
Phân trang pagination có ảnh hưởng gì đến website chuẩn SEO?
Pagination ảnh hưởng trực tiếp đến SEO website vì nó quyết định cách danh sách sản phẩm, bài viết hoặc tài nguyên được chia nhỏ, liên kết, crawl và index. Một hệ thống phân trang tốt giúp người dùng duyệt nội dung dài dễ hơn, giảm tải trang, cải thiện trải nghiệm và tạo đường dẫn tuần tự để Googlebot khám phá các URL sâu trong category, blog archive, trang tag hoặc thư viện nội dung. Tuy nhiên, nếu triển khai sai, pagination có thể khiến website mất index, loãng internal link, lãng phí crawl budget và làm nhiều sản phẩm hoặc bài viết quan trọng bị “chôn” ở các trang sâu. Các lỗi phổ biến gồm canonical toàn bộ page 2, 3… về page 1, noindex hàng loạt nhưng vẫn muốn bot theo link, chặn pagination bằng robots.txt, tạo URL tham số trùng lặp hoặc dùng JavaScript, infinite scroll, load more mà không có URL crawlable.

Để tối ưu, mỗi trang phân trang nên có cấu trúc URL nhất quán, liên kết dạng a href, canonical phù hợp, title/meta rõ ngữ cảnh và không phụ thuộc hoàn toàn vào rel next/prev. Với website lớn, pagination cần kết hợp cùng breadcrumb, XML sitemap, HTML sitemap, hub page, internal link từ category và các block nội dung nổi bật để rút ngắn crawl depth, ưu tiên URL có giá trị và đảm bảo toàn bộ nội dung quan trọng luôn được Google phát hiện kịp thời. Infinite scroll và nút load more chỉ nên dùng khi vẫn có URL phân trang tương ứng để bot truy cập. Nếu nội dung phụ thuộc hoàn toàn vào JavaScript, crawlability có thể bị ảnh hưởng. Trong thiết kế web chuẩn SEO, trải nghiệm hiện đại cần đi kèm cấu trúc HTML và liên kết rõ cho công cụ tìm kiếm.
Pagination ảnh hưởng trực tiếp đến crawl, index và trải nghiệm duyệt nội dung
Pagination tác động đồng thời đến khả năng crawl, index và trải nghiệm duyệt nội dung vì nó quyết định cách nội dung danh sách được chia nhỏ, liên kết và ưu tiên. Về crawl, cấu trúc phân trang tạo nên một mạng liên kết tuần tự, giúp bot lần lượt khám phá các URL sâu trong danh mục mà không bị “đứt đoạn”. Về index, cách thiết lập canonical, meta robots và robots.txt trên chuỗi page 2, 3, 4… sẽ quyết định phần nào nội dung được index đầy đủ hay bị bỏ sót. Về trải nghiệm, pagination giúp người dùng tải trang nhanh hơn, tránh phải xử lý quá nhiều phần tử cùng lúc, đồng thời định hướng họ qua các bước duyệt nội dung rõ ràng, nhất quán và dễ hiểu. Pagination cũng ảnh hưởng đến cách người dùng cảm nhận tốc độ và sự rõ ràng của website. Thay vì tải một danh sách quá dài, việc chia trang giúp nội dung dễ quét và dễ kiểm soát hơn. Trong thiết kế web, phân trang cần cân bằng giữa số lượng item mỗi trang và tốc độ tải.
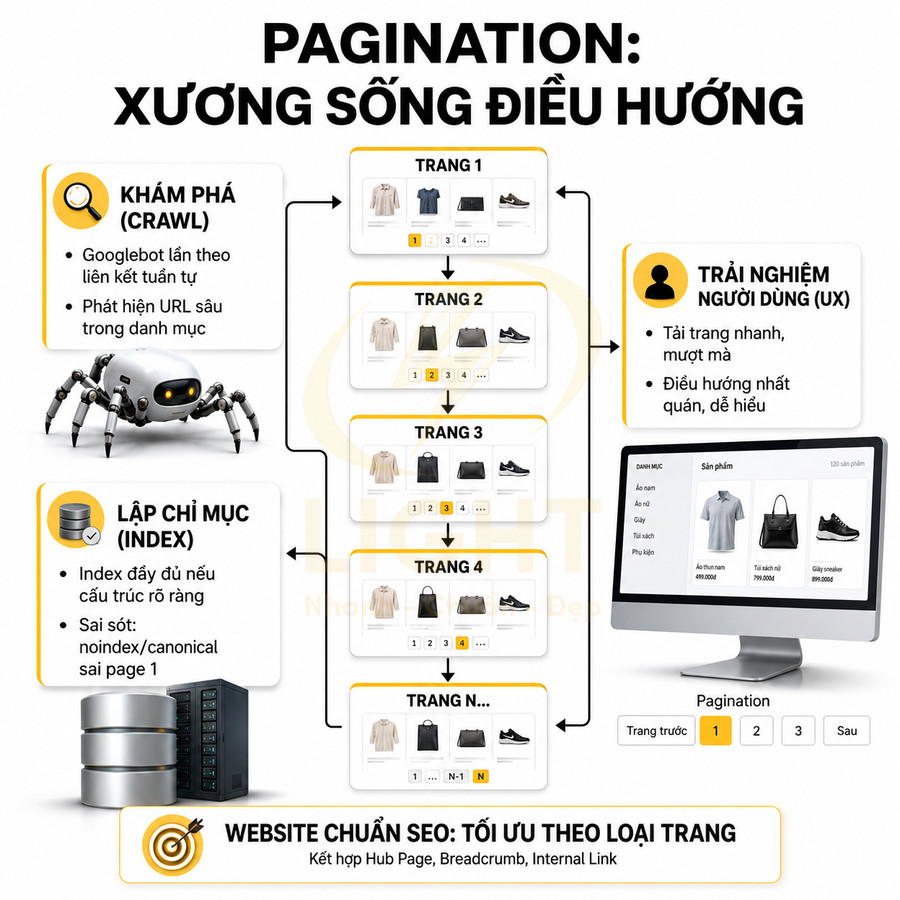
Pagination giúp chia nhỏ danh sách sản phẩm, bài viết hoặc kết quả tìm kiếm theo từng trang
Pagination là cơ chế chia danh sách nội dung dài thành nhiều trang nhỏ hơn, thường được đánh số như page 1, page 2, page 3…. Ở mức kỹ thuật, mỗi trang phân trang tương ứng với một URL riêng biệt, thường có tham số hoặc cấu trúc thư mục rõ ràng (ví dụ: /category/giay?page=2 hoặc /category/giay/p2/). Điều này cho phép máy chủ chỉ trả về một phần dữ liệu thay vì toàn bộ danh sách, giảm tải cho server và cải thiện hiệu năng. Pagination nên được hiểu như một dạng kiểm soát tải nhận thức trong giao diện danh sách dài, không chỉ là thao tác kỹ thuật chia dữ liệu. Sharma và Murano (2020) khi đánh giá các kiểu cuộn trên web cho thấy trải nghiệm giữa phân trang, cuộn vô hạn và “load more” thay đổi theo loại nhiệm vụ; người dùng có mục tiêu rõ thường cần cấu trúc điều hướng ổn định hơn để biết mình đang ở đâu và quay lại điểm trước đó. Với danh mục sản phẩm, blog hoặc thư viện tài liệu, pagination giúp chia nội dung thành các điểm dừng dễ hiểu, hỗ trợ wayfinding và giảm cảm giác mất kiểm soát khi danh sách quá dài.

Về mặt trải nghiệm, phân trang giúp người dùng không phải tải một trang quá nặng, giảm thời gian tải, hạn chế tình trạng trình duyệt bị “đơ” khi phải render quá nhiều phần tử DOM, đồng thời tăng khả năng tìm được nội dung mong muốn thông qua cấu trúc điều hướng rõ ràng. Khi được thiết kế tốt, pagination thường đi kèm:
- Thanh điều hướng phân trang cố định (pagination bar) ở đầu hoặc cuối danh sách
- Hiển thị số trang hiện tại, các trang lân cận và nút “Trang trước/Trang sau”
- Thông tin ngữ cảnh như “Hiển thị 1–20 của 356 sản phẩm” để người dùng hiểu phạm vi nội dung
Về mặt SEO, pagination tạo ra một chuỗi URL có cấu trúc, giúp bot tìm kiếm có thể lần lượt thu thập dữ liệu các phần nội dung trong danh mục, blog, kết quả tìm kiếm nội bộ hoặc thư viện tài nguyên. Chuỗi này đóng vai trò như một “đường xương sống” (backbone) cho toàn bộ cụm nội dung dạng danh sách, giúp Google hiểu được:
- Thứ tự tương đối của các phần tử (mới nhất, cũ hơn, sâu hơn trong danh mục)
- Mối quan hệ giữa trang danh mục chính và các trang con phân trang
- Quy mô thực tế của danh mục (bao nhiêu trang, mỗi trang bao nhiêu item)
Pagination có giá trị SEO vì nó biến một danh sách lớn thành một chuỗi liên kết có thể crawl, thay vì một vùng nội dung ẩn sau thao tác giao diện. Boldi, Marino, Santini và Vigna (2016) khi mô tả hệ thống crawler quy mô lớn BUbiNG nhấn mạnh crawler phải xử lý throughput, phân phối tải và politeness constraints khi thu thập web ở quy mô lớn. Trong bối cảnh website, pagination rõ ràng giúp crawler đi theo các liên kết tuần tự thay vì phải đoán nội dung nằm sau JavaScript hoặc form. Mỗi URL phân trang có href chuẩn là một điểm vào giúp bot khám phá sản phẩm, bài viết và tài nguyên sâu hơn.
Khi được thiết kế đúng, pagination đóng vai trò như một “xương sống” điều hướng cho các trang danh sách, đảm bảo cả người dùng lẫn Googlebot đều có thể tiếp cận toàn bộ nội dung mà không bị bỏ sót. Ngược lại, nếu cấu trúc phân trang mơ hồ, thiếu liên kết rõ ràng hoặc phụ thuộc quá nhiều vào JavaScript, bot có thể chỉ nhìn thấy một phần nhỏ nội dung, dẫn đến tình trạng index không đầy đủ.
Trong thực tế, pagination thường xuất hiện ở các loại trang sau: category sản phẩm trên website thương mại điện tử, chuyên mục blog, trang lưu trữ (archive) theo tháng hoặc năm, trang tag, trang kết quả tìm kiếm nội bộ, và các thư viện hình ảnh, video, tài liệu. Mỗi loại trang có mục tiêu SEO khác nhau, nhưng điểm chung là đều cần một cơ chế phân trang rõ ràng, nhất quán, dễ crawl và dễ hiểu với công cụ tìm kiếm. Ở các website lớn, pagination còn là nền tảng để triển khai các pattern nâng cao như:
- Phân trang kết hợp lọc (faceted navigation + pagination)
- Phân trang theo thời gian (time-based pagination) cho tin tức, blog
- Phân trang theo nhóm chủ đề (topic-based pagination) trong thư viện nội dung chuyên sâu
Khi pagination được triển khai hợp lý, website có thể mở rộng số lượng nội dung rất lớn mà vẫn giữ được cấu trúc logic, tránh tình trạng “mê cung URL” khó kiểm soát, giảm rủi ro trùng lặp nội dung và giúp đội ngũ SEO dễ dàng quản lý, ưu tiên và tối ưu các cụm trang quan trọng.
Phân trang đúng giúp Googlebot phát hiện URL sâu trong danh mục
Googlebot hoạt động dựa trên liên kết nội bộ (internal link). Pagination chính là một dạng cấu trúc liên kết tuần tự, dẫn bot từ trang đầu tiên của danh mục đến các trang sâu hơn, nơi chứa nhiều sản phẩm hoặc bài viết cũ hơn. Về bản chất, mỗi liên kết phân trang là một tín hiệu cho Google về việc “còn nội dung phía sau”, giúp bot tiếp tục mở rộng phạm vi crawl thay vì dừng lại ở page 1. Tầm quan trọng của liên kết nội bộ có thể được giải thích từ nền tảng của tìm kiếm web dựa trên hyperlink. Brin và Page (1998) mô tả Google là search engine sử dụng mạnh cấu trúc hypertext; PageRank phân tích liên kết để đánh giá mức độ quan trọng tương đối của trang, còn anchor text có thể hỗ trợ mô tả trang đích. Với pagination, mỗi liên kết “Trang 2”, “Trang sau” hoặc số trang cụ thể không chỉ phục vụ người dùng mà còn là tín hiệu cấu trúc cho bot. Nếu chuỗi phân trang bị đứt, nhiều URL sâu có thể mất đường dẫn crawl tự nhiên trong graph nội bộ.

Khi mỗi trang phân trang có liên kết rõ ràng đến trang trước và trang sau, đồng thời được liên kết từ trang danh mục chính, Googlebot có thể lần lượt thu thập dữ liệu toàn bộ chuỗi mà không bị “đứt đoạn”. Một cấu trúc tốt thường bao gồm:
- Liên kết từ trang danh mục chính (hoặc hub page) đến page 1 của chuỗi
- Liên kết từ page 1 đến page 2, từ page 2 đến page 3, v.v.
- Liên kết quay lại (prev) từ các page sau về page trước để tạo vòng liên kết hai chiều
Điều này đặc biệt quan trọng với các website lớn, nơi hàng nghìn URL sản phẩm hoặc bài viết nằm ở các trang page 3, page 5, thậm chí page 20 trở đi. Nếu không có pagination rõ ràng, các URL sâu này có thể trở thành “orphan URL” (không có hoặc rất ít liên kết nội bộ trỏ tới), khiến Google khó phát hiện hoặc chỉ phát hiện thông qua sitemap XML với mức độ ưu tiên thấp hơn.
Một cấu trúc pagination tốt thường đảm bảo các yếu tố: liên kết dạng thẻ a href crawlable, anchor text rõ ràng (ví dụ: “Trang 2”, “Trang sau”, “Next”), đường dẫn URL nhất quán và không bị chặn bởi robots.txt hoặc meta robots. Ngoài ra, cần tránh các pattern gây khó cho bot như:
- Pagination chỉ render sau khi scroll (infinite scroll) nhưng không có fallback HTML tĩnh
- Liên kết phân trang được gắn sự kiện onclick phức tạp, không có href rõ ràng
- Tham số URL thay đổi liên tục, tạo ra nhiều biến thể trùng lặp (ví dụ: &sort=, &view=, &layout=)
Khi đó, Googlebot có thể sử dụng các liên kết phân trang như một bản đồ để khám phá nội dung sâu, giảm nguy cơ bỏ sót sản phẩm, bài viết hoặc tài nguyên quan trọng. Đối với các site có crawl budget hạn chế, pagination rõ ràng còn giúp Google ưu tiên crawl theo chiều sâu một cách có kiểm soát, thay vì lãng phí tài nguyên vào các URL ngẫu nhiên hoặc ít giá trị.
Ngược lại, nếu pagination bị ẩn sau JavaScript khó crawl hoặc chỉ hiển thị sau tương tác (click, scroll, filter), bot có thể không theo được chuỗi, dẫn đến nhiều URL sâu không được index hoặc index rất chậm. Trong bối cảnh Google ngày càng ưu tiên trải nghiệm người dùng và tốc độ cập nhật nội dung, việc đảm bảo pagination “bot-friendly” là một phần quan trọng trong chiến lược kỹ thuật SEO tổng thể.
Phân trang sai có thể làm mất index, loãng internal link và giảm khả năng khám phá nội dung
Khi pagination được triển khai sai, tác động tiêu cực đến SEO thường xuất hiện ở ba khía cạnh: indexability, phân bổ sức mạnh internal link và khả năng khám phá nội dung mới. Về indexability, các lỗi phổ biến bao gồm:
- Đặt noindex cho toàn bộ chuỗi page 2, 3, 4… khiến Google không theo các liên kết nằm trên đó
- Canonical tất cả các trang phân trang về page 1, làm Google coi các page sau là bản trùng lặp không cần index
- Chặn crawl các tham số phân trang trong robots.txt, khiến bot không thể truy cập nội dung sâu

Nếu toàn bộ trang phân trang bị noindex hoặc canonical sai về page 1, Google có thể không theo dõi các liên kết nằm ở page 2 trở đi, khiến nhiều sản phẩm hoặc bài viết không được index. Điều này đặc biệt nguy hiểm với website thương mại điện tử, nơi phần lớn sản phẩm nằm ở các trang sâu trong danh mục, và doanh thu phụ thuộc trực tiếp vào khả năng hiển thị của các URL này trên kết quả tìm kiếm. Canonical trong pagination cần phản ánh đúng mức độ khác biệt nội dung giữa các trang. Google mô tả canonicalization là quá trình chọn URL đại diện cho một nhóm trang trùng lặp hoặc gần trùng lặp; canonical là tín hiệu hợp nhất, không phải công cụ mặc định để “dồn” mọi trang phân trang về page 1. Nếu page 2, page 3 chứa tập sản phẩm hoặc bài viết khác page 1, việc canonical toàn bộ về page 1 có thể làm Google hiểu sai rằng các trang sau không có giá trị riêng. Với danh mục lớn, canonical tự tham chiếu thường an toàn hơn để giữ đường crawl đến nội dung sâu.
Về internal link, khi pagination tạo ra quá nhiều trang mỏng, trùng lặp hoặc không được tối ưu, sức mạnh liên kết nội bộ bị phân tán vào các URL ít giá trị. Các trang quan trọng như sản phẩm chủ lực, bài viết trụ cột (pillar content) có thể nhận ít liên kết hơn, làm giảm khả năng xếp hạng. Một số pattern gây loãng internal link thường gặp:
- Phân trang với số lượng item quá ít mỗi trang (ví dụ: 5 sản phẩm/trang) tạo ra hàng chục page gần như giống nhau
- Cho phép kết hợp vô hạn giữa filter + sort + pagination, tạo ra hàng nghìn URL biến thể
- Không ưu tiên liên kết nổi bật đến các sản phẩm/bài viết chiến lược, chỉ dựa vào thứ tự thời gian hoặc ID
Ngoài ra, nếu pagination không rõ ràng, Googlebot có thể lãng phí crawl budget vào các trang phân trang ít giá trị, trong khi bỏ sót hoặc chậm cập nhật các URL mới, dẫn đến tốc độ index chậm và hiệu quả SEO tổng thể suy giảm. Ở các site tin tức hoặc blog cập nhật thường xuyên, việc bài viết mới bị “đẩy” nhanh xuống các page sâu mà không có liên kết bổ sung từ hub page, chuyên mục nổi bật hoặc sitemap được tối ưu sẽ khiến thời gian xuất hiện trên SERP bị kéo dài đáng kể.
Website chuẩn SEO cần xử lý pagination theo loại trang và mục tiêu tìm kiếm
Một website chuẩn SEO không áp dụng một quy tắc pagination duy nhất cho mọi loại trang, mà cần tùy biến theo mục tiêu tìm kiếm và giá trị nội dung. Cách tiếp cận hiệu quả thường bắt đầu từ việc phân loại rõ:
- Trang có tiềm năng nhận traffic từ tìm kiếm (category sản phẩm, chuyên mục blog, hub page)
- Trang chủ yếu phục vụ điều hướng nội bộ (kết quả tìm kiếm nội bộ, một số trang filter đặc thù)
- Trang hỗ trợ khám phá nội dung cũ nhưng không phải landing page chính (archive theo tháng, năm)
Với category sản phẩm có nhu cầu tìm kiếm cao, các trang phân trang thường nên được index, có canonical tự tham chiếu và được tối ưu title, meta description để hỗ trợ người dùng lọc, duyệt sản phẩm. Trong nhiều trường hợp, page 1 có thể nhắm đến từ khóa chính, trong khi các page sau vẫn được index nhưng tối ưu meta theo hướng hỗ trợ (ví dụ: “Trang 2 – Giày thể thao nam giá tốt”). Điều quan trọng là không “ép” toàn bộ chuỗi về một URL duy nhất bằng canonical, tránh làm mất khả năng crawl sâu.

Với trang kết quả tìm kiếm nội bộ, pagination thường không cần index vì không nhắm đến từ khóa cụ thể, chủ yếu phục vụ điều hướng nội bộ. Các trang này nên:
- Được crawl (follow) để Google có thể theo các liên kết sản phẩm/bài viết bên trong
- Nhưng đặt meta robots noindex, follow để tránh tạo ra hàng loạt trang mỏng, trùng lặp trên SERP
- Hạn chế để người dùng và bot truy cập trực tiếp từ bên ngoài (không xây dựng backlink về các URL search nội bộ)
Đối với blog, tin tức, thư viện nội dung, pagination cần đảm bảo bài viết cũ không bị “chôn vùi” quá sâu, đồng thời các trang phân trang có thể hỗ trợ Google khám phá nội dung mới và cũ một cách cân bằng. Một số kỹ thuật thường dùng:
- Hiển thị block “bài viết liên quan”, “bài viết nổi bật” trên mọi trang để tăng internal link đến nội dung quan trọng
- Tạo các hub page hoặc pillar page theo chủ đề, liên kết đến các bài viết cũ thay vì chỉ dựa vào chuỗi phân trang theo thời gian
- Sử dụng breadcrumb rõ ràng để thể hiện vị trí của bài viết trong cấu trúc site
Website chuẩn SEO thường kết hợp pagination với hub page, pillar page, breadcrumb, internal link từ bài viết để giảm phụ thuộc vào chuỗi phân trang thuần túy. Cách tiếp cận này giúp tối ưu cả trải nghiệm người dùng lẫn khả năng crawl và index, phù hợp với tiêu chí EEAT khi nội dung quan trọng luôn dễ tiếp cận và được tổ chức có hệ thống. Thay vì để Google chỉ dựa vào thứ tự thời gian hoặc ID trong pagination, cấu trúc nội dung theo chủ đề, mức độ ưu tiên và giá trị tìm kiếm sẽ giúp toàn bộ hệ thống URL hoạt động hiệu quả hơn về mặt SEO lẫn trải nghiệm.
Ảnh hưởng của pagination đến crawl budget và khả năng thu thập dữ liệu
Pagination tác động trực tiếp đến crawl budget thông qua cách phân bổ tài nguyên crawl giữa các URL phân trang và các trang nội dung quan trọng. Khi chuỗi phân trang quá sâu, bot dễ bị “mắc kẹt” trong các page giá trị thấp, làm giảm tần suất crawl cho category, sản phẩm và bài viết chiến lược. Cấu trúc internal link, độ sâu click, số lượng item trên mỗi trang và cách triển khai noindex, canonical quyết định mức độ ưu tiên crawl của từng cụm URL. Bên cạnh đó, vị trí của nội dung mới trong chuỗi pagination ảnh hưởng lớn đến tốc độ phát hiện và index. Một kiến trúc pagination tốt cần cân bằng giữa crawlability, UX và mục tiêu kinh doanh, đồng thời kết hợp chặt chẽ với sitemap và hệ thống hub page.
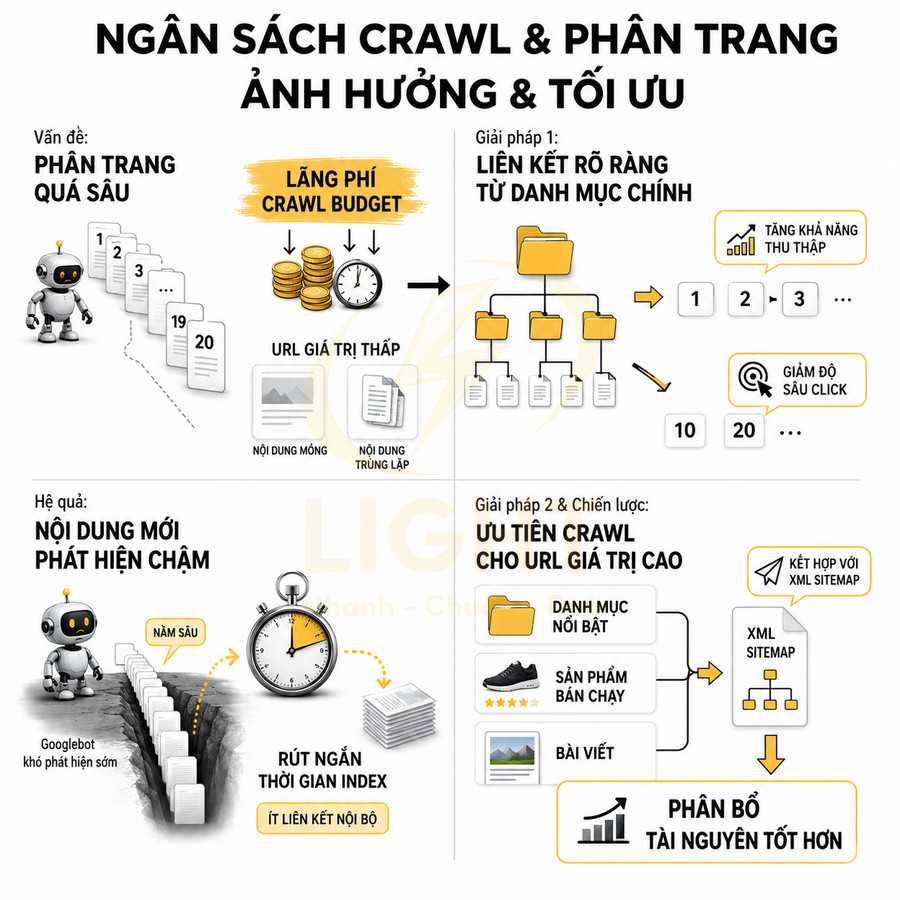
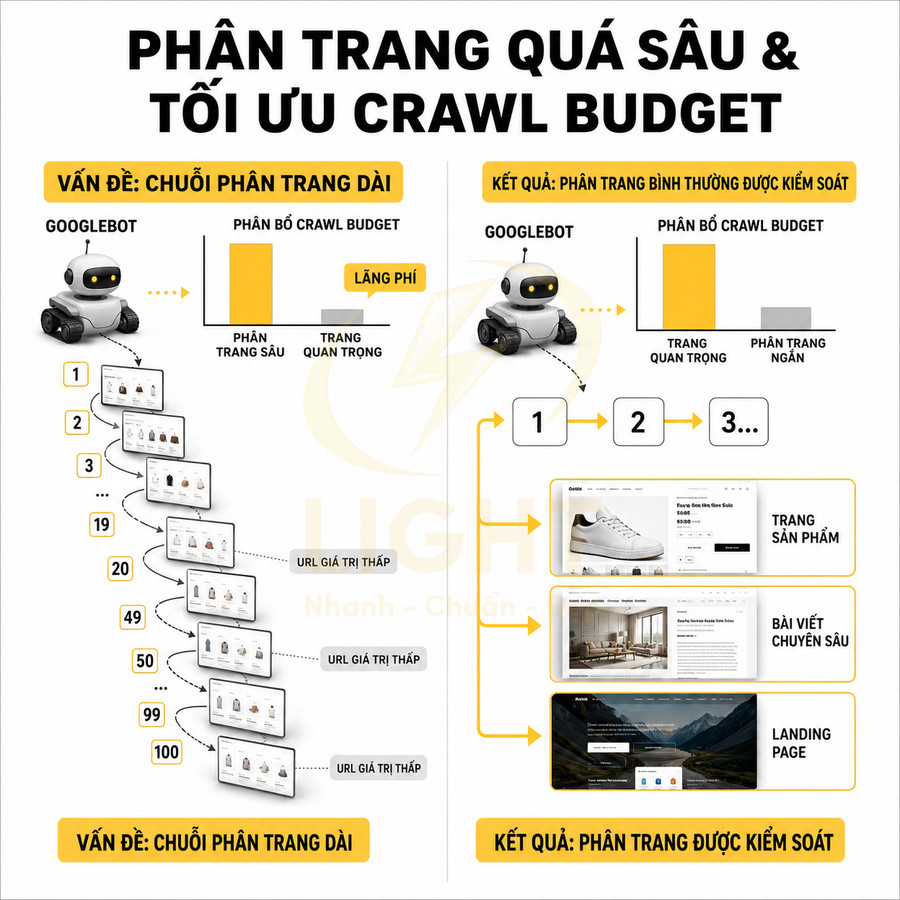
Chuỗi phân trang quá sâu khiến bot tốn tài nguyên crawl vào URL giá trị thấp
Trên các website lớn, crawl budget không chỉ là khái niệm tổng quát mà là một nguồn lực kỹ thuật hữu hạn, bị chi phối bởi hai thành phần chính: crawl rate limit (giới hạn tốc độ mà Googlebot có thể crawl mà không làm quá tải server) và crawl demand (nhu cầu thực sự của Google đối với nội dung trên site). Khi cấu trúc pagination kéo dài và không được tối ưu, phần lớn lượt crawl có thể bị “đốt” vào các URL phân trang có giá trị SEO thấp, trong khi những URL quan trọng hơn lại không được truy cập đủ thường xuyên.
Với các chuỗi phân trang lên đến hàng chục hoặc hàng trăm trang, Googlebot phải lần lượt đi qua từng bước “Next”, “Previous” hoặc từng số trang. Nếu mỗi trang chỉ thay đổi một phần nhỏ danh sách item, mức độ unique content giữa các trang là rất thấp, dẫn đến:
- Tỷ lệ trùng lặp nội dung cao giữa các page trong cùng một chuỗi.
- Giảm mức độ ưu tiên crawl cho toàn bộ cụm URL phân trang.
- Nguy cơ Google đánh giá nhiều trang là thin content hoặc “low-value add URLs”.
Trong bối cảnh đó, việc để pagination quá sâu mà không có chiến lược kiểm soát sẽ gây lãng phí crawl budget. Googlebot có thể dành hàng nghìn request mỗi ngày cho các trang page 20, page 30, page 50… vốn chỉ chứa danh sách sản phẩm lặp lại, trong khi các URL sản phẩm chi tiết, bài viết chuyên sâu hoặc landing page chuyển đổi cao lại không được crawl đủ. Về mặt kỹ thuật, đây là một dạng “crawl budget misallocation” – phân bổ sai tài nguyên crawl.
Đặc biệt, nếu mỗi trang phân trang chỉ hiển thị 5–10 sản phẩm, không có mô tả bổ sung, không có nội dung hướng dẫn, không có block nội dung hỗ trợ (FAQ, filter description, buyer guide…), Google có thể xem các trang này là mỏng nội dung (thin content). Khi đó, dù Googlebot có crawl sâu đến page 30, giá trị bổ sung cho chỉ mục tìm kiếm gần như không đáng kể. Điều này không chỉ ảnh hưởng đến hiệu quả crawl mà còn có thể kéo giảm chất lượng tổng thể của toàn bộ thư mục (directory) hoặc category trong mắt Google.
Để tối ưu crawl budget trong bối cảnh pagination sâu, cần xem xét các yếu tố kỹ thuật sau:
- Số lượng item trên mỗi trang: Tăng hợp lý số lượng sản phẩm/bài viết trên một page để giảm tổng số page, nhưng vẫn đảm bảo tốc độ tải trang và trải nghiệm người dùng.
- Giới hạn độ sâu pagination: Có thể áp dụng noindex cho các page quá sâu (ví dụ từ page 10 trở đi) nếu dữ liệu cho thấy chúng hầu như không mang lại traffic tự nhiên.
- Canonical thông minh: Trong một số trường hợp, có thể dùng canonical trỏ về page 1 hoặc về phiên bản lọc chính, nhằm gom tín hiệu và tránh phân tán giá trị.
- Ưu tiên crawl cho URL chi tiết: Đảm bảo mỗi item trong danh sách có liên kết nội bộ rõ ràng, dễ crawl, để Googlebot nhanh chóng “thoát” khỏi chuỗi pagination và đi vào trang sản phẩm/bài viết.
Khi các yếu tố này được tối ưu, pagination không còn là “hố đen crawl budget” mà trở thành một lớp điều hướng hỗ trợ, giúp Googlebot tiếp cận nội dung giá trị cao với chi phí crawl thấp hơn.
Trang page 2, page 3 và các trang sâu cần liên kết rõ ràng từ danh mục chính
Một vấn đề kỹ thuật thường bị bỏ qua là cấu trúc internal link đến các trang phân trang sâu. Nếu danh mục chính (category root) chỉ liên kết đến page 1, còn các page 2, 3, 4… chỉ được truy cập thông qua nút “Next” hoặc “Previous”, thì:
- Page 2, 3, 4… nhận rất ít link equity từ các trang mạnh như trang chủ, category chính, hub page.
- Độ ưu tiên crawl của các page này giảm, dẫn đến tần suất crawl thấp và độ trễ cập nhật cao.
- Các item nằm ở sâu trong chuỗi (ví dụ sản phẩm ở page 7, 8) khó được phát hiện nhanh, đặc biệt nếu không có liên kết từ nơi khác.
Các trang phân trang sâu không nên chỉ phụ thuộc vào một chuỗi “Next” tuyến tính, vì mỗi bước click bổ sung làm giảm khả năng người dùng và bot tiếp cận nhanh nội dung bên trong. Brin và Page (1998) cho thấy liên kết và anchor text là thành phần quan trọng trong cách search engine khai thác cấu trúc web. Vì vậy, category chính nên cung cấp dải số trang hợp lý, liên kết đến một vài mốc sâu hoặc block sản phẩm/bài viết quan trọng, thay vì chỉ có “Trang sau”. Mục tiêu là rút ngắn click depth cho nội dung quan trọng, không bắt bot đi từng bước qua hàng chục page.
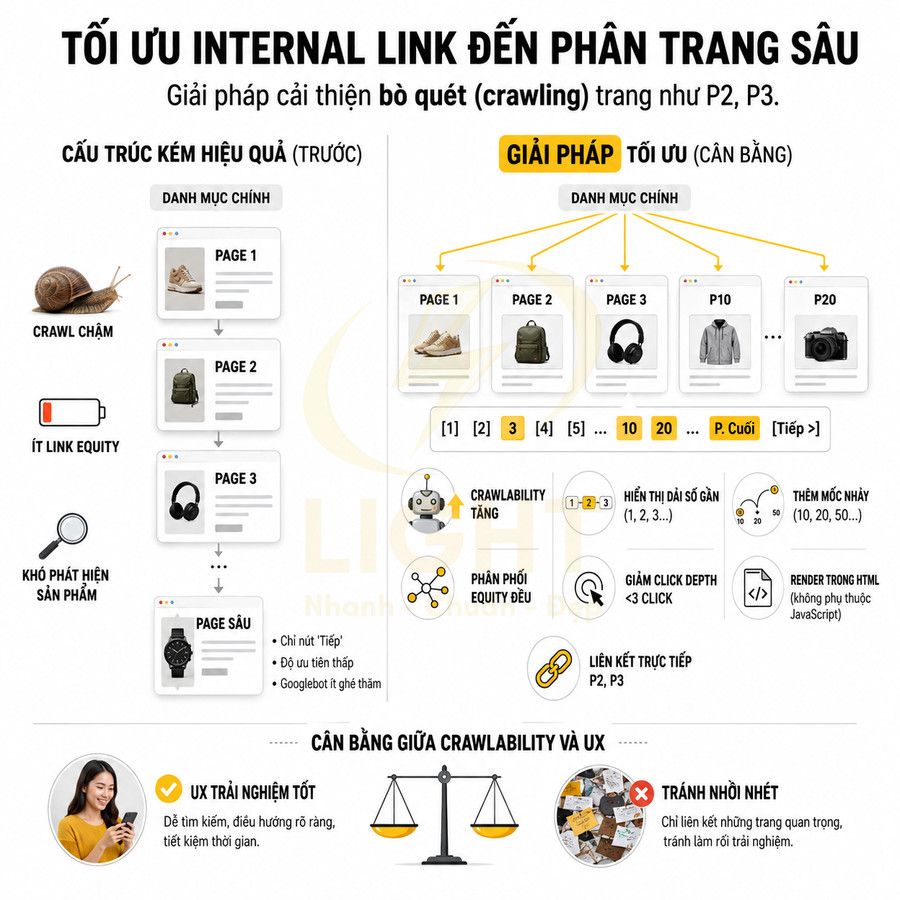
Để cải thiện, cần thiết kế pagination sao cho các trang phân trang quan trọng có liên kết rõ ràng từ danh mục chính hoặc từ các hub page liên quan. Một số mô hình liên kết thường dùng:
- Hiển thị dải số trang gần: 1, 2, 3, 4, 5, …, 10, “Next”.
- Hiển thị các mốc trang: 1, 5, 10, 20, 50… để bot có thể “nhảy cóc” đến các đoạn sâu hơn.
- Liên kết trực tiếp từ category chính đến một số page chiến lược (ví dụ page 2, 3) nếu dữ liệu cho thấy người dùng và bot thường xuyên truy cập các khu vực đó.
Về mặt crawlability, việc bổ sung các liên kết này giúp:
- Giảm số bước click (click depth) từ trang chủ hoặc category root đến các page sâu.
- Tăng khả năng Googlebot phát hiện và crawl đều các phần khác nhau của danh sách.
- Phân phối lại link equity hợp lý hơn trong toàn bộ cụm pagination.
Tuy nhiên, cần tránh cực đoan theo hướng ngược lại: nhồi nhét quá nhiều liên kết phân trang trên một trang duy nhất. Một block pagination chứa hàng chục hoặc hàng trăm số trang liên tiếp có thể:
- Làm rối giao diện, giảm trải nghiệm người dùng.
- Làm loãng sức mạnh liên kết vì mỗi link chỉ nhận được một phần rất nhỏ link equity.
- Tăng kích thước HTML không cần thiết, ảnh hưởng đến tốc độ tải trang.
Giải pháp là thiết kế một mô hình pagination cân bằng giữa tính crawlable và UX, ví dụ:
- Hiển thị một nhóm số trang gần vị trí hiện tại (current page ±2).
- Thêm một vài mốc nhảy xa (ví dụ page 1, page cuối, một số mốc giữa).
- Đảm bảo các liên kết phân trang được render trong HTML (không phụ thuộc hoàn toàn vào JavaScript khó crawl).
Nội dung mới nằm quá sâu trong pagination có thể được phát hiện chậm
Vấn đề không chỉ nằm ở việc Googlebot có crawl được hay không, mà còn là tốc độ phát hiện (discovery speed) của các URL mới. Trên nhiều website, nội dung mới được thêm vào cuối danh sách hoặc vào một category ít được ưu tiên, khiến chúng ngay lập tức bị đẩy xuống các page 3, 4, 5… hoặc sâu hơn. Trong khi đó, Googlebot thường ưu tiên crawl các URL:
- Có nhiều internal link trỏ đến.
- Nằm gần trang chủ hoặc các hub page quan trọng.
- Được liệt kê trong XML sitemap với timestamp cập nhật mới.
Tốc độ phát hiện nội dung mới phụ thuộc vào số đường dẫn mà crawler có thể dùng để tiếp cận URL đó. Baykan, Henzinger và Weber (2013) khi nghiên cứu phân loại ngôn ngữ dựa trên URL cho thấy crawler có thể tiết kiệm băng thông và thời gian nếu suy luận được thông tin từ URL trước khi tải nội dung; điều này nhấn mạnh rằng URL và cấu trúc đường dẫn có vai trò quan trọng trong hoạt động crawl quy mô lớn. Với website nội dung, bài mới không nên bị đẩy ngay xuống page sâu. Trang chủ, category, hub page, sitemap và block “bài mới” cần tạo nhiều đường vào ngắn để Google phát hiện nhanh hơn.
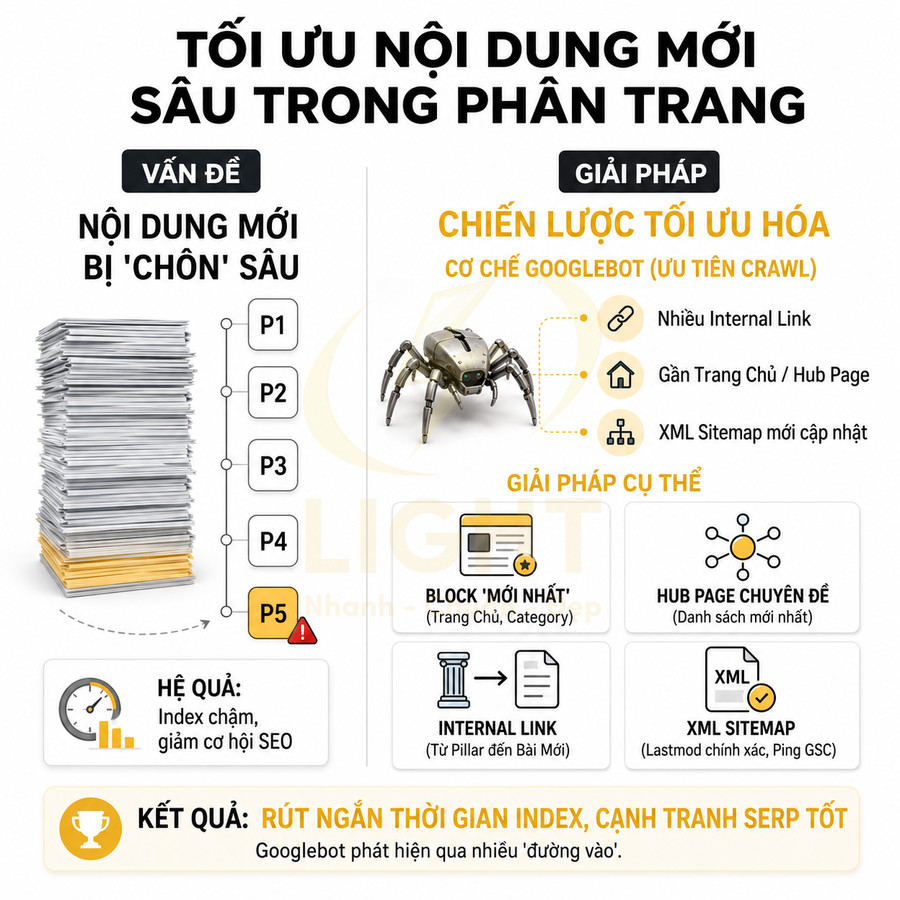
Nếu cấu trúc pagination không hỗ trợ việc đưa nội dung mới lên vị trí dễ thấy, các URL mới có thể bị “chôn” ở các page sâu ngay từ thời điểm tạo ra. Hệ quả:
- Thời gian từ lúc publish đến lúc được index kéo dài đáng kể.
- Đối với website tin tức, blog, hoặc e-commerce theo mùa, việc index chậm có thể khiến nội dung mất cơ hội xuất hiện đúng thời điểm nhu cầu tìm kiếm cao.
- Các tín hiệu tương tác ban đầu (click, share, backlink) khó được ghi nhận sớm, làm giảm đà phát triển tự nhiên của URL mới.
Để khắc phục, cần thiết kế cơ chế ưu tiên hiển thị nội dung mới ở những khu vực có độ crawl cao:
- Block “Sản phẩm mới”, “Bài viết mới nhất” trên trang chủ và trên các category chính.
- Các hub page chuyên đề (topic hub) luôn hiển thị danh sách bài mới nhất trong chủ đề đó.
- Internal link từ các bài viết trụ cột (pillar content) đến các bài mới liên quan.
Song song, XML sitemap cần được cập nhật tự động mỗi khi có URL mới, với trường lastmod phản ánh chính xác thời điểm cập nhật. Việc gửi lại sitemap qua Google Search Console hoặc ping sitemap giúp Googlebot nhanh chóng biết rằng site có nội dung mới cần crawl.
Khi pagination được kết hợp với chiến lược internal link và sitemap hợp lý, nội dung mới không còn phụ thuộc hoàn toàn vào vị trí trong chuỗi phân trang. Googlebot có thể phát hiện URL mới thông qua nhiều “đường vào” khác nhau, rút ngắn đáng kể thời gian index và cải thiện khả năng cạnh tranh trên SERP.
Website lớn cần ưu tiên crawl cho category, sản phẩm và bài viết có giá trị cao
Trên các website có hàng chục nghìn hoặc hàng trăm nghìn URL, không thể kỳ vọng Google sẽ crawl toàn bộ với tần suất cao. Một chiến lược pagination chuẩn SEO phải gắn liền với chiến lược ưu tiên crawl, trong đó:
- Các category mang lại nhiều traffic, doanh thu hoặc có tiềm năng SEO cao được đặt ở vị trí nông (gần trang chủ).
- Các sản phẩm bán chạy, bài viết có lượng tìm kiếm lớn được ưu tiên internal link từ nhiều vị trí khác nhau.
- Các khu vực ít giá trị (ví dụ sản phẩm hết hàng vĩnh viễn, nội dung cũ không còn nhu cầu) có thể bị giảm ưu tiên crawl bằng noindex, giảm internal link, hoặc thậm chí chặn crawl nếu cần.

