
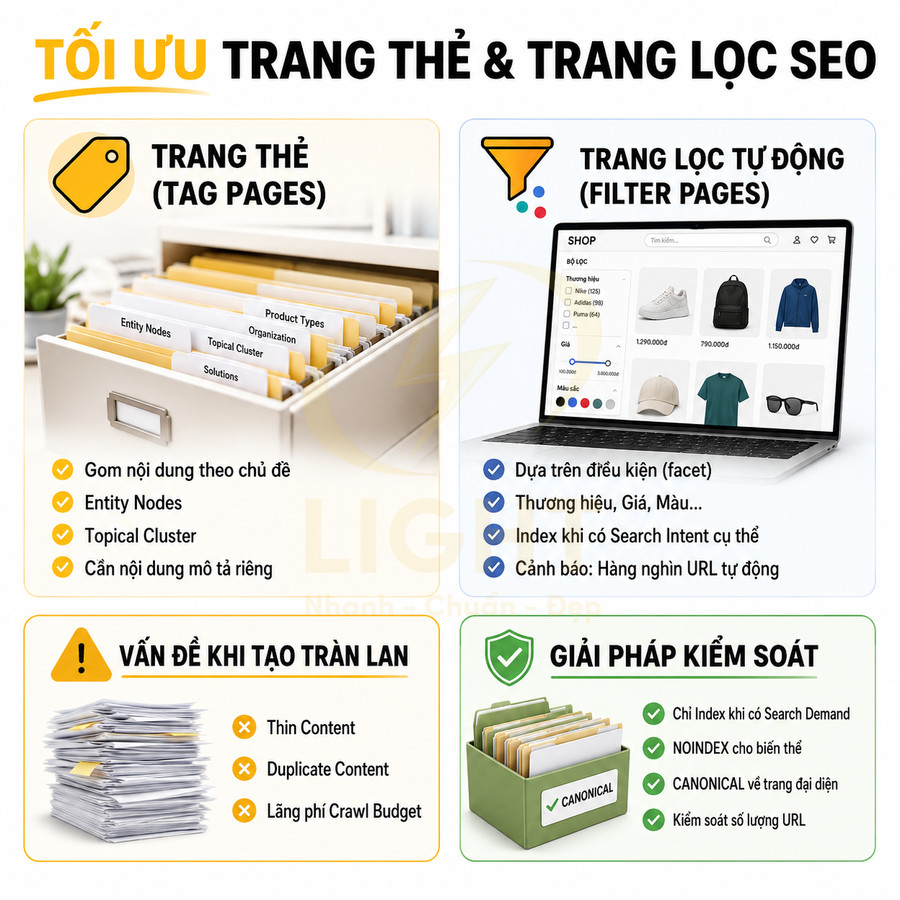
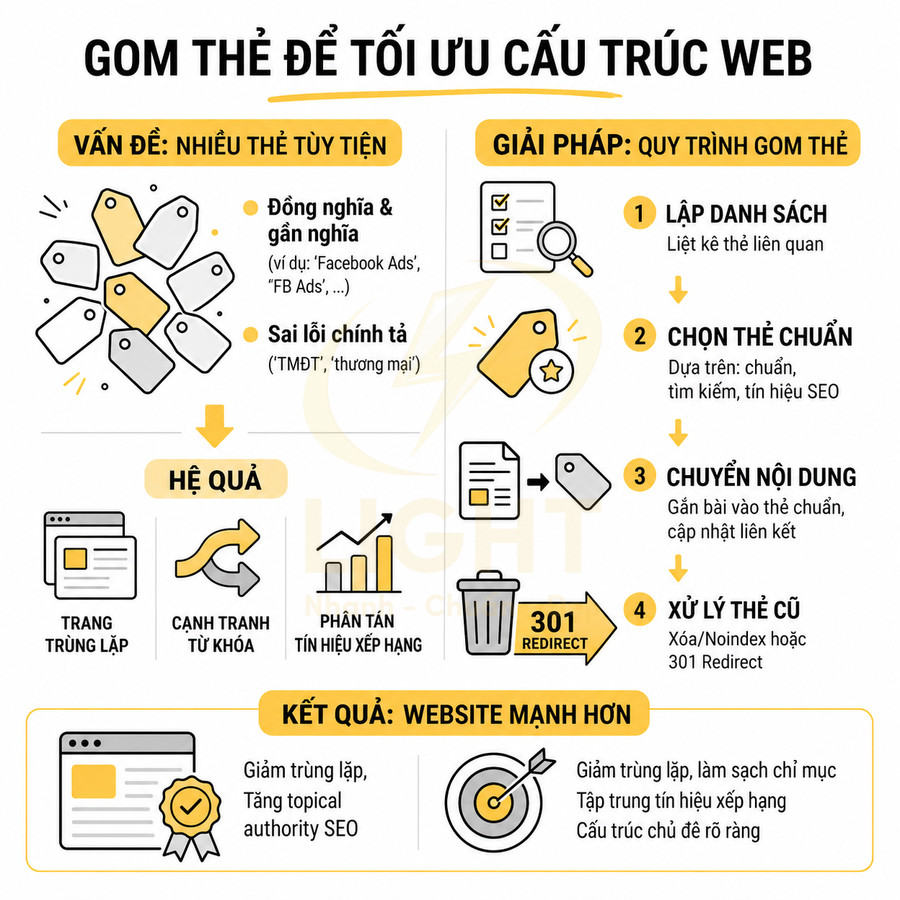
Website chuẩn SEO có nên tạo trang thẻ, trang lọc tự động không?
Trang thẻ và trang lọc tự động không nên được tạo hoặc index đại trà chỉ vì hệ thống có thể sinh URL. Với website chuẩn SEO, mỗi tag hoặc filter chỉ nên tồn tại như một landing page khi có search intent rõ ràng, đủ nội dung hoặc sản phẩm, khác biệt với category chính và có vai trò thật trong topical cluster hoặc hành trình mua hàng. Trang thẻ phù hợp để gom nhóm bài viết theo chủ đề, entity, vấn đề hoặc ngữ cảnh phụ, nhưng cần được chuẩn hóa taxonomy, tránh trùng với danh mục, không tạo thẻ rỗng, thẻ đồng nghĩa, thẻ sai chính tả hoặc thẻ chỉ có vài bài.

Trang lọc tự động chỉ nên index với những tổ hợp facet có nhu cầu tìm kiếm và giá trị kinh doanh rõ ràng như thương hiệu + danh mục, thuộc tính nổi bật, khoảng giá phổ biến hoặc vị trí địa lý; còn các biến thể sort, tracking, trạng thái tạm thời, phân trang sâu hoặc filter quá chi tiết nên dùng noindex, canonical hoặc kiểm soát crawl. Để tránh thin content, duplicate content, cannibalization và lãng phí crawl budget, các trang được index cần có H1, title, mô tả, nội dung bổ trợ, canonical, internal link, sitemap và schema phù hợp. Trọng tâm không phải là tạo thật nhiều URL, mà là kiểm soát index sạch, tập trung authority vào những trang thực sự có giá trị cho người dùng, Google và mục tiêu kinh doanh. Việc kiểm soát index cho tag và filter cần được đặt ngay từ giai đoạn thiết kế web chuẩn SEO, thay vì xử lý sau khi website đã sinh quá nhiều URL kém giá trị. Cấu trúc tốt giúp Google hiểu đâu là trang chính, đâu là trang hỗ trợ và đâu là URL không nên index.
Trang thẻ và trang lọc tự động chỉ nên tạo khi có search intent rõ ràng
Trang thẻ và trang lọc chỉ nên được index khi phản ánh rõ ràng nhu cầu tìm kiếm thực tế, có khả năng trở thành landing page độc lập và đóng góp vào topical authority của toàn site. Với trang thẻ, cần xem như một lớp taxonomy bổ sung, gom nhóm nội dung theo chủ đề, thực thể hoặc thuộc tính có search demand, được chuẩn hóa, tránh trùng với category và đủ số lượng bài viết để hình thành cụm nội dung giá trị. Với trang lọc, chỉ những tổ hợp facet có search intent cụ thể (brand + category, brand + thuộc tính nổi bật, location + loại sản phẩm/dịch vụ…) mới nên mở index, tối ưu URL, nội dung mô tả và metadata; phần lớn biến thể còn lại phải được kiểm soát bằng noindex, canonical và cấu hình tham số để bảo toàn crawl budget, hạn chế thin/duplicate content và duy trì chất lượng index site-wide.
Khi xây dựng hệ thống tag và filter, nền tảng thiết kế web cần cho phép kiểm soát URL, canonical, robots meta và sitemap ngay từ đầu. Nếu cấu trúc kỹ thuật yếu, website dễ sinh hàng loạt trang mỏng, trùng lặp và làm giảm chất lượng index toàn site.
Trang thẻ gom nội dung theo chủ đề, thực thể hoặc thuộc tính liên quan
Trong một website chuẩn SEO, trang thẻ (tag page) không phải là nơi “đổ” mọi từ khóa mà biên tập viên nghĩ ra, mà là lớp phân loại bổ sung, gom nhóm nội dung theo chủ đề, thực thể (entity) hoặc thuộc tính có liên hệ chặt chẽ. Về bản chất, tag nên được xem như một dạng topical cluster node, kết nối nhiều bài viết xoay quanh cùng một chủ đề hẹp, một thực thể cụ thể, hoặc một thuộc tính nổi bật mà người dùng thực sự quan tâm và có khả năng tìm kiếm. Khi được thiết kế đúng, trang thẻ giúp Google hiểu sâu hơn về cấu trúc chủ đề của website, đồng thời giúp người dùng dễ dàng khám phá thêm nội dung liên quan. Tag page chỉ có giá trị khi được quản trị như một hệ thống metadata có kiểm soát, không phải danh sách nhãn tùy hứng. Golder và Huberman (2006) mô tả collaborative tagging là quá trình người dùng gắn metadata dạng từ khóa cho nội dung, đồng thời phát hiện các quy luật ổn định trong tần suất tag và cách tag được dùng cho cùng một URL. Điều này cho thấy tag có thể phản ánh nhận thức tập thể về chủ đề, nhưng chỉ hữu ích khi được chuẩn hóa. Một tag SEO tốt cần có phạm vi rõ, tên nhất quán, gom được nhiều nội dung liên quan và không trùng vai trò với category.
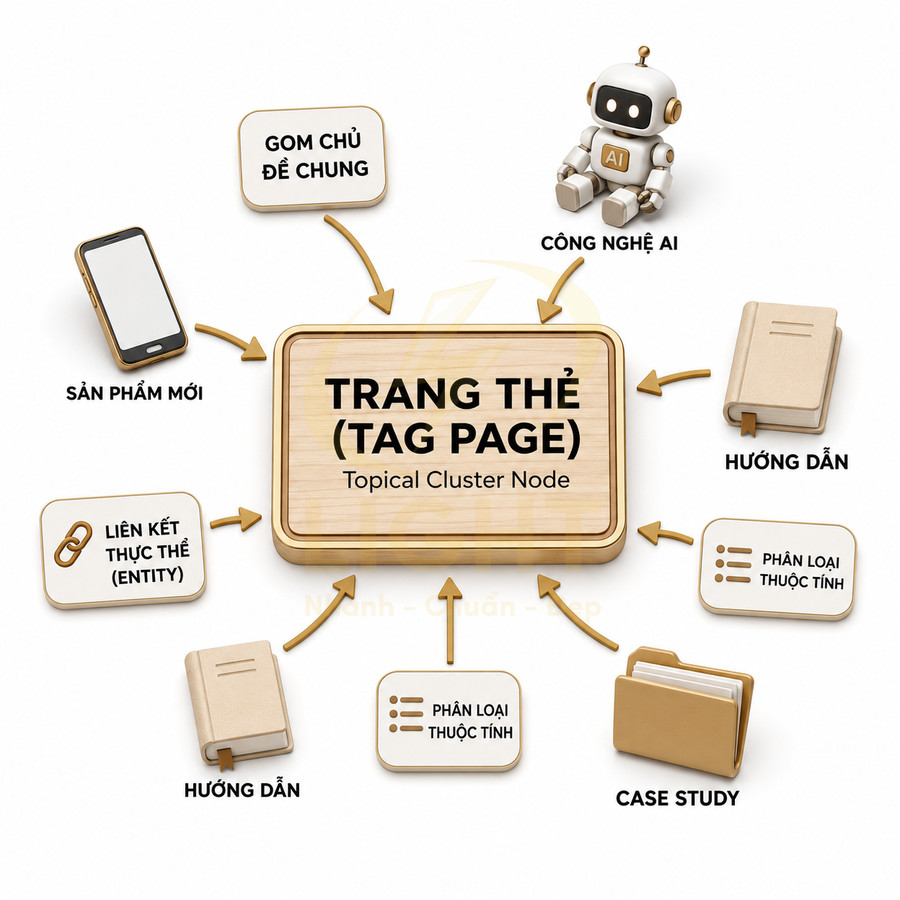
Trong thực hành SEO hiện đại, việc gắn thẻ nên dựa trên taxonomy được chuẩn hóa thay vì để mỗi tác giả tự do tạo tag mới. Một hệ thống tag tốt thường xoay quanh các nhóm như: thực thể (thương hiệu, địa điểm, nhân vật, công nghệ), chủ đề con (subtopic) của một pillar, hoặc thuộc tính nội dung (ví dụ: “case study”, “hướng dẫn chi tiết”, “template”). Mỗi tag lý tưởng sẽ có: tên rõ ràng, ý nghĩa nhất quán, không trùng với category, và đủ số lượng bài viết để tạo thành một cụm nội dung có giá trị. Khi đó, trang thẻ không chỉ là danh sách link mà trở thành một “hub” nhỏ, hỗ trợ xây dựng topical authority cho toàn site. Hệ thống tag tự do dễ tạo ra nhiều biến thể đồng nghĩa, sai chính tả hoặc quá hẹp, làm giảm hiệu quả tìm kiếm nội bộ và SEO. Marlow, Naaman, Boyd và Davis (2006) khi nghiên cứu tagging systems đã đề xuất mô hình và taxonomy để phân tích, thiết kế hệ thống gắn thẻ trên web, vì tagging không chỉ là hành vi đặt nhãn mà còn là cơ chế tổ chức thông tin. Với website nhiều tác giả, cần có quy chuẩn đặt tên tag, danh sách tag được duyệt, quy tắc gộp tag đồng nghĩa và ngưỡng nội dung tối thiểu. Nếu không, tag page sẽ nhanh chóng trở thành thin content và duplicate archive.
Ở mức độ chuyên sâu hơn, có thể xem mỗi tag như một “entity node” trong đồ thị tri thức (knowledge graph) nội bộ của website. Mỗi node này nên được định nghĩa rõ:
- Scope chủ đề: tag bao phủ phạm vi nào, giới hạn đến đâu, khác gì so với category hoặc subcategory.
- Loại entity: brand, product line, location, person, technology, use case, hoặc thuộc tính nội dung.
- Quan hệ với các node khác: tag nào là “sibling”, tag nào là “parent/child”, tag nào chỉ nên liên kết chéo chứ không overlap nội dung.
Tag có thể đóng vai trò như một nút ngữ nghĩa khi nó kết nối nhiều nội dung cùng xoay quanh một entity hoặc khái niệm. Cattuto, Baldassarri, Servedio và Loreto (2008) cho thấy trong social tagging systems, hoạt động gắn tag tập thể có thể làm lộ ra quan hệ ngữ nghĩa giữa các tài nguyên và tạo thành community structure. Áp dụng vào SEO, một tag như “Entity SEO”, “Core Web Vitals” hoặc “Facebook Ads” không nên chỉ là archive bài viết, mà nên là micro hub có mô tả riêng, bài nổi bật, liên kết đến pillar page và các tag liên quan để Google hiểu cụm chủ đề sâu hơn.
Để tránh trùng lặp và loãng chủ đề, hệ thống tag nên được thiết kế dựa trên nghiên cứu từ khóa và phân tích entity:
- Nhóm các truy vấn tìm kiếm tương đồng về intent vào cùng một tag thay vì tạo nhiều tag nhỏ lẻ.
- Ưu tiên những tag gắn với entity có volume tìm kiếm, có dữ liệu trong Google Trends, Google Suggest, hoặc các công cụ keyword research.
- Loại bỏ hoặc gộp các tag mang tính “editorial” nội bộ, không có khả năng trở thành landing page SEO (ví dụ: tag chỉ phục vụ workflow biên tập).
Về mặt triển khai onpage, một trang thẻ chất lượng cao thường có cấu trúc rõ ràng:
- Intro copy 150–300 từ giải thích chủ đề, entity hoặc thuộc tính mà tag đại diện, giúp Google hiểu ngữ nghĩa và giúp người dùng định hướng.
- Khối nội dung nổi bật (featured content) như 3–5 bài quan trọng nhất trong cụm, được internal link mạnh, có schema phù hợp.
- Danh sách bài viết đầy đủ được phân trang hợp lý, có sort/filter nội bộ nhưng kiểm soát index.
- Internal link ngữ nghĩa đến pillar page, category liên quan, hoặc các tag “sibling” để củng cố topical cluster.
Ở cấp độ kiến trúc thông tin, tag không nên trùng vai trò với category. Category thường đại diện cho cấu trúc chính (main taxonomy), còn tag là lớp phân loại chéo (cross-cutting taxonomy). Nếu một tag có phạm vi quá rộng, trùng với category, cần cân nhắc:
- Hoặc nâng nó thành category/subcategory chính thức.
- Hoặc giới hạn lại scope, tái định nghĩa thành subtopic cụ thể hơn.
Để đảm bảo chất lượng, có thể đặt ngưỡng tối thiểu trước khi cho phép một tag được index:
- Tối thiểu X bài viết (ví dụ: 5–8 bài) đã được crawl và index ổn định.
- Có search intent rõ ràng, thể hiện qua volume từ khóa và các biến thể truy vấn liên quan.
- Có nội dung mô tả riêng, không chỉ là danh sách link.
Khi đáp ứng các tiêu chí này, trang thẻ mới thực sự đóng vai trò như một node trong topical cluster, góp phần tăng semantic coverage và topical authority thay vì chỉ tạo thêm noise trong index.
Trang lọc tự động tạo danh sách nội dung theo điều kiện, facet hoặc tham số
Trang lọc tự động (filter/faceted navigation page) thường xuất hiện trên website thương mại điện tử, listing, bất động sản, việc làm, hoặc thư viện nội dung lớn. Khác với tag, filter page được sinh ra dựa trên điều kiện lọc (facet) như: thương hiệu, mức giá, màu sắc, kích thước, địa điểm, tình trạng, thời gian đăng, hoặc các tham số kỹ thuật. Mỗi tổ hợp điều kiện có thể tạo thành một URL riêng, ví dụ: ?brand=nike&color=black&price=1-2-trieu. Vấn đề là số lượng tổ hợp này có thể tăng theo cấp số nhân, dẫn đến hàng nghìn, thậm chí hàng triệu URL khác nhau. Trang lọc tự động thuộc nhóm faceted search, trong đó người dùng tinh chỉnh kết quả bằng nhiều facet như brand, price, location, size, color hoặc feature. Wei, Liu, Zheng, Zhang, Fu và Feng (2013) định nghĩa faceted search là cơ chế exploratory search cho phép người dùng lặp lại quá trình lọc kết quả bằng faceted taxonomy. Cơ chế này rất mạnh về UX vì giúp người dùng thu hẹp tập kết quả lớn, nhưng cũng tạo rủi ro SEO nếu mọi tổ hợp đều sinh URL indexable. Facet phục vụ khám phá không đồng nghĩa với facet đủ điều kiện trở thành landing page SEO.
Về mặt SEO, không phải mọi URL lọc đều nên được index. Chỉ những trang lọc nào trùng khớp với nhu cầu tìm kiếm cụ thể (ví dụ: “giày nike đen dưới 2 triệu”, “chung cư 2 phòng ngủ quận 7”) và có giá trị độc lập mới đáng để tối ưu như một landing page. Các trang lọc còn lại chủ yếu phục vụ trải nghiệm điều hướng nội bộ, không có search intent rõ ràng, nên cần được kiểm soát bằng noindex, canonical hoặc cấu hình tham số trong Google Search Console. Nếu không, website rất dễ rơi vào tình trạng crawl budget bị lãng phí và chỉ số index bị “loãng” bởi vô số URL gần như giống nhau.
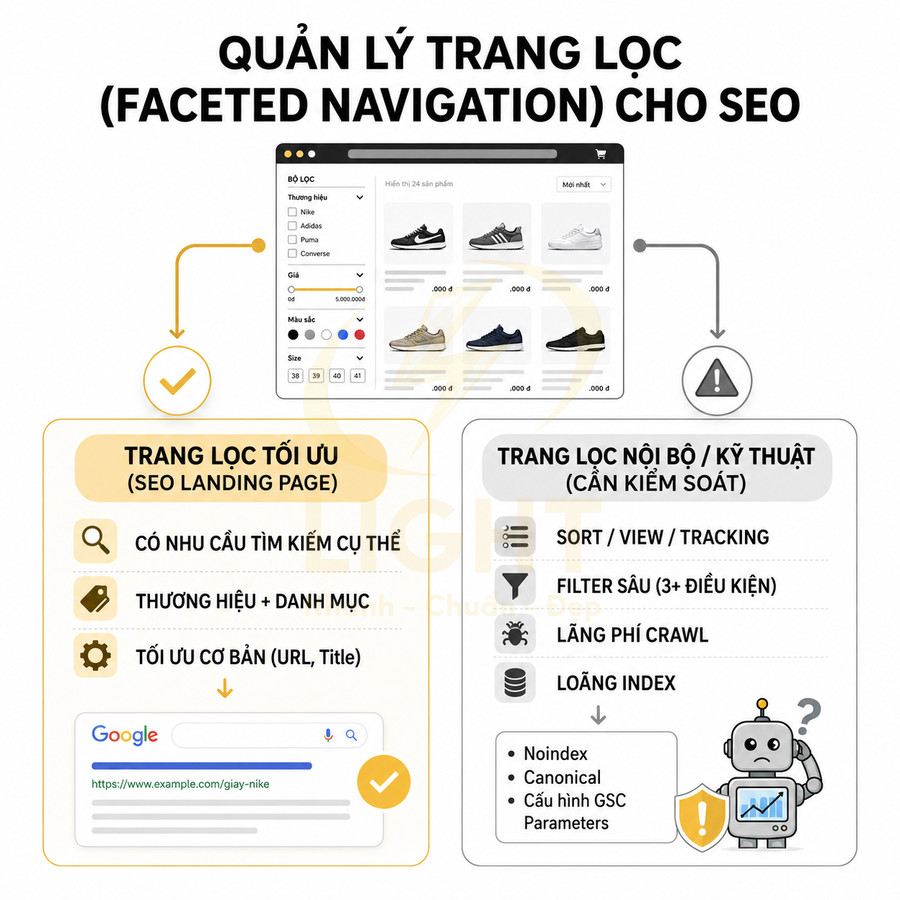
Ở góc độ kỹ thuật, cần phân biệt rõ các loại facet:
- Facet có search demand: brand + category, brand + attribute nổi bật (màu, size phổ biến), price range phổ biến, location + loại sản phẩm/dịch vụ.
- Facet mang tính kỹ thuật: sort theo giá, sort theo độ mới, tham số view mode, tham số tracking UTM, các filter rất chi tiết mà người dùng hiếm khi tìm kiếm trực tiếp.
- Facet kết hợp nhiều điều kiện sâu: 3–4 filter cùng lúc, thường tạo ra tập kết quả rất nhỏ, ít hoặc không có search volume.
Chỉ nhóm facet đầu tiên mới có tiềm năng trở thành landing page SEO. Khi đó, cần:
- Thiết kế URL thân thiện, có cấu trúc thư mục thay vì chuỗi tham số phức tạp (khi khả thi về mặt kỹ thuật).
- Viết nội dung mô tả ngắn cho trang lọc (intro text, FAQ, hướng dẫn chọn sản phẩm) để tránh thin content.
- Tối ưu title, meta description, heading theo đúng truy vấn mục tiêu, tránh trùng lặp với category hoặc tag.
Với các facet còn lại, chiến lược chuẩn là:
- Đặt noindex, follow cho các URL chỉ khác nhau về sort, view mode, hoặc tham số tracking.
- Sử dụng canonical trỏ về phiên bản chuẩn (thường là category hoặc filter cơ bản nhất) để gom tín hiệu.
- Cấu hình URL Parameters trong Google Search Console cho các tham số không tạo nội dung mới (sort, pagination, tracking).
Trong các website lớn, cần có faceted navigation policy rõ ràng giữa SEO và dev:
- Danh sách facet nào được phép index, facet nào luôn noindex.
- Quy tắc kết hợp facet: ví dụ chỉ cho phép index tối đa 2 facet “SEO-friendly” trên cùng một URL.
- Cơ chế tự động gắn canonical và noindex dựa trên pattern URL hoặc cấu hình trong CMS.
Cách tiếp cận này giúp kiểm soát số lượng URL sinh ra từ hệ thống lọc, tập trung crawl budget vào nhóm trang có khả năng mang lại traffic tự nhiên, đồng thời vẫn giữ được trải nghiệm lọc linh hoạt cho người dùng.
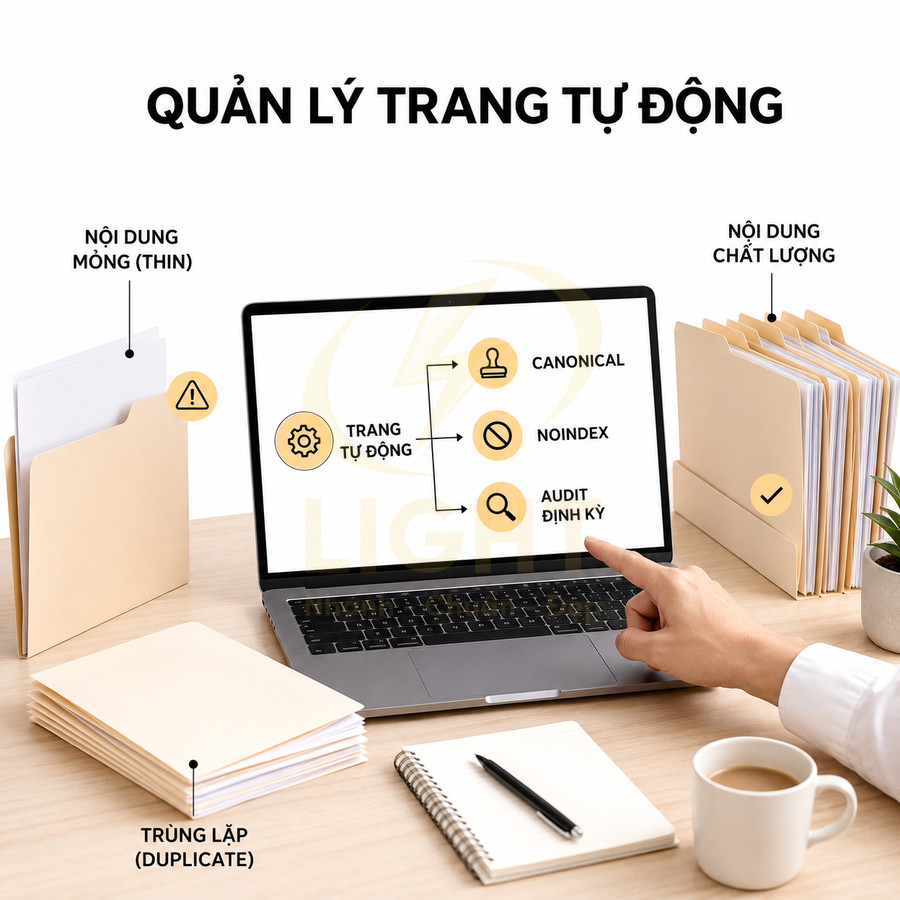
Trang tự động không có nhu cầu tìm kiếm dễ thành thin content và duplicate content
Khi trang thẻ và trang lọc được tạo hoàn toàn tự động, không dựa trên phân tích search intent, chúng thường rơi vào hai nhóm vấn đề: thin content và duplicate content. Thin content xảy ra khi một tag chỉ có 1–2 bài viết, không có mô tả, không có nội dung bổ trợ, chỉ là một danh sách link trống rỗng. Duplicate content xuất hiện khi nhiều tag hoặc filter khác nhau nhưng lại hiển thị gần như cùng một tập nội dung, cùng title, cùng H1, chỉ khác đôi chút về tham số URL. Cả hai dạng này đều làm giảm chất lượng tổng thể của khu vực indexable trong mắt Google. Trang tag hoặc filter tự động thường trở thành nội dung yếu khi chỉ khác nhau về URL, title hoặc một vài item trong danh sách. Manku, Jain và Das Sarma (2007) chỉ ra rằng near-duplicate web documents xuất hiện rất phổ biến trên web; hai tài liệu có thể chỉ khác một phần nhỏ nhưng vẫn gây tốn tài nguyên crawling và xử lý chỉ mục. Với tag/filter, hiện tượng này xảy ra khi nhiều trang hiển thị gần như cùng một tập bài viết hoặc sản phẩm. Nếu không có nội dung mô tả riêng, intent riêng và danh sách item đủ khác biệt, trang tự động nên noindex hoặc canonical về trang đại diện mạnh hơn.
Về mặt thuật toán, Google ngày càng đánh giá website ở cấp độ site-wide quality. Nếu tỷ lệ lớn URL index là trang mỏng, trùng lặp, không mang lại giá trị riêng, khả năng cao toàn bộ website sẽ bị đánh giá thấp hơn, ảnh hưởng đến khả năng xếp hạng của cả những trang chất lượng. Do đó, việc để hệ thống tự động sinh ra hàng loạt tag và filter page mà không có chiến lược SEO rõ ràng là một rủi ro lớn. Website chuẩn SEO cần chủ động quyết định trang nào xứng đáng được index, trang nào chỉ nên tồn tại để phục vụ điều hướng nội bộ.
Ở mức độ vận hành, có thể áp dụng một số nguyên tắc kiểm soát chất lượng:
- Thiết lập ngưỡng nội dung tối thiểu trước khi bỏ noindex cho một tag hoặc filter page (số lượng item, độ đa dạng, nội dung mô tả).
- Định kỳ audit các tag và filter có traffic thấp, impression thấp, hoặc tỷ lệ index thấp để gộp, xóa, hoặc chuyển về noindex.
- Tránh tạo nhiều tag/filter khác nhau cho cùng một khái niệm (ví dụ: “giày chạy bộ”, “giày chạy”, “giày running”) nếu không có khác biệt rõ về intent.
Về duplicate content, ngoài nội dung chính, cần chú ý đến:
- Title, H1, meta description của các trang danh sách rất dễ bị trùng nếu được sinh tự động theo pattern giống nhau.
- Thứ tự sắp xếp sản phẩm/bài viết khác nhau nhưng tập nội dung giống nhau, tạo cảm giác “near-duplicate” trong mắt crawler.
- Pagination của category, tag, filter nếu không canonical đúng cách có thể tạo ra nhiều phiên bản tương tự.
Giải pháp thường dùng là kết hợp:
- Canonical về trang gốc hoặc trang đại diện mạnh nhất cho cụm nội dung.
- Noindex cho các biến thể không mang thêm giá trị (sort, view, filter sâu).
- Tùy chỉnh template để mỗi trang danh sách có phần nội dung tĩnh riêng (intro, FAQ, hướng dẫn) giúp tăng độ khác biệt.
Website chuẩn SEO cần kiểm soát index thay vì tạo mọi biến thể URL
Trong bối cảnh Google ưu tiên chất lượng hơn số lượng, một website chuẩn SEO không nên theo đuổi chiến lược “càng nhiều URL càng tốt”. Thay vào đó, trọng tâm phải là kiểm soát index: chỉ cho phép những trang thực sự có giá trị, có search intent rõ ràng, có nội dung khác biệt được xuất hiện trong chỉ mục. Các biến thể URL sinh ra từ tag, filter, sort, phân trang, tham số tracking… cần được phân loại và xử lý bằng noindex, canonical, hoặc chặn crawl hợp lý. Cách tiếp cận này giúp tập trung sức mạnh crawl và tín hiệu xếp hạng vào nhóm trang quan trọng, đồng thời giảm thiểu nguy cơ cannibalization và duplicate. Kiểm soát index là nguyên tắc quan trọng vì công cụ tìm kiếm cần lọc bỏ nhiều nội dung trùng lặp hoặc gần trùng lặp để bảo vệ chất lượng kết quả. Fröbe và cộng sự (2021) cho biết commercial web search engines sử dụng near-duplicate detection để người dùng chỉ thấy mỗi kết quả liên quan một lần, dù web crawl thường chứa rất nhiều bản trùng hoặc gần trùng. Với website lớn, điều này có nghĩa là không nên đưa mọi tag, filter, sort, pagination và parameter vào index. Chỉ URL có intent rõ, nội dung khác biệt, internal link có chủ đích và giá trị người dùng mới nên được index.

Để làm được điều đó, đội ngũ SEO và phát triển cần phối hợp xây dựng một chiến lược taxonomy và indexation rõ ràng: định nghĩa loại trang nào được phép index, tiêu chí để một tag hoặc filter trở thành landing page SEO, quy tắc đặt canonical, quy tắc thêm vào sitemap, và cơ chế tự động gắn noindex cho các biến thể không đủ điều kiện. Khi mọi thứ được chuẩn hóa, website có thể mở rộng nội dung và sản phẩm mà không đánh đổi chất lượng SEO tổng thể.
Ở tầng chiến lược, có thể chia toàn bộ URL thành các nhóm:
- Core SEO pages: homepage, category, subcategory, pillar page, một số tag và filter chiến lược.
- Supportive pages: bài blog, landing page chiến dịch, trang thông tin, FAQ.
- Utility/navigation pages: phần lớn tag, filter, sort, pagination, search result nội bộ.
Mỗi nhóm cần có chính sách index riêng:
- Core SEO pages: luôn index, tối ưu onpage đầy đủ, có trong sitemap, được internal link mạnh.
- Supportive pages: index có chọn lọc, ưu tiên nội dung chất lượng, tránh trùng lặp chủ đề.
- Utility/navigation pages: mặc định noindex trừ khi đáp ứng tiêu chí rõ ràng về search intent và giá trị độc lập.
Về mặt kỹ thuật, nên chuẩn hóa:
- Pattern URL cho từng loại trang để dễ nhận diện và áp dụng rule (robots, canonical, noindex) tự động.
- Quy tắc thêm/bỏ URL khỏi sitemap XML dựa trên trạng thái index và hiệu suất (traffic, impression, conversion).
- Cơ chế log và monitor crawl để phát hiện sớm các cụm URL bùng nổ do cấu hình filter hoặc tag sai.
Khi chiến lược taxonomy và indexation được thiết kế bài bản, website có thể mở rộng số lượng sản phẩm, bài viết, tag, filter mà vẫn giữ được crawl efficiency, index hygiene và khả năng xây dựng topical authority bền vững.
Khác biệt SEO giữa trang thẻ, trang danh mục và trang lọc tự động
Trong chiến lược SEO, ba loại trang này cần được phân vai rõ ràng để tránh cạnh tranh nội bộ và lãng phí crawl. Trang danh mục giữ vai trò “trang chuẩn” cho các từ khóa head term, đại diện nhóm chủ đề hoặc nhóm sản phẩm chính, được ưu tiên về URL, điều hướng, internal link và quyền index. Trang thẻ hoạt động như các “micro hub”, gom nội dung quanh một thực thể, vấn đề hoặc ngữ cảnh phụ, hỗ trợ mở rộng topical cluster và tăng topical authority khi được tối ưu có chọn lọc. Trang lọc tự động phục vụ truy vấn dài, mang tính thương mại cao dựa trên tổ hợp thuộc tính; chỉ một số ít filter có search demand và giá trị rõ ràng mới nên được index và tối ưu như landing page.

Trang danh mục đại diện cho nhóm nội dung chính trong cấu trúc website
Trang danh mục (category page) là trụ cột trong cấu trúc thông tin của hầu hết website, đặc biệt với các site thương mại điện tử, site tin tức lớn hoặc blog chuyên sâu. Về mặt kiến trúc thông tin (information architecture), category thường đại diện cho nhóm chủ đề hoặc nhóm sản phẩm chính, gắn trực tiếp với:
- Cấu trúc URL cấp cao (thường là level 1 hoặc level 2)
- Điều hướng chính (main navigation, mega menu)
- Breadcrumb và sơ đồ trang (HTML sitemap)

Về SEO, category thường nhắm đến các từ khóa có volume lớn, intent rộng, mang tính “head term” hoặc “short-tail”, ví dụ: “giày thể thao nam”, “máy giặt”, “marketing online”, “học tiếng Anh”. Đây là những landing page quan trọng, thường được đầu tư:
- Nội dung mô tả chuyên sâu về chủ đề hoặc nhóm sản phẩm (mô tả trên/dưới danh sách sản phẩm, FAQ, hướng dẫn chọn mua)
- Cấu trúc heading rõ ràng (H1, H2, block nội dung bổ trợ)
- Internal link đến các subcategory, bài viết hướng dẫn, trang so sánh, trang thương hiệu
- Schema phù hợp (Product, ItemList, FAQ, Breadcrumb, Article list…)
- Chiến lược backlink: thường là điểm rơi của các chiến dịch link building, PR, guest post
Trong mô hình content hub hoặc silo, category đóng vai trò hub chính, kết nối đến các subcategory, tag, bài viết chi tiết, sản phẩm. Ở cấp độ kiến trúc SEO, category thường là “trang chuẩn” (canonical topic page) cho một chủ đề lớn. Vì vậy, việc để tag hoặc filter cạnh tranh trực tiếp với category về cùng một từ khóa là điều cần tránh.
Category nên được ưu tiên về:
- Cấu trúc URL ngắn, ổn định: thường dạng /category/ hoặc /chu-de/, hạn chế tham số, hạn chế thay đổi slug
- Vị trí trong menu: xuất hiện ở main navigation, mega menu, footer menu; được nhấn mạnh trong breadcrumb
- Internal link từ nhiều nơi: từ homepage, bài viết liên quan, tag, filter quan trọng, landing page chiến dịch
- Quyền được index mặc định: luôn được index, không noindex, không chặn trong robots.txt, canonical tự trỏ chính nó
Về mặt chiến lược, category là nơi thể hiện “ý định xếp hạng chính thức” của website cho một chủ đề. Tag và filter chỉ nên bổ trợ, mở rộng, hoặc cụ thể hóa thêm cho category, chứ không thay thế vai trò của nó. Khi lập kế hoạch SEO, cần xác định rõ:
- Mỗi nhóm từ khóa chính (topic) sẽ map với một category duy nhất
- Các biến thể dài hơn (long-tail) hoặc ngữ cảnh phụ sẽ được xử lý bằng tag, bài viết, hoặc filter, nhưng vẫn quy chiếu về category qua internal link
- Canonical và anchor text phải nhất quán, ưu tiên category cho từ khóa chính
Trang thẻ mở rộng topical cluster theo thực thể, vấn đề, ngữ cảnh phụ
Nếu category là “xương sống” của cấu trúc, thì tag là các nhánh phụ giúp mở rộng và làm sâu thêm topical cluster. Về bản chất, tag là một lớp phân loại linh hoạt hơn, không nhất thiết phải phản ánh cấu trúc điều hướng chính, nhưng lại rất hữu ích cho SEO theo hướng entity-based và problem-based. Tag page có thể hỗ trợ topical cluster khi nó gom đúng các tài nguyên cùng chủ đề và làm rõ quan hệ giữa chúng. Peters và Stock (2007) nghiên cứu folksonomy trong information retrieval và xem tag như một lớp indexing có thể hỗ trợ truy xuất thông tin khi được khai thác đúng. Với SEO content hub, tag không nên được dùng để lặp lại category, mà nên mở rộng theo entity, vấn đề hoặc ngữ cảnh phụ như “case study Facebook Ads”, “SEO audit checklist”, “GA4 cho ecommerce”. Tag mạnh là tag giúp người dùng tiếp tục khám phá một cụm nội dung hẹp, không phải tag chỉ để nhồi thêm từ khóa.
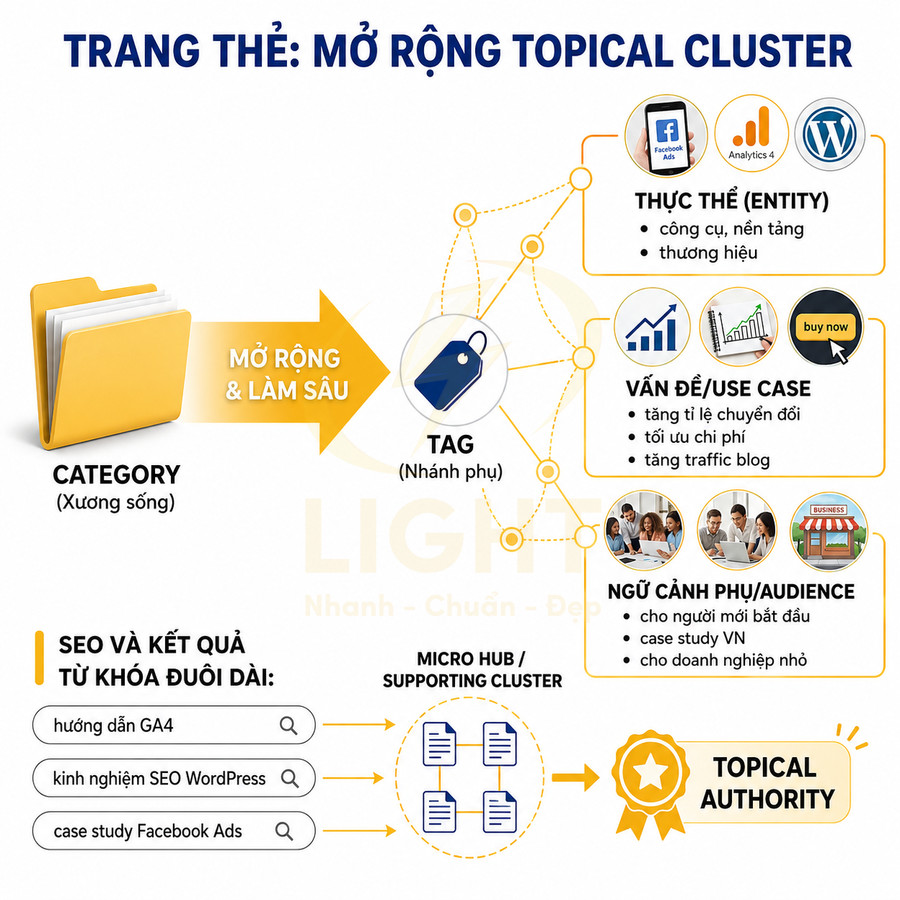
Một tag tốt thường tập trung vào:
- Thực thể cụ thể (entity): công cụ, nền tảng, thương hiệu, công nghệ, ví dụ: “Facebook Ads”, “Google Analytics 4”, “WordPress”, “Shopee”, “TikTok Shop”
- Vấn đề hoặc use case: “tăng tỉ lệ chuyển đổi”, “tối ưu chi phí quảng cáo”, “tăng traffic blog”, “giảm tỷ lệ bỏ giỏ hàng”
- Ngữ cảnh phụ hoặc audience segment: “cho người mới bắt đầu”, “case study Việt Nam”, “cho doanh nghiệp nhỏ”, “B2B SaaS”
Nhờ đó, tag giúp gom lại những bài viết nằm rải rác trong nhiều category nhưng cùng xoay quanh một entity hoặc vấn đề. Về mặt cấu trúc topical, tag tạo ra các “micro hub” hoặc “supporting cluster” xoay quanh một chủ đề hẹp, bổ sung cho hub chính là category.
Về SEO, trang thẻ có thể trở thành landing page cho các truy vấn dạng:
- “hướng dẫn + entity” (hướng dẫn Facebook Ads, hướng dẫn GA4)
- “kinh nghiệm + entity” (kinh nghiệm chạy Google Ads, kinh nghiệm SEO WordPress)
- “case study + entity” (case study Facebook Ads Việt Nam)
- Các truy vấn thông tin trung bình – dài, kết hợp entity + ngữ cảnh (Facebook Ads cho người mới, GA4 cho ecommerce…)
Khi được tối ưu đúng cách (title riêng, H1 riêng, mô tả, nội dung bổ trợ, block giới thiệu, FAQ ngắn), tag page giúp Google nhận diện rõ hơn mối liên hệ giữa các bài viết, từ đó củng cố topical authority của website trên một lĩnh vực. Một số thực hành chuyên sâu:
- Giới hạn số lượng tag, chỉ tạo khi có tối thiểu một số bài viết (ví dụ >= 3–5 bài) xoay quanh cùng entity/vấn đề
- Viết đoạn mô tả ngắn (intro) cho mỗi tag, giải thích chủ đề, liên kết đến category chính liên quan
- Thiết lập canonical rõ ràng, tránh để tag trùng hoàn toàn với category về từ khóa và nội dung
- Ưu tiên index cho các tag có search demand, có giá trị thông tin; noindex các tag rác, tag chỉ xuất hiện 1–2 bài
Tuy nhiên, nếu tag bị tạo tràn lan, không có chiến lược, chúng sẽ nhanh chóng biến thành tập hợp các trang mỏng, trùng lặp, gây hại nhiều hơn lợi. Các rủi ro thường gặp:
- Hàng trăm, hàng nghìn tag chỉ có 1 bài, nội dung gần như giống nhau (chỉ khác danh sách bài viết)
- Tag trùng tên hoặc gần trùng với category, dẫn đến cannibalization
- Tag sinh ra từ thói quen biên tập, không dựa trên nghiên cứu từ khóa hoặc entity (ví dụ: mỗi bài tự nghĩ 3–5 tag khác nhau)
Trang lọc tự động phục vụ truy vấn cụ thể theo thuộc tính hoặc tổ hợp điều kiện
Filter page khác với category và tag ở chỗ nó gắn chặt với thuộc tính sản phẩm hoặc nội dung. Về mặt kỹ thuật, filter thường được sinh ra từ hệ thống faceted navigation (lọc theo thương hiệu, giá, màu sắc, kích thước, tính năng, vị trí địa lý…). Người dùng thường tìm đến các trang lọc thông qua truy vấn có nhiều ràng buộc, ví dụ:
- “laptop i7 16gb ram dưới 20 triệu”
- “chung cư 2 phòng ngủ quận 2 có hồ bơi”
- “áo thun nam cotton trắng size L”

