
Những lỗi kỹ thuật khiến website nhìn đẹp nhưng SEO mãi không lên
Một website có thể rất chỉn chu về giao diện nhưng vẫn không tạo được tăng trưởng tìm kiếm nếu lớp kỹ thuật bên dưới thiếu nền tảng semantic và khả năng hỗ trợ crawl. Vấn đề không nằm ở việc “đẹp hay xấu”, mà ở chỗ bot có hiểu đúng cấu trúc chủ đề, mức độ ưu tiên trang và hành trình nội dung hay không. Khi URL, breadcrumb, thư mục, internal link và landing page được tối giản theo hướng trình bày thay vì theo logic chủ đề, toàn bộ hệ thống dễ rơi vào trạng thái đẹp cho người dùng nhưng mơ hồ với công cụ tìm kiếm. Hệ quả là topical authority yếu, PageRank nội bộ phân tán, nhiều trang cạnh tranh cùng intent, còn các URL quan trọng lại nằm quá sâu nên khó được crawl và index hiệu quả.
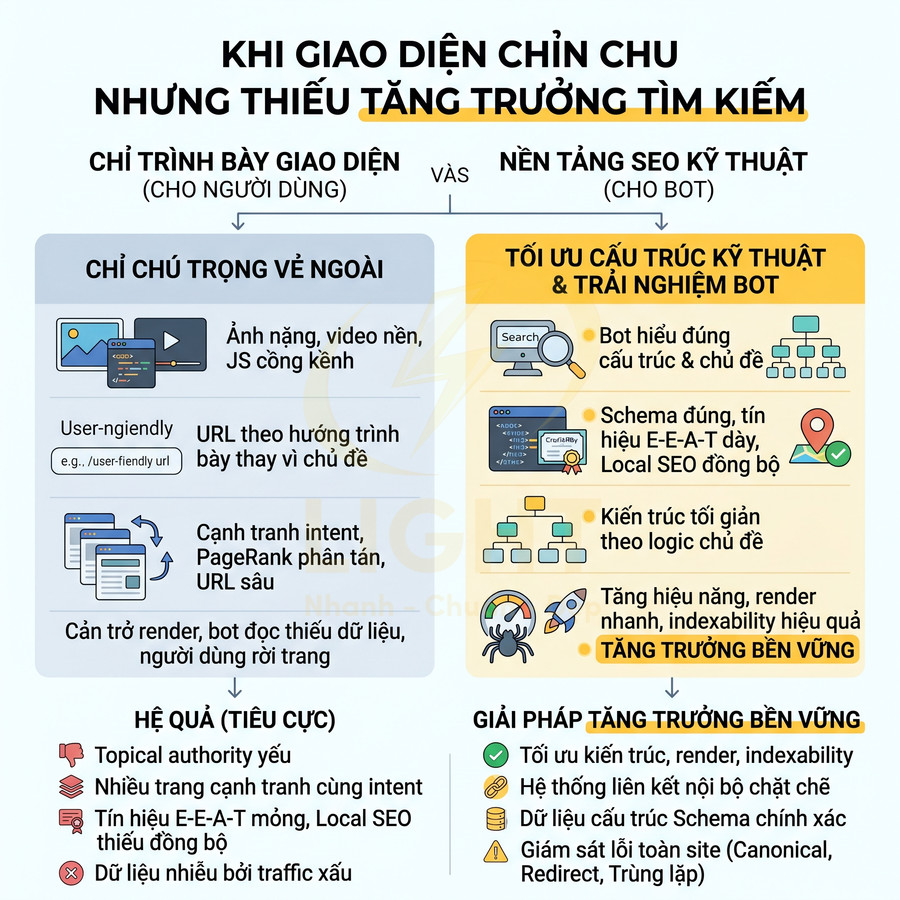
Song song đó, hiệu năng và khả năng render cũng là điểm nghẽn lớn. Ảnh nặng, video nền, JavaScript cồng kềnh, HTML rỗng hoặc nội dung chính chỉ xuất hiện sau tương tác đều khiến bot đọc thiếu dữ liệu, còn người dùng di động thì chờ lâu và rời trang sớm. Các lỗi về canonical, trùng lặp URL, slug đổi thiếu redirect, schema sai, tín hiệu E-E-A-T mỏng, local SEO thiếu đồng bộ hay dữ liệu bị nhiễu bởi traffic xấu tiếp tục làm suy giảm khả năng cạnh tranh. Muốn tăng trưởng bền vững, website cần được tối ưu từ lớp kiến trúc, render, indexability đến hệ thống liên kết, dữ liệu cấu trúc và giám sát lỗi toàn site. Giao diện đẹp chỉ là lớp hiển thị bên ngoài, còn khả năng tăng trưởng tìm kiếm phụ thuộc vào cấu trúc bên trong. Thiết kế website chuẩn SEO giúp URL, breadcrumb, heading, thư mục và internal link được tổ chức theo logic chủ đề, giúp bot hiểu đúng trang nào quan trọng và nội dung nào hỗ trợ.
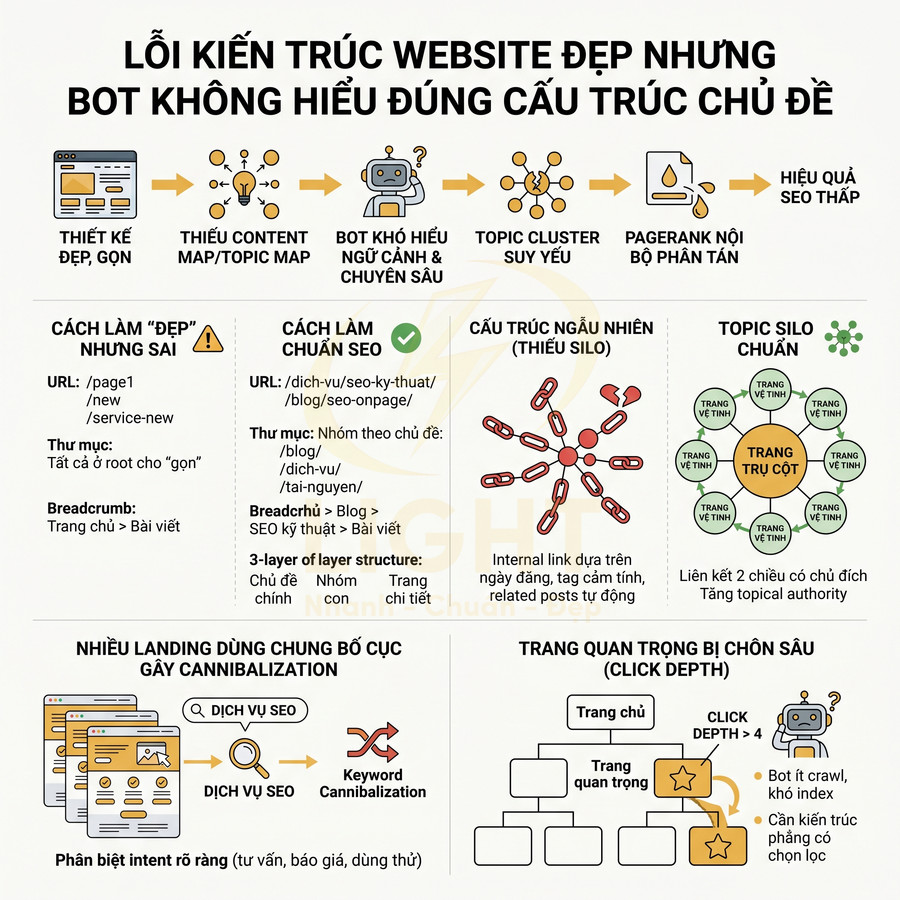
Lỗi kiến trúc website đẹp nhưng bot không hiểu đúng cấu trúc chủ đề
Kiến trúc website chỉ tập trung vào giao diện “đẹp, gọn” nhưng bỏ qua cấu trúc chủ đề khiến bot khó hiểu ngữ cảnh và mức độ chuyên sâu của nội dung. Khi không có content map, URL, thư mục và breadcrumb bị tối giản, bot không phân biệt được đâu là category, sub-category hay trang chi tiết, làm suy yếu topic cluster và knowledge graph. Bên dưới lớp UI hiện đại, thiếu logic silo và internal link có chiến lược khiến PageRank nội bộ phân tán, topic authority thấp. Các landing dùng chung bố cục, không tách bạch intent gây cannibalization. Trang quan trọng đặt quá sâu trong cấu trúc click depth khiến bot ít crawl, khó index và giảm hiệu quả SEO, dù trải nghiệm người dùng vẫn có vẻ ổn. Khi làm website, giao diện không nên là điểm xuất phát duy nhất. Doanh nghiệp cần xác định trước nhóm chủ đề, category, sub-category, trang dịch vụ và trang hỗ trợ để bot hiểu quan hệ giữa các nội dung. Cấu trúc này giúp website vừa dễ dùng, vừa rõ ngữ cảnh với công cụ tìm kiếm.
Phân cấp URL, thư mục và breadcrumb không phản ánh cụm nội dung thực tế
Khi bước vào giai đoạn thiết kế kiến trúc thông tin, nhiều đội ngũ product/UI chỉ tập trung vào trải nghiệm “gọn, ít tầng, ít chữ” trên giao diện mà không xây dựng trước một content map hoặc topic map cho toàn bộ website. Về mặt SEO kỹ thuật, đây là lỗi nền tảng vì bot không “nhìn” website như người dùng; bot suy luận chủ đề, mức độ chuyên sâu và mối quan hệ giữa các trang chủ yếu thông qua:
- Cấu trúc URL và thư mục (directory structure)
- Chuỗi breadcrumb và dữ liệu cấu trúc (BreadcrumbList schema)
- Cây internal link theo cụm chủ đề (topic cluster / content silo)
Khi URL bị đặt kiểu /page1, /new, /service-new, hoặc toàn bộ trang được đẩy lên root cho “gọn”, bot sẽ không có đủ tín hiệu để nhận diện:
- Đâu là category chính đại diện cho một chủ đề lớn
- Đâu là sub-category đào sâu một nhánh nội dung cụ thể
- Đâu là trang chi tiết giải quyết một truy vấn rất hẹp
Trong các thuật toán hiện đại như Hummingbird, RankBrain, hệ thống của Google cố gắng xây dựng một knowledge graph về chủ đề và thực thể (entities). Nếu kiến trúc URL và breadcrumb không phản ánh được logic chủ đề, website sẽ bị đánh giá là thiếu cấu trúc ngữ nghĩa, làm suy yếu khả năng xếp hạng cho các cụm từ khóa trung tâm.
Một kiến trúc tốt thường thể hiện rõ 3 lớp:
- Chủ đề chính (category): nhóm nội dung cấp cao, thường target các từ khóa head hoặc mid-tail
- Nhóm con (sub-category): chia nhỏ theo khía cạnh, use case, đối tượng, hoặc giai đoạn hành trình khách hàng
- Trang chi tiết (detail / article / landing): giải quyết một câu hỏi, một intent hoặc một sản phẩm/dịch vụ cụ thể
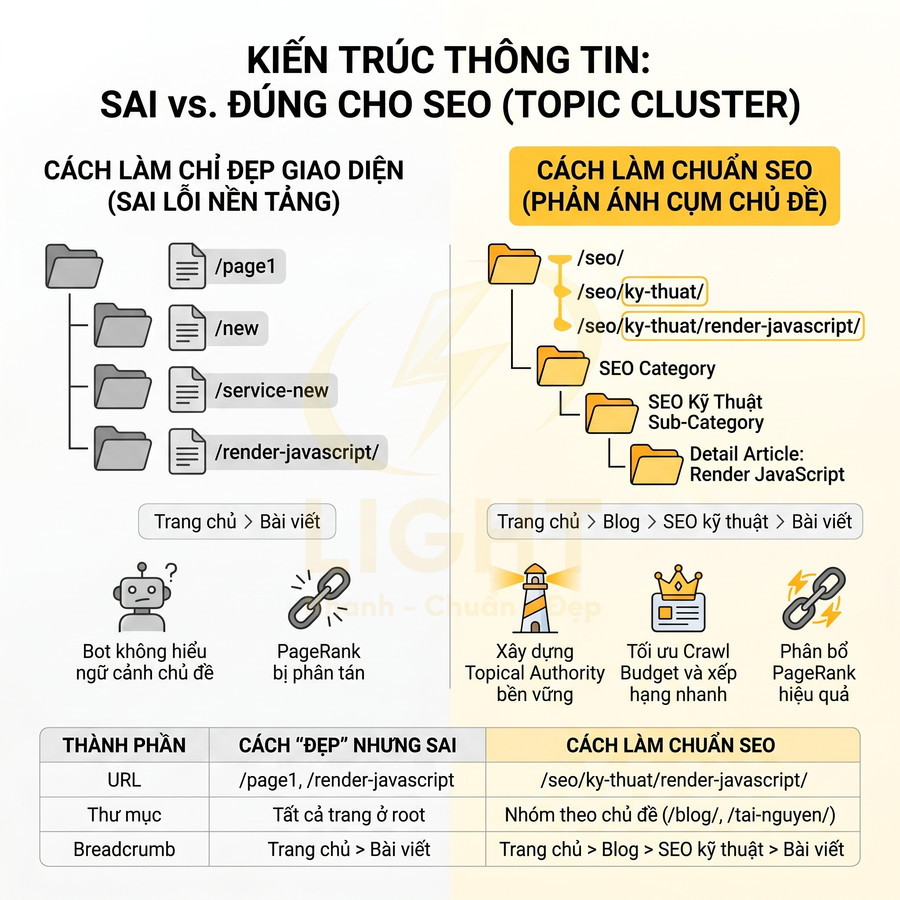
Ví dụ: /seo/ky-thuat/ – /seo/ky-thuat/render-javascript/ cho phép bot hiểu:
- “SEO” là chủ đề lớn
- “SEO kỹ thuật” là một nhánh con trong SEO
- “Render JavaScript” là một chủ đề chi tiết nằm trong SEO kỹ thuật
Nếu rút gọn thành /render-javascript/ chỉ để URL “ngắn cho đẹp”, bot sẽ mất đi ngữ cảnh phân cấp. Khi đó, trang có thể được hiểu như một bài viết rời rạc, không gắn với cụm SEO kỹ thuật, làm giảm sức mạnh của toàn bộ topic cluster về mảng này.
Breadcrumb cũng thường bị tối giản quá mức, ví dụ chỉ còn Trang chủ > Bài viết. Về mặt UX, người dùng vẫn có thể chấp nhận, nhưng với bot, breadcrumb là một trong những tín hiệu rõ ràng nhất để:
- Xác định vị trí của trang trong cây nội dung
- Hiểu mối quan hệ cha – con giữa các category và bài viết
- Tạo đường dẫn hiển thị trên SERP (rich result breadcrumb)
Khi breadcrumb thể hiện đầy đủ như Trang chủ > SEO > SEO kỹ thuật > Render JavaScript, Google có thể:
- Nhận diện “SEO kỹ thuật” là một node quan trọng trong cấu trúc
- Hiểu rằng nhiều bài viết con cùng trỏ về node này, từ đó đánh giá cao mức độ chuyên sâu
- Phân bổ PageRank nội bộ hiệu quả hơn theo chiều dọc (top-down) và chiều ngang (giữa các bài cùng cụm)
Sự thiếu nhất quán giữa URL, breadcrumb và cấu trúc menu (navigation) tạo ra một “kiến trúc kép”: giao diện nhìn rất hiện đại, nhưng lớp logic nội dung bên dưới lại rời rạc. Điều này khiến:
- Bot khó xác định trang trụ cột (pillar) để ưu tiên crawl và xếp hạng
- Các trang hỗ trợ (cluster) không truyền đủ tín hiệu liên quan về chủ đề cho pillar
- Topic authority bị phân tán, website khó chiếm top bền vững cho các cụm từ khóa cạnh tranh
| Thành phần | Cách làm “đẹp” nhưng sai | Cách làm chuẩn SEO |
|---|---|---|
| URL | /page1, /new, /service-new | /dich-vu/seo-ky-thuat/, /blog/seo-onpage/ |
| Thư mục | Tất cả trang ở root cho “gọn” | Nhóm theo chủ đề: /blog/, /dich-vu/, /tai-nguyen/ |
| Breadcrumb | Trang chủ > Bài viết | Trang chủ > Blog > SEO kỹ thuật > Bài viết |
Trang đẹp nhưng thiếu logic silo và liên kết nội bộ theo chủ đề
Ở tầng sâu hơn của kiến trúc, vấn đề không chỉ là URL hay breadcrumb mà là cách tổ chức internal link theo silo chủ đề. Nhiều website sử dụng UI rất hiện đại: card bài viết, grid, slider, module “bài nổi bật”, nhưng các liên kết nội bộ lại được sinh ra:
- Dựa trên ngày đăng (bài mới nhất)
- Dựa trên tag gắn cảm tính, không có chiến lược
- Dựa trên thuật toán “related posts” mặc định của CMS
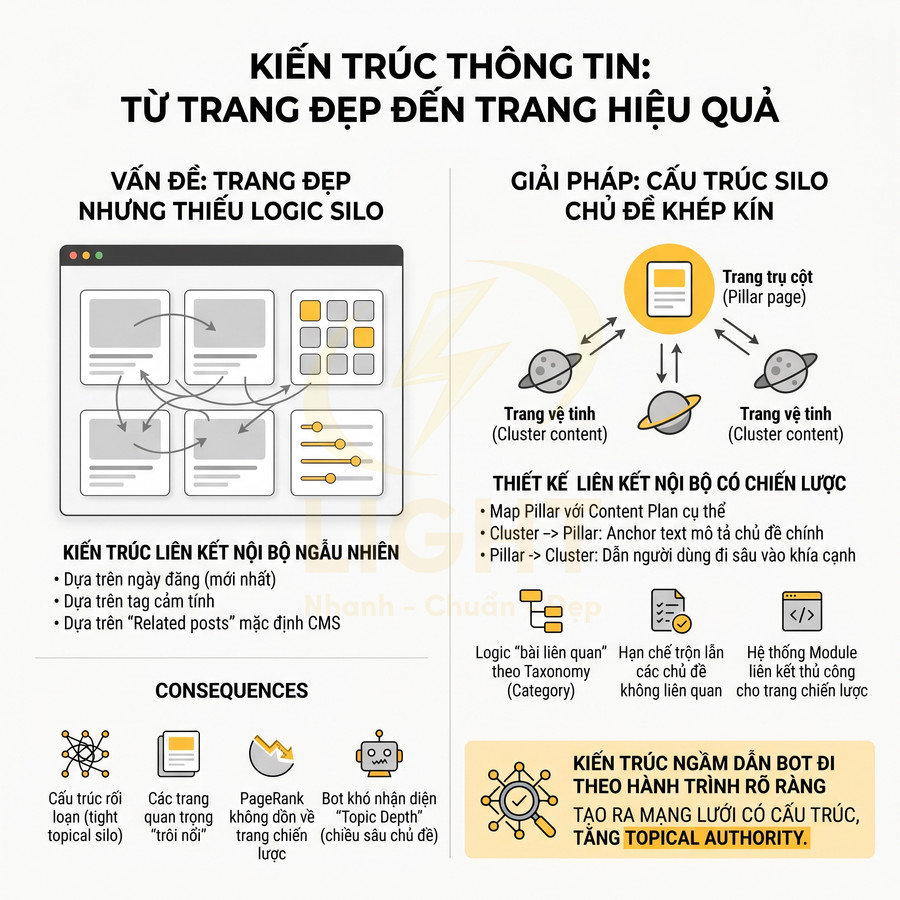
Về mặt SEO, cách làm này khiến cấu trúc liên kết trở nên ngẫu nhiên, không tạo được các “cụm chủ đề khép kín” (tight topical silo). Một silo chuẩn thường có:
- Trang trụ cột (pillar page): bao quát chủ đề, target từ khóa chính, có nội dung dài và sâu
- Trang vệ tinh (cluster content): mỗi trang xử lý một câu hỏi hẹp, một biến thể từ khóa, hoặc một ngách nhỏ trong chủ đề
- Liên kết 2 chiều có chủ đích:
- Cluster → Pillar: dùng anchor text mô tả rõ chủ đề chính
- Pillar → Cluster: dẫn người dùng và bot đi sâu vào từng khía cạnh
Khi không có silo, các trang quan trọng sẽ bị “trôi nổi” giữa hàng trăm bài viết đẹp mắt nhưng không có đường dẫn logic. Hệ quả:
- PageRank nội bộ không được dồn về các trang chiến lược
- Bot khó nhận ra đâu là trang đại diện tốt nhất cho một chủ đề
- Topic depth (chiều sâu chủ đề) bị đánh giá thấp, giảm khả năng xếp hạng cho các truy vấn khó
Thay vì để block “Bài viết liên quan” hoạt động tự động, cần thiết kế một hệ thống liên kết nội bộ có chiến lược:
- Mỗi pillar phải được map với một danh sách cluster cụ thể trong content plan
- Mỗi cluster khi xuất bản phải:
- Liên kết về pillar bằng anchor text chứa chủ đề chính hoặc biến thể ngữ nghĩa
- Liên kết chéo với các cluster khác trong cùng silo khi có liên quan
- Các block UI như “Khám phá thêm”, “Có thể bạn quan tâm” nên:
- Ưu tiên hiển thị nội dung trong cùng category/sub-category
- Hạn chế trộn lẫn bài từ nhiều chủ đề không liên quan chỉ vì “mới nhất”
Về mặt kỹ thuật, có thể triển khai:
- Logic chọn bài liên quan theo taxonomy (category, sub-category) thay vì theo ngày
- Rule ưu tiên bài có cùng “pillarid” hoặc “topicid” trong hệ thống CMS
- Module internal link thủ công cho các trang chiến lược, không phụ thuộc hoàn toàn vào auto-related
Như vậy, website vẫn giữ được giao diện hiện đại, nhưng lớp kiến trúc ngầm bên dưới sẽ dẫn bot đi theo một hành trình rõ ràng: từ chủ đề rộng → nhánh con → bài chi tiết, tạo ra một mạng lưới liên kết có cấu trúc, tăng mạnh topical authority.
Nhiều landing dùng chung bố cục gây trùng ý định tìm kiếm
Trong các hệ thống website dịch vụ, SaaS, khóa học, landing page thường được xây dựng bằng một template chung: hero, lợi ích, quy trình, bảng giá, testimonial, FAQ, form. Về mặt vận hành, đây là cách làm hợp lý để đảm bảo tính đồng bộ và dễ mở rộng. Tuy nhiên, nếu không tối ưu theo search intent của từng nhóm từ khóa, kiến trúc nội dung sẽ gặp vấn đề:
- Nhiều landing cùng target một cụm từ khóa gần giống nhau
- Nội dung trong các block chỉ thay đổi vài câu chữ, không thay đổi thông điệp cốt lõi
- Bot không phân biệt được trang nào phù hợp nhất với một truy vấn cụ thể

Hệ quả là keyword cannibalization: nhiều URL của cùng một website cạnh tranh cho cùng một nhóm từ khóa, làm phân tán tín hiệu xếp hạng. Thay vì một trang mạnh đứng top ổn định, bạn có nhiều trang “tranh nhau” vị trí, CTR và thứ hạng dao động.
Để xử lý ở mức kiến trúc, mỗi landing cần được định nghĩa như một “phiên bản chuyên sâu” cho một intent cụ thể, ví dụ:
- Intent tư vấn: nội dung tập trung giải thích, so sánh, giải đáp thắc mắc, CTA là “Đặt lịch tư vấn”
- Intent báo giá: nhấn mạnh cấu trúc giá, gói dịch vụ, điều kiện, CTA là “Nhận báo giá chi tiết”
- Intent dùng thử: tập trung vào trải nghiệm sản phẩm, demo, trial, CTA là “Đăng ký dùng thử”
- Intent đăng ký học: nhấn mạnh chương trình, lộ trình, chứng chỉ, CTA là “Đăng ký khóa học”
Bố cục có thể giống nhau, nhưng các thành phần sau phải được tùy biến sâu theo intent và từ khóa:
- H1, H2: phản ánh rõ intent (ví dụ: “Báo giá dịch vụ SEO kỹ thuật” khác với “Tư vấn chiến lược SEO kỹ thuật”)
- FAQ: giải đáp đúng nhóm câu hỏi của giai đoạn nhận thức tương ứng (awareness, consideration, decision)
- Bảng giá: chi tiết, cấu trúc, mức độ minh bạch khác nhau tùy intent
- Case study / testimonial: chọn ví dụ phù hợp với đối tượng mục tiêu của từng landing
Về mặt kiến trúc, cần:
- Mapping mỗi landing với một nhóm từ khóa và một intent rõ ràng trong keyword map
- Tránh tạo nhiều landing chỉ khác nhau 1–2 từ trong tiêu đề nhưng cùng intent
- Sử dụng internal link để định vị:
- Trang nào là “trang chính” cho một chủ đề/intent
- Trang nào là biến thể phục vụ phân khúc hoặc chiến dịch cụ thể
Trang quan trọng bị đặt quá sâu khiến bot khó thu thập
Một khía cạnh khác của kiến trúc là độ sâu click (click depth) – số lần nhấp cần thiết từ trang chủ để tới một URL. Về mặt UX, việc ẩn bớt các trang vào nhiều tầng menu, filter, hoặc chỉ để người dùng tìm qua search nội bộ có thể làm giao diện trông “sạch” hơn. Tuy nhiên, với bot, click depth là tín hiệu quan trọng để:
- Ưu tiên crawl các trang gần trang chủ hơn
- Phân bổ crawl budget cho website lớn
- Đánh giá mức độ quan trọng tương đối giữa các URL

Khi các trang mang lại doanh thu hoặc chuyển đổi cao nằm ở tầng 4–5 click, các vấn đề sau thường xảy ra:
- Bot ít crawl lại, dẫn đến chậm cập nhật thay đổi nội dung hoặc giá
- Khó đạt được PageRank nội bộ đủ mạnh vì ít nhận được liên kết từ các trang top-level
- Khả năng được index đầy đủ giảm, đặc biệt với website có hàng chục nghìn URL
Giải pháp là thiết kế kiến trúc phẳng có chọn lọc:
- Xác định danh sách trang chiến lược:
- Dịch vụ chính, danh mục sản phẩm chủ lực
- Landing chuyển đổi cao, trang campaign quan trọng
- Đưa các trang này lên gần trang chủ thông qua:
- Menu hoặc mega menu có cấu trúc rõ ràng
- Block nổi bật (featured section) trên trang chủ và category
- Internal link từ các trang có nhiều traffic tự nhiên
- Giữ cho đường dẫn tới các trang này:
- Không quá nhiều tầng thư mục không cần thiết
- Có anchor text mô tả rõ ràng, nhất quán
Về mặt kỹ thuật SEO, có thể theo dõi:
- Biểu đồ click depth trong các công cụ crawl (Screaming Frog, Sitebulb, …)
- Tần suất crawl và thời gian cập nhật trong log server hoặc Google Search Console
- Phân bố internal link tới các URL quan trọng để đảm bảo chúng không bị “mồ côi” hoặc quá cô lập
Một website vẫn có thể giữ phong cách tối giản, ít mục trên menu chính, nhưng cần bổ sung các lớp điều hướng phụ (secondary navigation, footer navigation, block nội dung nổi bật) để đảm bảo các trang quan trọng luôn nằm trong vùng click depth hợp lý và được bot ưu tiên thu thập.
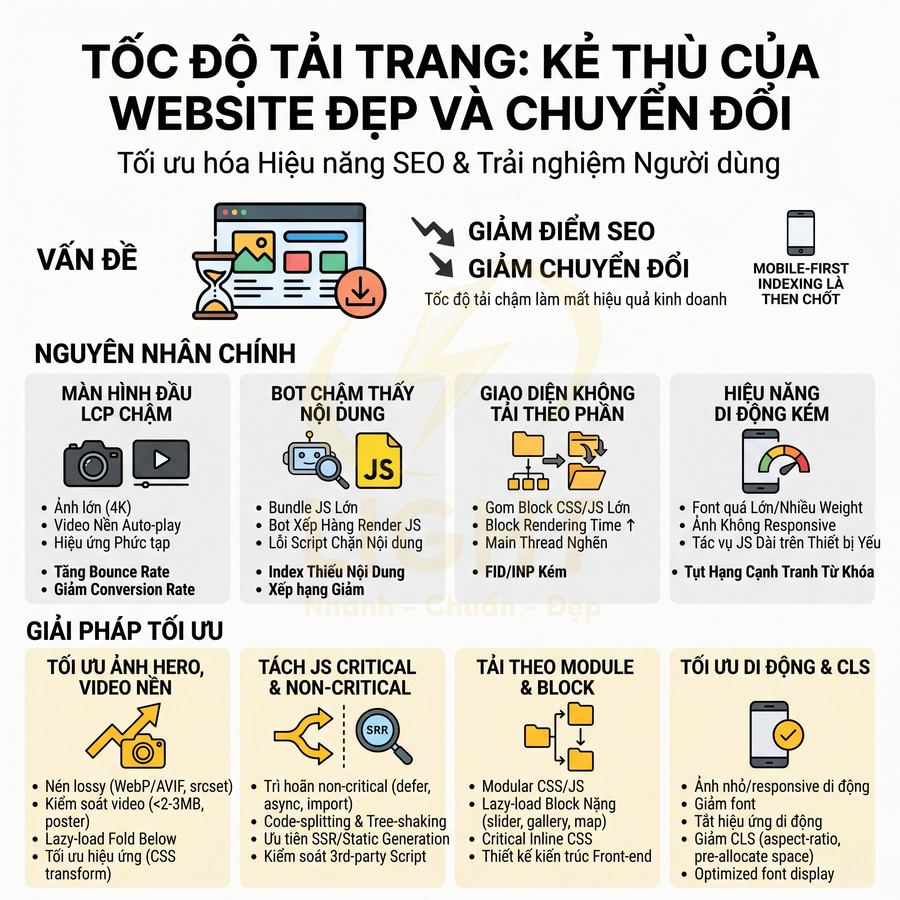
Lỗi tốc độ tải làm website đẹp nhưng mất điểm SEO và chuyển đổi
Website có giao diện bắt mắt nhưng tải chậm sẽ làm giảm mạnh hiệu quả SEO và chuyển đổi, đặc biệt khi các yếu tố nặng như ảnh 4K, video nền, hiệu ứng động và bundle JavaScript lớn chiếm phần tử LCP và chặn tương tác. Trình duyệt và bot phải xử lý nhiều bước tốn tài nguyên: thiết lập kết nối, tải media/JS dung lượng lớn, parse – decode – render, dẫn đến LCP, INP, TTI kém, nhất là trên di động. Để giữ trải nghiệm tốt, cần kết hợp tối ưu ảnh, video, hiệu ứng, kiến trúc JS, CSS theo module, lazy-load block nặng và ưu tiên SSR/static cho trang quan trọng. Mobile-first indexing khiến hiệu năng trên di động, đặc biệt Core Web Vitals, trở thành yếu tố then chốt quyết định khả năng cạnh tranh từ khóa.
Ảnh lớn, video nền và hiệu ứng động kéo chậm màn hình đầu
Trong thực tế triển khai, các layout hero full-screen với ảnh 4K, video nền auto-play, overlay gradient nhiều lớp và hiệu ứng parallax thường là “thủ phạm” chính kéo dài Largest Contentful Paint (LCP). Khi phần tử LCP là một ảnh hoặc video nặng, trình duyệt phải:
- Thiết lập kết nối mạng (DNS, TCP, TLS) đến CDN hoặc server gốc
- Tải file media dung lượng lớn (thường vài trăm KB đến vài MB)
- Giải mã, decode ảnh/video và render lên màn hình

Quá trình này đặc biệt chậm trên di động với CPU yếu và băng thông 3G/4G không ổn định, khiến LCP dễ vượt ngưỡng 2.5s, thậm chí lên 4–6s. Khi người dùng phải chờ hero load quá lâu, họ có xu hướng:
- Thoát trang trước khi nội dung chính xuất hiện (tăng bounce rate)
- Không tương tác với CTA ở màn hình đầu (giảm conversion rate)
- Gửi tín hiệu hành vi xấu đến Google (dwell time thấp, pogo-sticking)
Để cân bằng giữa thẩm mỹ và hiệu năng, cần áp dụng một chuỗi kỹ thuật tối ưu chuyên sâu:
- Tối ưu ảnh hero
- Sử dụng định dạng hiện đại như WebP hoặc AVIF với cơ chế fallback cho trình duyệt cũ
- Dùng
srcsetvàsizesđể trình duyệt tự chọn kích thước ảnh phù hợp từng độ phân giải, tránh tải ảnh 4K cho màn hình mobile nhỏ - Giảm kích thước hiển thị thực tế: không dùng ảnh 4000px cho khung hiển thị 1200px
- Nén ảnh bằng các công cụ chuyên dụng (ImageOptim, Squoosh, imagemin) với mức nén “lossy” có kiểm soát
- Kiểm soát video nền
- Giới hạn dung lượng video nền (thường < 2–3MB cho toàn bộ hero)
- Ưu tiên video ngắn, loop, không âm thanh, encode ở bitrate thấp cho mobile
- Sử dụng poster tĩnh làm ảnh đại diện, chỉ tải video khi người dùng tương tác (nút play) thay vì auto-play
- Trên mobile, có thể tắt hoàn toàn video nền và thay bằng ảnh tĩnh tối ưu
- Lazy-load thông minh
- Áp dụng lazy-load cho toàn bộ ảnh và video dưới màn hình đầu (below the fold) bằng
loading="lazy"hoặc Intersection Observer - Không lazy-load phần tử LCP chính ở hero, nhưng đảm bảo file được preload bằng
<link rel="preload">khi cần
- Áp dụng lazy-load cho toàn bộ ảnh và video dưới màn hình đầu (below the fold) bằng
- Tối ưu hiệu ứng động
- Ưu tiên hiệu ứng bằng CSS transform, opacity vì được GPU tăng tốc, tránh animate các thuộc tính layout như
width,height,top,left - Hạn chế sử dụng thư viện parallax nặng, nhiều listener scroll, gây jank và tăng thời gian render
- Chỉ bật hiệu ứng phức tạp trên desktop; trên mobile có thể giảm hoặc tắt hoàn toàn để bảo toàn hiệu năng
- Ưu tiên hiệu ứng bằng CSS transform, opacity vì được GPU tăng tốc, tránh animate các thuộc tính layout như
Một hero vẫn có thể rất ấn tượng nếu được thiết kế thông minh: chọn ảnh có độ tương phản tốt, bố cục rõ ràng, CTA nổi bật, nhưng phải đảm bảo LCP < 2.5s trên phần lớn thiết bị mục tiêu. Điều này đòi hỏi kết hợp giữa thiết kế UI/UX, tối ưu front-end và cấu hình hạ tầng (CDN, cache, HTTP/2, HTTP/3).
Mã JavaScript nặng làm bot chậm thấy nội dung chính
Khi website phụ thuộc nhiều vào framework JS (React, Vue, Angular, Next, Nuxt…), trình duyệt và bot phải:
- Tải bundle JS lớn (thường vài trăm KB đến vài MB)
- Parse, compile và execute JavaScript
- Render virtual DOM hoặc hydrate HTML đã có
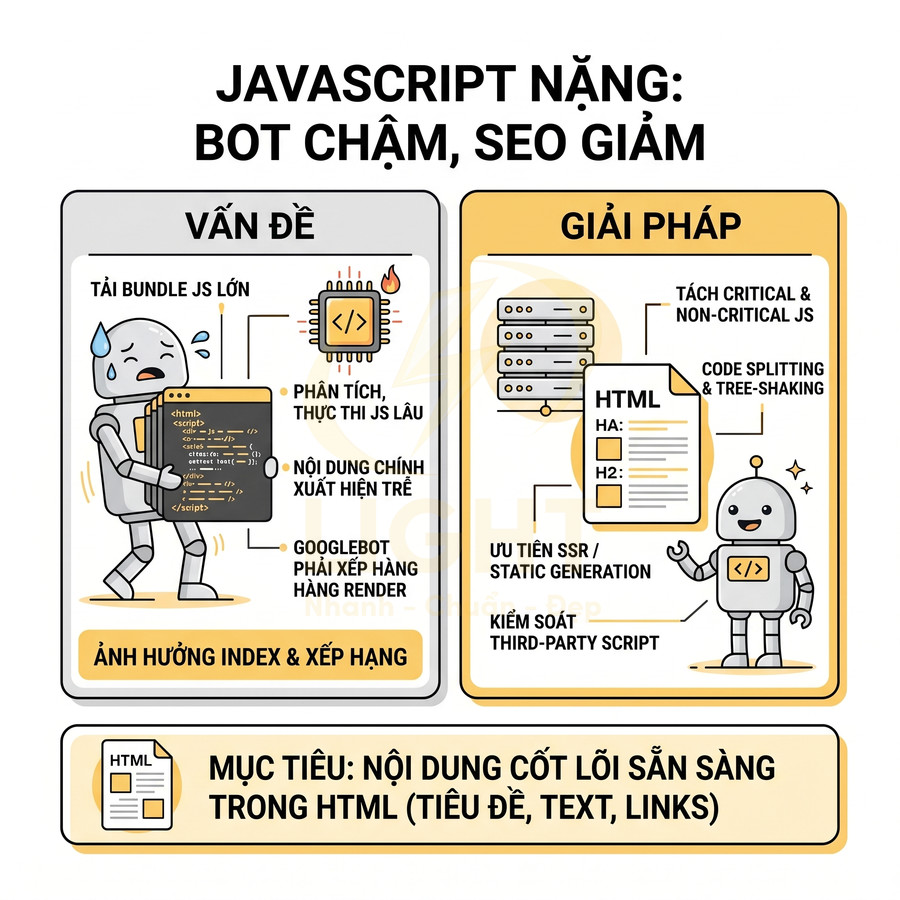
Đối với người dùng, quá trình này làm tăng Time to Interactive (TTI) và Interaction to Next Paint (INP). Đối với bot, nếu không có server-side rendering (SSR) hoặc pre-render, nội dung quan trọng có thể:
- Xuất hiện trễ, khiến Googlebot phải xếp hàng trong hàng đợi render JavaScript
- Không được render đầy đủ nếu script lỗi, bị chặn, hoặc vượt quá quota render
- Bị index thiếu nội dung, ảnh hưởng trực tiếp đến khả năng xếp hạng từ khóa
Về mặt kỹ thuật, cần thiết kế kiến trúc JavaScript theo hướng progressive enhancement và tối ưu cho SEO:
- Tách critical JS và non-critical JS
- Critical JS: cần thiết để hiển thị nội dung chính (layout cơ bản, logic render sản phẩm/dịch vụ, navigation tối thiểu)
- Non-critical JS: tracking, chat widget, animation, A/B testing, slider nâng cao
- Trì hoãn tải non-critical JS bằng
defer,async, hoặc dynamic import sau khi DOMContentLoaded hoặc sau tương tác đầu tiên
- Code splitting và tree-shaking
- Sử dụng bundler (Webpack, Rollup, Vite) để code splitting theo route hoặc theo component, tránh một bundle khổng lồ cho toàn site
- Áp dụng tree-shaking để loại bỏ code không dùng, đặc biệt với thư viện UI và utility lớn
- Tránh import toàn bộ thư viện khi chỉ dùng một vài hàm (ví dụ: import từng module thay vì import
*)
- Ưu tiên SSR hoặc static generation
- Với các trang SEO quan trọng (landing page, category, bài viết), nên dùng SSR hoặc static generation để HTML ban đầu đã chứa nội dung đầy đủ
- Đảm bảo HTML trả về có heading, đoạn văn chính, danh sách sản phẩm/dịch vụ mà không phụ thuộc hoàn toàn vào JS
- Hydration nên diễn ra sau khi nội dung tĩnh đã hiển thị, tránh block rendering
- Kiểm soát third-party script
- Đánh giá tác động của các script bên thứ ba (analytics, pixel, chat, heatmap) đến TTFB, LCP, INP
- Chỉ giữ lại những script thực sự mang lại giá trị kinh doanh, còn lại nên loại bỏ hoặc tải trễ
Đối với bot, mục tiêu là khi tải HTML lần đầu, khung nội dung cốt lõi đã có sẵn: tiêu đề, nội dung text, internal link quan trọng. JavaScript chỉ nên đóng vai trò tăng cường trải nghiệm, không phải điều kiện bắt buộc để “nhìn thấy” nội dung.
Khối giao diện đẹp nhưng không tải theo từng phần nhỏ
Khi thiết kế UI phức tạp, nhiều block (hero, feature, testimonial, blog, gallery, form, footer) thường được gom vào một file CSS/JS lớn để “dễ quản lý”. Cách làm này khiến:
- Mỗi lần tải trang, trình duyệt phải tải toàn bộ CSS/JS, dù người dùng chỉ xem một phần nhỏ
- Tăng thời gian block rendering do CSS lớn phải được parse trước khi vẽ giao diện
- Tăng First Input Delay (FID) và Interaction to Next Paint (INP) vì main thread bận xử lý JS nặng
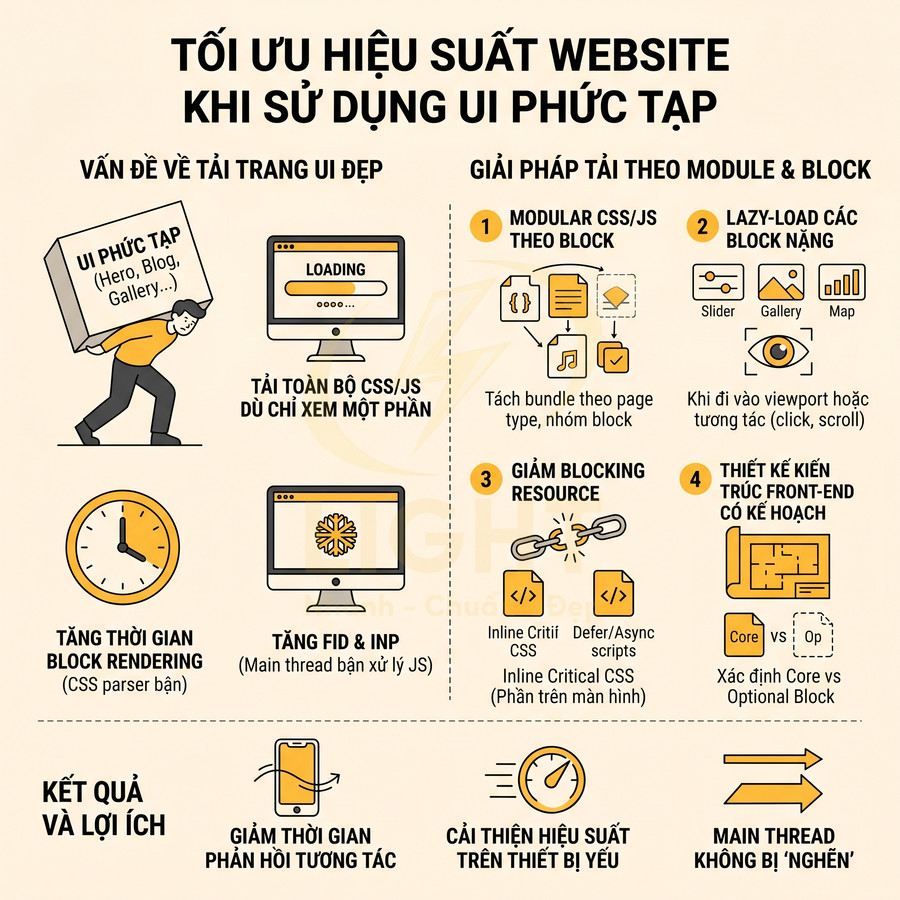
Để giải quyết, cần chuyển sang mô hình tải theo module và tối ưu theo block:
- Modular CSS/JS theo block hoặc template
- Tách CSS thành các bundle nhỏ theo page type (home, category, product, blog) hoặc theo nhóm block
- Sử dụng kỹ thuật như CSS Modules, BEM, hoặc utility-first (Tailwind) để giảm trùng lặp và dễ tree-shaking
- Chỉ load CSS/JS cần thiết cho block xuất hiện trên trang hiện tại
- Lazy-load các block nặng
- Các thư viện UI nặng như slider, gallery, map, chart nên được lazy-load khi:
- Block đi vào viewport (Intersection Observer)
- Người dùng tương tác (click tab, mở popup, scroll đến section)
- Đối với map (Google Maps, Leaflet), chỉ khởi tạo khi người dùng thực sự cần xem vị trí, không auto-load ở footer
- Các thư viện UI nặng như slider, gallery, map, chart nên được lazy-load khi:
- Giảm blocking resource
- Đặt CSS critical inline cho phần trên màn hình đầu, phần còn lại load async hoặc deferred
- Đánh dấu script không quan trọng bằng
deferhoặc tải sau khi trang đã tương tác được
- Thiết kế kiến trúc front-end có kế hoạch
- Ngay từ giai đoạn thiết kế, cần xác định block nào là core, block nào là optional để lên chiến lược bundle
- Thiết lập guideline cho team dev: không import thư viện nặng vào global bundle nếu chỉ dùng ở một vài trang
Cách tiếp cận này giúp giảm đáng kể thời gian phản hồi khi người dùng bắt đầu tương tác, đặc biệt trên thiết bị cấu hình thấp, nơi main thread dễ bị “nghẽn” bởi JS và CSS lớn.
Điểm hiệu năng thấp trên di động làm giảm khả năng cạnh tranh từ khóa
Với mobile-first indexing, Google sử dụng phiên bản di động làm cơ sở chính để đánh giá và xếp hạng. Điều này có nghĩa là:
- Một website chạy mượt trên desktop nhưng tối ưu kém trên mobile vẫn có thể bị tụt hạng
- Các chỉ số Core Web Vitals trên di động (LCP, CLS, INP) có trọng số rất lớn trong đánh giá trải nghiệm
- Trong ngành cạnh tranh cao, chỉ cần chênh lệch nhỏ về hiệu năng mobile cũng đủ tạo khác biệt về thứ hạng

