
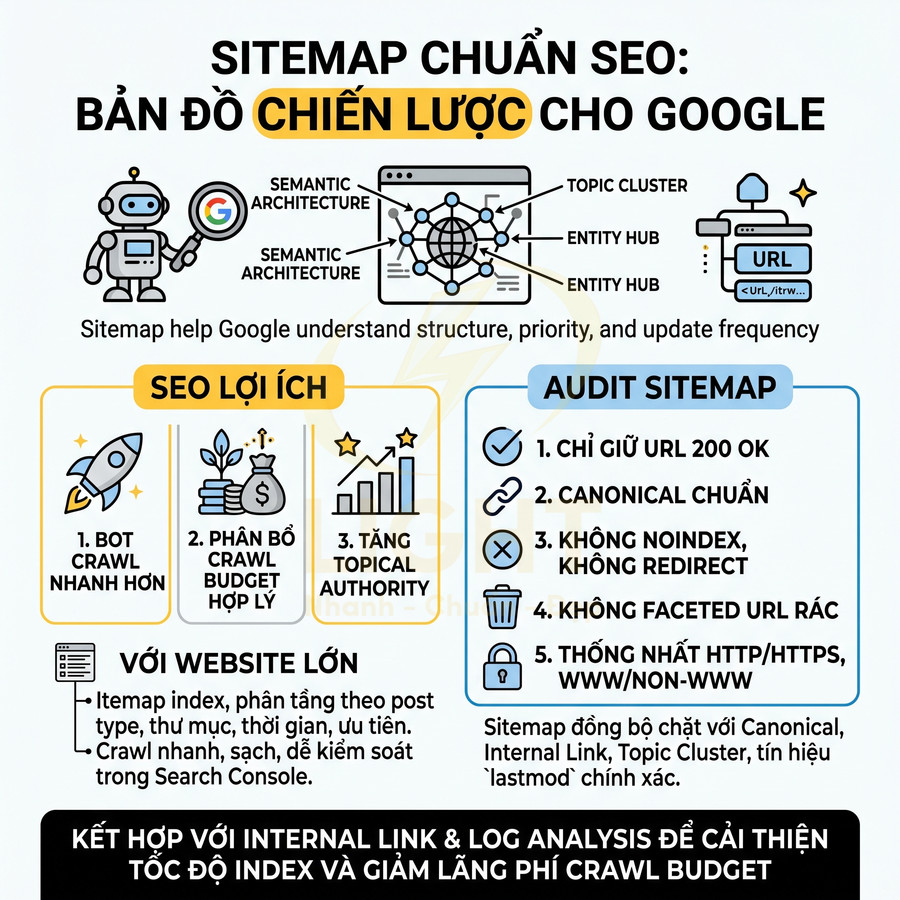
Cách lên sitemap website chuẩn SEO để Google crawl nhanh hơn
Sitemap chuẩn SEO không chỉ là một file XML liệt kê URL, mà là “bản đồ chiến lược” giúp Google hiểu cấu trúc, mức độ ưu tiên và nhịp cập nhật của toàn website. Khi được thiết kế đúng theo semantic architecture, sitemap hỗ trợ bot khám phá nhanh các cụm nội dung quan trọng, phân bổ crawl budget hợp lý và tăng tốc độ phát hiện URL mới, URL vừa cập nhật hoặc các trang sâu trong cấu trúc site. Giá trị lớn nhất của sitemap nằm ở việc đồng bộ chặt với canonical, internal link, topic cluster, entity hub và tín hiệu lastmod chính xác, từ đó giúp Google crawl đúng khu vực mang giá trị SEO và kinh doanh cao nhất.
Với website lớn như blog, ecommerce, news hay SaaS, việc phân tầng bằng sitemap index, chia theo post type, thư mục, thời gian và mức độ ưu tiên giúp quá trình crawl trở nên nhanh hơn, sạch hơn và dễ kiểm soát hơn trong Search Console. Tuy nhiên, hiệu quả chỉ đến khi sitemap được audit kỹ: chỉ giữ URL trả về 200, canonical chuẩn, không noindex, không redirect, không faceted URL rác và luôn thống nhất HTTP/HTTPS, www/non-www. Khi kết hợp cùng log analysis và hệ thống internal link tốt, sitemap trở thành lớp tối ưu kỹ thuật cốt lõi để cải thiện tốc độ index, tăng topical authority và giảm lãng phí crawl budget trên toàn website. Khi xây dựng sitemap, cấu trúc website cần được thiết kế mạch lạc ngay từ đầu để Google nhận diện đúng nhóm nội dung chính, trang trụ cột và các URL hỗ trợ. Một nền tảng thiết kế website chuẩn SEO giúp sitemap phản ánh đúng kiến trúc thông tin, thay vì chỉ gom URL rời rạc thiếu định hướng crawl.
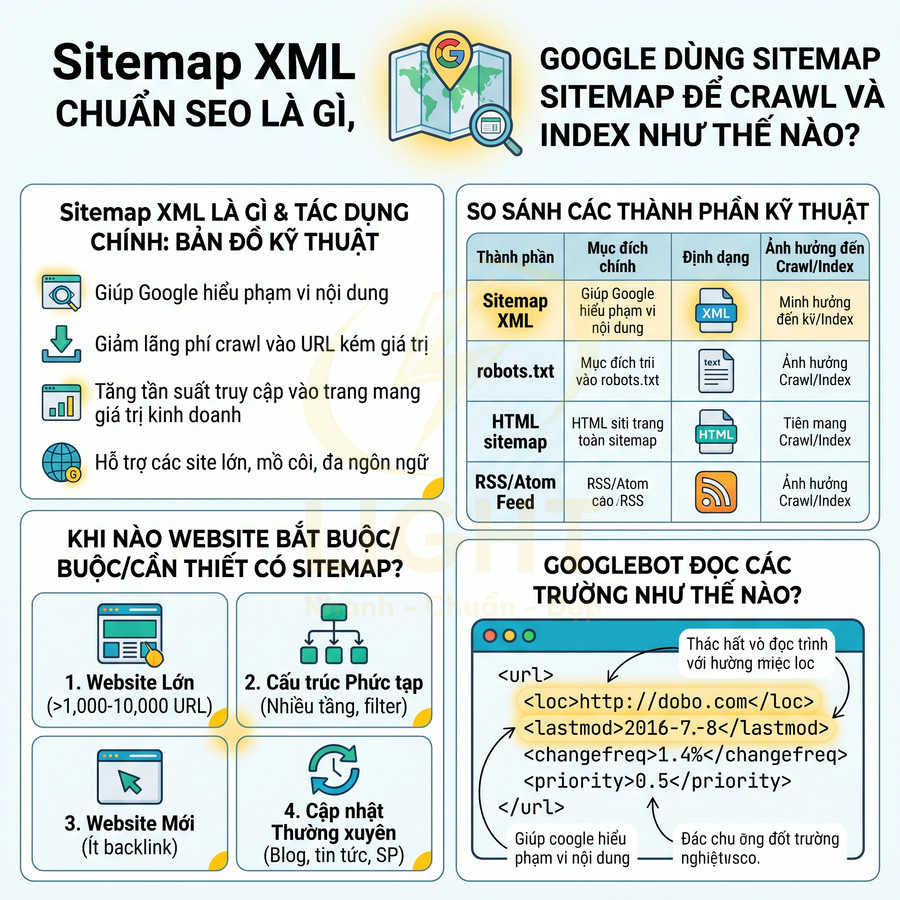
Sitemap XML chuẩn SEO là gì, Google dùng sitemap để crawl và index như thế nào
Sitemap XML chuẩn SEO là tệp cấu trúc giúp Google hiểu phạm vi và mức độ ưu tiên nội dung trên website, từ đó tối ưu quá trình crawl và index. Thông qua các trường như <loc> và <lastmod>, Google có thể phát hiện nhanh URL mới, nội dung vừa cập nhật và phân bổ crawl budget hiệu quả hơn, đặc biệt với site lớn, nhiều tầng hoặc cập nhật thường xuyên. Tuy sitemap là tín hiệu gợi ý chứ không phải mệnh lệnh, nó vẫn là lớp tối ưu hóa quan trọng để giảm lãng phí crawl vào URL kém giá trị, tăng tần suất truy cập vào trang mang giá trị kinh doanh, hỗ trợ quản lý URL mồ côi, đa ngôn ngữ và các nhóm nội dung chuyên biệt như sản phẩm, blog, news. Khi sitemap XML được triển khai đúng, cấu trúc website cần đủ rõ để Google hiểu đâu là trang chính, đâu là nội dung hỗ trợ. Một nền tảng thiết kế website hợp lý giúp URL, danh mục, menu và liên kết nội bộ phối hợp tốt hơn, từ đó tăng hiệu quả crawl và index.
Sitemap XML khác robots.txt, HTML sitemap và RSS feed ở điểm nào
Sitemap XML chuẩn SEO là một file XML tuân thủ protocol tại sitemaps.org, đóng vai trò như một “bản đồ crawl” có cấu trúc, liệt kê các URL quan trọng nhất của website cùng với các metadata kỹ thuật như <lastmod>, <changefreq>, <priority>. Ở góc độ kỹ thuật, sitemap không chỉ là danh sách URL đơn thuần mà còn là một lớp tín hiệu bổ sung giúp công cụ tìm kiếm:
- Hiểu phạm vi nội dung mà website muốn được crawl và index.
- Ưu tiên phân bổ crawl budget cho các khu vực, nhóm URL quan trọng.
- Nhận biết nhanh các thay đổi nội dung quan trọng (update, thêm mới, xóa).
Về mặt chuẩn kỹ thuật, định nghĩa này phù hợp với Sitemap Protocol, trong đó sitemap được mô tả là cách để webmaster thông báo cho công cụ tìm kiếm về các URL có thể crawl, kèm metadata như thời điểm cập nhật, tần suất thay đổi và mức độ quan trọng tương đối của từng URL trong website (Sitemaps.org, 2016). Google cũng định nghĩa sitemap là file cung cấp thông tin về page, video, file khác và mối quan hệ giữa chúng, giúp Google crawl website hiệu quả hơn (Google Search Central, n.d.). Vì vậy, nên hiểu sitemap XML là một lớp khai báo kỹ thuật bổ sung, không thay thế internal link, canonical hay kiểm soát index.

Với các website lớn hoặc có cấu trúc phức tạp, sitemap XML giúp giảm đáng kể độ phụ thuộc vào internal link để khám phá URL. Về mặt kiến trúc crawl, Google thường:
- Thu thập sitemap từ:
- Khai báo trong Google Search Console.
- Khai báo trong file robots.txt qua directive
Sitemap:. - Tự phát hiện khi sitemap được link từ các URL đã biết.
- Đưa toàn bộ URL trong sitemap vào một hàng đợi crawl riêng, sau đó hợp nhất với các nguồn URL khác (internal link, backlink, RSS, file log cũ).
- Áp dụng các thuật toán đánh giá chất lượng site, lịch sử crawl, tần suất cập nhật để quyết định nhịp crawl tối ưu.
Điểm này cần nhấn mạnh để tránh hiểu sai vai trò của sitemap. Google Search Central nêu rõ việc gửi sitemap chỉ là một “hint”, không đảm bảo Google sẽ tải sitemap hoặc dùng sitemap để crawl toàn bộ URL được khai báo (Google Search Central, n.d.). Nghiên cứu của Schonfeld và Shivakumar (2009) cũng xem sitemap như một nguồn URL bổ sung bên cạnh discovery crawling truyền thống, chứ không phải cơ chế ép công cụ tìm kiếm index trang. Do đó, nếu một URL trong sitemap bị noindex, canonical sang URL khác, nội dung mỏng hoặc bị chặn bởi robots.txt, Google vẫn có thể bỏ qua URL đó. Sitemap chỉ phát huy hiệu quả khi danh sách URL sạch, indexable và phù hợp với cấu trúc internal link.
Google sử dụng sitemap như một tín hiệu gợi ý, không phải mệnh lệnh tuyệt đối. Một URL có mặt trong sitemap:
- Không được đảm bảo sẽ được crawl hoặc index.
- Có thể bị bỏ qua nếu:
- Bị chặn bởi robots.txt.
- Bị noindex trong meta robots hoặc HTTP header.
- Bị đánh giá là trùng lặp, mỏng nội dung, hoặc chất lượng thấp.
Ngược lại, một URL không có trong sitemap vẫn có thể được crawl và index nếu được phát hiện qua internal link hoặc backlink. Vì vậy, sitemap là một lớp tối ưu hóa bổ sung cho chiến lược crawl, không phải cơ chế kiểm soát index.
Sitemap XML khác với các thành phần kỹ thuật khác trên website ở nhiều khía cạnh quan trọng. Bảng sau tóm tắt sự khác biệt:
| Thành phần | Mục đích chính | Định dạng | Ảnh hưởng đến crawl/index |
|---|---|---|---|
| Sitemap XML | Khai báo URL quan trọng, gợi ý tần suất và thời điểm crawl | XML chuẩn theo protocol sitemaps.org | Giúp bot khám phá URL nhanh hơn, ưu tiên crawl URL mới/cập nhật |
| robots.txt | Cho phép hoặc chặn bot truy cập một số đường dẫn | Text thuần, theo chuẩn Robots Exclusion Protocol | Có thể chặn hoàn toàn crawl; không điều khiển index trực tiếp |
| HTML sitemap | Hỗ trợ người dùng và bot điều hướng nội bộ | Trang HTML liệt kê link | Tăng internal link, hỗ trợ crawl nhưng không có metadata như lastmod |
| RSS/Atom feed | Thông báo nội dung mới/cập nhật cho client, aggregator | XML theo chuẩn RSS/Atom | Có thể dùng như tín hiệu phát hiện nội dung mới, nhưng không thay thế sitemap XML |
Ở mức độ chuyên sâu hơn:
- Sitemap XML:
- Có thể chia nhỏ thành nhiều file con (index sitemap) để tối ưu hiệu suất và giới hạn 50.000 URL hoặc 50MB mỗi file.
- Hỗ trợ nhiều loại sitemap chuyên biệt: image, video, news, hreflang… giúp Google hiểu ngữ cảnh nội dung đa phương tiện.
- Được Google log và báo cáo chi tiết trong Search Console (Coverage, Sitemaps report).
- robots.txt:
- Chỉ điều khiển quyền crawl, không đảm bảo ngăn index nếu URL đã được phát hiện từ nguồn khác và có tín hiệu mạnh.
- Sai cấu hình có thể khiến toàn bộ site bị chặn crawl, gây mất index diện rộng.
- HTML sitemap:
- Hoạt động như một hub internal link, giúp phân phối PageRank nội bộ.
- Không mang metadata thời gian, tần suất, độ ưu tiên nên không tối ưu sâu cho crawl scheduling.
- RSS/Atom feed:
- Thường chỉ chứa một tập con nội dung mới nhất (ví dụ 10–50 bài), không phản ánh toàn bộ cấu trúc site.
- Phù hợp để phát hiện nội dung mới, nhưng không đủ để quản lý crawl cho toàn bộ website.
robots.txt là lớp kiểm soát truy cập, HTML sitemap là công cụ điều hướng cho người dùng, RSS feed là kênh phân phối nội dung, còn Sitemap XML là bản đồ kỹ thuật dành riêng cho bot để tối ưu quá trình crawl và index. Cần phân biệt rõ “khai báo URL” và “chặn truy cập”. Robots.txt cho bot biết URL nào crawler có thể truy cập, chủ yếu nhằm tránh quá tải server; Google nhấn mạnh robots.txt không phải cơ chế đáng tin cậy để giữ một trang khỏi kết quả tìm kiếm, muốn chặn index cần dùng noindex hoặc bảo vệ bằng xác thực (Google Search Central, n.d.). Ngược lại, sitemap XML là cơ chế inclusion, giúp công cụ tìm kiếm biết URL nào webmaster cho là quan trọng để crawl. HTML sitemap thiên về điều hướng và internal link cho người dùng/bot, còn RSS/Atom thường chỉ phản ánh nội dung mới nhất, không đại diện đầy đủ cho toàn bộ kiến trúc website.
Khi nào website bắt buộc cần sitemap để tối ưu crawl budget
Trong thực tế SEO chuyên nghiệp, sitemap gần như là thành phần mặc định của mọi website nghiêm túc về organic traffic. Tuy nhiên, mức độ “bắt buộc” phụ thuộc vào quy mô, cấu trúc và chiến lược nội dung. Google cho biết nếu các trang quan trọng đã được liên kết tốt, Google thường có thể tự phát hiện phần lớn website; tuy nhiên, sitemap đặc biệt hữu ích với website lớn, website có nhiều trang mới, website có ít external link, hoặc website có nhiều media/news content (Google Search Central, n.d.). Điều này khớp với nghiên cứu về sitemap của Schonfeld và Shivakumar (2009), trong đó sitemap được xem là nguồn bổ sung giúp tăng coverage và freshness so với crawling truyền thống dựa hoàn toàn vào link. Vì vậy, sitemap không phải “bắt buộc” theo nghĩa pháp lý/kỹ thuật, nhưng là best practice quan trọng khi website tăng quy mô, có cấu trúc sâu hoặc cần Google phát hiện URL mới nhanh hơn.
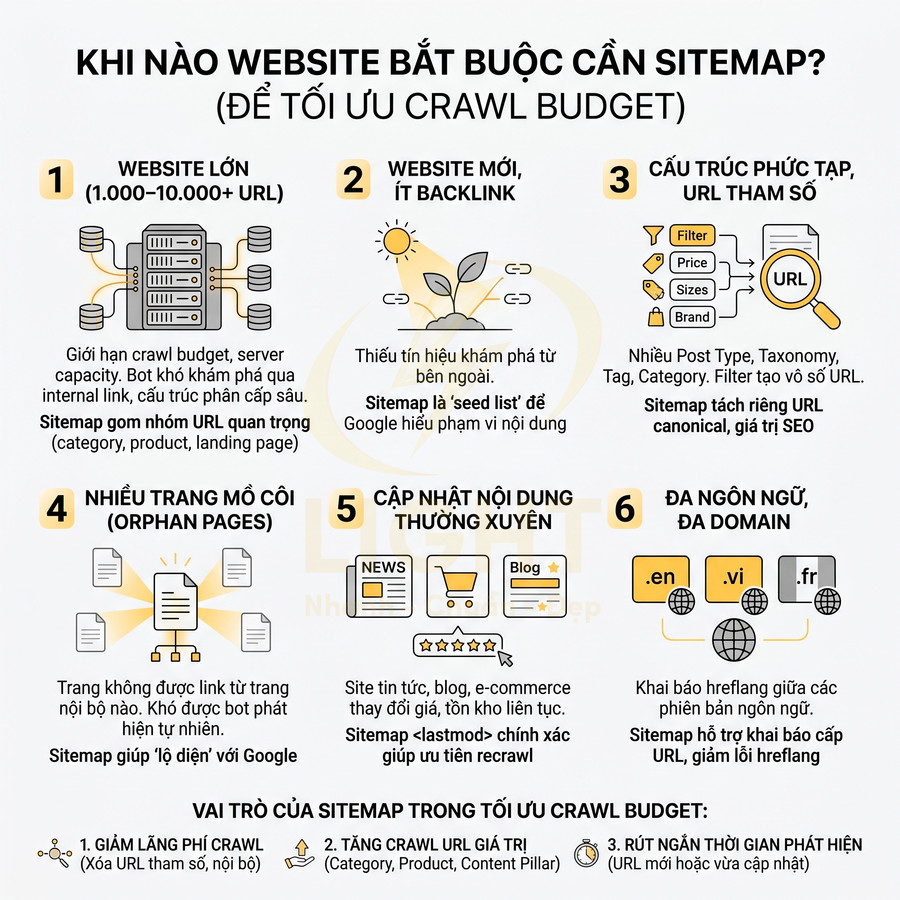
- Website lớn trên 1.000–10.000 URL:
- Crawl budget bị giới hạn theo domain, server capacity và chất lượng site.
- Bot khó có thể khám phá toàn bộ URL chỉ qua internal link, đặc biệt khi:
- Cấu trúc phân cấp sâu (nhiều cấp thư mục, nhiều filter).
- Có nhiều trang chỉ xuất hiện sau thao tác filter, sort, paginate.
- Sitemap giúp gom nhóm URL quan trọng (category, product, landing page) để Google ưu tiên crawl.
- Website mới, ít backlink:
- Thiếu tín hiệu khám phá từ bên ngoài (referring domains, social, mention).
- Sitemap đóng vai trò như “seed list” ban đầu để Google hiểu phạm vi nội dung.
- Đặc biệt quan trọng khi site mới nhưng đã có nhiều URL (import sản phẩm, migration từ hệ thống cũ).
- Website có cấu trúc phức tạp:
- Nhiều loại post type, taxonomy, tag, category, archive.
- Nhiều lớp filter (màu, size, brand, price) tạo ra vô số URL tham số.
- Sitemap cho phép:
- Tách riêng nhóm URL canonical, có giá trị SEO.
- Loại bỏ các URL tham số, session, sort khỏi danh sách ưu tiên crawl.
- Website có nhiều trang mồ côi (orphan pages):
- Trang không được link từ bất kỳ trang nội bộ nào, chỉ tồn tại qua direct URL hoặc dữ liệu hệ thống.
- Không có internal link nên rất khó được bot phát hiện tự nhiên.
- Sitemap là một trong số ít cơ chế giúp các trang này “lộ diện” với Google, trước khi bạn kịp tối ưu internal link.
- Website cập nhật nội dung thường xuyên:
- Site tin tức, blog, ecommerce với:
- Bài viết mới mỗi ngày.
- Thay đổi giá, tồn kho, khuyến mãi liên tục.
- Sitemap với <lastmod> chính xác giúp Google:
- Ưu tiên recrawl các URL vừa cập nhật.
- Giảm crawl lãng phí vào các URL ít thay đổi.
- Site tin tức, blog, ecommerce với:
- Website đa ngôn ngữ, đa domain:
- Cần khai báo hreflang giữa:
- Các phiên bản ngôn ngữ (vi, en, fr…).
- Các domain hoặc subdomain khác nhau (.com, .com.vn, .de…).
- Sitemap hỗ trợ khai báo hreflang ở cấp URL, giúp Google:
- Hiểu quan hệ tương đương giữa các phiên bản.
- Giảm lỗi hreflang không đối xứng, thiếu cặp.
- Cần khai báo hreflang giữa:
Trong bối cảnh tối ưu crawl budget, sitemap giúp:
- Giảm lãng phí crawl:
- Không đưa vào sitemap các URL:
- Tham số filter, sort, paginate không mang giá trị SEO.
- Trang test, staging, trang nội bộ không dành cho index.
- Kết hợp với noindex, canonical, robots.txt để định hình rõ “vùng nội dung SEO”.
- Không đưa vào sitemap các URL:
- Tăng tỷ lệ crawl vào URL mang giá trị kinh doanh:
- Ưu tiên:
- Category, collection, landing page chuyển đổi.
- Product page, service page, content pillar.
- Phân tách sitemap theo nhóm (ví dụ: sitemap-products.xml, sitemap-blog.xml) để theo dõi coverage và lỗi riêng từng nhóm.
- Ưu tiên:
- Rút ngắn thời gian phát hiện URL mới hoặc URL vừa cập nhật:
- Đặc biệt quan trọng với:
- Site tin tức cạnh tranh thời gian index.
- Chiến dịch khuyến mãi ngắn hạn, landing page theo mùa.
- Khi <lastmod> được cập nhật chính xác, Google có xu hướng recrawl nhanh hơn so với chỉ dựa vào tín hiệu link.
- Đặc biệt quan trọng với:
Google bot đọc các trường <loc>, <lastmod>, <priority>, <changefreq> ra sao
Mỗi URL trong sitemap XML thường có cấu trúc cơ bản:
<url> <loc>https://example.com/sample-page/</loc> <lastmod>2026-04-10T10:30:00+00:00</lastmod> <changefreq>weekly</changefreq> <priority>0.8</priority></url>

