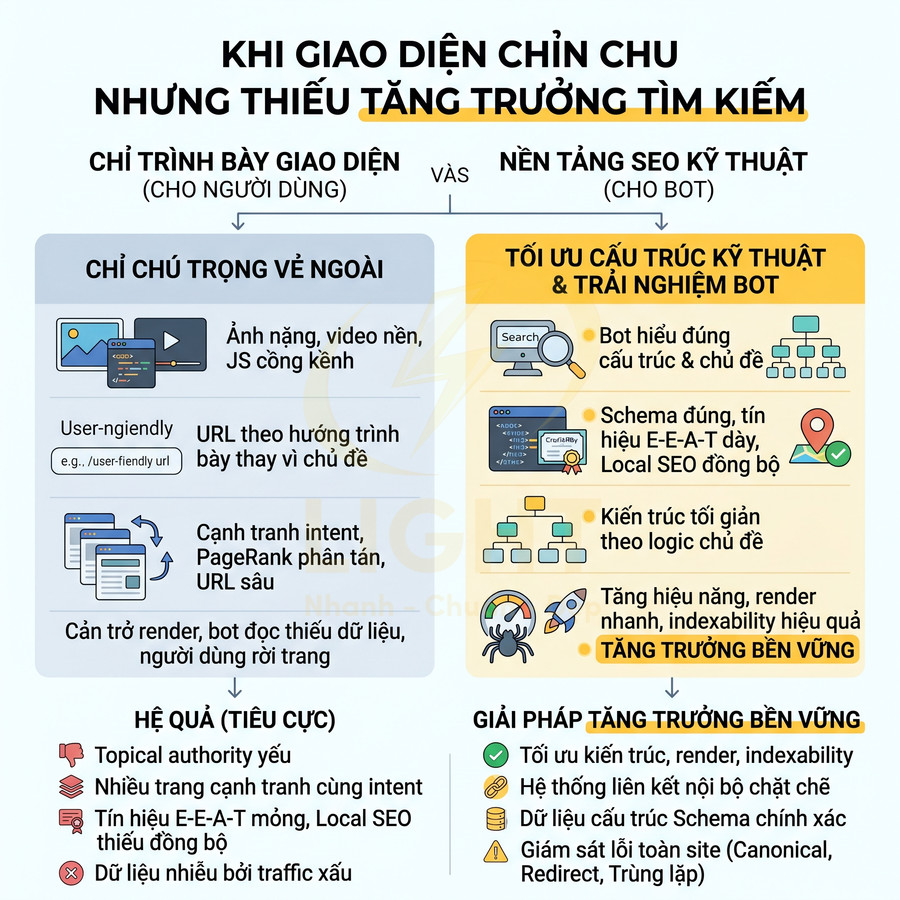

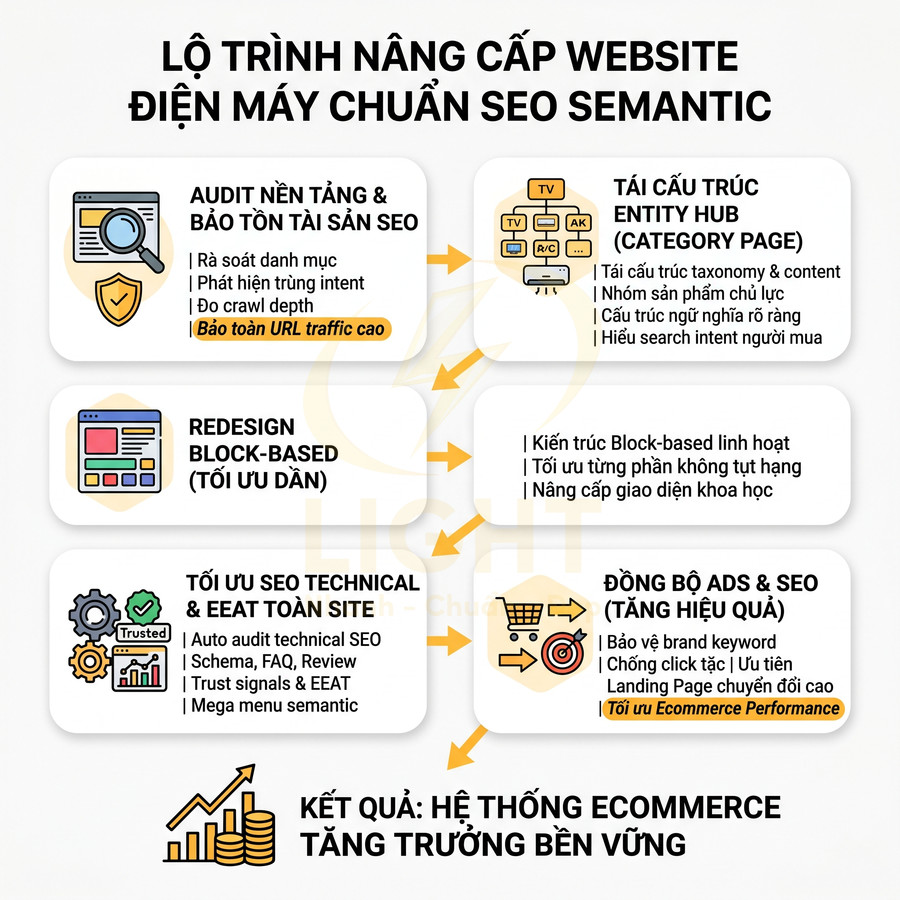