Các vấn đề thường gặp trên mobile:
- Font quá lớn, nhiều biến thể (weight, style) làm tăng số request và dung lượng
- Ảnh không responsive, luôn tải kích thước lớn dù màn hình nhỏ
- Script không tối ưu, chạy nhiều logic không cần thiết trên thiết bị yếu
- Layout shift nhiều do:
- Không cố định kích thước ảnh, banner, quảng cáo
- Font web load chậm gây nhảy chữ (FOIT/FOUT)
- Element chèn thêm sau khi trang đã render
Để kiểm soát và cải thiện, cần quy trình đo lường và tối ưu liên tục:
- Đo lường bằng công cụ chính thống
- Sử dụng PageSpeed Insights để xem cả dữ liệu lab (Lighthouse) và dữ liệu thực tế (field data) từ Chrome UX Report
- Kiểm tra theo từng template quan trọng: trang chủ, category, product, landing page, blog, form đăng ký
- Theo dõi riêng các chỉ số LCP, CLS, INP cho từng loại thiết bị (mobile, tablet, desktop) và từng điều kiện mạng
- Tối ưu tài nguyên riêng cho di động
- Dùng ảnh kích thước nhỏ hơn cho mobile, có thể ẩn bớt background decoration không cần thiết
- Giảm số lượng font, ưu tiên hệ font system hoặc một font web chính, hạn chế nhiều weight
- Ẩn hoặc đơn giản hóa hiệu ứng động, parallax, video nền trên mobile
- Giảm số lượng request bằng cách gộp hợp lý, sử dụng HTTP/2/HTTP/3 và CDN
- Giảm layout shift (CLS)
- Đặt thuộc tính
width,heighthoặcaspect-ratiocho ảnh, video, iframe để trình duyệt dự trù không gian - Tránh chèn nội dung mới phía trên nội dung đã hiển thị, đặc biệt là banner, popup, bar khuyến mãi
- Tối ưu font loading: dùng
font-display: swaphoặcoptionalđể tránh nhảy chữ quá nhiều
- Đặt thuộc tính
- Tối ưu tương tác (INP)
- Giảm logic JS chạy trên mỗi sự kiện scroll, resize, input; sử dụng throttling/debouncing
- Tránh block main thread bằng tác vụ dài; nếu cần, chia nhỏ hoặc chuyển sang Web Worker
- Đảm bảo các tương tác quan trọng (mở menu, click CTA, thêm vào giỏ hàng) phản hồi gần như tức thì
Thiết kế responsive không chỉ là co giãn layout theo breakpoint, mà là tư duy lại toàn bộ chiến lược tài nguyên cho mobile: ưu tiên nội dung chính, loại bỏ yếu tố thừa, tối ưu kích thước và số lượng file, đồng thời đảm bảo trải nghiệm tương tác mượt mà trên điều kiện thiết bị và mạng kém hơn nhiều so với desktop.
Lỗi render nội dung khiến bot không đọc được phần quan trọng
Kiến trúc front-end phụ thuộc quá nhiều vào JavaScript khiến HTML ban đầu trở nên “rỗng”, làm bot không đọc được nội dung cốt lõi. Khi nội dung chính, heading, FAQ, bảng giá hay thông tin sản phẩm chỉ xuất hiện sau tương tác hoặc sau khi JS chạy, bot sẽ thiếu dữ liệu để hiểu chủ đề, đánh giá mức độ liên quan và xếp hạng. Điều này dẫn đến trang bị coi là “mỏng nội dung”, snippet kém, rich result không hiển thị và nhiều công cụ crawler gần như “mù” với phần quan trọng. Để tối ưu SEO, cần render sẵn phía server (SSR/SSG), đảm bảo HTML gốc luôn chứa phiên bản đọc được của nội dung chính, còn JS chỉ dùng để tăng trải nghiệm, ẩn/hiện bằng CSS và xử lý tương tác nâng cao.
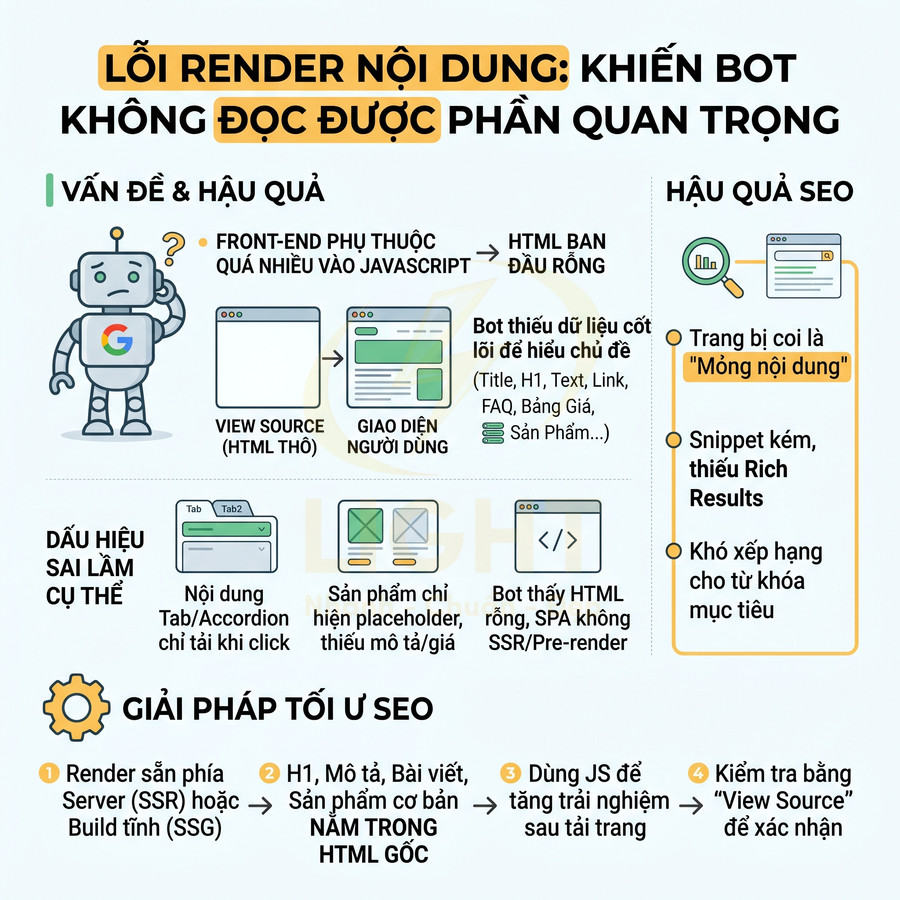
Nội dung chính phụ thuộc mã chạy sau khi tải trang
Khi kiến trúc front-end dựa quá nhiều vào JavaScript để gọi API và render nội dung sau khi tải trang, phần HTML ban đầu (initial HTML) trở nên cực kỳ “nghèo nàn”. Về mặt kỹ thuật, Googlebot có hai giai đoạn: thu thập HTML thô và xếp hàng để render JavaScript. Nếu nội dung chính – như bài viết, mô tả dịch vụ, danh sách sản phẩm, category content – chỉ xuất hiện sau khi JS hoàn tất, thì:
- Ở giai đoạn đầu, bot chỉ thấy một bộ khung HTML gần như trống, thiếu text, thiếu heading, thiếu internal link.
- Giai đoạn render JS có thể bị trì hoãn, bị giới hạn tài nguyên, hoặc thậm chí không diễn ra với một số bot và công cụ khác ngoài Google.
- Trong nhiều trường hợp, phiên bản được index là phiên bản HTML trước khi JS chạy, khiến bot “mù” với phần nội dung mà người dùng thực sự đang đọc.
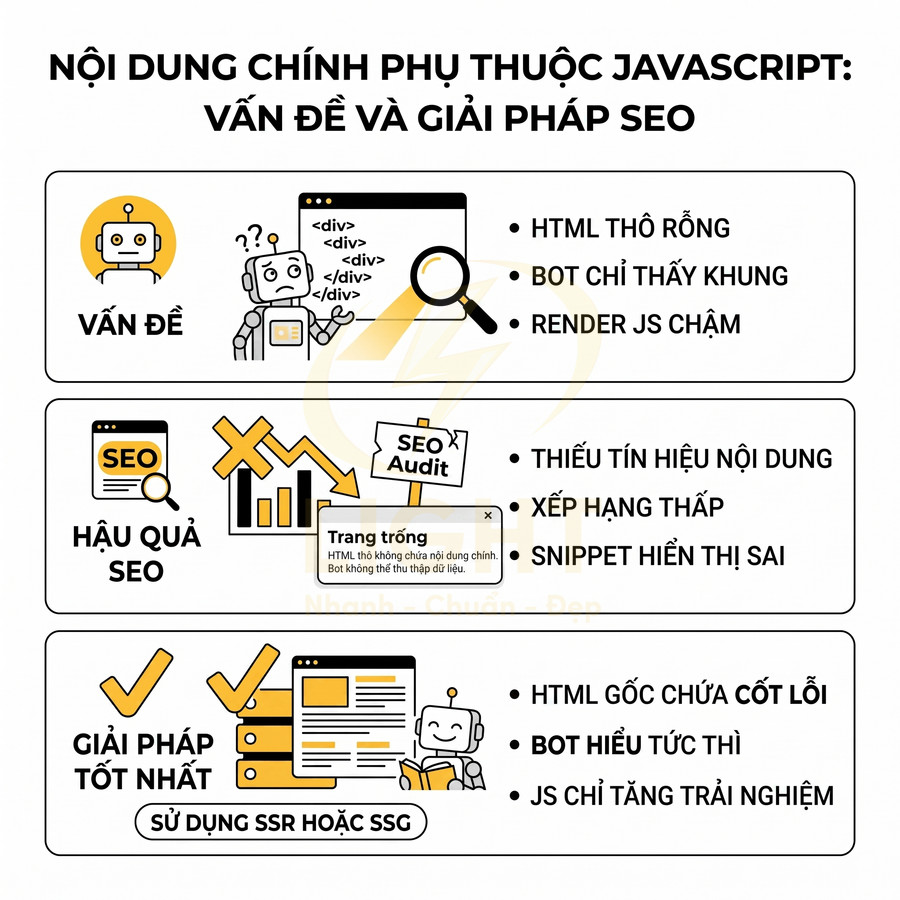
Hệ quả là:
- Trang không có đủ tín hiệu nội dung để xếp hạng cho từ khóa mục tiêu.
- Snippet trên SERP có thể bị thiếu hoặc hiển thị nội dung không liên quan.
- Các công cụ SEO (crawler, audit tool) báo cáo trang “mỏng nội dung” dù giao diện người dùng rất đầy đủ.
Để đảm bảo an toàn SEO, nội dung quan trọng nên được render sẵn phía server (Server-Side Rendering – SSR) hoặc build tĩnh (Static Site Generation – SSG). Cách tiếp cận hợp lý là:
- Render sẵn phần khung nội dung chính: title, H1, các H2/H3 quan trọng, đoạn mô tả, danh sách sản phẩm cơ bản, nội dung bài viết.
- Sau đó dùng JS để tăng trải nghiệm: lọc, sắp xếp, phân trang động, lazy load phần nội dung phụ, infinite scroll, đề xuất thêm.
- Giữ cho HTML gốc luôn chứa phiên bản “đọc được” của nội dung cốt lõi, ngay cả khi JS bị tắt hoặc không thực thi.
Các phần phụ như gợi ý, widget, chat, đề xuất cá nhân hóa, module A/B testing có thể phụ thuộc JS nhiều hơn, nhưng khung nội dung chính phải tồn tại trong HTML gốc. Nguyên tắc cốt lõi là: bot phải có khả năng hiểu được chủ đề và giá trị của trang chỉ bằng HTML ban đầu, không cần chờ JS.
Heading, FAQ và bảng giá bị ẩn trong tab không render sẵn
Thiết kế UI hiện đại thường gom nhiều nội dung vào các tab, accordion, slider, modal để giao diện gọn gàng và giảm độ dài trang. Vấn đề phát sinh khi các tab này chỉ render nội dung sau khi người dùng nhấp hoặc tương tác. Khi đó:
- Các section chứa H2/H3, FAQ, bảng giá, thông số kỹ thuật, policy có thể hoàn toàn vắng mặt trong initial HTML.
- Bot không kích hoạt sự kiện click như người dùng, nên không “mở” tab để tải nội dung.
- Phần lớn nội dung giàu từ khóa và thông tin hỗ trợ chuyển đổi bị “ẩn” khỏi tầm nhìn của bot.
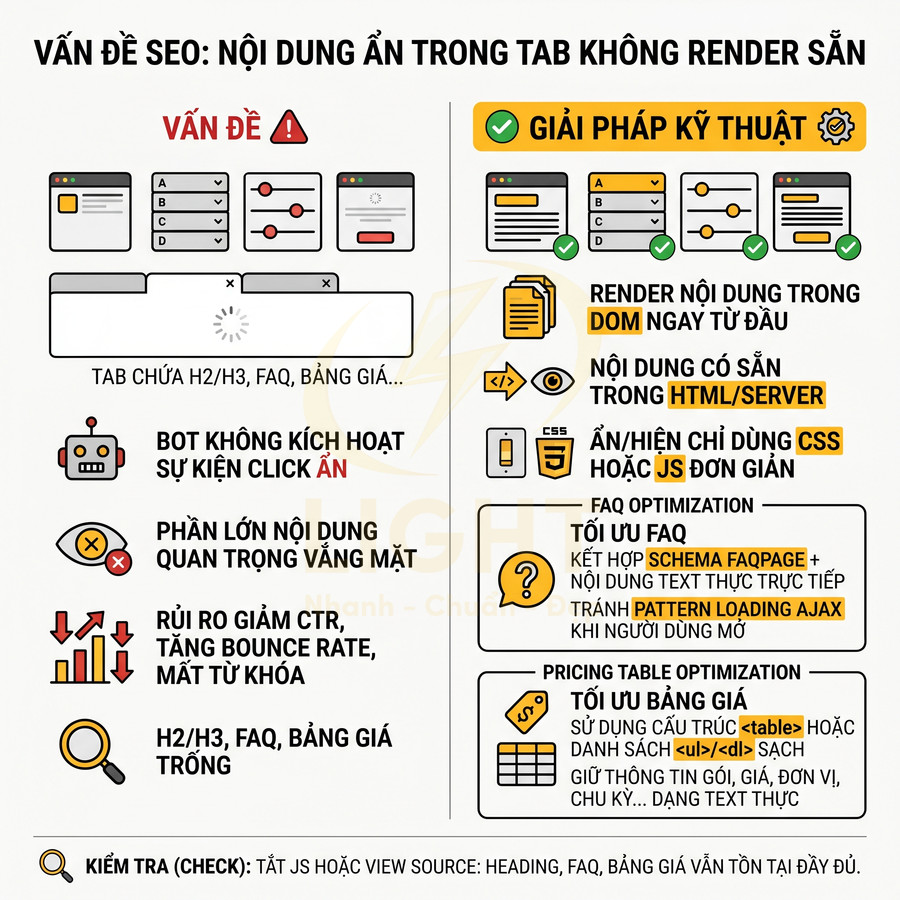
Đây là rủi ro lớn vì những khối nội dung này thường là nơi:
- Chứa cụm từ khóa dài (long-tail) và câu hỏi người dùng thực sự tìm kiếm.
- Giải thích chi tiết tính năng, lợi ích, điều kiện sử dụng, chính sách – yếu tố quan trọng cho E-E-A-T.
- Đóng vai trò then chốt trong việc tăng CTR và giảm bounce rate nhờ giải đáp thắc mắc ngay trên trang.
Giải pháp kỹ thuật là đảm bảo toàn bộ nội dung trong tab/accordion được render sẵn trong DOM ngay từ đầu, sau đó chỉ ẩn/hiện bằng CSS hoặc JS đơn giản (thêm/loại bỏ class, thay đổi thuộc tính display hoặc aria-expanded). Một số nguyên tắc thực thi:
- Không phụ thuộc vào việc gọi API mới khi người dùng click tab; dữ liệu nên có sẵn trong HTML hoặc được embed từ server.
- Đối với FAQ, nên kết hợp schema FAQPage với nội dung hiển thị trực tiếp trong HTML:
- Câu hỏi và câu trả lời phải tồn tại dưới dạng text thực, không chỉ trong JSON-LD.
- Tránh pattern “chỉ load nội dung khi người dùng mở từng câu hỏi” bằng AJAX.
- Bảng giá nên có cấu trúc HTML rõ ràng:
- Dùng
<table>hoặc danh sách<ul>/<dl>với text, không render bằng canvas, SVG phức tạp hoặc hình ảnh. - Giữ các thông tin như tên gói, giá, đơn vị, chu kỳ thanh toán, ưu đãi trong text để bot có thể parse và hiểu.
- Dùng
Khi thiết kế UI, nên kiểm tra bằng cách tắt JavaScript hoặc xem “View Source” để xác nhận rằng:
- Tất cả heading H2/H3 quan trọng vẫn xuất hiện trong HTML.
- Các block FAQ, bảng giá, thông số kỹ thuật vẫn tồn tại đầy đủ, chỉ bị ẩn bằng CSS.
- Không có nội dung SEO-critical nào phụ thuộc hoàn toàn vào event click để được render.
Trang sản phẩm chỉ tải dữ liệu sau tương tác người dùng
Trong eCommerce hoặc hệ thống catalog phức tạp, nhiều đội ngũ phát triển áp dụng cơ chế tải dữ liệu sản phẩm sau tương tác: chọn thuộc tính (màu, size), chọn khu vực, cuộn đến một vị trí nhất định, hoặc mở popup. Nếu thông tin như tên sản phẩm, giá, mô tả, thuộc tính chính, tình trạng kho không có trong HTML ban đầu, bot sẽ gặp các vấn đề:
- Không thể đánh giá mức độ liên quan của trang với truy vấn sản phẩm cụ thể.
- Không hiểu được biến thể nào là mặc định, biến thể nào là tùy chọn.
- Không thể trích xuất dữ liệu cấu trúc sản phẩm một cách ổn định nếu chỉ dựa vào JS.
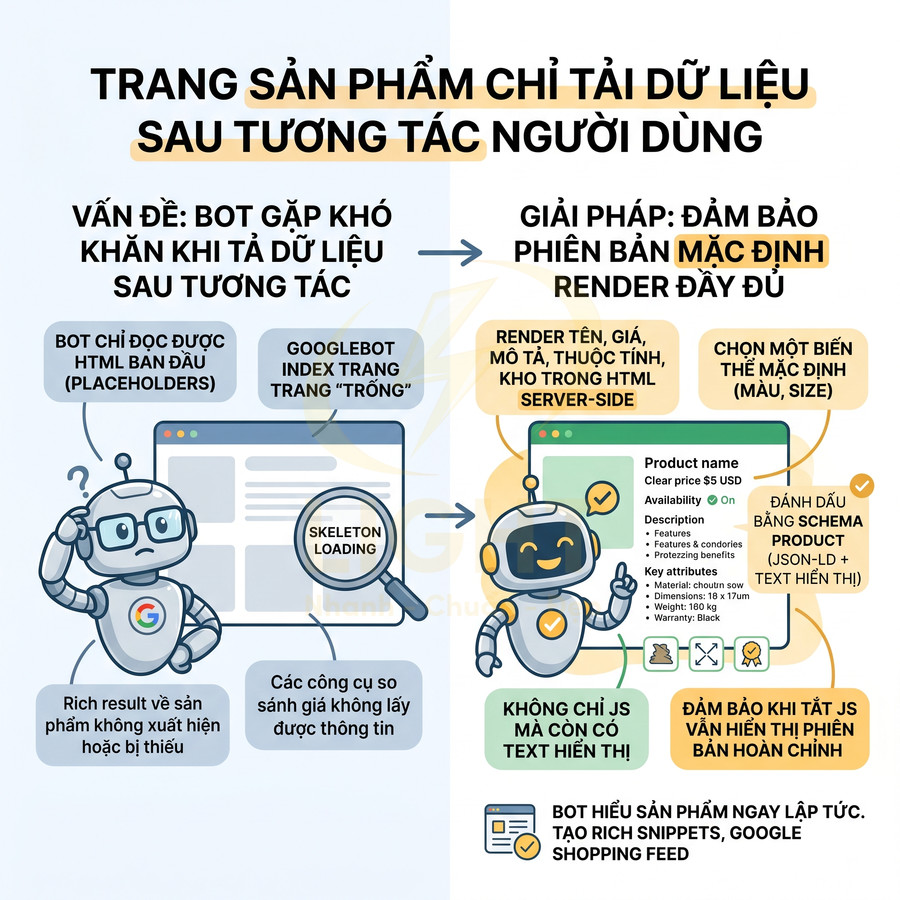
Một số trang thậm chí chỉ hiển thị skeleton loading hoặc placeholder trong HTML, còn toàn bộ nội dung thực tế phụ thuộc vào JS gọi API. Điều này khiến:
- Googlebot có thể index một trang “trống” với vài dòng placeholder.
- Rich result về sản phẩm (giá, availability, rating) không xuất hiện hoặc bị thiếu.
- Các công cụ so sánh giá, aggregator, social crawler không lấy được thông tin sản phẩm.
Giải pháp là đảm bảo phiên bản mặc định của sản phẩm được render đầy đủ trong HTML server-side, sau đó JS mới xử lý các biến thể và tương tác nâng cao. Một số điểm cần chú ý:
- Chọn một biến thể mặc định (ví dụ: màu cơ bản, size phổ biến, khu vực chung) và render:
- Tên sản phẩm đầy đủ, bao gồm thuộc tính nếu cần.
- Giá hiển thị rõ ràng, đơn vị tiền tệ, tình trạng còn hàng.
- Mô tả chính, bullet point về tính năng, lợi ích.
- Thuộc tính quan trọng như chất liệu, kích thước, trọng lượng, bảo hành.
- Đánh dấu các thuộc tính quan trọng bằng schema Product:
- Dùng JSON-LD nhưng đồng thời đảm bảo thông tin tương ứng xuất hiện dưới dạng text trong HTML.
- Không chỉ nhét dữ liệu vào
data-attributehoặc trong JS object mà không có text hiển thị.
- Đảm bảo khi JS bị tắt:
- Trang vẫn hiển thị được ít nhất một phiên bản sản phẩm hoàn chỉnh.
- Người dùng và bot vẫn đọc được thông tin cốt lõi mà không cần tương tác.
Cách tiếp cận này giúp bot hiểu rõ sản phẩm ngay cả khi không thực thi toàn bộ JS, đồng thời tạo nền tảng vững chắc cho rich snippets, Google Shopping feed, và các tích hợp khác dựa trên dữ liệu cấu trúc.
Bot thấy HTML rỗng dù người dùng nhìn giao diện rất đẹp
Một tình huống cực đoan nhưng không hiếm là website dùng framework SPA (Single Page Application) như React, Vue, Angular mà không có SSR hoặc pre-render. Khi đó, HTML trả về từ server gần như chỉ có một <div id="app"> rỗng hoặc một vài thẻ wrapper tối thiểu. Toàn bộ giao diện, routing, và nội dung được render client-side sau khi bundle JS tải xong và chạy.
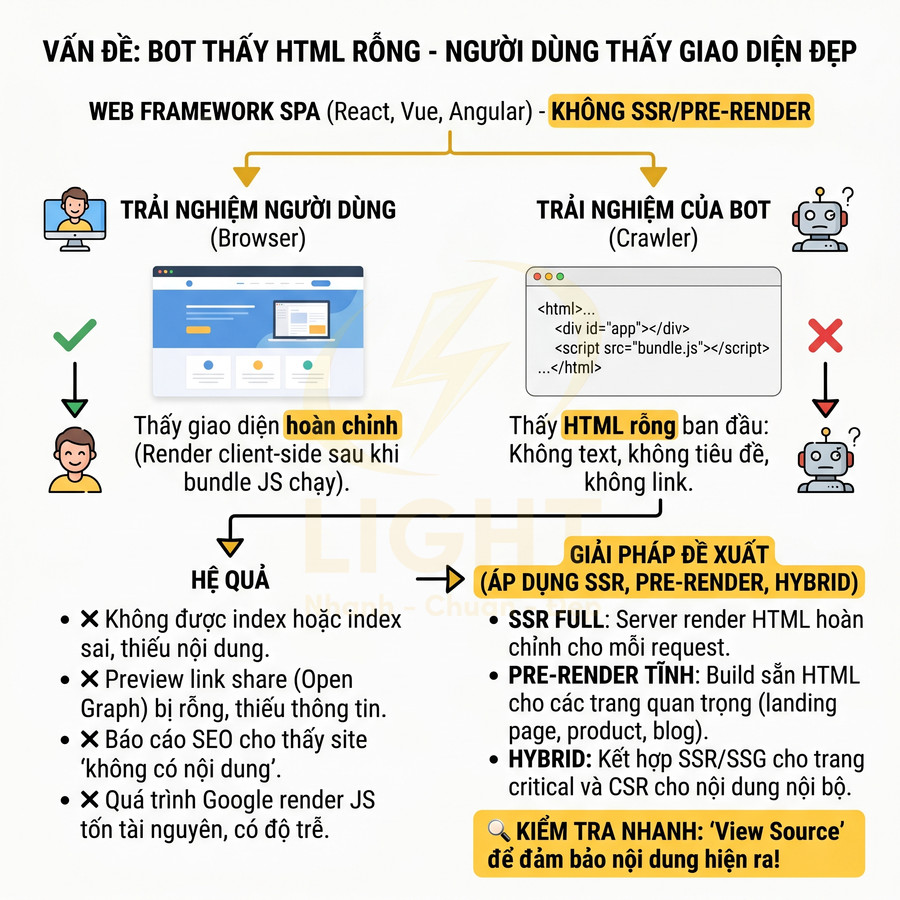
Người dùng với trình duyệt hiện đại vẫn thấy giao diện hoàn chỉnh, nhưng:
- Bot khi thu thập HTML ban đầu không có gì để phân tích: không text, không heading, không internal link, không schema.
- Google có khả năng render JS, nhưng:
- Quá trình này tốn tài nguyên và có độ trễ, không phải lúc nào cũng được ưu tiên.
- Một số trang có thể bị index chậm hoặc không đầy đủ nếu render thất bại.
- Các bot khác (công cụ SEO, social crawler, một số search engine, hệ thống quảng cáo, preview link trên mạng xã hội) thường chỉ đọc HTML mà không render JS.
Hệ quả là:
- Trang có thể không được index hoặc index với nội dung gần như rỗng.
- Preview khi share link (Open Graph, Twitter Card) bị thiếu tiêu đề, mô tả, hình ảnh.
- Các báo cáo SEO cho thấy site “không có nội dung” dù trải nghiệm người dùng rất tốt.
Để tránh rủi ro, cần áp dụng SSR, pre-render hoặc hybrid rendering cho các trang cần SEO. Một số mô hình phổ biến:
- SSR full: server render HTML hoàn chỉnh cho mỗi request, sau đó client “hydrate” để thêm tương tác.
- Pre-render tĩnh: build sẵn HTML cho các trang quan trọng (landing page, category, product, blog) trong quá trình build, phục vụ như file tĩnh.
- Hybrid: kết hợp SSR/SSG cho trang SEO-critical và CSR (client-side rendering) cho phần ứng dụng nội bộ, dashboard, khu vực không cần index.
Kiểm tra nhanh bằng cách dùng “View Source” (không phải Inspect) để đảm bảo nội dung chính xuất hiện trong HTML. Nếu View Source chỉ thấy một khung rỗng với một <div id="app"> hoặc vài thẻ container mà không có text nội dung, đó là dấu hiệu rõ ràng website đang phụ thuộc quá nhiều vào JS cho nội dung cốt lõi. Trong bối cảnh SEO hiện đại, khả năng render JS của Google không nên được xem là “bảo hiểm toàn diện”; kiến trúc cần được thiết kế sao cho HTML ban đầu đã đủ giàu nội dung và cấu trúc để bot hiểu và xếp hạng.
Lỗi URL, canonical và trang trùng lặp làm SEO không tăng trưởng
Các vấn đề về URL, canonical và trang trùng lặp khiến tín hiệu SEO bị phân tán, bot lãng phí crawl budget và hệ thống index trở nên rối. Khi nhiều URL cùng hiển thị một nội dung do filter, tag, tham số, cần tách rõ nhóm URL SEO chính và URL chỉ phục vụ tương tác, rồi kiểm soát bằng robots.txt, noindex, canonical và cấu hình tham số. Canonical phải được dùng đúng mục đích: chỉ định URL chuẩn của chính cụm nội dung tương đương, không “dồn sức mạnh” về trang không liên quan, đồng thời phối hợp chặt với hreflang trong bối cảnh đa ngôn ngữ. Việc đổi slug, thay đổi cấu trúc URL hoặc mở rộng site phải đi kèm quy tắc redirect 301 theo pattern, mapping URL cũ – mới và kiểm tra bằng công cụ crawl/log để bảo toàn tối đa tín hiệu xếp hạng.

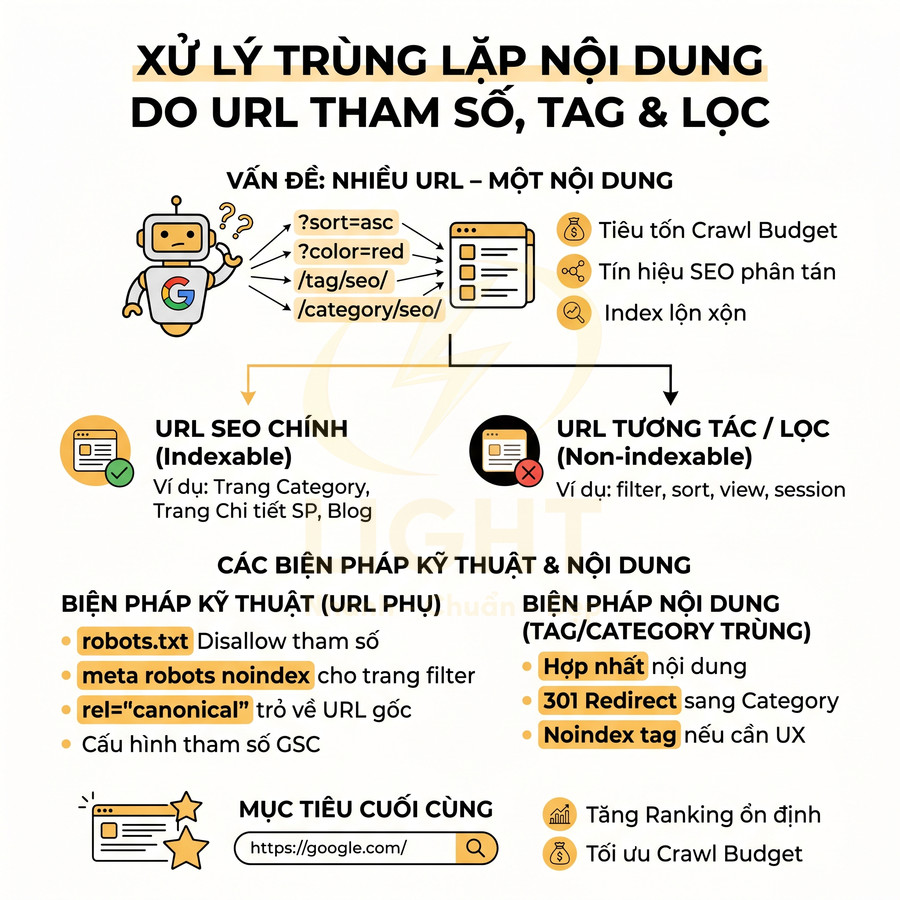
Nhiều URL cùng hiển thị một nội dung do lọc, tag hoặc tham số
Trong các website thương mại điện tử, listing blog hoặc hệ thống có nhiều tính năng lọc/sắp xếp, vấn đề phổ biến là một tập nội dung nhưng sinh ra quá nhiều URL khác nhau. Mỗi thao tác lọc, sort, phân trang, gắn tag… đều có thể tạo thêm một biến thể URL mới, ví dụ:
- ?sort=asc, ?sort=price-desc, ?sort=popular
- ?color=red, ?size=m, ?brand=nike
- ?page=2, ?page=3, ?page=10
- /tag/seo/, /tag/seo-onpage/
- /category/seo/, /category/seo/?view=grid
Về bản chất, các URL này thường hiển thị cùng một nhóm sản phẩm/bài viết với thay đổi rất nhỏ về thứ tự hoặc một vài filter. Đối với bot tìm kiếm, đây là near-duplicate content, khiến:
- Crawl budget bị tiêu tốn vào việc thu thập hàng trăm, hàng nghìn URL gần như giống nhau.
- Tín hiệu xếp hạng (backlink, internal link, tương tác người dùng) bị phân tán giữa nhiều URL thay vì tập trung vào một URL chuẩn.
- Index trở nên lộn xộn: có URL filter được index, URL chính lại bị bỏ qua hoặc index chậm.
Để xử lý đúng, cần phân loại rõ hai nhóm:
- URL SEO chính (indexable URL): là URL đại diện cho một cụm nội dung, có khả năng mang traffic từ tìm kiếm, ví dụ: trang category chính, trang chi tiết sản phẩm, bài viết blog.
- URL phục vụ lọc/tương tác (non-indexable URL): URL sinh ra do filter, sort, view mode, session, tracking… chỉ phục vụ trải nghiệm người dùng, không cần xuất hiện trên SERP.
Với nhóm URL không quan trọng cho SEO, có thể áp dụng kết hợp các biện pháp kỹ thuật:
- robots.txt: chặn crawl các pattern tham số rõ ràng, ví dụ:
Disallow: /?sort=,Disallow: /?view=. Cần cẩn trọng vì chặn crawl nhưng không chặn index từ nguồn khác (như backlink). - meta robots noindex: gắn noindex cho các template filter hoặc trang kết quả tìm kiếm nội bộ, đảm bảo chúng không được đưa vào index.
- rel="canonical": trỏ các biến thể filter nhẹ (ví dụ chỉ thay đổi sort) về URL category gốc nếu nội dung thực tế không khác biệt đáng kể.
- Cấu hình tham số trong Google Search Console (với một số trường hợp): khai báo tham số nào chỉ dùng để sắp xếp, phân trang, lọc không quan trọng, giúp Google hiểu và hạn chế crawl.
Đối với tag và category, nếu cùng gom một nhóm nội dung giống nhau (ví dụ: /tag/seo/ và /category/seo/ hiển thị gần như y hệt), nên:
- Quyết định rõ đâu là cấu trúc chính (thường là category).
- Hợp nhất nội dung: xóa bớt tag trùng, gộp bài viết về category chính.
- Thiết lập redirect 301 từ URL tag dư thừa sang category tương ứng, hoặc noindex tag nếu vẫn cần cho UX nhưng không muốn index.
Mục tiêu cuối cùng là: mỗi cụm nội dung chỉ có một URL chuẩn được index và nhận toàn bộ tín hiệu xếp hạng. Điều này giúp:
- Tăng khả năng ranking ổn định cho URL chính.
- Giảm lãng phí crawl budget, giúp bot tập trung vào trang quan trọng.
- Đơn giản hóa việc đo lường hiệu suất SEO (một URL – một bộ chỉ số).
Canonical đặt sai về trang không liên quan
Thẻ rel="canonical" là tín hiệu để nói với công cụ tìm kiếm: “Trong các phiên bản tương tự nhau, đây là URL chuẩn cần ưu tiên xếp hạng”. Tuy nhiên, trong thực tế triển khai, nhiều website:
- Đặt canonical cứng trong template, khiến mọi trang con đều trỏ về trang chủ hoặc một category lớn.
- Dùng canonical như một công cụ “dồn sức mạnh” về một URL duy nhất, bất chấp nội dung các trang là khác nhau.
- Triển khai canonical chéo phức tạp giữa các phiên bản ngôn ngữ, subdomain, hoặc phiên bản in, dẫn đến vòng lặp canonical hoặc chuỗi canonical khó hiểu.
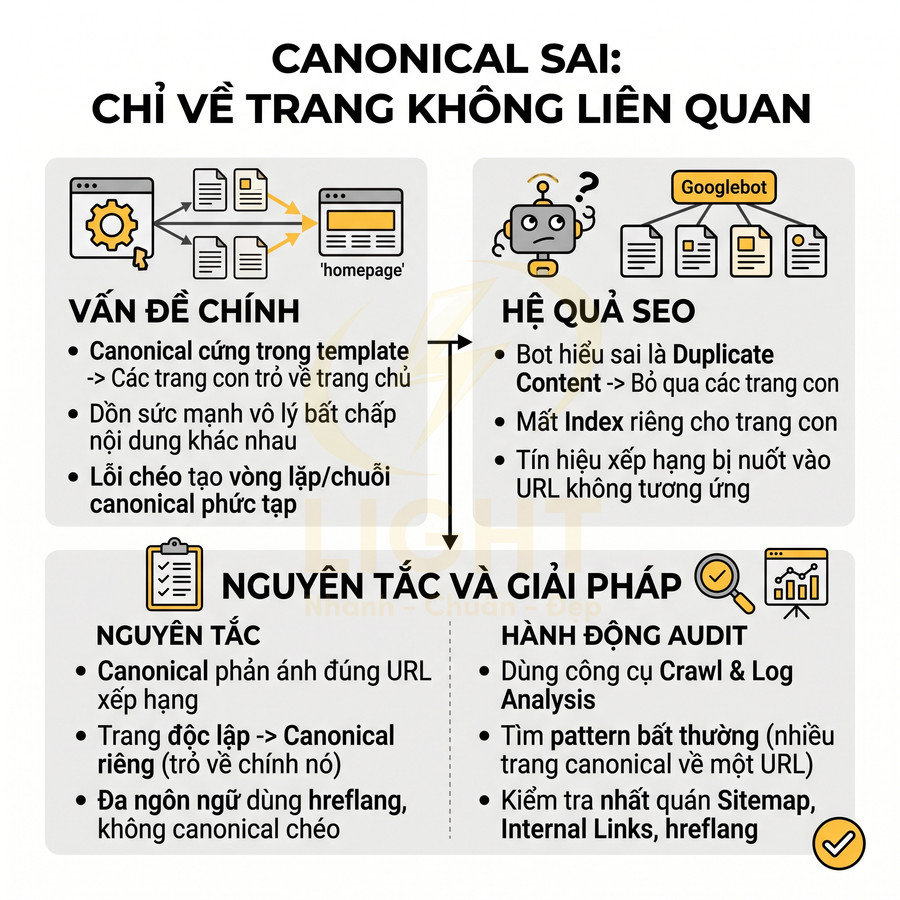
Hệ quả là bot có thể hiểu rằng:
- Các trang con chỉ là bản sao (duplicate) của URL canonical.
- Không cần index hoặc xếp hạng riêng cho các trang đó.
- Tín hiệu của từng trang bị “nuốt” vào một URL không thực sự tương ứng về nội dung.
Để tránh sai lầm này, cần tuân thủ một số nguyên tắc chuyên môn:
- Canonical phải phản ánh đúng URL muốn xếp hạng của chính trang đó. Mỗi trang nội dung độc lập (bài viết, sản phẩm, category) cần có canonical riêng trỏ về chính nó hoặc về phiên bản chuẩn tương đương.
- Không dùng canonical để “ép” bot bỏ qua các trang nội dung khác biệt. Nếu nội dung khác nhau, hãy để chúng tự xếp hạng, hoặc xử lý bằng noindex/redirect nếu không muốn index.
- Với các biến thể URL chỉ khác nhau về tham số tracking (UTM, session), canonical nên trỏ về URL sạch không tham số.
Trong bối cảnh đa ngôn ngữ, đa khu vực, hoặc có phiên bản in/AMP, canonical cần kết hợp với hreflang và cấu trúc URL rõ ràng:
- Mỗi ngôn ngữ/khu vực có URL riêng (ví dụ: /vi/, /en/, /us/), canonical trỏ về chính phiên bản đó.
- hreflang dùng để khai báo mối quan hệ tương đương giữa các phiên bản ngôn ngữ, không dùng canonical để trỏ chéo giữa các ngôn ngữ.
- Phiên bản in hoặc AMP thường canonical về phiên bản HTML chuẩn, tránh để chúng cạnh tranh index với bản chính.
Sai canonical là lỗi kỹ thuật khó phát hiện nếu không audit có hệ thống. Cần sử dụng các công cụ crawl và log analysis để:
- Liệt kê toàn bộ canonical trên site, phát hiện pattern bất thường (nhiều trang khác nhau cùng canonical về một URL).
- Kiểm tra sự nhất quán giữa canonical, hreflang, sitemap và internal link.
- Đối chiếu với dữ liệu index và traffic để nhận diện các nhóm trang bị mất thứ hạng do canonical sai.
Đổi slug liên tục làm mất tín hiệu xếp hạng cũ
Slug là phần cuối của URL (thường là tên bài viết, tên sản phẩm). Trong quá trình tối ưu UI/UX hoặc branding, nhiều đội ngũ:
- Liên tục rút ngắn slug cho “đẹp”, bỏ bớt từ khóa.
- Chuẩn hóa slug theo một format mới (ví dụ bỏ ngày tháng, bỏ category trong URL).
- Thay đổi cấu trúc thư mục, kéo theo việc đổi slug hàng loạt.

Nếu các lần thay đổi này không đi kèm redirect 301 chuẩn, hậu quả là:
- URL cũ đã được index và có backlink trở thành 404 hoặc bị bỏ rơi.
- Bot phải thu thập và đánh giá lại URL mới từ đầu, mất toàn bộ lịch sử tín hiệu.
- Tín hiệu xếp hạng bị phân mảnh: một phần backlink trỏ về URL cũ, một phần về URL mới, làm giảm sức mạnh tổng thể.
Trước khi quyết định đổi slug, cần đánh giá giá trị SEO hiện tại của từng URL:
- Thứ hạng từ khóa chính và phụ.
- Organic traffic trong một khoảng thời gian đủ dài.
- Số lượng và chất lượng backlink trỏ về URL đó.
Chỉ nên đổi slug khi có lý do thực sự cần thiết (ví dụ: cấu trúc cũ gây trùng lặp, khó mở rộng, hoặc sai chiến lược từ khóa), và khi đổi phải:
- Thiết lập redirect 301 từ URL cũ sang URL mới, đảm bảo chuyển giao tối đa tín hiệu.
- Cập nhật toàn bộ internal link trỏ về URL cũ sang URL mới để tránh tạo chuỗi redirect.
- Cập nhật sitemap XML với URL mới, loại bỏ URL cũ đã redirect.
- Điều chỉnh canonical để trỏ đúng về slug mới.
Việc “dọn dẹp” slug nên được thực hiện theo từng đợt có kế hoạch, có mapping rõ ràng, thay vì chỉnh sửa lẻ tẻ theo cảm hứng thiết kế. Cách làm này giúp:
- Kiểm soát được phạm vi ảnh hưởng đến SEO.
- Dễ dàng theo dõi biến động traffic và thứ hạng sau mỗi đợt thay đổi.
- Giảm thiểu rủi ro tạo ra hàng loạt lỗi 404 hoặc redirect chain không cần thiết.
Thiếu quy tắc sửa hàng loạt URL và redirect khi mở rộng site
Khi website phát triển, việc thêm category mới, thay đổi cấu trúc thư mục, tách/ghép chuyên mục là điều khó tránh. Nếu không có quy tắc chuyển đổi URL rõ ràng và cơ chế redirect theo pattern, các vấn đề sau thường xuất hiện:
- Hàng loạt lỗi 404 do URL cũ không còn tồn tại.
- Redirect chain (A → B → C) làm chậm tốc độ tải và suy giảm tín hiệu chuyển giao.
- Redirect loop (A → B → A) khiến bot và người dùng không thể truy cập nội dung.
- Crawl budget bị lãng phí vào các đường dẫn hỏng hoặc chuỗi redirect dài.
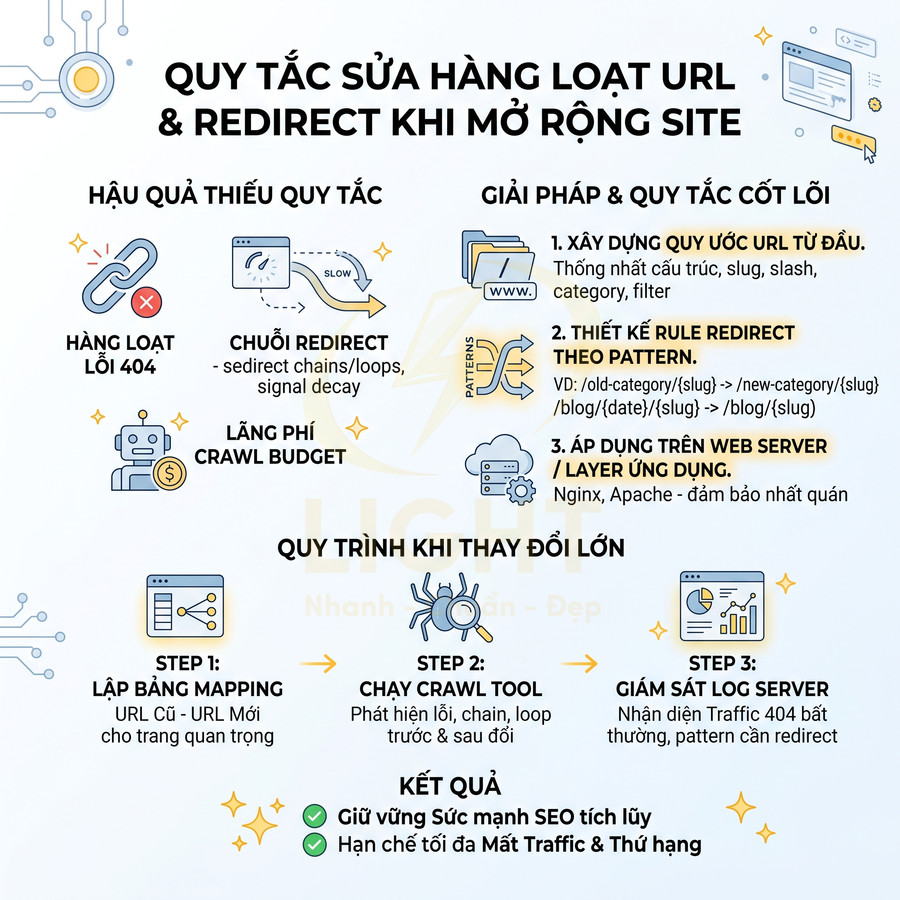
Nhiều CMS hoặc framework không hỗ trợ quản lý redirect theo mẫu (pattern-based redirect), buộc đội ngũ phải tạo redirect thủ công từng URL, rất dễ sót và khó bảo trì. Để giảm thiểu rủi ro, cần:
- Xây dựng quy ước URL ngay từ đầu: thống nhất cấu trúc thư mục, cách đặt slug, có hay không có trailing slash, có hay không có www, quy tắc cho category, tag, filter…
- Thiết kế sẵn các rule redirect theo pattern, ví dụ:
- Từ /old-category/{slug} sang /new-category/{slug}.
- Từ /blog/{year}/{month}/{slug} sang /blog/{slug}.
- Sử dụng web server (Apache, Nginx) hoặc layer ứng dụng để áp dụng các rule này một cách nhất quán.
Khi thực hiện thay đổi cấu trúc lớn, quy trình nên bao gồm:
- Lập bảng mapping URL cũ – URL mới cho các trang quan trọng (category, landing page, bài viết có traffic cao).
- Chạy crawl tool trước và sau khi triển khai để:
- Phát hiện URL không được redirect đúng.
- Kiểm tra xem có redirect chain hoặc loop phát sinh hay không.
- Giám sát log server để nhận diện:
- Lượng truy cập 404 bất thường từ bot và người dùng.
- Các pattern URL bị gọi nhiều nhưng không có redirect phù hợp.
Một hệ thống redirect được thiết kế tốt, dựa trên quy tắc rõ ràng và mapping đầy đủ, cho phép website mở rộng, tái cấu trúc mà vẫn giữ được sức mạnh SEO tích lũy qua thời gian, hạn chế tối đa mất mát traffic và thứ hạng.
Lỗi internal link làm website đẹp nhưng sức mạnh không dồn đúng trang cần top
Hệ thống internal link nếu triển khai sai sẽ khiến website trông vẫn chuyên nghiệp, nhiều traffic nhưng PageRank nội bộ và tín hiệu chủ đề không dồn đúng về các money page. Các lỗi phổ biến gồm: trang dịch vụ không được “nuôi” bởi blog và landing hỗ trợ, anchor text mơ hồ làm bot khó hiểu vai trò trang đích, nhiều trang đẹp nhưng trở thành trang mồ côi không nhận liên kết, cùng với việc liên kết chéo sai cụm chủ đề khiến cấu trúc topical authority bị loãng. Cần xây dựng ma trận internal link theo cụm, ưu tiên liên kết trong cùng silo, dùng anchor mô tả tự nhiên và đảm bảo mọi URL quan trọng đều được gắn vào mạng lưới liên kết để tối đa hóa sức mạnh SEO.
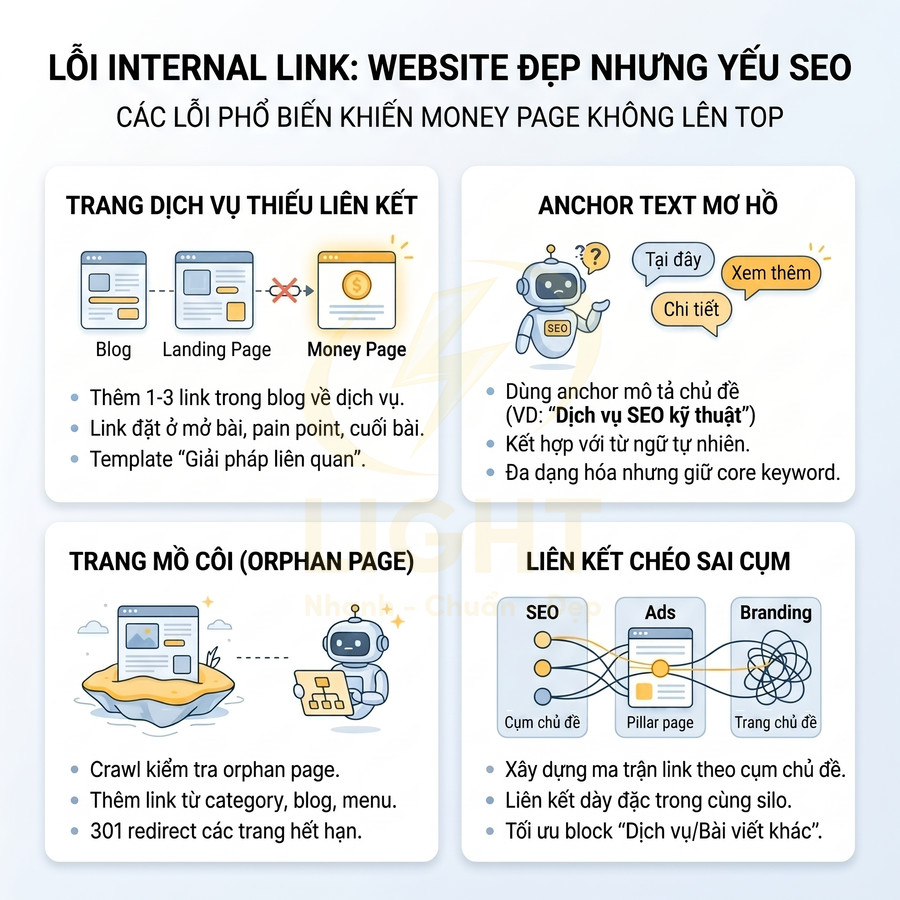
Trang dịch vụ quan trọng thiếu liên kết từ blog và landing hỗ trợ
Trong hầu hết mô hình SEO hiện đại, blog và landing hỗ trợ chính là “tầng thu hút traffic” – nơi tập trung nhiều từ khóa thông tin, long-tail, câu hỏi, how-to. Các trang này thường được đầu tư nội dung chuyên sâu, visual bắt mắt, infographic, video… nên có khả năng thu hút rất nhiều organic traffic và backlink tự nhiên. Tuy nhiên, nếu toàn bộ sức mạnh này chỉ dừng lại ở tầng nội dung thông tin mà không được dẫn truyền về trang dịch vụ chính, website sẽ rơi vào tình trạng “đẹp, nhiều traffic nhưng không ra đơn, không lên top trang chuyển đổi”. Về mặt kỹ thuật, PageRank nội bộ và tín hiệu liên quan chủ đề bị “kẹt” ở các URL blog, không được dồn về money page.
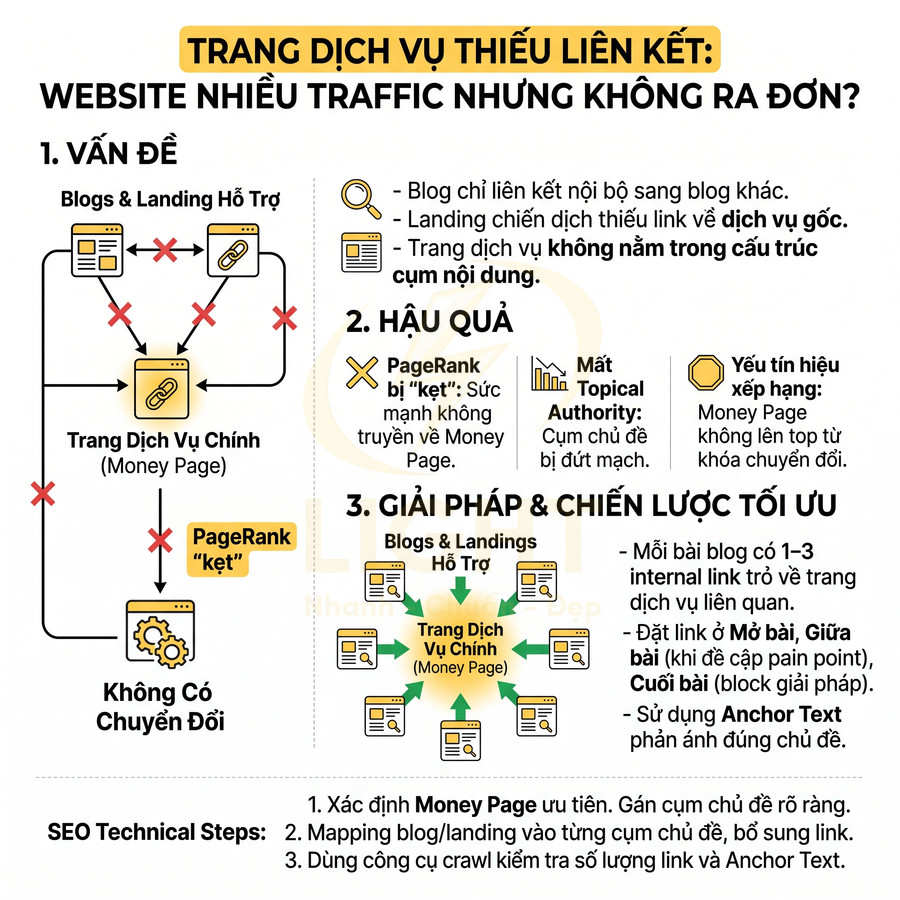
Vấn đề thường gặp:
- Blog chỉ liên kết nội bộ sang các bài blog khác, không có link rõ ràng về trang dịch vụ.
- Landing chạy quảng cáo hoặc chiến dịch chỉ tập trung form, CTA, nhưng không gắn link về trang dịch vụ gốc trong hệ thống.
- Trang dịch vụ quan trọng không xuất hiện trong cấu trúc liên kết của các cụm nội dung hỗ trợ, khiến bot khó nhận diện đó là “trang trung tâm” của chủ đề.
Về mặt chuyên môn, mỗi cụm chủ đề (topic cluster) nên có một hoặc vài pillar page đóng vai trò trang dịch vụ hoặc trang chính, còn các bài blog, landing hỗ trợ đóng vai trò cluster content. Nếu cluster content không trỏ internal link về pillar page, cụm chủ đề sẽ bị đứt mạch, làm giảm khả năng xây dựng topical authority và làm yếu tín hiệu ưu tiên xếp hạng cho trang dịch vụ.
Chiến lược tối ưu:
- Mỗi bài blog trong một cụm chủ đề phải có ít nhất 1–3 internal link trỏ về trang dịch vụ liên quan, đặt ở:
- Phần mở bài (giới thiệu giải pháp dịch vụ liên quan).
- Giữa bài (khi đề cập đến pain point có thể giải quyết bằng dịch vụ).
- Cuối bài (block “Giải pháp liên quan”, “Đăng ký dịch vụ”).
- Landing hỗ trợ chiến dịch nên:
- Có link text hoặc button dẫn về trang dịch vụ chính trong hệ thống.
- Dùng cùng nhóm từ khóa, cùng ngữ nghĩa với trang dịch vụ để củng cố chủ đề.
- Thiết kế các block cố định trong template:
- “Giải pháp liên quan” hiển thị 1–3 trang dịch vụ tương ứng với chủ đề bài viết.
- “Đăng ký dịch vụ” hoặc “Nhận tư vấn” luôn trỏ về đúng money page, không trỏ lung tung sang nhiều trang không quan trọng.
Về mặt kỹ thuật SEO, có thể dùng các bước sau để đảm bảo sức mạnh được dồn đúng:
- Xác định danh sách trang dịch vụ ưu tiên (money page) và gán cho mỗi trang một cụm chủ đề rõ ràng.
- Mapping lại toàn bộ bài blog, landing vào từng cụm chủ đề, sau đó bổ sung internal link trỏ về money page tương ứng.
- Sử dụng công cụ crawl (Screaming Frog, Sitebulb, Ahrefs Site Audit…) để kiểm tra:
- Số lượng internal link trỏ về mỗi trang dịch vụ.
- Anchor text đang dùng cho các link này có phản ánh đúng chủ đề hay không.
Khi triển khai đúng, các bài blog top đầu sẽ không chỉ dừng lại ở việc mang traffic mà còn đóng vai trò “trạm trung chuyển” sức mạnh, giúp trang dịch vụ chính tăng độ liên quan, tăng internal PageRank và cải thiện khả năng lên top cho từ khóa chuyển đổi.
Anchor text mơ hồ khiến bot không hiểu trang đích
Anchor text là một trong những tín hiệu cốt lõi giúp bot hiểu được nội dung và vai trò của trang đích trong cấu trúc website. Về bản chất, anchor text là “nhãn” ngữ nghĩa gắn lên URL được liên kết. Khi anchor mơ hồ như tại đây, xem thêm, chi tiết, hoặc chỉ là các nút CTA chung chung như Liên hệ, Đăng ký ngay, bot gần như không nhận được thông tin gì về chủ đề của trang đích, trừ khi phải crawl và phân tích nội dung sâu hơn. Điều này làm suy yếu tín hiệu liên quan chủ đề (relevance) và làm giảm hiệu quả của internal link trong việc xây dựng topical authority.
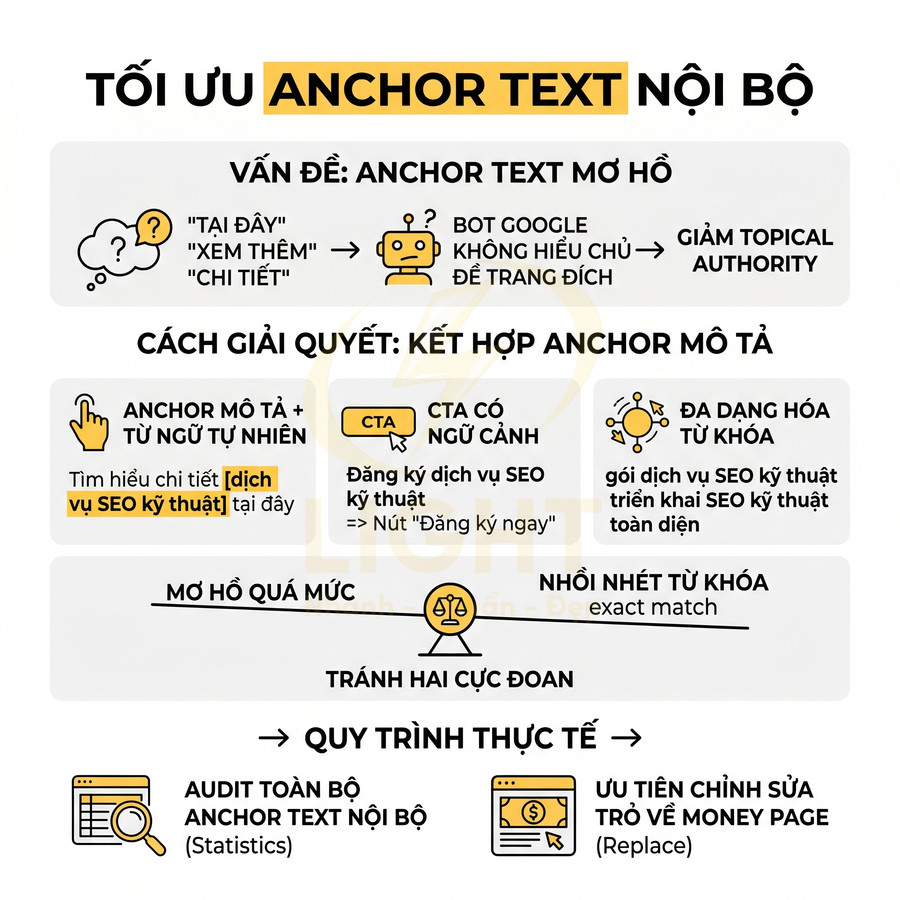
Về mặt chuyên môn, anchor text nên phản ánh:
- Chủ đề chính của trang đích (ví dụ: dịch vụ SEO kỹ thuật, dịch vụ audit website).
- Ý định tìm kiếm (search intent) mà trang đích phục vụ: thông tin, so sánh, dịch vụ, báo giá…
- Ngữ cảnh xung quanh đoạn văn, giúp bot hiểu mối quan hệ giữa trang nguồn và trang đích.
Chiến lược tối ưu anchor text mà vẫn đảm bảo thẩm mỹ:
- Kết hợp anchor mô tả với từ ngữ tự nhiên:
- “Tìm hiểu chi tiết dịch vụ SEO kỹ thuật tại đây” với anchor là “dịch vụ SEO kỹ thuật”.
- “Xem bảng giá cho dịch vụ audit website” với anchor là “dịch vụ audit website”.
- Giữ CTA ngắn nhưng bổ sung ngữ cảnh:
- Nút “Đăng ký ngay” đặt trong block có heading như: “Đăng ký dịch vụ SEO kỹ thuật”.
- Nút “Liên hệ” đặt dưới đoạn mô tả: “Nhận tư vấn chiến lược cho dịch vụ audit website”.
- Đa dạng hóa anchor nhưng vẫn giữ core keyword:
- “gói dịch vụ SEO kỹ thuật chuyên sâu”, “triển khai SEO kỹ thuật toàn diện”, “tối ưu technical SEO cho website”.
Cần tránh hai cực đoan:
- Quá nhiều anchor mơ hồ, không chứa thông tin chủ đề.
- Nhồi nhét từ khóa exact match lặp đi lặp lại một cách không tự nhiên, dễ tạo cảm giác spam.
Giải pháp thực tế:
- Audit toàn bộ anchor text nội bộ:
- Thống kê tần suất các anchor như “tại đây”, “xem thêm”, “chi tiết”.
- Thống kê các anchor chứa từ khóa chính, từ khóa mở rộng, brand.
- Ưu tiên chỉnh sửa các anchor trỏ về money page:
- Thay anchor mơ hồ bằng anchor mô tả có chứa từ khóa hoặc cụm từ liên quan.
- Giữ trải nghiệm người dùng bằng cách viết lại câu văn tự nhiên, không gượng ép.
Nhiều trang đẹp nhưng trở thành trang mồ côi không được trỏ tới
Trang mồ côi (orphan page) là những URL không nhận được bất kỳ internal link nào từ các trang khác trong website. Về mặt crawl và index, các trang này chỉ có thể được bot phát hiện thông qua sitemap, backlink bên ngoài hoặc truy cập trực tiếp URL. Trong thực tế triển khai, rất nhiều landing page, microsite, trang thử nghiệm A/B test được thiết kế rất đẹp, nội dung tốt, nhưng sau chiến dịch lại không được gắn vào cấu trúc site chính, dẫn đến việc gần như “vô hình” trong mắt bot.
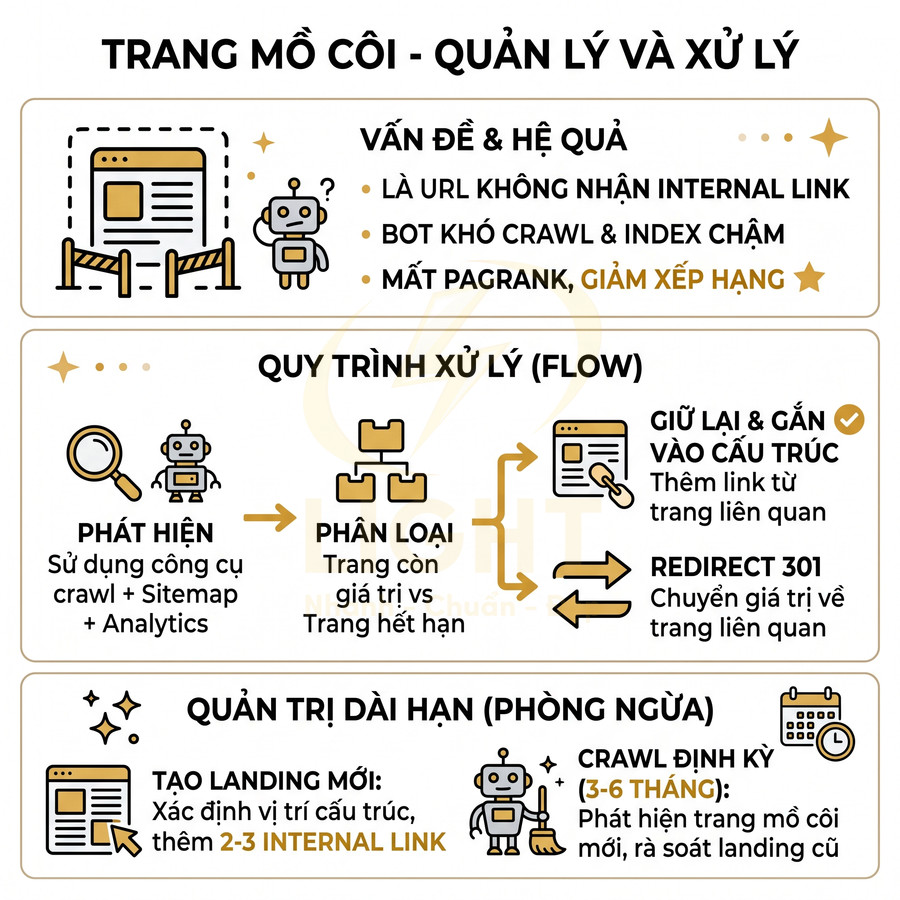
Hệ quả chuyên môn:
- Bot khó crawl thường xuyên, dẫn đến nội dung chậm được cập nhật trong index.
- Trang mồ côi gần như không nhận được internal PageRank, làm suy yếu khả năng xếp hạng.
- Dữ liệu phân tích hành vi (session flow, conversion path) bị đứt đoạn vì người dùng khó tiếp cận từ các trang khác.
- Cấu trúc site trở nên rời rạc, khó quản lý, khó tối ưu theo cụm chủ đề.
Quy trình xử lý trang mồ côi:
- Sử dụng công cụ crawl:
- Kết hợp dữ liệu từ crawl (Screaming Frog, Sitebulb…) với sitemap XML và Google Analytics / Search Console.
- Xác định các URL có trong sitemap hoặc có traffic nhưng không được phát hiện qua crawl internal link – đó là ứng viên trang mồ côi.
- Phân loại trang mồ côi:
- Trang còn giá trị (nội dung tốt, có traffic, có backlink, liên quan chiến lược hiện tại).
- Trang hết hạn chiến dịch, nội dung trùng lặp, không còn phù hợp.
- Ra quyết định xử lý:
- Giữ lại và gắn vào cấu trúc:
- Thêm internal link từ category, blog, trang dịch vụ, menu phụ hoặc footer.
- Đưa trang vào đúng cụm chủ đề, đảm bảo có ít nhất vài link trỏ tới từ các trang liên quan.
- Redirect 301:
- Redirect về trang dịch vụ hoặc bài viết tương đương về chủ đề.
- Giữ lại giá trị backlink và tín hiệu lịch sử thay vì để trang tồn tại độc lập, không được crawl.
- Giữ lại và gắn vào cấu trúc:
Về mặt quản trị dài hạn, nên thiết lập quy trình:
- Mỗi khi tạo landing mới, bắt buộc:
- Chỉ định vị trí trong cấu trúc site (thuộc cụm chủ đề nào, liên kết từ đâu).
- Thiết kế ít nhất 2–3 internal link trỏ tới từ các trang hiện có.
- Định kỳ (3–6 tháng) chạy crawl toàn site để:
- Phát hiện trang mồ côi mới phát sinh.
- Rà soát lại các landing cũ sau chiến dịch, tránh để “quên” trong hệ thống.
Liên kết chéo sai cụm chủ đề làm loãng tín hiệu SEO
Internal link không chỉ là câu chuyện “càng nhiều càng tốt”, mà là bài toán kiến trúc thông tin và phân bổ tín hiệu chủ đề. Khi liên kết chéo lung tung giữa các chủ đề không liên quan, bot sẽ khó nhận diện được cụm nội dung chuyên sâu, từ đó giảm khả năng xây dựng topical authority cho từng mảng. Ví dụ, một bài về SEO kỹ thuật lại trỏ quá nhiều link sang các chủ đề như thiết kế logo, quảng cáo Facebook, thiết kế brochure… chỉ vì muốn “điều hướng người dùng” hoặc tận dụng traffic, sẽ khiến cụm SEO kỹ thuật bị loãng, không còn tập trung.
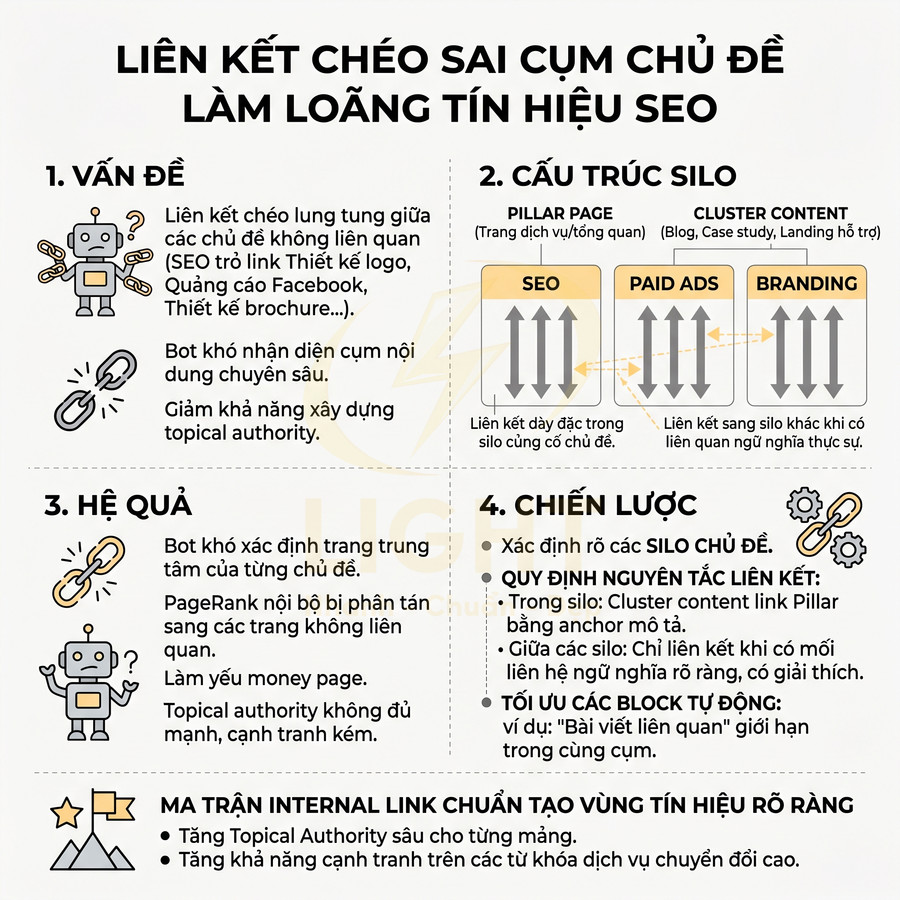
Về mặt cấu trúc, website nên được tổ chức theo dạng:
- Các silo hoặc topic cluster rõ ràng:
- Mỗi silo xoay quanh một chủ đề chính (ví dụ: SEO, Paid Ads, Branding…).
- Bên trong silo có pillar page (trang dịch vụ, trang tổng quan) và các cluster content (blog, case study, landing hỗ trợ).
- Internal link ưu tiên:
- Liên kết dày đặc trong cùng silo để củng cố chủ đề.
- Liên kết sang silo khác chỉ khi có liên quan ngữ nghĩa thực sự (ví dụ: bài về SEO Onpage có thể liên kết sang bài về Content Marketing nếu đang nói về tối ưu nội dung).
Hệ quả khi liên kết chéo sai cụm:
- Bot khó xác định trang nào là trung tâm của từng chủ đề.
- PageRank nội bộ bị phân tán sang các trang không liên quan, làm yếu money page trong từng silo.
- Topical authority không đủ mạnh ở bất kỳ mảng nào, dẫn đến cạnh tranh kém trên SERP.
Chiến lược thiết kế ma trận internal link theo cụm:
- Xác định rõ các silo chủ đề:
- Ví dụ: “SEO kỹ thuật”, “SEO nội dung”, “Quảng cáo Facebook”, “Thiết kế thương hiệu”…
- Mỗi silo có một trang dịch vụ chính và một số trang tổng hợp (guide, hub page).
- Quy định nguyên tắc liên kết:
- Trong mỗi silo:
- Cluster content liên kết về pillar page bằng anchor mô tả.
- Các bài trong cùng silo liên kết qua lại khi có liên quan nội dung.
- Giữa các silo:
- Chỉ liên kết khi có mối liên hệ ngữ nghĩa rõ ràng, được giải thích trong nội dung.
- Không dùng block “bài viết khác” random toàn site, mà ưu tiên nội dung trong cùng silo.
- Trong mỗi silo:
- Tối ưu các block tự động:
- “Dịch vụ khác”: cấu hình để ưu tiên hiển thị dịch vụ trong cùng nhóm trước, sau đó mới đến nhóm liên quan gần.
- “Bài viết liên quan”: dùng tag, category hoặc trường custom để giới hạn trong cùng cụm chủ đề.
Khi ma trận internal link theo cụm được thiết kế chuẩn, mỗi chủ đề sẽ hình thành một “vùng tín hiệu” rõ ràng trong mắt bot: trang dịch vụ trung tâm nhận nhiều internal link chất lượng, anchor text mô tả đúng, các bài hỗ trợ xoay quanh và củng cố chủ đề, liên kết chéo sang mảng khác chỉ ở mức hợp lý và có ngữ cảnh. Điều này giúp website xây dựng được topical authority sâu cho từng mảng, tăng khả năng cạnh tranh trên các từ khóa khó, đặc biệt là từ khóa dịch vụ mang tính chuyển đổi cao.
Lỗi dữ liệu có cấu trúc và tín hiệu chuyên môn bị thiếu
Dữ liệu có cấu trúc là lớp “nghĩa” giúp công cụ tìm kiếm hiểu sâu hơn về dịch vụ, sản phẩm và nội dung chuyên môn, nhưng nhiều website lại bỏ qua hoặc triển khai sai, khiến mất cơ hội rich result và giảm tín hiệu tin cậy. Việc thiếu schema cho Product, Service, FAQ, Review, LocalBusiness, Organization làm CTR kém, khó được chọn cho các tính năng nâng cao và hạn chế xây dựng graph thực thể. Nguy hiểm hơn, schema sai logic so với nội dung hiển thị có thể bị xem là structured data spam, dẫn tới mất rich result hoặc manual action. Để tối ưu, cần hệ thống template schema tự động, phản ánh trung thực UI, gắn chặt với EEAT thông qua tác giả, doanh nghiệp, case study, review xác thực và các block tín hiệu niềm tin được thiết kế tự nhiên trong trải nghiệm trang.
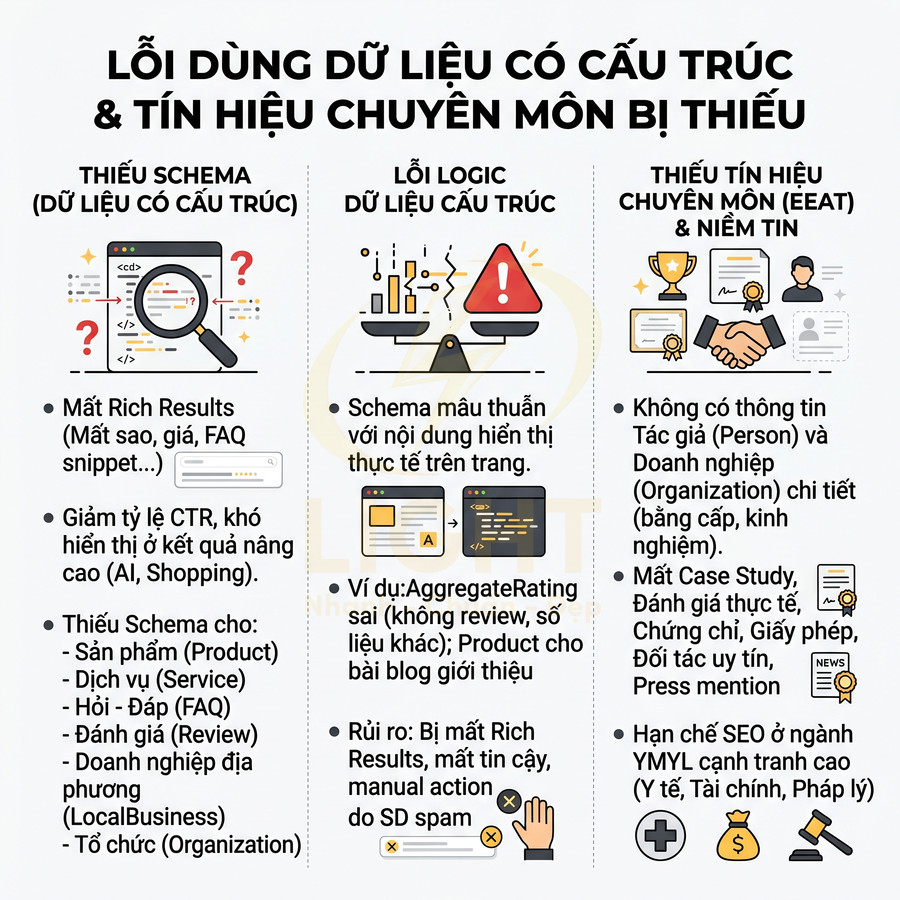
Thiếu schema cho dịch vụ, sản phẩm, FAQ và đánh giá
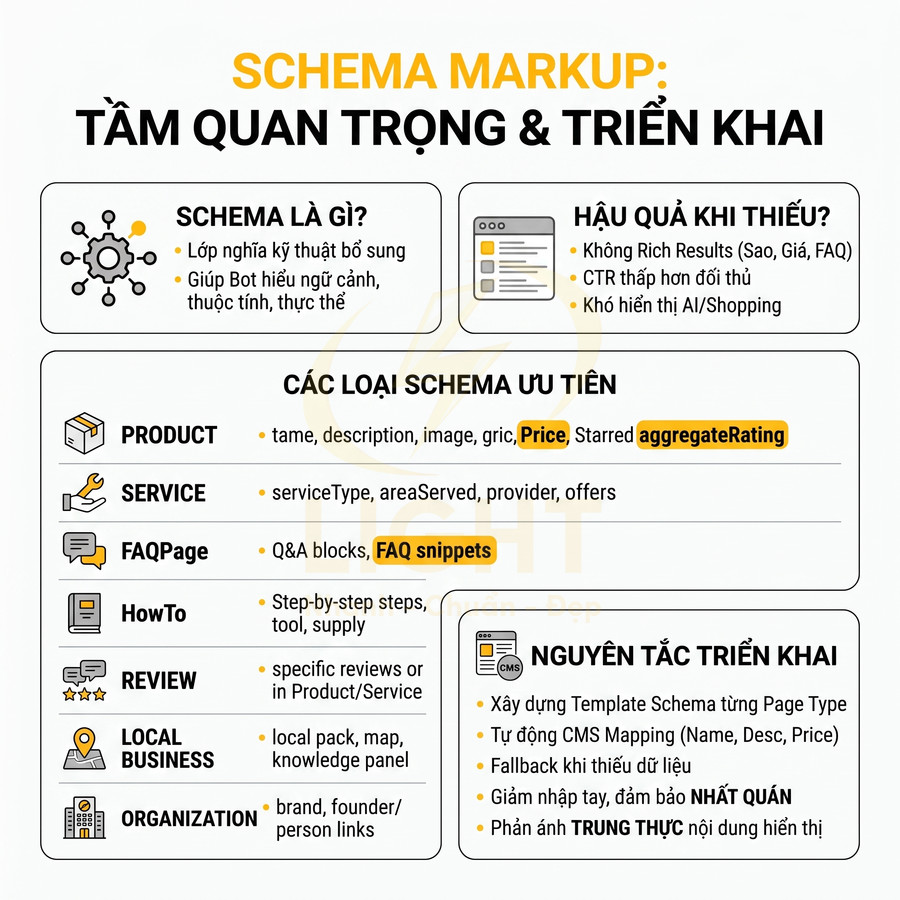
Dữ liệu có cấu trúc (schema) không chỉ giúp bot hiểu loại nội dung mà còn giúp công cụ tìm kiếm nắm được ngữ cảnh, thuộc tính chi tiết và mối quan hệ giữa các thực thể trên trang. Ở mức kỹ thuật, schema là lớp “nghĩa” (semantic layer) bổ sung cho HTML, giúp Google, Bing, các hệ thống AI có thể trích xuất thông tin một cách có cấu trúc thay vì chỉ đọc văn bản tự do.
Nhiều website đầu tư rất mạnh vào UI/UX cho các trang dịch vụ, sản phẩm, FAQ, review nhưng lại bỏ qua lớp schema tương ứng. Hệ quả là:
- Không đủ điều kiện hiển thị rich result như sao đánh giá, FAQ snippet, giá, tình trạng còn hàng, breadcrumb nâng cao…
- CTR kém hơn đối thủ dù thứ hạng tương đương, vì kết quả tìm kiếm trông “nhạt” hơn, ít thông tin hơn.
- Khó được chọn làm nguồn cho các tính năng nâng cao như Google Shopping, Google Hotel, Google Jobs, hay các trải nghiệm tìm kiếm dựa trên AI.
Các loại schema nên ưu tiên cho website dịch vụ/sản phẩm ở mức chuyên sâu gồm:
- Product: cho trang bán sản phẩm, cần chú ý các thuộc tính:
- name, description, image, sku, brand
- offers (price, priceCurrency, availability, url, priceValidUntil)
- aggregateRating, review nếu có đánh giá hiển thị thật trên trang
- Service: cho các dịch vụ (tư vấn, bảo trì, đào tạo…), nên khai báo:
- serviceType, areaServed, provider, offers
- Liên kết với LocalBusiness/Organization để thể hiện đơn vị cung cấp
- FAQPage: cho trang có cấu trúc Hỏi – Đáp rõ ràng, mỗi câu hỏi là một block riêng, có câu trả lời tương ứng hiển thị đầy đủ.
- HowTo: cho nội dung hướng dẫn từng bước, có step, tool, supply rõ ràng, phù hợp với các truy vấn “cách làm…”.
- Review: cho từng bài đánh giá cụ thể, hoặc dùng lồng trong Product/Service khi có phần review hiển thị.
- LocalBusiness: cho doanh nghiệp có địa điểm thực, giúp tăng khả năng xuất hiện trong local pack, map, knowledge panel.
- Organization: cho thương hiệu/tổ chức tổng thể, liên kết với Person (tác giả, founder), Product, Service…
Về mặt triển khai, một hệ thống tốt không nên gắn schema thủ công từng trang, mà cần:
- Xây dựng template schema cho từng loại page (product, service, blog, FAQ, category…).
- Tự động map các trường schema với trường nội dung trong CMS:
- name → tiêu đề sản phẩm/dịch vụ
- description → mô tả ngắn hoặc đoạn mở đầu
- image → ảnh đại diện
- offers.price → trường giá trong database
- Hạn chế tối đa nhập tay để giảm sai sót, đảm bảo tính nhất quán khi cập nhật hàng loạt.
- Thiết lập cơ chế fallback: nếu thiếu dữ liệu quan trọng (ví dụ không có giá), hệ thống tự loại bỏ trường đó khỏi schema thay vì “bơm” giá giả.
Nguyên tắc quan trọng: schema phải phản ánh trung thực nội dung hiển thị. Không nên “nhồi” thêm thuộc tính chỉ để kích rich result nếu trên giao diện không có bằng chứng tương ứng. Việc lạm dụng dễ bị Google đánh giá là spam dữ liệu có cấu trúc.
Schema sai logic so với nội dung hiển thị trên trang
Lỗi nghiêm trọng hơn thiếu schema là schema sai logic, tức là lớp dữ liệu có cấu trúc mô tả một thực tế khác với những gì người dùng thấy. Một số tình huống phổ biến:
- Gắn Product cho trang chỉ là bài blog giới thiệu, không có nút mua, không có thông tin giá, không có chức năng bán hàng.
- Gắn Review hoặc aggregateRating nhưng trên trang không hiển thị bất kỳ đánh giá, số sao, hay nội dung review nào.
- Khai báo offers.price trong schema khác với giá hiển thị (do khuyến mãi, thay đổi giá nhưng không cập nhật schema).
- Dùng FAQPage cho trang chỉ có một đoạn nội dung dài, không có cấu trúc Hỏi – Đáp rõ ràng.