Những truy vấn này mang tính commercial hoặc transactional intent rất rõ, và nếu inventory đủ lớn, một trang lọc được tối ưu tốt có thể trở thành landing page SEO cực kỳ hiệu quả, đặc biệt trong ecommerce, bất động sản, tuyển dụng.
Khác với tag, filter thường không được tạo thủ công từng cái, mà sinh ra từ hệ thống faceted navigation. Mỗi lần người dùng chọn một hoặc nhiều thuộc tính, hệ thống tạo ra một URL mới (thường có tham số hoặc path mở rộng). Vì vậy, nhiệm vụ của SEO là chọn lọc trong số vô số tổ hợp điều kiện, xem tổ hợp nào:
- Có search demand đủ lớn (dựa trên keyword research, log search nội bộ, Google Search Console)
- Có nội dung đủ khác biệt so với category và các filter khác (tập sản phẩm khác rõ rệt, giá trị sử dụng cao)
- Có giá trị thương mại đủ cao (biên lợi nhuận, tỉ lệ chuyển đổi, mức độ cạnh tranh SERP)
Những trang lọc được chọn này cần được “nâng cấp” thành trang indexable và tối ưu như landing page:
- Có title, H1, meta description được viết tay, phản ánh chính xác tổ hợp điều kiện (ví dụ: “Laptop Core i7 16GB RAM dưới 20 triệu – Chính hãng, trả góp 0%”)
- Có nội dung bổ trợ: đoạn mô tả ngắn, hướng dẫn chọn sản phẩm theo tiêu chí, FAQ, link đến category cha
- Có canonical rõ ràng, tránh trùng với category hoặc các filter khác
- Nhận internal link từ danh mục, menu phụ, banner, hoặc các bài viết hướng dẫn
Phần lớn các tổ hợp filter còn lại nên:
- Noindex (meta robots noindex, follow) hoặc
- Được canonical về category cha hoặc về một filter “chuẩn” đã được chọn
- Được kiểm soát crawl bằng robots.txt, rules trong Search Console, hoặc cấu trúc URL (hạn chế tạo vô hạn tham số)
Dùng sai loại trang khiến cannibalization và crawl waste tăng mạnh
Khi không phân biệt rõ vai trò của category, tag và filter, website rất dễ rơi vào tình trạng keyword cannibalization và crawl waste. Ví dụ: một website thời trang có category “Áo thun nam”, đồng thời tạo tag “áo thun nam”, và filter “/ao-thun-nam?gender=male”. Cả ba trang này đều nhắm đến cùng một từ khóa, cùng tập sản phẩm, cùng intent. Kết quả là Google phải chọn một trong ba để xếp hạng, trong khi tín hiệu (backlink, internal link, CTR) bị chia nhỏ, làm giảm sức mạnh của trang quan trọng nhất. Cannibalization thường xuất hiện khi category, tag, filter và bài pillar cùng nhắm một intent. Về mặt cấu trúc web, Brin và Page (1998) cho thấy liên kết và anchor text là tín hiệu quan trọng trong cách search engine khai thác graph trang web. Nếu nhiều URL cùng nhận internal link với cùng anchor như “áo thun nam”, Google sẽ khó xác định trang đại diện chính. Category nên giữ head term, tag nên giữ entity/subtopic, filter nên giữ tổ hợp thuộc tính có intent thương mại, còn bài pillar nên phục vụ intent thông tin chuyên sâu. Mapping sai vai trò sẽ chia nhỏ authority và làm bot crawl nhiều trang dư thừa.
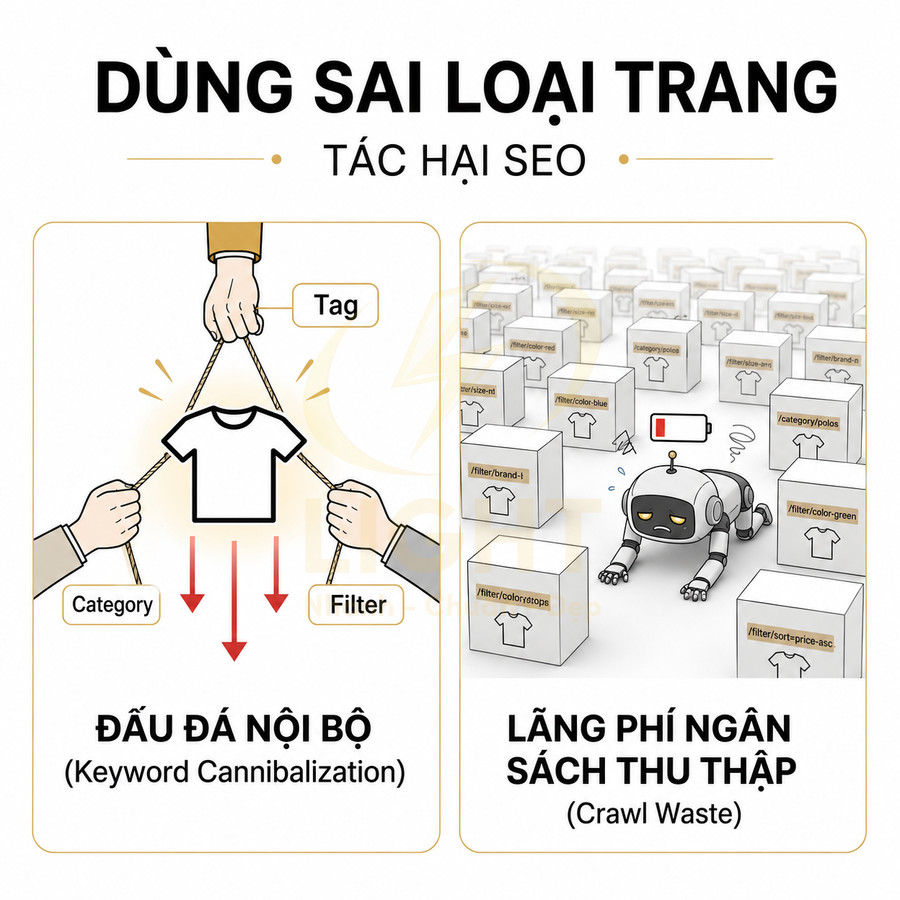
Ở góc độ chuyên môn, có thể phân tích:
- Category lẽ ra phải là trang chuẩn cho từ khóa “áo thun nam” (head term)
- Tag trùng tên là dư thừa, nên:
- Hoặc đổi thành tag theo entity/vấn đề (ví dụ: “áo thun oversize”, “áo thun local brand”)
- Hoặc gộp/xóa và redirect về category
- Filter “gender=male” thực chất không tạo khác biệt nội dung so với category (vì category đã là áo thun nam), nên nên:
- Noindex hoặc canonical về category
- Không cho phép index các filter trùng logic với category
Ở chiều ngược lại, nếu mọi tổ hợp filter đều được index, Googlebot sẽ phải crawl một lượng lớn URL gần như giống nhau, tiêu tốn crawl budget mà không mang lại thêm giá trị. Điều này đặc biệt nguy hiểm với các site lớn, inventory thay đổi liên tục (ecommerce, rao vặt, bất động sản, tuyển dụng). Các vấn đề thường gặp:
- Hàng trăm nghìn URL filter chỉ khác nhau chút ít về giá, màu, size, nhưng gần như không có search demand
- Duplicate content ở mức danh sách sản phẩm, khiến Google khó xác định trang nào là “chuẩn” để xếp hạng
- Crawl budget bị tiêu tốn vào các URL ít giá trị, trong khi các trang quan trọng (category, tag chiến lược, landing page nội dung) lại được crawl ít hơn
Do đó, việc xác định đúng loại trang cho đúng mục đích, và giới hạn số lượng trang indexable, là yếu tố then chốt để duy trì hiệu suất SEO bền vững. Ở mức triển khai, cần:
- Xây dựng mapping từ khóa → loại trang (keyword-to-page mapping) ngay từ giai đoạn lập kế hoạch
- Định nghĩa rõ:
- Từ khóa nào thuộc về category (head, mid-tail, transactional rộng)
- Từ khóa nào thuộc về tag (entity, vấn đề, ngữ cảnh phụ)
- Từ khóa nào thuộc về filter (tổ hợp thuộc tính, long-tail mang tính thương mại cao)
- Thiết lập quy tắc kỹ thuật:
- Canonical, noindex, robots.txt cho filter
- Quy chuẩn đặt tên, tạo mới, xóa/gộp tag
- Chuẩn hóa cấu trúc URL category để giữ vai trò trung tâm
Khi nào nên index trang thẻ trên website chuẩn SEO?
Trang thẻ nên được index khi thực sự đóng vai trò như một hub nội dung có giá trị, không chỉ là danh sách bài viết rời rạc. Điều kiện cốt lõi gồm: chủ đề rõ ràng, đủ số lượng bài chuyên sâu, mạng lưới liên kết nội bộ tự nhiên và có search volume, intent riêng, không trùng với category hay landing khác. Mỗi thẻ cần được tối ưu như một landing page: có title, H1, mô tả, nội dung bổ trợ, internal link nổi bật và cấu trúc kỹ thuật chuẩn (canonical, phân trang, schema). Khi được xây dựng xoay quanh entity, thẻ giúp củng cố topical authority, hỗ trợ E-E-A-T, tối ưu crawl budget và giảm cannibalization trên toàn bộ website.
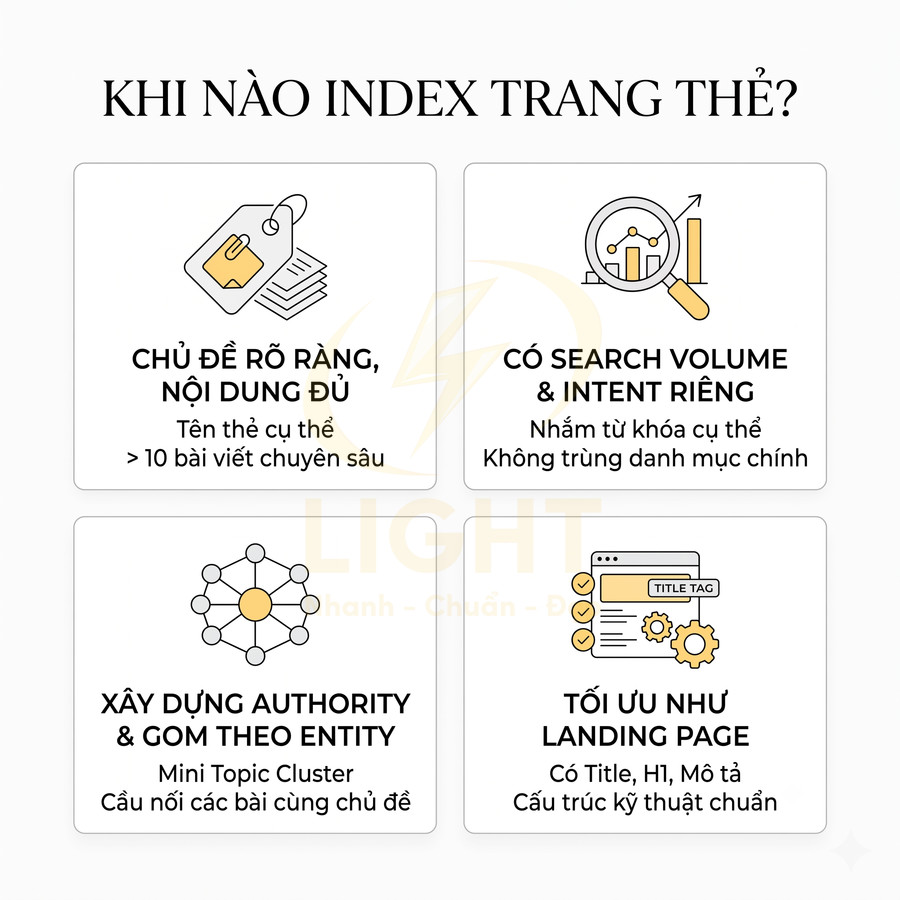
Thẻ có chủ đề rõ, số lượng nội dung đủ và liên kết nội bộ tự nhiên
Một trang thẻ chỉ nên được index khi nó đáp ứng được ba tiêu chí cơ bản: chủ đề rõ ràng, số lượng nội dung đủ, và liên kết nội bộ tự nhiên. Chủ đề rõ ràng nghĩa là tên thẻ phản ánh chính xác một entity, một chủ đề con, hoặc một vấn đề cụ thể, không mơ hồ, không đa nghĩa. Số lượng nội dung đủ thường tối thiểu từ 8–10 bài viết trở lên, để danh sách không bị mỏng và có đủ “chất liệu” cho Google đánh giá. Liên kết nội bộ tự nhiên nghĩa là nhiều bài viết liên quan thực sự cần gắn thẻ này, không phải gắn cho có hoặc gắn cưỡng ép. Một tag đủ điều kiện index cần cho thấy độ ổn định chủ đề và khả năng truy xuất nội dung tốt. Harvey, Baillie, Ruthven và Elsweiler (2009) cho thấy tag clouds có thể giúp người dùng chọn tag ổn định và nhất quán hơn trong quá trình indexing, qua đó làm hệ thống tag hữu ích hơn cho tổ chức nội dung. Với website SEO, điều này củng cố nguyên tắc: tag không nên sinh ra cho một bài duy nhất hoặc một ý tưởng mơ hồ. Tag indexable nên có tối thiểu một cụm bài đủ dày, có internal link tự nhiên từ bài liên quan, có mô tả riêng và có khả năng phát triển thành topic hub.

Ở mức chuyên sâu hơn, có thể xem mỗi tag như một “mini topic cluster” xoay quanh một entity hoặc một ngữ cảnh tìm kiếm cụ thể. Khi đánh giá một thẻ có đủ điều kiện index hay không, nên kiểm tra thêm:
- Mức độ tập trung chủ đề: Các bài trong thẻ có xoay quanh cùng một câu hỏi trung tâm, một nhóm vấn đề hoặc một hành trình người dùng cụ thể hay không. Nếu nội dung trong thẻ quá phân tán, Google khó nhận diện được “chủ đề cốt lõi”.
- Độ sâu nội dung: Không chỉ là số lượng bài, mà còn là chiều sâu. Một thẻ có 10 bài nhưng đều là nội dung mỏng, trùng lặp ý, sẽ kém giá trị hơn một thẻ có 8 bài nhưng mỗi bài giải quyết một khía cạnh khác nhau của cùng chủ đề.
- Cấu trúc liên kết nội bộ: Các bài trong thẻ có liên kết chéo với nhau (contextual internal link) hay chỉ đơn thuần cùng gắn một tag. Một mạng lưới link ngữ cảnh, đặt trong nội dung, giúp Google hiểu rõ mối quan hệ giữa các bài hơn là chỉ dựa vào danh sách tag.
Khi ba yếu tố này hội tụ, trang thẻ sẽ trở thành một “hub” tự nhiên, nơi người dùng có thể tiếp tục khám phá nội dung liên quan mà không bị cảm giác trống rỗng. Đồng thời, Google cũng dễ dàng nhận diện đây là một cụm chủ đề có chiều sâu, tăng khả năng xếp hạng cho cả tag page lẫn các bài viết con. Trong bối cảnh E-E-A-T, việc tổ chức nội dung theo các thẻ có chủ đề rõ ràng còn giúp thể hiện chuyên môn và mức độ bao phủ chủ đề của website.
Về mặt crawl budget và index efficiency, một hệ thống tag được kiểm soát tốt (chỉ index các thẻ “đủ chuẩn”) giúp bot tập trung crawl vào những URL có giá trị cao, hạn chế lãng phí vào các tag mỏng, trùng lặp hoặc không mang lại traffic. Điều này đặc biệt quan trọng với các site lớn, site tin tức, blog nhiều năm tuổi có hàng nghìn bài viết và hàng trăm thẻ phát sinh tự do.
Thẻ có search volume, intent riêng và không trùng với danh mục chính
Bên cạnh yếu tố nội bộ, quyết định index một tag còn cần dựa trên dữ liệu tìm kiếm bên ngoài. Một thẻ nên được index khi nó nhắm đến một nhóm từ khóa có search volume đủ lớn, intent riêng biệt, và không trùng lặp với category hoặc landing page khác. Ví dụ, nếu website có category “SEO tổng thể”, một tag “SEO tổng thể” gần như chắc chắn gây cannibalization. Ngược lại, một tag “SEO onpage” hoặc “Entity SEO” có thể có intent riêng, không trùng với category, và xứng đáng được index nếu có đủ nội dung.
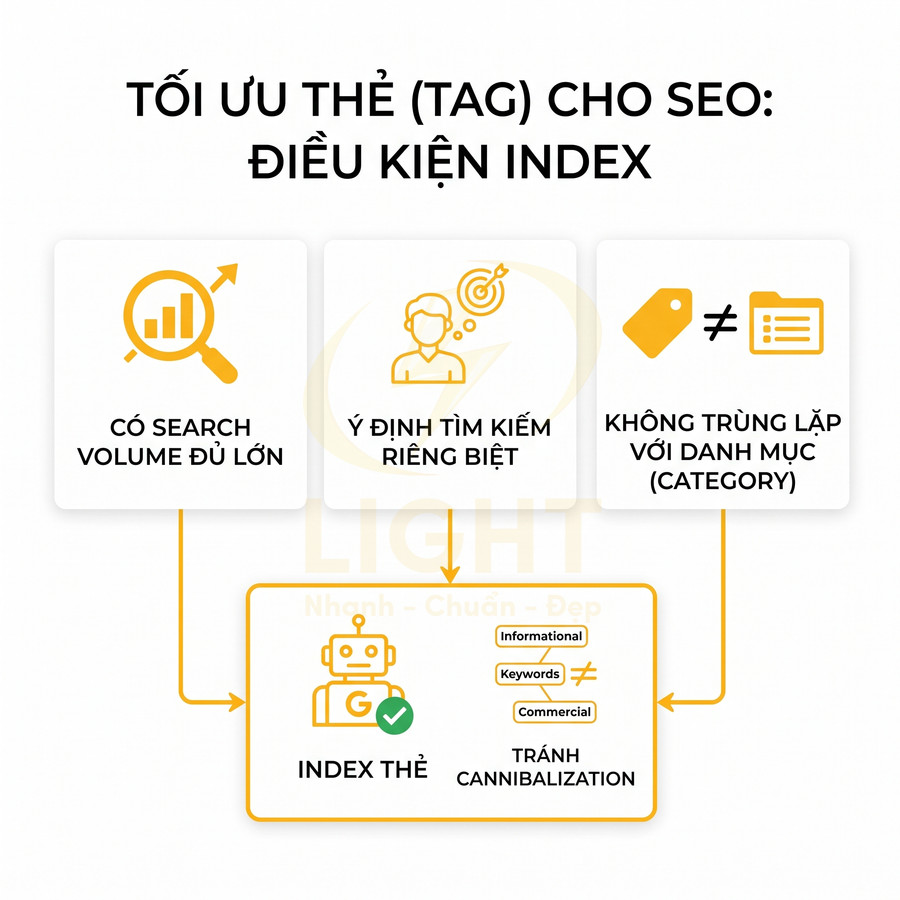
Ở góc độ nghiên cứu từ khóa, nên phân tích tag như một landing page tiềm năng:
- Nhóm từ khóa chính – phụ: Xác định từ khóa chính mà tag sẽ target (thường là chính tên thẻ) và các biến thể dài hơn (long-tail) xoay quanh chủ đề đó. Điều này giúp định hướng nội dung mô tả, nội dung bổ trợ và cấu trúc internal link.
- Search intent: Phân loại intent (informational, commercial investigation, transactional, navigational). Nhiều tag phù hợp nhất với informational hoặc commercial investigation, nơi người dùng muốn khám phá, so sánh, học sâu về một chủ đề.
- Overlap với category/landing khác: So sánh SERP và nội dung hiện có trên site. Nếu một category hoặc landing page đã bao phủ gần trùng khớp intent, tag nên được noindex hoặc chỉ dùng cho điều hướng nội bộ.
Để đánh giá, có thể sử dụng các công cụ như Google Keyword Planner, Ahrefs, Semrush, hoặc đơn giản là phân tích SERP: xem Google đang trả về loại trang nào cho từ khóa tương ứng. Nếu SERP chủ yếu là bài blog, guide, hoặc tag page của đối thủ, đó là tín hiệu tốt cho việc tối ưu tag như một landing page. Nếu SERP chủ yếu là category hoặc trang sản phẩm, có thể cân nhắc dùng category hoặc filter thay vì tag.
Ở mức triển khai thực tế, nên xây dựng một “ma trận URL” để tránh cannibalization:
- Mapping mỗi nhóm từ khóa chính vào đúng loại trang (homepage, category, tag, bài blog, landing page dịch vụ).
- Đảm bảo mỗi intent chính chỉ có một URL đại diện; các URL khác nếu buộc phải tồn tại (ví dụ do hệ thống CMS) thì đặt noindex, canonical hoặc điều chỉnh nội dung để tách intent.
- Định kỳ audit các tag đã index: nếu search volume giảm mạnh, intent thay đổi, hoặc xuất hiện trùng lặp với một landing mới, có thể chuyển tag sang noindex hoặc merge nội dung sang một hub khác mạnh hơn.
Thẻ hỗ trợ topical authority bằng cách kết nối nhiều bài viết cùng entity
Một trong những lý do mạnh mẽ nhất để index tag là khi nó đóng vai trò cầu nối entity, giúp củng cố topical authority. Ví dụ, một website về marketing có rất nhiều bài viết liên quan đến “Facebook Ads”: hướng dẫn, case study, cập nhật chính sách, phân tích chiến dịch. Một tag “Facebook Ads” được tối ưu tốt sẽ gom tất cả nội dung này lại, tạo thành một hub thể hiện rõ chuyên môn sâu về entity đó. Khi Google thấy một website có nhiều nội dung chất lượng xoay quanh cùng một entity, được liên kết chặt chẽ với nhau, khả năng cao website sẽ được đánh giá cao hơn về chủ đề đó.
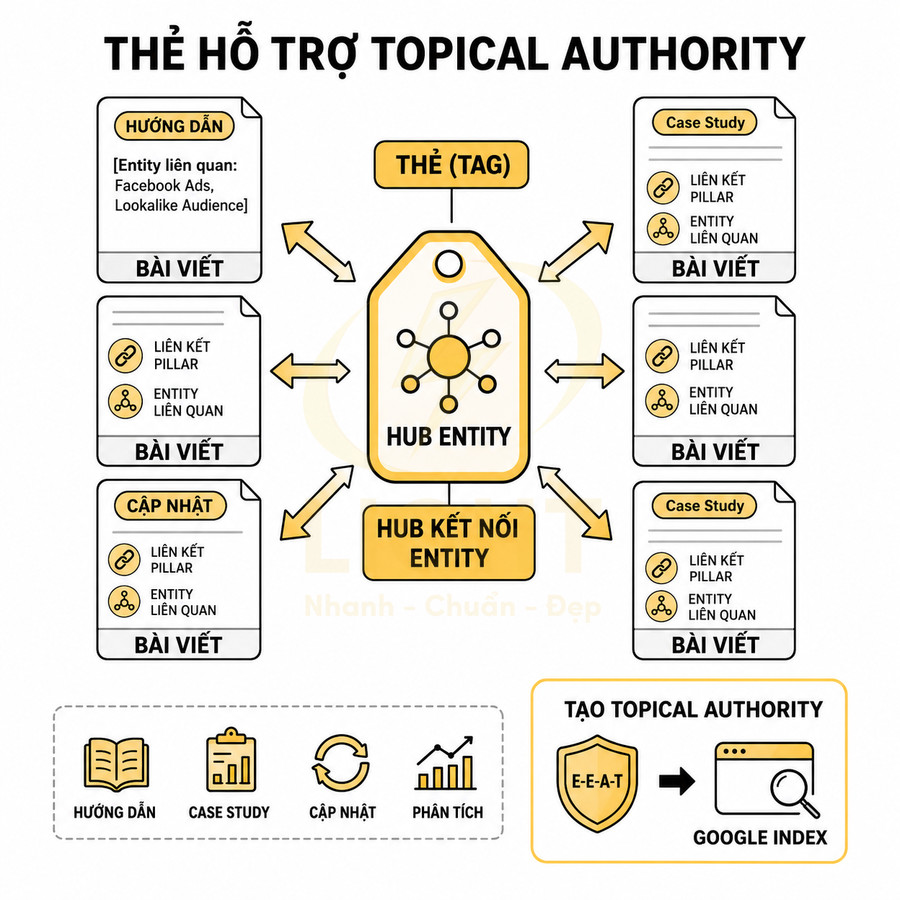
Trong mô hình entity-based SEO, mỗi tag có thể được xem như một “entry point” vào graph kiến thức của website:
- Entity chính: Tên thẻ thường trùng với entity hoặc một khái niệm rõ ràng (ví dụ: “Facebook Ads”, “Technical SEO”, “Tối ưu chuyển đổi”).
- Entity liên quan: Các bài viết trong thẻ nên đề cập và liên kết đến các entity liên quan (ví dụ: “Facebook Pixel”, “Custom Audience”, “Lookalike Audience” trong thẻ “Facebook Ads”).
- Liên kết đến pillar page: Tag page có thể đóng vai trò “bridge” giữa nhiều bài lẻ và một pillar page chuyên sâu, giúp Google hiểu cấu trúc chủ đề theo chiều dọc (pillar) và chiều ngang (các bài vệ tinh).
Trong bối cảnh Google ngày càng sử dụng entity-based indexing, việc tổ chức tag theo entity không chỉ giúp người dùng dễ tìm nội dung, mà còn giúp máy học của Google hiểu rõ hơn “bản đồ kiến thức” của website. Điều này đặc biệt quan trọng với các site chuyên ngành (YMYL, tài chính, sức khỏe, pháp lý), nơi E-E-A-T và topical authority là yếu tố then chốt để được xếp hạng ổn định.
Với các site YMYL, mỗi tag được index nên được “bảo chứng” bởi:
- Tác giả có chuyên môn: Các bài trong thẻ nên gắn với author profile rõ ràng, có thông tin chuyên môn, chứng chỉ, kinh nghiệm.
- Review/medical/legal review (nếu có): Với chủ đề nhạy cảm, việc thể hiện bài đã được chuyên gia thẩm định càng củng cố tín hiệu E-E-A-T cho toàn bộ cụm nội dung trong thẻ.
- Consistency về quan điểm chuyên môn: Các bài trong cùng một thẻ không nên đưa ra các khuyến nghị mâu thuẫn nhau; nếu có cập nhật, nên có bài “tổng hợp/cập nhật” được ưu tiên hiển thị trong tag page.
Thẻ có title, H1, mô tả và nội dung bổ trợ được biên tập riêng
Một trang thẻ được chọn index không nên chỉ là danh sách bài viết mặc định. Để tối ưu SEO, cần biên tập riêng: title, H1, meta description, đoạn mô tả ngắn, và nếu phù hợp là nội dung bổ trợ như FAQ, hướng dẫn, internal link nổi bật. Điều này giúp tag page trở thành một landing page thực thụ, có khả năng trả lời intent của người dùng ngay trên trang, thay vì buộc họ phải click thêm vào từng bài viết con.
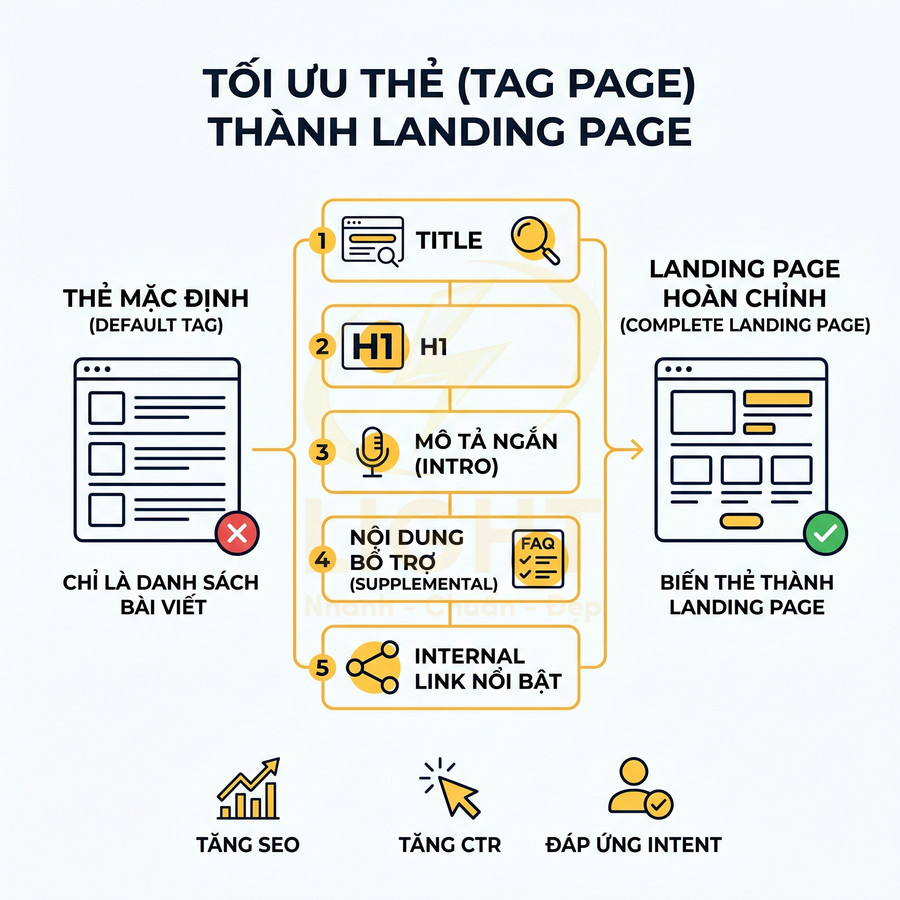
Ở cấp độ triển khai, có thể coi mỗi tag được index như một “category thu nhỏ” với cấu trúc nội dung rõ ràng:
- Title: Tối ưu cho CTR và từ khóa chính, có thể bổ sung yếu tố lợi ích hoặc phạm vi (ví dụ: “Facebook Ads – Hướng dẫn, Case Study, Chiến lược mới nhất”).
- H1: Tập trung vào việc định nghĩa chủ đề, có thể tự nhiên hơn title, tránh nhồi nhét từ khóa.
- Mô tả ngắn (intro): 2–4 câu giải thích entity, phạm vi nội dung, đối tượng phù hợp (beginner, intermediate, advanced), và gợi ý cách sử dụng danh sách bài viết (đọc theo thứ tự, chọn theo nhu cầu, v.v.).
- Nội dung bổ trợ: Có thể là một đoạn tóm tắt “roadmap học tập”, checklist, hoặc các anchor link dẫn đến nhóm bài quan trọng trong thẻ (ví dụ: “Bài cho người mới bắt đầu”, “Case study nâng cao”).
- Internal link nổi bật: Ưu tiên 1–3 bài trụ cột (pillar/guide) được đặt ở vị trí trên cùng hoặc trong một block nổi bật, giúp người dùng mới nhanh chóng tiếp cận nội dung giá trị nhất.
Bảng dưới đây minh họa các thành phần tối thiểu nên tối ưu cho một trang thẻ được index:
| Thành phần | Mục đích | Lưu ý tối ưu |
|---|---|---|
| Title | Tín hiệu xếp hạng và CTR trên SERP | Chứa từ khóa chính, thể hiện rõ chủ đề thẻ, tránh trùng với category |
| H1 | Định nghĩa chủ đề trang cho người dùng và bot | Có thể gần giống title nhưng ưu tiên tự nhiên, dễ đọc |
| Mô tả ngắn | Giải thích phạm vi nội dung trong thẻ | 2–4 câu, nêu rõ người dùng sẽ tìm thấy gì trong danh sách |
| Nội dung bổ trợ | Tăng giá trị trang, tránh thin content | Có thể là hướng dẫn, note quan trọng, link đến pillar page |
| Internal link nổi bật | Điều hướng đến bài viết/pillar quan trọng nhất | Ưu tiên các bài có traffic, chuyển đổi, hoặc giá trị cao |
Về mặt kỹ thuật, khi quyết định index một tag, nên kiểm tra thêm:
- Canonical: Đảm bảo canonical của tag trỏ về chính nó, không trùng với category hoặc một URL khác, tránh tín hiệu lẫn lộn.
- Pagination: Với tag có nhiều bài, cần cấu hình pagination chuẩn (rel="next"/"prev" hoặc pattern URL rõ ràng) và đảm bảo trang đầu tiên là landing chính được tối ưu nội dung.
- Schema (nếu phù hợp): Có thể cân nhắc thêm breadcrumb schema, hoặc Article list markup (tùy bối cảnh) để giúp Google hiểu cấu trúc danh sách nội dung.
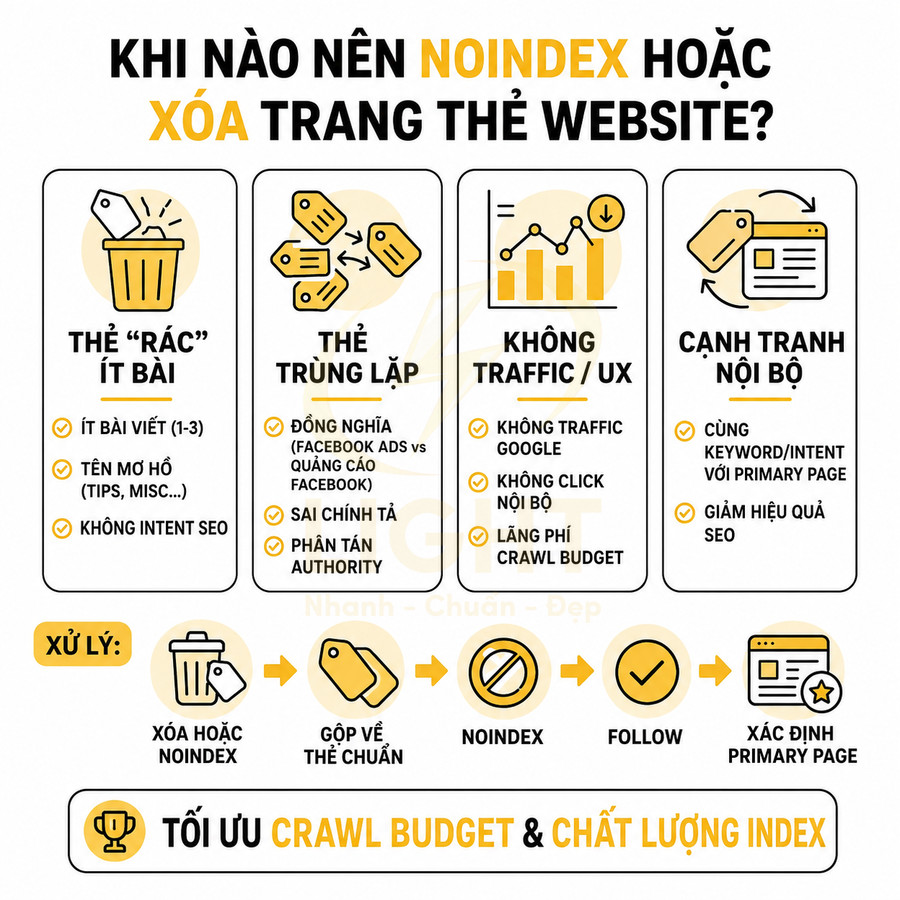
Khi nào nên noindex hoặc xóa trang thẻ khỏi website?
Các trang thẻ nên được noindex hoặc xóa khi chúng không mang lại giá trị SEO lẫn trải nghiệm người dùng. Nhóm phổ biến nhất là thẻ “rác”: chỉ gắn cho vài bài, tên mơ hồ, không có search intent, không đóng vai trò trong cấu trúc điều hướng. Với nhóm này, nên xóa hẳn hoặc giữ nội bộ và gắn noindex, follow đến khi đủ nội dung. Một trường hợp khác là nhiều thẻ đồng nghĩa, gần nghĩa hoặc sai chính tả khiến trang thẻ bị trùng lặp, phân tán tín hiệu xếp hạng; cần gom về một thẻ chuẩn, xóa/noindex hoặc 301 các thẻ còn lại. Cuối cùng, những thẻ không có traffic, không được click từ internal link và không góp phần vào hành trình người dùng cũng nên được noindex để tránh loãng chỉ mục và lãng phí crawl budget.
Thẻ chỉ có một vài bài viết, tên mơ hồ hoặc bị tạo tùy tiện
Các thẻ được tạo một cách tùy tiện, không theo bất kỳ taxonomy hay content model chuẩn nào, thường dẫn đến tình trạng: ít bài viết, tên mơ hồ, không có giá trị điều hướng, không có search intent rõ ràng. Đây là nhóm thẻ “rác” phổ biến nhất trên các blog lâu năm hoặc website có nhiều tác giả, nơi mỗi người tự do tạo tag theo cảm tính.
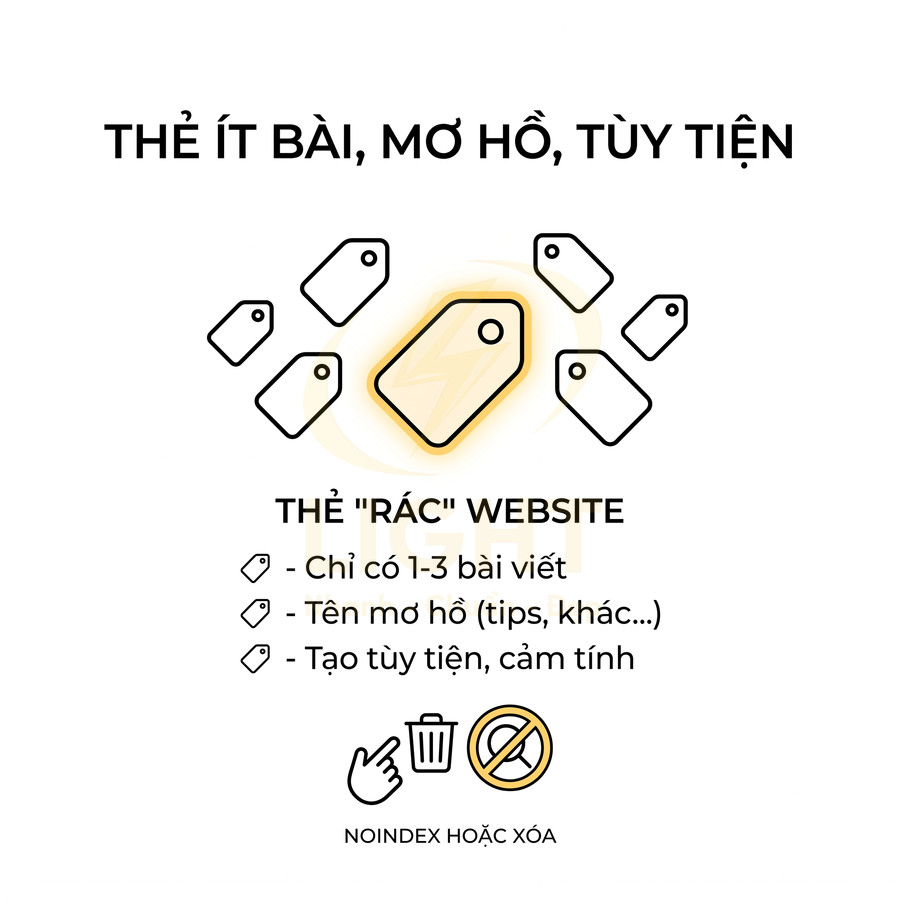
Những thẻ kiểu này thường có một số đặc điểm nhận diện:
- Chỉ gắn cho 1–3 bài viết, không có kế hoạch mở rộng thêm nội dung.
- Tên thẻ quá chung chung, không thể hiện chủ đề cụ thể: “tips”, “misc”, “khác”, “tổng hợp”, “chia sẻ”, “note”, “random”…
- Tên thẻ mang tính “tâm trạng” hoặc nội bộ, không ai tìm kiếm: “chuyện linh tinh”, “góc suy nghĩ”, “behind the scenes”…
- Không có từ khóa rõ ràng, không map được với bất kỳ truy vấn tìm kiếm nào có volume.
- Không đóng vai trò trong cấu trúc điều hướng chính (main navigation, breadcrumb, menu phụ).
Với các thẻ như vậy, khả năng chúng trở thành landing page SEO gần như bằng 0, vì:
- Nội dung trên trang thẻ quá mỏng (thin content): chỉ liệt kê vài bài, không có mô tả, không có nội dung bổ sung.
- Không có search demand: người dùng không tìm kiếm theo đúng cụm từ đó, hoặc intent quá mơ hồ.
- Không tạo được cụm chủ đề (topic cluster) đủ mạnh để Google hiểu và đánh giá cao.
Trong bối cảnh đó, lựa chọn hợp lý là noindex hoặc thậm chí xóa thẻ và gỡ gắn thẻ khỏi bài viết. Quy trình xử lý có thể chi tiết hơn như sau:
- Trích xuất toàn bộ danh sách tag và số lượng bài gắn với mỗi tag từ CMS (WordPress, custom CMS…).
- Đặt một ngưỡng tối thiểu (ví dụ: >= 5 hoặc >= 8 bài/tag) để xem xét giữ lại cho mục đích SEO.
- Với các thẻ dưới ngưỡng:
- Nếu tên mơ hồ, không có giá trị điều hướng: xóa thẻ, gỡ khỏi bài viết.
- Nếu tên có tiềm năng nhưng hiện ít bài: giữ lại nội bộ, gắn noindex, follow cho đến khi đủ nội dung.
- Cập nhật template hiển thị để các thẻ noindex không được ưu tiên trong giao diện (ví dụ: không hiển thị trong tag cloud).
Việc giữ lại quá nhiều thẻ mỏng không chỉ làm rối giao diện (tag cloud, danh sách thẻ dưới bài viết) mà còn khiến hệ thống khó quản lý, khó phân tích dữ liệu. Về SEO, nếu để index, chúng sẽ trở thành thin content, kéo chất lượng tổng thể đi xuống, làm loãng crawl budget và khiến Googlebot tốn tài nguyên cho các URL không có giá trị.
Trong quá trình audit, nên bổ sung thêm một số tiêu chí chuyên sâu:
- Depth of coverage: thẻ có bao phủ đầy đủ các khía cạnh của một chủ đề hay chỉ là tập hợp rời rạc vài bài?
- Topical focus: các bài trong thẻ có cùng chủ đề, cùng intent hay bị trộn lẫn nhiều chủ đề khác nhau?
- Internal linking potential: thẻ có thể trở thành hub liên kết nội bộ cho một topic cluster hay không?
Chỉ những thẻ đáp ứng được các tiêu chí trên mới nên được giữ ở trạng thái indexable và được đầu tư nội dung bổ sung (mô tả thẻ, nội dung giới thiệu, internal link có chủ đích).
Nhiều thẻ đồng nghĩa, gần nghĩa hoặc sai chính tả tạo trang trùng lặp
Một lỗi phổ biến khác là để tồn tại song song nhiều thẻ đồng nghĩa, gần nghĩa, hoặc sai chính tả. Điều này thường xuất phát từ việc không có quy chuẩn đặt tên (tag naming convention) và không có người “duyệt” thẻ trước khi tạo mới. Tag đồng nghĩa làm hệ thống phân loại bị phân mảnh và khiến tín hiệu nội dung bị chia nhỏ. Quattrone, Capra, De Meo, Ferrara và Ursino (2012) chỉ ra rằng social tagging thường bị chỉ trích vì tag được định nghĩa không chính thức, thay đổi liên tục và thiếu kiểm soát, có thể làm giảm hiệu quả tìm kiếm thay vì tăng. Vì vậy, các cặp như “SEO Onpage”, “SEO on-page”, “Onpage SEO” hoặc “Facebook Ads”, “FB Ads”, “Quảng cáo Facebook” cần được gom về một phiên bản chuẩn. Tag phụ nên 301, noindex hoặc xóa; tag chuẩn cần giữ nội dung, internal link và canonical nhất quán.
Các pattern thường gặp:
- Đa dạng hóa cách viết nhưng cùng nghĩa:
- “Facebook Ads”, “Quảng cáo Facebook”, “FB Ads”, “Facebook quảng cáo”.
- “SEO Onpage”, “SEO on-page”, “Onpage SEO”.
- Viết tắt vs viết đầy đủ:
- “thương mại điện tử”, “TMĐT”, “thuong mai dien tu”.
- “Google Tag Manager”, “GTM”.
- Sai chính tả, sai dấu, sai khoảng trắng:
- “thương mai điện tử”, “thuong mại điện tử”, “thuong-mai-dien-tu”.
- “facebookads”, “facebook ads”, “face book ads”.
Mỗi thẻ có vài bài viết, nhưng tập nội dung thực tế lại trùng lặp rất lớn. Kết quả là website có nhiều trang thẻ gần như giống nhau, tạo ra:
- Duplicate / near-duplicate tag pages: nội dung list bài gần như y hệt, chỉ khác URL và tên thẻ.
- Internal keyword cannibalization: nhiều URL cùng nhắm đến một nhóm từ khóa, khiến Google khó chọn trang “đại diện”.
- Phân tán tín hiệu xếp hạng: backlink, internal link, engagement bị chia nhỏ cho nhiều trang thay vì tập trung vào một.
Trong trường hợp này, cần tiến hành gom thẻ (tag consolidation) theo một quy trình chặt chẽ hơn:
- Bước 1 – Lập danh sách tất cả các thẻ liên quan đến cùng một chủ đề (dựa trên tên, nội dung bài, anchor text internal link).
- Bước 2 – Chọn một phiên bản chuẩn (canonical tag) dựa trên:
- Cách viết chuẩn về mặt ngôn ngữ và thương hiệu.
- Search intent rõ ràng, gần với cách người dùng tìm kiếm.
- Hiện đang có nhiều bài viết và/hoặc nhiều tín hiệu SEO nhất (traffic, backlink, internal link).
- Bước 3 – Chuyển toàn bộ bài viết từ các thẻ phụ sang thẻ chuẩn, đảm bảo:
- Không bỏ sót bài, không để bài gắn với thẻ phụ đã bị loại bỏ.
- Cập nhật lại internal link (nếu có) trỏ về URL thẻ chuẩn.
- Bước 4 – Xử lý các thẻ còn lại:
- Nếu các thẻ cũ chưa index hoặc không có giá trị SEO: xóa hoặc noindex.
- Nếu các thẻ cũ đã được index và có thể có backlink: cân nhắc 301 redirect về thẻ chuẩn.
Việc dùng 301 redirect thay vì chỉ noindex đặc biệt quan trọng khi:
- Thẻ cũ đã có lịch sử ranking, impression, click trong Google Search Console.
- Có backlink từ domain khác trỏ trực tiếp vào URL thẻ.
- Thẻ cũ đã được chia sẻ nhiều trên mạng xã hội, diễn đàn, email…
Cách làm này giúp:
- Giảm số lượng trang trùng lặp, làm sạch chỉ mục (index) của website.
- Tập trung tín hiệu xếp hạng (link equity, engagement) về một URL mạnh nhất.
- Làm rõ taxonomy, giúp cả người dùng lẫn Google hiểu cấu trúc chủ đề của site.
Thẻ không có traffic, không có internal link và không phục vụ hành trình người dùng
Một tiêu chí thực tế để đánh giá giá trị của thẻ là dữ liệu sử dụng: traffic organic, traffic nội bộ, thời gian trên trang, số lần được click từ bài viết, vai trò trong hành trình người dùng (user journey). Về mặt kỹ thuật, có thể chia thành ba nhóm chỉ số:
- SEO performance:
- Impression, click, CTR, average position trong Google Search Console.
- Organic sessions, new users trong Google Analytics.
- On-site engagement:
- Pageviews nội bộ (từ internal link, menu, breadcrumb…).
- Average time on page, scroll depth (nếu có tracking).
- Bounce rate hoặc exit rate bất thường.
- Role in user journey:
- Thẻ có xuất hiện trong các path chuyển đổi (conversion path) hay không.
- Thẻ có thường xuyên là bước trung gian giữa bài top-of-funnel và trang chuyển đổi không.
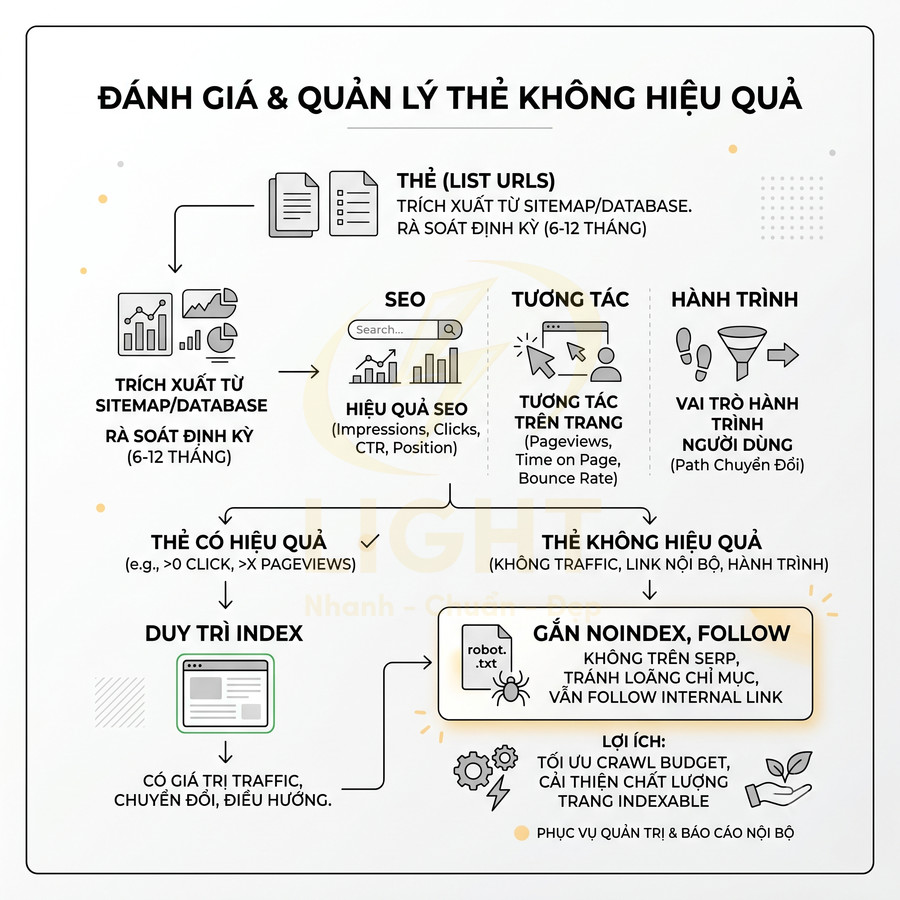
Nếu một thẻ không có traffic từ Google, gần như không có lượt click từ internal link, và không đóng vai trò gì trong hành trình người dùng, khả năng cao nó không cần được index. Những thẻ như vậy vẫn có thể hữu ích cho:
- Quản trị nội dung nội bộ (phân loại bài viết cho biên tập viên, filter trong CMS).
- Báo cáo nội bộ (nhóm bài theo chủ đề để phân tích performance).
Trong trường hợp đó, nên gắn noindex, follow cho các trang thẻ này để:
- Không xuất hiện trong SERP, tránh loãng chỉ mục.
- Vẫn cho phép Googlebot follow các link bên trong, không làm “chết” internal link graph.
Việc đánh giá này nên được thực hiện định kỳ, ví dụ mỗi 6–12 tháng, theo một quy trình có hệ thống:
- Trích xuất danh sách toàn bộ URL thẻ từ sitemap hoặc database.
- Kéo dữ liệu performance 6–12 tháng gần nhất từ Google Analytics và Google Search Console.
- Nếu có, kết hợp thêm log server để xem tần suất crawl của Googlebot cho từng URL thẻ.
- Đặt ngưỡng tối thiểu (ví dụ: > 0 click organic, > X pageviews nội bộ, > Y giây time on page).
- Những thẻ không đạt bất kỳ ngưỡng nào sẽ được chuyển sang trạng thái noindex, follow.
Mục tiêu là đảm bảo rằng phần lớn trang thẻ được index đều có một dạng giá trị đo lường được: traffic, chuyển đổi, hoặc ít nhất là vai trò điều hướng quan trọng trong site. Điều này giúp tối ưu crawl budget, cải thiện chất lượng trung bình của tập URL indexable, và làm rõ hơn cấu trúc nội dung trong mắt công cụ tìm kiếm.
Thẻ cạnh tranh trực tiếp với danh mục, landing page hoặc bài viết pillar
Khi một thẻ nhắm đến cùng từ khóa, cùng intent với một category, landing page hoặc bài viết pillar, nó sẽ tạo ra cạnh tranh nội bộ (keyword cannibalization ở cấp độ loại trang). Vấn đề thường xuất hiện ở các site phát triển tự phát, không có content map rõ ràng.
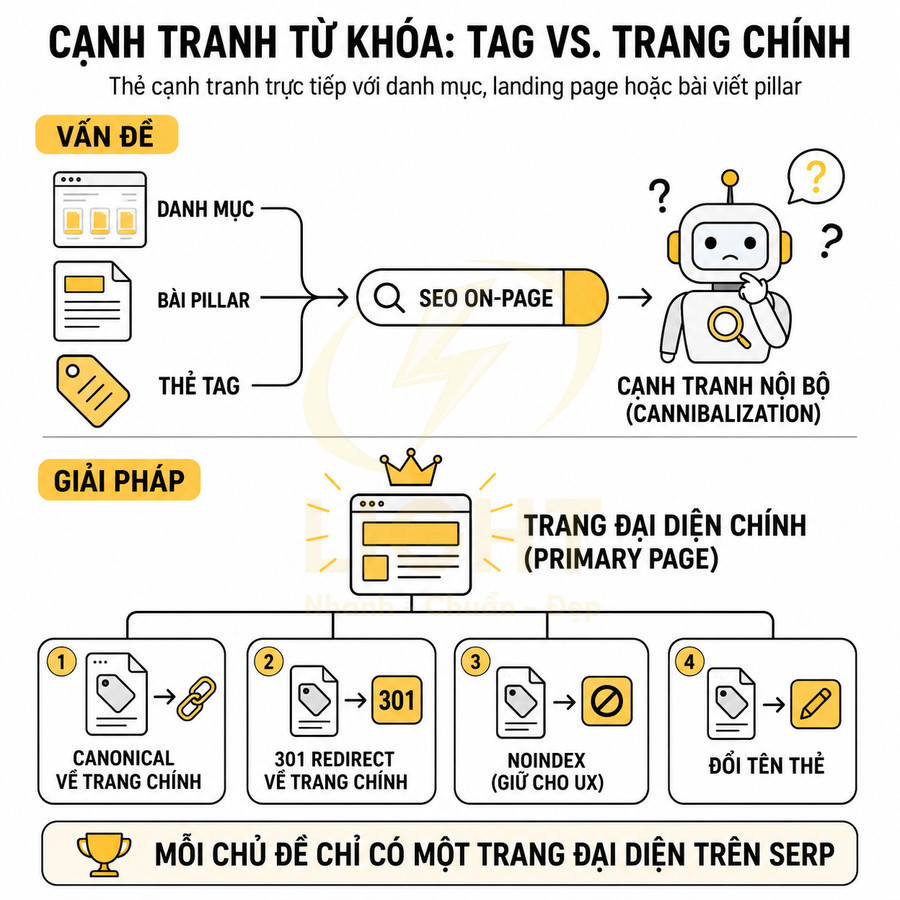
Ví dụ điển hình:
- Website có category “SEO onpage”, đồng thời có tag “SEO onpage” và một bài pillar “SEO Onpage là gì? Hướng dẫn chi tiết”.
- Cả ba đều được index, đều chứa từ khóa “SEO onpage” trong title, H1, meta description.
- Google phải chọn một trang để hiển thị cho truy vấn “seo onpage là gì”, “hướng dẫn seo onpage”…
Trong nhiều trường hợp, tag page – vốn ít nội dung hơn, chỉ là list bài – lại được xếp hạng thay cho pillar, làm giảm hiệu quả chiến lược nội dung. Nguyên nhân:
- Internal link trỏ về tag nhiều hơn (do tự động gắn dưới bài viết).
- Anchor text chứa từ khóa chính lại trỏ về tag thay vì pillar.
- Google nhận tín hiệu rằng tag là hub chính cho chủ đề đó.
Để tránh tình trạng này, cần xác định trang đại diện chính (primary page) cho mỗi chủ đề quan trọng trong content strategy:
- Với các chủ đề lớn, mang tính category-level: ưu tiên dùng category làm primary page.
- Với các chủ đề cụ thể, mang tính transactional hoặc lead-gen: dùng landing page chuyên biệt.
- Với các chủ đề mang tính kiến thức sâu, cần giải thích chi tiết: dùng pillar / cornerstone content.
Các thẻ trùng chủ đề nên được xử lý theo một trong các hướng:
- Noindex tag page, giữ lại chỉ để điều hướng nội bộ (nếu thực sự cần cho UX).
- Đổi tên thẻ để chuyển sang một ngữ cảnh phụ khác, không trùng với từ khóa chính của primary page.
- Nếu tag đã lỡ index và có traffic nhưng muốn hợp nhất hoàn toàn:
- Dùng canonical trỏ từ tag về trang chính nếu vẫn muốn giữ tag cho UX.
- Hoặc 301 redirect tag về primary page nếu không cần giữ URL tag nữa.
Nguyên tắc cốt lõi là: mỗi chủ đề quan trọng chỉ có một trang indexable cốt lõi đứng ra “đại diện” trên SERP. Các loại trang khác (tag, archive, pagination…) chỉ nên đóng vai trò hỗ trợ điều hướng, không cạnh tranh trực tiếp về từ khóa với primary page.
Trong quá trình audit, nên lập một bảng mapping chủ đề – URL như sau (giữ nguyên số lượng cột nếu đã có sẵn):
- Chủ đề / từ khóa chính.
- URL primary page (category / pillar / landing).
- Các URL phụ đang cạnh tranh (tag, bài cũ, archive…).
- Hành động: giữ, noindex, canonical, 301.
Cách làm có hệ thống này giúp giảm triệt để cannibalization, tập trung authority cho đúng URL, và đảm bảo cấu trúc site phản ánh chính xác chiến lược nội dung và ưu tiên SEO.
Trang lọc tự động có nên cho Google index không?
Trang lọc tự động chỉ nên được index khi có search demand rõ ràng, intent thương mại hoặc thông tin cụ thể và tập sản phẩm đủ khác biệt, mang lại giá trị kinh doanh cao. Khi đó, hãy tối ưu chúng như landing page: viết tay title, H1, meta description, bổ sung nội dung hỗ trợ, cấu trúc internal link hợp lý, đưa vào XML sitemap và đảm bảo hiệu năng tải trang.
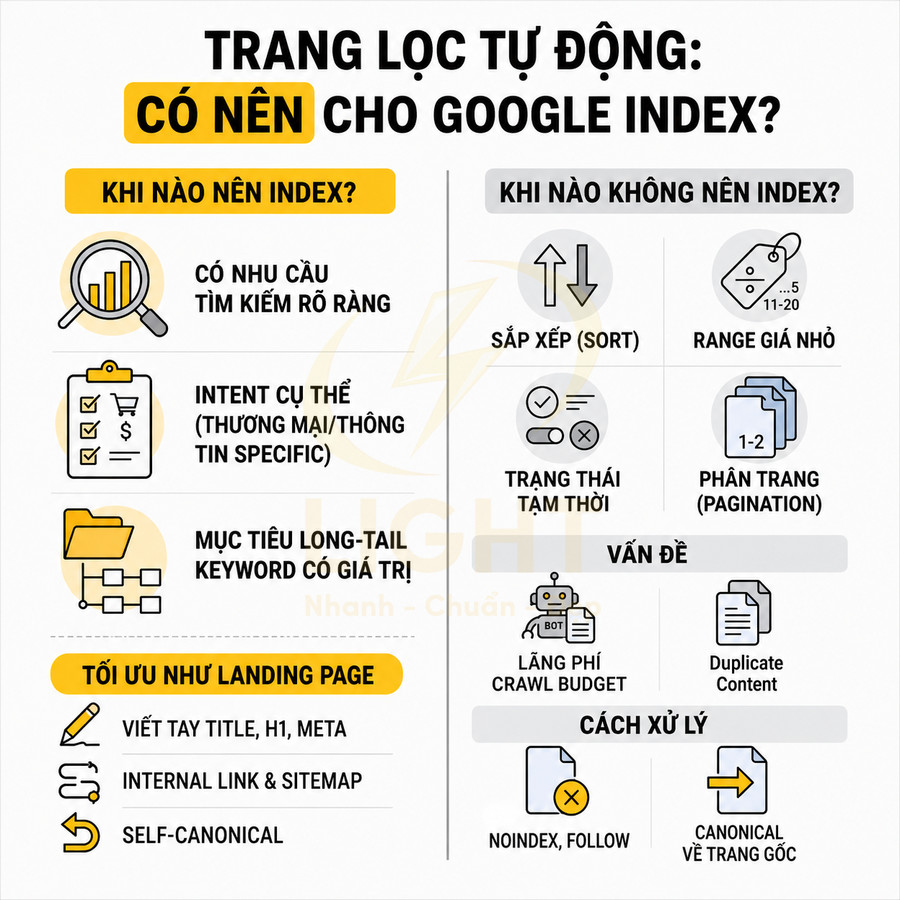
Ngược lại, các trang lọc theo sort, bước giá nhỏ, trạng thái tạm thời, phân trang hoặc biến thể quá chi tiết nên dùng noindex, follow để tránh lãng phí crawl budget và trùng lặp nội dung. Với các filter không có giá trị độc lập, ưu tiên canonical về trang gốc; còn các filter chiến lược được tối ưu như landing page riêng thì dùng self-canonical và tích hợp chặt vào kiến trúc SEO tổng thể.
Index trang lọc có nhu cầu tìm kiếm thương mại hoặc thông tin rõ ràng
Không phải mọi trang lọc đều nên bị noindex. Với các website thương mại điện tử, bất động sản, việc làm, du lịch…, nhiều truy vấn người dùng thực tế trùng khớp với các tổ hợp filter cụ thể. Ví dụ: “giày chạy bộ nike nữ size 38”, “chung cư 2 phòng ngủ quận 7 dưới 3 tỷ”, “việc làm lập trình viên Java Hà Nội lương cao”. Nếu inventory đủ phong phú, một trang lọc tương ứng có thể trở thành landing page SEO mang lại traffic và chuyển đổi trực tiếp.
Ở góc độ chuyên môn SEO, các trang lọc dạng này thường nằm trong nhóm “faceted navigation pages with search demand”. Chúng có thể target các long-tail keyword mang tính thương mại rất cao, cạnh tranh thấp hơn so với category tổng, nhưng lại có conversion rate tốt hơn vì đáp ứng chính xác nhu cầu người dùng.
Tiêu chí để quyết định index một filter page thường bao gồm:
- Có search demand rõ ràng: từ khóa hoặc nhóm từ khóa tương ứng có volume đáng kể, được xác nhận qua các công cụ như Google Keyword Planner, Ahrefs, Semrush, GSC. Không chỉ nhìn volume tuyệt đối, mà còn cần đánh giá:
- Mức độ ổn định theo thời gian (seasonality, xu hướng dài hạn).
- Tỷ lệ click tự nhiên (CTR ước tính) so với paid.
- Mức độ cạnh tranh trên SERP (số domain mạnh đã chiếm top).
- Có intent thương mại hoặc thông tin cụ thể: người dùng thực sự muốn xem danh sách sản phẩm/nội dung theo điều kiện đó, không chỉ là truy vấn mang tính tham khảo chung chung. Có thể kiểm tra bằng:
- Phân tích SERP: đa số kết quả là category, listing, trang sản phẩm hay bài blog?
- Kiểm tra các “People Also Ask”, “Related searches” để hiểu rõ hơn ngữ cảnh.
- Đối chiếu với dữ liệu onsite: nếu người dùng thường xuyên áp dụng filter này trong phiên truy cập, khả năng intent là thực.
- Nội dung đủ khác biệt: danh sách kết quả không trùng hoàn toàn với category hoặc filter khác. Cần đánh giá:
- Tỷ lệ trùng sản phẩm/bài viết giữa filter và category gốc (ví dụ >80% trùng thì nên cân nhắc noindex hoặc canonical).
- Khả năng tạo thêm nội dung bổ trợ độc đáo (mô tả, FAQ, hướng dẫn chọn sản phẩm cho đúng filter).
- Khả năng mở rộng inventory trong tương lai để tránh trang bị “mỏng” (thin content).
- Giá trị kinh doanh cao: nhóm sản phẩm/dịch vụ trong filter có biên lợi nhuận hoặc tỉ lệ chuyển đổi tốt. Nên ưu tiên index các filter:
- Tập trung vào brand, phân khúc giá, loại sản phẩm có margin cao.
- Gắn với khu vực địa lý, loại bất động sản, ngành nghề có giá trị đơn hàng lớn.
- Được team kinh doanh/merchandising ưu tiên đẩy mạnh.
Khi đáp ứng các tiêu chí này, filter page nên được tối ưu như một landing page:
- Title, H1, meta description được viết tay, bám sát keyword chính và biến thể, tránh để auto-generate quá chung chung.
- Nội dung bổ trợ (mô tả ngắn, hướng dẫn chọn, FAQ, block nội dung SEO) giúp tăng độ liên quan chủ đề và giảm tỷ lệ bounce.
- Cấu trúc internal link rõ ràng:
- Link từ category cha, hub page, bài blog liên quan.
- Breadcrumb thể hiện vị trí trong cấu trúc site.
- Anchor text phản ánh đúng tổ hợp filter (ví dụ: “giày chạy bộ Nike nữ size 38”).
- Đưa vào XML sitemap cho nhóm filter chiến lược, giúp Google phát hiện và crawl nhanh hơn.
- Performance: tốc độ tải, khả năng render JS (nếu filter sinh URL bằng JS), tránh để Googlebot chỉ thấy một trang trống hoặc thiếu sản phẩm.
Noindex trang lọc theo sort, giá, trạng thái tạm thời, phân trang và biến thể nhỏ
Ngược lại, các trang lọc sinh ra từ sort, range giá nhỏ, trạng thái tạm thời, phân trang, hoặc biến thể quá chi tiết thường không có search intent độc lập. Ví dụ: sort theo “mới nhất”, “giá tăng dần”, “giảm giá nhiều nhất”; filter giá theo từng bước 100.000đ; filter trạng thái “còn hàng/tạm hết”; trang phân trang ?page=2,3,4… Những URL này chủ yếu phục vụ trải nghiệm người dùng trong site, không cần xuất hiện trên SERP.
Nhóm URL này thường gây ra các vấn đề:
- Lãng phí crawl budget: Googlebot phải crawl hàng nghìn biến thể gần như giống nhau, trong khi các trang quan trọng hơn lại bị crawl ít.
- Trùng lặp nội dung (duplicate/near-duplicate): nhiều URL khác nhau hiển thị cùng một tập sản phẩm, chỉ khác thứ tự hoặc một điều kiện nhỏ.
- Pha loãng tín hiệu xếp hạng: backlink, internal link, tín hiệu tương tác bị phân tán cho nhiều URL thay vì dồn về một trang chuẩn.
- Khó kiểm soát index: GSC có thể hiển thị rất nhiều URL “Crawled – currently not indexed” hoặc “Duplicate, Google chose different canonical”, gây nhiễu khi phân tích.
Với các loại filter này, chiến lược an toàn là gắn meta robots noindex, follow. Bot vẫn có thể crawl để hiểu cấu trúc và theo các internal link, nhưng sẽ không đưa trang vào chỉ mục. Cách triển khai thường gặp:
- Thêm thẻ <meta name="robots" content="noindex,follow"> cho:
- Các URL có tham số sort (sort=priceasc, sort=newest…).
- Các bước giá quá chi tiết (price=0-100k, 100k-200k… nếu không có search demand).
- Các filter trạng thái tạm thời (instock, outofstock, on_sale nếu không có intent riêng).
- Các trang phân trang (?page=2,3,4…) nếu không muốn index từng page.
- Đảm bảo internal link từ các trang quan trọng không ưu tiên trỏ tới các URL noindex, tránh lãng phí PageRank.
Đồng thời, có thể cấu hình trong Google Search Console (mục URL Parameters, nếu còn khả dụng) để hướng dẫn Google cách xử lý các tham số sort, page, status. Mặc dù Google đã giảm vai trò của tính năng này, nhưng về mặt nguyên tắc, cần:
- Xác định rõ tham số nào thay đổi nội dung thực (ví dụ: brand, category con) và tham số nào chỉ thay đổi cách hiển thị (sort, view, layout).
- Đánh dấu các tham số chỉ thay đổi hiển thị là “doesn’t affect page content” để hạn chế crawl.
- Kết hợp với robots.txt (nếu cần) để chặn crawl các pattern tham số gây bùng nổ URL.
Mục tiêu là tránh để Google lãng phí crawl budget vào vô số biến thể không mang lại giá trị SEO, đồng thời giữ cho index sạch, tập trung vào các URL có khả năng mang lại traffic và chuyển đổi.
Canonical về trang gốc khi trang lọc không có giá trị độc lập
Trong nhiều trường hợp, một filter page không đủ điều kiện để trở thành landing page riêng, nhưng vẫn cần tồn tại để phục vụ điều hướng. Ví dụ: filter “giá từ 1–2 triệu” trong khi category “giày thể thao nam” đã bao phủ gần hết inventory. Khi đó, có thể sử dụng canonical về trang gốc (category hoặc landing page chính) để báo cho Google rằng nội dung của filter này không có giá trị độc lập, và tín hiệu nên được gộp về trang gốc.

