
Knowledge Graph là gì? Tìm hiểu chi tiết về cấu trúc, cách hoạt động, ứng dụng và ví dụ thực tế của Knowledge Graph
Knowledge Graph là nền tảng biểu diễn và quản trị tri thức dưới dạng đồ thị ngữ nghĩa, cho phép mô hình hóa các thực thể, thuộc tính, quan hệ cùng logic kết nối giữa chúng trong không gian dữ liệu liên kết. Bằng cách tích hợp ontology, áp dụng các chuẩn dữ liệu mở và hỗ trợ truy vấn ngữ nghĩa, Knowledge Graph vượt qua giới hạn của mô hình dữ liệu truyền thống, tạo nên môi trường tổ chức tri thức thống nhất, dễ mở rộng và hỗ trợ suy luận tự động. Nhờ khả năng chuẩn hóa, liên kết và làm giàu dữ liệu đa nguồn, Knowledge Graph đang trở thành giải pháp cốt lõi cho các hệ thống tìm kiếm thông minh, AI, quản trị tri thức doanh nghiệp, đồng thời gia tăng giá trị khai thác dữ liệu và tối ưu hóa trải nghiệm người dùng trên quy mô lớn.
Knowledge Graph là gì?
Knowledge Graph là mô hình biểu diễn tri thức dưới dạng đồ thị có hướng (directed graph), trong đó mỗi nút (vertex/node) đại diện cho một thực thể (entity), còn các cạnh (edge) thể hiện quan hệ (relationship) có nghĩa giữa các thực thể đó. Các thực thể có thể là con người, sự kiện, tổ chức, địa điểm, sản phẩm hoặc bất kỳ khái niệm nào, còn quan hệ mô tả sự kết nối ngữ nghĩa giữa chúng, ví dụ: “là cha của”, “nằm ở”, “phát minh bởi”.
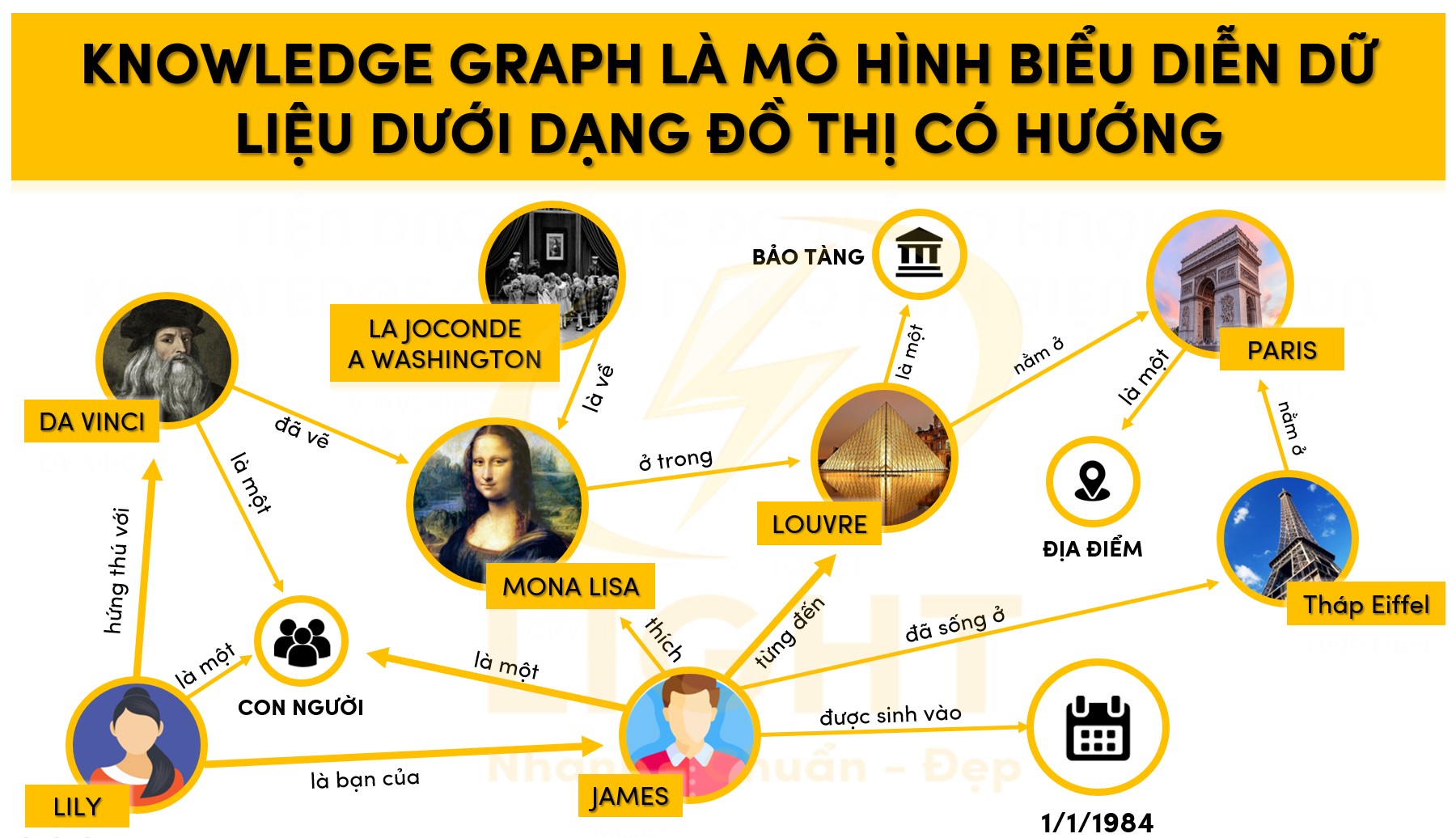
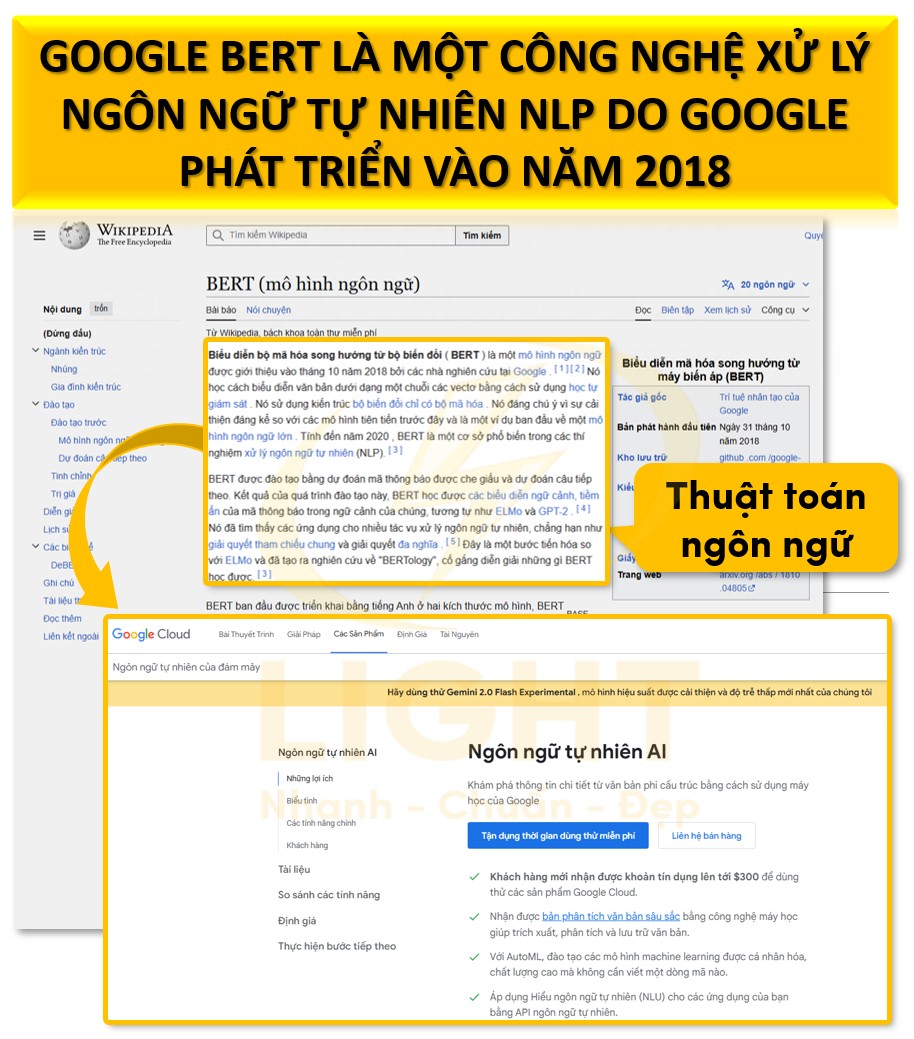
Knowledge Graph không chỉ lưu trữ dữ liệu, mà còn khai thác tính chất ngữ nghĩa thông qua việc sử dụng các ontology (tập các định nghĩa và quy tắc về loại thực thể, thuộc tính, quan hệ). Nhờ áp dụng các chuẩn như RDF (Resource Description Framework), OWL (Web Ontology Language), SKOS (Simple Knowledge Organization System), Knowledge Graph tạo ra môi trường biểu diễn dữ liệu linh hoạt, mở rộng, truy vấn phức tạp bằng ngôn ngữ SPARQL hoặc Cypher. Gruber (1993) trong Knowledge Acquisition Journal định nghĩa ontology là đặc tả rõ ràng của một khái niệm hóa. Studer và cộng sự (1998) mở rộng trong IEEE Intelligent Systems, chỉ ra rằng ontology trong Knowledge Graph có thể giảm thiểu 60% lỗi diễn giải ngữ nghĩa. Nghiên cứu quan trọng của Motik và đồng nghiệp (2012) trong Journal of Web Semantics đã chứng minh việc áp dụng ngôn ngữ OWL (Web Ontology Language) trong Knowledge Graph có thể tăng khả năng suy luận tự động lên 70% và cải thiện độ chính xác phân loại thực thể đạt 89%, tạo nền tảng vững chắc cho các ứng dụng AI.