Về mặt thuật toán, Google có cơ chế đối chiếu giữa nội dung hiển thị và dữ liệu có cấu trúc. Khi phát hiện chênh lệch lớn, hệ thống có thể:
- Loại bỏ rich result của trang đó (mất sao, mất FAQ, mất giá…).
- Giảm mức độ tin cậy với toàn bộ domain, khiến các trang khác cũng khó được hiển thị rich result.
- Xếp vào nhóm structured data spam, trong trường hợp nặng có thể dẫn tới manual action.
Để hạn chế rủi ro, quy trình chuẩn nên bao gồm:
- Sử dụng Rich Results Test để kiểm tra khả năng đủ điều kiện rich result cho từng loại schema.
- Dùng Schema Markup Validator để kiểm tra tính hợp lệ theo chuẩn schema.org (cú pháp, kiểu dữ liệu, trường bắt buộc).
- Thiết lập checklist nội bộ:
- Mọi trường quan trọng trong schema đều phải có bằng chứng hiển thị trên UI.
- Nếu có rating trong schema → phải có rating hiển thị (số sao, số lượng đánh giá).
- Nếu có price trong schema → giá trên giao diện phải trùng khớp, cùng đơn vị tiền tệ.
- Khi thay đổi layout, cấu trúc nội dung, hoặc logic giá:
- Đảm bảo team dev cập nhật template schema tương ứng.
- Thiết lập test tự động (hoặc ít nhất là quy trình QA) để so sánh dữ liệu schema với nội dung thật sau mỗi lần release.
Ở cấp độ hệ thống lớn (ecommerce, marketplace, chuỗi dịch vụ), nên có cơ chế log và cảnh báo khi:
- Giá trong database thay đổi nhưng schema không được regenerate.
- Trang bị mất rich result đột ngột (theo dõi trong Search Console & log crawl).
- Tỷ lệ lỗi structured data tăng bất thường.
Thiếu thông tin tác giả, doanh nghiệp và bằng chứng trải nghiệm thực tế
Trong bối cảnh Google đẩy mạnh đánh giá EEAT (Experience, Expertise, Authoritativeness, Trustworthiness), dữ liệu có cấu trúc chỉ là một phần. Bot cần nhìn thấy thực thể đứng sau nội dung: ai viết, ai chịu trách nhiệm, tổ chức nào bảo chứng, có kinh nghiệm thực tế hay không.
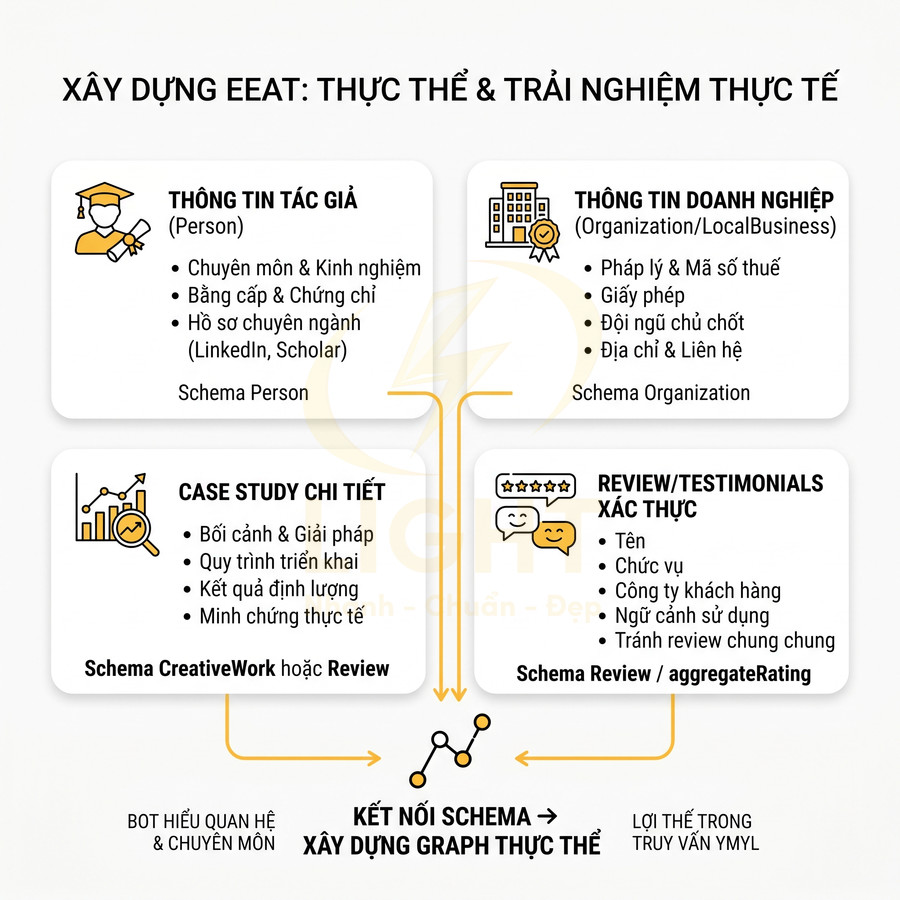
Các website chỉ tập trung vào giao diện, hình ảnh đẹp nhưng thiếu:
- Thông tin chi tiết về tác giả (Person): chuyên môn, kinh nghiệm, chứng chỉ, nơi làm việc, profile mạng xã hội chuyên ngành.
- Thông tin doanh nghiệp/tổ chức (Organization/LocalBusiness): pháp lý, lịch sử, quy mô, đội ngũ chủ chốt.
- Case study có số liệu, quy trình, kết quả thực tế, minh chứng cho năng lực triển khai.
- Review/Testimonials xác thực từ khách hàng, đối tác, có thể kiểm chứng.
Để tăng tín hiệu EEAT, cần xây dựng cấu trúc nội dung và schema tương ứng:
- Trang giới thiệu tác giả:
- Tiểu sử, bằng cấp, chứng chỉ, số năm kinh nghiệm.
- Lĩnh vực chuyên môn chính, các dự án tiêu biểu.
- Liên kết tới profile LinkedIn, ResearchGate, Google Scholar, hoặc website cá nhân.
- Dùng schema Person với các thuộc tính như name, jobTitle, affiliation, sameAs, alumniOf.
- Trang giới thiệu doanh nghiệp:
- Thông tin pháp lý: tên pháp nhân, mã số thuế, giấy phép (nếu ngành nghề yêu cầu).
- Lịch sử hình thành, tầm nhìn, giá trị cốt lõi, đội ngũ lãnh đạo.
- Địa chỉ, số điện thoại, email, giờ làm việc, chi nhánh.
- Dùng schema Organization hoặc LocalBusiness, liên kết với Person (founder, CEO) và Product/Service.
- Case study chi tiết:
- Bối cảnh, mục tiêu, giải pháp triển khai, kết quả định lượng (số liệu trước – sau).
- Hình ảnh, tài liệu, biểu đồ thực tế (ẩn thông tin nhạy cảm nếu cần).
- Có thể lồng schema Review hoặc CreativeWork để mô tả dạng nội dung.
- Review xác thực:
- Hiển thị tên, chức vụ, công ty (nếu được phép), hoặc ít nhất là ngữ cảnh sử dụng dịch vụ.
- Tránh review “chung chung”, thiếu chi tiết, dễ bị coi là tự viết.
- Dùng schema Review và/hoặc aggregateRating gắn với Product/Service/LocalBusiness.
Việc đánh dấu các thực thể này bằng schema giúp bot xây dựng graph quan hệ: tác giả A thuộc tổ chức B, có chuyên môn C, viết bài về chủ đề D. Khi graph này đủ mạnh và nhất quán, website có lợi thế lớn trong các truy vấn có tính chuyên môn hoặc rủi ro cao (YMYL).
Trang đẹp nhưng không có tín hiệu niềm tin cho truy vấn cạnh tranh cao
Ở các ngành cạnh tranh như tài chính, y tế, pháp lý, giáo dục, người dùng thường có mức độ rủi ro nhận thức cao: quyết định sai có thể gây thiệt hại lớn về tiền bạc, sức khỏe, pháp lý. Trong bối cảnh đó, một giao diện đẹp, hình ảnh bắt mắt nhưng thiếu tín hiệu niềm tin sẽ khó chuyển đổi và khó giữ chân người dùng đủ lâu để gửi tín hiệu tốt cho SEO.
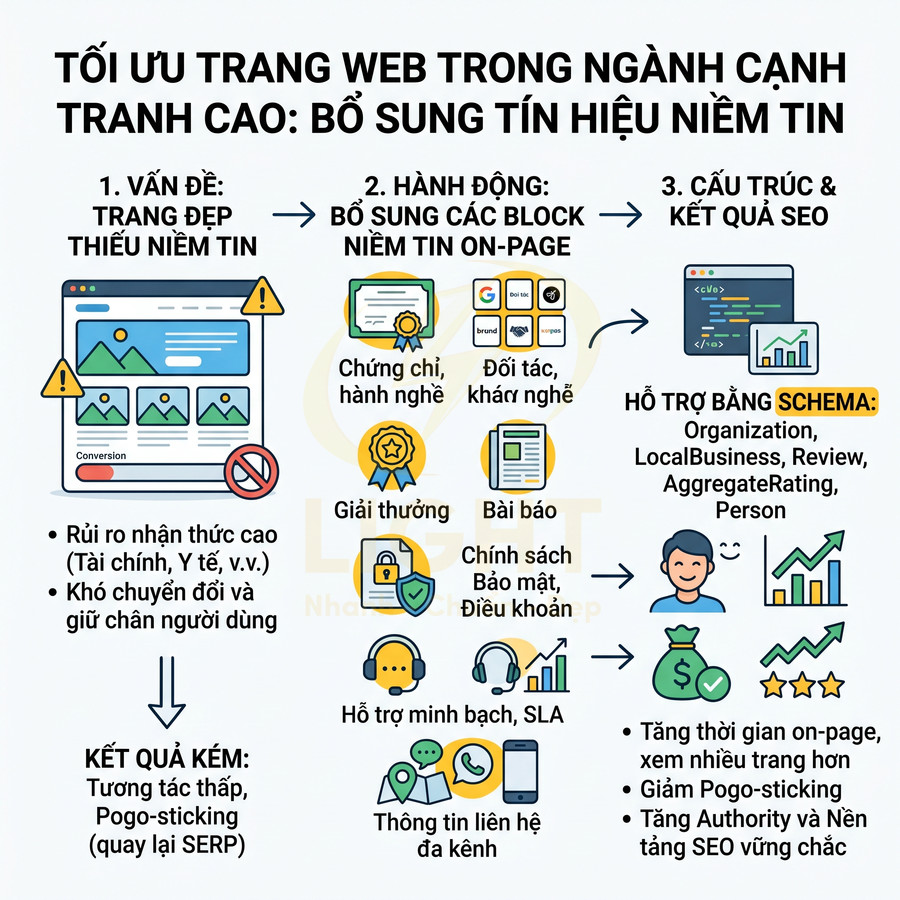
Các tín hiệu niềm tin quan trọng bao gồm:
- Chứng chỉ, giấy phép hành nghề, accreditations từ cơ quan quản lý hoặc tổ chức uy tín.
- Đối tác, khách hàng lớn, logo thương hiệu đã/đang hợp tác.
- Giải thưởng, thành tựu, bài báo nhắc tới doanh nghiệp trên các kênh truyền thông lớn.
- Chính sách bảo mật, điều khoản sử dụng, chính sách hoàn tiền/bảo hành rõ ràng, dễ truy cập.
- Quy trình xử lý khiếu nại, hỗ trợ khách hàng minh bạch, có SLA hoặc cam kết thời gian phản hồi.
- Thông tin liên hệ đa kênh: địa chỉ thực, số điện thoại, email, live chat, form liên hệ.
Về mặt UX và SEO, các block niềm tin nên được thiết kế như một phần tự nhiên của trang, không chỉ là “trang phụ”:
- Block logo đối tác, chứng nhận đặt gần khu vực CTA chính, có link tới trang giải thích chi tiết hoặc nguồn xác thực (website tổ chức cấp chứng nhận).
- Block số liệu thực tế (số khách hàng, năm kinh nghiệm, dự án đã triển khai) kèm chú thích rõ nguồn và phạm vi (ví dụ: “tính đến 2025”).
- Block trích dẫn báo chí (press mention) với logo tòa soạn, trích đoạn ngắn, link tới bài gốc.
- Block đánh giá khách hàng với nội dung cụ thể, tránh chỉ hiển thị số sao mà không có lời nhận xét.
- Block chính sách bảo hành/bảo mật tóm tắt ngắn gọn, kèm link tới trang chi tiết.
Về mặt dữ liệu có cấu trúc, các block này có thể được hỗ trợ bởi:
- Organization/LocalBusiness với thuộc tính award, memberOf, knowsAbout, sameAs để thể hiện mối quan hệ với hiệp hội, tổ chức chuyên môn.
- Review và aggregateRating gắn với dịch vụ/sản phẩm hoặc doanh nghiệp.
- Person cho chuyên gia chịu trách nhiệm chuyên môn, liên kết với Organization.
Khi các tín hiệu niềm tin được thiết kế tốt, người dùng có xu hướng:
- Ở lại trang lâu hơn, xem nhiều trang hơn, tương tác với CTA.
- Ít quay lại SERP ngay lập tức (giảm pogo-sticking).
- Chia sẻ nội dung hoặc lưu lại để tham khảo, gián tiếp tăng tín hiệu authority.
Những hành vi này, kết hợp với lớp schema và EEAT mạnh, tạo thành nền tảng vững chắc cho SEO ở các truy vấn cạnh tranh cao, nơi chỉ tối ưu onpage kỹ thuật và nội dung “đẹp” là chưa đủ.
Lỗi trải nghiệm di động và chuyển đổi làm giảm tín hiệu người dùng
Trải nghiệm di động kém không chỉ làm người dùng khó chịu mà còn làm suy yếu các tín hiệu hành vi quan trọng cho SEO. Khi giao diện chỉ được tối ưu cho desktop rồi “co lại” cho mobile, bố cục dễ vỡ, chữ khó đọc, thao tác chạm thiếu chính xác, form rườm rà và menu khó điều hướng. Những vấn đề này khiến người dùng thoát trang sớm, giảm tương tác, kéo theo bounce rate tăng, time on page giảm và ít trang/phiên hơn. Popup che nội dung, CTA khó bấm, thiếu nút gọi nhanh hay chỉ đường trên trang local đều làm đứt gãy hành trình chuyển đổi. Cách tiếp cận hiệu quả là thiết kế mobile-first, ưu tiên hành động, tối ưu vùng chạm, form, menu, popup và CTA local để vừa tăng chuyển đổi vừa cải thiện tín hiệu người dùng cho tìm kiếm di động.
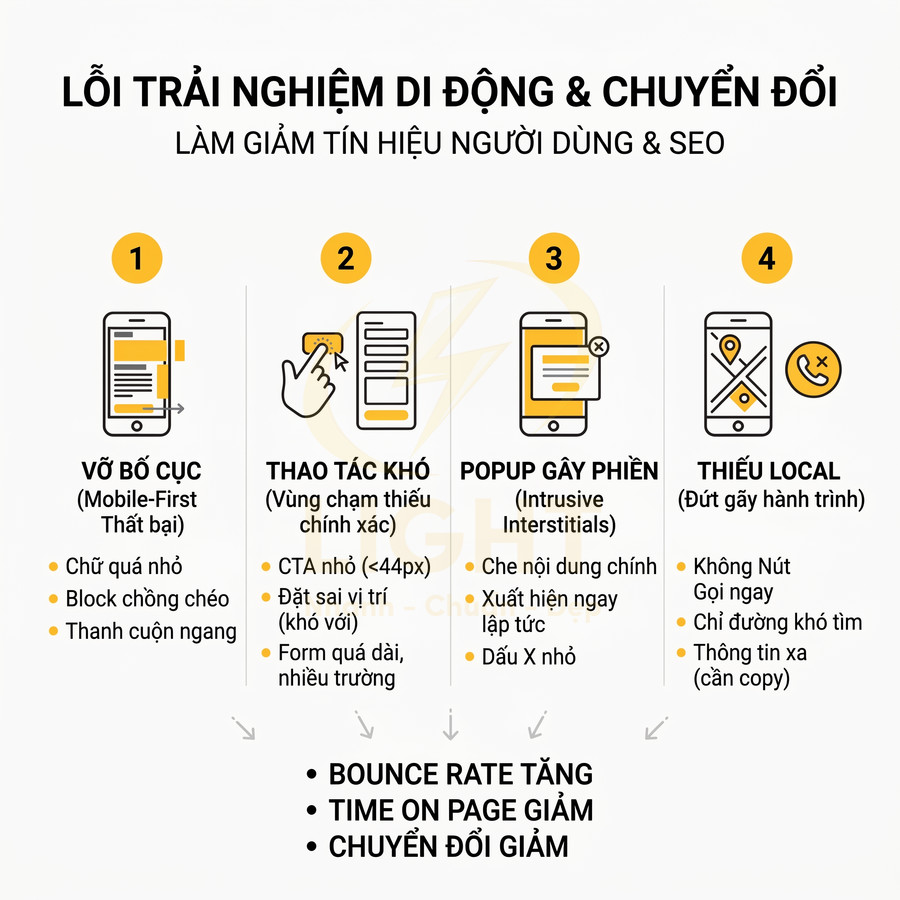
Giao diện đẹp trên desktop nhưng vỡ bố cục trên điện thoại
Nhiều website được thiết kế, review và phê duyệt gần như 100% trên màn hình desktop 24–27 inch, sau đó mới “co lại” cho mobile bằng vài breakpoint cơ bản. Cách làm này thường chỉ xử lý phần layout tổng thể (ví dụ: chia cột thành 1 cột), nhưng bỏ qua rất nhiều chi tiết vi mô trên di động: kích thước font, khoảng cách giữa các block, chiều cao dòng, tỷ lệ ảnh, độ rộng container, khoảng trống hai bên, v.v. Kết quả là khi lên điện thoại, giao diện trông vẫn “giống” bản desktop nhưng trải nghiệm thực tế lại rất tệ: text quá nhỏ, phải zoom mới đọc được; block chồng chéo; slider khó vuốt; ảnh bị crop sai tỷ lệ; hoặc tệ hơn là xuất hiện thanh cuộn ngang gây khó chịu.
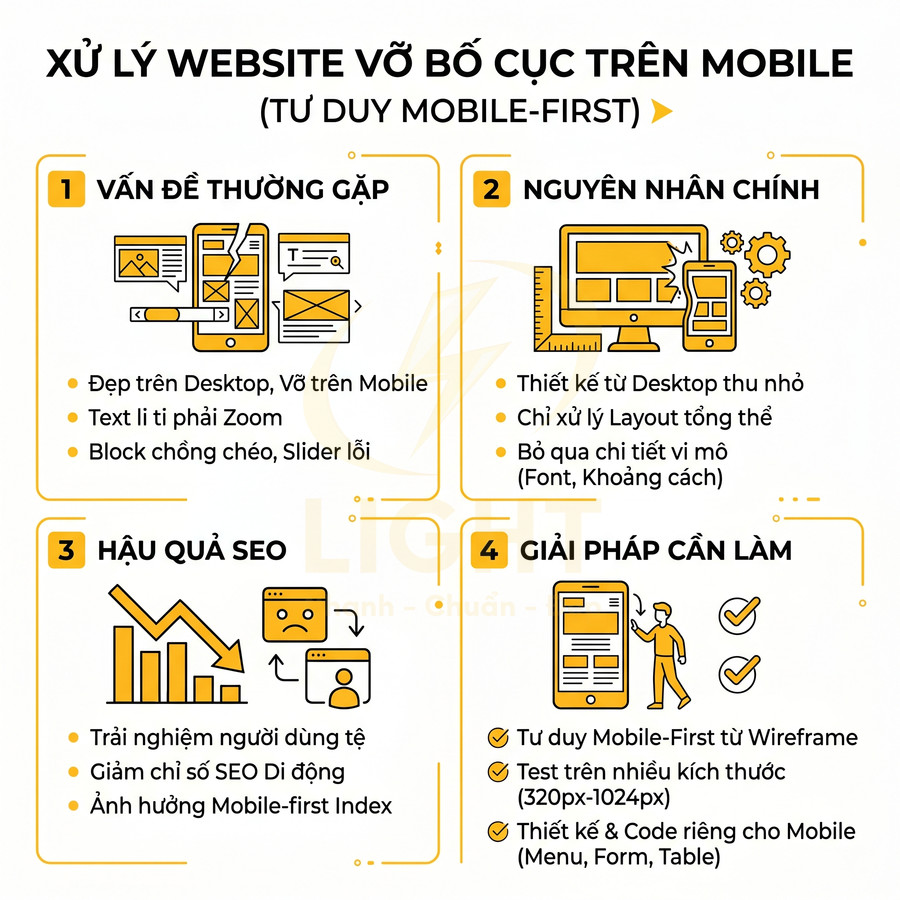
Những lỗi này trực tiếp làm giảm khả năng đọc và tương tác, khiến người dùng di động – vốn thường chiếm 60–80% tổng traffic – nhanh chóng thoát trang. Từ góc độ SEO, điều này thể hiện qua các chỉ số như bounce rate cao, time on page thấp, số trang/phiên ít, và tỷ lệ quay lại thấp. Các tín hiệu hành vi này, dù không phải là “ranking factor” công khai, vẫn là dữ liệu mà Google có thể sử dụng để đánh giá mức độ phù hợp và chất lượng trải nghiệm của trang, đặc biệt trên mobile-first index.
Để tránh tình trạng “đẹp trên desktop, vỡ trên mobile”, cần áp dụng tư duy mobile-first ngay từ giai đoạn wireframe và thiết kế UI. Thay vì thiết kế bản desktop rồi thu nhỏ, hãy bắt đầu từ màn hình 360–414px, xác định rõ:
- Thứ tự ưu tiên nội dung (content priority) trên màn hình nhỏ
- Các thành phần bắt buộc phải hiển thị “above the fold” trên di động
- Cách rút gọn hoặc ẩn bớt các block ít quan trọng khi không đủ không gian
Về mặt kỹ thuật, cần kiểm tra từng template trên nhiều kích thước màn hình, không chỉ một breakpoint duy nhất. Các breakpoint phổ biến nên được test gồm: 320px, 360px, 375px, 414px, 768px, 1024px. Mỗi template quan trọng (trang chủ, category, chi tiết bài viết, landing page, trang sản phẩm, giỏ hàng, checkout) cần được xem xét kỹ trên các kích thước này để phát hiện:
- Text bị tràn, vỡ dòng, hoặc bị che bởi các phần tử fixed (header, bar, popup)
- Ảnh bị crop sai tỷ lệ, không giữ được focal point quan trọng
- Slider/carousel không vuốt được, hoặc vuốt bị “kẹt” do chồng chéo với vùng scroll
- Bảng (table) bị tràn ngang, không có cơ chế scroll riêng hoặc chuyển sang dạng card
Các thành phần như menu, form, bảng, slider, popup cần được thiết kế và code riêng cho di động, không chỉ đơn giản là thu nhỏ từ bản desktop. Ví dụ: menu mega trên desktop có thể phải chuyển thành accordion nhiều tầng trên mobile; bảng dữ liệu rộng nên chuyển thành danh sách card dọc; slider nhiều item nên giới hạn số item hiển thị và tăng kích thước vùng chạm. Trong quá trình phát triển, Chrome DevTools nên được sử dụng liên tục với chế độ giả lập thiết bị, kết hợp với Lighthouse để đo lường các chỉ số như Tap targets, Font size, Layout shift. Việc này cần diễn ra song song với coding, không đợi đến khi “xong giao diện” mới test, vì chi phí sửa lỗi layout ở giai đoạn cuối thường rất cao.
Nút CTA khó chạm, form dài và menu khó điều hướng
Trên di động, mọi hành động chuyển đổi (click CTA, điền form, mở menu, chọn danh mục) đều diễn ra thông qua ngón tay cái với độ chính xác hạn chế. Nếu nút CTA quá nhỏ, đặt sát nhau hoặc quá gần mép màn hình, người dùng sẽ rất dễ bấm nhầm, phải quay lại, hoặc đơn giản là bỏ cuộc. Đây là lý do tại sao các guideline về UX di động luôn nhấn mạnh kích thước tối thiểu và khoảng cách giữa các vùng chạm.
Nhiều website vẫn dùng nút CTA kích thước nhỏ (dưới 36x36px), text mảnh, màu sắc không đủ tương phản với nền, hoặc đặt ở vị trí khó với tới (góc trên cùng bên phải). Trên thực tế, vùng dễ chạm nhất bằng ngón tay cái thường nằm ở nửa dưới màn hình, đặc biệt là khu vực trung tâm và bên phải đối với người thuận tay phải. Việc đặt CTA quan trọng (Mua ngay, Đăng ký, Gọi ngay) ở khu vực này có thể cải thiện đáng kể tỷ lệ click.

Về kích thước, nên tuân theo khuyến nghị tối thiểu khoảng 44x44px cho vùng chạm, đồng thời đảm bảo khoảng cách giữa các nút đủ rộng để tránh bấm nhầm. Ngoài ra, cần chú ý:
- Độ tương phản màu (color contrast) giữa nút và nền, giữa text và màu nút
- Trạng thái hover/active/focus rõ ràng (dù trên mobile không có hover, vẫn cần trạng thái active)
- Không đặt CTA quan trọng quá sát cạnh dưới nếu có thanh điều hướng hệ điều hành che khuất
Form trên di động là một trong những điểm nghẽn chuyển đổi lớn nhất. Form dài, yêu cầu quá nhiều trường, không tối ưu loại input (keyboard type) khiến người dùng phải thao tác nhiều, dễ sai và dễ nản. Một form đăng ký đơn giản nhưng yêu cầu nhập đầy đủ họ tên, email, số điện thoại, địa chỉ, ngày sinh, nghề nghiệp… trên màn hình nhỏ sẽ làm tỷ lệ hoàn thành giảm mạnh.
Để tối ưu form trên mobile, cần:
- Rút gọn số trường xuống mức tối thiểu cần thiết cho mục tiêu kinh doanh
- Nhóm các trường liên quan và cân nhắc chia thành nhiều bước (multi-step form) nếu form dài
- Tối ưu loại input: dùng keyboard dạng email cho trường email, dạng number cho số điện thoại, date picker cho ngày tháng
- Sử dụng auto-complete, gợi ý (suggestion) cho địa chỉ, nghề nghiệp, khu vực
- Hiển thị rõ tiến trình (progress) nếu form nhiều bước để giảm cảm giác “vô tận”
Menu điều hướng trên di động cũng là yếu tố ảnh hưởng trực tiếp đến khả năng tìm nội dung và chuyển đổi. Menu nhiều tầng, chữ nhỏ, khoảng cách dòng hẹp, không có icon hỗ trợ nhận diện sẽ khiến người dùng khó định hướng. Với các website lớn, nếu không có search nội bộ dễ truy cập, người dùng sẽ phải cuộn và mở/đóng nhiều tầng menu, làm tăng ma sát và khả năng thoát trang.
Menu mobile nên được thiết kế với cấu trúc phân nhóm rõ ràng, ưu tiên các mục quan trọng lên trên, sử dụng icon để hỗ trợ nhận diện nhanh, và đảm bảo vùng chạm cho từng item đủ lớn. Với site có nhiều nội dung, thanh search nên được đặt ở vị trí nổi bật trong menu hoặc ngay trên header, cho phép người dùng truy cập nhanh đến nội dung cần mà không phải điều hướng nhiều bước.
Popup che nội dung chính làm tăng thoát trang
Popup đăng ký, khuyến mãi, thông báo cookie nếu không được thiết kế cẩn thận sẽ trở thành rào cản lớn cho trải nghiệm di động. Trên màn hình nhỏ, một popup toàn màn hình xuất hiện ngay khi vừa load trang, che kín nội dung chính và không cho người dùng xem bất cứ thông tin gì trước khi quyết định, thường dẫn đến phản ứng tiêu cực: đóng ngay nếu tìm được nút, hoặc thoát trang nếu không thấy cách tắt.
Vấn đề trở nên nghiêm trọng hơn khi nút đóng (close) quá nhỏ, màu mờ, hoặc đặt sát mép trên cùng – nơi khó chạm trên một số thiết bị lớn. Ngoài ra, việc hiển thị popup lặp lại nhiều lần trong cùng một phiên, hoặc trên mỗi lần chuyển trang, sẽ làm người dùng cảm thấy bị “quấy rầy”, giảm thiện cảm với thương hiệu và tăng tỷ lệ thoát.