Cách Google xử lý các trường này ở mức độ kỹ thuật:
- <loc>:
- Là URL tuyệt đối, đã được chuẩn hóa (canonical form) theo:
- Protocol: ưu tiên HTTPS nếu site đã hỗ trợ.
- Hostname: thống nhất www hoặc non-www.
- Đường dẫn: tránh session ID, tracking parameter, ký tự thừa.
- Google:
- Dùng <loc> để đưa URL vào hàng đợi crawl.
- So sánh với:
- Canonical tag trên trang.
- Redirect chain (301, 302).
- Hreflang và alternate link.
- Nếu <loc> khác với canonical thực tế, Google có thể:
- Chọn canonical khác với URL trong sitemap.
- Giảm độ tin cậy vào sitemap nếu phát hiện nhiều sai lệch.
- Là URL tuyệt đối, đã được chuẩn hóa (canonical form) theo:
- <lastmod>:
- Là tín hiệu mạnh về việc URL có thay đổi nội dung gần đây, đặc biệt khi:
- Định dạng theo chuẩn ISO 8601 (ví dụ: 2026-04-10T10:30:00+00:00).
- Phản ánh đúng thời điểm thay đổi nội dung chính (text, data, cấu trúc).
- Google ưu tiên recrawl URL có lastmod mới, nhất là:
- Site tin tức (news), blog cập nhật thường xuyên.
- Trang sản phẩm có giá, tồn kho, thông số thay đổi.
- Thực hành tốt:
- Chỉ cập nhật <lastmod> khi nội dung thực sự thay đổi, không phải:
- Thay đổi nhỏ về CSS, JS, layout không ảnh hưởng nội dung.
- Chỉnh sửa metadata không quan trọng.
- Đồng bộ <lastmod> với ngày cập nhật hiển thị trên trang (nếu có) để tránh tín hiệu mâu thuẫn.
- Chỉ cập nhật <lastmod> khi nội dung thực sự thay đổi, không phải:
- Là tín hiệu mạnh về việc URL có thay đổi nội dung gần đây, đặc biệt khi:
- <changefreq>:
- Là gợi ý mềm (hint), không phải tín hiệu bắt buộc.
- Các giá trị hợp lệ: always, hourly, daily, weekly, monthly, yearly, never.
- Google ngày càng ít phụ thuộc vào <changefreq> vì:
- Bot có thể tự học tần suất thay đổi dựa trên lịch sử crawl.
- Nhiều site cấu hình <changefreq> không chính xác (spam “daily”, “always”).
- Nếu vẫn sử dụng:
- Gán giá trị hợp lý:
- Homepage, category lớn: daily hoặc weekly.
- Bài blog evergreen: monthly hoặc yearly.
- Trang archive cũ, ít thay đổi: yearly hoặc never.
- Giữ nhất quán với thực tế để tránh làm giảm độ tin cậy của sitemap.
- Gán giá trị hợp lý:
- <priority>:
- Giá trị từ 0.0 đến 1.0, thể hiện mức độ quan trọng tương đối trong nội bộ site, không so sánh giữa các domain khác nhau.
- Google coi đây là tín hiệu rất yếu, thường bị lấn át bởi:
- Internal link (số lượng, độ sâu, anchor text).
- Backlink từ domain khác.
- Engagement và chất lượng nội dung.
- Thực hành hợp lý:
- Không đặt tất cả URL priority 1.0.
- Phân tầng:
- Homepage: 1.0 hoặc 0.9.
- Category, hub page: 0.8–0.9.
- Bài viết, sản phẩm quan trọng: 0.6–0.8.
- Trang phụ, policy, trang ít giá trị SEO: 0.3–0.5.
- Tránh thay đổi priority liên tục, giữ cấu trúc ổn định để Google “học” được pattern ưu tiên.
Trong thực hành SEO hiện đại, <loc> và <lastmod> là hai trường quan trọng nhất. <changefreq> và <priority> có thể dùng hoặc bỏ, nhưng nếu dùng phải nhất quán, tránh spam giá trị cao cho mọi URL. Sự chính xác và nhất quán của sitemap ảnh hưởng trực tiếp đến mức độ Google tin tưởng và sử dụng nó như một nguồn dữ liệu ưu tiên trong quá trình crawl và index. Sitemap Protocol quy định <loc> là trường bắt buộc, còn <lastmod>, <changefreq> và <priority> là các trường tùy chọn nhằm cung cấp thêm metadata cho crawler (Sitemaps.org, 2016). Trong thực hành hiện đại, Google khuyến nghị cung cấp sitemap chính xác, có URL hợp lệ và có thể crawl, nhưng cũng nhấn mạnh sitemap chỉ là tín hiệu gợi ý. Vì vậy, <lastmod> có giá trị khi phản ánh đúng lần thay đổi nội dung thực tế, còn <changefreq> và <priority> không nên bị dùng như công cụ “ép” Google crawl nhanh hơn. Nếu toàn bộ URL đều có priority 1.0 hoặc lastmod bị cập nhật ảo mỗi lần deploy, sitemap dễ trở thành tín hiệu nhiễu thay vì tín hiệu đáng tin.
Cấu trúc sitemap website chuẩn semantic SEO cho từng loại site: blog, ecommerce, news, SaaS
Sitemap semantic SEO cho từng loại website cần phản ánh rõ cấu trúc thông tin, mối quan hệ chủ đề và mức độ ưu tiên crawl, thay vì chỉ liệt kê URL. Với blog lớn, sitemap nên tổ chức theo post type, taxonomy và topic cluster, chọn lọc category/tag có giá trị SEO, đảm bảo hub page luôn xuất hiện và được cập nhật <lastmod> chính xác. Ecommerce tập trung vào URL canonical cho product, collection và static page, hạn chế filter page, biến thể và tham số gây nhiễu, chỉ index các landing page filter có search intent rõ ràng. Website tin tức cần kết hợp sitemap thường, Google News, image và video để tối ưu tốc độ index và rich results. SaaS ưu tiên core pages, use case, blog, docs, gắn chặt với topic cluster và customer journey, tránh đưa URL test hoặc landing page ngắn hạn.
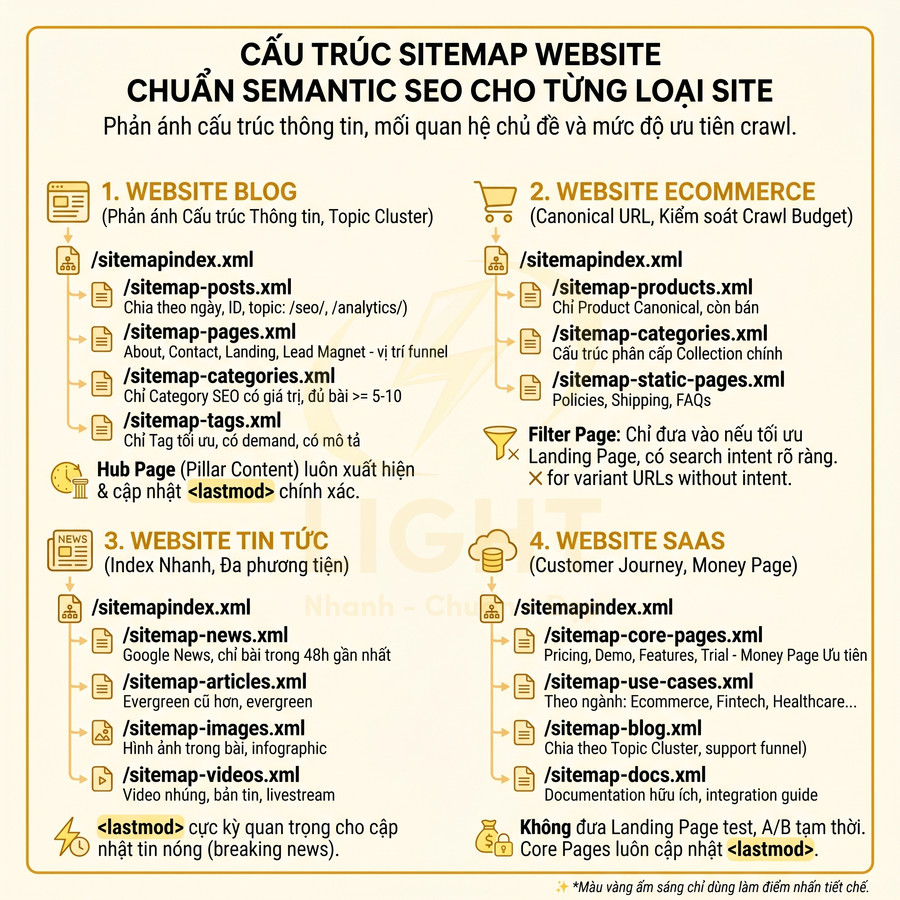
Sitemap cho website blog nhiều bài viết và taxonomy category/tag
Với blog lớn, mục tiêu không chỉ là liệt kê toàn bộ URL mà còn phải giúp Google hiểu rõ ngữ nghĩa cấu trúc nội dung, mối quan hệ giữa các chủ đề, và mức độ ưu tiên crawl. Sitemap cần được thiết kế như một “bản đồ chủ đề” (semantic map), phản ánh rõ:
- Post type: phân tách rõ bài viết (post) và trang tĩnh (page) để Google nhận diện đâu là nội dung thông tin, đâu là trang hỗ trợ (about, contact, policy…).
- Taxonomy: category, tag, custom taxonomy (nếu có) phải thể hiện được tầng phân cấp chủ đề, tránh trùng lặp ngữ nghĩa.
- Topic cluster: nhóm bài viết xoay quanh một chủ đề chính, trong đó có 1 hub page (pillar) và nhiều cluster content hỗ trợ.
Ở góc độ kiến trúc thông tin, sitemap không chỉ giúp crawler tìm URL mà còn phản ánh cách website tổ chức nội dung theo hệ thống. Lin (2011) cho rằng sitemap do webmaster thiết kế không chỉ trình bày luồng sử dụng chính cho người dùng, mà còn thể hiện cấu trúc khái niệm phân cấp của website. Với blog lớn, điều này có nghĩa là category, tag và pillar page nên được chọn lọc theo chủ đề thật sự có chiến lược, không đưa toàn bộ taxonomy rác vào sitemap. Khi sitemap phản ánh topic cluster rõ ràng, Google dễ phân biệt hub page, cluster content và các trang phụ trợ, từ đó crawl theo cụm nội dung có ý nghĩa hơn.
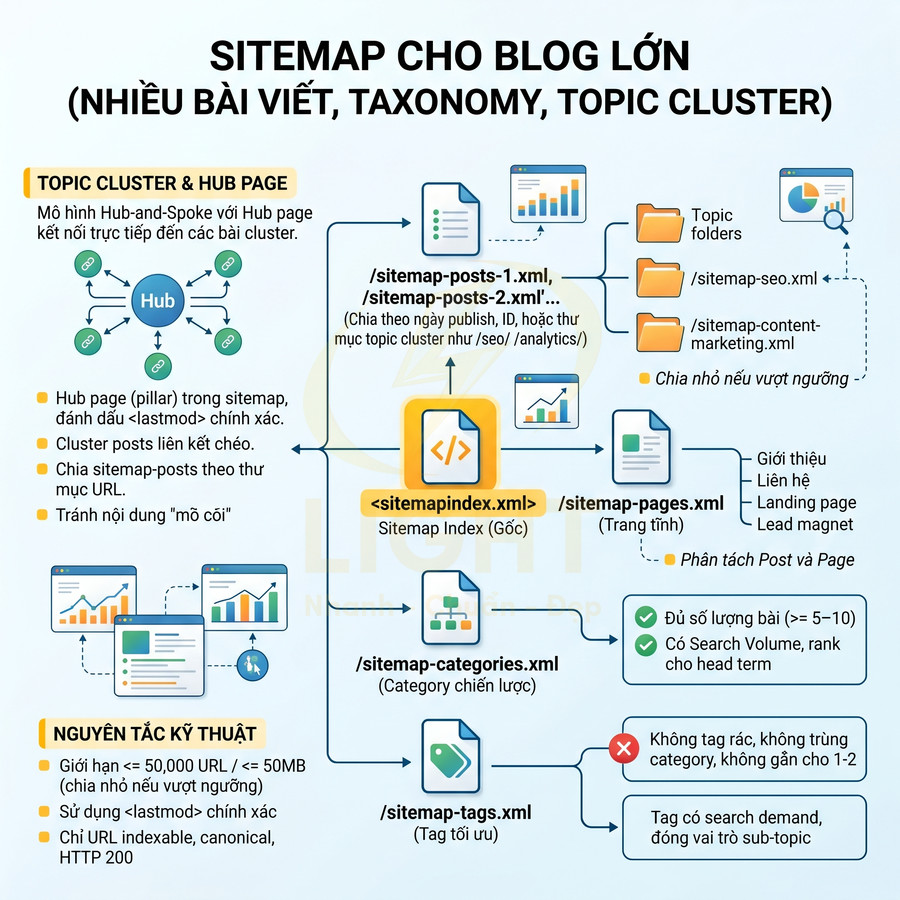
Một cấu trúc sitemap gợi ý cho blog lớn:
- /sitemapindex.xml:
- /sitemap-posts-1.xml, /sitemap-posts-2.xml… (chia theo ngày publish, ID, hoặc theo thư mục /seo/, /analytics/… để phản ánh topic cluster).
- /sitemap-pages.xml (chỉ chứa các page có vai trò rõ ràng trong funnel: about, contact, landing page, lead magnet…).
- /sitemap-categories.xml (chỉ category có chiến lược SEO, không đưa category rỗng hoặc trùng lặp chủ đề).
- /sitemap-tags.xml (chỉ khi tag được tối ưu onpage, có nội dung mô tả, có search demand và đóng vai trò như sub-topic).
Nguyên tắc chọn taxonomy đưa vào sitemap:
- Chỉ đưa category/tag có giá trị SEO thực sự:
- Có đủ số lượng bài liên quan (ví dụ >= 5–10 bài) để thể hiện rõ một chủ đề con.
- Có search volume, có khả năng rank cho các query dạng “chủ đề tổng quan” (head term hoặc mid-tail).
- Không phải tag rác, không trùng lặp với category, không chỉ gắn cho 1–2 bài mà không có chiến lược mở rộng.
- Topic cluster và hub page:
- Hub page (pillar content) phải luôn nằm trong sitemap và được đánh dấu <lastmod> chính xác khi cập nhật.
- Các bài cluster liên kết nội bộ về hub (contextual internal link) và liên kết chéo giữa các bài trong cùng cluster để Google hiểu cấu trúc chủ đề.
- Có thể chia sitemap-posts theo thư mục URL phản ánh chủ đề, ví dụ:
- /sitemap-seo.xml (chứa các URL /seo/…)
- /sitemap-content-marketing.xml (chứa các URL /content-marketing/…)
- Đảm bảo mỗi URL trong sitemap thuộc về một hoặc vài cluster rõ ràng, tránh nội dung “mồ côi” (orphan content).
Về mặt kỹ thuật, mỗi file sitemap nên:
- Giới hạn <= 50.000 URL hoặc <= 50MB uncompressed, chia nhỏ nếu vượt ngưỡng.
- Sử dụng <lastmod> chính xác để ưu tiên crawl các bài mới cập nhật, đặc biệt với evergreen content được tối ưu lại.
- Không đưa URL noindex, redirect, 404, 410; chỉ chứa URL indexable, canonical, trả về HTTP 200.
Sitemap cho ecommerce: product, collection, filter page, biến thể URL canonical
Website ecommerce thường có số lượng URL cực lớn do product, collection, filter/faceted navigation và biến thể (variant). Nếu không kiểm soát, sitemap sẽ bị “nhiễu” bởi vô số URL không có giá trị SEO, gây lãng phí crawl budget và làm mờ tín hiệu semantic. Cấu trúc sitemap nên:
- Chia sitemap theo loại nội dung:
- /sitemap-products.xml (chỉ chứa product canonical, còn bán, không 404, không out-of-stock vĩnh viễn).
- /sitemap-categories.xml (chứa category/collection chính, thể hiện cấu trúc phân cấp sản phẩm).
- /sitemap-static-pages.xml (about, policy, contact, shipping, return, FAQ…).
- Chỉ đưa URL canonical:
- Product chính, không đưa từng biến thể nếu biến thể không có search intent riêng (ví dụ size, màu chỉ là thuộc tính, không phải keyword mục tiêu).
- Category chính, không đưa filter URL (ví dụ ?color=red&size=m) nếu không được tối ưu như landing page độc lập với title, H1, content riêng.
- Đảm bảo mỗi product/collection chỉ có một URL canonical trong sitemap để tránh phân tán tín hiệu.
- Filter page (faceted navigation):
- Chỉ đưa vào sitemap nếu:
- Được tối ưu onpage như landing page: title, H1, meta description, nội dung mô tả riêng, internal link.
- Có search demand rõ ràng, ví dụ: “áo thun nam màu đen”, “giày chạy bộ nữ size 38”, “laptop gaming i7 16GB ram”.
- Được cố định cấu trúc URL (không phải URL tham số ngẫu nhiên), ví dụ /ao-thun-nam/mau-den/ thay vì ?color=black.
- Các filter còn lại nên noindex, không đưa vào sitemap, có thể dùng rel="nofollow" hoặc xử lý bằng rules trong robots.txt nếu cần hạn chế crawl.
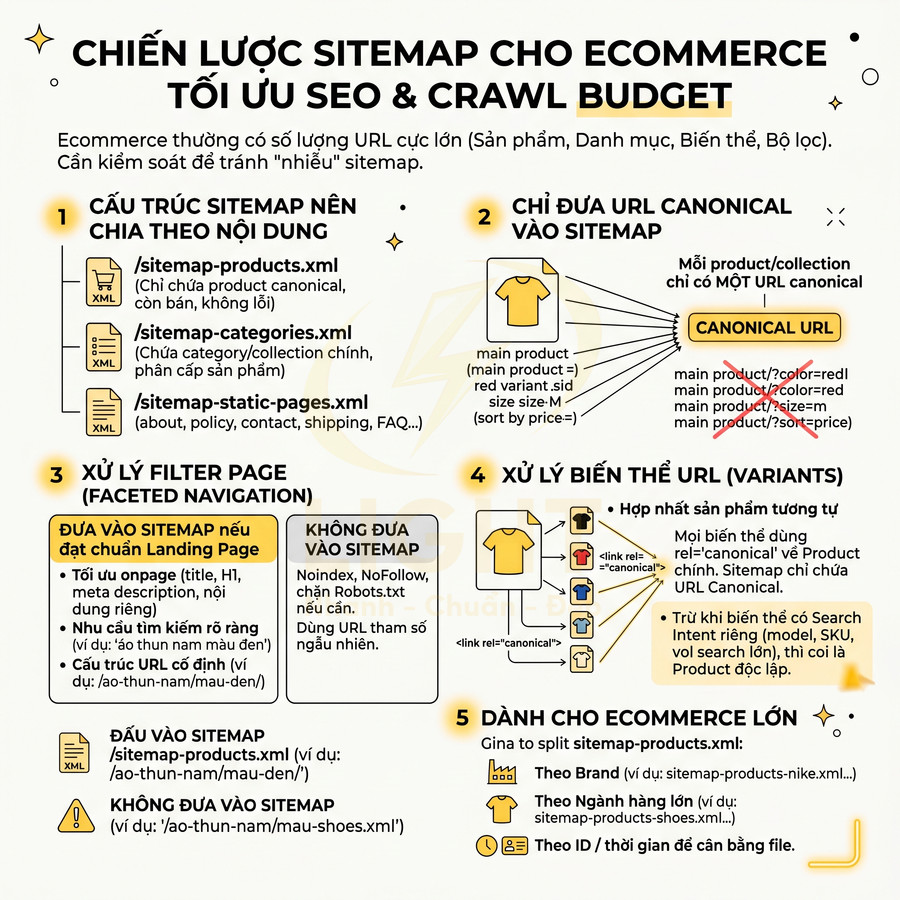
Với biến thể URL, cần đảm bảo:
- Canonical trỏ về product chính:
- Mọi biến thể (màu, size, material…) dùng <link rel="canonical"> về URL product canonical nếu nội dung gần như giống nhau.
- Nếu một biến thể có search intent riêng (ví dụ model riêng, SKU riêng, volume search riêng), có thể coi là product độc lập và đưa vào sitemap như một URL riêng.
- Sitemap chỉ chứa URL canonical, không chứa URL biến thể có tham số (utm, sort, filter, session ID…).
- Tránh trùng lặp nội dung giữa nhiều URL sản phẩm gần như giống nhau:
- Hợp nhất sản phẩm tương tự thành một product với variant nếu không có lý do SEO để tách.
- Đảm bảo mỗi cụm sản phẩm chỉ có một URL “đại diện” trong sitemap để tập trung authority.
Đối với ecommerce lớn, có thể chia nhỏ sitemap-products theo:
- Brand (sitemap-products-nike.xml, sitemap-products-adidas.xml…).
- Category lớn (sitemap-products-shoes.xml, sitemap-products-shirts.xml…).
- Hoặc theo ID/time để cân bằng kích thước file và tần suất cập nhật.
Sitemap cho website tin tức: Google News sitemap, image sitemap, video sitemap
Website tin tức yêu cầu tốc độ index nhanh, cập nhật liên tục và khả năng hiểu ngữ cảnh đa phương tiện (text, image, video). Ngoài sitemap XML thông thường, nên triển khai thêm các loại sitemap chuyên biệt để tối ưu cho Google News và rich results. Google cung cấp hướng dẫn riêng cho News sitemap, image sitemap và video sitemap vì mỗi loại nội dung có metadata khác nhau. News sitemap giúp publisher cung cấp thông tin bổ sung về bài viết tin tức; Google cũng khuyến nghị có thể tách riêng news sitemap để theo dõi nội dung tốt hơn trong Search Console (Google Search Central, n.d.). Image sitemap giúp Google phát hiện hình ảnh, đặc biệt là ảnh có thể khó tìm qua HTML thông thường hoặc được tải bằng JavaScript (Google Search Central, n.d.). Video sitemap hoặc mRSS feed giúp Google phát hiện và index video trên website, bao gồm metadata như thumbnail, mô tả và thời lượng. Vì vậy, site tin tức nên dùng sitemap chuyên biệt để tăng khả năng hiểu nội dung đa phương tiện.
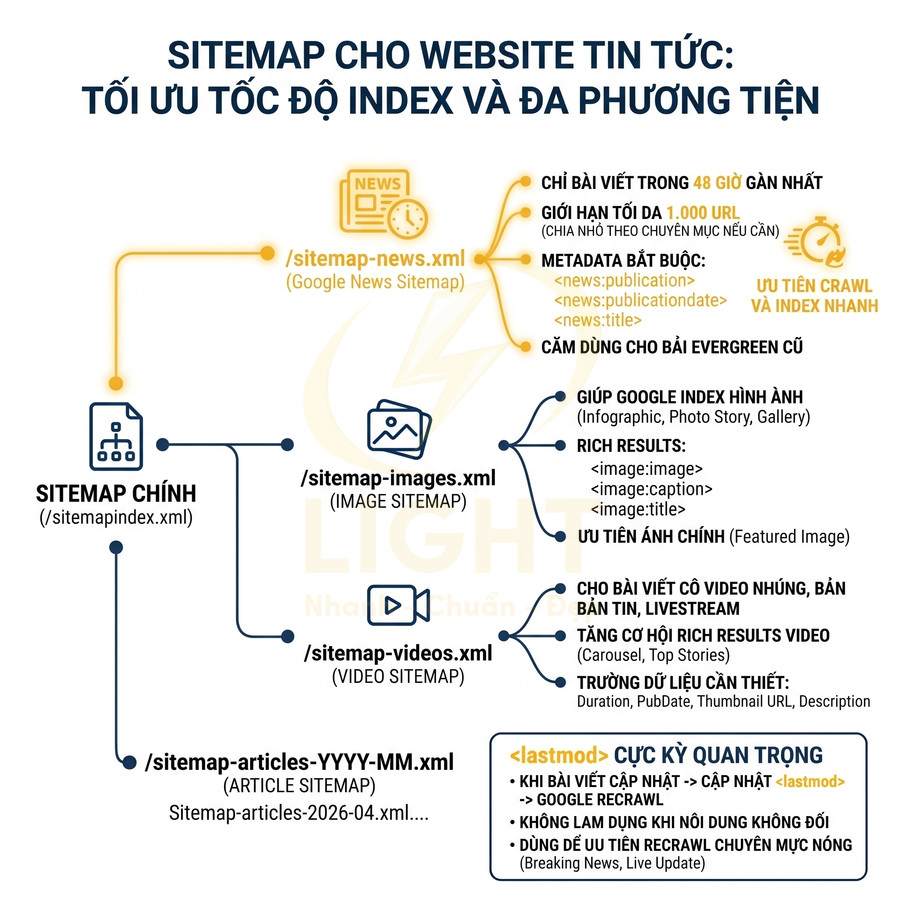
- Google News sitemap:
- Chỉ chứa bài viết trong 48 giờ gần nhất theo guideline của Google News, giúp Google ưu tiên crawl nội dung mới.
- Giới hạn tối đa 1.000 URL; nếu xuất bản nhiều hơn, cần chia nhỏ theo chuyên mục (politics, sports, tech…).
- Phải có các trường như <news:publication>, <news:publicationdate>, <news:title> để Google hiểu rõ metadata của bài báo.
- Không dùng Google News sitemap cho bài evergreen cũ; các bài này nên nằm trong sitemap articles thông thường.
- Image sitemap:
- Giúp Google hiểu và index hình ảnh trong bài viết, đặc biệt quan trọng với site tin tức nhiều ảnh, infographic, photo story, gallery.
- Có thể khai báo nhiều <image:image> cho mỗi URL bài viết, kèm <image:caption>, <image:title> để tăng khả năng xuất hiện trong Google Images.
- Ưu tiên ảnh chính (featured image) và các ảnh có giá trị thông tin cao, tránh spam ảnh không liên quan.
- Video sitemap:
- Dùng cho bài viết có video nhúng, bản tin video, phóng sự, livestream replay.
- Giúp tăng khả năng xuất hiện rich result video, video carousel, Top Stories với thumbnail nổi bật.
- Cần khai báo các trường như duration, publication date, thumbnail URL, description để Google hiểu rõ nội dung video.
Cấu trúc gợi ý:
- /sitemapindex.xml:
- /sitemap-news.xml (Google News, chỉ bài trong 48 giờ gần nhất).
- /sitemap-articles-2026-04.xml (chia theo tháng/năm: sitemap-articles-YYYY-MM.xml để quản lý lịch sử nội dung dài hạn).
- /sitemap-images.xml (hoặc chia nhỏ theo chuyên mục nếu số lượng ảnh rất lớn).
- /sitemap-videos.xml (hoặc chia theo series/chuyên mục video).
Đối với site tin tức, <lastmod> cực kỳ quan trọng:
- Mỗi khi bài viết được cập nhật, đính chính, bổ sung thông tin mới, <lastmod> phải được update để Google recrawl.
- Không nên lạm dụng update <lastmod> nếu nội dung không thay đổi đáng kể; tránh tín hiệu nhiễu.
- Có thể dùng <lastmod> để ưu tiên recrawl các chuyên mục nóng (breaking news, live update) so với các bài phân tích dài hạn.
Sitemap cho website SaaS và landing page theo cụm topic cluster
Website SaaS thường tập trung vào việc dẫn dắt người dùng qua customer journey: từ nhận thức vấn đề (awareness) đến cân nhắc (consideration) và quyết định (decision). Sitemap cần phản ánh rõ cấu trúc này, đồng thời bám sát topic cluster xoay quanh sản phẩm, tính năng và use case.
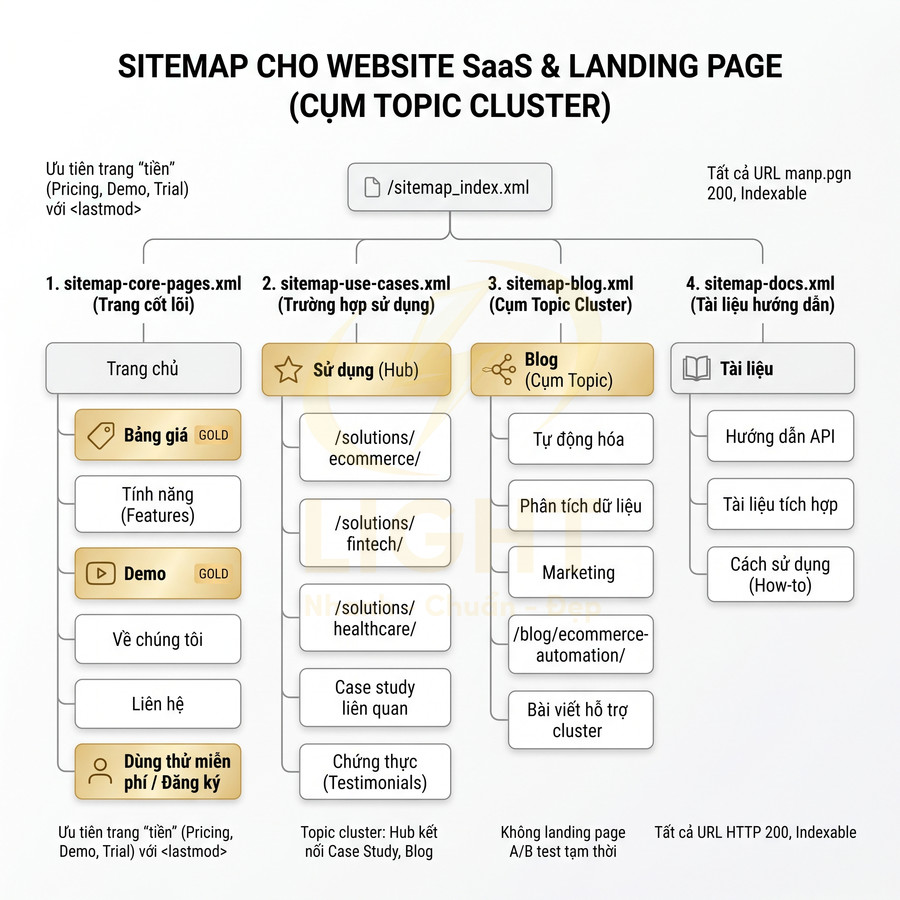
- Nhóm URL cốt lõi (core pages):
- Landing page tính năng (feature pages): mỗi tính năng chính nên có 1 URL riêng, tối ưu cho keyword transactional và solution-aware.
- Use case / solution theo ngành: các trang “{Product} for {Industry}” (ecommerce, fintech, healthcare…) đóng vai trò hub cho cluster nội dung ngành.
- Pricing, demo, trial: money page quan trọng nhất, cần được ưu tiên trong sitemap và cập nhật <lastmod> chính xác.
- Blog, resource, documentation: hỗ trợ SEO thông tin (informational), giải thích vấn đề, hướng dẫn sử dụng, onboarding.
Chiến lược sitemap nên gắn chặt với topic cluster và customer journey:
- /sitemap_index.xml:
- /sitemap-core-pages.xml (home, pricing, features, demo, about, contact, sign-up…):
- Chỉ chứa các trang stable, có vai trò lâu dài trong funnel.
- Đảm bảo không có URL test, staging, hoặc subdomain thử nghiệm.
- /sitemap-use-cases.xml (theo ngành: ecommerce, fintech, healthcare…):
- Mỗi use case page là hub, liên kết đến case study, testimonial, blog post liên quan.
- Có thể nhóm URL theo thư mục /solutions/ecommerce/, /solutions/fintech/… để Google hiểu rõ cấu trúc ngành.
- /sitemap-blog.xml (chia nhỏ nếu nhiều bài):
- Có thể chia theo topic cluster: /sitemap-blog-analytics.xml, /sitemap-blog-automation.xml…
- Hoặc chia theo thời gian nếu số lượng bài rất lớn.
- /sitemap-docs.xml (documentation, knowledge base):
- Chỉ đưa các bài docs indexable, hữu ích cho organic search (how-to, API docs, integration guide…).
- Các trang nội bộ, private docs, hoặc chỉ dành cho user login không nên xuất hiện trong sitemap.
- /sitemap-core-pages.xml (home, pricing, features, demo, about, contact, sign-up…):
Nguyên tắc tối ưu sitemap cho SaaS:
- Ưu tiên URL money page:
- Pricing, demo, free trial, feature chính phải luôn nằm trong sitemap-core-pages, với <lastmod> cập nhật khi có thay đổi về offer, plan, tính năng.
- Đảm bảo các URL này không bị chặn bởi robots.txt, không noindex, không canonical nhầm sang URL khác.
- Topic cluster:
- Hub page cho từng use case hoặc ngành phải có trong sitemap-use-cases, đóng vai trò trung tâm liên kết.
- Các bài blog hỗ trợ cluster (case study, hướng dẫn, so sánh giải pháp) cũng có trong sitemap-blog và liên kết về hub.
- Giữ cấu trúc URL nhất quán để Google dễ nhận diện cluster, ví dụ:
- /solutions/ecommerce/ (hub)
- /blog/ecommerce-email-automation/ (cluster content liên quan)
- Không đưa landing page test A/B tạm thời:
- Các URL campaign ngắn hạn, A/B test, hoặc landing page chỉ dùng cho paid traffic (không có chiến lược SEO) không nên đưa vào sitemap.
- Nếu cần index tạm thời, có thể để Google tự khám phá qua internal link hoặc canonical, nhưng không nên “cố định” trong sitemap.
Về mặt kỹ thuật, sitemap SaaS nên:
- Đảm bảo tất cả URL trong sitemap trả về HTTP 200, indexable, canonical tự trỏ.
- Sử dụng <lastmod> để ưu tiên crawl các trang có thay đổi về pricing, feature, policy, tránh thông tin lỗi thời trong SERP.
- Đồng bộ sitemap với kiến trúc thông tin (information architecture) thực tế, tránh để sitemap trở thành “danh sách URL rời rạc” không phản ánh customer journey.
Quy trình audit URL trước khi đưa vào sitemap để tránh Google lãng phí crawl budget
Quy trình audit URL trước khi đưa vào sitemap tập trung lọc ra tập URL “sạch” để Googlebot ưu tiên crawl, tránh lãng phí ngân sách. Trước hết, cần kiểm tra HTTP status, chỉ giữ URL trả về 200 OK, loại bỏ toàn bộ 3xx, 4xx, 5xx. Tiếp theo, rà soát canonical, đảm bảo URL trong sitemap là phiên bản canonical cuối cùng, không tạo chain, không canonical chéo domain và không mâu thuẫn với internal link. Sau đó đánh giá indexability: không noindex (meta hoặc X-Robots-Tag), không bị Disallow trong robots.txt, ưu tiên HTTPS. Đồng thời loại bỏ URL noindex, redirect, 404/soft 404, trang phân trang, trang tìm kiếm nội bộ và tham số mỏng nội dung. Toàn bộ bước nên được bán tự động hóa bằng crawler, log và checklist định kỳ.
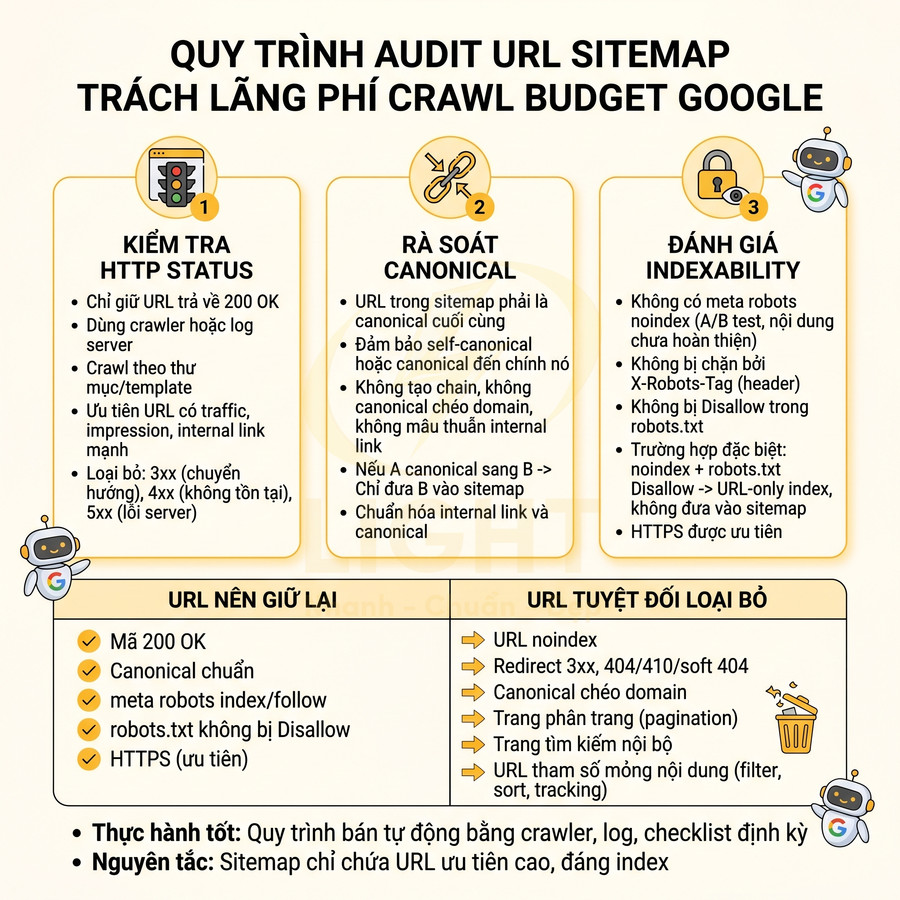
Chỉ giữ URL canonical trả về mã 200 và được phép index
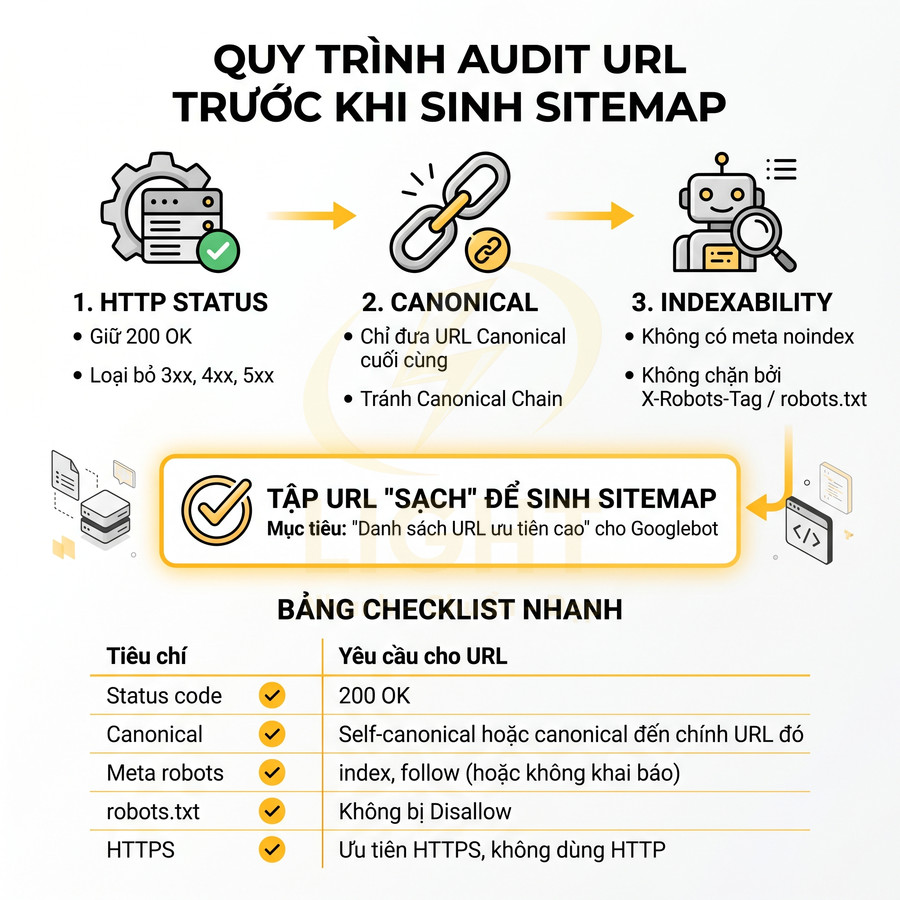
Trước khi sinh sitemap, cần audit toàn bộ URL một cách có hệ thống để đảm bảo chỉ những trang thực sự đáng index mới xuất hiện. Mục tiêu là biến sitemap thành “danh sách URL ưu tiên cao” cho Googlebot, không phải bản dump toàn bộ URL của site. Quy trình chi tiết có thể chia thành 3 lớp kiểm tra chính: HTTP status, canonical và indexability. Cách tiếp cận này phù hợp với nguyên tắc crawl efficiency trong nghiên cứu web crawling. Olston và Najork (2010) mô tả web crawling không chỉ là duyệt theo chiều rộng đơn giản, mà là bài toán phức tạp liên quan đến lựa chọn URL, quản lý tài nguyên, cập nhật nội dung và tránh nội dung không mong muốn. Nếu sitemap chứa nhiều URL lỗi, redirect, noindex, duplicate hoặc thin content, crawler phải tiêu tốn tài nguyên xác minh những URL ít giá trị. Do đó, audit sitemap cần coi indexability là điều kiện bắt buộc: URL phải trả về 200, canonical đúng, không noindex, không bị robots.txt chặn và có giá trị nội dung rõ ràng trước khi được đưa vào sitemap.
- HTTP status:
- Chỉ giữ URL trả về 200 OK: – Dùng crawler (Screaming Frog, Sitebulb, JetOctopus…) hoặc log server để kiểm tra. – Với site lớn, nên crawl theo từng thư mục (directory) hoặc theo nhóm template (product, category, blog…) để dễ phân tích. – Ưu tiên giữ các URL 200 có traffic, có impression hoặc có internal link mạnh; URL 200 nhưng không có tín hiệu nào có thể cần đánh giá thêm về giá trị SEO.
- Loại bỏ 3xx, 4xx, 5xx khỏi sitemap: – 3xx (301, 302, 307, 308): thể hiện URL đã chuyển hướng; nếu vẫn nằm trong sitemap, Google phải crawl 2 lần (URL cũ → URL mới) → lãng phí crawl budget. – 4xx (404, 410, 403…): trang không tồn tại hoặc bị chặn truy cập; không có giá trị index. – 5xx (500, 502, 503…): lỗi server; nếu xuất hiện trong sitemap, Google có thể đánh giá site không ổn định, giảm tần suất crawl.
- Canonical:
- URL trong sitemap phải là URL canonical cuối cùng mà bạn muốn Google index: – Kiểm tra thẻ
<link rel="canonical">trên từng trang. – Đảm bảo canonical không trỏ đến URL khác dạng (HTTP → HTTPS, có/không có slash, có/không có www) nếu bạn muốn index chính URL đó. – Tránh canonical chain (A canonical → B, B canonical → C); sitemap chỉ nên chứa C. - Nếu trang A canonical sang trang B, chỉ đưa B vào sitemap: – A có thể vẫn tồn tại để phục vụ người dùng (ví dụ URL có tham số), nhưng về mặt SEO, Google sẽ tập trung vào B. – Nếu A vẫn nằm trong sitemap, Google nhận tín hiệu mâu thuẫn: sitemap bảo index A, canonical bảo index B.
- Đảm bảo canonical không mâu thuẫn với internal link: – Nếu internal link chủ yếu trỏ đến A nhưng canonical lại trỏ sang B, cần chuẩn hóa lại: hoặc đổi internal link sang B, hoặc điều chỉnh canonical.
- URL trong sitemap phải là URL canonical cuối cùng mà bạn muốn Google index: – Kiểm tra thẻ
- Indexability:
- Không có meta robots noindex: – Kiểm tra thẻ
<meta name="robots" content="noindex">hoặc các biến thể nhưnoindex,follow. – Nếu trang đang noindex vì lý do chiến lược (test A/B, nội dung chưa hoàn thiện…), tuyệt đối không đưa vào sitemap. - Không bị chặn bởi X-Robots-Tag trên header: – Một số hệ thống dùng X-Robots-Tag ở level server (Apache, Nginx) để noindex file PDF, hình ảnh, hoặc một nhóm URL. – Dùng crawler có khả năng đọc header response để phát hiện
X-Robots-Tag: noindexhoặcnoindex, nofollow. - Không bị chặn crawl trong robots.txt: – Nếu một URL bị
Disallowtrong robots.txt, Google không thể crawl nội dung để xác minh, dù sitemap có liệt kê. – Trường hợp đặc biệt: nếu muốn noindex nhưng vẫn chặn crawl bằng robots.txt, Google có thể giữ URL trong index dưới dạng “URL only” → không nên đưa vào sitemap. - Kiểm tra thêm các tín hiệu indexability khác: – Thẻ
noindexở cấp độ từng bot (ví dụ<meta name="googlebot" content="noindex">). – Các directive trong HTTP header dành riêng cho Googlebot hoặc các bot khác.
- Không có meta robots noindex: – Kiểm tra thẻ
Bảng checklist nhanh:
| Tiêu chí | Yêu cầu cho URL trong sitemap |
|---|---|
| Status code | 200 OK |
| Canonical | Self-canonical hoặc canonical đến chính URL đó |
| Meta robots | index, follow (hoặc không khai báo) |
| robots.txt | Không bị Disallow |
| HTTPS | Ưu tiên HTTPS, không dùng HTTP |
Trong thực tế, nên xây dựng một quy trình bán tự động:
- Export toàn bộ URL từ CMS, log server hoặc database.
- Crawl để lấy status code, canonical, meta robots, X-Robots-Tag, robots.txt.
- Lọc theo các tiêu chí trong bảng checklist, chỉ giữ lại tập URL “sạch” để sinh sitemap.
- Thiết lập lịch audit định kỳ (ví dụ hàng tuần hoặc hàng tháng) để cập nhật sitemap khi có thay đổi lớn về cấu trúc site.
Loại bỏ URL noindex, redirect 3xx, 404, soft 404, canonical chéo domain
Các loại URL sau không nên xuất hiện trong sitemap vì gây lãng phí crawl budget, tạo tín hiệu mâu thuẫn và làm “loãng” tập URL quan trọng. Việc loại bỏ cần dựa trên dữ liệu crawl và log để đảm bảo không bỏ sót các pattern ẩn.
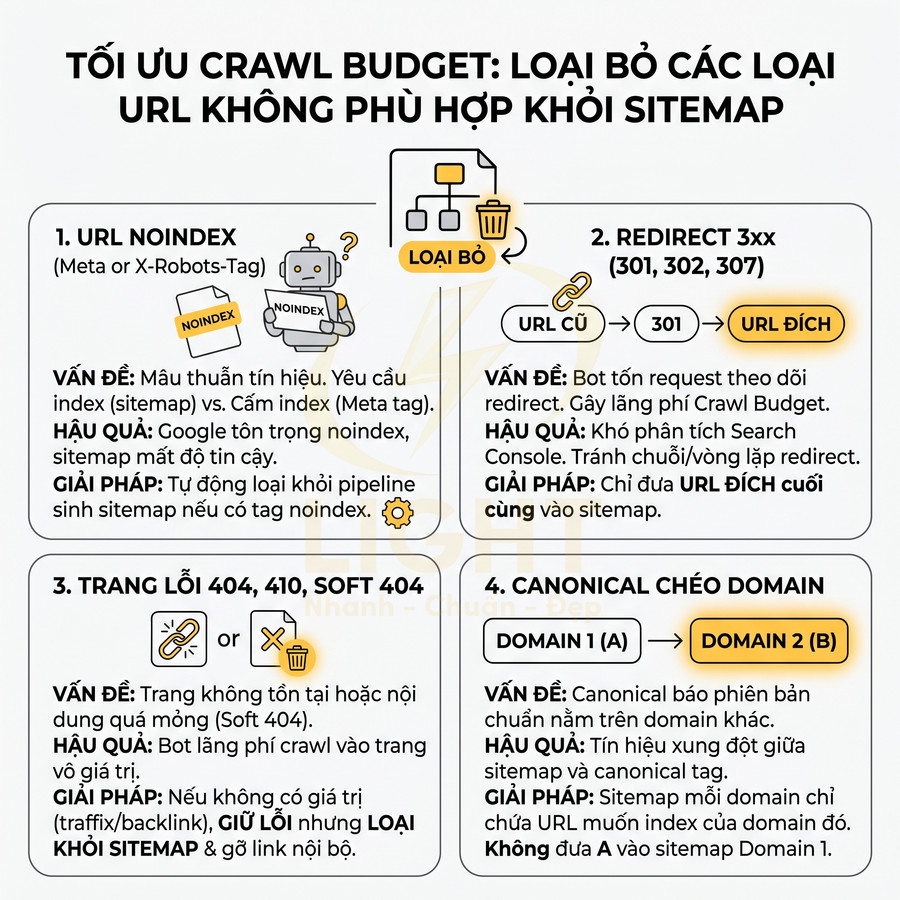
- URL noindex:
- Meta robots noindex hoặc X-Robots-Tag noindex: – Nếu một URL đã được đánh dấu noindex, nghĩa là bạn không muốn nó xuất hiện trong kết quả tìm kiếm. – Đưa URL đó vào sitemap là hành vi tự mâu thuẫn: một bên yêu cầu index (sitemap), một bên cấm index (meta/X-Robots-Tag).
- Sitemap yêu cầu index, meta lại cấm index → tín hiệu xung đột: – Google thường tôn trọng noindex hơn, nhưng việc xung đột làm giảm độ tin cậy của sitemap. – Về mặt quản trị, sitemap nên phản ánh chính xác chiến lược index của bạn; nếu một URL tạm thời noindex, hãy loại khỏi sitemap cho đến khi được phép index trở lại.
- Thực hành tốt: – Tạo segment “noindex” trong crawler để lọc nhanh các URL đang noindex nhưng vẫn nằm trong sitemap. – Thiết lập rule trong pipeline sinh sitemap: nếu
meta robotshoặcX-Robots-Tagchứa “noindex” → tự động loại.
- Redirect 3xx:
- 301, 302, 307… nên được cập nhật thành URL đích trong sitemap: – Với 301 (permanent redirect), URL cũ nên được xóa khỏi sitemap và thay bằng URL đích. – Với 302/307 (temporary), nếu thực tế redirect kéo dài, cần xem lại: hoặc chuyển sang 301, hoặc cập nhật sitemap theo URL đích nếu đó mới là trang bạn muốn index.
- Không giữ URL cũ đã redirect lâu dài: – Mỗi lần Googlebot crawl URL cũ trong sitemap, nó phải follow redirect → tốn thêm một request. – Với site lớn, hàng nghìn redirect trong sitemap có thể tiêu tốn đáng kể crawl budget. – Ngoài ra, việc giữ URL cũ trong sitemap khiến báo cáo trong Search Console khó đọc, khó phân tích hiệu suất.
- Kiểm soát redirect chain và loop: – Nếu sitemap chứa URL A, nhưng A → B → C, Google phải đi qua cả chain; tốt nhất sitemap chỉ nên chứa C. – Redirect loop (A → B → A) không nên xuất hiện trong sitemap; cần xử lý triệt để ở level kỹ thuật.
- 404, 410, soft 404:
- Trang không tồn tại hoặc nội dung quá mỏng, Google coi là soft 404: – 404/410: URL đã bị xóa hoặc không còn nội dung hữu ích. – Soft 404: trả về 200 nhưng nội dung rất ít, thông báo lỗi, hoặc không đáp ứng bất kỳ search intent nào; Google tự đánh giá là “gần như 404”.
- Giữ trong sitemap khiến bot lãng phí crawl vào trang vô giá trị: – Google vẫn phải crawl để xác nhận trạng thái 404/410/soft 404. – Với số lượng lớn, điều này làm giảm tần suất crawl cho các URL quan trọng khác.
- Chiến lược xử lý: – Nếu URL 404 từng có giá trị (backlink, traffic), cân nhắc redirect 301 sang trang tương đương. – Nếu không còn giá trị, giữ 404/410 nhưng loại khỏi sitemap và dọn internal link trỏ đến URL đó.
- Canonical chéo domain:
- URL A trên domain1.com canonical sang URL B trên domain2.com: – Trường hợp thường gặp khi có site đa ngôn ngữ, site mirror, hoặc khi di chuyển nội dung sang domain mới. – Canonical chéo domain báo cho Google rằng phiên bản chuẩn để index là trên domain2.com.
- Không nên đưa A vào sitemap domain1; chỉ nên index B trên domain2: – Sitemap của mỗi domain nên chỉ chứa các URL mà domain đó muốn index cho chính mình. – Nếu A vẫn nằm trong sitemap domain1, Google nhận tín hiệu mâu thuẫn: sitemap domain1 muốn index A, canonical lại bảo index B trên domain2.
- Thực hành tốt: – Với migration domain, tạo sitemap riêng cho domain mới với toàn bộ URL đích, và giảm dần (hoặc xóa) sitemap cũ sau khi Google đã xử lý phần lớn redirect. – Đảm bảo canonical chéo domain được cấu hình nhất quán với hreflang (nếu có) và với chiến lược index tổng thể.
Không đưa trang phân trang, trang tìm kiếm nội bộ và URL tham số mỏng nội dung vào sitemap
Một trong những nguồn lãng phí crawl lớn nhất đến từ các URL sinh động (dynamic) hoặc lặp lại cấu trúc, không mang search intent riêng. Những URL này vẫn có thể tồn tại để phục vụ người dùng, nhưng không nên được ưu tiên trong sitemap.
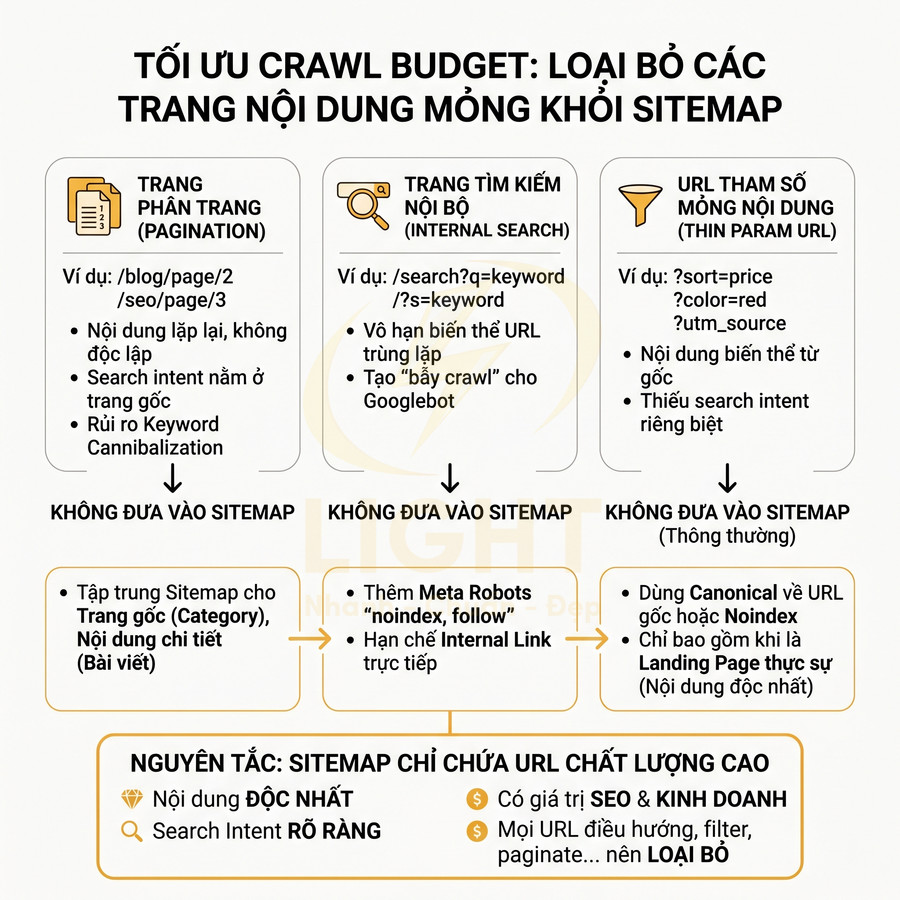
- Trang phân trang (pagination):
- Ví dụ:
/blog/page/2/,/category/seo/page/3/… – Các trang này thường chỉ là danh sách bài viết hoặc sản phẩm, không có nội dung độc lập. – Search intent chủ yếu nằm ở trang category chính hoặc các bài viết/sản phẩm chi tiết. - Thường không mang search intent riêng, chỉ là danh sách bài: – Người dùng hiếm khi tìm kiếm “blog page 2” trên Google. – Nếu được index, các trang này dễ cạnh tranh nội bộ (keyword cannibalization) với chính category hoặc landing page chính.
- Google có thể tự khám phá qua link rel="next"/"prev" hoặc internal link: – Nếu vẫn muốn Google hiểu mối quan hệ giữa các trang phân trang, có thể dùng
rel="next"vàrel="prev"(dù Google đã giảm trọng số, nhưng vẫn hữu ích về mặt cấu trúc). – Internal link từ category chính đến các trang page 2, page 3… là đủ để Google crawl khi cần. - Chiến lược: – Không đưa các URL phân trang vào sitemap. – Tập trung sitemap cho category chính và các URL nội dung chi tiết (bài viết, sản phẩm, landing page).
- Ví dụ:
- Trang tìm kiếm nội bộ:
- Ví dụ:
/search?q=keyword,/?s=keyword… – Các trang này thường sinh ra vô hạn biến thể URL dựa trên truy vấn người dùng. – Nội dung thường là tập hợp kết quả đã có ở các trang khác (category, tag, product list…). - Nội dung trùng lặp, dễ sinh vô hạn URL: – Mỗi truy vấn khác nhau tạo một URL khác nhau, nhưng phần lớn kết quả trùng lặp. – Google có thể bị “bẫy crawl” nếu các trang này được index và liên kết lẫn nhau.
- Nên noindex, không đưa vào sitemap: – Thiết lập
meta robots="noindex,follow"cho các trang search result nội bộ. – Đảm bảo không có internal link quan trọng (menu, footer) trỏ trực tiếp đến các URL search; chỉ nên xuất hiện khi người dùng thực hiện tìm kiếm.
- Ví dụ:
- URL tham số mỏng nội dung:
- Ví dụ:
?sort=price,?page=2,?color=red&size=m… – Các tham số này thường dùng cho sort, filter, paginate, tracking (utmsource, utmmedium…). – Nếu không được tối ưu như landing page độc lập, nội dung thường chỉ là biến thể của một trang gốc. - Nếu không được tối ưu như landing page độc lập, nên noindex hoặc canonical: – Với filter/sort không mang search intent riêng, dùng canonical trỏ về URL gốc (không tham số). – Với tham số tracking (utm, gclid…), cấu hình để không index, không xuất hiện trong sitemap, và tốt nhất là không để bot crawl (qua robots.txt hoặc parameter handling).
- Khi nào tham số có thể xuất hiện trong sitemap: – Chỉ khi mỗi URL tham số được xây dựng như một landing page thực sự: nội dung độc nhất, title/description riêng, internal link riêng, có search demand rõ ràng (ví dụ category “giày chạy bộ màu đỏ size 42” nếu có volume tìm kiếm). – Trong trường hợp này, nên chuẩn hóa URL (rewrite thành path thay vì query string) để dễ quản lý và thân thiện hơn với người dùng.
- Ví dụ:
Nguyên tắc: sitemap chỉ nên chứa URL có nội dung độc nhất, có search intent rõ ràng, có giá trị SEO hoặc kinh doanh. Mọi URL phục vụ chủ yếu cho điều hướng nội bộ, filter, sort, paginate, test, hoặc tracking đều nên được loại khỏi sitemap, trừ khi được nâng cấp thành landing page chiến lược với nội dung riêng biệt.
Cách phân tầng sitemap index để Google crawl nhanh website lớn trên 10.000 URL
Sitemap index giúp tổ chức và ưu tiên crawl cho website lớn bằng cách gom các sitemap con theo logic SEO thay vì dồn toàn bộ URL vào một file. Với site trên 10.000 URL, việc phân tầng sitemap theo post type, thư mục, thời gian xuất bản và mức độ ưu tiên cho phép Google hiểu rõ cấu trúc thông tin, tập trung crawl vào nhóm URL quan trọng và dễ dàng debug trong Search Console. Nên chia nhỏ mỗi sitemap con khoảng 10.000–20.000 URL, kết hợp giới hạn kỹ thuật 50.000 URL hoặc 50MB để tránh lỗi và tối ưu hiệu suất server. Chiến lược này hỗ trợ phân bổ crawl budget, đo lường hiệu quả index theo từng cụm nội dung và linh hoạt mở rộng khi website tăng trưởng mạnh.
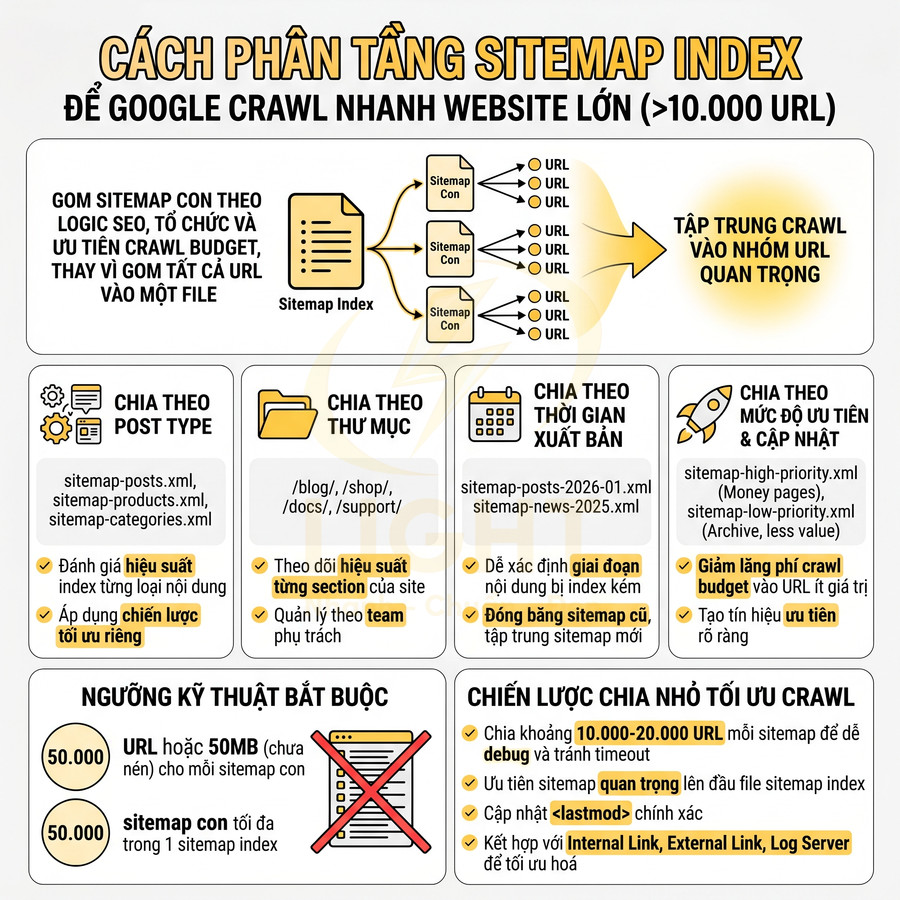
Khi nào dùng sitemap index thay vì một file sitemap đơn
Sitemap index là một file XML đặc biệt liệt kê nhiều sitemap con, đóng vai trò như “bản đồ của các bản đồ”. Với website lớn, việc hiểu rõ khi nào nên dùng sitemap index không chỉ là vấn đề kỹ thuật, mà còn là chiến lược phân bổ crawl budget và kiểm soát index. Theo Sitemap Protocol, mỗi sitemap con không được vượt quá 50.000 URL hoặc 50MB chưa nén, và sitemap index có thể dùng để liệt kê nhiều sitemap con (Sitemaps.org, 2016). Tuy nhiên, giá trị thực tế của sitemap index không chỉ nằm ở giới hạn kỹ thuật. Nghiên cứu của Schonfeld và Shivakumar (2009) cho thấy sitemap có thể bổ sung cho discovery crawling bằng cách cung cấp nguồn URL có cấu trúc. Khi website lớn được chia sitemap theo post type, thư mục, thời gian hoặc mức độ ưu tiên, SEO team có thể phân tích tỷ lệ submitted/indexed theo từng nhóm trong Search Console, phát hiện section có vấn đề và điều chỉnh crawl strategy chính xác hơn.