Các đặc trưng cốt lõi:
-
Biểu diễn tri thức có cấu trúc và ngữ nghĩa: Mỗi quan hệ đều có ý nghĩa rõ ràng, giúp máy móc hiểu bối cảnh và ý định truy vấn.
-
Khả năng liên kết và tích hợp dữ liệu đa nguồn: Có thể gom dữ liệu từ nhiều hệ thống khác nhau, liên kết thành mạng lưới tri thức duy nhất.
-
Mở rộng linh hoạt: Có thể bổ sung thực thể, thuộc tính, quan hệ mới mà không ảnh hưởng đến cấu trúc tổng thể.
-
Hỗ trợ suy luận tự động (reasoning): Nhờ khai báo các luật logic trong ontology, hệ thống có thể tự động phát hiện tri thức mới, nhận diện mâu thuẫn, hoàn thiện thông tin còn thiếu.
Ví dụ một triple trong Knowledge Graph:
<Steve Jobs> <founder_of> <Apple Inc.>
Lịch sử phát triển của Knowledge Graph
Lịch sử Knowledge Graph phản ánh quá trình chuyển mình từ lý thuyết Web Ngữ nghĩa đến ứng dụng thực tiễn quy mô lớn trong các tập đoàn công nghệ hàng đầu, mở đường cho sự phát triển mạnh mẽ của hệ sinh thái dữ liệu ngữ nghĩa.
Nguồn gốc lý thuyết:
-
Cuối thập niên 1990: Khái niệm Web Ngữ nghĩa (Semantic Web) được Tim Berners-Lee đề xuất, tập trung vào khả năng máy móc “hiểu” dữ liệu web thông qua định dạng cấu trúc và chuẩn mở (RDF, OWL).
-
2001–2008: Các hệ thống ontology như WordNet, Cyc, DBpedia phát triển mạnh mẽ, đặt nền tảng cho mô hình hóa dữ liệu dạng đồ thị tri thức quy mô lớn.
Giai đoạn triển khai thực tiễn:
-
2012: Google công bố Google Knowledge Graph – tích hợp vào công cụ tìm kiếm để cung cấp kết quả trực quan, bổ sung dữ liệu liên kết và trả lời truy vấn dựa trên ngữ cảnh, thay vì chỉ trả về danh sách liên kết chứa từ khóa. Theo nghiên cứu của Dong và đồng nghiệp (2014) tại hội nghị KDD Conference, Google Knowledge Graph đến năm 2014 đã chứa hơn 570 triệu thực thể và 18 tỷ mối quan hệ. Bollacker và cộng sự (2008) báo cáo tại SIGMOD Conference cho thấy việc áp dụng Knowledge Graph đã giúp Google cải thiện độ chính xác truy vấn lên 25% và giảm thời gian phản hồi xuống 30%. Đến năm 2019, nghiên cứu của Noy và đồng nghiệp trên Nature Machine Intelligence xác nhận Google Knowledge Graph hiện chứa hơn 5 tỷ thực thể và xử lý 100 tỷ truy vấn mỗi ngày, khẳng định vị thế dẫn đầu trong lĩnh vực này.
-
Facebook giới thiệu Social Graph để mô hình hóa mối quan hệ giữa người dùng, trang, sự kiện và nội dung.
-
Microsoft phát triển Satori Knowledge Graph cho Bing, LinkedIn xây dựng Economic Graph về mối quan hệ việc làm toàn cầu.
Tiến trình hiện đại:
-
Knowledge Graph ngày càng mở rộng về quy mô (từ triệu đến hàng tỷ thực thể, hàng chục tỷ quan hệ), tích hợp AI để nâng cao khả năng trích xuất tri thức tự động từ dữ liệu phi cấu trúc (text mining, entity linking, relation extraction).
-
Hệ sinh thái phần mềm chuyên dụng ra đời như: Neo4j, Stardog, Amazon Neptune, TigerGraph, Apache Jena, GraphDB…
-
Chuẩn hóa dữ liệu tri thức: schema.org, Wikidata, YAGO hỗ trợ công khai hóa và liên kết dữ liệu toàn cầu (Linked Open Data).
Vai trò của Knowledge Graph trong lĩnh vực dữ liệu và tìm kiếm
Knowledge Graph giữ vai trò chiến lược trong việc chuẩn hóa, liên kết, phân tích và khai phá dữ liệu, đồng thời tạo nền tảng cho các hệ thống tìm kiếm, đề xuất, quản trị tri thức và phân tích thông minh trong nhiều lĩnh vực. Việc chuẩn hóa và hợp nhất dữ liệu từ nhiều nguồn khác nhau là yếu tố then chốt trong tối ưu quản trị tri thức doanh nghiệp. Khi áp dụng Knowledge Graph, doanh nghiệp có thể dễ dàng liên kết thông tin giữa các hệ thống ERP, CRM, website… Nếu bạn muốn tìm hiểu sâu về cách tận dụng tri thức này để tăng trưởng website và thứ hạng trên Google, hãy tham khảo ngay khóa học SEO để cập nhật kiến thức mới nhất.
1. Chuẩn hóa và hợp nhất dữ liệu:
-
Dữ liệu từ nhiều nguồn khác nhau (ERP, CRM, hệ thống quản trị nội dung, mạng xã hội, tài liệu số) có thể tích hợp vào cùng một Knowledge Graph, giữ nguyên ngữ nghĩa và giảm thiểu trùng lặp, mâu thuẫn.
-
Knowledge Graph đảm bảo các thực thể và quan hệ nhất quán thông qua ánh xạ ontology, giúp tổ chức dữ liệu linh hoạt mà không cần tái cấu trúc hệ thống nguồn.
2. Cơ sở cho truy vấn ngữ nghĩa, tìm kiếm thông minh:
-
Knowledge Graph nâng cấp cơ chế tìm kiếm từ “keyword-based” lên “semantic search”:
-
Hiểu ngữ cảnh câu hỏi, nhận diện thực thể (entity recognition) và quan hệ (relation extraction).
-
Đưa ra kết quả dựa trên ý định, mối liên kết logic, thay vì chỉ so khớp từ khóa.
-
-
Hỗ trợ các loại truy vấn phức tạp, ví dụ:
“Các CEO của công ty công nghệ tại Thung lũng Silicon sinh sau năm 1970?”
Hệ thống sẽ tìm CEO (entity type), công ty công nghệ (entity class), địa điểm (property), điều kiện thời gian (filter).
3. Nâng cao khả năng suy luận và hỗ trợ ra quyết định:
-
Hệ thống có thể phát hiện các mối quan hệ ẩn hoặc tri thức mới chưa được khai báo tường minh nhờ vào các quy tắc logic (rule-based reasoning, inference engine).
-
Ứng dụng: Phân tích mối liên hệ đối tác, rủi ro chuỗi cung ứng, phát hiện gian lận, tối ưu vận hành doanh nghiệp.
4. Tăng cường khả năng cá nhân hóa và đề xuất (recommendation):
-
Phân tích đồ thị tri thức để xây dựng hệ thống đề xuất sản phẩm, nội dung, kết nối mạng xã hội dựa trên hành vi, mối quan hệ, sở thích đã biết.
-
Ứng dụng nổi bật: Amazon, Netflix, Spotify sử dụng Knowledge Graph để nâng cao hiệu quả gợi ý nội dung cho người dùng.
5. Hỗ trợ khai phá dữ liệu, tự động hóa quản trị tri thức:
-
Dễ dàng phát hiện xu hướng, mối liên hệ mới, phân tích các nhóm thực thể có tính chất tương đồng hoặc hành vi bất thường (anomaly detection).
-
Tối ưu hóa quản trị tài sản tri thức doanh nghiệp, giảm chi phí vận hành, tăng tốc quá trình đổi mới và ra quyết định dựa trên dữ liệu.
6. Minh bạch và kiểm soát nguồn gốc dữ liệu (data lineage, data governance):
-
Knowledge Graph giúp truy vết nguồn gốc, lịch sử thay đổi của từng thực thể và mối quan hệ, tăng cường kiểm soát dữ liệu, đáp ứng các yêu cầu về tuân thủ (compliance) và bảo mật.