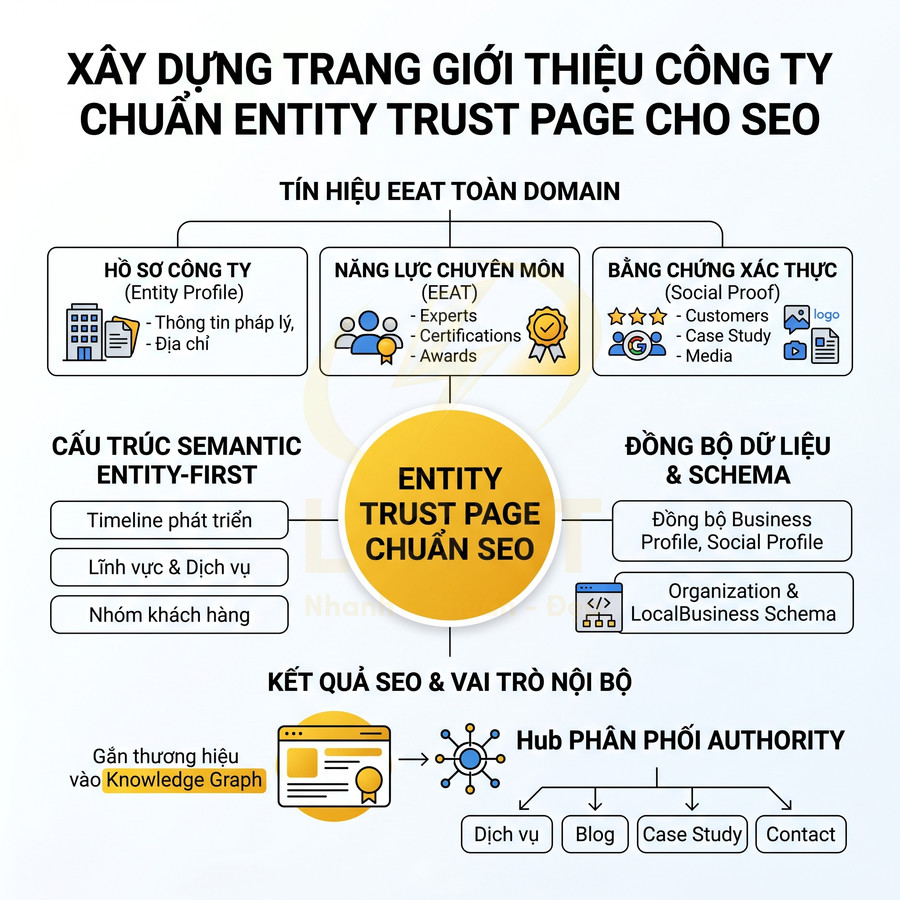
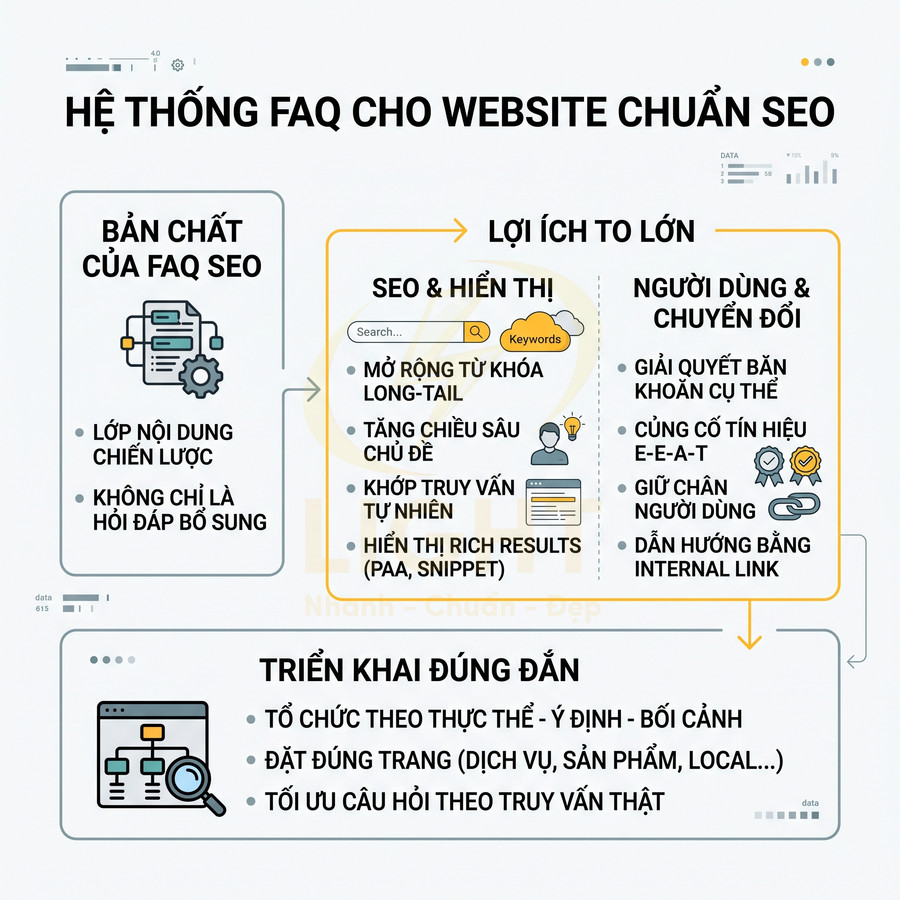

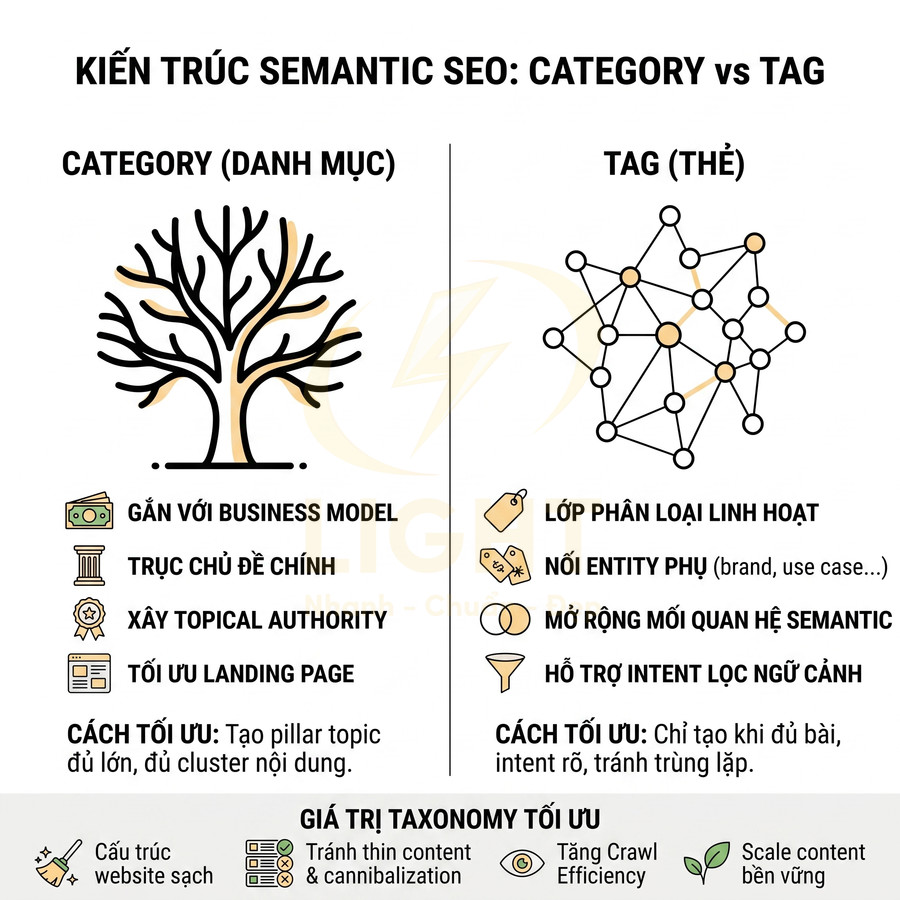