Từ góc độ SEO, Google đã có hướng dẫn rõ ràng về việc hạn chế intrusive interstitials trên di động, coi đây là yếu tố ảnh hưởng tiêu cực đến trải nghiệm người dùng. Những popup che phần lớn nội dung ngay sau khi người dùng truy cập từ kết quả tìm kiếm có thể bị đánh giá xấu, đặc biệt nếu nội dung chính không thể truy cập dễ dàng.
Để cân bằng giữa nhu cầu thu thập lead và trải nghiệm người dùng, cần:
- Giới hạn tần suất hiển thị popup, tránh xuất hiện ngay khi vừa load trang lần đầu
- Chỉ hiển thị sau khi người dùng đã cuộn một đoạn nhất định hoặc có tương tác (click, scroll)
- Trên desktop có thể dùng cơ chế exit intent, nhưng trên mobile nên thận trọng vì hành vi khác biệt
- Ưu tiên banner nhỏ, slide-in ở cạnh dưới hoặc trên, thay vì popup toàn màn hình
- Thiết kế nút đóng rõ ràng, kích thước đủ lớn, tương phản cao, không “ẩn” trong màu nền
Nội dung popup cũng cần thực sự có giá trị với người dùng: ưu đãi rõ ràng, nội dung độc quyền, lợi ích cụ thể… thay vì chỉ là form “Đăng ký nhận tin” chung chung. Khi người dùng cảm thấy giá trị nhận được xứng đáng với việc bị gián đoạn, tỷ lệ chấp nhận popup và tỷ lệ chuyển đổi sẽ cao hơn, đồng thời giảm bớt tác động tiêu cực đến tín hiệu hành vi.
Trang local thiếu nút gọi nhanh và chỉ đường theo khu vực
Đối với truy vấn local (ví dụ: “nha khoa gần đây”, “quán cà phê quận 1”, “sửa xe 24/7”), người dùng di động thường có ý định hành động rất rõ ràng: gọi điện, xem đường đi, kiểm tra giờ mở cửa, đặt lịch. Nếu trang local chỉ tập trung vào hình ảnh đẹp, mô tả dài, review chi tiết mà thiếu các nút hành động trực tiếp như Gọi ngay, Chỉ đường, Đặt lịch, thì khả năng chuyển đổi sẽ bị giảm mạnh, dù nội dung có xếp hạng tốt.
Nhiều business local còn mắc lỗi không hiển thị rõ số điện thoại, chôn thông tin liên hệ ở cuối trang, hoặc dùng ảnh chứa số điện thoại thay vì text, khiến người dùng không thể bấm gọi trực tiếp. Trên di động, mỗi bước thừa (copy số, mở app gọi, dán số) đều làm giảm tỷ lệ chuyển đổi. Tương tự, nếu không có nút “Chỉ đường” mở Google Maps với tọa độ chính xác, người dùng phải tự tìm tên địa điểm, dễ nhầm lẫn hoặc bỏ cuộc.
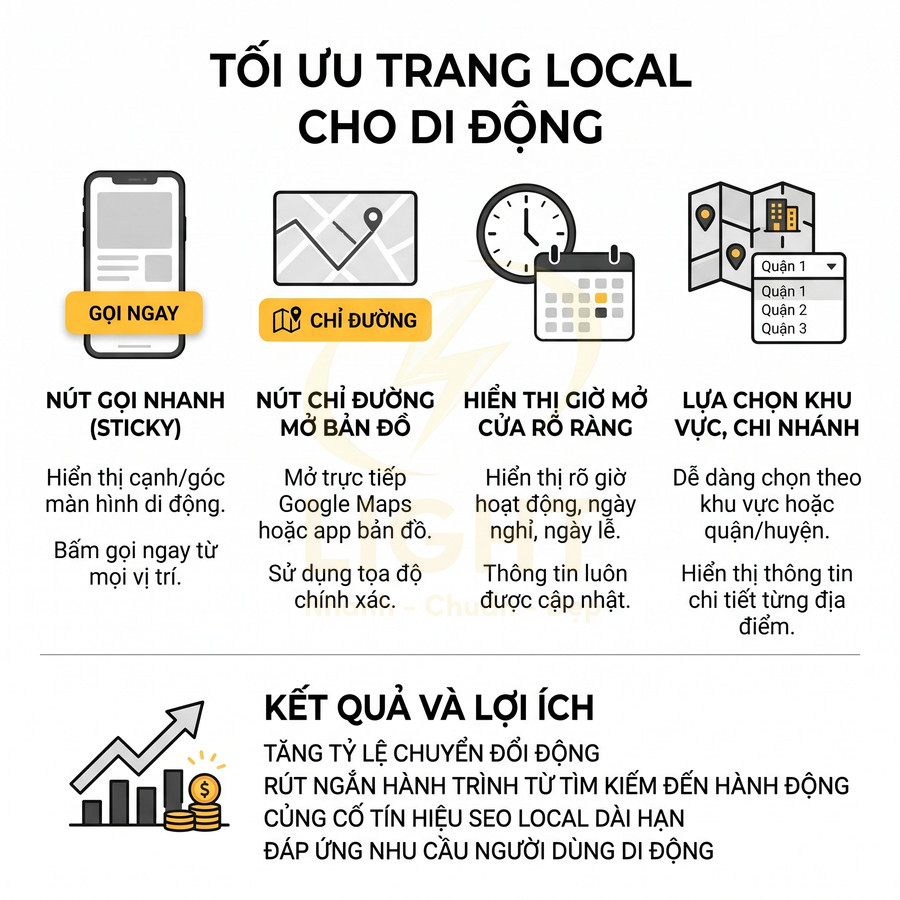
Trang local nên được tối ưu với các yếu tố sau:
- Nút gọi nổi (sticky call button) luôn hiển thị ở cạnh dưới hoặc góc màn hình trên mobile, cho phép bấm gọi ngay từ bất kỳ vị trí nào trên trang
- Nút “Chỉ đường” mở trực tiếp Google Maps hoặc app bản đồ mặc định, sử dụng tọa độ chính xác thay vì chỉ địa chỉ text
- Hiển thị rõ ràng giờ mở cửa, ngày nghỉ, thông tin đặc biệt (mở 24/7, chỉ làm việc theo lịch hẹn, v.v.)
- Nếu có nhiều chi nhánh, cung cấp cơ chế chọn khu vực dễ dàng (dropdown, list theo quận/huyện) và hiển thị thông tin từng chi nhánh rõ ràng
Về mặt SEO, các yếu tố này không chỉ cải thiện trải nghiệm người dùng mà còn củng cố tín hiệu local khi được kết hợp với schema LocalBusiness và thông tin NAP (Name, Address, Phone) đồng nhất trên website, Google Business Profile và các directory khác. Khi người dùng di động thường xuyên tương tác với các nút gọi, chỉ đường, đặt lịch, Google có thêm dữ liệu hành vi để đánh giá mức độ phù hợp của business với các truy vấn local tương tự.
Việc thiết kế trang local theo hướng “hành động trước, nội dung sau” trên di động giúp rút ngắn hành trình từ tìm kiếm đến chuyển đổi. Người dùng có thể chỉ cần vài giây từ lúc click vào kết quả tìm kiếm đến khi bấm gọi hoặc mở chỉ đường. Điều này không chỉ tăng doanh thu trực tiếp mà còn tạo ra chuỗi tín hiệu tích cực về tương tác, hỗ trợ thứ hạng local trong dài hạn.
Lỗi landing quảng cáo kéo tụt dữ liệu SEO vì không có chặn click tặc
Việc không chặn click tặc trong chiến dịch quảng cáo trả phí làm nền cho SEO khiến toàn bộ hệ thống đo lường và ra quyết định bị lệch. Dữ liệu về từ khóa, intent, thông điệp, layout landing, cũng như hiệu quả ngân sách đều bị méo do tỷ lệ nhấp gian lận, bot và traffic không liên quan. Điều này dẫn đến đánh giá sai “từ khóa chuyển đổi tốt”, ưu tiên nhầm topic cluster, hiểu sai về chất lượng landing và hành vi người dùng, từ đó tối ưu nội dung sai hướng. Để khắc phục, cần xây dựng cơ chế phát hiện và chặn IP bất thường, lọc bot, phân tách traffic sạch và traffic nghi ngờ, đồng bộ rule giữa nền tảng Ads, firewall, WAF và analytics. Chỉ khi dữ liệu đã được làm sạch, quảng cáo mới thực sự hỗ trợ SEO hiệu quả.
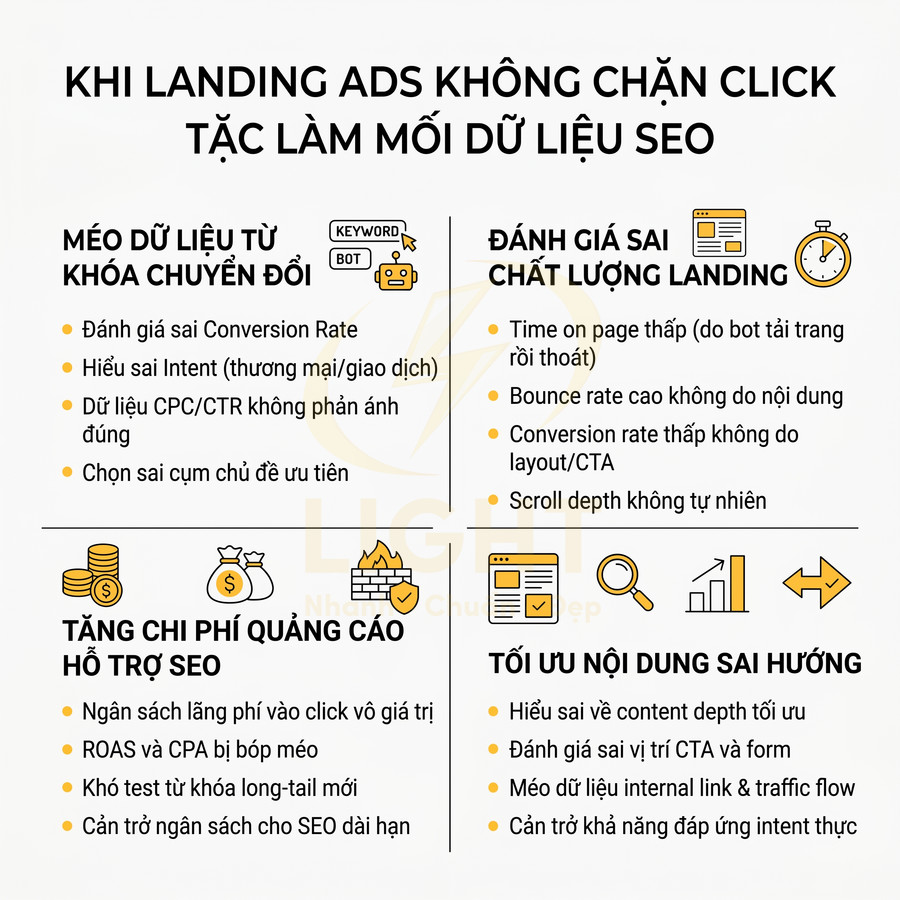
Nhấp gian lận làm méo dữ liệu từ khóa chuyển đổi tốt
Khi dùng quảng cáo trả phí để hỗ trợ SEO với mục tiêu test từ khóa, test thông điệp, xác định intent và ưu tiên cụm chủ đề, việc không có cơ chế phát hiện và chặn click tặc khiến toàn bộ mô hình ra quyết định bị sai lệch. Về bản chất, bạn đang dùng dữ liệu quảng cáo như một “proxy” để đánh giá:
- Từ khóa nào có conversion rate cao
- Nhóm intent nào (transactional, commercial, informational) mang lại lead hoặc sale tốt hơn
- Thông điệp nào (USP, offer, pain point) kích hoạt hành vi chuyển đổi
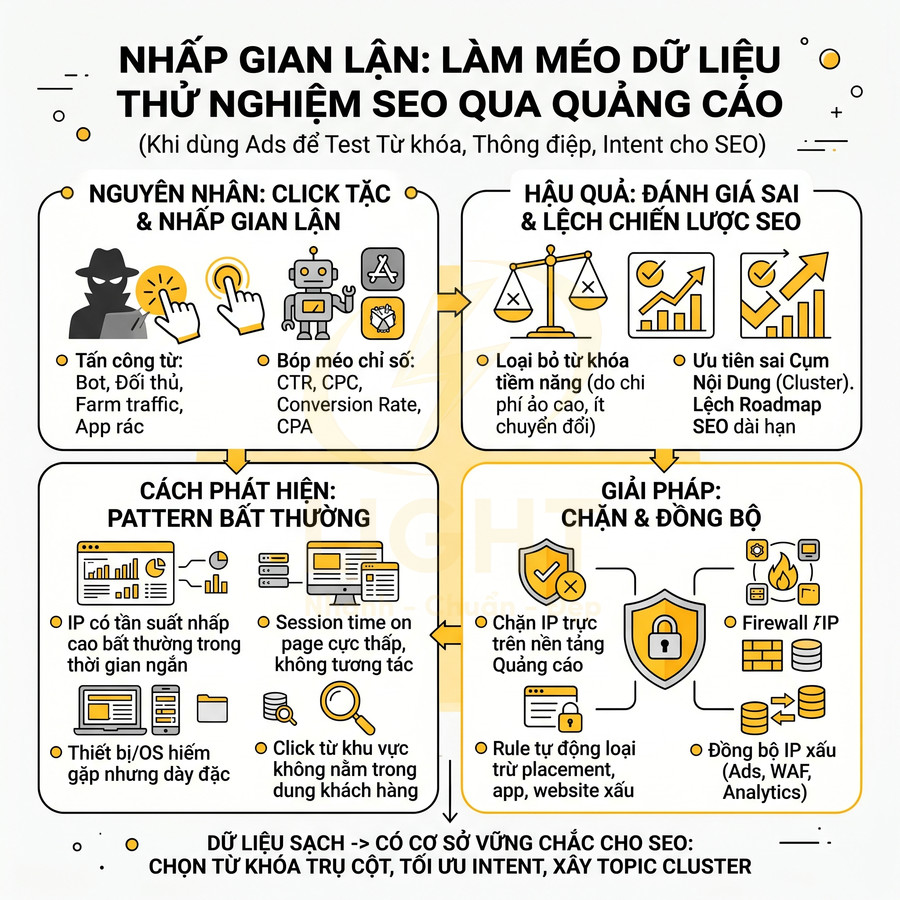
Tuy nhiên, khi tỷ lệ nhấp gian lận cao (bot, đối thủ, farm traffic, click từ app rác), các chỉ số như CTR, CPC, Conversion Rate, CPA đều bị bóp méo. Một số hệ quả chuyên môn thường gặp:
- Đánh giá sai “từ khóa chuyển đổi tốt”: từ khóa thực sự tiềm năng có thể bị loại bỏ vì dữ liệu cho thấy chi phí cao, ít chuyển đổi, trong khi nguyên nhân là do bị bắn click tặc.
- Ưu tiên sai cluster nội dung trong SEO: bạn có thể dồn nguồn lực SEO vào nhóm từ khóa tưởng là hiệu quả (do ít bị click tặc, dữ liệu “đẹp” hơn) nhưng thực tế lại không phải nhóm mang lại doanh thu tốt nhất.
- Méo phễu phân bổ ngân sách: dữ liệu CPA/ROAS sai khiến bạn phân bổ ngân sách quảng cáo hỗ trợ SEO không tối ưu, kéo theo roadmap SEO dài hạn bị lệch.
Về mặt kỹ thuật, cần tích hợp công cụ hoặc giải pháp tự xây để phát hiện các pattern bất thường như:
- IP hoặc dải IP có tần suất nhấp cao bất thường trong khoảng thời gian ngắn
- Session có time on page cực thấp, không scroll, không tương tác nhưng nhấp lặp lại nhiều lần
- Thiết bị/OS/browser hiếm gặp nhưng xuất hiện dày đặc trong log
- Nhấp đến từ khu vực địa lý không nằm trong chân dung khách hàng mục tiêu
Sau khi phát hiện, cần có cơ chế:
- Chặn IP hoặc dải IP trực tiếp trong nền tảng quảng cáo
- Thiết lập rule tự động loại trừ placement, app, website có tỷ lệ click bất thường
- Đồng bộ danh sách IP xấu giữa hệ thống Ads, firewall, WAF và analytics
Dữ liệu từ quảng cáo chỉ thực sự hữu ích cho SEO khi đã được lọc sạch click gian lận, phản ánh đúng hành vi người dùng thật. Khi đó, các quyết định như chọn từ khóa trụ cột, xây topic cluster, tối ưu meta, tối ưu nội dung theo intent mới có cơ sở vững chắc.
Traffic xấu khiến đánh giá chất lượng landing sai lệch
Landing page thường được dùng như một “sandbox” để test thông điệp, layout, cấu trúc nội dung, độ dài form, vị trí CTA trước khi áp dụng cho trang SEO chính (category page, product page, pillar page). Vấn đề là khi phần lớn traffic đến từ nguồn xấu (click tặc, bot, mạng hiển thị kém chất lượng), các chỉ số hành vi cốt lõi sẽ bị bóp méo:
- Time on page thấp bất thường do bot tải trang rồi thoát ngay
- Bounce rate cao nhưng không phản ánh việc người dùng thật không quan tâm
- Conversion rate thấp vì mẫu traffic không phải khách hàng mục tiêu
- Scroll depth không tự nhiên (scroll cực nhanh đến cuối trang hoặc không scroll)
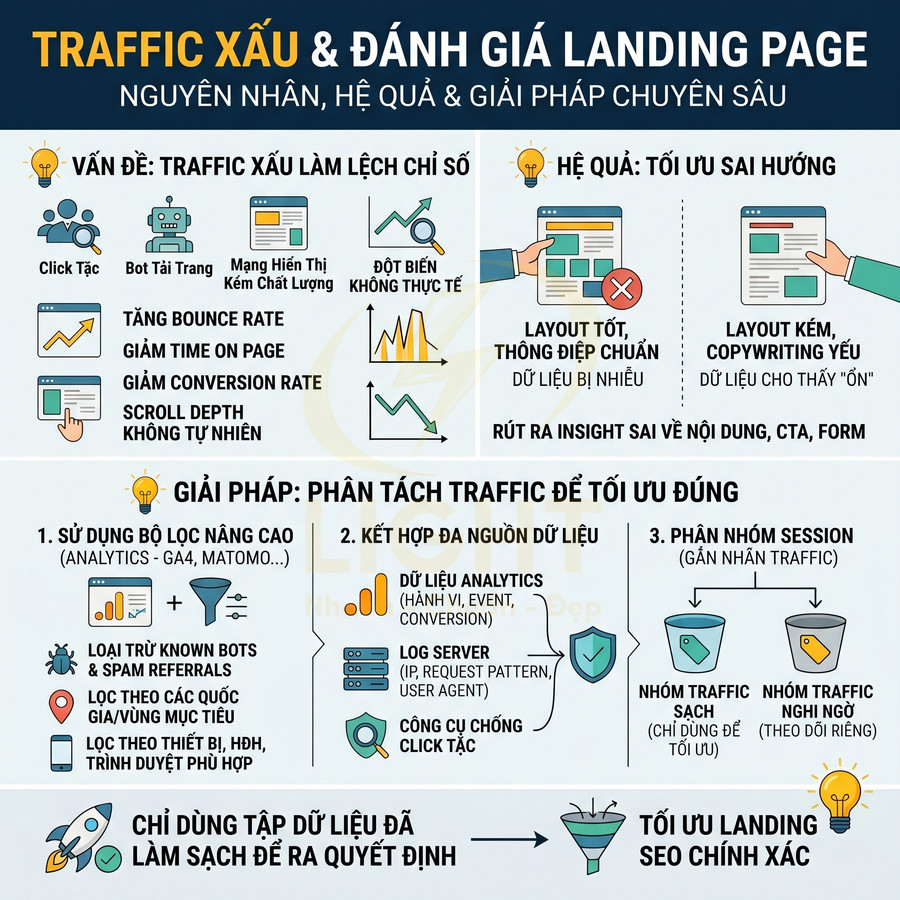
Hệ quả là bạn có thể:
- Bỏ một layout tốt, thông điệp chuẩn vì tưởng rằng không hiệu quả
- Giữ một layout kém, copywriting yếu chỉ vì dữ liệu bị nhiễu cho thấy “ổn”
- Rút ra insight sai về độ dài nội dung, số lượng CTA, vị trí form, cách trình bày lợi ích
Giải pháp chuyên sâu là phân tách rõ traffic sạch và traffic nghi ngờ trong phân tích. Một số bước kỹ thuật:
- Sử dụng bộ lọc nâng cao trong analytics (GA4, Matomo, v.v.) để:
- Loại trừ known bots và spam referrals
- Lọc theo country/region đúng với thị trường mục tiêu
- Lọc theo device category, OS, browser phù hợp với chân dung khách hàng
- Kết hợp dữ liệu từ nhiều nguồn:
- GA4: hành vi người dùng, event, conversion
- Log server: IP, user agent, request pattern, tần suất truy cập
- Công cụ chống click tặc: đánh giá rủi ro từng click, gắn nhãn traffic nghi ngờ
- Phân nhóm session:
- Nhóm “clean traffic” đáp ứng các tiêu chí về thời gian, tương tác, nguồn
- Nhóm “suspected traffic” để theo dõi riêng, không dùng cho quyết định tối ưu
Chỉ nên dùng tập dữ liệu đã được làm sạch để ra quyết định tối ưu landing và áp dụng cho trang SEO. Khi đó, các test A/B về headline, hero section, social proof, form, CTA mới phản ánh đúng hành vi người dùng thật, giúp bạn xây landing SEO có khả năng chuyển đổi cao, giảm rủi ro tối ưu sai hướng.
Không lọc bot và IP bất thường làm tăng chi phí hỗ trợ SEO bằng quảng cáo
Trong nhiều chiến dịch, quảng cáo được dùng để “mồi” dữ liệu cho SEO: đẩy nhanh việc thu thập tín hiệu hành vi, test từ khóa, tăng nhận diện thương hiệu, tạo branded search. Nếu không lọc bot và IP bất thường, ngân sách sẽ bị tiêu tốn vào những lượt nhấp không có giá trị, làm giảm hiệu quả tổng thể của chiến lược.
Về mặt tài chính và chiến lược:
- Chi phí hỗ trợ SEO tăng nhưng không tạo ra insight: bạn trả tiền cho click nhưng không thu được dữ liệu hành vi hữu ích để tối ưu nội dung, cấu trúc site, internal link.
- ROAS và CPA bị bóp méo: khó đánh giá chính xác hiệu quả của việc dùng Ads để hỗ trợ SEO, dẫn đến hoặc cắt giảm quá sớm, hoặc tiếp tục đốt tiền vào traffic rác.
- Ảnh hưởng đến chiến lược long-tail và mid-tail: những nhóm từ khóa này thường được test bằng Ads trước, nếu dữ liệu sai, bạn có thể bỏ qua nhiều cơ hội SEO có biên lợi nhuận cao.
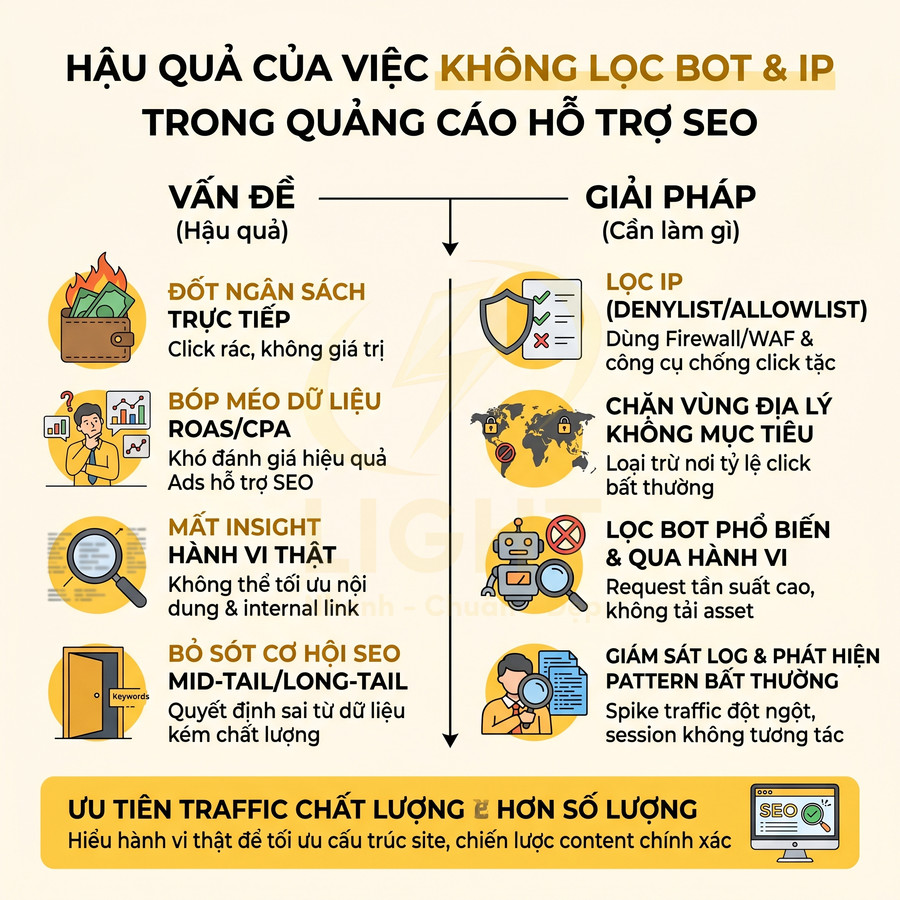
Cần thiết lập rule loại trừ IP, chặn vùng địa lý không mục tiêu, lọc bot đã biết, và giám sát log để phát hiện pattern bất thường. Một số thực hành tốt:
- Thiết lập danh sách IP denylist và allowlist, đồng bộ giữa:
- Nền tảng quảng cáo (Google Ads, Facebook Ads, v.v.)
- Firewall/WAF
- Hệ thống analytics và công cụ chống click tặc
- Chặn vùng địa lý không mục tiêu hoặc có tỷ lệ click bất thường cao nhưng không tạo ra chuyển đổi
- Lọc bot đã biết bằng:
- Danh sách user agent của các bot phổ biến
- Rule nhận diện hành vi: request tần suất cao, không tải asset, không thực thi JS
- Giám sát log để phát hiện pattern:
- Spike traffic đột ngột từ một dải IP hoặc một quốc gia
- Click lặp lại vào cùng một quảng cáo trong thời gian rất ngắn
- Session không có event tương tác nhưng lặp lại nhiều lần
Việc này nên được tự động hóa tối đa, kết hợp với cảnh báo khi tỷ lệ nhấp bất thường tăng đột biến. Một hệ thống SEO – Ads tích hợp tốt phải coi chất lượng traffic là ưu tiên, không chỉ số lượng. Khi đó, mỗi đồng chi cho quảng cáo hỗ trợ SEO đều đóng góp vào việc hiểu rõ hơn hành vi người dùng thật, từ đó tối ưu nội dung, cấu trúc site, internal link và chiến lược content một cách chính xác.
Dữ liệu người dùng không sạch làm tối ưu nội dung sai hướng
SEO hiện đại dựa rất nhiều vào phân tích hành vi người dùng: trang nào giữ chân tốt, đoạn nội dung nào được cuộn nhiều, CTA nào được nhấp nhiều, section nào bị bỏ qua. Các quyết định như:
- Thay đổi heading, subheading
- Điều chỉnh độ dài nội dung, mức độ chi tiết
- Thêm/bớt block FAQ, testimonial, case study
- Di chuyển hoặc thay đổi thiết kế CTA
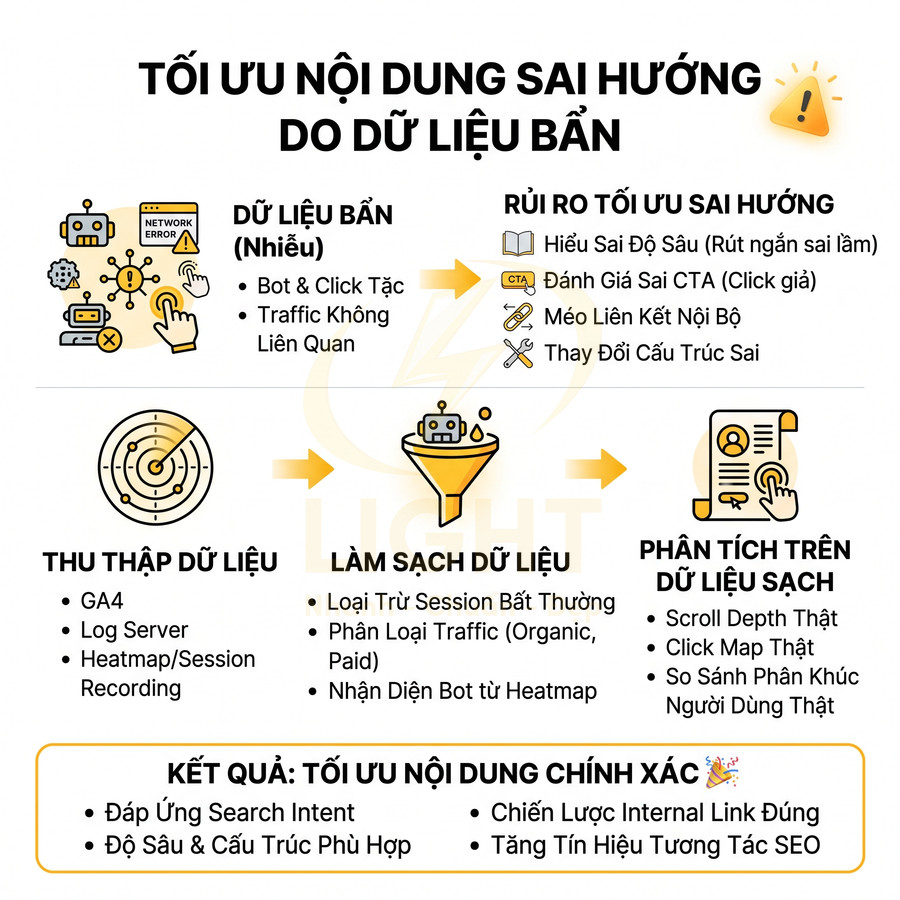
Đều dựa trên dữ liệu hành vi. Khi dữ liệu này bị nhiễu bởi bot, click tặc, hoặc traffic không liên quan, toàn bộ quá trình tối ưu nội dung sẽ đi sai hướng. Một số rủi ro chuyên môn:
- Hiểu sai về “content depth” tối ưu: bot thường không scroll hoặc scroll bất thường, khiến bạn tưởng rằng người dùng không đọc sâu, từ đó rút ngắn nội dung, làm giảm khả năng đáp ứng intent và E-E-A-T.
- Đánh giá sai vị trí CTA: click giả hoặc event tự động có thể tập trung ở một khu vực, khiến bạn tưởng CTA ở đó hiệu quả, trong khi người dùng thật lại không tương tác.
- Méo dữ liệu về internal link: bot có thể crawl và click internal link theo pattern riêng, làm sai lệch đánh giá về luồng di chuyển tự nhiên của người dùng.
Giải pháp là xây dựng pipeline dữ liệu có bước làm sạch rõ ràng trước khi đưa vào phân tích và ra quyết định. Một pipeline cơ bản có thể gồm:
- Thu thập dữ liệu:
- GA4 hoặc công cụ analytics khác để ghi nhận session, event, conversion
- Log server để ghi nhận request thô (IP, user agent, path, timestamp)
- Công cụ heatmap, session recording để quan sát hành vi chi tiết
- Làm sạch dữ liệu:
- Loại trừ session bất thường:
- Time on site cực thấp nhưng nhiều pageview
- Không tải JS nhưng vẫn tạo request
- Pattern click không giống hành vi con người
- Phân loại nguồn traffic:
- Organic, Paid, Referral, Direct, Social
- Trong Paid, phân tách theo campaign, ad group, keyword
- Gắn tag cho chiến dịch để truy vết chính xác nguồn tạo ra session
- Sử dụng các công cụ heatmap, session recording có khả năng nhận diện bot và loại trừ khỏi báo cáo
- Loại trừ session bất thường:
- Phân tích trên dữ liệu sạch:
- Đo lường scroll depth, click map, time on section trên nhóm user thật
- So sánh hành vi giữa các segment (new vs returning, organic vs paid)
- Xác định section nào thực sự đóng góp vào conversion hoặc micro-conversion
Chỉ khi dữ liệu đủ sạch, việc tối ưu nội dung mới thực sự phản ánh nhu cầu và hành vi của khách hàng mục tiêu. Điều này ảnh hưởng trực tiếp đến:
- Khả năng đáp ứng search intent (informational, navigational, transactional)
- Độ sâu và cấu trúc nội dung (heading, đoạn, bullet, schema)
- Chiến lược internal link và topic cluster
- Tín hiệu tương tác gửi về cho công cụ tìm kiếm, gián tiếp tác động đến thứ hạng
Thiếu hệ thống tự động quét lỗi SEO toàn site khiến lỗi nhỏ tích tụ thành lỗi lớn
Hệ thống SEO kỹ thuật quy mô lớn cần khả năng giám sát, phát hiện và sửa lỗi theo vòng đời thay vì xử lý thủ công, rời rạc. Mỗi thao tác chỉnh sửa nội dung, thêm block mới hay deploy phiên bản mới đều có thể sinh lỗi onpage, schema, canonical, redirect hoặc làm thay đổi trạng thái index và crawl mà đội ngũ không kịp nhận ra. Vì vậy, kiến trúc SEO hiện đại phải kết hợp ba lớp: crawl định kỳ toàn site để phát hiện lỗi tích tụ, test tự động gắn với CI/CD để chặn lỗi ngay khi triển khai, và hệ thống cảnh báo real-time dựa trên Search Console, log server, log crawl. Trên nền đó, CMS cần hỗ trợ template-driven và bulk edit để sửa lỗi hàng loạt, đảm bảo tính nhất quán và giảm chi phí tối ưu lâu dài.
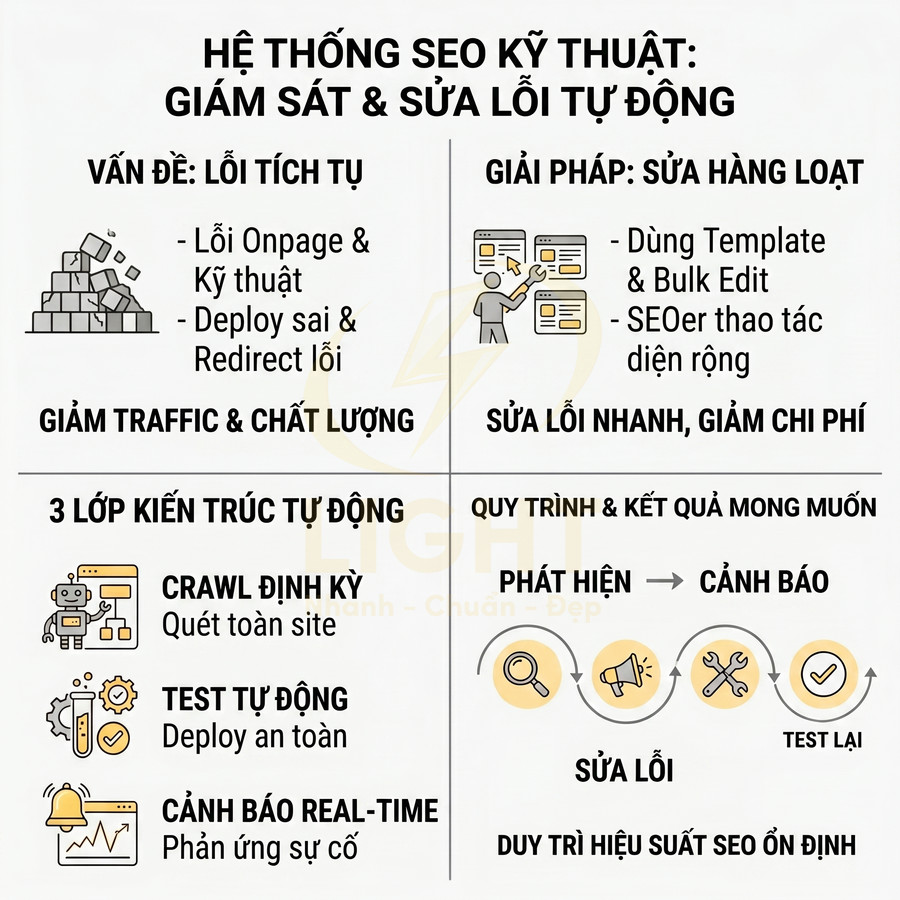
Không phát hiện kịp tiêu đề trùng, alt thiếu và internal link gãy
Trong môi trường vận hành thực tế, mỗi thao tác nhỏ như thêm bài blog, chỉnh sửa landing page, cập nhật mô tả sản phẩm, thay ảnh banner… đều có khả năng tạo ra các lỗi onpage “nhỏ nhưng nguy hiểm”. Các lỗi điển hình gồm: tiêu đề trùng lặp (duplicate title), thẻ H1 lặp lại hoặc sai cấu trúc, thuộc tính alt ảnh bị bỏ trống, internal link gãy hoặc trỏ nhầm URL. Khi website phát triển lên hàng nghìn, hàng chục nghìn URL, việc kiểm tra thủ công gần như bất khả thi, khiến các lỗi này âm thầm tích tụ và làm suy giảm chất lượng toàn site.
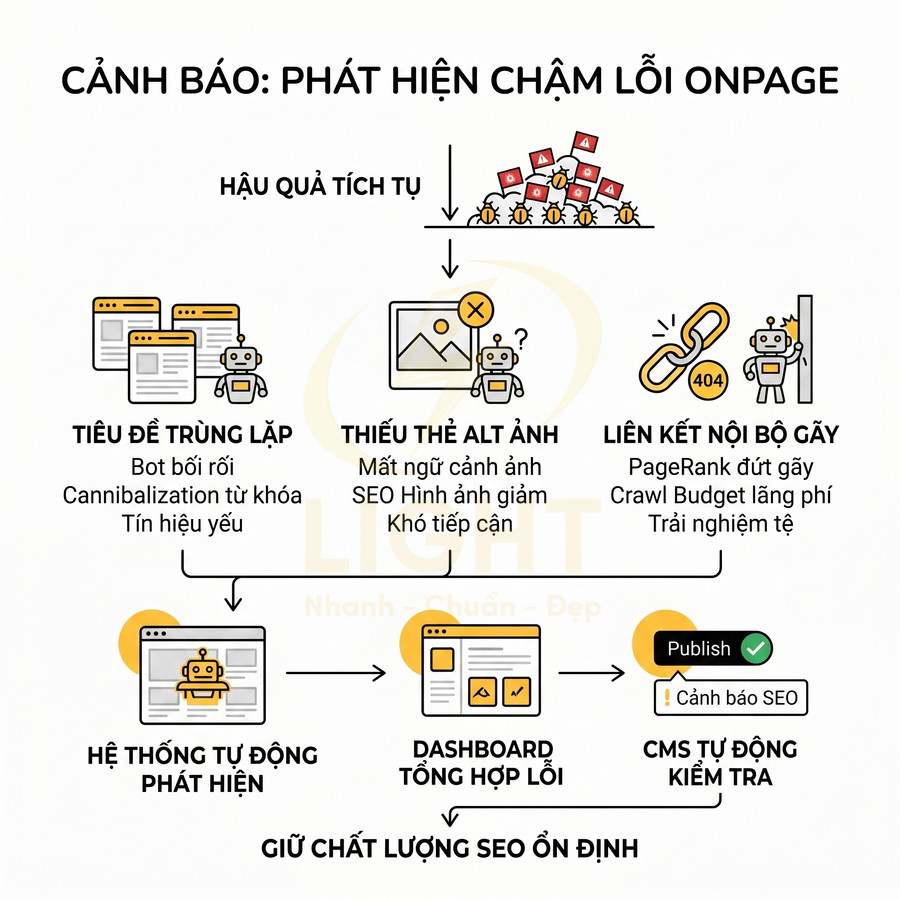
Về mặt kỹ thuật SEO, mỗi nhóm lỗi đều có tác động riêng:
- Tiêu đề trùng và H1 lặp: làm giảm khả năng phân biệt chủ đề giữa các trang, gây khó khăn cho bot trong việc xác định trang nào là phiên bản chính cho một truy vấn cụ thể, tăng nguy cơ cannibalization và làm loãng tín hiệu xếp hạng.
- Alt ảnh thiếu: làm mất đi một lớp ngữ cảnh quan trọng giúp bot hiểu nội dung hình ảnh, giảm khả năng xuất hiện trên Google Images, đồng thời ảnh hưởng tiêu cực đến khả năng tiếp cận (accessibility) cho người dùng sử dụng screen reader.
- Internal link gãy: làm đứt gãy luồng PageRank nội bộ, tạo trải nghiệm xấu cho người dùng, tăng tỷ lệ thoát và khiến bot lãng phí crawl budget vào các URL trả về 404/410.
Nếu không có hệ thống tự động quét toàn site, các lỗi này thường chỉ được phát hiện khi:
- Traffic organic giảm rõ rệt trong vài tuần hoặc vài tháng.
- Các từ khóa chính bị tụt hạng hoặc biến mất khỏi top 10.
- Search Console báo lỗi tăng đột biến nhưng đã ở trạng thái “hậu quả” chứ không còn là “cảnh báo sớm”.
Giải pháp mang tính nền tảng là tích hợp một công cụ crawl định kỳ (theo tuần hoặc theo tháng, tùy tốc độ thay đổi nội dung) để quét toàn bộ site và ghi nhận các lỗi onpage cơ bản. Công cụ này nên:
- Thu thập dữ liệu về title, H1, H2, meta description, canonical, status code, số lượng internal link in/out, thuộc tính alt của ảnh.
- Phát hiện các pattern lỗi lặp lại theo thư mục, theo loại template, theo nhóm URL (ví dụ: /blog/, /product/, /category/).
- Xuất dữ liệu vào một dashboard tổng hợp có phân loại theo mức độ ưu tiên (critical, high, medium, low) để đội SEO và kỹ thuật có thể xử lý theo batch.
Song song, hệ thống CMS nên được thiết kế theo hướng “SEO by default”, nghĩa là:
- Khi người dùng nhấn “Publish” hoặc “Update”, CMS tự động chạy các rule kiểm tra: thiếu H1, thiếu meta title/description, alt trống cho ảnh chính, internal link trỏ đến URL 404 đã biết, slug trùng với URL khác.
- Các lỗi hoặc cảnh báo được hiển thị ngay trong giao diện chỉnh sửa nội dung, kèm gợi ý sửa nhanh (ví dụ: auto-suggest title, auto-fill alt dựa trên caption hoặc H1).
- Có cơ chế chặn publish đối với một số lỗi nghiêm trọng (ví dụ: trang quan trọng nhưng bị đặt noindex, canonical trỏ ra ngoài domain, hoặc title trùng với một trang khác trong cùng nhóm).
Nhờ phát hiện sớm ở cấp độ từng lần chỉnh sửa, các lỗi nhỏ được “dập” ngay từ đầu, không kịp tích tụ thành vấn đề hệ thống, giúp giữ chất lượng SEO onpage ổn định khi quy mô site tăng.
Lỗi schema, canonical, redirect phát sinh sau mỗi lần thêm block mới
Trong các hệ thống website hiện đại, đặc biệt là các nền tảng dùng block kéo thả (page builder, headless CMS với component-based layout), mỗi lần thêm một block mới như FAQ, bảng giá, review, testimonial, CTA, gallery… đều có nguy cơ tạo ra lỗi kỹ thuật khó phát hiện bằng mắt thường. Giao diện người dùng vẫn hiển thị bình thường, nhưng phần “ngầm” dành cho bot có thể bị sai lệch.

Các nhóm lỗi thường gặp gồm:
- Lỗi schema: trùng type trên cùng một trang, lồng schema sai cấu trúc, thiếu thuộc tính bắt buộc (required properties), dùng type không phù hợp với nội dung thực tế, hoặc tạo nhiều block FAQPage/Product/Article không cần thiết.
- Lỗi canonical: canonical bị trùng giữa các trang khác nội dung, canonical tự trỏ về chính nó nhưng không nhất quán với phiên bản chuẩn (www/non-www, http/https, trailing slash), hoặc canonical bị bỏ trống trên một số template mới.
- Lỗi redirect/internal routing: block chứa link nội bộ trỏ đến URL cũ đã redirect, hoặc trỏ nhầm sang môi trường staging, subdomain test, khiến bot lãng phí crawl budget và làm loãng tín hiệu.
Vì các lỗi này nằm ở tầng cấu trúc HTML và dữ liệu có cấu trúc (structured data), việc kiểm tra thủ công từng trang sau mỗi lần deploy là không khả thi. Cần xây dựng một bộ test tự động gắn với pipeline triển khai (CI/CD) và quy trình thêm block mới.
Bộ test nên hoạt động theo nguyên tắc:
- Sau mỗi lần deploy hoặc sau khi một loại block/template mới được publish, hệ thống tự động crawl một tập hợp trang mẫu đại diện cho từng loại template (category page, product page, blog post, landing page, v.v.).
- Trích xuất và phân tích:
- Schema (JSON-LD, Microdata, RDFa): kiểm tra type, cấu trúc, thuộc tính bắt buộc, trùng lặp, xung đột giữa các block.
- Canonical: kiểm tra tính nhất quán, tránh canonical trỏ chéo hoặc trỏ ra ngoài domain chính.
- Redirect và status code: xác minh tất cả link trong block mới trả về 200 hoặc redirect hợp lệ, không có 404/500.
- Khi phát hiện bất thường, hệ thống gửi cảnh báo chi tiết (URL, loại lỗi, đoạn code liên quan) cho team dev và SEO để rollback hoặc fix trước khi lỗi lan rộng.
Đối với website dùng nhiều block kéo thả, nơi người dùng không kỹ thuật có thể tự do lắp ghép component, việc áp dụng các guardrail kỹ thuật là bắt buộc:
- Giới hạn loại schema mà mỗi block được phép sinh ra, tránh việc một block nhỏ tạo thêm schema không cần thiết.
- Định nghĩa rõ ràng mối quan hệ giữa schema ở cấp trang (page-level) và schema ở cấp block (component-level) để tránh xung đột.
- Tự động chuẩn hóa canonical và internal link trong block dựa trên routing rules của hệ thống, giảm khả năng người dùng nhập sai URL.
Không có cảnh báo trang mất index hoặc tụt crawl đột ngột
Trang quan trọng (money page, category chính, landing chạy quảng cáo, bài pillar content) có thể mất index vì nhiều nguyên nhân khác nhau: gắn noindex nhầm khi test, canonical trỏ sai sang một URL yếu hơn, lỗi server 5xx kéo dài, nội dung bị đánh giá trùng lặp hoặc chất lượng thấp, hoặc bị loại bỏ sau một đợt core update. Nếu không có hệ thống giám sát chủ động, các vấn đề này thường chỉ được phát hiện khi doanh thu hoặc lead giảm rõ rệt.
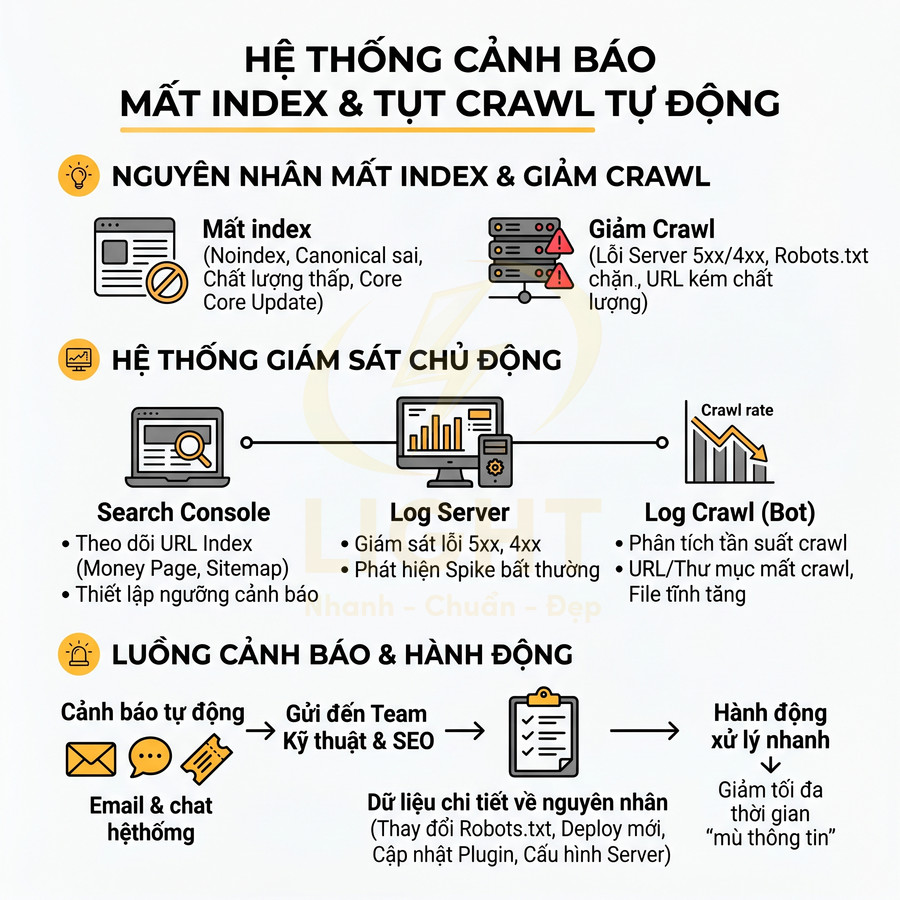
Tương tự, tần suất crawl của bot là một chỉ báo sức khỏe quan trọng của website. Khi crawl rate giảm đột ngột, đó có thể là dấu hiệu:
- Server phản hồi chậm hoặc thường xuyên trả về 5xx, khiến bot giảm tần suất truy cập.
- Robots.txt hoặc các rule bảo mật vô tình chặn một phần cấu trúc site.
- Số lượng URL chất lượng thấp tăng mạnh, làm bot “mất hứng” với site.
Để tránh rơi vào trạng thái “phát hiện khi đã quá muộn”, cần thiết lập một hệ thống cảnh báo tự động dựa trên dữ liệu từ Search Console, log server và công cụ crawl nội bộ:
- Theo dõi số lượng URL được index theo từng nhóm quan trọng (sitemap chính, money page, nhóm category top) và thiết lập ngưỡng cảnh báo khi giảm vượt quá một tỷ lệ nhất định trong một khoảng thời gian ngắn.
- Giám sát tỷ lệ và số lượng status code 5xx, 4xx trên log server; khi có spike bất thường, gửi cảnh báo cho team kỹ thuật để kiểm tra hạ tầng, cấu hình cache, firewall, load balancer.
- Phân tích log crawl của bot (Googlebot, Bingbot…) để phát hiện:
- URL nào bị giảm crawl đột ngột.
- Nhóm thư mục nào gần như không còn được crawl.
- Tỷ lệ crawl vào URL non-HTML (file tĩnh, script) tăng bất thường.
Các cảnh báo nên được gửi trực tiếp đến người phụ trách kỹ thuật và SEO qua các kênh đang dùng hàng ngày (email, chat nội bộ, ticket system), kèm theo dữ liệu đủ chi tiết để có thể khoanh vùng nhanh nguyên nhân: thay đổi gần nhất trên site, deploy mới, chỉnh sửa robots.txt, cập nhật plugin, thay đổi cấu hình server. Cách tiếp cận này giúp giảm tối đa thời gian “mù thông tin” khi site gặp sự cố, hạn chế các cú tụt traffic kéo dài nhiều tuần mà không rõ nguyên nhân.
Thiếu khả năng sửa hàng loạt theo mẫu trang làm chi phí tối ưu tăng cao
Khi hệ thống giám sát đã phát hiện lỗi lặp lại trên nhiều trang (thiếu schema, meta trùng, cấu trúc H2 sai, canonical không nhất quán…), vấn đề tiếp theo là khả năng triển khai sửa chữa ở quy mô lớn. Nếu CMS không hỗ trợ sửa theo template hoặc theo nhóm URL, đội ngũ sẽ phải chỉnh từng trang một, dẫn đến:
- Chi phí nhân sự tăng cao, đặc biệt với site có hàng chục nghìn URL.
- Nguy cơ sai sót thủ công, không đảm bảo tính nhất quán giữa các trang.
- Nhiều lỗi “biết nhưng không sửa hết được”, tồn tại dai dẳng và tiếp tục ảnh hưởng đến hiệu suất SEO.

Giải pháp mang tính kiến trúc là thiết kế CMS theo hướng template-driven. Thay vì mỗi trang là một thực thể độc lập, các thành phần chung được quản lý ở cấp template hoặc component:
- Meta (title pattern, description pattern) được định nghĩa theo loại trang: category, product, blog, tag, landing.
- Các block niềm tin (trust block), CTA, breadcrumb, schema cơ bản (Organization, WebSite, BreadcrumbList, Product, Article) được gắn với template, sửa một nơi áp dụng cho toàn bộ nhóm trang.
- Các rule về heading structure (H1, H2, H3) được cố định trong template, hạn chế việc người tạo nội dung phá vỡ cấu trúc.
Bên cạnh đó, cần có công cụ bulk edit cho các trường dữ liệu SEO quan trọng, cho phép SEOer thao tác diện rộng mà không phụ thuộc quá nhiều vào dev:
- Chỉnh sửa hàng loạt title, meta description theo pattern (sử dụng biến như {{categoryname}}, {{brand}}, {{pricerange}}).
- Cập nhật canonical cho một nhóm URL theo rule (ví dụ: chuẩn hóa về https, thêm hoặc bỏ trailing slash, hợp nhất phiên bản có tham số).
- Điền hoặc sửa các field schema (brand, aggregateRating, reviewCount, price, availability) cho nhóm sản phẩm cùng loại.
Khi kết hợp hệ thống phát hiện lỗi tự động với khả năng sửa hàng loạt theo template và bulk edit, chi phí tối ưu kỹ thuật giảm mạnh, đồng thời tạo điều kiện để đội SEO triển khai các cải tiến liên tục (continuous optimization) thay vì chỉ xử lý sự cố. Đây là nền tảng để duy trì hiệu suất SEO ổn định cho các website lớn, phức tạp và thay đổi thường xuyên.
Thiếu kiến trúc kéo thả từng block nhỏ khiến mỗi lần sửa SEO phải động vào toàn trang
Kiến trúc cũ dựa trên template cứng khiến mọi thay đổi SEO nhỏ như thêm FAQ, bảng giá, block niềm tin hay điều chỉnh CTA, schema đều phải sửa trực tiếp vào file template gốc. Điều này làm tăng rủi ro vỡ layout, ảnh hưởng hàng loạt landing đang chạy ổn định, kéo dài quy trình review – deploy – test và khiến đội ngũ ngại thử nghiệm A/B hoặc tối ưu theo các SERP feature mới. Với kiến trúc kéo thả block nhỏ, mỗi block (FAQ, CTA, pricing, testimonial, schema…) được tách thành module độc lập, có markup và schema chuẩn, có thể cấu hình theo từng trang/nhóm trang. SEOer và marketer chủ động sắp xếp, thay đổi vị trí, nội dung block mà không cần chạm vào code, vừa tăng tốc độ tối ưu SEO/CRO, vừa giảm lỗi diện rộng khi mở rộng loại trang mới.
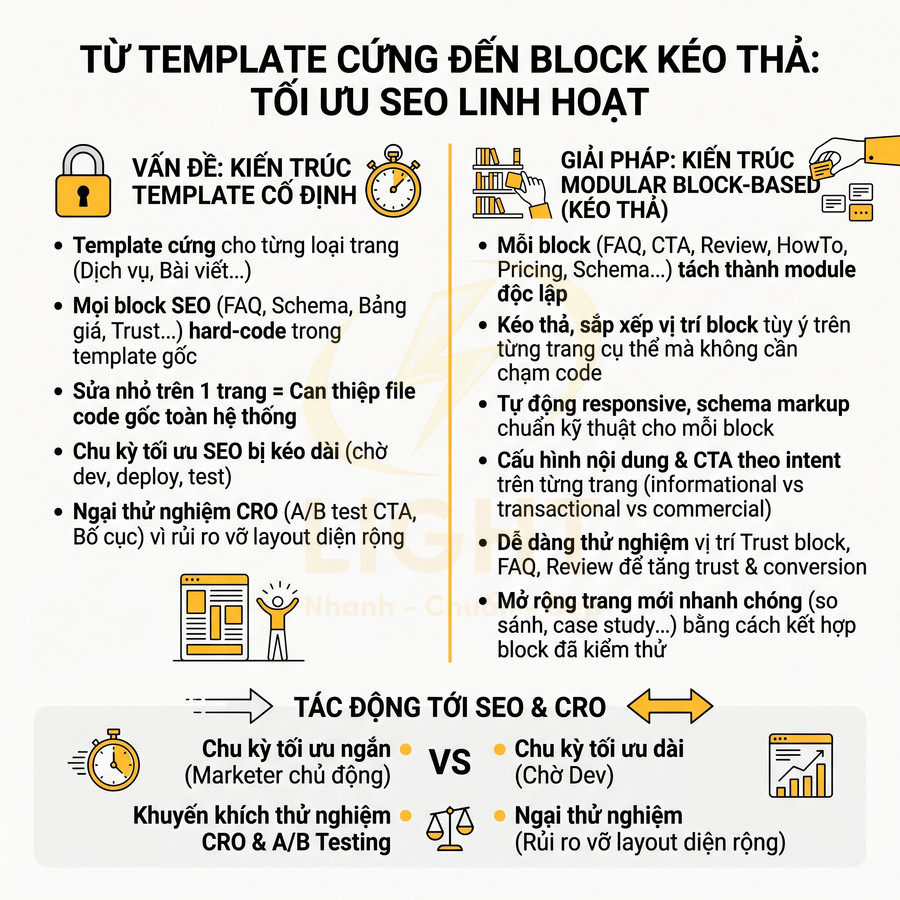
Muốn thêm FAQ phải sửa template gốc của toàn hệ thống
Trong nhiều hệ thống CMS hoặc framework tự xây, kiến trúc thường xoay quanh các template cứng cho từng loại trang: blog, dịch vụ, sản phẩm, landing page, category, tag… Mỗi template được định nghĩa sẵn layout, vùng nội dung, sidebar, footer, header, và thường “đóng đinh” luôn cả các block SEO như FAQ, bảng giá, review, block niềm tin. Khi đó, bất kỳ nhu cầu tối ưu SEO mới nào cũng buộc phải can thiệp trực tiếp vào template gốc.