Nên dùng sitemap index trong các trường hợp:
- Website có trên 10.000 URL hoặc roadmap phát triển nội dung cho thấy số URL sẽ tăng nhanh trong 6–12 tháng tới.
- Cần phân nhóm URL theo:
- Loại nội dung (bài viết, sản phẩm, category, landing page…)
- Thư mục (blog, shop, docs, support…)
- Thời gian xuất bản hoặc cập nhật (theo tháng, quý, năm)
- Mức độ quan trọng và tần suất cập nhật (money page vs archive cũ)
- Muốn quản lý, debug và tối ưu crawl chi tiết hơn trong Google Search Console:
- Xem tỷ lệ Indexed / Submitted theo từng sitemap con.
- Phát hiện nhóm URL bị lỗi (404, redirect chain, canonical sai, noindex…).
- So sánh hiệu suất index giữa các nhóm nội dung khác nhau.
Giới hạn kỹ thuật bắt buộc:
- Mỗi sitemap con tối đa 50.000 URL hoặc 50MB chưa nén.
- Một sitemap index có thể chứa tối đa 50.000 sitemap con.
Lý do nên dùng sitemap index ngay cả khi chưa chạm 50.000 URL:
- Dễ mở rộng khi scale:
- Khi số URL tăng đột biến (thêm nhiều sản phẩm, bài viết, landing page), chỉ cần bổ sung sitemap con mới mà không phải refactor toàn bộ cấu trúc sitemap.
- Giảm rủi ro sai sót khi chỉnh sửa một file sitemap khổng lồ.
- Dễ phân tích lỗi crawl theo từng nhóm nội dung:
- Ví dụ: sitemap-products.xml có tỷ lệ index thấp hơn sitemap-blog.xml, từ đó khoanh vùng vấn đề ở layer sản phẩm (internal link, content quality, faceted navigation…).
- Có thể tạm thời loại bỏ hoặc điều chỉnh một nhóm URL khỏi sitemap mà không ảnh hưởng nhóm khác.
- Dễ ưu tiên nhóm URL quan trọng:
- Tách money page, hub page, category chính vào sitemap riêng, cập nhật
<lastmod>thường xuyên để gửi tín hiệu mạnh hơn cho Google. - Giảm “nhiễu” từ các URL ít giá trị SEO (archive sâu, tag, filter URL…).
- Tách money page, hub page, category chính vào sitemap riêng, cập nhật
Về mặt chiến lược SEO, sitemap index không chỉ là giải pháp cho giới hạn 50.000 URL, mà là công cụ để:
- Điều hướng crawl budget đến đúng nhóm URL.
- Phân lớp ưu tiên nội dung (priority layering).
- Đo lường hiệu quả index theo từng cụm nội dung (content cluster).
Chia sitemap theo post type, thư mục, ngày xuất bản và mức độ cập nhật
Chiến lược phân tầng sitemap nên phản ánh cấu trúc thông tin (information architecture) và mức độ ưu tiên crawl. Việc chia sitemap không chỉ để “cho gọn”, mà để Google hiểu rõ hơn về logic tổ chức nội dung và tần suất thay đổi của từng nhóm URL.
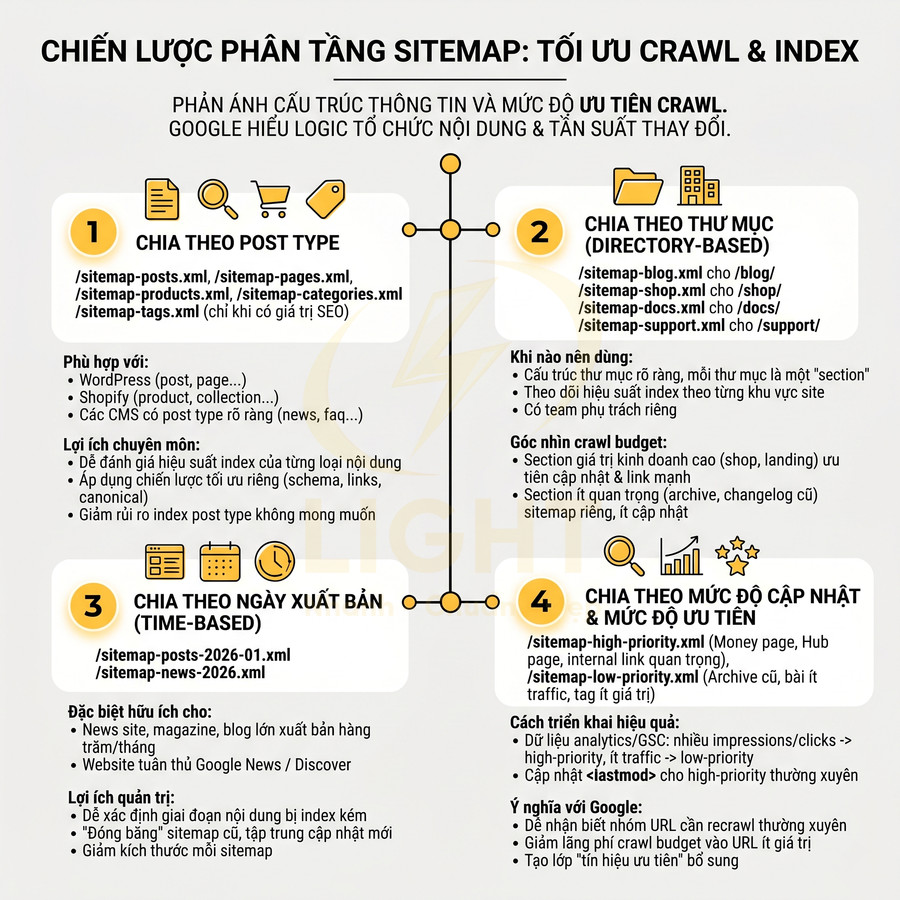
1. Chia theo post type
- Ví dụ cấu trúc:
- /sitemap-posts.xml
- /sitemap-pages.xml
- /sitemap-products.xml
- /sitemap-categories.xml
- /sitemap-tags.xml (chỉ nên dùng nếu tag thực sự có giá trị SEO)
- Phù hợp với:
- WordPress (post, page, product, category, tag…)
- Shopify (product, collection, page, blog)
- Các CMS có post type rõ ràng (news, article, guide, faq…)
- Lợi ích chuyên môn:
- Dễ đánh giá hiệu suất index của từng loại nội dung: sản phẩm vs bài viết blog.
- Có thể áp dụng chiến lược tối ưu riêng cho từng post type (schema, internal link, canonical…).
- Giảm rủi ro index những post type không mong muốn (ví dụ: attachment, test page) bằng cách không đưa vào sitemap.
2. Chia theo thư mục (directory-based)
- Ví dụ:
- /sitemap-blog.xml cho URL bắt đầu bằng /blog/
- /sitemap-shop.xml cho URL bắt đầu bằng /shop/
- /sitemap-docs.xml cho URL bắt đầu bằng /docs/
- /sitemap-support.xml cho URL bắt đầu bằng /support/
- Khi nào nên dùng:
- Website có cấu trúc thư mục rõ ràng, mỗi thư mục tương ứng một “section” nội dung.
- Muốn theo dõi hiệu suất index theo từng khu vực site (blog vs docs vs shop).
- Có team phụ trách riêng từng section, cần tách bạch để quản lý.
- Góc nhìn crawl budget:
- Section có giá trị kinh doanh cao (shop, pricing, landing) có thể được ưu tiên cập nhật sitemap và internal link mạnh hơn.
- Section ít quan trọng (archive, log, changelog cũ) có thể đưa vào sitemap riêng, cập nhật ít thường xuyên.
3. Chia theo ngày xuất bản (time-based)
- Ví dụ:
- /sitemap-posts-2026-01.xml
- /sitemap-posts-2026-02.xml
- /sitemap-posts-2025-.xml (theo quý)
- /sitemap-news-2026.xml (theo năm cho site tin tức lớn)
- Đặc biệt hữu ích cho:
- News site, magazine, blog lớn xuất bản hàng trăm/tháng.
- Website có yêu cầu tuân thủ Google News / Discover (kết hợp với News sitemap riêng).
- Lợi ích quản trị:
- Dễ xác định giai đoạn nội dung bị index kém (ví dụ: từ 2025-08 đến 2025-10).
- Có thể “đóng băng” sitemap cũ (không cập nhật thêm) và tập trung cập nhật sitemap mới.
- Giảm kích thước mỗi sitemap khi số bài viết tăng theo thời gian.
4. Chia theo mức độ cập nhật và mức độ ưu tiên
- Ví dụ:
- /sitemap-high-priority.xml:
- Money page (landing bán hàng, category chính).
- Hub page (pillar content, topic cluster hub).
- Trang có internal link quan trọng (navigation, main category).
- /sitemap-low-priority.xml:
- Archive cũ, bài ít traffic, tag page ít giá trị.
- Trang ít thay đổi nội dung, không phải trọng tâm SEO.
- /sitemap-high-priority.xml:
- Cách triển khai hiệu quả:
- Sử dụng dữ liệu từ analytics và search console:
- URL có nhiều impressions, clicks, revenue → đưa vào high-priority.
- URL ít hoặc không có traffic, không quan trọng → low-priority hoặc loại khỏi sitemap.
- Cập nhật
<lastmod>cho high-priority sitemap thường xuyên hơn để báo hiệu nội dung mới hoặc thay đổi quan trọng.
- Sử dụng dữ liệu từ analytics và search console:
- Ý nghĩa với Google:
- Giúp Google dễ nhận biết nhóm URL cần recrawl thường xuyên.
- Giảm lãng phí crawl budget vào các URL ít giá trị.
- Tạo một lớp “tín hiệu ưu tiên” bổ sung bên cạnh internal link và external link.
Ngưỡng 50.000 URL hoặc 50MB và chiến lược chia nhỏ file tối ưu crawl
Theo chuẩn sitemaps.org và tài liệu Google:
- Mỗi sitemap con tối đa 50.000 URL.
- Kích thước tối đa 50MB chưa nén (thường tương đương khoảng 10MB–15MB khi gzip).
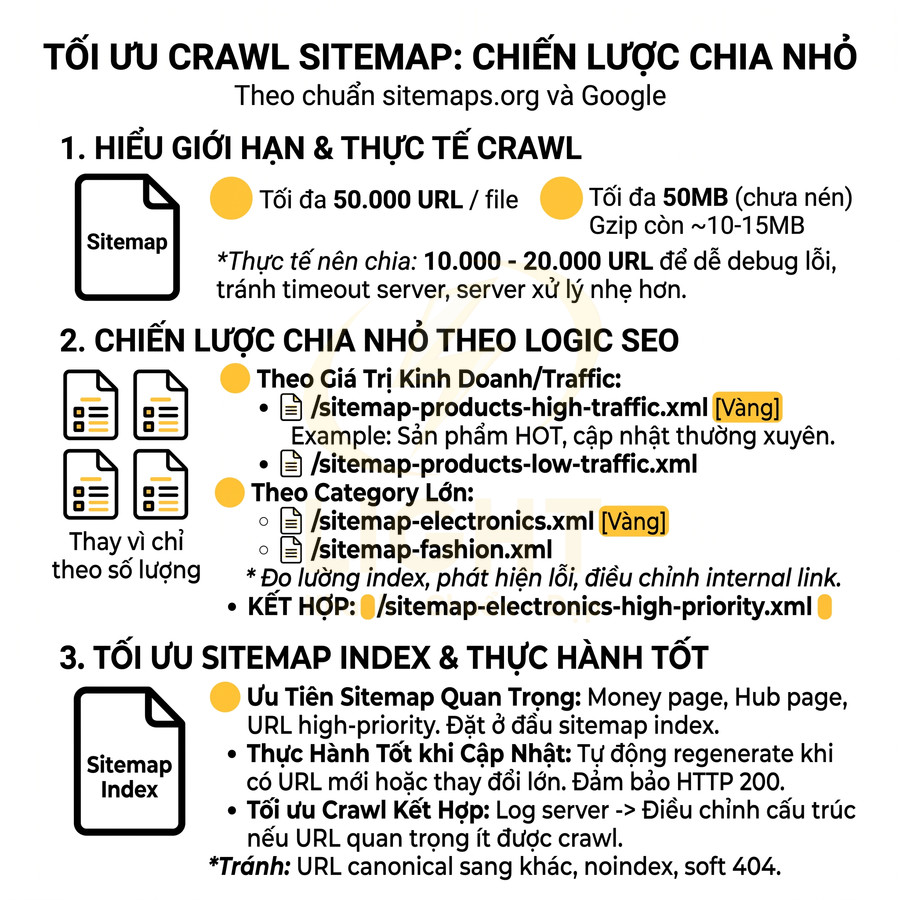
1. Không chờ đến 50.000 URL mới chia
- Về mặt thực tiễn:
- Nên chia khoảng 10.000–20.000 URL/sitemap để:
- Dễ debug khi một nhóm URL gặp vấn đề index.
- Giảm nguy cơ file quá lớn gây timeout hoặc lỗi server khi generate.
- Dễ xoay vòng (rotate) sitemap cũ và mới.
- Với site cực lớn (hàng triệu URL), có thể chia nhỏ hơn (5.000–10.000 URL/sitemap) để tăng độ chi tiết khi phân tích.
- Nên chia khoảng 10.000–20.000 URL/sitemap để:
- Lý do kỹ thuật:
- File sitemap quá lớn dễ bị ảnh hưởng nếu có lỗi nhỏ (encoding, ký tự đặc biệt, URL sai định dạng).
- Server phải xử lý nhiều hơn khi regenerate một file khổng lồ so với nhiều file nhỏ.
2. Chia theo logic SEO thay vì chỉ theo số lượng
- Chia theo giá trị kinh doanh / traffic:
- /sitemap-products-1.xml cho sản phẩm bán chạy, có traffic cao, thường xuyên được cập nhật.
- /sitemap-products-2.xml cho sản phẩm ít traffic, ít quan trọng hơn.
- Giúp ưu tiên crawl cho nhóm sản phẩm mang lại doanh thu, đồng thời vẫn giữ khả năng index cho nhóm còn lại.
- Chia theo category lớn:
- /sitemap-products-electronics.xml
- /sitemap-products-fashion.xml
- /sitemap-products-home-garden.xml
- Góc nhìn chuyên môn:
- Việc chia theo category giúp:
- Đo lường khả năng index của từng vertical (electronics vs fashion).
- Phát hiện category bị vấn đề (thin content, duplicate, filter URL tràn lan…).
- Điều chỉnh chiến lược internal link và content cho từng nhóm.
- Kết hợp với phân tầng theo mức độ ưu tiên để tạo nhiều lớp kiểm soát:
- /sitemap-products-electronics-high-priority.xml
- /sitemap-products-electronics-low-priority.xml
- Việc chia theo category giúp:
3. Ưu tiên sitemap quan trọng trong sitemap index
- Vị trí trong sitemap index không phải là “ranking factor”, nhưng có thể dùng sitemap index như một lớp tổ chức ưu tiên:
- Đặt nhóm sitemap quan trọng (high-priority, money page, hub page) ở phần đầu file sitemap index để dễ quản lý và theo dõi.
- Đảm bảo các sitemap này:
- Được cập nhật
<lastmod>chính xác khi nội dung thay đổi. - Không chứa URL lỗi (404, 5xx, redirect chain, noindex).
- Không trộn lẫn với URL ít giá trị.
- Được cập nhật
- Thực hành tốt khi cập nhật sitemap:
- Tự động regenerate sitemap khi:
- Có URL mới được publish.
- Có thay đổi lớn về nội dung hoặc cấu trúc internal link.
- Đảm bảo server trả về HTTP 200 cho tất cả sitemap và sitemap index.
- Tránh đưa vào sitemap:
- URL có canonical trỏ sang URL khác.
- URL bị noindex, blocked by robots.txt, hoặc soft 404.
- Tự động regenerate sitemap khi:
- Tối ưu crawl thông qua tín hiệu kết hợp:
- Sitemap index + internal link + external link + log server:
- Dùng log server để xem Googlebot crawl nhóm sitemap nào nhiều nhất.
- Điều chỉnh cấu trúc sitemap nếu phát hiện nhóm URL quan trọng bị crawl ít.
- Sitemap index + internal link + external link + log server:
Cách tạo sitemap tự động bằng WordPress, Shopify, Next.js, Laravel và website custom code
Hệ thống sitemap tự động cần được thiết kế xoay quanh mục tiêu kiểm soát URL được index, tối ưu crawl budget và đảm bảo dữ liệu luôn cập nhật. Với WordPress, plugin SEO như Yoast, Rank Math hay Google XML Sitemaps cho phép bật/tắt từng post type, taxonomy, loại trừ URL rác và tự động cập nhật lastmod. Shopify tạo sitemap mặc định nhưng phải quản lý chặt collection, tag, canonical và dùng noindex/unpublish để lọc URL. Next.js tận dụng SSR/ISR để sinh sitemap động từ database hoặc headless CMS, dễ mở rộng với sitemap index cho site lớn. Laravel và hệ thống custom code thường dùng command + cron job để generate file XML, chia nhỏ theo loại nội dung, tuân thủ chuẩn kỹ thuật như UTF-8, gzip, absolute URL và giới hạn 50.000 URL/sitemap.
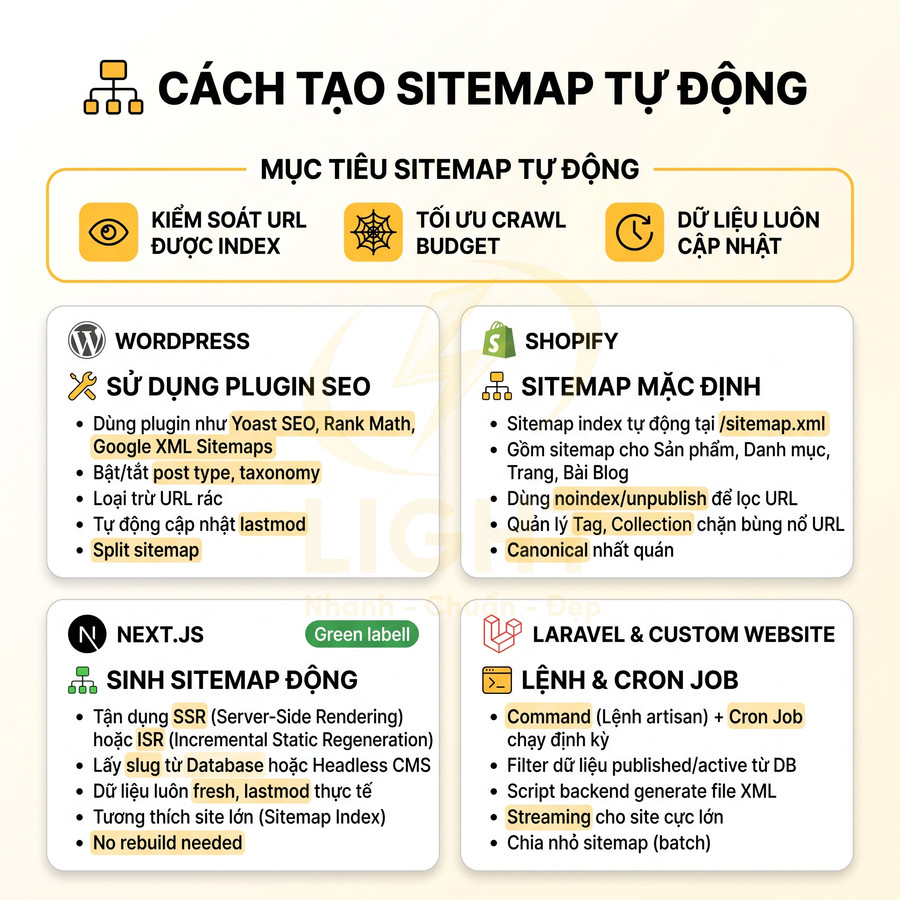
Cấu hình sitemap bằng plugin WordPress: Yoast SEO, Rank Math, Google XML Sitemaps
WordPress có lợi thế lớn vì hệ sinh thái plugin SEO rất trưởng thành, cho phép tạo sitemap XML chuẩn SEO chỉ với vài thao tác cấu hình. Điểm quan trọng không chỉ là “có sitemap”, mà là kiểm soát chính xác loại URL nào được index, tần suất cập nhật, và cách chia nhỏ sitemap để tối ưu crawl budget.
![]()
Yoast SEO:
- Tự động tạo sitemap index tại /sitemapindex.xml ngay khi bật tính năng XML sitemaps trong phần cài đặt.
- Tạo sitemap con cho:
- Post (bài viết), Page (trang), Category, Tag.
- Custom post type (product, event, course…) và custom taxonomy nếu được đăng ký đúng chuẩn.
- Trong mục Search Appearance:
- Có thể bật/tắt từng post type (post, page, product…) khỏi sitemap.
- Có thể bật/tắt từng taxonomy (category, tag, custom taxonomy) khỏi sitemap.
- Ẩn author archive, date archive nếu không dùng cho SEO để tránh trùng lặp nội dung.
- Hỗ trợ tự động cập nhật
<lastmod>dựa trên ngày cập nhật nội dung, giúp Google hiểu URL nào mới được chỉnh sửa.
Rank Math:
- Cũng tạo sitemap index tương tự Yoast, nhưng cho phép cấu hình chi tiết hơn:
- Giới hạn số URL trong mỗi sitemap con (ví dụ 1.000 URL/sitemap) để tránh file quá lớn.
- Chia sitemap theo taxonomy hoặc post type rõ ràng: sitemap-posts.xml, sitemap-pages.xml, sitemap-products.xml…
- Cho phép:
- Tắt sitemap cho author archive, tag, category không có giá trị SEO.
- Loại trừ URL cụ thể bằng pattern hoặc ID (ví dụ loại trừ các landing page chạy ads không muốn index).
- Hữu ích với site lớn vì có thể tối ưu cấu trúc sitemap để Google crawl hiệu quả hơn.
Google XML Sitemaps:
- Plugin chuyên biệt cho sitemap, không kèm các tính năng SEO on-page khác.
- Phù hợp khi:
- Không muốn dùng plugin SEO tổng hợp như Yoast/Rank Math.
- Cần một plugin nhẹ, chỉ tập trung vào việc sinh sitemap XML.
- Có thể cấu hình:
- Loại post type nào được đưa vào sitemap.
- Ưu tiên (priority) và tần suất thay đổi (changefreq) cho từng loại nội dung, dù Google hiện không còn quá coi trọng hai thuộc tính này, nhưng vẫn hữu ích về mặt cấu trúc.
Cấu hình chuẩn SEO cho sitemap WordPress:
- Tắt sitemap cho:
- Các trang search nội bộ (URL dạng
/?s=keyword) vì không mang giá trị SEO, dễ gây trùng lặp. - Các tag “rác” hoặc tag sinh ra tự động không có search intent rõ ràng.
- Author archive nếu site chỉ có 1 tác giả hoặc không tối ưu nội dung theo tác giả.
- Attachment page (trang media riêng) nếu không dùng để SEO hình ảnh, vì thường chỉ là trang mỏng nội dung.
- Các trang search nội bộ (URL dạng
- Bật sitemap cho:
- Post, page, category quan trọng, có khả năng mang traffic organic.
- Custom post type có giá trị SEO như product, case study, portfolio, service…
- Các taxonomy được dùng để cấu trúc nội dung (ví dụ product category, topic) thay vì tag tự do.
- Lưu ý kỹ thuật:
- Đảm bảo không có URL noindex xuất hiện trong sitemap; nếu một URL đã noindex, nên loại khỏi sitemap để tránh tín hiệu mâu thuẫn.
- Kiểm tra sitemap sau khi cài plugin mới hoặc thay đổi permalink để tránh lỗi 404 trong sitemap.
- Gửi sitemap index lên Google Search Console và Bing Webmaster Tools để theo dõi trạng thái index.
Sitemap mặc định trên Shopify và cách kiểm soát URL collection, tag, product
Shopify tự động tạo sitemap tại /sitemap.xml cho mọi store, không cần cài thêm app. Sitemap này là một sitemap index, trỏ tới các sitemap con cho từng loại nội dung, giúp các công cụ tìm kiếm hiểu rõ cấu trúc site thương mại điện tử.
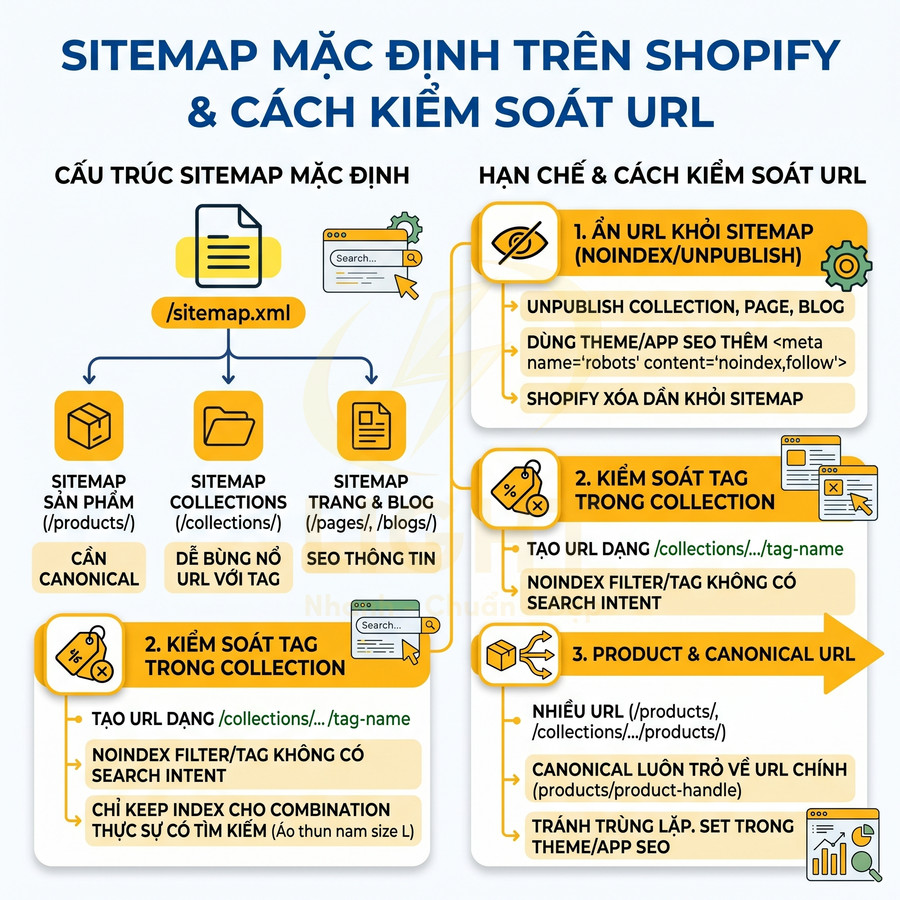
- Sitemap cho products:
- Liệt kê tất cả sản phẩm đang publish, thường theo dạng
/products/product-handle. - Mỗi URL sản phẩm nên có canonical rõ ràng để tránh trùng lặp khi sản phẩm xuất hiện trong nhiều collection.
- Liệt kê tất cả sản phẩm đang publish, thường theo dạng
- Sitemap cho collections:
- Gồm các collection chính (manual hoặc automated) đang publish.
- Shopify có thể tạo thêm URL dạng
/collections/collection-handlekết hợp với tag, dễ gây bùng nổ số lượng URL.
- Sitemap cho pages và blog posts:
- Gồm các trang nội dung tĩnh (About, Contact, Policy…) và bài blog.
- Thường là nơi tập trung nội dung SEO thông tin (informational content).
Hạn chế và cách kiểm soát:
- Ẩn URL khỏi sitemap bằng noindex hoặc bỏ publish:
- Shopify không cho chỉnh sửa sitemap.xml trực tiếp, nên cách khả thi là:
- Unpublish collection, page, blog không muốn index.
- Dùng theme (chỉnh file theme.liquid hoặc template) hoặc app SEO để thêm meta
<meta name="robots" content="noindex,follow">cho các collection phụ, tag rác.
- Khi một resource bị noindex hoặc unpublish, Shopify sẽ dần loại bỏ khỏi sitemap trong các lần cập nhật tiếp theo.
- Shopify không cho chỉnh sửa sitemap.xml trực tiếp, nên cách khả thi là:
- Kiểm soát tag trong collection:
- Shopify tự tạo URL dạng
/collections/collection-name/tag-namecho mỗi tag được filter trong collection. - Nếu không kiểm soát, số lượng URL có thể tăng rất lớn, gây lãng phí crawl budget.
- Nên:
- Noindex các URL filter/tag không có search intent (ví dụ tag nội bộ dùng cho merchandising).
- Chỉ giữ index cho một số ít combination thực sự có nhu cầu tìm kiếm (ví dụ “áo thun nam size L”).
- Shopify tự tạo URL dạng
- Product và canonical:
- Một sản phẩm có thể truy cập qua nhiều URL:
/products/product-handle/collections/collection-handle/products/product-handle
- Cần đảm bảo:
- Canonical luôn trỏ về URL chính (thường là
/products/product-handle). - Không để nhiều URL khác nhau của cùng một sản phẩm xuất hiện trong sitemap, tránh trùng lặp nội dung.
- Canonical luôn trỏ về URL chính (thường là
- Có thể dùng app SEO hoặc chỉnh theme để set canonical nhất quán.
- Một sản phẩm có thể truy cập qua nhiều URL:
Sinh sitemap động bằng Next.js App Router, SSR và ISR để giữ dữ liệu fresh
Với Next.js (đặc biệt là App Router từ Next.js 13+), sitemap có thể được sinh động (dynamic) dựa trên dữ liệu từ database, headless CMS hoặc microservices. Thay vì build sitemap tĩnh mỗi lần deploy, có thể render sitemap server-side và cache thông minh.
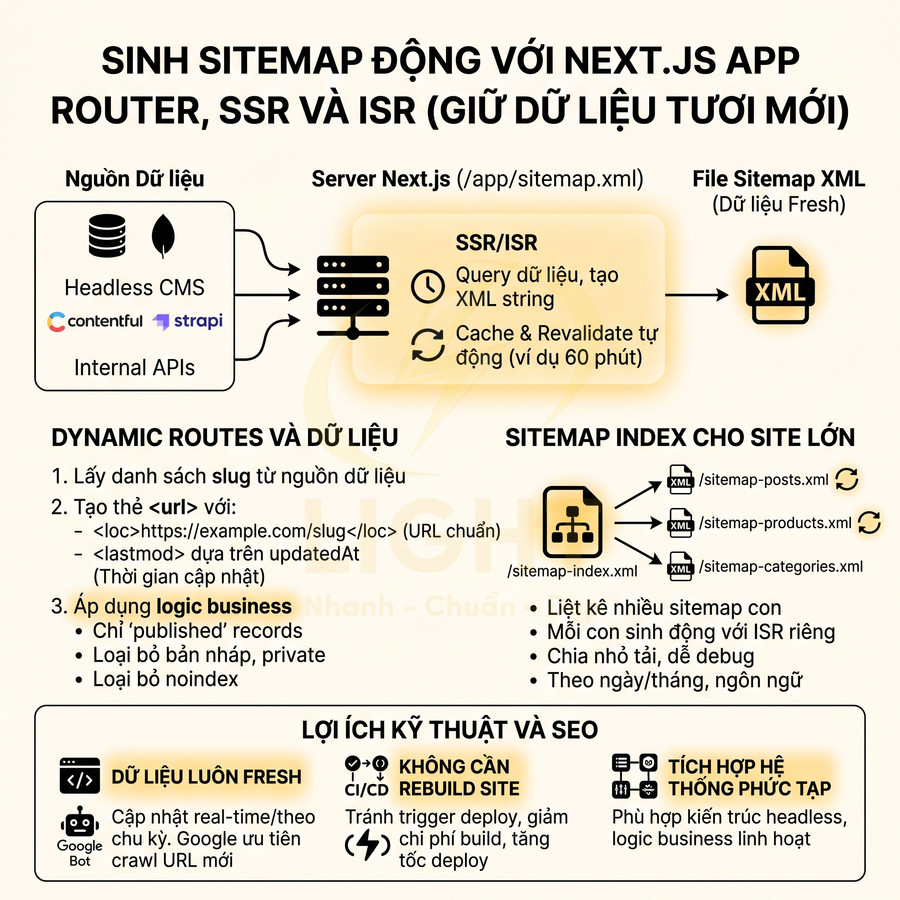
- SSR/ISR cho sitemap:
- Tạo route đặc biệt
/sitemap.xmltrong thư mụcapp(App Router) hoặcpages(Pages Router). - Trong route này:
- Query database hoặc gọi API để lấy danh sách slug (post, product, docs…).
- Generate XML string với các thẻ
<url>,<loc>,<lastmod>,<changefreq>(nếu cần).
- Kết hợp ISR (Incremental Static Regeneration):
- Cho phép cache sitemap như một file static nhưng tự động revalidate sau một khoảng thời gian (ví dụ 60 phút).
- Giảm tải cho server, đồng thời đảm bảo sitemap luôn cập nhật khi có nội dung mới.
- Tạo route đặc biệt
- Dynamic routes và dữ liệu:
- Lấy danh sách slug từ:
- Database (MySQL, PostgreSQL, MongoDB…).
- Headless CMS (Contentful, Strapi, Sanity, Ghost…).
- API nội bộ (microservices) nếu kiến trúc phân tán.
- Với mỗi record, generate:
<loc>https://example.com/post-slug</loc><lastmod>dựa trên trườngupdatedAthoặcmodifiedattrong database.
- Có thể áp dụng logic:
- Chỉ đưa vào sitemap những record có trạng thái published.
- Loại bỏ bản nháp, bản private, hoặc nội dung bị noindex.
- Lấy danh sách slug từ:
- Sitemap index cho site lớn:
- Tạo
/sitemap-index.xmllàm sitemap index, liệt kê nhiều sitemap con:/sitemap-posts.xml/sitemap-products.xml/sitemap-categories.xml
- Mỗi sitemap con có thể được sinh động tương tự, với ISR riêng, giúp chia nhỏ tải và dễ debug.
- Với site cực lớn, có thể chia sitemap theo:
- Ngày/tháng (ví dụ
/sitemap-posts-2024-01.xml). - Ngôn ngữ (ví dụ
/sitemap-en.xml,/sitemap-fr.xml).
- Ngày/tháng (ví dụ
- Tạo
Lợi ích kỹ thuật và SEO:
- Dữ liệu luôn fresh:
- Mỗi khi nội dung thay đổi,
lastmodđược cập nhật gần như real-time hoặc theo chu kỳ revalidate. - Giúp Google ưu tiên crawl các URL mới hoặc vừa cập nhật.
- Mỗi khi nội dung thay đổi,
- Không cần rebuild toàn bộ site:
- Tránh việc phải trigger CI/CD chỉ để cập nhật sitemap.
- Giảm chi phí build và thời gian deploy cho các site lớn.
- Dễ tích hợp với hệ thống phức tạp:
- Phù hợp với kiến trúc headless, nơi dữ liệu đến từ nhiều nguồn.
- Có thể áp dụng logic business (ví dụ chỉ index sản phẩm còn hàng, bài viết đã được duyệt).
Tạo sitemap XML bằng cron job cho Laravel hoặc hệ thống CMS riêng
Với Laravel hoặc các hệ thống CMS custom code, sitemap thường được sinh bằng script backend, cho phép kiểm soát hoàn toàn cấu trúc và logic. Cách tiếp cận phổ biến là dùng command artisan kết hợp cron job để tự động hóa.
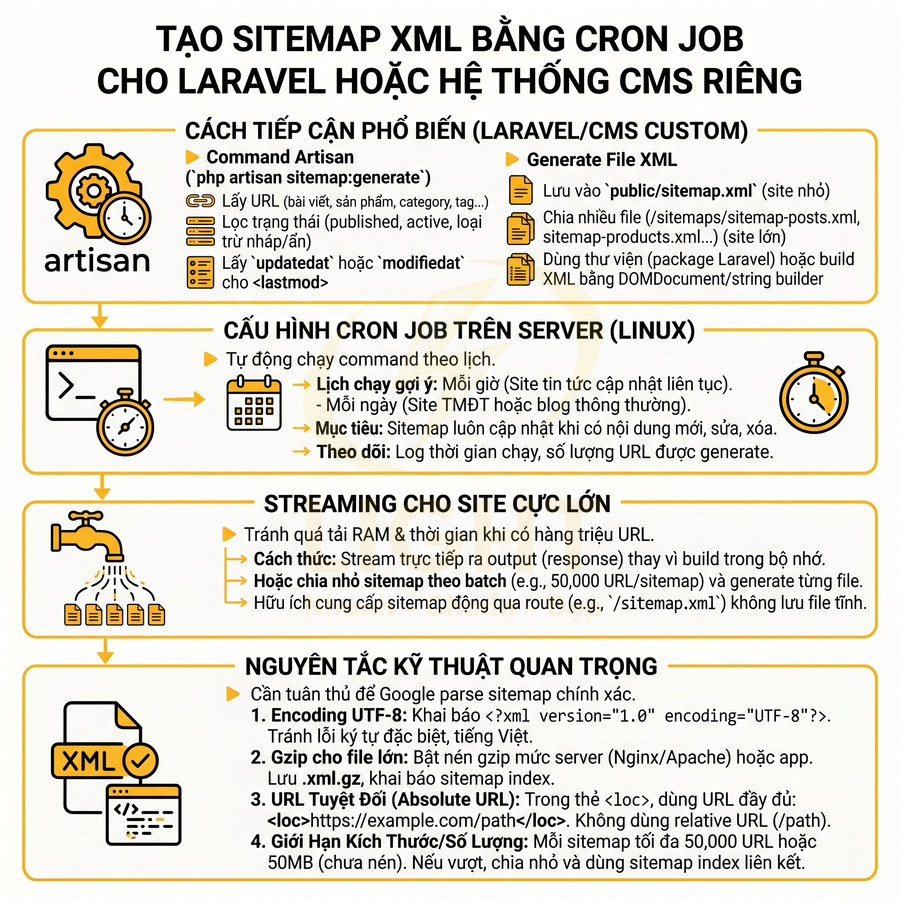
- Command artisan:
- Tạo một command (ví dụ
php artisan sitemap:generate) để:- Query database lấy danh sách URL (bài viết, sản phẩm, category, tag…).
- Lọc theo trạng thái (published, active) và loại trừ bản nháp, bản bị ẩn.
- Lấy trường
updatedathoặcmodifiedatđể đưa vào<lastmod>.
- Generate file XML:
- Lưu vào
public/sitemap.xmlnếu site nhỏ. - Hoặc chia thành nhiều file con:
public/sitemaps/sitemap-posts.xml,public/sitemaps/sitemap-products.xml…
- Lưu vào
- Có thể dùng thư viện hỗ trợ (ví dụ các package sitemap cho Laravel) hoặc tự build XML bằng DOMDocument/string builder.
- Tạo một command (ví dụ
- Cron job:
- Thiết lập cron trên server (Linux) để chạy command theo lịch:
- Mỗi giờ cho site tin tức cập nhật liên tục.
- Mỗi ngày cho site thương mại điện tử hoặc blog thông thường.
- Đảm bảo sitemap luôn cập nhật khi có nội dung mới, chỉnh sửa hoặc xóa.
- Có thể log lại thời gian chạy, số URL được generate để theo dõi.
- Thiết lập cron trên server (Linux) để chạy command theo lịch:
- Streaming cho site cực lớn:
- Với site có hàng triệu URL, việc generate một file XML khổng lồ có thể tốn RAM và thời gian.
- Có thể:
- Stream XML trực tiếp ra output (response) thay vì build toàn bộ trong bộ nhớ.
- Hoặc chia nhỏ sitemap theo batch (ví dụ 50.000 URL/sitemap) và generate từng file một.
- Streaming cũng hữu ích khi cung cấp sitemap động qua một route (ví dụ
/sitemap.xml) mà không cần lưu file tĩnh.
Nguyên tắc kỹ thuật quan trọng:
- Encoding UTF-8:
- Đảm bảo file XML có khai báo
<?xml version="1.0" encoding="UTF-8"?>. - Tránh lỗi ký tự đặc biệt (accent, ký tự tiếng Việt, ký tự quốc tế) khi Google parse sitemap.
- Đảm bảo file XML có khai báo
- Gzip cho file lớn:
- Nếu sitemap hoặc sitemap index quá lớn, nên bật nén gzip ở mức server (Nginx, Apache) hoặc ứng dụng.
- Có thể lưu file với đuôi
.xml.gzvà khai báo trong sitemap index.
- URL tuyệt đối (absolute URL):
- Trong thẻ
<loc>luôn dùng URL đầy đủ, bao gồm protocol và domain:<loc>https://example.com/path</loc>
- Không dùng relative URL (ví dụ
/path) vì không chuẩn theo spec của XML sitemap.
- Trong thẻ
- Giới hạn kích thước và số lượng URL:
- Mỗi sitemap tối đa 50.000 URL hoặc 50MB (chưa nén) theo chuẩn.
- Nếu vượt, cần chia nhỏ và dùng sitemap index để liên kết các file con.
Tối ưu thẻ lastmod để Google recrawl nhanh các URL quan trọng
Thẻ lastmod cần được sử dụng như một tín hiệu crawl có chọn lọc, chỉ phản ánh những thay đổi nội dung thực sự mang lại giá trị mới cho người dùng. Nên ưu tiên cập nhật khi có bổ sung thông tin, số liệu, cấu trúc nội dung, chính sách hoặc tính năng sản phẩm/dịch vụ, đồng thời bỏ qua các chỉnh sửa thuần kỹ thuật, giao diện hoặc lỗi nhỏ không làm đổi meaning. Để tăng độ tin cậy, lastmod phải được mapping chặt chẽ với dateModified trong schema, ngày “Last updated” trên UI, update log và author review date theo chuẩn EEAT, đặc biệt với nội dung YMYL. Cuối cùng, hãy dùng lastmod như đòn bẩy phân bổ crawl budget, ưu tiên money page, content hub và các URL traffic cao thông qua sitemap riêng cho nhóm URL quan trọng.
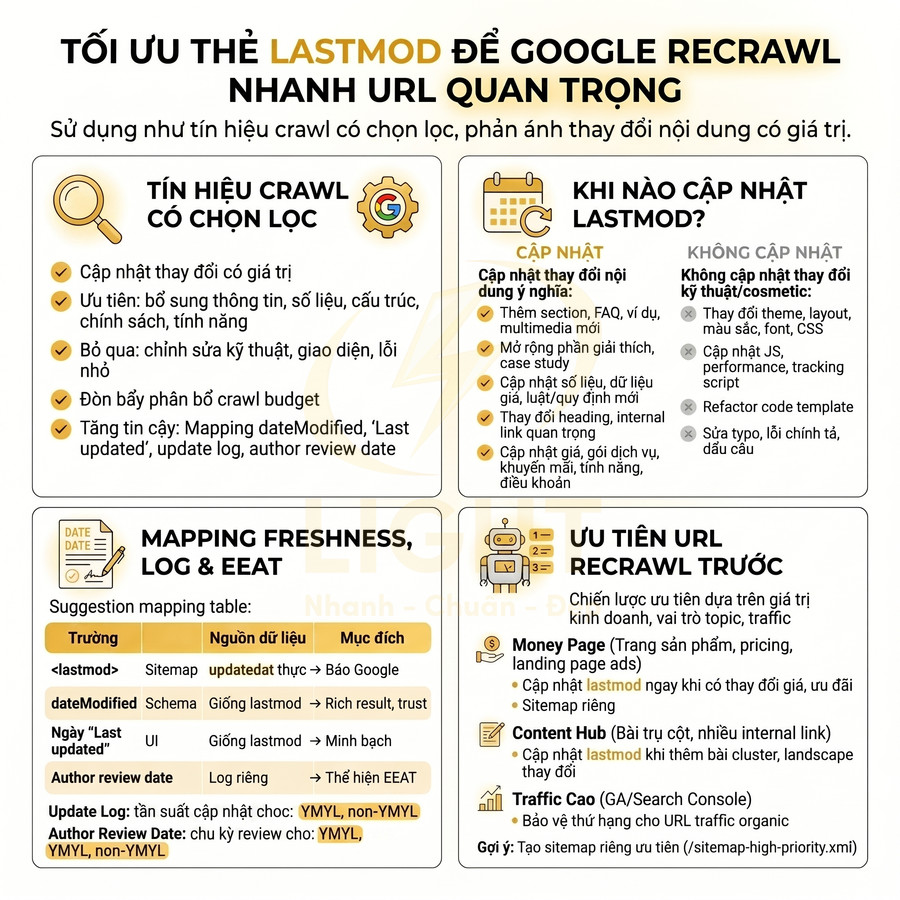
Khi nào nên cập nhật lastmod theo thay đổi nội dung thực tế thay vì modified theme
lastmod không chỉ là “ngày sửa bài” đơn thuần mà là một tín hiệu crawl quan trọng trong hệ thống lập chỉ mục của Google. Khi Googlebot đọc sitemap, nó dùng lastmod để:
- Ước lượng mức độ “fresh” của URL so với lần crawl trước.
- Quyết định có nên ưu tiên crawl lại URL đó trong quota crawl hạn chế hay không.
- Phân bổ crawl budget giữa các nhóm URL (money page, blog, trang hệ thống…).
Cần diễn đạt thận trọng hơn: <lastmod> là tín hiệu metadata giúp crawler hiểu thời điểm URL được cập nhật, nhưng hiệu quả phụ thuộc vào độ chính xác. Cho và Garcia-Molina (2003) nghiên cứu bài toán ước lượng tần suất thay đổi của nguồn dữ liệu Web để cải thiện crawler, còn Cho và Garcia-Molina (2003) về page refresh policies cho thấy việc duy trì “freshness” đòi hỏi crawler phải phân bổ lượt revisit theo mức thay đổi thực tế của trang. Vì vậy, <lastmod> nên phản ánh thay đổi nội dung thật như cập nhật dữ liệu, thêm section, thay đổi giá/chính sách hoặc review chuyên môn. Nếu hệ thống cập nhật <lastmod> vì sửa CSS, deploy theme hoặc thay tracking script, tín hiệu freshness sẽ kém tin cậy.