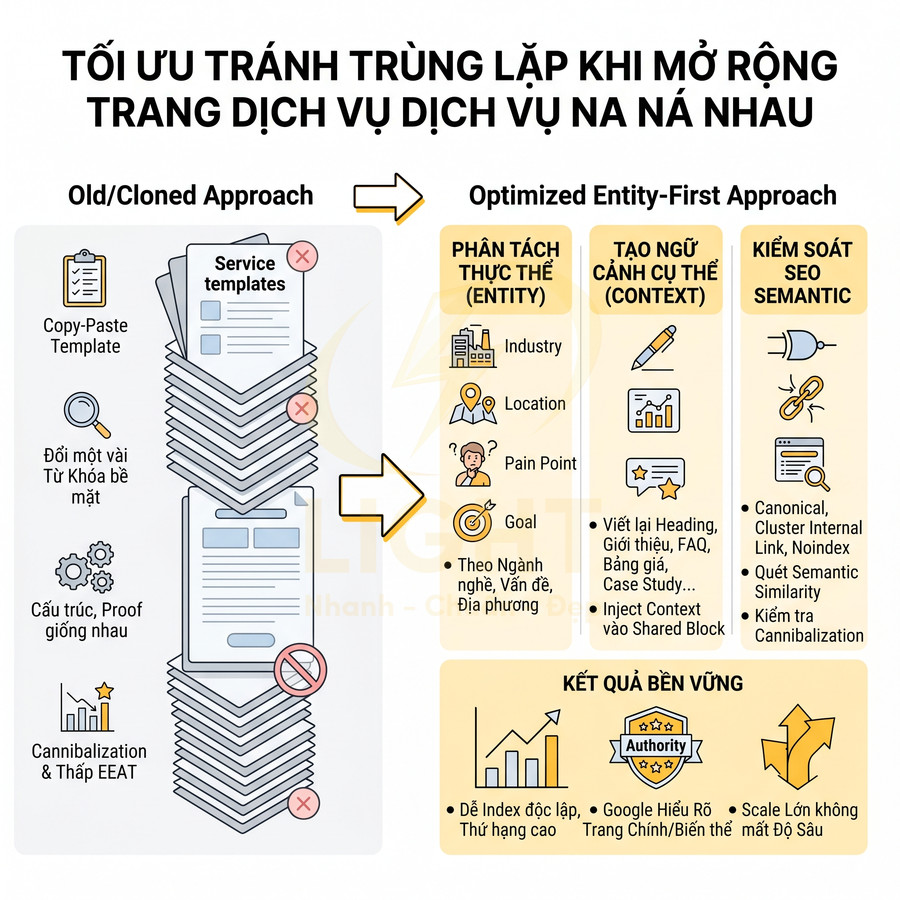

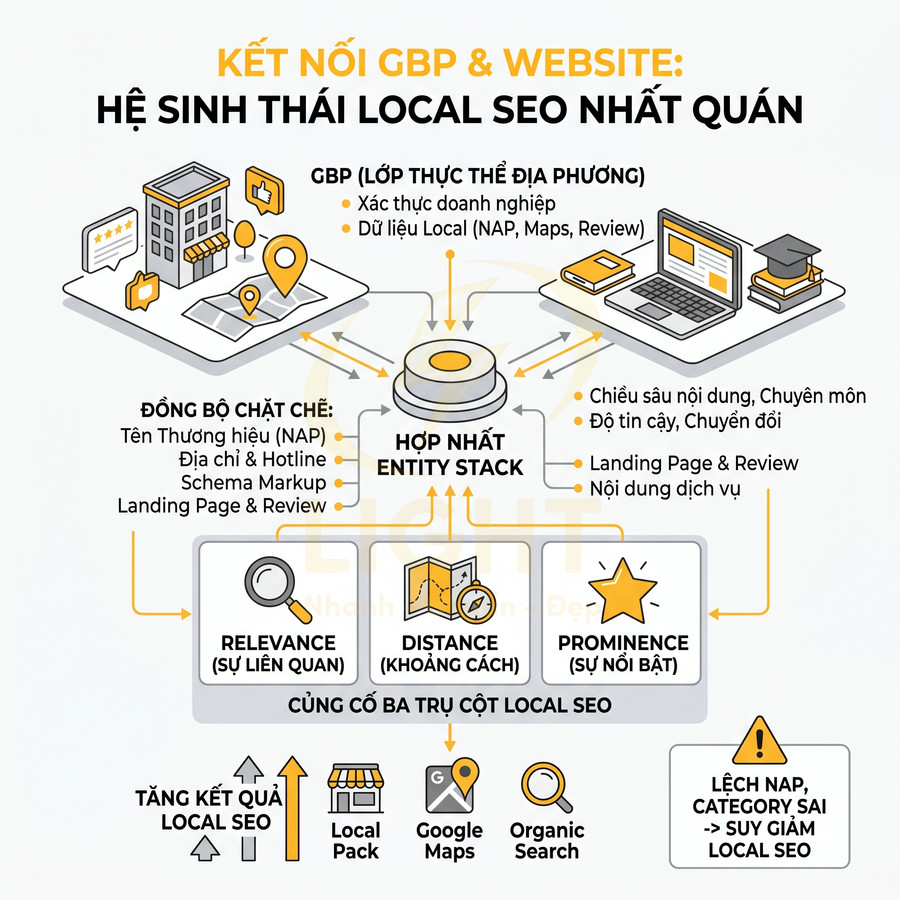