Canonical đặc biệt hữu ích khi có nhiều biến thể URL khác nhau dẫn đến cùng một tập nội dung, ví dụ: /giay-the-thao-nam?price=1-2-trieu và /giay-the-thao-nam?sort=popular&price=1-2-trieu. Nếu không dùng canonical, Google có thể index nhiều phiên bản gần giống nhau, gây trùng lặp và phân tán tín hiệu.
Một số nguyên tắc chuyên sâu khi dùng canonical cho trang lọc:
- Chỉ canonical khi nội dung thực sự tương đương:
- Nếu filter chỉ loại bỏ một vài sản phẩm nhưng phần lớn vẫn giống category, có thể canonical về category.
- Nếu filter tạo ra một tập sản phẩm khác biệt rõ rệt và có search demand, không nên canonical về category.
- Tránh mâu thuẫn canonical:
- Không để category canonical về chính nó, trong khi filter lại canonical về category, nhưng một URL khác lại canonical về filter.
- Giữ cấu trúc “một chiều”: filter phụ canonical về trang gốc; trang gốc self-canonical.
- Kết hợp với noindex khi cần:
- Canonical là tín hiệu gợi ý, không phải mệnh lệnh tuyệt đối; Google có thể bỏ qua nếu thấy không hợp lý.
- Với các URL chắc chắn không muốn index (sort, phân trang), nên dùng noindex thay vì chỉ canonical.
Trong bối cảnh faceted navigation phức tạp, canonical giúp “gom” sức mạnh SEO về một số ít URL trụ cột, giảm rủi ro duplicate content và giúp Google hiểu rõ đâu là phiên bản chuẩn cần ưu tiên xếp hạng.
Self-canonical cho trang lọc được tối ưu như landing page riêng
Với các filter page được chọn làm landing page SEO (ví dụ: “giày nike đen dưới 2 triệu”), nên sử dụng self-canonical (canonical trỏ về chính nó). Điều này khẳng định với Google rằng đây là phiên bản chuẩn, có giá trị độc lập, không phải biến thể phụ thuộc vào category. Đồng thời, cần đảm bảo không có canonical ngược từ các trang khác trỏ về category khi nói về cùng tổ hợp điều kiện, để tránh tín hiệu mâu thuẫn.
Khi đã quyết định self-canonical, trang lọc đó cần được đối xử như một landing page thực thụ:
- Chiến lược keyword rõ ràng:
- Xác định primary keyword (ví dụ: “giày nike nữ size 38”) và các secondary keyword liên quan.
- Đảm bảo không trùng lặp hoàn toàn với keyword của category hoặc brand page.
- Tối ưu onpage:
- Title, H1, URL slug (nếu có thể rewrite) phản ánh đúng tổ hợp filter.
- Thêm đoạn mô tả ngắn phía trên listing để giải thích filter, gợi ý lựa chọn, chèn keyword tự nhiên.
- Thêm block FAQ, tips, hướng dẫn chọn size/màu/loại phù hợp với filter.
- Internal link và kiến trúc site:
- Link từ category cha, từ các hub page (ví dụ: “Giày Nike cho nữ”).
- Link từ bài blog liên quan (ví dụ: “Cách chọn giày chạy bộ Nike cho nữ”).
- Tránh để trang lọc quan trọng chỉ có thể truy cập qua thao tác filter JS mà không có URL tĩnh hoặc link HTML.
- Self-canonical nhất quán:
- Thẻ <link rel="canonical"> trỏ về chính URL của trang lọc.
- Không có trang khác canonical về một URL khác cho cùng intent, tránh “cạnh tranh nội bộ”.
- Đưa vào sitemap và theo dõi hiệu suất:
- Thêm vào XML sitemap dành cho các landing page SEO.
- Theo dõi trong GSC: coverage, impressions, clicks, vị trí trung bình.
- Dựa trên dữ liệu thực tế để quyết định tiếp tục tối ưu, giữ nguyên, hoặc chuyển sang canonical/noindex nếu hiệu quả thấp.
Nếu chỉ đặt self-canonical nhưng không có bất kỳ tín hiệu hỗ trợ nào khác (internal link, nội dung, backlink, sitemap), khả năng được index và xếp hạng vẫn sẽ rất thấp. Self-canonical chỉ phát huy tác dụng khi trang lọc thực sự được tích hợp vào chiến lược SEO tổng thể, có vai trò rõ ràng trong funnel chuyển đổi và được đầu tư nội dung, liên kết tương xứng.
Rủi ro SEO khi tạo quá nhiều trang thẻ và trang lọc tự động
Việc tạo quá nhiều trang thẻ và trang lọc tự động khiến cấu trúc website phình to mất kiểm soát, làm Googlebot phải xử lý khối lượng URL khổng lồ nhưng phần lớn không mang lại thêm giá trị. Hệ quả là crawl budget bị lãng phí vào URL tham số, tag rỗng, tổ hợp facet vô hạn; trong khi các trang sản phẩm, bài viết và landing page chiến lược lại bị crawl chậm, index trễ. Song song đó, hệ thống dễ phát sinh duplicate title, meta, H1 và danh sách nội dung trùng lặp, làm giảm độ “unique” của từng URL, gây nhiễu canonical và báo cáo Search Console. Tỷ lệ lớn các trang mỏng (thin content) tiếp tục kéo tụt chất lượng tổng thể, tạo ra keyword cannibalization giữa category, tag, filter và bài viết, khiến tín hiệu SEO bị phân tán và khó tối ưu dài hạn.
Crawl budget bị lãng phí vào URL tham số, tag rỗng và tổ hợp facet vô hạn
Trên các website lớn, đặc biệt là sàn thương mại điện tử, site rao vặt, site tin tức nhiều chuyên mục, Googlebot luôn phải phân bổ crawl budget – số lượng URL mà nó sẵn sàng crawl trong một khoảng thời gian nhất định cho từng domain. Crawl budget không phải là con số cố định, mà phụ thuộc vào:
- Sức mạnh và độ uy tín của domain (authority, trust, lịch sử hoạt động ổn định).
- Hiệu suất server, tốc độ phản hồi, tỷ lệ lỗi 5xx, 4xx.
- Mức độ thường xuyên cập nhật nội dung mới, thay đổi cấu trúc.
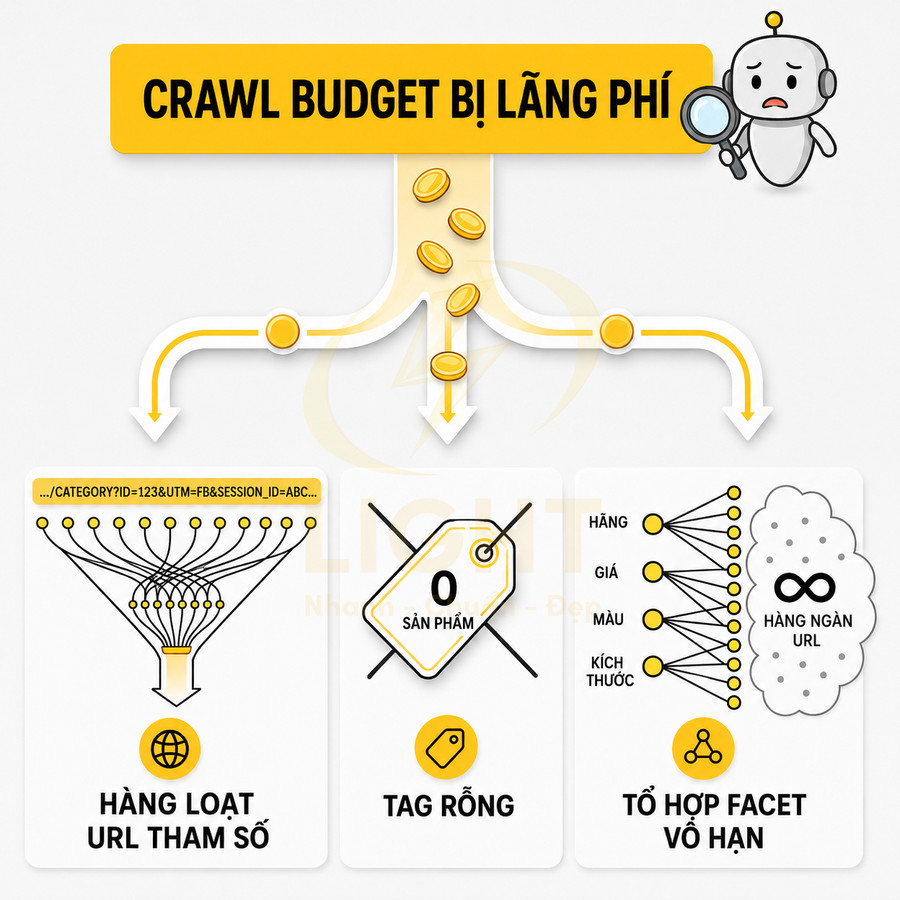
Khi hệ thống tự động sinh ra hàng loạt tag rỗng, filter theo mọi tổ hợp facet, và URL tham số không được kiểm soát, phần lớn crawl budget sẽ bị tiêu tốn vào các trang không quan trọng. Những nhóm URL thường gây lãng phí gồm:
- Tag rỗng hoặc gần như rỗng: trang chỉ có 0–3 bài viết/sản phẩm, không có mô tả, không có nội dung bổ trợ.
- URL tham số cho sort, paginate, view mode (grid/list), tracking (utm, ref, session id) nhưng lại để index.
- Facet kết hợp vô hạn: nhiều bộ lọc được chọn cùng lúc (màu, size, brand, price, rating, material, location, …) cộng thêm sort và phân trang.
Trong thực tế, Google sẽ ưu tiên crawl những URL mà nó phát hiện nhiều internal link, sitemap, hoặc có tín hiệu từ bên ngoài. Nếu hệ thống điều hướng (navigation) và internal link đẩy mạnh các trang tag/filter sinh tự động, Googlebot sẽ liên tục quay lại những URL này, trong khi:
- Các trang sản phẩm mới, bài viết mới, hoặc landing page chiến lược có thể bị crawl chậm.
- Các thay đổi quan trọng (giá, tồn kho, nội dung cập nhật) bị index trễ, làm giảm hiệu quả SEO và trải nghiệm người dùng đến từ organic.
Đặc biệt, faceted navigation có thể tạo ra tổ hợp vô hạn nếu không giới hạn: người dùng có thể chọn nhiều thuộc tính cùng lúc, kết hợp với sort, phân trang, dẫn đến số lượng URL tăng theo cấp số nhân. Một category với:
- 10 brand
- 5 mức giá
- 5 màu sắc
- 3 kiểu sort
- 10 trang phân trang
về mặt lý thuyết có thể tạo ra hàng chục ngàn URL khác nhau, trong khi phần lớn chỉ là biến thể của cùng một tập sản phẩm. Nếu không có chiến lược noindex, canonical, robots.txt và cấu trúc internal link rõ ràng, Googlebot sẽ “lạc” trong mê cung URL này, trong khi phần lớn không mang lại thêm giá trị nào.
Một số hệ quả kỹ thuật thường thấy:
- Tỷ lệ URL trong báo cáo Crawl Stats tăng mạnh nhưng số URL thực sự hữu ích được index không tăng tương ứng.
- Nhiều URL tham số xuất hiện trong Search Console với trạng thái “Discovered – currently not indexed” hoặc “Crawled – currently not indexed”.
- Log server cho thấy Googlebot tốn phần lớn request cho các URL có query string dài, nhiều tham số, hoặc pattern filter.
Giải pháp chuyên sâu thường bao gồm:
- Xác định subset facet thực sự có giá trị SEO (ví dụ: brand, category chính, 1–2 filter quan trọng) và cho phép index có kiểm soát.
- Thiết lập noindex,follow cho các tổ hợp filter không mang lại giá trị tìm kiếm, hoặc chỉ cho phép index 1–2 cấp filter đầu tiên.
- Dùng canonical trỏ về phiên bản chuẩn (category chính hoặc filter chính) cho các URL tham số chỉ thay đổi sort, view, paginate.
- Hạn chế để các URL tham số xuất hiện trong menu, breadcrumb, sitemap; chỉ nên để internal link trỏ về phiên bản canonical.
Duplicate title, meta description, H1 và danh sách nội dung lặp lại
Khi có quá nhiều tag và filter tương tự nhau, rất dễ xảy ra tình trạng trùng lặp title, meta description, H1. Vấn đề không chỉ nằm ở việc giống nhau về mặt text, mà còn ở việc Google nhìn thấy nhiều URL có:
- Cùng hoặc gần giống title (chỉ khác 1–2 từ không mang tính phân biệt intent).
- Cùng H1 hoặc H1 chỉ thay đổi thứ tự từ, không thay đổi ý nghĩa.
- Meta description được auto-generate từ cùng một template, chỉ thay tên tag/filter.
- Danh sách bài viết/sản phẩm trùng lặp phần lớn (80–90% inventory giống nhau).
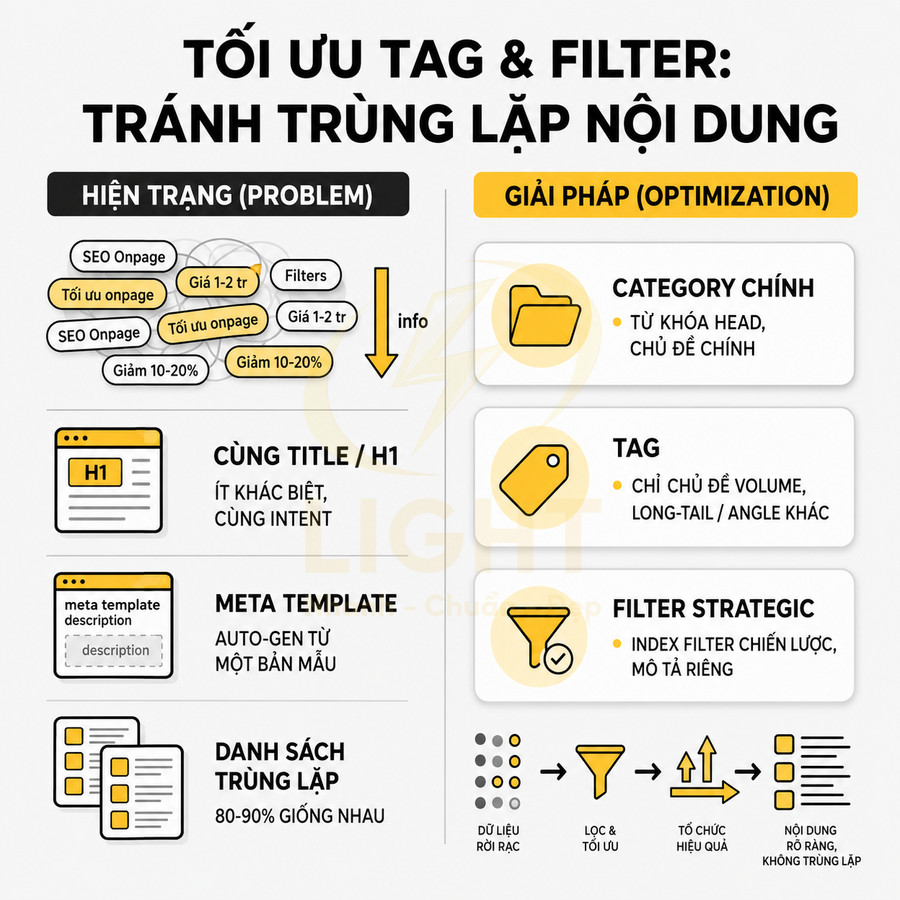
Ví dụ: tag “SEO onpage” và “Tối ưu onpage” có thể được đặt title gần như giống nhau, trong khi danh sách bài viết hiển thị cũng trùng lặp phần lớn. Trong mắt Google, đây là các trang có near-duplicate content, khiến hệ thống khó phân biệt trang nào nên được ưu tiên, và có thể đánh giá đây là dấu hiệu của việc tối ưu kém hoặc cố tình tạo nội dung trùng lặp.
Duplicate còn xảy ra khi nhiều filter khác nhau nhưng inventory thực tế lại giống nhau, ví dụ: filter “giá 1–2 triệu” và “giảm giá 10–20%” trong một category nhỏ, nơi số lượng sản phẩm ít và phần giao nhau giữa hai filter gần như trùng khít. Nếu cả hai đều được index, Google sẽ thấy hai trang với nội dung gần như giống nhau, chỉ khác đôi chút về sắp xếp hoặc vài sản phẩm biên. Điều này dẫn đến:
- Lãng phí crawl budget cho các biến thể không mang thêm giá trị.
- Giảm độ “độc đáo” (uniqueness) của từng URL trong chỉ mục.
- Tăng nguy cơ Google tự động chọn canonical khác với canonical bạn khai báo, gây khó kiểm soát.
Ở cấp độ kỹ thuật, duplicate title/H1/meta trên diện rộng còn có thể:
- Làm loãng tín hiệu anchor text từ internal link, vì nhiều URL cùng nhắm đến một cụm từ khóa.
- Khiến báo cáo trong Search Console trở nên nhiễu, khó phân tích hiệu suất từng URL.
- Tạo ra các “cluster” nội dung mà Google phải tự gom nhóm, đôi khi chọn nhầm URL ít giá trị làm đại diện.
Để giảm duplicate, cần xây dựng quy tắc đặt title/H1/meta description cho từng loại trang:
- Category chính: ưu tiên từ khóa head, thể hiện rõ chủ đề tổng quát.
- Tag: chỉ tạo cho các chủ đề thực sự có volume tìm kiếm, title/H1 nên nhắm long-tail hoặc angle khác.
- Filter: chỉ cho index một số filter chiến lược, có mô tả riêng, tránh trùng với category/tag.
Thin content làm giảm chất lượng tổng thể của khu vực indexable
Thin content không chỉ là các bài viết ngắn, mà còn bao gồm các trang danh sách (tag, filter, category con) chỉ có vài item, không có mô tả, không có nội dung bổ trợ, không giải thích intent. Trên các site lớn, khi hệ thống tự động sinh trang theo mọi tag và mọi filter, tỷ lệ trang mỏng trong khu vực indexable thường tăng rất nhanh.
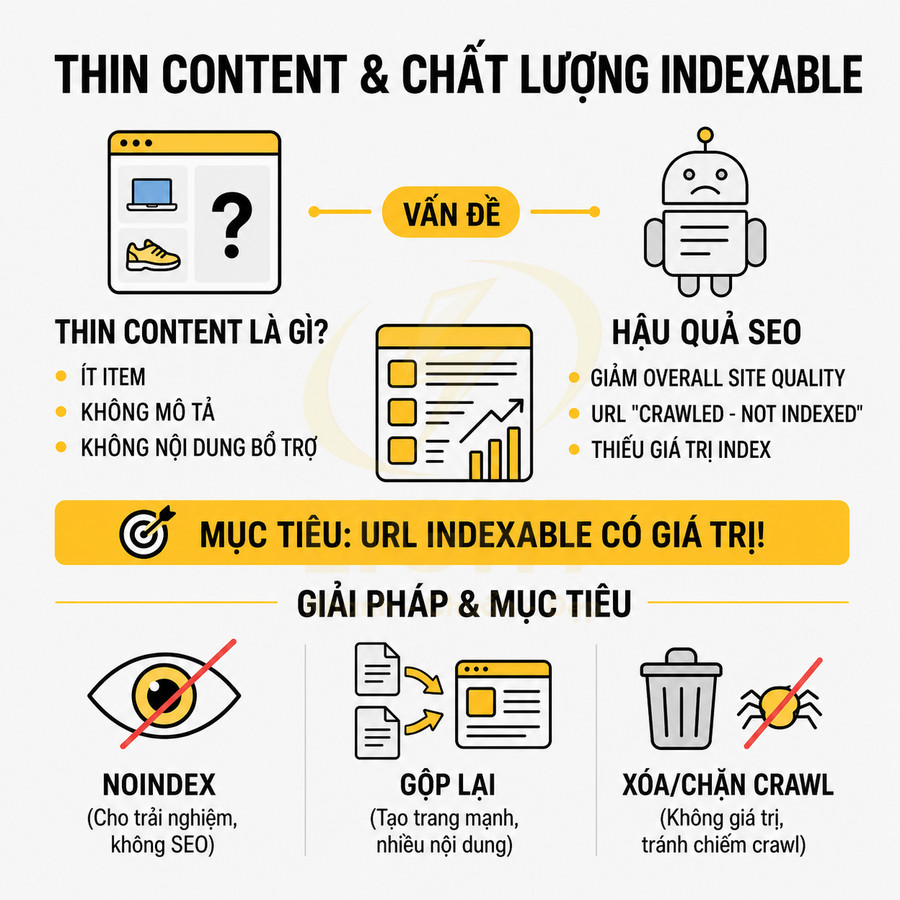
Một số dạng thin content phổ biến trong bối cảnh tag/filter:
- Tag chỉ gắn cho 1–2 bài viết, không có mô tả, không có internal link trỏ đến.
- Filter tạo ra trang chỉ có 1–3 sản phẩm, không có text mô tả, không có hướng dẫn lựa chọn.
- Trang phân trang sâu (page 5, page 6…) của category nhỏ, nơi số lượng sản phẩm ít và không có nội dung bổ sung.
Khi tỷ lệ trang mỏng trong khu vực indexable quá cao, Google có xu hướng đánh giá website là ít giá trị, ít hữu ích, đặc biệt trong các lĩnh vực cạnh tranh. Điều này có thể dẫn đến:
- Nhiều URL bị rơi vào trạng thái “Crawled – currently not indexed” trong Search Console vì Google không thấy đủ giá trị để đưa vào index.
- Nhiều URL bị gắn nhãn “Duplicate, Google chose different canonical” do nội dung quá giống hoặc quá mỏng.
- Giảm overall site quality signal, khiến cả các trang chất lượng cao cũng khó cải thiện thứ hạng.
Với website chuẩn SEO, mục tiêu là giữ cho phần lớn URL indexable đều có giá trị rõ ràng:
- Nội dung chuyên sâu, giải quyết trọn vẹn một intent tìm kiếm.
- Danh sách sản phẩm phong phú, có đủ inventory, có mô tả category/filter rõ ràng.
- Landing page được tối ưu tốt, có cấu trúc nội dung, FAQ, schema markup (nếu phù hợp).
Các trang mỏng nên được:
- Noindex nếu vẫn cần cho trải nghiệm người dùng (ví dụ: filter phục vụ điều hướng nhưng không cần SEO).
- Gộp lại với các trang liên quan để tạo thành một trang mạnh hơn, nhiều nội dung hơn.
- Xóa bỏ hoặc chặn crawl nếu không còn giá trị sử dụng, tránh để chúng chiếm crawl budget và làm nhiễu index.
Ở mức độ chiến lược, cần định nghĩa rõ “ngưỡng chất lượng” cho một URL được phép index, ví dụ:
- Tối thiểu X sản phẩm/bài viết trong danh sách.
- Tối thiểu Y từ mô tả unique, không trùng lặp với category khác.
- Có internal link từ các khu vực quan trọng (menu, breadcrumb, hub page) nếu là trang chiến lược.
Keyword cannibalization giữa tag, category, filter page và bài viết chính
Khi tag, category, filter và bài viết đều nhắm đến cùng một nhóm từ khóa, keyword cannibalization là điều khó tránh. Vấn đề không chỉ là nhiều URL cùng chứa một từ khóa trong title/H1, mà còn là việc các URL này cùng cạnh tranh cho cùng một intent tìm kiếm, khiến tín hiệu bị phân tán.

Ví dụ: từ khóa “giày chạy bộ nữ” có thể xuất hiện trong:
- Category “Giày chạy bộ nữ” – trang chính để liệt kê toàn bộ sản phẩm liên quan.
- Tag “giày chạy bộ nữ” – gắn cho các bài blog hoặc sản phẩm, nhưng lại được index như một landing page riêng.
- Filter “/giay-chay-bo?gender=female” – trang filter tự động, inventory gần giống category chính.
- Bài blog “Cách chọn giày chạy bộ nữ” – nội dung tư vấn, review, hướng dẫn.
Nếu tất cả đều được index và tối ưu cho từ khóa này, Google sẽ phải chọn một trang để xếp hạng cho truy vấn “giày chạy bộ nữ”, trong khi các trang còn lại bị “đè” xuống, CTR thấp, tín hiệu yếu dần. Một số biểu hiện thường gặp của cannibalization:
- Thứ hạng biến động giữa nhiều URL khác nhau cho cùng một từ khóa theo thời gian.
- CTR thấp bất thường vì Google hiển thị URL không đúng với loại nội dung người dùng mong đợi (ví dụ: hiển thị tag page thay vì category chính).
- Khó scale internal link vì không rõ nên ưu tiên trỏ về URL nào cho anchor text chính.
Để giảm cannibalization, cần:
- Xác định trang đại diện chính cho mỗi từ khóa quan trọng, thường là:
- Category hoặc subcategory cho intent transactional/browse.
- Bài blog/guide cho intent informational.
- Landing page chuyên biệt cho campaign hoặc intent mixed.
- Điều chỉnh title, H1, nội dung của các trang phụ để nhắm đến long-tail hoặc intent khác, ví dụ:
- Category: “Giày chạy bộ nữ chính hãng, giảm giá, giao nhanh”.
- Bài blog: “Cách chọn giày chạy bộ nữ cho người mới bắt đầu”.
- Filter: “Giày chạy bộ nữ Nike dưới 2 triệu” (nếu thực sự có volume và inventory đủ lớn).
- Noindex hoặc canonical các trang không cần cạnh tranh:
- Noindex tag trùng với category.
- Canonical filter về category chính nếu inventory gần như giống nhau.
- Sử dụng internal link để củng cố trang chính, thay vì dàn trải:
- Tất cả bài viết liên quan nên trỏ về category chính với anchor text được chuẩn hóa.
- Hạn chế internal link trỏ về tag/filter không phải là trang đại diện.
Ở mức độ quản trị, nên xây dựng một keyword-to-URL map cho các từ khóa quan trọng, trong đó mỗi từ khóa chính chỉ có một URL “owner”. Tag, filter và các trang phụ khác chỉ nên nhắm đến biến thể long-tail hoặc intent bổ trợ, tránh trùng hoàn toàn với từ khóa head của trang chính.
Cấu trúc URL, canonical và robots cho trang thẻ, trang lọc tự động
Cấu trúc URL cho trang thẻ và trang lọc cần được chuẩn hóa như một phần của hệ thống taxonomy và entity. URL trang thẻ nên ngắn, ổn định, phản ánh đúng chủ đề, tránh nhiều biến thể gây phân tán tín hiệu và phát sinh duplicate; khi buộc phải đổi cấu trúc cần 301 redirect một–một, cập nhật toàn bộ internal link và dùng self-canonical chính xác. Với phân trang, page 1 là URL chính, các page sâu có thể dùng noindex, follow hoặc rel="next/prev" tùy mức độ giá trị tìm kiếm.
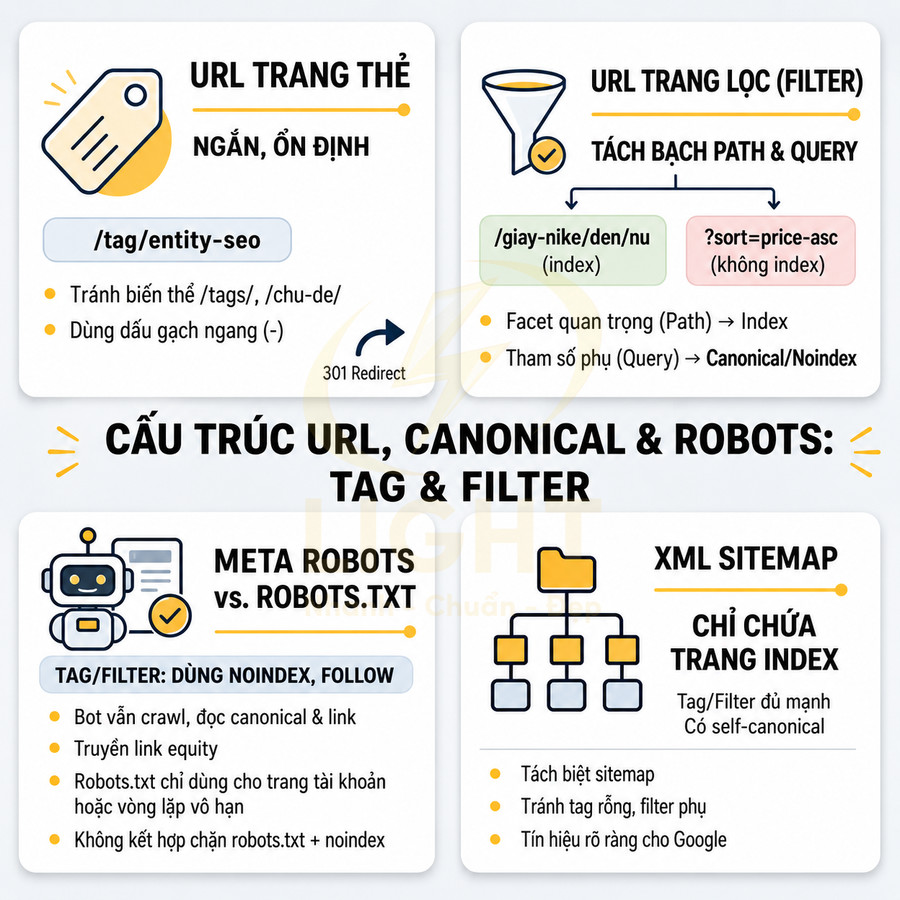
Trang lọc phải tách bạch facet quan trọng (dùng path, được phép index) và tham số phụ (dùng query, canonical hoặc noindex). Cần quy tắc rõ ràng cho canonical, thứ tự tham số và phạm vi URL filter được index, dựa trên search demand và khả năng tối ưu như landing page.
Về kiểm soát index, meta robots noindex, follow thường phù hợp hơn robots.txt cho tag và filter vì vẫn cho phép bot crawl, đọc canonical và truyền link equity. Robots.txt chỉ nên dùng cho khu vực thực sự không cần crawl hoặc tham số vô nghĩa. Tránh kết hợp chặn robots.txt với noindex trên cùng URL, và không canonical về URL đã bị chặn.
XML sitemap chỉ nên chứa các trang thẻ và trang lọc được chọn index, có self-canonical và nội dung đủ mạnh. Không đưa URL noindex, tag rỗng hoặc filter phụ vào sitemap để tránh tín hiệu mâu thuẫn và lãng phí crawl budget. Với site lớn, nên tách sitemap theo loại trang (category, sản phẩm/bài viết, tag, filter chiến lược) để dễ giám sát tỷ lệ index, lỗi canonical và tối ưu riêng từng nhóm. Khi cập nhật sitemap, chỉ thêm URL đã quyết định index, có nội dung tối thiểu và canonical chuẩn; đồng thời loại bỏ URL đã noindex lâu dài, redirect hoặc xóa/hợp nhất.
URL trang thẻ nên ngắn, ổn định và phản ánh đúng entity chủ đề
Với các trang thẻ được chọn index, URL không chỉ là “địa chỉ” mà còn là một phần của hệ thống taxonomy và hệ thống entity của toàn site. URL nên:
- Ngắn gọn, dễ đọc, dễ nhớ: ví dụ /tag/facebook-ads, /tag/entity-seo.
- Ổn định theo thời gian, hạn chế tối đa việc đổi slug hoặc đổi cấu trúc thư mục.
- Phản ánh đúng entity hoặc chủ đề cốt lõi, tránh dùng các cụm từ mơ hồ, đa nghĩa.
- Không chứa ký tự đặc biệt, không dùng dấu tiếng Việt, hạn chế số, ký tự underscore; ưu tiên kebab-case (dùng dấu gạch ngang).
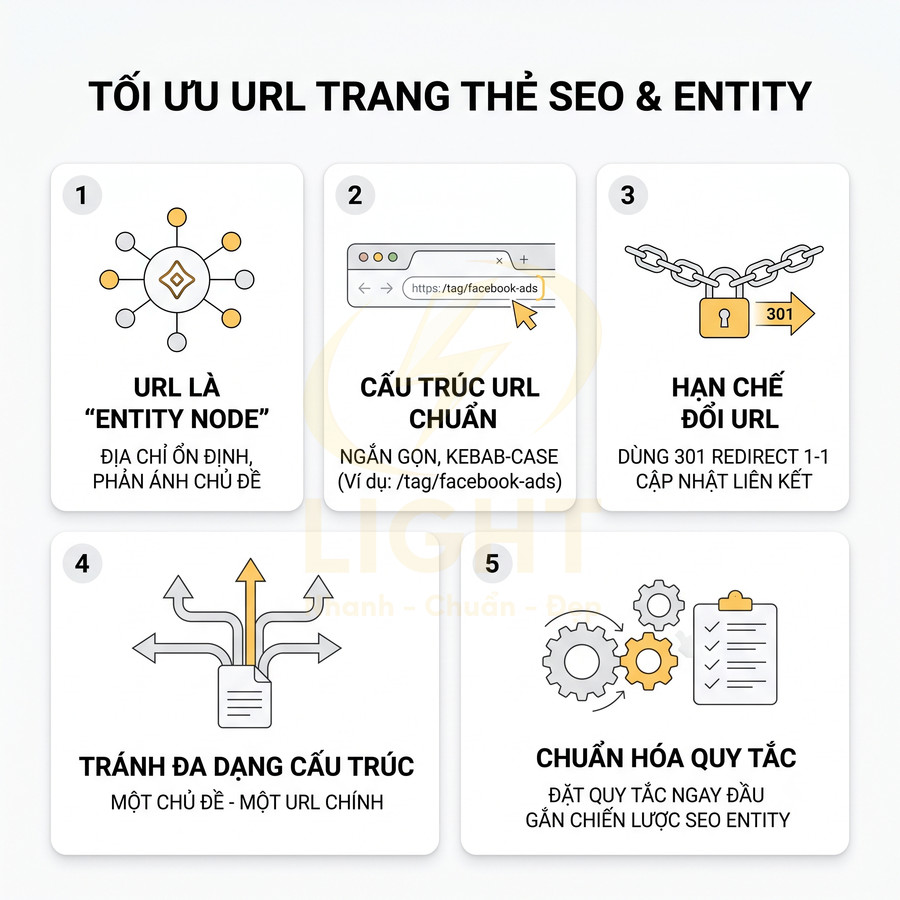
Về mặt kỹ thuật SEO, mỗi URL trang thẻ nên được xem như một “node” trong đồ thị entity của website. Khi đổi URL, bắt buộc phải dùng 301 redirect để chuyển tín hiệu, nhưng:
- Luôn tồn tại rủi ro mất một phần tín hiệu (link equity, lịch sử crawl, tín hiệu hành vi).
- Có thể tạo ra chuỗi redirect nếu không quản lý tốt (A → B → C), làm giảm hiệu quả crawl và truyền PageRank.
- Dễ phát sinh lỗi 404 nếu internal link không được cập nhật đồng bộ.
Cần tránh tạo nhiều cấu trúc URL khác nhau cho cùng một thẻ, ví dụ:
- /tag/facebook-ads
- /tags/facebook-ads
- /chu-de/facebook-ads
Việc tồn tại nhiều biến thể như vậy dẫn đến:
- Phân tán tín hiệu giữa các URL gần như trùng nội dung.
- Khó kiểm soát canonical, dễ tạo duplicate content.
- Tăng chi phí crawl (crawl budget) cho những URL không mang thêm giá trị.
Nếu bắt buộc phải đổi cấu trúc (ví dụ từ /tag/ sang /topic/):
- Thiết lập 301 redirect một–một từ URL cũ sang URL mới.
- Cập nhật toàn bộ internal link (menu, breadcrumb, bài viết, sitemap) trỏ về URL mới.
- Đảm bảo URL mới có self-canonical trùng chính xác với URL hiển thị.
Với phân trang của trang thẻ, không nên để các URL dạng tham số như /tag/facebook-ads?page=2 được index như các trang độc lập có giá trị tương đương landing page. Một số nguyên tắc:
- Trang đầu (page 1) là URL chính, không nên có tham số: /tag/facebook-ads.
- Các trang sâu (page 2, 3, …) có thể:
- Dùng rel="next" và rel="prev" để hỗ trợ UX và cấu trúc phân trang (dù đã deprecated chính thức, vẫn hữu ích về mặt logic nội bộ).
- Hoặc dùng meta robots noindex, follow cho các trang rất sâu nếu nội dung trùng lặp cao và không mang thêm giá trị tìm kiếm.
- Không canonical tất cả các trang phân trang về page 1 nếu nội dung khác nhau đáng kể, vì có thể làm Google bỏ qua nội dung ở các page sau.
Với các site lớn, nên chuẩn hóa quy tắc đặt URL cho tag ngay từ đầu, gắn chặt với chiến lược entity SEO: mỗi tag tương ứng một entity rõ ràng, có khả năng trở thành landing page cho một cụm truy vấn cụ thể, và URL chính là “identifier” ổn định của entity đó trong hệ thống.
URL trang lọc nên phân biệt facet quan trọng và tham số phụ cần kiểm soát
Trang lọc (filter / faceted navigation) là nguồn sinh ra rất nhiều URL biến thể. Nếu không kiểm soát, hệ thống có thể tạo ra hàng triệu URL gần như trùng lặp, gây lãng phí crawl budget và làm loãng tín hiệu. Cần phân biệt rõ:
- Facet quan trọng: các chiều lọc có giá trị tìm kiếm độc lập, có thể trở thành landing page (ví dụ: thương hiệu, màu sắc, giới tính, loại sản phẩm).
- Tham số phụ: chỉ phục vụ trải nghiệm người dùng, không có hoặc rất ít giá trị tìm kiếm (ví dụ: sort, view=grid/list, số sản phẩm trên trang, trạng thái tạm thời).