Pagination trong trường hợp này chỉ nên là một kênh điều hướng, không phải kênh duy nhất. Các URL quan trọng cần được liên kết từ:
- Trang chủ và menu chính.
- Hub page theo chủ đề hoặc theo thương hiệu.
- Các block “sản phẩm nổi bật”, “bài viết được xem nhiều”, “top deals”.
- Các bài viết liên quan, trang hướng dẫn, landing page chiến dịch.
Để ra quyết định chính xác, đội ngũ SEO và kỹ thuật nên phân tích dữ liệu thực tế:
- Log server: Xác định Googlebot đang crawl những URL nào nhiều nhất, tần suất ra sao, có bao nhiêu request dành cho các page phân trang sâu.
- Google Search Console: Kiểm tra các báo cáo về “Pages crawled”, “Crawl stats”, các URL bị “Discovered – currently not indexed” hoặc “Crawled – currently not indexed”.
- Công cụ crawl: Dùng các crawler như Screaming Frog, Sitebulb… để mô phỏng cách bot di chuyển qua pagination, đo độ sâu click, phát hiện các cụm URL bị cô lập hoặc quá sâu.
Từ các dữ liệu này, có thể trả lời các câu hỏi quan trọng:
- Bot đang tiêu tốn bao nhiêu crawl budget cho pagination so với cho trang sản phẩm/bài viết chi tiết?
- Các URL quan trọng có được crawl đủ thường xuyên để phản ánh kịp thời thay đổi giá, tồn kho, nội dung mới không?
- Có bao nhiêu URL sâu (deep URLs) chưa được index hoặc index rất chậm?
Dựa trên kết quả phân tích, có thể triển khai các biện pháp kỹ thuật:
- Điều chỉnh số lượng item trên mỗi trang để giảm tổng số page trong chuỗi.
- Áp dụng noindex, hoặc thậm chí chặn crawl bằng robots.txt cho các pattern pagination ít giá trị, nếu chắc chắn không cần chúng xuất hiện trên SERP.
- Tối ưu canonical để gom tín hiệu về các URL đại diện có giá trị cao.
- Tái cấu trúc category và hub page để rút ngắn đường đi từ trang chủ đến các URL chiến lược.
Khi pagination được đặt trong bối cảnh chiến lược crawl tổng thể, website lớn có thể kiểm soát tốt hơn cách Googlebot phân bổ tài nguyên, tập trung crawl vào những phần nội dung mang lại hiệu quả SEO và kinh doanh cao nhất, thay vì để bot “lang thang” trong các chuỗi phân trang dài và ít giá trị.
Pagination và indexability của trang danh mục, blog, sản phẩm
Pagination trong trang danh mục, blog, sản phẩm cần được xem như một phần của kiến trúc thông tin, không chỉ là chức năng điều hướng. Mỗi page 2, 3… là một URL độc lập, có thể mang lại traffic, tín hiệu tương tác và backlink riêng nếu được tối ưu đúng cách. Khi cho phép index, nên đảm bảo các trang này có title, meta description, heading và nội dung hỗ trợ đủ khác biệt, giúp Google hiểu đây là các danh sách có giá trị điều hướng và khám phá URL sâu, không phải bản sao của page 1.
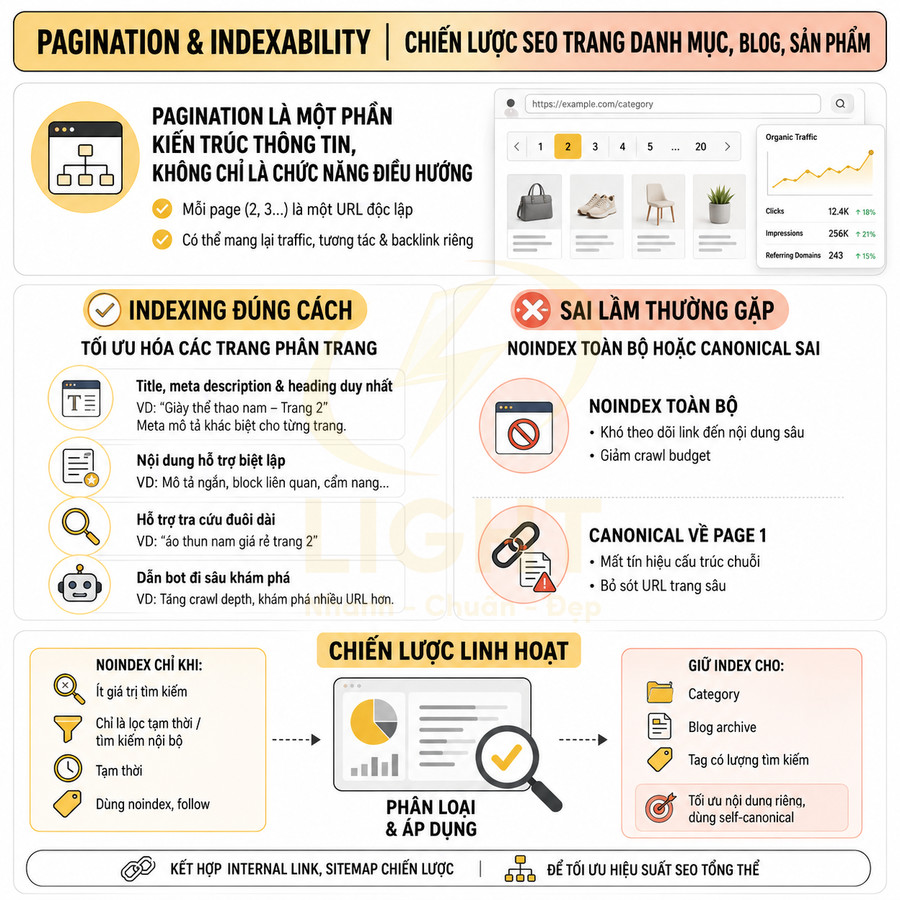
Ngược lại, noindex hoặc canonical sai cho toàn bộ pagination có thể làm suy yếu khả năng crawl, phân phối PageRank và bỏ lỡ nhiều URL quan trọng. Cần áp dụng chiến lược linh hoạt: chỉ noindex những pagination ít giá trị tìm kiếm, mang tính tạm thời hoặc không cần hỗ trợ crawl, đồng thời duy trì internal link, sitemap và cấu trúc URL rõ ràng để tối ưu hiệu suất SEO tổng thể.
Trang phân trang có thể được index khi chứa nội dung riêng và hỗ trợ khám phá URL
Không có quy tắc bắt buộc rằng mọi trang phân trang đều phải noindex. Trong nhiều trường hợp, cho phép index các trang page 2, page 3… là hợp lý, đặc biệt khi chúng mang lại giá trị tìm kiếm riêng và đóng vai trò như một phần mở rộng tự nhiên của category. Về mặt kỹ thuật, mỗi trang phân trang là một URL độc lập, có thể nhận impression, click, backlink và tín hiệu tương tác riêng, nên nếu được tối ưu đúng cách, chúng có thể đóng góp trực tiếp vào hiệu suất SEO tổng thể.

Ví dụ, một category sản phẩm lớn có thể được người dùng tìm kiếm với các truy vấn dài như “áo thun nam giá rẻ trang 2”, “giày chạy bộ giảm giá trang 3”, hoặc người dùng quay lại một trang phân trang cụ thể để tiếp tục duyệt sản phẩm đã xem dở. Khi đó, mỗi trang phân trang nên có title, meta description và heading được tối ưu, phản ánh rõ:
- Loại nội dung (danh mục sản phẩm, blog archive, tag, landing list)
- Ngữ cảnh từ khóa chính của category
- Vị trí trong chuỗi pagination (Page 2, Page 3…)
Ví dụ về cấu trúc title có thể áp dụng:
- Áo thun nam giá rẻ | Trang 2 | Thương hiệu X
- Blog SEO kỹ thuật – Bài viết mới nhất (Page 3)
Cách đặt title và heading như vậy giúp Google hiểu đây là các trang danh sách có giá trị điều hướng, không phải bản sao hoàn toàn của page 1. Đồng thời, người dùng cũng dễ nhận biết mình đang ở đâu trong chuỗi, giảm bounce khi quay lại từ SERP.
Để các trang phân trang index hiệu quả, cần đảm bảo chúng không chỉ là bản sao gần như giống hệt nhau về nội dung. Một số cách tăng “độ độc đáo” và giá trị tìm kiếm cho từng page:
- Thêm mô tả ngắn cho category ở đầu hoặc cuối trang, có thể cố định trên mọi page nhưng được tối ưu để không trùng lặp hoàn toàn với các category khác.
- Chèn block nội dung hướng dẫn lựa chọn sản phẩm (size guide, chất liệu, cách phối đồ, tips sử dụng) hoặc hướng dẫn đọc bài viết (đối với blog) để tăng chiều sâu nội dung.
- Thêm liên kết đến các danh mục con, bài viết liên quan, bộ sưu tập nổi bật để tạo cấu trúc hub & spoke, giúp Google hiểu mối quan hệ chủ đề.
- Hiển thị các block như “Sản phẩm bán chạy”, “Bài viết nổi bật”, “Chủ đề liên quan” cố định trên mọi page nhưng được tối ưu nội dung để bổ sung ngữ cảnh.
Khi đó, mỗi trang phân trang vừa hỗ trợ khám phá URL sản phẩm, vừa cung cấp thêm ngữ cảnh nội dung, giúp Google đánh giá cao hơn về độ hữu ích và tránh bị xem là thin content. Về mặt crawl, các trang này hoạt động như một “lưới liên kết” dày hơn, giúp bot dễ dàng đi sâu vào các URL ít được liên kết từ nơi khác.
Noindex toàn bộ trang phân trang có thể khiến Google khó theo dõi link đến nội dung sâu
Nhiều website áp dụng chiến lược noindex cho tất cả các trang page 2 trở đi với mục đích tránh trùng lặp nội dung và tập trung sức mạnh SEO cho page 1. Tuy nhiên, cách làm này thường chỉ nhìn vào khía cạnh index mà bỏ qua khía cạnh crawl và phân phối PageRank nội bộ. Khi sử dụng meta robots noindex, follow hoặc thậm chí noindex, nofollow trên toàn bộ pagination, Google có thể giảm tần suất crawl các trang này theo thời gian, vì chúng được đánh dấu là không có giá trị hiển thị trên SERP.

Hệ quả là các liên kết đến sản phẩm hoặc bài viết nằm ở trang sâu không được theo dõi đầy đủ, đặc biệt với:
- Sản phẩm mới chỉ xuất hiện ở page 3, page 4 do sắp xếp theo “mới nhất” hoặc “bán chạy”.
- Bài viết cũ nhưng vẫn có giá trị, chỉ còn nằm ở các page archive sâu.
- URL không được liên kết từ menu, sidebar, hoặc các hub page khác.
Kết quả là nhiều URL quan trọng bị bỏ sót hoặc index rất chậm, nhất là với website lớn, crawl budget hạn chế, hoặc cấu trúc internal link nghèo nàn. Trong bối cảnh Google ngày càng ưu tiên khả năng khám phá nội dung toàn diện và đánh giá chất lượng site ở mức hệ thống, việc noindex toàn bộ pagination mà không có chiến lược internal link bổ sung là rủi ro đáng kể.
Nếu cần noindex một phần pagination, website phải đảm bảo rằng các URL sản phẩm, bài viết sâu vẫn được liên kết từ:
- Category chính hoặc hub page được index, có cấu trúc liên kết rõ ràng.
- Sitemap XML được cập nhật thường xuyên, phản ánh đầy đủ các URL quan trọng.
- Block nội dung liên quan (related products, related posts) trên các trang đã index.
- Các trang chuyên đề (collection, landing page theo chủ đề, theo mùa, theo campaign).
Trong trường hợp pagination là đường dẫn crawl gần như duy nhất đến nội dung sâu, việc noindex toàn bộ có thể vô tình cắt đứt đường dẫn crawl đến một phần lớn nội dung, làm suy giảm hiệu quả SEO tổng thể. Khi đó, nên cân nhắc:
- Giữ index cho một số page đầu (ví dụ page 1–3) và chỉ noindex từ page rất sâu trở đi.
- Tăng cường internal link từ các trang nội dung chất lượng cao đến các URL sâu.
- Đảm bảo sử dụng noindex, follow thay vì noindex, nofollow nếu vẫn cần Google theo link.
Canonical tất cả page 2 trở đi về page 1 có thể làm mất tín hiệu của các URL phân trang
Một lỗi kỹ thuật phổ biến là đặt canonical của page 2, page 3… về page 1 với suy nghĩ rằng toàn bộ chuỗi phân trang chỉ là một nội dung duy nhất và cần “gom tín hiệu” về page 1. Thực tế, mỗi trang phân trang hiển thị một tập hợp item khác nhau, có thể có filter, sort, hoặc trạng thái tồn kho khác nhau, nên chúng không phải là bản sao trùng lặp hoàn toàn.
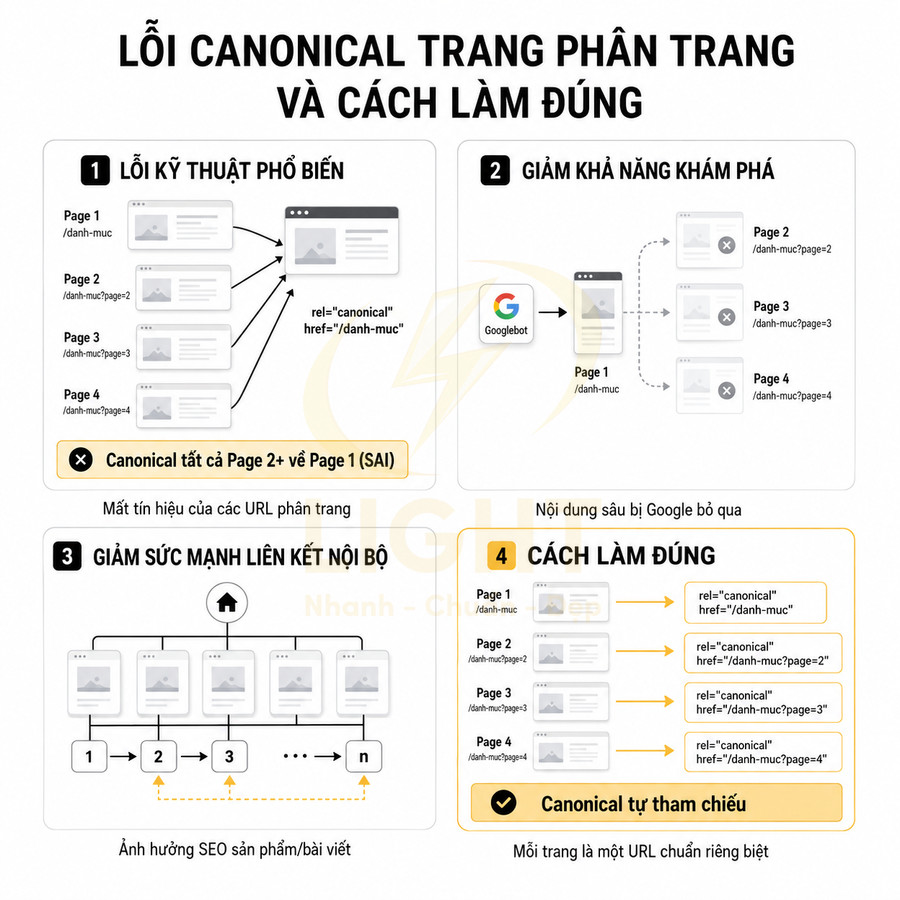
Khi canonical tất cả về page 1, Google có thể hiểu rằng chỉ page 1 là URL chuẩn, các trang còn lại không cần index và không cần xem xét riêng. Điều này dẫn đến:
- Mất tín hiệu về cấu trúc chuỗi phân trang, khiến Google khó hiểu độ sâu và phạm vi của danh mục.
- Giảm khả năng Google khám phá đầy đủ các URL nằm ở trang sâu, vì các trang đó bị xem là “phiên bản phụ” không quan trọng.
- Nguy cơ Google bỏ qua hoặc giảm trọng số các internal link xuất phát từ page 2, 3… khi phân phối PageRank.
Trong nhiều trường hợp, canonical sai còn khiến Google bỏ qua các trang phân trang khi đánh giá internal link, làm suy yếu đường dẫn crawl đến sản phẩm hoặc bài viết. Điều này đặc biệt nghiêm trọng với:
- Site thương mại điện tử có hàng chục nghìn sản phẩm, phụ thuộc mạnh vào pagination để phân phối link.
- Blog lớn, nơi archive theo tháng/năm là kênh chính để Google tìm bài cũ.
Thay vì canonical về page 1, các trang phân trang nên canonical về chính nó nếu nội dung khác nhau về tập hợp item. Chỉ canonical về page 1 trong các trường hợp:
- Trang phân trang là bản sao gần như trùng lặp (ví dụ lỗi kỹ thuật tạo ra URL khác nhưng hiển thị cùng tập sản phẩm).
- Trang phân trang không có giá trị sử dụng (ví dụ page rỗng, không có item, hoặc chỉ có 1–2 item trùng với page 1).
Cách làm này giúp Google hiểu rõ từng trang trong chuỗi, đồng thời vẫn giữ được cấu trúc điều hướng logic cho người dùng. Về mặt kỹ thuật, mỗi page có thể:
- Có canonical tự tham chiếu (self-referencing canonical).
- Sử dụng cấu trúc URL rõ ràng, nhất quán (ví dụ /category/, /category/page/2/, /category/page/3/…).
- Kết hợp với các tín hiệu khác như breadcrumb, schema (nếu có) để tăng khả năng hiểu ngữ cảnh.
Chỉ nên noindex pagination khi trang không có giá trị tìm kiếm và không cần hỗ trợ crawl
Quyết định noindex pagination cần dựa trên giá trị tìm kiếm và vai trò hỗ trợ crawl của từng loại trang, thay vì áp dụng một quy tắc cứng cho toàn bộ website. Có thể phân loại sơ bộ:
- Trang có giá trị tìm kiếm thấp, tính tạm thời cao: kết quả tìm kiếm nội bộ, trang lọc tạm thời theo nhiều tham số, trang sort đặc biệt chỉ phục vụ trải nghiệm người dùng tức thời.
- Trang danh sách không nhắm đến từ khóa cụ thể: các view dữ liệu kỹ thuật, danh sách log, hoặc trang chỉ phục vụ quản trị.
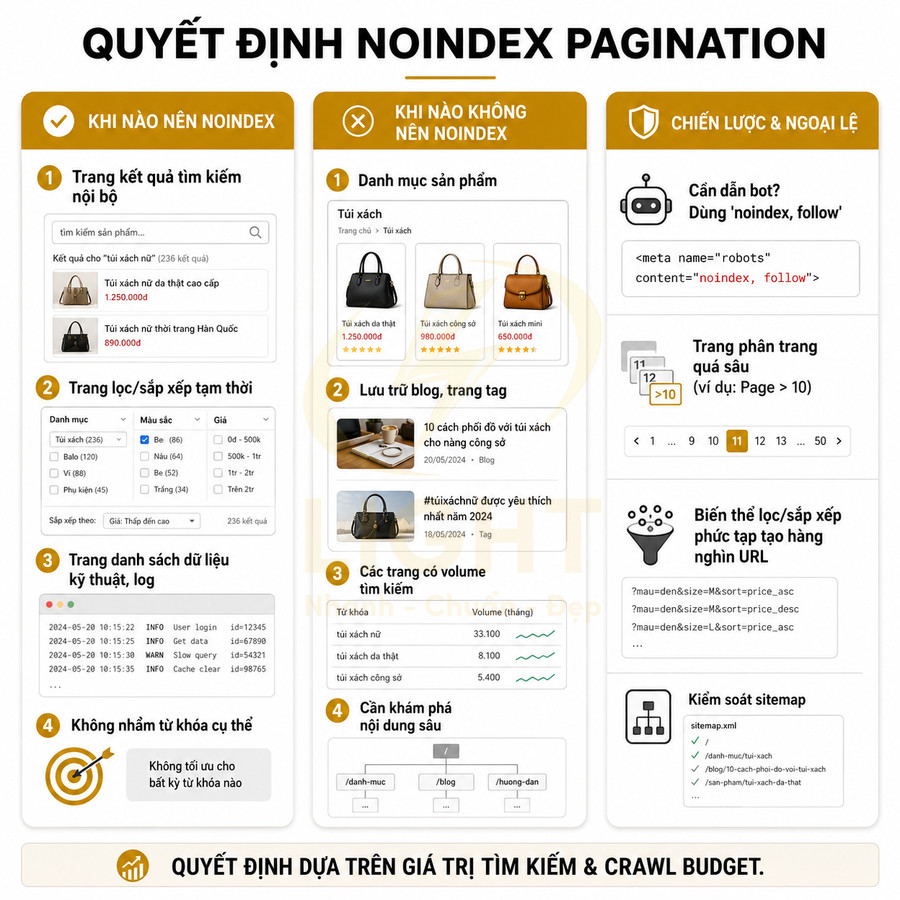
Với các trang như kết quả tìm kiếm nội bộ, trang lọc tạm thời hoặc trang danh sách không nhắm đến từ khóa cụ thể, noindex là hợp lý vì chúng không mang lại giá trị trực tiếp trên SERP, dễ gây trùng lặp và loãng tín hiệu. Tuy nhiên, nếu các trang này vẫn đóng vai trò quan trọng trong việc dẫn bot đến nội dung sâu, nên sử dụng noindex, follow thay vì noindex, nofollow, để Google tiếp tục theo các liên kết bên trong và duy trì khả năng crawl.
Với category sản phẩm, blog archive, trang tag có lượng tìm kiếm nhất định, việc noindex toàn bộ pagination thường không tối ưu. Các loại trang này thường:
- Nhắm đến các nhóm từ khóa rõ ràng (ví dụ “áo sơ mi nam công sở”, “hướng dẫn SEO kỹ thuật”).
- Có nhu cầu khám phá nội dung theo chiều sâu (người dùng sẵn sàng xem nhiều page).
- Đóng vai trò hub trong cấu trúc internal link.
Thay vào đó, có thể chỉ noindex các trang phân trang rất sâu, ít được truy cập, hoặc các biến thể lọc, sắp xếp không cần xuất hiện trên kết quả tìm kiếm, chẳng hạn:
- Page > 10 của một category rất lớn, nơi gần như không có traffic organic.
- Các URL kết hợp nhiều filter/sort tạo ra hàng nghìn biến thể tương tự nhau.
Cách tiếp cận linh hoạt này giúp website vừa tránh trùng lặp và lãng phí crawl budget, vừa giữ được khả năng khám phá nội dung sâu thông qua các trang phân trang có giá trị. Về mặt triển khai, có thể kết hợp:
- Quy tắc noindex dựa trên tham số URL hoặc độ sâu page.
- Internal link chiến lược từ các trang có index đến các cụm nội dung quan trọng nằm sâu.
- Kiểm soát sitemap để chỉ đưa vào các URL có giá trị cao, tránh “ngập” sitemap bằng các biến thể pagination không cần thiết.
Canonical tag cho pagination trong website chuẩn SEO
Thẻ canonical cho pagination cần được thiết lập nhất quán để Google hiểu đúng cấu trúc danh mục và phân bổ tín hiệu SEO hiệu quả. Khi nội dung giữa các trang phân trang khác nhau rõ rệt, mỗi trang nên dùng canonical tự tham chiếu để khẳng định đây là URL độc lập, giúp giữ trọn tín hiệu từ internal link, external link, dữ liệu tương tác và structured data. Cách làm này đặc biệt quan trọng với category sản phẩm, blog archive và các listing lớn, đồng thời giảm rủi ro trùng lặp do tham số URL, trailing slash hay biến thể kỹ thuật.
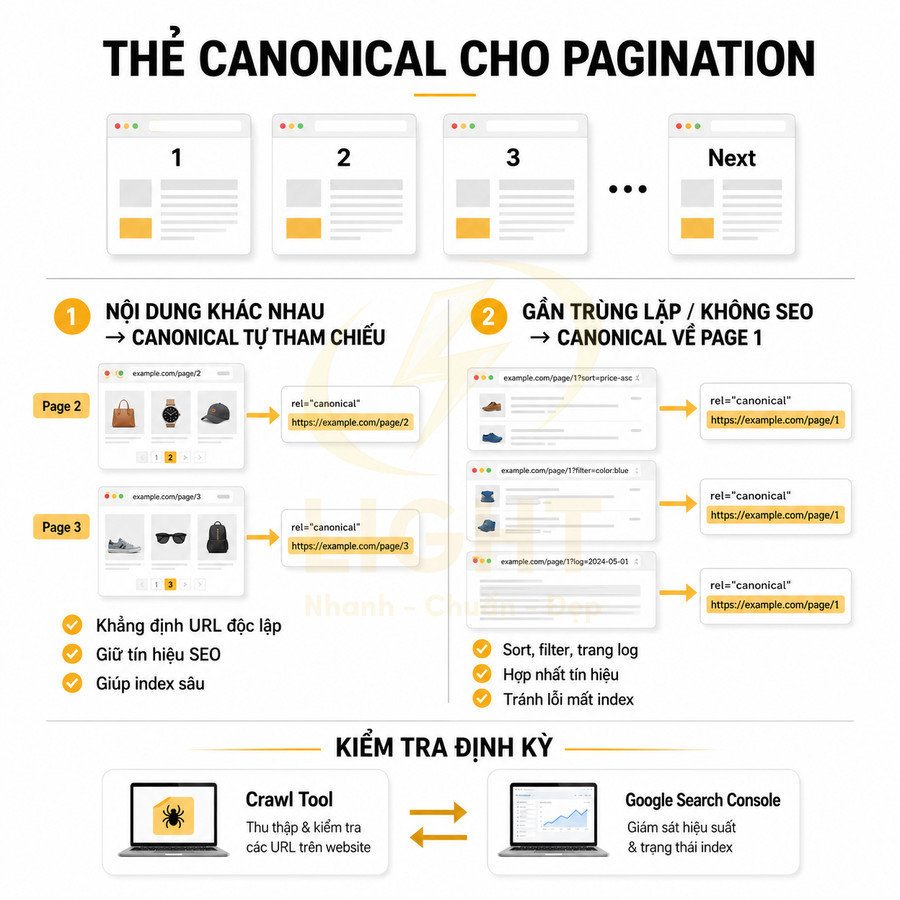
Trong một số trường hợp near-duplicate hoặc trang không phục vụ mục tiêu SEO (sort, filter, log, feed…), có thể canonical về page 1 hoặc URL gốc. Tuy vậy, cần tránh cấu hình sai khiến Google bỏ qua các page sâu, làm mất index sản phẩm, bài viết quan trọng. Việc kiểm tra định kỳ bằng crawl tool kết hợp dữ liệu Google Search Console giúp phát hiện canonical bất thường, điều chỉnh lại mối quan hệ giữa canonical, hreflang, sitemap và internal link, đảm bảo chuỗi pagination được index tối ưu.
Mỗi trang phân trang nên canonical về chính nó khi nội dung khác nhau
Trong hầu hết các trường hợp, mỗi trang phân trang nên có thẻ canonical trỏ về chính URL của nó. Lý do cốt lõi là nội dung hiển thị trên page 1, page 2, page 3… không giống nhau; mỗi trang chứa một tập hợp item riêng, một tập hợp URL con riêng (product detail, bài viết, landing page…), nên không thể xem là bản sao trùng lặp. Về mặt thuật toán, Google đánh giá từng URL dựa trên nội dung thực tế được render, vì vậy canonical tự tham chiếu giúp khẳng định với Google rằng đây là một URL độc lập, hợp lệ, cần được xem xét riêng trong quá trình crawl, index và xếp hạng.

Khi một trang phân trang sử dụng canonical tự tham chiếu, các tín hiệu SEO như internal link, external link, dữ liệu tương tác người dùng, structured data… sẽ được gắn trực tiếp với chính URL đó, thay vì bị dồn về một URL khác. Điều này đặc biệt quan trọng với:
- Category sản phẩm có nhiều trang (page 1, 2, 3…)
- Blog archive theo chuyên mục, tag, author, date
- Listing tin tức, bất động sản, việc làm, diễn đàn
Mỗi trang trong chuỗi pagination thường chứa một phần nội dung tổng thể của danh mục, nên việc canonical về chính nó giúp Google hiểu đầy đủ “bề rộng” nội dung của toàn bộ category.
Canonical tự tham chiếu cũng giúp giảm rủi ro khi website có nhiều tham số URL hoặc biến thể truy cập cùng một trang phân trang, ví dụ:
?page=2,&sort=priceasc,&utmsource=…- Đường dẫn có trailing slash và không trailing slash
- Đường dẫn có hoặc không có
index.php,index.html
Trong các trường hợp này, canonical tự tham chiếu về phiên bản URL chuẩn (clean URL, không tham số tracking, không biến thể kỹ thuật) giúp Google hợp nhất tín hiệu về đúng URL mong muốn, tránh phân tán tín hiệu và hạn chế duplicate URL do tham số.
Khi triển khai canonical cho pagination, cần đảm bảo tính nhất quán giữa canonical, hreflang (nếu có), sitemap và internal link. Một số nguyên tắc chuyên sâu:
- Canonical vs. hreflang: Mỗi cặp URL đa ngôn ngữ trong chuỗi pagination phải:
- Canonical tự tham chiếu trong từng ngôn ngữ
- Hreflang trỏ chéo đúng phiên bản tương ứng (page 2 ngôn ngữ A <-> page 2 ngôn ngữ B)
- Canonical vs. sitemap: URL trong sitemap nên là URL chuẩn trùng với canonical. Nếu sitemap liệt kê
/category?page=2nhưng canonical lại trỏ về/category/, Google phải tự quyết định URL chuẩn, làm chậm quá trình index và có thể bỏ qua một số trang sâu. - Canonical vs. internal link: Anchor trong breadcrumb, menu, link phân trang (pagination component) nên trỏ tới đúng URL chuẩn. Nếu internal link trỏ tới một URL khác với canonical, Google nhận tín hiệu mâu thuẫn, làm giảm độ tin cậy của cấu trúc site.
Một cấu trúc canonical rõ ràng, tự tham chiếu cho từng trang phân trang là nền tảng để Google hiểu đúng cấu trúc danh mục, phân bổ tín hiệu SEO hợp lý và crawl sâu hơn vào các URL chi tiết nằm ở các page sau.
Canonical về page 1 chỉ phù hợp khi các trang phân trang gần như trùng lặp hoặc không cần index
Có một số trường hợp đặc biệt, canonical các trang phân trang về page 1 là chấp nhận được, ví dụ khi các trang này gần như trùng lặp nội dung, chỉ thay đổi rất ít item hoặc chỉ là biến thể hiển thị không mang thêm giá trị nội dung mới. Về bản chất, Google coi các URL này là “near-duplicate” và việc hợp nhất tín hiệu về page 1 không làm mất mát thông tin quan trọng.

Tuy nhiên, điều này hiếm khi xảy ra với category sản phẩm hoặc blog archive, nơi mỗi trang thường chứa danh sách item khác nhau. Với các listing dạng này, canonical về page 1 có thể gây ra:
- Giảm khả năng index các item nằm ở page sâu (page 3, 4, 5…)
- Giảm khả năng xuất hiện của các trang phân trang trong kết quả tìm kiếm khi người dùng tìm theo truy vấn rộng (ví dụ: “áo thun nam giá rẻ” có thể phù hợp với page 3 hơn page 1)
- Phân bổ tín hiệu internal link không tối ưu, vì toàn bộ link từ page 2, 3, 4… đều dồn canonical về page 1
Canonical về page 1 thường phù hợp hơn với:
- Các trang lọc, sắp xếp (faceted navigation, sort, filter) mà website không muốn index riêng, ví dụ:
/category?sort=price_asc/category?color=red&size=m
- Các trang phân trang tự động sinh ra nhưng không phục vụ mục tiêu SEO, chẳng hạn:
- Danh sách log, lịch sử, feed nội bộ
- Trang archive theo ngày quá chi tiết (theo giờ, theo phút)
Khi quyết định canonical về page 1, website cần đánh giá kỹ các câu hỏi chuyên môn:
- Người dùng có nhu cầu truy cập trực tiếp vào các trang phân trang đó từ Google không? Nếu người dùng chỉ cần page 1, hoặc các page sau không mang thêm giá trị tìm kiếm, canonical về page 1 có thể chấp nhận được.
- Các trang này có giúp Google khám phá thêm URL mới không? Nếu các page sau chỉ lặp lại cùng một nhóm URL hoặc chỉ thay đổi thứ tự hiển thị, giá trị crawl discovery thấp, có thể hợp nhất về page 1.
- Việc hợp nhất tín hiệu về page 1 có mang lại lợi ích rõ ràng? Ví dụ: tập trung toàn bộ link equity vào một URL mạnh nhất, phục vụ mục tiêu xếp hạng cho một truy vấn chính.
Nếu câu trả lời cho các câu hỏi trên không rõ ràng, giải pháp an toàn hơn là canonical tự tham chiếu, kết hợp với chiến lược noindex, kiểm soát crawl bằng robots.txt, hoặc hạn chế tạo biến thể URL nếu cần.
Canonical sai khiến Google bỏ qua sản phẩm, bài viết hoặc URL nằm ở trang sâu
Khi canonical được cấu hình sai, ví dụ canonical của page 3 trỏ về một URL không liên quan hoặc về một trang đã bị noindex, Google có thể bỏ qua toàn bộ trang phân trang đó trong quá trình index. Về mặt kỹ thuật, Google coi canonical là gợi ý mạnh về URL chuẩn; nếu canonical trỏ tới một URL không nên index, Google có thể:
- Không index URL phân trang hiện tại
- Giảm crawl depth đối với các link nằm trên trang đó
- Bỏ qua hoặc giảm giá trị internal link trỏ tới sản phẩm, bài viết nằm trên page sâu

Trên các website thương mại điện tử lớn, chỉ một lỗi canonical nhỏ trong template pagination cũng có thể ảnh hưởng đến hàng nghìn URL sản phẩm. Ví dụ:
- Canonical của tất cả page 2, 3, 4… trỏ nhầm về một URL tĩnh (ví dụ: trang giới thiệu)
- Canonical của page 3, 4… trỏ về page 2 thay vì chính nó
- Canonical trỏ về URL đã bị gắn
noindexhoặc bị chặn crawl
Hệ quả là nhiều sản phẩm chỉ xuất hiện ở các page sâu sẽ không được index đầy đủ, dẫn đến sụt giảm traffic organic và doanh thu đáng kể.
Để tránh rủi ro, đội ngũ SEO và kỹ thuật cần xây dựng quy trình kiểm tra định kỳ cấu hình canonical trên các trang phân trang, đặc biệt sau khi:
- Thay đổi theme, template frontend
- Cập nhật hoặc cài mới plugin SEO, plugin pagination
- Chuyển đổi hoặc nâng cấp hệ thống CMS, framework
Việc sử dụng các công cụ crawl chuyên sâu giúp phát hiện nhanh các mẫu canonical bất thường, như:
- Canonical trỏ về URL 404 hoặc 410
- Canonical trỏ về URL khác domain (cross-domain canonical không chủ đích)
- Canonical vòng lặp (URL A canonical sang B, B canonical ngược lại A)
- Canonical trỏ về URL có redirect 3xx thay vì URL đích cuối cùng
Khi canonical được thiết lập chính xác, pagination sẽ hỗ trợ tốt cho quá trình index, giúp Google crawl sâu hơn, hiểu rõ cấu trúc danh mục và phân bổ tín hiệu nội bộ hiệu quả, thay vì trở thành điểm nghẽn kỹ thuật.
Kiểm tra canonical pagination bằng crawl tool và Google Search Console
Để đảm bảo canonical cho pagination hoạt động đúng, cần kết hợp công cụ crawl và dữ liệu từ Google Search Console. Các công cụ như Screaming Frog, Sitebulb, JetOctopus hoặc các crawler tương tự có thể quét toàn bộ website, nhận diện pattern URL phân trang (ví dụ: ?page=, /page/2/) và liệt kê canonical tương ứng.

Một số bước kiểm tra chuyên sâu với crawl tool:
- Lọc toàn bộ URL phân trang (theo pattern URL)
- Xuất danh sách cột:
- URL thực tế
- Canonical URL
- Status code của canonical (200, 3xx, 4xx, 5xx)
- Meta robots (index/noindex)
- Tạo báo cáo các trường hợp:
- Canonical không tự tham chiếu mà không có lý do rõ ràng
- Canonical trỏ về page 1 trong khi nội dung khác biệt rõ rệt
- Canonical trỏ về URL noindex, 404, hoặc khác domain
- Canonical trùng lặp bất thường giữa các page khác nhau
Trong Google Search Console, phần Coverage và Page indexing cung cấp thông tin về các URL bị loại khỏi chỉ mục do các trạng thái như “Duplicate, Google chose different canonical than user” hoặc “Alternate page with proper canonical tag”. Khi nhiều trang phân trang rơi vào các trạng thái này, có thể:
- Google không đồng ý với canonical do website khai báo (chọn canonical khác)
- Google coi các page phân trang là near-duplicate và hợp nhất về một URL khác
- Cấu trúc canonical, internal link, sitemap đang gửi tín hiệu mâu thuẫn
Kết hợp dữ liệu từ crawl tool và Search Console giúp xây dựng một bức tranh đầy đủ về cách Google hiểu và xử lý chuỗi pagination. Từ đó, có thể:
- Điều chỉnh canonical để phù hợp hơn với cách Google đánh giá nội dung
- Tối ưu indexability cho các page sâu có giá trị SEO cao
- Giảm số lượng URL bị gắn nhãn duplicate hoặc alternate không mong muốn
Rel next/prev và cách Google hiện xử lý chuỗi phân trang
Google hiện không còn dùng rel="next"/"prev" như tín hiệu chính để hợp nhất chuỗi phân trang, nên trọng tâm tối ưu đã chuyển sang cách website tổ chức cấu trúc và luồng liên kết. Pagination được đánh giá trong bối cảnh tổng thể: kiến trúc thông tin, internal link, canonical, sitemap và cấu trúc URL. Các trang phân trang cần được crawl dễ dàng, tránh bị “mồ côi”, có canonical nhất quán và pattern URL rõ ràng để Google suy luận thứ tự trang, phân bổ PageRank và chọn URL phù hợp cho từng truy vấn. Rel next/prev vẫn hữu ích cho trình duyệt, accessibility và một số search engine khác, nhưng chỉ đóng vai trò bổ trợ, không thể thay thế một hệ thống internal link và kiến trúc site được thiết kế tốt.

Rel next/prev không còn là tín hiệu hợp nhất index chính của Google
Trong giai đoạn trước 2019, Google từng khuyến nghị mạnh mẽ việc sử dụng thuộc tính rel="next" và rel="prev" trong thẻ <link> ở phần <head> để khai báo mối quan hệ tuần tự giữa các trang trong chuỗi pagination (ví dụ: page 1, page 2, page 3…). Mục tiêu là giúp Google hiểu rằng các URL này thuộc cùng một tập nội dung, từ đó có thể hợp nhất tín hiệu, phân phối PageRank và lựa chọn trang đại diện phù hợp để hiển thị trên kết quả tìm kiếm. Rel=next/prev từng được Google giới thiệu như cách khai báo quan hệ giữa các URL trong một chuỗi phân trang, tương tự việc giúp Google hiểu các component URL thuộc cùng một series. Tuy nhiên, trọng tâm hiện nay không nên đặt vào một thẻ kỹ thuật đơn lẻ, mà vào internal link, canonical, URL pattern, sitemap và nội dung thực tế trên từng page. Việc giữ next/prev đúng cú pháp có thể hỗ trợ trình duyệt, accessibility hoặc hệ thống crawler khác, nhưng không thể thay thế một cấu trúc pagination có href crawlable, canonical nhất quán và page sâu không bị cô lập.

Tuy nhiên, Google đã chính thức xác nhận rằng họ không còn sử dụng rel="next"/"prev" như một tín hiệu đặc biệt để hợp nhất hoặc xử lý chuỗi phân trang. Điều này không có nghĩa là các thẻ này trở nên “sai” về mặt kỹ thuật, mà chỉ đơn giản là Google không còn dựa vào chúng như một cơ chế ưu tiên để hiểu cấu trúc chuỗi. Thay vào đó, Google chuyển sang đánh giá dựa trên:
- Internal link giữa các trang category, hub page và các trang con.
- Cấu trúc URL thể hiện rõ thứ tự và mối quan hệ phân cấp.
- Thẻ canonical được khai báo chính xác, nhất quán.
- Nội dung thực tế trên từng trang (context, pattern, anchor text).
Trong thực tế crawl và index, Googlebot sẽ:
- Thu thập tất cả các URL pagination mà nó tìm thấy qua internal link, sitemap, breadcrumb, menu.
- Phân tích pattern URL (ví dụ:
/category/page/2/,?page=3) để suy luận chuỗi. - Đánh giá mức độ trùng lặp nội dung giữa các trang phân trang và trang category chính.
- Quyết định trang nào phù hợp nhất để xếp hạng cho từng truy vấn (có thể là page 1, một trang sâu hơn, hoặc một trang sản phẩm/bài viết cụ thể).
Việc Google ngừng sử dụng rel next/prev như một tín hiệu riêng biệt khiến nhiều website phải điều chỉnh chiến lược pagination. Thay vì “kỳ vọng” rằng chỉ cần thêm cặp thẻ này là Google sẽ tự động hiểu và hợp nhất chuỗi, các website cần đầu tư nhiều hơn vào:
- Thiết kế kiến trúc thông tin (information architecture) rõ ràng, có logic.
- Luồng internal link giúp bot dễ dàng đi từ trang tổng quan đến từng trang con và ngược lại.
- Quy tắc canonical nhất quán, tránh xung đột giữa các trang phân trang.
- Trải nghiệm người dùng (UX) trên chuỗi phân trang, đặc biệt với site thương mại điện tử, blog lớn, forum.
Cách tiếp cận này phù hợp với xu hướng chung của Google: đánh giá website dựa trên tổng thể cấu trúc, nội dung và trải nghiệm, thay vì dựa vào một vài “tín hiệu kỹ thuật” đơn lẻ. Pagination vì thế vẫn rất quan trọng, nhưng vai trò của nó được đặt trong bối cảnh rộng hơn của toàn bộ hệ thống internal link và kiến trúc site.
Website vẫn có thể dùng next/prev cho trình duyệt, accessibility và công cụ tìm kiếm khác
Mặc dù Google không còn sử dụng rel next/prev như trước, các thẻ này vẫn có giá trị trong nhiều ngữ cảnh khác ngoài Google Search. Về mặt chuẩn web, rel="next" và rel="prev" là những giá trị hợp lệ trong thẻ <link> và có thể được các user agent khác nhau diễn giải để cải thiện trải nghiệm người dùng.

Một số trường hợp sử dụng điển hình:
- Trình duyệt: Một số trình duyệt hoặc extension có thể tận dụng rel next/prev để cung cấp phím tắt “Next page” / “Previous page”, hoặc để preload trang tiếp theo nhằm tăng tốc độ tải.
- Công cụ hỗ trợ truy cập (accessibility): Trình đọc màn hình (screen reader) hoặc các công cụ hỗ trợ người khiếm thị có thể dùng thông tin này để thông báo cho người dùng rằng đang có chuỗi trang và hỗ trợ di chuyển tuần tự.
- Công cụ tìm kiếm khác: Một số search engine nhỏ, công cụ tìm kiếm nội bộ (site search), hoặc hệ thống index riêng (enterprise search, intranet) vẫn có thể sử dụng rel next/prev như một tín hiệu để hiểu chuỗi nội dung.
Về mặt SEO, việc giữ lại rel next/prev:
- Không gây hại nếu được triển khai đúng cú pháp và không mâu thuẫn với canonical.
- Không nên được xem là giải pháp chính để tối ưu pagination cho Google.
Cách triển khai phổ biến trong phần <head> của các trang phân trang:
- Trang 1:
<link rel="next" href="https://example.com/category/page/2/">
- Trang 2:
<link rel="prev" href="https://example.com/category/"><link rel="next" href="https://example.com/category/page/3/">
- Trang cuối:
<link rel="prev" href="https://example.com/category/page/n-1/">
Trong bối cảnh hiện tại, rel next/prev nên được xem như một yếu tố bổ trợ cho trải nghiệm và khả năng truy cập, chứ không phải “trụ cột” SEO. Trọng tâm tối ưu hóa cho pagination vẫn phải nằm ở:
- Internal link (menu, breadcrumb, block “sản phẩm liên quan”, “bài viết mới nhất”…).
- Canonical tự tham chiếu hoặc theo chiến lược rõ ràng.
- Sitemap (đặc biệt là XML sitemap) được cập nhật và ưu tiên URL quan trọng.
- Cấu trúc URL nhất quán, dễ hiểu cho cả người dùng lẫn bot.
SEO pagination hiện cần ưu tiên internal link, canonical, sitemap và cấu trúc URL rõ ràng
Khi rel next/prev không còn là tín hiệu đặc biệt cho Google, chiến lược SEO pagination hiệu quả cần xoay quanh bốn trụ cột kỹ thuật chính: internal link, canonical, sitemap và cấu trúc URL. Mỗi trụ cột đóng một vai trò riêng trong việc giúp Googlebot crawl, hiểu và index chuỗi phân trang một cách tối ưu.