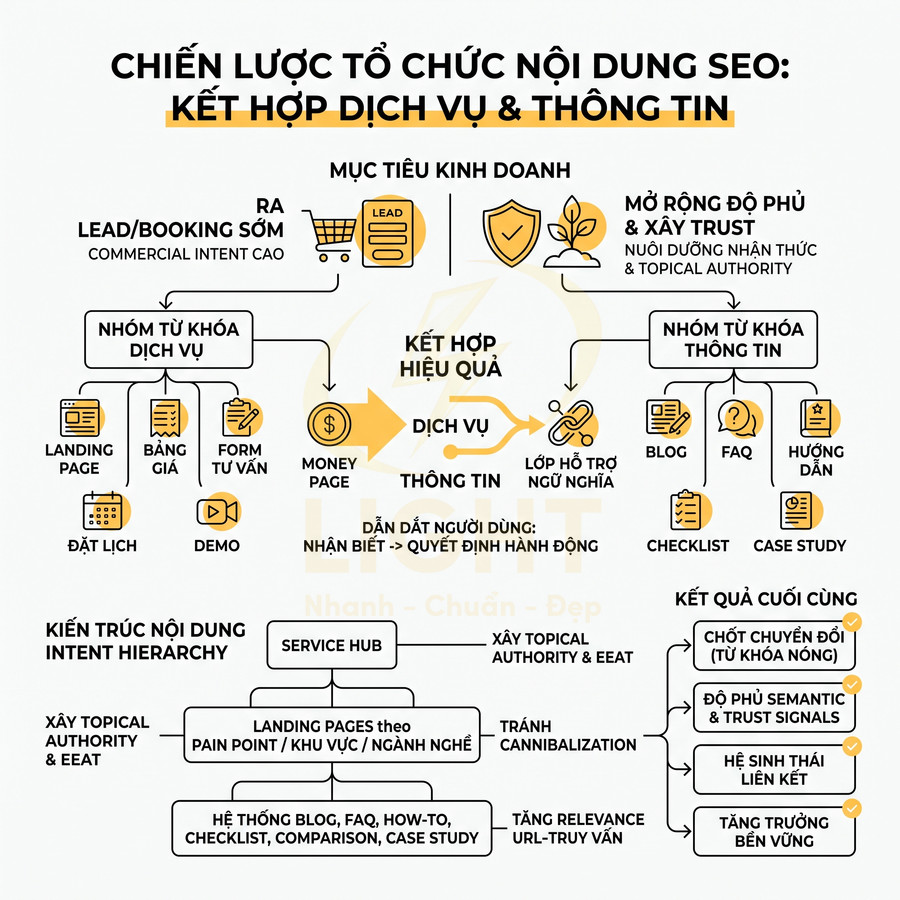
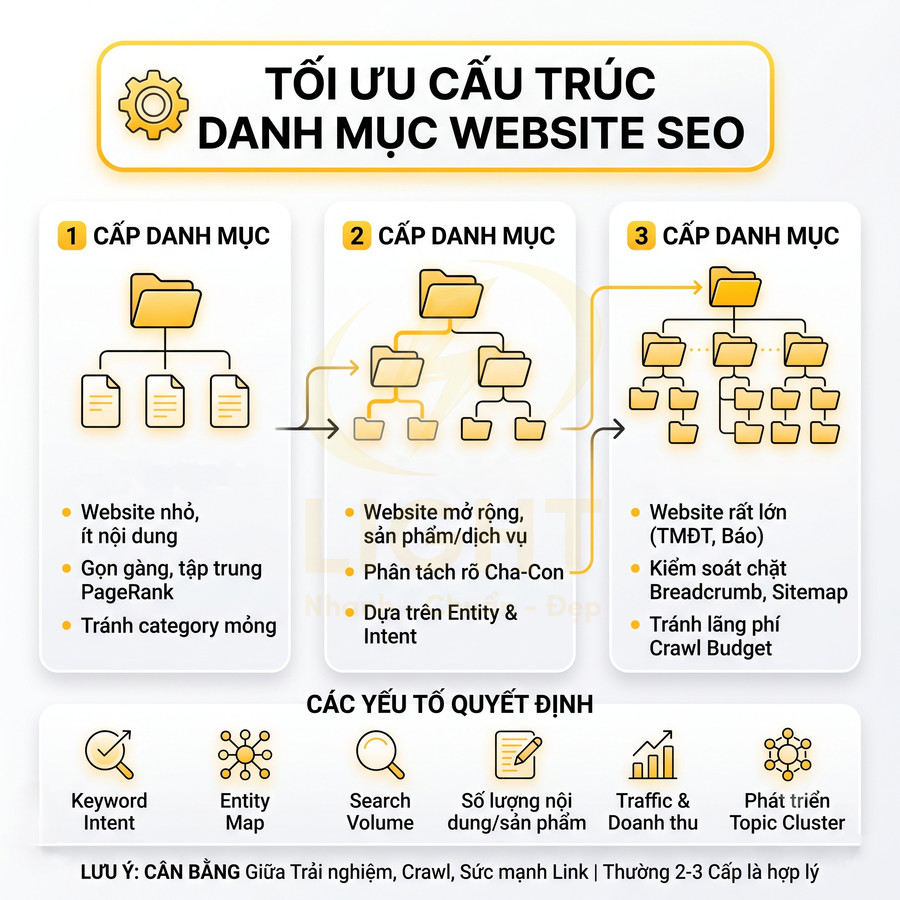

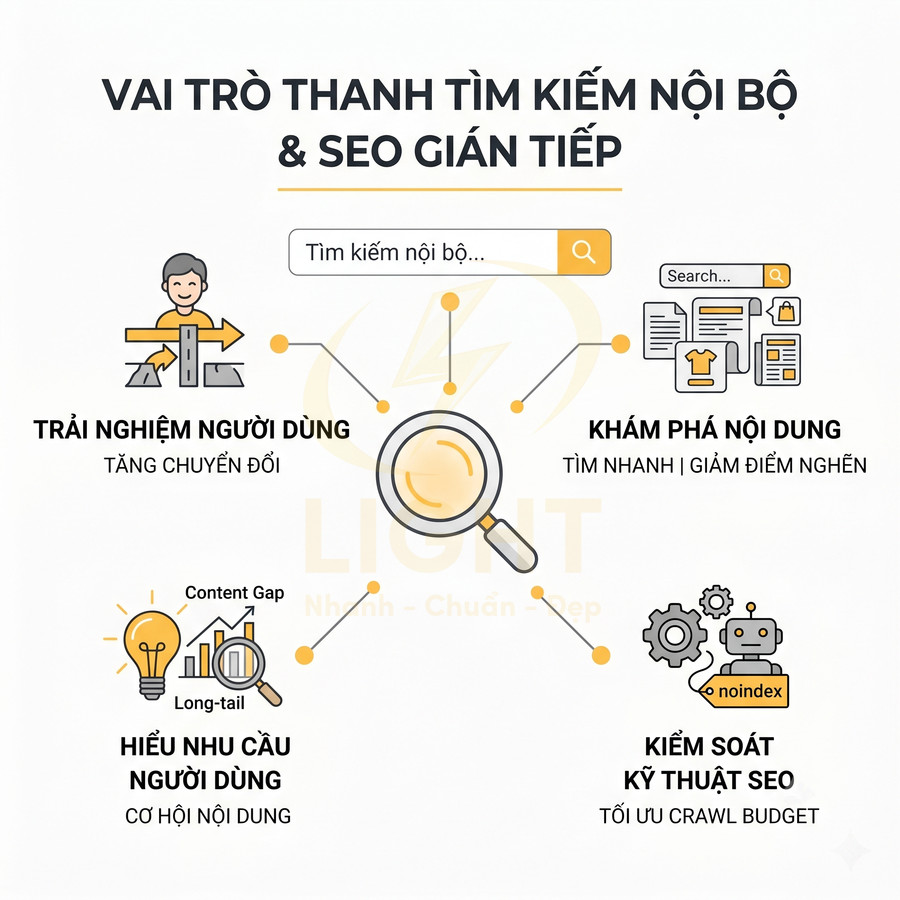