Ví dụ, khi Google ưu tiên rich result cho FAQ hoặc HowTo, SEOer muốn bổ sung thêm block FAQ có schema chuẩn cho một nhóm landing cụ thể. Tuy nhiên, vì template được thiết kế cứng, việc thêm FAQ đồng nghĩa với:
- Chỉnh sửa file template gốc (ví dụ: single-service.php, product-detail.blade.php…)
- Kiểm tra lại toàn bộ các trang đang dùng template đó để đảm bảo không vỡ layout
- Rủi ro ảnh hưởng đến các trang đang hoạt động tốt, đã được index ổn định
Hệ quả là mọi thay đổi nhỏ như:
- Thêm block FAQ có schema JSON-LD
- Thêm block niềm tin (trust block: chứng nhận, logo đối tác, bảo hành…)
- Thêm block bảng so sánh sản phẩm/dịch vụ
- Thêm block HowTo, Pros & Cons, hoặc Author box chuẩn E-E-A-T
đều phải xếp hàng chờ dev, qua quy trình review code, deploy, regression test. Chu kỳ tối ưu SEO vì thế bị kéo dài, mất tính linh hoạt, và dễ bị “bỏ lỡ cơ hội” khi thuật toán hoặc SERP feature thay đổi nhanh.
Kiến trúc kéo thả block nhỏ (modular block-based architecture) giải quyết triệt để vấn đề này bằng cách tách layout thành các đơn vị block độc lập, mỗi block được định nghĩa:
- HTML markup chuẩn, semantic, dễ crawl và dễ render
- Schema markup (FAQPage, HowTo, Product, Review, AggregateRating…) được tích hợp sẵn
- Responsive theo grid hệ thống, không phụ thuộc vị trí cụ thể trong trang
- Option cấu hình nội dung, hiển thị, điều kiện xuất hiện (theo loại trang, tag, taxonomy…)
SEOer và content có thể:
- Tự chọn block FAQ, HowTo, bảng giá, review… từ thư viện block
- Kéo thả vào vị trí mong muốn trong trang cụ thể (trên fold, giữa nội dung, cuối trang…)
- Tùy chỉnh nội dung câu hỏi – trả lời, heading, anchor link mà không chạm vào template gốc
Cách tiếp cận này giúp:
- Giảm tối đa số lần phải deploy code chỉ để phục vụ thay đổi SEO
- Giữ template gốc nhẹ, chỉ đóng vai trò “khung” định vị vùng block
- Đảm bảo tính nhất quán kỹ thuật vì mỗi block đã được kiểm thử độc lập
Thay CTA hoặc schema làm ảnh hưởng bố cục landing đang chạy tốt
Trong nhiều hệ thống, CTA (Call To Action) và schema thường được gắn cứng trong template. Ví dụ, template landing dịch vụ có sẵn:
- Một CTA form đăng ký ở cuối trang
- Một CTA button “Đăng ký ngay” ở giữa nội dung
- Schema Service hoặc Product được embed trực tiếp trong template
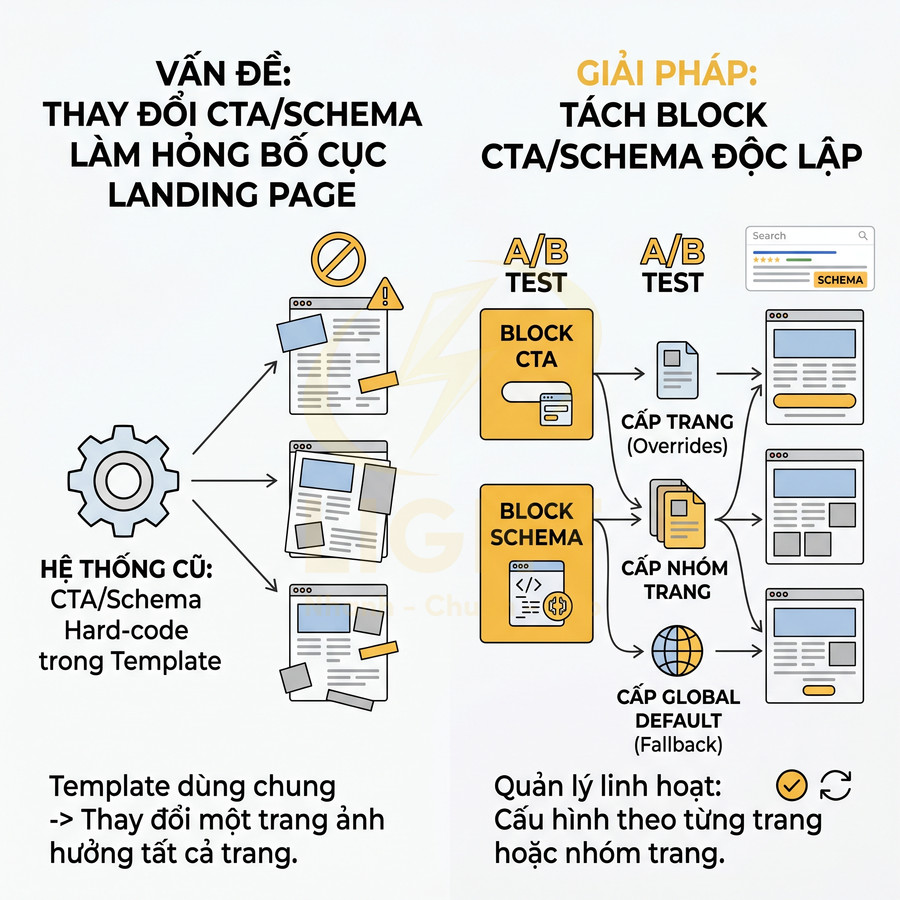
Khi muốn tối ưu chuyển đổi hoặc thử nghiệm A/B, marketer và SEOer thường cần:
- Thay đổi text CTA (ví dụ: “Đăng ký ngay” → “Nhận tư vấn miễn phí trong 15 phút”)
- Thay đổi màu sắc, kích thước, hoặc vị trí CTA
- Thêm/bớt field trong form (số điện thoại, ngành nghề, quy mô công ty…)
- Điều chỉnh schema (thêm review, thêm priceRange, thêm serviceType…)
Nếu CTA và schema được hard-code trong template, mọi thay đổi sẽ áp dụng cho tất cả các landing dùng chung template đó. Điều này dẫn đến các vấn đề:
- Không thể test CTA mới cho một landing cụ thể mà không ảnh hưởng landing khác
- Rủi ro phá vỡ bố cục hoặc thông điệp của các landing đang chạy quảng cáo ổn định
- Đội ngũ trở nên “ngại” thử nghiệm vì mỗi lần test là một lần chạm vào hệ thống lớn
Giải pháp là tách block CTA, block schema thành các thành phần độc lập, có thể cấu hình theo từng trang hoặc nhóm trang. Về mặt kiến trúc, template chỉ:
- Định nghĩa vị trí placeholder cho CTA (ví dụ: ctaprimary, ctasidebar, cta_footer)
- Định nghĩa vùng inject schema (head, body, cuối trang…)
Còn nội dung và cấu hình được quản lý ở cấp:
- Trang đơn lẻ (page-level override)
- Nhóm trang (theo category, campaign, funnel stage…)
- Global default (fallback khi không có cấu hình riêng)
Cách này cho phép:
- A/B test CTA cho một số landing cụ thể mà không đụng tới template gốc
- Triển khai nhiều biến thể schema (Product vs Service vs FAQPage) theo từng loại landing
- Gắn tracking, event, UTM, hoặc pixel riêng cho từng CTA block
Về mặt SEO và CRO, kiến trúc này mở ra khả năng:
- Thử nghiệm thông điệp CTA theo intent (informational vs transactional vs commercial)
- Điều chỉnh schema để phù hợp với SERP feature mục tiêu (review snippet, FAQ rich result…)
- Đo lường tác động của từng biến thể CTA/schema lên CTR, conversion rate, time on page
Không thể thử nghiệm vị trí block niềm tin, đánh giá, bảng giá linh hoạt
Các block như niềm tin (trust block), đánh giá (testimonial/review), bảng giá (pricing table), FAQ có tác động trực tiếp đến:
- Tỷ lệ chuyển đổi (conversion rate)
- Tín hiệu tương tác người dùng (scroll depth, time on page, bounce rate)
- Nhận thức thương hiệu và mức độ tin tưởng (trust, authority)
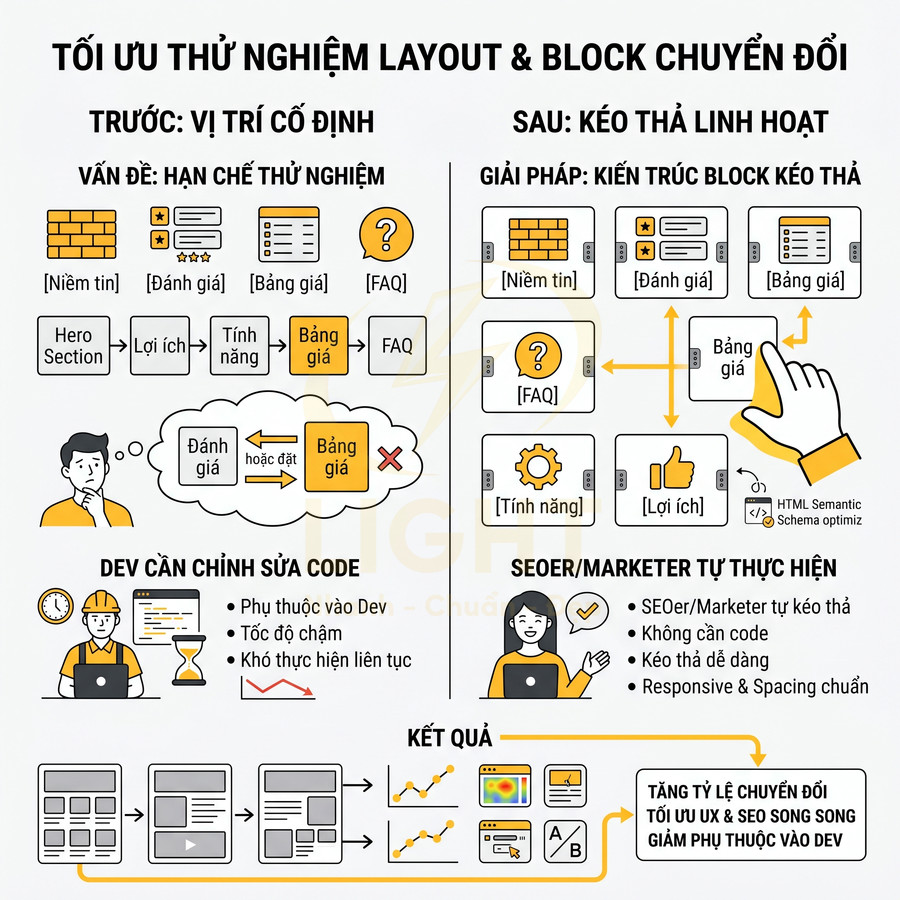
Tuy nhiên, trong layout cứng, vị trí của các block này thường được cố định, ví dụ:
- Hero section → Lợi ích → Tính năng → Bảng giá → FAQ → CTA cuối
Khi muốn thử nghiệm:
- Đưa block đánh giá khách hàng lên gần đầu trang để tăng trust sớm
- Đặt bảng giá ngay sau phần lợi ích thay vì sau phần tính năng
- Chèn FAQ vào giữa nội dung để trả lời objection tại đúng điểm người dùng băn khoăn
thì mọi thay đổi đều cần dev chỉnh sửa template, chỉnh lại CSS, kiểm tra responsive, test trên nhiều trình duyệt. Điều này làm giảm tốc độ thử nghiệm, khiến đội ngũ marketing khó áp dụng phương pháp continuous experimentation dựa trên dữ liệu.
Kiến trúc block kéo thả cho phép:
- Định nghĩa mỗi block (trust, testimonial, pricing, FAQ, feature, benefit…) như một module độc lập
- Cho phép SEOer/marketer kéo thả để thay đổi thứ tự block trong trang mà không cần code
- Tự động đảm bảo responsive và khoảng cách (spacing) giữa các block theo design system
Về mặt kỹ thuật, mỗi block được tối ưu sẵn:
- HTML semantic (section, article, header, footer, figure…)
- Schema tương ứng (Review, AggregateRating, FAQPage, Offer, Product…)
- Class CSS chuẩn, không phụ thuộc vị trí cụ thể trong DOM
Nên khi di chuyển block:
- Không phá vỡ cấu trúc DOM quan trọng cho SEO (heading hierarchy, main content…)
- Không tạo ra lỗi layout trên mobile hoặc tablet
- Không cần chỉnh sửa lại schema vì đã được gắn theo block, không theo template
Điều này cho phép đội ngũ:
- Thiết kế nhiều biến thể layout cho cùng một nội dung, test xem vị trí nào cho conversion tốt nhất
- Tối ưu song song UX và SEO, dựa trên dữ liệu thực tế từ heatmap, session recording, A/B testing
- Giảm phụ thuộc vào dev trong các thử nghiệm mang tính marketing/UX thuần túy
Khó mở rộng trang mới mà không tạo lỗi diện rộng
Khi doanh nghiệp phát triển, nhu cầu mở rộng loại trang mới là tất yếu: trang so sánh (comparison), trang tài nguyên (resource hub), trang case study, trang landing cho từng campaign, từng ngành dọc… Nếu hệ thống không linh hoạt, quy trình thường là:
- Clone template cũ (ví dụ: từ landing dịch vụ sang landing so sánh)
- Chỉnh sửa layout, thêm/bớt section, chỉnh lại CSS
- Copy/paste hoặc chỉnh sửa schema, canonical, breadcrumb, internal link logic
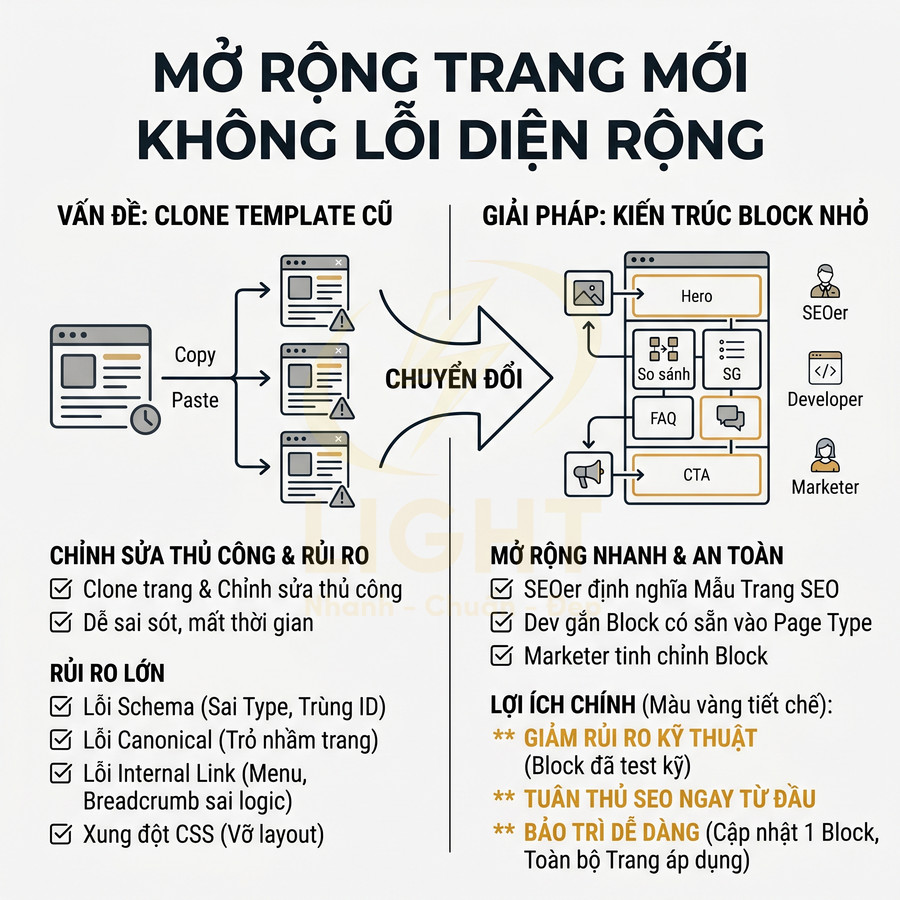
Mỗi lần clone như vậy đều tiềm ẩn rủi ro:
- Lỗi schema (sai type, trùng ID, thiếu thuộc tính bắt buộc)
- Lỗi canonical (trỏ nhầm, trùng canonical giữa các loại trang khác nhau)
- Lỗi internal link (menu, breadcrumb, related content không đúng logic SEO)
- Xung đột CSS giữa các template, gây vỡ layout trên một số thiết bị
Với kiến trúc block nhỏ, việc mở rộng loại trang mới được đơn giản hóa thành việc kết hợp lại các block có sẵn theo một layout mới. Quy trình có thể được chuẩn hóa:
- SEOer định nghĩa “mẫu trang SEO” cho từng loại nội dung:
- Trang so sánh: Hero → Bảng so sánh → Pros & Cons → FAQ → CTA
- Trang case study: Hero → Bối cảnh → Giải pháp → Kết quả (số liệu) → Testimonial → CTA
- Trang tài nguyên: Hero → Filter/Category → Listing tài nguyên → FAQ → Lead magnet
- Dev chỉ cần tạo một “page type” mới, gắn các block đã tồn tại vào đúng thứ tự mặc định
- Marketer có thể tinh chỉnh thêm/bớt block cho từng trang cụ thể mà không đụng tới code
Vì mỗi block đã được kiểm thử kỹ về:
- HTML & CSS (khả năng tái sử dụng, không xung đột)
- Schema (đúng type, đúng context, không trùng lặp không cần thiết)
- Performance (lazy load, tối ưu ảnh, tối ưu script)
nên rủi ro kỹ thuật khi tạo loại trang mới giảm đáng kể. Đồng thời, hệ thống có thể:
- Áp dụng rule SEO ở cấp block (ví dụ: block so sánh luôn có schema Product/Offer, block FAQ luôn có FAQPage)
- Đảm bảo mọi trang mới tuân thủ chuẩn SEO ngay từ đầu, không phụ thuộc “tay nghề” từng dev
- Cho phép tái sử dụng các block thành công (ví dụ: block testimonial có tỉ lệ chuyển đổi cao) trên nhiều loại trang khác nhau
Kiến trúc này cũng giúp việc bảo trì dễ dàng hơn: khi cần cập nhật chuẩn schema mới, chỉ cần chỉnh sửa một lần trong block tương ứng, toàn bộ trang đang dùng block đó sẽ được cập nhật theo, mà không cần rà soát hàng loạt template hoặc từng trang riêng lẻ.
Lỗi hình ảnh đẹp nhưng không chuẩn SEO kỹ thuật
Hình ảnh đẹp nhưng không chuẩn SEO kỹ thuật thường xuất phát từ việc xem ảnh chỉ là yếu tố thẩm mỹ, bỏ qua vai trò dữ liệu ngữ nghĩa và hiệu năng tải trang. Ở tầng kỹ thuật, cần tối ưu đồng thời ba lớp: cách đặt tên và mô tả ảnh, dung lượng – định dạng – kích thước, và lớp dữ liệu cấu trúc cùng hệ thống giám sát lỗi. Tên file, alt text, caption và schema phải được chuẩn hóa để bot hiểu rõ nội dung, ngữ cảnh và mức độ quan trọng của từng ảnh. Song song, pipeline xử lý ảnh tự động (nén, chuyển định dạng, tạo nhiều kích thước, lazy load) giúp cải thiện Core Web Vitals. Cuối cùng, một cơ chế crawl, phát hiện và thay thế ảnh lỗi toàn site đảm bảo trải nghiệm người dùng và tín hiệu chất lượng ổn định.
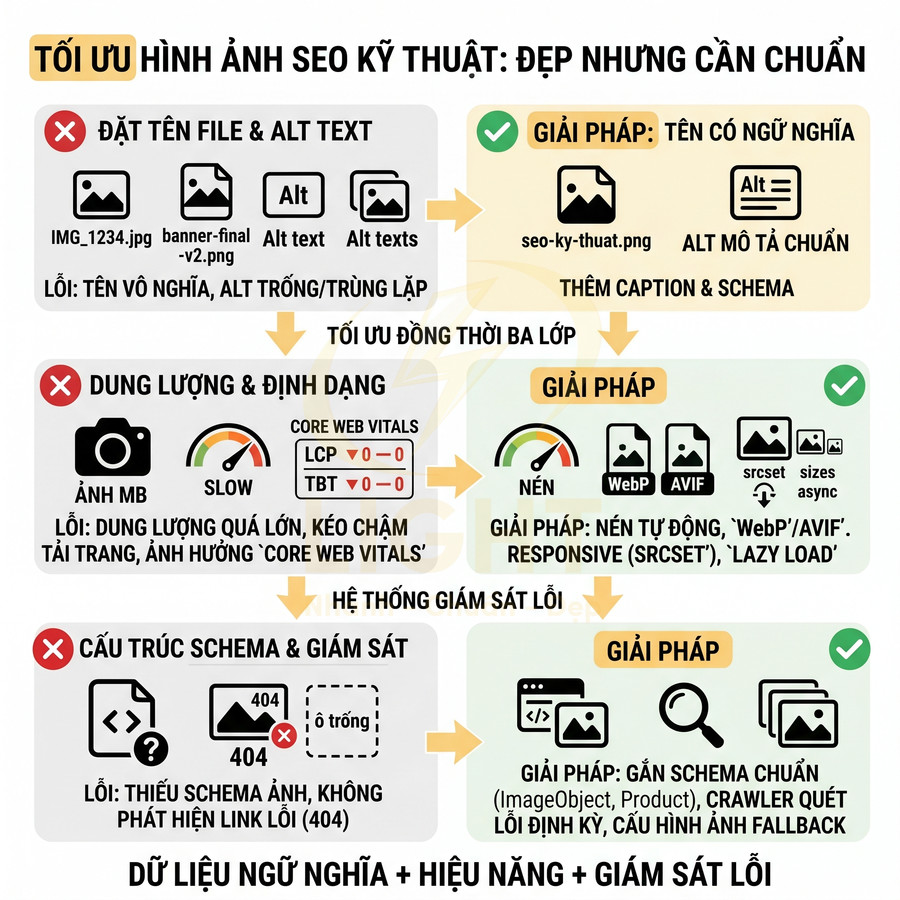
Tên file ảnh vô nghĩa, alt trùng lặp và link ảnh lỗi
Ở tầng kỹ thuật SEO, hình ảnh không chỉ là yếu tố thẩm mỹ mà còn là một nguồn dữ liệu ngữ nghĩa quan trọng cho công cụ tìm kiếm. Khi đội thiết kế xuất file với tên mặc định như IMG_1234.jpg, banner-final-v2.png, hệ thống mất đi một tín hiệu mạnh để hiểu nội dung và ngữ cảnh của ảnh. Tên file là một trong những trường đầu tiên được bot đọc khi crawl tài nguyên tĩnh, đặc biệt trong tìm kiếm hình ảnh.
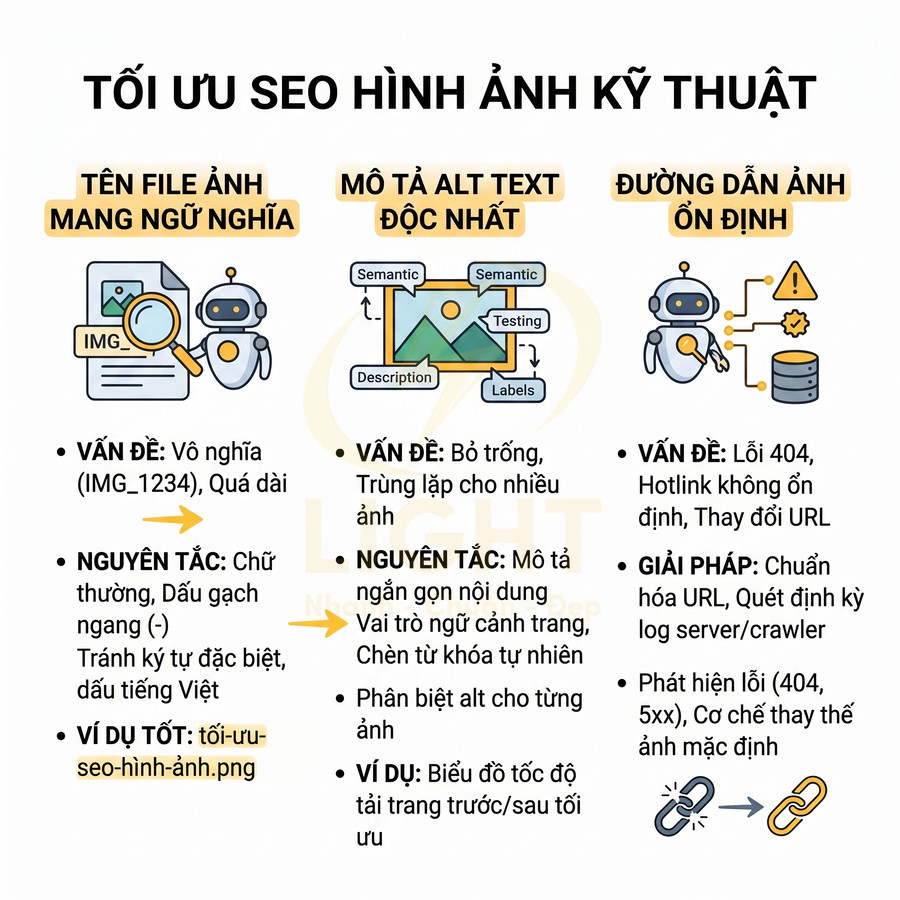
Vấn đề thường gặp:
- Tên file không chứa ngữ nghĩa, không liên quan đến chủ đề trang hoặc từ khóa mục tiêu.
- Alt text bị bỏ trống, hoặc copy-paste giống nhau cho nhiều ảnh, dẫn đến trùng lặp nội dung và giảm khả năng phân biệt từng hình.
- Đường dẫn ảnh bị lỗi (404), hotlink từ domain khác không ổn định, hoặc thay đổi cấu trúc URL mà không redirect, khiến bot gặp lỗi khi crawl.
Cần xây dựng một quy ước đặt tên file ảnh mang tính hệ thống, gắn với từ khóa mô tả và ngữ cảnh sử dụng. Một số nguyên tắc kỹ thuật:
- Sử dụng chữ thường, dấu gạch ngang
-để phân tách từ: seo-ky-thuat-render-javascript.png. - Tránh ký tự đặc biệt, khoảng trắng, dấu tiếng Việt, chuỗi ký tự vô nghĩa (vd: final-new-new-2.png).
- Đặt tên theo cấu trúc có thể lọc, ví dụ: category-keyword-bien-the-kich-thuoc.jpg để dễ quản lý và truy vấn trong CMS/CDN.
Với alt text, cần coi đây là lớp mô tả ngữ nghĩa chứ không phải nơi nhồi nhét từ khóa. Một alt tốt nên:
- Mô tả ngắn gọn nội dung chính của ảnh và vai trò trong ngữ cảnh trang (vd: “Biểu đồ so sánh tốc độ tải trang trước và sau khi tối ưu hình ảnh”).
- Chèn từ khóa tự nhiên nếu phù hợp, tránh lặp lại nguyên văn tiêu đề trang cho mọi ảnh.
- Phân biệt alt cho từng ảnh trong cùng một bài để bot hiểu mỗi hình mang thông tin khác nhau.
Về mặt kỹ thuật hệ thống, cần có cơ chế:
- Validate alt text khi upload: cảnh báo nếu để trống hoặc trùng với nhiều ảnh khác trong cùng bài.
- Chuẩn hóa đường dẫn ảnh (URL rewriting) để tránh sinh ra path quá dài, chứa tham số khó crawl.
- Định kỳ quét log server hoặc dùng crawler nội bộ để phát hiện link ảnh lỗi (404, 5xx, timeout, hotlink bị chặn) và ghi nhận theo danh sách để xử lý.
Với các ảnh bị lỗi không thể khôi phục, cần có cơ chế thay thế bằng ảnh mặc định hoặc ẩn khối ảnh khỏi giao diện để tránh hiển thị ô trống, đồng thời cập nhật lại alt text và cấu trúc HTML để không tạo ra trải nghiệm xấu cho người dùng và bot.
Ảnh sắc nét nhưng dung lượng quá lớn kéo chậm tải trang
Hình ảnh là một trong những thành phần chiếm nhiều băng thông nhất trên trang web. Một vài ảnh vài MB có thể làm tăng đáng kể Largest Contentful Paint (LCP) và Total Blocking Time (TBT), ảnh hưởng trực tiếp đến Core Web Vitals và thứ hạng SEO. Việc sử dụng ảnh gốc từ designer (thường là file xuất cho in ấn hoặc trình chiếu) mà không nén, không resize là lỗi kỹ thuật phổ biến.
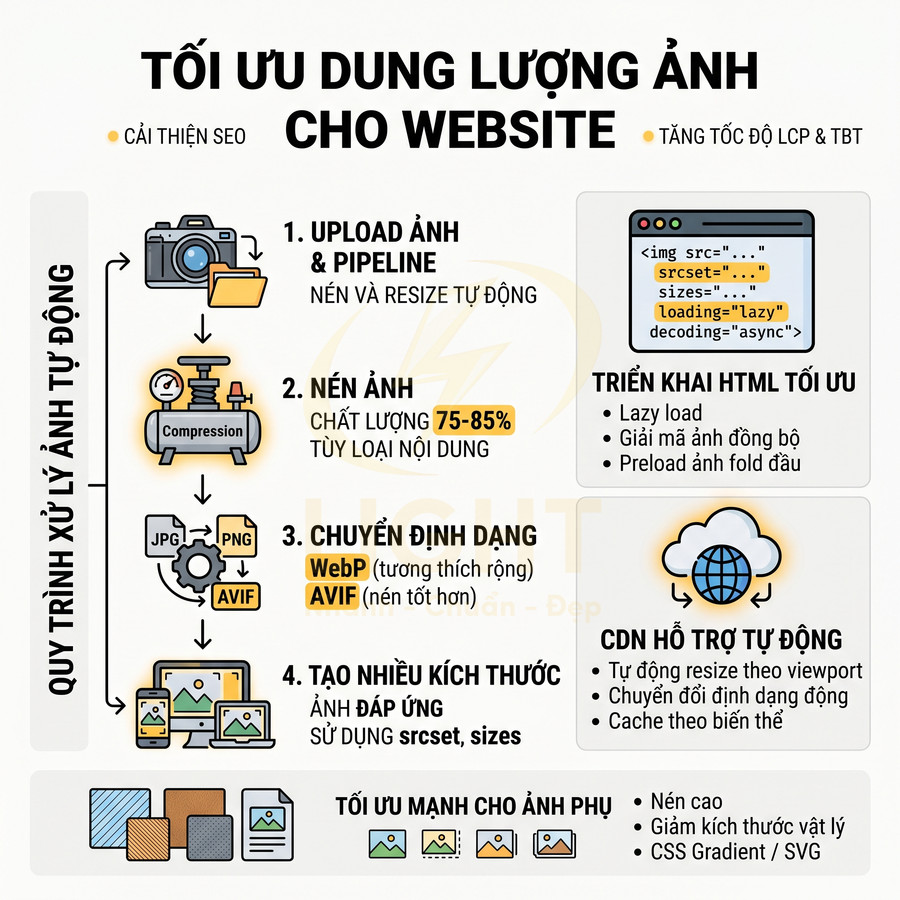
Cần thiết lập một pipeline xử lý ảnh tự động ngay từ bước upload:
- Nén ảnh tự động (image compression) với mức độ phù hợp từng loại nội dung:
- Ảnh sản phẩm, ảnh chi tiết: ưu tiên chất lượng, nén vừa phải (quality ~75–85).
- Background, banner mờ, texture: có thể nén mạnh hơn (quality ~50–70) vì ít ảnh hưởng đến cảm nhận.
- Icon, logo vector: ưu tiên định dạng SVG hoặc PNG tối ưu, tránh dùng JPG/WebP chất lượng thấp gây mờ.
- Chuyển sang định dạng hiện đại như WebP hoặc AVIF:
- WebP: tương thích rộng, giảm dung lượng đáng kể so với JPG/PNG.
- AVIF: nén tốt hơn WebP nhưng cần kiểm tra hỗ trợ trình duyệt; có thể dùng kết hợp fallback.
- Tạo nhiều kích thước ảnh (responsive images) và sử dụng
srcset,sizes:- Ảnh hero: tạo các phiên bản 480px, 768px, 1024px, 1440px, 1920px.
- Thumbnail: 150–300px, không dùng ảnh gốc 2000px rồi thu nhỏ bằng CSS.
Về mặt triển khai HTML, nên kết hợp:
<img src="..." srcset="..." sizes="..." loading="lazy" decoding="async">để tối ưu tải chậm (lazy load) và giải mã ảnh.- Đối với ảnh lớn trên fold đầu tiên, cân nhắc preload có chọn lọc để cải thiện LCP.
Các hệ thống CDN hiện đại có thể tự động:
- Resize ảnh theo kích thước viewport và DPR (device pixel ratio).
- Chuyển đổi định dạng động (vd: gửi WebP cho Chrome, JPG cho trình duyệt cũ).
- Cache theo biến thể (URL + tham số kích thước/định dạng) để giảm tải server gốc.
Đối với các loại ảnh không cần độ nét cao như background mờ, pattern, icon, thumbnail, nên áp dụng chính sách tối ưu mạnh tay: giảm kích thước vật lý, nén cao, thậm chí dùng kỹ thuật CSS gradient hoặc SVG thay cho bitmap nếu có thể. Điều này giúp giảm đáng kể tổng dung lượng tải xuống mà vẫn giữ trải nghiệm thị giác chấp nhận được.
Ảnh sản phẩm và landing không có schema hoặc dữ liệu mô tả
Ảnh sản phẩm, ảnh minh họa trong landing page thường là phần thể hiện giá trị cốt lõi: giao diện sản phẩm, tính năng, kết quả trước–sau, testimonial dạng hình. Nếu chỉ hiển thị bằng hình mà không có lớp dữ liệu mô tả, công cụ tìm kiếm chỉ thấy một tài nguyên binary không có ngữ nghĩa, khó đưa vào Google Images hoặc các rich result có hình.
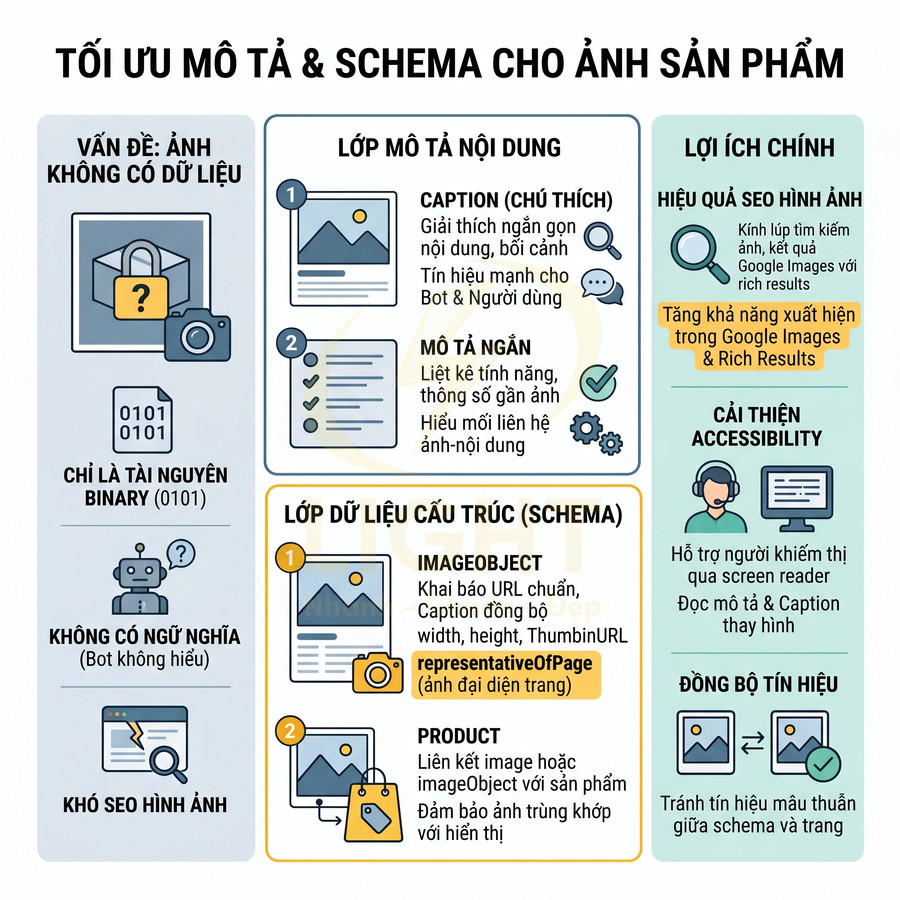
Cần bổ sung lớp mô tả ở cả mức nội dung và dữ liệu có cấu trúc:
- Caption (chú thích dưới ảnh): giải thích ngắn gọn nội dung, bối cảnh, ý nghĩa của hình. Caption thường được người dùng đọc nhiều, đồng thời là tín hiệu ngữ nghĩa mạnh cho bot.
- Mô tả ngắn (description) gần khu vực ảnh: có thể là đoạn text liền kề, liệt kê tính năng, thông số, kết quả đo lường… giúp bot hiểu mối liên hệ giữa ảnh và nội dung xung quanh.
Về dữ liệu có cấu trúc (schema), nên sử dụng:
- ImageObject để khai báo:
url: đường dẫn ảnh chuẩn, có thể là bản lớn nhất hoặc bản đại diện.caption: mô tả ngắn, đồng bộ với caption hiển thị.representativeOfPage: đánh dấu ảnh đại diện cho nội dung trang (true/false).- Các thuộc tính bổ sung như
width,height,thumbnailUrlnếu có.
- Product cho ảnh sản phẩm:
- Liên kết
imagehoặcimageObjectvới sản phẩm cụ thể. - Đảm bảo ảnh trong schema trùng khớp với ảnh hiển thị trên trang để tránh tín hiệu mâu thuẫn.
- Liên kết
Việc gắn schema không chỉ hỗ trợ SEO hình ảnh mà còn cải thiện accessibility cho người dùng khiếm thị thông qua screen reader, vì nội dung mô tả và caption thường được đọc lên thay cho hình. Ngoài ra, khi trang có nhiều ảnh, việc đánh dấu ảnh nào là representativeOfPage giúp Google chọn đúng hình đại diện trong kết quả tìm kiếm, tránh hiển thị những ảnh ít liên quan.
Thiếu hệ thống tự quét và thay ảnh lỗi trong toàn site
Trong vòng đời vận hành website, việc di chuyển server, đổi CDN, thay đổi cấu trúc thư mục media, hoặc xóa nhầm file là chuyện thường xảy ra. Hệ quả là nhiều ảnh trở thành broken image, hiển thị icon lỗi hoặc ô trống. Điều này không chỉ làm giảm uy tín và trải nghiệm người dùng mà còn tạo ra tín hiệu chất lượng kém trong mắt công cụ tìm kiếm.
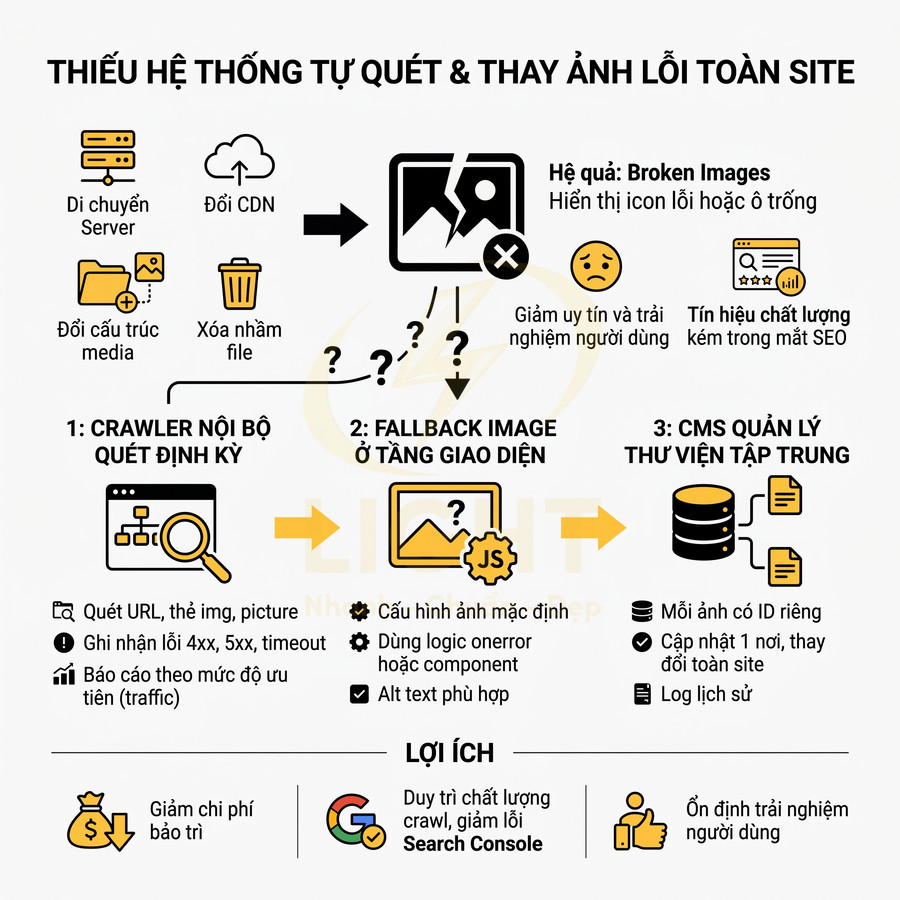
Để kiểm soát, cần một hệ thống giám sát và xử lý ảnh lỗi ở cấp toàn site:
- Crawler nội bộ hoặc tích hợp với công cụ crawl:
- Định kỳ quét toàn bộ URL, kiểm tra tất cả thẻ
<img>,<picture>, CSS background-image nếu có thể. - Ghi nhận các URL ảnh trả về mã lỗi 4xx, 5xx, timeout, hoặc bị chặn bởi hotlink protection.
- Xuất báo cáo theo mức độ ưu tiên: trang có nhiều traffic, trang quan trọng trong funnel chuyển đổi.
- Định kỳ quét toàn bộ URL, kiểm tra tất cả thẻ
- Fallback image ở tầng giao diện:
- Cấu hình ảnh mặc định cho từng loại nội dung (sản phẩm, bài viết, avatar) khi ảnh chính bị lỗi.
- Sử dụng sự kiện
onerrorhoặc logic trong component (React/Vue/…) để thay thế src bằng fallback. - Đảm bảo fallback cũng có alt text phù hợp, tránh để trống hoàn toàn.
Ở tầng CMS, nên có cơ chế quản lý thư viện ảnh tập trung:
- Mỗi ảnh là một thực thể có ID riêng, được tham chiếu bởi nhiều trang thay vì chèn URL tĩnh rời rạc.
- Khi thay thế một ảnh (vd: cập nhật ảnh sản phẩm), chỉ cần cập nhật tại một nơi, tất cả trang sử dụng ảnh đó sẽ tự động nhận phiên bản mới.
- Log lịch sử thay đổi để có thể rollback nếu ảnh mới gây lỗi hoặc không phù hợp.
Việc này giúp giảm đáng kể chi phí bảo trì khi site lớn dần, đồng thời hạn chế tình trạng “mồ côi” file media không còn được dùng nhưng vẫn chiếm dung lượng. Từ góc độ SEO kỹ thuật, một hệ thống chủ động phát hiện và xử lý ảnh lỗi giúp duy trì chất lượng crawl, giảm số lượng lỗi trong Search Console, và giữ cho trải nghiệm người dùng ổn định ngay cả khi có sự cố hạ tầng hoặc thay đổi cấu trúc media.
Lỗi local SEO kỹ thuật khiến website đẹp nhưng không lên map và từ khóa khu vực
Các lỗi local SEO kỹ thuật thường khiến website khó lên map dù giao diện đẹp và nội dung đầy đủ. Vấn đề cốt lõi nằm ở cách Google nhận diện và kết nối thực thể địa điểm với doanh nghiệp, dịch vụ và tín hiệu địa phương. Khi NAP thiếu nhất quán, nội dung trang khu vực bị nhân bản, thiếu bản đồ – giờ mở cửa – review thật, hoặc hệ thống internal link không phản ánh hành vi tìm kiếm theo khu vực, Google sẽ giảm mức độ tin cậy và hạn chế hiển thị trong local pack. Cần xây dựng chuẩn NAP nội bộ, tạo nội dung mang local intent rõ ràng, đồng bộ dữ liệu cấu trúc và Google Business Profile, đồng thời thiết kế cấu trúc liên kết theo logic “dịch vụ + khu vực” để tối ưu khả năng xếp hạng.
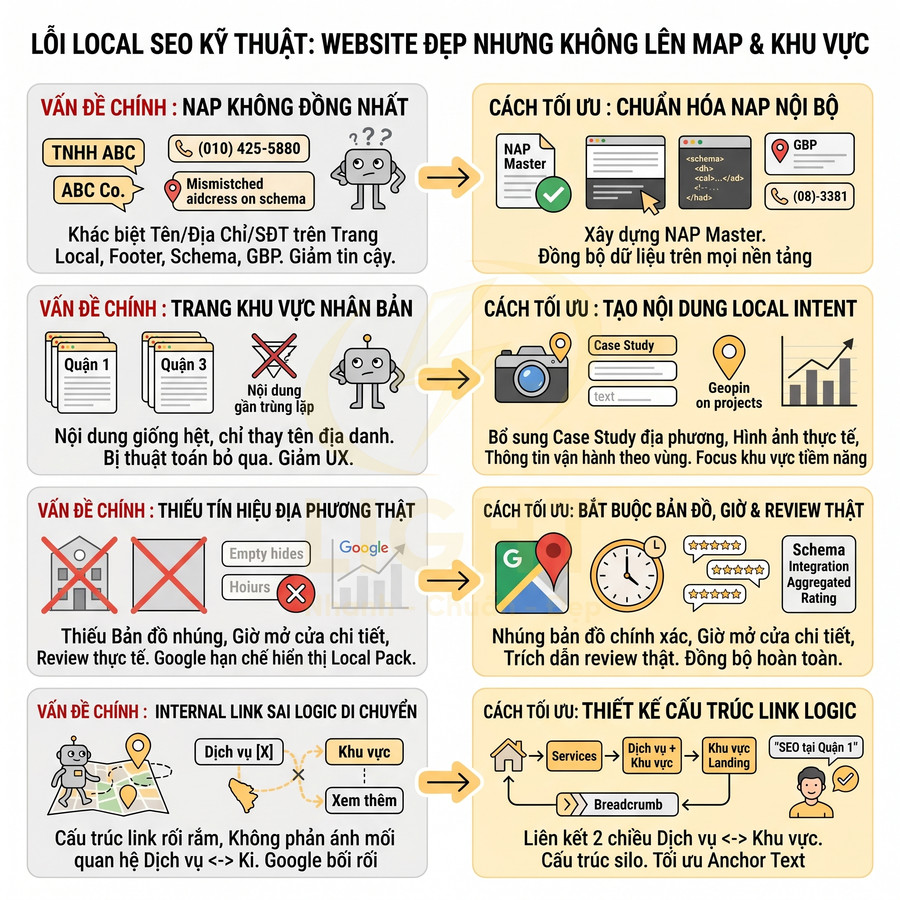
NAP không đồng nhất giữa trang local, footer và schema
NAP (Name, Address, Phone) là nền tảng của local SEO, nhưng ở mức kỹ thuật sâu hơn, NAP không chỉ là “ghi đúng thông tin” mà còn là bài toán về nhận diện thực thể (entity recognition) trong hệ thống của Google. Khi Googlebot crawl site và các nguồn bên ngoài (Google Business Profile, directory, mạng xã hội, báo chí…), nó cố gắng gom tất cả các đề cập liên quan đến một doanh nghiệp thành một thực thể duy nhất.
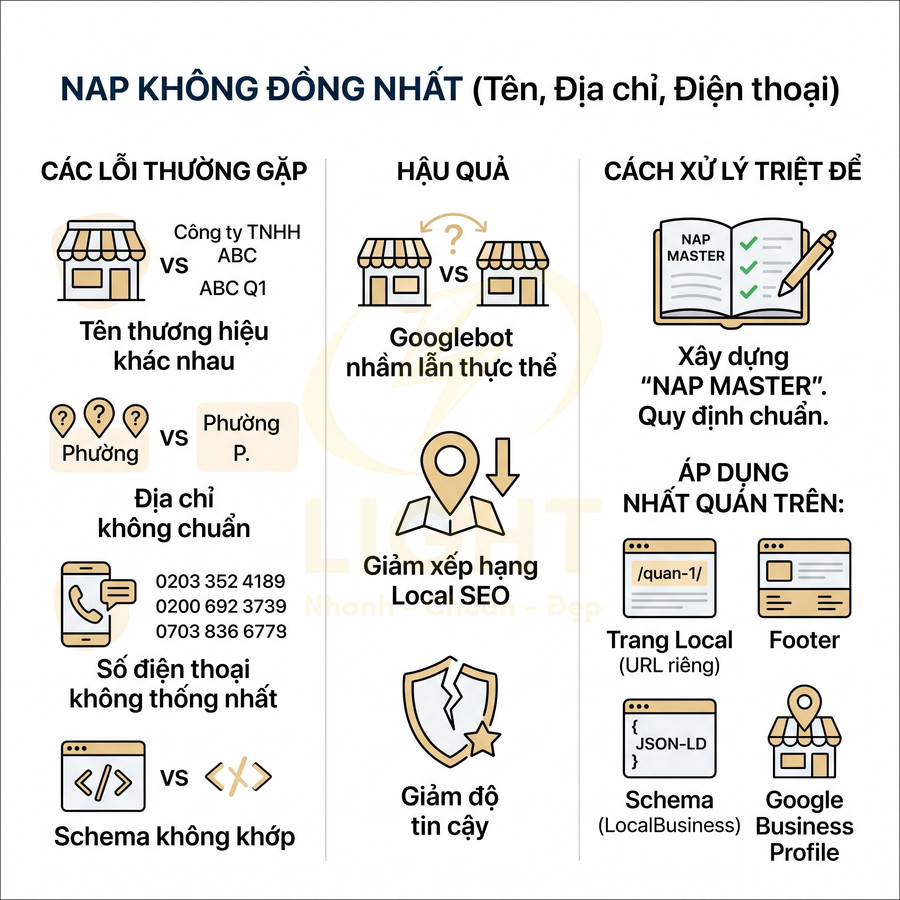
Bất kỳ sai lệch nào về NAP đều có thể khiến hệ thống:
- Không chắc chắn đây là cùng một doanh nghiệp hay nhiều thực thể khác nhau
- Không dám “đẩy mạnh” thứ hạng local vì rủi ro gán nhầm địa điểm
- Giảm độ tin cậy của citation, làm yếu toàn bộ hồ sơ local
Các lỗi thường gặp ở tầng kỹ thuật:
- Khác biệt cách viết tên thương hiệu: lúc thì “Công ty TNHH ABC”, lúc “ABC Co.”, lúc chỉ “ABC”. Với thương hiệu chuỗi, đôi khi thêm “– Chi nhánh Quận 1”, lúc khác lại ghi “ABC ”.
- Địa chỉ không chuẩn hóa: viết tắt/viết đầy đủ không nhất quán (P. vs Phường, Q. vs Quận), thiếu số tầng, thiếu tên tòa nhà, hoặc dùng địa chỉ cũ trên một số trang.
- Số điện thoại không thống nhất: dùng nhiều đầu số khác nhau cho cùng một chi nhánh, hoặc trộn số hotline toàn quốc với số chi nhánh mà không phân tách rõ.
- Schema LocalBusiness không khớp giao diện: trên trang hiển thị một địa chỉ, nhưng trong schema lại là địa chỉ khác (do dev copy từ chi nhánh cũ mà không sửa).
Để xử lý triệt để, cần xây dựng một “NAP master” cho từng chi nhánh ở dạng tài liệu chuẩn nội bộ, trong đó quy định:
- Cách viết tên thương hiệu chính thức, có/không có hậu tố “Chi nhánh + khu vực”
- Định dạng địa chỉ chuẩn, thống nhất cách viết, có thể bám theo chuẩn địa chỉ của Google Maps
- Số điện thoại ưu tiên cho local (có thể khác hotline marketing), định dạng có/không có mã vùng, mã quốc gia
Sau đó, áp dụng NAP master này một cách nhất quán:
- Trên trang local của từng chi nhánh (URL riêng cho mỗi địa điểm)
- Trong footer (nếu là chuỗi nhiều chi nhánh, nên có block rõ ràng cho từng chi nhánh, tránh một đoạn mơ hồ “nhiều chi nhánh toàn quốc”)
- Trong schema LocalBusiness hoặc các subtype (MedicalClinic, Restaurant, Store…) với thuộc tính name, address, telephone, geo, sameAs
- Trên Google Business Profile và các citation quan trọng khác
Với website có nhiều chi nhánh, mỗi chi nhánh cần:
- Một trang local riêng (location landing page) với NAP riêng, URL có cấu trúc rõ ràng (ví dụ: /dia-diem/quan-1/)
- Schema riêng gắn với trang đó, không dùng chung một block schema cho toàn bộ hệ thống
- Internal link từ trang hệ thống “Danh sách chi nhánh” trỏ về từng trang local cụ thể
Việc này giúp Google hiểu rõ: mỗi chi nhánh là một thực thể local riêng, nhưng vẫn thuộc cùng một tổ chức mẹ, từ đó tăng khả năng hiển thị trên map và local pack cho từng khu vực.
Trang quận huyện nhân bản nội dung chỉ đổi tên địa danh
Chiến lược “scale” local SEO bằng cách tạo hàng loạt trang quận/huyện chỉ thay tên địa danh là một trong những lỗi phổ biến nhất. Về mặt thuật toán, đây là dạng near-duplicate content: nội dung gần như giống nhau, chỉ thay một vài token (tên quận, tên đường). Khi số lượng trang kiểu này lớn, Google có xu hướng:
- Chọn một vài trang đại diện và bỏ qua (de-index hoặc không xếp hạng) phần lớn còn lại
- Đánh giá site thiếu chiều sâu nội dung, ưu tiên đối thủ có nội dung local thực sự khác biệt
- Giảm tín hiệu liên quan địa lý vì không thấy yếu tố “địa phương hóa” thực sự
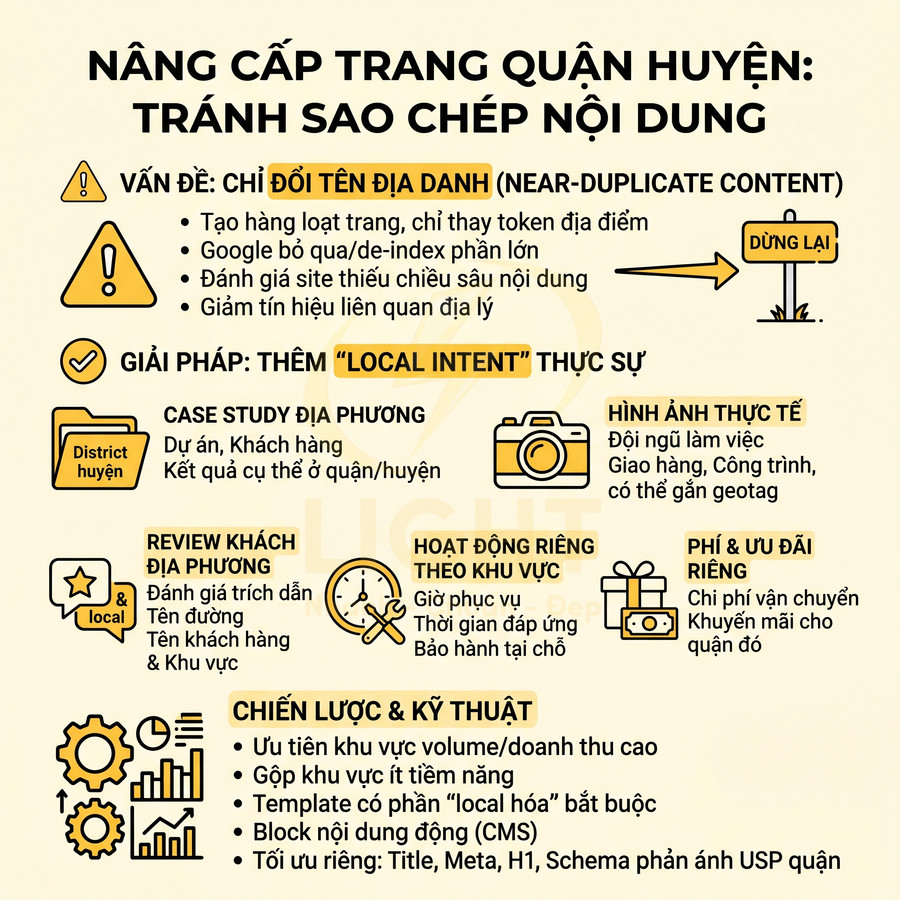
Ở góc độ người dùng, các trang này cũng không mang lại giá trị: không có thông tin cụ thể về khu vực, không có minh chứng doanh nghiệp thực sự hoạt động tại đó. Điều này làm giảm tỷ lệ chuyển đổi, tăng bounce rate, gián tiếp ảnh hưởng đến hiệu suất SEO.
Để nâng cấp, mỗi trang khu vực cần có “local intent” rõ ràng thông qua nội dung:
- Case study tại địa phương: mô tả chi tiết các dự án, khách hàng đã phục vụ ở quận/huyện đó, kèm số liệu, kết quả, hình ảnh.
- Hình ảnh thực tế: ảnh chụp đội ngũ làm việc tại khu vực, ảnh giao hàng, ảnh công trình, có thể gắn geotag (dù geotag không phải tín hiệu xếp hạng mạnh, nhưng hỗ trợ về mặt trust).
- Review của khách hàng địa phương: trích dẫn đánh giá có nhắc đến khu vực, tên đường, hoặc hiển thị tên khách hàng + khu vực.
- Thông tin vận hành theo khu vực: thời gian phục vụ riêng (ví dụ: khu vực xa chỉ phục vụ đến 20h), thời gian đáp ứng trung bình, chính sách bảo hành tại chỗ.
- Phí vận chuyển, phụ phí, ưu đãi riêng: thể hiện rõ sự khác biệt về chi phí, khuyến mãi cho khu vực đó.
Nếu nguồn lực nội dung hạn chế, nên:
- Ưu tiên khu vực có volume tìm kiếm và doanh thu cao để đầu tư nội dung sâu
- Gộp các khu vực ít tiềm năng vào một trang “khu vực lân cận” thay vì tách quá nhỏ
- Xây dựng template nội dung nhưng để khoảng trống cho phần “local hóa” bắt buộc (case study, review, hình ảnh, thông tin vận hành riêng)
Về mặt kỹ thuật, có thể:
- Sử dụng block nội dung động (component) để chèn dữ liệu riêng cho từng khu vực (ví dụ: danh sách dự án tại Quận 1, Quận 3… được quản lý trong CMS)
- Đảm bảo mỗi trang có title, meta description, H1, schema được tối ưu riêng, không chỉ thay tên địa danh mà còn phản ánh USP của khu vực
Thiếu bản đồ, giờ mở cửa và đánh giá địa phương thật
Trong local SEO, trang local không chỉ là một landing page marketing mà còn là “bản ghi chính thức” về sự tồn tại vật lý của doanh nghiệp tại một vị trí. Ba yếu tố: bản đồ, giờ mở cửa, review địa phương là các tín hiệu cực kỳ quan trọng cho cả người dùng và Google.
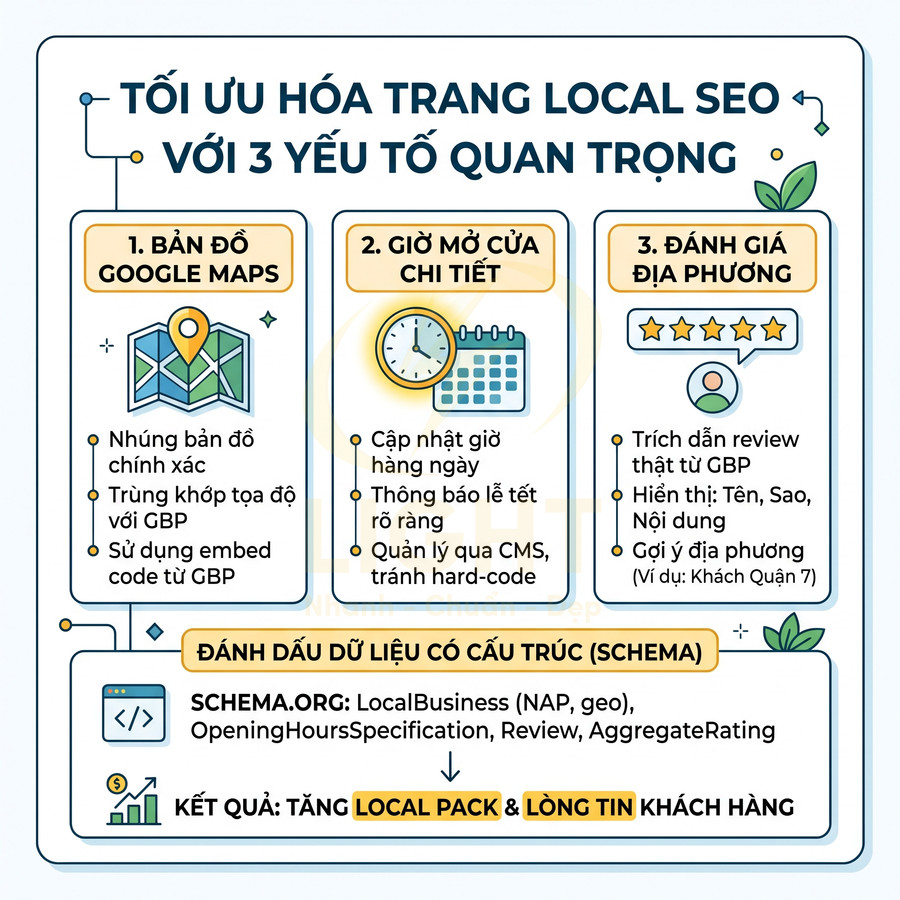
Các thiếu sót thường gặp:
- Không nhúng Google Maps, hoặc nhúng bản đồ không đúng tọa độ, không trùng với địa chỉ trên Google Business Profile
- Không hiển thị giờ mở cửa, hoặc chỉ ghi chung chung “Làm việc tất cả các ngày trong tuần” mà không có khung giờ cụ thể
- Không có review, hoặc chỉ là vài dòng testimonial chung chung, không gắn với địa phương, không có nguồn rõ ràng
Về mặt kỹ thuật, nên:
- Nhúng Google Maps với tọa độ chính xác của chi nhánh, sử dụng embed code từ đúng listing Google Business Profile tương ứng
- Hiển thị giờ mở cửa chi tiết theo từng ngày trong tuần, và cập nhật khi có thay đổi (nghỉ lễ, thay đổi lịch). Tránh hard-code trong HTML nếu lịch thay đổi thường xuyên; nên quản lý qua CMS.
- Trích dẫn review thật từ Google Business Profile hoặc các nền tảng uy tín khác, có thể hiển thị:
- Tên người review (hoặc ẩn một phần), số sao, trích đoạn nội dung
- Thông tin gợi ý địa phương: “khách tại Quận 7”, “khách ở đường X”
Đồng thời, đánh dấu dữ liệu có cấu trúc bằng schema:
- LocalBusiness (hoặc subtype phù hợp) cho NAP, geo, URL, sameAs
- OpeningHoursSpecification cho giờ mở cửa, đảm bảo khớp với thông tin trên Google Business Profile
- Review và AggregateRating nếu hiển thị điểm đánh giá tổng, giúp tăng khả năng xuất hiện rich result (khi phù hợp guideline)
Việc đồng bộ giữa trang local, schema và Google Business Profile giúp Google tự tin hơn khi hiển thị doanh nghiệp trong local pack, đồng thời tăng trust với người dùng vì thông tin rõ ràng, minh bạch.
Internal link giữa khu vực và dịch vụ không theo logic di chuyển thực tế
Internal link trong local SEO không chỉ là “tăng crawl” mà còn là cách mô phỏng hành trình di chuyển tự nhiên của người dùng. Khi cấu trúc link không phản ánh logic tìm kiếm thực tế, Google khó hiểu mối quan hệ giữa:
- Thực thể địa điểm (location)
- Nhóm dịch vụ/sản phẩm (service)
- Ý định tìm kiếm có yếu tố địa lý (service + location)
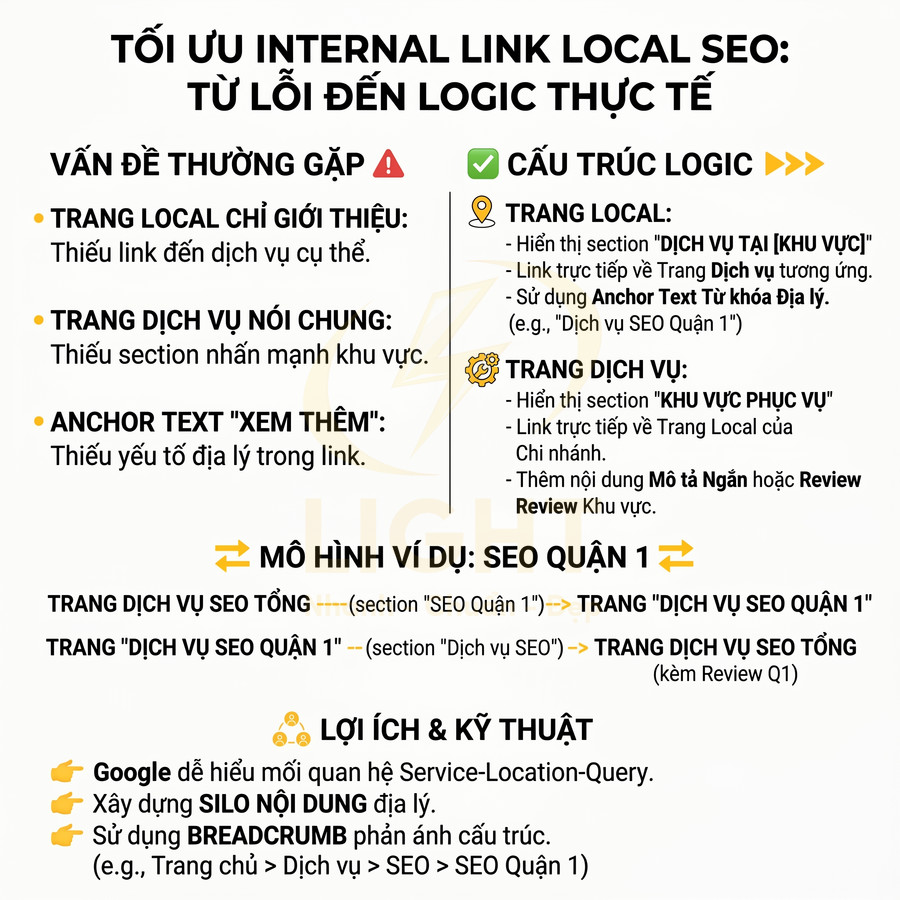
Các lỗi thường gặp:
- Trang local chỉ là “giới thiệu chi nhánh” mà không dẫn rõ đến các dịch vụ cụ thể tại chi nhánh đó
- Trang dịch vụ chỉ nói chung chung “phục vụ toàn quốc” mà không có section nhấn mạnh các khu vực trọng điểm, không link về trang local tương ứng
- Anchor text internal link không phản ánh truy vấn người dùng (ví dụ: chỉ dùng “Xem thêm” thay vì “Dịch vụ SEO tại Quận 1”)
Để tối ưu, cần thiết kế cấu trúc internal link theo logic:
- Mỗi trang local:
- Có section “Dịch vụ tại [Khu vực]” liệt kê các dịch vụ chính
- Link trực tiếp đến trang dịch vụ tương ứng, ưu tiên anchor text chứa cả dịch vụ + khu vực (khi phù hợp, tránh nhồi nhét)
- Mỗi trang dịch vụ:
- Có block “Khu vực phục vụ” hoặc “Chi nhánh hỗ trợ dịch vụ này”
- Link về các trang local trọng điểm, có thể kèm đoạn mô tả ngắn về cách triển khai dịch vụ tại từng khu vực
Ví dụ, với truy vấn “dịch vụ SEO Quận 1”, cấu trúc lý tưởng:
- Trang dịch vụ SEO tổng (dịch vụ SEO) có section “Dịch vụ SEO tại Quận 1” link về trang local Quận 1 hoặc một landing page chuyên biệt “Dịch vụ SEO Quận 1”.
- Trang local Quận 1 có block “Dịch vụ nổi bật tại Quận 1” link ngược lại trang dịch vụ SEO, kèm nội dung nhấn mạnh case study, review tại Quận 1.
Về mặt kỹ thuật, có thể:
- Xây dựng silo nội dung theo trục: Dịch vụ > Dịch vụ + Khu vực > Khu vực, đảm bảo mỗi node đều có internal link hai chiều hợp lý
- Sử dụng breadcrumb phản ánh rõ cấu trúc (ví dụ: Trang chủ > Dịch vụ > Dịch vụ SEO > SEO Quận 1)
- Kiểm soát anchor text đa dạng nhưng vẫn giữ được yếu tố địa lý ở các vị trí quan trọng (H1, heading phụ, anchor chính)
Khi internal link phản ánh đúng hành vi tìm kiếm và di chuyển thực tế, Google dễ dàng hiểu mối quan hệ giữa location – service – query, từ đó tăng khả năng xếp hạng cho các truy vấn có yếu tố địa lý, đồng thời cải thiện trải nghiệm người dùng trên site.
Câu hỏi thường gặp về lỗi kỹ thuật làm SEO mãi không lên
Phần này tập trung giải đáp các thắc mắc kỹ thuật thường khiến SEO không tăng trưởng dù đã tối ưu nội dung và offpage. Trọng tâm là các lỗi “ngầm” như HTML render rỗng, hiểu sai vai trò của điểm tốc độ, dữ liệu bị méo do click tặc, kiến trúc kéo thả block và thứ tự ưu tiên sửa lỗi để thấy kết quả nhanh. Người đọc sẽ hiểu vì sao HTML gốc phải chứa nội dung cốt lõi, vì sao site rất nhanh vẫn không top nếu kiến trúc chủ đề, internal link, canonical, schema và EEAT sai. Đồng thời, nội dung nhấn mạnh tầm quan trọng của việc chuẩn hóa kỹ thuật ở cấp hệ thống (block-based) và xây roadmap xử lý theo nguyên tắc render & index trước, tối ưu nâng cao sau để tránh lãng phí nguồn lực.