1. Internal link
Internal link là “mạch máu” của pagination. Một hệ thống liên kết nội bộ tốt sẽ:
- Cho phép Googlebot đi từ trang category/hub đến từng trang phân trang và đến từng sản phẩm/bài viết mà không bị “ngắt quãng”.
- Phân phối PageRank từ các trang có nhiều backlink (thường là category/hub) xuống các trang sâu hơn.
- Giúp Google hiểu được mức độ ưu tiên của từng URL dựa trên số lượng và chất lượng internal link trỏ đến.
Các thực hành tốt:
- Hiển thị rõ ràng block pagination (1, 2, 3, Next, Previous) dưới dạng HTML crawlable, không ẩn hoàn toàn sau JavaScript khó render.
- Liên kết từ category/hub page đến một số sản phẩm/bài viết nổi bật trên các trang sâu (không chỉ page 1) để đảm bảo nội dung mới không bị “chôn vùi”.
- Sử dụng breadcrumb để thể hiện mối quan hệ phân cấp và cung cấp thêm đường dẫn nội bộ.
2. Canonical
Canonical giúp Google xác định URL chuẩn cho mỗi trang, tránh trùng lặp và nhầm lẫn. Với pagination, có hai chiến lược chính:
- Canonical tự tham chiếu cho từng trang phân trang:
- Page 1 canonical đến chính nó.
- Page 2 canonical đến page 2, page 3 canonical đến page 3, v.v.
- Phù hợp khi mỗi trang phân trang chứa tập nội dung riêng (sản phẩm/bài viết khác nhau) và đều có giá trị index.
- Canonical về page 1:
- Tất cả các trang phân trang canonical về page 1.
- Chỉ nên dùng trong các trường hợp rất đặc biệt, khi các trang sau gần như không mang thêm giá trị nội dung riêng biệt.
- Dễ gây mất index các sản phẩm/bài viết nằm ở trang sâu nếu áp dụng sai.
Trong đa số website thương mại điện tử, blog, listing lớn, chiến lược an toàn và hiệu quả hơn là canonical tự tham chiếu cho từng trang phân trang, kết hợp với internal link mạnh đến các item quan trọng.
3. Sitemap
XML sitemap đóng vai trò như “bản đồ” giúp Google phát hiện nhanh các URL quan trọng. Với pagination, không nhất thiết phải liệt kê mọi trang phân trang trong sitemap, đặc biệt khi số lượng trang rất lớn.
Cách tiếp cận thường dùng:
- Tập trung sitemap vào:
- Trang sản phẩm, bài viết, landing page quan trọng.
- Các category/hub page chính.
- Không bắt buộc đưa từng page 2, page 3… của category vào sitemap, miễn là chúng được internal link tốt và Google có thể crawl qua luồng liên kết.
- Cập nhật
<lastmod>hợp lý để Google ưu tiên crawl lại các URL thay đổi thường xuyên.
4. Cấu trúc URL
Một cấu trúc URL rõ ràng giúp cả bot lẫn người dùng hiểu vị trí của từng trang trong hệ thống. Các pattern phổ biến và thân thiện với SEO:
/category/(page 1) và/category/page/2/,/category/page/3/…/blog/và/blog/page/2/…- Hoặc dạng query:
/category/?page=2, miễn là:- Tham số
pageđược xử lý ổn định, không tạo ra URL trùng lặp. - Không kết hợp quá nhiều tham số gây bùng nổ số lượng URL (faceted navigation).
- Tham số
Các trang phân trang quan trọng nên:
- Có canonical tự tham chiếu rõ ràng.
- Có title và meta description riêng, thể hiện thứ tự trang (ví dụ: “Category X – Page 2”).
- Được liên kết từ category chính hoặc hub page, không bị “mồ côi” (orphan page).
Khi bốn yếu tố này được triển khai đồng bộ, pagination sẽ hỗ trợ tốt cho cả crawl, index và trải nghiệm người dùng, ngay cả khi không còn dựa vào rel next/prev như một tín hiệu đặc biệt.
Không nên phụ thuộc vào next/prev để Google hiểu toàn bộ chuỗi phân trang
Việc Google không còn sử dụng rel next/prev như trước là một lời nhắc quan trọng rằng không nên phụ thuộc vào một tín hiệu kỹ thuật duy nhất để truyền đạt cấu trúc website. Ngay cả khi website vẫn sử dụng rel next/prev, chúng chỉ nên được coi là lớp thông tin bổ sung, không phải nền tảng chính của chiến lược SEO pagination.

Nếu:
- Internal link yếu, nhiều trang phân trang hoặc sản phẩm/bài viết bị “mồ côi”.
- Canonical khai báo sai, tự mâu thuẫn hoặc dồn hết về page 1 một cách máy móc.
- Cấu trúc URL rối rắm, nhiều tham số, khó suy luận thứ tự.
- Sitemap thiếu sót, không phản ánh đúng các URL quan trọng.
thì rel next/prev, dù được khai báo đúng, cũng không thể cứu vãn hiệu quả SEO của pagination. Google sẽ vẫn gặp khó khăn trong việc crawl sâu, phân bổ crawl budget, hiểu mối quan hệ giữa các trang và lựa chọn URL phù hợp để xếp hạng.
Thay vì tập trung quá nhiều vào rel next/prev, đội ngũ SEO nên đầu tư vào việc thiết kế kiến trúc thông tin hợp lý, đảm bảo mỗi trang phân trang và mỗi URL nội dung đều nằm trong một mạng lưới liên kết nội bộ chặt chẽ. Một số nguyên tắc thực tiễn:
- Xây dựng hub page hoặc category page mạnh, có nội dung giới thiệu, internal link đến các nhóm nội dung con và một phần nội dung nổi bật từ các trang sâu.
- Đảm bảo mỗi sản phẩm/bài viết quan trọng có ít nhất một đường dẫn nội bộ trực tiếp từ một trang đã được crawl thường xuyên (category, tag, bài viết liên quan…).
- Hạn chế tạo quá nhiều lớp pagination lồng nhau (pagination trong pagination) khiến độ sâu click tăng cao.
- Kiểm soát faceted navigation (lọc theo màu, size, giá…) để tránh tạo ra vô số URL phân trang kết hợp tham số khó quản lý.
Khi cấu trúc tổng thể tốt, Google có thể tự suy luận mối quan hệ giữa các trang mà không cần dựa vào một cặp thẻ cụ thể. Cách tiếp cận này bền vững hơn, phù hợp với các nguyên tắc EEAT, vì website được xây dựng dựa trên logic nội dung, cấu trúc thông tin và trải nghiệm người dùng, thay vì dựa trên “mẹo” kỹ thuật đơn lẻ. Pagination trong bối cảnh đó trở thành một phần tự nhiên của kiến trúc site, hỗ trợ cả người dùng lẫn công cụ tìm kiếm một cách nhất quán và lâu dài.
URL pagination chuẩn SEO và kiểm soát tham số trang
URL phân trang chuẩn SEO cần đảm bảo tính deterministic, mỗi trạng thái nội dung chỉ có một URL duy nhất, đồng thời cấu trúc phải ổn định và dễ mở rộng khi số trang tăng. Có thể dùng dạng thư mục hoặc query string, nhưng bắt buộc triển khai đồng bộ trên toàn site, tránh trộn nhiều pattern cho cùng một trang để không tạo duplicate URL, phân tán tín hiệu và khiến Google chọn sai canonical. Hệ thống cần chuẩn hóa URL ở cả tầng ứng dụng và server, dùng canonical, redirect 301 và sitemap để khẳng định URL chuẩn, đồng thời kiểm soát chặt tham số sort, filter, tracking. Pagination phải crawlable bằng thẻ a href, mỗi trang có URL tĩnh trả về HTTP 200, có thể kết hợp infinite scroll nhưng luôn giữ fallback phân trang truyền thống.

URL phân trang nên nhất quán như /page/2/ hoặc ?page=2
Một URL pagination chuẩn SEO cần đơn giản, nhất quán và dễ hiểu, nhưng ở mức kỹ thuật sâu hơn, nó còn phải đảm bảo tính deterministic (một trạng thái nội dung chỉ tương ứng với một URL chuẩn duy nhất) và khả năng mở rộng khi website tăng số lượng trang. Hai dạng phổ biến là /page/2/ (dạng thư mục, thường gắn với URL rewriting) và ?page=2 (dạng query string). Cả hai đều có thể hoạt động tốt nếu được triển khai đồng bộ trên toàn website, có quy tắc rewrite rõ ràng và mapping 1–1 giữa trạng thái phân trang và URL. URL phân trang cần nhất quán vì crawler và hệ thống phân tích thường phải suy luận nhiều thông tin từ pattern URL. Baykan, Henzinger và Weber (2013) chứng minh rằng URL có thể chứa đủ tín hiệu để hỗ trợ phân loại ngôn ngữ khi nội dung chưa được tải, cho thấy cấu trúc URL không chỉ là yếu tố hiển thị mà còn có giá trị xử lý máy. Với SEO, cùng một trạng thái “page 2” không nên tồn tại đồng thời dưới nhiều dạng như /page/2/, ?page=2, ?p=2 hoặc kèm tracking. Một trạng thái nội dung phải có một URL chuẩn duy nhất, canonical và internal link cùng trỏ về URL đó.

Ở góc độ crawl và index, Google không ưu tiên tuyệt đối dạng thư mục hay tham số, mà quan trọng là:
- Cấu trúc URL ổn định, không thay đổi thường xuyên theo thời gian.
- Không tạo ra nhiều đường dẫn khác nhau dẫn tới cùng một tập nội dung phân trang.
- Canonical, internal link và sitemap cùng “nói một tiếng nói” về URL chuẩn.
Ví dụ, nếu chọn dạng thư mục, toàn bộ hệ thống cần tuân thủ:
- Trang 1: /category/ (hoặc /category/page/1/ nếu bắt buộc, nhưng nên tránh).
- Trang 2: /category/page/2/.
- Trang 3: /category/page/3/, …
Nếu chọn dạng tham số, pattern cần rõ ràng và không bị “nhiễu” bởi các tham số khác:
- Trang 1: /category/ hoặc /category/?page=1 (nên canonical về /category/).
- Trang 2: /category/?page=2.
- Trang 3: /category/?page=3, …
Quan trọng là không nên trộn lẫn nhiều kiểu URL cho cùng một mục đích, ví dụ vừa dùng /page/2/ vừa dùng ?p=2 hoặc ?page=2&start=10 cho cùng một trang. Sự không nhất quán này có thể tạo ra nhiều biến thể URL trùng lặp, gây khó khăn cho Google trong việc xác định URL chuẩn, làm tăng khả năng:
- Google chọn nhầm canonical không mong muốn.
- Phân tán tín hiệu liên kết (link equity) giữa nhiều URL tương đương.
- Index các URL “bẩn” chứa tham số kỹ thuật hoặc tracking.
Khi chọn cấu trúc URL, cần cân nhắc khả năng mở rộng và tích hợp với các tham số khác như sort, filter, tracking. Dạng /page/2/ thường thân thiện với người dùng, dễ đọc, dễ chia sẻ, và thường được ưa chuộng trong các hệ thống CMS có hỗ trợ rewrite tốt. Dạng ?page=2 linh hoạt hơn khi kết hợp với nhiều tham số, đặc biệt trong các hệ thống web app phức tạp, nơi việc thêm, xoá, hoặc thay đổi tham số diễn ra thường xuyên.
Dù chọn dạng nào, website cần đảm bảo rằng các liên kết phân trang luôn sử dụng cùng một mẫu URL, canonical phản ánh đúng URL hiển thị, và không có các biến thể không cần thiết được index. Một số nguyên tắc kỹ thuật chuyên sâu:
- Luôn render link phân trang trong HTML server-side (không chỉ trong JS) với href trỏ tới đúng URL chuẩn.
- Không để các tham số không liên quan (session id, tracking, layout) xuất hiện trong href của pagination.
- Trong sitemap XML, chỉ liệt kê URL chuẩn của từng trang phân trang (không kèm tham số phụ).
- Đảm bảo redirect 301 từ các biến thể không chuẩn (ví dụ /page/2, /page/2//, ?page=02) về đúng URL canonical duy nhất.
Tránh tạo nhiều biến thể URL cho cùng một trang phân trang
Một trong những nguyên nhân chính gây ra duplicate content và lãng phí crawl budget là việc tạo ra nhiều biến thể URL cho cùng một trang phân trang. Ở cấp độ hệ thống, điều này thường xuất phát từ:
- Frontend tự ý gắn thêm tham số vào URL (ví dụ sort, view, layout) mà không có quy ước SEO.
- Tracking được gắn trực tiếp vào href (UTM, click id) thay vì xử lý qua JS hoặc server-side.
- Thiếu canonical nhất quán, khiến mỗi biến thể được xem như một URL độc lập.
Ví dụ, cùng là page 2 nhưng có thể truy cập qua:
- /page/2/
- ?page=2
- ?page=2&utmsource=abc
- ?page=2&sort=asc&view=grid

Nếu không có canonical hoặc noindex phù hợp, Google có thể phải crawl nhiều URL gần như giống hệt nhau, trong khi chỉ một URL là cần thiết cho index. Điều này dẫn tới:
- Crawl budget bị tiêu tốn vào các URL không mang thêm giá trị nội dung.
- Chậm phát hiện và index các trang mới thực sự quan trọng (sản phẩm mới, bài viết mới).
- Khó kiểm soát báo cáo trong Search Console do số lượng URL “near-duplicate” tăng mạnh.
Để tránh tình trạng này, website cần có chiến lược chuẩn hóa URL ở cả tầng ứng dụng và tầng server:
- Chỉ một dạng URL được phép index cho mỗi trang phân trang (ví dụ /category/page/2/).
- Các biến thể khác được canonical về URL chuẩn hoặc noindex nếu không cần thiết.
- Thiết lập redirect 301 từ các pattern sai (ví dụ ?page=2&page=2, ?page=2&unused=1) về URL sạch.
- Đảm bảo canonical không chứa tham số tracking, session, hoặc các tham số chỉ phục vụ UI.
Các tham số tracking như UTM nên được xử lý ở phía phân tích (analytics), không để Google index. Cách tiếp cận chuyên sâu hơn:
- Gắn UTM chỉ trong các chiến dịch ngoài site (email, ads, social), không dùng trong internal link.
- Nếu buộc phải xuất hiện trong URL người dùng thấy, đảm bảo canonical luôn trỏ về URL không có UTM.
- Có thể dùng middleware hoặc reverse proxy để tách tracking ra khỏi URL trước khi lưu log phân tích.
Trong Google Search Console, phần URL Parameters (nếu còn khả dụng) hoặc các quy tắc trên server cũng có thể được sử dụng để kiểm soát cách bot xử lý tham số, giảm thiểu trùng lặp và lãng phí crawl. Tuy nhiên, lớp kiểm soát chính vẫn nên nằm ở:
- Thiết kế URL ngay từ đầu (URL design).
- Canonical và internal linking nhất quán.
- Quy tắc rewrite/redirect rõ ràng trên server (Apache, Nginx, CDN rules).
Tham số sort, filter và tracking cần được kiểm soát để tránh duplicate content
Trên các website thương mại điện tử và thư viện nội dung, tham số sort (sắp xếp), filter (lọc) và tracking thường được sử dụng rộng rãi. Về mặt kỹ thuật, mỗi tổ hợp tham số là một trạng thái khác nhau của cùng một tập dữ liệu, nhưng không phải trạng thái nào cũng có giá trị SEO. Nếu không kiểm soát, mỗi tổ hợp tham số có thể tạo ra một URL mới cho cùng một tập hợp nội dung, dẫn đến hàng nghìn URL trùng lặp hoặc gần trùng lặp.
![]()
Khi kết hợp với pagination, số lượng biến thể URL có thể tăng theo cấp số nhân, ví dụ:
- 5 kiểu sort (giá tăng, giá giảm, mới nhất, bán chạy, tên A–Z).
- 10 filter (màu, size, brand, price range, …).
- 20 trang phân trang.
Trong trường hợp xấu, có thể tạo ra hàng nghìn URL cho cùng một category, trong khi chỉ một phần nhỏ trong số đó thực sự mang lại traffic tìm kiếm. Điều này gây áp lực lớn lên crawl budget và làm rối chỉ mục.
Chiến lược chuẩn SEO là phân loại tham số theo vai trò:
- Tham số tạo nội dung mới có giá trị tìm kiếm: ví dụ filter theo thuộc tính quan trọng (brand, category con, tính năng chính) tạo ra tập sản phẩm đủ lớn, có nhu cầu tìm kiếm rõ ràng. Các URL này có thể được index có chọn lọc, có title, meta, heading tối ưu riêng.
- Tham số chỉ thay đổi cách hiển thị: sort theo giá, theo tên, thay đổi dạng lưới/list, số item trên trang. Các tham số này không tạo nội dung mới mà chỉ thay đổi order hoặc layout, nên được noindex hoặc canonical về URL chuẩn không sort.
- Tham số tracking: utmsource, utmmedium, clickid, gclid, fbclid… chỉ phục vụ phân tích hành vi, tuyệt đối không nên index.
Khi kết hợp với pagination, cần đảm bảo rằng chỉ những tổ hợp tham số thực sự có giá trị SEO mới được phép index, còn lại được kiểm soát chặt chẽ. Một số nguyên tắc chuyên sâu:
- Với filter có giá trị SEO:
- Cho phép index nhưng vẫn giữ pagination sạch (ví dụ /category/brand-x/page/2/ thay vì /category/?brand=x&page=2&sort=price).
- Thiết kế URL thân thiện (URL rewriting) thay vì để filter ở dạng query string phức tạp.
- Với sort:
- Không để sort xuất hiện trong canonical.
- Có thể dùng meta robots noindex,follow cho các URL có sort nếu vẫn cần bot crawl để phát hiện sản phẩm.
- Với tracking:
- Không gắn tracking vào internal link phân trang.
- Nếu bắt buộc, luôn canonical về URL không tracking và có thể chặn crawl bằng robots.txt cho một số pattern tracking nhất định (cân nhắc kỹ để không chặn nhầm).
Pagination URL phải crawlable bằng thẻ a href, không chỉ tải bằng JavaScript
Một yêu cầu kỹ thuật quan trọng là URL pagination phải có liên kết dạng thẻ a href mà Googlebot có thể theo dõi trực tiếp. Ở mức render, Google có thể xử lý JavaScript, nhưng việc phụ thuộc hoàn toàn vào JS để tạo pagination mang lại nhiều rủi ro:
- Google có thể không kích hoạt các event click để tải thêm nội dung (load more, infinite scroll).
- Các URL “ảo” chỉ tồn tại trong state của JS, không có đường dẫn tĩnh để bot truy cập trực tiếp.
- Khó debug và kiểm soát vì kết quả crawl phụ thuộc vào khả năng render JS của bot tại từng thời điểm.

Nếu pagination chỉ được tải thông qua JavaScript, ví dụ nút “Load more” không có URL riêng, hoặc các số trang được render động mà không có href, Google có thể gặp khó khăn trong việc khám phá các trang sâu. Điều này đặc biệt nguy hiểm với các website lớn, nơi phần lớn sản phẩm hoặc bài viết nằm ở các trang phân trang sâu.
Giải pháp chuẩn SEO là đảm bảo mỗi trang phân trang có một URL tĩnh, có thể truy cập trực tiếp, và các nút phân trang sử dụng thẻ a href trỏ đến các URL này. Một số yêu cầu kỹ thuật:
- Mỗi số trang (1, 2, 3, …) là một thẻ <a href="…"> chứ không phải <button> hoặc <span> gắn event JS.
- Nút “Next”, “Previous” cũng phải là <a href> với URL rõ ràng, không chỉ là trigger JS.
- Các URL này phải trả về HTTP 200, nội dung đầy đủ, không phụ thuộc vào JS để load phần chính.
Nếu sử dụng kỹ thuật hiện đại như infinite scroll hoặc load more, cần có fallback dạng pagination truyền thống để Google có thể crawl toàn bộ nội dung mà không cần tương tác. Cách tiếp cận phổ biến:
- Trên giao diện người dùng: hiển thị infinite scroll hoặc nút “Load more” để trải nghiệm mượt mà.
- Trong HTML cơ bản: vẫn render block pagination với các thẻ <a href> tới từng trang.
- JS có thể “ẩn” block pagination với người dùng (hoặc chuyển thành UI khác), nhưng Googlebot vẫn thấy và crawl được.
Cách tiếp cận này vừa đảm bảo trải nghiệm người dùng mượt mà, vừa giữ được khả năng crawl và index ổn định cho công cụ tìm kiếm. Ở mức nâng cao, có thể kết hợp:
- Server-side rendering (SSR) hoặc hybrid rendering để đảm bảo nội dung phân trang có sẵn trong HTML.
- Pre-render hoặc dynamic rendering cho các trang có JS nặng, nhưng vẫn giữ pagination dạng link tĩnh.
- Kiểm tra định kỳ bằng công cụ “URL Inspection” và “View crawled page” trong Search Console để xác nhận Google thấy đầy đủ các link phân trang.
Pagination trên website thương mại điện tử và category sản phẩm
Pagination trong bối cảnh thương mại điện tử vừa là giải pháp chia nhỏ danh sách sản phẩm, vừa là phần quan trọng của kiến trúc SEO. Với số lượng SKU lớn, việc phân trang hợp lý giúp giảm tải HTML, tối ưu hiệu suất Core Web Vitals và tạo cấu trúc URL tuần tự để bot dễ crawl. Mỗi trang phân trang cần được tối ưu title, heading, breadcrumb và hệ thống internal link rõ ràng, đảm bảo người dùng và bot tiếp cận trọn vẹn danh mục.
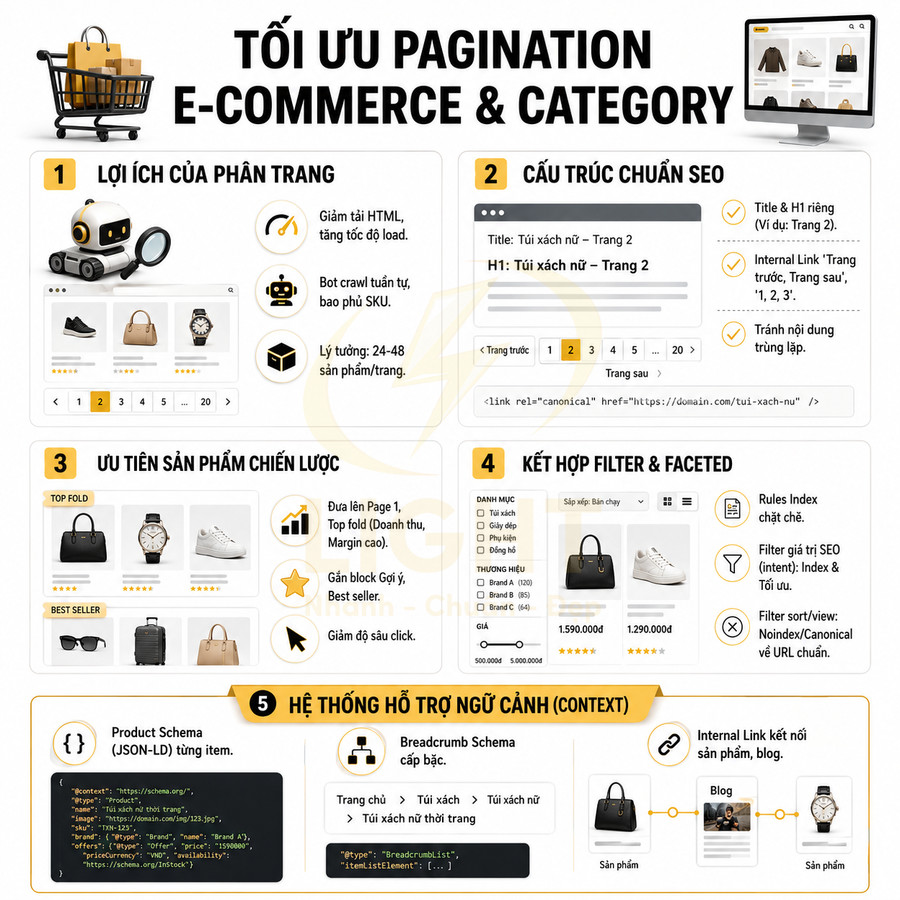
Bên cạnh đó, sản phẩm có doanh thu, lợi nhuận hoặc search demand cao cần được đưa lên các vị trí nông (page 1, khu vực nổi bật) và được hỗ trợ bởi block gợi ý, internal link từ blog/landing page. Khi kết hợp với filter, phải có chiến lược canonical, noindex và rules index chặt chẽ để tránh trùng lặp, lãng phí crawl budget. Cuối cùng, việc triển khai đồng bộ Product schema, breadcrumb và internal link giúp Google hiểu rõ ngữ cảnh danh mục, mối quan hệ giữa các entity, từ đó tăng khả năng index, xếp hạng và chuyển đổi.
Category sản phẩm cần pagination để bot và người dùng tiếp cận toàn bộ sản phẩm
Trong bối cảnh website thương mại điện tử có hàng trăm đến hàng chục nghìn SKU, pagination không chỉ là giải pháp chia nhỏ danh sách sản phẩm mà còn là một thành phần kiến trúc thông tin quan trọng. Về mặt kỹ thuật, pagination giúp:
- Giảm kích thước HTML và số lượng request trên mỗi trang, cải thiện LCP, FID, CLS.
- Phân bổ tải cho server, tránh việc một category duy nhất phải render quá nhiều block sản phẩm.
- Tạo cấu trúc URL tuần tự, giúp bot có lộ trình crawl rõ ràng.

Một category lý tưởng thường giới hạn khoảng 24–48 sản phẩm mỗi trang (tùy ngành và layout). Số lượng này đủ để người dùng có cảm giác “khám phá” nhưng không gây mệt mỏi khi scroll, đồng thời giữ kích thước DOM ở mức hợp lý. Về SEO, mỗi trang phân trang nên có:
- Title có pattern rõ ràng, ví dụ: “Áo thun nam | Trang 2” hoặc “Áo thun nam (Page 2)”.
- H1 giữ nguyên focus chính của category, có thể bổ sung thông tin vị trí trang nếu cần.
- Breadcrumb phản ánh đúng cấp bậc: Trang chủ > Thời trang nam > Áo thun nam > Trang 2.
- Internal link “Trang trước”, “Trang sau”, “Trang 1, 2, 3…” với anchor text rõ ràng.
Về mặt crawl, khi pagination được liên kết tuần tự và có cấu trúc, Googlebot có thể lần lượt đi qua toàn bộ chuỗi trang để phát hiện tất cả sản phẩm. Nếu category chỉ hiển thị một phần sản phẩm (ví dụ chỉ page 1) mà không có đường dẫn đến các page sau, phần còn lại của danh mục có nguy cơ không được index hoặc bị index chậm. Pagination vì vậy là cầu nối giữa “tập sản phẩm đầy đủ” và “khả năng tiếp cận thực tế” của cả người dùng lẫn bot.
Một điểm quan trọng là tránh để pagination tạo ra nội dung mỏng hoặc trùng lặp. Các trang phân trang không nên có nội dung text SEO hoàn toàn giống nhau; có thể giữ phần mô tả chính ở page 1, còn các page sau tập trung vào listing sản phẩm, nhưng vẫn đảm bảo meta title, heading và breadcrumb thể hiện rõ vị trí trong chuỗi. Điều này giúp Google hiểu rằng toàn bộ chuỗi pagination là một cụm nội dung có tổ chức xoay quanh cùng một chủ đề category.
Sản phẩm bán chạy, có lợi nhuận hoặc search demand cao không nên nằm quá sâu
Trong kiến trúc SEO cho thương mại điện tử, độ sâu click (click depth) từ trang chủ hoặc từ các hub page đến từng sản phẩm là một chỉ số quan trọng. Sản phẩm càng nằm sâu trong pagination (ví dụ chỉ xuất hiện từ page 5 trở đi), càng ít nhận được:
- Internal link trực tiếp từ các trang có authority cao (trang chủ, category top, hub page).
- Tần suất crawl từ bot, dẫn đến chậm cập nhật giá, tồn kho, nội dung.
- Cơ hội được người dùng nhìn thấy trong các phiên truy cập ngắn.

Với các sản phẩm có doanh thu cao, biên lợi nhuận tốt hoặc search demand lớn (thường được xác định qua dữ liệu Google Search Console, Google Ads, công cụ keyword research và dữ liệu bán hàng nội bộ), nên ưu tiên:
- Đưa lên các vị trí đầu của category (page 1, top fold nếu có thể).
- Gắn vào các block như “Sản phẩm nổi bật”, “Best seller”, “Gợi ý cho bạn” trên category và trang chủ.
- Liên kết từ các bài blog, guide, landing page nội bộ có traffic tốt về các sản phẩm này.
Chiến lược sắp xếp mặc định (default sorting) nên được thiết kế dựa trên dữ liệu, không chỉ đơn thuần là “mới nhất”. Một số mô hình phổ biến:
- Sắp xếp theo độ phổ biến (số đơn hàng, lượt xem, tỉ lệ chuyển đổi).
- Sắp xếp theo điểm tổng hợp (kết hợp doanh thu, margin, tồn kho, search demand).
- Ưu tiên các sản phẩm có tỷ lệ chuyển đổi cao từ organic để khuếch đại hiệu ứng SEO.
Nhờ vậy, pagination vẫn đảm bảo bao phủ toàn bộ danh mục, nhưng các sản phẩm chiến lược không bị “chôn” ở các page sâu. Về mặt SEO, điều này giúp:
- Tăng số lượng và chất lượng internal link trỏ đến sản phẩm quan trọng.
- Giảm click depth, giúp bot dễ phát hiện và crawl thường xuyên hơn.
- Tăng khả năng các sản phẩm này nhận được backlink tự nhiên do được người dùng nhìn thấy nhiều hơn.
Cách tiếp cận này tạo ra sự đồng bộ giữa mục tiêu kinh doanh (đẩy sản phẩm lợi nhuận cao) và mục tiêu SEO (tăng hiển thị cho sản phẩm có search demand), thay vì để thuật toán sắp xếp mặc định hoặc pagination quyết định ngẫu nhiên.
Filter kết hợp pagination cần canonical, noindex hoặc rules index rõ ràng
Hệ thống filter (faceted navigation) kết hợp với pagination là một trong những nguồn phát sinh URL lớn nhất trên website thương mại điện tử. Mỗi tổ hợp filter (màu, size, brand, price range, material, tag…) cộng với tham số page có thể tạo ra hàng nghìn đến hàng triệu URL khác nhau. Nếu không có chiến lược kiểm soát, hậu quả thường gặp:
- Trùng lặp nội dung giữa các URL chỉ khác nhau nhẹ về filter.
- Lãng phí crawl budget khi bot phải xử lý quá nhiều URL ít giá trị.
- Khó quản lý index, khó theo dõi hiệu suất từng nhóm trang.

Để giải quyết, cần thiết lập rules index rõ ràng cho các nhóm URL filter + pagination:
- Xác định nhóm filter có giá trị SEO: thường là các thuộc tính gắn với intent tìm kiếm cụ thể như màu sắc phổ biến, size phổ biến, brand lớn, khoảng giá có volume tìm kiếm, hoặc combination như “áo thun nam màu đen”, “giày chạy bộ nữ size 38”. Các URL này có thể:
- Được phép index.
- Có title, H1, meta description được tối ưu như landing page chuyên biệt.
- Có nội dung bổ sung (mô tả, FAQ, hướng dẫn chọn size, style guide) để tăng độ liên quan.
- Xác định nhóm filter ít giá trị SEO: ví dụ filter rất chi tiết, ít search demand, hoặc chỉ thay đổi nhẹ thứ tự hiển thị sản phẩm. Các URL này nên:
- Dùng noindex, follow để không cho index nhưng vẫn cho phép bot theo link đến sản phẩm.
- Hoặc sử dụng canonical trỏ về category chính (không filter) hoặc về phiên bản filter chính được chọn làm đại diện.
Khi kết hợp với pagination, cần đảm bảo:
- Các URL filter được phép index có thể có pagination (page=2,3,4…), nhưng nên giới hạn số page nếu danh sách quá dài.
- Các URL filter không được phép index thì toàn bộ chuỗi pagination phía sau cũng phải tuân theo cùng rule (noindex hoặc canonical về URL chuẩn).
- Tránh để nhiều URL khác nhau (ví dụ tham số sắp xếp, view mode) cùng canonical về một URL nhưng lại có nội dung khác biệt lớn, gây tín hiệu nhiễu.
Việc thiết kế hệ thống filter + pagination nên được phối hợp giữa SEO, dev và product để đảm bảo:
- Cấu trúc URL rõ ràng, có thể đọc được (SEO-friendly) cho các filter quan trọng.
- Tham số kỹ thuật (sort, view, tracking) không tạo thêm indexable URL không cần thiết.
- Robots.txt, meta robots, canonical, và sitemap hoạt động đồng bộ, không mâu thuẫn.
Product schema, breadcrumb và internal link hỗ trợ hiểu ngữ cảnh danh mục
Pagination chỉ giải quyết bài toán phân phối sản phẩm theo chiều ngang (nhiều trang). Để Google hiểu sâu hơn về ngữ cảnh và mối quan hệ giữa các entity trên website, cần kết hợp thêm Product schema, breadcrumb và internal link được thiết kế có chủ đích.

Product schema (thường ở dạng JSON-LD) giúp đánh dấu rõ từng sản phẩm trong listing và trên trang chi tiết, bao gồm:
- Tên sản phẩm, mô tả, hình ảnh.
- Giá, currency, tình trạng còn hàng (availability), SKU, brand.
- Rating, review count, offer, variant (màu, size…).
Khi được triển khai đúng, Product schema giúp Google hiểu rằng các item trong pagination không chỉ là text và hình ảnh rời rạc, mà là các entity sản phẩm có thuộc tính rõ ràng, thuộc về một category cụ thể. Điều này hỗ trợ hiển thị rich result, tăng CTR và giúp bot ưu tiên crawl các URL sản phẩm quan trọng.
Breadcrumb đóng vai trò thể hiện cấu trúc phân cấp nội dung. Trên mỗi trang category và mỗi trang sản phẩm, breadcrumb nên phản ánh chính xác đường dẫn:
- Trang chủ > Nhóm ngành > Category > Subcategory > Sản phẩm.
Với pagination, breadcrumb thường không cần hiển thị từng page (tránh rối), nhưng có thể thể hiện vị trí trang trong UI bằng text hoặc component riêng. Về mặt SEO, breadcrumb schema giúp Google hiểu:
- Sản phẩm thuộc category nào, subcategory nào.
- Category nào là cấp cao hơn, category nào là nhánh phụ.
- Mối quan hệ “cha – con” giữa các trang trong hệ thống.
Internal link là lớp kết nối bổ sung, giúp củng cố ngữ cảnh và phân phối authority:
- Từ trang sản phẩm link về category chính, category phụ, hub page liên quan.
- Từ bài blog, guide, landing page nội dung link đến các sản phẩm chủ lực và category tương ứng.
- Từ các block “Sản phẩm liên quan”, “Sản phẩm cùng danh mục”, “Frequently bought together” tạo thêm đường dẫn giữa các sản phẩm trong cùng cụm chủ đề.
Khi Product schema, breadcrumb và internal link được triển khai đồng bộ, pagination không còn là chuỗi trang danh sách rời rạc mà trở thành một phần của mạng lưới nội dung có cấu trúc. Mỗi sản phẩm được đặt trong bối cảnh rõ ràng: thuộc category nào, liên quan đến chủ đề nào, có vai trò gì trong chiến lược kinh doanh. Điều này phù hợp với tiêu chí EEAT, khi website không chỉ hiển thị sản phẩm mà còn cung cấp thông tin có cấu trúc, dễ hiểu cho cả người dùng và công cụ tìm kiếm, giúp tăng khả năng index, xếp hạng và chuyển đổi.
Pagination trên blog, tin tức và thư viện nội dung
Pagination trên blog, tin tức và thư viện nội dung cần được xem như một phần của kiến trúc thông tin, không chỉ là yếu tố giao diện. Với blog archive, phân trang rõ ràng giúp Googlebot lần lượt khám phá toàn bộ bài viết, tránh tình trạng nội dung cũ bị “cô lập” và mất dần giá trị SEO. Cấu trúc URL, số bài trên mỗi trang, liên kết “Trang trước / Trang sau” dạng HTML tĩnh và hạn chế infinite scroll là những yếu tố quan trọng để duy trì dòng chảy nội dung ổn định.