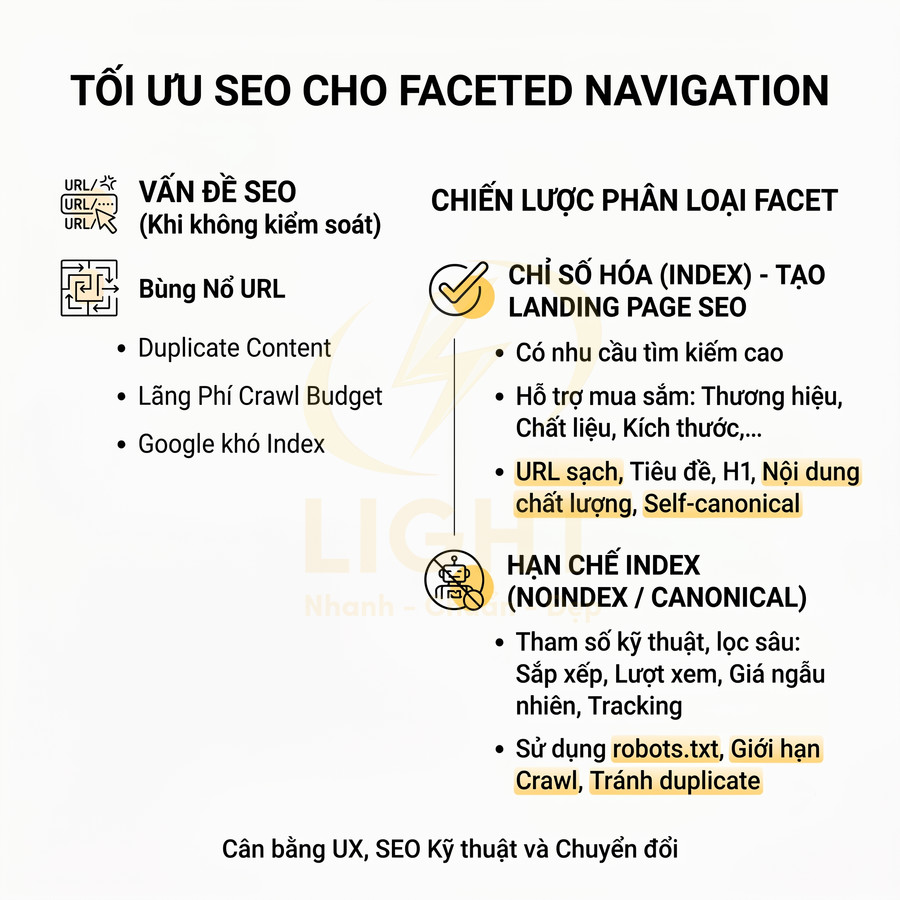

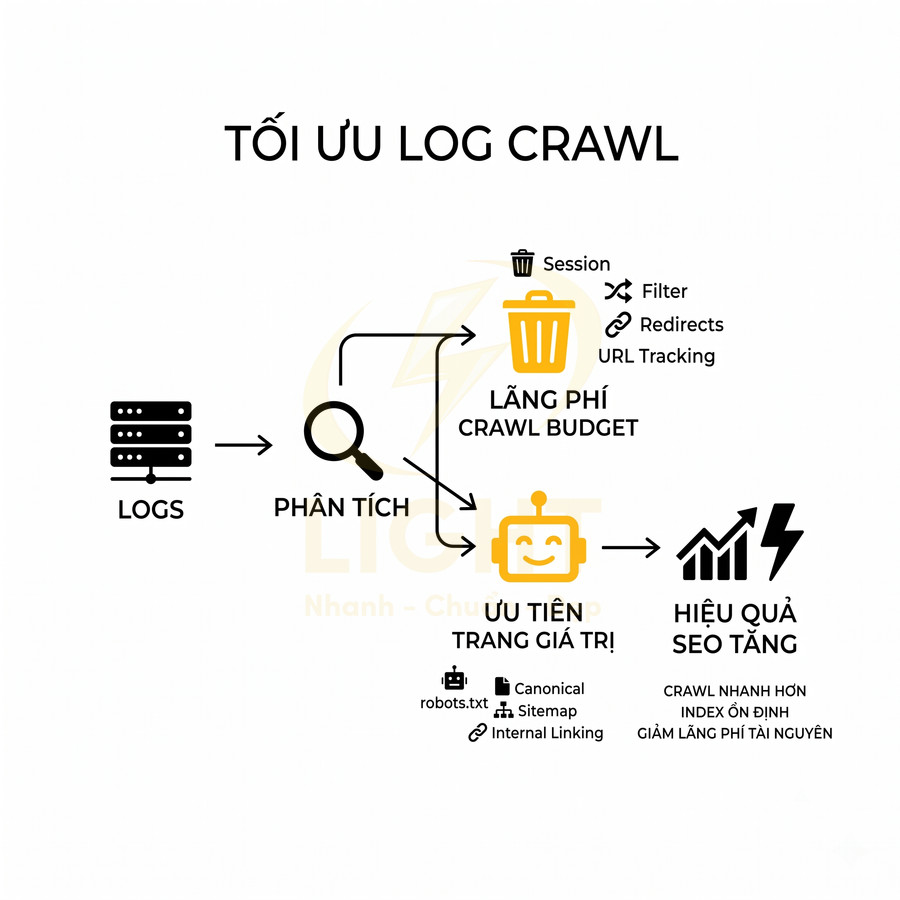