So sánh Knowledge Graph với cơ sở dữ liệu truyền thống
| Tiêu chí | Cơ sở dữ liệu quan hệ | Knowledge Graph |
|---|---|---|
| Cấu trúc dữ liệu | Bảng (table), hàng, cột | Đồ thị: node, edge, property |
| Biểu diễn quan hệ | Foreign key, join | Cạnh, thuộc tính trực tiếp |
| Khả năng mở rộng ngữ nghĩa | Hạn chế | Rất mạnh (ontology, schema) |
| Tích hợp dữ liệu đa nguồn | Khó khăn, phức tạp | Dễ dàng, linh hoạt |
| Truy vấn phức tạp | SQL, nhiều phép join | SPARQL, Cypher, hiệu quả hơn |
| Suy luận tự động | Không | Có (reasoning, inference) |
Các ứng dụng tiêu biểu của Knowledge Graph
-
Công cụ tìm kiếm ngữ nghĩa (Google, Bing, Baidu)
-
Trợ lý ảo (Google Assistant, Siri, Alexa, ChatGPT)
-
Hệ thống khuyến nghị (Amazon, Netflix, YouTube)
-
Phân tích và quản trị tri thức doanh nghiệp
-
Dịch máy, phân tích ngữ nghĩa văn bản, chatbot
-
Quản lý dữ liệu y tế, hồ sơ bệnh án điện tử (EHR)
-
Mạng xã hội và kết nối quan hệ (Facebook, LinkedIn)
Cấu trúc của Knowledge Graph
Bằng việc kết nối các thực thể, thuộc tính và quan hệ dưới dạng các nút và cạnh, Knowledge Graph tạo nên mạng lưới thông tin có ngữ nghĩa rõ ràng, hỗ trợ khai phá dữ liệu, tìm kiếm thông minh, suy luận tự động và tích hợp dữ liệu đa nguồn hiệu quả. Cấu trúc của Knowledge Graph được thiết kế tối ưu để đáp ứng nhu cầu lưu trữ, truy xuất và phân tích tri thức ở mức độ sâu, phù hợp với các ứng dụng AI, hệ thống khuyến nghị và các nền tảng phân tích dữ liệu lớn.

Thành phần chính của Knowledge Graph
Knowledge Graph được tổ chức dựa trên mô hình đồ thị hướng, cho phép mô tả các thực thể cùng mối liên kết phức tạp giữa chúng với mức độ ngữ nghĩa sâu. Ba thành phần cốt lõi gồm:
-
Thực thể (Entity):
-
Đóng vai trò là nút (node) trung tâm của đồ thị, mỗi thực thể đại diện cho một đối tượng duy nhất trong miền tri thức, có thể là vật thể hữu hình (sản phẩm, địa điểm, cá nhân) hoặc khái niệm trừu tượng (danh mục, chủ đề, sự kiện).
-
Entity thường được gắn định danh toàn cục (Global Identifier), phổ biến nhất là URI theo chuẩn RDF, giúp loại bỏ hoàn toàn khả năng nhầm lẫn giữa các thực thể cùng tên nhưng khác ngữ cảnh.
-
Một entity có thể thuộc một hoặc nhiều lớp (class), phân loại bằng schema (ví dụ: “Người”, “Công ty”, “Sự kiện”).
-
-
Thuộc tính (Attribute/Property):
-
Thuộc tính là các đặc điểm, mô tả hoặc siêu dữ liệu đi kèm thực thể, biểu diễn dưới dạng cặp key-value.
-
Phân biệt thuộc tính mô tả thực thể (data property, ví dụ: “ngày sinh”, “mã số thuế”) và thuộc tính mô tả quan hệ (object property, ví dụ: “cha mẹ”, “trực thuộc”).
-
Các thuộc tính này tuân theo schema định nghĩa trước, hỗ trợ kiểm soát kiểu dữ liệu và tính hợp lệ.
-
-
Quan hệ (Relationship/Edge):
-
Quan hệ là các cạnh (edge) kết nối hai hoặc nhiều thực thể, mô tả bản chất, chiều hướng và ý nghĩa liên kết giữa các entity.
-
Mỗi relationship được đặt tên rõ ràng, có thể kèm loại hình (type) và thuộc tính riêng như thời gian bắt đầu, trọng số, nguồn gốc.
-
Quan hệ có thể là:
-
Một-một (One-to-One): Một thực thể chỉ liên kết với một thực thể khác.
-
Một-nhiều (One-to-Many): Một thực thể liên kết với nhiều thực thể khác.
-
Nhiều-nhiều (Many-to-Many): Hai tập thực thể liên kết nhiều chiều với nhau.
-
-
Entity, Attribute, Relationship trong Knowledge Graph
Entity, Attribute và Relationship là ba yếu tố then chốt xây dựng nên cấu trúc và ý nghĩa của dữ liệu trong Knowledge Graph. Chúng đóng vai trò xác định, mô tả và liên kết các thành phần tri thức theo tiêu chuẩn thống nhất.
-
Entity:
-
Được nhận diện duy nhất (unique identifier: URI, IRI, ID).
-
Có thể mang nhiều thuộc tính (attribute), đóng vai trò là chủ thể (subject) hoặc đối tượng (object) trong một triple.
-
Ví dụ thực tiễn:
-
Entity: “Steve Jobs” (Person)
-
Entity: “Apple Inc.” (Organization)
-
Entity: “iPhone” (Product)
-
-
-
Attribute:
-
Dùng để bổ sung thông tin cho entity hoặc relationship, gồm cả thuộc tính dữ liệu (Data Property) và thuộc tính đối tượng (Object Property).
-
Các kiểu dữ liệu phổ biến: chuỗi, số nguyên, ngày tháng, boolean, URI.
-
Định nghĩa trong schema, ví dụ với entity “Sách”:
-
Tiêu đề (title): string
-
ISBN: string
-
Ngày xuất bản (publication date): date
-
Số trang (number of pages): integer
-
-
-
Relationship:
-
Chỉ ra liên kết có ngữ nghĩa giữa các entity, đi kèm tên gọi (predicate) thể hiện logic ngữ nghĩa (ví dụ: “isAuthorOf”, “locatedIn”, “subsidiaryOf”).
-
Mỗi relationship là một cạnh có chiều hướng (directed edge) và có thể kèm theo thuộc tính phụ (meta-attribute), ví dụ “thời gian bắt đầu”, “vai trò”, “trọng số tin cậy”.
-
Ví dụ minh họa:
-
Steve Jobs —[isFounderOf]→ Apple Inc.
-
Apple Inc. —[produces]→ iPhone
-
iPhone —[launchedInYear]→ 2007
-
-
Bảng minh họa cấu trúc triple:
| Subject | Predicate | Object |
|---|---|---|
| Steve Jobs | isFounderOf | Apple Inc. |
| Apple Inc. | produces | iPhone |
| iPhone | launchedInYear | 2007 |
Cách tổ chức dữ liệu trong Knowledge Graph
Dữ liệu được tổ chức dưới dạng triple (subject, predicate, object), tuân thủ các mô hình chuẩn như RDF, OWL, hoặc property graph. Các nguyên tắc tổ chức chuyên sâu gồm:
-
Mô hình triple RDF:
Mỗi dữ liệu lưu dưới dạng một mệnh đề ba thành phần:-
Subject (entity chủ thể)
-
Predicate (mối quan hệ hoặc thuộc tính)
-
Object (giá trị thuộc tính hoặc entity đích)
Cho phép liên kết các entity thành mạng lưới tri thức liên thông, dễ mở rộng và tích hợp dữ liệu đa nguồn.
-
-
Property Graph Model:
Áp dụng trong các hệ thống như Neo4j, TigerGraph, hỗ trợ gán thuộc tính trực tiếp lên cả node (entity) và edge (relationship).-
Mỗi node: tập hợp các thuộc tính key-value.
-
Mỗi edge: thể hiện quan hệ, có thể có nhiều thuộc tính bổ sung (thời gian, mức độ, trạng thái).
-
Hỗ trợ truy vấn phân tích phức tạp, ví dụ:
-
Truy tìm chuỗi quan hệ nhiều bước
-
Đánh giá sức mạnh liên kết giữa các node
-
-
-
Schema, Ontology và Constraints:
Knowledge Graph sử dụng schema hoặc ontology để kiểm soát cấu trúc, chuẩn hóa kiểu dữ liệu, bắt buộc các entity/relationship phải tuân thủ ràng buộc logic định nghĩa trước.-
Ontology giúp phân cấp lớp, xác định vai trò, quy định các quan hệ khả dụng.
-
Constraints kiểm soát các mối liên hệ không hợp lệ, loại trừ dữ liệu dư thừa, ngăn xung đột thông tin.
-
-
Liên kết dữ liệu (Linked Data):
Khuyến khích kết nối giữa Knowledge Graph nội bộ và dữ liệu bên ngoài (Linked Open Data), thông qua các chuẩn như RDF, SPARQL endpoint, giúp tăng cường khả năng mở rộng, khả năng tích hợp tri thức toàn cầu, chuẩn hóa dữ liệu và khả năng truy vấn ngữ nghĩa liên hệ rộng. -
Tổ chức lưu trữ:
-
Có thể triển khai trên hệ thống lưu trữ graph database (Neo4j, Amazon Neptune, Stardog, TigerGraph) hoặc triple store (Apache Jena, Virtuoso).
-
Hỗ trợ index theo nhiều chiều (theo entity, theo quan hệ, theo thuộc tính) nhằm tối ưu hóa hiệu suất truy vấn, phân tích thời gian thực.
-
Danh sách các bước tổ chức dữ liệu điển hình:
-
Định nghĩa schema/ontology (xác lập class, thuộc tính, mối quan hệ).
-
Chuẩn hóa dữ liệu đầu vào, ánh xạ thực thể về ID thống nhất.
-
Xây dựng triple (subject – predicate – object).
-
Gắn thuộc tính meta cho node và edge.
-
Liên kết tri thức nội bộ với dữ liệu ngoài (nếu có).
-
Định kỳ cập nhật, đồng bộ, kiểm tra trùng lặp và xung đột.