Tuy nhiên, pagination không đủ để bảo vệ các bài evergreen quan trọng. Cần xây dựng hệ thống pillar page – cluster content và block “bài viết liên quan” tối ưu theo chủ đề, giúp các bài cốt lõi luôn nằm trong mạng lưới internal link mạnh, giảm phụ thuộc vào vị trí trên archive.
Với website tin tức, pagination phải hỗ trợ tốc độ index: tin mới cần xuất hiện ở các vị trí dễ crawl như trang chủ, chuyên mục chính, block “Tin mới nhất”, đồng thời được bổ trợ bởi RSS, XML sitemap cập nhật thường xuyên và liên kết chéo giữa các bài cùng sự kiện. Điều này đảm bảo dù bài đã trôi khỏi trang đầu, Google vẫn có nhiều đường dẫn để quay lại crawl và cập nhật.
Cuối cùng, các loại trang danh sách như category, tag, tác giả, archive theo thời gian cần chiến lược pagination nhất quán để tránh trùng lặp nội dung. Category thường là trục chính nên được index đầy đủ, tối ưu title, meta, schema và phân trang rõ ràng. Ngược lại, tag, tác giả, archive có thể được noindex hoặc canonical phù hợp, giới hạn độ sâu phân trang và kiểm soát số lượng tag trên mỗi bài. Sự phân vai rõ ràng giữa trang ưu tiên và trang phụ giúp tiết kiệm crawl budget, tăng topical authority và tạo trải nghiệm điều hướng mạch lạc cho người dùng.
Blog archive cần phân trang rõ để bài cũ không bị cô lập
Trên blog và website tin tức, pagination không chỉ là vấn đề giao diện mà là một phần quan trọng của kiến trúc thông tin và chiến lược SEO. Pagination thường xuất hiện ở trang archive theo chuyên mục, theo tháng, theo năm, và mỗi chuỗi archive này cần được thiết kế sao cho Googlebot có thể lần lượt khám phá toàn bộ nội dung mà không bị “đứt mạch”. Nếu không có pagination rõ ràng, các bài viết cũ có thể bị “cô lập”, chỉ còn được truy cập qua tìm kiếm nội bộ hoặc liên kết ngẫu nhiên. Điều này làm giảm khả năng Googlebot quay lại crawl và cập nhật các bài viết evergreen, đồng thời làm mất cơ hội tận dụng giá trị nội dung cũ cho SEO.
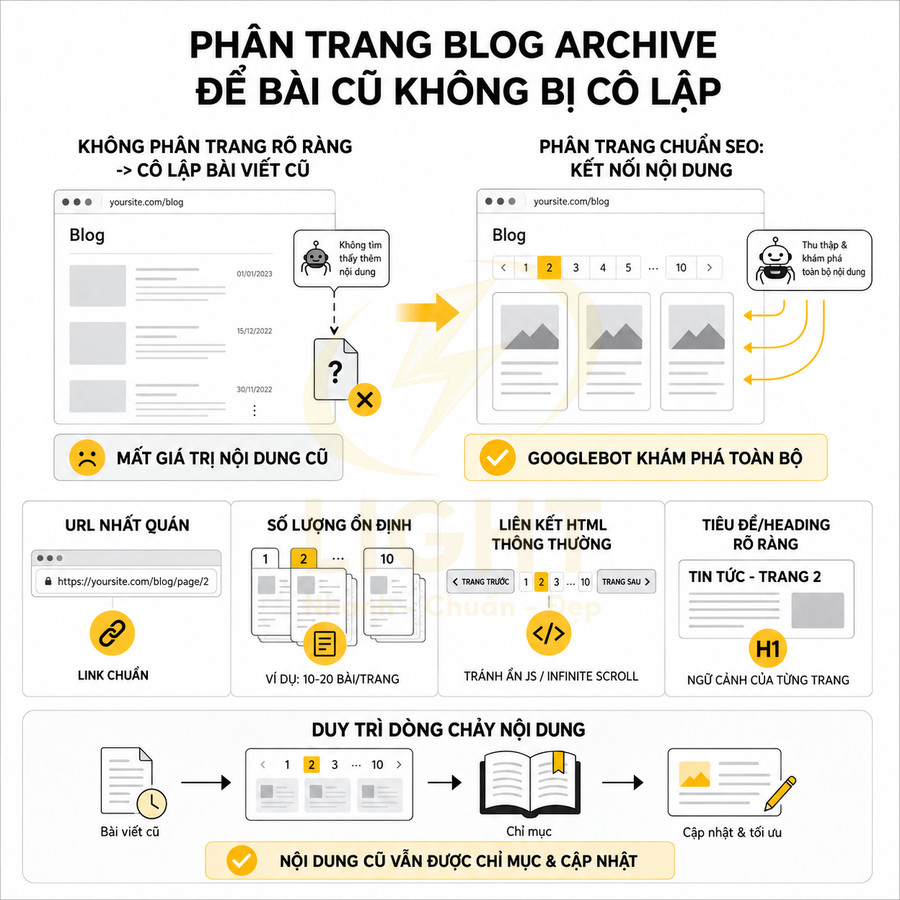
Một cấu trúc blog archive chuẩn SEO cần có pagination với liên kết rõ ràng đến các trang cũ hơn, đồng thời mỗi trang archive nên có title, heading phản ánh đúng nội dung (ví dụ “Tin tức SEO – Trang 2”, “Blog tháng 01/2024 – Trang 3”). Ngoài ra, cần chú ý:
- Mỗi trang archive nên có URL nhất quán, dễ hiểu (ví dụ: /blog/seo/page/2/ thay vì chuỗi query phức tạp).
- Số lượng bài viết trên mỗi trang nên ổn định (ví dụ 10–20 bài/trang) để Google dễ ước lượng độ sâu crawl.
- Các nút điều hướng như “Trang trước”, “Trang sau”, “Trang đầu”, “Trang cuối” nên là liên kết HTML thông thường, tránh ẩn trong JavaScript khó crawl.
- Tránh vô hạn hóa pagination (infinite scroll) mà không có giải pháp fallback dạng liên kết phân trang tĩnh.
Khi đó, Google có thể lần lượt khám phá toàn bộ bài viết trong chuyên mục, không chỉ tập trung vào các bài mới trên trang đầu. Pagination giúp blog duy trì “dòng chảy nội dung” liên tục, tránh tình trạng nội dung cũ bị bỏ quên trong chỉ mục. Về mặt kỹ thuật, có thể tăng hiệu quả crawl bằng cách:
- Đảm bảo các trang archive sâu (trang 3, 4, 5…) vẫn được liên kết từ những điểm quan trọng như sitemap HTML hoặc footer.
- Giữ cho thời gian tải của các trang archive nhẹ, hạn chế script và thành phần nặng để Googlebot crawl nhanh hơn.
- Sử dụng cấu trúc heading rõ ràng (H1 cho tiêu đề archive, H2/H3 cho nhóm nội dung nếu cần) để Google hiểu ngữ cảnh của từng trang phân trang.
Bài viết evergreen quan trọng nên được liên kết thêm từ pillar page và bài liên quan
Pagination trên blog giúp điều hướng theo thời gian hoặc theo danh mục, nhưng không đảm bảo rằng bài viết evergreen quan trọng sẽ luôn ở vị trí dễ thấy. Khi số lượng bài viết tăng lên, các bài evergreen có thể bị đẩy xuống các trang archive sâu hơn, nhận ít traffic và ít internal link hơn. Về mặt SEO, điều này làm suy yếu “PageRank nội bộ” của các bài quan trọng, khiến chúng khó duy trì thứ hạng cao dù nội dung vẫn chất lượng. Pagination theo thời gian không đủ để bảo vệ các bài evergreen vì bài cũ sẽ bị đẩy dần xuống archive sâu, nhận ít internal link hơn. Broder (2002) phân loại nhu cầu tìm kiếm web thành informational, navigational và transactional; bài evergreen thường phục vụ intent informational bền vững, nên không nên chỉ tồn tại trong chuỗi phân trang cũ. Pierre (2001) cũng nhấn mạnh vai trò của metadata và semantic hyperlinks trong việc phân loại website tự động. Vì vậy, bài evergreen cần được liên kết từ pillar page, topic hub, bài liên quan và các trang có authority cao, giúp Google hiểu đây là nội dung trụ cột chứ không phải bài cũ bị chôn trong archive.
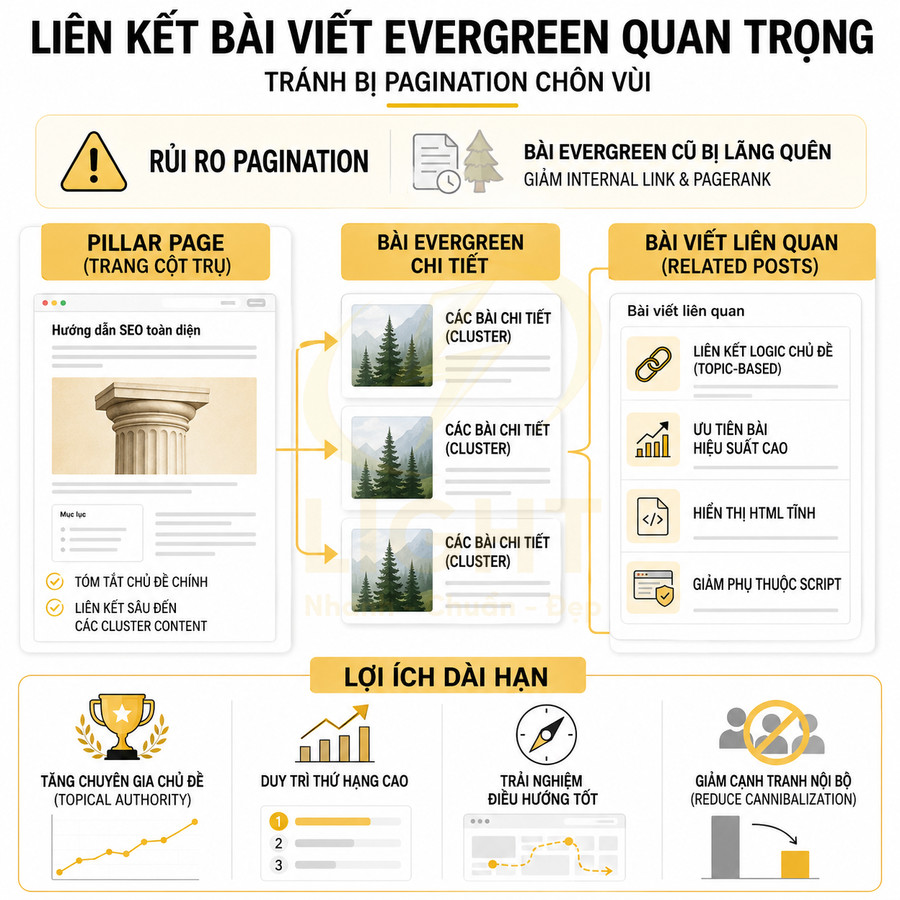
Để khắc phục, website cần xây dựng pillar page hoặc hub page cho từng chủ đề lớn, liên kết đến các bài evergreen quan trọng, đồng thời sử dụng block “bài viết liên quan” trong từng bài. Một pillar page chuẩn thường có các đặc điểm:
- Tập trung vào một chủ đề cốt lõi (ví dụ: “Hướng dẫn SEO Onpage toàn diện”).
- Tóm tắt các khía cạnh chính của chủ đề và dẫn link sâu đến các bài evergreen chi tiết (cluster content).
- Được đặt ở vị trí có nhiều internal link trỏ đến (menu chính, sidebar, footer, trang chủ).
- Có cấu trúc nội dung rõ ràng, sử dụng anchor text giàu ngữ nghĩa khi liên kết đến bài evergreen.
Bên cạnh đó, block “bài viết liên quan” trong từng bài nên được tối ưu:
- Ưu tiên hiển thị các bài evergreen hoặc bài có hiệu suất tốt (nhiều traffic, nhiều backlink) thay vì chỉ bài mới nhất.
- Sử dụng logic liên quan theo chủ đề (topic-based) thay vì chỉ theo tag hoặc ngày đăng.
- Đảm bảo các liên kết này là HTML tĩnh, không phụ thuộc hoàn toàn vào script để Google có thể crawl.
Cách làm này giúp giảm phụ thuộc vào pagination trong việc phân phối traffic và tín hiệu SEO. Các bài evergreen quan trọng luôn được đặt trong một mạng lưới liên kết nội bộ mạnh, dễ được Googlebot crawl thường xuyên và duy trì thứ hạng ổn định. Pagination vẫn đóng vai trò điều hướng theo thời gian hoặc theo danh mục, nhưng không còn là kênh duy nhất để người dùng và bot tiếp cận nội dung cũ. Về lâu dài, cấu trúc pillar–cluster còn giúp:
- Tăng topical authority cho từng chủ đề, vì Google thấy rõ mối liên hệ giữa các bài trong cùng cụm.
- Giảm rủi ro cannibalization khi nhiều bài viết cùng chủ đề cạnh tranh nhau trên SERP.
- Tạo trải nghiệm điều hướng mạch lạc hơn cho người dùng, dẫn dắt họ đi sâu vào nội dung thay vì chỉ lướt qua trang archive.
Tin tức mới cần xuất hiện ở vị trí dễ crawl trước khi bị đẩy xuống trang sâu
Với website tin tức, tốc độ index là yếu tố sống còn. Pagination cần được thiết kế sao cho tin tức mới luôn xuất hiện ở vị trí dễ crawl nhất, thường là trên trang chủ, trang chuyên mục chính và các block “tin mới nhất”. Khi bài viết mới được xuất bản, nó nên được liên kết ngay từ các trang này, trước khi dần dần bị đẩy xuống các trang archive sâu hơn theo thời gian. Nếu pagination hoặc cấu trúc archive không hỗ trợ tốt, tin mới có thể bị “chôn” nhanh chóng, khiến Google phát hiện chậm và mất cơ hội xuất hiện sớm trên SERP, đặc biệt trong Google News hoặc Top Stories.
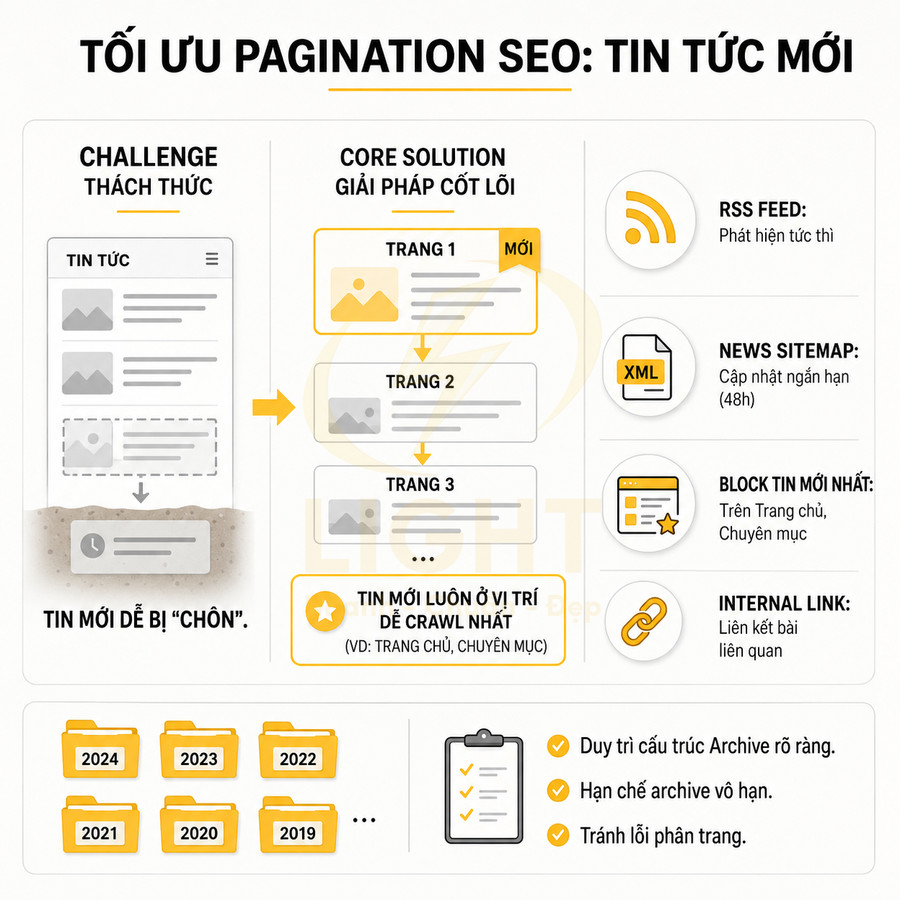
Để tối ưu, website tin tức thường kết hợp pagination với RSS feed, XML sitemap cập nhật thường xuyên, internal link từ bài viết liên quan. Cách triển khai chi tiết có thể bao gồm:
- RSS feed chuyên mục và RSS tổng, cập nhật ngay khi có bài mới, giúp các hệ thống thu thập tin (bao gồm một số dịch vụ của Google) phát hiện nhanh.
- XML sitemap tin tức (news sitemap) với thời gian cập nhật ngắn, chỉ chứa các bài mới trong khoảng thời gian nhất định (ví dụ 48–72 giờ) để Google ưu tiên crawl.
- Đặt block “Tin mới nhất”, “Tin nổi bật” ở các vị trí có nhiều internal link trỏ đến (trang chủ, trang chuyên mục, trang tag quan trọng).
- Liên kết chéo giữa các bài tin liên quan theo chủ đề, sự kiện, timeline để tạo thêm đường dẫn cho Googlebot.
Khi đó, dù bài viết đã rời khỏi trang đầu của chuyên mục, Google vẫn có nhiều đường dẫn để quay lại crawl và cập nhật. Pagination đóng vai trò duy trì cấu trúc archive rõ ràng, trong khi các kênh khác đảm bảo tốc độ phát hiện và cập nhật nội dung mới. Ngoài ra, cần lưu ý:
- Không để số lượng trang archive tin tức tăng vô hạn mà không có chiến lược (ví dụ: gom theo năm, theo quý) để tránh loãng crawl budget.
- Đảm bảo các trang archive cũ vẫn có cấu trúc nhất quán, không bị lỗi phân trang hoặc liên kết gãy, vì Google vẫn có thể quay lại kiểm tra các bài cũ.
- Hạn chế sử dụng các cơ chế lọc, sắp xếp (sort, filter) tạo ra quá nhiều biến thể URL phân trang cho cùng một tập nội dung tin tức.
Trang tác giả, chuyên mục và tag cần pagination nhất quán để tránh trùng lặp
Blog và website tin tức thường có nhiều loại trang danh sách: trang chuyên mục (category), trang tag, trang tác giả, trang archive theo thời gian. Nếu mỗi loại trang này đều có pagination riêng mà không được kiểm soát, cùng một bài viết có thể xuất hiện trên nhiều chuỗi pagination khác nhau, tạo ra nhiều URL danh sách trùng lặp về nội dung. Điều này không chỉ gây khó khăn cho người dùng mà còn làm Google phải xử lý nhiều trang gần giống nhau, lãng phí crawl budget và làm mờ tín hiệu xếp hạng.

Chiến lược chuẩn SEO là xác định loại trang danh sách nào là ưu tiên (thường là category), loại nào chỉ phục vụ điều hướng nội bộ (tag, tác giả, archive theo tháng). Một số nguyên tắc chuyên sâu:
- Category thường là trục chính của kiến trúc nội dung, nên:
- Được index đầy đủ, tối ưu title, meta description, heading, schema (nếu phù hợp).
- Có pagination rõ ràng, nhất quán về URL và cấu trúc liên kết.
- Có nội dung mô tả (category description) giúp Google hiểu chủ đề, không chỉ là danh sách link.
- Tag, tác giả, archive theo tháng thường là trang phụ:
- Có thể để index có chọn lọc (chỉ một số tag quan trọng) và noindex phần còn lại.
- Có thể canonical về trang category hoặc về trang đầu của chính chuỗi archive nếu nội dung quá trùng lặp.
- Pagination trên các trang này nên tuân theo cùng một quy ước URL, tránh tạo thêm tham số không cần thiết.
Pagination trên các trang ưu tiên nên được tối ưu title, meta, canonical rõ ràng, trong khi pagination trên các trang phụ có thể được noindex hoặc canonical về trang chính nếu cần. Sự nhất quán trong cách xử lý pagination cho từng loại trang giúp giảm trùng lặp, tăng hiệu quả crawl và giữ cho cấu trúc nội dung rõ ràng, dễ hiểu. Một số điểm kỹ thuật cần chú ý thêm:
- Không để một bài viết xuất hiện trên quá nhiều tag không cần thiết; mỗi tag tạo thêm một chuỗi pagination tiềm năng.
- Đảm bảo các trang tác giả có giá trị riêng (thông tin tác giả, chuyên môn, liên kết đến profile mạng xã hội) nếu quyết định cho index; nếu chỉ là danh sách bài thì nên cân nhắc noindex.
- Kiểm tra định kỳ các chuỗi pagination dài (ví dụ trang tag có hàng trăm trang) để xem có cần giới hạn độ sâu hoặc gom nhóm lại hay không.
- Giữ cấu trúc internal link từ các trang danh sách ưu tiên (category) mạnh hơn rõ rệt so với trang phụ, giúp Google hiểu đâu là trục chính của site.
Pagination, infinite scroll và load more trong SEO hiện đại
Pagination, infinite scroll và load more đều nhằm giải quyết bài toán phân phối lượng nội dung lớn nhưng mỗi mô hình có tác động SEO khác nhau. Infinite scroll mang lại trải nghiệm cuộn mượt, nhưng nếu chỉ dựa vào JavaScript và không có URL phân trang riêng, Google thường chỉ index phần nội dung đầu. Load more cũng gặp vấn đề tương tự khi nội dung bổ sung không gắn với URL crawlable. Để tối ưu, cần kiến trúc “hybrid”: mỗi nhóm nội dung phải có URL truy cập trực tiếp, liên kết nội bộ dạng <a href> và có thể hiển thị đầy đủ không cần tương tác. Khi đó, infinite scroll hoặc load more chỉ là lớp UX nâng cao, còn lớp nền vẫn là pagination truyền thống, giúp cân bằng giữa trải nghiệm người dùng và khả năng crawl/index.

Infinite scroll cần URL riêng cho từng phần nội dung để Google có thể truy cập
Infinite scroll (cuộn vô hạn) là một pattern UX phổ biến trong các trang listing lớn như blog, category sản phẩm, feed mạng xã hội, đặc biệt trên mobile. Người dùng chỉ cần cuộn xuống là nội dung mới tự động xuất hiện, giảm ma sát so với việc phải bấm sang trang 2, trang 3. Tuy nhiên, về mặt SEO kỹ thuật, infinite scroll thuần JavaScript tiềm ẩn rất nhiều rủi ro nếu không được thiết kế đúng cách. Infinite scroll chỉ an toàn cho SEO khi mỗi phần nội dung có URL phân trang riêng, có thể truy cập trực tiếp. Google khuyến nghị biến infinite scroll thành một paginated series để search engine có thể crawl từng component page; mỗi phần nên có URL riêng, không phụ thuộc vào việc bot phải cuộn như người dùng. Sharma và Murano (2020) cũng cho thấy các kiểu cuộn khác nhau phù hợp với nhiệm vụ khác nhau: infinite scroll có thể hữu ích cho khám phá, nhưng pagination hoặc load more có cấu trúc rõ thường tốt hơn khi người dùng có mục tiêu cụ thể. Infinite scroll nên là lớp UX nâng cao, còn lớp SEO nền phải là pagination crawlable.
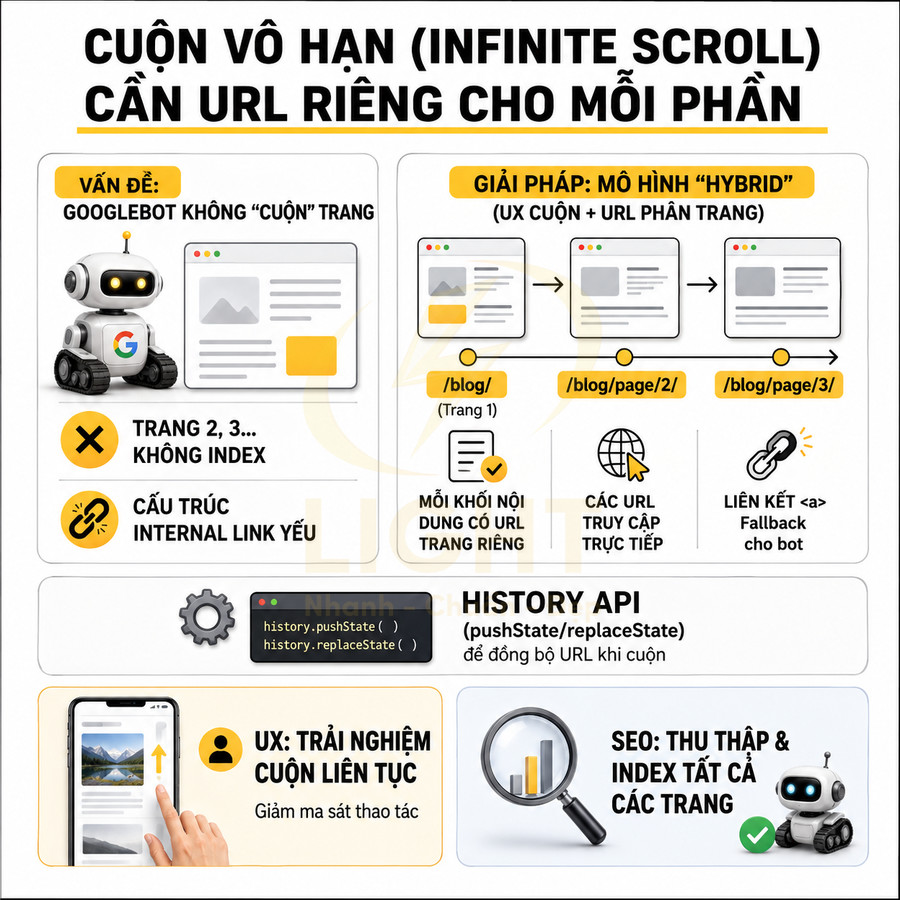
Vấn đề cốt lõi nằm ở chỗ Googlebot và các bot tìm kiếm khác không “cuộn” trang giống người dùng. Dù Google đã hỗ trợ render JavaScript, bot vẫn có giới hạn về thời gian và tài nguyên. Nếu nội dung chỉ xuất hiện sau khi người dùng cuộn đến một vị trí nhất định, nhưng không có URL riêng biệt, crawlable cho từng phần, thì:
- Bot có thể chỉ index phần nội dung đầu tiên (trên màn hình initial load).
- Các sản phẩm/bài viết nằm ở “trang” 2, 3, 4… sẽ không được phát hiện đầy đủ.
- Cấu trúc internal link bị suy yếu, vì không có các liên kết phân trang rõ ràng.
Để infinite scroll thân thiện với SEO, cần triển khai mô hình “hybrid” giữa UX cuộn vô hạn và pagination truyền thống. Nguyên tắc kỹ thuật quan trọng:
- Mỗi “khối” nội dung tương đương một trang phải có URL phân trang riêng, ví dụ:
- /blog/ (trang 1)
- /blog/page/2/
- /blog/page/3/
- Các URL này phải có thể truy cập trực tiếp, hiển thị đầy đủ nội dung tương ứng mà không cần cuộn hay tương tác.
- Trong HTML, cần có các liên kết <a href> crawlable trỏ tới /page/2/, /page/3/… ở dạng fallback (ví dụ block pagination ở cuối trang, hoặc trong một khối chỉ hiển thị cho bot).
Về mặt front-end, có thể sử dụng History API (pushState/replaceState) để đồng bộ URL với vị trí cuộn. Khi người dùng cuộn đến phần nội dung tương ứng với /page/2/, script sẽ:
- Tải nội dung của /page/2/ qua Ajax hoặc prefetch.
- Append nội dung vào cuối danh sách hiện tại.
- Cập nhật URL trên thanh địa chỉ thành /page/2/ mà không reload trang.
Cách làm này tạo ra hai “lớp” trải nghiệm:
- Lớp UX: người dùng cảm nhận như đang cuộn vô hạn, không bị ngắt quãng bởi việc chuyển trang.
- Lớp SEO: Google vẫn nhìn thấy một cấu trúc pagination truyền thống, với các URL phân trang rõ ràng, có liên kết nội bộ, có thể crawl và index độc lập.
Khi triển khai, cần chú ý:
- Đảm bảo mỗi URL phân trang có title, meta, heading hợp lý, tránh trùng lặp hoàn toàn.
- Tránh để nội dung quan trọng chỉ tồn tại trong “phiên bản cuộn vô hạn” mà không có bản tương ứng trên URL phân trang.
- Kiểm tra bằng công cụ “URL Inspection” và “View crawled page” để xác nhận Google thực sự thấy được nội dung ở các URL /page/2/, /page/3/…
Load more nên có fallback dạng pagination crawlable
Nút “Load more” là một biến thể UX khác, thường được dùng khi muốn giảm độ dài trang ban đầu nhưng vẫn tránh cảm giác “bị chia nhỏ” như pagination cổ điển. Người dùng chủ động bấm nút để tải thêm nội dung, thay vì cuộn tự động như infinite scroll. Tuy nhiên, về bản chất kỹ thuật, nếu “Load more” chỉ là một request Ajax không gắn với URL riêng, vấn đề SEO sẽ tương tự:
- Googlebot không bấm nút “Load more”, nên chỉ index phần nội dung trước nút.
- Các item được load thêm không có URL phân trang tương ứng, dẫn đến bị bỏ sót.
- Không có cấu trúc phân trang rõ ràng để phân phối PageRank và anchor text.

Để tối ưu SEO, load more cần có fallback dạng pagination crawlable. Về mặt kiến trúc, có thể thiết kế như sau:
- Mỗi lần “load thêm” tương ứng với một URL phân trang:
- Lần đầu: /category/ (page 1)
- Lần load more thứ nhất: /category/page/2/
- Lần load more thứ hai: /category/page/3/
- Trong HTML gốc, vẫn tồn tại block pagination hoặc danh sách link:
- <a href="/category/page/2/">2</a>
- <a href="/category/page/3/">3</a>
Về mặt tương tác người dùng, khi bấm “Load more”:
- Front-end gửi request đến /category/page/2/ (hoặc API tương đương nhưng vẫn dựa trên cùng nguồn dữ liệu).
- Server trả về HTML hoặc JSON chứa danh sách item của trang 2.
- Script append nội dung vào danh sách hiện tại, đồng thời có thể:
- Cập nhật URL bằng History API thành /category/page/2/.
- Hoặc giữ nguyên URL nhưng vẫn đảm bảo /category/page/2/ có thể truy cập trực tiếp và hiển thị đúng nội dung.
Cách tiếp cận này cho phép:
- Người dùng: trải nghiệm mượt, không bị chuyển trang, đặc biệt phù hợp với mobile.
- Google: vẫn có thể crawl từng URL phân trang, hiểu cấu trúc danh sách, index đầy đủ các item.
Khi thiết kế load more, cần lưu ý thêm:
- Không để toàn bộ listing chỉ tồn tại trong một “super page” duy nhất với vô hạn load more, vì:
- Thời gian tải và render sẽ tăng mạnh.
- Khó kiểm soát phân phối internal link và crawl budget.
- Nên giới hạn số item trên mỗi URL phân trang (ví dụ 20–40 item) để giữ hiệu năng và khả năng crawl.
- Đảm bảo khi truy cập trực tiếp /page/2/, người dùng vẫn có trải nghiệm hợp lý (có thể hiển thị cả nội dung trang 1 + 2, hoặc chỉ trang 2 nhưng có điều hướng rõ ràng).
Nội dung chỉ xuất hiện sau tương tác người dùng có thể không được Google phát hiện đầy đủ
Một nguyên tắc nền tảng trong SEO kỹ thuật là: mọi nội dung quan trọng cần phải có thể truy cập được mà không yêu cầu tương tác phức tạp. Tương tác phức tạp ở đây bao gồm:
- Cuộn đến một vị trí rất sâu mới load nội dung.
- Bấm nút “Load more”, “Xem thêm”, “Hiển thị thêm kết quả”.
- Đăng nhập, chọn filter, chọn tab, hoặc thực hiện nhiều bước JS khác.
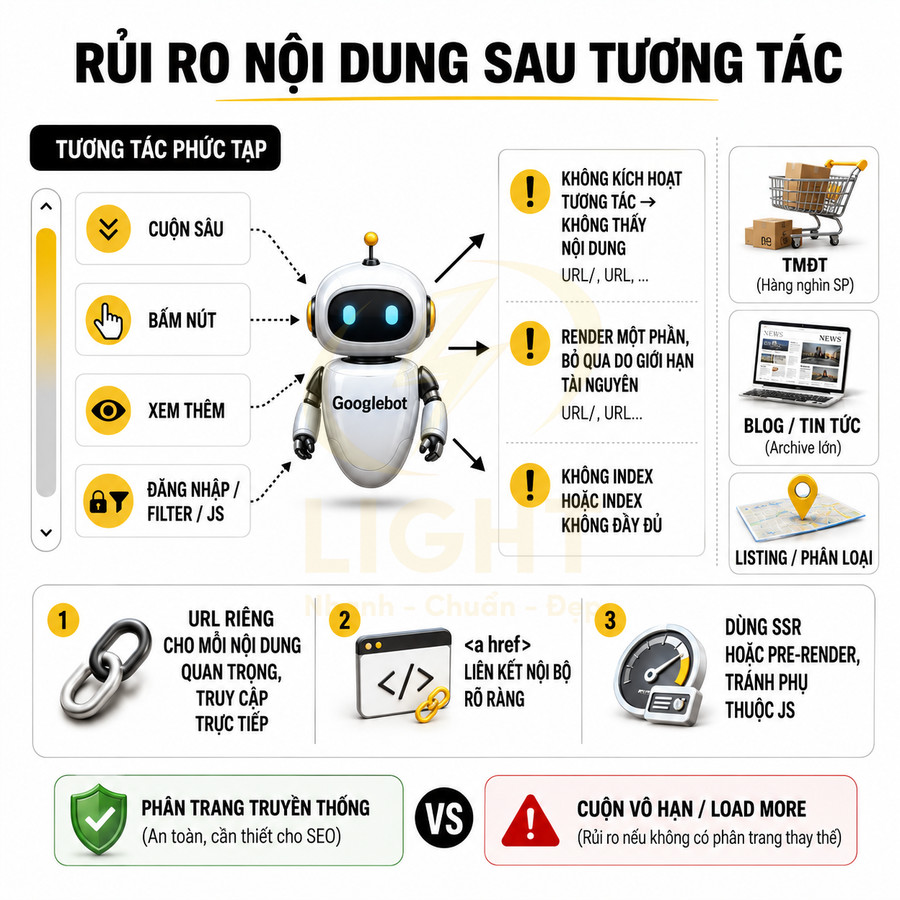
Nếu nội dung chỉ xuất hiện sau các tương tác này, Google có thể:
- Không kích hoạt tương tác, dẫn đến không thấy nội dung.
- Render một phần nhưng bỏ qua phần còn lại do giới hạn tài nguyên.
- Không index hoặc index không đầy đủ, khiến nhiều URL/item không xuất hiện trên kết quả tìm kiếm.
Trong bối cảnh pagination với infinite scroll hoặc load more thuần JS, rủi ro này càng rõ rệt. Toàn bộ sản phẩm/bài viết nằm sau “lần cuộn thứ N” hoặc “lần bấm load more thứ N” có thể trở thành “vùng tối” với bot. Điều này đặc biệt nguy hiểm với:
- Website thương mại điện tử có hàng nghìn sản phẩm.
- Blog/tin tức có archive lớn.
- Trang listing job, bất động sản, classified…
Để đảm bảo nội dung được index đầy đủ, cần tuân thủ các nguyên tắc:
- Mỗi nhóm nội dung quan trọng phải có URL riêng, truy cập trực tiếp mà không cần tương tác.
- Mỗi URL phải có ít nhất một liên kết nội bộ dạng <a href> từ một trang đã được index.
- Tránh phụ thuộc hoàn toàn vào JS để hiển thị nội dung quan trọng; nếu dùng JS, nên có server-side rendering hoặc pre-render.
Pagination truyền thống (page 1, 2, 3…) đáp ứng khá tốt các yêu cầu này vì:
- Mỗi trang là một URL độc lập, có thể crawl trực tiếp.
- Các liên kết phân trang tạo thành một chuỗi internal link rõ ràng.
- Bot không cần cuộn hay bấm nút để thấy nội dung.
Trong khi đó, infinite scroll và load more chỉ thực sự an toàn cho SEO khi được bổ sung fallback phân trang như đã phân tích. Khi đó, Google có thể thu thập dữ liệu toàn bộ nội dung thông qua các URL phân trang, thay vì phải mô phỏng hành vi người dùng, giúp kết quả index ổn định và dễ dự đoán hơn.
Kết hợp UX mượt với URL phân trang rõ giúp cân bằng SEO và trải nghiệm
Thách thức của SEO hiện đại không chỉ nằm ở việc “bot có thấy nội dung hay không”, mà còn ở việc cân bằng giữa trải nghiệm người dùng (UX) và yêu cầu kỹ thuật của công cụ tìm kiếm. Pagination cổ điển (1, 2, 3, Next) tuy thân thiện với bot nhưng đôi khi tạo cảm giác rời rạc, đặc biệt trên mobile. Ngược lại, infinite scroll và load more mang lại cảm giác liền mạch, nhưng nếu triển khai sai sẽ làm suy yếu khả năng crawl và index.
Giải pháp tối ưu là áp dụng mô hình “progressive enhancement”:
- Lớp cơ bản: pagination truyền thống với các URL /page/2/, /page/3/… đầy đủ, crawlable, có liên kết nội bộ rõ ràng.
- Lớp nâng cao: infinite scroll hoặc load more được kích hoạt bằng JS để cải thiện UX cho người dùng thực.

Để làm được điều này, cần sự phối hợp chặt chẽ giữa:
- Đội UX/UI: thiết kế flow cuộn, vị trí nút load more, cách hiển thị nội dung khi chuyển “trang” mà không gây mất phương hướng.
- Đội front-end: triển khai History API, quản lý state phân trang, đảm bảo fallback HTML vẫn hoạt động khi JS bị tắt.
- Đội SEO/technical SEO: định nghĩa cấu trúc URL, logic internal link, kiểm tra khả năng crawl/index, xử lý canonical nếu cần.
Một số thực hành tốt khi kết hợp UX mượt với URL phân trang rõ:
- Giữ cấu trúc URL phân trang nhất quán, dễ hiểu cho cả người dùng và bot.
- Đảm bảo mỗi URL phân trang có nội dung đủ “độc lập” để có thể xuất hiện riêng trên SERP mà không gây khó hiểu.
- Không ẩn hoàn toàn các liên kết phân trang; có thể tối giản giao diện nhưng vẫn để bot truy cập được.
- Thường xuyên kiểm tra log server, Search Console để xem Google có crawl sâu đến các trang phân trang hay không.
Khi kiến trúc được thiết kế đúng, website có thể vừa cung cấp trải nghiệm cuộn mượt mà, hiện đại cho người dùng, vừa duy trì một nền tảng SEO kỹ thuật vững chắc, trong đó mọi phần nội dung quan trọng đều có URL rõ ràng, được liên kết nội bộ hợp lý và có khả năng được index đầy đủ.
Internal link và sitemap cho nội dung nằm trong pagination
Pagination chỉ nên đóng vai trò điều hướng tuần tự, còn “xương sống” internal link phải dựa trên các tầng authority rõ ràng: trang chủ, category, hub page và các block liên kết có chủ đích. Những URL quan trọng cần được kéo gần trang chủ về mặt click depth, được liên kết trực tiếp từ các trang có authority cao thay vì để “trôi” ở page sâu. Breadcrumb giúp củng cố quan hệ phân cấp giữa category và item, tạo lớp internal link ngược ổn định, giàu ngữ nghĩa và không bị ảnh hưởng bởi vị trí trong chuỗi phân trang. Về mặt kỹ thuật, XML sitemap nên ưu tiên URL có giá trị tìm kiếm, trong khi HTML sitemap và hub page hỗ trợ khám phá nội dung sâu, rút ngắn crawl depth và tăng topical authority.
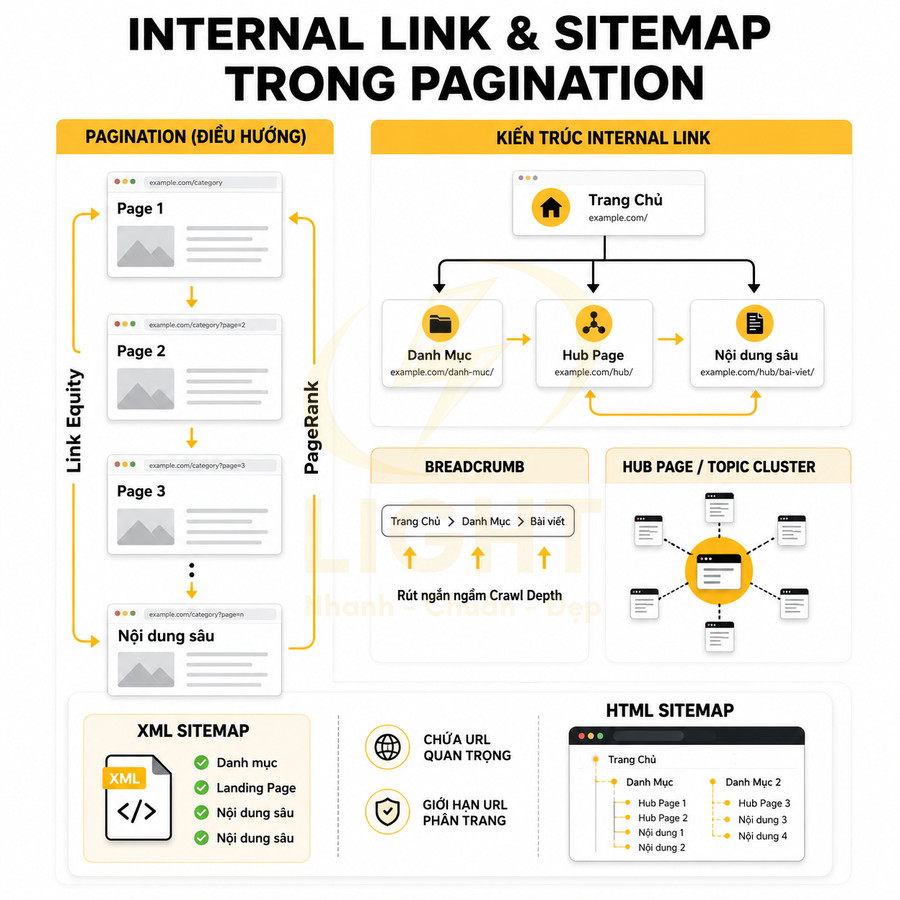
Link từ trang chủ, category và hub page nên ưu tiên URL quan trọng thay vì phụ thuộc vào pagination
Trong kiến trúc SEO hiện đại, pagination chỉ nên được xem như lớp điều hướng tuần tự, không phải là trục xương sống của hệ thống internal link. Khi các URL quan trọng (money page, bài viết chiến lược, collection quan trọng, landing cho chiến dịch…) chỉ xuất hiện ở page 3, page 5 của một danh mục và không có liên kết trực tiếp từ các trang có authority cao, chúng sẽ:
- Nhận ít PageRank/Link Equity hơn so với các URL được link trực tiếp từ trang chủ, menu, category chính hoặc hub page.
- Khó được crawl thường xuyên, đặc biệt trên website lớn với hàng chục nghìn URL.
- Dễ bị “chìm” khi thứ tự sắp xếp sản phẩm/bài viết thay đổi (sort by, filter, sản phẩm mới đẩy sản phẩm cũ sang page sâu hơn).
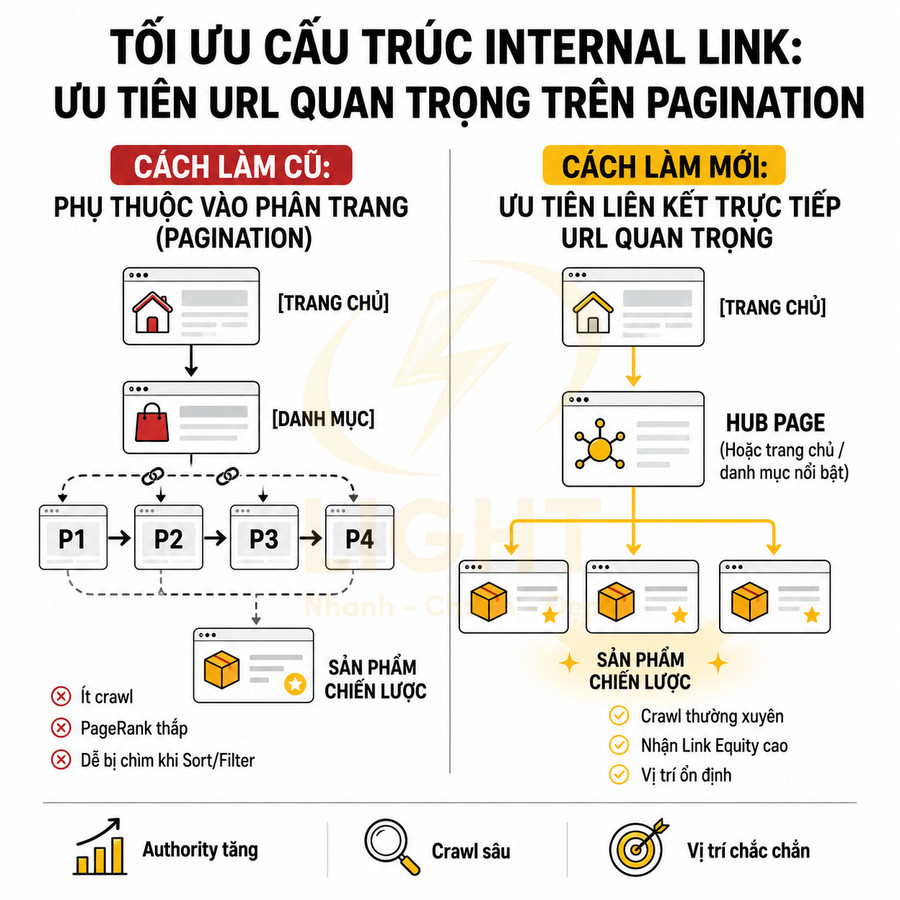
Chiến lược internal link chuẩn SEO cần thiết kế các tầng authority rõ ràng:
- Tầng 1 – Trang chủ, menu chính, footer quan trọng: liên kết đến các category trụ cột, hub page chủ đề, landing chiến dịch, các page mang tính thương hiệu hoặc chuyển đổi cao.
- Tầng 2 – Category chính, subcategory, hub page: phân phối sức mạnh tiếp theo đến các nhóm URL chiến lược (bài viết pillar, sản phẩm chủ lực, collection ưu tiên).
- Tầng 3 – Bài viết chi tiết, sản phẩm, tài nguyên: liên kết chéo theo chủ đề (topic cluster), liên kết ngược về hub page và category, hạn chế để chúng chỉ được tìm thấy qua pagination.
Thay vì để sản phẩm/bài viết quan trọng “trôi” trong chuỗi phân trang, nên:
- Đặt chúng trong các block nổi bật trên category (ví dụ: “Sản phẩm nổi bật”, “Bài viết nên đọc trước”, “Top lựa chọn cho bạn”).
- Đưa vào hub page theo chủ đề, nơi tập trung toàn bộ nội dung liên quan, có cấu trúc internal link dạng topic cluster.
- Liên kết trực tiếp từ các bài viết có traffic cao, từ trang chủ (nếu phù hợp) hoặc từ các trang chiến dịch.
Về mặt crawl và index, Googlebot thường ưu tiên:
- URL được link từ các trang có nhiều backlink ngoài (trang chủ, category lớn, bài viết viral).
- URL xuất hiện trong sitemap và được nhắc lại nhiều lần trong cấu trúc internal link.
- URL nằm gần trang chủ về mặt “click depth” (số lần click từ trang chủ đến URL đó).
Nếu một URL quan trọng chỉ có đường dẫn: Trang chủ > Category > Page 4 > Sản phẩm, trong khi một URL khác có đường dẫn: Trang chủ > Hub page > Sản phẩm, thì URL thứ hai thường có lợi thế hơn về crawl, index và xếp hạng. Do đó, khi thiết kế pagination, cần xem nó là lớp điều hướng bổ trợ, còn “xương sống” internal link phải đến từ:
- Trang chủ và menu.
- Category/hub page được tối ưu theo chủ đề.
- Các block internal link có chủ đích (related products, related posts, recommended resources).
Cách tiếp cận này giúp:
- Tăng khả năng được crawl sâu và thường xuyên cho các URL chiến lược.
- Giảm rủi ro khi thay đổi logic phân trang, sắp xếp hoặc lọc (sort/filter) làm thay đổi vị trí URL trong chuỗi pagination.
- Củng cố cấu trúc chủ đề (topic architecture), giúp Google hiểu rõ đâu là nội dung trụ cột, đâu là nội dung hỗ trợ.
Breadcrumb giúp củng cố quan hệ giữa danh mục và item trong chuỗi phân trang
Breadcrumb không chỉ là yếu tố UX, mà còn là một thành phần quan trọng trong kiến trúc thông tin và SEO onpage, đặc biệt trên các website có nhiều cấp danh mục và sử dụng pagination sâu. Khi triển khai đúng, breadcrumb:
- Thể hiện rõ cấu trúc phân cấp từ trang chủ đến category, subcategory và item.
- Tạo thêm một lớp internal link ngược (upward links) từ item về category và các cấp trên.
- Giảm sự phụ thuộc vào chuỗi pagination để thể hiện mối quan hệ giữa item và danh mục.