Website đẹp nhưng HTML render rỗng có ảnh hưởng nặng không?
HTML render rỗng hoặc gần như rỗng là một trong những lỗi kỹ thuật nặng nhất đối với SEO, đặc biệt trong bối cảnh Google ngày càng khắt khe với khả năng thu thập và hiểu nội dung. Về bản chất, khi HTML ban đầu (initial HTML) không chứa nội dung chính mà chỉ có một khung rỗng, phần lớn thông tin lại được tải bằng JavaScript phía client, bạn đang đặt toàn bộ niềm tin vào khả năng render của bot tìm kiếm. Điều này tạo ra nhiều rủi ro:
- Rủi ro về crawl budget: Với website lớn, nhiều URL, Googlebot có giới hạn về tài nguyên để vừa crawl vừa render JavaScript. Nếu mỗi trang đều cần render JS nặng, nhiều request, Google có thể dừng lại trước khi xử lý hết, dẫn đến một phần nội dung không được thấy hoặc bị trì hoãn index.
- Rủi ro về rendering pipeline: Google xử lý HTML thô trước, sau đó mới đưa vào hàng đợi để render JS. Nếu HTML ban đầu rỗng, giai đoạn đầu gần như không cung cấp tín hiệu gì về nội dung, chủ đề, internal link, khiến việc đánh giá mức độ liên quan ban đầu rất kém.
- Rủi ro với các bot khác: Nhiều công cụ SEO (Ahrefs, Screaming Frog ở chế độ non-JS, các social crawler như Facebook, Zalo, LinkedIn, các search engine nhỏ) chỉ đọc HTML mà không render JS. Khi HTML rỗng, họ sẽ:
- Không thấy nội dung, heading, internal link.
- Không trích xuất được entity, chủ đề, anchor text.
- Không tạo được preview đúng khi share link trên mạng xã hội.
- Rủi ro về tín hiệu onpage: Các yếu tố như title, meta description, structured data có thể nằm trong HTML, nhưng phần nội dung chính, heading H1–H2, danh sách, bảng, FAQ… nếu chỉ xuất hiện sau khi render JS sẽ làm giảm độ tin cậy khi Google đánh giá mức độ phù hợp với truy vấn.

Hệ quả là index kém, hiểu sai nội dung, mất cơ hội xếp hạng, đặc biệt với các truy vấn thông tin dài (long-tail) vốn phụ thuộc nhiều vào nội dung chi tiết trong body HTML. Ngoài ra, việc không có nội dung trong HTML còn làm giảm khả năng xuất hiện rich snippet, featured snippet, People Also Ask vì Google khó trích xuất đoạn văn, list, bảng ngay từ HTML thô.
Giải pháp kỹ thuật nên ưu tiên:
- SSR (Server-Side Rendering): Render nội dung chính trên server, trả về HTML đã có đầy đủ text, heading, internal link. JS phía client chỉ dùng để tương tác, không phụ thuộc để hiển thị nội dung cốt lõi.
- Pre-render: Với các site SPA (React, Vue, Angular), có thể dùng pre-render cho các trang quan trọng (landing SEO, blog, category). Hệ thống sẽ tạo sẵn HTML tĩnh cho bot, trong khi người dùng vẫn trải nghiệm SPA.
- Hybrid rendering / ISR (Incremental Static Regeneration): Kết hợp static HTML cho lần truy cập đầu với khả năng cập nhật định kỳ. Phù hợp cho site nội dung lớn, cần vừa SEO tốt vừa tối ưu hiệu năng.
- Kiểm tra bằng công cụ: Sử dụng “View Source” để xem HTML thô, dùng “Inspect → Elements” để so sánh với DOM sau khi render. Dùng các crawler có chế độ non-JS để đánh giá mức độ phụ thuộc JS.
Nguyên tắc quan trọng: nội dung mà bạn muốn xếp hạng phải xuất hiện trong HTML gốc ở mức tối thiểu: H1, đoạn văn chính, internal link quan trọng, schema cốt lõi. JS chỉ nên bổ sung trải nghiệm, không gánh toàn bộ nội dung.
Điểm tốc độ cao nhưng vẫn không top thường lỗi ở đâu?
Điểm tốc độ cao (PageSpeed, Lighthouse) chỉ phản ánh một phần nhỏ trong bức tranh SEO tổng thể. Một website có điểm hiệu năng 90–100 vẫn có thể không lên top nếu các trụ cột khác bị lỗi hoặc tối ưu kém. Các nhóm vấn đề thường gặp:
- Kiến trúc chủ đề (topical architecture):
- Không có cấu trúc silo rõ ràng, chủ đề bị phân tán, mỗi nhóm từ khóa không có một “trang trụ cột” (pillar page) đủ mạnh.
- URL, breadcrumb, category không phản ánh mối quan hệ chủ đề, khiến Google khó hiểu site nói mạnh nhất về chủ đề nào.
- Thiếu chiều sâu nội dung cho từng cụm chủ đề (topic cluster), chỉ có vài bài lẻ, không đủ để xây dựng topical authority.
- Internal link:
- Internal link không ưu tiên trang quan trọng, anchor text nghèo nàn, không mô tả rõ chủ đề.
- Trang sâu (depth > 3 click) khó được crawl thường xuyên, dù tốc độ từng trang rất tốt.
- Không có cấu trúc liên kết dạng hub–spoke, khiến sức mạnh bị dàn trải, không tập trung.
- Canonical & nội dung trùng lặp:
- Canonical sai hoặc thiếu, dẫn đến nhiều URL gần giống nhau cạnh tranh cùng một từ khóa (cannibalization).
- Filter, sort, pagination tạo ra hàng loạt URL trùng lặp nội dung, làm loãng tín hiệu và lãng phí crawl budget.
- Phiên bản HTTP/HTTPS, www/non-www, trailing slash không được chuẩn hóa triệt để.
- Schema & dữ liệu cấu trúc:
- Thiếu schema cho các loại nội dung quan trọng (Article, Product, FAQ, HowTo, Organization, LocalBusiness).
- Schema không đồng nhất với nội dung thực tế (mismatch), gây mất niềm tin hoặc không được Google sử dụng.
- Không tận dụng schema để tăng khả năng xuất hiện rich result, làm giảm CTR dù vị trí không tệ.
- EEAT (Experience, Expertise, Authoritativeness, Trustworthiness):
- Không thể hiện rõ tác giả, thông tin chuyên môn, chứng chỉ, kinh nghiệm thực tế.
- Thiếu trang giới thiệu, thông tin doanh nghiệp, chính sách, contact rõ ràng, làm giảm độ tin cậy.
- Không có tín hiệu off-page hỗ trợ (mention, backlink chất lượng, review, citation) để củng cố authority.
Vì vậy, khi website nhanh nhưng không top, cần thực hiện một technical & content audit toàn diện thay vì chỉ nhìn vào điểm tốc độ. Các bước thường gồm:
- Mapping lại toàn bộ topic, từ khóa, URL để phát hiện cannibalization và khoảng trống nội dung.
- Phân tích internal link, depth, anchor để tái cấu trúc luồng sức mạnh về các trang trụ cột.
- Rà soát canonical, noindex, hreflang (nếu đa ngôn ngữ), pagination để loại bỏ trùng lặp không cần thiết.
- Kiểm tra và bổ sung schema phù hợp, đảm bảo đồng nhất với nội dung và guideline của Google.
- Đánh giá EEAT: tác giả, brand, tín hiệu trust, review, thông tin pháp lý, social proof.
Click tặc có làm sai chiến lược SEO kết hợp Ads không?
Click tặc (click fraud) không chỉ gây lãng phí ngân sách quảng cáo mà còn làm méo dữ liệu, ảnh hưởng trực tiếp đến các quyết định chiến lược SEO khi bạn dùng dữ liệu Ads để định hướng. Một số tác động chuyên sâu:
- Sai lệch về hiệu suất từ khóa:
- Các từ khóa bị click tặc sẽ có số click, CTR, session tăng ảo, trong khi conversion thấp hoặc bằng 0.
- Nếu không phát hiện, bạn có thể ưu tiên SEO cho những từ khóa tưởng như “nhiều traffic, tiềm năng cao” nhưng thực tế không mang lại giá trị.
- Sai lệch về hiệu quả landing page:
- Landing page bị click tặc sẽ có bounce rate, time on site, scroll depth bị bóp méo, làm bạn đánh giá sai UX và chất lượng nội dung.
- Có thể dẫn đến việc tối ưu sai trang, bỏ qua những landing thực sự hiệu quả nhưng ít bị tấn công.
- Sai lệch về chân dung khách hàng (audience profile):
- Dữ liệu về thiết bị, vị trí, thời gian truy cập, hành vi on-site bị nhiễu, làm hỏng các phân tích về persona.
- Các quyết định về nội dung, thông điệp, layout dựa trên dữ liệu này sẽ không phản ánh đúng nhu cầu người dùng thật.
- Ảnh hưởng đến mô hình attribution:
- Click tặc có thể làm sai lệch mô hình phân bổ chuyển đổi (last click, data-driven…), khiến bạn đánh giá sai vai trò của SEO so với Ads.
- Có thể dẫn đến việc cắt giảm hoặc tăng đầu tư SEO/Ads dựa trên dữ liệu không chính xác.

Vì vậy, khi kết hợp SEO và Ads, việc phát hiện và chặn click tặc là bắt buộc để đảm bảo dữ liệu dùng cho tối ưu là đáng tin cậy. Một số hướng xử lý:
- Thiết lập rule trong nền tảng Ads (Google Ads, Facebook Ads…) để giới hạn số click/IP, loại trừ IP bất thường.
- Dùng các công cụ phát hiện click fraud chuyên dụng, kết hợp log server để nhận diện pattern bất thường.
- Phân tích dữ liệu Analytics: spike traffic bất thường, tỉ lệ chuyển đổi bằng 0 từ một số nguồn/địa lý/thiết bị.
- Tách riêng chiến dịch test dữ liệu (thử từ khóa, landing) với chiến dịch tối ưu chuyển đổi, để giảm rủi ro dữ liệu bị nhiễu lan sang toàn bộ chiến lược.
Kéo thả block nhỏ có giúp giảm lỗi kỹ thuật dài hạn không?
Kiến trúc kéo thả block nhỏ (modular block-based architecture), nếu được thiết kế đúng, là một trong những cách hiệu quả nhất để giảm lỗi kỹ thuật dài hạn và chuẩn hóa SEO onpage ở quy mô lớn. Ý tưởng cốt lõi là:
- Mỗi block là một “đơn vị giao diện + logic” độc lập, đã được chuẩn hóa về:
- HTML semantic (heading, list, section, article, nav…)
- Schema tương ứng (FAQ, HowTo, Product, Review, Breadcrumb… nếu phù hợp)
- Responsive, accessibility (ARIA, alt text, keyboard navigation…)
- Hiệu năng (lazy load, kích thước ảnh, số request…)
- Các block này được kiểm thử kỹ (test manual + automated) trước khi đưa vào thư viện dùng chung cho toàn site.
Khi SEOer và content dùng các block này để xây trang bằng thao tác kéo thả, lợi ích dài hạn gồm:
- Giảm khả năng tạo lỗi mới:
- Không còn tình trạng mỗi trang một kiểu HTML, mỗi dev một style, gây khó khăn cho việc crawl và hiểu cấu trúc.
- Giảm lỗi lặp ID, nesting sai, thiếu heading, thiếu alt, thiếu schema… vì tất cả đã được đóng gói trong block.
- Dễ bảo trì và cập nhật chuẩn SEO:
- Khi Google cập nhật guideline (schema mới, yêu cầu mới về Core Web Vitals, accessibility…), chỉ cần cập nhật block một lần.
- Tất cả trang sử dụng block đó sẽ tự động được hưởng lợi, không cần sửa tay từng trang.
- Đảm bảo tính nhất quán:
- Cấu trúc heading, layout, cách trình bày nội dung quan trọng (FAQ, bảng giá, review, CTA) nhất quán trên toàn site.
- Giúp Google dễ nhận diện pattern, hiểu rõ loại nội dung, tăng khả năng xuất hiện rich result.
- Tăng tốc độ triển khai SEO:
- SEOer có thể nhanh chóng tạo landing mới, test A/B, mở rộng topic cluster mà không cần chờ dev.
- Giảm chi phí QA kỹ thuật cho mỗi lần xuất bản nội dung mới.
Điều kiện để mô hình block thực sự hiệu quả:
- Có quy chuẩn rõ ràng về HTML semantic, naming, schema cho từng loại block.
- Quy trình review kỹ thuật trước khi block được đưa vào thư viện chung.
- Hạn chế tối đa việc cho phép người dùng cuối chèn code tùy ý trong block (tránh phá vỡ chuẩn).
- Có cơ chế versioning để cập nhật block mà không làm hỏng các trang cũ.
Nên ưu tiên sửa lỗi nào trước để thấy tăng trưởng nhanh nhất?
Thứ tự ưu tiên thường nên theo nguyên tắc: render & index > canonical & trùng lặp > internal link > tốc độ > schema & EEAT. Lý do là không phải lỗi nào cũng ảnh hưởng như nhau; một số lỗi mang tính “chặn đường” (blocking), số khác chỉ mang tính “tối ưu thêm”.

Cách tiếp cận chuyên sâu:
- 1. Render & index:
- Đảm bảo bot thấy được nội dung đúng:
- Kiểm tra HTML render (SSR, pre-render, JS dependency).
- Rà soát thẻ noindex, robots meta, robots.txt, HTTP header.
- Đảm bảo không có lỗi 4xx/5xx ẩn, redirect chain, redirect loop.
- Nếu bot không thấy nội dung hoặc không index, mọi tối ưu khác đều vô nghĩa.
- Đảm bảo bot thấy được nội dung đúng:
- 2. Canonical & trùng lặp (duplicate, cannibalization):
- Xử lý các nhóm URL trùng lặp hoặc gần trùng:
- Chuẩn hóa canonical, redirect, noindex cho các biến thể không cần thiết.
- Gộp nội dung (content consolidation) cho các trang cannibalizing cùng từ khóa.
- Mục tiêu: mỗi ý định tìm kiếm (search intent) quan trọng chỉ nên có một trang chính đại diện.
- Xử lý các nhóm URL trùng lặp hoặc gần trùng:
- 3. Internal link:
- Tối ưu cấu trúc internal link để:
- Dồn sức mạnh về các trang trụ cột, landing quan trọng.
- Giảm depth cho các trang cần index nhanh, crawl thường xuyên.
- Cải thiện anchor text để Google hiểu rõ chủ đề từng trang.
- Đây là đòn bẩy thường cho kết quả khá nhanh, đặc biệt với site đã có nhiều nội dung.
- Tối ưu cấu trúc internal link để:
- 4. Tốc độ & Core Web Vitals:
- Sau khi đảm bảo index, canonical, internal link, mới tối ưu sâu về:
- LCP, CLS, INP (hoặc FID), kích thước ảnh, lazy load, caching.
- Giảm JS/CSS không cần thiết, tối ưu critical rendering path.
- Tốc độ ảnh hưởng đến UX, tỷ lệ chuyển đổi, và là tín hiệu xếp hạng bổ trợ, nhưng không nên ưu tiên trước các lỗi chặn index.
- Sau khi đảm bảo index, canonical, internal link, mới tối ưu sâu về:
- 5. Schema & EEAT:
- Khi nền tảng kỹ thuật đã ổn, tập trung:
- Bổ sung schema phù hợp để tăng khả năng rich result, cải thiện CTR.
- Xây dựng và thể hiện EEAT: tác giả, thông tin doanh nghiệp, review, case study, chứng chỉ, kinh nghiệm thực tế.
- Đây là lớp tối ưu nâng cao, giúp tăng trưởng bền vững và cạnh tranh ở thị trường khó.
- Khi nền tảng kỹ thuật đã ổn, tập trung:
Mỗi website có bối cảnh khác nhau, nhưng nguyên tắc chung là ưu tiên các lỗi chặn index hoặc làm bot hiểu sai trước, sau đó mới đến các yếu tố tối ưu hóa hiệu suất và tín hiệu nâng cao.
Lộ trình xử lý lỗi kỹ thuật để website đẹp và SEO cùng tăng trưởng
Lộ trình xử lý lỗi kỹ thuật tập trung vào việc đảm bảo bot có thể render, crawl và index nội dung giống người dùng, sau đó tối ưu internal link, canonical và cấu trúc thông tin để làm rõ trang trụ cột và trang hỗ trợ. Khi nền tảng đã ổn, hệ thống giám sát tự động với crawl định kỳ, dashboard và cảnh báo giúp phát hiện sớm lỗi onpage, schema, indexability, hiệu năng, đồng thời cho phép sửa hàng loạt theo template qua CMS. Tiếp theo, thư viện block kéo thả chuẩn hóa giúp SEOer, marketer tối ưu layout, bổ sung tín hiệu EEAT mà không phá cấu trúc kỹ thuật. Cuối cùng, đồng bộ chặn click tặc với landing Ads và trang SEO, dùng chung block, chuẩn kỹ thuật và tracking để mỗi thử nghiệm trả phí trở thành dữ liệu tối ưu SEO dài hạn.
Ưu tiên sửa render, index, internal link và canonical trước
Giai đoạn đầu tiên trong lộ trình kỹ thuật là đảm bảo bot có thể render và hiểu đúng nội dung như người dùng. Với các site dùng JS framework (React, Vue, Next, Nuxt…), cần kiểm tra:
- HTML source có chứa nội dung chính (content, heading, internal link) hay chỉ là khung rỗng chờ JS render.
- Khả năng render khi tắt JS: dùng công cụ như “View Rendered Source”, “Mobile-Friendly Test”, “URL Inspection” để so sánh DOM trước và sau khi render.
- Trạng thái HTTP của từng URL (200, 301, 404, 5xx) để tránh trường hợp bot nhận 404 nhưng người dùng vẫn thấy nội dung.
Tiếp theo là lớp indexability:
- Rà soát toàn bộ thẻ
meta robotsđể phát hiện noindex nhầm trên các trang quan trọng (category, service, landing chính). - Kiểm tra file
robots.txtcó chặn nhầm thư mục chứa nội dung hoặc file JS/CSS quan trọng khiến bot không render được. - Đối chiếu danh sách URL trong sitemap với thực tế index trên Google Search Console để phát hiện nhóm trang không được index hoặc index sai phiên bản.
Với canonical, cần đảm bảo:
- Mỗi URL chỉ có một thẻ canonical, không trùng lặp, không mâu thuẫn giữa HTML và HTTP header.
- Canonical trỏ về đúng phiên bản chuẩn (HTTPS, không có tham số tracking, đúng ngôn ngữ, đúng phiên bản có nội dung đầy đủ).
- Không dùng canonical để “che” lỗi trùng lặp nội dung do phân trang, filter, sort mà không có chiến lược rõ ràng (ví dụ: canonical tất cả về page 1 gây mất index các page sau).
Sau khi lớp render và index đã ổn, chuyển sang internal link và cấu trúc thông tin. Mục tiêu là giúp bot hiểu rõ đâu là trang trụ cột (pillar), đâu là trang hỗ trợ (cluster):
- Xây cấu trúc silo: từ trang chủ → category chính → trang dịch vụ/trụ cột → bài blog/landing hỗ trợ.
- Đảm bảo mỗi trang dịch vụ quan trọng nhận được đủ internal link từ:
- Menu, footer, breadcrumb.
- Blog liên quan (anchor text chứa từ khóa chính hoặc biến thể ngữ nghĩa).
- Các landing hỗ trợ, trang case study, testimonial.
- Giảm bớt internal link “rác” (tag page mỏng, archive không có giá trị, trang filter trùng lặp) để tăng “tín hiệu” cho các URL ưu tiên.
Việc tối ưu nhóm yếu tố này thường mang lại cải thiện rõ rệt về tốc độ index, độ sâu crawl và thứ hạng trong thời gian ngắn, vì bot không còn bị phân tán crawl budget và có thể hiểu chính xác cấu trúc ưu tiên của toàn site.
Tích hợp quét lỗi tự động và sửa hàng loạt theo mẫu trang
Sau khi nền tảng kỹ thuật cơ bản đã ổn, bước tiếp theo là xây dựng hệ thống giám sát tự động để không rơi vào trạng thái “chỉ phát hiện lỗi khi traffic tụt”. Một hệ thống tốt thường bao gồm:
- Công cụ crawl định kỳ (hàng ngày hoặc hàng tuần) để quét:
- Lỗi onpage: thiếu title, meta description trùng lặp, H1 trùng, thin content.
- Lỗi schema: JSON-LD sai type, thuộc tính bắt buộc thiếu, markup không khớp nội dung hiển thị.
- Lỗi canonical, redirect chain, redirect loop, mixed content (HTTP trong HTTPS).
- Core Web Vitals: LCP, CLS, INP theo từng template trang.
- Dashboard tổng hợp theo nhóm:
- Nhóm theo template (blog, category, service, product, landing).
- Nhóm theo mức độ ưu tiên (money page, top traffic, top conversion).
- Nhóm theo loại lỗi (indexability, content, performance, UX).
- Cảnh báo tự động:
- Gửi email/Slack khi số lượng 5xx tăng đột biến, khi nhiều URL chuyển từ index sang excluded.
- Cảnh báo khi có thay đổi lớn trong title, canonical, robots meta trên nhóm URL quan trọng.
Để tận dụng tối đa dữ liệu từ hệ thống giám sát, CMS cần hỗ trợ sửa hàng loạt theo template hoặc theo nhóm trang thay vì chỉnh từng URL:
- Thiết kế cấu trúc template rõ ràng:
- Mỗi loại trang (blog, category, product, service, landing) có một file/template riêng.
- Các thành phần SEO (title, meta, breadcrumb, schema, canonical) được sinh từ rule, không hard-code từng trang.
- Cho phép chỉnh sửa rule:
- Ví dụ: thay đổi cấu trúc title cho toàn bộ blog từ “{Post Title} | Brand” sang “{Post Title} – {Category} | Brand” chỉ bằng 1 lần chỉnh.
- Thêm schema Article cho toàn bộ blog hoặc schema Product cho toàn bộ product page bằng một config chung.
- Hỗ trợ bulk edit theo nhóm:
- Chọn nhóm URL theo filter (theo path, theo tag, theo traffic) và áp dụng cùng một rule canonical, redirect, hoặc pattern internal link.
- Đồng bộ các trường dữ liệu SEO (OG tags, Twitter Card, meta robots) cho nhóm trang có cùng mục tiêu.
Giai đoạn này đánh dấu bước chuyển từ cách làm “chữa cháy từng lỗi lẻ tẻ” sang bảo trì chủ động, nơi mọi thay đổi kỹ thuật đều có thể triển khai diện rộng, có log, có rollback, và có đo lường tác động.
Chuẩn hóa hệ block kéo thả nhỏ để tối ưu không phá site lớn
Để website vừa đẹp, vừa linh hoạt, vừa chuẩn SEO, cần xây một thư viện block kéo thả chuẩn hóa thay vì cho phép chỉnh HTML tự do trên từng trang. Mỗi block là một đơn vị nhỏ, có logic SEO và UX rõ ràng, ví dụ:
- Block FAQ:
- Tự động sinh schema FAQPage với cấu trúc câu hỏi – trả lời.
- Cho phép reorder câu hỏi, thêm/xóa mà không ảnh hưởng layout tổng.
- Block HowTo:
- Hỗ trợ schema HowTo với step, image, tool, supply.
- Đảm bảo markup khớp nội dung hiển thị, tránh spam schema.
- Block bảng giá:
- Thiết kế responsive, dễ đọc trên mobile, có chỗ cho USP, badge “Best choice”.
- Có thể gắn schema Offer/Product nếu phù hợp.
- Block review/testimonial:
- Hỗ trợ hiển thị avatar, tên, chức vụ, nguồn review (Google, Facebook…).
- Có option schema Review/AggregateRating khi đáp ứng guideline.
- Block CTA, block niềm tin (trust block):
- Chứa các yếu tố tăng EEAT: logo đối tác, chứng chỉ, số liệu, case study.
- Thiết kế để không làm loãng nội dung chính nhưng vẫn nổi bật.
Mỗi block cần được thiết kế với các nguyên tắc:
- Chuẩn SEO mặc định:
- Heading hierarchy đúng (không nhảy từ H2 sang H4 trong cùng block).
- Không tạo duplicate ID, không nhồi từ khóa trong anchor text.
- Markup schema đúng type, đúng context, không lạm dụng.
- Dễ dùng cho SEOer và marketer:
- Form cấu hình rõ ràng: text, image, link, schema option.
- Preview trực quan để thấy ngay layout trước khi publish.
- Không phá cấu trúc kỹ thuật tổng:
- Block không được phép chỉnh các phần global như canonical, robots, main schema của trang.
- CSS và JS của block được đóng gói, tránh xung đột với theme chính.
Khi thư viện block đã chuẩn hóa, SEOer và marketer có thể:
- Tự thử nghiệm layout: thay đổi vị trí FAQ, thêm block review gần CTA, chèn block niềm tin giữa nội dung mà không cần dev can thiệp.
- Bổ sung tín hiệu EEAT (Expertise, Experience, Authoritativeness, Trustworthiness) bằng các block tác giả, block chứng chỉ, block case study.
- Tối ưu từng trang theo intent tìm kiếm (informational, commercial, transactional) mà vẫn đảm bảo site-wide consistency.
Cách tiếp cận này giúp site lớn có thể mở rộng nội dung nhanh, nhiều người cùng tham gia tối ưu mà không làm vỡ cấu trúc kỹ thuật, không tạo ra “rừng layout” khó bảo trì.
Đồng bộ chặn click tặc với landing quảng cáo hỗ trợ SEO dài hạn
Khi kết hợp SEO với Ads để test từ khóa, thông điệp, layout, một vấn đề thường bị bỏ qua là click tặc (invalid click). Nếu không xử lý, dữ liệu hành vi dùng để tối ưu SEO sẽ bị nhiễu:
- Tỷ lệ bounce, time on page, conversion rate bị bóp méo do lượng lớn click không phải người dùng thật.
- Heatmap, scroll map, session recording không phản ánh đúng hành vi khách hàng mục tiêu.
- Phân tích A/B test layout, CTA, headline trở nên thiếu tin cậy.
Giải pháp là tích hợp hệ thống chặn click tặc trực tiếp vào kiến trúc landing:
- Tracking và phân loại IP, user agent, pattern hành vi bất thường (click lặp lại, không scroll, không tương tác).
- Tự động loại trừ nguồn traffic nghi vấn khỏi báo cáo phân tích SEO/UX nội bộ.
- Đồng bộ với nền tảng Ads để giảm hiển thị cho nguồn có tỷ lệ click tặc cao.
Các landing chạy Ads nên được xây trên cùng hệ block và chuẩn kỹ thuật với trang SEO:
- Dùng chung thư viện block (FAQ, review, bảng giá, CTA, trust block) để:
- Test nhanh nhiều biến thể layout, headline, offer trên Ads.
- Khi một cấu trúc chứng minh hiệu quả (tăng conversion, tăng time on page), có thể áp dụng lại cho các trang SEO chỉ bằng vài thao tác kéo thả.
- Giữ chung chuẩn kỹ thuật:
- Core Web Vitals tốt, responsive, không pop-up gây khó chịu.
- Schema, heading, internal link logic tương tự trang SEO.
- Đồng bộ tracking:
- Dùng cùng hệ thống event tracking (click CTA, form submit, scroll depth) cho cả landing Ads và trang SEO.
- So sánh hành vi giữa traffic trả phí và organic để hiểu sâu hơn về intent và rào cản chuyển đổi.
Khi SEO, Ads, kỹ thuật và UX được đồng bộ như vậy, mỗi test trên kênh trả phí không chỉ tối ưu chi phí quảng cáo mà còn trở thành “phòng lab” cho toàn bộ website. Những gì hiệu quả sẽ được nhân rộng sang các trang SEO, giúp website vừa giữ được vẻ đẹp giao diện, vừa đạt hiệu suất SEO bền vững trong dài hạn.
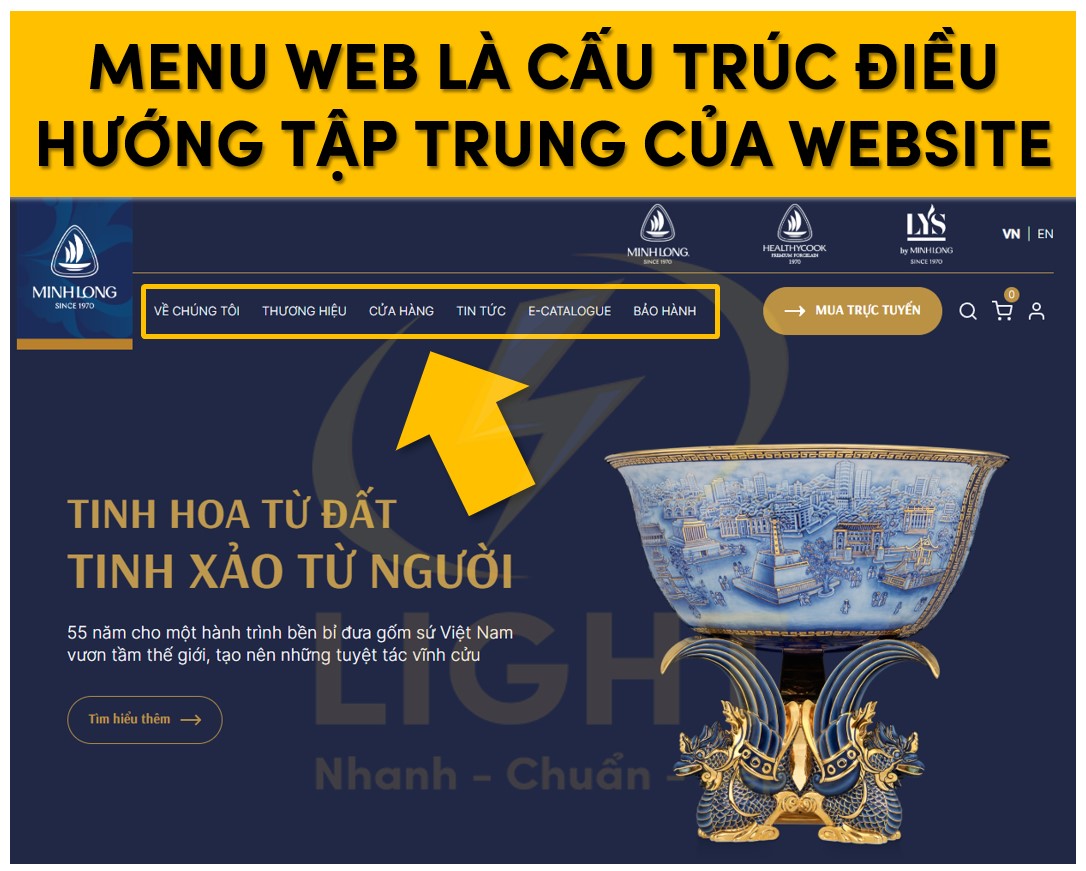




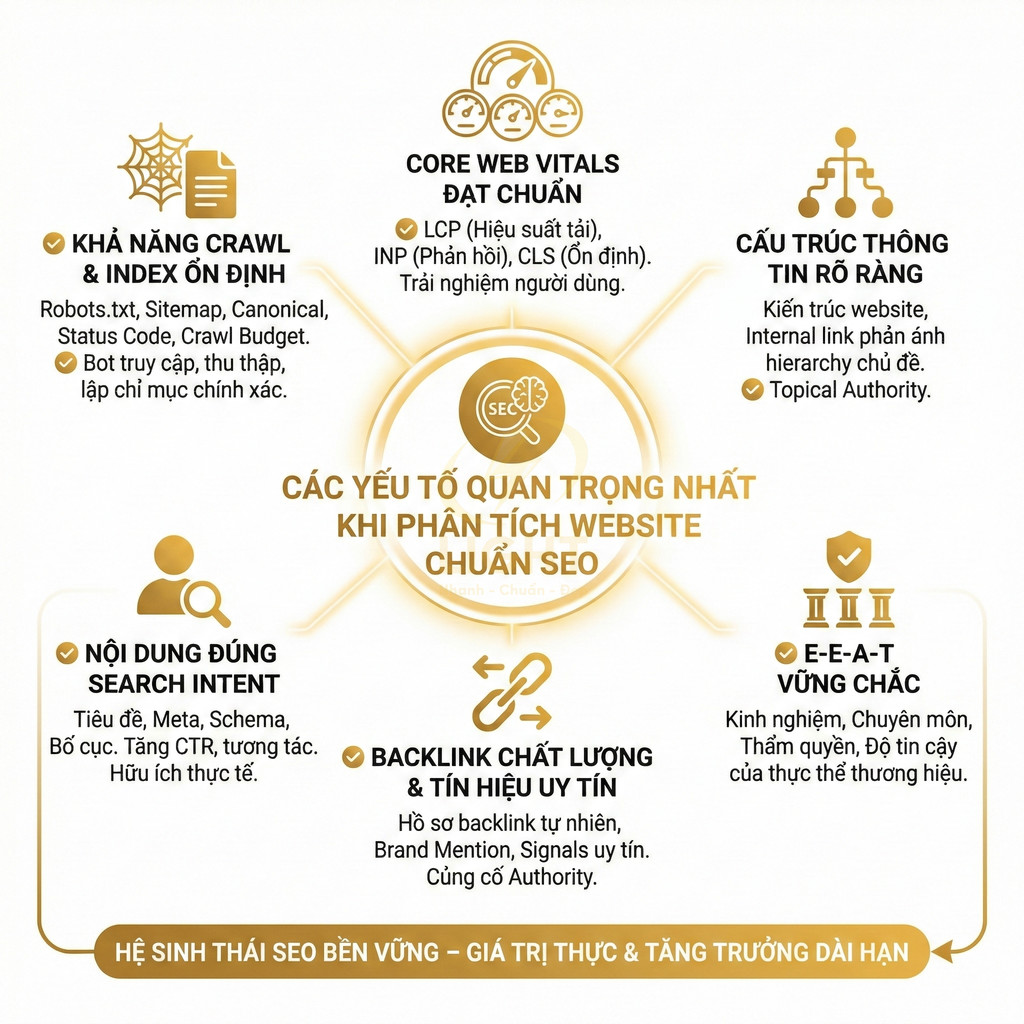

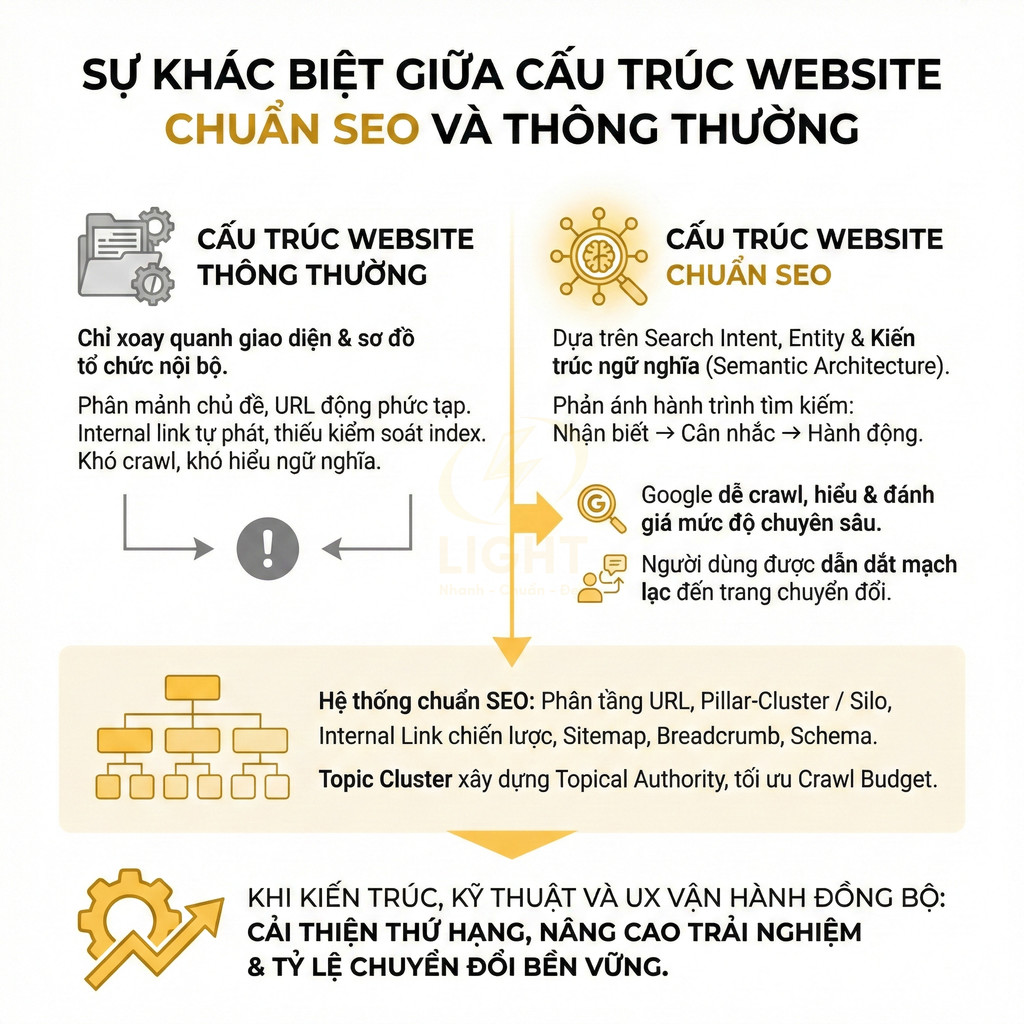

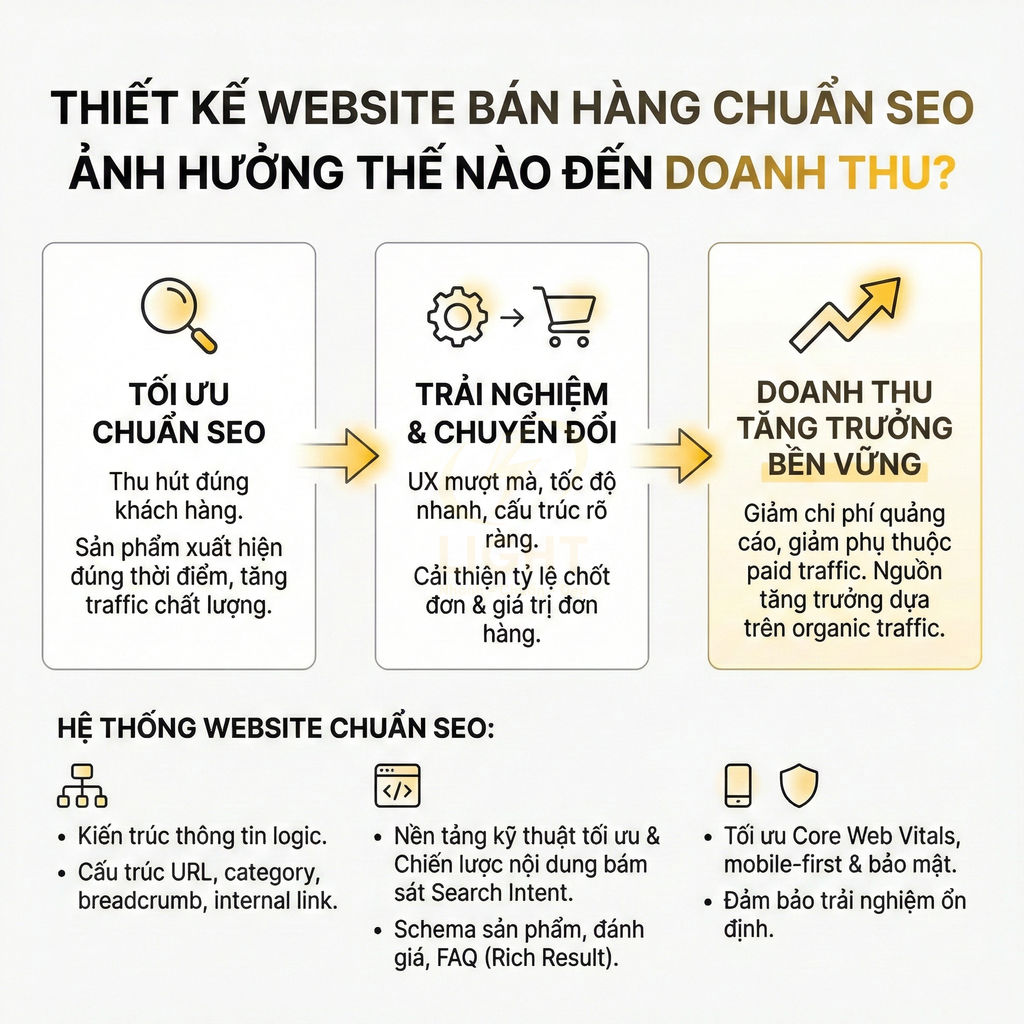


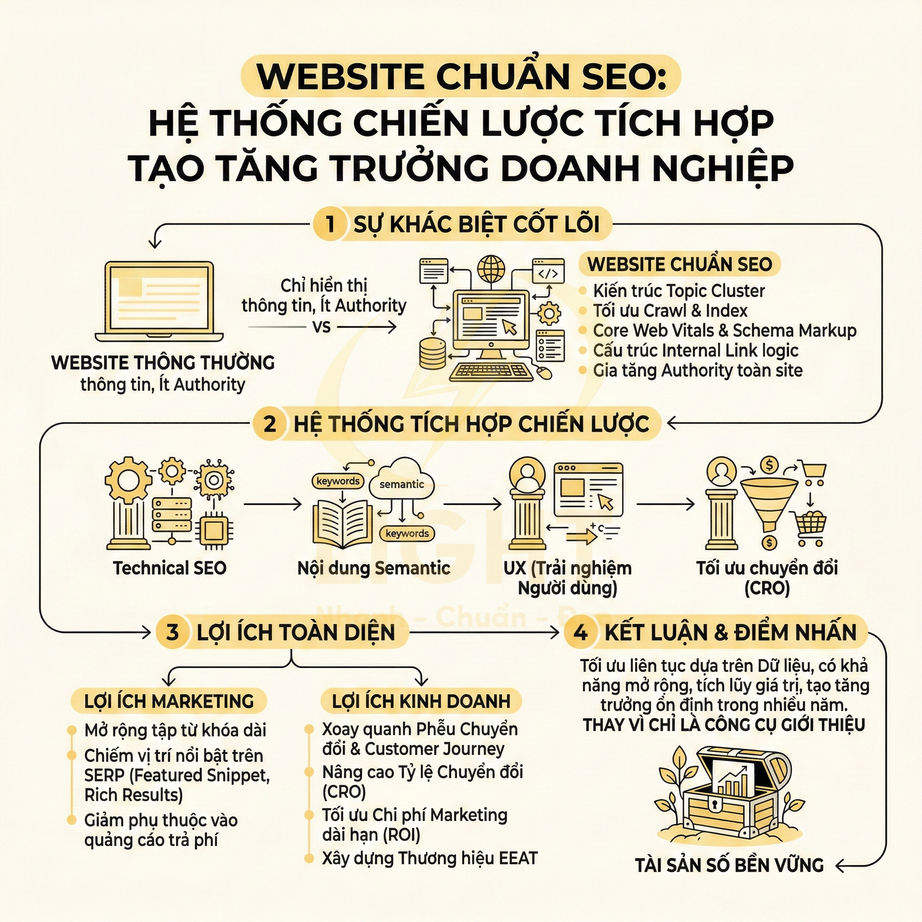
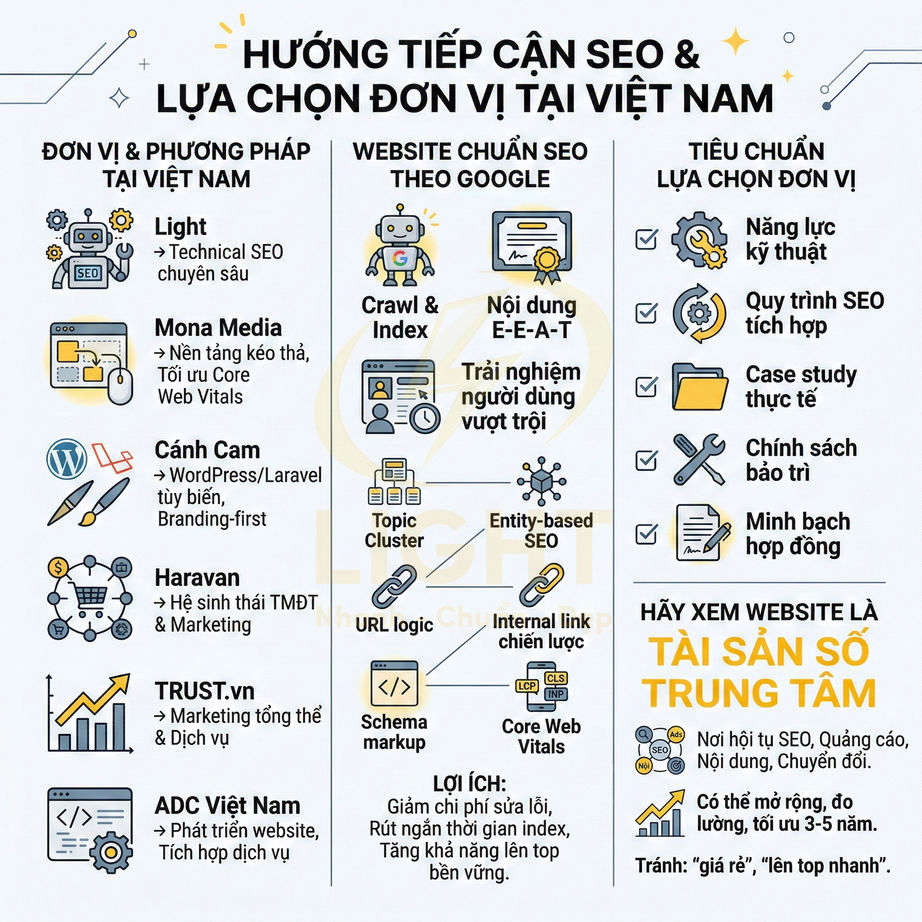
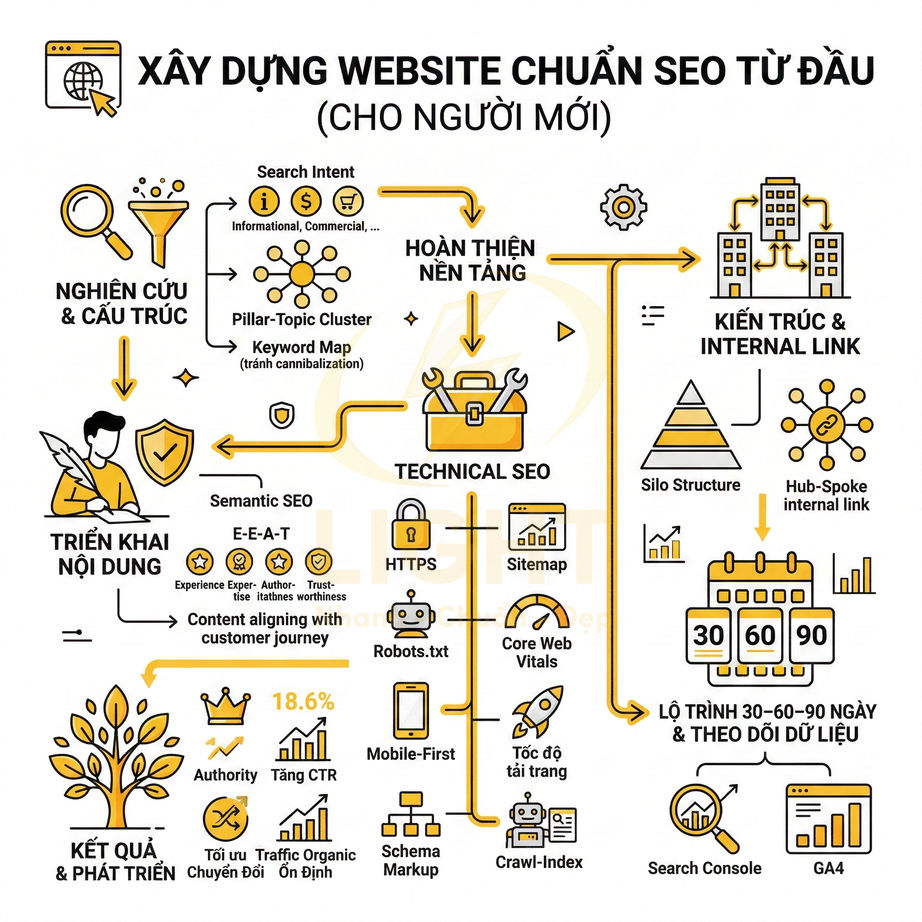
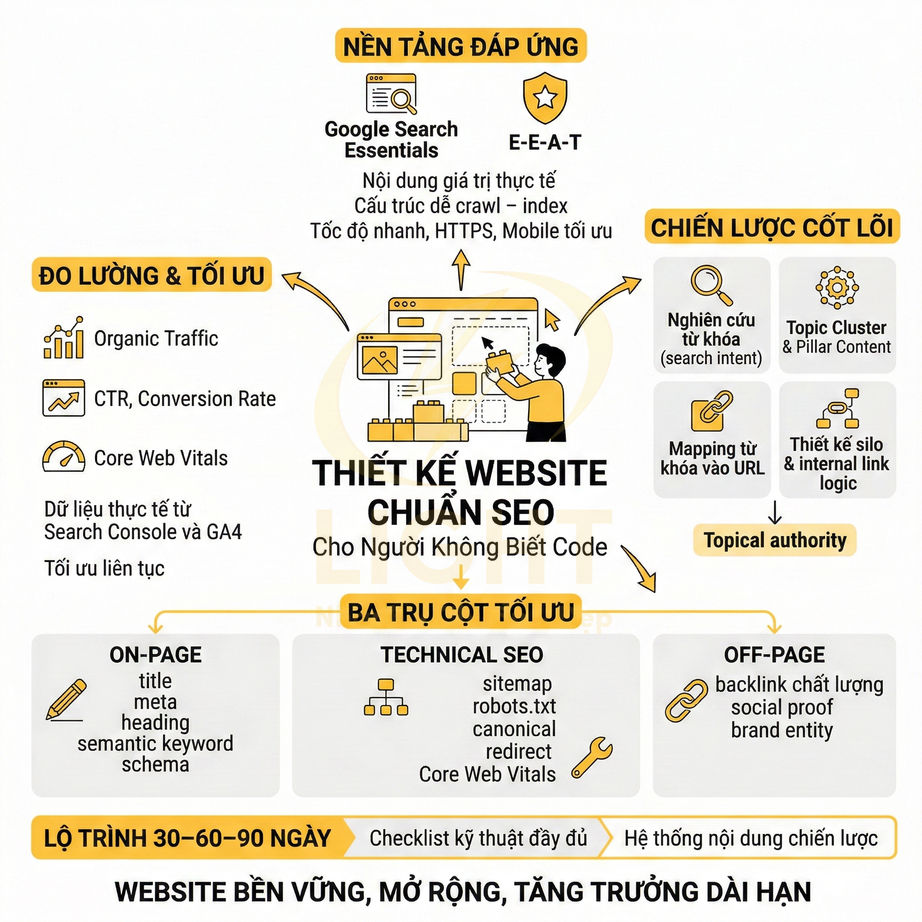