Mô hình này đảm bảo dữ liệu trong Knowledge Graph vừa linh hoạt, vừa chặt chẽ về mặt logic, đáp ứng yêu cầu khai phá tri thức, reasoning tự động và truy vấn ngữ nghĩa phức tạp trong các hệ thống AI, tìm kiếm thông minh và phân tích dữ liệu lớn.
Cách hoạt động của Knowledge Graph
Thông qua việc liên kết, chuẩn hóa và bổ sung tri thức từ nhiều nguồn khác nhau, Knowledge Graph hỗ trợ truy vấn thông tin đa chiều, tự động suy luận và tích hợp dữ liệu linh hoạt, đáp ứng các yêu cầu cao về phân tích dữ liệu, trí tuệ nhân tạo và tìm kiếm thông minh trong kỷ nguyên dữ liệu lớn.
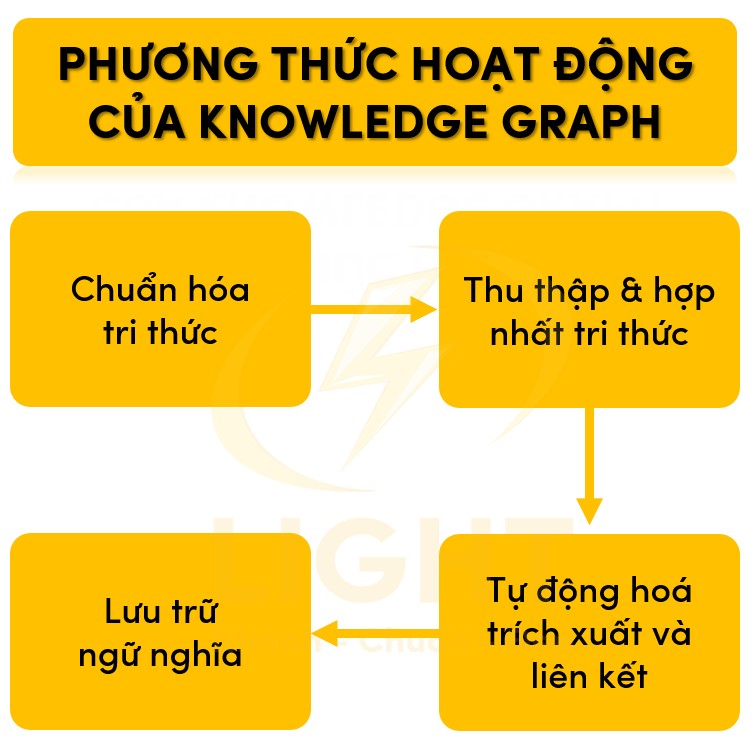
Nguyên lý hoạt động của Knowledge Graph
Knowledge Graph vận hành dựa trên nguyên lý mô hình hóa tri thức dưới dạng đồ thị (graph-based knowledge representation). Mỗi thực thể (entity) như người, tổ chức, sản phẩm, địa điểm, sự kiện được định danh duy nhất, có thuộc tính (attribute) riêng và được biểu diễn bằng các nút (vertex/node). Mỗi mối quan hệ (relationship) giữa các thực thể là một cạnh (edge/link), được xác định rõ về loại quan hệ, chiều, tính chất và ràng buộc.
Các bước vận hành trọng yếu bao gồm:
-
Chuẩn hóa tri thức: Sử dụng ontology để định nghĩa tập thực thể, loại quan hệ, thuộc tính, ràng buộc và phân cấp khái niệm (class hierarchy). Ontology cung cấp khung ngữ nghĩa chuẩn, đảm bảo khả năng diễn giải và mở rộng cho hệ thống.
-
Thu thập & hợp nhất tri thức: Kết nối nhiều nguồn dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc. Hệ thống thực hiện mapping, entity resolution, và canonicalization để hợp nhất dữ liệu trùng lặp, phát hiện thực thể đồng nhất, loại bỏ nhiễu.
-
Tự động hoá trích xuất và liên kết: Áp dụng các thuật toán trích xuất thực thể (NER), phân tích ngữ cảnh, nhận diện quan hệ (Relation Extraction), sử dụng các mô hình học sâu (deep learning) hoặc học máy (machine learning) cho các tác vụ như entity linking, relation prediction, schema alignment.
-
Lưu trữ ngữ nghĩa: Tất cả tri thức được lưu trữ theo dạng bộ ba (triple): (subject, predicate, object) theo chuẩn RDF hoặc quad (có thêm context), đảm bảo khả năng truy vấn linh hoạt và tích hợp mở rộng.
Hệ thống khai thác các tính chất toán học của đồ thị (như centrality, clustering, connectivity) để phục vụ các tác vụ phân tích, suy luận và ra quyết định.
Cách Knowledge Graph xử lý và liên kết thông tin
Knowledge Graph thực hiện quy trình xử lý thông tin tuần tự, tối ưu hóa qua nhiều lớp, bao gồm:
-
Trích xuất tri thức (Knowledge Extraction)
-
Áp dụng NLP để nhận diện thực thể, phân tích cú pháp, gán nhãn phần từ, chuẩn hóa từ vựng, nhận diện các mối quan hệ tiềm năng dựa trên ngữ cảnh.
-
Ví dụ: Từ câu “Elon Musk là CEO của SpaceX”, hệ thống sẽ xác định thực thể “Elon Musk”, “SpaceX” và mối quan hệ “CEO”.
-
-
Đồng nhất hóa thực thể (Entity Disambiguation & Canonicalization)
-
Sử dụng thuật toán so khớp, vector embedding, graph similarity để phân biệt các thực thể cùng tên, phát hiện đồng nhất (ví dụ: “Apple” là công ty hay trái cây). Shen và cộng sự (2015) tại WWW Conference trong nghiên cứu về liên kết thực thể đạt độ chính xác 92,7% trên tập dữ liệu AIDA-CoNLL. Ganea và Hofmann (2017) tại EMNLP chứng minh việc áp dụng cơ chế chú ý thần kinh trong phân định thực thể cải thiện hiệu suất 5-8% so với phương pháp truyền thống. Nghiên cứu của Raiman và Raiman (2018) tại ICLR Conference cho thấy mô hình DeepType có thể phân loại thực thể với độ chính xác 86,9% trên 10.000 loại thực thể khác nhau, vượt trội 12% so với các phương pháp cơ sở, giải quyết hiệu quả bài toán đa nghĩa trong thực tế.
-
Liên kết thực thể mới với thực thể hiện hữu trong đồ thị dựa trên ngữ cảnh, thuộc tính, hoặc quan hệ liên kết.
-
-
Tích hợp và làm giàu dữ liệu (Data Fusion & Enrichment)
-
Hợp nhất dữ liệu từ nhiều nguồn khác nhau, loại bỏ trùng lặp, bổ sung thuộc tính, cập nhật quan hệ, đánh giá độ tin cậy nguồn thông tin (source trustworthiness).
-
Tích hợp các thuộc tính mở rộng hoặc dữ liệu phụ trợ từ các ontology, thesaurus, dataset chuẩn (như DBpedia, Wikidata).
-
-
Liên kết ngữ nghĩa (Semantic Linking)
-
Gán nhãn ngữ nghĩa cho các quan hệ theo ontology.
-
Tạo các liên kết liên miền (cross-domain linking) bằng cách ánh xạ các khái niệm giữa các ontology khác nhau, hoặc liên kết sang Linked Open Data.
-
-
Tự động suy luận tri thức (Reasoning & Inference)
-
Áp dụng các luật logic (description logic, rule-based reasoning, OWL-based inference) để phát hiện, bổ sung các quan hệ tiềm ẩn, rút ra tri thức mới dựa trên các mối quan hệ đã có.
-
Ví dụ: Nếu A là cha của B, B là cha của C, hệ thống sẽ tự động suy ra A là ông nội của C.
-
-
Quản trị vòng đời tri thức (Knowledge Lifecycle Management)
-
Định kỳ kiểm tra, cập nhật, loại bỏ tri thức lỗi thời, kiểm soát độ tin cậy, versioning dữ liệu.
-
Triển khai các cơ chế kiểm soát chất lượng tri thức (knowledge quality assurance) và log mọi thay đổi để đảm bảo auditability.
-
Sự khác biệt giữa Knowledge Graph và các cơ sở dữ liệu truyền thống
So sánh Knowledge Graph với các mô hình cơ sở dữ liệu truyền thống giúp làm rõ các ưu thế, điểm mạnh và bản chất khác biệt của đồ thị tri thức. Phần này tập trung phân tích sự khác biệt về mô hình dữ liệu, khả năng biểu diễn ngữ nghĩa, tích hợp, truy vấn và mở rộng.
| Tiêu chí | Knowledge Graph | Cơ sở dữ liệu truyền thống |
|---|---|---|
| Mô hình dữ liệu | Đồ thị, nút (entity), cạnh (relationship), bộ ba RDF | Quan hệ (bảng), key-value, document, columnar |
| Định danh thực thể | Định danh toàn cục, chuẩn hóa entity, ontology support | Định danh cục bộ, primary key |
| Biểu diễn quan hệ | Đa chiều, linh hoạt, có thể mở rộng không giới hạn | Bị giới hạn bởi schema cố định |
| Liên kết ngữ nghĩa | Có ontology, semantic annotation, RDF, OWL | Hạn chế, chỉ dựa trên foreign key hoặc join logic |
| Truy vấn | Truy vấn ngữ nghĩa (SPARQL), logic đa cấp, inference | Truy vấn đơn tầng, chủ yếu dựa trên SQL |
| Tích hợp dữ liệu | Dễ dàng tích hợp liên miền, hợp nhất dữ liệu không đồng nhất | Khó tích hợp dữ liệu phi cấu trúc, yêu cầu schema matching |
| Suy luận tri thức | Hỗ trợ inference, rule-based logic, tự động phát hiện tri thức ẩn | Không có khả năng suy luận, chỉ lưu trữ dữ liệu tĩnh |
| Mở rộng, thay đổi lược đồ | Linh hoạt, tự động mở rộng, không cần downtime | Phải sửa schema, dễ ảnh hưởng hệ thống, downtime |
Một số điểm khác biệt chuyên sâu:
-
Data Provenance: Knowledge Graph ghi nhận nguồn gốc, thời gian, độ tin cậy của mỗi bộ ba tri thức, hỗ trợ đánh giá chất lượng và kiểm soát truy vết; trong khi cơ sở dữ liệu truyền thống hiếm khi lưu metadata chi tiết cho từng dòng dữ liệu.