Ví dụ một breadcrumb chuẩn cho sản phẩm nằm ở page 5 của category:
Trang chủ > Áo thun nam > Áo thun cotton cổ tròn
Dù sản phẩm này đang nằm ở page 1 hay page 5, breadcrumb vẫn:
- Cho Google biết nó thuộc category “Áo thun nam”.
- Giữ nguyên cấu trúc phân cấp, không bị ảnh hưởng bởi vị trí trong pagination.
- Cung cấp anchor text giàu ngữ nghĩa (tên category, tên subcategory) cho các internal link ngược.
Về mặt kỹ thuật, nên:
- Đánh dấu breadcrumb bằng structured data (schema.org/BreadcrumbList) để Google có thể hiển thị trên SERP.
- Đảm bảo mỗi cấp breadcrumb là một URL tĩnh, có thể crawl được, không phụ thuộc tham số filter phức tạp.
- Giữ breadcrumb nhất quán trên toàn bộ website, kể cả khi người dùng truy cập item từ nhiều đường dẫn khác nhau (search, filter, tag…).
Trong bối cảnh pagination, breadcrumb giúp:
- Giảm số bước cần thiết để Googlebot “leo” từ item lên category, rồi từ category lên các cấp cao hơn.
- Hỗ trợ Google nhóm nội dung theo chủ đề và danh mục, từ đó cải thiện khả năng hiển thị theo cụm chủ đề.
- Tạo thêm một lớp internal link ổn định, không bị thay đổi khi cấu trúc pagination hoặc logic sắp xếp thay đổi.
Khi kết hợp breadcrumb với pagination và internal link từ category/hub page, website hình thành một mạng lưới liên kết ba chiều:
- Liên kết ngang: giữa các item trong cùng chủ đề (related products/posts).
- Liên kết dọc: từ category > item và từ item > category (breadcrumb).
- Liên kết tuần tự: giữa các trang page 1, page 2, page 3… trong pagination.
Mạng lưới này giúp bot dễ dàng khám phá, hiểu ngữ cảnh và đánh giá mức độ liên quan theo chủ đề, thay vì chỉ dựa vào chuỗi phân trang tuyến tính.
XML sitemap nên chứa URL sản phẩm, bài viết hoặc trang đích quan trọng, không cần chứa mọi pagination URL
XML sitemap là “bản đồ kỹ thuật” gửi cho Google để khai báo các URL quan trọng. Với các website có pagination sâu, nếu đưa toàn bộ page 2, page 3, page 10… của mọi category vào sitemap, sẽ:
- Làm phình kích thước sitemap, gây lãng phí crawl budget.
- Pha loãng tín hiệu về mức độ ưu tiên giữa URL quan trọng và URL chỉ mang tính điều hướng.
- Tăng rủi ro trùng lặp hoặc nội dung mỏng (thin content) nếu các trang phân trang không có giá trị tìm kiếm riêng.
Sitemap nên làm nổi bật URL có giá trị tìm kiếm, không nên trở thành danh sách mọi biến thể phân trang. Google cho biết với site không có nhiều trang thay đổi nhanh, việc giữ sitemap cập nhật và kiểm tra index coverage thường là đủ; với site lớn, crawl budget cần được tối ưu để Google tập trung vào URL quan trọng. Điều này nghĩa là sitemap nên ưu tiên sản phẩm, bài viết, category chính, hub page, landing page có chuyển đổi, còn pagination có thể được phát hiện qua internal link nếu cấu trúc tốt. Đưa quá nhiều page phân trang ít giá trị vào sitemap có thể làm nhiễu tín hiệu ưu tiên crawl.
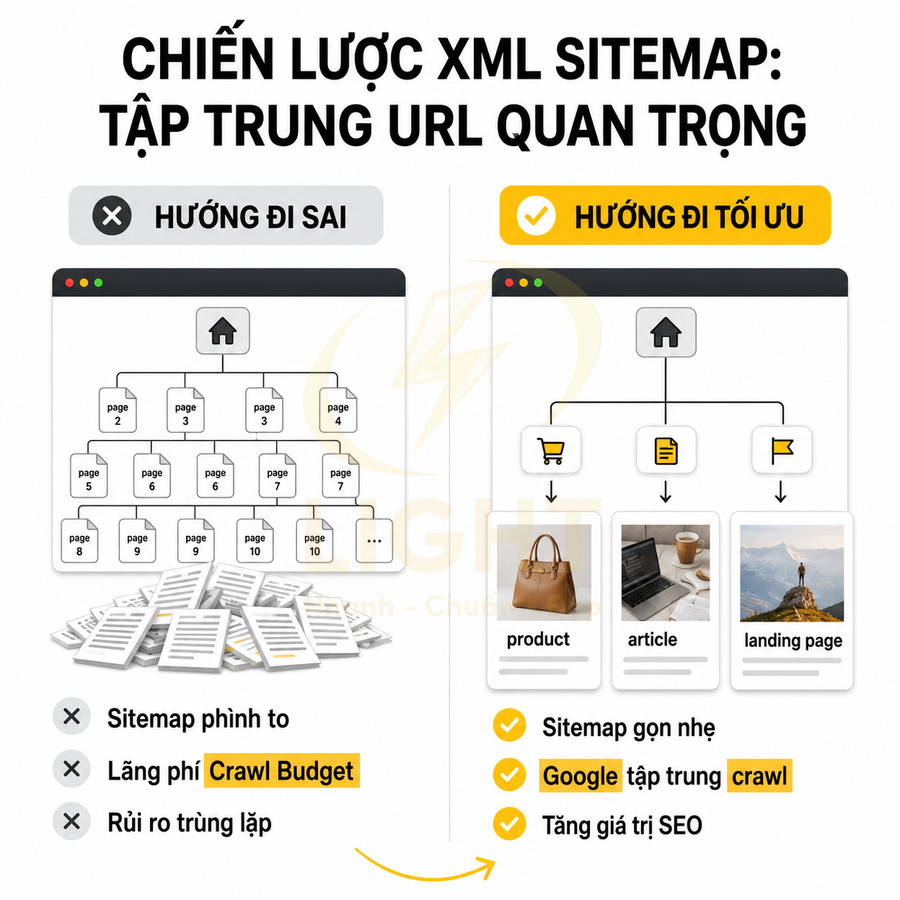
Chiến lược tối ưu là:
- Tập trung sitemap vào URL sản phẩm, bài viết, trang đích, category chính và các hub page quan trọng.
- Không bắt buộc đưa mọi URL pagination vào sitemap, trừ khi:
- Trang phân trang đó có nội dung độc lập, có thể tự xếp hạng cho một truy vấn cụ thể.
- Hoặc được thiết kế như một landing page lọc nội dung (ví dụ: /ao-thun-nam?page=2 nhưng có nội dung mô tả riêng, target keyword riêng).
- Đảm bảo các URL trong sitemap:
- Có thể crawl được (không chặn robots.txt, không noindex).
- Trùng khớp với canonical URL thực tế.
- Được cập nhật trạng thái (lastmod) khi nội dung thay đổi đáng kể.
Pagination vẫn sẽ được Google phát hiện thông qua internal link từ category và từ các trang phân trang liền kề (page 1 <-> page 2 <-> page 3…). Do đó, không cần dùng sitemap như một “danh sách đầy đủ” của mọi trang phân trang. Việc giới hạn sitemap ở các URL mang lại giá trị tìm kiếm và chuyển đổi cao giúp:
- Google tập trung crawl vào phần nội dung quan trọng nhất.
- Tối ưu crawl budget cho website lớn, nơi số lượng URL phân trang có thể lên đến hàng trăm nghìn.
- Giảm khả năng Google dành quá nhiều tài nguyên cho các trang chỉ mang tính điều hướng.
Với website lớn, nên chia sitemap theo loại nội dung:
- Sitemap cho sản phẩm.
- Sitemap cho bài viết/blog.
- Sitemap cho category/hub page.
Cách chia này giúp dễ quản lý, dễ debug trong Google Search Console và đảm bảo các nhóm URL quan trọng luôn được cập nhật, không bị “chìm” giữa hàng loạt URL phân trang ít giá trị.
HTML sitemap hoặc hub page hỗ trợ phát hiện nội dung sâu trong website lớn
Bên cạnh XML sitemap, HTML sitemap và hub page đóng vai trò như “bản đồ cho người dùng và bot” ở tầng giao diện. Chúng đặc biệt hữu ích với website lớn, nhiều lớp phân trang, nhiều cấp danh mục, nơi mà việc chỉ dựa vào pagination để khám phá nội dung sâu là không đủ.
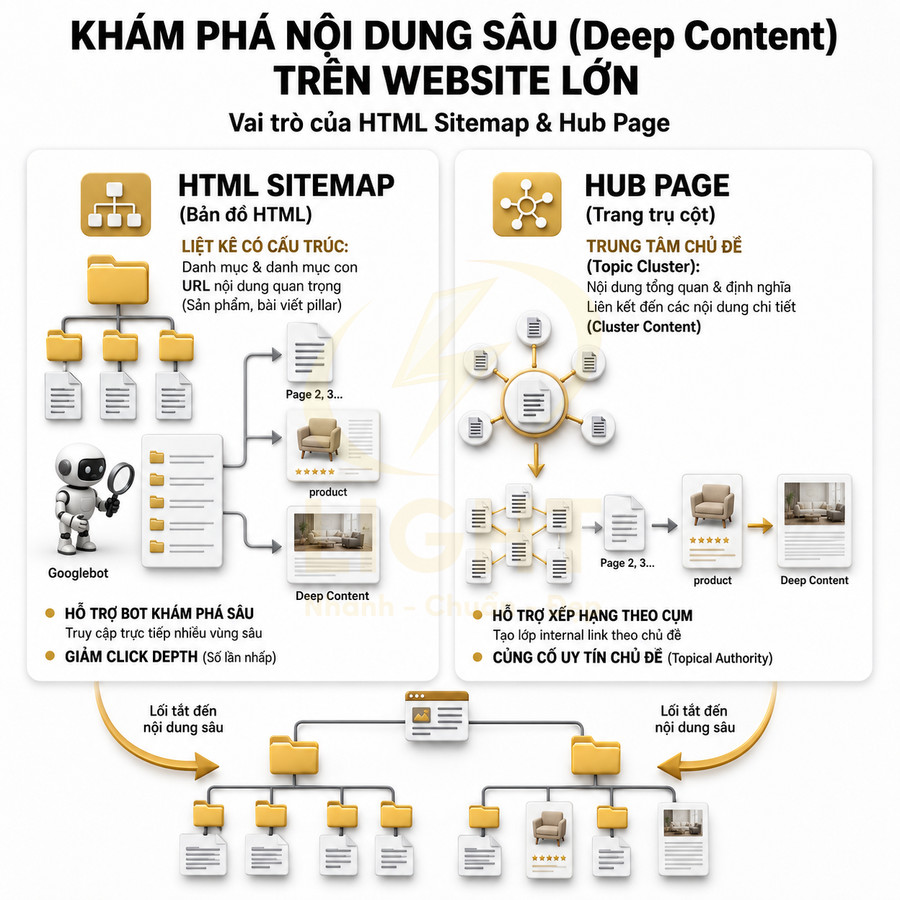
HTML sitemap thường là một (hoặc một nhóm) trang liệt kê có cấu trúc:
- Các category và subcategory chính.
- Các hub page theo chủ đề.
- Các URL nội dung quan trọng (sản phẩm chủ lực, bài viết pillar, tài nguyên quan trọng).
HTML sitemap giúp:
- Cung cấp một điểm truy cập duy nhất, từ đó bot có thể “nhảy” trực tiếp đến nhiều khu vực sâu mà không cần đi qua nhiều lớp pagination.
- Giảm click depth cho các URL quan trọng, đưa chúng lại gần trang chủ hơn về mặt cấu trúc liên kết.
- Cải thiện trải nghiệm người dùng khi họ muốn có cái nhìn tổng quan về cấu trúc nội dung.
Hub page là các trang trụ cột theo chủ đề, được tối ưu như một “trung tâm” cho một cụm nội dung (topic cluster). Mỗi hub page thường:
- Target một chủ đề hoặc nhóm keyword chính.
- Chứa nội dung tổng quan, giải thích khái niệm, phân nhóm vấn đề.
- Liên kết đến nhiều bài viết chi tiết, sản phẩm hoặc tài nguyên liên quan (cluster content).
Trong bối cảnh pagination, hub page giúp:
- Giảm phụ thuộc vào việc người dùng hoặc bot phải đi qua page 2, page 3… để tìm thấy nội dung sâu.
- Tạo một lớp internal link theo chủ đề, thay vì chỉ theo thứ tự thời gian hoặc thứ tự sắp xếp trong danh mục.
- Củng cố tín hiệu topical authority, vì toàn bộ nội dung liên quan được gom về một “trung tâm” rõ ràng.
Trên các website lớn, việc kết hợp HTML sitemap và hệ thống hub page theo chủ đề mang lại nhiều lợi ích:
- Google có nhiều đường dẫn trực tiếp đến nội dung sâu, không bị giới hạn bởi cấu trúc phân trang tuyến tính.
- Crawl depth được rút ngắn, giúp bot tiếp cận nhanh hơn đến các URL mới hoặc ít được liên kết.
- Cấu trúc chủ đề trở nên rõ ràng, hỗ trợ tốt cho việc xếp hạng theo cụm chủ đề (topic-based ranking).
Pagination vẫn giữ vai trò điều hướng tuần tự trong category (đặc biệt với eCommerce, listing tin tức, listing bài viết), nhưng khi đã có:
- Internal link từ trang chủ, category, hub page đến URL quan trọng.
- Breadcrumb thể hiện rõ quan hệ phân cấp.
- XML sitemap tập trung vào URL có giá trị tìm kiếm.
- HTML sitemap và hub page hỗ trợ khám phá nội dung sâu.
Thì pagination không còn là con đường duy nhất để bot tiếp cận nội dung sâu, từ đó giảm đáng kể rủi ro khi thay đổi cấu trúc phân trang, logic sắp xếp hoặc khi website mở rộng quy mô nội dung.
Lỗi pagination thường gặp làm giảm hiệu quả SEO

| Lỗi pagination | Hậu quả SEO | Cách khắc phục |
|---|---|---|
| Canonical page 2 trở đi về page 1 không đúng ngữ cảnh | Mất tín hiệu của các trang phân trang, khó khám phá URL sâu | Đặt canonical tự tham chiếu cho từng trang phân trang |
| Noindex toàn bộ pagination nhưng vẫn muốn Google crawl sâu | Bot ít theo liên kết trên trang phân trang, URL sâu index chậm | Dùng noindex, follow có chọn lọc và tăng internal link từ nơi khác |
| Pagination bị chặn robots.txt | Google không thể truy cập chuỗi phân trang, bỏ sót nội dung | Cho phép crawl thư mục hoặc tham số pagination trong robots.txt |
| JavaScript pagination không có URL crawlable | Nội dung sau tương tác không được index đầy đủ | Thêm URL phân trang tĩnh và liên kết a href làm fallback |
| Thin content, duplicate title/meta trên các trang phân trang | Giảm chất lượng tổng thể, lãng phí crawl budget | Tối ưu title/meta theo trang, bổ sung nội dung hỗ trợ trên category |
Canonical page 2 trở đi về page 1 không đúng ngữ cảnh
Một trong những sai lầm kỹ thuật phổ biến nhất trong triển khai phân trang là đặt thẻ canonical của tất cả các trang page 2, page 3, page 4… về page 1 mà không đánh giá đúng bản chất nội dung. Về mặt thuật toán, Google coi canonical là tín hiệu hợp nhất tín hiệu xếp hạng và nội dung về một URL chuẩn. Tuy nhiên, các trang phân trang thường chứa tập hợp item khác nhau, thứ tự hiển thị khác nhau, trạng thái tồn kho khác nhau, nên chúng không phải là bản sao trùng lặp hoàn toàn của page 1.
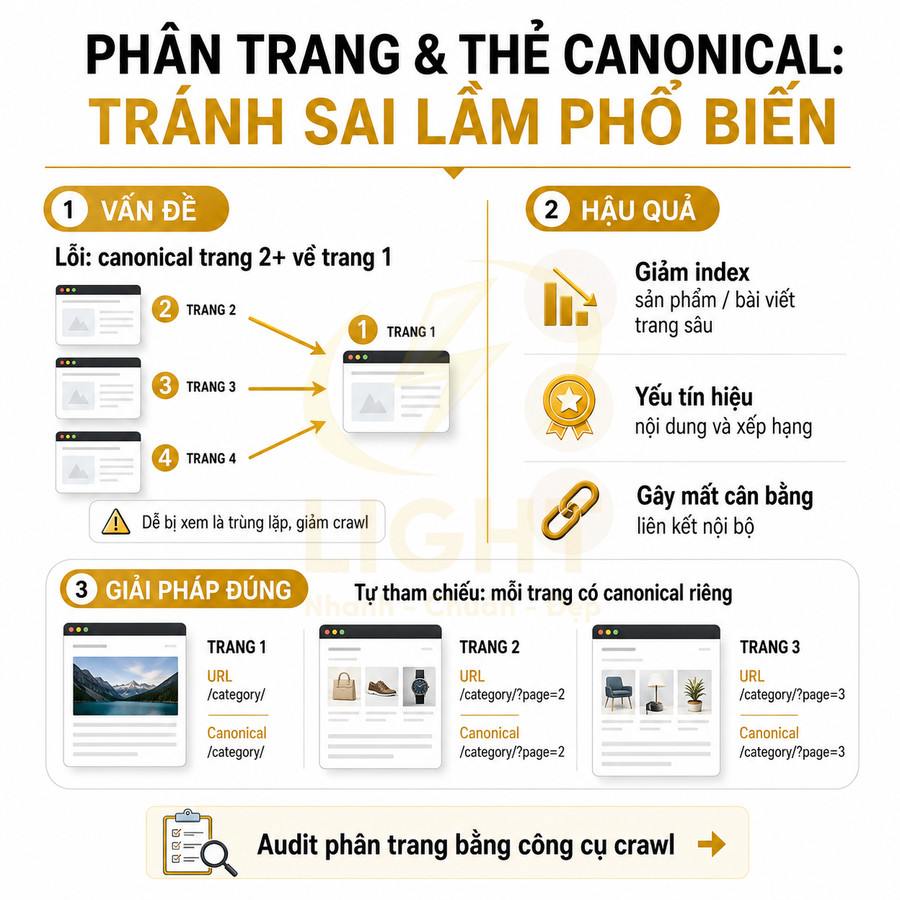
Khi toàn bộ chuỗi pagination bị canonical về page 1, Google có thể:
- Giảm crawl hoặc bỏ qua hoàn toàn các page 2, 3, 4… vì cho rằng chúng không mang thêm giá trị nội dung.
- Làm yếu tín hiệu nội dung của các sản phẩm/bài viết chỉ xuất hiện ở các trang sâu, khiến khả năng index và xếp hạng của chúng suy giảm đáng kể.
- Làm đứt gãy cấu trúc internal link tự nhiên từ category đến các URL sâu, khiến hệ thống liên kết nội bộ mất cân bằng.
Điều này đặc biệt nghiêm trọng với:
- Website thương mại điện tử có hàng trăm, hàng nghìn sản phẩm trong một danh mục, nơi nhiều sản phẩm chỉ xuất hiện từ page 3 trở đi.
- Blog/portal tin tức lớn, nơi bài cũ hoặc bài ít được liên kết từ nơi khác phụ thuộc mạnh vào đường dẫn từ pagination để được crawl.
Về mặt triển khai, cần rà soát template category, tag, search result và bất kỳ module nào có phân trang để đảm bảo:
- Mỗi trang phân trang sử dụng canonical tự tham chiếu (self-referencing canonical), ví dụ:
- Page 1: canonical = /category/
- Page 2: canonical = /category/?page=2
- Page 3: canonical = /category/?page=3
- Chỉ trong các trường hợp đặc biệt như hợp nhất phiên bản URL có tham số lọc không quan trọng, hoặc xử lý trùng lặp do sort/ordering, mới cân nhắc canonical về một URL chuẩn, và phải đánh giá kỹ tác động đến khả năng khám phá nội dung.
Ở mức độ audit SEO kỹ thuật, nên sử dụng các công cụ crawl chuyên sâu (Screaming Frog, Sitebulb, JetOctopus,…) để:
- Lọc toàn bộ URL có pattern phân trang (ví dụ chứa ?page=, /page/).
- Kiểm tra cột canonical để phát hiện các mẫu canonical sai (canonical về page 1 hoặc về URL không tồn tại).
- Đối chiếu với log server để xem Googlebot có đang cố gắng crawl các page sâu nhưng bị canonical “kéo” về page 1 hay không.
Noindex pagination nhưng vẫn muốn Google crawl nội dung ở các trang sâu
Nhiều website áp dụng chiến lược noindex hàng loạt cho pagination với mục tiêu “làm sạch” chỉ mục, giảm số lượng URL mỏng hoặc ít traffic xuất hiện trên SERP. Tuy nhiên, nếu cấu hình sai, đặc biệt là dùng noindex, nofollow hoặc kết hợp noindex với canonical không chuẩn, Google có thể:
- Giảm tần suất crawl các trang phân trang vì coi đó là vùng nội dung không cần thiết cho chỉ mục.
- Không theo các liên kết nằm trên các trang phân trang, dẫn đến URL sâu khó được phát hiện và index.
- Làm mất đi một lớp internal link quan trọng từ category đến sản phẩm/bài viết, khiến cấu trúc liên kết trở nên nông và thiếu chiều sâu.
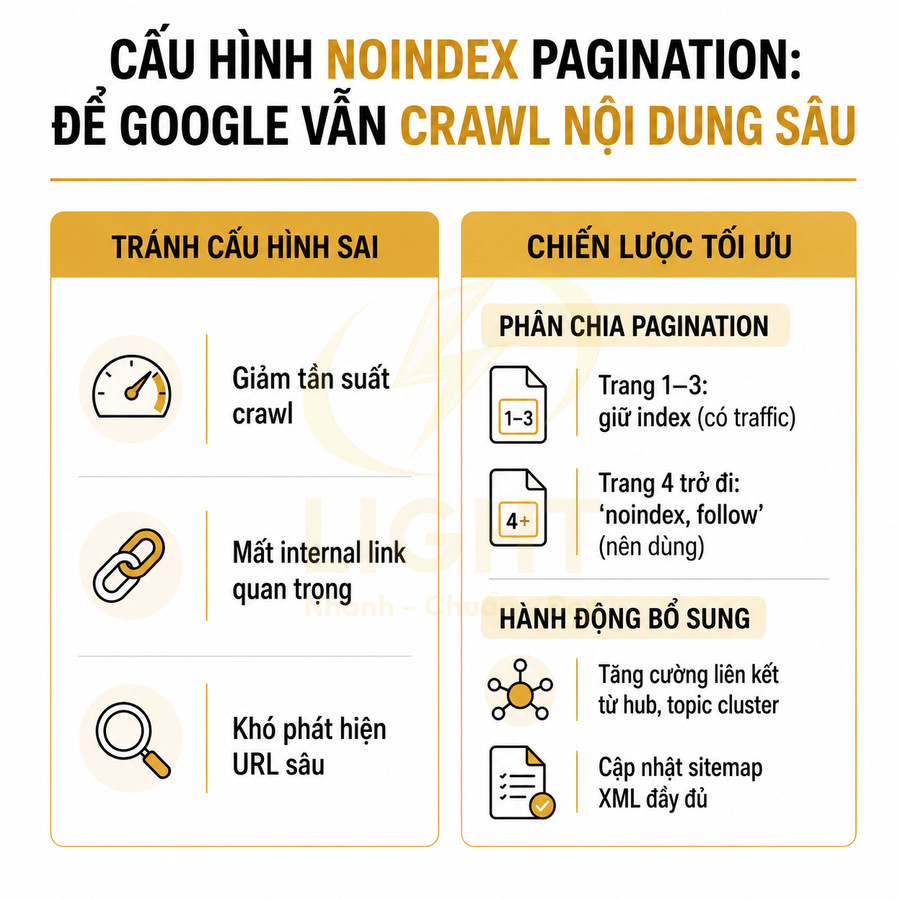
Về mặt kỹ thuật, cần phân biệt rõ:
- noindex, follow: Google không đưa trang vào chỉ mục, nhưng vẫn được phép theo các liên kết trên trang. Đây là lựa chọn an toàn hơn nếu vẫn muốn tận dụng pagination như một “cầu nối” crawl đến URL sâu.
- noindex, nofollow: Google không index trang và cũng không theo liên kết trên trang. Cấu hình này gần như “cắt đứt” pagination khỏi đồ thị liên kết nội bộ.
Nếu bắt buộc phải noindex một phần pagination, nên:
- Ưu tiên dùng noindex, follow cho các trang phân trang ít giá trị tìm kiếm nhưng vẫn chứa nhiều liên kết đến sản phẩm/bài viết.
- Tăng cường internal link từ:
- Category chính (page 1) đến các sản phẩm/bài viết quan trọng ở trang sâu.
- Hub page, trang chủ, trang chuyên đề (topic cluster) đến các URL sâu có giá trị.
- Sitemap XML đầy đủ, cập nhật thường xuyên, bao phủ cả các URL ít được liên kết.
- Dựa trên dữ liệu thực tế (traffic organic, impression, conversion) để quyết định trang nào thực sự nên noindex, tránh noindex theo cảm tính toàn bộ chuỗi pagination.
Về chiến lược, có thể chia pagination thành các nhóm:
- Page 1–3: giữ index vì thường chứa nội dung mới, phổ biến, có khả năng mang traffic.
- Page 4 trở đi: cân nhắc noindex, follow nếu dữ liệu cho thấy gần như không có traffic organic, nhưng vẫn cần duy trì vai trò dẫn link.
Pagination bị chặn robots.txt khiến bot không tiếp cận URL con
Một lỗi cấu hình khác thường gặp là chặn thư mục hoặc tham số pagination trong robots.txt, ví dụ:
- Disallow: /*?page=
- Disallow: /page/
Khi đó, Googlebot và các bot tuân thủ robots.txt sẽ không thể truy cập các URL phân trang, dẫn đến:
- Không thể theo các liên kết từ pagination đến sản phẩm/bài viết nằm ở trang sâu.
- Giảm mạnh khả năng khám phá nội dung mới hoặc nội dung ít được liên kết từ các khu vực khác.
- Phụ thuộc gần như hoàn toàn vào sitemap XML để phát hiện URL, trong khi sitemap có thể không đầy đủ hoặc không được cập nhật kịp thời.
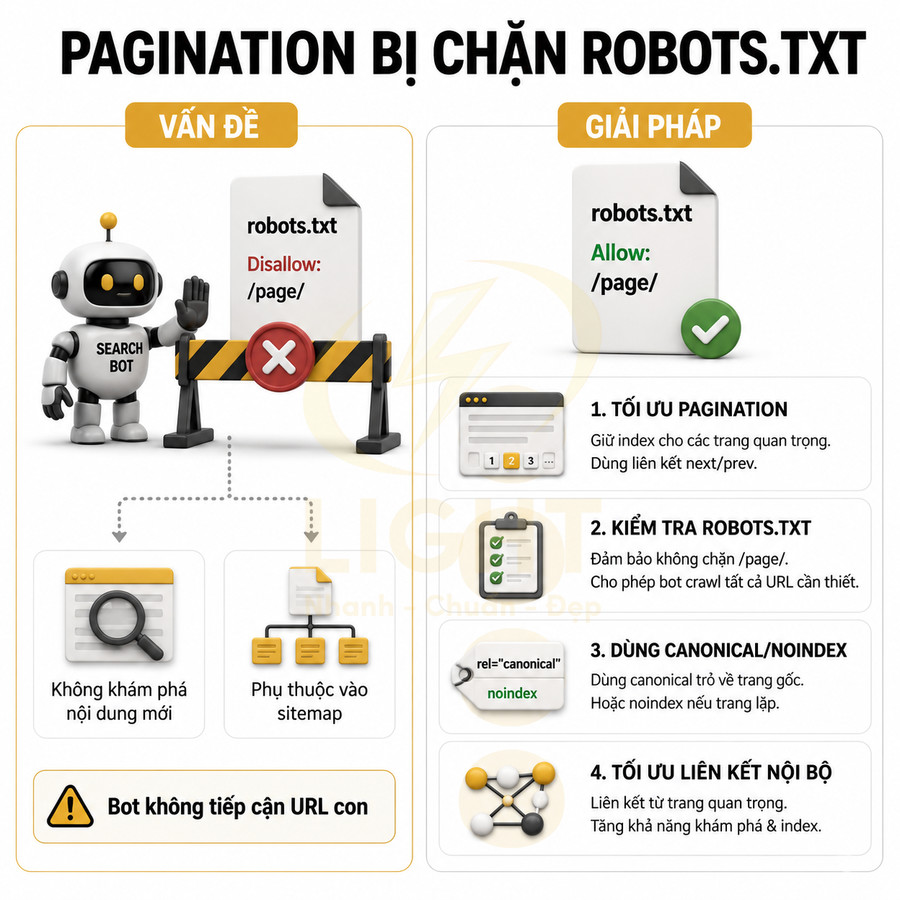
Về mặt nguyên tắc, robots.txt nên được dùng để:
- Ngăn crawl các vùng thực sự không cần thiết (admin, script, file tĩnh không liên quan đến nội dung).
- Giảm lãng phí crawl budget ở các vùng sinh ra vô hạn URL (kết hợp filter phức tạp, session ID, sort vô hạn).
Không nên dùng robots.txt để xử lý vấn đề trùng lặp nội dung hoặc “dọn chỉ mục” cho pagination, vì:
- Robots.txt chỉ chặn crawl, không chặn index nếu URL được phát hiện từ nguồn khác (ví dụ link ngoài, sitemap).
- Google không thể nhìn thấy canonical, meta robots, hoặc nội dung trên trang nếu bị chặn, nên không thể đánh giá đúng ngữ cảnh.
Giải pháp kỹ thuật nên tập trung vào:
- Kiểm tra lại file robots.txt để đảm bảo không chặn pattern URL dùng cho pagination.
- Nếu lo ngại về trùng lặp hoặc lãng phí crawl, sử dụng:
- Canonical tự tham chiếu hoặc canonical hợp nhất hợp lý cho các biến thể lọc/sort.
- Meta robots noindex, follow có chọn lọc cho các trang thực sự không cần xuất hiện trên SERP.
- Cấu trúc internal link rõ ràng, hạn chế tạo ra quá nhiều kết hợp filter dẫn đến bùng nổ URL.
Phân trang tạo thin content, duplicate title và meta description hàng loạt
Khi pagination chỉ đơn thuần là danh sách item lặp đi lặp lại, không có nội dung bổ trợ, và sử dụng title, meta description giống nhau cho toàn bộ chuỗi, hệ quả là:
- Các trang phân trang bị coi là thin content, làm giảm chất lượng tổng thể của domain trong mắt Google.
- Duplicate title/meta trên diện rộng khiến công cụ tìm kiếm khó phân biệt ngữ cảnh từng trang, làm loãng tín hiệu xếp hạng.
- Người dùng trên SERP khó nhận biết sự khác nhau giữa page 1, page 2, page 3…, dẫn đến CTR thấp và trải nghiệm tìm kiếm kém.

Về mặt tối ưu onpage, nên:
- Tùy biến title và meta description cho từng trang phân trang, ví dụ:
- “Giày chạy bộ nam chính hãng | Danh mục A – Trang 2”
- “Tin tức SEO kỹ thuật mới nhất – Trang 3”
- Mô tả rõ phạm vi hoặc ngữ cảnh nội dung của từng trang (ví dụ “sản phẩm từ 21–40”, “bài viết cũ hơn”, “ưu đãi còn lại”).
Để giảm tình trạng thin content, có thể bổ sung trên các trang phân trang:
- Mô tả category chuyên sâu: đoạn giới thiệu về chủ đề, hướng dẫn chọn sản phẩm, giải thích các tiêu chí lọc.
- Khối nội dung hướng dẫn: FAQ, tips, checklist liên quan đến danh mục.
- Liên kết đến danh mục con hoặc bài viết liên quan: giúp người dùng điều hướng tốt hơn và tăng chiều sâu internal link.
Về mặt UX, pagination không nên chỉ là danh sách item khô khan. Có thể:
- Thêm breadcrumb rõ ràng để người dùng hiểu vị trí của mình trong cấu trúc site.
- Hiển thị filter, sort thân thiện, nhưng cần kiểm soát để không tạo ra quá nhiều URL trùng lặp.
- Giữ nội dung mô tả category nhất quán trên toàn bộ chuỗi, nhưng có thể tinh chỉnh nhẹ theo từng page để tránh trùng lặp hoàn toàn.
JavaScript pagination không có URL crawlable cho từng trang
Việc sử dụng JavaScript để điều khiển pagination (Ajax load more, infinite scroll, nút “Xem thêm”) mà không cung cấp URL riêng, crawlable cho từng trạng thái trang là lỗi thường gặp trên các website hiện đại. Khi các nút phân trang chỉ kích hoạt Ajax để tải thêm nội dung mà:
- Không thay đổi URL (không có query string hoặc fragment có thể xử lý).
- Không có thẻ <a href> trỏ đến URL tĩnh tương ứng.
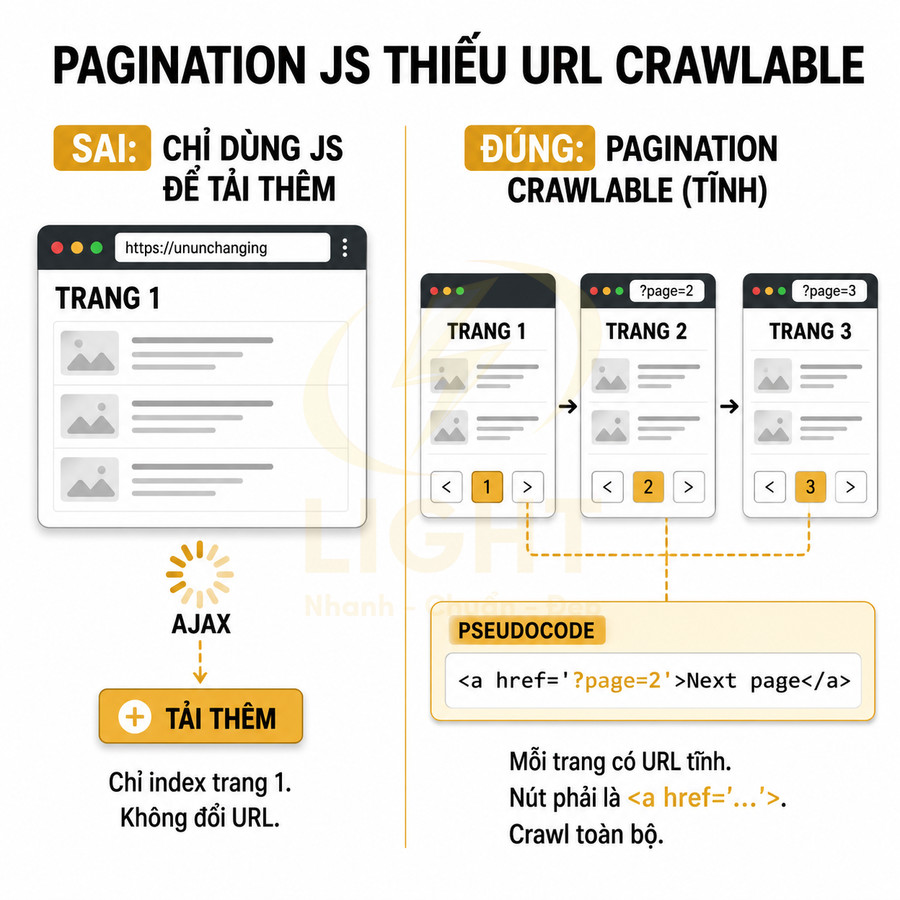
Google có thể:
- Chỉ index nội dung hiển thị ở lần tải đầu tiên (page 1), bỏ sót phần lớn item nằm ở các “trang” sau.
- Không nhận diện được cấu trúc phân trang, dẫn đến việc không thể điều hướng sâu vào danh mục.
- Phụ thuộc vào khả năng render JavaScript, vốn không phải lúc nào cũng đầy đủ và kịp thời, đặc biệt với site lớn.
Giải pháp kỹ thuật nên tuân theo nguyên tắc progressive enhancement:
- Mỗi trang phân trang cần có URL tĩnh, có thể truy cập trực tiếp, ví dụ:
- /category/
- /category/?page=2
- /category/?page=3
- Các nút phân trang phải sử dụng thẻ <a href="…"> trỏ đến các URL này, để:
- Trình duyệt không hỗ trợ JS vẫn có thể điều hướng.
- Bot có thể crawl theo liên kết mà không phụ thuộc vào JS.
- JavaScript chỉ nên được dùng để:
- Chặn hành vi load trang toàn bộ và thay bằng Ajax để cải thiện UX.
- Thay đổi nội dung động nhưng vẫn giữ URL và liên kết nền tảng.
Với mô hình infinite scroll, có thể áp dụng:
- Cập nhật URL bằng History API (pushState/replaceState) khi người dùng cuộn đến các “mốc” tương đương page 2, page 3…
- Đảm bảo mỗi trạng thái đó có thể được truy cập trực tiếp bằng URL tương ứng và hiển thị đúng nội dung khi load lần đầu.
Khi kết hợp đúng giữa JS và cấu trúc URL truyền thống, website vừa đảm bảo trải nghiệm người dùng mượt mà, vừa giữ được khả năng crawl và index ổn định cho toàn bộ chuỗi pagination, tránh mất index cho các item nằm sâu trong danh mục.
FAQ về pagination và website chuẩn SEO
Hệ thống câu hỏi thường gặp này tập trung giải thích cách triển khai pagination sao cho vừa thân thiện với người dùng vừa chuẩn SEO. Nội dung làm rõ khi nào nên index các trang page 2, 3…, khi nào nên áp dụng noindex,follow để tiết kiệm crawl budget, cũng như lý do nên dùng canonical tự tham chiếu thay vì dồn hết về page 1. Bên cạnh đó, phần FAQ phân tích vai trò hiện tại của rel next/prev, so sánh pagination truyền thống với infinite scroll và cách kết hợp cả hai để đảm bảo khả năng crawl/index. Cuối cùng, nội dung hướng dẫn lựa chọn cấu trúc URL (/page/2/ hay ?page=2), tối ưu title/meta cho trang phân trang, chiến lược đưa (hoặc không đưa) pagination vào XML sitemap và cách hạn chế ảnh hưởng tiêu cực của pagination lên crawl budget.

Có nên index trang page 2, page 3 của danh mục không?
Quyết định index hay không index các trang page 2, page 3 (và các page sâu hơn) cần dựa trên cả giá trị tìm kiếm tiềm năng lẫn vai trò điều hướng trong kiến trúc thông tin.
Với các danh mục có nhu cầu tìm kiếm rõ ràng (category sản phẩm thương mại, blog archive theo chủ đề, listing tin tức theo chuyên mục…), pagination thường:
- Giúp Google hiểu đầy đủ chiều sâu và phạm vi của danh mục (bao nhiêu sản phẩm/bài viết, phân bố ra sao).
- Tạo thêm cơ hội để người dùng tìm thấy nội dung phù hợp khi truy vấn dài (long-tail) dẫn đến page 2, page 3.
- Hỗ trợ phân bổ internal link từ các trang danh mục đến nhiều URL con hơn, giảm tình trạng “mồ côi” (orphan pages).
Trong bối cảnh đó, nên:
- Cho phép index các trang phân trang chính (page 2, 3, 4…).
- Dùng canonical tự tham chiếu cho từng page để khẳng định nội dung là duy nhất trong chuỗi.
- Tối ưu title/meta riêng cho từng page để tránh trùng lặp và tăng khả năng click.
Ngược lại, với các danh sách chỉ mang tính kỹ thuật hoặc điều hướng nội bộ, ví dụ:
- Danh sách log, lịch sử giao dịch, danh sách filter rất hẹp chỉ phục vụ user đã đăng nhập.
- Các trang listing sinh ra từ tham số lọc phức tạp, không có nhu cầu tìm kiếm tự nhiên.
Trong các trường hợp này có thể:
- Áp dụng noindex,follow cho một phần hoặc toàn bộ pagination để tránh lãng phí crawl và giảm trùng lặp.
- Vẫn đảm bảo bot có thể follow link đến sản phẩm/bài viết sâu (không chặn bằng robots.txt hoặc nofollow nội bộ).
Với website rất lớn, có thể kết hợp:
- Index các page đầu (ví dụ page 1–3) của danh mục quan trọng.
- Noindex các page rất sâu (page 10+), nếu chúng không mang thêm giá trị tìm kiếm mà chỉ lặp lại pattern nội dung.
Có nên canonical toàn bộ pagination về page 1 không?
Trong đa số trường hợp, không nên canonical toàn bộ pagination về page 1 vì điều này khiến Google hiểu rằng các trang page 2, page 3 chỉ là bản sao nội dung của page 1, trong khi thực tế mỗi page thường chứa một tập item khác nhau.
Hệ quả khi canonical tất cả về page 1:
- Google có thể bỏ qua hoặc giảm crawl các trang page 2, 3, 4…, làm giảm khả năng khám phá URL sản phẩm/bài viết nằm sâu.
- Giảm độ phủ index của danh mục, đặc biệt với site thương mại điện tử có hàng nghìn sản phẩm.
- Có thể gây nhầm lẫn về tín hiệu xếp hạng, vì nhiều URL khác nhau cùng tuyên bố page 1 là phiên bản chuẩn.
Chỉ nên canonical về page 1 trong các tình huống rất cụ thể:
- Các trang phân trang gần như trùng lặp nội dung (ví dụ chỉ thay đổi rất ít item, hoặc do lỗi hệ thống sinh thêm page rỗng).
- Chuỗi pagination không được dùng như landing page SEO, mà chỉ là lớp điều hướng phụ, trong khi đã có:
- Hệ thống internal link khác (menu, block “sản phẩm liên quan”, “bài viết nổi bật”…).
- Sitemap và cấu trúc category chính đủ mạnh để đảm bảo crawl đến mọi URL quan trọng.
Cách an toàn và chuẩn SEO cho hầu hết website là:
- Dùng canonical tự tham chiếu cho từng trang phân trang (page 2 canonical về chính page 2, v.v.).
- Đảm bảo nội dung mỗi page đủ khác biệt (tập item không trùng lặp hoàn toàn) để tránh bị xem là thin/duplicate.
Rel next/prev còn cần thiết cho SEO Google không?
Google đã công khai rằng họ không còn sử dụng rel="next" và rel="prev" như một tín hiệu đặc biệt để xử lý chuỗi pagination. Điều này có nghĩa:
- Không còn lợi thế xếp hạng trực tiếp khi thêm rel next/prev.
- Google sẽ tự suy luận cấu trúc chuỗi dựa trên internal link, URL pattern, anchor text, breadcrumb…
Tuy vậy, rel next/prev vẫn có thể hữu ích ở các khía cạnh khác:
- Hỗ trợ một số công cụ tìm kiếm hoặc hệ thống crawler khác ngoài Google.
- Cải thiện khả năng điều hướng cho trình đọc màn hình, công cụ hỗ trợ truy cập (accessibility).
- Giúp các hệ thống phân tích hoặc công cụ nội bộ hiểu rõ chuỗi trang.
Do đó, có thể:
- Tiếp tục sử dụng rel next/prev như một lớp thông tin bổ trợ, miễn là triển khai đúng logic.
- Không phụ thuộc vào chúng như “giải pháp SEO chính” cho pagination.
Trọng tâm SEO pagination hiện nay nên đặt vào:
- Internal link rõ ràng giữa các page (link đến page trước/sau, link nhảy đến page đầu/cuối khi hợp lý).
- Canonical chính xác cho từng page.
- Sitemap ưu tiên URL quan trọng, không phình to vì pagination.
- Cấu trúc URL nhất quán, dễ hiểu cho cả bot và người dùng.
Infinite scroll có tốt hơn pagination cho SEO không?
Infinite scroll (cuộn vô hạn) thường mang lại trải nghiệm người dùng mượt mà, đặc biệt trên mobile, nhưng không tự động tốt hơn pagination cho SEO. Vấn đề cốt lõi là khả năng crawl và index:
- Nếu nội dung chỉ được tải thêm bằng JavaScript khi cuộn, không có URL riêng cho từng “page” logic, Google có thể:
- Chỉ index phần nội dung ban đầu (trước khi cuộn).
- Bỏ sót nhiều sản phẩm/bài viết nằm sâu phía dưới.
- Nếu infinite scroll không tạo ra liên kết crawlable (thẻ <a> với href tĩnh) hoặc không có fallback HTML, bot sẽ khó khám phá hết nội dung.
Để tối ưu SEO khi dùng infinite scroll, nên:
- Kết hợp infinite scroll với URL phân trang tĩnh (ví dụ /category/page/2/) và:
- Mỗi “lần tải thêm” tương ứng với một URL phân trang có thể truy cập trực tiếp.
- Trình duyệt có thể cập nhật URL (history.pushState) khi user cuộn đến vùng tương ứng.
- Cung cấp fallback dạng pagination truyền thống:
- Nếu JavaScript bị tắt hoặc bot không kích hoạt scroll, vẫn có thể truy cập page 2, 3… qua link HTML.
- Đảm bảo nội dung quan trọng không phụ thuộc hoàn toàn vào hành vi cuộn.
Nếu không thể triển khai fallback kỹ thuật như trên, pagination truyền thống thường an toàn hơn cho SEO vì:
- Google dễ hiểu cấu trúc danh mục và thứ tự nội dung.
- Dễ kiểm soát canonical, title/meta, internal link.
- Giảm rủi ro mất index nội dung sâu do hạn chế render hoặc scroll.
Nên dùng /page/2/ hay ?page=2 cho URL phân trang?
Cả hai dạng /page/2/ (path-based) và ?page=2 (query parameter) đều có thể chuẩn SEO nếu được triển khai đúng và nhất quán. Sự khác biệt chủ yếu nằm ở:
- /page/2/:
- Thân thiện với người dùng, dễ đọc, dễ chia sẻ.
- Thường phù hợp với kiến trúc URL dạng thư mục (category rõ ràng).
- Dễ tạo cảm giác “tài nguyên tĩnh”, ít phụ thuộc tham số.
- ?page=2:
- Linh hoạt khi kết hợp với nhiều tham số khác (sort, filter, view…).
- Dễ triển khai trên nhiều framework hoặc CMS mặc định.
- Cần kiểm soát tốt để tránh sinh ra quá nhiều biến thể URL (page, sort, filter chồng chéo).
Nguyên tắc quan trọng:
- Không trộn lẫn nhiều kiểu URL cho cùng một mục đích, ví dụ vừa có /page/2/ vừa có ?page=2 cùng tồn tại cho một danh mục.
- Đảm bảo:
- Canonical phản ánh đúng dạng URL chuẩn đã chọn.
- Internal link (menu, breadcrumb, link phân trang) luôn dùng một dạng duy nhất.
- Sitemap (nếu có chứa pagination) cũng dùng đúng dạng đó.
Việc lựa chọn dạng nào nên dựa trên:
- Kiến trúc URL tổng thể của website (ưu tiên path-based hay parameter-based).
- Khả năng mở rộng khi thêm filter, sort, ngôn ngữ, khu vực…
- Giới hạn kỹ thuật của hệ thống, server, CMS, routing.
Trang phân trang có cần title và meta description riêng không?
Các trang phân trang nên có title và meta description riêng để:
- Tránh trùng lặp hoàn toàn với page 1, giảm nguy cơ bị xem là duplicate hoặc bị bỏ qua.
- Giúp người dùng hiểu rõ họ đang ở phần nào của danh mục khi nhìn thấy trên SERP.
- Cải thiện CTR trong trường hợp Google hiển thị page 2, 3 thay vì page 1 cho một truy vấn cụ thể.
Ví dụ cách đặt title:
- Page 1: “Áo thun nam giá tốt, nhiều mẫu mới | Thương hiệu X”.
- Page 2: “Áo thun nam – Trang 2 | Thương hiệu X”.
- Page 3: “Áo thun nam – Trang 3 | Thương hiệu X”.
Meta description có thể:
- Nhấn mạnh phạm vi nội dung trên page đó (ví dụ “Khám phá thêm các mẫu áo thun nam mới ở trang 2…”).
- Giữ thông điệp chính nhất quán với page 1 nhưng thêm yếu tố phân biệt về thứ tự/trang.
Mức độ tối ưu không cần chi tiết như trang sản phẩm hoặc bài viết:
- Mục tiêu chính là rõ ràng, nhất quán, không trùng lặp hoàn toàn.
- Không cần nhồi nhét từ khóa hoặc viết mô tả quá dài; ưu tiên tính định hướng cho người dùng.
Có nên đưa URL pagination vào XML sitemap không?
Thông thường, không cần đưa mọi URL pagination vào XML sitemap. Sitemap nên tập trung vào:
- URL sản phẩm, bài viết, trang đích quan trọng.
- Category chính, landing page SEO, hub page nội dung.
Lý do:
- Pagination thường được Google phát hiện dễ dàng thông qua internal link từ page 1.
- Đưa hàng trăm/thậm chí hàng nghìn URL pagination vào sitemap có thể:
- Làm sitemap phình to, khó quản lý.
- Phân tán tín hiệu ưu tiên crawl khỏi các URL thực sự quan trọng.
Chỉ trong một số trường hợp đặc biệt mới cân nhắc đưa pagination vào sitemap, ví dụ:
- Các trang phân trang được thiết kế như landing page có giá trị tìm kiếm riêng (ví dụ “Tin tức SEO – Trang 2” có lượng search đáng kể).
- Cấu trúc nội dung phụ thuộc mạnh vào pagination và không có nhiều đường dẫn khác đến các URL sâu.
Chiến lược phổ biến cho website lớn:
- Giữ sitemap gọn, tập trung vào:
- Sản phẩm/bài viết chính.
- Danh mục cấp cao, tag/hub quan trọng.
- Tận dụng internal link và breadcrumb để Google tự khám phá pagination.
Pagination có làm giảm crawl budget của website lớn không?
Pagination có thể làm giảm hiệu quả sử dụng crawl budget nếu được triển khai thiếu kiểm soát, đặc biệt trên website rất lớn (hàng chục/hàng trăm nghìn URL). Một số vấn đề thường gặp:
- Quá nhiều trang phân trang mỏng, lặp lại pattern nội dung, ít giá trị bổ sung.
- Chuỗi pagination rất sâu (page 50, 100…) trong khi phần lớn traffic và giá trị SEO nằm ở các page đầu.
- Kết hợp pagination với tham số sort/filter tạo ra vô số biến thể URL.
Hệ quả:
- Googlebot có thể tiêu tốn nhiều lần crawl cho các URL pagination ít giá trị.
- Crawl budget bị phân tán, làm chậm việc cập nhật index cho sản phẩm/bài viết mới hoặc quan trọng.
Để giảm tác động tiêu cực, cần thiết kế pagination hợp lý:
- Giới hạn độ sâu pagination khi có thể (ví dụ tăng số item mỗi page để giảm số page).
- Dùng canonical chính xác và tránh sinh ra các biến thể URL không cần thiết.
- Ưu tiên internal link đến:
- Sản phẩm/bài viết quan trọng.
- Danh mục/hub có giá trị SEO cao.
Trên website lớn, nên kết hợp:
- Chiến lược ưu tiên crawl (thông qua sitemap, internal link, server log analysis) cho URL quan trọng.
- Kiểm soát tham số URL (thông qua cấu hình hệ thống, robots.txt, hoặc công cụ quản lý tham số nếu phù hợp).
- Phân tích log để nhận diện:
- Những chuỗi pagination bị crawl quá nhiều nhưng không mang lại traffic.
- Những khu vực nội dung quan trọng nhưng ít được crawl.
Khi pagination được thiết kế tốt, với số lượng trang hợp lý, nội dung đủ giá trị, canonical chuẩn và internal link thông minh, tác động tiêu cực đến crawl budget sẽ giảm đáng kể và có thể trở thành một phần hữu ích trong chiến lược phân phối nội dung toàn site.