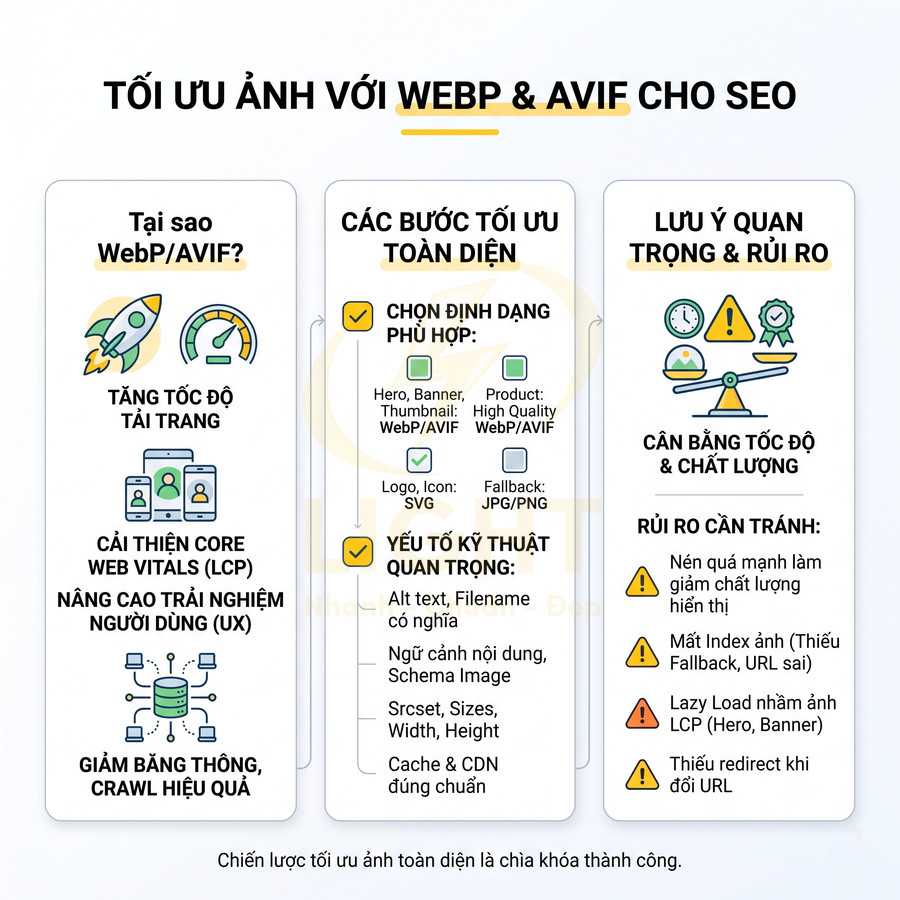
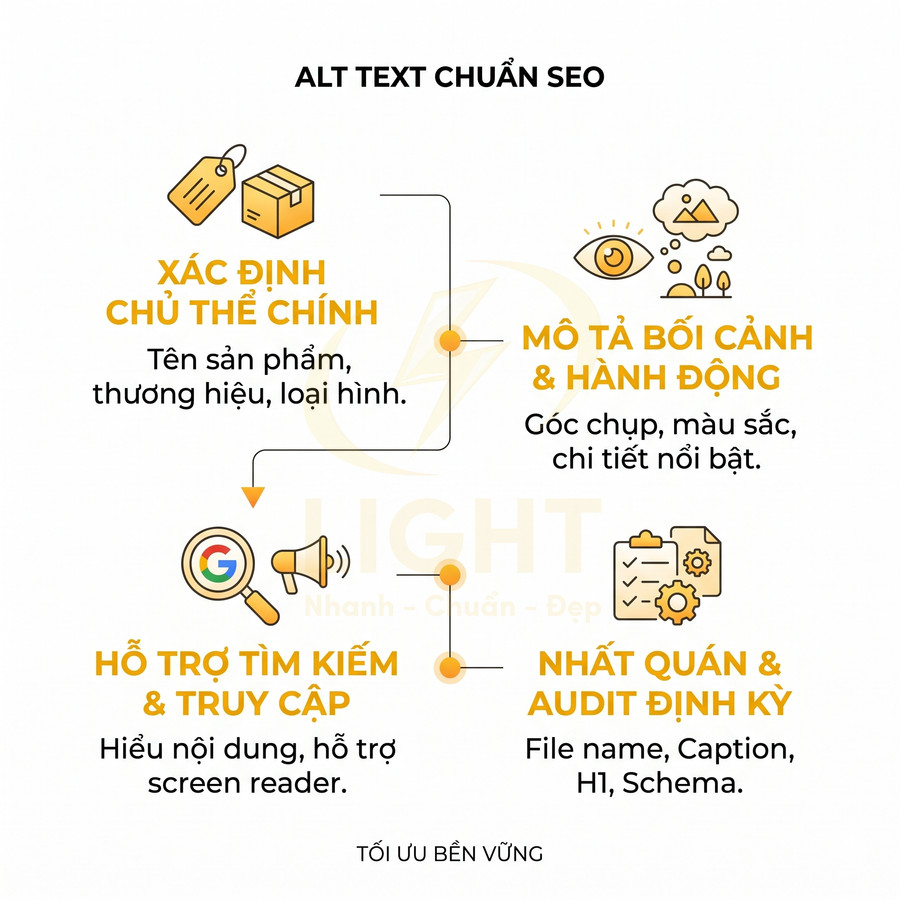