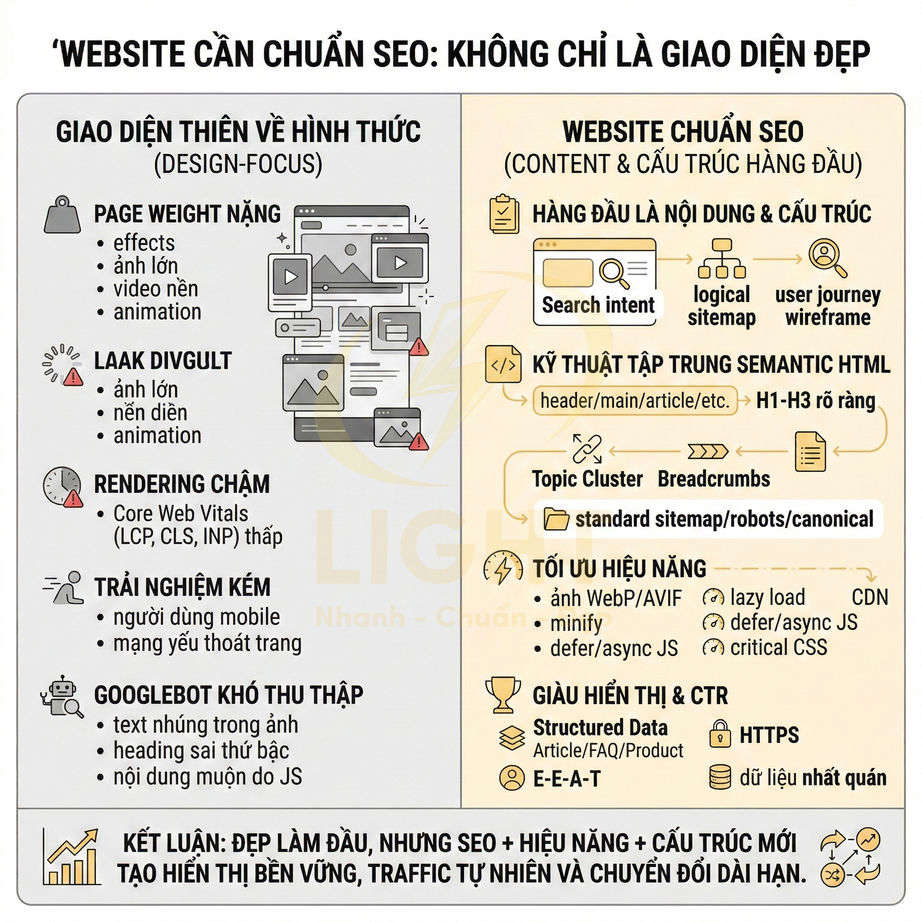
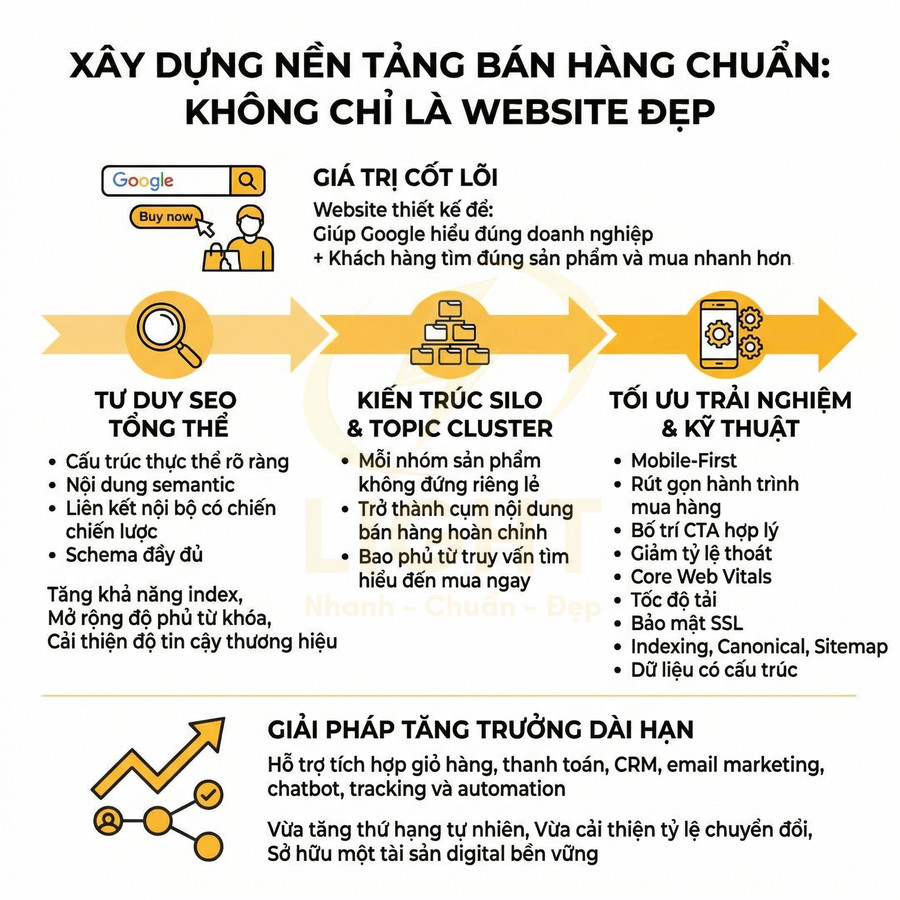

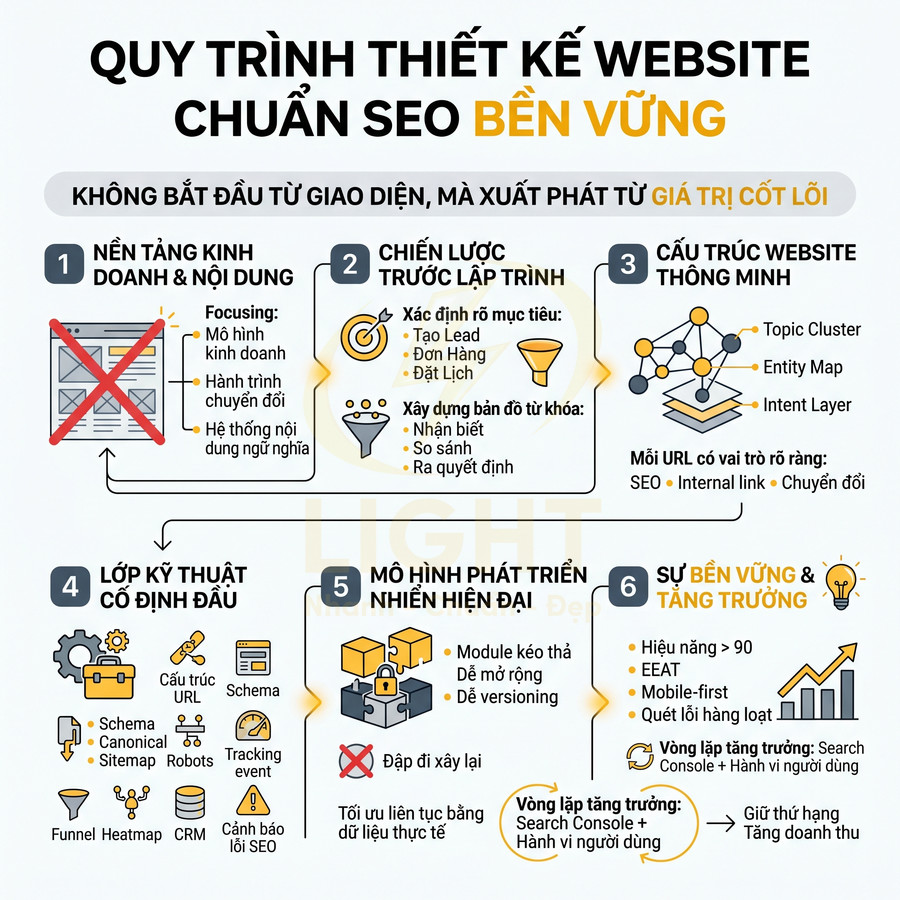
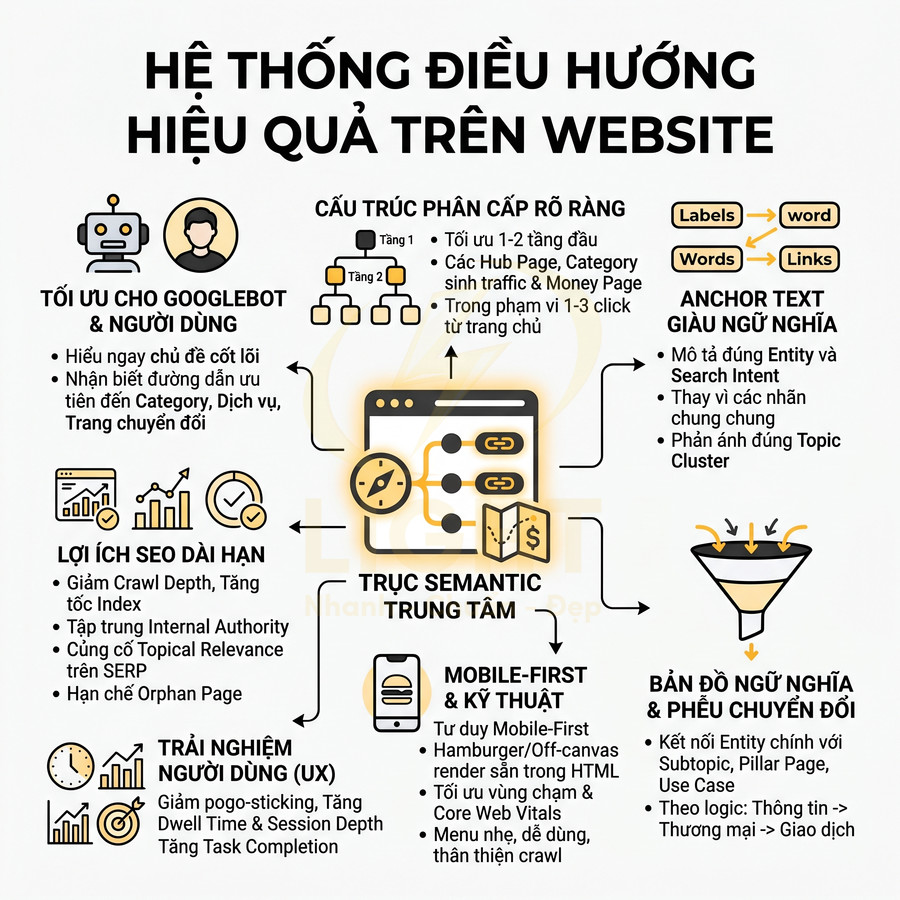
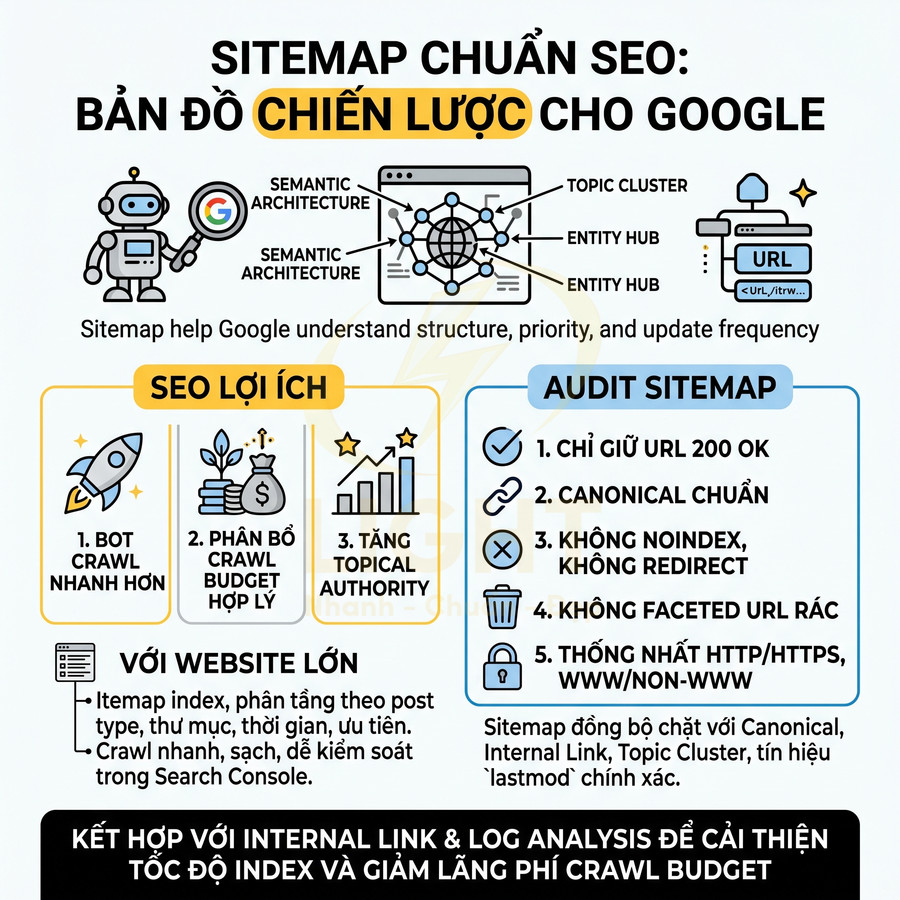
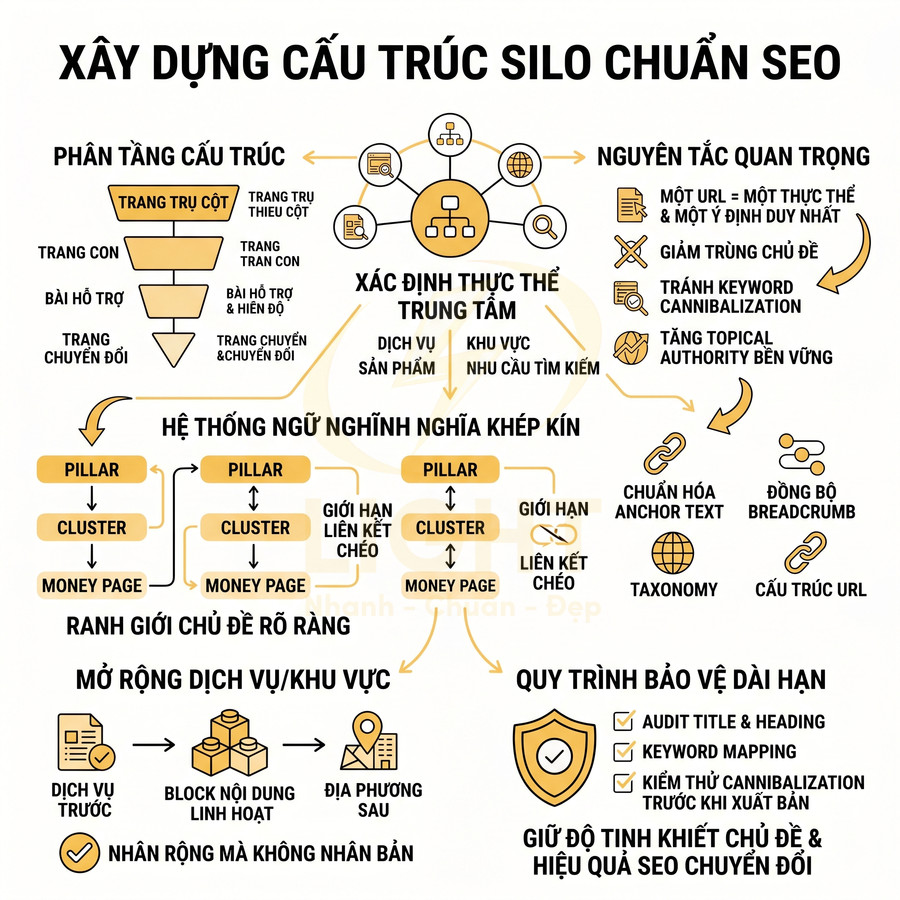
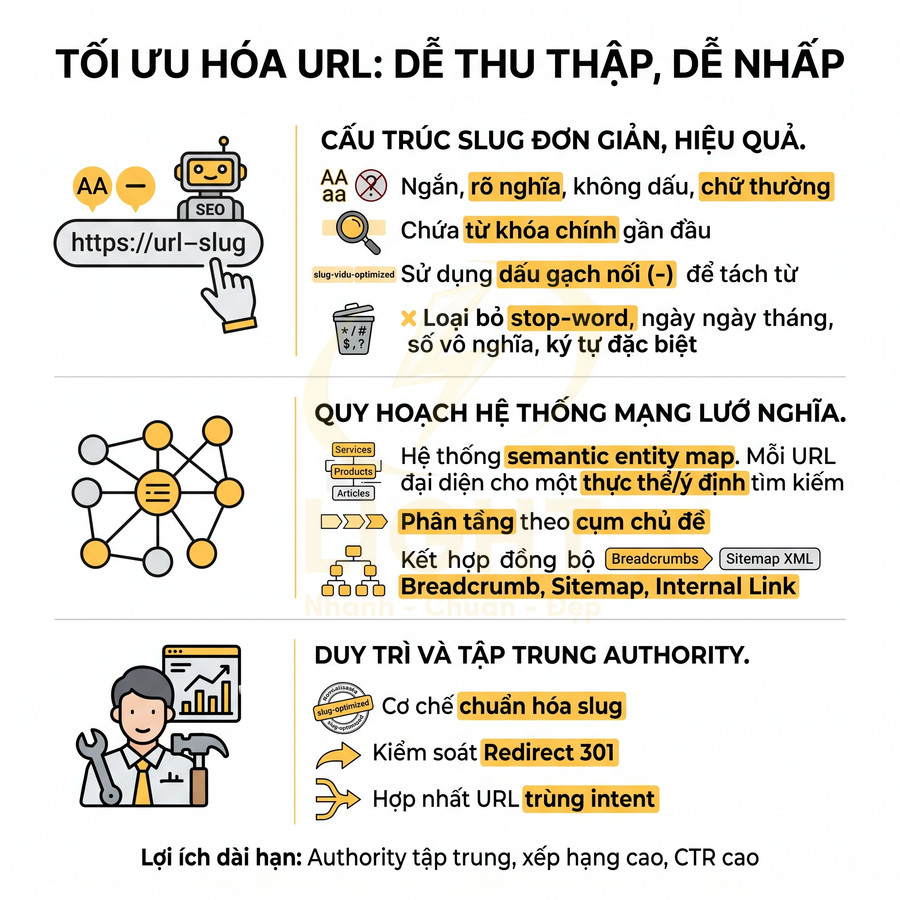
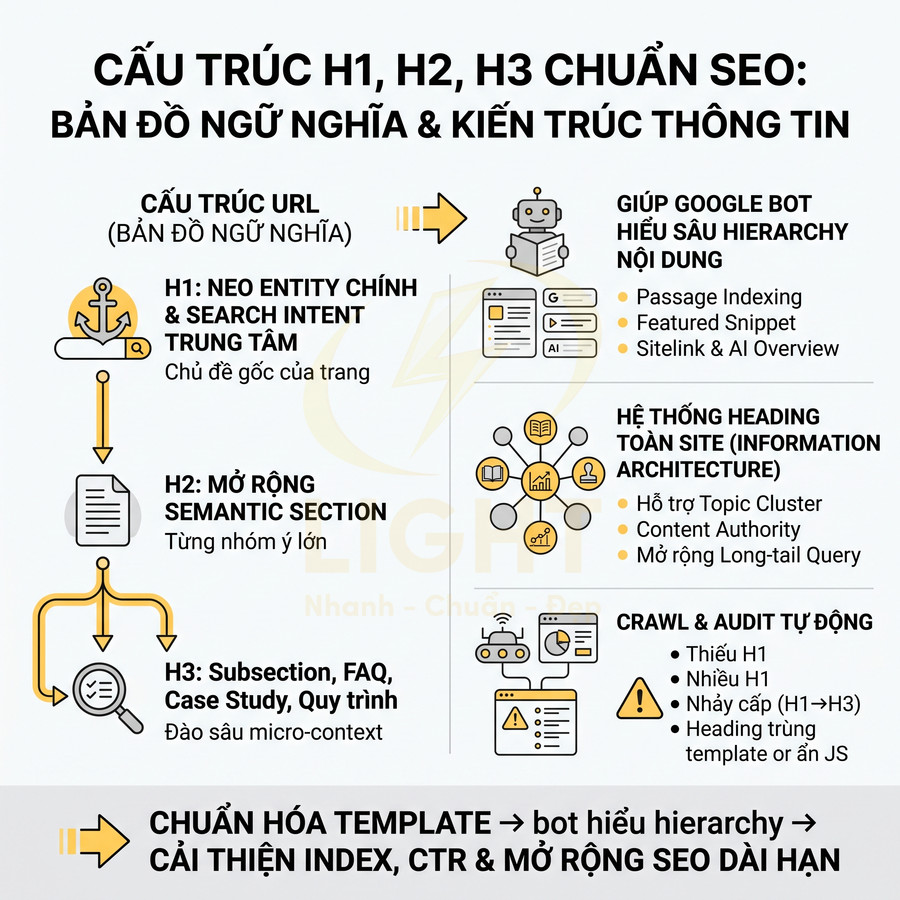
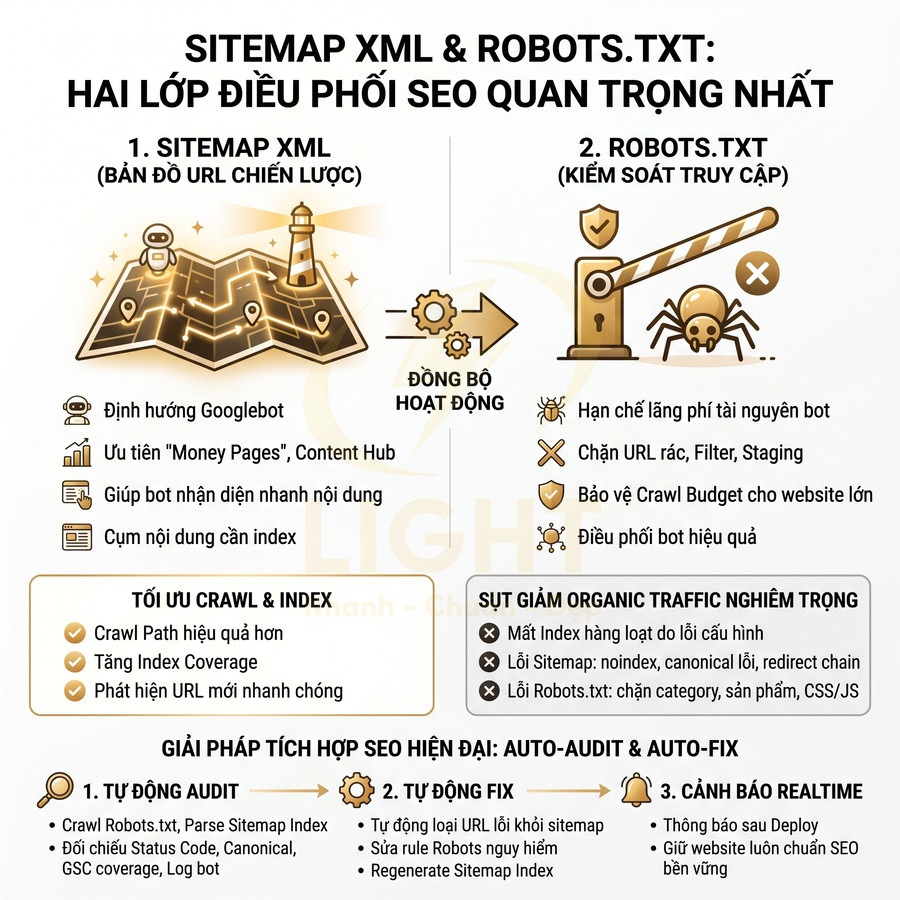
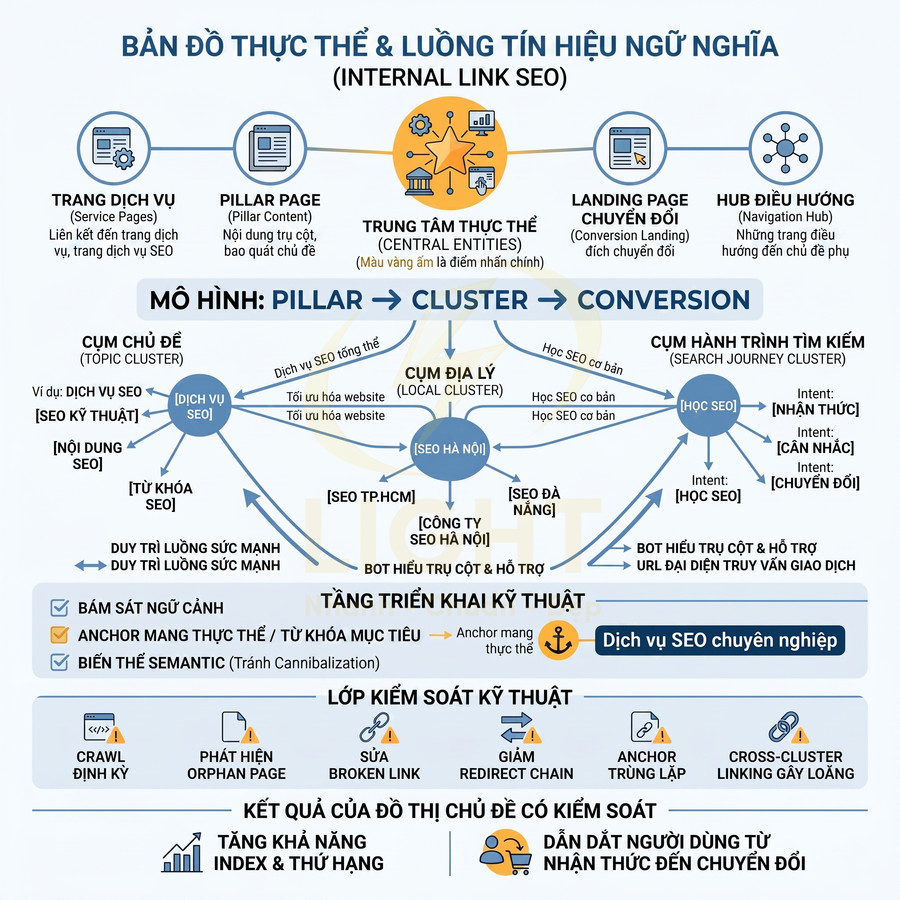
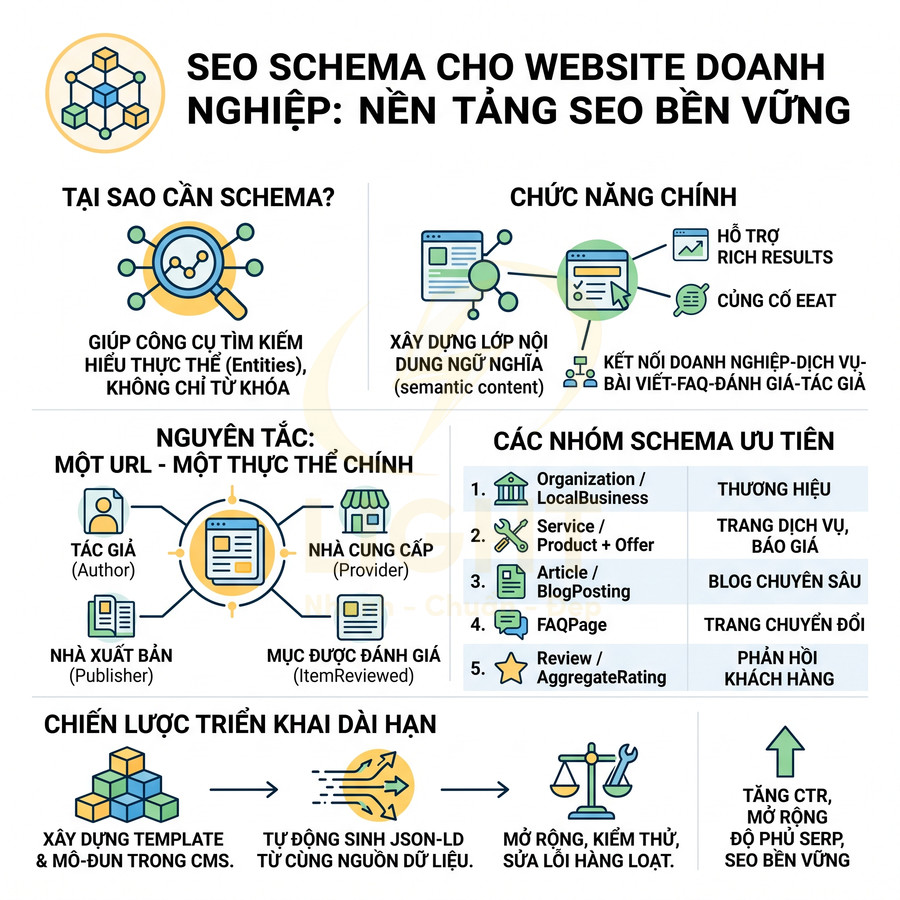
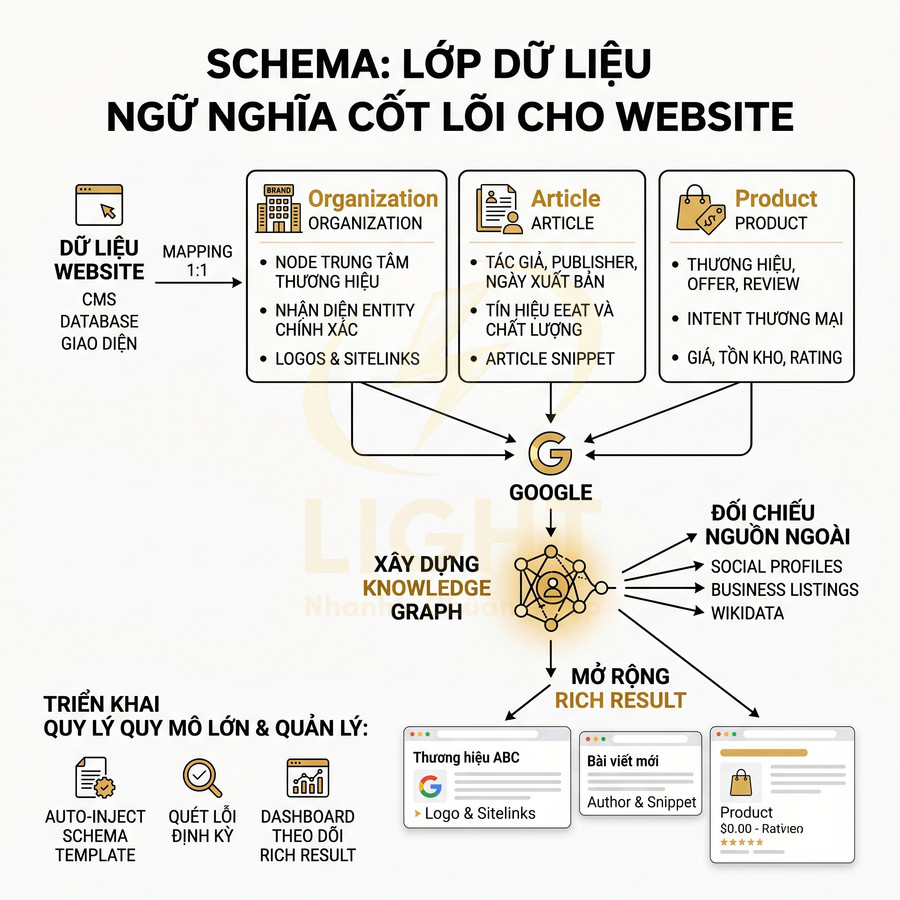

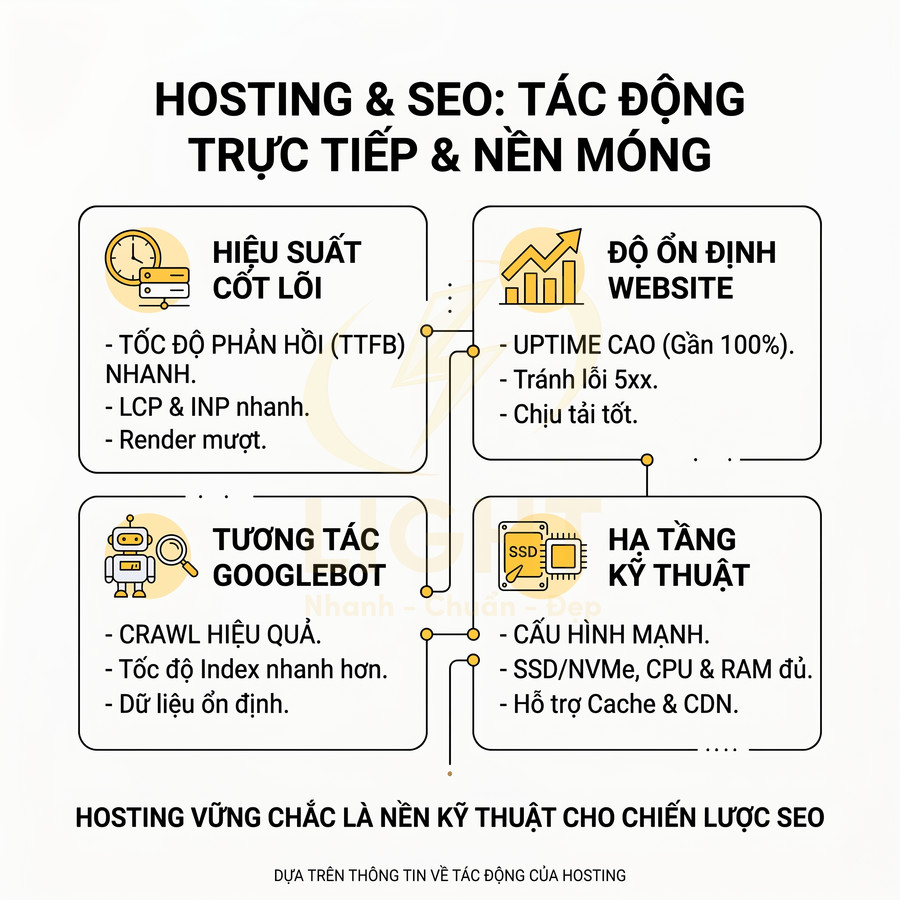
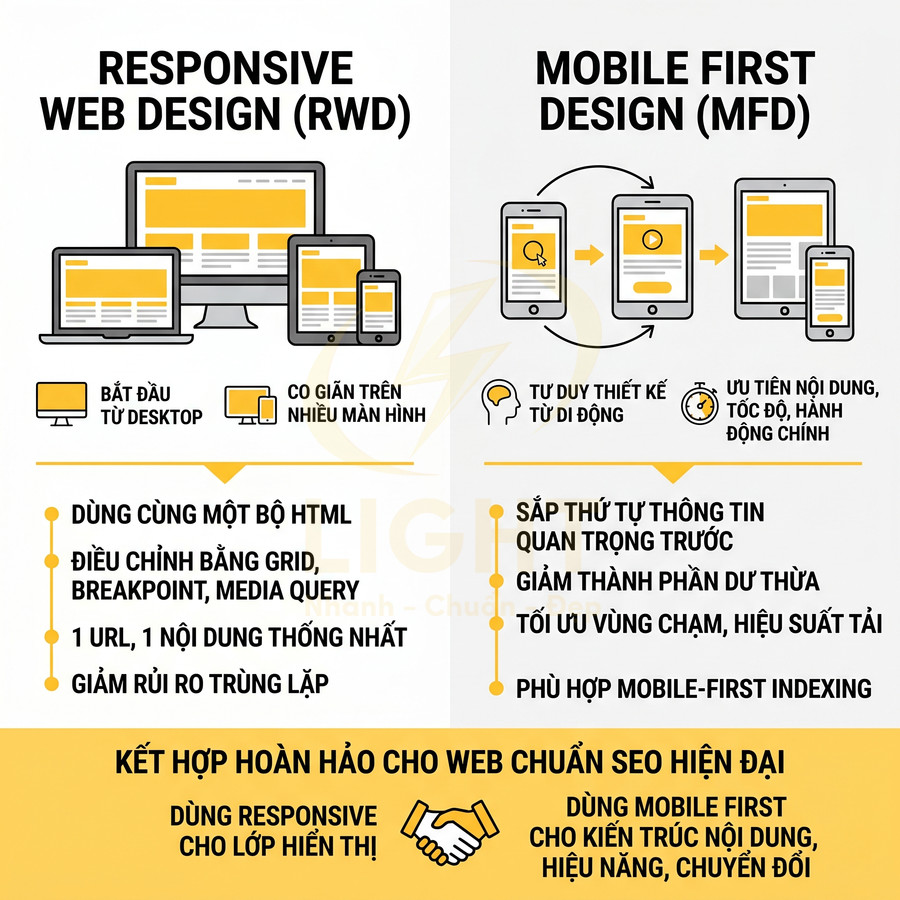

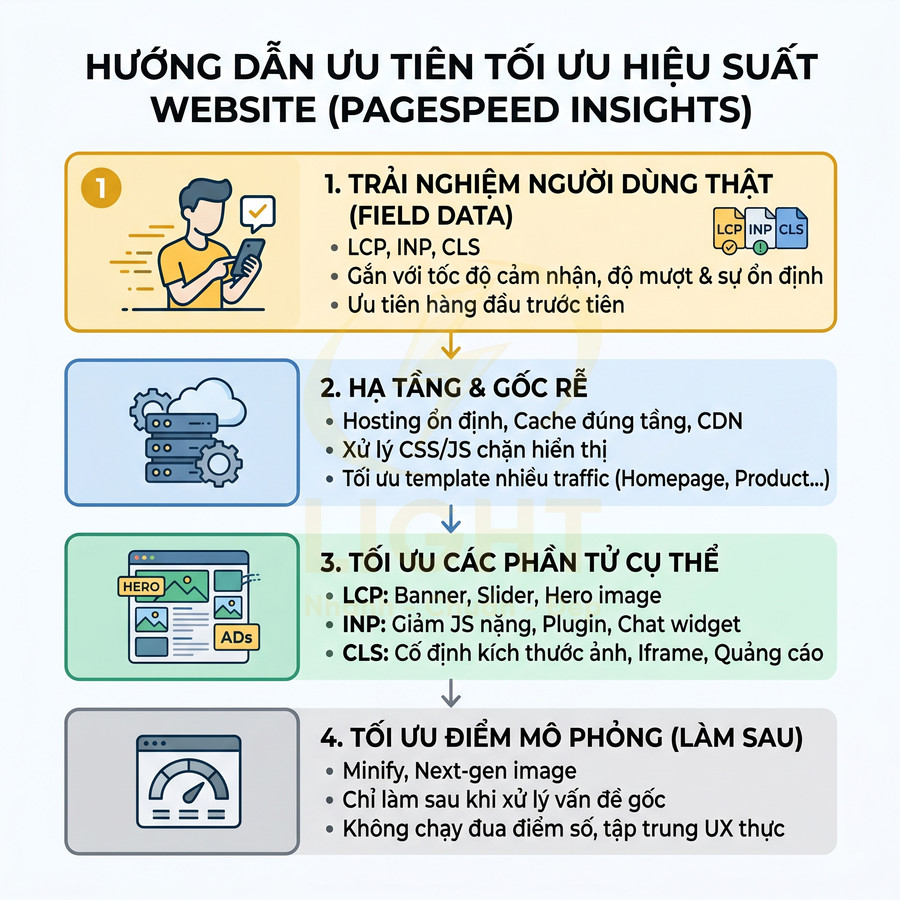
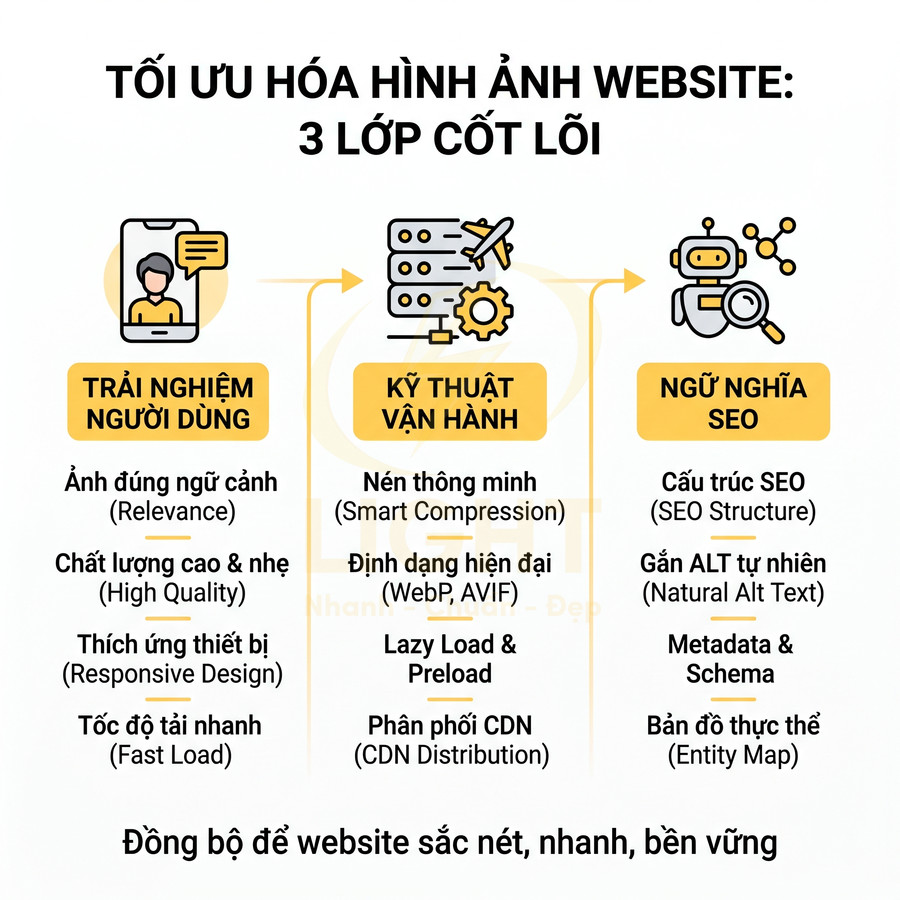