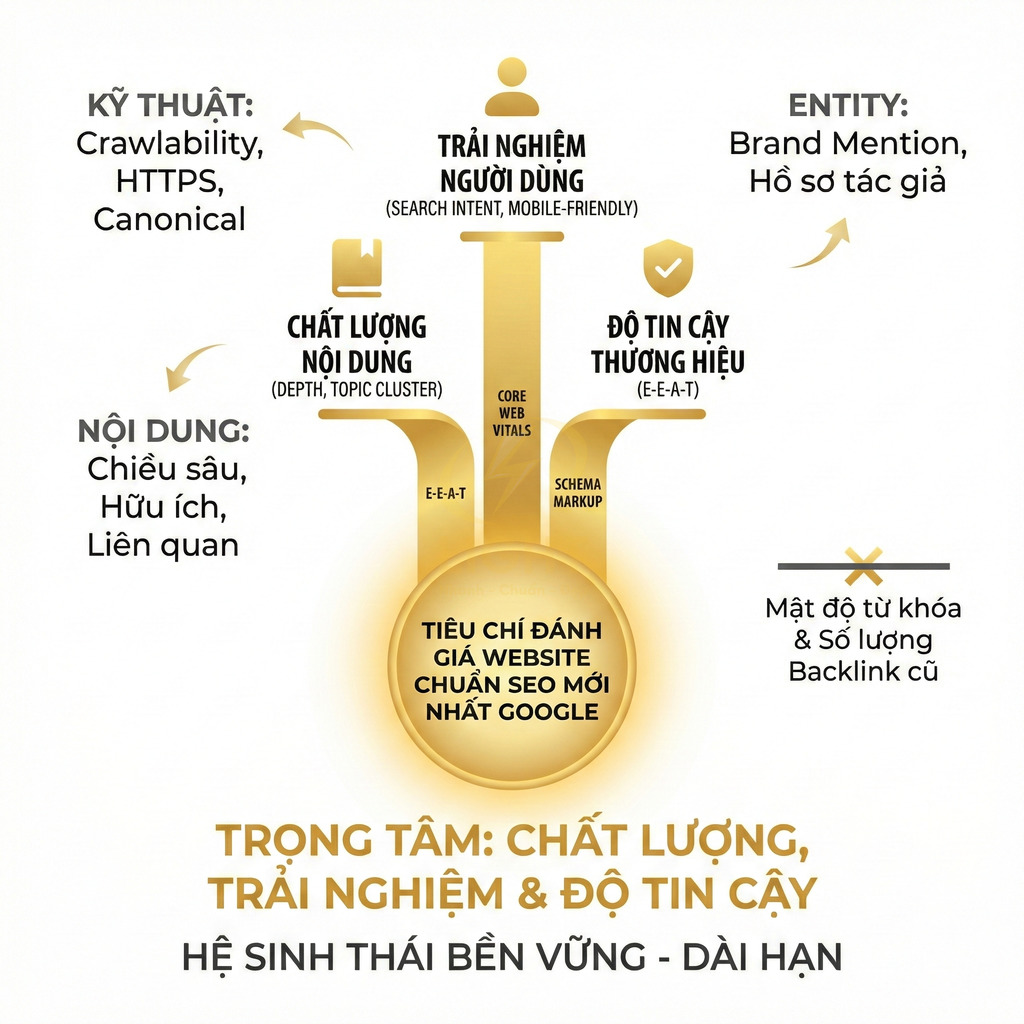

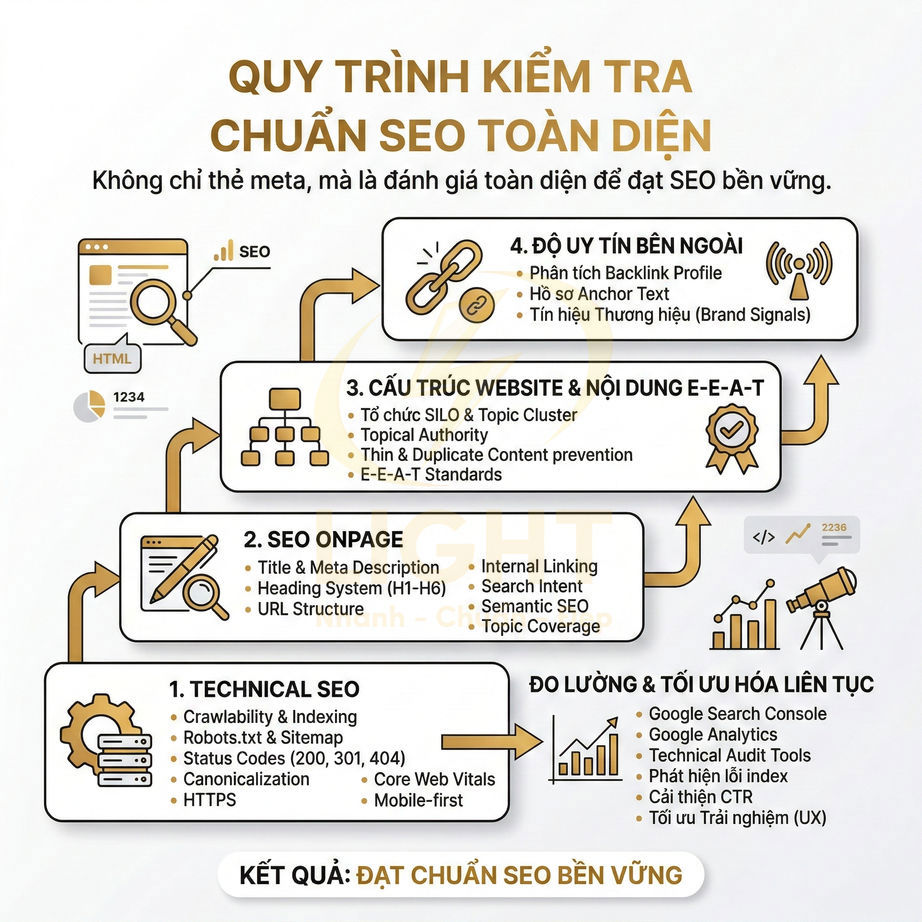
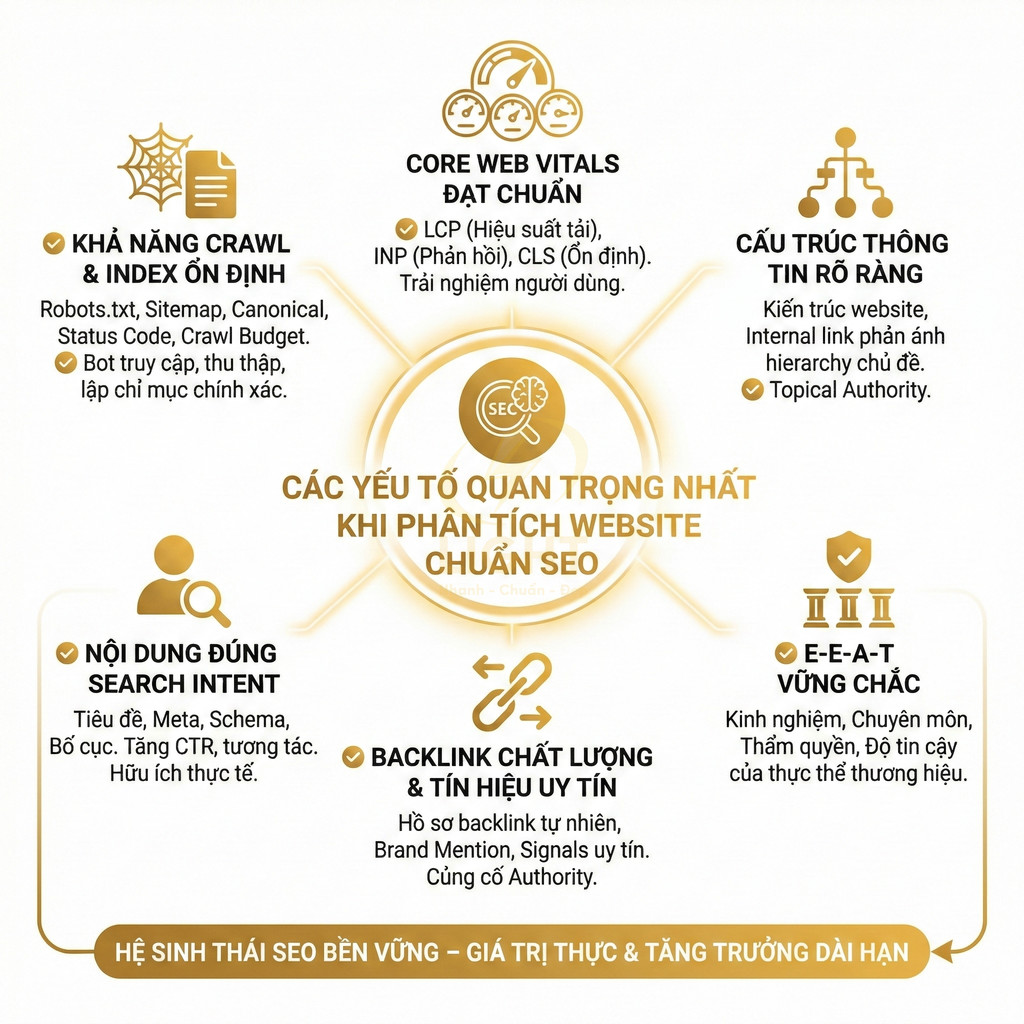

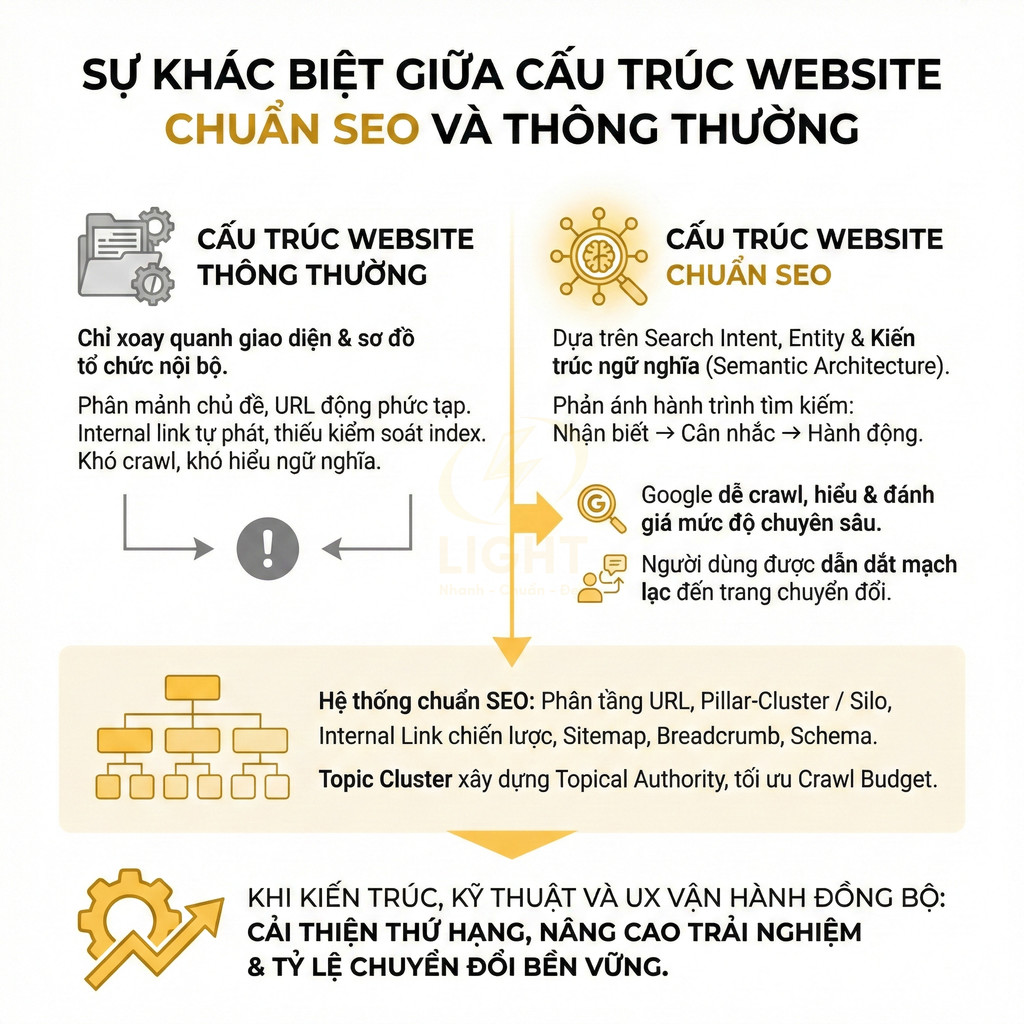

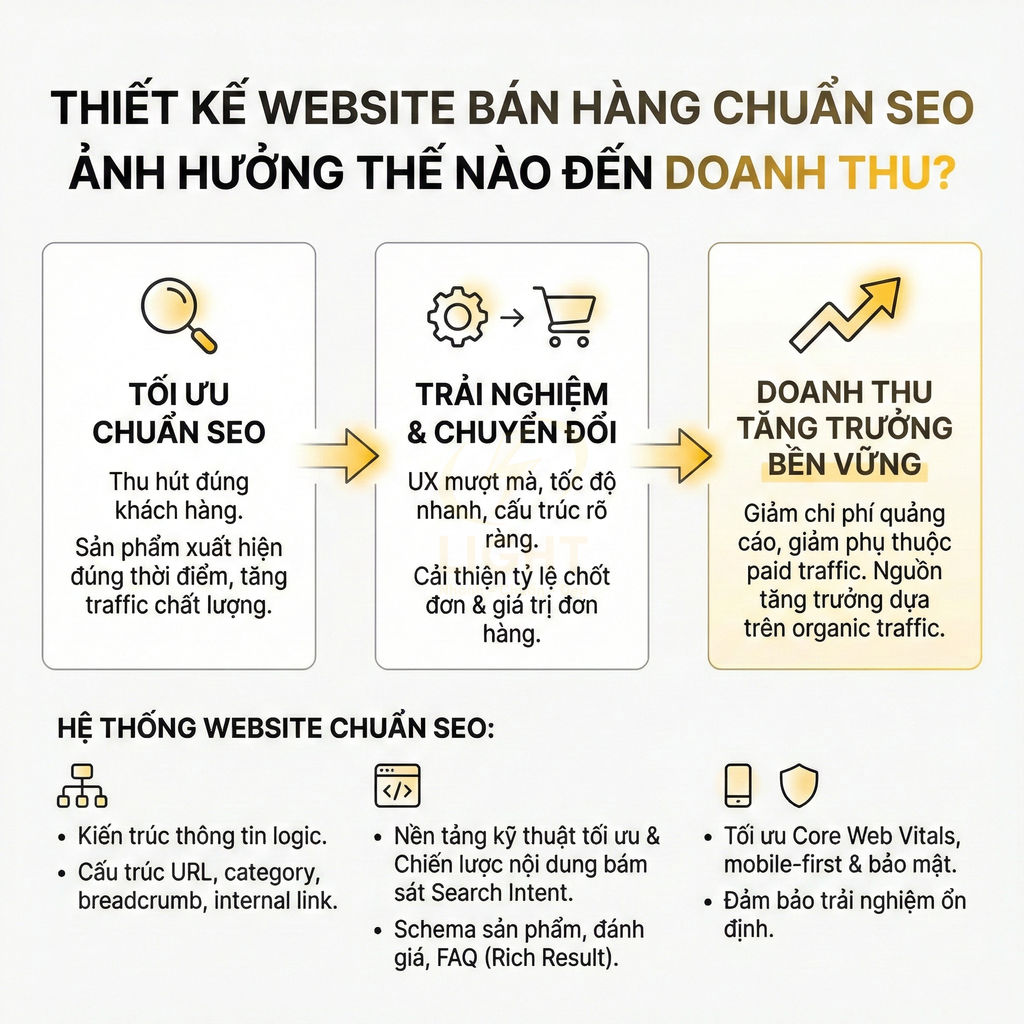


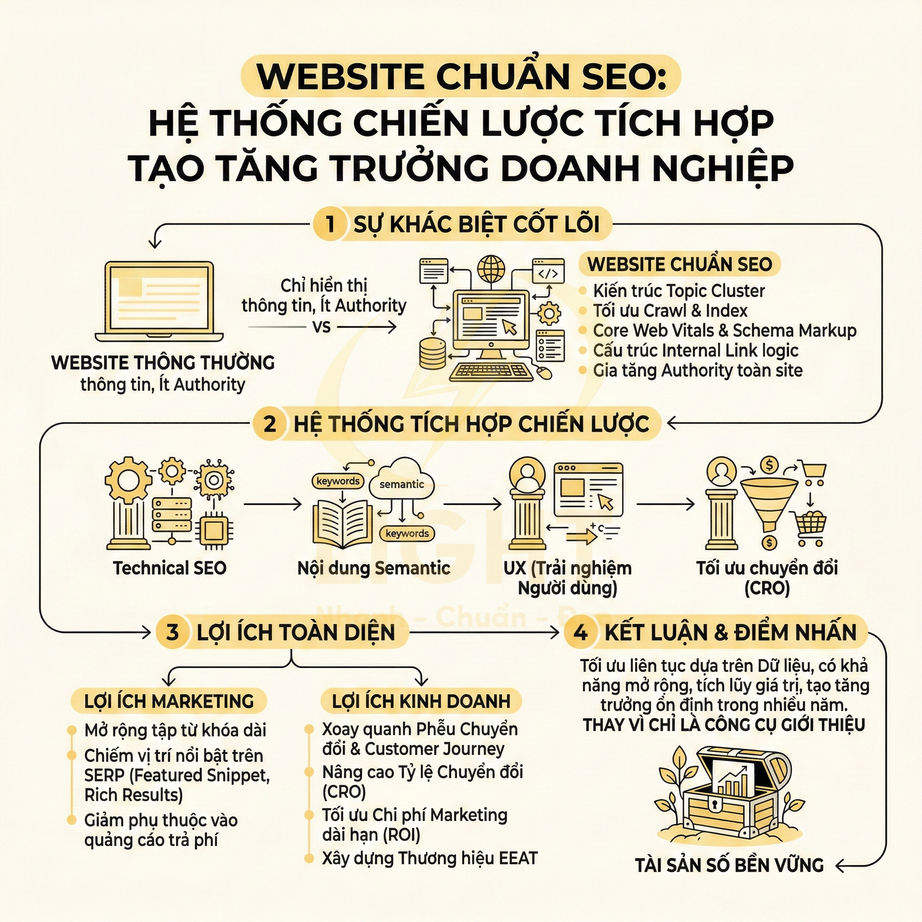
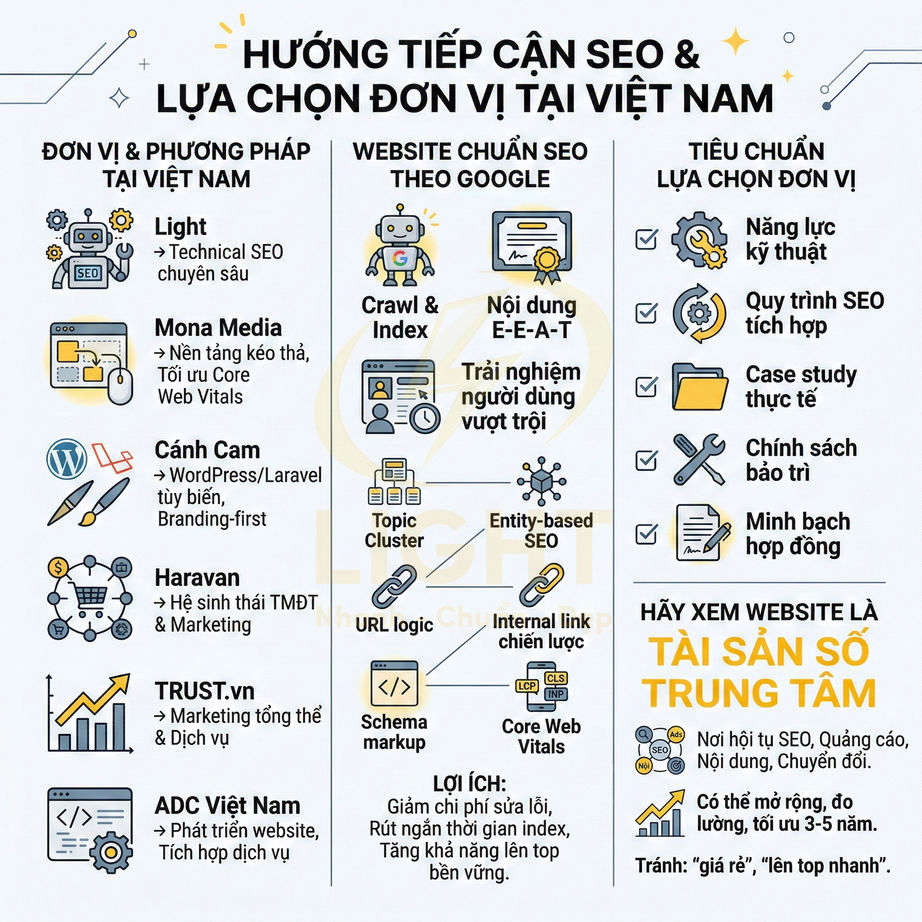
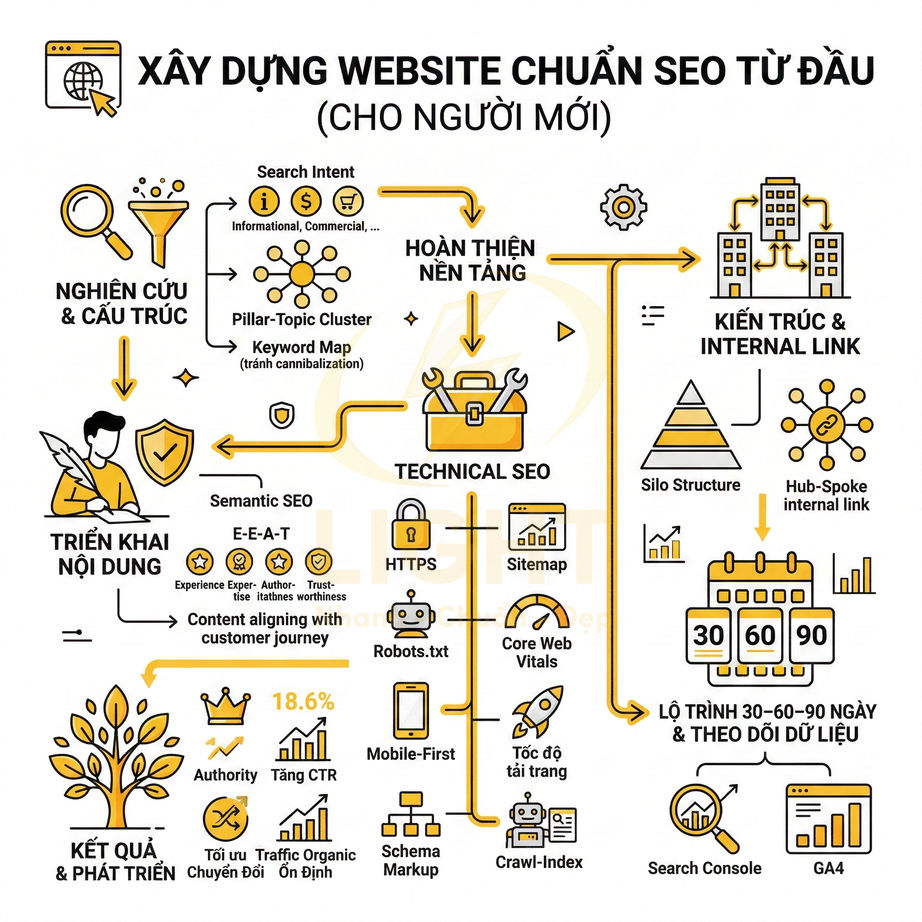
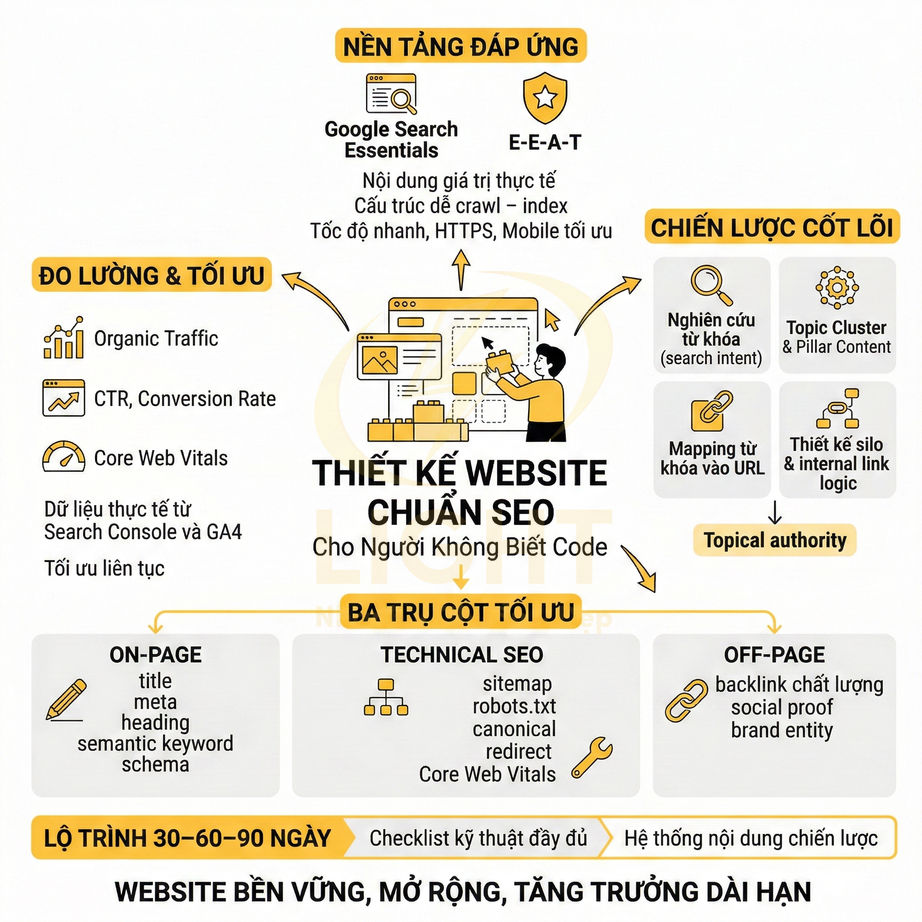



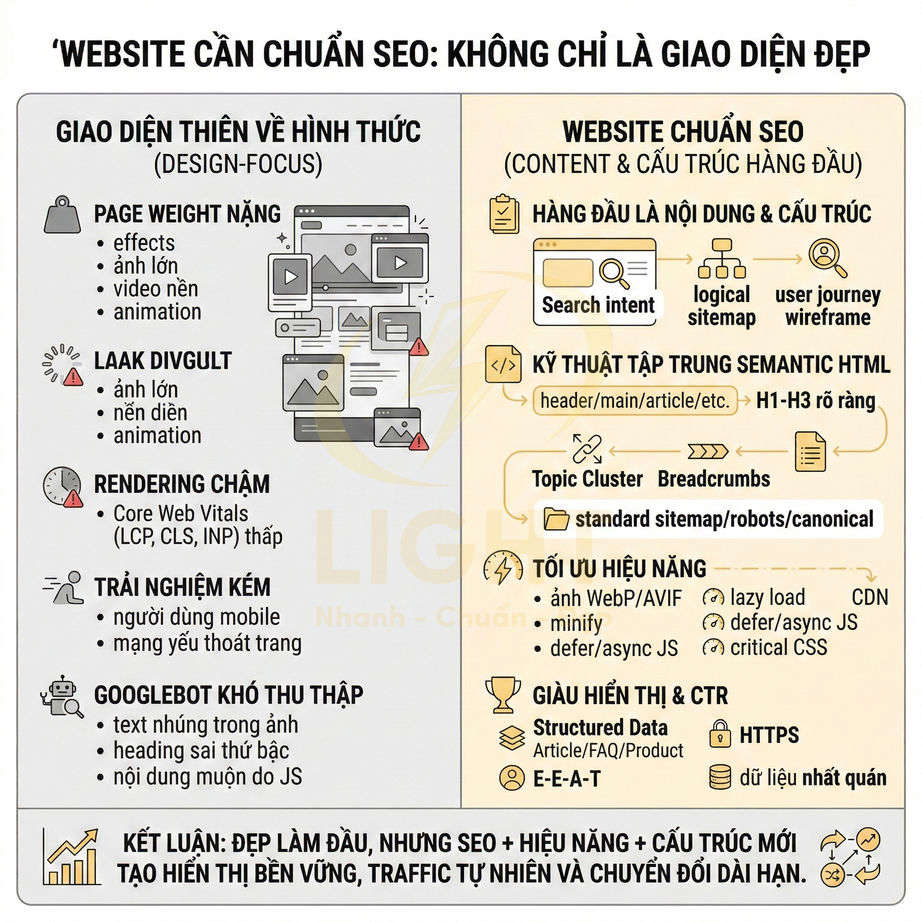
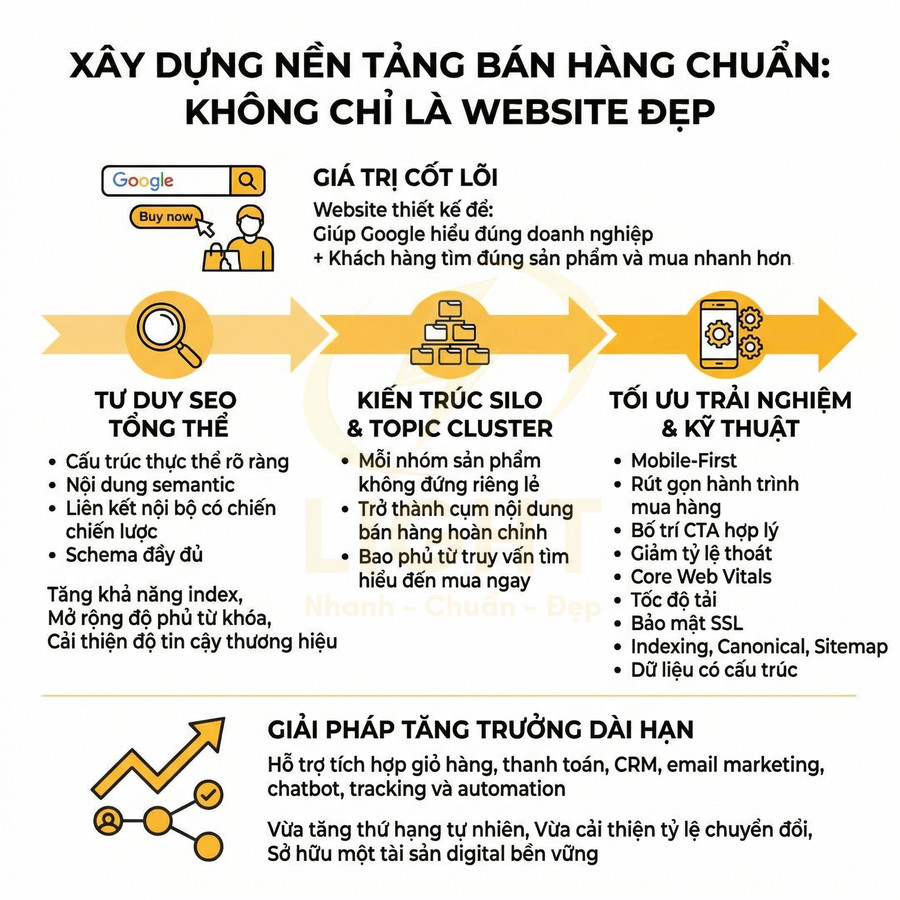