Tuy nhiên, nếu lastmod bị “lạm dụng” – cập nhật liên tục dù nội dung thực tế không đổi – Google có thể:
- Giảm mức độ tin cậy với tín hiệu lastmod của toàn site.
- Giảm tần suất recrawl cho các URL vốn được cập nhật “ảo”.
- Lãng phí crawl budget vào các thay đổi không mang giá trị nội dung.
Vì vậy, cần phân biệt rõ giữa thay đổi kỹ thuật và thay đổi nội dung có ý nghĩa với người dùng.
Chỉ cập nhật lastmod khi có thay đổi nội dung thực sự tác động đến:
- Giá trị thông tin mà người dùng nhận được:
- Thêm đoạn nội dung mới đáng kể (section mới, FAQ mới, ví dụ minh họa, checklist…).
- Mở rộng phần giải thích, thêm case study, thêm bước trong quy trình.
- Bổ sung multimedia mang tính nội dung (video hướng dẫn, infographic có thông tin mới).
- Tính chính xác và cập nhật:
- Cập nhật số liệu thống kê, báo cáo, nghiên cứu theo năm mới.
- Cập nhật dữ liệu giá, lãi suất, tỷ giá, hạn mức, điều kiện áp dụng.
- Điều chỉnh nội dung theo thay đổi của luật, quy định, chính sách nhà nước.
- Cấu trúc nội dung và điều hướng:
- Thay đổi cấu trúc heading (H2, H3) làm rõ chủ đề, tái cấu trúc topic.
- Thêm/bớt internal link quan trọng trong content hub, money page.
- Gộp hoặc tách các section lớn, thay đổi flow đọc của người dùng.
- Thông tin thương mại và tính năng sản phẩm/dịch vụ:
- Cập nhật giá, gói dịch vụ, chương trình khuyến mãi.
- Thêm/bớt tính năng sản phẩm, thay đổi điều khoản sử dụng.
- Điều chỉnh chính sách hoàn tiền, bảo hành, bảo mật, quyền riêng tư.
Không cập nhật lastmod khi chỉ có thay đổi kỹ thuật hoặc cosmetic:
- Thay đổi giao diện, không chạm nội dung:
- Thay đổi theme, layout, màu sắc, font chữ.
- Điều chỉnh CSS, responsive, spacing, animation.
- Thay đổi icon, hình minh họa không mang thông tin mới.
- Thay đổi kỹ thuật nền tảng:
- Cập nhật JS, bundler, tối ưu performance, lazy load.
- Thêm/bớt script tracking, pixel, tag quản lý qua GTM.
- Refactor code template nhưng nội dung text không đổi.
- Chỉnh sửa rất nhỏ không ảnh hưởng meaning:
- Sửa typo nhỏ, lỗi chính tả đơn lẻ.
- Thay đổi vài từ đồng nghĩa nhưng không đổi intent.
- Chỉnh dấu câu, xuống dòng, format nhẹ.
Để tránh “spam” lastmod, nên có quy tắc nội bộ hoặc workflow:
- Đặt ngưỡng thay đổi: ví dụ chỉ cập nhật lastmod khi thay đổi > 5–10% nội dung text hoặc có update thông tin quan trọng.
- Log lại loại thay đổi (content update, legal update, pricing update…) để mapping với lastmod.
- Phân quyền: chỉ một số role (SEO lead, content lead) được trigger cập nhật lastmod trong hệ thống.
Mapping lastmod với content freshness, update log và author review date theo EEAT
Trong bối cảnh Google nhấn mạnh EEAT (Experience, Expertise, Authoritativeness, Trustworthiness), lastmod không nên tồn tại “đơn lẻ” mà cần được đồng bộ với nhiều lớp dữ liệu khác để:
- Tăng độ tin cậy của tín hiệu freshness.
- Minh bạch với người dùng về thời điểm và phạm vi cập nhật.
- Thể hiện rõ vai trò của tác giả/chuyên gia trong việc review nội dung.
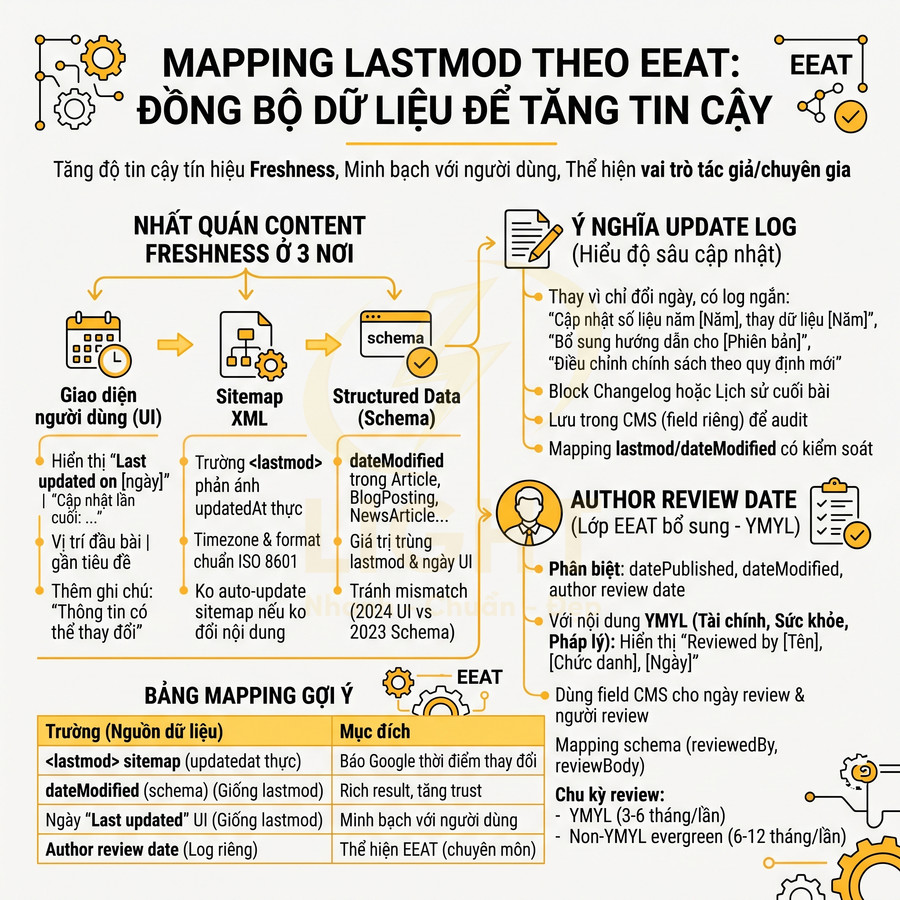
Content freshness cần được thể hiện nhất quán ở 3 nơi:
- Giao diện người dùng (UI):
- Hiển thị “Last updated on [ngày/tháng/năm]” hoặc “Cập nhật lần cuối: …”.
- Vị trí hiển thị nên gần tiêu đề hoặc đầu bài để người dùng dễ nhận biết.
- Với bài có tính thời sự cao, có thể thêm note: “Thông tin có thể thay đổi theo thời gian”.
- Sitemap XML:
- Trường
<lastmod>phải phản ánh đúng updatedAt nội dung thực, không lấy từ file modified time của theme. - Đảm bảo timezone và format chuẩn ISO 8601 để Google đọc chính xác.
- Không nên auto-update toàn bộ sitemap mỗi deploy nếu nội dung không đổi.
- Trường
- Structured data (schema):
- Sử dụng
dateModifiedtrong schemaArticle,BlogPosting,NewsArticle… - Giá trị
dateModifiednên trùng với lastmod trong sitemap và ngày “Last updated” trên UI. - Tránh mismatch (UI hiển thị 2024 nhưng schema/lastmod là 2023) vì có thể làm giảm trust.
- Sử dụng
Update log giúp Google và người dùng hiểu “độ sâu” của lần cập nhật:
- Thay vì chỉ đổi ngày, nên có log ngắn:
- “Cập nhật số liệu năm 2026, thay thế dữ liệu 2024.”
- “Bổ sung hướng dẫn cho phiên bản phần mềm v3.2.”
- “Điều chỉnh chính sách phí theo quy định mới.”
- Với bài quan trọng, có thể đặt một block “Changelog” hoặc “Lịch sử cập nhật” ở cuối bài.
- Log này có thể lưu trong CMS (field riêng) để:
- Phục vụ audit nội dung định kỳ.
- Mapping với lastmod và dateModified một cách có kiểm soát.
Author review date là lớp bổ sung quan trọng cho EEAT, đặc biệt với nội dung YMYL:
- Phân biệt rõ:
- datePublished: ngày xuất bản lần đầu.
- dateModified/lastmod: ngày nội dung được chỉnh sửa.
- author review date: ngày tác giả/chuyên gia xác nhận nội dung vẫn chính xác, cập nhật.
- Với nội dung tài chính, sức khỏe, pháp lý:
- Hiển thị “Reviewed by [Tên chuyên gia], [Chức danh], ngày [dd/mm/yyyy]”.
- Có thể dùng field riêng trong CMS để lưu ngày review và người review.
- Mapping field này vào schema (ví dụ
reviewedBy,reviewvớireviewBodyngắn).
- Chu kỳ review:
- YMYL: 3–6 tháng/lần hoặc khi có thay đổi lớn về luật/quy định.
- Non-YMYL nhưng evergreen: 6–12 tháng/lần.
Bảng mapping gợi ý:
| Trường | Nguồn dữ liệu | Mục đích |
|---|---|---|
| <lastmod> trong sitemap | updatedat nội dung thực | Báo cho Google biết thời điểm nội dung thay đổi |
| dateModified (schema) | Giống lastmod | Hiển thị trong rich result, tăng trust |
| Ngày “Last updated” trên UI | Giống lastmod | Minh bạch với người dùng về độ mới nội dung |
| Author review date | Log riêng | Thể hiện EEAT, nhất là nội dung chuyên môn |
Ưu tiên URL money page, content hub và trang traffic cao để recrawl trước
Crawl budget luôn có giới hạn, kể cả với site lớn. Không phải URL nào cũng cần recrawl với tần suất như nhau, nên cần chiến lược ưu tiên dựa trên:
- Giá trị kinh doanh (revenue, lead, conversion).
- Vai trò trong cấu trúc topic (hub, cluster, supporting).
- Lượng traffic và mức độ nhạy cảm với thay đổi thông tin.
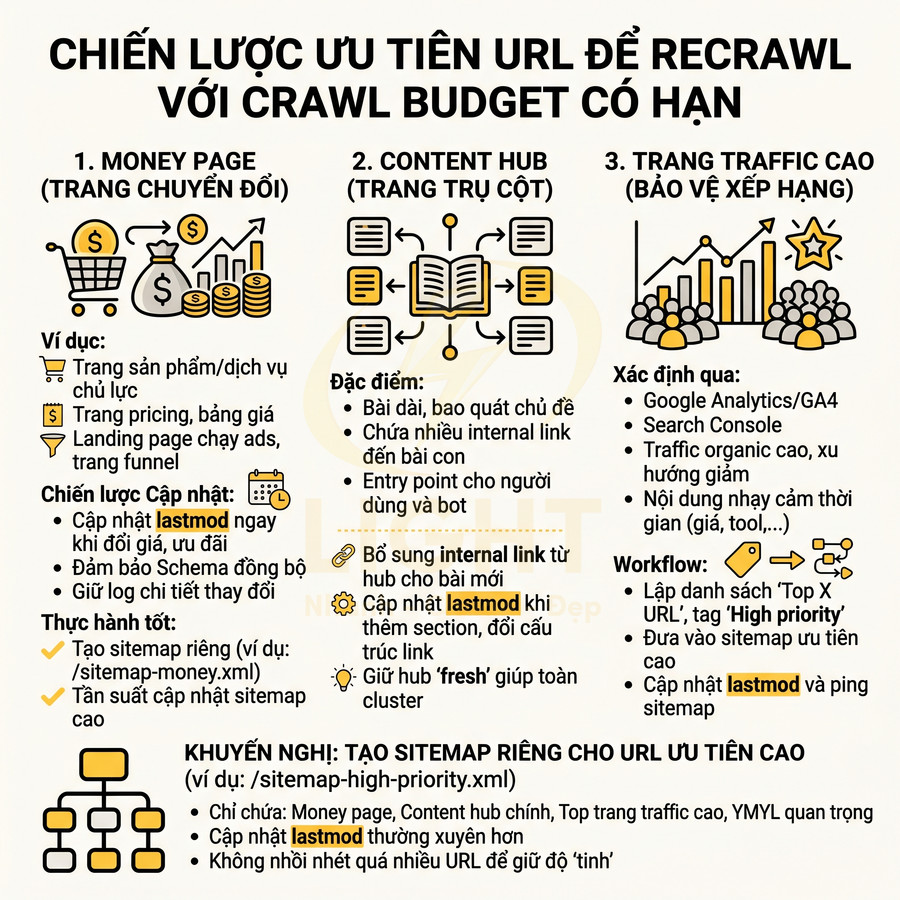
Money page là nhóm cần ưu tiên cao nhất:
- Gồm:
- Trang sản phẩm/dịch vụ chủ lực.
- Trang pricing, bảng giá, gói dịch vụ.
- Landing page chạy ads, trang funnel chuyển đổi cao.
- Chiến lược lastmod cho money page:
- Cập nhật lastmod ngay khi có thay đổi giá, ưu đãi, tính năng, điều khoản.
- Đảm bảo schema (Product, Offer, Service…) cũng được update đồng bộ.
- Giữ log chi tiết các lần thay đổi để đối chiếu với biến động thứ hạng và CR.
- Thực hành tốt:
- Tạo một sitemap riêng cho money page (ví dụ:
/sitemap-money.xml). - Đặt tần suất cập nhật sitemap này cao hơn các sitemap khác.
- Monitor trong Search Console để xem tần suất crawl và index.
- Tạo một sitemap riêng cho money page (ví dụ:
Content hub (trang trụ cột trong topic cluster) là “điểm neo” nội dung:
- Đặc điểm:
- Thường là bài dài, bao quát toàn bộ chủ đề.
- Chứa nhiều internal link đến bài con (cluster content).
- Được dùng làm entry point cho người dùng và bot vào một chủ đề.
- Chiến lược cập nhật:
- Mỗi khi xuất bản bài mới trong cluster, bổ sung internal link từ hub.
- Khi có thay đổi lớn trong landscape (thuật toán, luật, công nghệ), cập nhật overview trong hub.
- Cập nhật lastmod của hub khi:
- Thêm section mới quan trọng.
- Thay đổi cấu trúc link đến nhiều bài con.
- Vì hub thường là trang có nhiều backlink và authority:
- Recrawl nhanh giúp Google phát hiện và index nhanh các bài mới được link từ hub.
- Giữ hub “fresh” giúp toàn cluster hưởng lợi về tín hiệu topical authority.
Trang traffic cao cần được bảo vệ thứ hạng và trải nghiệm:
- Xác định qua:
- Google Analytics/GA4: session, user, revenue/goal per page.
- Search Console: click, impression, average position, CTR.
- Ưu tiên recrawl:
- Những URL mang nhiều traffic organic và có xu hướng giảm nhẹ về ranking.
- Những URL có nội dung nhạy cảm với thời gian (giá, hướng dẫn kỹ thuật, API, tool…).
- Workflow:
- Lập danh sách “Top X URL theo traffic/giá trị” và gắn tag “High priority”.
- Đưa các URL này vào sitemap ưu tiên cao.
- Khi có update nội dung, đảm bảo lastmod được cập nhật và ping lại sitemap.
Có thể tạo sitemap riêng cho URL ưu tiên cao (ví dụ: /sitemap-high-priority.xml) và:
- Chỉ chứa:
- Money page.
- Content hub chính.
- Top trang traffic cao, YMYL quan trọng.
- Cập nhật lastmod thường xuyên hơn so với sitemap khác.
- Đảm bảo:
- Không nhồi nhét quá nhiều URL để giữ độ “tinh” của sitemap ưu tiên.
- Không auto-include toàn bộ site, tránh mất ý nghĩa “high priority”.
Cách submit sitemap trong Google Search Console để index nhanh hơn
Sitemap cần được chuẩn bị chuẩn kỹ thuật trên server và gửi đúng property trong Google Search Console để tối ưu tốc độ index. Trước hết, đảm bảo file sitemap hoặc sitemap index truy cập ổn định, trả về mã HTTP 200, đúng định dạng XML và không bị robots.txt chặn. Trong Search Console, chọn chính xác loại property (Domain hoặc URL prefix) trùng khớp giao thức và hostname, sau đó submit sitemap tại mục Sitemaps và theo dõi trạng thái Success, Has issues hoặc Pending. Kết hợp báo cáo Sitemaps với mục Indexing để so sánh Submitted, Indexed, Discovered, nhận diện URL bị bỏ sót, tối ưu crawl budget và chất lượng nội dung. Khi migration domain, chuyển HTTPS, đổi cấu trúc URL hoặc thêm lượng lớn trang mới, nên resubmit sitemap để Google cập nhật nhanh bản đồ URL.
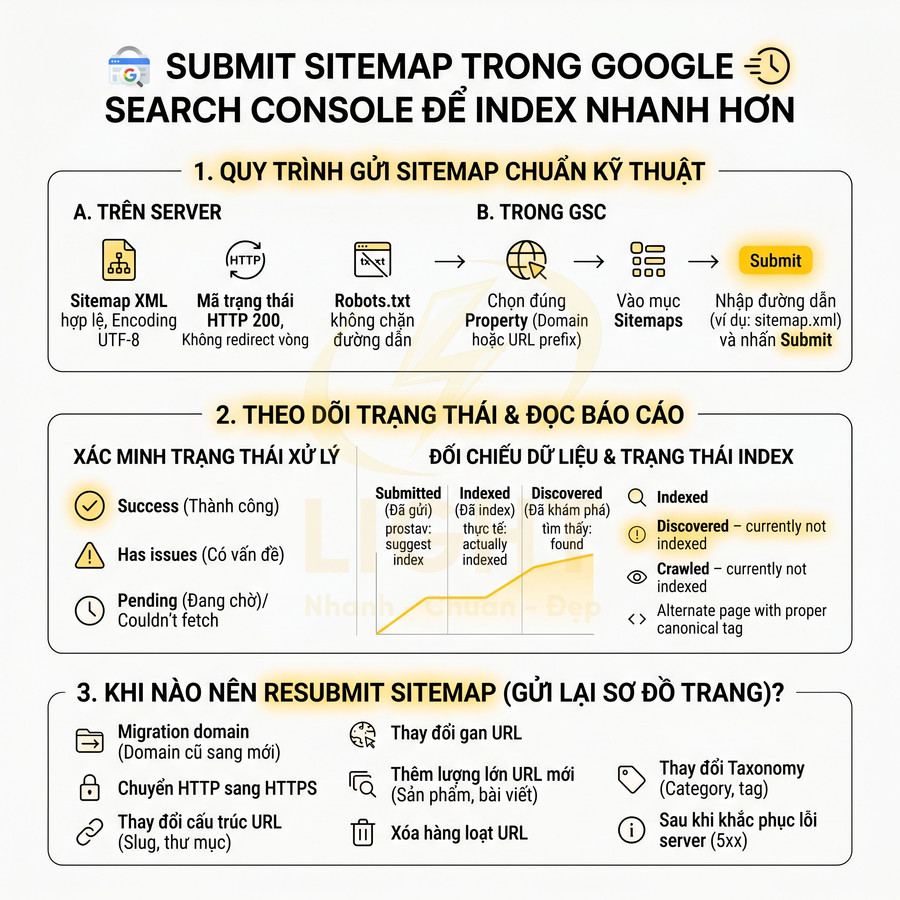
Quy trình gửi sitemap index đúng đường dẫn và xác minh trạng thái success
Để sitemap thực sự hỗ trợ tăng tốc quá trình index, cần đảm bảo cả phần kỹ thuật trên server lẫn thao tác trong Google Search Console đều chính xác. Sitemap không chỉ là một file liệt kê URL, mà còn là tín hiệu cấu trúc giúp Google hiểu rõ hệ thống nội dung, mức độ ưu tiên và tần suất cập nhật.