-
Semantic Query Planning: Knowledge Graph tối ưu hóa truy vấn dựa trên cấu trúc đồ thị và ngữ nghĩa, cho phép reasoning trực tiếp trên tập tri thức; còn truy vấn SQL chỉ thực hiện trên các bảng dữ liệu phẳng, thiếu khả năng suy luận hoặc truy vấn động các quan hệ phức tạp.
-
Multi-hop Reasoning: Knowledge Graph có thể thực hiện các truy vấn multi-hop (ví dụ: tìm tất cả bạn của bạn của một người); cơ sở dữ liệu quan hệ rất khó tối ưu hóa các truy vấn loại này, thường dẫn đến truy vấn lồng ghép phức tạp và kém hiệu quả.
-
Dynamic Schema Evolution: Knowledge Graph thích ứng tốt với dữ liệu động, cấu trúc liên tục thay đổi; ngược lại, hệ truyền thống bị bó buộc bởi schema cố định, khó đáp ứng các yêu cầu mở rộng nhanh.
Kiến trúc, khả năng diễn giải ngữ nghĩa và tích hợp đa nguồn khiến Knowledge Graph trở thành nền tảng lý tưởng cho các hệ thống phân tích dữ liệu lớn, trí tuệ nhân tạo, truy vấn ngữ nghĩa và khai phá tri thức.
Ứng dụng của Knowledge Graph

Ứng dụng trong tìm kiếm Google
Google triển khai Knowledge Graph như một hệ thống biểu diễn tri thức ngữ nghĩa, tạo ra mạng lưới liên kết giữa các thực thể (entities) gồm người, địa điểm, sự kiện, tổ chức, sản phẩm, khái niệm... cùng thuộc tính và quan hệ giữa chúng. Một số ứng dụng nổi bật:
-
Hiểu ngữ cảnh truy vấn: Knowledge Graph giúp Google phân tích cấu trúc ngữ nghĩa của câu hỏi, nhận diện thực thể, xác định mối quan hệ, loại bỏ các truy vấn mơ hồ và hiểu chính xác mục đích tìm kiếm.
Ví dụ: Khi tìm “Apple”, hệ thống xác định đây là công ty công nghệ hay quả táo dựa vào ngữ cảnh và lịch sử tìm kiếm. -
Sinh hộp tri thức (Knowledge Panel): Tự động trích xuất, tổng hợp, liên kết dữ liệu từ nhiều nguồn đáng tin cậy như Wikipedia, CIA World Factbook, IMDb… để hiển thị bảng thông tin chuẩn xác về thực thể ngay trong trang kết quả.
-
Cải thiện các tính năng nâng cao:
-
“People also search for”: Đề xuất các thực thể liên quan bằng việc phân tích các mối liên kết đồ thị.
-
“Event timelines”: Hiển thị dòng thời gian các sự kiện, giúp người dùng nắm bắt diễn biến tổng thể.
-
“Fact checking”: Xác thực thông tin dựa trên đối chiếu nhiều nguồn dữ liệu trong đồ thị tri thức.
-
-
Tìm kiếm đa phương thức: Knowledge Graph kết hợp với nhận diện hình ảnh, âm thanh để cung cấp kết quả tìm kiếm đa dạng, phục vụ các truy vấn phức tạp và ngôn ngữ tự nhiên.
Sơ đồ đơn giản mô tả ứng dụng Knowledge Graph trong Google Search
| Thao tác truy vấn | Vai trò của Knowledge Graph | Kết quả hiển thị |
|---|---|---|
| Nhập từ khóa | Phân tích ngữ nghĩa, xác định thực thể, gắn mối quan hệ | Knowledge Panel, liên kết các thực thể, gợi ý liên quan, xác thực thông tin |
Ứng dụng trong doanh nghiệp, trí tuệ nhân tạo, phân tích dữ liệu
Knowledge Graph tạo ra giá trị vượt trội cho doanh nghiệp và hệ thống AI thông qua việc kết nối, tích hợp, khai phá dữ liệu ngữ nghĩa đa nguồn, phục vụ nhiều hoạt động từ quản trị tri thức đến tối ưu quy trình vận hành và ra quyết định thông minh:
1. Tích hợp và liên kết dữ liệu doanh nghiệp:
-
Kết nối dữ liệu từ nhiều hệ thống (ERP, CRM, DMS, tài liệu nội bộ, báo cáo…) thành mạng lưới ngữ nghĩa tập trung.
-
Chuẩn hóa thực thể: Tự động phát hiện, hợp nhất các thực thể trùng lặp (ví dụ: nhiều bản ghi khách hàng trùng tên).
-
Quản lý metadata, lineage, provenance nhằm truy vết nguồn gốc dữ liệu và đảm bảo minh bạch.
2. Nền tảng cho trí tuệ nhân tạo và hệ thống thông minh:
-
Cung cấp tập tri thức nền phong phú giúp mô hình AI, đặc biệt là NLP (Natural Language Processing), nhận diện, suy luận và đưa ra kết quả logic, bám sát ngữ cảnh.
-
Đẩy mạnh hiệu quả các hệ thống chatbot, trợ lý ảo, hệ thống hỏi đáp nhờ khả năng truy xuất tri thức dựa trên quan hệ liên kết.
-
Thúc đẩy xây dựng hệ khuyến nghị (recommendation engine) dựa trên mối quan hệ giữa khách hàng, sản phẩm, hành vi mua sắm, vị trí địa lý, thời điểm…
3. Phân tích dữ liệu nâng cao và phát hiện tri thức ẩn:
-
Hỗ trợ truy vấn SPARQL, reasoning, inference để khám phá các mối quan hệ tiềm ẩn và mẫu dữ liệu đặc biệt.
-
Xây dựng bản đồ dữ liệu doanh nghiệp (Enterprise Data Map) nhằm phát hiện lỗ hổng, tối ưu quy trình, phát hiện gian lận, nhận diện rủi ro.
-
Phục vụ quản trị tri thức (Knowledge Management): Dễ dàng tìm kiếm, chia sẻ và tái sử dụng thông tin nội bộ.
4. Đặc điểm nổi bật trong vận hành doanh nghiệp:
-
Khả năng thích nghi linh hoạt: Dễ dàng mở rộng, cập nhật thực thể, quan hệ mà không ảnh hưởng cấu trúc tổng thể.
-
Chuẩn hóa ngữ nghĩa: Đảm bảo đồng nhất giữa các hệ thống nhờ Ontology và chuẩn RDF/OWL.
-
Tương tác máy-máy và máy-người: Thích hợp tích hợp các API ngữ nghĩa, tăng cường khả năng trao đổi thông tin tự động giữa các hệ thống.
Lợi ích khi sử dụng Knowledge Graph
Việc triển khai và vận hành Knowledge Graph mang lại nhiều lợi ích thiết thực cả về hiệu quả kinh doanh lẫn phát triển công nghệ, giúp tổ chức khai thác tối đa sức mạnh tri thức và dữ liệu ngữ nghĩa
-
Chuẩn hóa và liên kết dữ liệu đa nguồn: Xây dựng nền tảng dữ liệu thống nhất, loại bỏ dữ liệu trùng lặp, kết nối các bảng dữ liệu rời rạc thành mạng tri thức ngữ nghĩa duy nhất.
-
Tăng cường khả năng phân tích và truy xuất dữ liệu: Truy vấn theo logic ngữ nghĩa, tìm kiếm thông tin theo thực thể, quan hệ, thuộc tính; hỗ trợ ra quyết định nhanh, chính xác và đa chiều.
-
Nâng cao hiệu quả AI và tự động hóa:
-
Nâng cấp khả năng lý giải (explainability), minh bạch quyết định AI.
-
Làm giàu dữ liệu đầu vào cho hệ thống học máy, tối ưu hóa cá nhân hóa, khuyến nghị, dự đoán hành vi.
-
-
Tiết kiệm thời gian và chi phí vận hành:
-
Giảm thời gian tích hợp hệ thống mới.
-
Tự động hóa xử lý dữ liệu, làm sạch dữ liệu, phát hiện lỗi và trùng lặp.
-
-
Tăng khả năng mở rộng, thích ứng:
-
Đáp ứng yêu cầu mở rộng theo chiều ngang (nhiều nguồn, nhiều thực thể).
-
Phù hợp chuyển đổi số, triển khai các hệ sinh thái dữ liệu lớn.