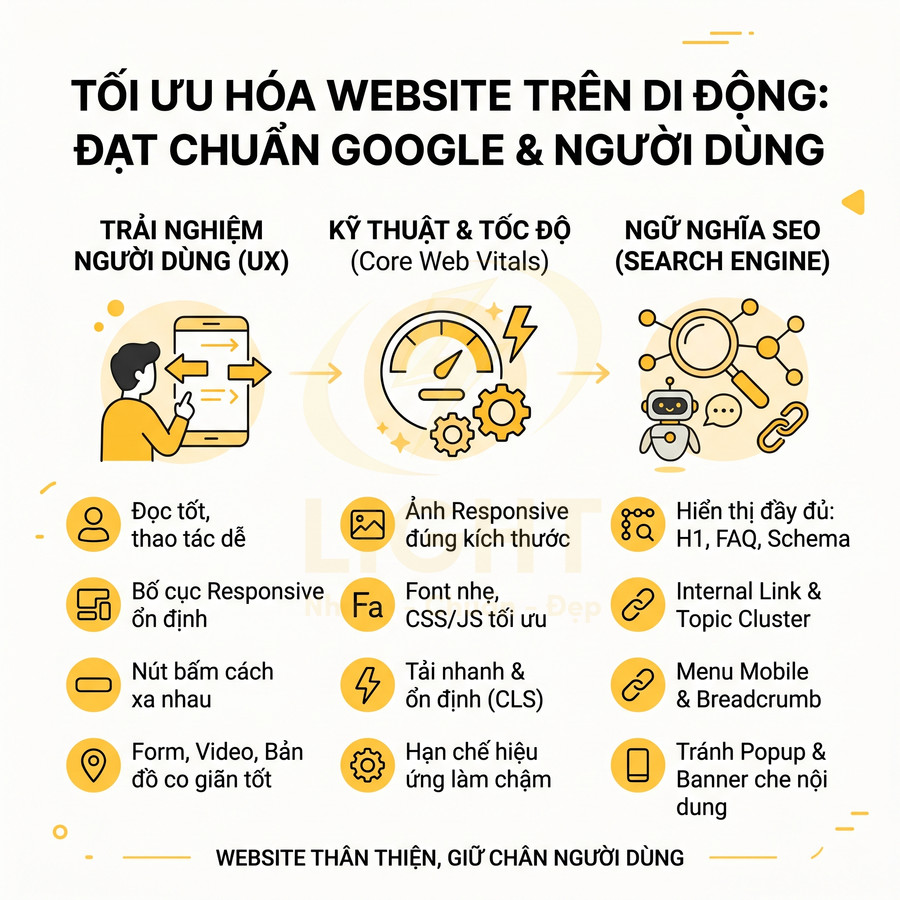



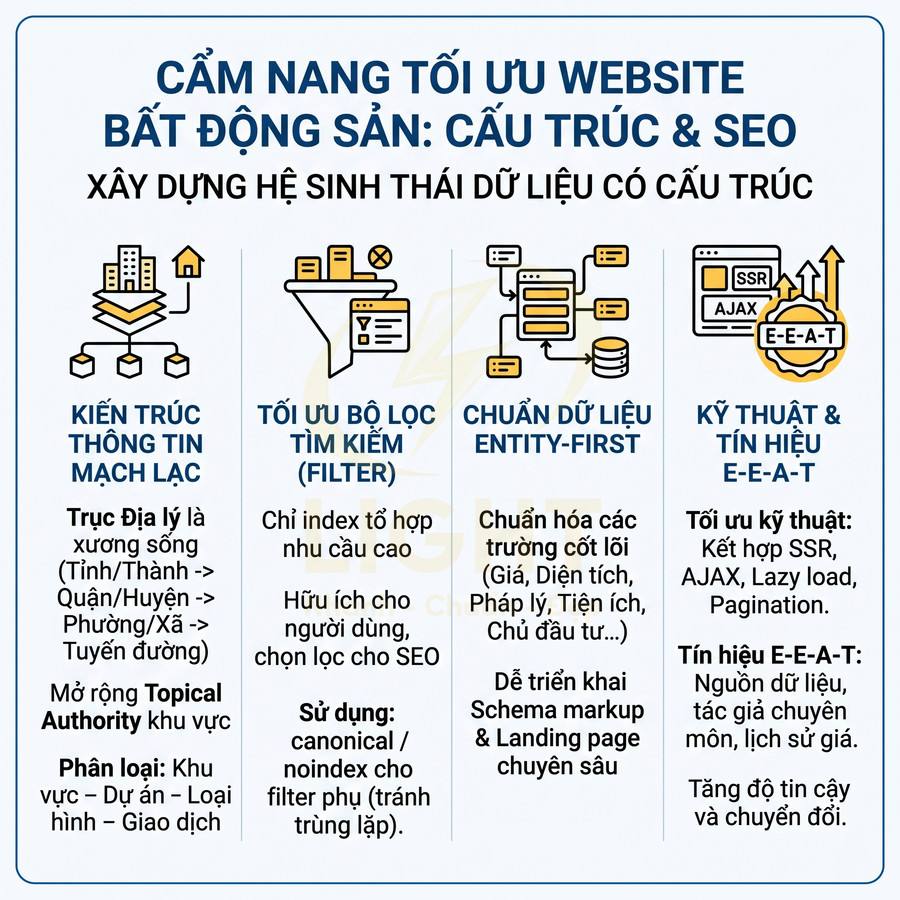


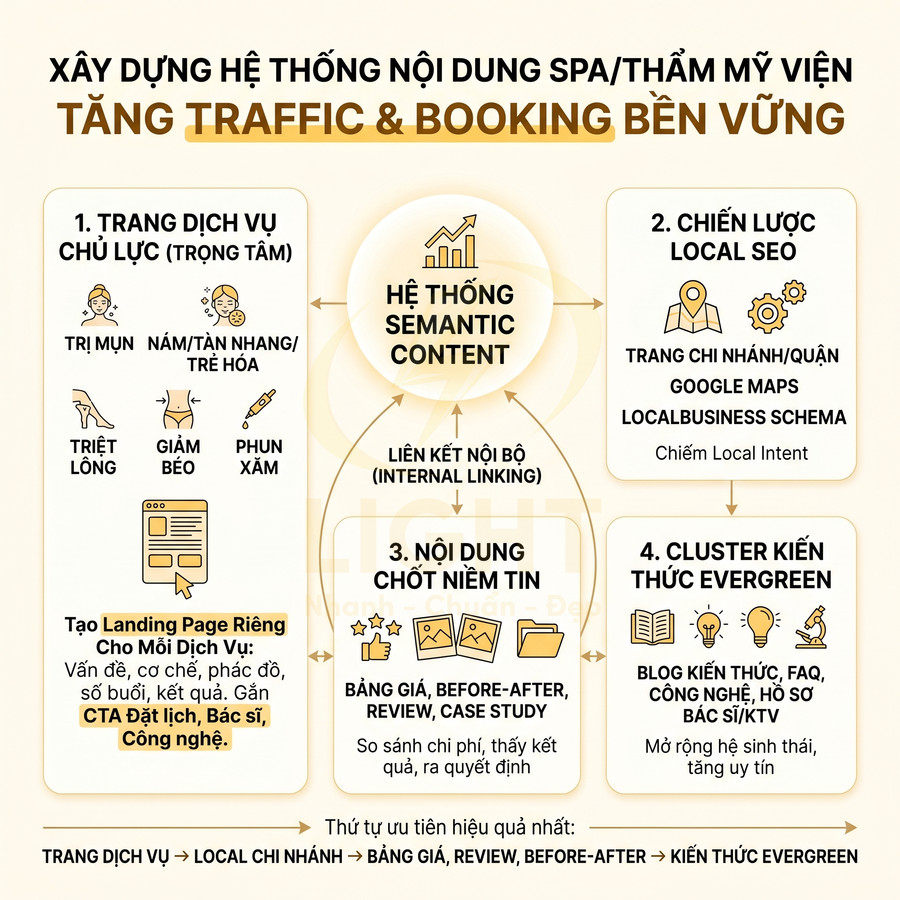
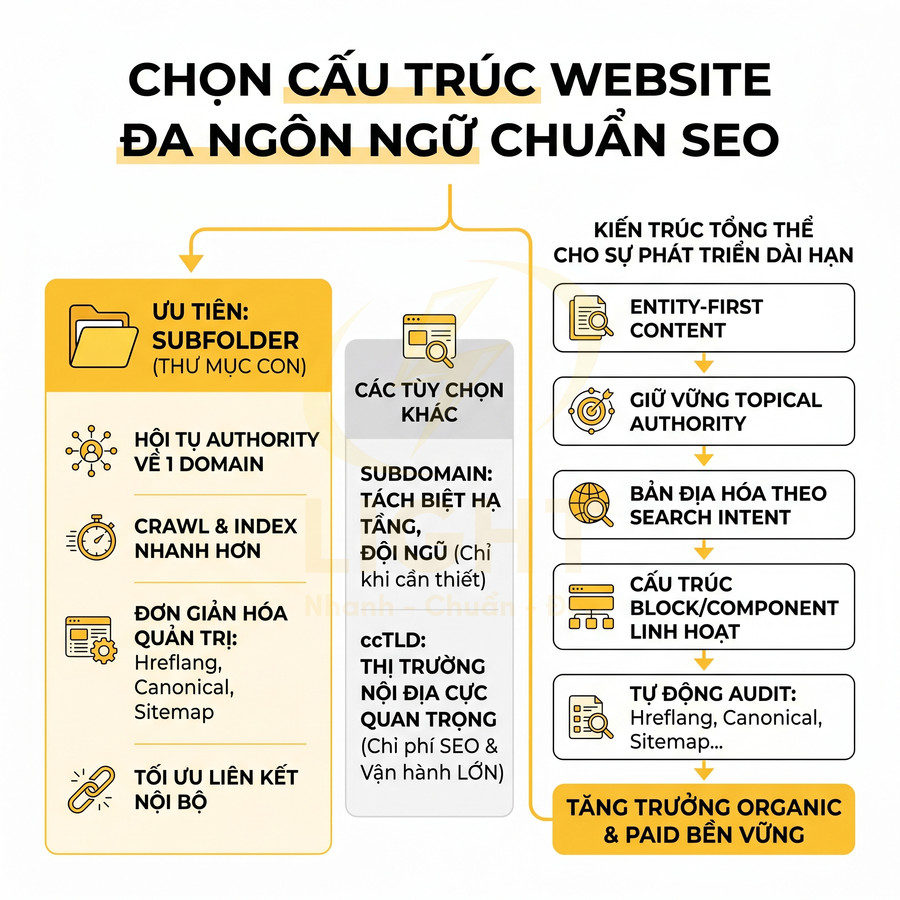
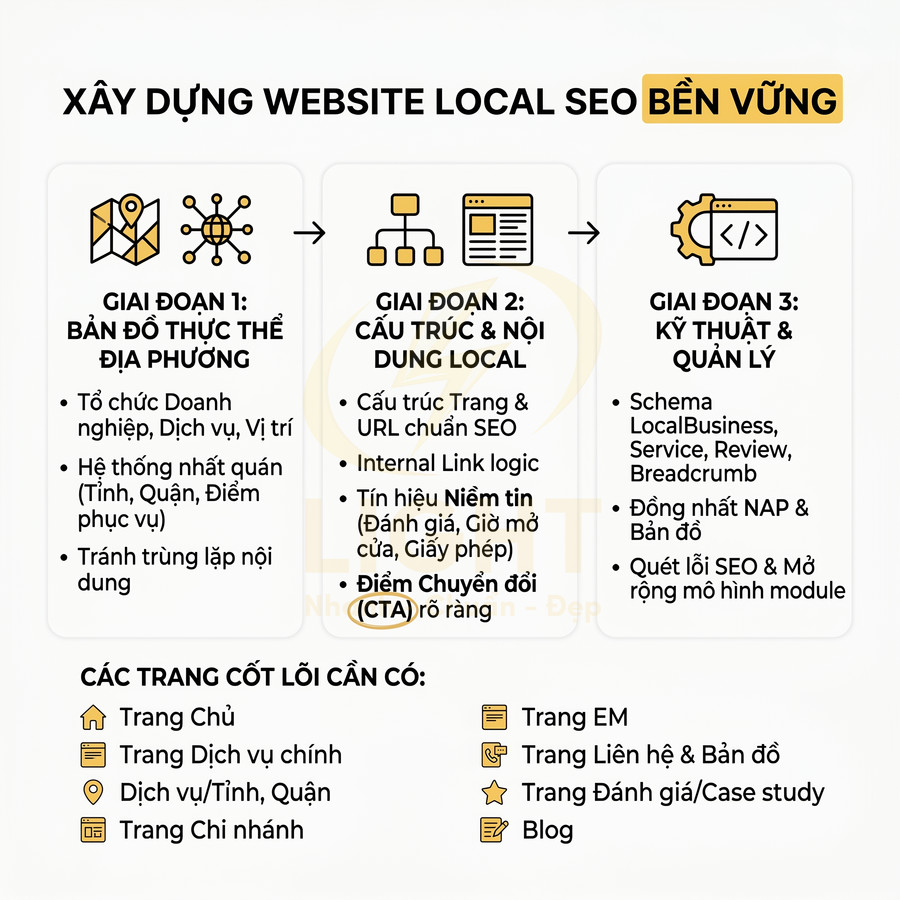

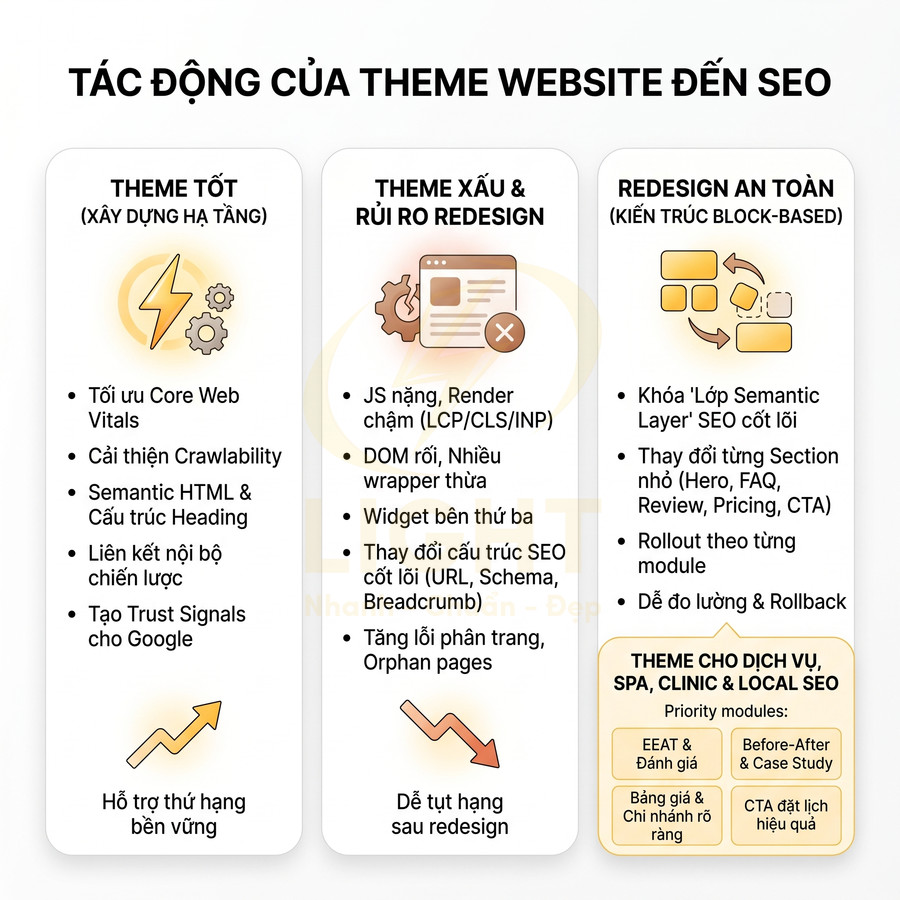
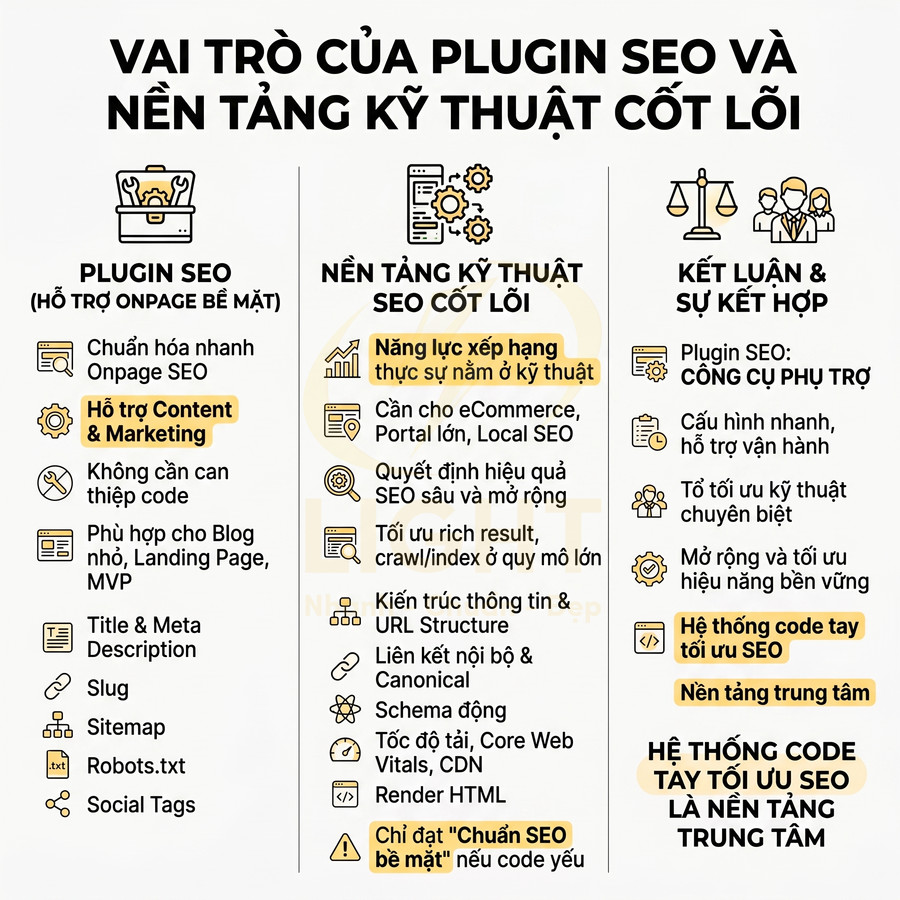

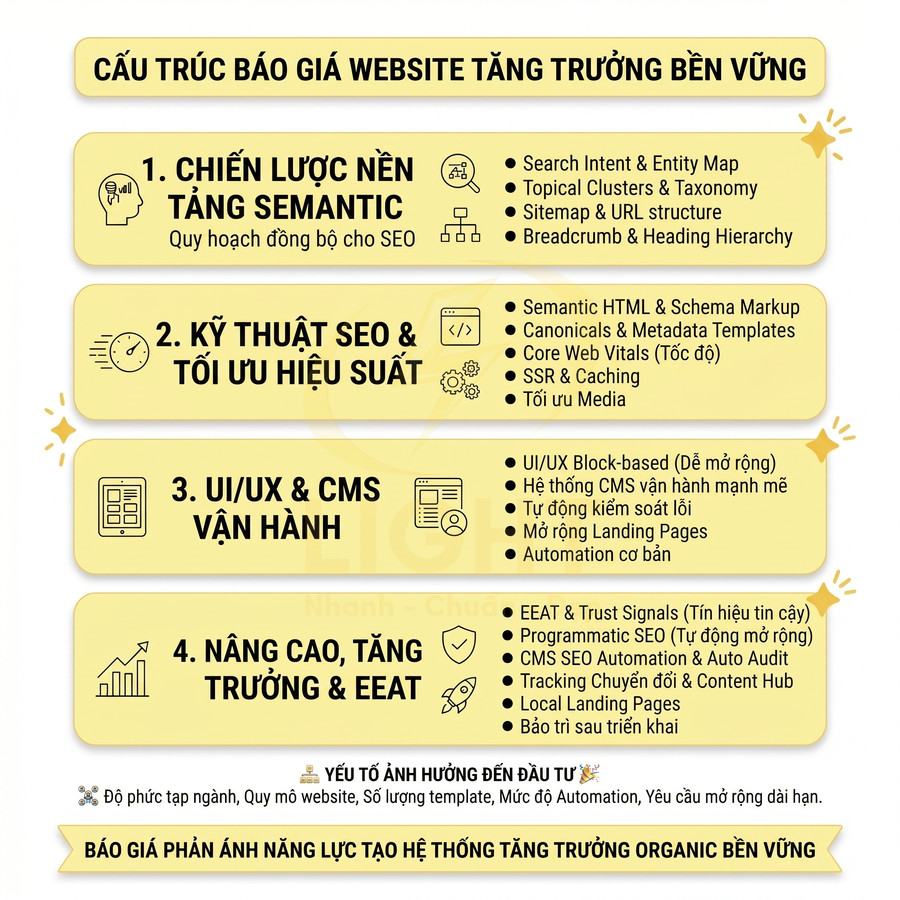

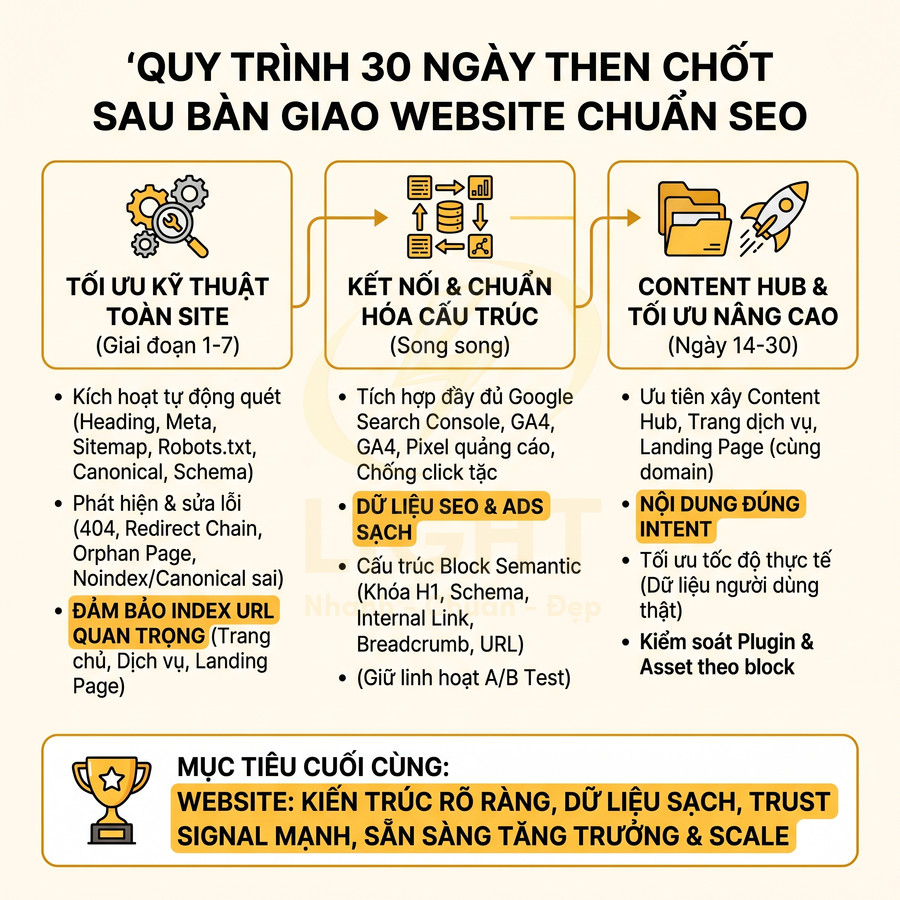

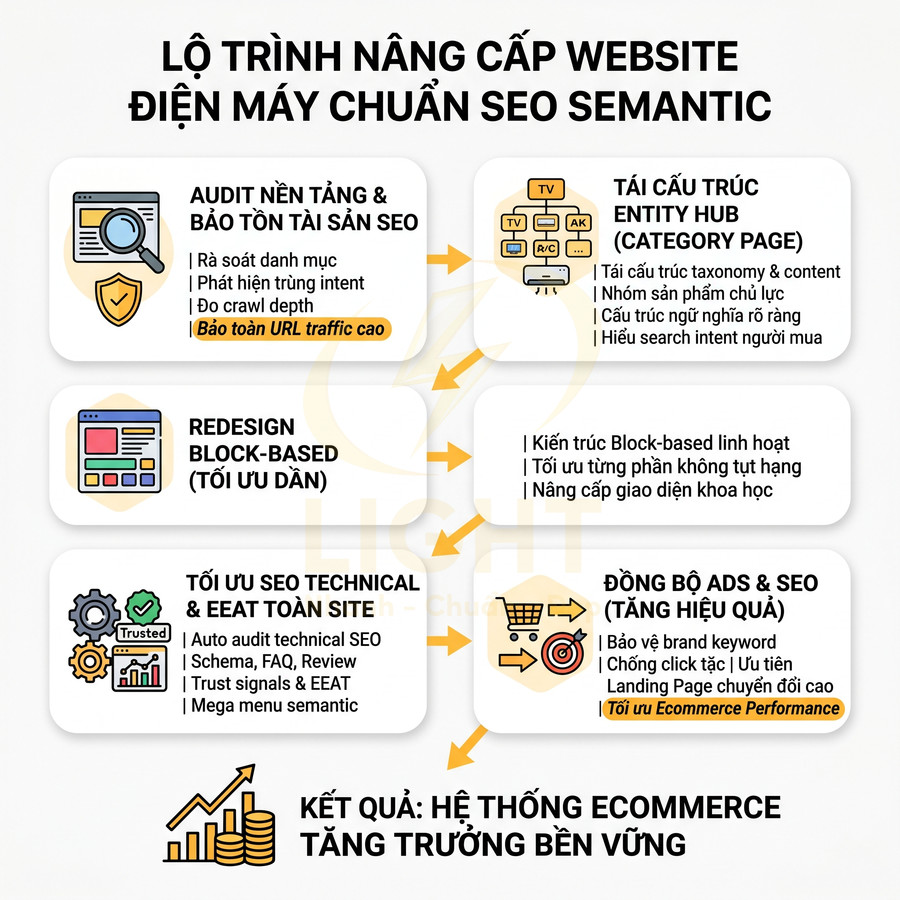
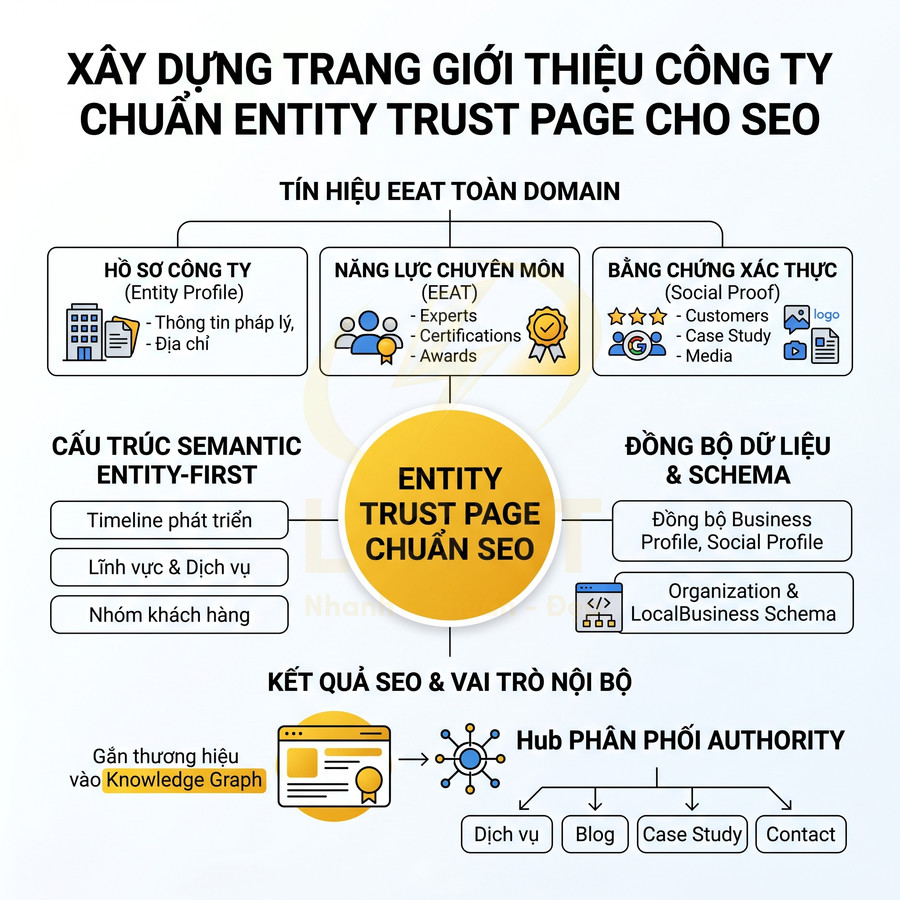
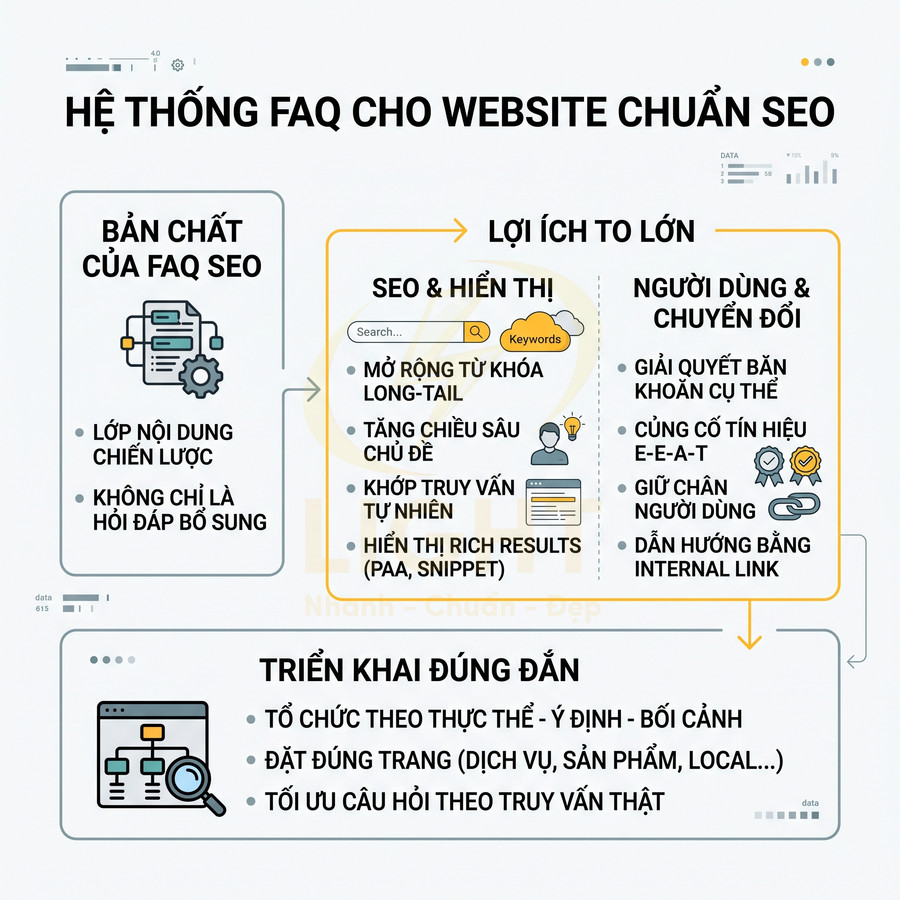
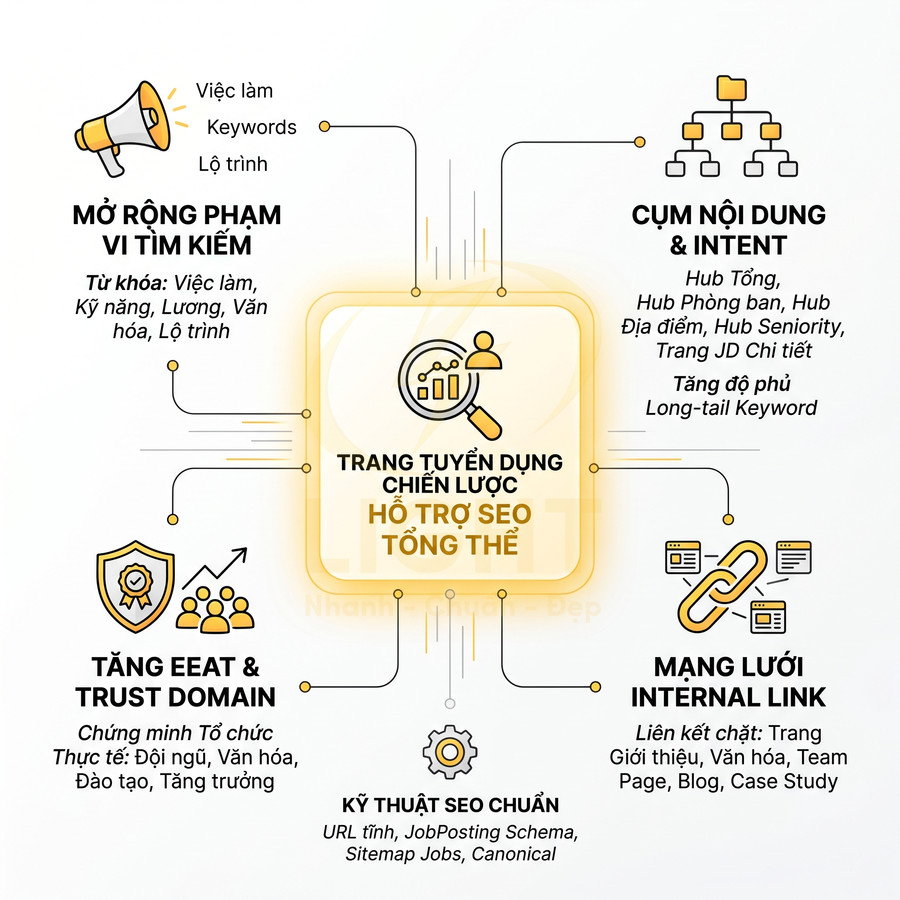

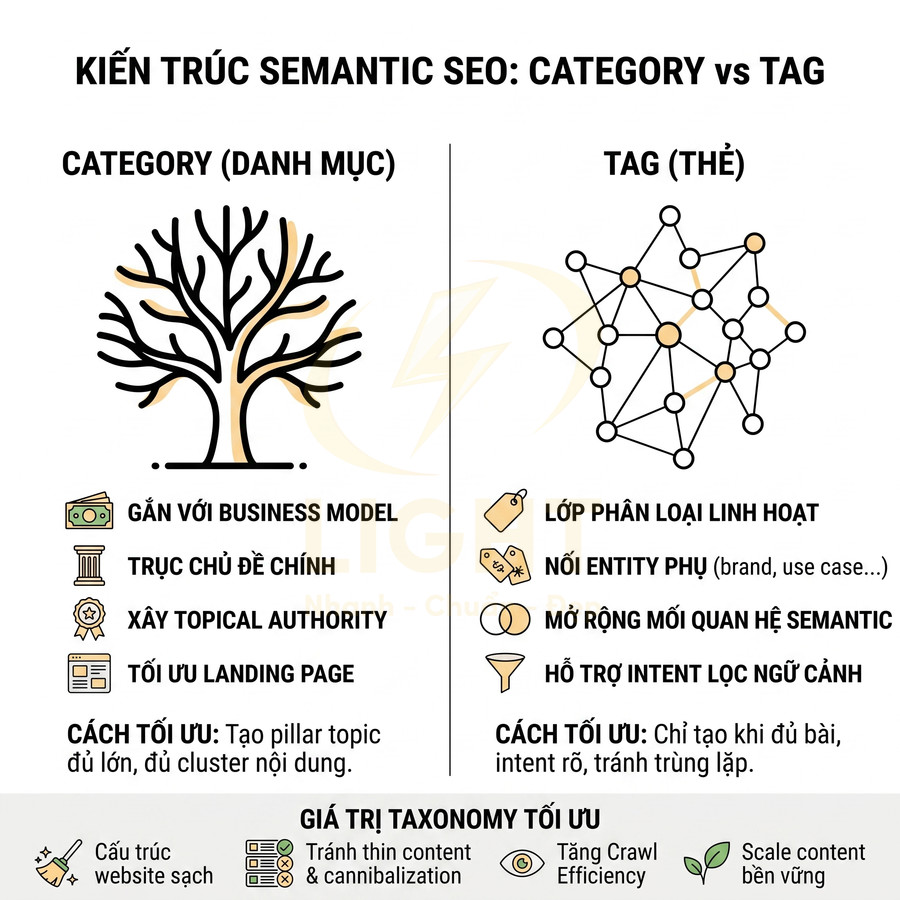
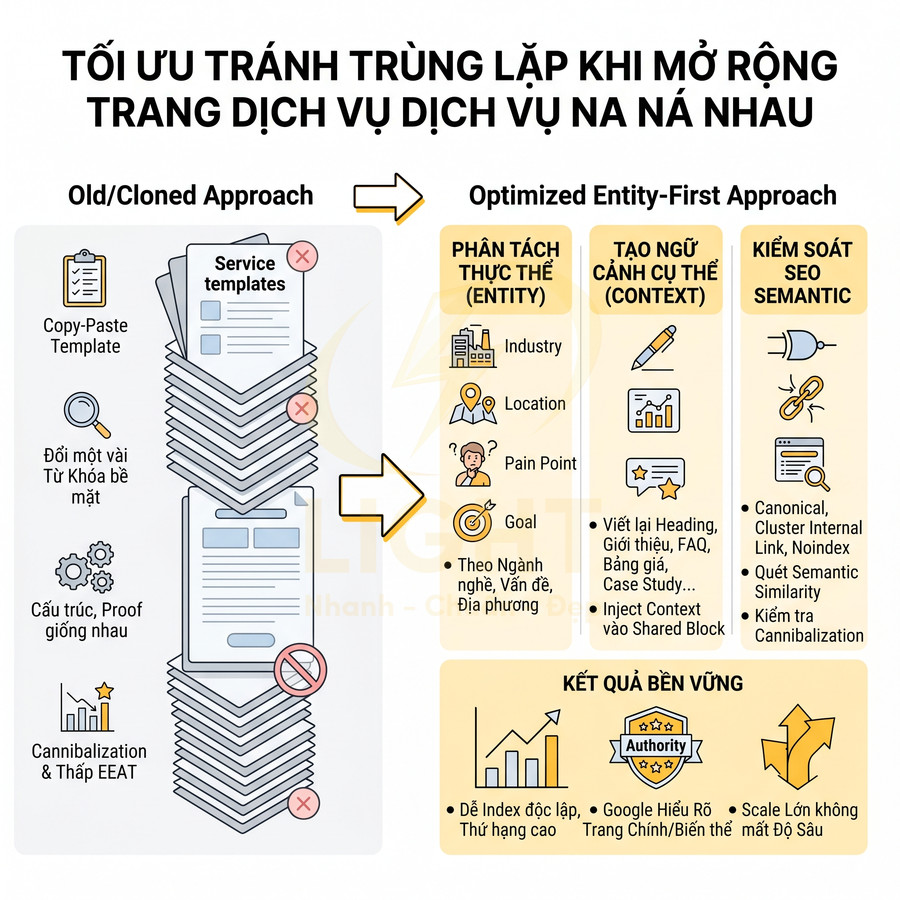

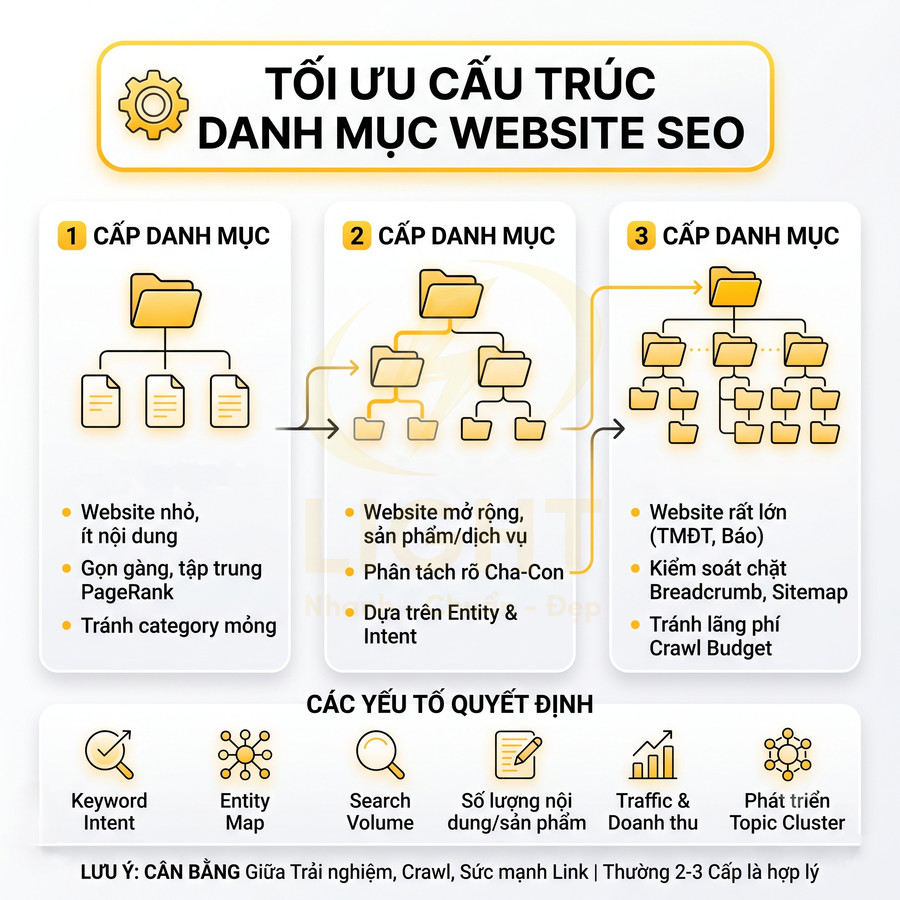



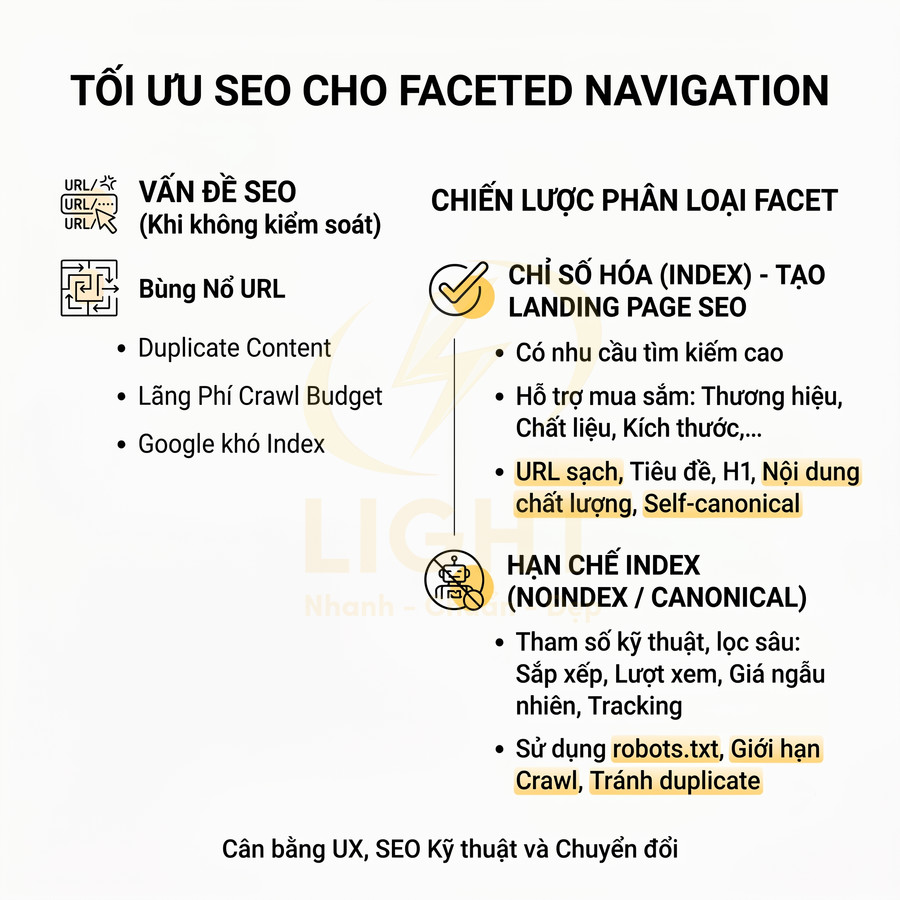

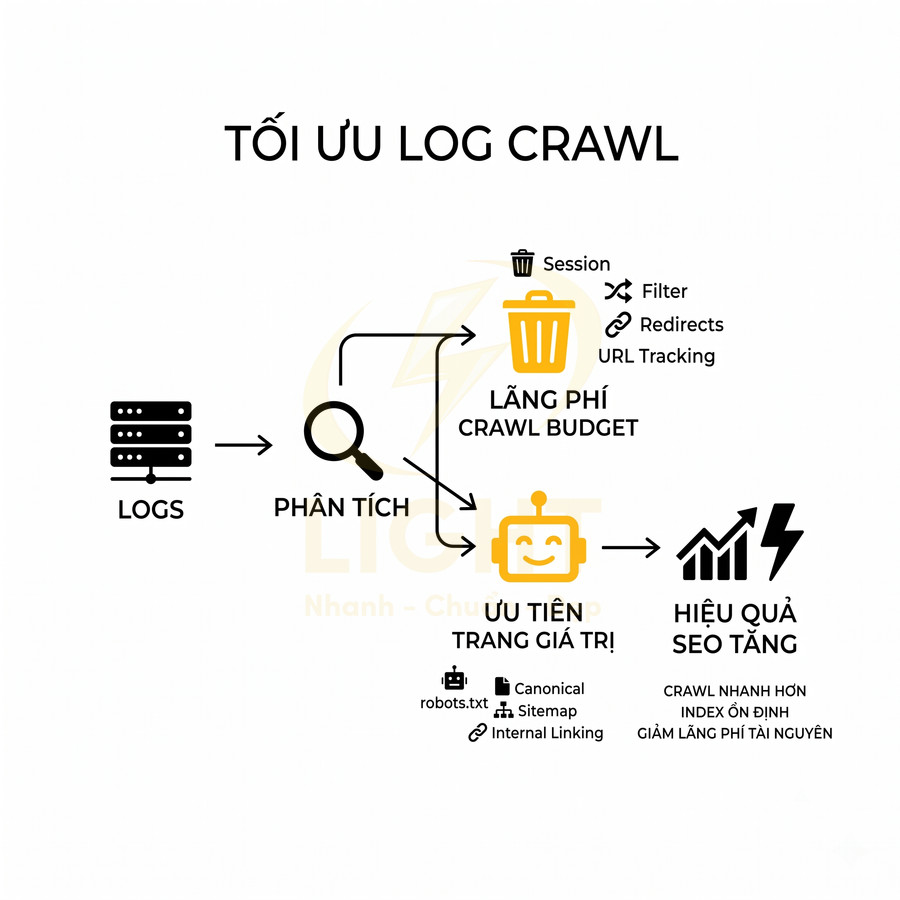




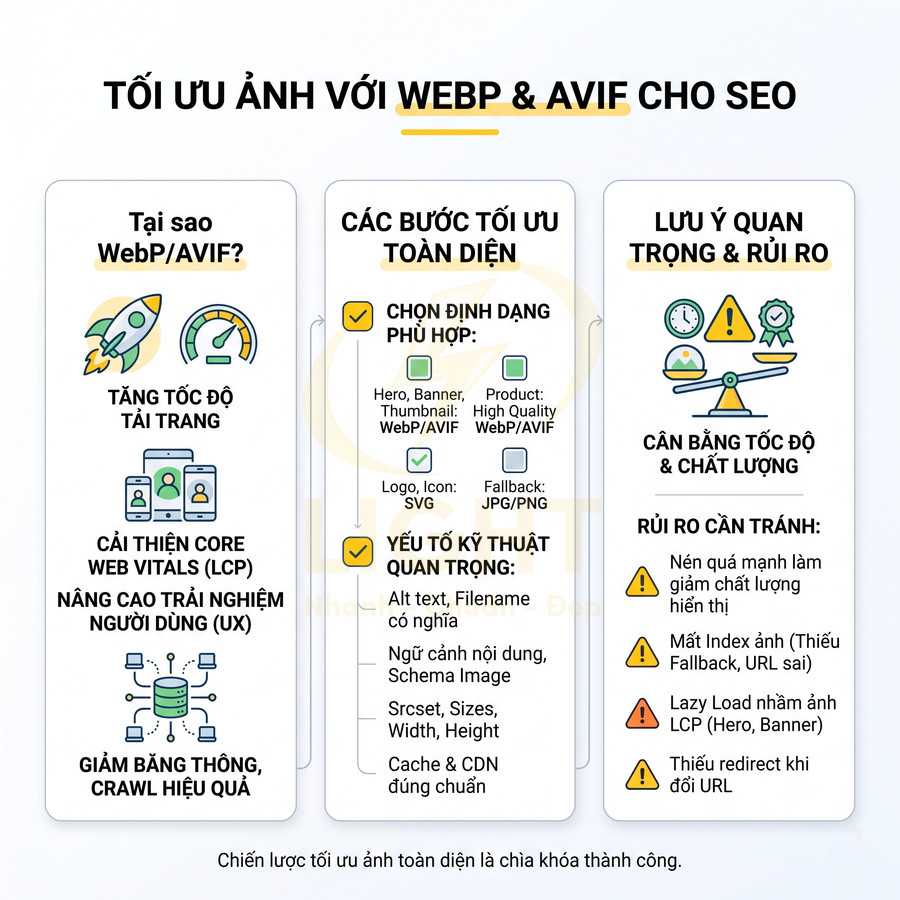

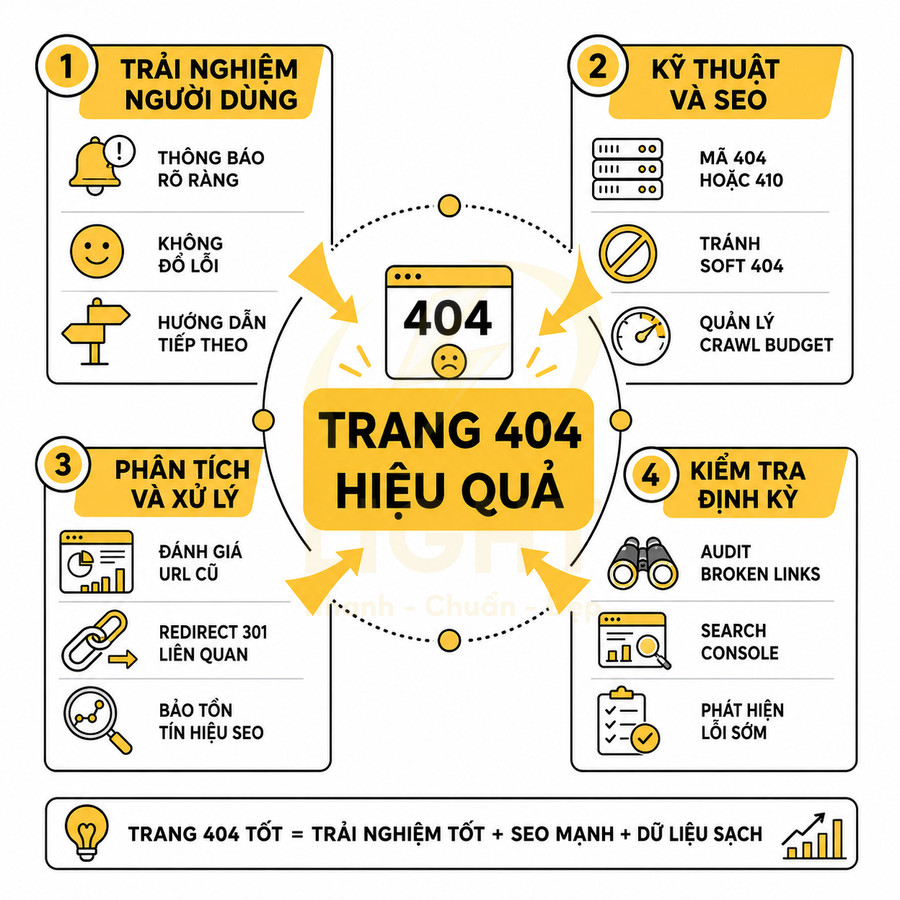

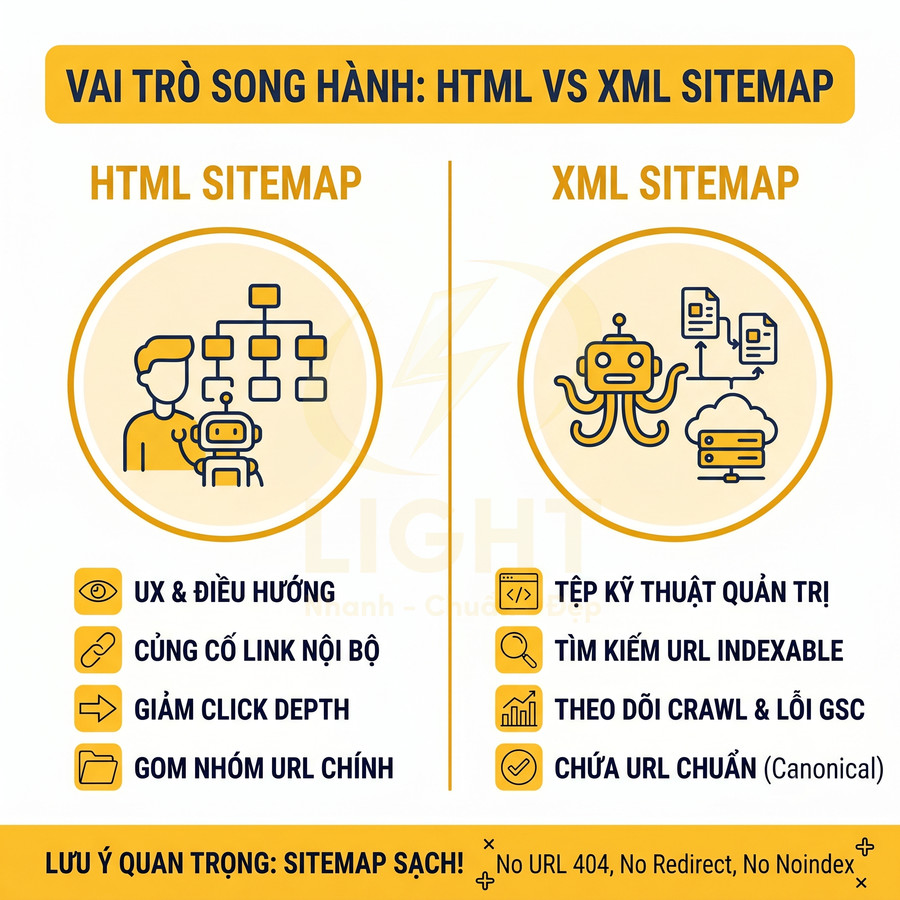

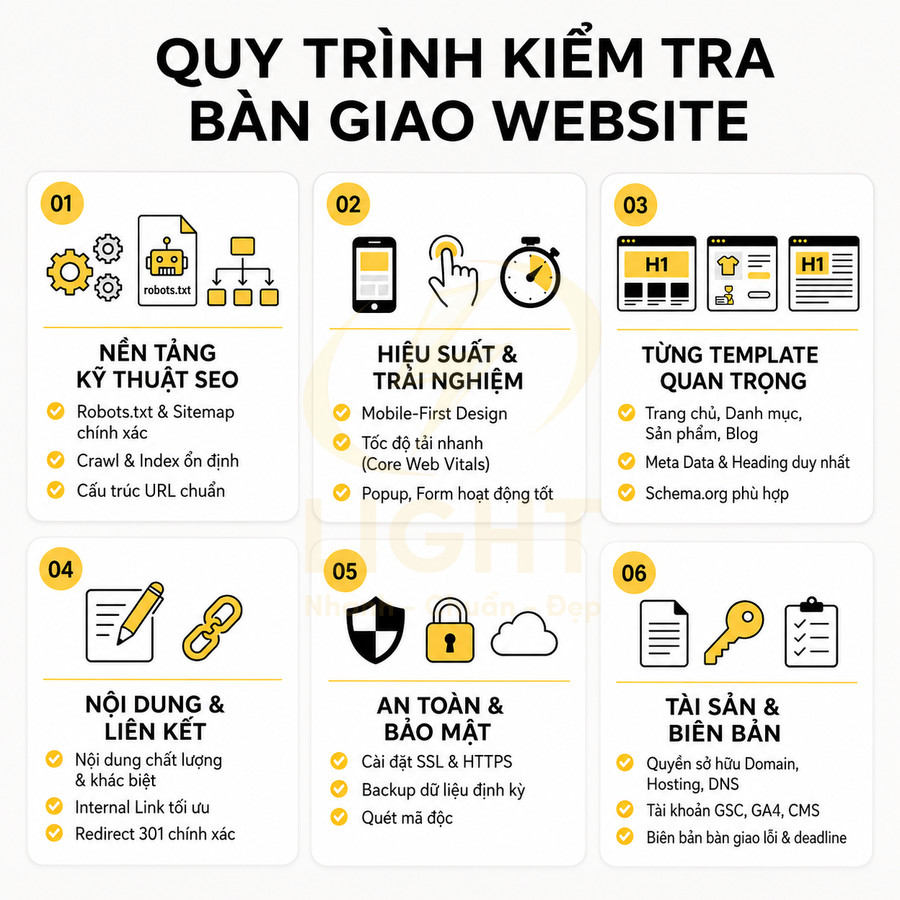
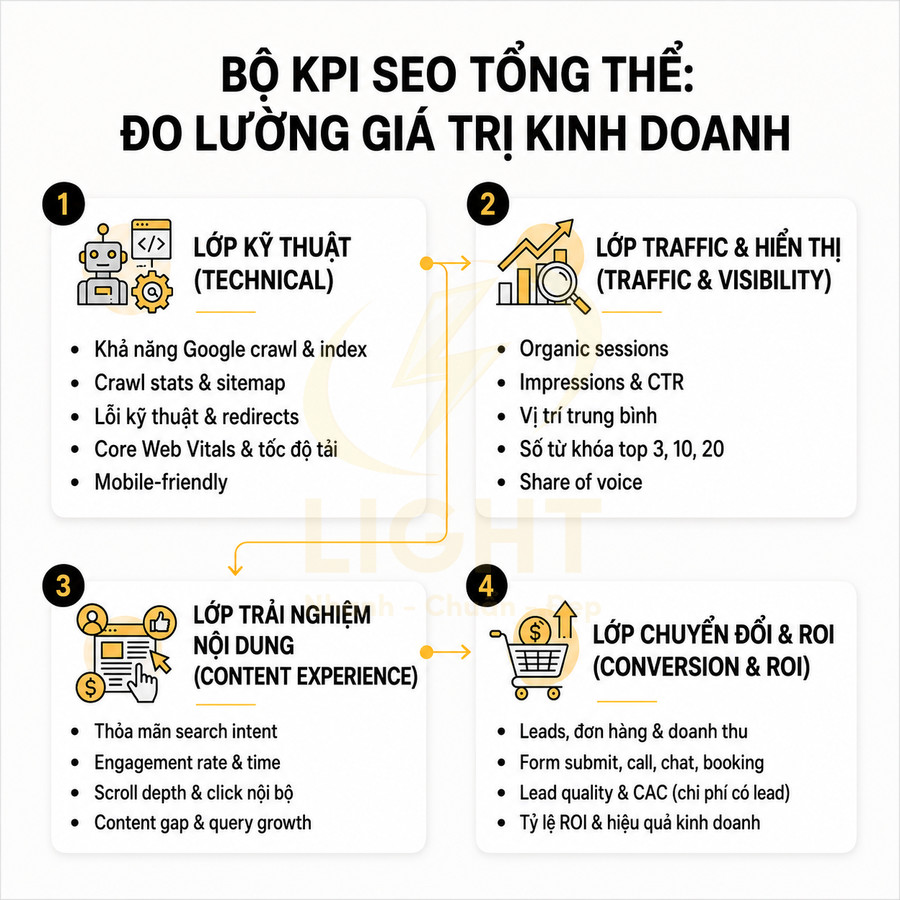



Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