1. Kiểm tra khả năng truy cập sitemap trên server
- Đảm bảo sitemap truy cập được tại một trong các đường dẫn chuẩn:
https://domain.com/sitemap.xmlhttps://domain.com/sitemapindex.xml(thường dùng với các plugin như Yoast, Rank Math, hoặc hệ thống lớn có nhiều sitemap con)
- Kiểm tra status code:
- Sitemap phải trả về HTTP 200.
- Không được redirect vòng (301 > 302 > …) hoặc trả về 4xx/5xx.
- Kiểm tra định dạng:
- File phải là XML hợp lệ, có khai báo
<urlset>hoặc<sitemapindex>đúng chuẩn. - Đảm bảo encoding UTF-8, không có ký tự lạ gây lỗi parser.
- File phải là XML hợp lệ, có khai báo
- Kiểm tra robots.txt:
- Không chặn đường dẫn sitemap bằng
Disallow. - Có thể (không bắt buộc) khai báo:
Sitemap: https://domain.com/sitemap.xml
- Không chặn đường dẫn sitemap bằng
2. Chọn đúng loại property trong Google Search Console
- Domain property:
- Áp dụng cho toàn bộ domain (bao gồm http/https, www/non-www, subdomain).
- Phù hợp cho site lớn, nhiều subdomain hoặc khi đã chuẩn hóa HTTPS.
- URL prefix property:
- Chỉ áp dụng cho một prefix cụ thể, ví dụ:
https://www.domain.com/. - Nếu sitemap dùng HTTPS, cần chọn đúng property HTTPS, không submit nhầm vào HTTP.
- Chỉ áp dụng cho một prefix cụ thể, ví dụ:
3. Thao tác submit sitemap trong Search Console
- Đăng nhập Google Search Console bằng tài khoản đã được xác minh quyền sở hữu.
- Chọn đúng property (domain hoặc URL prefix) tương ứng với giao thức và hostname của sitemap.
- Vào mục Sitemaps trong menu điều hướng bên trái.
- Tại ô Add a new sitemap:
- Chỉ nhập phần đường dẫn sau domain, ví dụ:
sitemap.xmlsitemapindex.xml
- Không nhập lại phần
https://domain.com/vì đã được cố định phía trước.
- Chỉ nhập phần đường dẫn sau domain, ví dụ:
- Nhấn Submit để gửi sitemap.
4. Xác minh trạng thái xử lý sitemap
- Success:
- Google đọc được sitemap, không lỗi cú pháp XML.
- Đường dẫn sitemap trả về HTTP 200, không bị chặn bởi robots.txt.
- Có thể click vào sitemap để xem số lượng URL được phát hiện, ngày crawl gần nhất.
- Has issues:
- Có thể do:
- URL trong sitemap trả về 404, 410, 5xx.
- URL bị chặn bởi robots.txt hoặc thẻ
noindex. - Lỗi định dạng XML, namespace sai, thẻ đóng/mở không khớp.
- Cần click vào chi tiết để xem loại lỗi, số lượng URL bị ảnh hưởng và xử lý:
- Xóa URL lỗi khỏi sitemap hoặc sửa để trả về 200.
- Điều chỉnh robots.txt hoặc meta robots nếu chặn nhầm.
- Có thể do:
- Pending hoặc Couldn’t fetch:
- Thường do Google chưa crawl kịp hoặc server phản hồi chậm, timeout.
- Cần kiểm tra lại server, firewall, CDN, sau đó thử Resubmit.
5. Một số lưu ý chuyên sâu khi cấu trúc sitemap index
- Với site lớn, nên dùng sitemap index để chia nhỏ:
post-sitemap.xml,page-sitemap.xml,product-sitemap.xml,category-sitemap.xml, …- Mỗi sitemap con nên giới hạn <= 50.000 URL hoặc <= 50MB nén.
- Ưu tiên:
- Chỉ đưa vào sitemap các URL có thể index (status 200, không noindex, không canonical sang nơi khác).
- Loại bỏ các trang tag, search, filter mỏng hoặc trùng lặp nếu không muốn index.
- Cập nhật sitemap tự động:
- Hệ thống CMS hoặc plugin nên tự cập nhật khi có URL mới, xóa URL cũ.
- Không nên để sitemap chứa quá nhiều URL 404 hoặc redirect 301 lâu ngày.
Đọc báo cáo Submitted URL, Discovered URL và lỗi crawl từ Search Console
Search Console cung cấp hai nhóm dữ liệu quan trọng liên quan đến sitemap và index: báo cáo trong mục Sitemaps và báo cáo trong mục Indexing (Pages). Kết hợp hai nguồn này giúp đánh giá hiệu quả crawl, phát hiện vấn đề chất lượng nội dung và cấu trúc site.
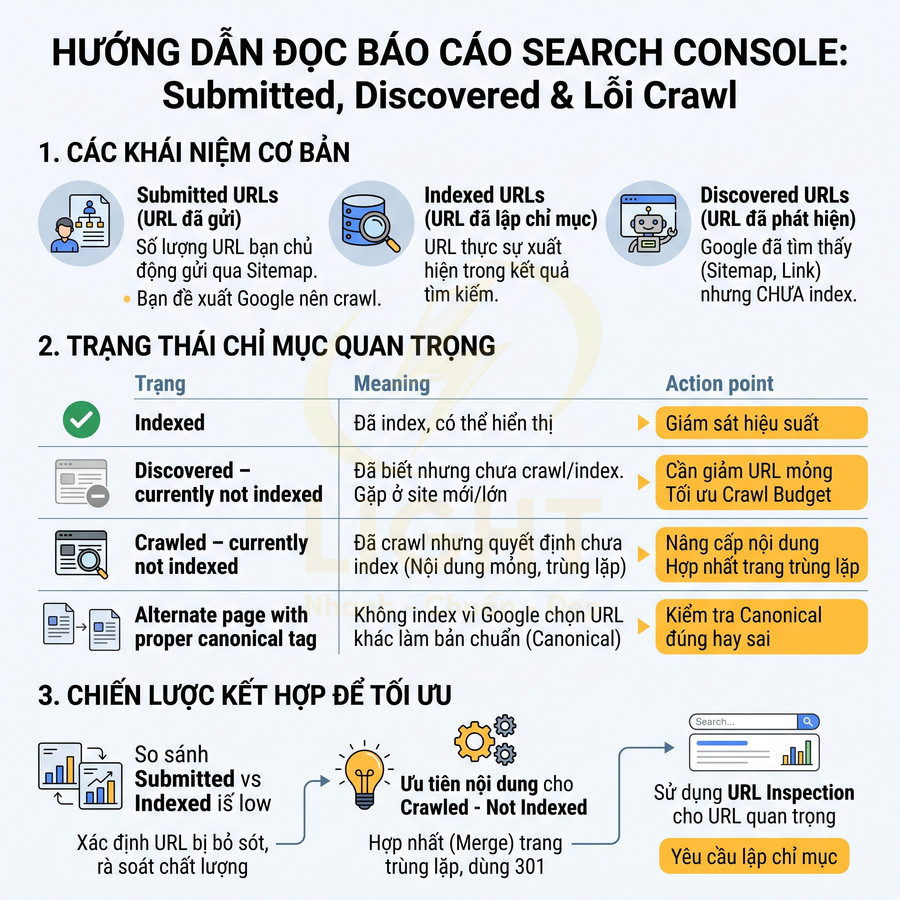
1. Khái niệm Submitted URLs, Indexed URLs, Discovered URLs
- Submitted URLs:
- Là số lượng URL bạn chủ động gửi cho Google thông qua sitemap.
- Đây là tập URL mà bạn “đề xuất” Google nên crawl và index.
- Nếu Submitted lớn nhưng Indexed thấp, có thể:
- Nội dung mỏng, trùng lặp, chất lượng thấp.
- URL bị chặn robots.txt, noindex, hoặc canonical sang URL khác.
- Site mới, chưa có đủ tín hiệu authority, cần thời gian.
- Indexed URLs:
- Là số URL thực sự đã được Google đưa vào chỉ mục.
- Đây là tập URL có khả năng xuất hiện trong kết quả tìm kiếm.
- Cần so sánh:
- Indexed / Submitted để đánh giá hiệu suất index.
- Nếu tỷ lệ quá thấp, cần rà soát chất lượng nội dung, cấu trúc internal link, tốc độ tải trang.
- Discovered URLs:
- Là các URL Google đã phát hiện (qua sitemap, internal link, external link) nhưng chưa index.
- Discovered có thể lớn hơn Submitted vì Google còn tìm thêm URL ngoài sitemap.
- Nếu nhiều URL ở trạng thái Discovered lâu ngày, thường liên quan:
- Hạn mức crawl budget bị giới hạn (site lớn, server chậm).
- Nội dung chưa đủ quan trọng hoặc trùng lặp với URL khác.
2. Các trạng thái index quan trọng và cách diễn giải
- Indexed:
- URL đã được index và có thể hiển thị trong kết quả tìm kiếm.
- Có thể kiểm tra nhanh bằng lệnh
site:domain.com/url-slughoặc dùng công cụ URL Inspection. - Nếu URL quan trọng không được index, cần:
- Đảm bảo không có
noindex, không canonical sang nơi khác. - Tăng internal link trỏ đến URL đó, cải thiện nội dung, E-E-A-T.
- Đảm bảo không có
- Discovered – currently not indexed:
- Google đã biết URL (qua sitemap hoặc link) nhưng chưa crawl hoặc chưa đưa vào index.
- Thường gặp ở:
- Site mới, ít tín hiệu authority.
- Site rất lớn, nhiều URL tương tự nhau.
- Hướng xử lý:
- Giảm số lượng URL mỏng, tự động sinh (tag, filter, pagination vô hạn).
- Tối ưu crawl budget: cải thiện tốc độ server, giảm redirect chain, loại bỏ URL rác khỏi sitemap.
- Crawled – currently not indexed:
- Google đã crawl URL nhưng quyết định chưa index.
- Nguyên nhân thường gặp:
- Nội dung mỏng, ít giá trị, trùng lặp với trang khác.
- Trang không mang tính tìm kiếm (ví dụ: trang điều khoản, trang hệ thống) hoặc chất lượng UX kém.
- Cách cải thiện:
- Nâng cấp nội dung: dài hơn, sâu hơn, độc đáo hơn, có dữ liệu, hình ảnh, schema.
- Hợp nhất (merge) các trang trùng lặp, dùng 301 và canonical hợp lý.
- Loại bỏ khỏi sitemap các trang không cần index, thêm
noindexnếu cần.
- Alternate page with proper canonical tag:
- URL không được index vì Google chọn URL khác làm bản chuẩn (canonical).
- Thường xảy ra với:
- Phiên bản có/không có tham số, UTM, sort, filter.
- Trang AMP, trang mobile riêng, hoặc phiên bản trùng lặp nội dung.
- Nếu canonical đúng:
- Không cần cố ép index URL alternate.
- Đảm bảo sitemap chỉ chứa URL canonical để tránh phân tán tín hiệu.
- Nếu canonical sai:
- Chỉnh lại thẻ
rel="canonical"về URL mong muốn. - Đảm bảo internal link trỏ về đúng bản canonical.
- Chỉnh lại thẻ
3. Kết hợp báo cáo Sitemaps và Indexing để tối ưu chiến lược crawl
- So sánh:
- Submitted (Sitemaps) vs Indexed (Pages) để xác định nhóm URL bị bỏ sót.
- Nhóm URL có trạng thái “Crawled – currently not indexed” để ưu tiên cải thiện nội dung.
- Phân loại theo loại trang:
- Product, category, blog, landing page, v.v.
- Tối ưu riêng từng nhóm: nội dung, internal link, schema, tốc độ.
- Sử dụng URL Inspection cho các URL quan trọng:
- Kiểm tra phiên bản đã index vs phiên bản live.
- Yêu cầu Request indexing sau khi sửa lỗi lớn hoặc nâng cấp nội dung.
Khi nào cần resubmit sitemap sau khi migration hoặc thay đổi cấu trúc URL
Resubmit sitemap không phải là thao tác phải làm hàng ngày, nhưng cực kỳ quan trọng trong các giai đoạn thay đổi lớn về cấu trúc site, domain, giao thức hoặc khi bổ sung khối lượng nội dung mới rất lớn. Mục tiêu là giúp Google nhanh chóng cập nhật bản đồ URL mới, giảm thời gian “chuyển giao” và hạn chế mất traffic.
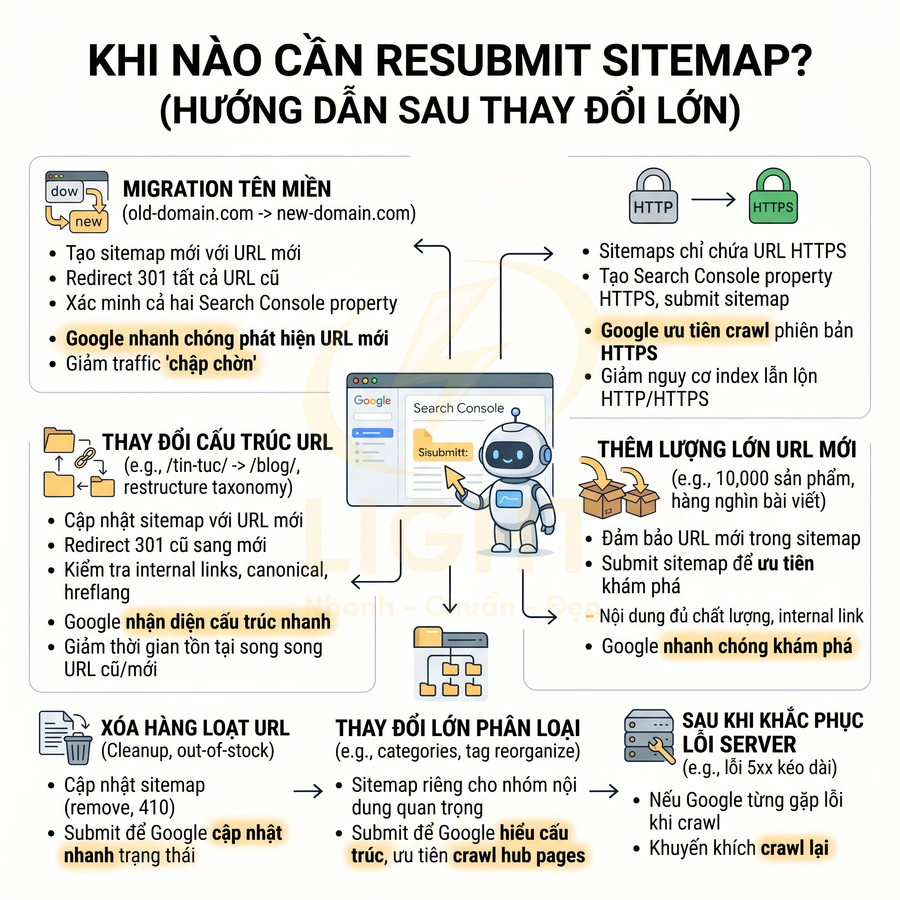
- Migration domain:
- Chuyển từ domain cũ sang domain mới (ví dụ:
old-domain.comsangnew-domain.com). - Cần:
- Tạo sitemap mới trên domain mới, chứa toàn bộ URL mới.
- Thiết lập redirect 301 từ từng URL cũ sang URL mới tương ứng.
- Xác minh cả hai domain trong Search Console (cũ và mới).
- Submit sitemap:
- Trên domain mới: sitemap với URL mới (HTTPS nếu đã chuẩn hóa).
- Trên domain cũ: có thể giữ sitemap cũ một thời gian để Google hiểu mapping 301.
- Resubmit sitemap giúp:
- Google nhanh chóng phát hiện URL mới và mối quan hệ 301.
- Giảm thời gian “chập chờn” index giữa domain cũ và mới.
- Chuyển từ domain cũ sang domain mới (ví dụ:
- Chuyển HTTP sang HTTPS:
- Khi chuyển toàn site sang HTTPS:
- Tất cả URL trong sitemap phải dùng HTTPS.
- Không để lẫn HTTP trong sitemap vì sẽ gây trùng lặp và tín hiệu mâu thuẫn.
- Thao tác trong Search Console:
- Tạo property cho
https://domain.com(nếu chưa có). - Submit sitemap HTTPS trong property HTTPS.
- Đảm bảo redirect 301 từ HTTP sang HTTPS hoạt động ổn định.
- Tạo property cho
- Resubmit sitemap trong giai đoạn này giúp:
- Google ưu tiên crawl phiên bản HTTPS.
- Giảm nguy cơ index lẫn lộn HTTP/HTTPS.
- Khi chuyển toàn site sang HTTPS:
- Thay đổi cấu trúc URL:
- Áp dụng khi:
- Thay đổi slug (ví dụ:
/tin-tuc/thành/blog/). - Thay đổi thư mục, cấu trúc permalink (ví dụ: bỏ
/category/khỏi URL). - Tái cấu trúc taxonomy, category, subfolder.
- Thay đổi slug (ví dụ:
- Cần thực hiện:
- Cập nhật sitemap với toàn bộ URL mới.
- Thiết lập redirect 301 từ URL cũ sang URL mới, tránh 404 hàng loạt.
- Kiểm tra lại internal link, canonical, hreflang (nếu có) để trỏ đúng URL mới.
- Resubmit sitemap:
- Giúp Google nhanh chóng nhận diện cấu trúc URL mới.
- Giảm thời gian tồn tại song song giữa URL cũ và mới trong index.
- Áp dụng khi:
- Thêm lượng lớn URL mới:
- Ví dụ:
- Import 10.000 sản phẩm mới vào e-commerce.
- Đăng tải hàng nghìn bài viết mới trong một chiến dịch nội dung.
- Thực hiện:
- Đảm bảo tất cả URL mới đã được thêm vào sitemap (tự động hoặc thủ công).
- Resubmit sitemap để Google ưu tiên khám phá các URL mới này.
- Lưu ý:
- Nội dung phải đủ chất lượng, tránh tạo hàng loạt trang mỏng, gần giống nhau.
- Tăng cường internal link từ các trang đã có authority đến nhóm URL mới.
- Ví dụ:
- Các trường hợp khác nên cân nhắc resubmit sitemap:
- Xóa hàng loạt URL (cleanup content, xóa sản phẩm hết hàng vĩnh viễn):
- Cập nhật sitemap để loại bỏ URL đã xóa hoặc chuyển 410.
- Resubmit để Google cập nhật nhanh trạng thái mới.
- Thay đổi lớn về cấu trúc phân loại (category, tag, hub page):
- Tạo sitemap riêng cho các nhóm nội dung quan trọng.
- Resubmit để Google hiểu rõ cấu trúc mới và ưu tiên crawl các hub page.
- Sau khi khắc phục lỗi server, lỗi 5xx kéo dài:
- Nếu trước đó Google gặp nhiều lỗi khi crawl sitemap, nên resubmit sau khi server ổn định.
- Xóa hàng loạt URL (cleanup content, xóa sản phẩm hết hàng vĩnh viễn):
Các lỗi sitemap phổ biến khiến Google crawl chậm và index kém
Sitemap tối ưu giúp Google hiểu rõ cấu trúc, ưu tiên crawl và index đúng những URL mang giá trị. Khi sitemap chứa URL bị chặn, trùng lặp hoặc cấu hình kỹ thuật sai, Google nhận tín hiệu nhiễu, làm giảm độ tin cậy và lãng phí crawl budget. Cần đảm bảo chỉ những URL thực sự muốn index, có khả năng crawl, không bị noindex, không bị chặn robots.txt và là bản canonical mới được đưa vào sitemap. Đồng thời, phải kiểm soát chặt các biến thể tham số, faceted navigation, chuẩn hóa HTTP/HTTPS, www/non-www và cấu hình chính xác trường lastmod theo chuẩn ISO 8601. Một sitemap “sạch”, nhất quán và cập nhật đúng sẽ hỗ trợ mạnh cho hiệu suất index tổng thể.

Sitemap chứa URL bị chặn robots.txt hoặc meta noindex
Sitemap là một trong những tín hiệu mạnh mẽ giúp Google hiểu cấu trúc website, ưu tiên crawl và index các URL quan trọng. Khi trong sitemap xuất hiện các URL bị chặn bởi robots.txt hoặc gắn meta noindex, Google nhận được những tín hiệu mâu thuẫn, làm giảm độ tin cậy của sitemap và có thể khiến tốc độ crawl, tỷ lệ index suy giảm đáng kể.
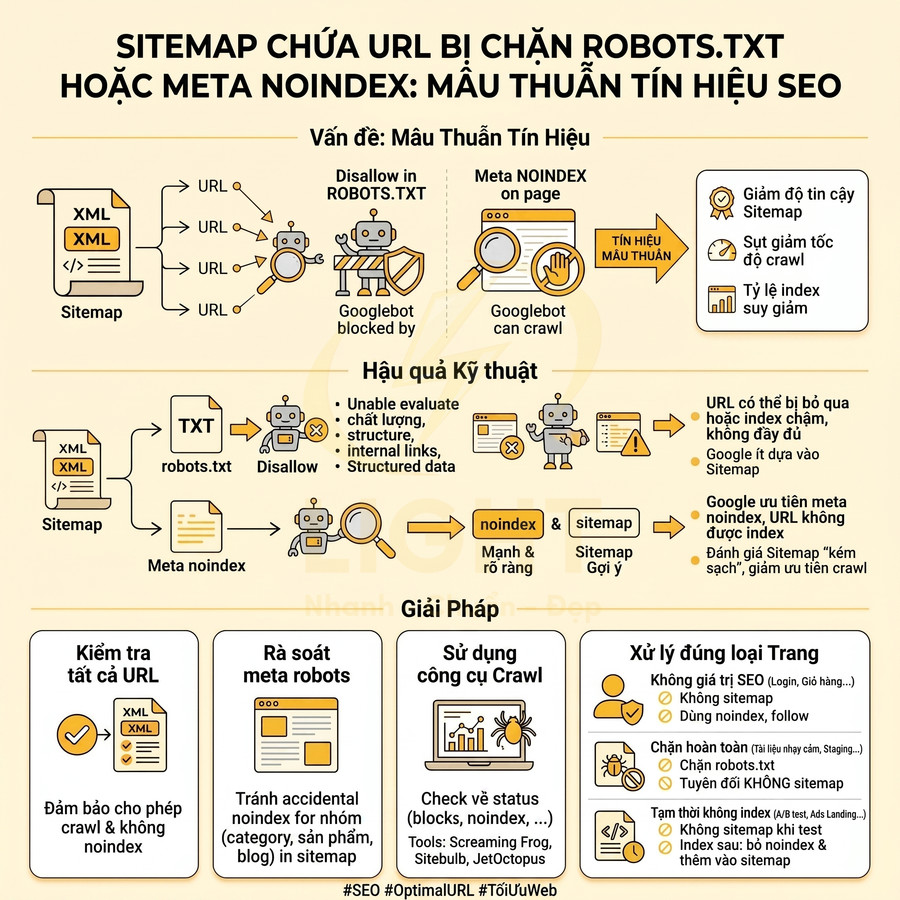
Lỗi phổ biến:
- URL trong sitemap bị Disallow trong robots.txt:
- Googlebot bị chặn ngay từ lớp robots.txt nên không thể truy cập nội dung để đánh giá chất lượng, tính liên quan, internal link, structured data…
- Sitemap lại “gợi ý” rằng đây là URL quan trọng cần index, tạo ra xung đột tín hiệu: một bên yêu cầu ưu tiên, một bên chặn hoàn toàn.
- Về mặt kỹ thuật, Google có thể vẫn nhìn thấy URL trong sitemap, nhưng không thể crawl nội dung, dẫn đến:
- URL có thể bị bỏ qua hoặc index rất chậm với thông tin không đầy đủ.
- Giảm độ tin cậy tổng thể của sitemap, khiến Google ít dựa vào sitemap để lập lịch crawl.
- URL trong sitemap có meta noindex:
- Khác với robots.txt, Google vẫn có thể crawl trang nhưng thẻ
<meta name="robots" content="noindex">yêu cầu không đưa URL vào chỉ mục. - Sitemap lại gửi tín hiệu rằng URL này nên được index, tạo ra mâu thuẫn trực tiếp giữa:
- Tín hiệu cấp trang (meta robots) – mạnh và rõ ràng.
- Tín hiệu cấp file (sitemap) – mang tính gợi ý.
- Trong đa số trường hợp, Google sẽ ưu tiên tuân thủ meta noindex, khiến URL không được index dù vẫn xuất hiện trong sitemap.
- Khi tỷ lệ URL noindex trong sitemap cao, Google có thể đánh giá sitemap “kém sạch”, giảm mức độ ưu tiên khi crawl các URL còn lại.
- Khác với robots.txt, Google vẫn có thể crawl trang nhưng thẻ
Giải pháp:
- Đảm bảo tất cả URL trong sitemap đều được phép crawl và không noindex:
- Kiểm tra file
robots.txtđể chắc chắn không có rule Disallow trùng với các path quan trọng trong sitemap (ví dụ:Disallow: /product/trong khi sitemap chứa hàng nghìn URL sản phẩm). - Rà soát meta robots ở cấp template (category, product, blog…) để tránh gắn noindex nhầm cho các nhóm URL đang được đưa vào sitemap.
- Sử dụng các công cụ crawl (Screaming Frog, Sitebulb, JetOctopus…) để đối chiếu:
- Danh sách URL trong sitemap.
- Trạng thái indexability (blocked by robots.txt, meta noindex, x-robots-tag…).
- Kiểm tra file
- Nếu muốn chặn index, loại URL đó khỏi sitemap và dùng noindex hoặc robots.txt tùy trường hợp:
- Với các trang thực sự không có giá trị SEO (trang login, giỏ hàng, bước checkout, trang nội bộ…):
- Không đưa vào sitemap.
- Có thể dùng noindex, follow để vẫn giữ luồng internal link.
- Với các trang cần chặn hoàn toàn (tài liệu nhạy cảm, staging, môi trường test…):
- Dùng robots.txt để chặn crawl.
- Đảm bảo tuyệt đối không xuất hiện trong sitemap.
- Với các trang tạm thời không muốn index (A/B test, landing page chạy ads…):
- Không đưa vào sitemap trong giai đoạn test.
- Khi muốn index, bỏ noindex và thêm vào sitemap để Google ưu tiên crawl lại.
- Với các trang thực sự không có giá trị SEO (trang login, giỏ hàng, bước checkout, trang nội bộ…):
Sitemap sinh thừa URL canonicalized, duplicate và faceted navigation
Khi sitemap chứa quá nhiều URL trùng lặp, biến thể tham số, hoặc các URL sinh ra từ hệ thống filter (faceted navigation), Google phải phân bổ crawl budget vào những trang không mang thêm giá trị nội dung. Điều này làm loãng tín hiệu, giảm hiệu quả index cho các URL thực sự quan trọng.
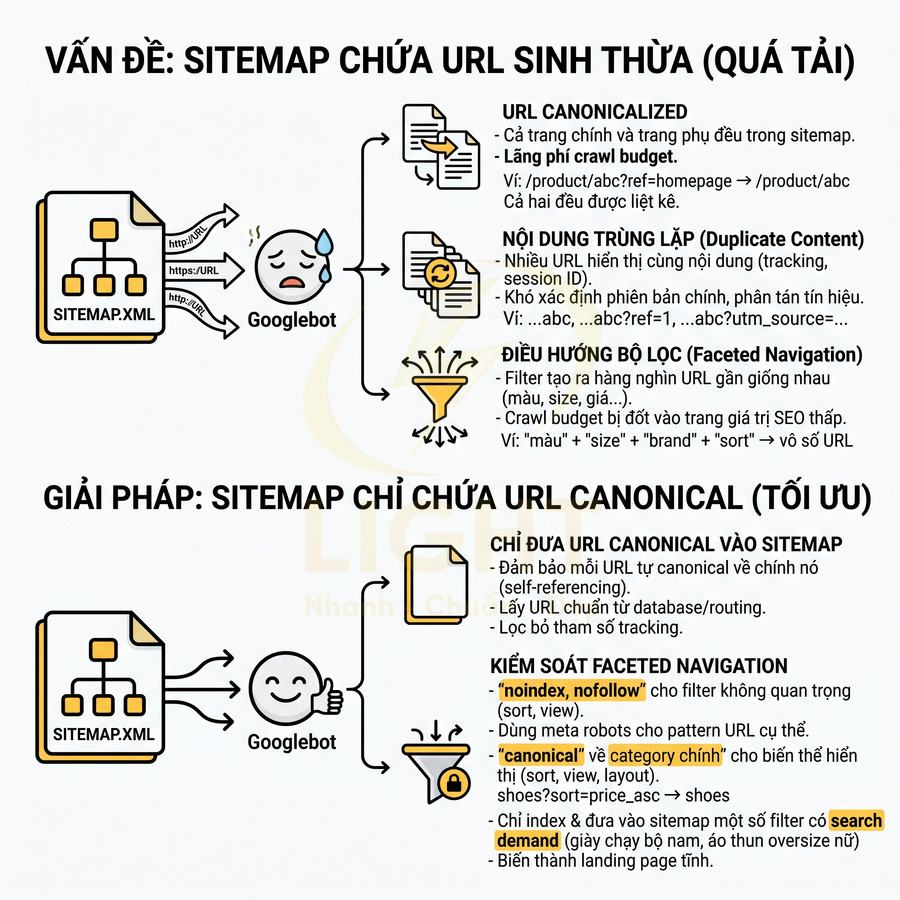
Các lỗi gây trùng lặp:
- URL canonicalized:
- Trang A canonical sang B nhưng cả A và B đều trong sitemap:
- Ví dụ:
/product/abc?ref=homepagecó<link rel="canonical" href="https://example.com/product/abc" />, nhưng sitemap vẫn liệt kê cả hai URL. - Google phải crawl cả A và B, sau đó mới hợp nhất tín hiệu về URL canonical, gây lãng phí crawl budget.
- Ví dụ:
- Về mặt chuẩn SEO, sitemap nên chỉ chứa URL canonical cuối cùng, không chứa các biến thể đã được canonical hóa.
- Trang A canonical sang B nhưng cả A và B đều trong sitemap:
- Duplicate content:
- Nhiều URL khác nhau hiển thị cùng nội dung (ví dụ:
/product/abc,/product/abc?ref=1,/product/abc?utmsource=...). - Hệ thống tracking, session ID, hoặc các tham số marketing thường tạo ra hàng loạt URL trùng nội dung nhưng khác query string.
- Nếu các URL này được đưa vào sitemap:
- Google phải crawl nhiều lần cùng một nội dung.
- Khó xác định đâu là phiên bản chính, có thể dẫn đến phân tán tín hiệu (link equity, signals) giữa các biến thể.
- Nhiều URL khác nhau hiển thị cùng nội dung (ví dụ:
- Faceted navigation:
- Filter tạo ra hàng nghìn URL với nội dung gần giống nhau:
- Ví dụ: filter theo màu, size, brand, price range… trên category e-commerce.
- Kết hợp nhiều filter (màu + size + brand + sort) có thể tạo ra số lượng URL gần như vô hạn.
- Nếu tất cả các URL filter này được tự động đưa vào sitemap:
- Crawl budget bị “đốt” vào các trang có giá trị SEO thấp hoặc trùng lặp cao.
- Google khó nhận diện được các category chính thực sự quan trọng.
- Filter tạo ra hàng nghìn URL với nội dung gần giống nhau:
Giải pháp:
- Chỉ đưa URL canonical vào sitemap:
- Đảm bảo mỗi URL trong sitemap:
- Tự canonical về chính nó (self-referencing canonical).
- Không phải là bản phụ (duplicate, near-duplicate) của một URL khác.
- Trong quá trình generate sitemap:
- Lấy URL từ database hoặc hệ thống routing đã chuẩn hóa, không lấy từ log hoặc từ các request có query string.
- Lọc bỏ các URL có tham số tracking (utmsource, utmmedium, gclid, fbclid…).
- Đảm bảo mỗi URL trong sitemap:
- Kiểm soát faceted navigation bằng:
- noindex, nofollow cho filter không quan trọng:
- Áp dụng cho các combination filter không mang giá trị tìm kiếm riêng (ví dụ: sort by, view=grid/list, filter cosmetic nhỏ).
- Có thể dùng
meta robotshoặcx-robots-tagđể gắn noindex cho các pattern URL cụ thể.
- canonical về category chính:
- Với các filter chỉ là biến thể hiển thị (sort, view, layout), canonical nên trỏ về URL category gốc.
- Ví dụ:
/category/shoes?sort=priceasccanonical về/category/shoes.
- Chỉ index và đưa vào sitemap một số ít filter thực sự có search demand:
- Ví dụ: “giày chạy bộ nam”, “áo thun oversize nữ” có volume tìm kiếm riêng, có thể được cấu trúc thành landing page tĩnh hoặc filter được tối ưu onpage.
- Các URL này nên:
- Có nội dung mô tả riêng (text, heading, FAQ…).
- Có internal link rõ ràng từ category hoặc menu.
- Được đưa vào sitemap như các landing page độc lập.
- noindex, nofollow cho filter không quan trọng:
lastmod sai, timezone lỗi và URL không đồng nhất HTTP/HTTPS, www/non-www
Các trường kỹ thuật trong sitemap như <lastmod> và tính nhất quán của URL (protocol, subdomain) giúp Google tối ưu lịch crawl. Khi cấu hình sai, Google có thể hiểu nhầm thời điểm cập nhật, hoặc coi nhiều phiên bản URL là các trang khác nhau, dẫn đến lãng phí crawl budget và giảm hiệu quả index.
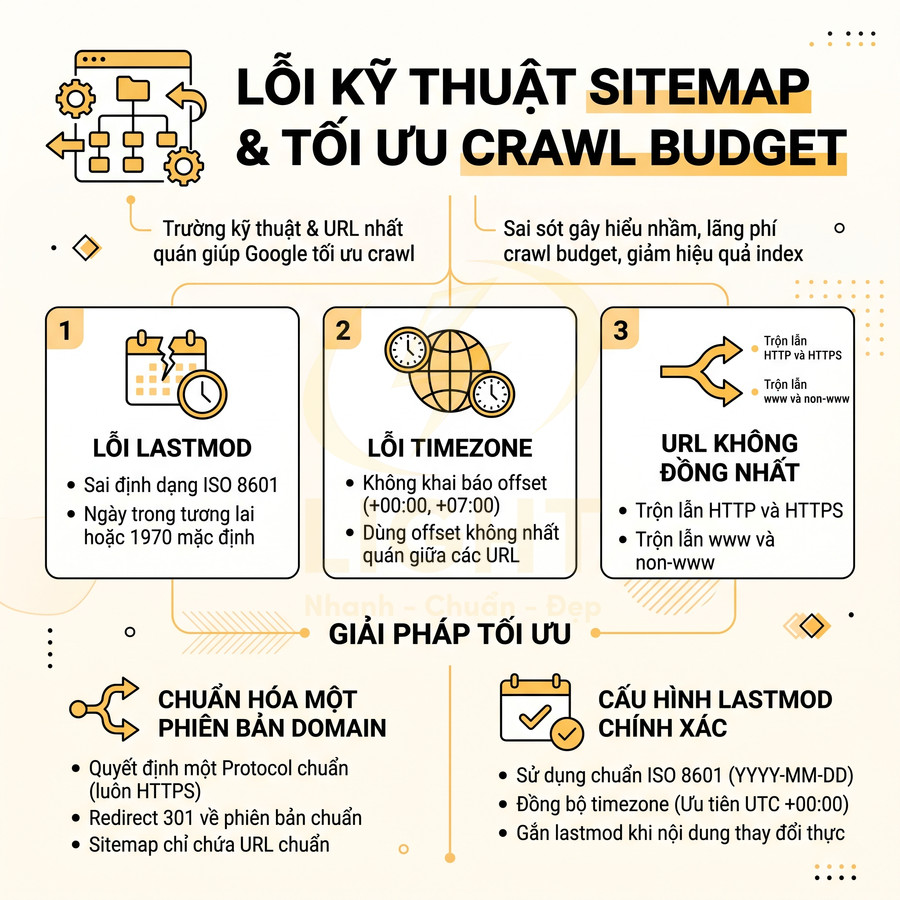
Các lỗi kỹ thuật:
- lastmod sai định dạng:
- Không theo chuẩn ISO 8601 (YYYY-MM-DD hoặc có time zone):
- Ví dụ: dùng định dạng
DD/MM/YYYYhoặcMM-DD-YYYYkhiến Google không parse đúng. - Google có thể bỏ qua trường lastmod, làm mất lợi thế ưu tiên crawl cho các trang mới cập nhật.
- Ví dụ: dùng định dạng
- Ngày trong tương lai, ngày 1970 mặc định:
- Ngày trong tương lai (ví dụ:
2099-01-01) khiến tín hiệu trở nên không đáng tin, có thể bị bỏ qua. - Ngày
1970-01-01hoặc một giá trị mặc định lặp lại cho mọi URL cho thấy hệ thống generate sitemap không gắn đúng timestamp thực tế.
- Ngày trong tương lai (ví dụ:
- Không theo chuẩn ISO 8601 (YYYY-MM-DD hoặc có time zone):
- Timezone lỗi:
- Không khai báo offset (+00:00, +07:00…), gây hiểu nhầm thời điểm cập nhật:
- Ví dụ:
2024-03-10T10:00:00không rõ là UTC hay local time. - Trong các hệ thống phân tán (CDN, multi-region), việc không thống nhất timezone có thể khiến một số URL trông như vừa được cập nhật, trong khi thực tế không.
- Ví dụ:
- Dùng offset không nhất quán giữa các URL (một số là
+00:00, một số là+07:00) gây khó khăn cho việc so sánh thời điểm cập nhật.
- Không khai báo offset (+00:00, +07:00…), gây hiểu nhầm thời điểm cập nhật:
- URL không đồng nhất:
- Trộn lẫn HTTP và HTTPS:
- Một số URL trong sitemap dùng
http://, số khác dùnghttps://. - Nếu site đã chuyển sang HTTPS, việc vẫn liệt kê HTTP có thể:
- Khiến Google crawl vào phiên bản cũ, phải redirect 301 sang HTTPS.
- Lãng phí crawl budget vào các redirect không cần thiết.
- Một số URL trong sitemap dùng
- Trộn lẫn www và non-www:
- Ví dụ: vừa có
https://www.example.com/vừa cóhttps://example.com/trong cùng sitemap. - Google có thể coi đây là hai host khác nhau, dẫn đến:
- Phân tán tín hiệu authority giữa hai phiên bản.
- Tăng nguy cơ duplicate content nếu canonical/redirect không được cấu hình chuẩn.
- Ví dụ: vừa có
- Trộn lẫn HTTP và HTTPS:
Giải pháp:
- Chuẩn hóa một phiên bản domain duy nhất (HTTPS, www hoặc non-www) và dùng nhất quán trong sitemap:
- Quyết định rõ:
- Protocol chuẩn: luôn là HTTPS nếu site hỗ trợ SSL.
- Host chuẩn: www.example.com hoặc example.com, không dùng cả hai.
- Cấu hình:
- Redirect 301 từ phiên bản không chuẩn về phiên bản chuẩn (HTTP → HTTPS, non-www → www hoặc ngược lại).
- Self-canonical trên tất cả URL về đúng phiên bản chuẩn.
- Sitemap chỉ chứa URL của phiên bản chuẩn, không liệt kê bất kỳ URL nào thuộc phiên bản phụ.
- Kiểm tra định kỳ bằng:
- Crawl sitemap và kiểm tra xem có URL nào trả về redirect, 4xx, 5xx hay không.
- Đảm bảo 100% URL trong sitemap trả về mã 200 và thuộc đúng host/protocol chuẩn.
- Quyết định rõ:
- Đảm bảo lastmod đúng định dạng, đúng timezone, phản ánh thời điểm cập nhật thực:
- Sử dụng chuẩn ISO 8601:
- Đơn giản:
YYYY-MM-DD(ví dụ:2024-03-10). - Chi tiết:
YYYY-MM-DDThh:mm:ss+00:00(ví dụ:2024-03-10T10:30:00+07:00).
- Đơn giản:
- Đồng bộ timezone:
- Ưu tiên dùng UTC (
+00:00) cho toàn bộ sitemap để tránh nhầm lẫn. - Nếu dùng local time, đảm bảo tất cả URL cùng một offset và hệ thống cập nhật chính xác khi có thay đổi DST (nếu áp dụng).
- Ưu tiên dùng UTC (
- Gắn lastmod dựa trên:
- Thời điểm nội dung thực sự thay đổi (content, structured data, internal link quan trọng…).
- Không nên cập nhật lastmod mỗi lần có thay đổi nhỏ không ảnh hưởng đến người dùng (ví dụ: log view, minor tracking script) để tránh “spam” tín hiệu cập nhật.
- Tránh:
- Dùng cùng một lastmod cho toàn bộ URL nếu chúng không thực sự được cập nhật cùng lúc.
- Đặt lastmod trong tương lai hoặc để mặc định 1970 cho các URL chưa có timestamp.
- Sử dụng chuẩn ISO 8601:
Cách kết hợp internal link, log file và sitemap để tăng tốc độ Google crawl
Việc kết hợp log file, sitemap và internal link cho phép kiểm soát trực tiếp cách Googlebot phân bổ crawl budget trên toàn site. Log analysis giúp phát hiện URL đã khai báo trong sitemap nhưng chưa hoặc ít được crawl, từ đó ưu tiên bằng cách tăng internal link, rút ngắn depth và đưa vào các khu vực điều hướng nổi bật. Ngược lại, các URL ít giá trị nhưng bị crawl nhiều sẽ được chặn, noindex hoặc canonical để giảm lãng phí tài nguyên.
Sitemap đóng vai trò bản đồ kỹ thuật, trong khi cấu trúc internal link và topic cluster thể hiện bản đồ ngữ nghĩa. Khi sitemap phản ánh đúng hub page, cluster và entity quan trọng, còn internal link đảm bảo liên kết hai chiều, Google có thể crawl sâu, nhanh và chính xác hơn vào những khu vực mang lại giá trị SEO và kinh doanh cao nhất.
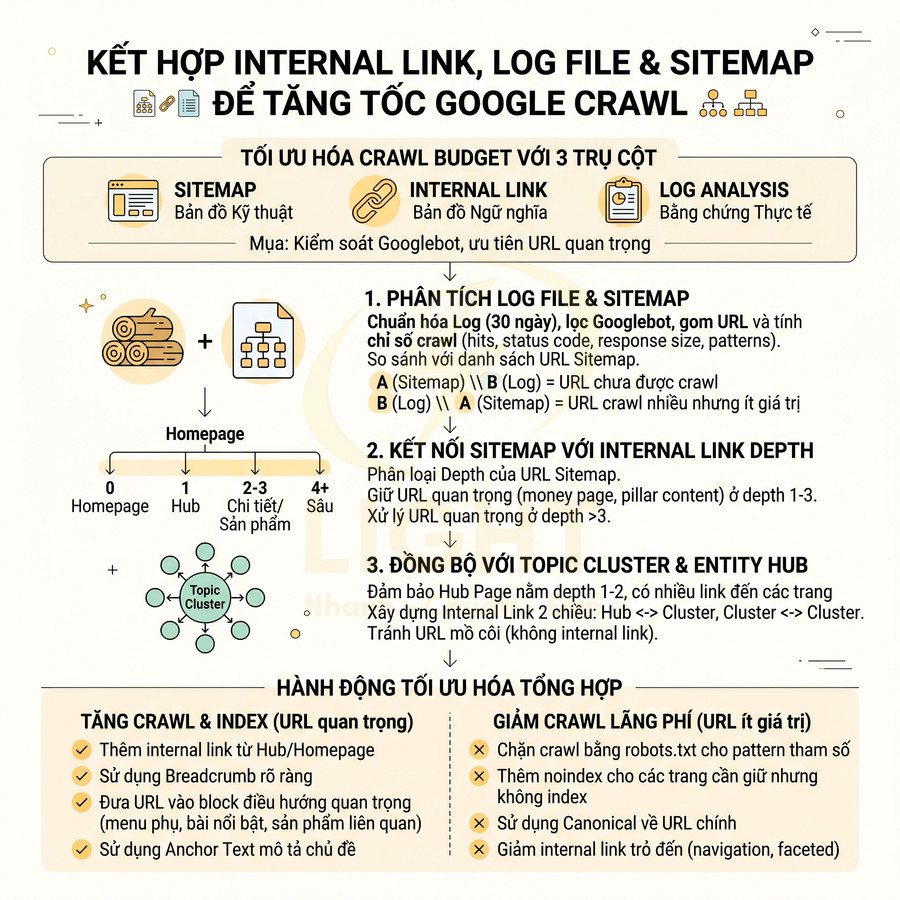
Dùng log analysis để xác định URL bot chưa crawl dù đã có trong sitemap
Log server là nguồn dữ liệu duy nhất phản ánh chính xác cách Googlebot tương tác với website ở cấp độ HTTP request. Khi kết hợp log analysis với sitemap, bạn có thể tối ưu trực tiếp crawl budget, ưu tiên URL quan trọng và giảm lãng phí vào các URL ít giá trị.
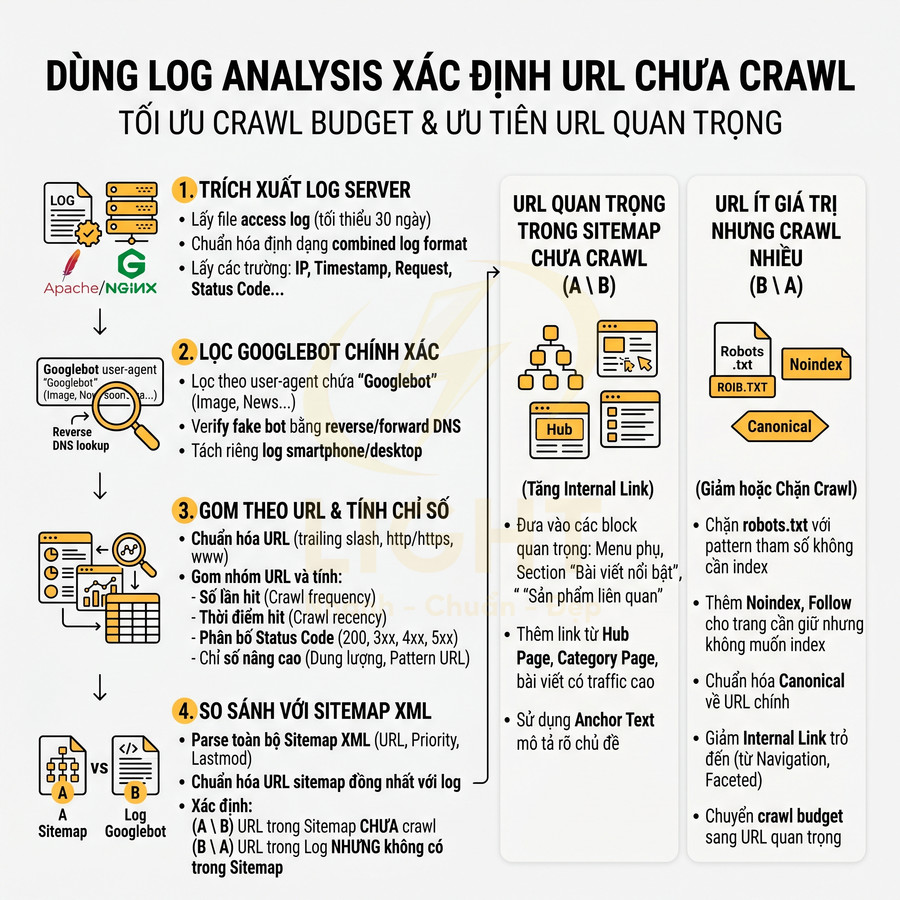
Quy trình phân tích log chi tiết:
- Trích xuất log từ server:
- Lấy file access log từ web server (Apache, Nginx, IIS…) trong khoảng thời gian đủ dài (tối thiểu 30 ngày) để có mẫu crawl representative.
- Chuẩn hóa định dạng log (combined log format hoặc tương đương) để dễ parse các trường: IP, timestamp, request, status code, user-agent, referrer, response size.
- Lọc user-agent Googlebot một cách chính xác:
- Lọc theo chuỗi user-agent chứa “Googlebot” (Googlebot, Googlebot-Image, Googlebot-News…).
- Để tránh fake bot, nên reverse DNS lookup một mẫu IP và verify lại bằng forward DNS để chắc chắn IP thuộc Google.
- Có thể tách riêng log cho từng loại bot (Googlebot smartphone, desktop) để phân tích hành vi crawl theo device.
- Gom theo URL và tính toán chỉ số crawl:
- Chuẩn hóa URL (loại bỏ trailing slash không cần thiết, thống nhất http/https, www/non-www) để không đếm trùng.
- Gom log theo URL và tính:
- Số lần hit (crawl frequency) trong khoảng thời gian phân tích.
- Thời điểm hit đầu tiên và gần nhất (crawl recency).
- Phân bố status code (200, 3xx, 4xx, 5xx) để phát hiện lỗi crawl.
- Có thể thêm các chỉ số nâng cao:
- Tổng dung lượng dữ liệu trả về cho mỗi URL (crawl cost).
- Tỷ lệ hit theo pattern URL (thư mục, tham số, loại page).
- So sánh với sitemap:
- Parse toàn bộ sitemap XML (và các sitemap con) để lấy danh sách URL, priority, lastmod.
- Chuẩn hóa URL trong sitemap theo cùng quy tắc với log để so sánh chính xác.
- Tạo hai tập:
- Tập A: URL trong sitemap.
- Tập B: URL xuất hiện trong log Googlebot.
- Xác định:
- URL có trong sitemap nhưng không xuất hiện trong log (A \ B) → Googlebot chưa crawl hoặc crawl rất ít trong giai đoạn phân tích.
- URL xuất hiện nhiều trong log nhưng không có trong sitemap (B \ A) → thường là URL ít quan trọng, URL sinh bởi tham số, filter, pagination sâu, hoặc URL lỗi.
Diễn giải kết quả và hành động tối ưu:
- Tăng internal link cho URL quan trọng chưa được crawl:
- Với các URL:
- Có trong sitemap.
- Được đánh giá là quan trọng (money page, landing page, bài pillar, trang sản phẩm chủ lực).
- Nhưng không có hoặc rất ít hit từ Googlebot trong log.
- Kiểm tra:
- Internal link depth của URL (bao nhiêu click từ homepage hoặc hub page).
- Số lượng và chất lượng internal link trỏ đến (từ trang có traffic, từ hub page, từ navigation).
- Hành động:
- Thêm internal link từ các hub page, category page, bài viết có traffic cao.
- Đưa URL vào các block điều hướng quan trọng: menu phụ, section “bài viết nổi bật”, “sản phẩm liên quan”.
- Sử dụng anchor text mô tả rõ chủ đề để hỗ trợ cả crawl lẫn hiểu ngữ nghĩa.
- Với các URL:
- Giảm hoặc chặn URL ít giá trị nhưng bị crawl nhiều:
- Nhóm URL có:
- Số lần hit từ Googlebot rất cao.
- Không có trong sitemap hoặc được đánh giá là low-value (filter, sort, session, tracking parameters, search result nội bộ).
- Hành động kỹ thuật:
- Chặn crawl bằng robots.txt với pattern tham số không cần index.
- Thêm noindex, follow cho các trang cần giữ để phục vụ user nhưng không muốn index.
- Chuẩn hóa bằng canonical về URL chính để gom tín hiệu và giảm crawl lặp.
- Giảm internal link trỏ đến các URL này, đặc biệt từ navigation hoặc faceted navigation.
- Mục tiêu là chuyển phần crawl budget đang bị tiêu tốn vào các URL ít giá trị sang nhóm URL quan trọng trong sitemap.
- Nhóm URL có:
Kết nối sitemap với internal link depth để đẩy nhanh crawl trang sâu
Sitemap chỉ đóng vai trò “khai báo tồn tại” URL với Google, trong khi internal link graph mới là tín hiệu mạnh về mức độ ưu tiên crawl và index. Internal link depth là một trong những chỉ số quan trọng nhất để đánh giá khả năng được crawl của một URL.
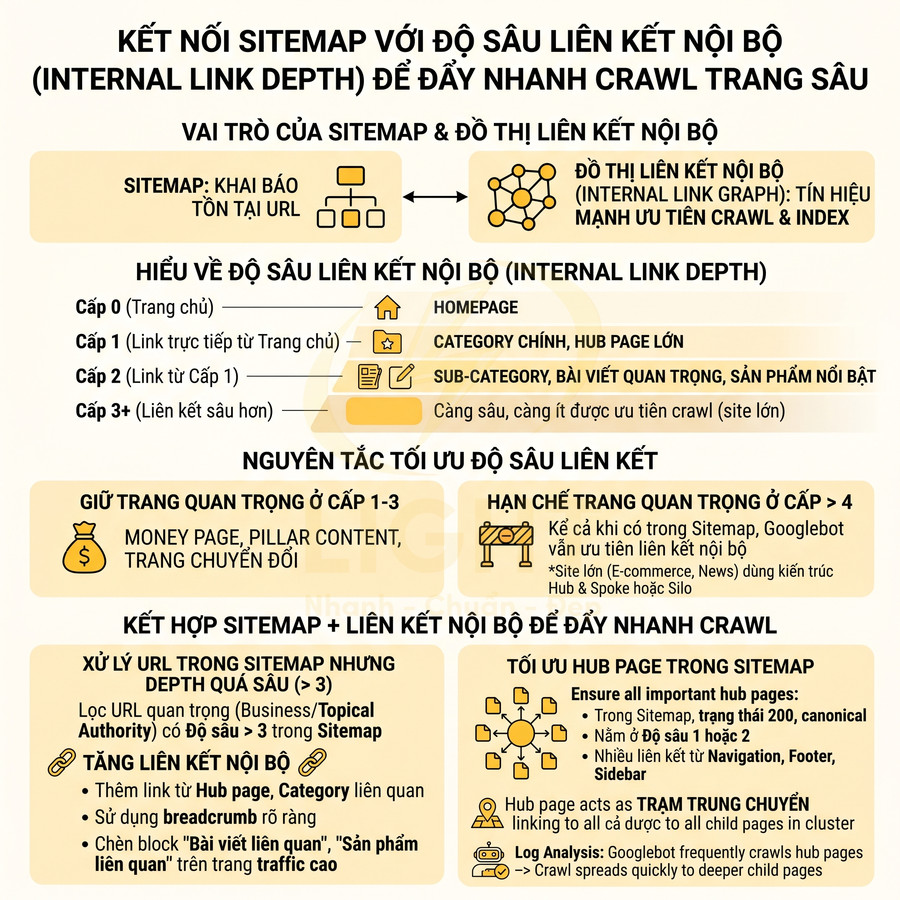
Internal link depth và tác động đến crawl:
- Định nghĩa internal link depth:
- Depth 0: Homepage.
- Depth 1: Trang được link trực tiếp từ homepage (category chính, hub page lớn).
- Depth 2: Trang được link từ depth 1 (sub-category, bài viết quan trọng, sản phẩm nổi bật).
- Depth 3+: Các trang càng sâu, càng ít được ưu tiên crawl, đặc biệt với site lớn.
- Nguyên tắc tối ưu depth:
- Giữ URL quan trọng (money page, pillar content, trang chuyển đổi) ở depth 1–3.
- Hạn chế để URL quan trọng nằm ở depth > 4, kể cả khi đã có trong sitemap, vì Googlebot vẫn ưu tiên theo internal link.
- Với site lớn (e-commerce, news), nên thiết kế kiến trúc thông tin dạng hub & spoke hoặc silo để giảm depth trung bình.
Kết hợp sitemap + internal link để đẩy nhanh crawl:
- Xử lý URL trong sitemap nhưng depth quá sâu:
- Trích xuất danh sách URL trong sitemap và gán thêm chỉ số internal link depth (tính bằng crawl nội bộ hoặc tool).
- Lọc ra:
- URL có trong sitemap.
- Depth > 3.
- Quan trọng về mặt business hoặc topical authority.
- Tăng internal link bằng:
- Thêm link từ hub page, category page liên quan trực tiếp đến chủ đề.
- Sử dụng breadcrumb rõ ràng để tạo đường đi ngắn hơn từ homepage đến trang sâu.
- Chèn block “bài viết liên quan” hoặc “sản phẩm liên quan” ở các trang có traffic cao, trỏ đến các URL sâu này.
- Tối ưu hub page trong sitemap:
- Đảm bảo tất cả hub page quan trọng đều:
- Có trong sitemap với trạng thái 200, canonical rõ ràng.
- Nằm ở depth 1 hoặc 2 từ homepage.
- Có nhiều internal link trỏ đến từ navigation, footer, sidebar.
- Hub page phải đóng vai trò “trạm trung chuyển”:
- Link ra toàn bộ trang con trong cluster (bài chi tiết, sản phẩm, hướng dẫn chuyên sâu).
- Giúp Googlebot khi vào hub page có thể khám phá nhanh toàn bộ cluster mà không phải đi qua nhiều cấp.
- Log analysis có thể cho thấy:
- Googlebot thường xuyên crawl hub page.
- Từ đó, nếu hub page được tối ưu internal link tốt, crawl sẽ lan tỏa nhanh đến các trang con sâu hơn.
- Đảm bảo tất cả hub page quan trọng đều:
Đồng bộ sitemap với chiến lược topic cluster và entity hub page
Trong semantic SEO, cấu trúc website không chỉ là cây thư mục mà là bản đồ chủ đề (topic map). Topic cluster và entity hub page là hai khối xây dựng chính để thể hiện chuyên môn sâu, rộng và mối liên kết ngữ nghĩa giữa các nội dung.
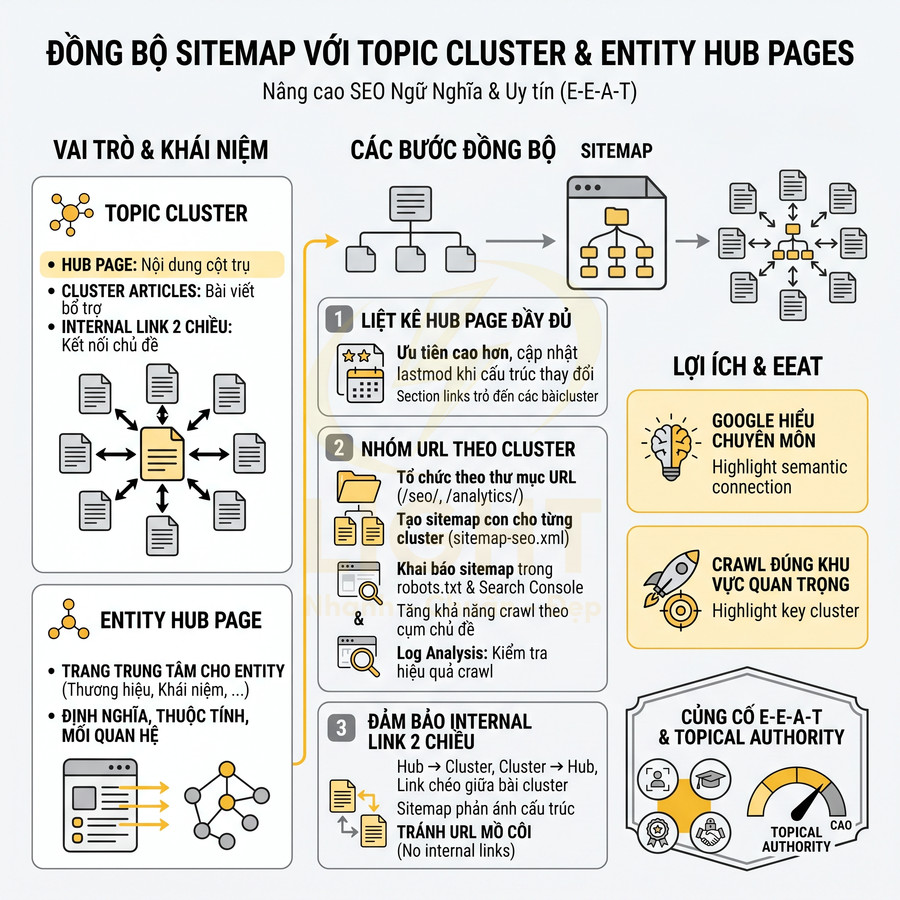
Vai trò của topic cluster và entity hub:
- Topic cluster:
- Là nhóm nội dung xoay quanh một chủ đề trung tâm (topic), bao gồm:
- Hub page (pillar content) bao quát chủ đề.
- Các bài cluster đi sâu vào từng khía cạnh cụ thể (how-to, case study, review, comparison…).
- Internal link hai chiều giữa hub và cluster giúp:
- Google hiểu mối quan hệ ngữ nghĩa giữa các bài.
- Phân phối PageRank nội bộ hiệu quả trong cluster.
- Là nhóm nội dung xoay quanh một chủ đề trung tâm (topic), bao gồm:
- Entity hub page:
- Là trang trung tâm cho một entity quan trọng (thương hiệu, sản phẩm, khái niệm, địa điểm…).
- Thường chứa:
- Định nghĩa, thuộc tính, mối quan hệ với entity khác.
- Link đến các bài viết, tài nguyên liên quan đến entity đó.
- Giúp Google xây dựng graph entity của website, hỗ trợ hiểu sâu về chuyên môn và ngữ cảnh.
Đồng bộ sitemap với topic cluster:
- Liệt kê đầy đủ hub page trong sitemap:
- Mỗi chủ đề chính (topic lớn) phải có một hub page rõ ràng, được:
- Đưa vào sitemap với priority cao hơn tương đối so với bài cluster.
- Cập nhật lastmod khi có thay đổi lớn về cấu trúc cluster (thêm/bớt bài quan trọng).
- Hub page nên có:
- Internal link đến tất cả (hoặc phần lớn) bài cluster quan trọng.
- Cấu trúc nội dung rõ ràng, có section link đến từng nhóm bài con.
- Mỗi chủ đề chính (topic lớn) phải có một hub page rõ ràng, được:
- Nhóm URL theo cluster trong sitemap:
- Có thể tổ chức theo:
- Thư mục URL (ví dụ: /seo/, /analytics/, /ecommerce/ tương ứng với từng cluster).
- Sitemap con riêng cho từng cluster (ví dụ: sitemap-seo.xml, sitemap-analytics.xml).
- Mục tiêu:
- Giúp Google nhận diện ranh giới và cấu trúc từng chủ đề.
- Tăng khả năng crawl theo cụm chủ đề, thay vì rời rạc từng URL.
- Khi log analysis cho thấy một cluster ít được crawl:
- Kiểm tra xem sitemap con của cluster đó có được khai báo trong robots.txt và Search Console chưa.
- Đánh giá lại internal link từ các hub page khác hoặc từ homepage đến cluster này.
- Có thể tổ chức theo:
- Đảm bảo internal link hai chiều trong mỗi cluster:
- Cấu trúc chuẩn của một cluster:
- Hub page (pillar content).
- Các bài cluster liên quan (supporting content).
- Internal link:
- Từ hub → tất cả bài cluster.
- Từ mỗi bài cluster → hub.
- Link chéo giữa các bài cluster khi có liên quan ngữ nghĩa.
- Sitemap phản ánh cấu trúc này bằng:
- Liệt kê hub và cluster trong cùng một sitemap con hoặc cùng một thư mục.
- Đảm bảo không có URL mồ côi (orphan) trong cluster: URL có trong sitemap nhưng không có internal link.
- Kết hợp với log:
- Nếu hub page được crawl thường xuyên nhưng nhiều bài cluster trong cùng sitemap ít được crawl:
- Kiểm tra lại internal link từ hub đến các bài đó (có bị ẩn trong tab, accordion, infinite scroll…).
- Tăng số lượng và độ nổi bật của link trong nội dung hub.
- Nếu hub page được crawl thường xuyên nhưng nhiều bài cluster trong cùng sitemap ít được crawl:
- Cấu trúc chuẩn của một cluster:
Khi sitemap được thiết kế để phản ánh rõ ràng topic cluster và entity hub, kết hợp với internal link depth hợp lý và log analysis liên tục, Google có thể hiểu tốt hơn chuyên môn sâu và rộng của website, ưu tiên crawl đúng khu vực quan trọng và củng cố EEAT cùng topical authority một cách bền vững.
Checklist sitemap chuẩn SEO technical audit trước khi deploy production
Sitemap chuẩn SEO technical audit cần đảm bảo tính chính xác, sạch và dễ crawl trước khi đưa lên production. Trọng tâm là xác thực cấu trúc XML, encoding, nén gzip, status code và khả năng truy cập của bot. Sau deploy, cần test trực tiếp bằng Google Search Console (URL Inspection, báo cáo Sitemaps, Coverage) và đối chiếu với server log để hiểu cách Googlebot thực sự crawl, tần suất truy cập và chênh lệch giữa URL trong sitemap với URL được crawl. Về dài hạn, cần checklist định kỳ sau mỗi lần publish nhiều nội dung, update quan trọng, migration hoặc khi scale số lượng URL lớn, nhằm giữ sitemap luôn phản ánh đúng cấu trúc site, ưu tiên URL có giá trị SEO và không lãng phí crawl budget.
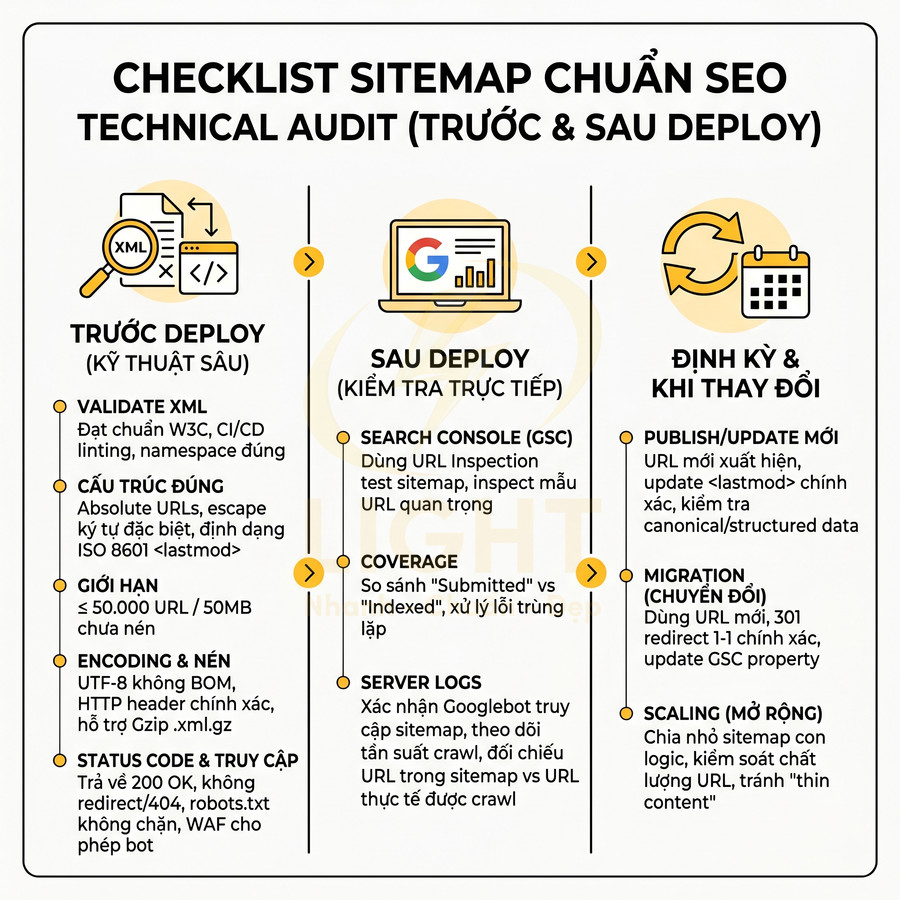
Validate XML, gzip, UTF-8, status code và khả năng truy cập bot
Checklist kỹ thuật trước khi đưa sitemap lên production (mức technical sâu hơn, phù hợp cho dev, SEO technical và sysadmin):
- XML valid:
- Sử dụng nhiều lớp kiểm tra:
- Validator online: W3C, Screaming Frog, Sitebulb, Ryte… để phát hiện lỗi cấu trúc.
- Kiểm tra bằng linter / parser XML trong CI/CD (ví dụ: xmllint) để chặn build nếu XML lỗi.
- Đảm bảo cấu trúc chuẩn:
- Thẻ gốc
<urlset>hoặc<sitemapindex>có namespace chuẩn:xmlns="http://www.sitemaps.org/schemas/sitemap/0.9". - Không lẫn lộn giữa sitemap index và sitemap con (index chỉ chứa
<sitemap>, sitemap con chỉ chứa<url>). - Không có thẻ đóng/mở sai thứ tự, không thừa thẻ, không thiếu thẻ bắt buộc.
- Thẻ gốc
- Quy tắc nội dung:
- URL trong
<loc>phải là absolute URL (bao gồm protocol và domain), không dùng relative path. - Không chứa ký tự đặc biệt chưa escape (ví dụ:
&phải viết&). - Không chứa khoảng trắng thừa ở đầu/cuối trong
<loc>,<lastmod>.
- URL trong
- Định dạng
<lastmod>:- Dùng ISO 8601:
YYYY-MM-DDhoặcYYYY-MM-DDThh:mm:ss+00:00. - Không dùng format mơ hồ (ví dụ:
DD/MM/YYYY). - Không cập nhật
lastmod“giả” cho tất cả URL mỗi lần build; chỉ update khi nội dung thực sự thay đổi.
- Dùng ISO 8601:
- Giới hạn kích thước:
- Mỗi sitemap tối đa ~50.000 URL hoặc ~50MB chưa nén (theo guideline Google).
- Nếu gần chạm ngưỡng, chia sitemap thành nhiều file con và dùng
sitemapindex.xml.