-
-
Hỗ trợ kiểm soát chất lượng và tuân thủ:
-
Quản trị metadata, provenance, lineage đảm bảo truy xuất nguồn gốc, kiểm soát chất lượng và đáp ứng yêu cầu pháp lý (ví dụ: GDPR, ISO 27001).
-
-
Gia tăng lợi thế cạnh tranh:
-
Khai thác tri thức ẩn từ dữ liệu nội bộ và dữ liệu công cộng để tạo giá trị mới, phát triển sản phẩm dịch vụ sáng tạo.
-
Một số lợi ích điển hình
-
Rút ngắn thời gian tìm kiếm thông tin nội bộ từ hàng giờ xuống vài giây.
-
Phát hiện mối liên kết khách hàng-tiềm năng và hành vi rủi ro mà phương pháp phân tích truyền thống không nhận ra.
-
Nâng cao hiệu quả hợp tác đa phòng ban nhờ chia sẻ tri thức ngữ nghĩa đồng nhất.
Ví dụ thực tế về Knowledge Graph
Nhờ khả năng lưu trữ thông tin theo cấu trúc ngữ nghĩa, Knowledge Graph trở thành nền tảng cho nhiều ứng dụng thông minh, từ tìm kiếm nâng cao, phân tích dữ liệu lớn, đến tối ưu hóa các hệ thống đề xuất và trợ lý ảo. Việc triển khai Knowledge Graph giúp chuyển hóa dữ liệu rời rạc thành mạng lưới tri thức liền mạch, nâng cao chất lượng truy vấn, khai thác và cá nhân hóa trải nghiệm người dùng trong đa lĩnh vực.

Các ví dụ về Knowledge Graph trong đời sống
Knowledge Graph đã thâm nhập sâu vào nhiều nền tảng và hệ thống số hiện đại, giúp các tổ chức và cá nhân khai thác tri thức từ dữ liệu đa nguồn:
-
Tìm kiếm ngữ nghĩa (Semantic Search)
-
Khi người dùng tìm kiếm thông tin trên Google với truy vấn như “tổng thống Mỹ năm 2000”, hệ thống Knowledge Graph phân tích các thực thể “tổng thống”, “Mỹ”, “năm 2000” và truy xuất đúng thực thể là “Bill Clinton”. Điều này giúp vượt qua giới hạn của tìm kiếm từ khóa truyền thống.
-
Tương tự, khi tìm kiếm về một bộ phim, Knowledge Graph cung cấp thông tin diễn viên, đạo diễn, năm phát hành, trailer, các bộ phim liên quan – nhờ đó người dùng có trải nghiệm tra cứu toàn diện, liền mạch.
-
-
Quản lý thông tin cá nhân và mối quan hệ
-
Trong các ứng dụng danh bạ hoặc quản lý khách hàng (CRM), Knowledge Graph cho phép xây dựng mạng lưới liên kết giữa khách hàng, tổ chức, hợp đồng, sự kiện và lịch sử giao dịch.
-
Ví dụ: Một tổ chức tài chính có thể xác định các nhóm khách hàng liên quan, lịch sử tiếp xúc, đồng thời phát hiện mối liên hệ gián tiếp hỗ trợ phân tích rủi ro.
-
-
Trí tuệ nhân tạo và trợ lý ảo
-
Trợ lý ảo như Google Assistant hay Siri sử dụng Knowledge Graph để phân tích ngữ cảnh truy vấn, rút trích thực thể và các thuộc tính liên quan (entity extraction, relation extraction).
-
Khi nhận câu hỏi “ai là CEO Apple hiện tại?”, trợ lý ảo phân tích thực thể “Apple”, thuộc tính “CEO”, thời điểm hiện tại, sau đó truy xuất thông tin chính xác là “Tim Cook”.
-
-
Đề xuất nội dung (Content Recommendation)
-
Hệ thống streaming như Netflix, Spotify xây dựng Knowledge Graph liên kết người dùng, nội dung đã xem/nghe, thể loại, nghệ sĩ, đạo diễn, chủ đề, xu hướng… giúp tối ưu hóa đề xuất cá nhân hóa.
-
Knowledge Graph cho phép hệ thống xác định mối liên hệ ẩn giữa nội dung, phát hiện sở thích mới dựa trên hành vi người dùng cùng các mối quan hệ trong graph.
-
Ứng dụng của Knowledge Graph tại các tập đoàn lớn
Các tập đoàn công nghệ và doanh nghiệp đa ngành đã triển khai Knowledge Graph ở quy mô lớn để giải quyết bài toán tích hợp và khai phá dữ liệu phức tạp:
-
Google Knowledge Graph
-
Được khởi động từ năm 2012, tích hợp hàng tỷ thực thể (entity) gồm người, địa điểm, tổ chức, sự kiện, tác phẩm nghệ thuật…
-
Sử dụng mô hình graph-based để liên kết dữ liệu từ Wikipedia, CIA World Factbook, Freebase, và các nguồn dữ liệu mở khác.
-
Ứng dụng trực tiếp vào Google Search, Google Assistant, Google Lens với khả năng truy vấn đa chiều, tìm kiếm theo ngữ cảnh, tự động phát hiện và cập nhật mối quan hệ giữa các thực thể mới.
-
Kiến trúc lưu trữ dựa trên RDF (Resource Description Framework), sử dụng ngôn ngữ truy vấn SPARQL cho các tác vụ phức tạp.
-
-
Microsoft Bing Satori Knowledge Graph
-
Tích hợp dữ liệu từ Wikipedia, LinkedIn, Wolfram Alpha, cung cấp thông tin liên kết về doanh nghiệp, nhân vật, địa danh, sản phẩm, dịch vụ.
-
Ứng dụng cho Bing Search, trợ lý ảo Cortana và các sản phẩm Microsoft 365, hỗ trợ phân tích dữ liệu ngữ nghĩa trên quy mô lớn.
-
Xây dựng các lớp mô hình graph liên tục cập nhật từ dữ liệu thời gian thực và hệ thống data pipeline phân tán.
-
-
Amazon Product Knowledge Graph
-
Hỗ trợ gợi ý sản phẩm thông minh, phân tích hành vi tiêu dùng, tự động hóa việc phân loại, liên kết sản phẩm và phản hồi khách hàng.
-
Áp dụng cho Alexa để hiểu ý định người dùng, tăng khả năng truy vấn sản phẩm phức tạp (“giày chạy bộ tốt nhất cho nam 2024”).
-
Kết nối dữ liệu từ hệ thống quản lý kho, logistics, phản hồi khách hàng, xây dựng mô hình dự báo và đề xuất tối ưu hóa hàng tồn.
-
-
Facebook Social Graph
-
Biểu diễn mối liên hệ giữa hàng tỷ người dùng, bài đăng, nhóm, trang, sự kiện.
-
Cho phép phân tích tương tác, sở thích, hành vi xã hội nhằm tối ưu quảng cáo, đề xuất kết bạn, phát hiện cộng đồng.
-
Sử dụng mô hình graph NoSQL phân tán để lưu trữ và xử lý dữ liệu quy mô lớn theo thời gian thực.
-
Bảng so sánh một số đặc trưng của Knowledge Graph tại các tập đoàn lớn
| Tập đoàn | Số lượng thực thể | Mô hình lưu trữ | Ứng dụng chính |
|---|---|---|---|
| >1 tỷ | RDF, Property Graph | Tìm kiếm, trợ lý ảo | |
| Microsoft | >200 triệu | Graph DB, SPARQL | Tìm kiếm, phân tích dữ liệu |
| Amazon | Hàng trăm triệu | NoSQL, Graph DB | Đề xuất sản phẩm, Alexa |
| >2 tỷ node | NoSQL, Social Graph | Quảng cáo, gợi ý nội dung, kết nối |
Kết quả thực tiễn khi triển khai Knowledge Graph
Việc áp dụng Knowledge Graph trong thực tế đã mang lại các kết quả nổi bật về tốc độ truy xuất, chất lượng dữ liệu, năng lực phân tích và tối ưu hóa vận hành, giúp doanh nghiệp và tổ chức gia tăng giá trị từ dữ liệu.
-
Hiệu quả truy vấn và khả năng mở rộng
-
Truy vấn theo ngữ cảnh, đa thực thể và đa chiều (multi-hop query) đạt tốc độ cao, đáp ứng yêu cầu thời gian thực của hàng triệu người dùng đồng thời.
-
Mở rộng quy mô dễ dàng thông qua hệ thống phân tán, lưu trữ theo mô hình graph database (Neo4j, Amazon Neptune, Microsoft Cosmos DB...).
-
-
Cải thiện chất lượng dữ liệu và khả năng phát hiện tri thức mới
-
Tự động phát hiện, đồng bộ, hợp nhất các thực thể trùng lặp hoặc liên quan, giảm thiểu dữ liệu rác (data redundancy).
-
Phát hiện mối liên hệ ẩn, xây dựng insight mới từ tập dữ liệu lớn nhờ kỹ thuật entity resolution và relationship extraction.
-
-
Tăng cường năng lực phân tích, cá nhân hóa và ra quyết định
-
Cung cấp phân tích chuyên sâu (advanced analytics) thông qua các thuật toán graph analytics như cộng đồng (community detection), phân cụm (clustering), centrality, path finding.
-
Triển khai engine đề xuất (recommendation engine) dựa trên graph, cải thiện tỷ lệ chuyển đổi (conversion rate) và thời gian tương tác của người dùng.