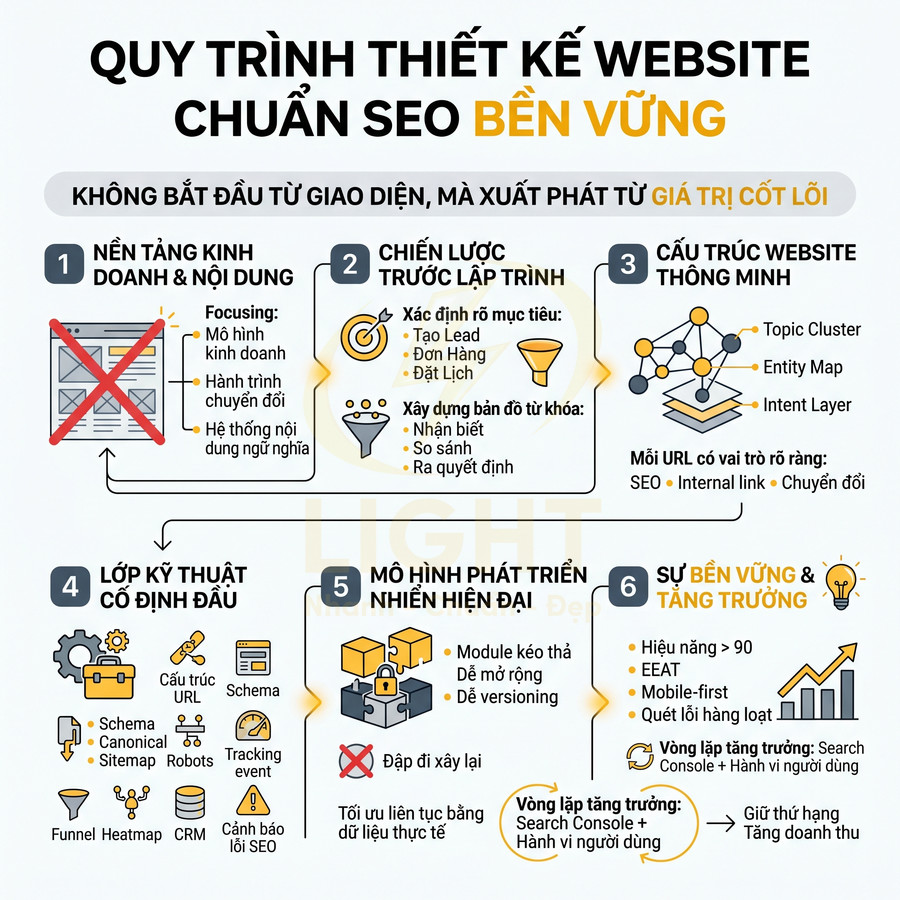
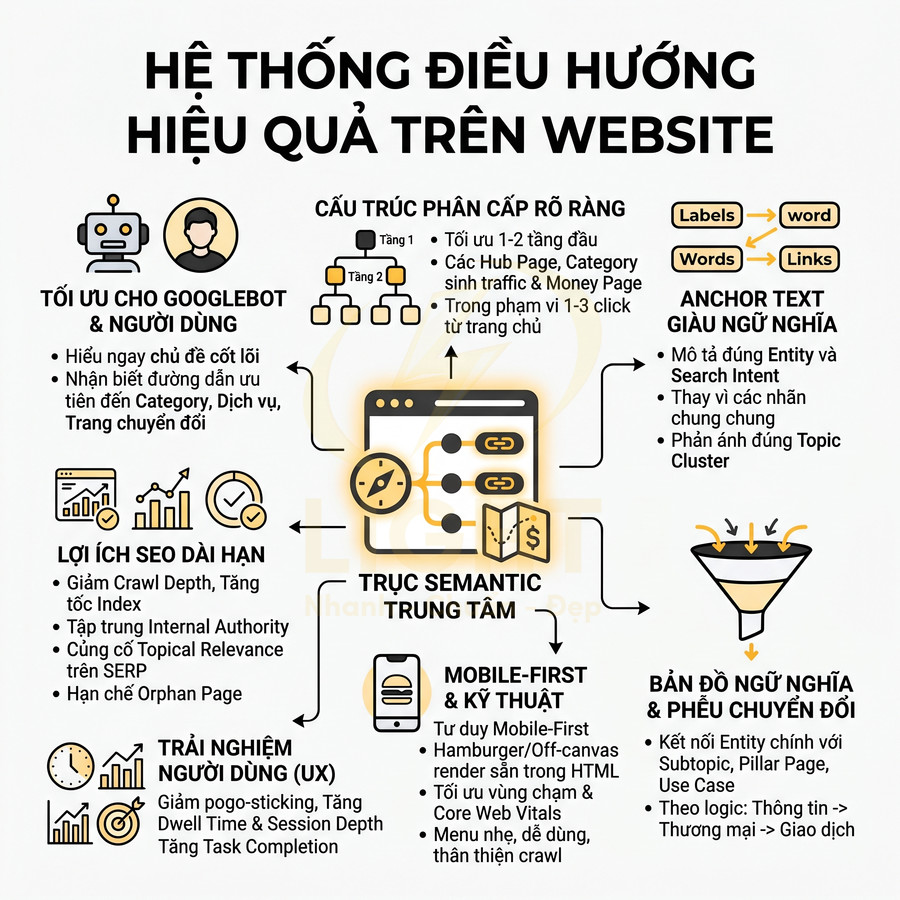
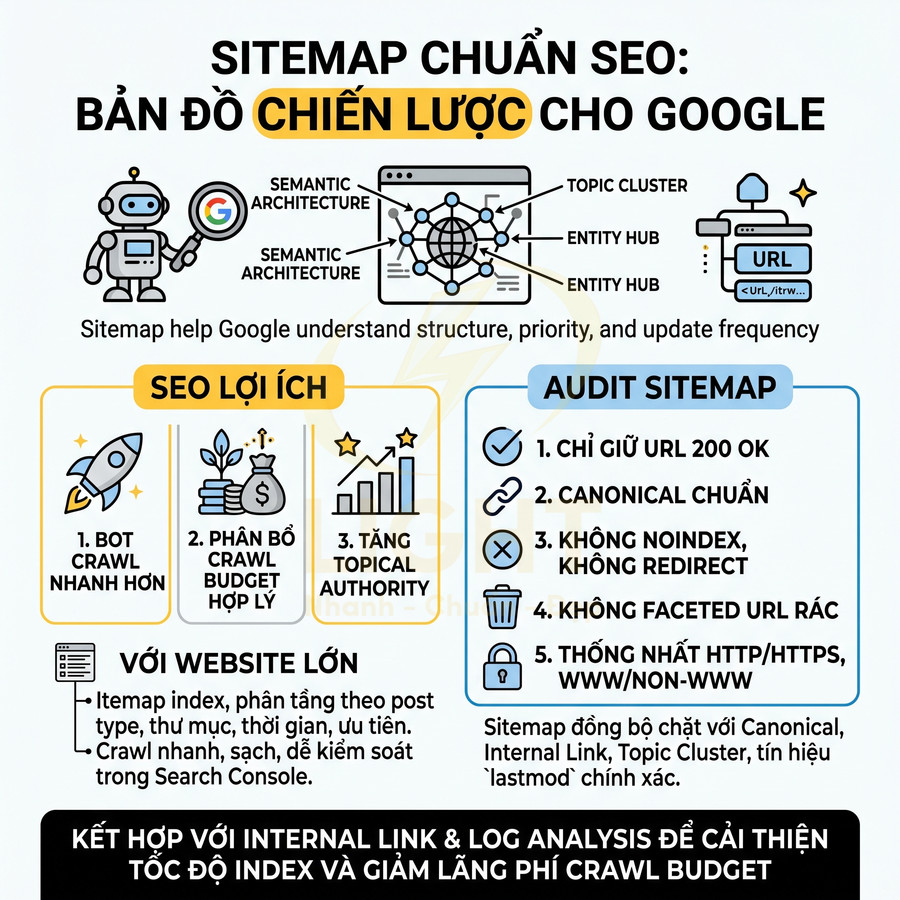
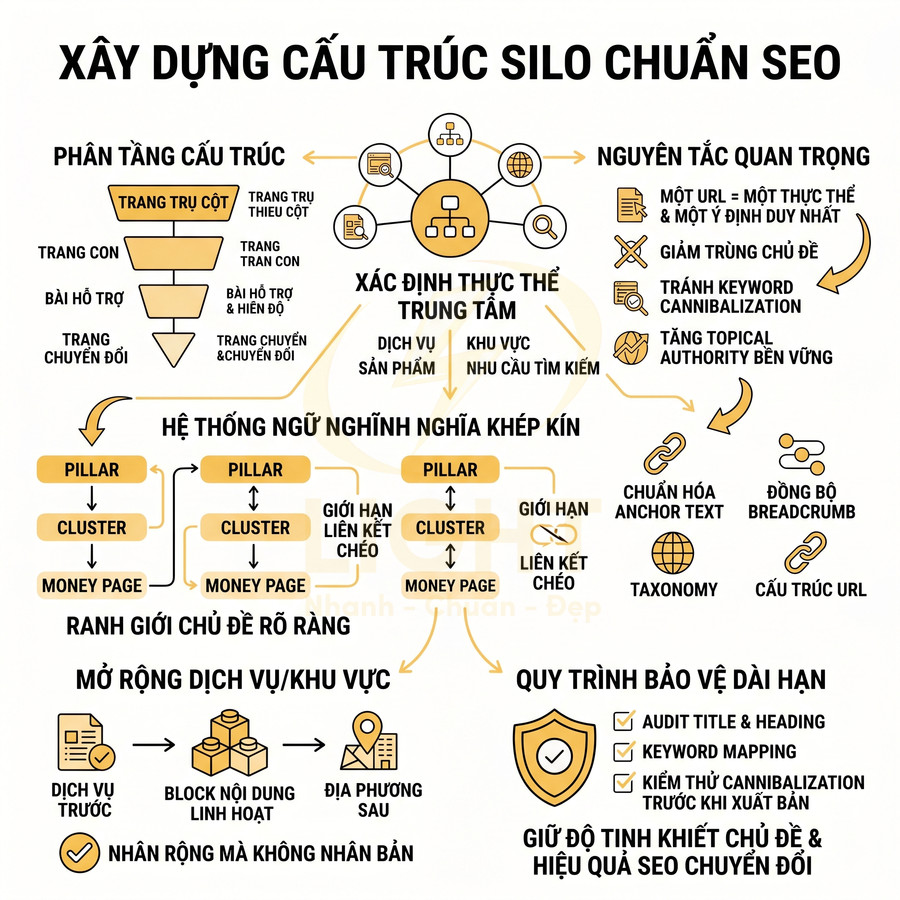
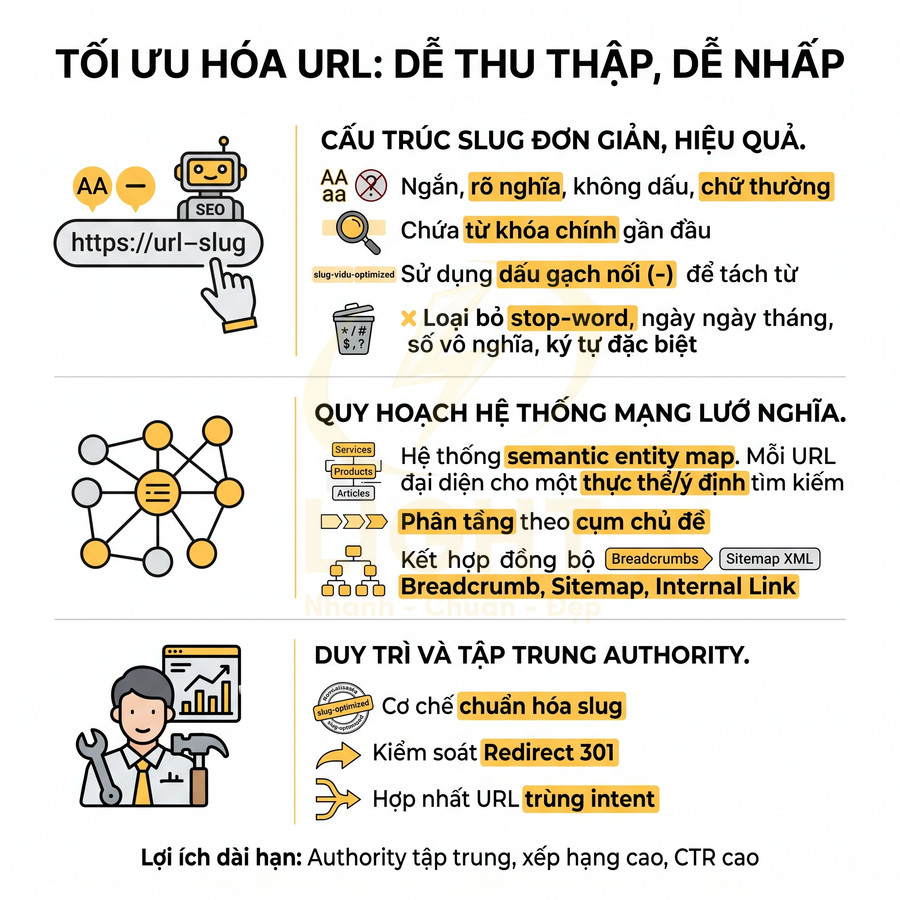
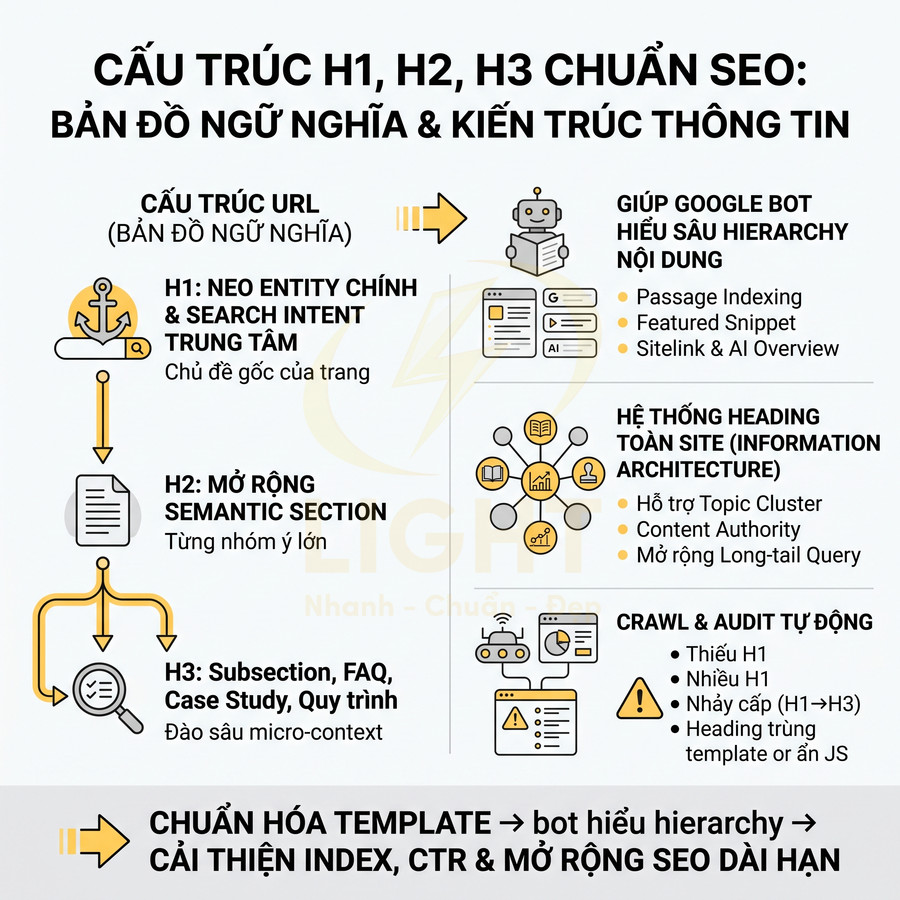
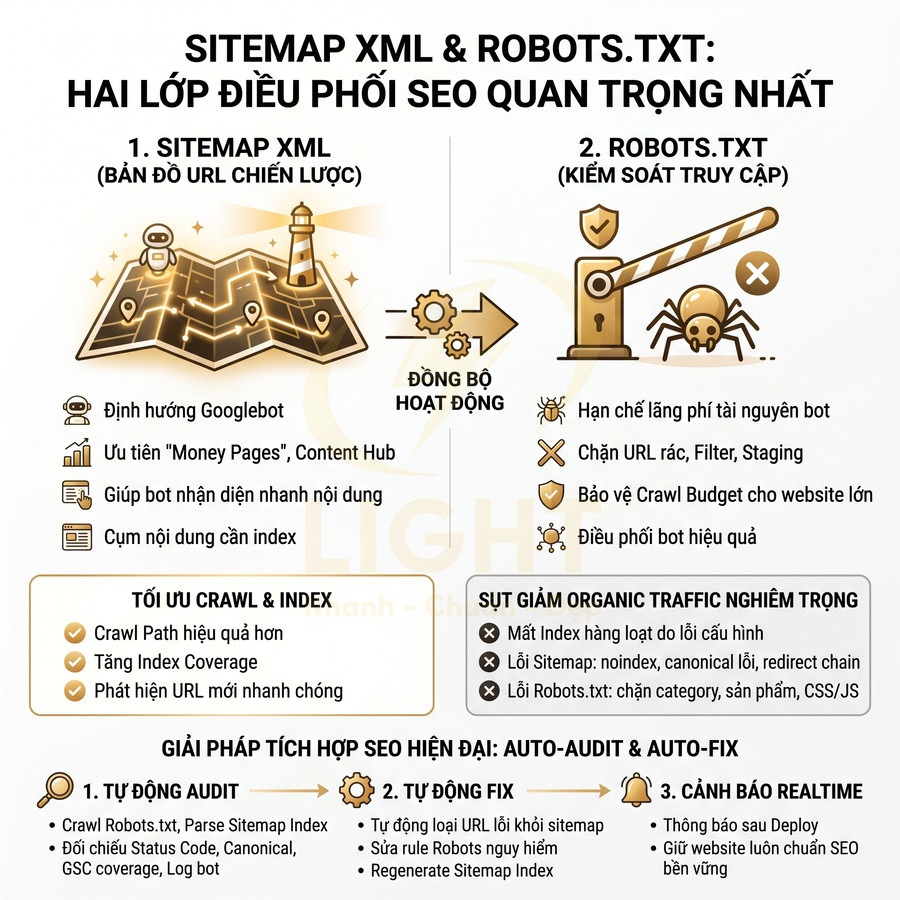
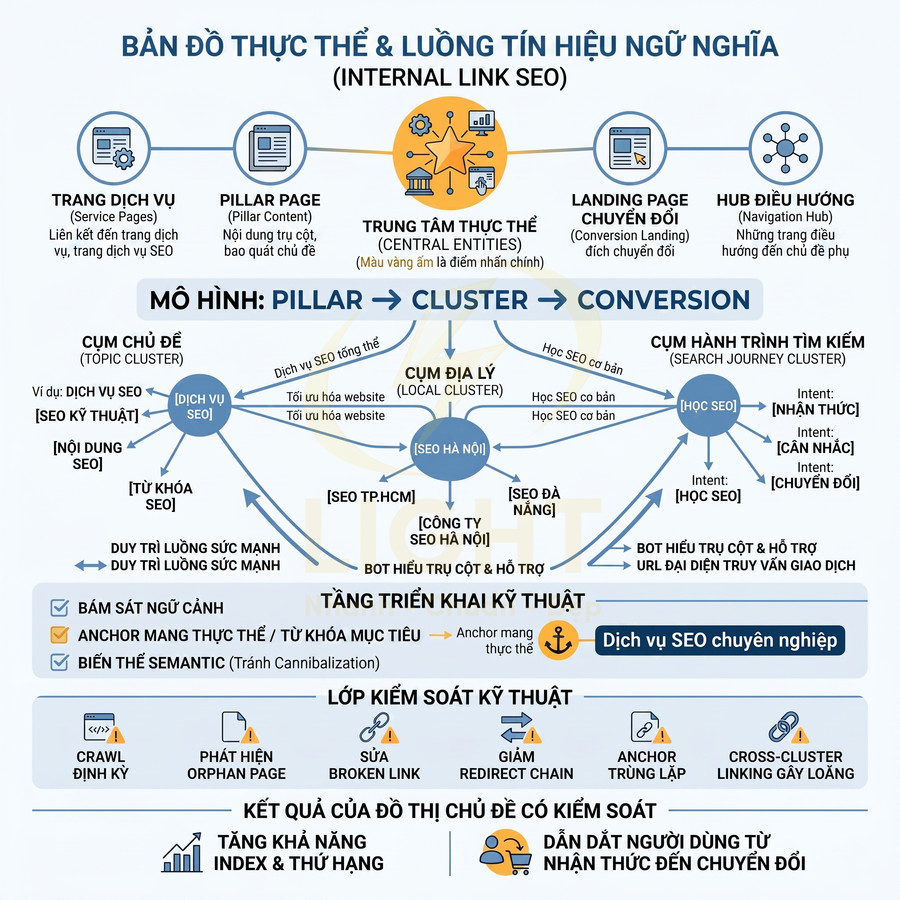
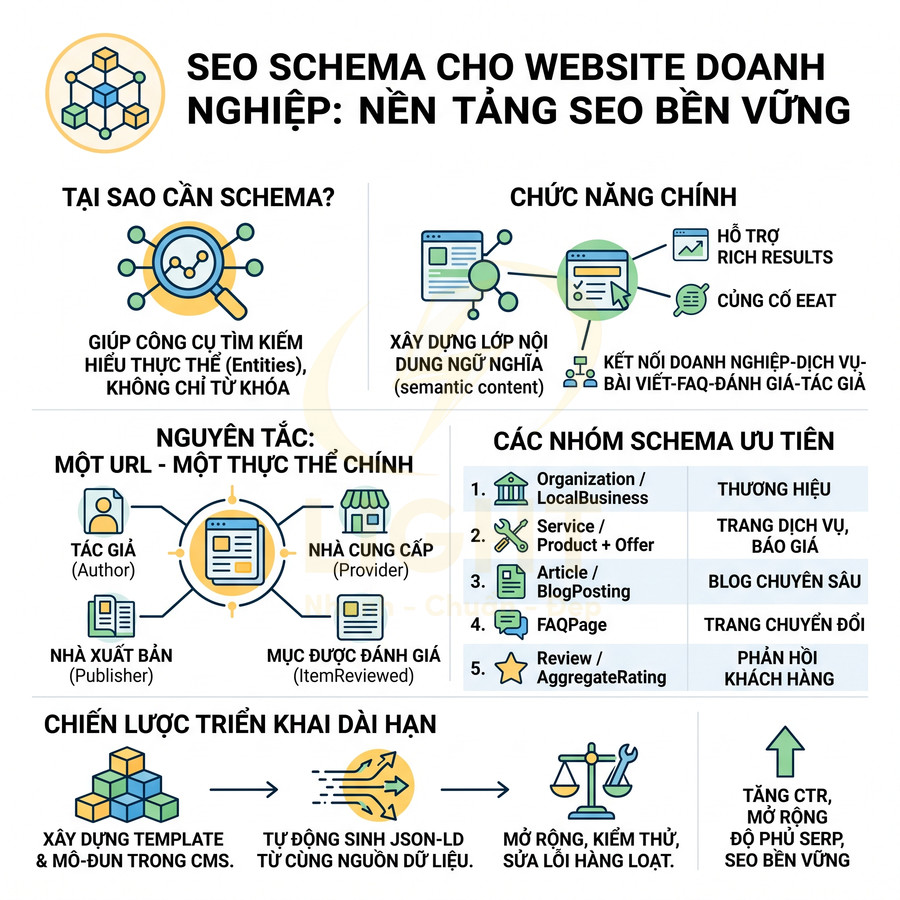
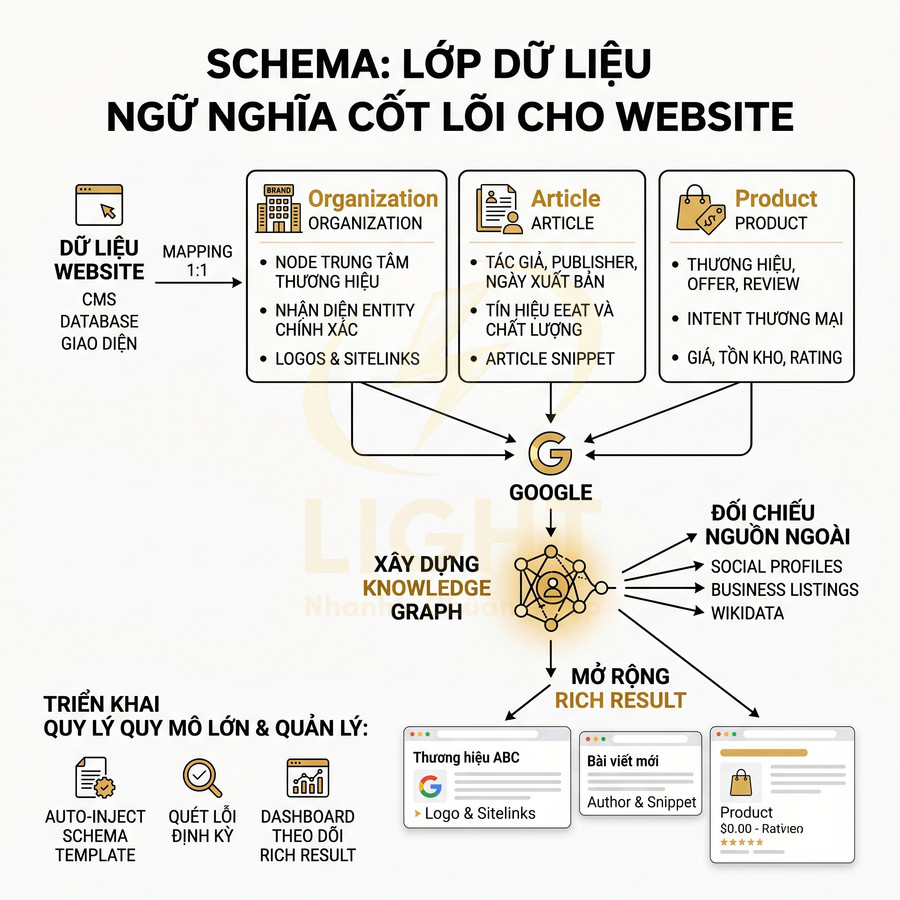

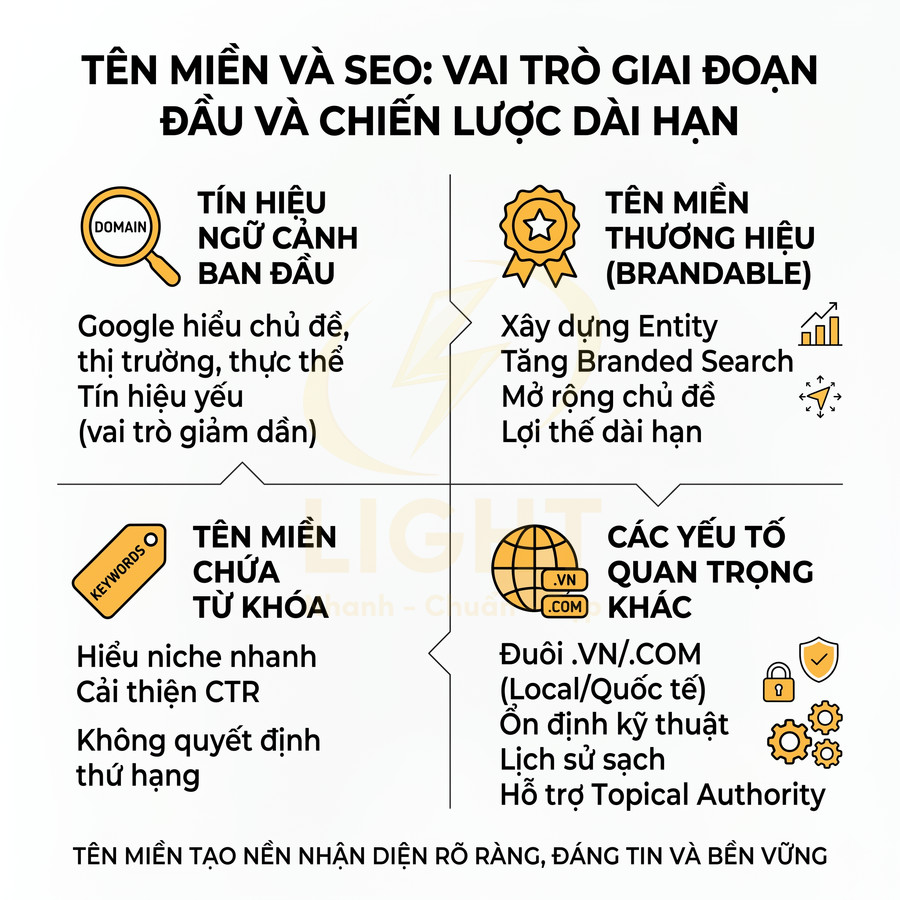
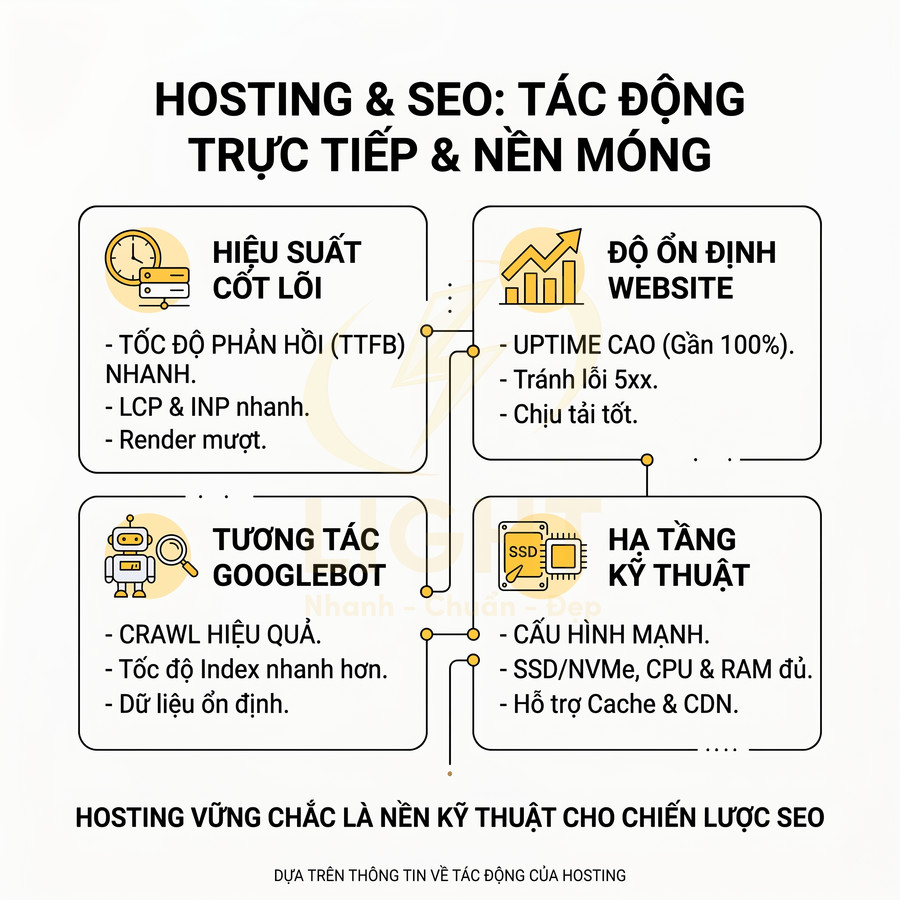
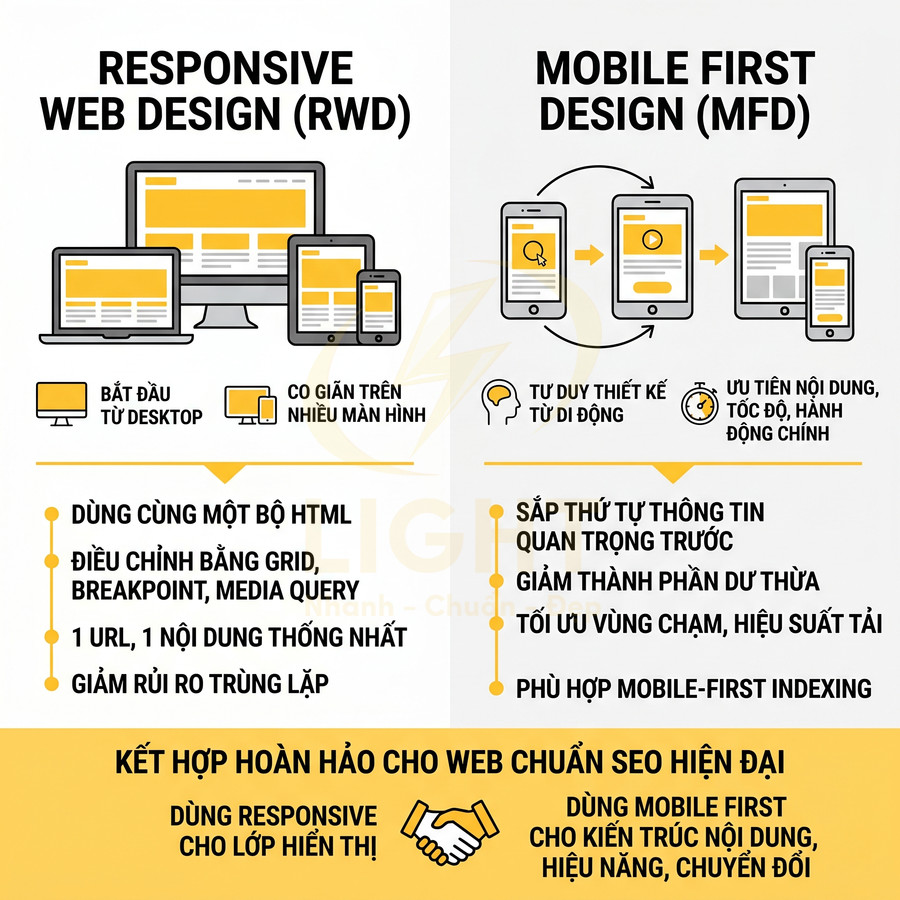


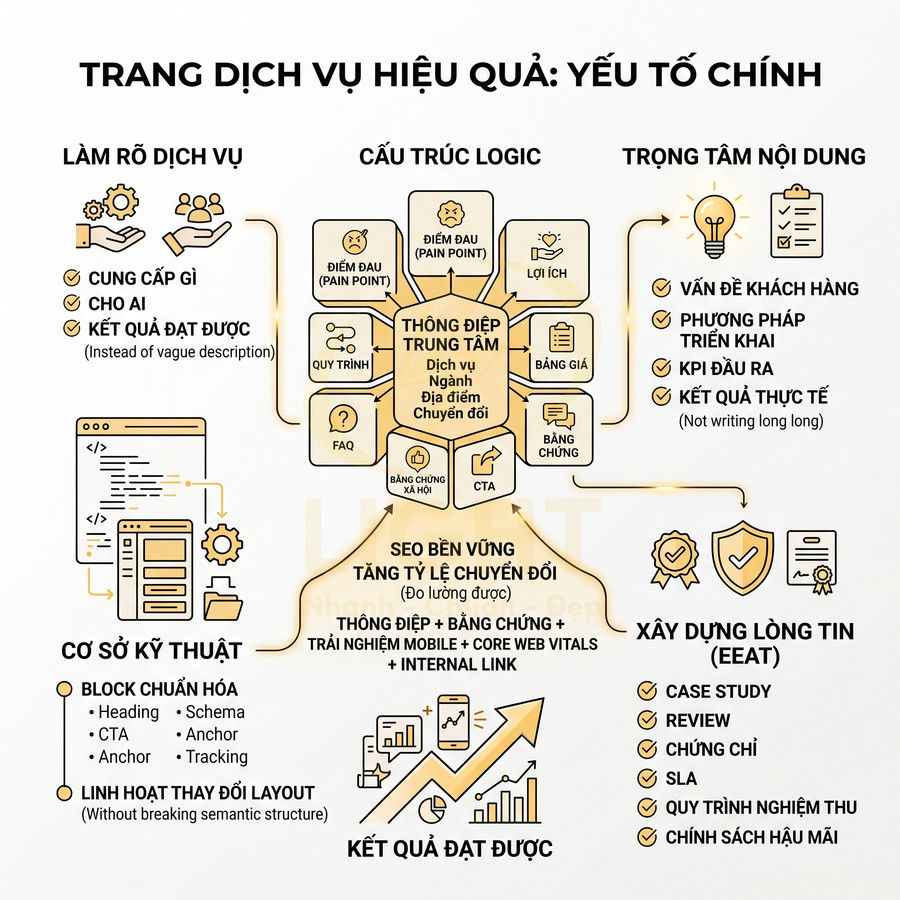
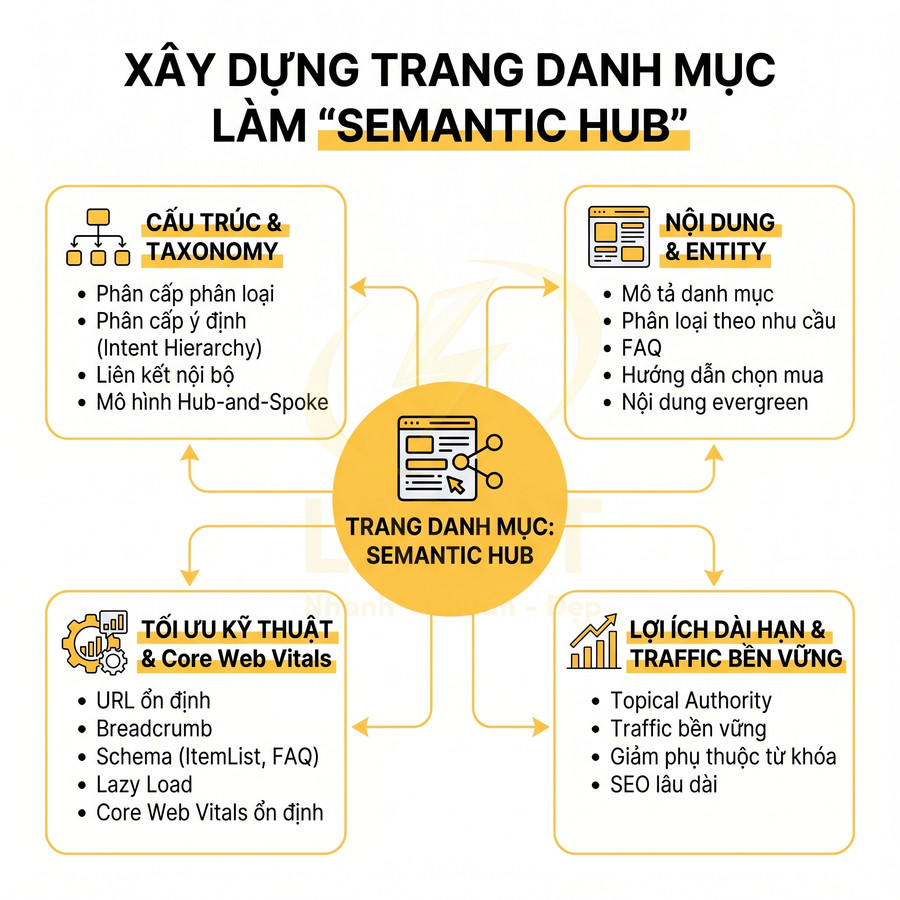

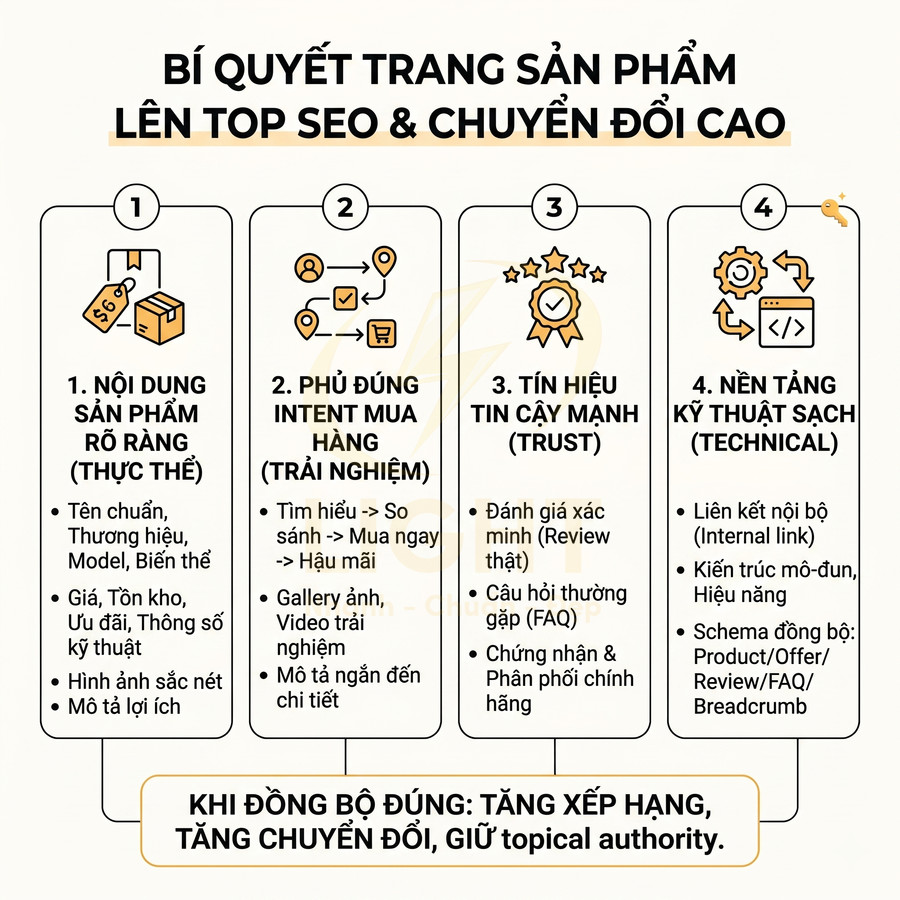


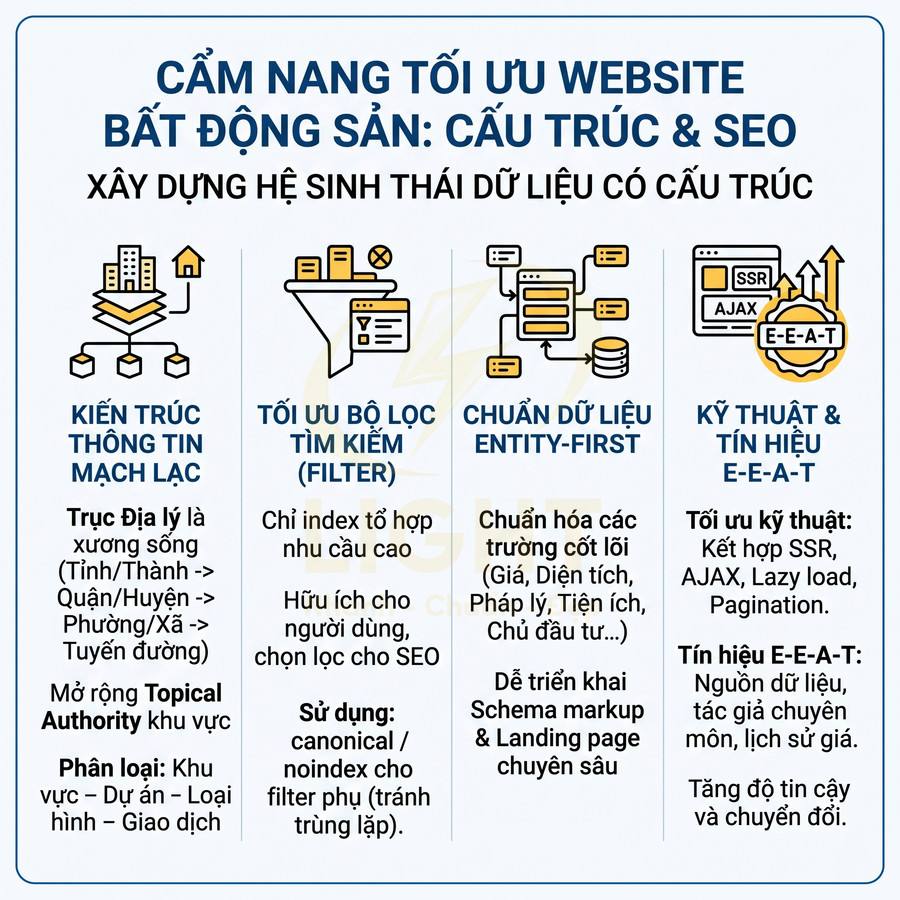


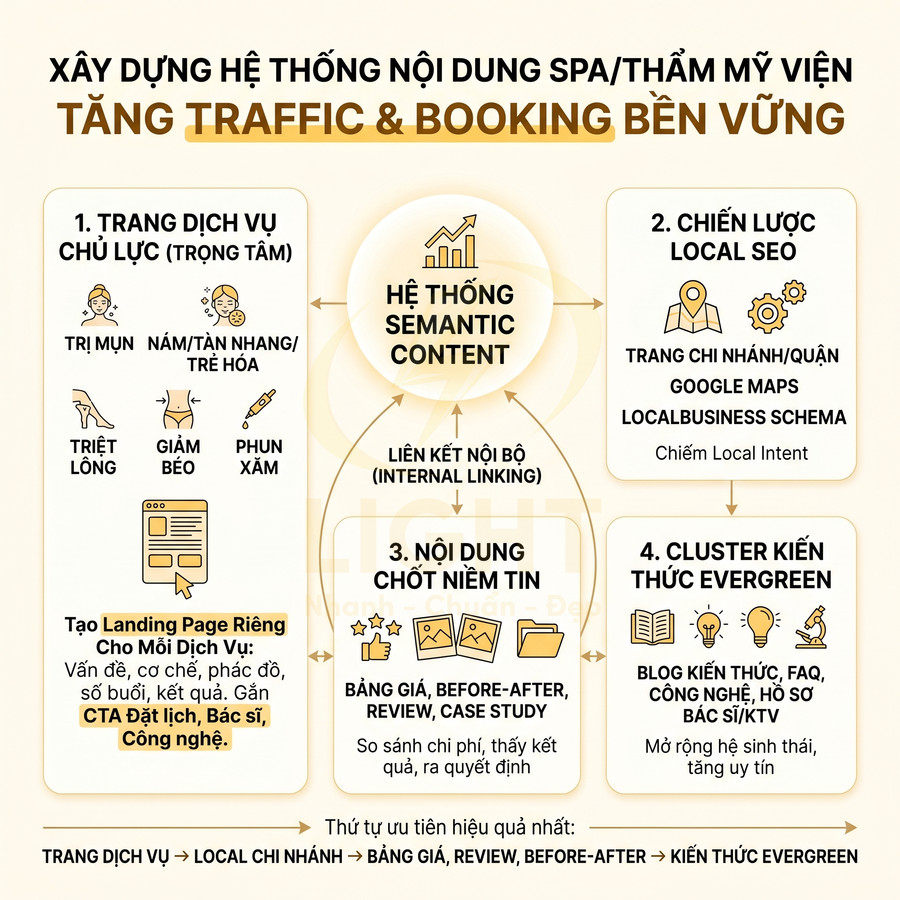
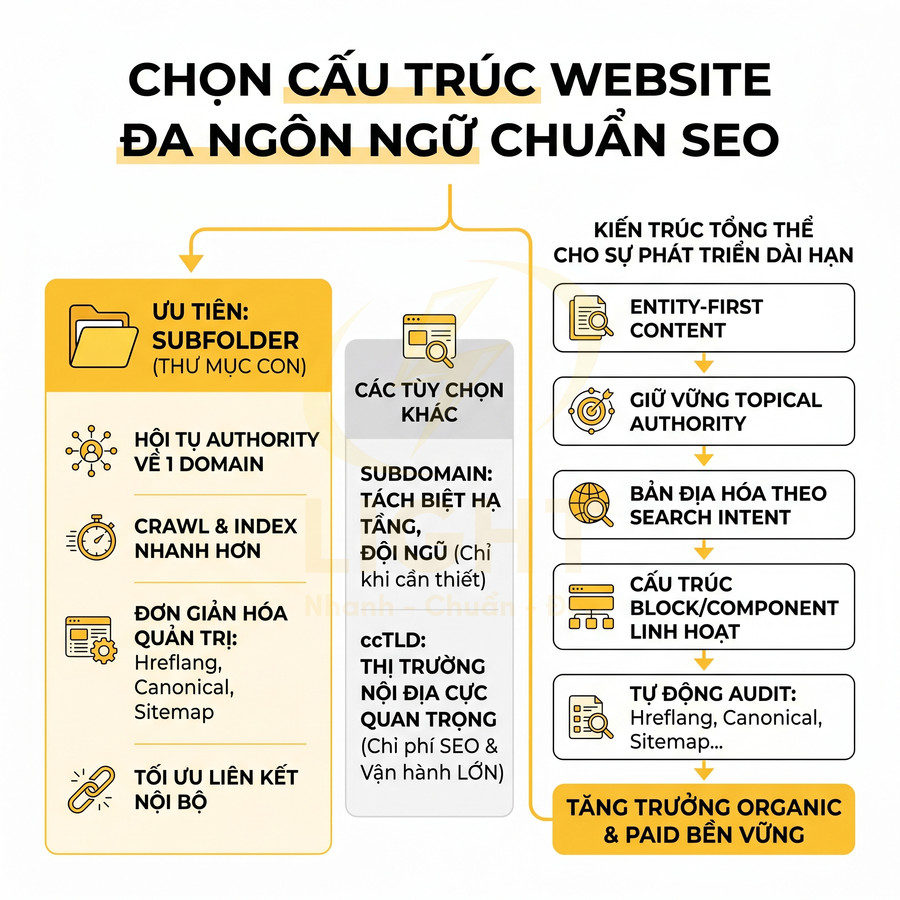
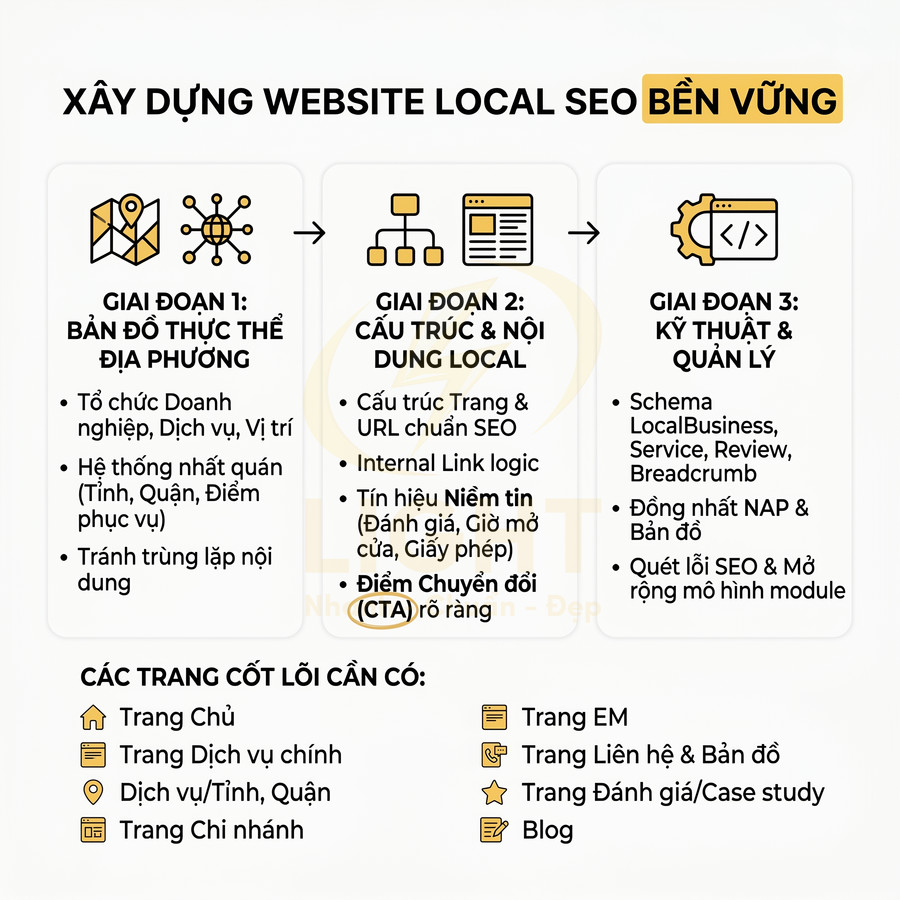