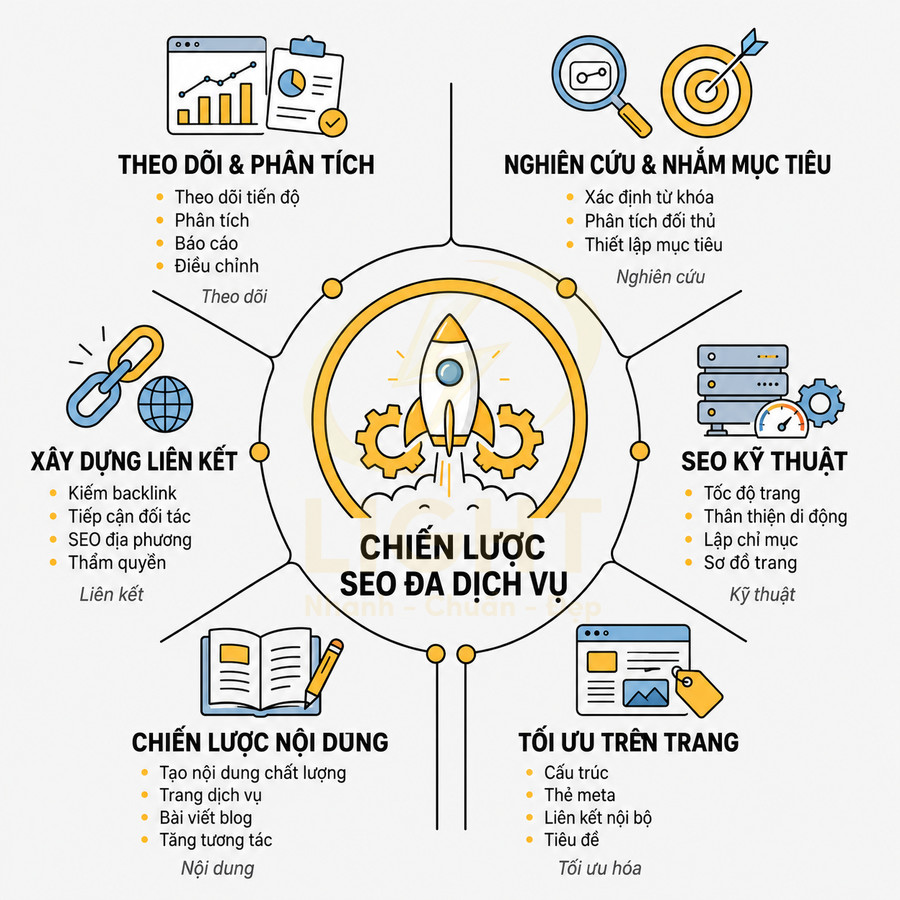

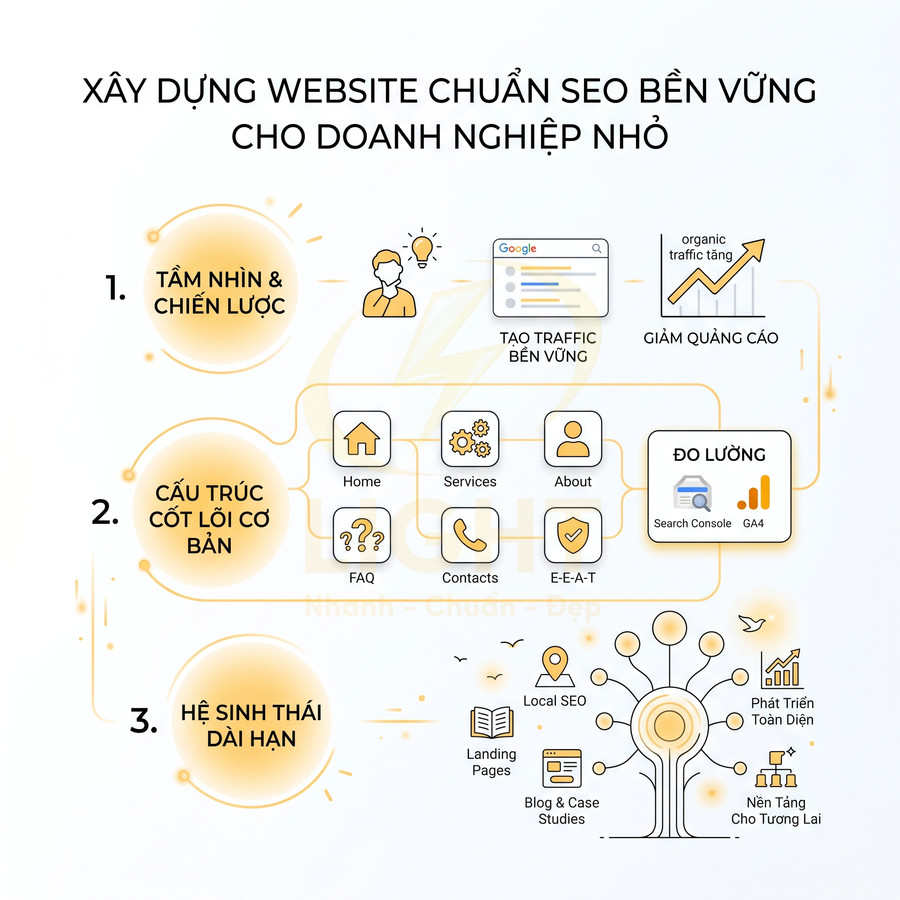
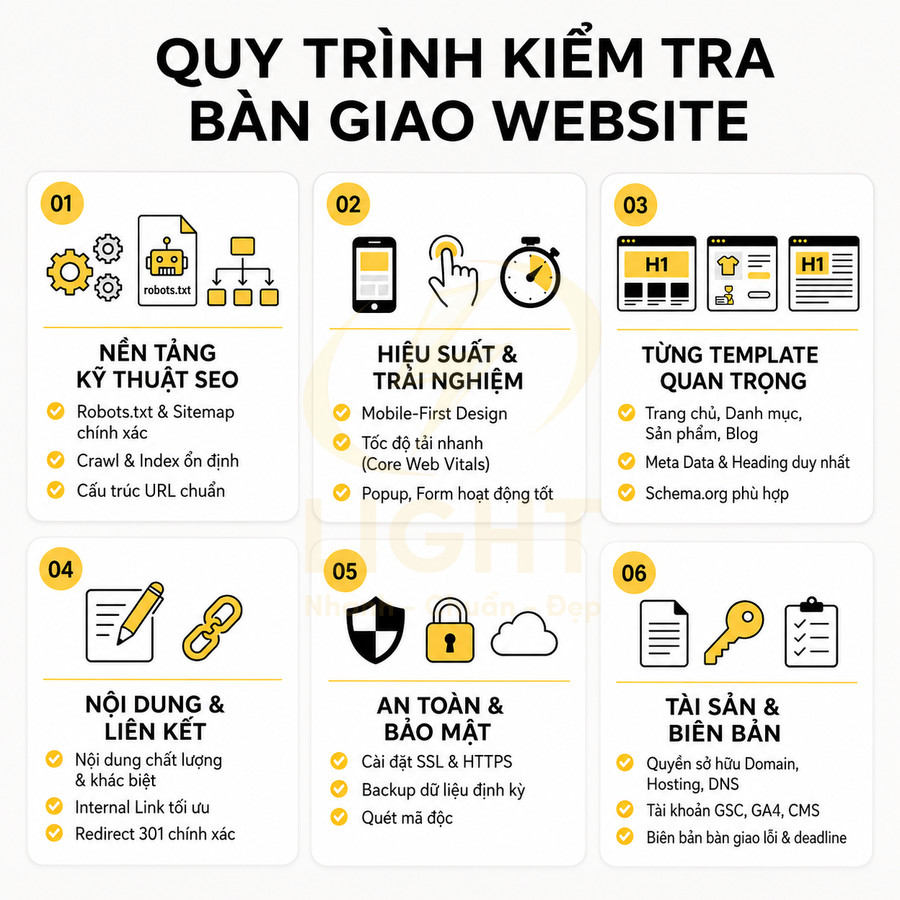