- Encoding:
- Thiết lập encoding chuẩn:
- Đảm bảo file sitemap được lưu và serve với encoding UTF-8 không BOM.
- Header HTTP nên có:
Content-Type: application/xml; charset=UTF-8(hoặctext/xmlnếu legacy, nhưng ưu tiênapplication/xml).
- Kiểm tra lỗi encoding:
- Không để ký tự lạ (�) xuất hiện trong URL hoặc thẻ text.
- Với URL có ký tự Unicode (tiếng Việt, ký tự đặc biệt), đảm bảo đã được percent-encode đúng chuẩn URL, không để raw UTF-8 trong path nếu hệ thống không hỗ trợ.
- Pipeline build:
- Trong quá trình generate sitemap (script, framework), ép encoding output là UTF-8, tránh để IDE hoặc server tự động convert.
- Thiết lập encoding chuẩn:
- Gzip:
- Hỗ trợ nén
.xml.gznếu file lớn:- Enable gzip trên web server (Nginx, Apache, CDN) cho MIME type
application/xml,text/xml. - Có thể generate sẵn file
sitemap.xml.gznếu số lượng URL rất lớn hoặc hệ thống build tĩnh.
- Enable gzip trên web server (Nginx, Apache, CDN) cho MIME type
- Kiểm tra header:
- Đảm bảo trả về
Content-Encoding: gzipkhi nén. - Không double-compress (CDN nén lại file đã nén).
- Đảm bảo trả về
- Test khả năng đọc:
- Dùng
curl -Iđể kiểm tra header và status code. - Mở file
.gzbằng tool giải nén để chắc chắn nội dung XML bên trong vẫn valid.
- Dùng
- Hỗ trợ nén
- Status code:
- Đảm bảo sitemap và sitemap index trả về 200 OK:
- Không trả về 3xx (301, 302) cho URL sitemap; nếu bắt buộc redirect (ví dụ HTTP → HTTPS), hãy update lại URL sitemap trong robots.txt và Search Console cho đúng bản cuối.
- Không trả về 4xx (404, 410) hoặc 5xx (500, 503) trong bất kỳ thời điểm crawl quan trọng.
- Kiểm tra consistency:
- Toàn bộ sitemap con trong
sitemapindex.xmlphải trả về 200. - Không để sitemap cũ (không còn dùng) vẫn được khai báo trong index hoặc robots.txt.
- Toàn bộ sitemap con trong
- Monitoring:
- Thiết lập health check định kỳ (cron, monitoring tool) để ping sitemap và alert khi status code ≠ 200.
- Đảm bảo sitemap và sitemap index trả về 200 OK:
- Khả năng truy cập bot:
- Không bị chặn bởi firewall, WAF, rate limit:
- Whitelist user-agent Googlebot, Bingbot, các bot search engine chính trong WAF / firewall nếu có rule chặn bot.
- Đảm bảo rate limit không quá chặt với IP Googlebot; tránh 429 (Too Many Requests) khi bot crawl sitemap.
- Kiểm tra log WAF để xem có rule nào block request đến
/sitemap.xmlhoặc/sitemapindex.xml.
- robots.txt không chặn đường dẫn sitemap:
- Không dùng
Disallow: /sitemap.xmlhoặc pattern có thể match nhầm (ví dụ:Disallow: /sitemapnếu sitemap nằm trong thư mục đó). - Đảm bảo có khai báo
Sitemap: https://www.example.com/sitemapindex.xml(hoặc sitemap chính) trong robots.txt.
- Không dùng
- Kiểm tra từ nhiều location:
- Dùng tool như
curltừ server khác region, hoặc dùng dịch vụ remote HTTP check để đảm bảo không có geo-block.
- Dùng tool như
- Không bị chặn bởi firewall, WAF, rate limit:
Test trực tiếp bằng Search Console URL Inspection và server log bot hit
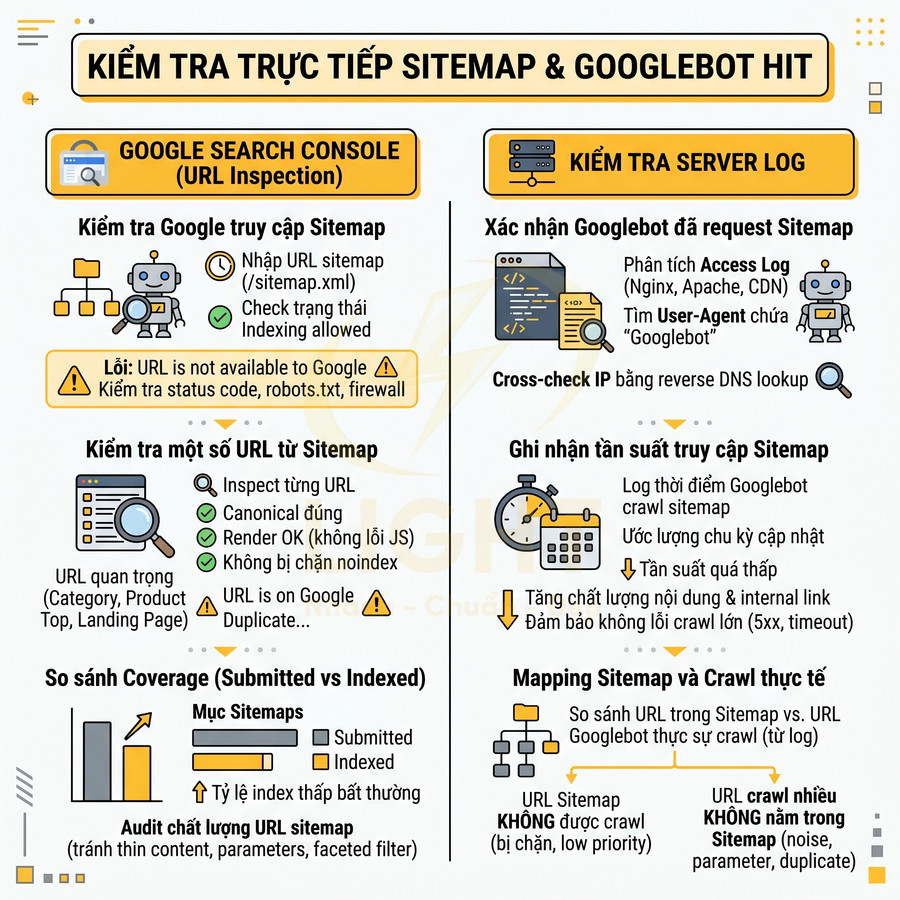
Sau khi deploy:
- Dùng URL Inspection:
- Nhập URL sitemap để kiểm tra Google có truy cập được không:
- Trong Google Search Console, dùng chức năng “URL Inspection” cho
/sitemap.xmlhoặc/sitemapindex.xml. - Kiểm tra trạng thái “Crawled” hoặc “Indexing allowed” cho sitemap; nếu báo lỗi “URL is not available to Google”, cần kiểm tra lại status code, robots.txt, firewall.
- Trong Google Search Console, dùng chức năng “URL Inspection” cho
- Kiểm tra một số URL trong sitemap để đảm bảo indexability:
- Chọn mẫu URL quan trọng (category, product top, landing page chính) từ sitemap và inspect từng URL.
- Xác minh:
- URL không bị chặn bởi
noindex, canonical không trỏ sang URL khác ngoài ý muốn. - Google có thể render (nếu là SPA / JS-heavy), không lỗi JS nghiêm trọng.
- Trạng thái “URL is on Google” hoặc ít nhất “URL is available to Google” nếu mới publish.
- URL không bị chặn bởi
- Nếu nhiều URL trong sitemap bị “Alternate page with proper canonical” hoặc “Duplicate without user-selected canonical”, cần xem lại chiến lược canonical và nội dung trùng lặp.
- So sánh coverage:
- Trong mục “Sitemaps” của Search Console, kiểm tra số URL “Submitted” vs “Indexed”.
- Nếu tỷ lệ index thấp bất thường, cần audit lại chất lượng URL trong sitemap (tránh đưa URL thin content, faceted filter, parameter noise…).
- Nhập URL sitemap để kiểm tra Google có truy cập được không:
- Kiểm tra server log:
- Xác nhận Googlebot đã request
sitemap.xml,sitemapindex.xml:- Phân tích access log (Nginx, Apache, load balancer, CDN) để tìm user-agent chứa “Googlebot”.
- Cross-check IP Googlebot bằng reverse DNS lookup nếu cần (tránh bot giả mạo).
- Ghi nhận tần suất truy cập sitemap:
- Log lại thời điểm Googlebot crawl sitemap để ước lượng chu kỳ cập nhật.
- Nếu tần suất quá thấp với site cập nhật thường xuyên, xem xét:
- Tăng chất lượng nội dung và internal link để Google đánh giá site quan trọng hơn.
- Đảm bảo không có lỗi crawl lớn (5xx, timeout) làm Google giảm crawl rate.
- Mapping giữa sitemap và crawl thực tế:
- So sánh danh sách URL trong sitemap với URL mà Googlebot thực sự crawl (từ log) để phát hiện:
- URL trong sitemap nhưng không được crawl (có thể bị chặn, hoặc bị đánh giá low priority).
- URL được crawl nhiều nhưng không nằm trong sitemap (có thể là URL noise, parameter, duplicate cần xử lý).
- So sánh danh sách URL trong sitemap với URL mà Googlebot thực sự crawl (từ log) để phát hiện:
- Xác nhận Googlebot đã request
Checklist định kỳ sau publish, update content, migration và scale URL mới
Checklist định kỳ:
- Sau khi publish nhiều nội dung mới:
- Đảm bảo URL mới đã xuất hiện trong sitemap:
- Kiểm tra pipeline generate sitemap (cron, job, plugin) có chạy đúng sau khi publish.
- Với site lớn, nên có cơ chế incremental update sitemap thay vì regenerate full để tránh lỗi build.
- Kiểm tra
lastmodcủa sitemap con liên quan:- Với sitemap index, mỗi sitemap con nên có
<lastmod>phản ánh lần cập nhật gần nhất của nhóm URL đó. - Không để tất cả sitemap con cùng một
lastmodcố định; điều này làm giảm tín hiệu freshness.
- Với sitemap index, mỗi sitemap con nên có
- Đảm bảo chỉ đưa URL “đáng index” vào sitemap:
- Không đưa URL test, staging, preview, hoặc URL có
noindexvào sitemap. - Không đưa URL filter, sort, search nội bộ (trừ khi có chiến lược SEO rõ ràng cho chúng).

- Sau khi update nội dung quan trọng:
- Cập nhật
lastmodcho URL đó:- Hệ thống CMS nên tự động update
lastmodtrong sitemap khi nội dung thay đổi (publish mới, chỉnh sửa lớn). - Tránh update
lastmodcho thay đổi nhỏ không ảnh hưởng nội dung (sửa typo nhẹ, chỉnh spacing) để không “spam” tín hiệu cập nhật.
- Hệ thống CMS nên tự động update
- Đảm bảo canonical, meta robots không thay đổi sai:
- Sau khi refactor template hoặc component, kiểm tra:
<link rel="canonical">vẫn trỏ đúng URL self-canonical (hoặc canonical mục tiêu nếu intentional).<meta name="robots" content="index,follow">không bị đổi thànhnoindexdo bug.
- Đối chiếu một số URL trong sitemap bằng URL Inspection để xác nhận Google nhận đúng canonical và robots.
- Sau khi refactor template hoặc component, kiểm tra:
- Kiểm tra structured data (nếu có):
- Với các URL quan trọng (product, article, FAQ…), sau update nội dung, validate lại schema để tránh lỗi rich result làm giảm giá trị SEO.
- Cập nhật
- Sau migration:
- Kiểm tra toàn bộ sitemap dùng URL mới, không còn URL cũ:
- Sau khi đổi domain, đổi cấu trúc URL, hoặc đổi CMS, regenerate toàn bộ sitemap dựa trên URL mới.
- Không để lẫn URL cũ (domain cũ, path cũ) trong sitemap mới; điều này gây lãng phí crawl budget và có thể tạo tín hiệu mâu thuẫn.
- Đảm bảo redirect 301 hoạt động:
- Toàn bộ URL cũ phải redirect 301 sang URL mới tương ứng (1–1 mapping càng rõ càng tốt).
- Test mẫu:
- Chọn một tập URL cũ lớn (top traffic, top revenue) và kiểm tra redirect chain (tránh 302, 307, hoặc chain nhiều bước).
- Đảm bảo không có redirect loop hoặc 404 sau redirect.
- Đồng bộ với Search Console:
- Cập nhật sitemap mới trong property tương ứng (đặc biệt khi đổi domain hoặc thêm subdomain mới).
- Theo dõi báo cáo “Coverage” để phát hiện nhanh lỗi 404, soft 404, redirect error sau migration.
- Kiểm tra toàn bộ sitemap dùng URL mới, không còn URL cũ:
- Khi scale URL mới:
- Đánh giá lại chiến lược chia sitemap index:
- Khi số lượng URL tăng mạnh (ví dụ: thêm hàng chục nghìn product, listing, article), cần phân nhóm sitemap theo:
- Loại nội dung (product, blog, category, landing page…).
- Ngôn ngữ / country (nếu site đa ngôn ngữ, đa vùng).
- Freshness (URL mới vs URL cũ, evergreen vs news…).
- Mục tiêu: giúp search engine hiểu rõ cấu trúc site và ưu tiên crawl nhóm URL quan trọng.
- Khi số lượng URL tăng mạnh (ví dụ: thêm hàng chục nghìn product, listing, article), cần phân nhóm sitemap theo:
- Chia nhỏ thêm sitemap con nếu cần:
- Không để một sitemap con quá lớn, gần ngưỡng 50.000 URL; chia nhỏ để:
- Dễ debug (biết nhóm nào lỗi, nhóm nào index kém).
- Dễ update (regenerate từng phần thay vì full).
- Đặt tên sitemap có logic:
sitemapproducts1.xml,sitemapproducts2.xml,sitemapblog1.xml…- Giúp team SEO, dev, data dễ mapping khi phân tích log và coverage.
- Không để một sitemap con quá lớn, gần ngưỡng 50.000 URL; chia nhỏ để:
- Kiểm soát chất lượng URL khi scale:
- Không tự động đưa mọi URL sinh ra (filter, sort, pagination sâu, internal tool) vào sitemap.
- Thiết lập rule rõ ràng: chỉ URL có giá trị SEO, có nội dung unique, có khả năng mang traffic mới được đưa vào sitemap.
- Đánh giá lại chiến lược chia sitemap index:
FAQ về sitemap website chuẩn SEO và tốc độ Google crawl
Sitemap chuẩn SEO giúp Google khám phá và ưu tiên những URL quan trọng, nhưng không thể thay thế vai trò của nội dung chất lượng và hệ thống internal link mạnh. Với bài mới, sitemap hỗ trợ phát hiện nhanh, trong khi internal link, authority domain và tín hiệu E-E-A-T quyết định tốc độ index. Việc cập nhật sitemap nên gắn với tần suất xuất bản và thay đổi dữ liệu, đảm bảo thuộc tính lastmod chính xác để không lãng phí crawl budget. Ngay cả website nhỏ vẫn nên có sitemap để dễ quản trị và mở rộng. Cần chọn lọc tag, author, filter page trước khi đưa vào sitemap, ưu tiên các trang có nội dung unique, có search intent rõ ràng. Trong mọi trường hợp, sitemap phải luôn đồng bộ với canonical, redirect và phiên bản URL chuẩn.