Một cách tiếp cận phổ biến và dễ quản lý:
- Dùng path cho facet quan trọng, ví dụ:
- /giay-nike/den/nu (category + màu + giới tính).
- /laptop/dell/core-i7 (category + brand + CPU).
- Dùng query parameter cho tham số phụ:
- ?sort=price-asc
- ?page=2
- ?view=grid
Cách tách bạch này giúp dễ áp dụng quy tắc:
- Chỉ index các URL path thể hiện facet quan trọng (ví dụ /giay-nike/den/nu).
- Các tham số phụ:
- Hoặc dùng canonical về phiên bản không tham số (ví dụ canonical của /giay-nike/den/nu?sort=price-asc trỏ về /giay-nike/den/nu).
- Hoặc dùng meta robots noindex, follow nếu cần giữ trạng thái riêng nhưng không muốn index.
Nếu hệ thống buộc phải dùng query parameter cho cả facet quan trọng (ví dụ: /giay?brand=nike&color=den&gender=nu), cần xây dựng một cơ chế kiểm soát chặt chẽ:
- Xác định rõ:
- Những tham số nào được phép index (brand, color, gender, size…).
- Những tham số nào luôn phải noindex hoặc canonical (sort, view, page, filter tạm thời).
- Thiết kế logic canonical:
- Chuẩn hóa thứ tự tham số (ví dụ luôn là ?brand=&color=&gender=), tránh tạo nhiều URL khác nhau cho cùng một tập filter.
- Loại bỏ tham số phụ khỏi canonical, chỉ giữ các facet quan trọng.
- Cấu hình tương ứng trong code:
- Middleware hoặc layer routing để chuẩn hóa URL trước khi render.
- Template HTML sinh canonical và meta robots theo đúng rule đã định nghĩa.
Về mặt chiến lược, không phải mọi tổ hợp facet quan trọng đều nên index. Cần đánh giá:
- Nhu cầu tìm kiếm (search demand) cho từng tổ hợp (ví dụ “giày nike đen nữ” có volume, nhưng “giày nike tím neon nam chân to” có thể không).
- Khả năng tạo nội dung đủ khác biệt (title, H1, mô tả, content bổ sung) cho từng landing page filter.
- Nguy cơ trùng lặp nội dung giữa các filter gần giống nhau.
Chỉ những URL filter hội đủ tiêu chí về search demand và khả năng tối ưu như landing page mới nên được index; phần còn lại nên được kiểm soát bằng canonical hoặc noindex.
Robots meta noindex phù hợp hơn robots.txt khi cần bot thấy canonical và link nội bộ
Khi muốn ngăn một trang thẻ hoặc filter khỏi chỉ mục, meta robots noindex, follow thường là lựa chọn tối ưu hơn so với chặn bằng robots.txt. Lý do:
- Nếu chặn crawl bằng robots.txt:
- Google không thể truy cập nội dung trang, không thấy được canonical, meta robots, structured data.
- Các internal link trên trang đó không được crawl đầy đủ, làm đứt gãy luồng link equity.
- Trong một số trường hợp, URL vẫn có thể xuất hiện trong kết quả tìm kiếm dưới dạng “soft result” (chỉ có URL, không snippet) nếu có nhiều link trỏ tới.
- Với noindex, follow:
- Bot vẫn crawl được trang, hiểu cấu trúc, đọc canonical, đọc internal link.
- Link equity vẫn được truyền qua các liên kết trên trang.
- URL đó sẽ dần bị loại khỏi chỉ mục sau một vài lần crawl.
Khi mục tiêu là loại trang tag/filter khỏi chỉ mục nhưng vẫn muốn Google hiểu cấu trúc liên kết, noindex, follow thường phù hợp hơn robots.txt. Google giải thích rằng nếu dùng noindex, crawler cần truy cập được trang để đọc directive; nếu URL bị chặn bởi robots.txt, Google có thể không thấy thẻ noindex trên trang. Với tag/filter còn chứa link đến bài viết, sản phẩm hoặc category quan trọng, chặn robots.txt quá sớm có thể làm bot mất khả năng đọc canonical và liên kết nội bộ. Robots.txt nên dành cho khu vực thật sự không cần crawl; tag/filter yếu nên ưu tiên noindex, follow.

Robots.txt nên được dùng cho các khu vực thực sự không cần bot truy cập, ví dụ:
- /wp-admin/, /cart/, /checkout/, /search/, khu vực tài khoản, giỏ hàng, bước thanh toán.
- Các pattern URL tham số vô nghĩa hoặc sinh ra vô hạn (ví dụ: ?sessionid=, ?ref=, *?utm_ nếu không được xử lý bằng canonical).
Với tag và filter, nơi thường chứa nhiều internal link quan trọng, việc dùng noindex, follow cho các URL không muốn index giúp:
- Giữ được cấu trúc internal link đầy đủ, hỗ trợ phân phối PageRank hợp lý.
- Cho phép Google hiểu mối quan hệ giữa các entity, category, sản phẩm/bài viết.
- Tránh lãng phí crawl budget vào các khu vực bị robots.txt chặn nhưng vẫn được nhiều trang khác link tới.
Cần lưu ý:
- Không nên kết hợp vừa chặn bằng robots.txt vừa đặt noindex trên cùng một URL, vì khi đã bị chặn crawl, bot sẽ không đọc được meta robots.
- Không nên đặt canonical trỏ tới một URL bị chặn robots.txt; canonical đó sẽ không được xem xét.
- Với các filter có khả năng trở thành landing page trong tương lai, có thể tạm thời noindex, follow, sau đó chuyển sang index khi đã tối ưu nội dung.
Sitemap chỉ nên chứa trang thẻ và trang lọc được chọn index
XML sitemap là tín hiệu rõ ràng cho Google về những URL mà website muốn được index và ưu tiên crawl. Vì vậy, chỉ nên đưa vào sitemap:
- Các trang thẻ đã được quyết định index, có self-canonical, được tối ưu như landing page (title, H1, nội dung mô tả, internal link).
- Các trang filter được chọn index dựa trên search demand và chiến lược SEO, không phải mọi tổ hợp filter.
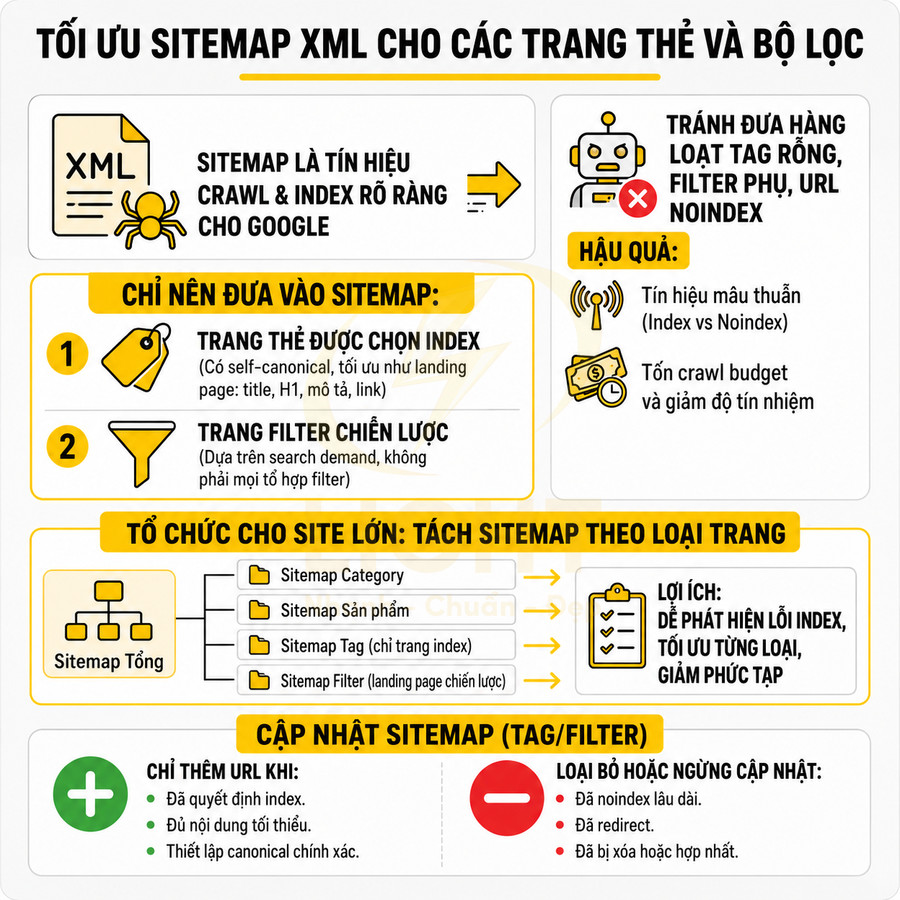
Việc đưa hàng loạt tag rỗng, filter phụ, hoặc URL noindex vào sitemap tạo ra tín hiệu mâu thuẫn:
- Sitemap “yêu cầu” index, trong khi meta robots lại “cấm” index.
- Google phải tốn crawl budget để kiểm tra các URL không có giá trị.
- Giảm độ “tín nhiệm” của sitemap như một nguồn tín hiệu chất lượng.
Với các site lớn, nên tách sitemap theo loại trang để dễ quản lý và theo dõi trong Search Console, ví dụ:
- Sitemap cho category (danh mục chính).
- Sitemap cho sản phẩm hoặc bài viết.
- Sitemap cho tag được index (chỉ những tag đủ nội dung, đủ traffic tiềm năng).
- Sitemap cho filter được index (các landing page filter chiến lược).
Cách tổ chức này giúp:
- Dễ phát hiện nhóm URL nào gặp vấn đề index (tỷ lệ indexed thấp, nhiều lỗi soft 404, canonical không nhất quán).
- Dễ tách bạch và tối ưu theo từng loại trang (ví dụ tối ưu riêng cho tag vs filter vs category).
- Giảm độ phức tạp khi cập nhật sitemap động cho các site có số lượng URL lớn và thay đổi thường xuyên.
Khi cập nhật sitemap cho tag và filter:
- Chỉ thêm URL khi:
- Đã quyết định cho index.
- Đã có nội dung tối thiểu (không rỗng, không chỉ là danh sách 1–2 item).
- Đã thiết lập canonical chính xác.
- Loại bỏ hoặc ngừng cập nhật các URL:
- Đã chuyển sang noindex lâu dài.
- Đã redirect sang URL khác.
- Đã bị xóa hoặc hợp nhất nội dung.
Nội dung tối thiểu cho trang thẻ và trang lọc được index
Trang thẻ và trang lọc muốn được index cần đảm bảo một số yếu tố nội dung cốt lõi. Trước hết, H1 phải mô tả chính xác chủ đề hoặc nhu cầu tìm kiếm, phản ánh đúng intent và tổ hợp thuộc tính của filter, đồng thời nhất quán với title và URL. Ngay dưới H1 nên có đoạn mô tả ngắn 2–4 câu, giải thích rõ phạm vi nội dung/sản phẩm, đối tượng phù hợp, điều kiện lọc đang áp dụng và gợi ý cách tinh chỉnh. Phần danh sách bài viết hoặc sản phẩm phải đủ sâu, cập nhật, không trùng hoàn toàn với trang khác, mỗi item có tiêu đề, hình ảnh, mô tả và thông tin quan trọng. Cuối cùng, chỉ bổ sung FAQ hoặc hướng dẫn chọn lọc khi có câu hỏi thật từ người dùng và nội dung trả lời mang tính thực tiễn, không trùng lặp.
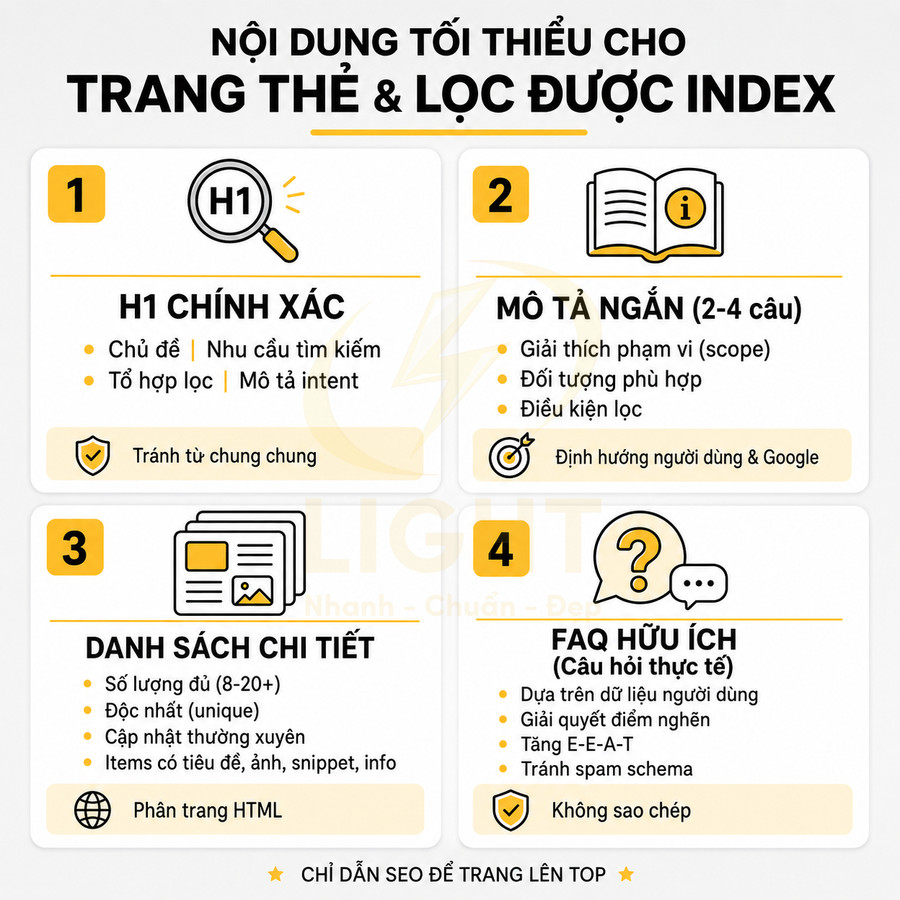
H1 mô tả chính xác chủ đề, thuộc tính hoặc nhu cầu tìm kiếm của trang
H1 của trang thẻ và filter được index cần mô tả chính xác chủ đề hoặc nhu cầu tìm kiếm mà trang phục vụ, đồng thời phản ánh đúng “search intent” mà người dùng thể hiện qua truy vấn. Với tag, H1 thường là tên chủ đề hoặc entity có khả năng đứng độc lập như một khái niệm: “Facebook Ads”, “Entity SEO”, “Marketing Automation”, “Content Hub”, “Technical SEO Audit”. Với filter, H1 nên phản ánh tổ hợp điều kiện càng cụ thể càng tốt: “Giày chạy bộ nữ Nike màu đen dưới 2 triệu”, “Chung cư 2 phòng ngủ quận 7 dưới 3 tỷ”, “Laptop gaming RTX 4060 16GB RAM dưới 30 triệu”.
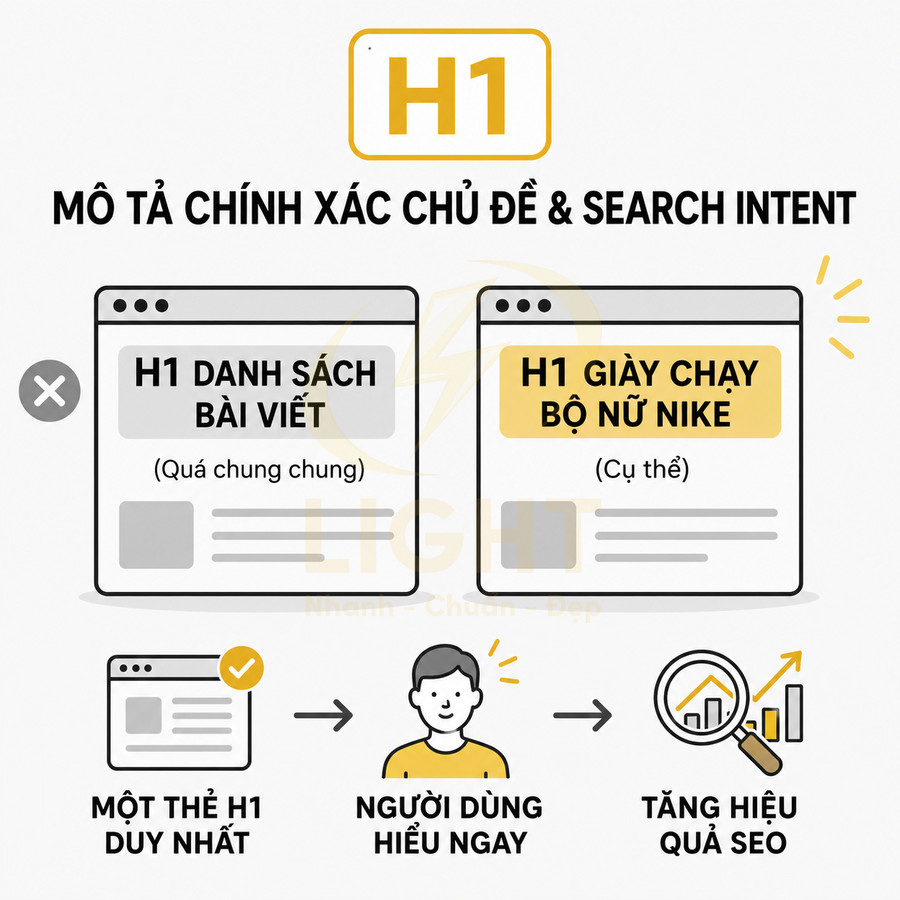
H1 rõ ràng giúp người dùng ngay lập tức hiểu họ đang ở đâu, đang xem nhóm nội dung/sản phẩm nào, và liệu trang có phù hợp với nhu cầu hiện tại hay không. Về mặt SEO, H1 là một trong những tín hiệu quan trọng giúp Google xác định intent của trang, phân loại trang vào đúng “topic cluster” và tránh nhầm lẫn với các trang category hoặc landing page khác. H1 nên chứa các cụm từ khóa chính hoặc long-tail đại diện cho tổ hợp filter, nhưng không nên nhồi nhét từ khóa một cách cơ học.
Nên tránh H1 quá chung chung như “Kết quả lọc”, “Danh sách bài viết”, “Sản phẩm”, “Tất cả bài viết”, vì chúng không mang thông tin ngữ nghĩa, không thể hiện được thuộc tính, phạm vi hay lợi ích cho người dùng. Những H1 này khiến trang trở nên mơ hồ, khó cạnh tranh trên SERP và dễ bị đánh giá là trang điều hướng đơn thuần (thin hoặc doorway). Đồng thời, H1 nên nhất quán với title và URL, tránh trường hợp title nói một đằng, H1 nói một nẻo, khiến tín hiệu bị nhiễu và làm giảm độ tin cậy của trang trong mắt cả người dùng lẫn công cụ tìm kiếm.
Về mặt triển khai kỹ thuật, nên đảm bảo:
- Mỗi trang chỉ có một thẻ H1 duy nhất, không lặp lại H1 cho các block nhỏ bên trong.
- H1 được render đầy đủ trong HTML (không chỉ xuất hiện sau khi JS chạy) để bot có thể crawl và hiểu nội dung.
- Với các trang filter động, hệ thống cần có logic sinh H1 dựa trên tổ hợp thuộc tính (brand, màu, size, giá, location…) theo một template rõ ràng, tránh tạo ra các H1 vô nghĩa hoặc trùng lặp hoàn toàn.
Mô tả ngắn giải thích phạm vi nội dung, sản phẩm hoặc bài viết được gom nhóm
Ngay dưới H1, một đoạn mô tả ngắn (2–4 câu, có thể dài hơn nếu cần) giúp giải thích phạm vi nội dung hoặc sản phẩm trong trang, làm rõ “scope” mà người dùng sắp tương tác. Với tag, mô tả có thể nêu: chủ đề chính, đối tượng phù hợp, loại nội dung (hướng dẫn, case study, tin tức, phân tích chuyên sâu), mức độ kiến thức (cơ bản, trung cấp, nâng cao) và bối cảnh ứng dụng. Với filter, mô tả có thể giải thích: loại sản phẩm, điều kiện lọc đang được áp dụng, các tiêu chí quan trọng khi lựa chọn, cũng như gợi ý cách tinh chỉnh filter để tìm đúng thứ mình cần.
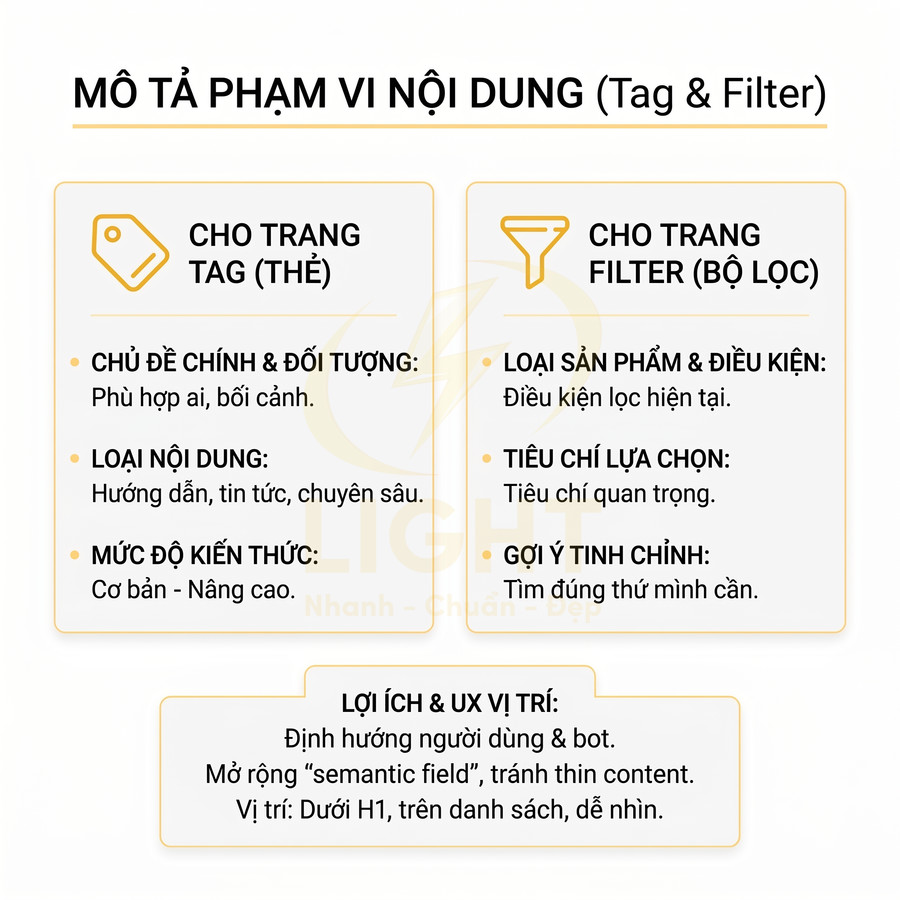
Đoạn mô tả này vừa giúp người dùng định hướng, vừa cung cấp thêm ngữ cảnh cho Google, giảm nguy cơ bị đánh giá là thin content hoặc trang chỉ có danh sách item khô khan. Về mặt ngữ nghĩa, mô tả nên sử dụng các biến thể từ khóa liên quan (synonym, LSI, entity liên quan) để mở rộng “semantic field” của trang, nhưng vẫn phải tự nhiên, dễ đọc. Có thể chèn thêm 1–2 internal link đến các trang pillar hoặc hướng dẫn tổng quan nếu thực sự hữu ích cho người dùng và không làm loãng mục tiêu chính của trang.
Ví dụ, với filter “giày chạy bộ nữ Nike màu đen dưới 2 triệu”, mô tả có thể là: “Trang này tổng hợp các mẫu giày chạy bộ nữ thương hiệu Nike, màu đen, mức giá dưới 2 triệu đồng, phù hợp cho chạy bộ hàng ngày và luyện tập cường độ trung bình. Bạn có thể dùng thêm bộ lọc size, chất liệu đế, hoặc công nghệ đệm để thu hẹp kết quả. Các sản phẩm được sắp xếp ưu tiên theo độ phổ biến, đánh giá của người dùng và tình trạng còn hàng để giúp bạn lựa chọn nhanh hơn.”
Với các trang tag nội dung, mô tả có thể chi tiết hơn một chút, ví dụ: “Chuyên mục Entity SEO tập hợp các bài viết chuyên sâu về cách xây dựng, tối ưu và triển khai chiến lược Entity trong SEO hiện đại. Nội dung phù hợp cho SEOer đã có kiến thức nền tảng, muốn nâng cấp hệ thống nội dung, schema và cấu trúc website để cải thiện khả năng hiểu của Google. Bạn sẽ tìm thấy hướng dẫn thực hành, case study, checklist và phân tích thuật toán liên quan đến entity.”
Về mặt UX, mô tả nên được đặt ở vị trí dễ nhìn (ngay dưới H1, phía trên danh sách), không bị che khuất bởi banner hoặc block quảng cáo. Có thể sử dụng định dạng:
- Đoạn văn ngắn 2–4 câu.
- Hoặc 1–2 câu mở đầu + 1 listing ngắn (3–4 bullet) tóm tắt lợi ích hoặc phạm vi.
Danh sách nội dung đủ sâu, cập nhật và không trùng hoàn toàn với trang khác
Phần danh sách (bài viết hoặc sản phẩm) là “trái tim” của trang thẻ và filter. Để xứng đáng được index, danh sách này cần:
- Đủ sâu: số lượng item đủ lớn để người dùng có lựa chọn, thường từ 8–10 trở lên, với các site lớn có thể đặt ngưỡng cao hơn (12–20) tùy ngành.
- Cập nhật: tự động loại bỏ sản phẩm hết hàng lâu dài, bài viết quá cũ (nếu không còn giá trị), ưu tiên hiển thị nội dung mới hoặc quan trọng, có thể gắn nhãn “mới”, “bán chạy”, “được đề xuất”.
- Không trùng hoàn toàn: tập item không nên giống 100% với một category hoặc filter khác đã được index, tránh tạo ra nhiều trang gần như bản sao chỉ khác nhẹ về URL hoặc tham số.
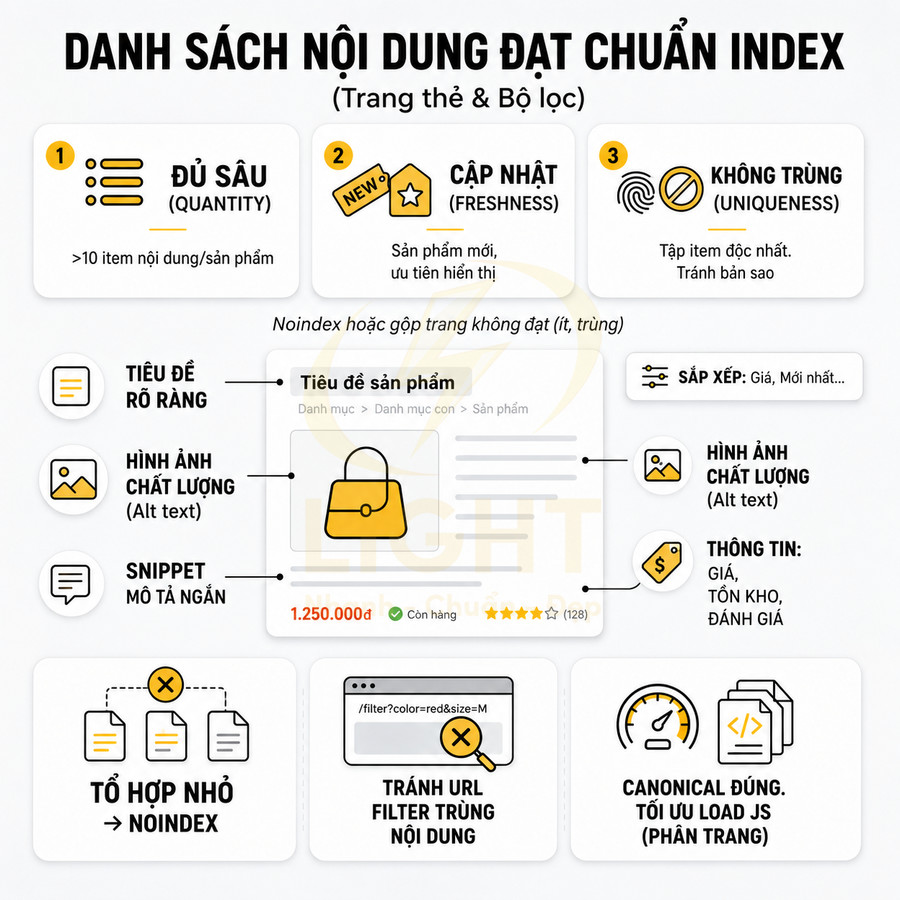
Nếu danh sách quá ít hoặc trùng lặp, nên cân nhắc noindex hoặc gộp với trang khác để tránh cannibalization và lãng phí crawl budget. Với các site nội dung, có thể bổ sung block “bài viết nổi bật”, “bài mới nhất” trong cùng chủ đề để tăng độ phong phú, nhưng vẫn cần giữ trọng tâm vào chủ đề chính của thẻ, không biến trang thành một “archive” tổng hợp vô định hướng.
Về mặt cấu trúc, mỗi item trong danh sách nên có tối thiểu:
- Tiêu đề rõ ràng, chứa từ khóa hoặc thuộc tính quan trọng.
- Hình ảnh đại diện chất lượng đủ tốt, kích thước thống nhất, có alt text mô tả.
- Đoạn mô tả ngắn (snippet) giúp người dùng hiểu nhanh nội dung hoặc tính năng chính.
- Thông tin quan trọng theo ngữ cảnh: giá, tình trạng còn hàng, rating, thời gian xuất bản/cập nhật, loại nội dung.
Với các trang filter sản phẩm, nên có cơ chế sắp xếp (sort) theo các tiêu chí phổ biến: giá, mới nhất, bán chạy, đánh giá cao. Tuy nhiên, chỉ nên cho index các tổ hợp filter có giá trị tìm kiếm rõ ràng và danh sách đủ sâu; các tổ hợp quá nhỏ, quá đặc thù hoặc không có nhu cầu tìm kiếm nên để noindex hoặc canonical về trang cha phù hợp.
Về mặt kỹ thuật SEO, cần lưu ý:
- Tránh tạo ra nhiều URL filter khác nhau nhưng danh sách item gần như giống hệt nhau (ví dụ chỉ khác thứ tự sort hoặc một thuộc tính không quan trọng).
- Sử dụng canonical hợp lý để chỉ định phiên bản “chính” của các trang có nội dung tương đồng.
- Đảm bảo tốc độ tải danh sách đủ nhanh, đặc biệt với infinite scroll hoặc lazy load; nếu dùng JS để load thêm item, nên hỗ trợ crawl bằng cách render server-side hoặc cung cấp link phân trang HTML.
FAQ hoặc hướng dẫn chọn lọc chỉ thêm khi có câu hỏi thật từ người dùng
Nhiều website cố gắng “nhồi” FAQ vào mọi trang với hy vọng chiếm thêm diện tích trên SERP. Tuy nhiên, FAQ chỉ thực sự hữu ích khi phản ánh câu hỏi thật của người dùng và giải quyết được các điểm nghẽn trong hành trình ra quyết định. Với tag và filter, chỉ nên thêm FAQ hoặc hướng dẫn khi:
- Có dữ liệu từ search query, chatbot, CSKH, heatmap hoặc survey cho thấy người dùng thường hỏi những câu đó, ví dụ: “Giày chạy bộ nữ Nike nên chọn size như thế nào?”, “Chung cư 2 phòng ngủ quận 7 khu nào yên tĩnh?”, “Bài viết Entity SEO này phù hợp cho người mới hay đã có kinh nghiệm?”.
- Câu trả lời giúp người dùng ra quyết định nhanh hơn (chọn sản phẩm, chọn bài viết phù hợp, hiểu rõ sự khác nhau giữa các lựa chọn) và giảm nhu cầu phải rời trang để tìm thêm thông tin ở nơi khác.
- Nội dung FAQ không trùng lặp hoàn toàn với các trang khác, đặc biệt là không copy nguyên FAQ từ trang category, trang sản phẩm hoặc trang hướng dẫn tổng quan.
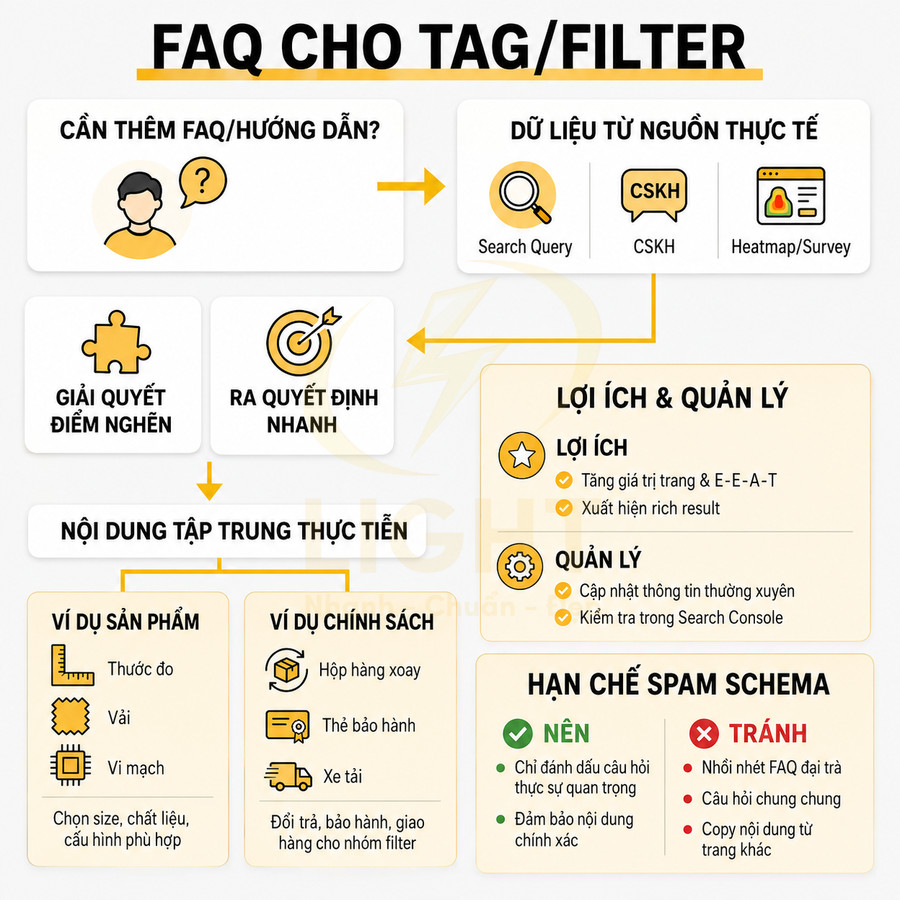
FAQ nên tập trung vào các câu hỏi mang tính thực tiễn, ví dụ:
- Cách chọn size, chất liệu, cấu hình phù hợp với nhu cầu cụ thể.
- Chính sách đổi trả, bảo hành, giao hàng áp dụng cho nhóm sản phẩm trong filter.
- Tiêu chí đánh giá, so sánh giữa các dòng sản phẩm hoặc loại nội dung trong tag.
Việc thêm FAQ hợp lý có thể tăng giá trị trang, cải thiện E-E-A-T thông qua việc thể hiện hiểu biết chuyên sâu và kinh nghiệm thực tế, và đôi khi giúp xuất hiện rich result. Tuy nhiên, lạm dụng FAQ schema cho mọi trang, mọi câu hỏi chung chung có thể bị Google bỏ qua hoặc thậm chí xem là spam structured data. Nên:
- Chỉ đánh dấu schema FAQ cho các câu hỏi thực sự quan trọng, có khả năng mang lại giá trị trên SERP.
- Đảm bảo nội dung FAQ được cập nhật khi chính sách, giá, điều kiện sản phẩm hoặc thông tin chuyên môn thay đổi.
- Kiểm tra định kỳ trong Search Console để xem rich result có hiển thị ổn định hay không, tránh lỗi cấu trúc dữ liệu.
Internal link cho trang thẻ và trang lọc tự động không làm loãng cấu trúc SEO
Hệ thống internal link cho trang thẻ và trang lọc cần bám chặt kiến trúc thông tin, ưu tiên truyền sức mạnh từ các trang có authority cao đến những tag/filter được chọn làm landing page SEO. Trọng tâm là xác định tag chiến lược, filter chiến lược và giới hạn số lượng link để không làm loãng PageRank. Internal link nên xuất phát từ bài viết, hub/pillar, breadcrumb mở rộng, menu phụ và các block “chủ đề liên quan”, với anchor text mô tả rõ entity, thuộc tính và intent thay vì từ khóa chung chung. Các trang tự động mỏng, trùng lặp hoặc chỉ phục vụ thao tác lọc nên được noindex/canonical hợp lý, không đưa vào sitemap và không đẩy mạnh internal link, giúp cấu trúc SEO vẫn tập trung, rõ ràng và giàu ngữ nghĩa.
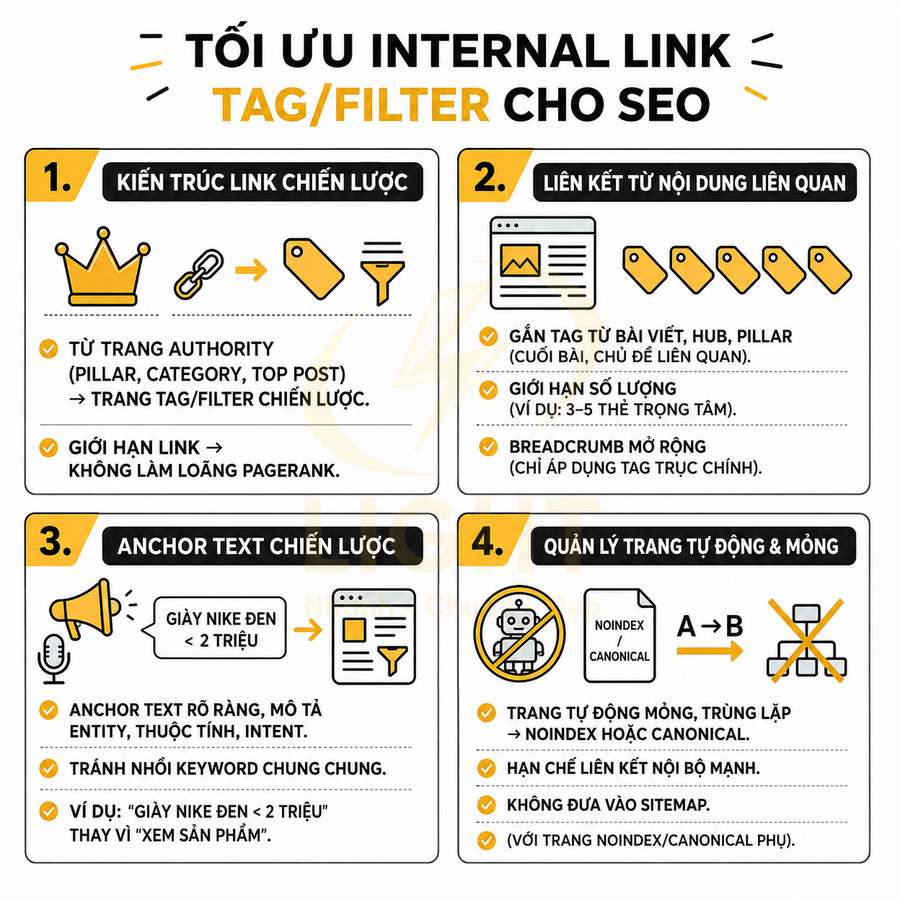
Liên kết đến tag quan trọng từ bài viết, breadcrumb hoặc hub page liên quan
Để các trang thẻ quan trọng có cơ hội được crawl, index và xếp hạng ổn định, cần thiết kế một hệ thống internal link chiến lược gắn chặt với kiến trúc thông tin (information architecture) tổng thể. Không chỉ đơn thuần “có link là được”, mà phải xác định rõ:
- Tag nào là tag chiến lược (có search demand, có khả năng trở thành landing page, có nội dung hỗ trợ đủ dày).
- Trang nào đang sở hữu authority cao (category, pillar, hub, bài viết top, trang thương hiệu mạnh).
- Đường đi của PageRank và tín hiệu ngữ nghĩa từ các trang mạnh về tag page.
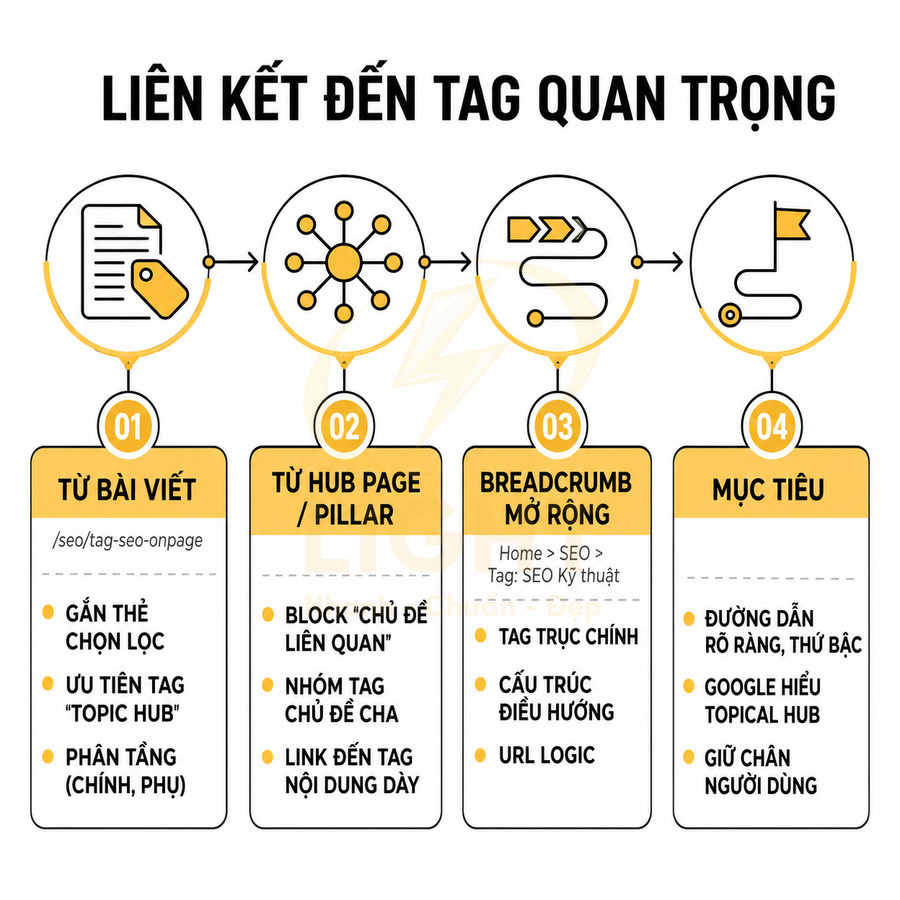
Một số vị trí internal link hiệu quả và có tính kiểm soát cao:
- Từ bài viết:
- Gắn tag ở vị trí hợp lý (thường cuối bài hoặc ngay dưới tiêu đề nếu là topic chính), nhưng chỉ với số lượng hạn chế và có chọn lọc.
- Ưu tiên các tag có khả năng trở thành “topic hub” cho một nhóm bài viết liên quan, thay vì các tag chỉ xuất hiện 1–2 lần.
- Có thể phân tầng: 1–2 tag chính (topic rộng, có volume) + 1–3 tag phụ (ngách hơn, hỗ trợ semantic).
- Từ hub page hoặc pillar:
- Đặt block “Chủ đề liên quan” hoặc “Khám phá theo chủ đề” trỏ đến các tag quan trọng trong cùng cluster.
- Nhóm các tag theo chủ đề cha để tránh tạo cảm giác rời rạc, ví dụ: “SEO Onpage”, “SEO Technical”, “SEO Content” nằm dưới hub “SEO”.
- Ưu tiên link đến các tag đã có nội dung dày (nhiều bài, nhiều sản phẩm) để tăng khả năng giữ chân người dùng.
- Breadcrumb mở rộng (nếu phù hợp):
- Với một số site, có thể hiển thị thêm layer tag trong breadcrumb cho các chủ đề trọng tâm, ví dụ: Trang chủ > Marketing > Facebook Ads > Case study.
- Chỉ nên áp dụng với một số tag “trục chính” đã được xác định là một phần của cấu trúc điều hướng, tránh đưa mọi tag vào breadcrumb.
- Cần đảm bảo tính nhất quán: một URL chỉ nên có một đường breadcrumb logic, tránh thay đổi theo từng session hoặc filter.
Mục tiêu là tạo ra đường dẫn rõ ràng, có thứ bậc từ các trang có authority cao (pillar, category, bài viết top, brand page) đến tag page, giúp Google hiểu:
- Tag nào là “trung tâm” của một chủ đề (topic hub).
- Tag nào chỉ mang tính bổ trợ, không cần ưu tiên crawl nhiều.
- Mối quan hệ ngữ nghĩa giữa các tag, category và nội dung con.
Tuy nhiên, không nên biến mọi tag thành một phần của menu chính hoặc mega menu, vì:
- Làm loãng cấu trúc điều hướng, khiến người dùng khó định hướng.
- Giảm trọng số của các trang cốt lõi (category, pillar, brand) do PageRank bị phân tán quá mỏng.
- Tăng nguy cơ trùng lặp chủ đề giữa category và tag, gây khó cho Google trong việc xác định canonical topic page.
- Phân loại tag thành:
- Tag chiến lược (có thể xuất hiện trong điều hướng phụ, hub, block chủ đề).
- Tag hỗ trợ (chỉ dùng để nhóm nội dung, không cần đẩy mạnh SEO).
- Tag nội bộ (chỉ phục vụ quản trị, không index hoặc không hiển thị).
- Định nghĩa rõ mỗi tag chiến lược sẽ nhận internal link từ:
- X hub page / pillar.
- Y bài viết top / trang sản phẩm chủ lực.
- Z block điều hướng phụ (sidebar, footer, section “Chủ đề hot”).
- PageRank bị chia nhỏ cho rất nhiều URL yếu, làm giảm sức mạnh của các trang cần ưu tiên.
- Googlebot phải crawl nhiều URL ít giá trị, lãng phí crawl budget, đặc biệt với site lớn.
- Người dùng khó nhận diện chủ đề chính, vì danh sách tag quá dài và trùng lặp.
Cách tiếp cận tốt là xây dựng một “tag taxonomy” nội bộ:
Không hiển thị quá nhiều tag link dưới mỗi bài viết hoặc sản phẩm
Một lỗi phổ biến là hiển thị hàng chục tag dưới mỗi bài viết hoặc sản phẩm, khiến giao diện rối mắt và loãng internal link. Khi mỗi bài có 10–20 tag, tổng số link trên trang tăng mạnh, trong khi phần lớn tag là mỏng hoặc không quan trọng. Điều này dẫn đến:
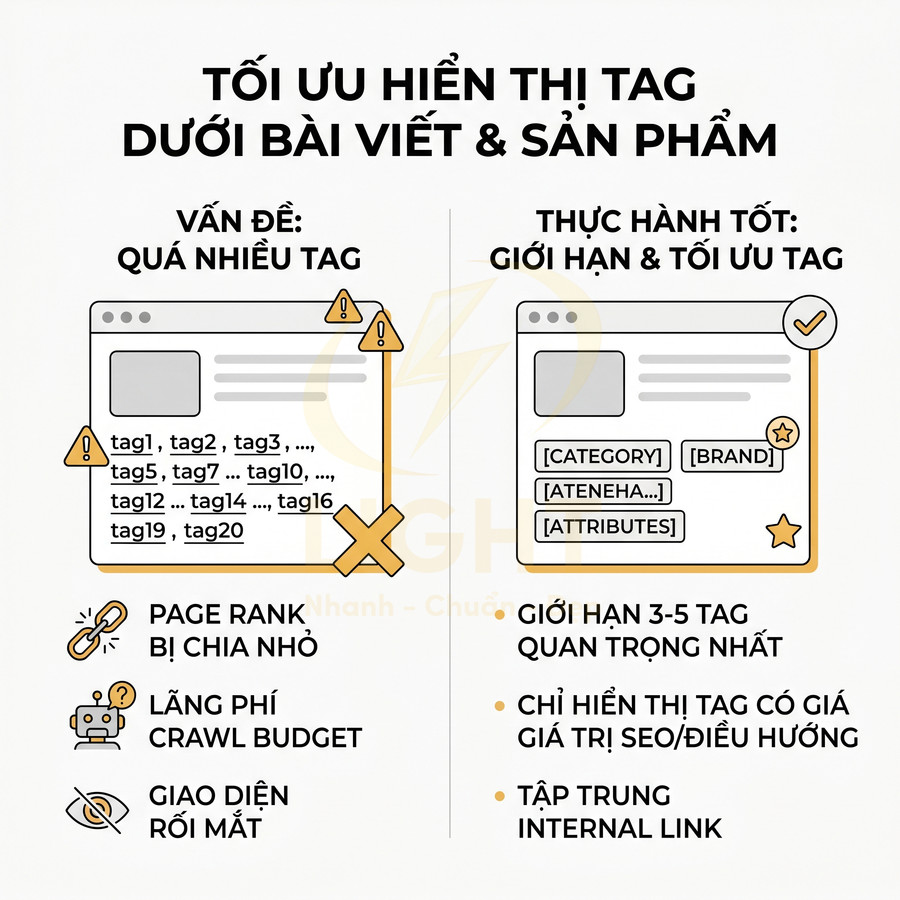
- Giới hạn số lượng tag hiển thị (ví dụ: 3–5 thẻ quan trọng nhất):
- Chỉ hiển thị các tag có vai trò SEO hoặc điều hướng rõ ràng.
- Các tag ít dùng, mang tính nội bộ có thể vẫn gắn trong CMS nhưng không render ra giao diện.
- Ẩn các thẻ nội bộ chỉ dùng cho quản trị:
- Dùng tag để phân luồng workflow, trạng thái nội dung, chiến dịch… nhưng đánh dấu là “internal only”.
- Có thể noindex hoặc chặn index các tag này, đồng thời không hiển thị link trên front-end.
- Đảm bảo mỗi tag được gắn vì lý do nội dung thực sự:
- Tag phải phản ánh chủ đề hoặc thuộc tính mà người dùng thực sự quan tâm, có khả năng trở thành điểm vào (entry point) từ search.
- Tránh tạo tag chỉ để “tăng số lượng link” hoặc vì một từ khóa xuất hiện trong bài.
- Category (danh mục chính, danh mục phụ nếu cần).
- Brand (thương hiệu, nhà sản xuất).
- Một vài thuộc tính chính (giới tính, dòng sản phẩm, use case như “chạy bộ”, “leo núi”).
- Chỉ dùng trong hệ thống filter, không hiển thị như tag dưới sản phẩm.
- Hoặc hiển thị nhưng không link ra một trang riêng nếu trang đó không có giá trị SEO (noindex hoặc canonical về trang cha).
- Tập trung sức mạnh internal link vào một số ít trang tag / category thực sự quan trọng.
- Giữ giao diện gọn gàng, tăng khả năng người dùng tương tác với các link có giá trị.
- Giảm rủi ro tạo ra hàng loạt tag page mỏng, khó kiểm soát chất lượng.
- Được liên kết từ các trang quan trọng trong site.
- Có vai trò rõ ràng trong hành trình người dùng (user journey).
- Được nhấn mạnh bằng anchor text mô tả chính xác intent.
Thực hành tốt là:
Với trang sản phẩm, có thể ưu tiên hiển thị:
Các thuộc tính nhỏ như màu sắc hiếm, mã nội bộ, tag chiến dịch ngắn hạn… có thể:
Cách làm này giúp:
Trang lọc index cần nhận link nội bộ từ danh mục, menu phụ hoặc nội dung liên quan
Các filter page được chọn index như landing page cần được gắn vào cấu trúc internal link một cách rõ ràng, có chủ đích. Việc chỉ để filter tự sinh ra URL, thêm self-canonical và đưa vào sitemap là chưa đủ. Google ưu tiên những URL:
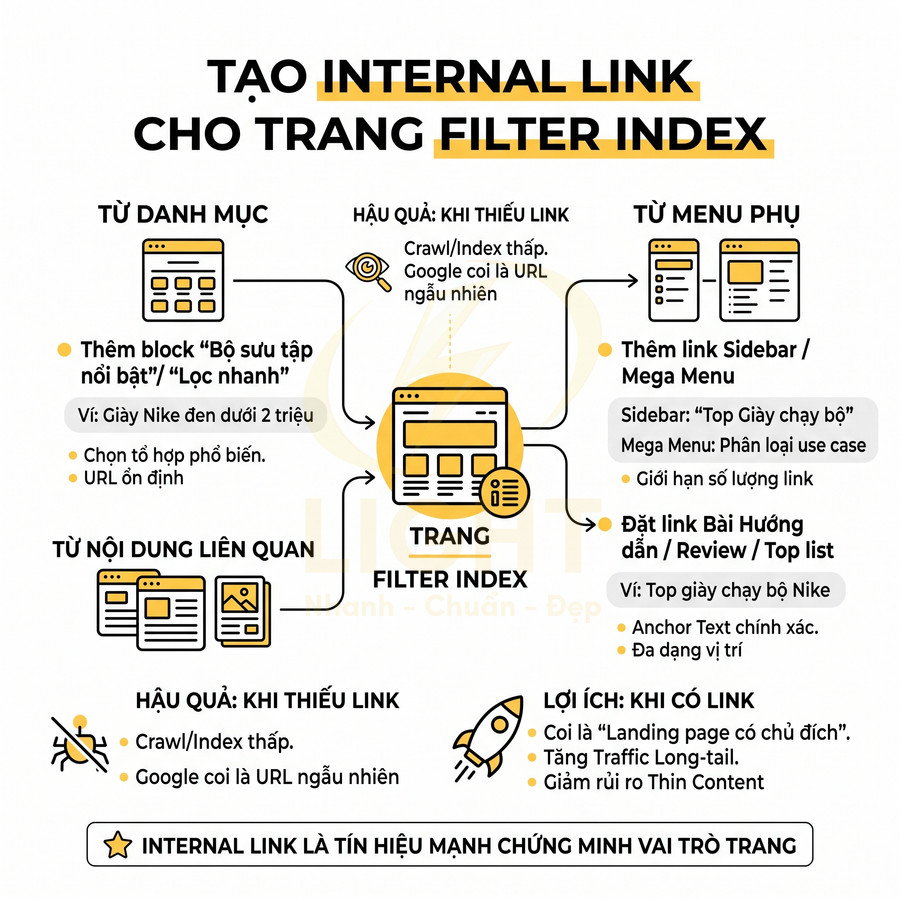
- Thêm link từ category:
- Tạo các block “Bộ sưu tập nổi bật” hoặc “Lọc nhanh” trong trang category, ví dụ: “Xem tất cả giày Nike màu đen dưới 2 triệu”.
- Chỉ chọn một số tổ hợp filter có volume tìm kiếm, có doanh thu tốt hoặc phản ánh nhu cầu phổ biến.
- Đảm bảo URL filter ổn định, không thay đổi tham số liên tục (tránh tạo duplicate URL cho cùng một tổ hợp).
- Đưa vào menu phụ (sidebar, mega menu) cho các tổ hợp phổ biến:
- Sidebar trong category có thể chứa các link “Top lựa chọn” như “Giày chạy bộ nữ Nike màu đen dưới 2 triệu”.
- Mega menu có thể nhóm các filter landing page theo use case: “Chạy bộ”, “Tập gym”, “Đi học”, mỗi nhóm lại có các tổ hợp brand + price range.
- Cần giới hạn số lượng để tránh biến mega menu thành danh sách filter vô tận.
- Link từ bài viết hướng dẫn chọn sản phẩm:
- Các bài blog dạng “hướng dẫn chọn”, “review”, “top list” là nơi lý tưởng để đặt link đến filter page, ví dụ: “Danh sách giày chạy bộ nữ Nike màu đen dưới 2 triệu”.
- Anchor text nên mô tả rõ intent mua hàng, giúp người đọc chuyển thẳng sang danh sách sản phẩm phù hợp.
- Có thể đặt nhiều link đến cùng một filter page trong các bài khác nhau, miễn là bối cảnh phù hợp.
- Giúp Google hiểu filter page đó là một “landing page có chủ đích”, không phải URL ngẫu nhiên sinh ra từ hệ thống.
- Tăng khả năng filter page nhận được traffic từ các truy vấn long-tail, transactional.
- Giảm rủi ro bị xem là thin/duplicate nếu nội dung được bổ sung thêm text mô tả, FAQ, hướng dẫn chọn sản phẩm.
- Trải nghiệm người dùng: người đọc biết chính xác họ sẽ đến đâu, giảm bounce do click nhầm.
- Tín hiệu ngữ nghĩa cho Google: giúp máy hiểu được:
- Entity chính (thương hiệu, sản phẩm, chủ đề).
- Thuộc tính (màu sắc, giới tính, mức giá, use case).
- Intent (học, tham khảo, mua hàng, so sánh).
Một số cách triển khai hiệu quả:
Nếu một filter page không nhận được bất kỳ internal link nào, khả năng được crawl và index sẽ rất thấp, dù có self-canonical và nằm trong sitemap. Internal link là tín hiệu mạnh mẽ cho thấy trang đó có vai trò trong kiến trúc thông tin của website, đồng thời:
Anchor text phải rõ entity, thuộc tính và intent thay vì nhồi keyword
Khi liên kết đến tag hoặc filter, anchor text nên mô tả rõ entity, thuộc tính hoặc intent, thay vì chỉ nhồi từ khóa chung chung. Điều này quan trọng ở cả hai khía cạnh:
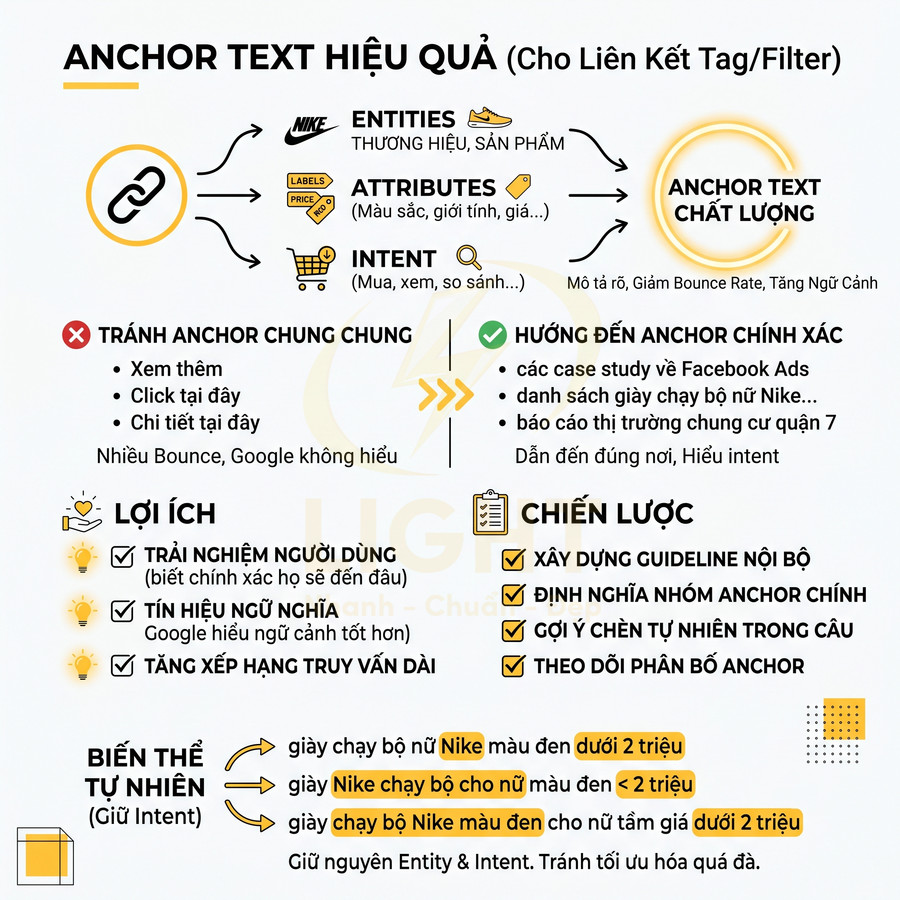
- “các case study về Facebook Ads” tốt hơn “xem thêm tại đây”.
- “danh sách giày chạy bộ nữ Nike màu đen dưới 2 triệu” tốt hơn “xem sản phẩm”.
- Tăng khả năng filter/tag page xếp hạng cho các truy vấn dài, cụ thể.
- Giảm sự phụ thuộc vào on-page keyword trong title, H1, vì anchor đã bổ sung thêm ngữ cảnh.
- Tạo mạng lưới semantic internal link, trong đó mỗi link là một “câu mô tả” về trang đích.
- “giày chạy bộ nữ Nike màu đen dưới 2 triệu”.
- “giày Nike chạy bộ cho nữ màu đen < 2 triệu”.
- “giày chạy bộ Nike màu đen cho nữ tầm giá dưới 2 triệu”.
- Giữ nguyên entity (Nike, giày chạy bộ nữ) và intent (mua, xem danh sách sản phẩm).
- Thay đổi cấu trúc câu, cách diễn đạt, giúp anchor tự nhiên hơn, giống ngôn ngữ người dùng.
- Giảm nguy cơ bị xem là tối ưu quá đà (over-optimization) khi Google phân tích pattern anchor text.
- Dùng anchor quá chung chung: “xem thêm”, “tại đây”, “click vào đây” cho các trang tag/filter quan trọng.
- Nhồi nhiều từ khóa không cần thiết vào anchor, khiến câu văn mất tự nhiên.
- Dùng anchor không khớp với nội dung trang đích (ví dụ anchor nói về “giày chạy bộ” nhưng link đến trang “giày bóng rổ”).
- Định nghĩa 3–5 nhóm anchor chính cho mỗi tag/filter quan trọng (bao gồm biến thể tự nhiên).
- Gợi ý cách chèn anchor trong câu văn sao cho mượt, không gượng ép.
- Theo dõi phân bố anchor qua thời gian để tránh lệch quá nhiều về một mẫu anchor duy nhất.
- Intent thông tin (informational): người dùng muốn đọc bài hướng dẫn, so sánh, review, checklist… Trong trường hợp này, một tag page chỉ là danh sách bài viết, thường không thỏa mãn intent nếu không được bổ sung nội dung giới thiệu, tóm tắt, hướng dẫn.
- Intent thương mại / giao dịch (commercial / transactional): người dùng muốn xem danh sách sản phẩm, dịch vụ, ưu đãi, hoặc có xu hướng “chuẩn bị mua”. Với eCommerce, các filter theo thuộc tính (màu sắc, kích thước, thương hiệu, mức giá…) thường phù hợp với intent này nếu được cấu hình đúng.
- Intent điều hướng (navigational): người dùng muốn vào một thương hiệu, danh mục, hoặc landing page cụ thể. Nếu truy vấn mang tính điều hướng mạnh (ví dụ: “áo thun nam Uniqlo”), một trang category hoặc brand page tối ưu tốt thường phù hợp hơn là một tag rời rạc.
- Không chỉ nhìn volume của 1 keyword chính, mà cần gom cả các biến thể dài (long-tail), từ đồng nghĩa, cách diễn đạt khác nhau.
- Xác định ngưỡng volume tối thiểu phù hợp với quy mô website và nguồn lực. Ví dụ: với site lớn, có thể chỉ ưu tiên nhóm từ khóa > 500–1.000 search/tháng; với niche site, nhóm 100–200 search/tháng vẫn có thể đáng làm.
- Đánh giá xu hướng (trend): volume đang tăng, ổn định hay giảm. Một tag/filter gắn với chủ đề đang tăng trưởng dài hạn sẽ đáng đầu tư hơn.
- Với blog / content site: số lượng bài viết đã xuất bản liên quan chặt chẽ đến chủ đề của tag. Một tag chỉ có 2–3 bài, lại không có kế hoạch mở rộng thêm, thường là tag mỏng.
- Với eCommerce: số lượng sản phẩm phù hợp với filter đó (ví dụ: “áo thun nam màu đen size L”). Filter quá hẹp khiến trang chỉ có vài sản phẩm, trải nghiệm kém và khó cạnh tranh SEO.
- Độ cập nhật: inventory có được bổ sung thường xuyên hay không. Một tag/filter gắn với chủ đề “sống” (liên tục có bài mới, sản phẩm mới) sẽ có sức mạnh nội dung tốt hơn.
- Category chính (danh mục cha)
- Các tag/filter khác đã index
- Các landing page chuyên biệt (ví dụ: trang brand, trang campaign)
- Nên cân nhắc gộp nội dung về một trang trung tâm mạnh hơn.
- Hoặc giữ tag/filter chỉ phục vụ điều hướng nội bộ, nhưng đặt noindex, follow để không cạnh tranh nội bộ trên SERP.
- Intent rõ + volume cao + inventory mạnh + khác biệt cao → Tạo mới & cho index, đầu tư nội dung bổ trợ (mô tả, FAQ, internal link).
- Intent rõ + volume trung bình + inventory vừa phải + khác biệt trung bình → Có thể index thử, theo dõi hiệu suất; tối ưu dần hoặc gộp nếu không hiệu quả.
- Intent mơ hồ hoặc volume thấp + inventory ít + trùng lặp cao → Noindex hoặc xóa, gộp về trang mạnh hơn.
- Trùng lặp chủ đề: nhiều tag nói về cùng một khái niệm.
- Tag mỏng: chỉ có 1–2 bài, không rõ chủ đề.
- Cấu trúc internal link rối, khó crawl, khó quản lý.
Ví dụ:
Anchor rõ ràng giúp:
Tuy nhiên, cũng không nên lặp đi lặp lại cùng một anchor text cứng nhắc ở mọi nơi. Nên sử dụng các biến thể tự nhiên, nhưng vẫn giữ được entity và intent cốt lõi, ví dụ:
Các biến thể này:
Cần tránh các lỗi thường gặp:
Cách tốt nhất là xây dựng một guideline anchor text nội bộ cho team content/SEO:
Quy trình quyết định tạo, index, noindex hoặc xóa trang thẻ và trang lọc
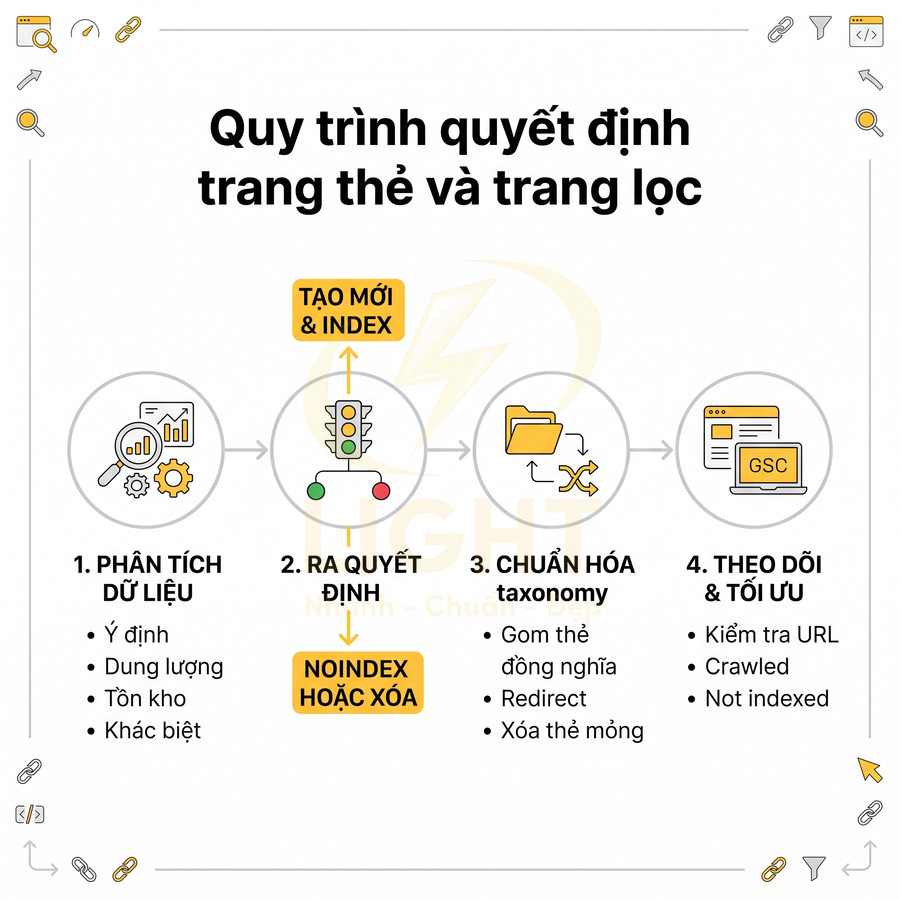
Phân tích search intent, search volume, inventory và độ khác biệt nội dung
Quy trình chuẩn để quyết định có nên tạo mới, cho index, noindex hay xóa một trang thẻ (tag) hoặc trang lọc (filter) luôn bắt đầu từ bước phân tích dữ liệu đa chiều. Mục tiêu là tránh tạo ra các URL “rác” chỉ tồn tại cho bot mà không mang lại giá trị cho người dùng hoặc hiệu quả SEO.
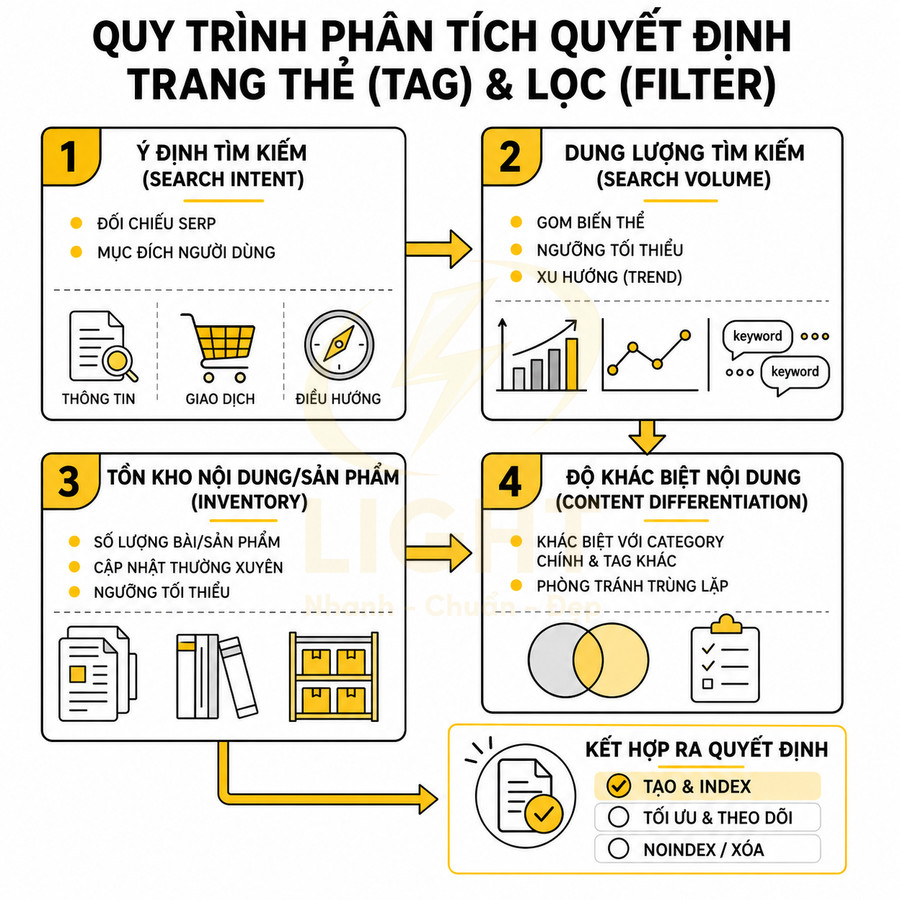
1. Search intent (ý định tìm kiếm)
Cần phân tích rõ người dùng thực sự muốn gì khi tìm kiếm cụm từ liên quan đến tag/filter đó:
Cần đối chiếu SERP thực tế (kết quả top 10) để xem Google đang ưu tiên loại trang nào: category, product, bài blog, tag page, hay trang so sánh. Nếu SERP chủ yếu là bài hướng dẫn, việc cố gắng đẩy một tag page dạng listing lên top sẽ khó và không phù hợp intent.
2. Search volume (dung lượng tìm kiếm)
Sau khi hiểu intent, cần đánh giá nhóm từ khóa liên quan đến tag/filter đó:
Nếu search volume quá thấp hoặc chỉ đến từ vài truy vấn rất rời rạc, việc tạo một trang tag/filter riêng biệt thường không mang lại ROI tốt, nên cân nhắc gộp vào các trang hiện có.
3. Inventory (tồn kho nội dung / sản phẩm)
Inventory là yếu tố quyết định trang tag/filter có đủ “chất liệu” để trở thành một hub nội dung hay không:
Cần đặt ra ngưỡng tối thiểu cho mỗi loại site. Ví dụ: một tag blog nên có ít nhất 8–10 bài chất lượng; một filter sản phẩm nên có tối thiểu 15–20 sản phẩm để đảm bảo trải nghiệm và khả năng ranking.
4. Độ khác biệt nội dung (content differentiation)
Độ khác biệt nội dung là mức độ mà danh sách kết quả trên trang tag/filter khác với:
Nếu 70–80% item (bài viết hoặc sản phẩm) trên tag/filter trùng với một category hoặc tag khác đã index, Google rất dễ xem đó là trang trùng lặp hoặc giá trị thấp. Khi đó:
5. Kết hợp 4 yếu tố để ra quyết định
Chỉ khi cả bốn yếu tố (intent rõ ràng, search volume đủ, inventory dồi dào, nội dung khác biệt) đều có tín hiệu tích cực, việc tạo mới hoặc index một trang thẻ/filter mới mới thực sự có ý nghĩa. Một số kịch bản điển hình:
Gom thẻ đồng nghĩa, chuẩn hóa taxonomy và loại bỏ tag mỏng
Với các website hoạt động lâu năm, hệ thống tag thường bị “phình to” do nhiều tác giả tạo thẻ tùy hứng, không theo chuẩn. Điều này dẫn đến:
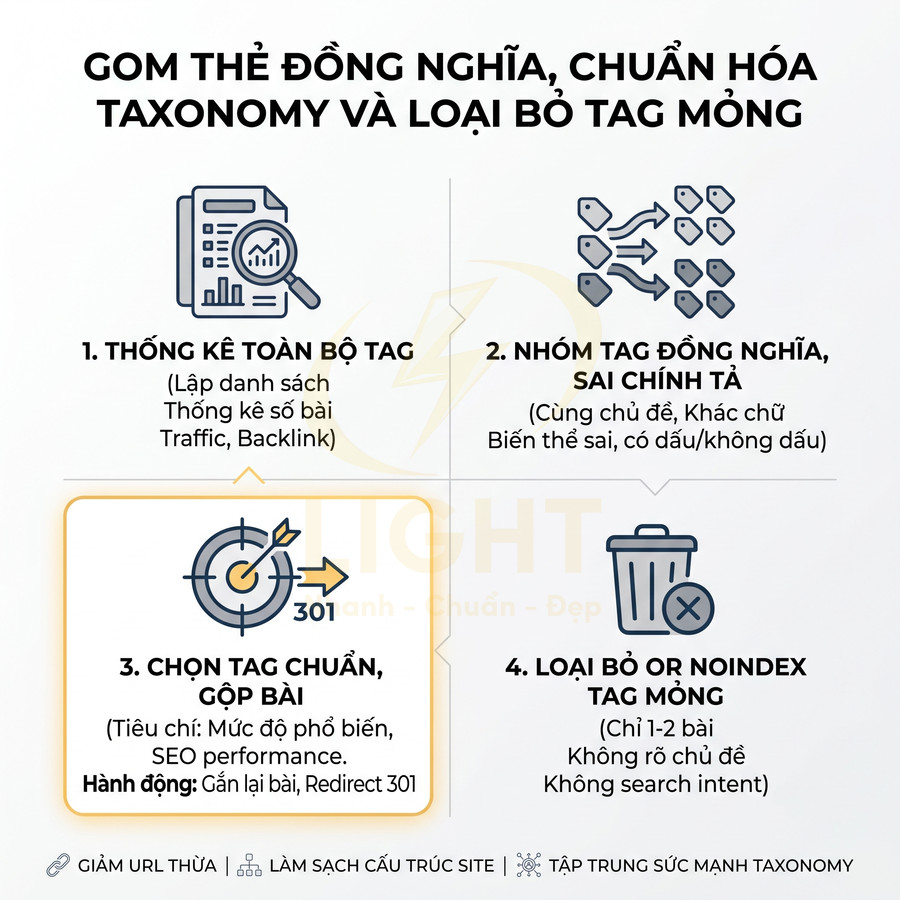
- Số bài viết gắn với mỗi tag.
- Traffic organic hiện tại (nếu có).
- Backlink trỏ đến từng tag page (nếu có).
- Trạng thái index / noindex hiện tại.
- Nhóm các tag khác nhau về mặt chữ nhưng cùng nói về một chủ đề (ví dụ: “SEO onpage”, “on-page SEO”, “tối ưu onpage”).
- Nhận diện các biến thể sai chính tả, viết tắt, có dấu/không dấu.
- Phân biệt tag theo chủ đề (topic) với tag theo định dạng (ví dụ: “case study”, “hướng dẫn”, “checklist”) để tránh trộn lẫn.
- Mức độ phổ biến trong ngôn ngữ tự nhiên (cách người dùng hay tìm kiếm).
- Hiệu suất SEO hiện tại (tag nào đang có traffic, backlink tốt hơn).
- Tính nhất quán với taxonomy tổng thể của website.
- Gắn lại toàn bộ bài viết từ các tag phụ về tag chuẩn.
- Thiết lập redirect 301 từ các tag cũ (nếu đã index và có traffic/backlink) về tag chuẩn.
- Hoặc đặt noindex, remove internal link đối với các tag phụ không có giá trị.
- Chỉ có 1–2 bài, không có kế hoạch mở rộng.
- Không mang ý nghĩa chủ đề rõ ràng (ví dụ: “misc”, “khác”, “tổng hợp”).
- Không có search intent cụ thể, không có search volume.
- Xóa hoàn toàn nếu không có traffic, không backlink, không cần cho điều hướng.
- Hoặc giữ để phục vụ UX nội bộ nhưng đặt noindex, follow để tránh loãng cấu trúc index.
- Các tag/filter đã có impression, click từ organic search chứng tỏ Google và người dùng đã có nhu cầu nhất định với trang đó.
- Traffic referral từ các nguồn khác (social, email, website đối tác) cho thấy trang đang đóng vai trò trong hành trình người dùng.
- Nếu một tag/filter đóng góp trực tiếp vào chuyển đổi (đơn hàng, lead, đăng ký) hoặc là bước trung gian quan trọng trong funnel (ví dụ: nhiều người xem trang này trước khi mua), trang đó có giá trị kinh doanh cao.
- Cần phân tích path người dùng trong analytics để nhận diện các trang “hỗ trợ mạnh cho hành trình người dùng”, không chỉ nhìn last-click conversion.
- Tag/filter nhận được backlink tự nhiên là tín hiệu mạnh về giá trị nội dung hoặc khả năng thu hút liên kết.
- Trong trường hợp này, nên:
- Giữ index (hoặc chuyển từ noindex sang index nếu phù hợp intent).
- Tối ưu nội dung trên trang để tận dụng sức mạnh backlink.
- Nếu cần gộp, sử dụng redirect 301 sang trang đích mạnh hơn để bảo toàn link equity.
- Tập hợp các bài viết hoặc sản phẩm xoay quanh một chủ đề con quan trọng.
- Liên kết chặt chẽ với pillar page và các bài cluster khác.
- Được dùng làm điểm điều hướng chính trong kiến trúc site.
- Noindex nếu vẫn cần cho UX nội bộ.
- Xóa hoặc gộp nếu hoàn toàn không cần thiết, sau khi đánh giá kỹ rủi ro (mất backlink, mất traffic tiềm năng).
- Crawled – currently not indexed: Google đã crawl nhưng chưa index. Nguyên nhân thường là nội dung mỏng, trùng lặp, hoặc trang chưa đủ tín hiệu chất lượng. Với các tag/filter quan trọng, nên:
- Bổ sung nội dung mô tả, heading, internal link.
- Cải thiện tốc độ tải, UX, cấu trúc dữ liệu.
- Xem lại mức độ trùng lặp với các trang khác.
- Duplicate, Google chose different canonical: Google cho rằng trang là bản sao của một URL khác và tự chọn canonical. Cần:
- Đánh giá xem canonical Google chọn có đúng với chiến lược của bạn không.
- Nếu không, điều chỉnh thẻ canonical, nội dung, internal link để làm rõ trang nào là bản chính.
- Alternate page with proper canonical tag: Trang được đánh dấu là bản phụ với canonical trỏ về trang chính. Nếu đây là chủ đích (ví dụ: các filter không cần index), trạng thái này là bình thường. Nếu không, cần xem lại cấu hình canonical.
- Kiểm tra trạng thái index thực tế (trong index hay không, canonical nào được Google chọn).
- Xem phiên bản đã crawl gần nhất, phát hiện các vấn đề về render, nội dung không hiển thị, lỗi kỹ thuật.
- Yêu cầu reindex sau khi đã tối ưu nội dung hoặc thay đổi cấu hình index/noindex, canonical.
- Các tag/filter đang nhận nhiều internal link: đây thường là các trang quan trọng trong cấu trúc site, nên được ưu tiên tối ưu và index nếu phù hợp.
- Các tag/filter có backlink từ domain bên ngoài: cần bảo vệ, tránh xóa hoặc noindex mà không có phương án chuyển hướng hợp lý.
- Tăng cường nội dung, internal link cho các trang bị “Crawled – currently not indexed” nhưng vẫn muốn index.
- Điều chỉnh canonical, cấu trúc nội dung cho các trang bị đánh dấu duplicate không mong muốn.
- Đặt noindex cho các trang filter không cần thiết nhưng vẫn được crawl nhiều, nhằm tiết kiệm crawl budget và tập trung vào các URL quan trọng.
- Không tạo tag chỉ vì một từ khóa xuất hiện trong bài viết; mỗi tag nên đại diện cho một chủ đề đủ lớn, có khả năng gom nhóm nhiều nội dung liên quan.
- Ưu tiên các tag tương ứng với topic cluster hoặc sub-topic có search intent rõ ràng (ví dụ: “SEO onpage”, “SEO technical”, “Entity SEO” thay vì các tag rời rạc, ít nội dung).
- Đảm bảo mỗi tag có:
- Tối thiểu một số lượng bài viết/sản phẩm nhất định (tùy ngành, thường >= 5–10) để tránh trang tag mỏng.
- Khả năng mở rộng nội dung trong tương lai (không phải chủ đề “chết” hoặc quá hẹp).
- Liên hệ rõ ràng với hành trình người dùng (awareness, consideration, decision).
- Không index mọi tổ hợp filter chỉ vì hệ thống có khả năng sinh URL; chỉ chọn những tổ hợp có:
- Search intent cụ thể (ví dụ: “giày chạy bộ nam Nike size 42”, “khách sạn 5 sao gần biển Đà Nẵng”).
- Search volume đủ lớn hoặc có giá trị chuyển đổi cao (dù volume thấp nhưng mang lại doanh thu tốt).
- Inventory đủ phong phú để trang không bị trống hoặc quá ít kết quả.
- Phân loại filter:
- Filter chính (core filters): thương hiệu, loại sản phẩm, phân khúc giá, khu vực địa lý… có thể trở thành landing page SEO.
- Filter phụ (secondary filters): màu sắc, size, trạng thái kho, sort… thường không nên index.
- Phát triển bền vững, tránh bùng nổ URL vô nghĩa gây loãng cấu trúc site.
- Giảm rủi ro duplicate content, thin content và cannibalization giữa các trang.
- Tập trung crawl budget và tín hiệu xếp hạng vào những landing page thực sự quan trọng, có khả năng mang lại traffic và chuyển đổi.
- Title riêng, không trùng với trang khác:
- Title nên phản ánh chính xác intent của tổ hợp tag/filter, tránh chỉ lặp lại tên category gốc.
- Có thể sử dụng template động nhưng cần kiểm soát để không tạo ra hàng loạt title gần như giống nhau.
- Ưu tiên chèn từ khóa chính + yếu tố phân biệt (thương hiệu, thuộc tính, khu vực, mục đích sử dụng…).
1. Lập danh sách toàn bộ tag và thống kê
Cần xuất danh sách đầy đủ tất cả tag hiện có, kèm theo các chỉ số cơ bản:
Bước này có thể thực hiện bằng cách kết hợp dữ liệu từ CMS, Google Analytics, Google Search Console và các công cụ crawl (Screaming Frog, Sitebulb…).
2. Nhóm các tag đồng nghĩa, gần nghĩa, sai chính tả
Sau khi có danh sách, tiến hành phân cụm:
Có thể sử dụng thêm dữ liệu từ search console (truy vấn thực tế) để hiểu người dùng thường dùng cách diễn đạt nào, từ đó ưu tiên phiên bản chuẩn.
3. Chọn phiên bản chuẩn và gộp bài viết
Với mỗi nhóm tag đồng nghĩa, cần chọn một phiên bản chuẩn dựa trên:
Sau đó:
4. Xóa hoặc noindex các tag mỏng, không rõ chủ đề
Tag mỏng là các tag:
Với nhóm này, nên:
Quy trình chuẩn hóa taxonomy giúp giảm số lượng URL thừa, làm sạch cấu trúc site, tập trung sức mạnh vào các tag page thực sự có tiềm năng trở thành hub nội dung chất lượng cao.
Ưu tiên index trang có traffic, chuyển đổi, backlink hoặc vai trò topical cluster
Khi phải lựa chọn giữa nhiều tag/filter tiềm năng, cần có tiêu chí ưu tiên rõ ràng để phân bổ nguồn lực tối ưu.
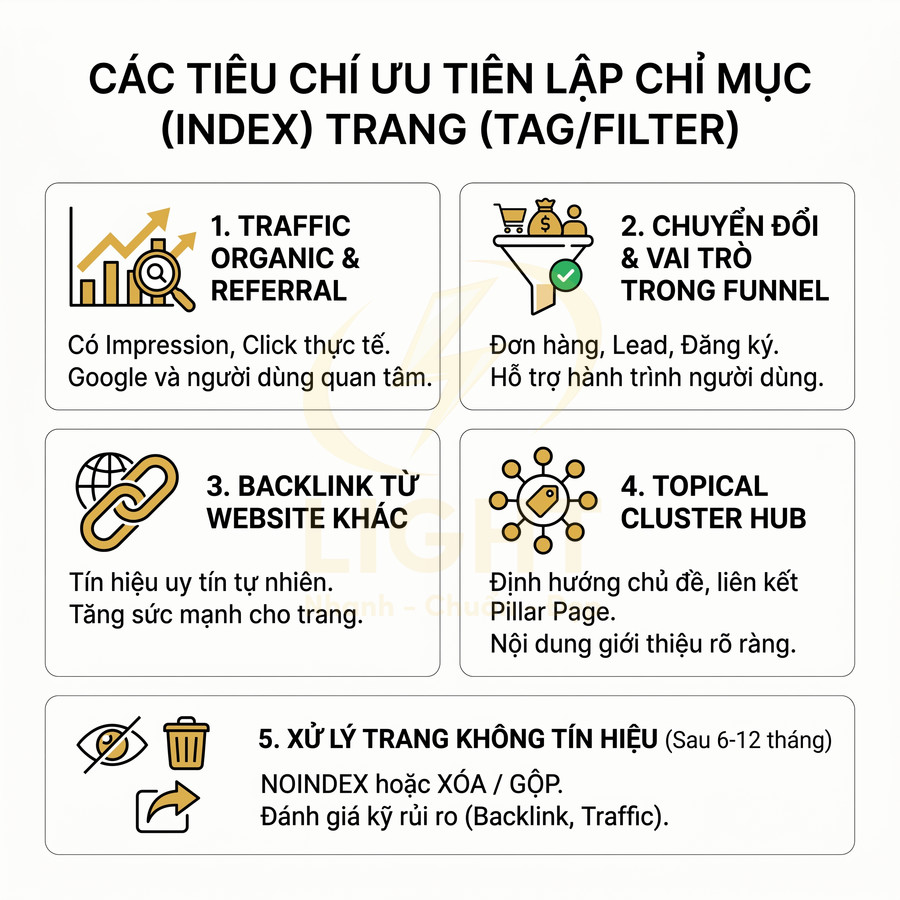
Các tín hiệu sau nên được xem là “bằng chứng giá trị”:
1. Traffic organic hoặc referral
Những trang này nên được ưu tiên index (nếu chưa) và tối ưu thêm nội dung, meta, schema, internal link.
2. Chuyển đổi và vai trò trong funnel
3. Backlink từ website khác
4. Vai trò trung tâm trong topical cluster
Một tag/filter có thể được thiết kế như “hub” trong một topical cluster:
Trong mô hình này, tag/filter không chỉ là trang listing, mà còn có phần nội dung giới thiệu, tóm tắt, liên kết nổi bật, giúp Google hiểu rõ cấu trúc chủ đề của website. Những trang như vậy nên được ưu tiên index và đầu tư tối ưu onpage sâu.
5. Loại bỏ hoặc noindex các trang không có tín hiệu
Các tag/filter không có traffic, không chuyển đổi, không backlink, không đóng vai trò trong cluster sau một thời gian đủ dài (ví dụ 6–12 tháng) có thể được đưa vào danh sách:
Theo dõi Google Search Console để phát hiện excluded, crawled not indexed và duplicate
Sau khi triển khai chiến lược index/noindex, việc theo dõi định kỳ trong Google Search Console là bắt buộc để điều chỉnh chiến thuật dựa trên phản hồi thực tế từ Googlebot.