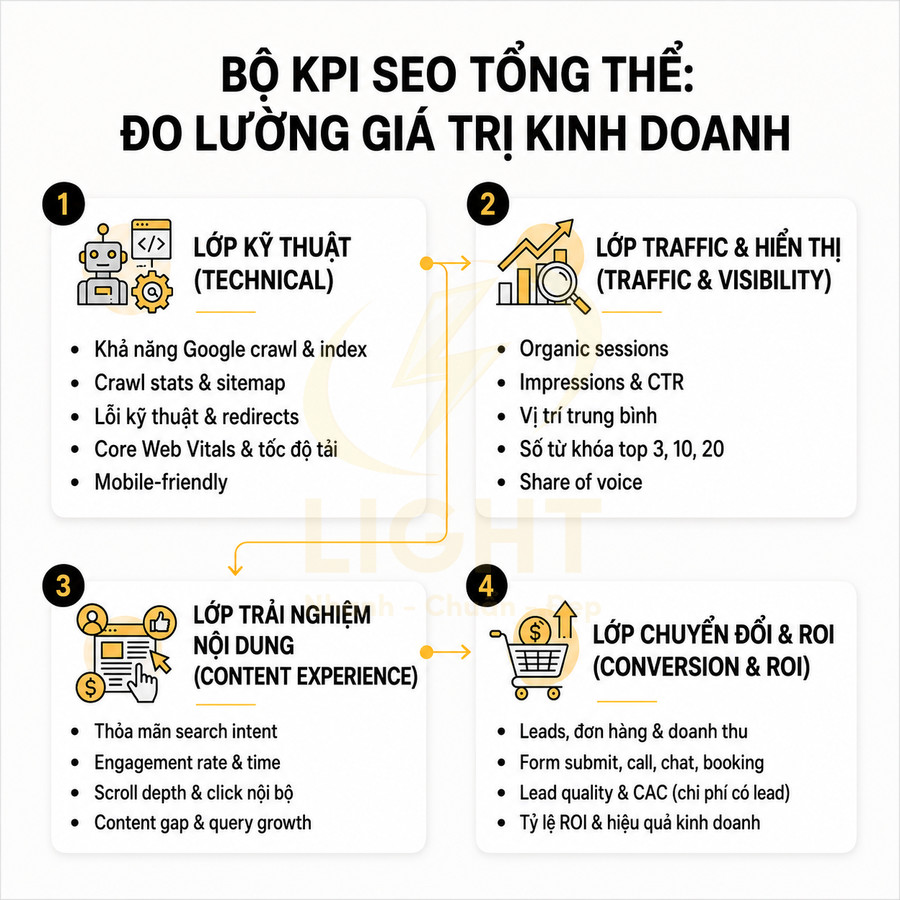



Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