Sitemap có giúp Google index ngay sau khi publish bài viết không
Sitemap không đảm bảo index ngay lập tức, vì Google vẫn phải:
- Thu thập (crawl) URL trong sitemap.
- Đánh giá chất lượng nội dung, mức độ trùng lặp, tín hiệu E-E-A-T.
- Quyết định có index hay không, và index trong bao lâu.
Tuy vậy, sitemap vẫn là một tín hiệu kỹ thuật quan trọng vì:
- Giúp Google phát hiện URL mới nhanh hơn, đặc biệt với site lớn, cấu trúc phức tạp.
- Giảm rủi ro bỏ sót URL quan trọng nếu internal link chưa tối ưu.
- Hỗ trợ Google hiểu mức độ cập nhật nội dung thông qua thuộc tính lastmod.
Khi kết hợp sitemap với các yếu tố khác, khả năng index sớm sẽ cao hơn:
- Internal link từ các trang đã được crawl thường xuyên.
- Chất lượng nội dung: unique, depth, đáp ứng search intent.
- Authority domain: backlink chất lượng, thương hiệu được nhắc đến nhiều.
Để tăng tốc index cho bài mới, ngoài sitemap, nên:
- Đặt internal link từ các bài cũ có traffic, đã được crawl đều:
- Ưu tiên đặt link trong phần nội dung chính (body content).
- Dùng anchor text liên quan trực tiếp đến chủ đề bài mới.
- Chia sẻ trên các kênh có bot thường xuyên crawl:
- Social media (Facebook, X, LinkedIn) – Google thường phát hiện URL qua share.
- RSS feed – đặc biệt hiệu quả với blog/tin tức.
- Backlink từ site khác đã được index tốt.
- Dùng URL Inspection “Request indexing” cho:
- Landing page chiến dịch.
- Trang money page (product, service) quan trọng.
- Trang cập nhật thông tin khẩn (thông báo, chính sách, báo chí).
Bao lâu nên cập nhật sitemap XML một lần để Google recrawl hiệu quả
Tần suất cập nhật sitemap phụ thuộc vào mô hình vận hành nội dung và kiến trúc hệ thống:
- Tần suất xuất bản:
- Blog/tin tức:
- Nên cập nhật gần như real-time khi có bài mới hoặc chỉnh sửa lớn.
- Có thể dùng cơ chế hook (publish/update) để tự động ping sitemap.
- Ecommerce:
- Cập nhật khi thêm/sửa/xóa sản phẩm, thay đổi trạng thái (còn hàng, hết hàng).
- Có thể tách sitemap sản phẩm đang active và sản phẩm ngừng kinh doanh.
- Blog/tin tức:
- Hệ thống sinh sitemap:
- Nếu sitemap động (Next.js, Laravel, Node, cron job):
- Có thể cập nhật hàng giờ hoặc theo event (khi có thay đổi dữ liệu).
- Phù hợp với site có dữ liệu biến động liên tục (bất động sản, tin tức, sàn TMĐT).
- Nếu sitemap tĩnh:
- Tối thiểu mỗi ngày với site cập nhật thường xuyên.
- Hoặc mỗi lần deploy, sync dữ liệu lớn.
- Nếu sitemap động (Next.js, Laravel, Node, cron job):
Yếu tố quan trọng nhất là lastmod chính xác cho từng URL:
- Chỉ cập nhật lastmod khi nội dung thực sự thay đổi (không phải chỉ sửa nhỏ về UI).
- Không nên ép cập nhật sitemap liên tục nếu không có thay đổi nội dung, vì:
- Có thể khiến Google đánh giá tín hiệu cập nhật không đáng tin.
- Lãng phí crawl budget vào các trang không có thay đổi giá trị.
Website nhỏ dưới 100 URL có cần sitemap riêng không
Với website rất nhỏ (<100 URL), Google thường có thể khám phá toàn bộ thông qua:
- Internal link rõ ràng, cấu trúc menu đơn giản.
- Một vài backlink trỏ về trang chủ hoặc trang con.
Tuy nhiên, sitemap vẫn nên có vì:
- Dễ quản lý và kiểm tra index:
- Có thể đối chiếu số URL trong sitemap với số URL đã index trong Search Console.
- Hỗ trợ khi site mở rộng sau này:
- Khi số lượng URL tăng lên hàng trăm/hàng nghìn, không cần thay đổi kiến trúc sitemap quá nhiều.
- Dễ dàng tách sitemap theo loại nội dung (blog, product, category).
- Chi phí triển khai thấp:
- CMS phổ biến (WordPress, Magento, Shopify) đều hỗ trợ tự động tạo sitemap.
- Với site custom, chỉ cần một script đơn giản để generate XML.
Có nên đưa trang tag, author archive và trang filter vào sitemap không
Tùy chiến lược SEO và cách tối ưu từng loại trang, không nên đưa tất cả vào sitemap một cách mặc định.
- Tag:
- Chỉ đưa vào sitemap nếu:
- Tag được tối ưu như landing page:
- Có phần giới thiệu nội dung riêng, không chỉ là list bài viết.
- Có cấu trúc heading, nội dung giải thích chủ đề tag.
- Có nhiều bài liên quan, có search demand:
- Tag trùng với từ khóa người dùng tìm kiếm.
- Không bị trùng lặp với category hoặc landing page khác.
- Tag được tối ưu như landing page:
- Tag rác, trùng lặp → nên:
- noindex, follow hoặc chặn index bằng meta robots.
- Không đưa vào sitemap để tránh loãng crawl budget.
- Chỉ đưa vào sitemap nếu:
- Author archive:
- Chỉ nên index và đưa vào sitemap nếu:
- Tác giả là chuyên gia, có trang profile chi tiết (EEAT):
- Thông tin chuyên môn, kinh nghiệm, chứng chỉ.
- Liên kết đến social profile, website cá nhân (nếu phù hợp).
- Author page được tối ưu như entity page:
- Có structured data (Person) nếu phù hợp.
- Có nội dung giới thiệu, không chỉ là list bài viết.
- Tác giả là chuyên gia, có trang profile chi tiết (EEAT):
- Nếu author chỉ là tài khoản kỹ thuật, không có giá trị thương hiệu:
- Có thể noindex author archive.
- Không đưa vào sitemap để tránh trùng lặp với category/tag.
- Chỉ nên index và đưa vào sitemap nếu:
- Filter page:
- Chỉ đưa vào sitemap nếu là landing page SEO:
- Có nội dung riêng, mô tả rõ sản phẩm/dịch vụ trong filter.
- Target search intent cụ thể (ví dụ: “giày chạy bộ nam size 42”).
- Filter kỹ thuật (sort, page, view, color param không có search intent riêng) → không đưa vào sitemap:
- Nên dùng noindex hoặc canonical về phiên bản chính.
- Tránh tạo ra hàng nghìn URL mỏng, gây lãng phí crawl budget.
- Chỉ đưa vào sitemap nếu là landing page SEO:
Vì sao đã submit sitemap nhưng URL vẫn ở trạng thái Discovered – currently not indexed
Trạng thái “Discovered – currently not indexed” trong Search Console cho thấy Google đã biết URL (qua sitemap hoặc link), nhưng chưa crawl hoặc chưa index. Nguyên nhân thường gặp:
- Crawl budget hạn chế:
- Site lớn, nhiều URL, nhưng authority thấp.
- Server phản hồi chậm, Google giảm tần suất crawl để tránh gây tải.
- Nội dung mỏng hoặc trùng lặp:
- Trang chỉ có vài dòng text, không mang lại giá trị mới.
- Nội dung gần giống nhiều URL khác trên site (hoặc trên web).
- Trang filter, tag, archive không có nội dung unique.
- Internal link yếu:
- URL chỉ xuất hiện trong sitemap, không có link nội bộ trỏ tới.
- Link chỉ nằm ở khu vực ít được crawl (footer, trang ít traffic).
Giải pháp thực tế:
- Tăng chất lượng nội dung:
- Mở rộng chiều sâu, thêm dữ liệu, ví dụ, case study.
- Giảm trùng lặp bằng cách gộp các trang quá giống nhau.
- Tăng internal link từ trang mạnh:
- Ưu tiên link từ trang có nhiều backlink, nhiều traffic.
- Dùng cấu trúc topic cluster, pillar page – cluster page.
- Giảm số URL rác, tham số, trùng lặp để giải phóng crawl budget:
- Chặn tham số không cần thiết bằng URL Parameters (nếu còn dùng) hoặc robots.txt.
- Noindex các trang không có giá trị SEO, không đưa vào sitemap.
Sitemap XML và internal link, yếu tố nào ảnh hưởng crawl nhanh hơn
Cả sitemap XML và internal link đều quan trọng, nhưng vai trò khác nhau và mức độ ảnh hưởng đến crawl không giống nhau.
- Internal link:
- Là tín hiệu mạnh hơn về mức độ quan trọng của URL:
- Trang được nhiều trang khác link tới thường được crawl thường xuyên hơn.
- Vị trí link (trong nội dung, menu, sidebar) cũng ảnh hưởng.
- Ảnh hưởng trực tiếp đến:
- Crawl: bot dễ dàng di chuyển qua các tầng nội dung.
- Index: trang được kết nối tốt thường được ưu tiên index.
- Ranking: phân phối PageRank, hỗ trợ xây dựng topical authority.
- Là tín hiệu mạnh hơn về mức độ quan trọng của URL:
- Sitemap XML:
- Giúp khám phá URL nhanh hơn:
- Đặc biệt hữu ích với URL sâu trong cấu trúc site, khó tìm qua crawl bình thường.
- Hữu ích cho site mới, ít backlink.
- Không đảm bảo index nếu:
- Internal link yếu, URL bị “mồ côi” (orphan page).
- Nội dung không đủ chất lượng hoặc trùng lặp.
- Giúp khám phá URL nhanh hơn:
Kết luận thực hành: sitemap là bản đồ, internal link là đường đi thực tế. Cần tối ưu cả hai, nhưng không thể dùng sitemap để bù cho internal link kém. Trong đa số trường hợp, cải thiện internal link mang lại tác động lớn hơn đến tốc độ crawl và index.
Một website nên có bao nhiêu sitemap index là tối ưu
Không có con số cố định cho mọi website, nhưng có thể áp dụng một số nguyên tắc tổ chức:
- Ít nhưng có tổ chức:
- Thường 1 sitemap index chính là đủ cho hầu hết website.
- Bên trong chứa nhiều sitemap con theo loại nội dung:
- post-sitemap.xml, page-sitemap.xml, product-sitemap.xml,…
- Có thể tách thêm theo ngôn ngữ, khu vực nếu site đa ngôn ngữ.
- Tránh phân mảnh quá mức:
- Không cần hàng chục sitemap index trừ khi hệ thống cực lớn, đa domain, đa ngôn ngữ phức tạp.
- Quá nhiều sitemap index gây khó quản lý, khó debug khi có lỗi index.
Điểm quan trọng là cấu trúc logic và khả năng quản trị:
- Dễ xác định nhóm URL nào đang gặp vấn đề index (ví dụ: chỉ product-sitemap bị giảm index).
- Dễ tách, thêm, hoặc loại bỏ một nhóm nội dung khỏi sitemap mà không ảnh hưởng toàn hệ thống.
Có cần submit lại sitemap sau khi đổi domain hoặc chuyển HTTPS không
Khi thay đổi phiên bản URL chuẩn, sitemap phải được cập nhật để phản ánh chính xác canonical version mà bạn muốn Google index.
- Sau khi đổi domain:
- Tạo property mới cho domain mới trong Search Console:
- Nên dùng domain property để bao phủ tất cả subdomain (nếu phù hợp).
- Submit sitemap mới với URL domain mới:
- Đảm bảo tất cả URL trong sitemap dùng domain mới, không lẫn domain cũ.
- Giữ redirect 301 từ domain cũ, dùng Change of Address tool nếu phù hợp:
- Redirect 1-1 từ từng URL cũ sang URL mới tương ứng.
- Giữ redirect đủ lâu để Google chuyển toàn bộ tín hiệu.
- Tạo property mới cho domain mới trong Search Console:
- Sau khi chuyển HTTPS:
- Tạo property HTTPS (nếu trước đó chỉ có HTTP).
- Submit sitemap dùng URL HTTPS:
- Không để lẫn HTTP trong sitemap, tránh tín hiệu mâu thuẫn.
- Đảm bảo redirect 301 từ HTTP sang HTTPS:
- Kiểm tra không có redirect chain (HTTP → WWW → HTTPS → WWW HTTPS,…).
- Update internal link, canonical, hreflang (nếu có) sang HTTPS.
Sitemap phải luôn phản ánh phiên bản URL chuẩn mà bạn muốn Google index, đồng bộ với canonical, redirect và cấu hình server.



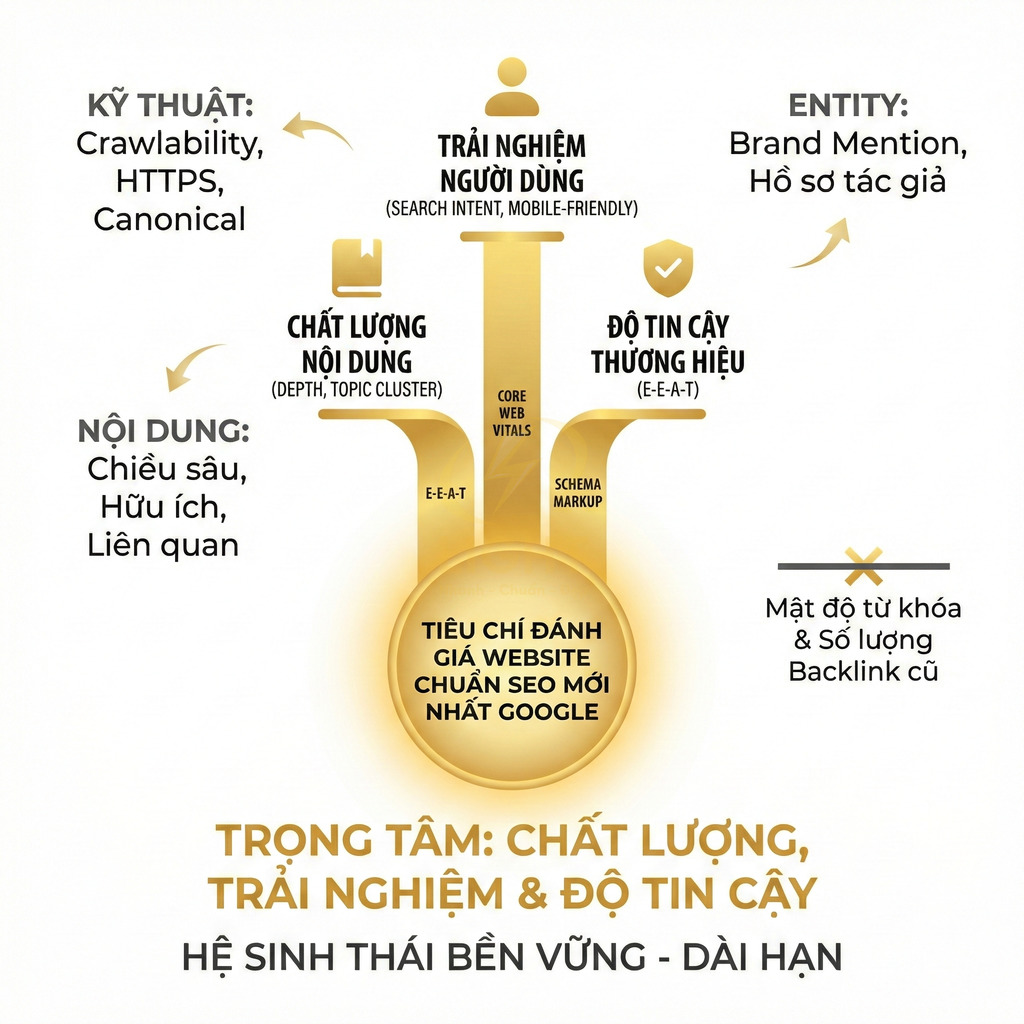

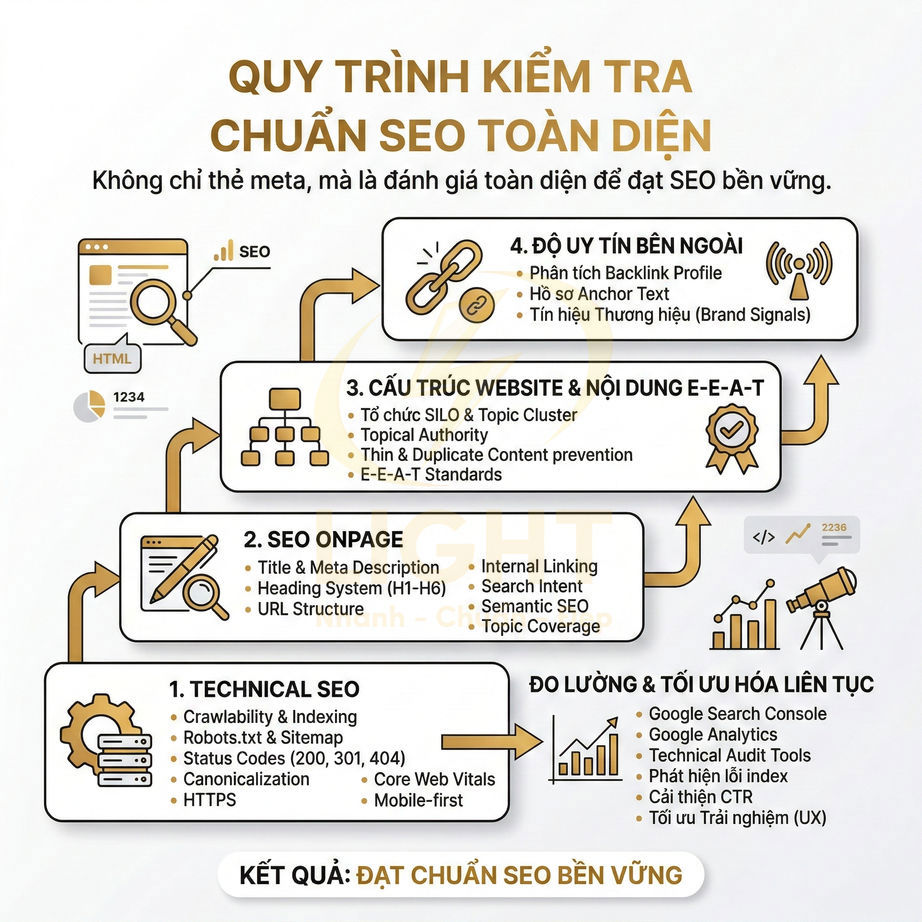
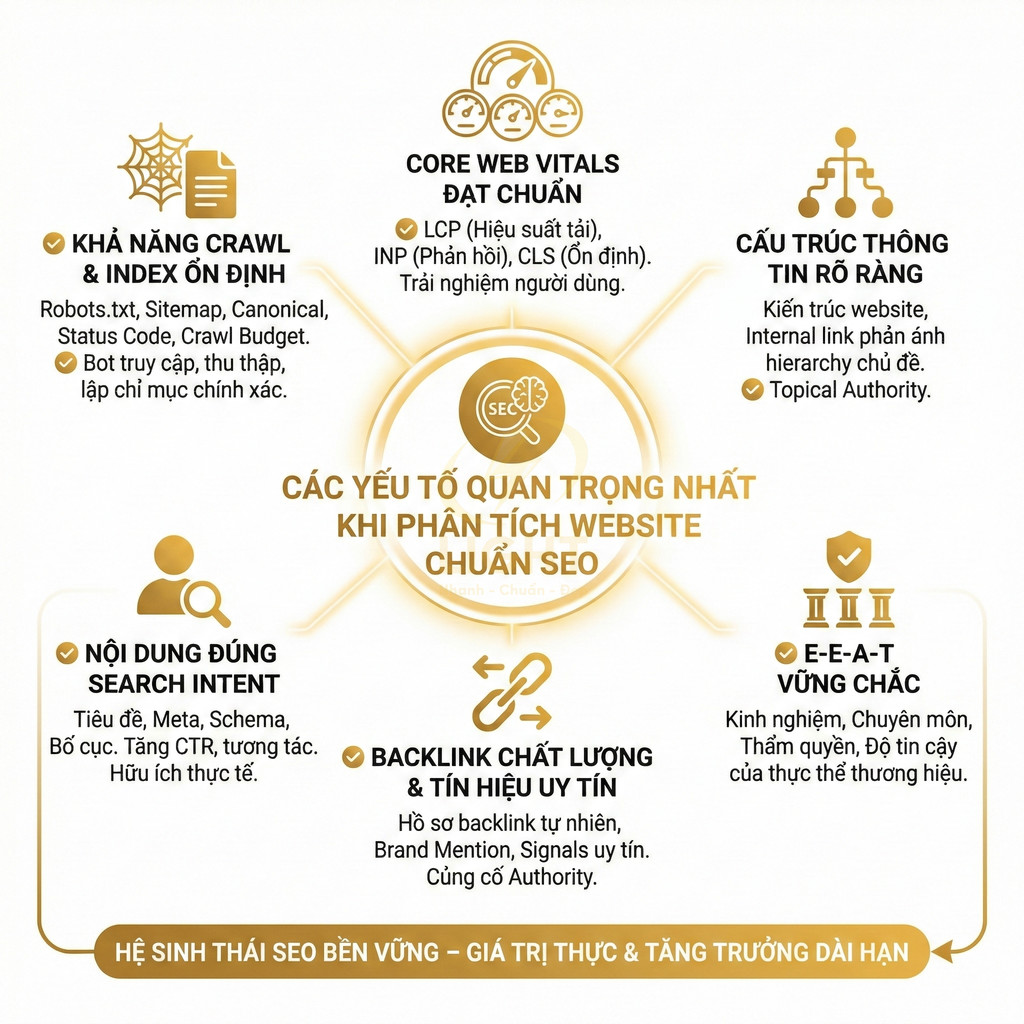

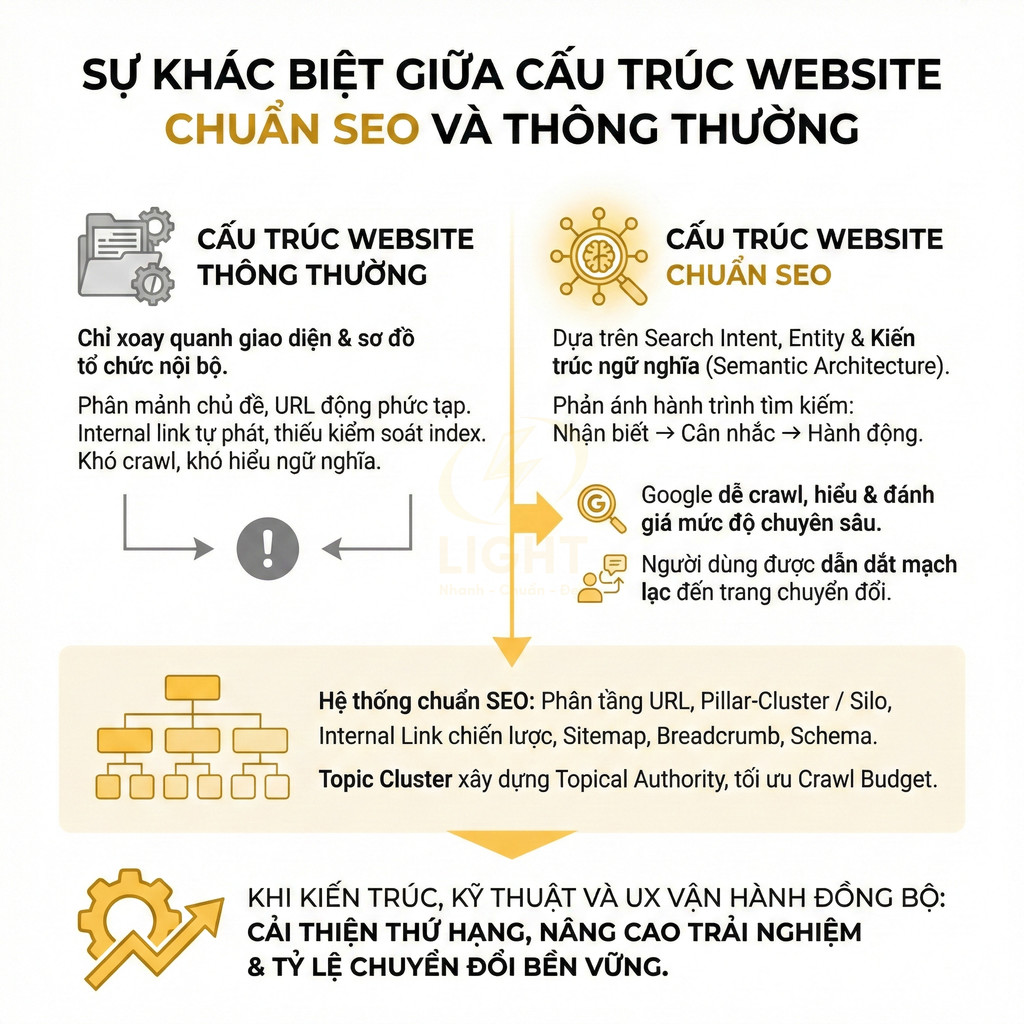

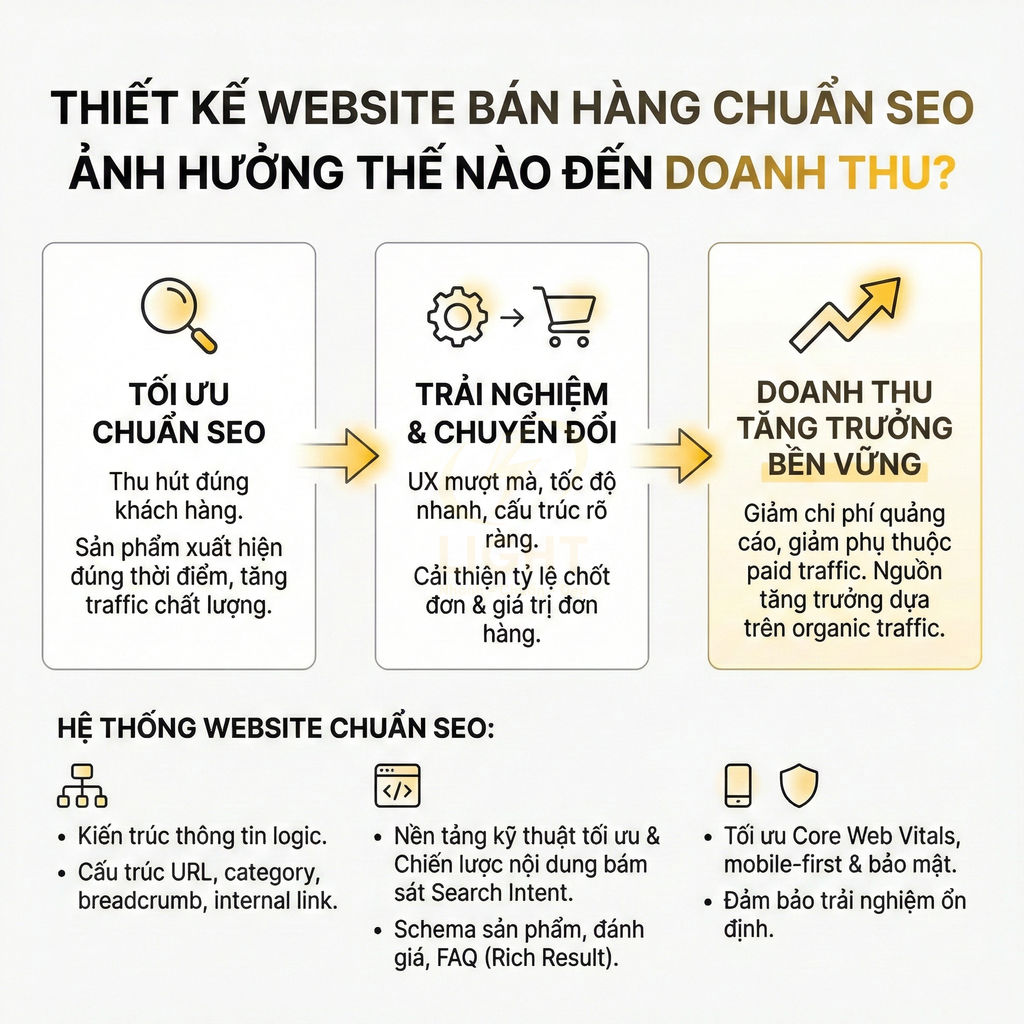


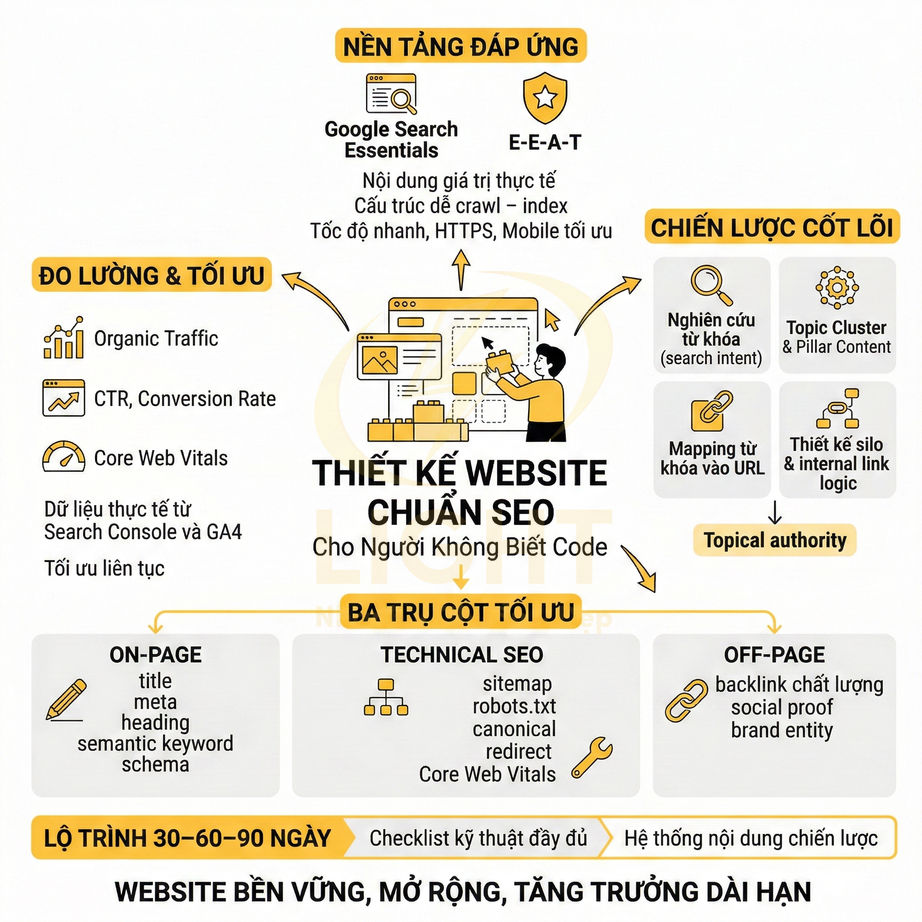




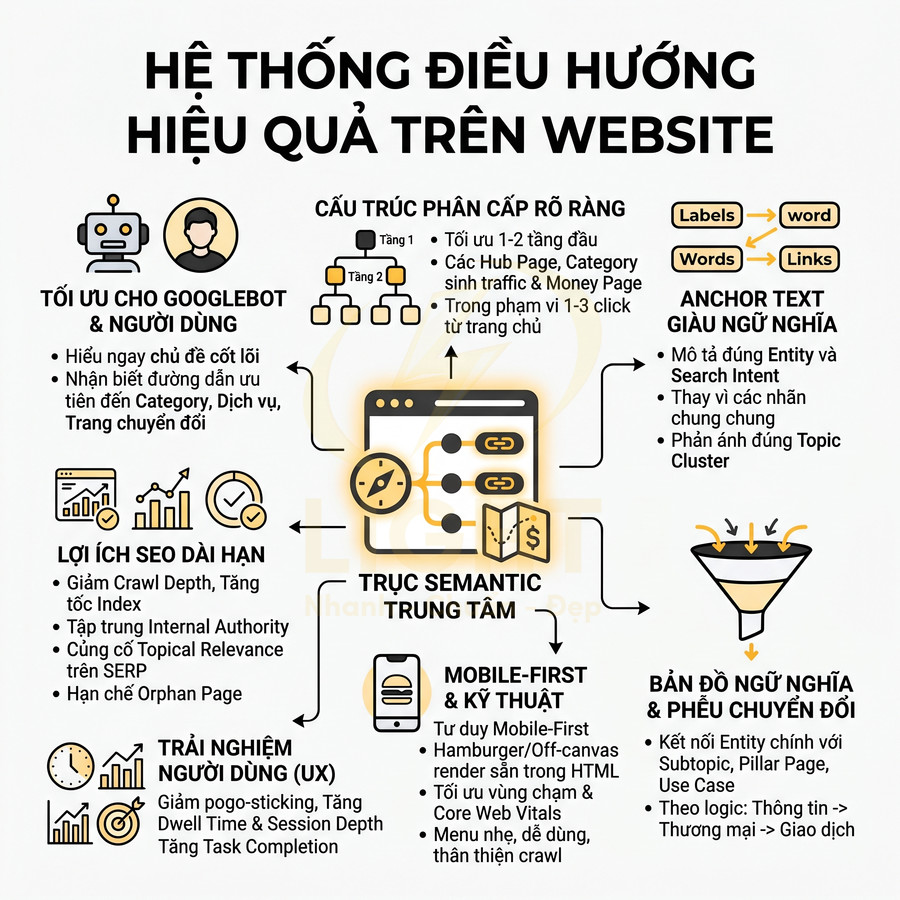
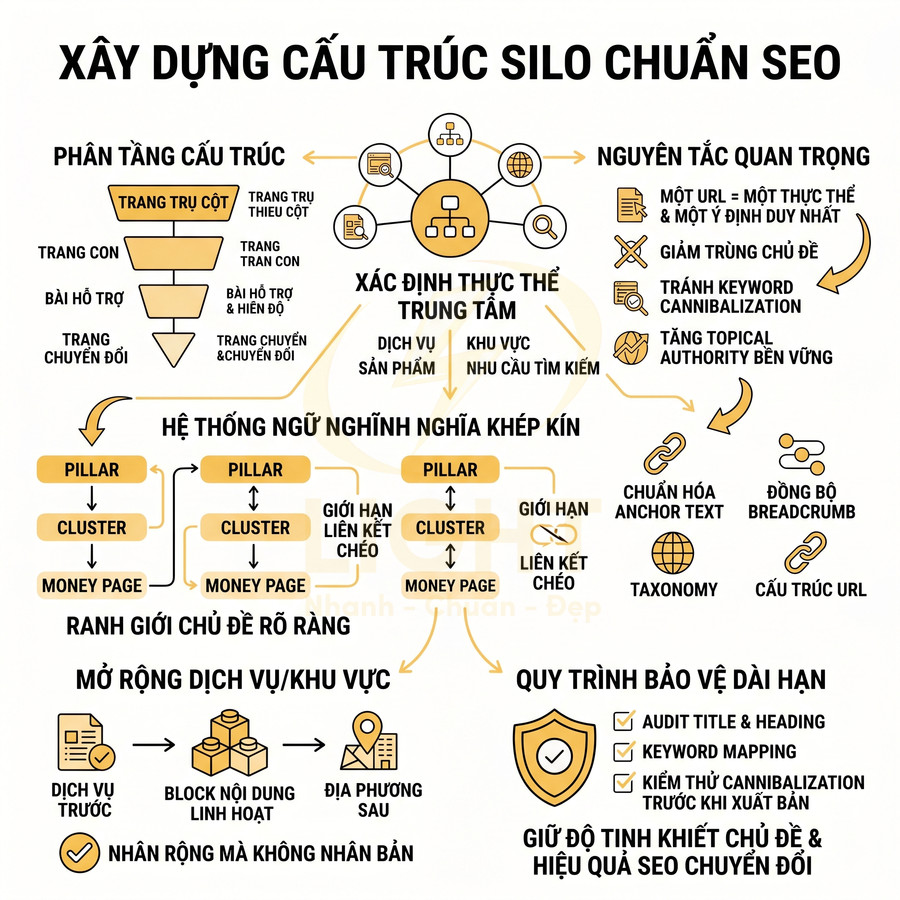
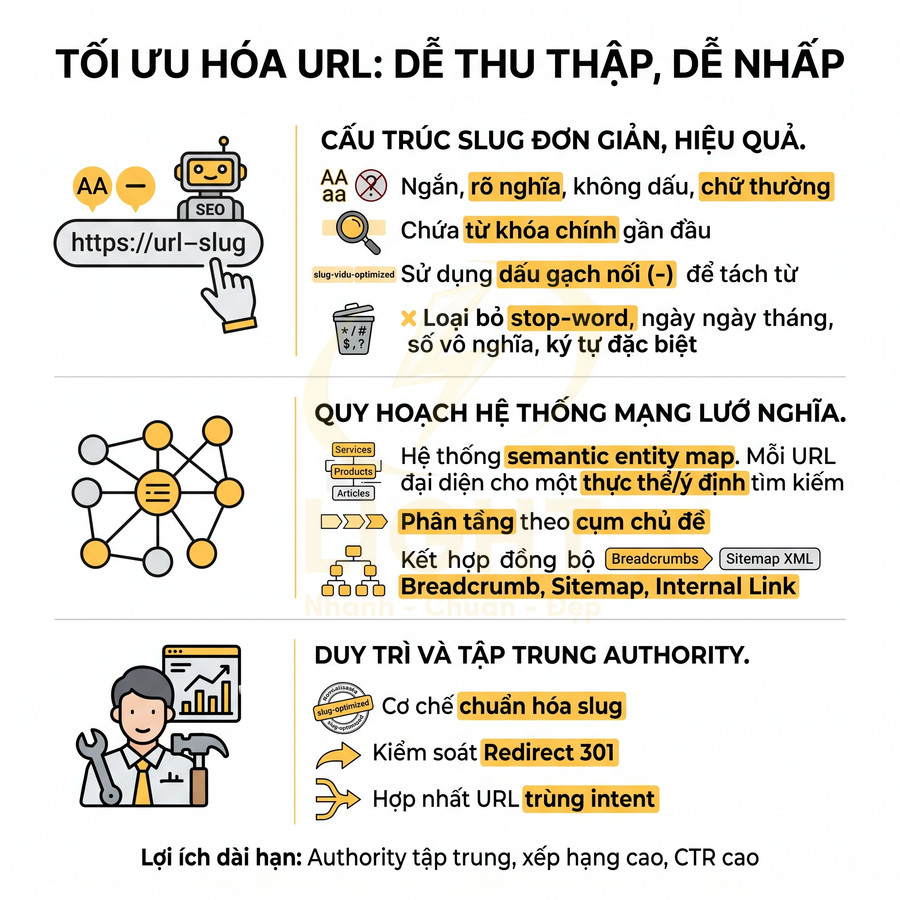
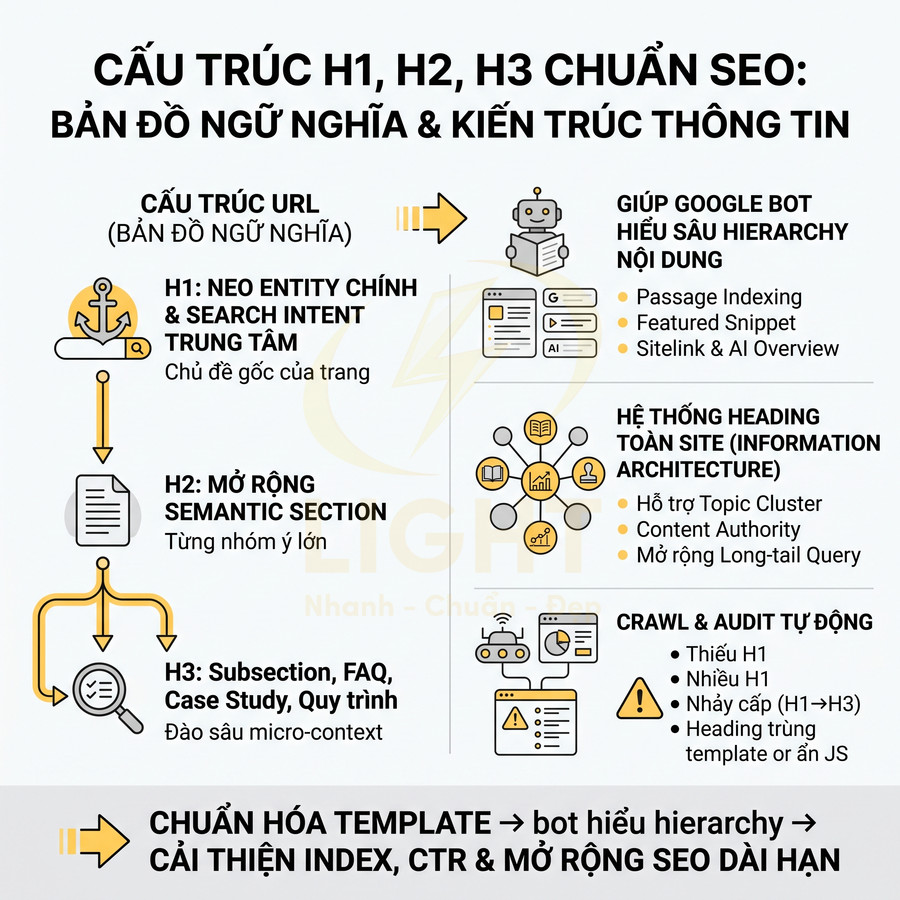
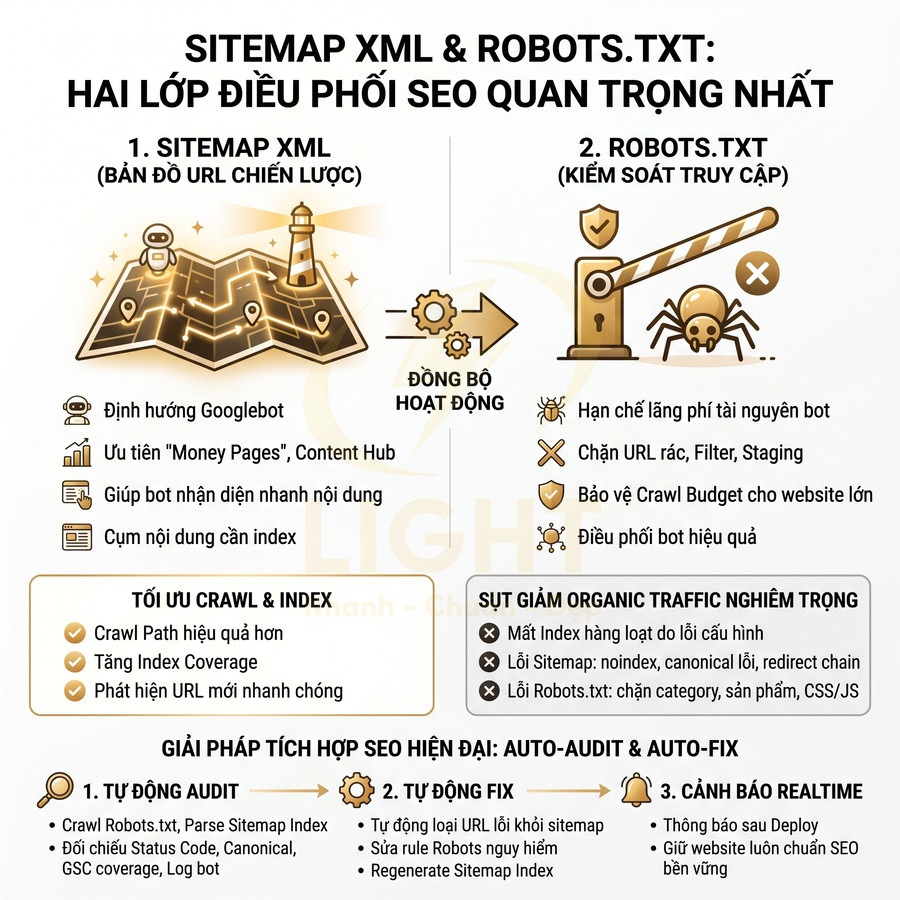