1. Báo cáo Pages > Indexed / Not indexed
Cần chú ý đặc biệt đến các trạng thái:
2. URL Inspection cho từng URL quan trọng
Với các tag/filter chiến lược, nên dùng URL Inspection để:
3. Báo cáo Links
Trong mục Links, cần theo dõi:
4. Điều chỉnh chiến lược dựa trên dữ liệu
Dựa trên các báo cáo trong Search Console, có thể:
Checklist website chuẩn SEO khi dùng trang thẻ và trang lọc tự động
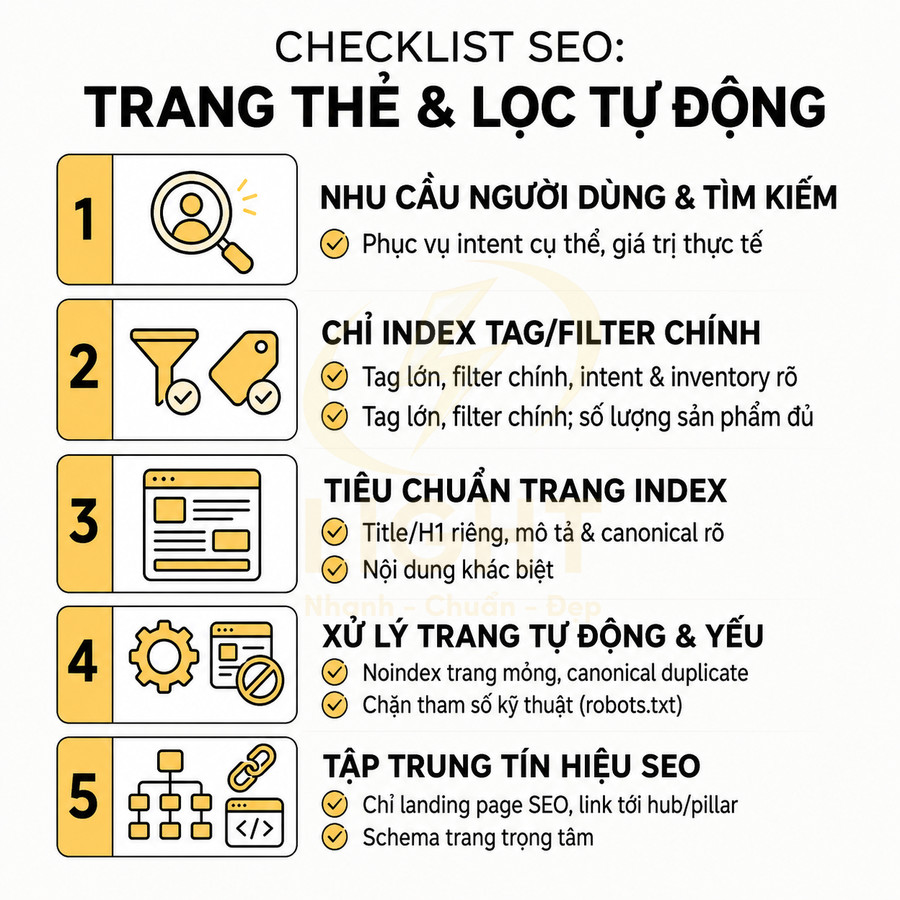
Chỉ tạo trang thẻ, trang lọc phục vụ người dùng và có giá trị tìm kiếm riêng
Một website chuẩn SEO nên tuân thủ nguyên tắc cốt lõi: mỗi trang indexable phải phục vụ một nhu cầu người dùng rõ ràng, có thể đo lường và có khả năng mang lại giá trị kinh doanh. Với tag và filter, cần chuyển từ tư duy “sinh URL càng nhiều càng tốt” sang tư duy “mỗi URL là một landing page có mục tiêu cụ thể”. Điều này bao gồm cả góc độ search intent, search volume, lẫn inventory thực tế trên site.
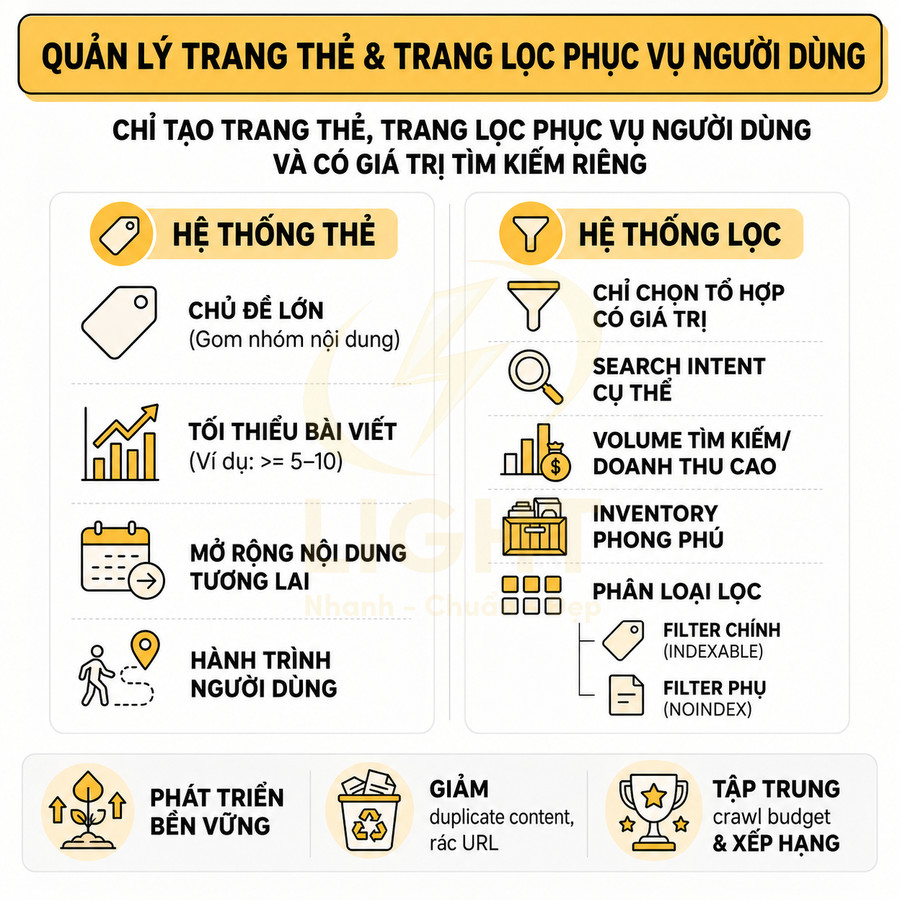
Với hệ thống tag:
Với hệ thống filter (lọc sản phẩm/dịch vụ):
Cách tiếp cận này giúp website:
Mỗi trang indexable có title, H1, mô tả, canonical và nội dung đủ khác biệt
Một tiêu chuẩn cơ bản cho mọi trang thẻ/filter được index là phải được đối xử như một landing page SEO hoàn chỉnh, không phải trang tự động “phụ”. Tối thiểu cần đáp ứng:
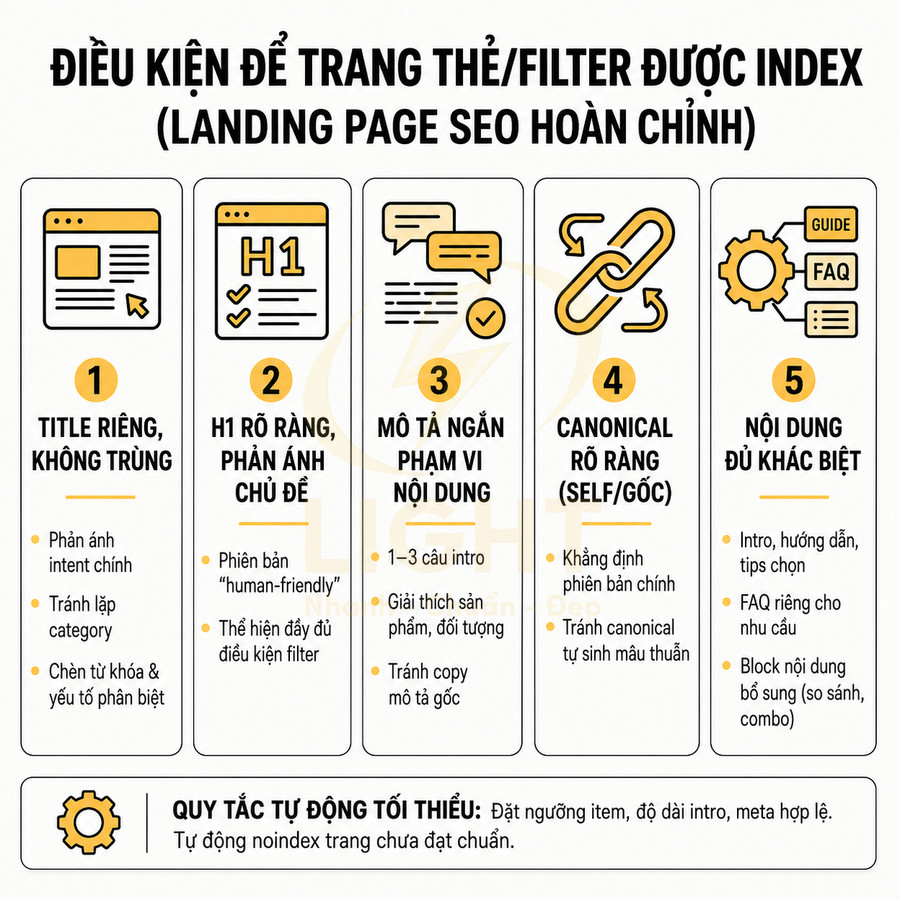
- H1 rõ ràng, phản ánh đúng chủ đề hoặc tổ hợp điều kiện:
- H1 nên là phiên bản “human-friendly” của title, giúp người dùng hiểu ngay họ đang ở trang nào.
- Với filter, H1 nên thể hiện đầy đủ các điều kiện quan trọng (ví dụ: “Giày chạy bộ nam Nike dưới 2 triệu”).
- Mô tả ngắn giải thích phạm vi nội dung:
- Một đoạn intro 1–3 câu ở đầu trang giúp làm rõ phạm vi: loại sản phẩm/dịch vụ, đối tượng, ngữ cảnh sử dụng.
- Có thể bổ sung bullet ngắn về lợi ích, USP, hoặc hướng dẫn chọn sản phẩm phù hợp với filter/tag đó.
- Tránh copy-paste mô tả từ category gốc cho mọi tag/filter, dễ gây trùng lặp nội dung.
- Canonical rõ ràng (self-canonical hoặc trỏ về trang gốc):
- Trang được chọn làm landing page SEO nên dùng self-canonical để khẳng định đây là phiên bản chính.
- Các trang filter gần như trùng lặp với category hoặc với nhau nên canonical về trang gốc phù hợp.
- Tránh để hệ thống tự sinh canonical không nhất quán giữa các tổ hợp filter, gây tín hiệu mâu thuẫn cho bot.
- Nội dung đủ khác biệt so với các trang khác trong site:
- Không chỉ khác biệt về danh sách sản phẩm/bài viết, mà còn khác biệt về:
- Intro, hướng dẫn, tips chọn sản phẩm theo filter/tag đó.
- FAQ riêng cho nhu cầu người dùng tương ứng.
- Block nội dung bổ sung (so sánh, gợi ý combo, case study, review…).
- Nếu không thể tạo khác biệt nội dung, cần xem lại lý do tồn tại của trang đó trong chiến lược SEO.
- Không chỉ khác biệt về danh sách sản phẩm/bài viết, mà còn khác biệt về:
- Chỉ cho phép index khi trang đạt ngưỡng tối thiểu về:
- Số lượng item (sản phẩm/bài viết).
- Độ dài intro hoặc nội dung bổ sung.
- Cấu hình meta (title, H1, canonical) hợp lệ.
- Tự động gắn noindex cho các trang chưa đạt chuẩn, sau đó chuyển sang index khi đã được tối ưu.
- Noindex, follow để giữ internal link nhưng không index:
- Áp dụng cho:
- Tag mới, ít nội dung, đang trong giai đoạn “ươm mầm”.
- Filter phụ có thể hữu ích cho người dùng nhưng không có search intent riêng.
- Các trang trạng thái tạm thời (ví dụ: filter “hết hàng”, “sắp về hàng”).
- Giữ thuộc tính follow để bot vẫn đi theo link đến các trang quan trọng phía sau.
- Có thể chuyển dần từ noindex sang index khi trang đạt ngưỡng nội dung và giá trị.
Nếu một trang không đáp ứng được các tiêu chí trên, khả năng cao nó không nên được index, hoặc cần được chỉnh sửa, bổ sung nội dung trước khi đưa vào sitemap. Về mặt thực thi, nên xây dựng bộ quy tắc tự động:
Trang tự động mỏng, trùng lặp hoặc tham số phụ được noindex, canonical hoặc chặn hợp lý
Các trang tự động sinh ra nhưng không có giá trị riêng (tag mỏng, filter phụ, sort, phân trang, trạng thái tạm thời) nếu để mặc cho bot crawl và index sẽ gây lãng phí crawl budget, làm loãng tín hiệu và tăng nguy cơ duplicate. Cần phân loại và áp dụng đúng công cụ kỹ thuật:
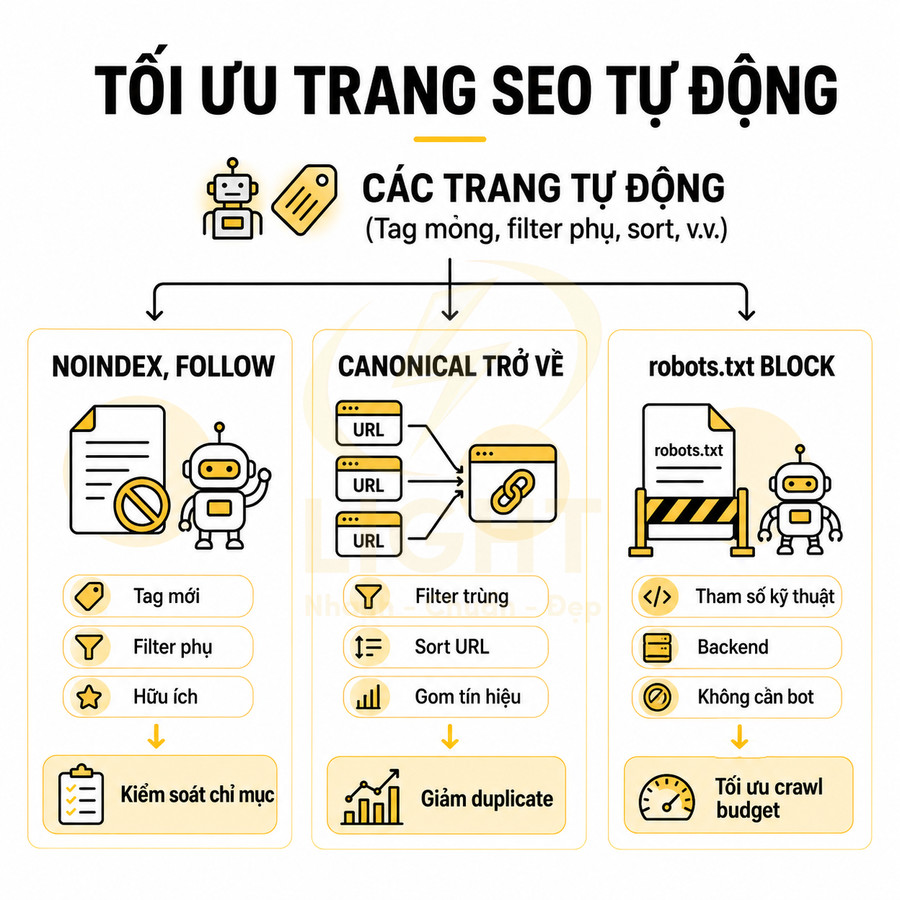
- Canonical về trang gốc nếu nội dung trùng lặp:
- Áp dụng cho:
- Các tổ hợp filter tạo ra danh sách gần như giống hệt category hoặc một filter khác.
- Các URL có tham số không làm thay đổi đáng kể tập nội dung (ví dụ: sort theo giá, sort theo độ phổ biến).
- Canonical giúp gom tín hiệu về một URL chuẩn, tránh phân tán sức mạnh xếp hạng.
- Cần đảm bảo canonical nhất quán hai chiều, tránh trường hợp A canonical về B, B lại canonical về A hoặc về C.
- Áp dụng cho:
- Chặn crawl bằng robots.txt nếu thực sự không cần bot truy cập:
- Áp dụng cho:
- Các tham số kỹ thuật (session, tracking, sort phức tạp) không phục vụ SEO.
- Các khu vực backend, trang test, staging, hoặc module không dành cho người dùng cuối.
- Không nên lạm dụng robots.txt cho các trang đã được index; trong trường hợp đó, noindex hoặc canonical thường phù hợp hơn.
- Cần kết hợp với cấu hình URL parameter trong Google Search Console (nếu phù hợp) để tối ưu thêm việc xử lý tham số.
- Áp dụng cho:
- Kiểm soát chỉ mục, tránh tình trạng hàng chục nghìn URL tự động lọt vào index mà không mang lại traffic.
- Giảm duplicate content và near-duplicate giữa các tổ hợp filter.
- Tối ưu crawl budget mà không làm gãy luồng internal link quan trọng.
- Chỉ đưa vào sitemap:
- Các trang đã được xác định là landing page SEO, có khả năng mang lại traffic hoặc chuyển đổi.
- Các trang đã hoàn thiện meta, nội dung, canonical và không bị noindex.
- Không đưa các trang filter phụ, sort, phân trang, tag mỏng vào sitemap.
- Có thể tách sitemap theo nhóm:
- Sitemap cho category/pillar.
- Sitemap cho tag/filter quan trọng.
- Sitemap cho bài viết/sản phẩm.
- Xây dựng cấu trúc internal link ưu tiên:
- Từ homepage, menu, footer, breadcrumb trỏ mạnh về các landing page chính.
- Từ bài viết/sản phẩm liên quan trỏ về các tag/filter quan trọng như một phần của topic cluster.
- Hạn chế:
- Link trực tiếp đến các trang filter phụ không có chiến lược SEO, tránh làm chúng trở nên “nổi” không cần thiết.
- Tạo quá nhiều link đến các URL tham số, sort, hoặc trạng thái tạm thời.
- Ưu tiên triển khai schema cho:
- Category, pillar, tag/filter quan trọng (ví dụ: BreadcrumbList, ItemList, FAQ, Product, Article… tùy ngữ cảnh).
- Các trang có khả năng hiển thị rich result, giúp tăng CTR và hỗ trợ hiểu ngữ nghĩa.
- Không dàn trải schema cho:
- Các trang tự động không có chiến lược rõ ràng.
- Các URL tham số, sort, filter phụ, nơi schema không mang lại thêm giá trị.
- Thin content ở quy mô lớn: đa số tag chỉ có 1–3 bài, nội dung lặp lại nhiều với category, author archive, date archive. Điều này làm tăng tỷ lệ trang mỏng trong chỉ mục, ảnh hưởng đến đánh giá chất lượng tổng thể (site-wide quality).
- Keyword cannibalization: nhiều tag trùng hoặc gần trùng với category, với tiêu đề bài viết, hoặc với nhau (ví dụ: “SEO”, “SEO Onpage”, “Tối ưu SEO Onpage”). Khi tất cả đều index, Google khó xác định URL nào là đại diện tốt nhất cho chủ đề, dẫn đến chia nhỏ tín hiệu xếp hạng.
- Lãng phí crawl budget: với site lớn, hàng nghìn tag khiến bot phải crawl nhiều URL ít giá trị, làm chậm việc cập nhật và index các trang quan trọng như category, landing page, bài viết trụ cột.
- Trải nghiệm tìm kiếm kém: người dùng từ SERP vào một tag chỉ có vài bài, không có mô tả, không có cấu trúc điều hướng rõ ràng sẽ dễ thoát trang, tăng bounce rate và giảm tín hiệu tương tác.
- Mặc định áp dụng meta robots noindex, follow cho toàn bộ tag archive ngay từ đầu (cấu hình qua plugin như Rank Math, Yoast, SEOPress…). Điều này vẫn cho phép Google crawl và theo link, nhưng không index URL tag.
- Định kỳ audit hệ thống tag:
- Gom nhóm các tag trùng nghĩa hoặc quá gần nhau.
- Xóa hoặc hợp nhất các tag chỉ có 1 bài hoặc không còn phù hợp với chiến lược nội dung.
- Chuẩn hóa cách đặt tên tag theo entity, chủ đề con rõ ràng, tránh dùng tag như “tips”, “hay”, “mới nhất”.
- Chọn ra một nhóm nhỏ tag chiến lược để index:
- Có từ 8–10 bài trở lên, nội dung xoay quanh một chủ đề rõ ràng.
- Có search intent riêng biệt so với category, ví dụ: tag theo thương hiệu, theo công nghệ, theo dạng bài (case study, checklist) nhưng có volume tìm kiếm.
- Có tiềm năng trở thành hub phụ trong topical map (ví dụ: “Core Web Vitals”, “Entity SEO”, “Technical Audit”).
- Với nhóm tag được chọn:
- Bật index, thêm vào sitemap XML.
- Tối ưu onpage: title, meta description, H1, mô tả mở đầu, internal link, breadcrumb.
- Kiểm soát phân trang (pagination) bằng rel="next/prev" (nếu còn dùng) hoặc cấu trúc internal link hợp lý để tránh trùng lặp giữa page 1, page 2…
- Category:
- Đóng vai trò hub chính (primary hub) cho các nhóm chủ đề lớn, thường tương ứng với các từ khóa head hoặc mid-tail có volume cao, ví dụ: “SEO”, “Content Marketing”, “Thương mại điện tử”.
- Thường xuất hiện trong cấu trúc URL (ví dụ: /seo/onpage-seo/), trong menu chính, breadcrumb, và sitemap HTML.
- Được ưu tiên về:
- Internal link từ homepage, footer, sidebar.
- Schema (BreadcrumbList, ItemList, đôi khi là FAQ hoặc HowTo nếu có nội dung mô tả).
- Onpage content: nên có đoạn giới thiệu, mô tả chi tiết về chủ đề, link đến các bài trụ cột (pillar) và cluster.
- Thường là điểm đến chính cho các truy vấn tổng quát, mang tính khám phá (discovery intent).
- Tag:
- Đóng vai trò hub phụ (secondary hub), linh hoạt hơn, dùng để gom nhóm nội dung theo:
- Entity (thương hiệu, công cụ, nhân vật, địa điểm).
- Chủ đề con (subtopic) trong một category lớn.
- Ngữ cảnh phụ hoặc dạng nội dung (case study, checklist, template…).
- Thường nhắm đến long-tail hoặc intent cụ thể hơn, ví dụ: “SEO audit checklist”, “Content brief template”.
- Không nhất thiết xuất hiện trong URL hoặc menu chính; có thể chỉ tồn tại như một lớp điều hướng bổ sung.
- Chỉ một phần nhỏ tag được chọn để index, với mục tiêu:
- Mở rộng topical cluster sang các ngách nhỏ nhưng có search demand.
- Tạo landing page cho các truy vấn mà category không bao phủ tốt (quá rộng hoặc không đủ tập trung).
- Đóng vai trò hub phụ (secondary hub), linh hoạt hơn, dùng để gom nhóm nội dung theo:
- Đảm bảo mỗi category có một hoặc vài bài pillar mạnh, nhiều cluster bài con, và mô tả rõ ràng.
- Dùng tag chiến lược để gom các bài liên quan đến một entity hoặc subtopic, sau đó tối ưu tag archive như một hub phụ với mô tả, internal link, và cấu trúc rõ ràng.
- Trùng lặp nội dung ở quy mô lớn giữa các tổ hợp filter (màu + size + giá + thương hiệu…).
- Lãng phí crawl budget và làm phình chỉ mục với các trang không có giá trị tìm kiếm.
- Khó kiểm soát canonical, dẫn đến tín hiệu xếp hạng bị phân tán.
- Nhu cầu tìm kiếm (search demand):
- Phân tích keyword: người dùng có thực sự tìm “áo thun nam màu đen size L”, “giày nike đen dưới 2 triệu”, “chung cư 2 phòng ngủ quận 7 dưới 3 tỷ” không.
- Dùng dữ liệu từ Google Search Console, Google Keyword Planner, các công cụ như Ahrefs, Semrush để xác định các pattern phổ biến: theo màu, theo size, theo khoảng giá, theo thương hiệu + thuộc tính.
- Chỉ cân nhắc index các tổ hợp filter có volume hoặc thể hiện rõ intent thương mại (transactional/commercial intent).
- Inventory (số lượng sản phẩm):
- Một trang filter chỉ nên index nếu có đủ sản phẩm để tạo cảm giác “đầy đặn”, thường tối thiểu 15–20 sản phẩm, tùy ngành.
- Nếu inventory biến động mạnh (hết hàng thường xuyên), cần cơ chế fallback: khi số sản phẩm dưới ngưỡng, có thể:
- Tự động noindex hoặc chuyển canonical về category gốc.
- Hiển thị gợi ý sản phẩm liên quan để tránh trang “trống”.
- Độ khác biệt (content differentiation):
- Danh sách sản phẩm trên trang filter phải khác đáng kể so với category gốc hoặc các filter khác. Nếu chỉ thay đổi 1–2 sản phẩm, không nên index.
- Các filter có tính “định danh” mạnh (ví dụ: màu đen, size lớn, dưới 2 triệu, chính hãng, giảm giá) thường tạo ra tập sản phẩm đủ khác biệt để trở thành landing page riêng.
- Tối ưu title, meta description theo pattern: [Loại sản phẩm] + [Thuộc tính chính] + [Brand/Location] + [Yếu tố giá/ưu đãi].
- Thêm mô tả ngắn giải thích phạm vi filter (ví dụ: chỉ hiển thị sản phẩm màu đen, size L, còn hàng).
- Thiết lập canonical chính xác cho từng tổ hợp filter được chọn index.
- Đặt noindex, follow.
- Hoặc chặn crawl bằng robots.txt / parameter handling (Search Console) nếu số lượng biến thể quá lớn và không có giá trị SEO.
- Google vẫn crawl trang tag, đọc nội dung và các liên kết trên đó.
- Thu thập và truyền PageRank qua các link outbound (internal link đến bài viết, category, tag khác).
- Chỉ không đưa chính URL tag vào chỉ mục (không xuất hiện trên SERP).
- Nếu bạn dùng noindex, nofollow, Google có thể dần ngừng crawl các link trên trang đó, làm suy giảm giá trị internal link. Vì vậy, với tag dùng để gom link, nên giữ noindex, follow.
- Chỉ khi chặn bằng robots.txt (disallow) thì bot mới không truy cập được trang, không thấy được các link trên đó, và không thể truyền tín hiệu qua các link này.
- Nếu một tag đang từ noindex chuyển sang index, cần:
- Đảm bảo trang đã được tối ưu onpage, có mô tả, cấu trúc rõ ràng.
- Thêm vào sitemap để thúc đẩy tái crawl và index.
- Đánh giá giá trị hiện tại của tag:
- Kiểm tra traffic từ organic, referral, direct (Google Analytics, Search Console).
- Kiểm tra backlink trỏ vào URL tag bằng các công cụ như Ahrefs, Majestic, Semrush.
- Đánh giá số lượng bài viết gắn tag và mức độ liên quan giữa chúng.
- Nếu tag không có traffic, không backlink, không vai trò điều hướng:
- Có thể xóa, nhưng trước đó:
- Gỡ gắn thẻ khỏi bài viết để tránh tạo link gãy nội bộ (nếu theme hiển thị tag như link).
- Kiểm tra xem tag có đang được dùng trong logic hiển thị (widget, block, shortcode) hay không.
- Với các tag chỉ tồn tại nội bộ, chưa từng index (noindex từ đầu), có thể xóa trực tiếp sau khi kiểm tra ảnh hưởng đến CMS.
- Có thể xóa, nhưng trước đó:
- Nếu tag đã được index lâu hoặc có backlink:
- Không nên xóa trắng (404) ngay, vì sẽ mất tín hiệu từ backlink và có thể tạo trải nghiệm xấu cho người dùng truy cập từ link cũ.
- Cân nhắc 301 redirect:
- Về category liên quan nhất nếu tag mang tính chủ đề rộng.
- Về một tag khác mạnh hơn, có nội dung tương đương hoặc bao quát hơn.
- Trong trường hợp không có trang tương đương, có thể redirect về homepage, nhưng nên hạn chế.
- Giới hạn số lượng tag tối đa cho mỗi bài (ví dụ: 3–5 tag).
- Chỉ tạo tag mới khi có kế hoạch dùng cho nhiều bài và có ý nghĩa trong topical map.
- Định kỳ audit để hợp nhất hoặc xóa các tag trùng lặp, ít bài, không còn phù hợp.
- Tăng giá trị trang, tránh bị xem là thin content khi chỉ có danh sách sản phẩm hoặc bài viết.
- Giải thích rõ phạm vi sản phẩm/nội dung trong filter (ví dụ: chỉ hiển thị sản phẩm còn hàng, thuộc một phân khúc giá, một thuộc tính cụ thể).
- Cải thiện khả năng xếp hạng cho các truy vấn có intent cụ thể, đặc biệt là các truy vấn dạng câu hỏi hoặc có yếu tố điều kiện (màu, size, giá, thương hiệu, khu vực…).
- Thêm đoạn mô tả ngắn (100–200 từ) phía trên hoặc dưới danh sách:
- Giải thích tiêu chí lọc.
- Nhấn mạnh lợi ích, ưu điểm của nhóm sản phẩm này.
- Chèn một số từ khóa long-tail tự nhiên, không nhồi nhét.
- Nếu phù hợp, bổ sung:
- FAQ về cách chọn size, màu, chất liệu, mức giá.
- Hướng dẫn bảo quản, chính sách đổi trả liên quan đến nhóm sản phẩm đó.
- Internal link đến các bài blog hướng dẫn chi tiết hơn.
- Tối ưu cấu trúc heading (H1, H2) để phản ánh rõ intent của trang filter, tránh trùng hoàn toàn với category gốc.
- Không cần đầu tư mô tả riêng, chỉ cần đảm bảo:
- Danh sách kết quả hiển thị nhanh, chính xác.
- UI/UX rõ ràng, dễ thay đổi hoặc xóa filter.
- Có thể dùng AJAX hoặc parameter trên URL mà không cần tối ưu SEO onpage.
Việc áp dụng đúng công cụ cho đúng trường hợp giúp:
Sitemap, internal link và schema chỉ ưu tiên trang được chọn làm landing page SEO
Các tín hiệu hỗ trợ SEO như sitemap, internal link, schema nên được xem là tài nguyên hữu hạn và cần được phân bổ có chiến lược. Nhóm trang được chọn làm landing page (category, pillar, tag quan trọng, filter quan trọng) phải được ưu tiên rõ ràng, thay vì dàn trải cho hàng loạt trang tự động.
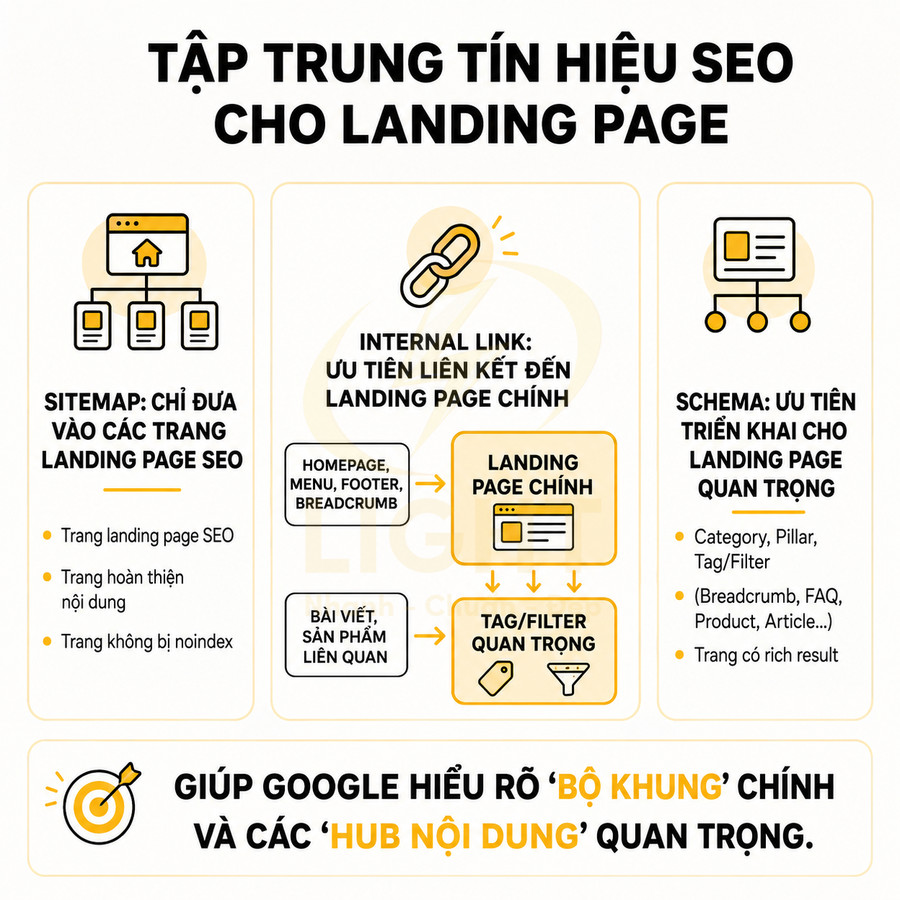
Về sitemap:
Về internal link:
Về schema:
Sự tập trung này giúp Google hiểu rõ đâu là “bộ khung” chính của website, đâu là các hub nội dung quan trọng, từ đó phân bổ tín hiệu xếp hạng hiệu quả hơn, giảm nguy cơ Google “lạc” vào ma trận URL tự động và bỏ sót những trang thực sự cần được ưu tiên.
Câu hỏi thường gặp về trang thẻ, trang lọc tự động và SEO
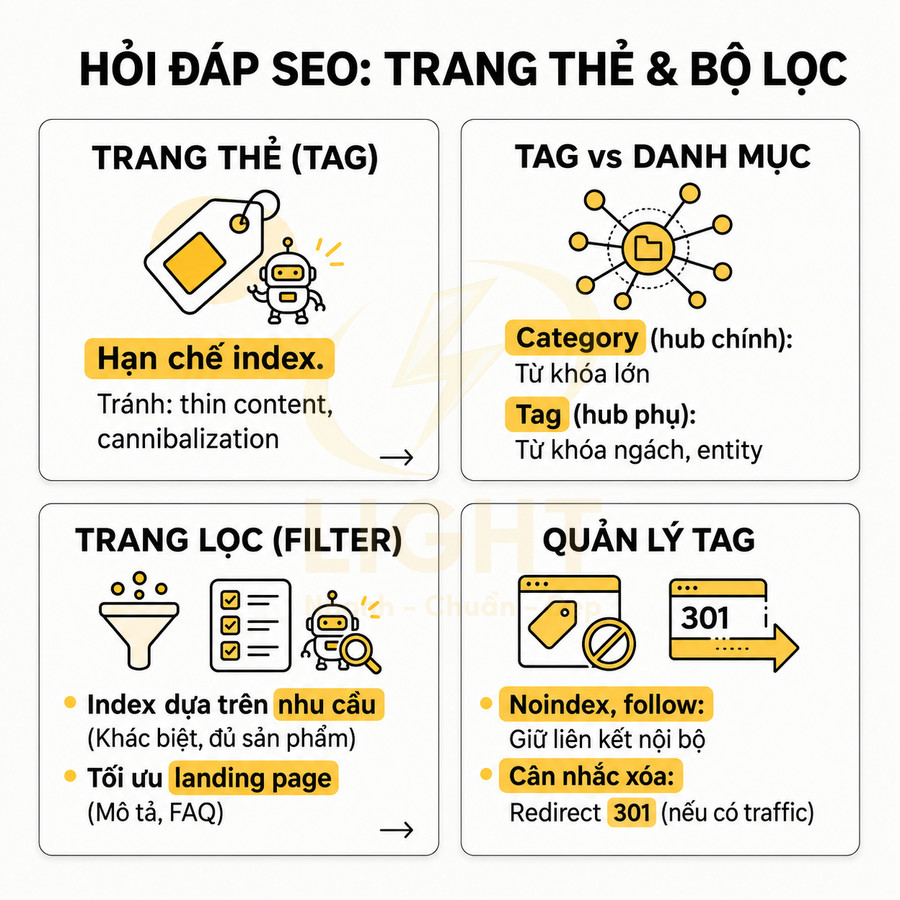
Có nên index toàn bộ trang tag trên WordPress không?
Không nên index toàn bộ trang tag trên WordPress một cách mặc định, đặc biệt với các site đã hoạt động lâu năm hoặc có nhiều cộng tác viên. Về mặt kỹ thuật, mỗi tag archive là một trang danh sách (listing page) có nội dung chính là tập hợp excerpt hoặc tiêu đề bài viết. Khi số lượng tag tăng lên một cách thiếu kiểm soát, bạn sẽ gặp các vấn đề:
Cách tiếp cận tốt hơn mang tính chiến lược:
Trang tag khác gì với category trong SEO content hub?
Trong mô hình content hub hiện đại, category và tag không chỉ là yếu tố điều hướng mà còn là các node trong cấu trúc topical authority. Sự khác biệt chính nằm ở vai trò, cấp độ và cách tối ưu:
Về mặt chiến lược, category nên được xem là “xương sống” của cấu trúc site, trong khi tag là “mạng lưới thần kinh” giúp kết nối các bài viết theo chiều sâu chủ đề. Khi xây content hub, nên:
Trang lọc sản phẩm theo màu, size, giá có nên index không?
Với website thương mại điện tử hoặc listing (bất động sản, việc làm, xe cộ…), trang lọc (faceted navigation) là nguồn sinh ra vô số URL biến thể. Nếu index không kiểm soát, bạn sẽ gặp:
Quyết định index cần dựa trên ba trụ cột:
Các filter phổ biến, có search demand rõ ràng, inventory lớn có thể được index và tối ưu như landing page SEO:
Các filter quá chi tiết (kết hợp nhiều thuộc tính nhỏ), ít sản phẩm, hoặc chỉ phục vụ thao tác nội bộ nên:
Dùng noindex cho trang thẻ có làm mất link nội bộ không?
Dùng meta robots noindex, follow cho trang thẻ không làm mất giá trị link nội bộ. Cơ chế hoạt động:
Điều này khiến tag trở thành một lớp điều hướng nội bộ hữu ích mà không gây “ồn ào” trong chỉ mục. Một số lưu ý chuyên sâu:
Có nên xóa tag cũ không có traffic khỏi website không?
Có thể xóa các tag cũ không có traffic, không có vai trò điều hướng, và không được dùng trong chiến lược nội dung hiện tại, nhưng cần xử lý cẩn thận để tránh tạo ra lỗi kỹ thuật và mất tín hiệu SEO tích lũy. Quy trình an toàn:
Về lâu dài, nên thiết lập quy tắc quản lý tag:
Trang lọc tự động có cần viết mô tả riêng như landing page không?
Với các trang lọc được chọn index như landing page SEO, nên viết mô tả riêng và nếu phù hợp, bổ sung nội dung hỗ trợ (hướng dẫn chọn, FAQ, note quan trọng). Điều này giúp:
Cách triển khai hiệu quả cho trang lọc được index:
Ngược lại, với các filter chỉ phục vụ UX nội bộ và được noindex:



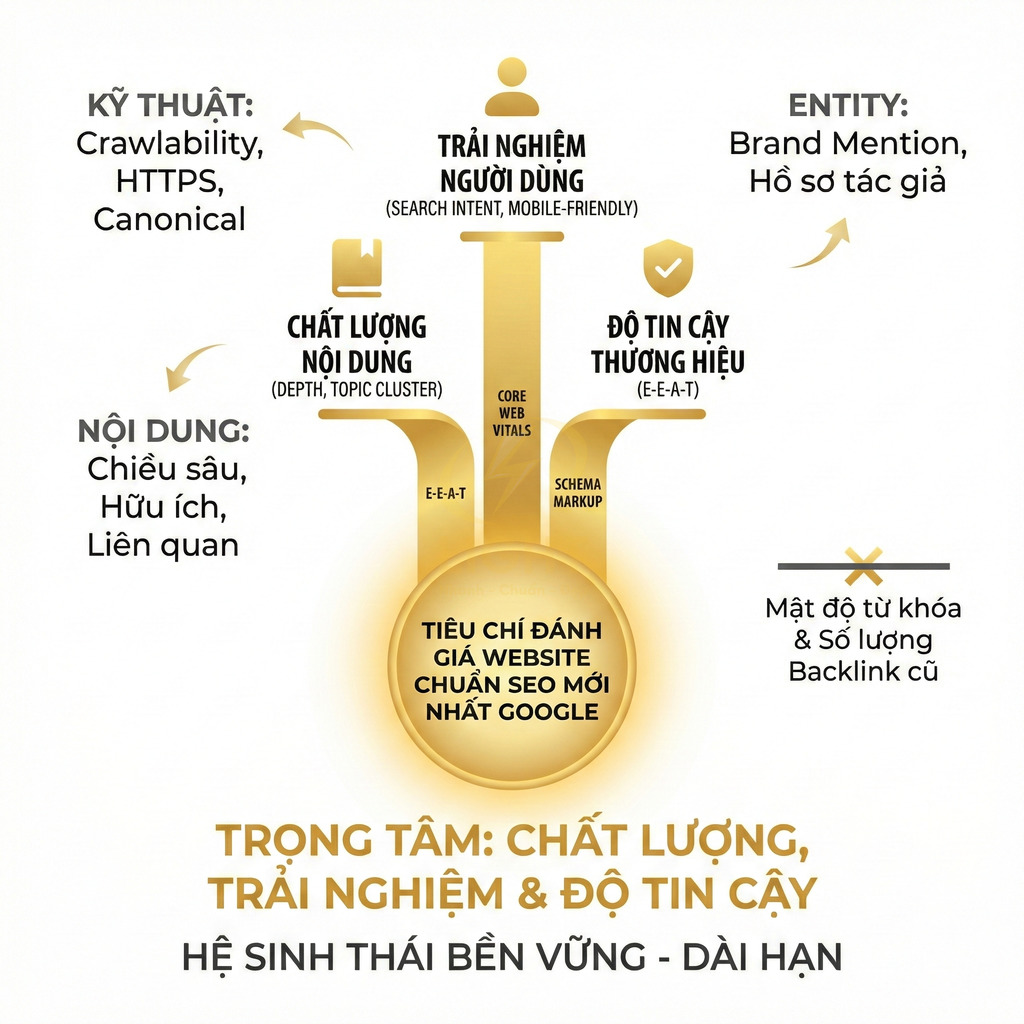

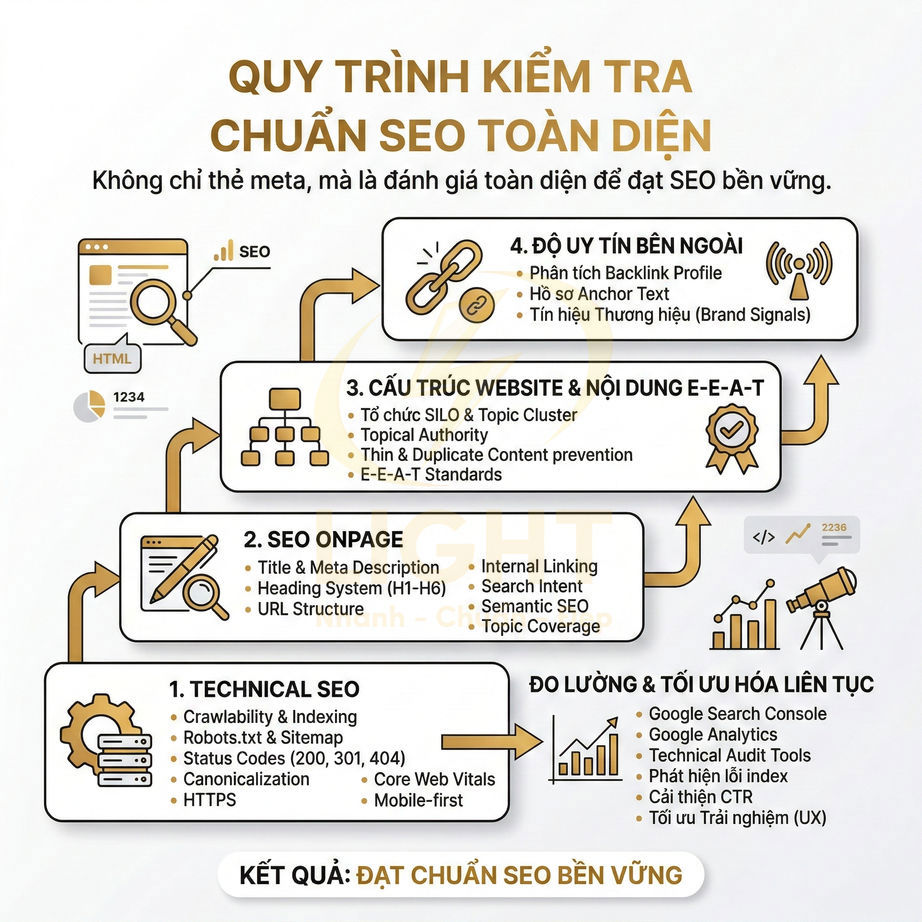
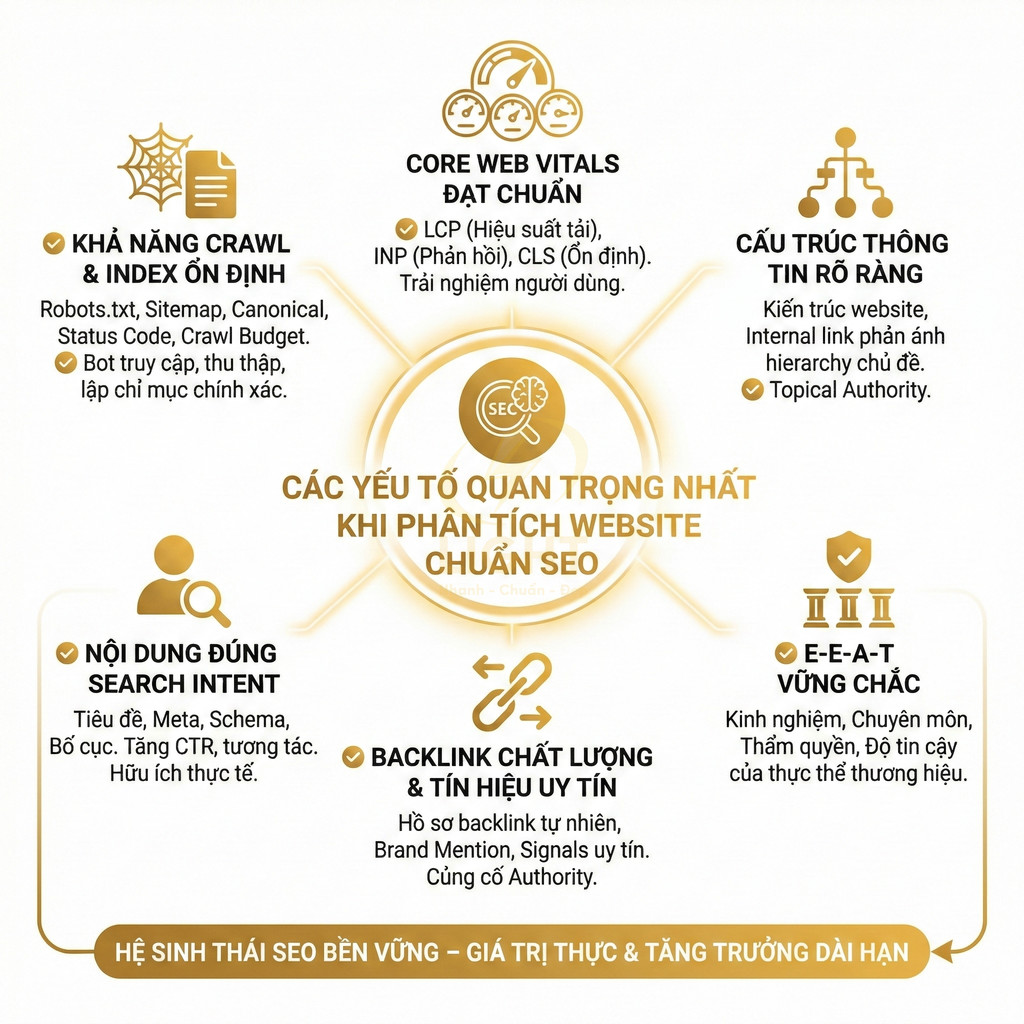

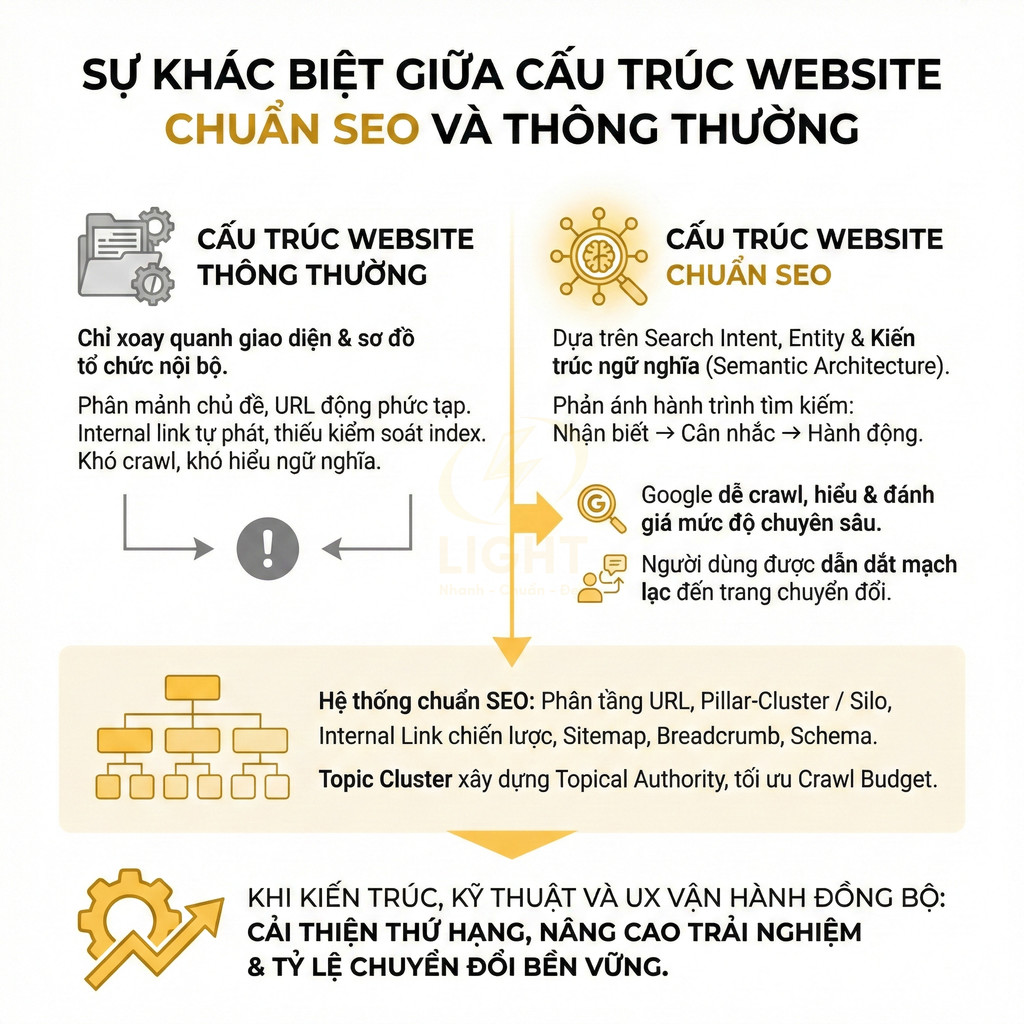

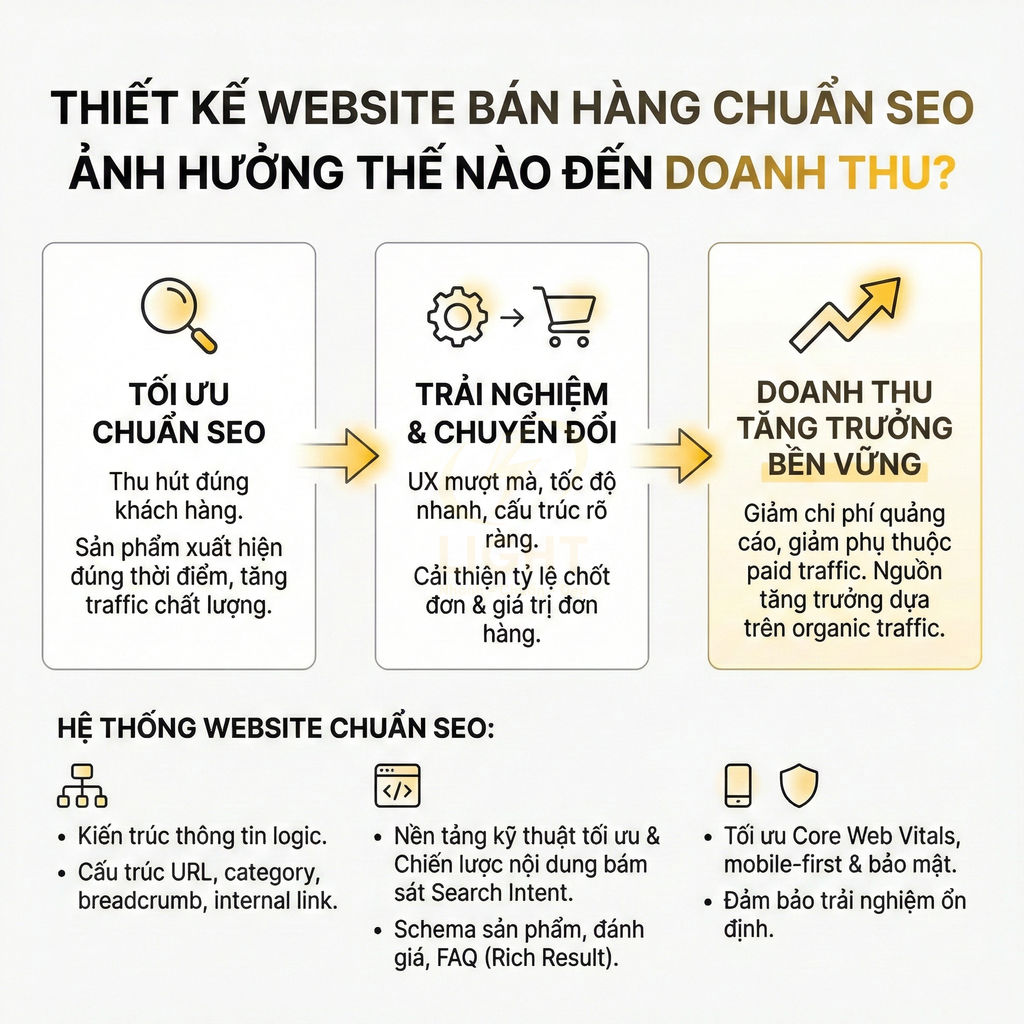


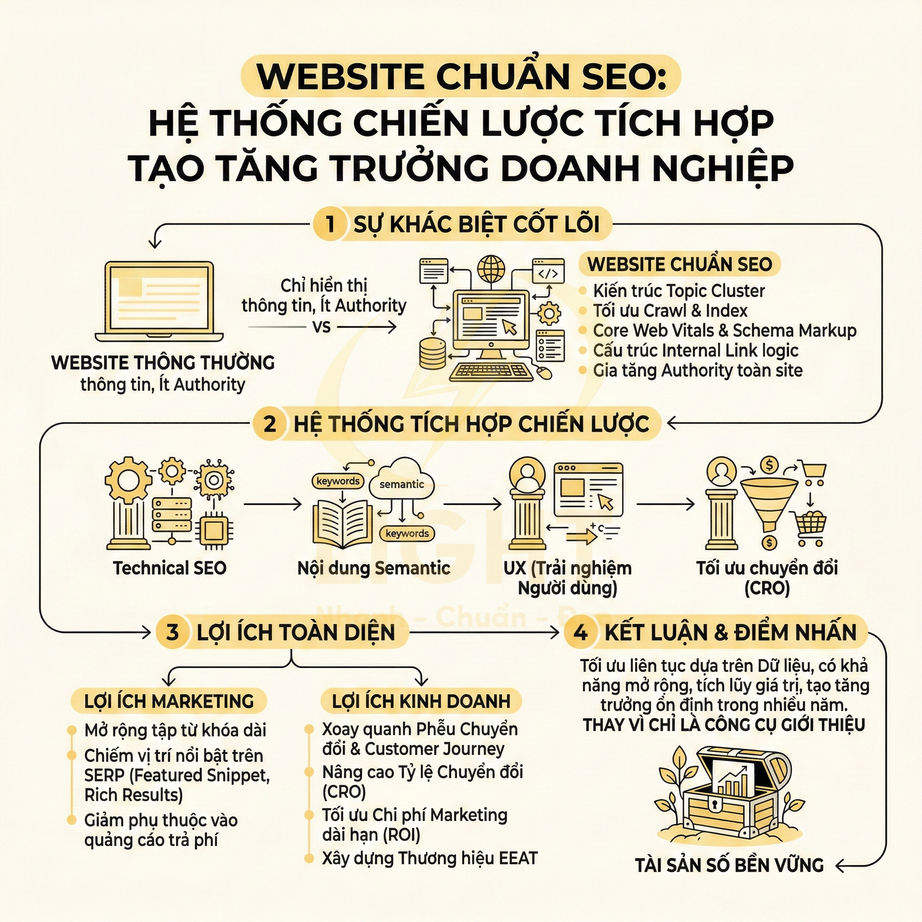
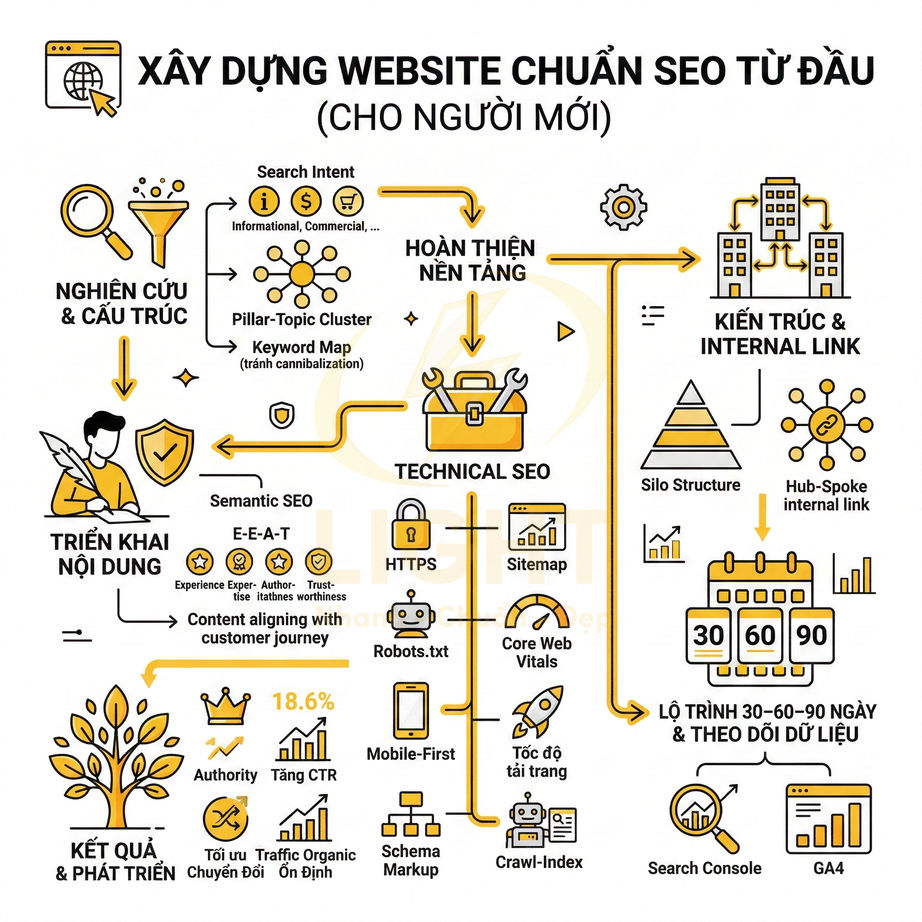
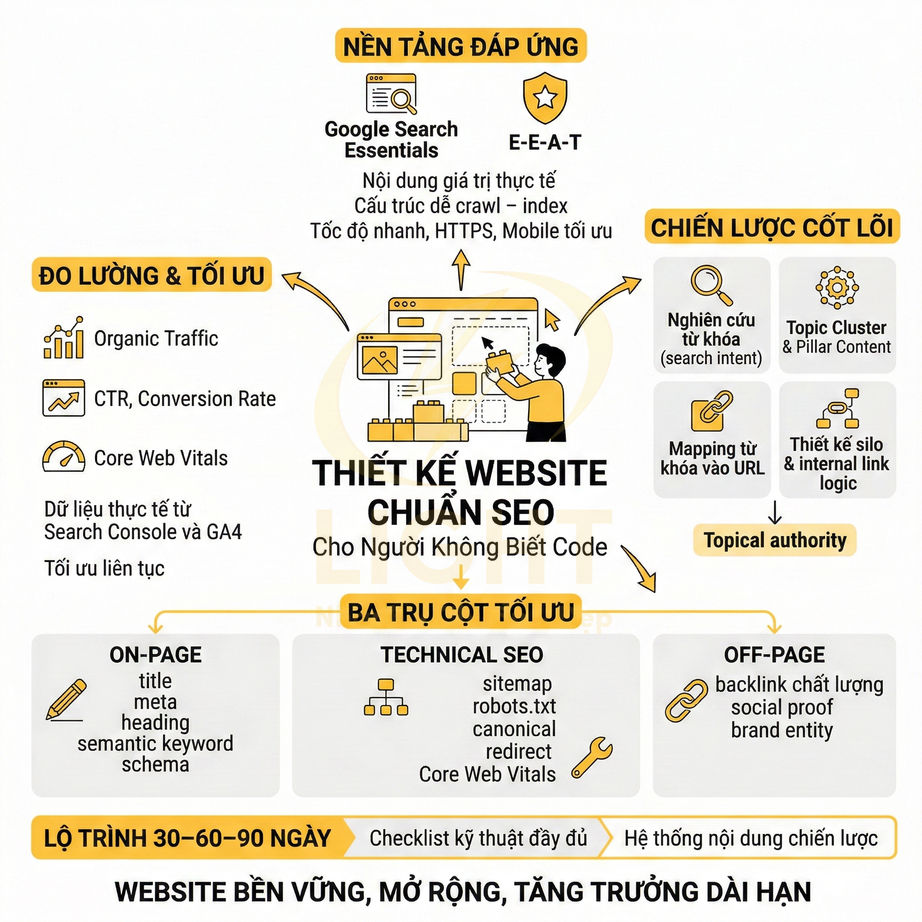