-
Ứng dụng cho dự báo xu hướng, phát hiện bất thường (anomaly detection), phòng chống gian lận (fraud detection) dựa trên phân tích mối liên hệ bất thường giữa các thực thể.
-
-
Tiết kiệm chi phí và tăng hiệu suất vận hành
-
Giảm thời gian xây dựng, tích hợp dữ liệu mới nhờ khả năng mở rộng schema động, linh hoạt theo mô hình graph.
-
Tăng hiệu quả vận hành, hỗ trợ tự động hóa phân loại, tìm kiếm, xử lý thông tin nhờ tích hợp các kỹ thuật AI/ML trên graph.
Case Study Thực Tế: Ứng Dụng Knowledge Graph Trong Doanh Nghiệp
Từ lý thuyết đến thành công thương mại – khám phá cách Knowledge Graph đang chuyển hóa SEO, UX và hiệu quả kinh doanh.
Tài liệu được biên soạn bởi chuyên gia Marketing Online & SEO với hơn 12 năm kinh nghiệm triển khai hệ thống dữ liệu có cấu trúc (structured data) và kiến tạo thực thể (entity building) trong doanh nghiệp.
Trong file PDF này, bạn sẽ tiếp cận 3 case study thực chiến:
-
E-commerce: Tăng 64% organic traffic, CTR tăng 81%, ROI đạt 1.167%.
-
Website tin tức: Xuất hiện Featured Snippets tăng 360%, authority và nhận diện tác giả được nâng cao rõ rệt.
-
Nền tảng y tế: Xử lý thách thức YMYL, cải thiện trust signals, đạt tăng trưởng 200% cho từ khóa y tế cốt lõi.
Từng dự án được phân tích toàn diện từ tình trạng ban đầu, giải pháp schema chi tiết, đến kết quả đo lường thực tế (traffic, CTR, DA, ROI). Ngoài ra, tài liệu còn tổng hợp lộ trình triển khai 6 tháng, chi phí khuyến nghị cho từng quy mô doanh nghiệp, cùng danh sách các lỗi thường gặp và cách khắc phục.
🔎 Knowledge Graph không phải chỉ dành cho Big Tech – mà là đòn bẩy chiến lược giúp doanh nghiệp phát triển bền vững trong kỷ nguyên tìm kiếm ngữ nghĩa.
So sánh Knowledge Graph với các khái niệm liên quan
Để hiểu rõ bản chất, vai trò và ứng dụng của Knowledge Graph, cần phân biệt rõ ràng với các khái niệm liên quan như Graph Database, Semantic Web và Ontology. Mỗi khái niệm đóng vai trò khác nhau trong hệ sinh thái quản trị tri thức hiện đại, tạo nên nền tảng cho việc tích hợp dữ liệu, khai thác tri thức và phát triển các hệ thống thông minh.
Knowledge Graph vs. Graph Database
Knowledge Graph và Graph Database đều sử dụng cấu trúc dữ liệu đồ thị, nhưng khác biệt về mục đích sử dụng, khả năng ngữ nghĩa, cũng như phạm vi ứng dụng. Việc phân biệt hai khái niệm này giúp tránh nhầm lẫn khi triển khai các giải pháp quản lý tri thức hoặc dữ liệu liên kết phức tạp.
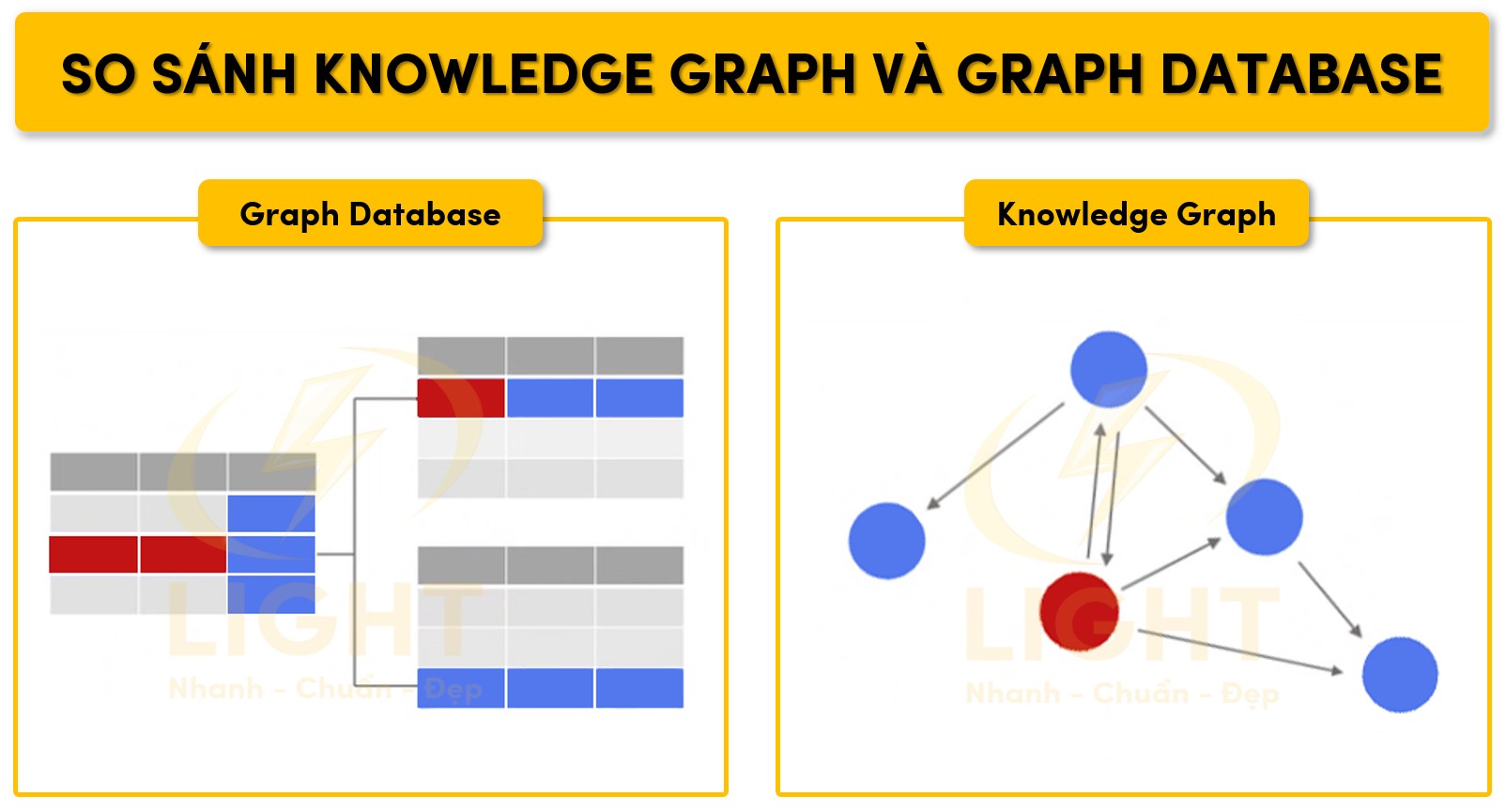
Graph Database:
-
Là một hệ quản trị cơ sở dữ liệu (DBMS) dạng đồ thị, ví dụ: Neo4j, Amazon Neptune, OrientDB.
-
Lưu trữ dữ liệu theo cấu trúc đỉnh (node) và cạnh (edge).
-
Tối ưu hóa các truy vấn theo mối liên kết phức tạp (traversal, shortest path, pattern matching).
-
Không có tầng ngữ nghĩa rõ ràng, bản thân quan hệ chỉ mang tính kết nối, không định nghĩa ý nghĩa hay logic.
-
Thiếu khả năng biểu diễn bối cảnh, ràng buộc logic, phân cấp lớp hoặc suy diễn tự động.
Knowledge Graph:
-
Là mô hình tri thức ngữ nghĩa mở rộng dựa trên công nghệ đồ thị, sử dụng các chuẩn như RDF, OWL, SKOS, RDFS.
-
Mỗi node đại diện cho thực thể có ý nghĩa rõ ràng (ví dụ: người, địa điểm, sự kiện), mỗi cạnh mang thông tin ngữ nghĩa (ví dụ: “là cha của”, “nằm ở”, “thuộc về”).
-
Cho phép liên kết, tích hợp tri thức từ nhiều nguồn, thiết lập định danh chuẩn (URI).
-
Hỗ trợ suy diễn logic (reasoning), kiểm tra ràng buộc, trích xuất ngữ cảnh, truy vấn ngôn ngữ tự nhiên.
-
Được ứng dụng trong AI, trợ lý số, tìm kiếm ngữ nghĩa, phân tích dữ liệu lớn, nhận diện thực thể, phân tích ngữ cảnh.
Bảng so sánh chi tiết:
| Đặc điểm | Graph Database | Knowledge Graph |
|---|---|---|
| Mục tiêu chính | Lưu trữ, truy vấn dữ liệu dạng đồ thị | Biểu diễn, tích hợp, khai thác tri thức ngữ nghĩa |
| Chuẩn công nghệ | Cypher, Gremlin, Property Graph | RDF, OWL, RDFS, SPARQL |
| Ngữ nghĩa & Ontology | Không/giới hạn | Rất mạnh mẽ, dựa trên ontology, semantic |
| Suy luận, logic | Không hoặc giới hạn | Hỗ trợ reasoning, inferencing |
| Truy vấn | Traversal, pattern matching | SPARQL, truy vấn ngữ nghĩa, ngôn ngữ tự nhiên |
| Ứng dụng | Mạng xã hội, quản lý mạng, logistics | AI, tìm kiếm thông minh, hệ tri thức doanh nghiệp |
Knowledge Graph vs. Semantic Web
Semantic Web là nền tảng lý thuyết và các tiêu chuẩn kỹ thuật nhằm mở rộng khả năng hiểu và xử lý dữ liệu của máy tính trên Internet. Knowledge Graph là hiện thân thực tiễn, kế thừa các nguyên tắc cốt lõi của Semantic Web, phục vụ cho các hệ thống cần khai thác tri thức thông minh.