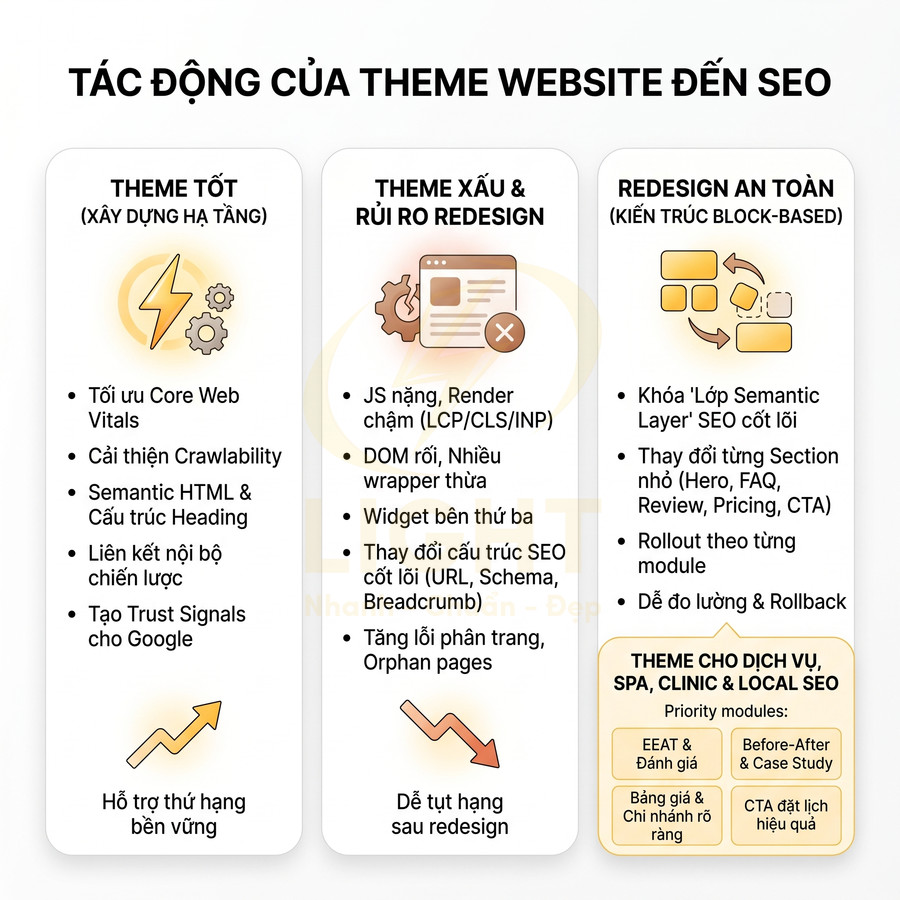
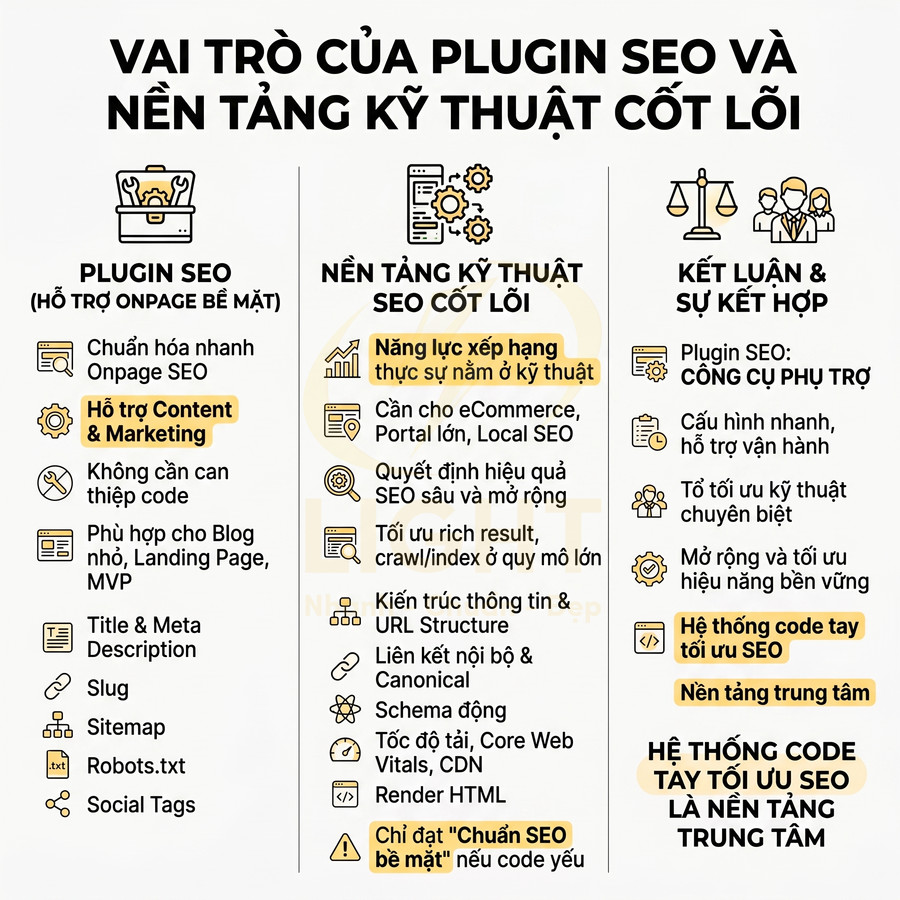

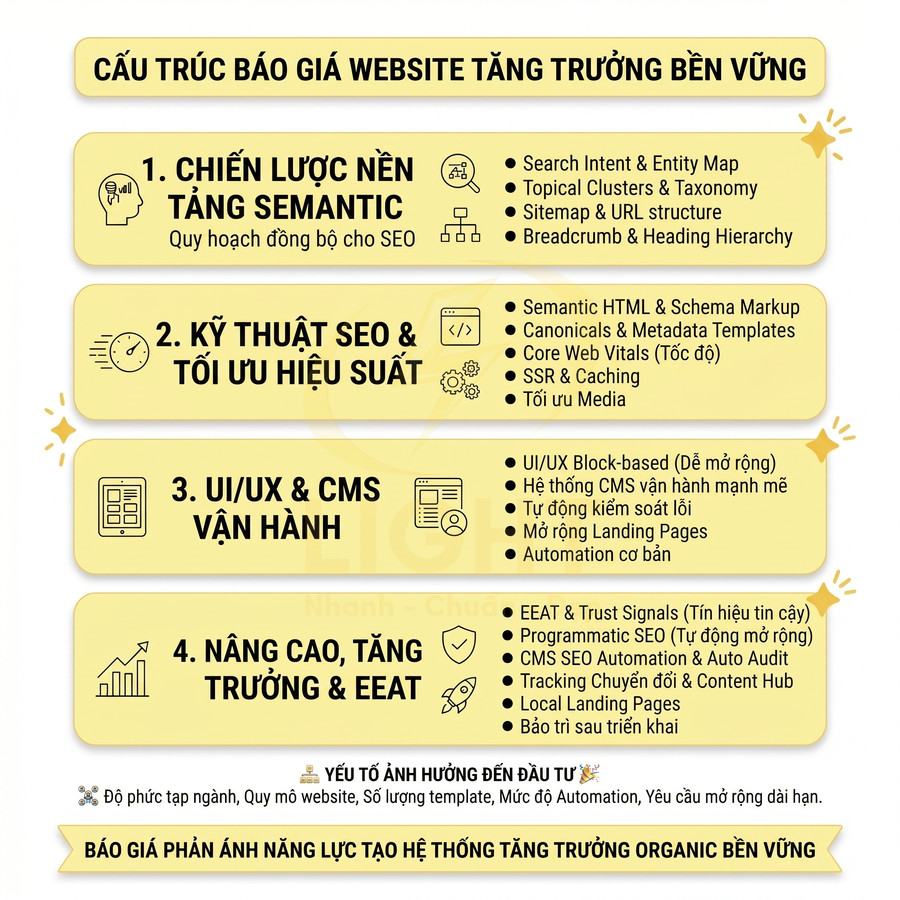

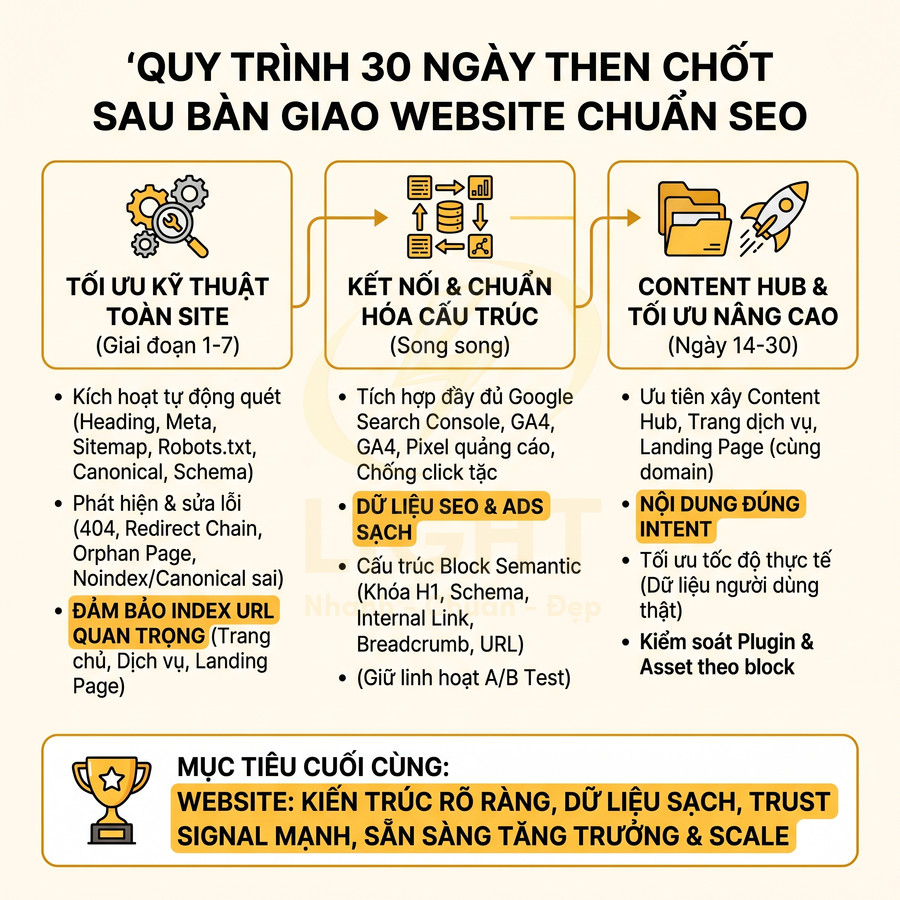
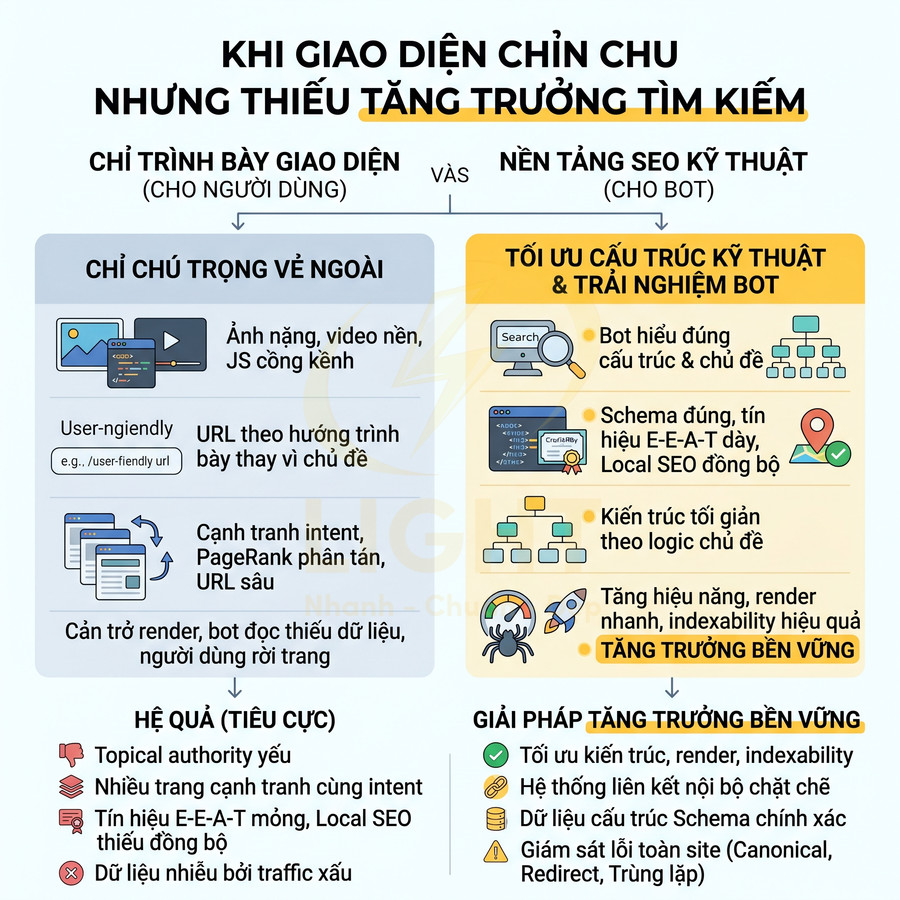

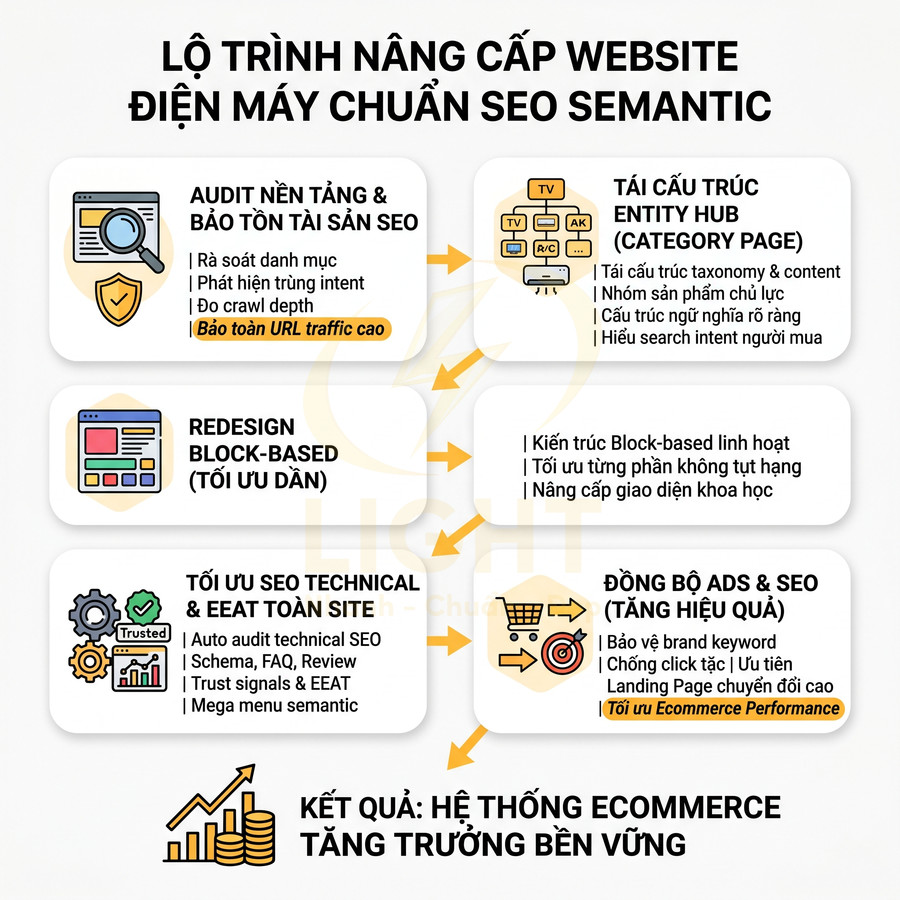
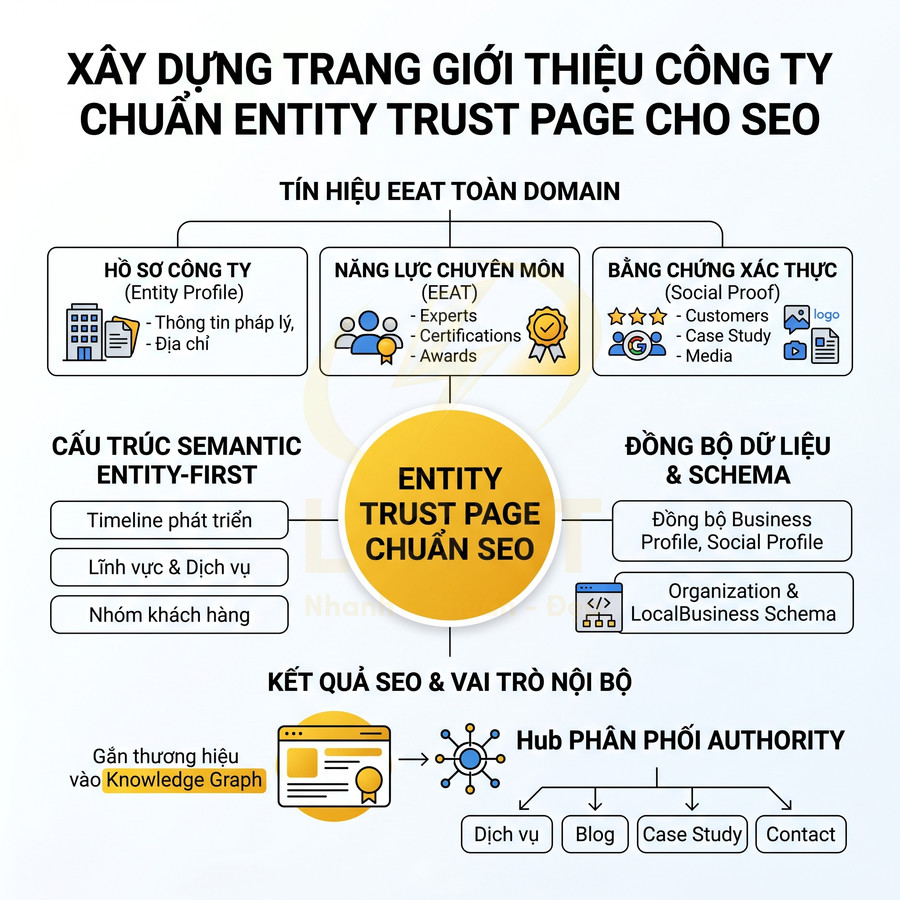
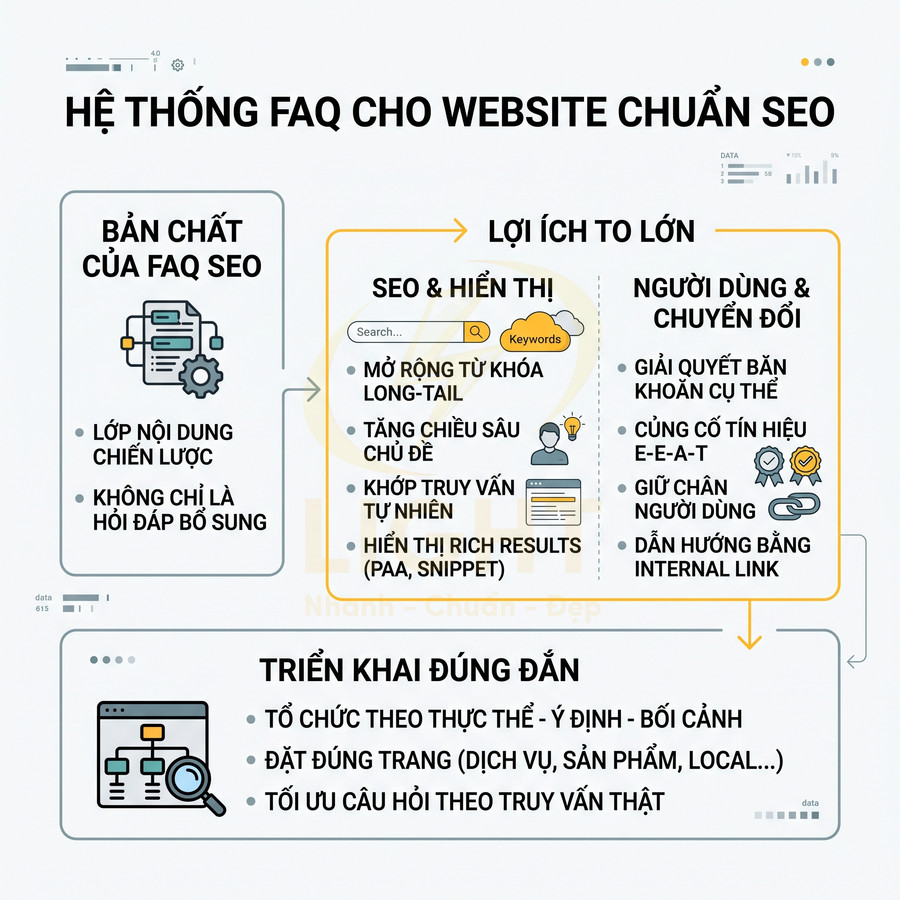
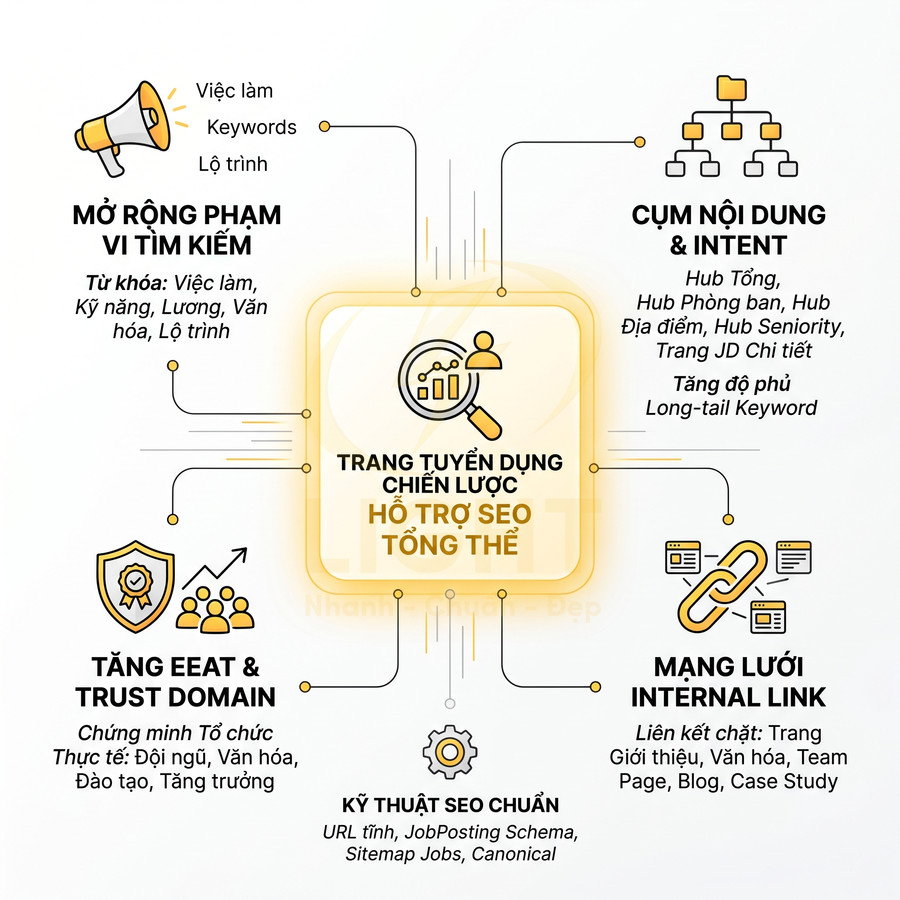

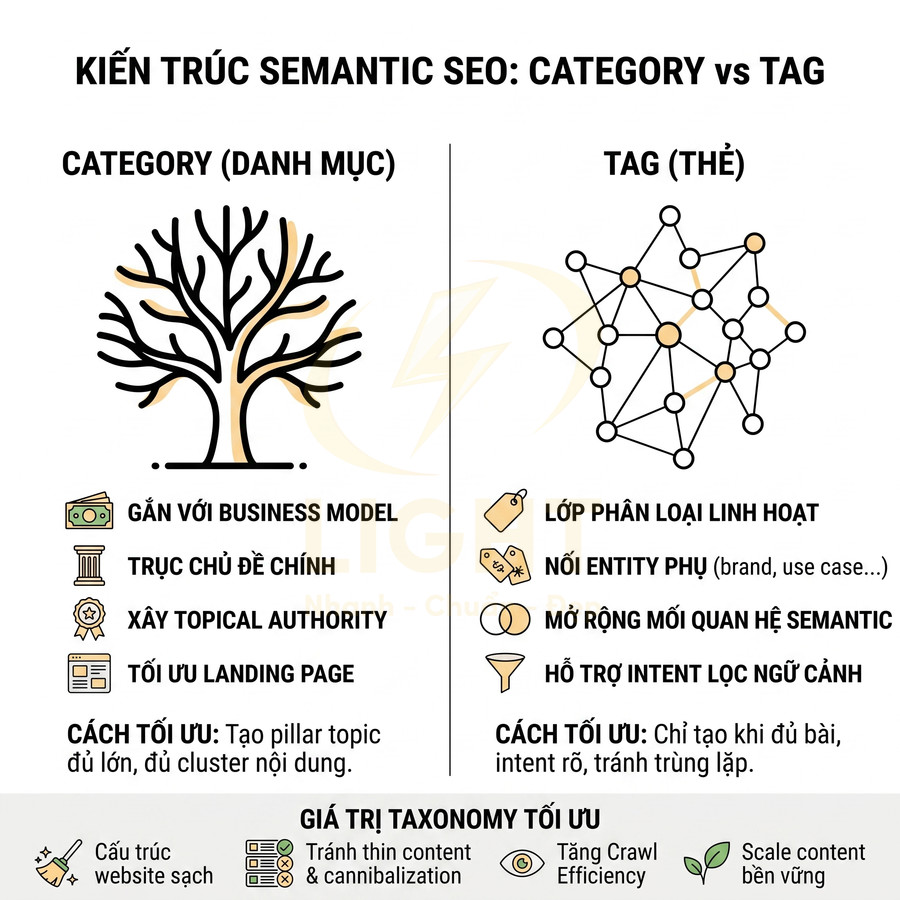
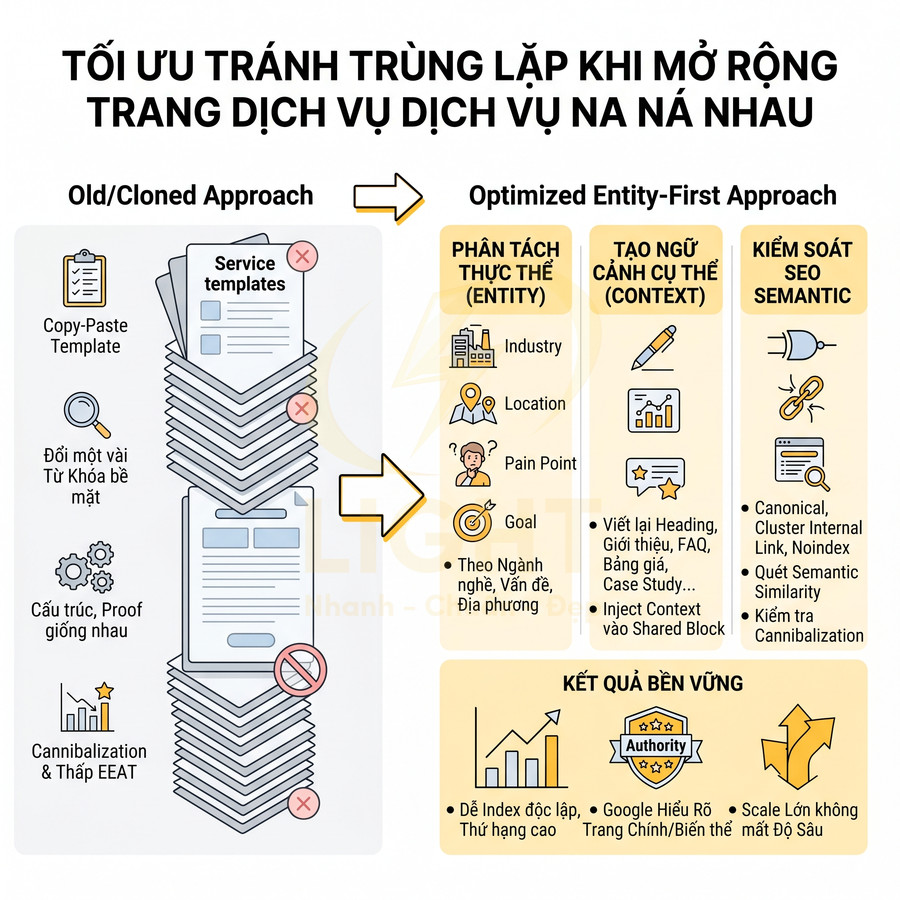

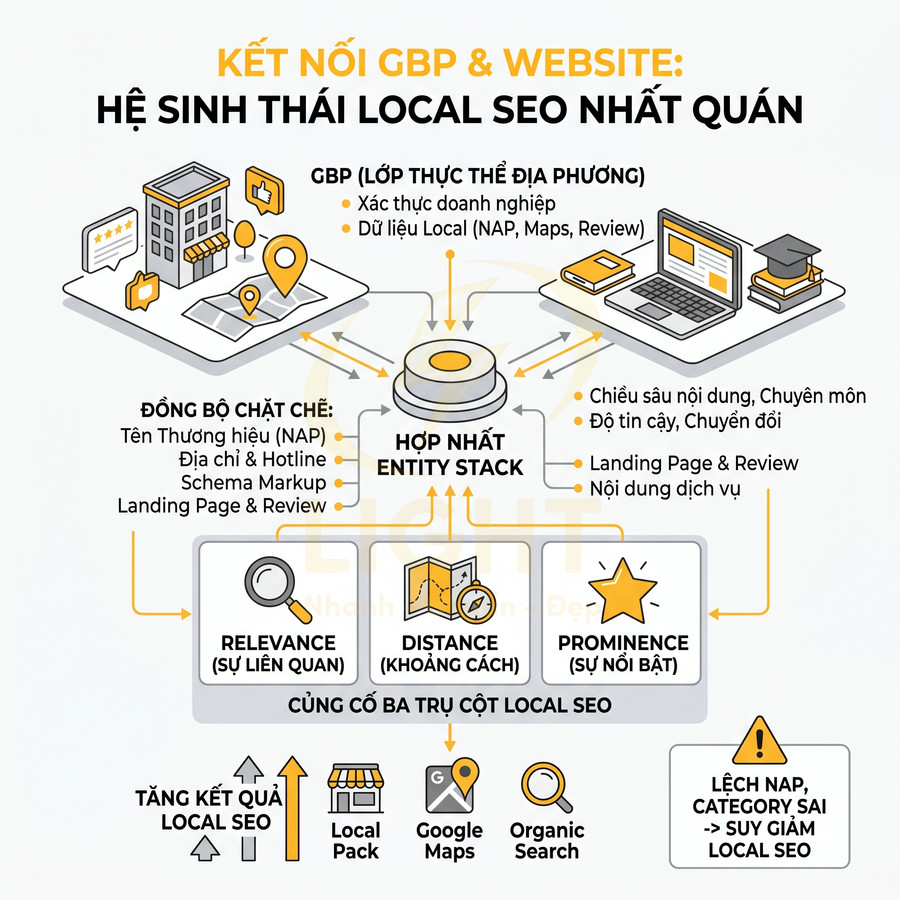
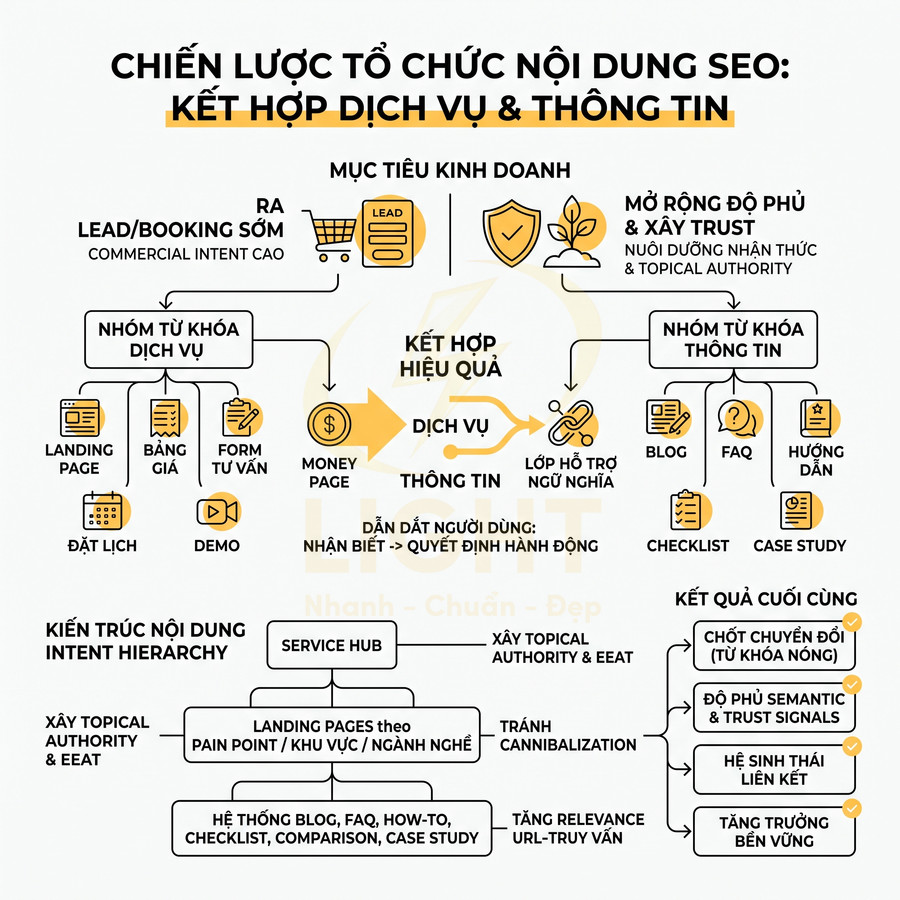
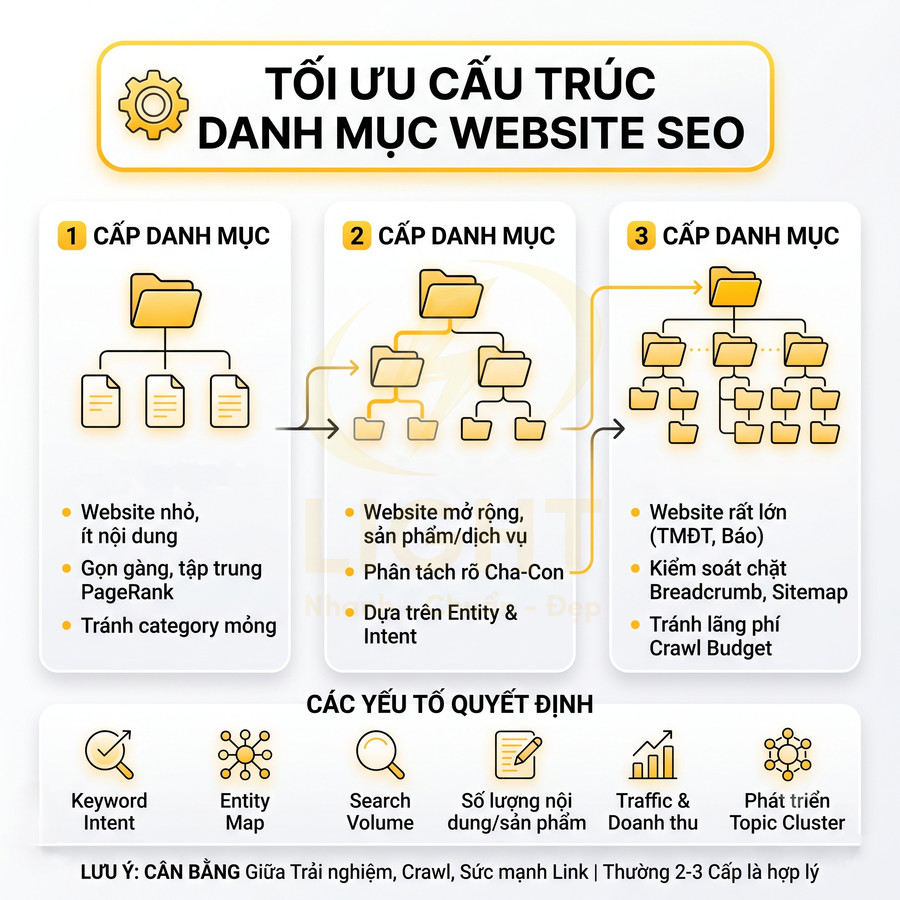



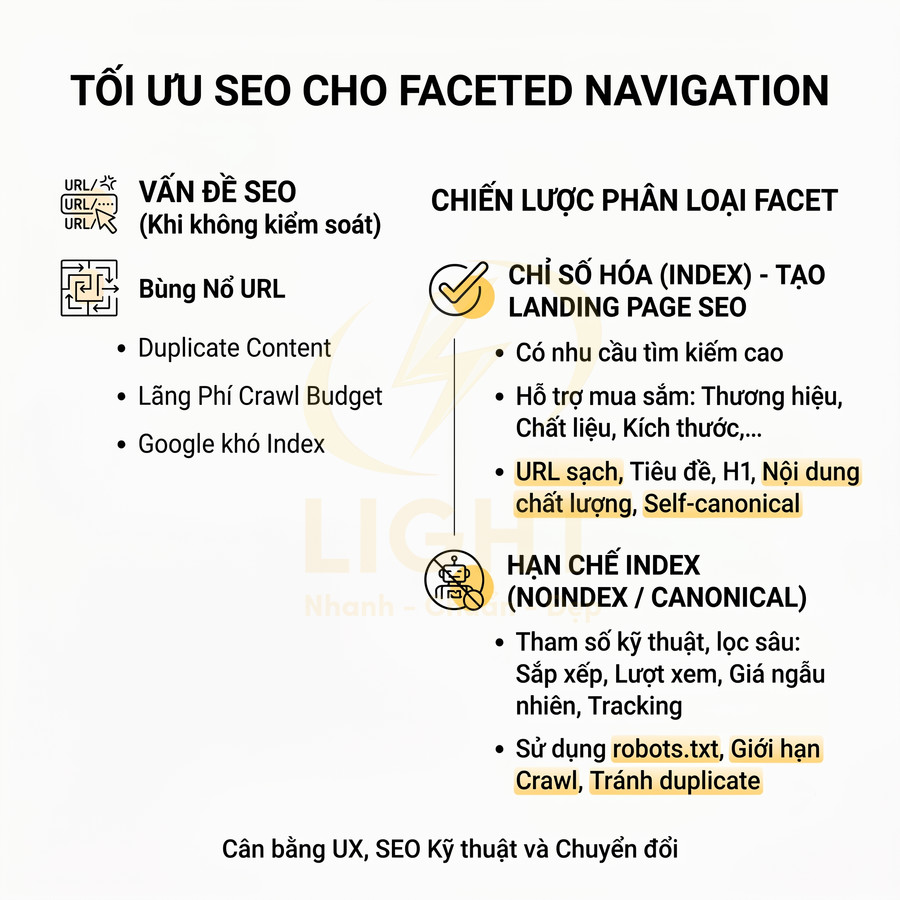

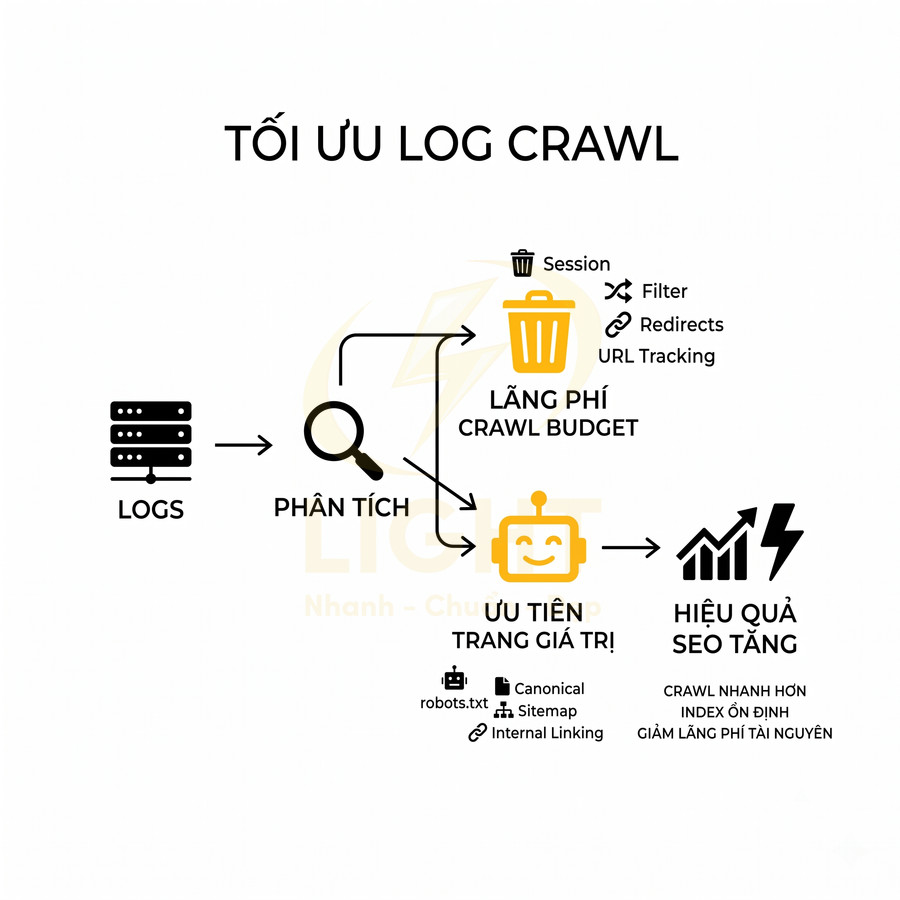







Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