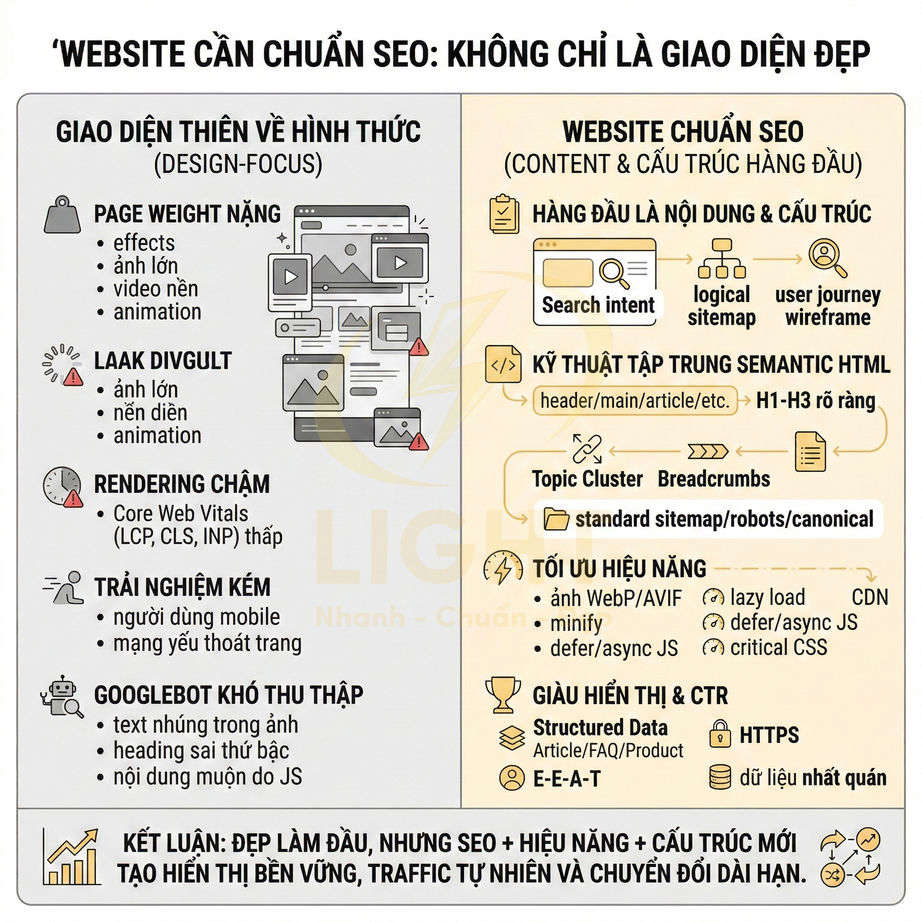
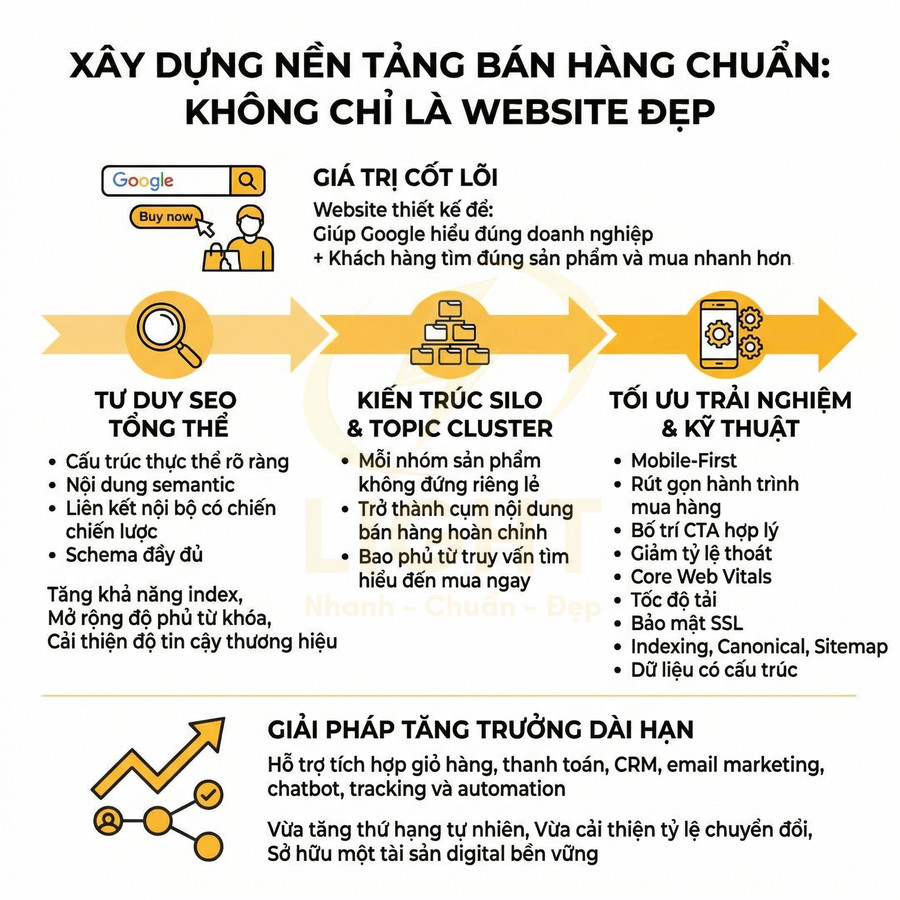

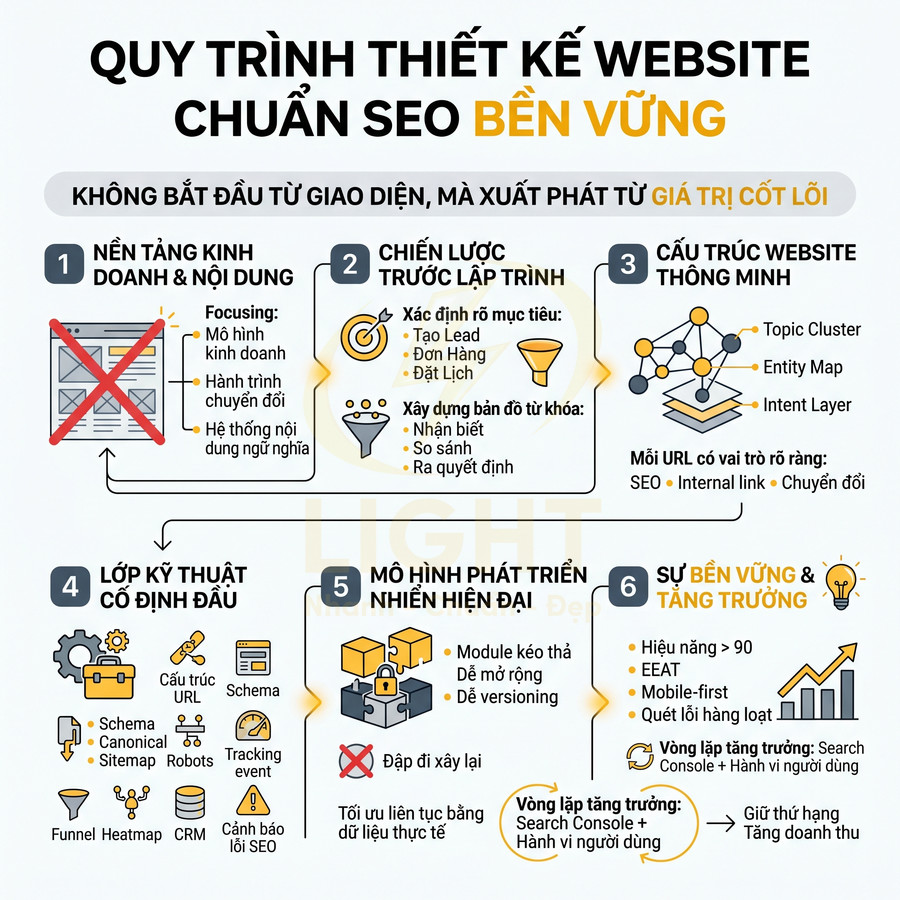
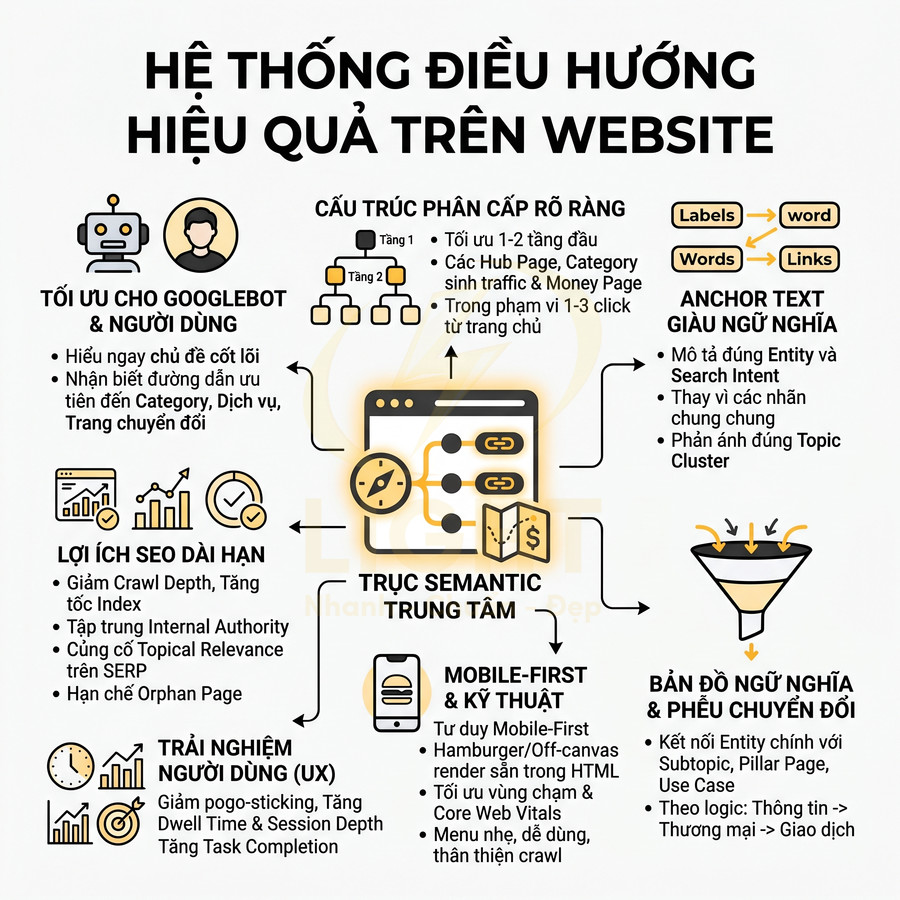
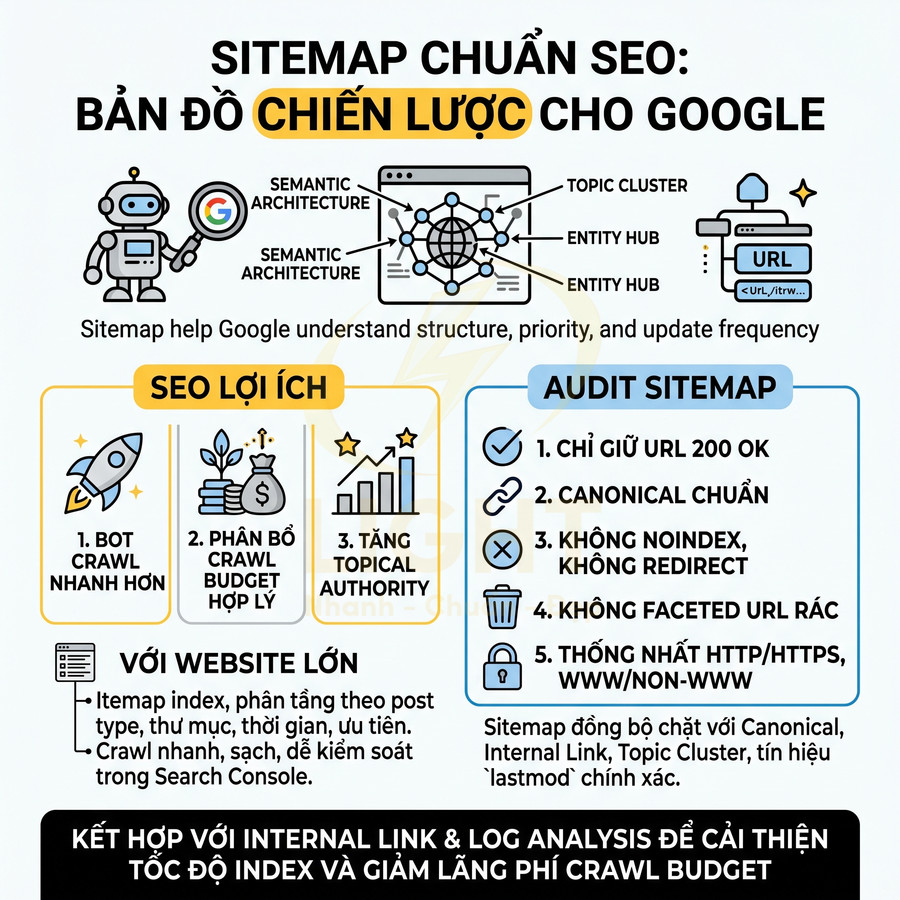
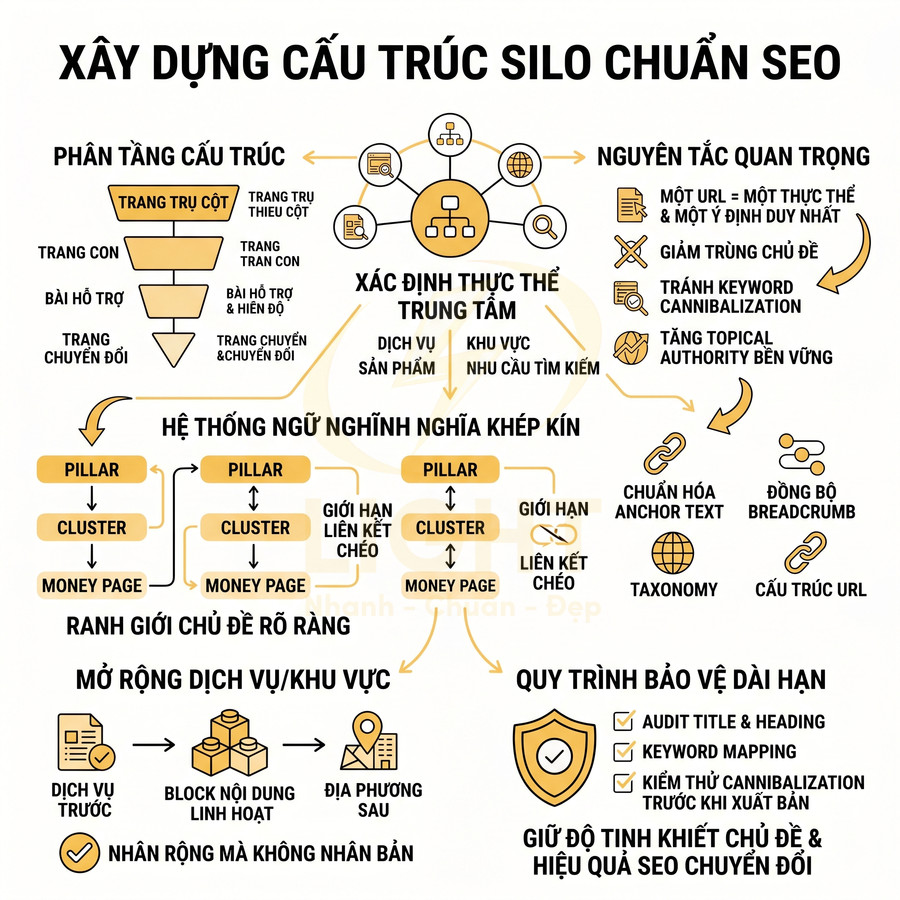
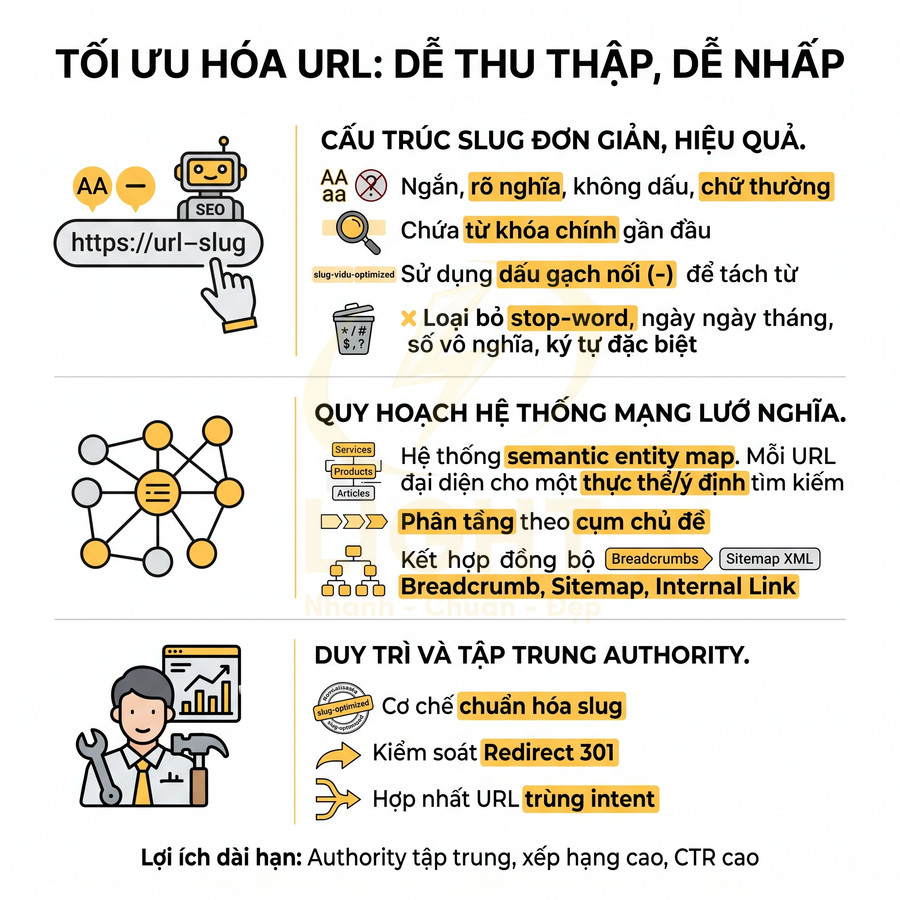
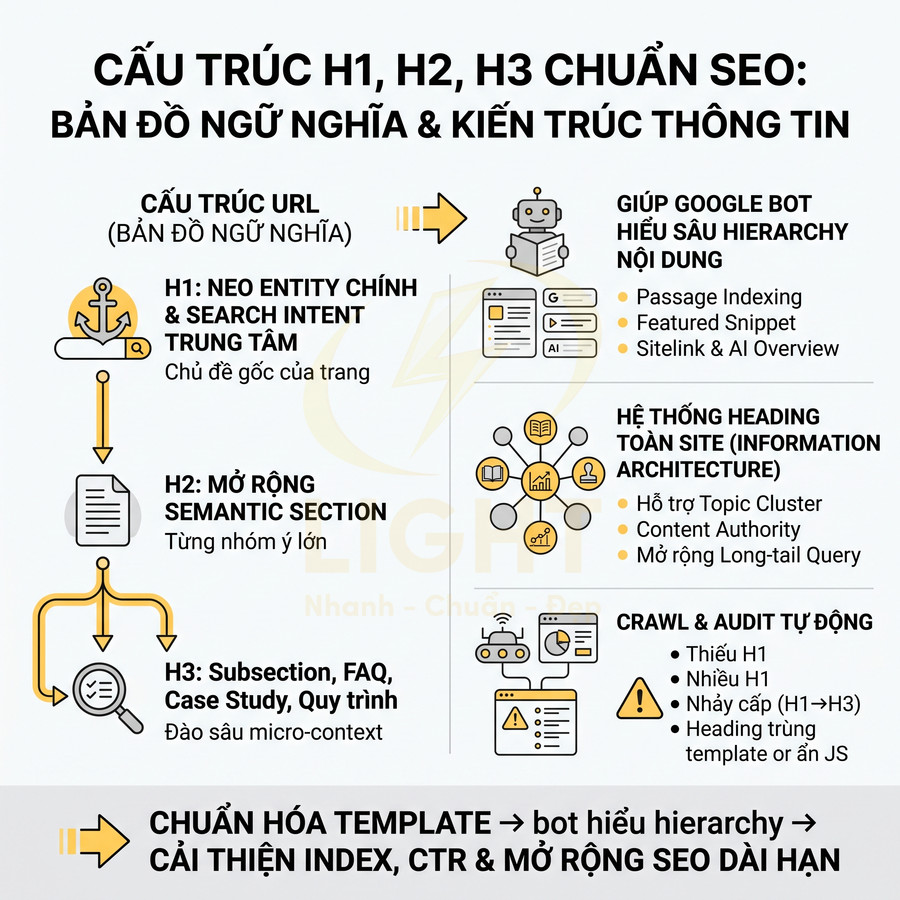
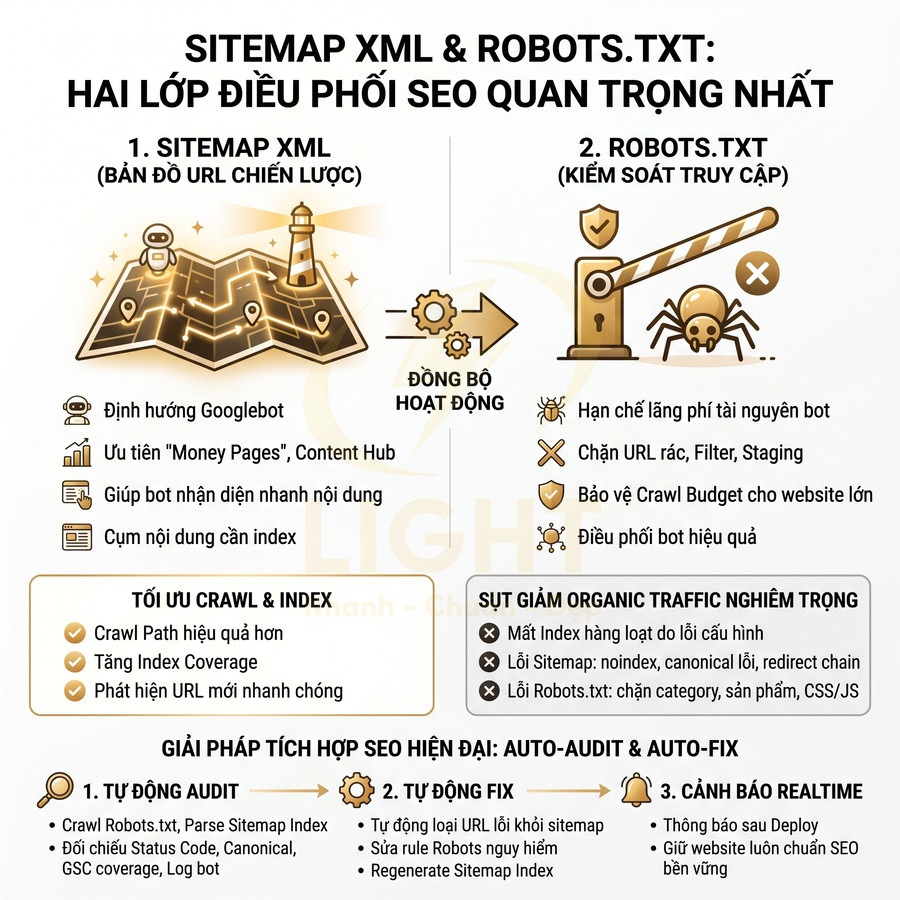
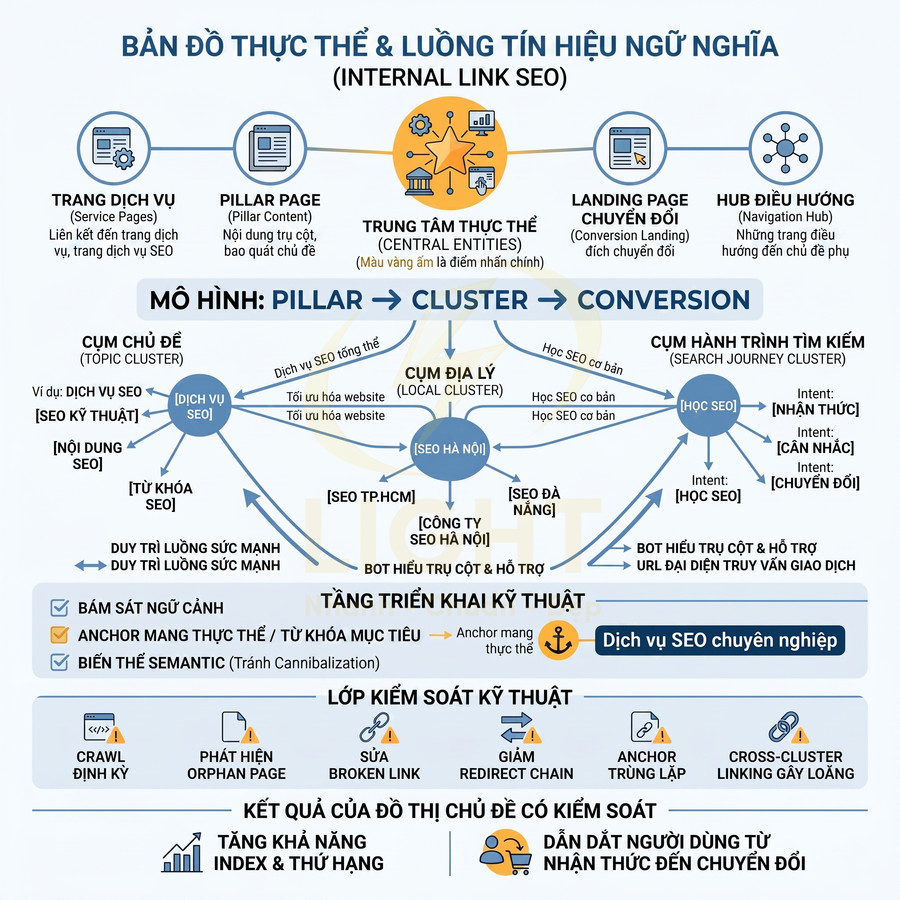
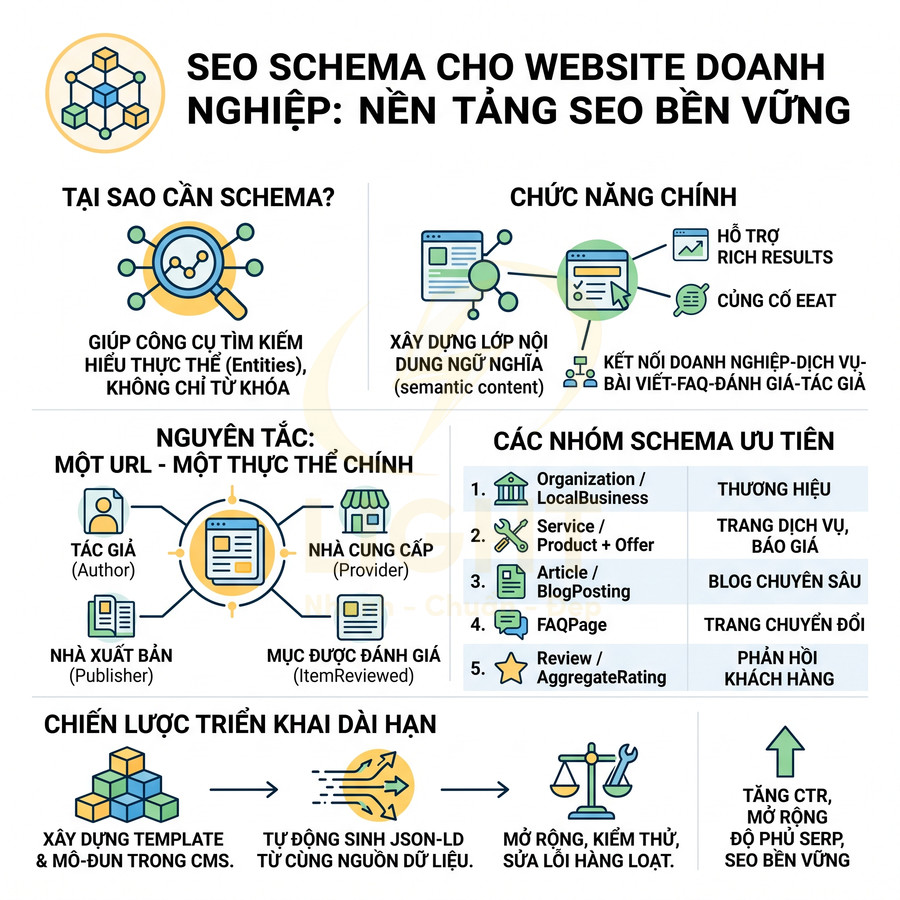
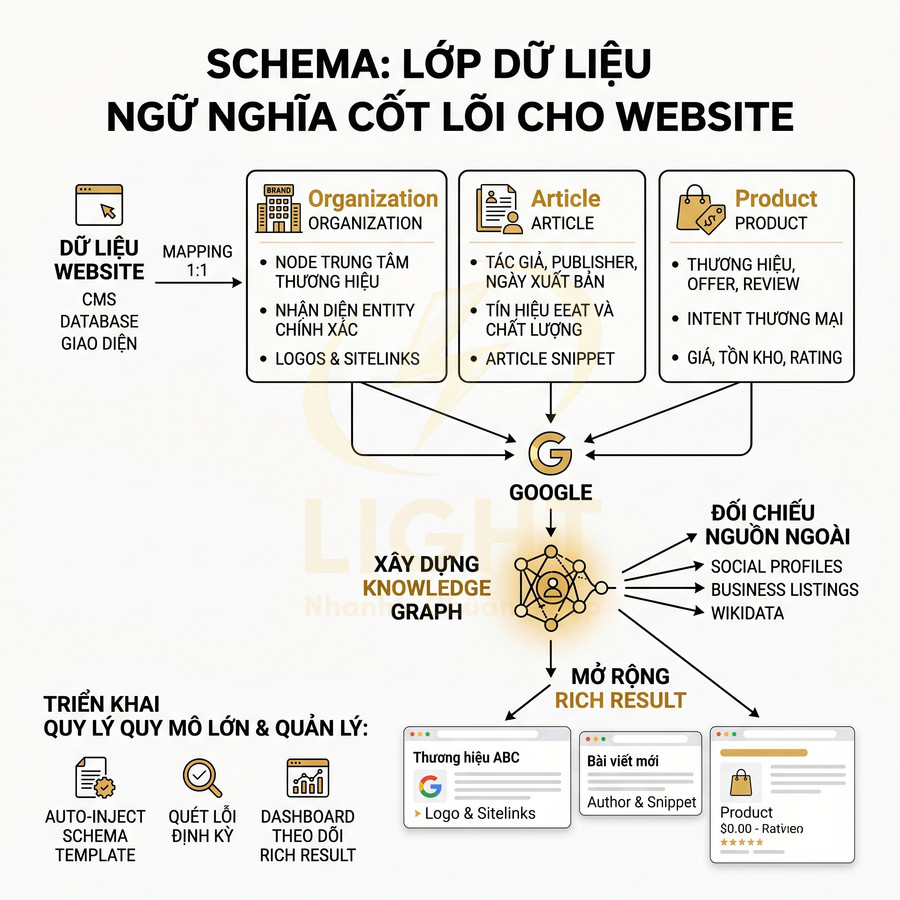

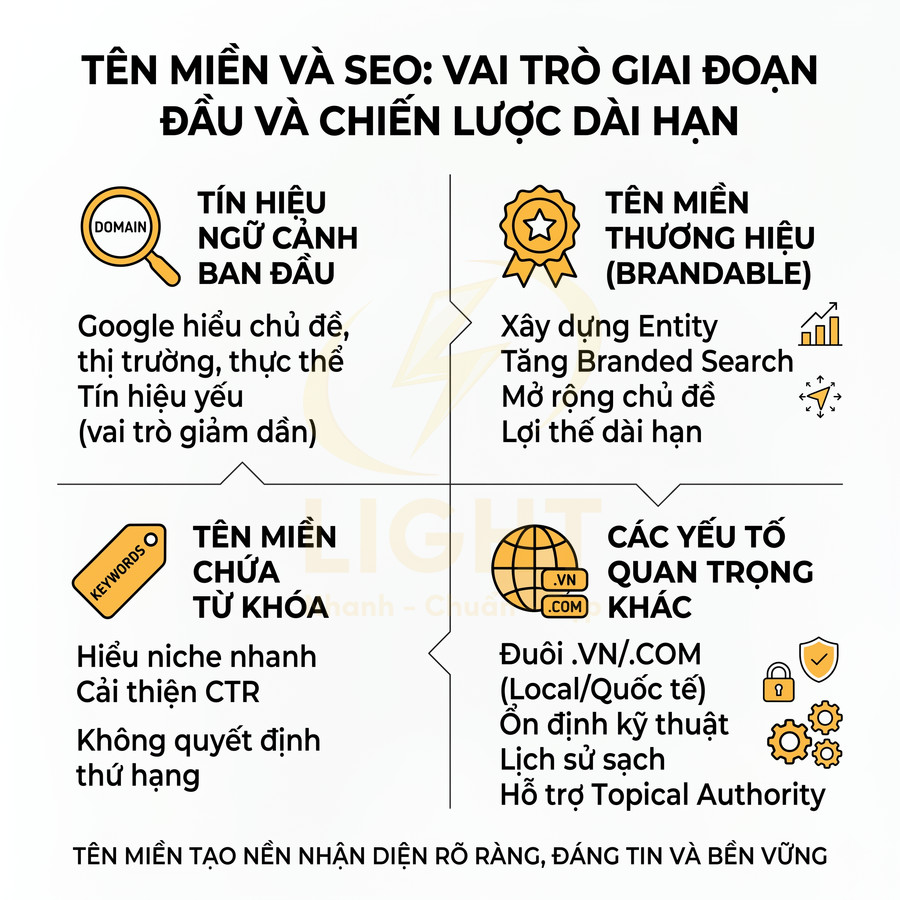
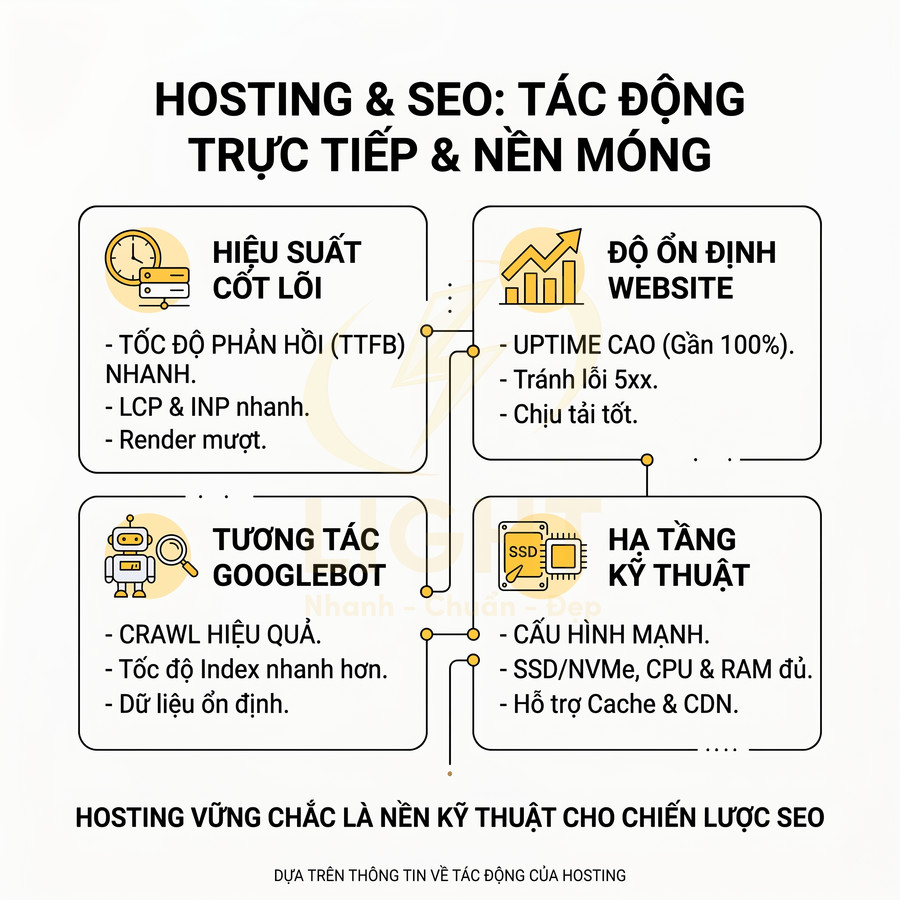
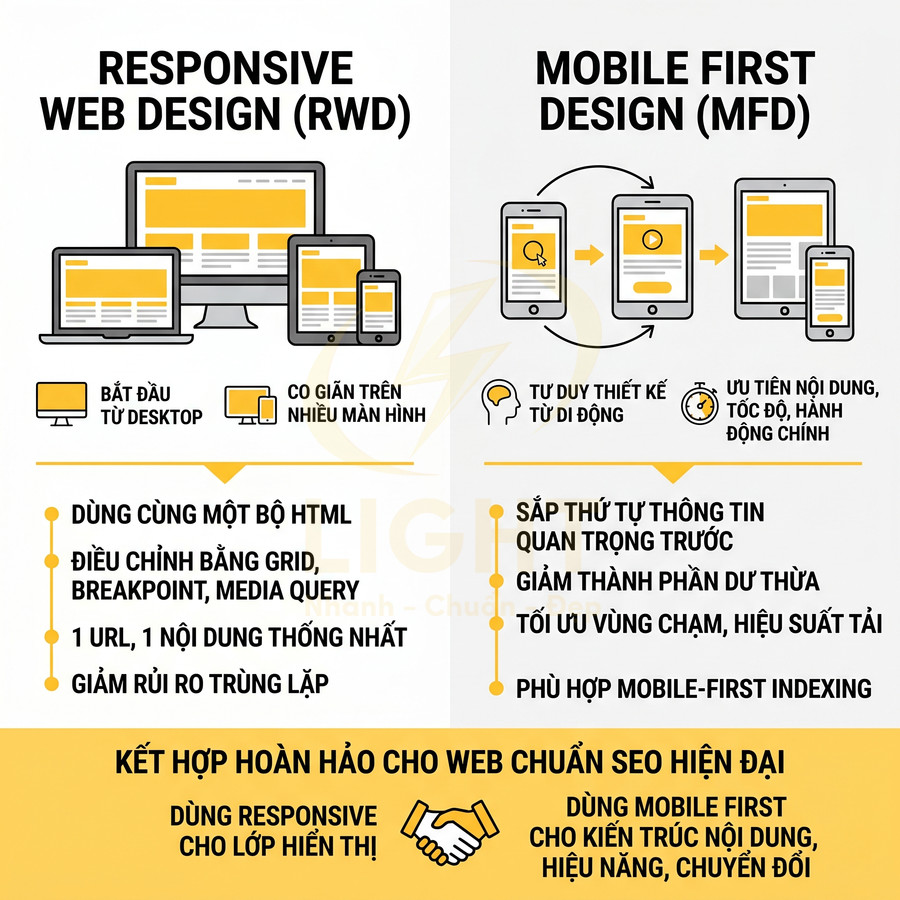

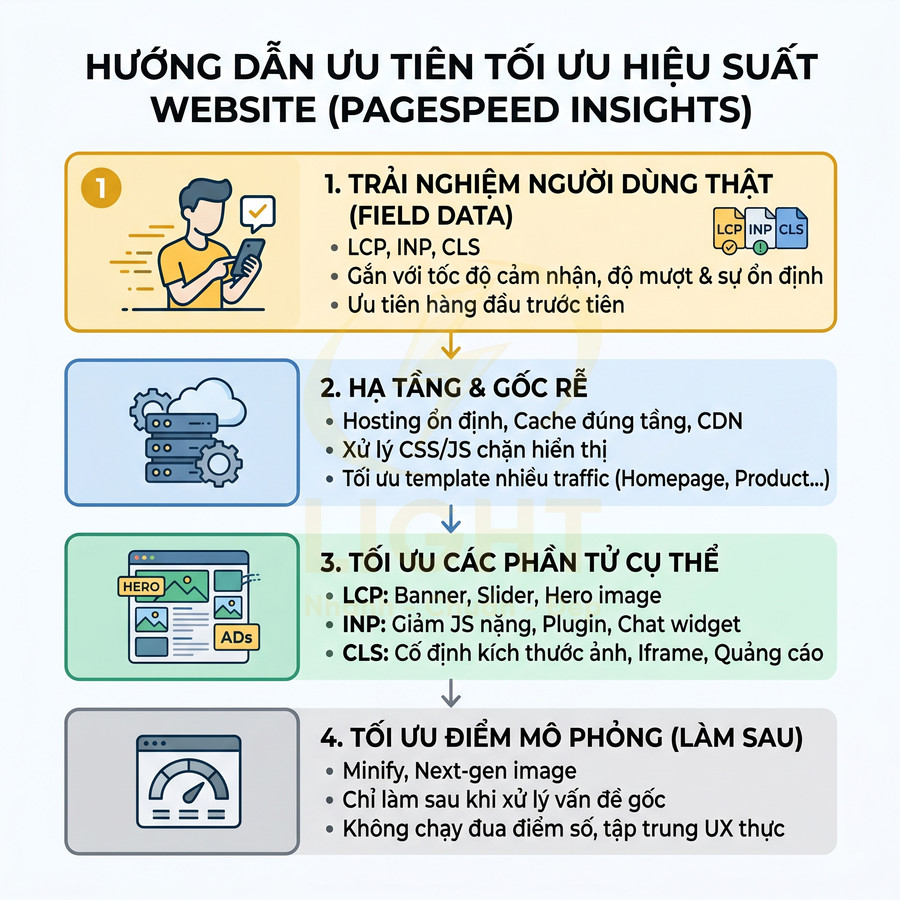
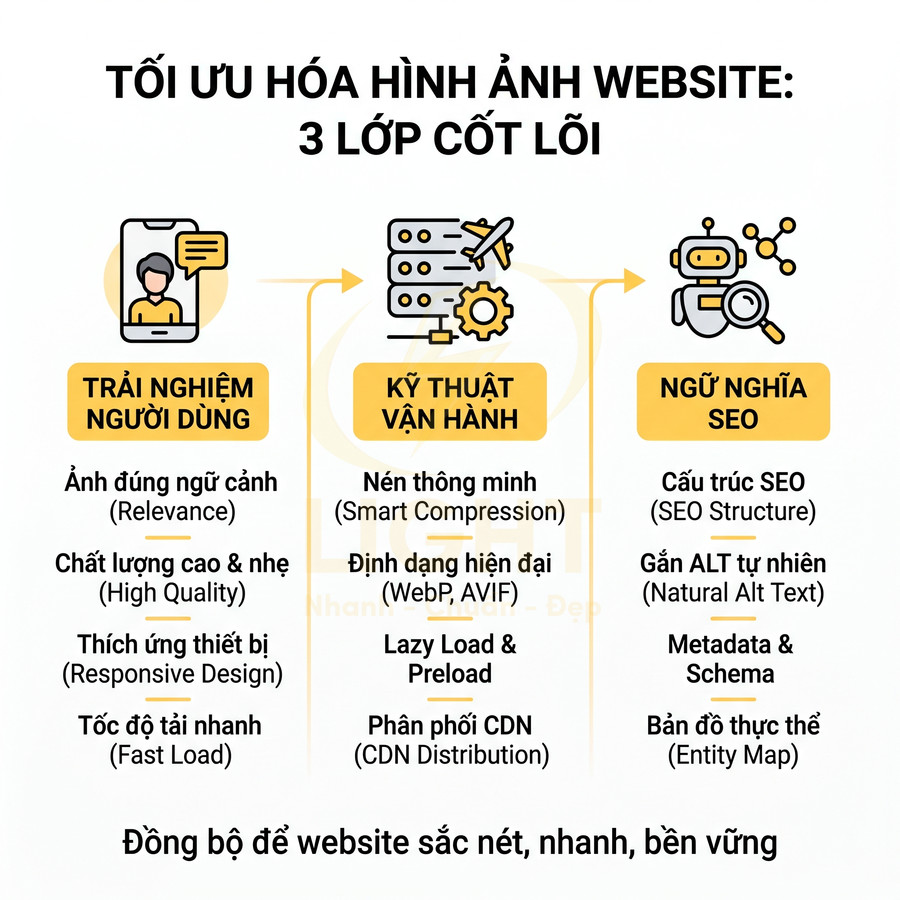