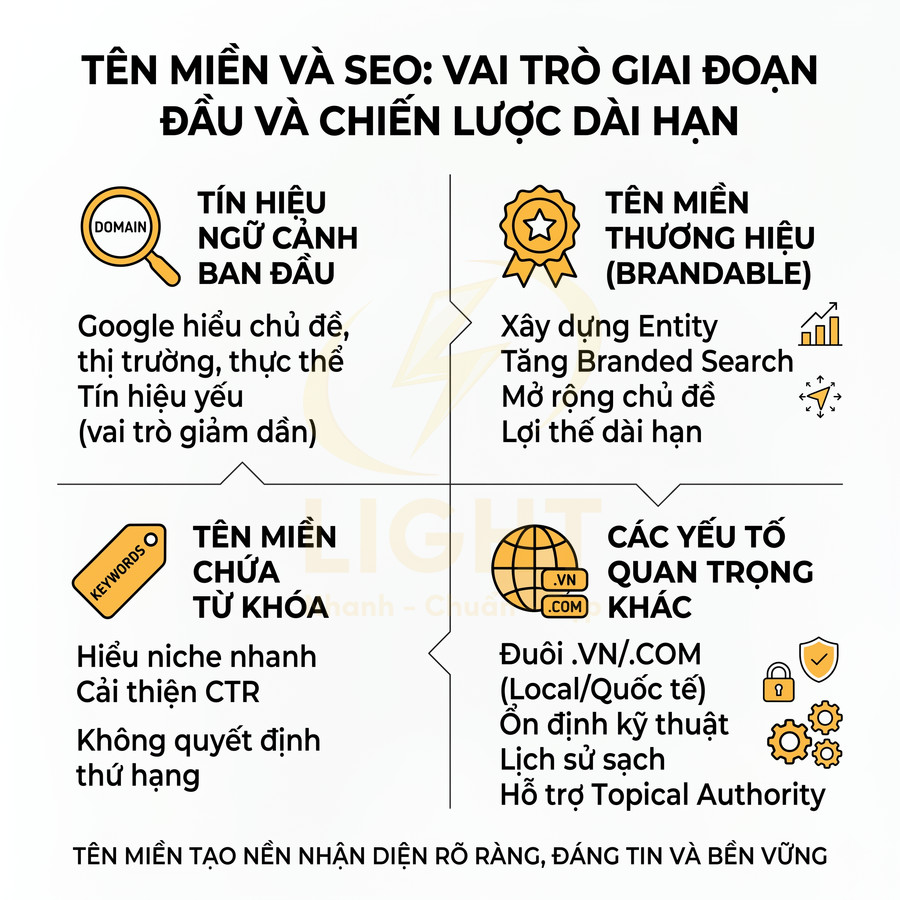

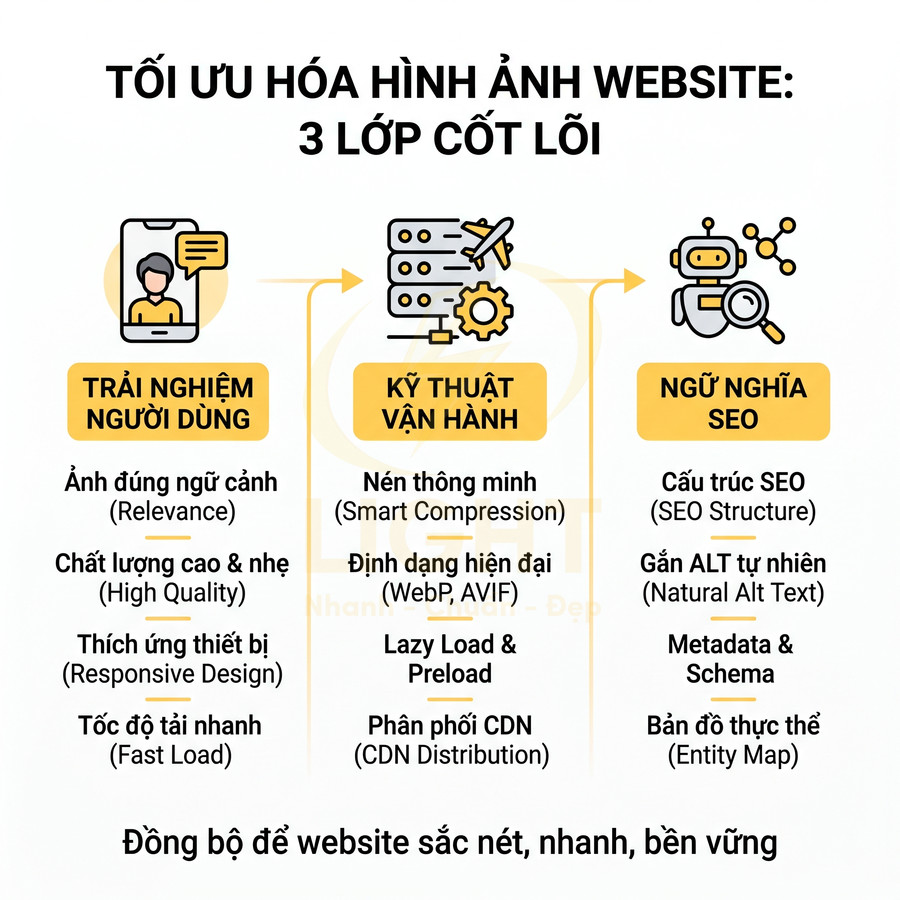


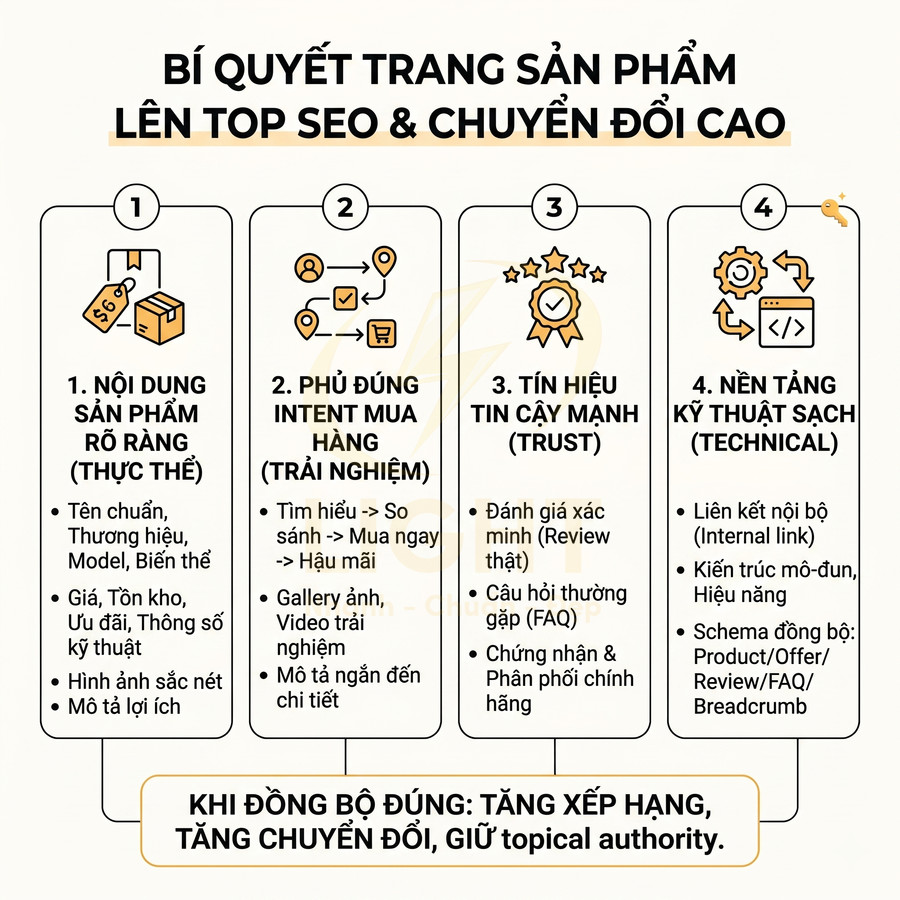




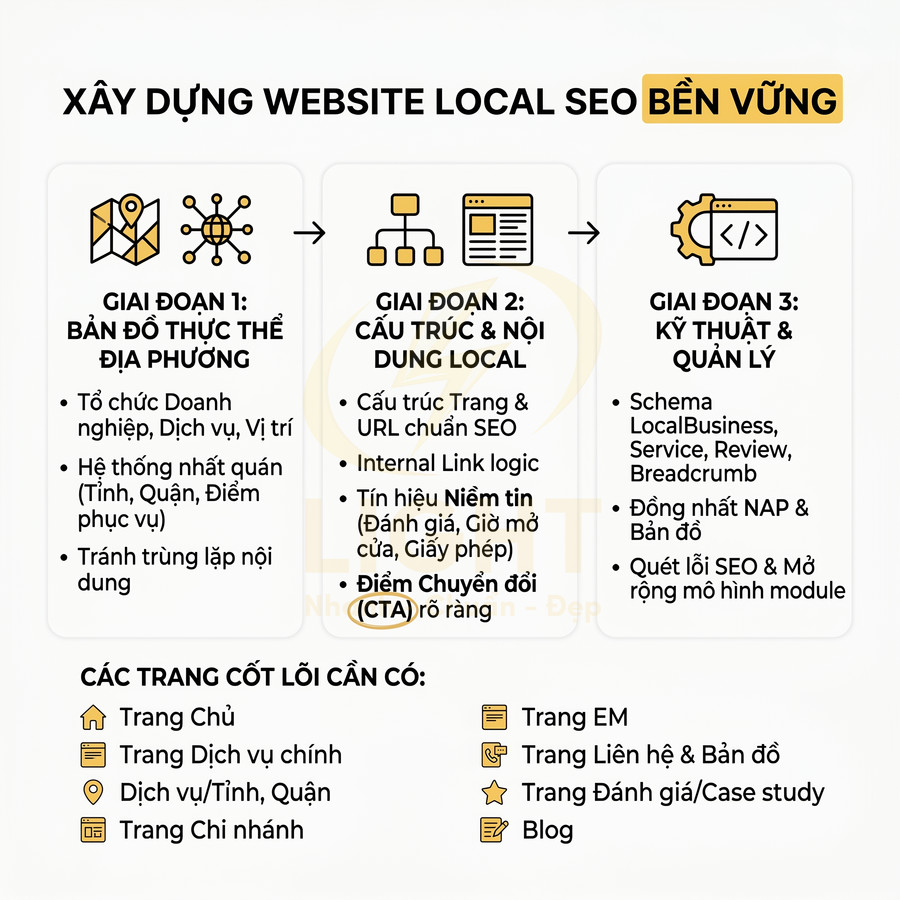



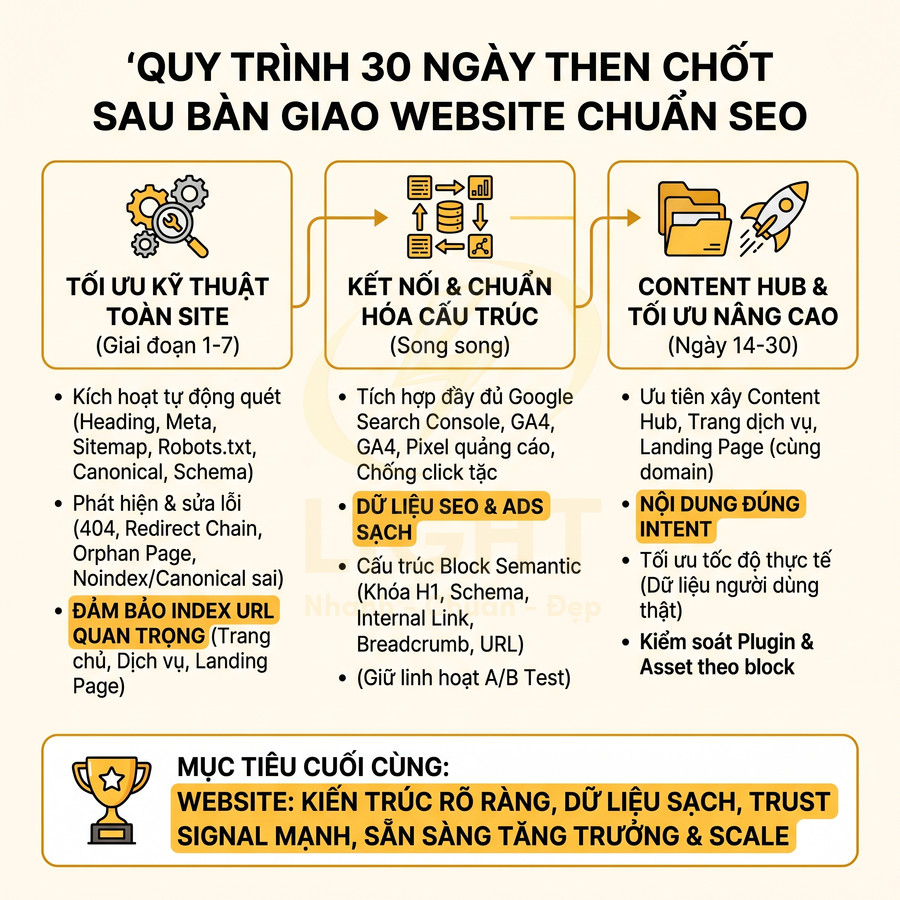

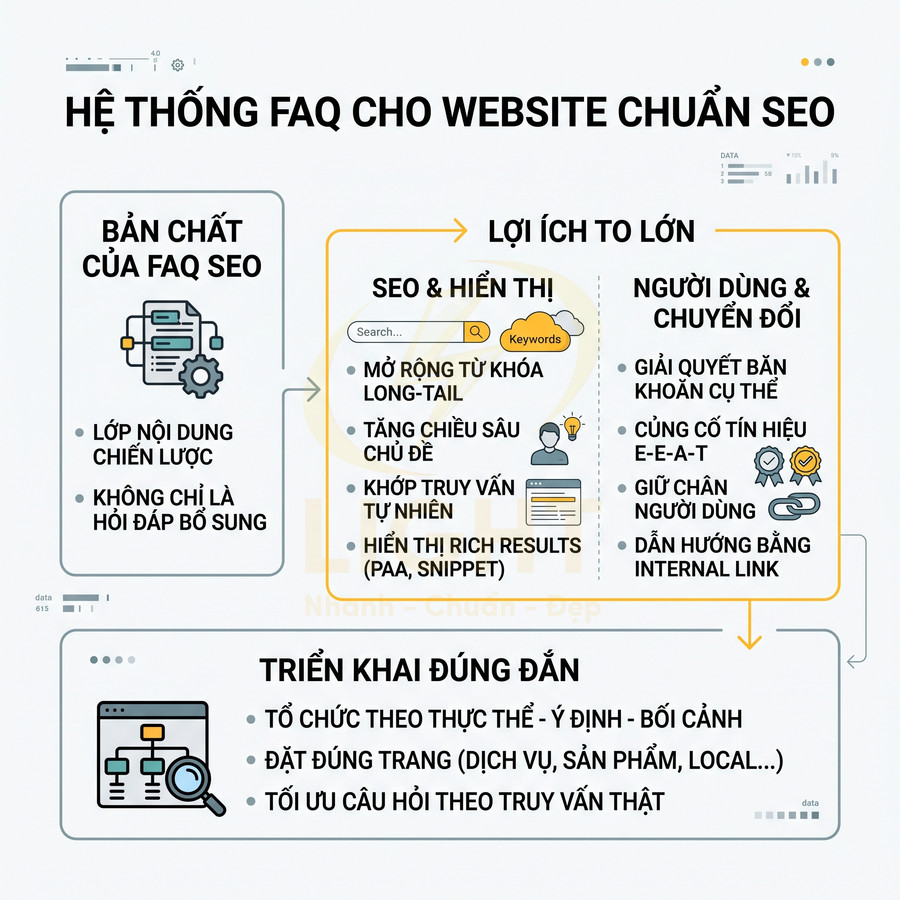


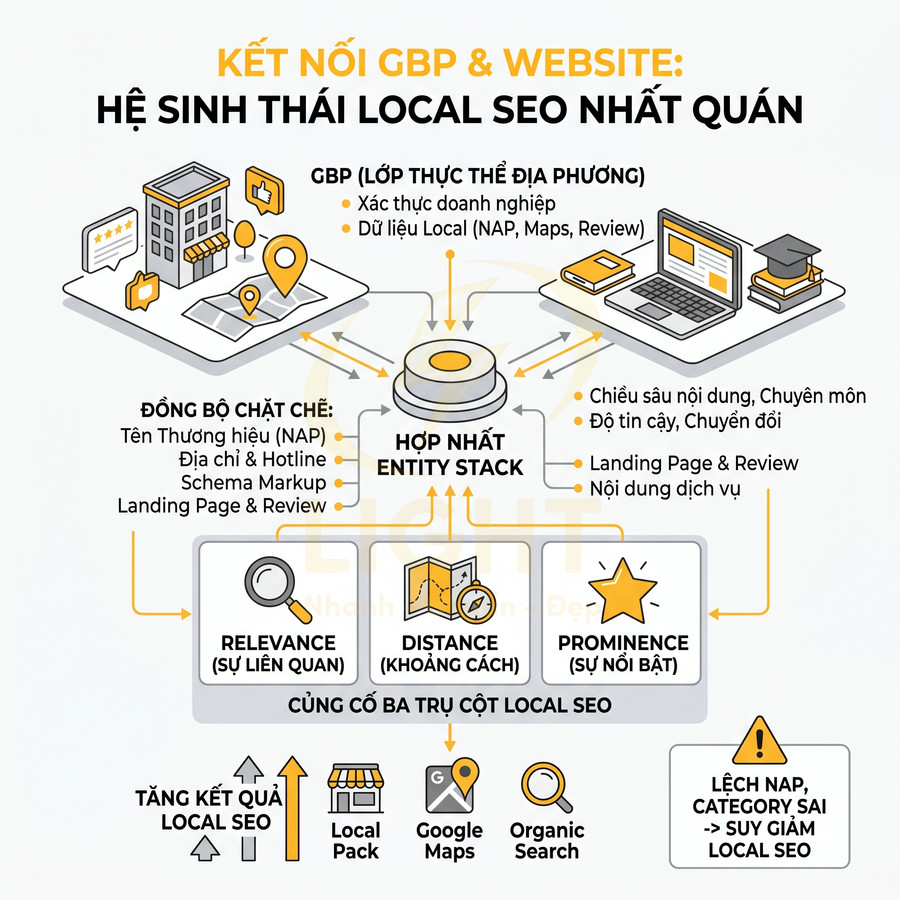
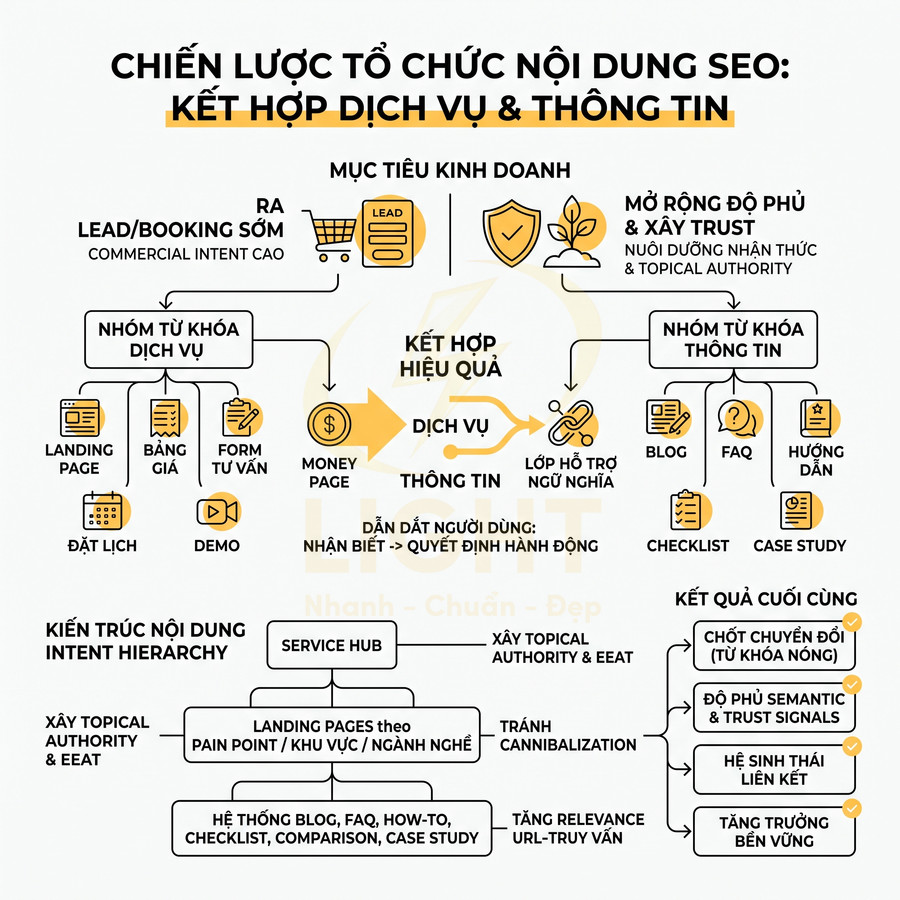
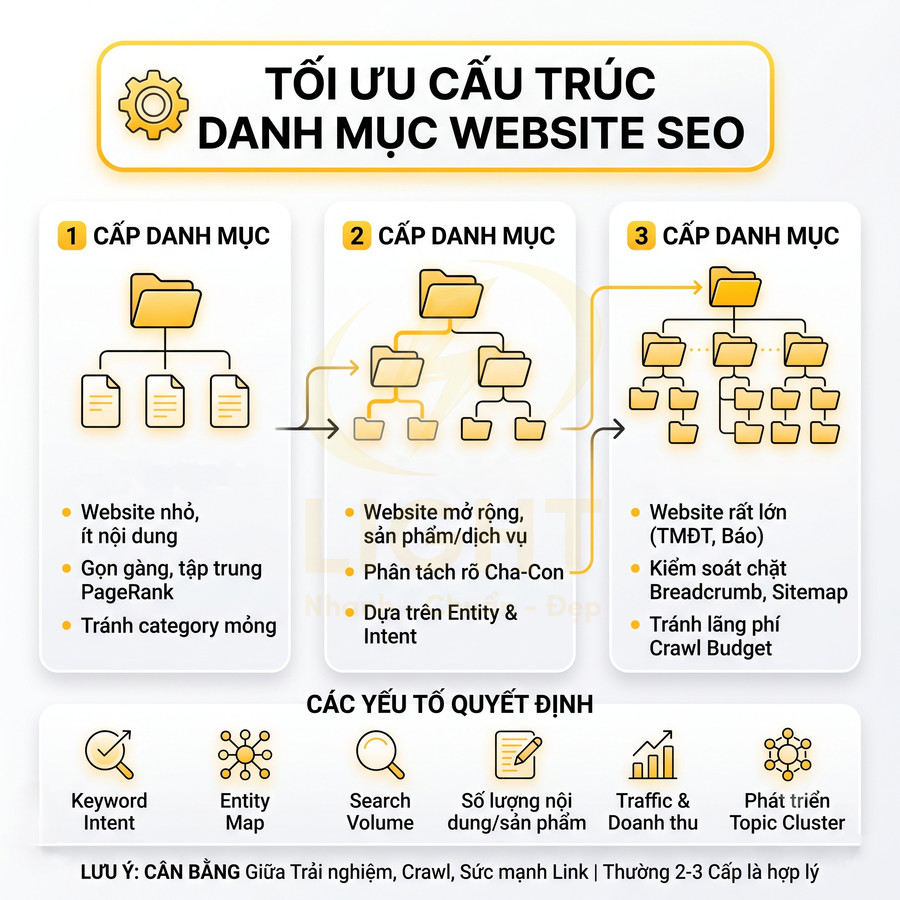

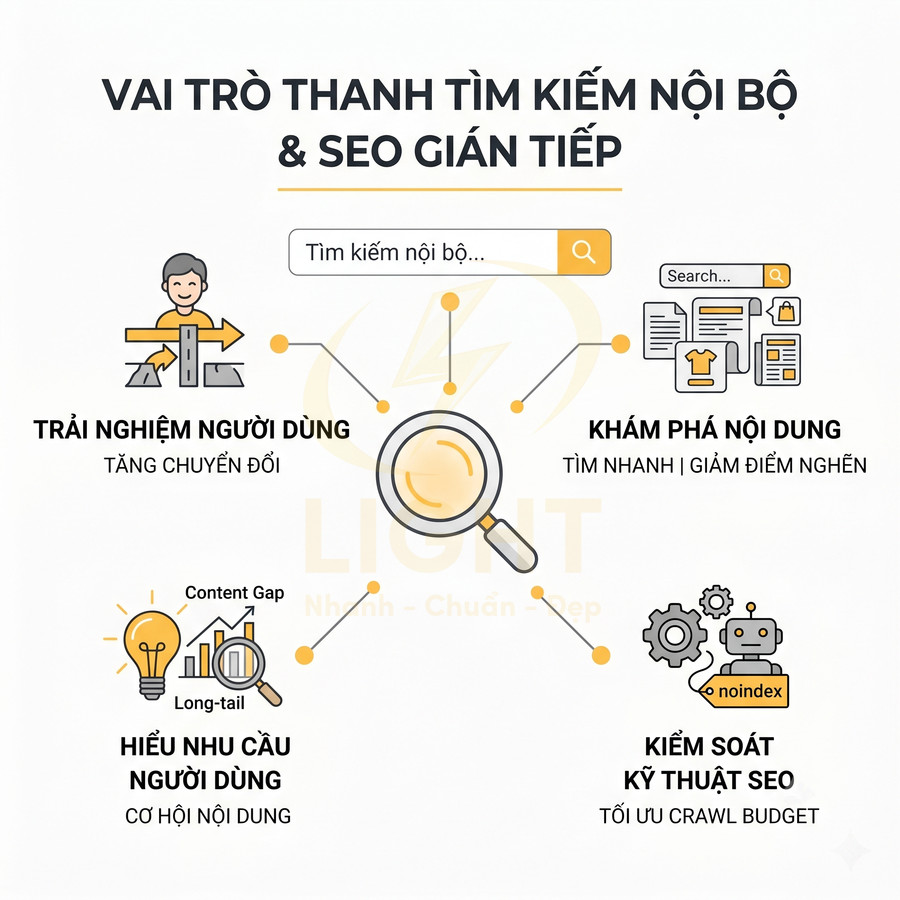


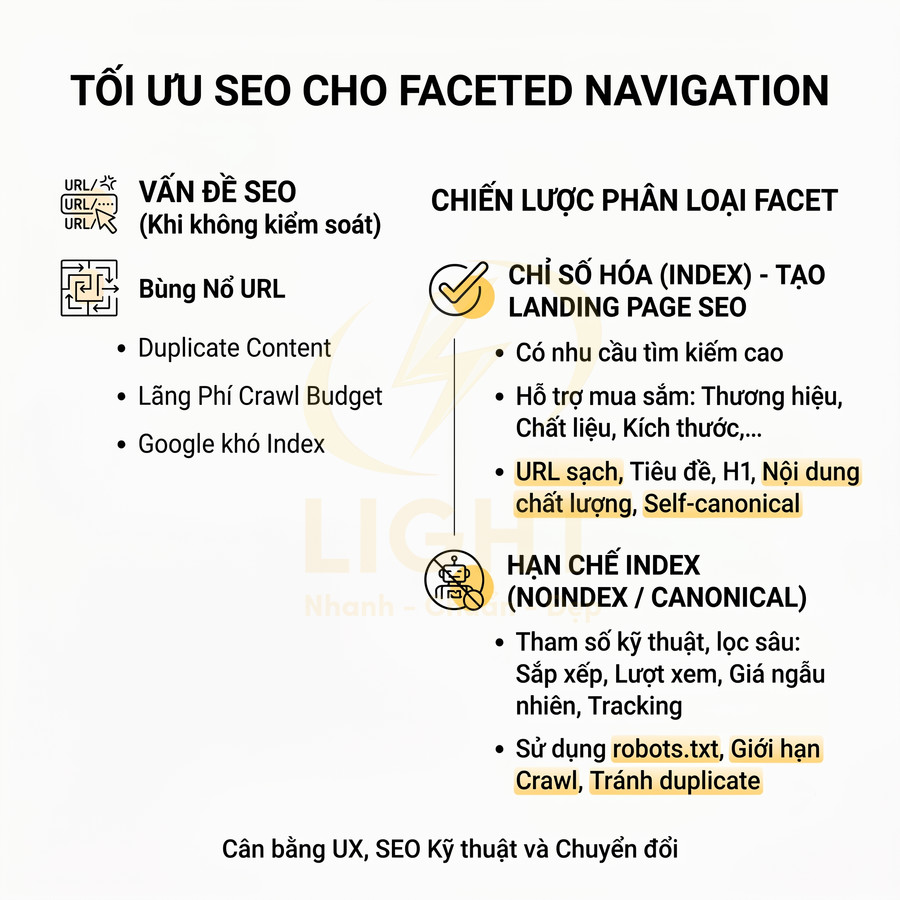





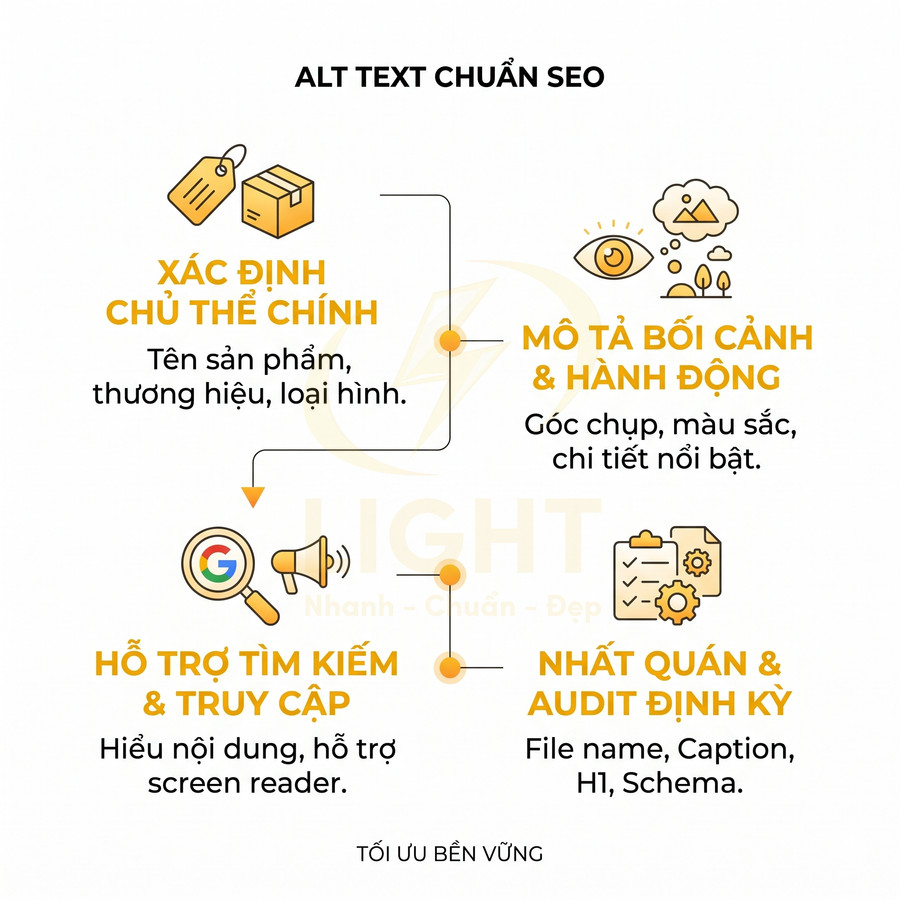

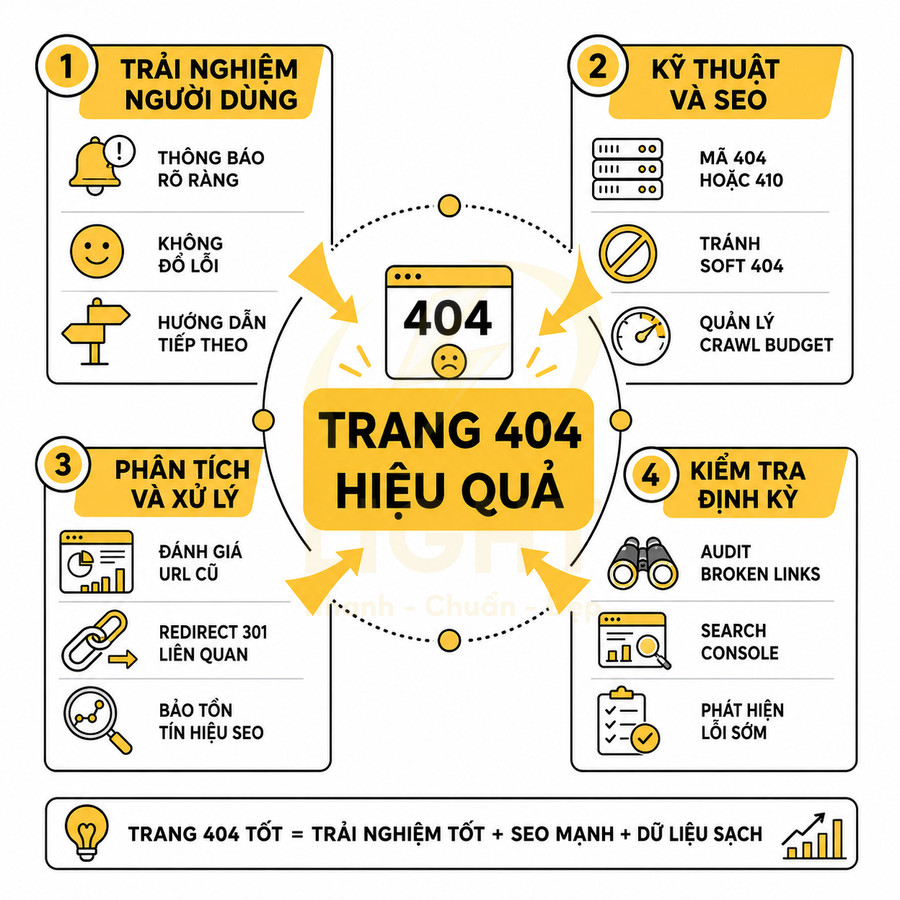

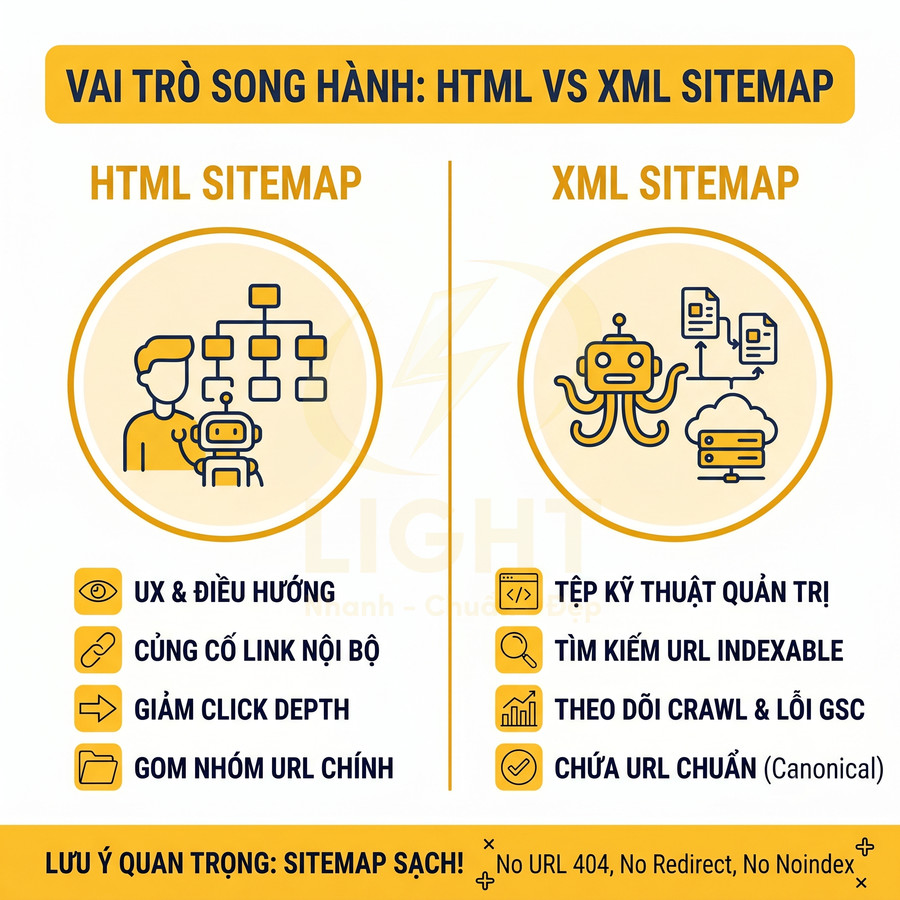
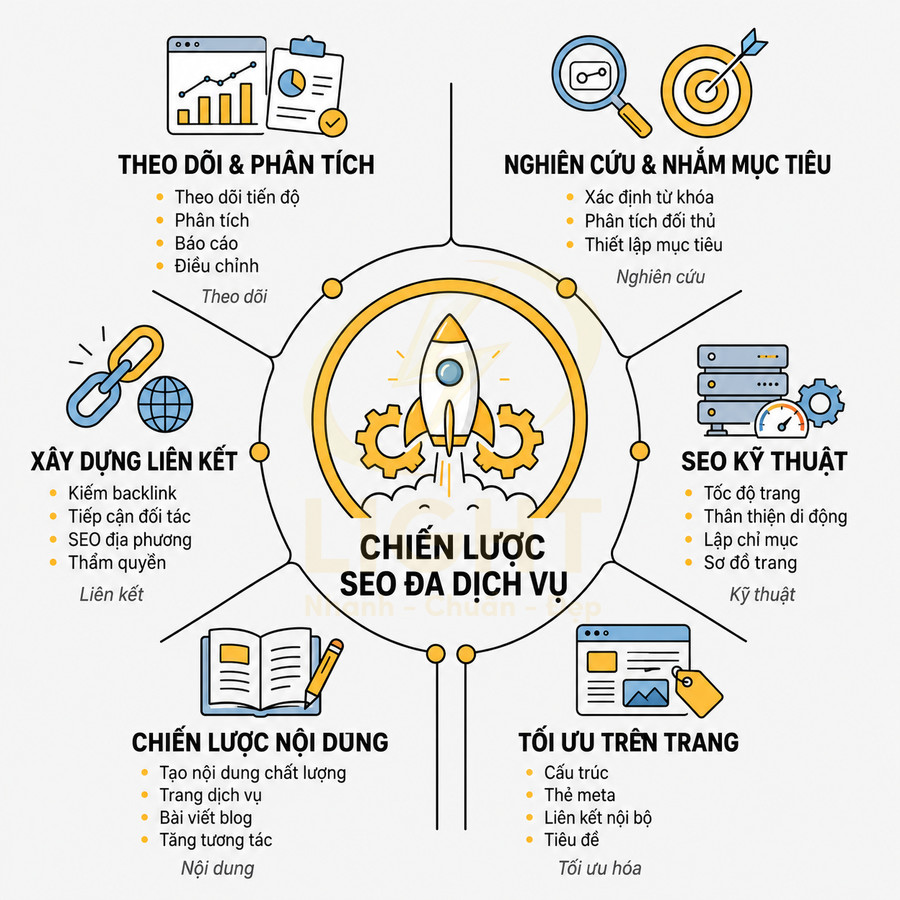




Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