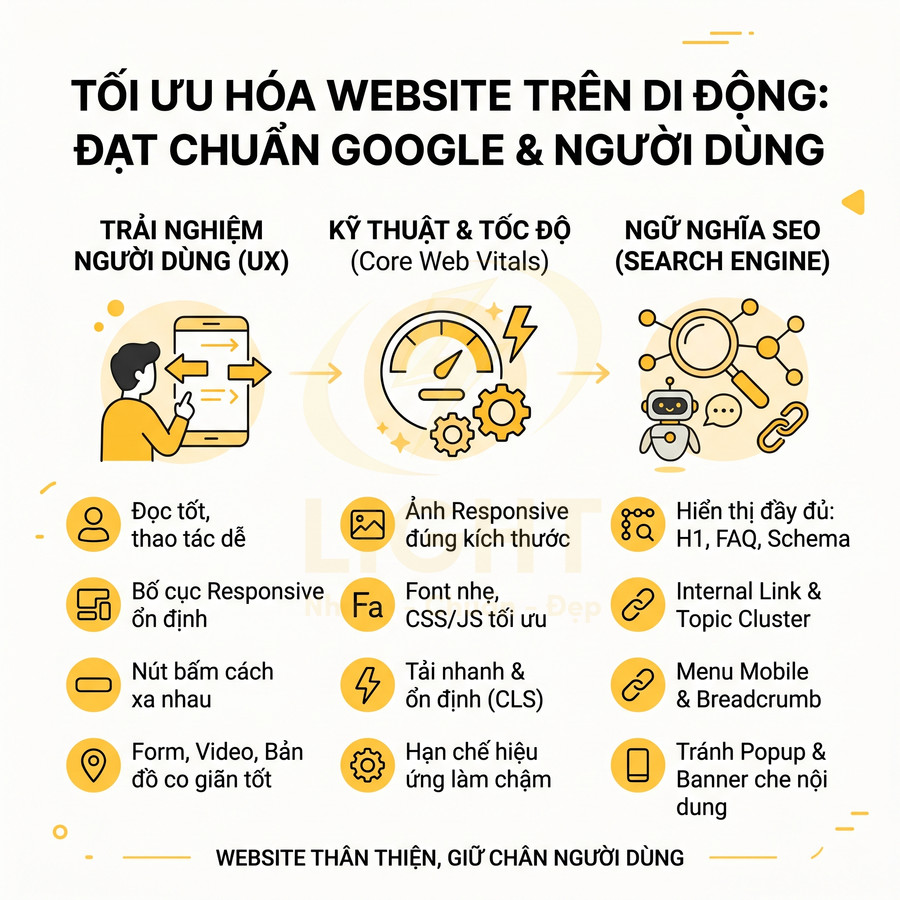
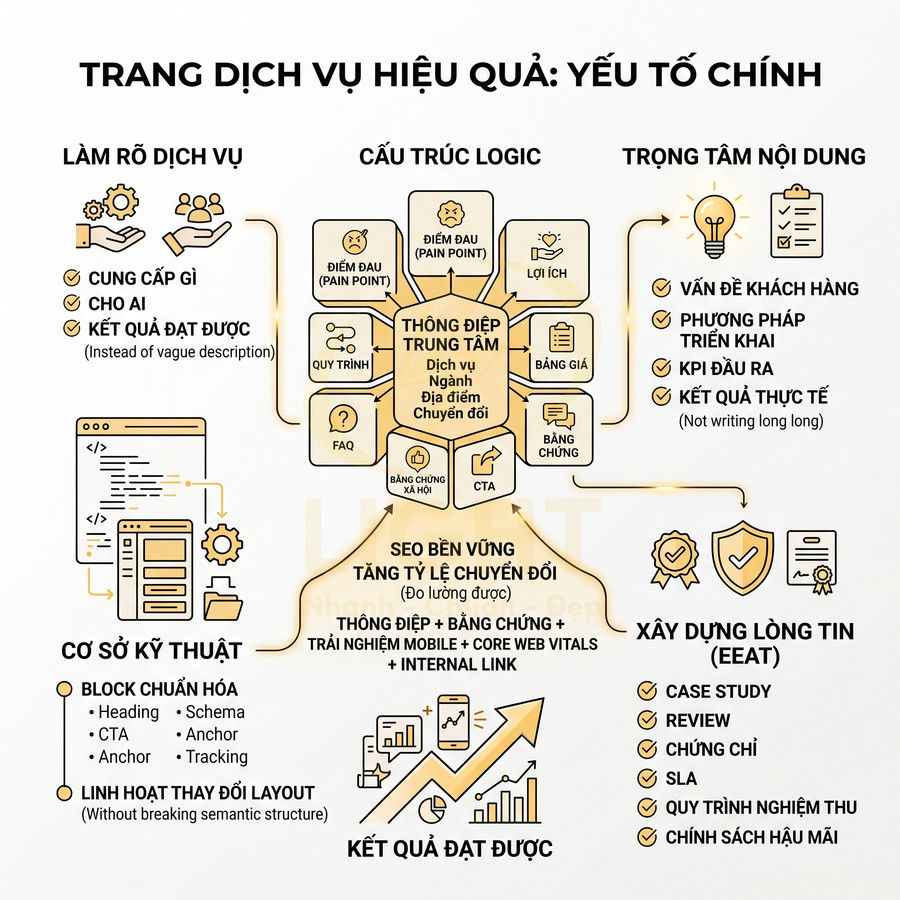
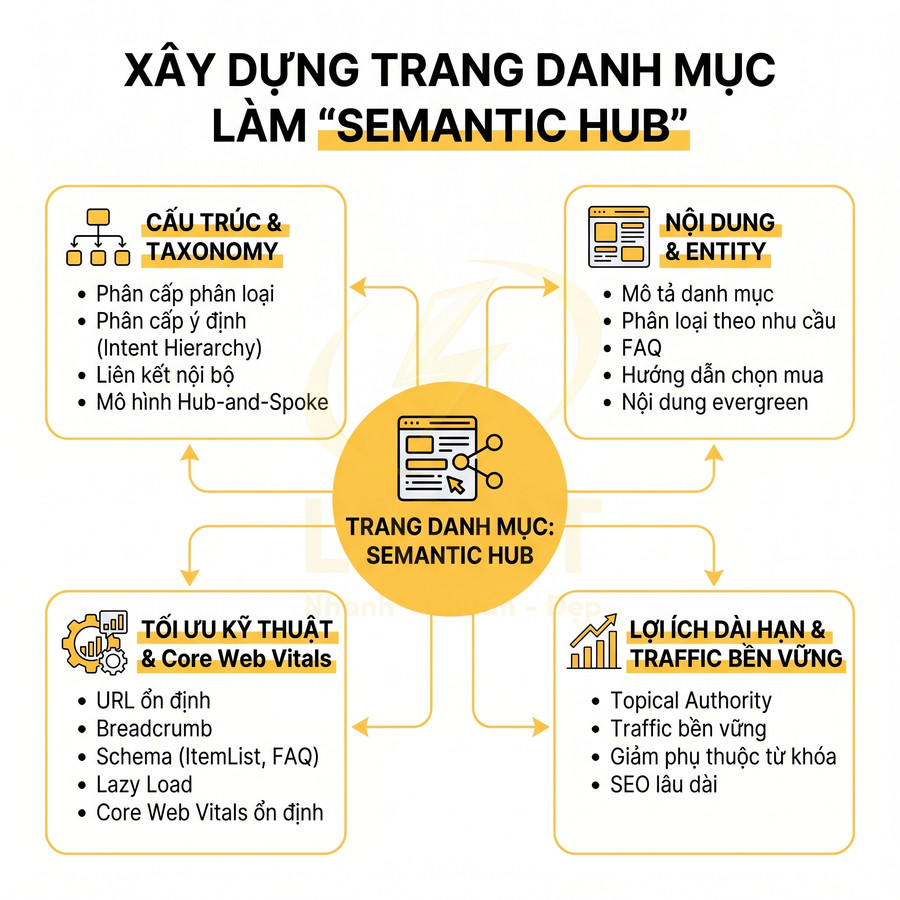





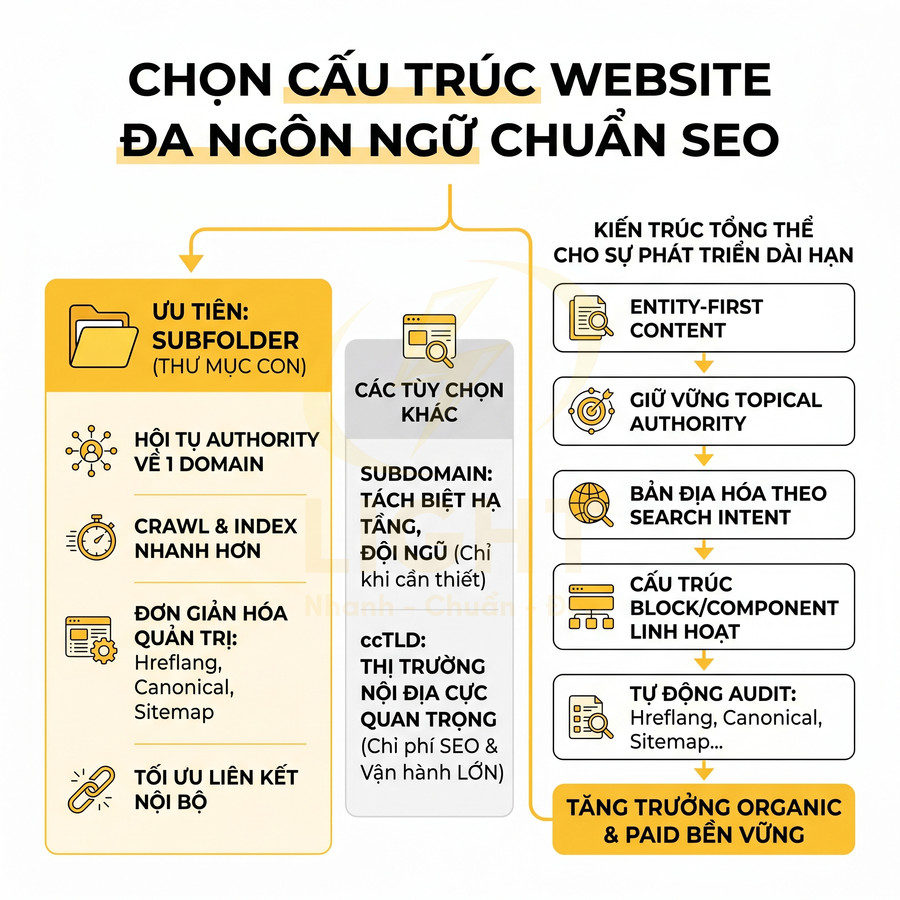
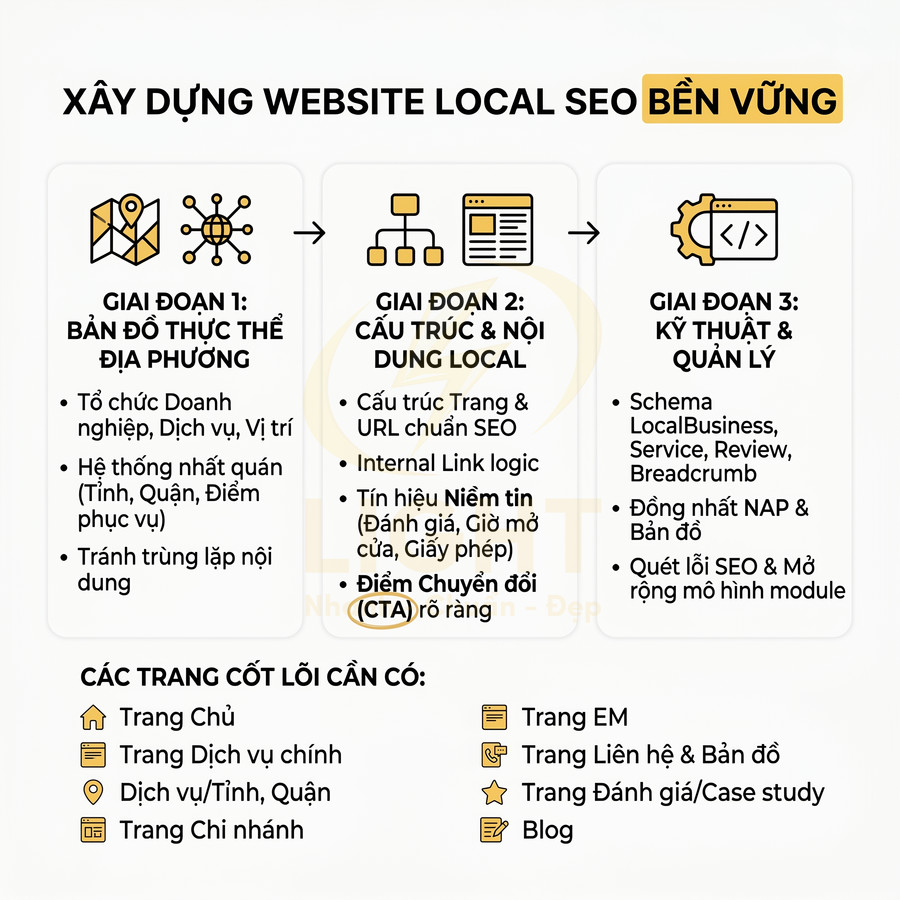

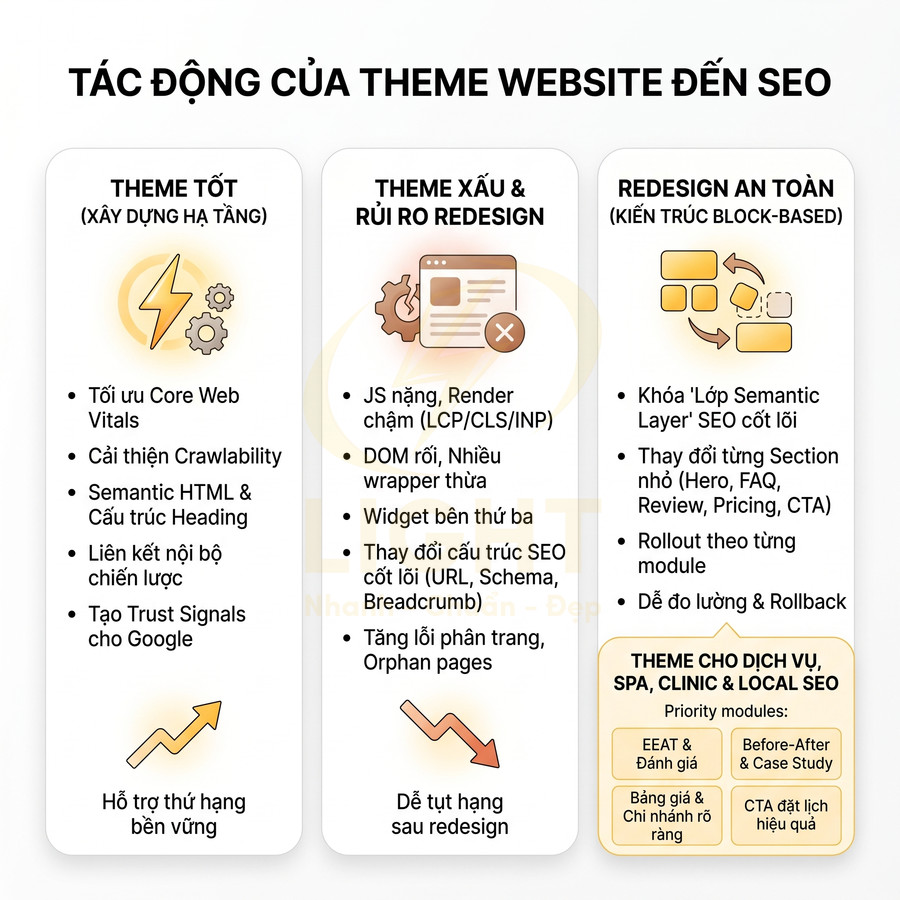
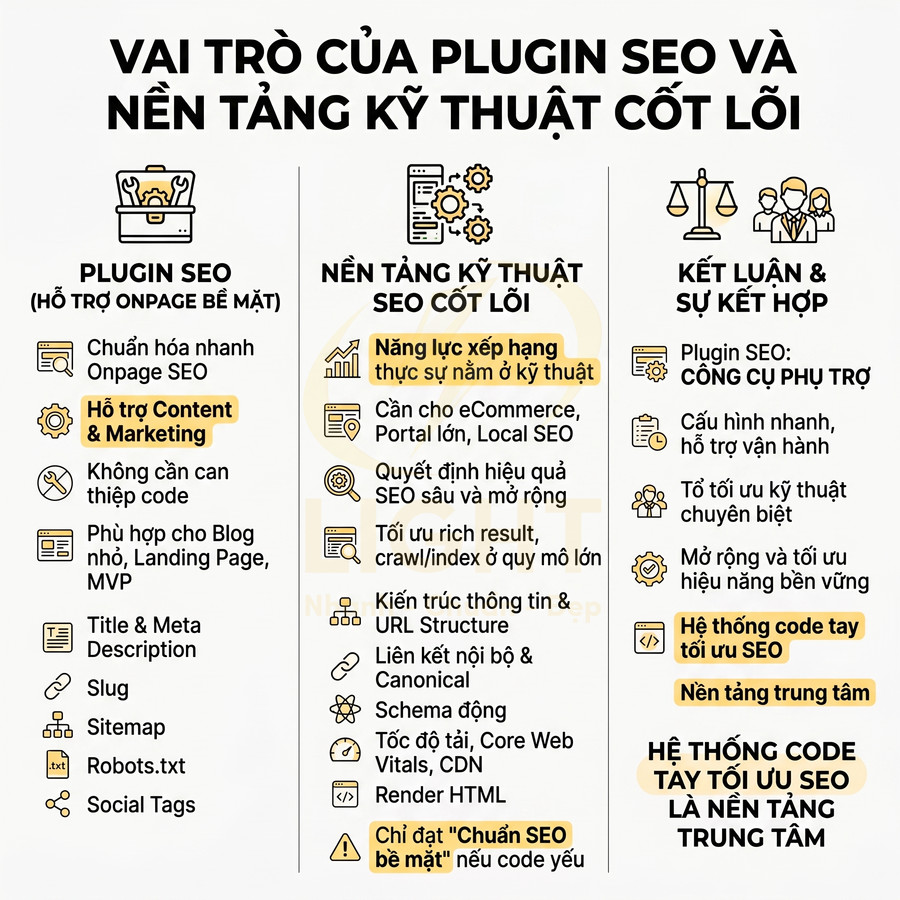

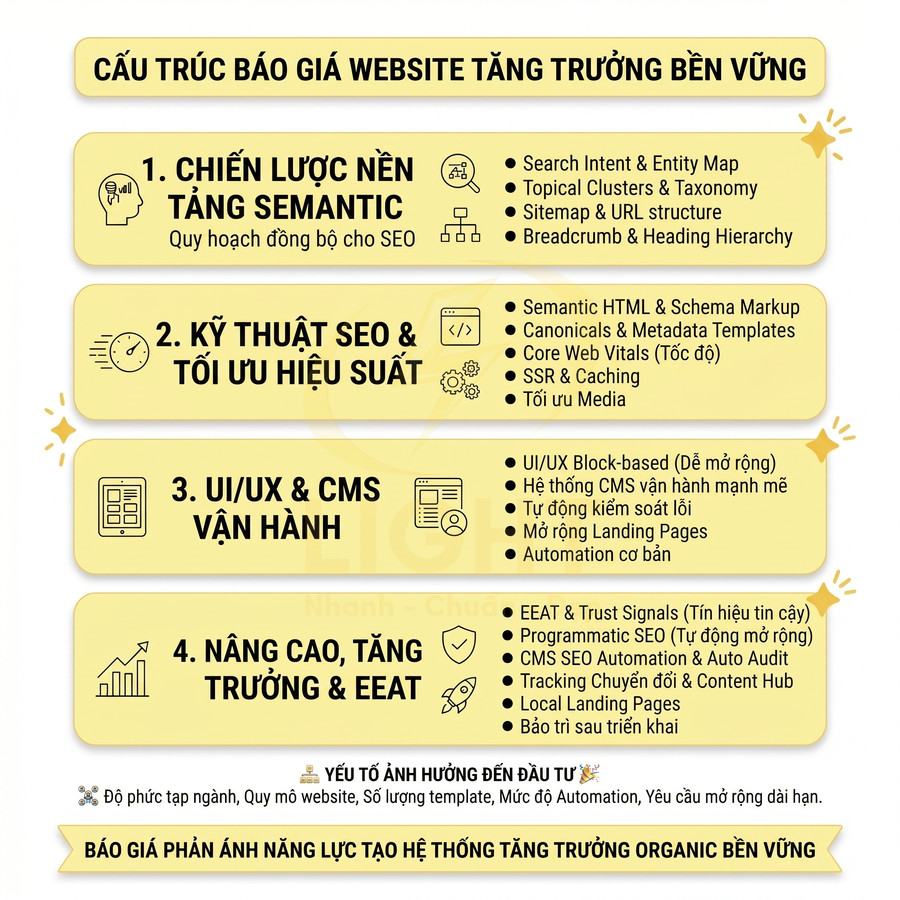

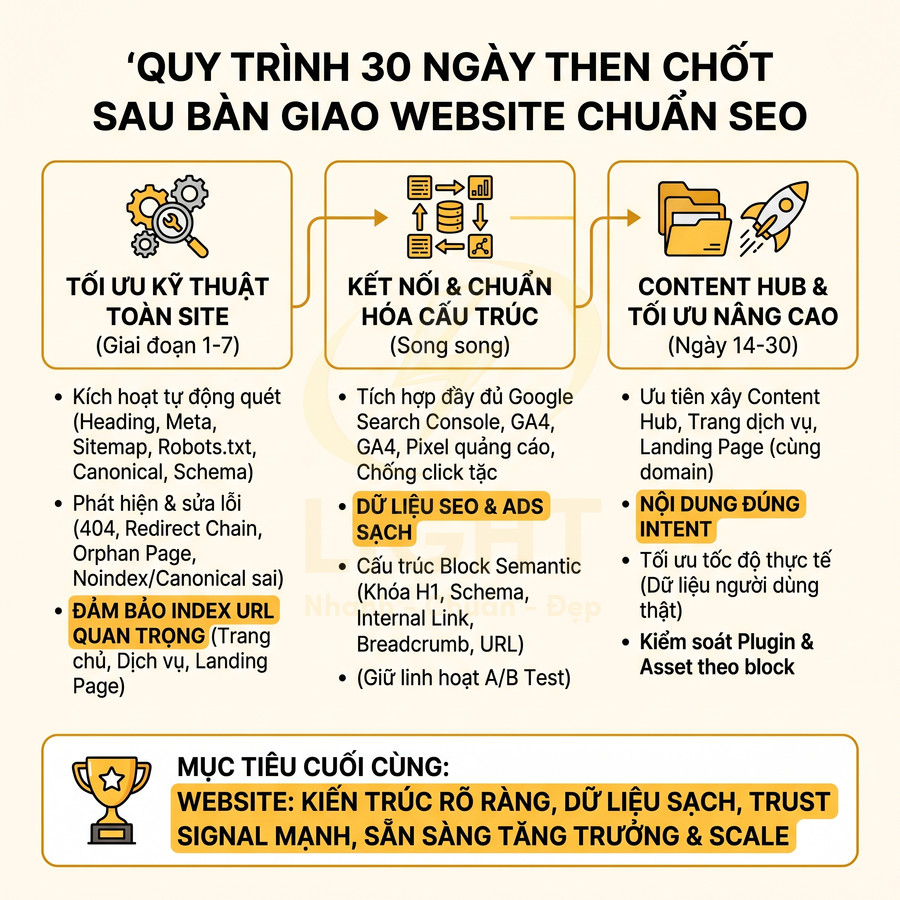
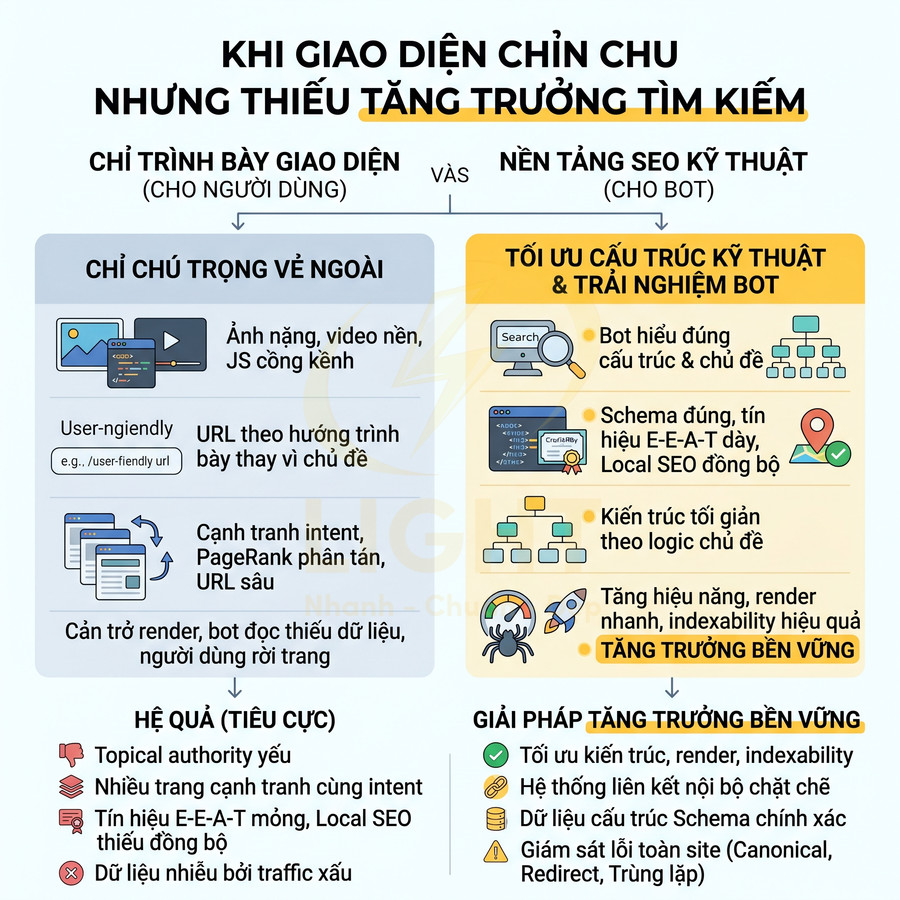

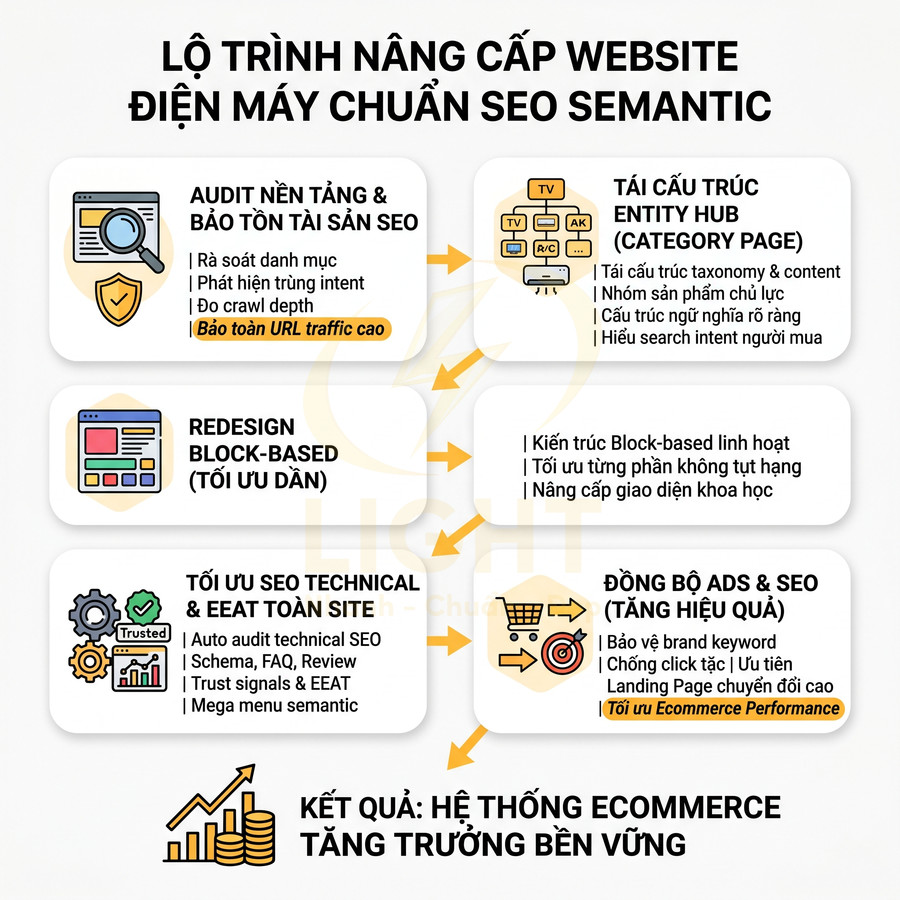
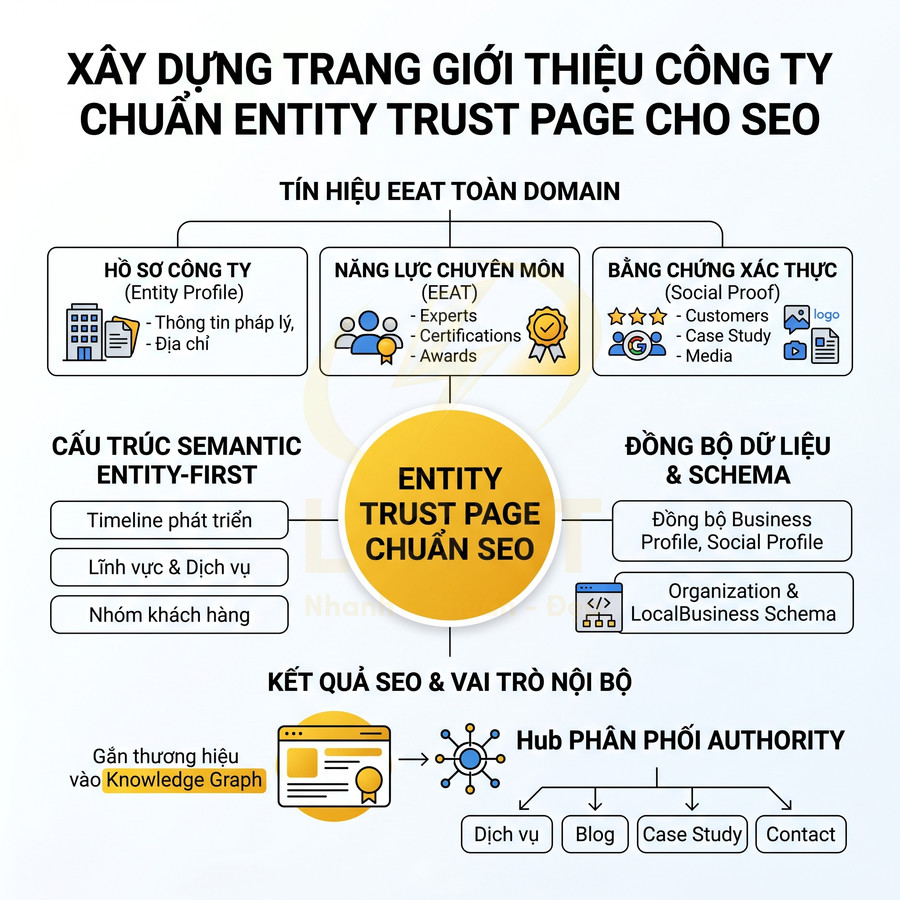
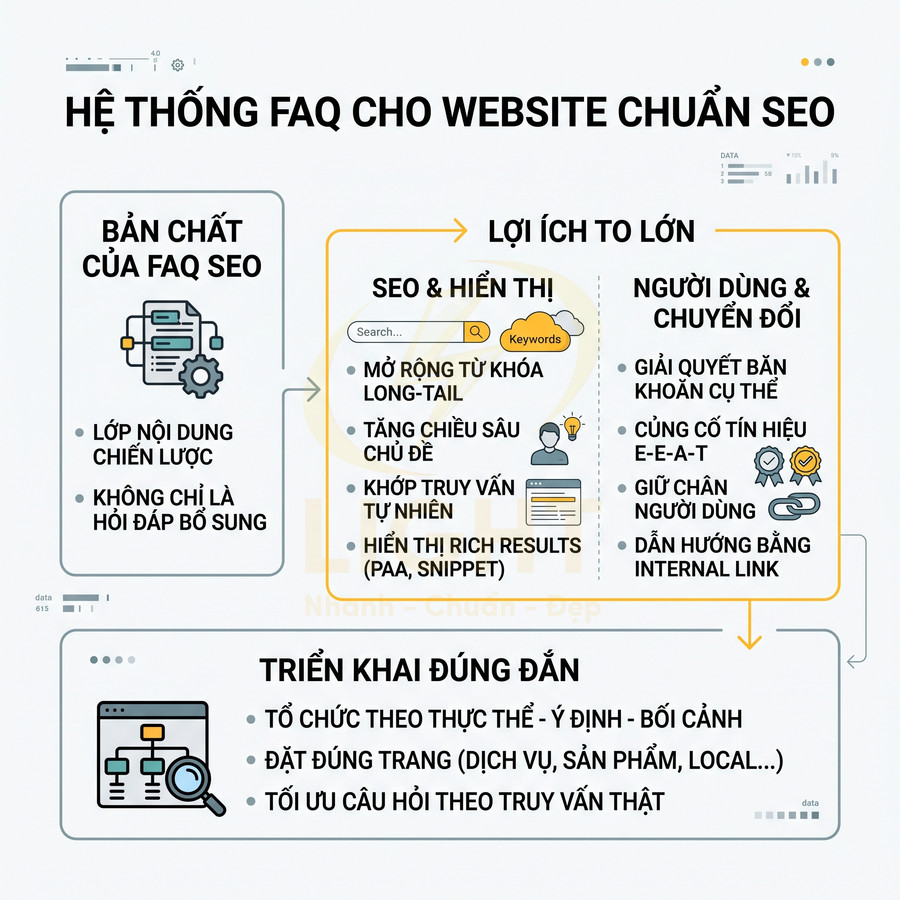
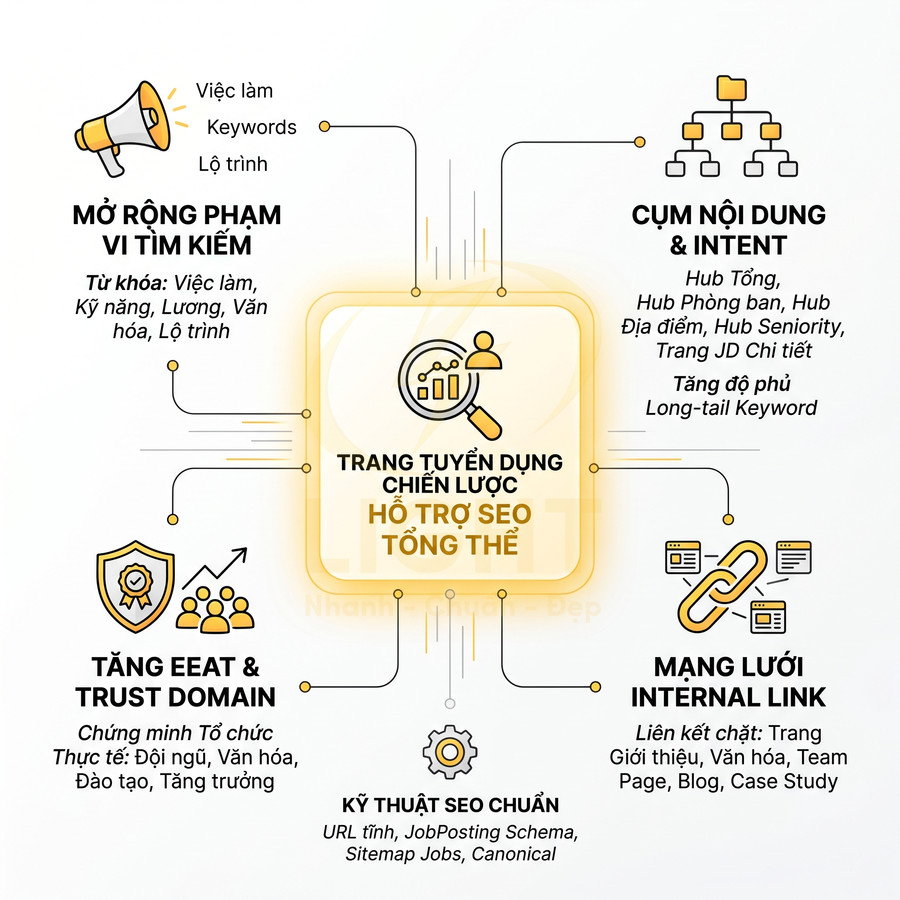

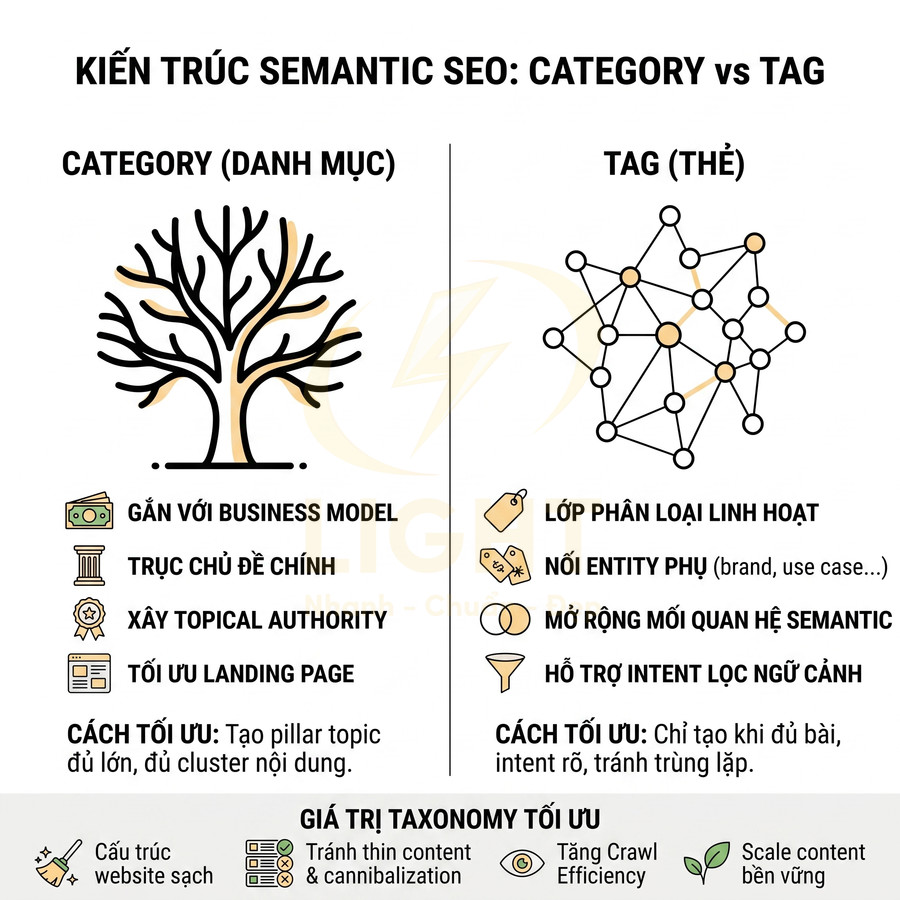
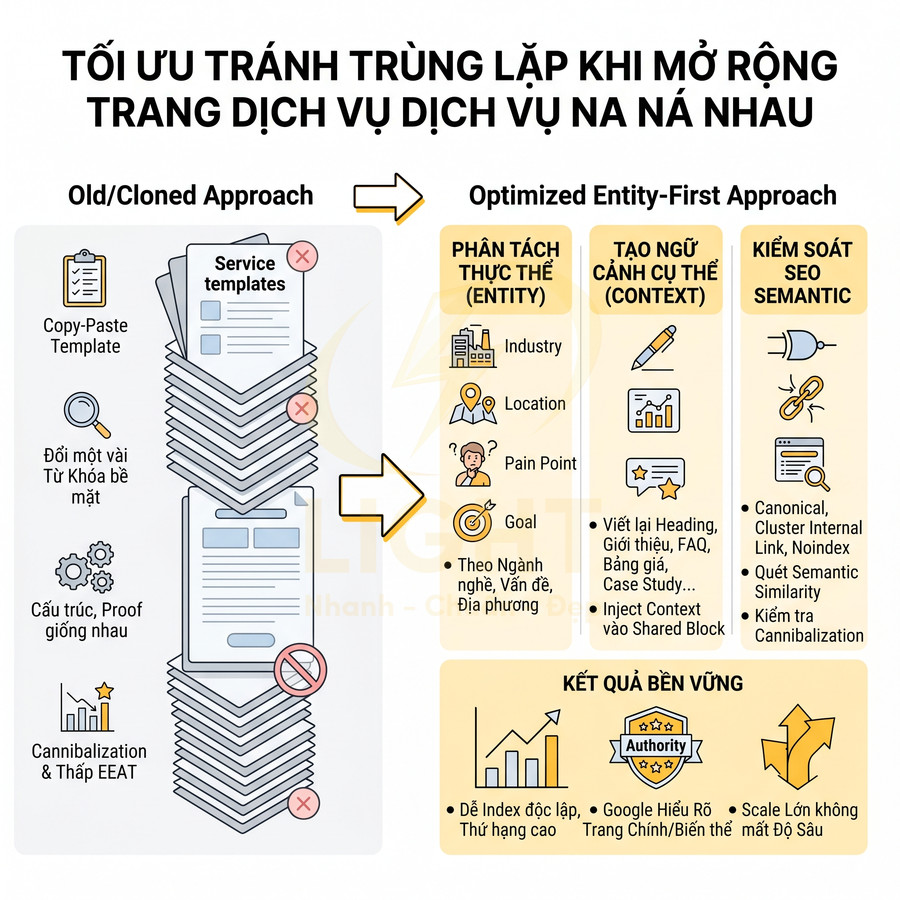


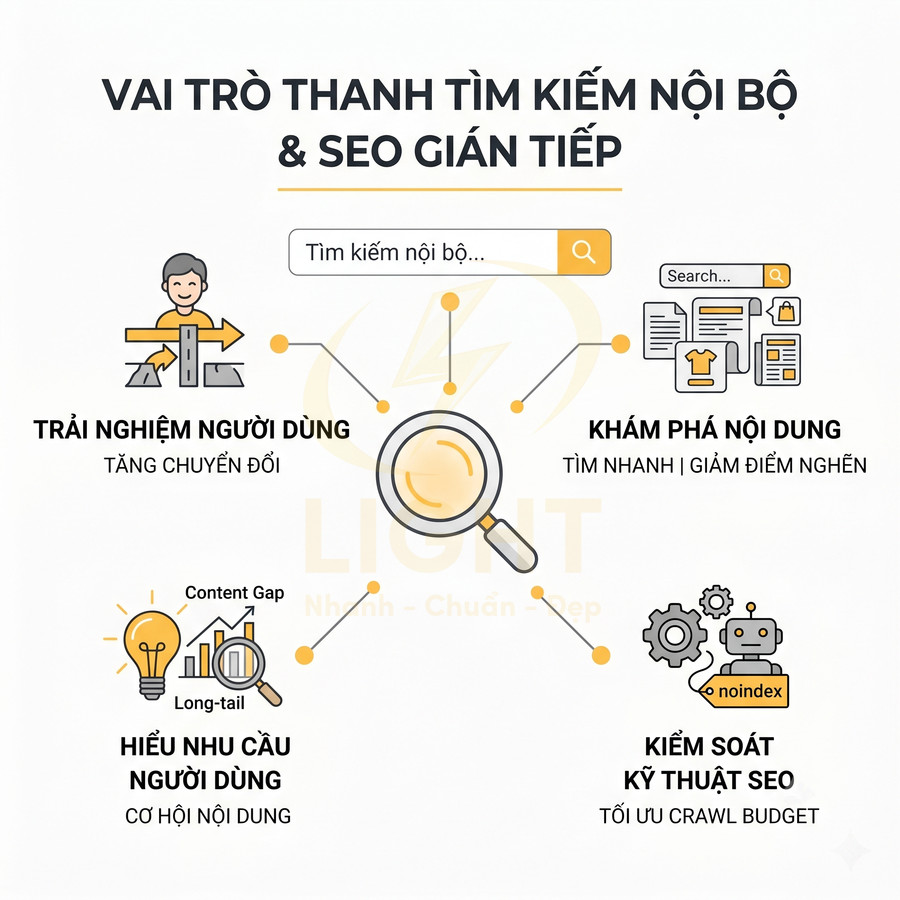


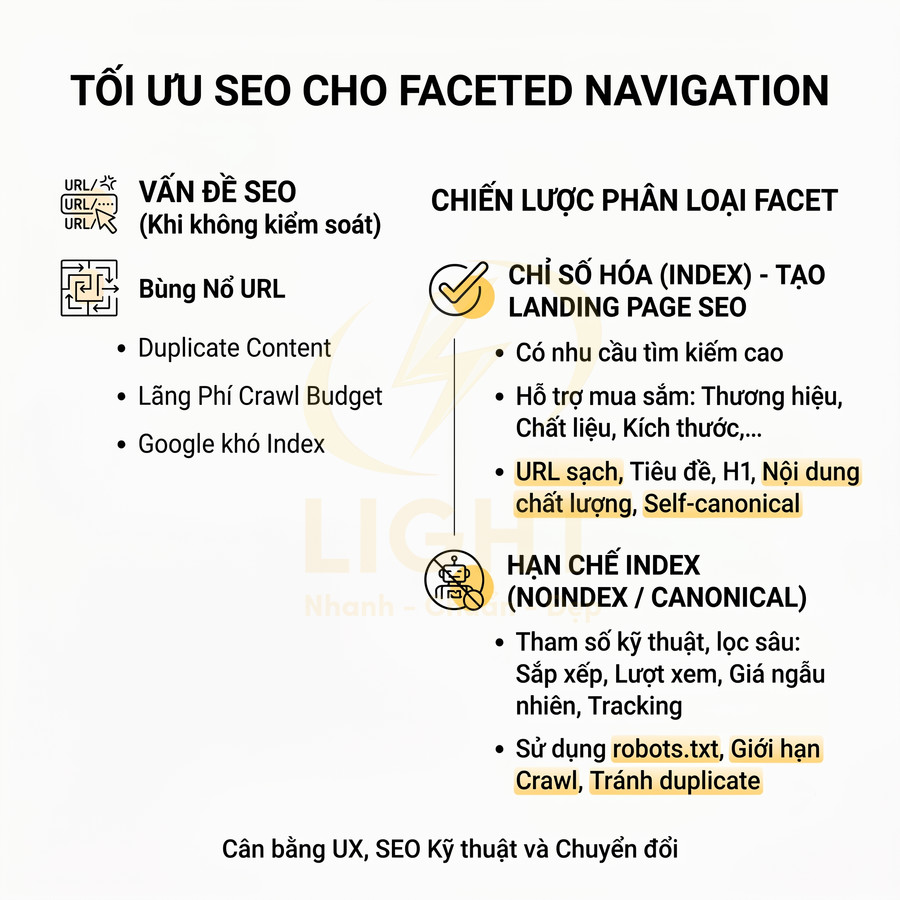

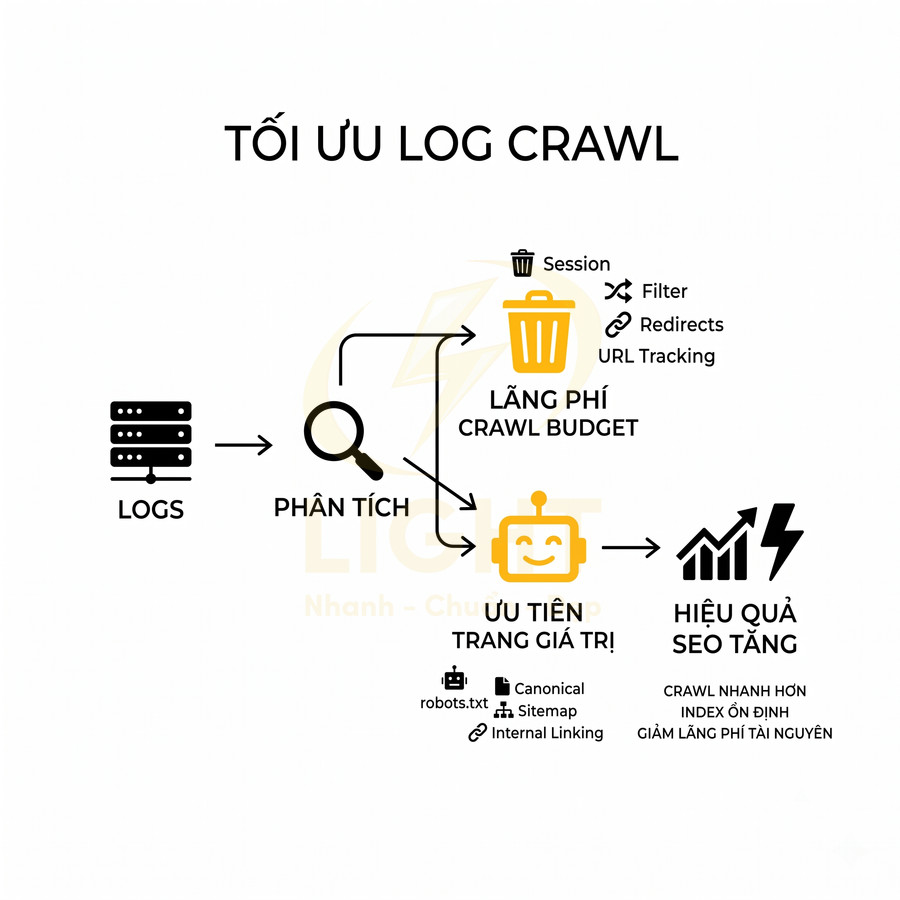




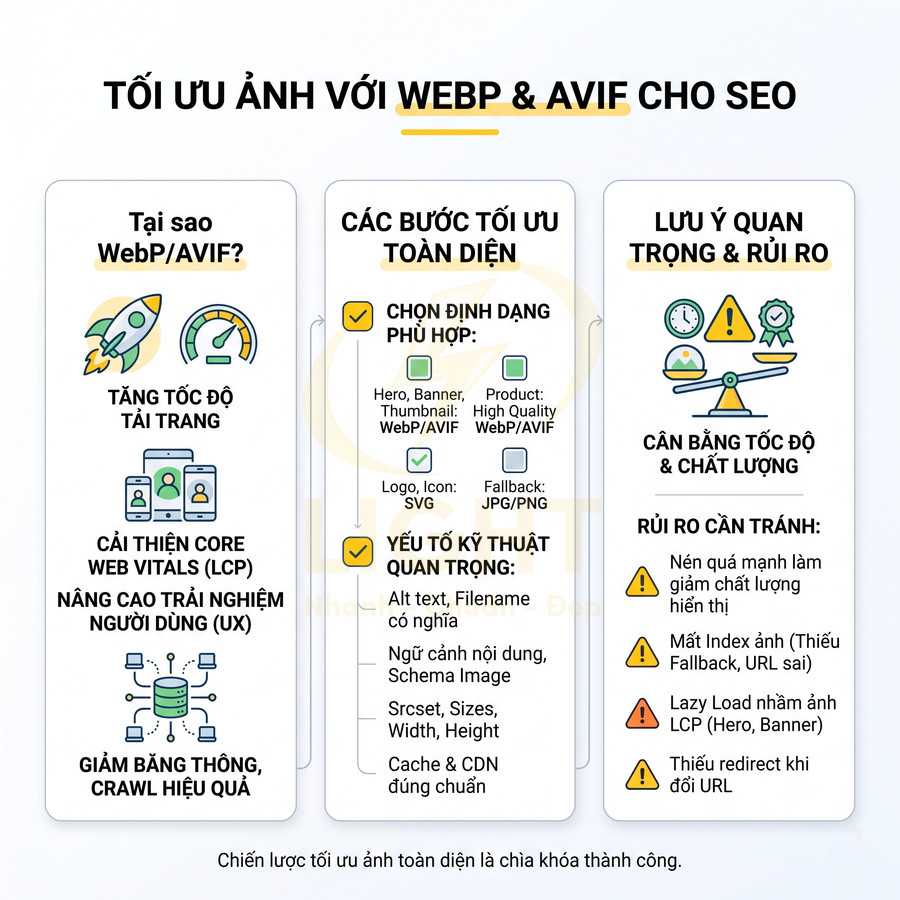



Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