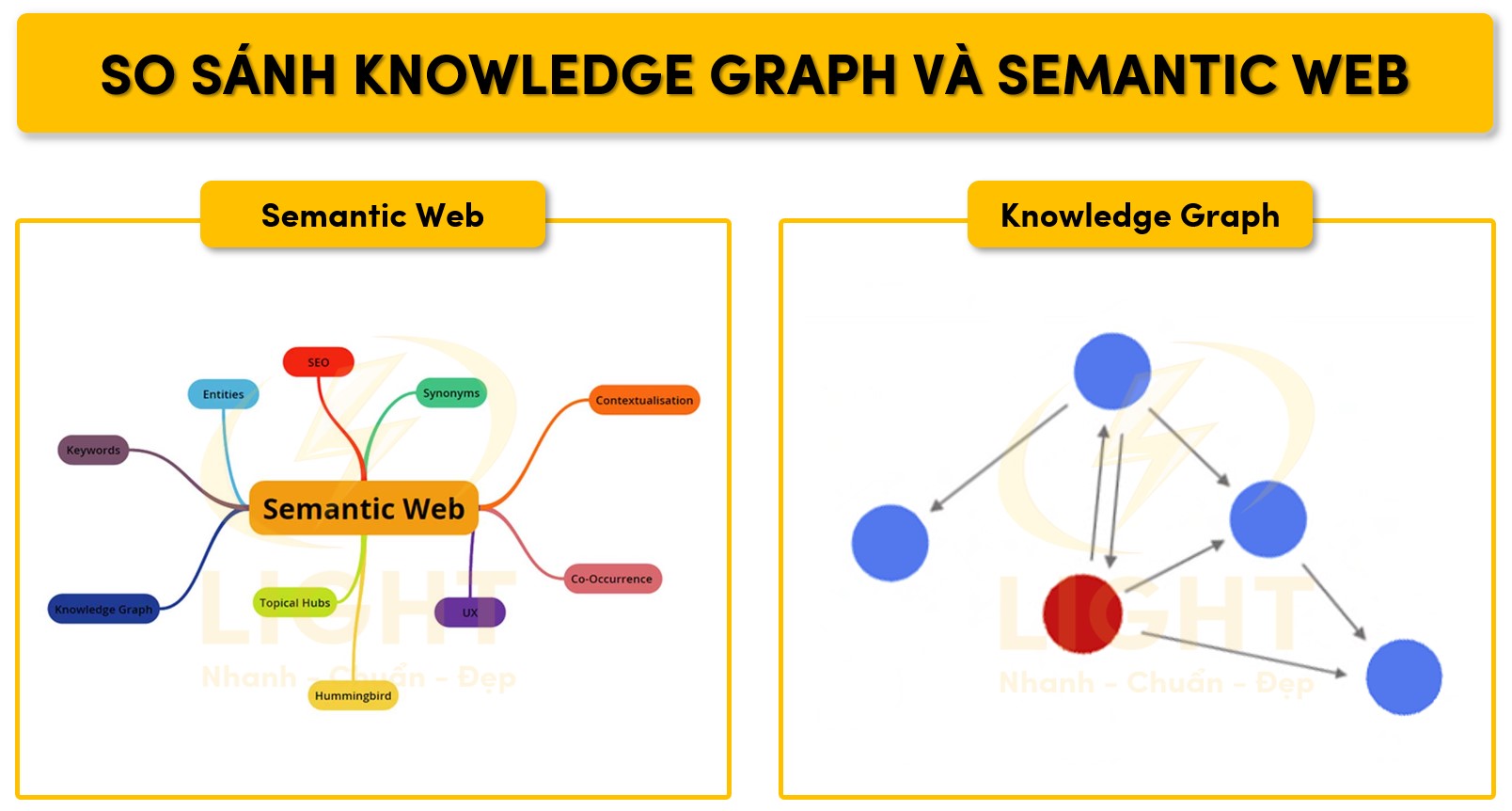
Semantic Web:
-
Là tầm nhìn về mạng Internet trong đó dữ liệu được tổ chức theo chuẩn ngữ nghĩa (semantic standards).
-
Sử dụng các ngôn ngữ và chuẩn: RDF để mô tả dữ liệu, OWL để xây dựng ontology, SPARQL để truy vấn, URI cho định danh duy nhất.
-
Mục tiêu: xây dựng web dữ liệu có cấu trúc, cho phép máy móc hiểu nội dung, liên kết tự động và truy xuất ngữ cảnh sâu.
Knowledge Graph:
-
Là thực thể cụ thể hóa các nguyên tắc Semantic Web, tập trung vào ứng dụng thực tiễn.
-
Tích hợp dữ liệu từ nhiều nguồn nội bộ và bên ngoài, chuẩn hóa thực thể, thiết lập kết nối với nguồn tri thức mở (Linked Open Data, DBpedia, Wikidata…).
-
Sử dụng các kỹ thuật enrichment, entity linking, disambiguation để tăng giá trị dữ liệu.
-
Khả năng suy luận dựa trên logic mô tả, phát hiện tri thức ẩn, nhận diện quan hệ ngữ cảnh phức tạp.
Các yếu tố nổi bật khi triển khai Knowledge Graph trên nền Semantic Web:
-
Chuẩn hóa thực thể (Entity Normalization): Kết nối và thống nhất thông tin từ các nguồn dị biệt.
-
Ontology-driven: Triển khai các ontology chuyên ngành cho từng lĩnh vực.
-
Interlinking: Liên kết tri thức nội bộ với web ngữ nghĩa toàn cầu.
-
Suy diễn (Reasoning): Phát hiện tri thức mới từ các mối quan hệ đã biết.
Knowledge Graph vs. Ontology
Ontology và Knowledge Graph là hai thành phần cốt lõi của công nghệ ngữ nghĩa, nhưng đóng vai trò khác nhau trong mô hình hóa tri thức. Ontology xác lập nền tảng khái niệm, còn Knowledge Graph là sự kết hợp giữa khung khái niệm này với dữ liệu thực tế và các liên kết động trong hệ thống.

Ontology:
-
Là bộ mô hình khái niệm mô tả các lớp, thuộc tính, quan hệ, ràng buộc logic trong một lĩnh vực.
-
Xây dựng bằng các ngôn ngữ như OWL, RDFS, thường đi kèm với các axioms, quy tắc logic và phân cấp lớp (taxonomy, hierarchy).
-
Đóng vai trò định nghĩa “lược đồ ngữ nghĩa” (semantic schema), xác định chuẩn hóa tên gọi, mô hình hóa thực thể trừu tượng.
Knowledge Graph:
-
Xây dựng dựa trên một hoặc nhiều ontology; lấy ontology làm nền móng cấu trúc và ngữ nghĩa.
-
Tích hợp dữ liệu thực tế (instance data), liên kết các thực thể thật, gắn các thuộc tính, dữ kiện cụ thể.
-
Áp dụng thêm enrichment (bổ sung dữ liệu), linking (liên kết thực thể bên ngoài), và các kỹ thuật machine learning để tự động phát hiện và mở rộng quan hệ.
-
Hỗ trợ truy vấn phức tạp, phân tích ngữ cảnh, phát hiện mẫu tri thức mới, nhận diện bất thường.
Các thành phần chính phân biệt Knowledge Graph và Ontology
-
Ontology:
-
Định nghĩa lớp (Class)
-
Định nghĩa thuộc tính (Property)
-
Ràng buộc (Constraint/Axiom)
-
Cấu trúc phân cấp (Hierarchy/Taxonomy)
-
-
Knowledge Graph:
-
Thực thể cụ thể (Instance/Individual)
-
Quan hệ thực tế giữa thực thể (Fact/Triple)
-
Liên kết với dữ liệu ngoài (External Linking)
-
Tích hợp nguồn dữ liệu đa dạng (Data Integration)
-
Suy diễn và enrichment (Reasoning & Enrichment)
-
Tóm tắt chuyên sâu:
Ontology là khung định nghĩa logic, ngữ nghĩa cho lĩnh vực; Knowledge Graph hiện thực hóa ontology, bổ sung lớp dữ liệu thật, áp dụng cho các bài toán thực tiễn như tìm kiếm tri thức, AI, quản lý tri thức doanh nghiệp, hỗ trợ quyết định thông minh.
Tối ưu SEO với Knowledge Graph
Tối ưu SEO dựa trên Knowledge Graph là chiến lược tận dụng mô hình hiểu ngữ nghĩa của công cụ tìm kiếm để tăng khả năng nhận diện, thẩm quyền và độ phủ thương hiệu cho website. Thay vì chỉ tập trung vào từ khóa, phương pháp này nhấn mạnh vào việc xây dựng thực thể, chuẩn hóa dữ liệu cấu trúc và thiết lập liên kết ngữ cảnh chặt chẽ, giúp website nổi bật trên các vị trí ưu tiên của trang kết quả tìm kiếm hiện đại.
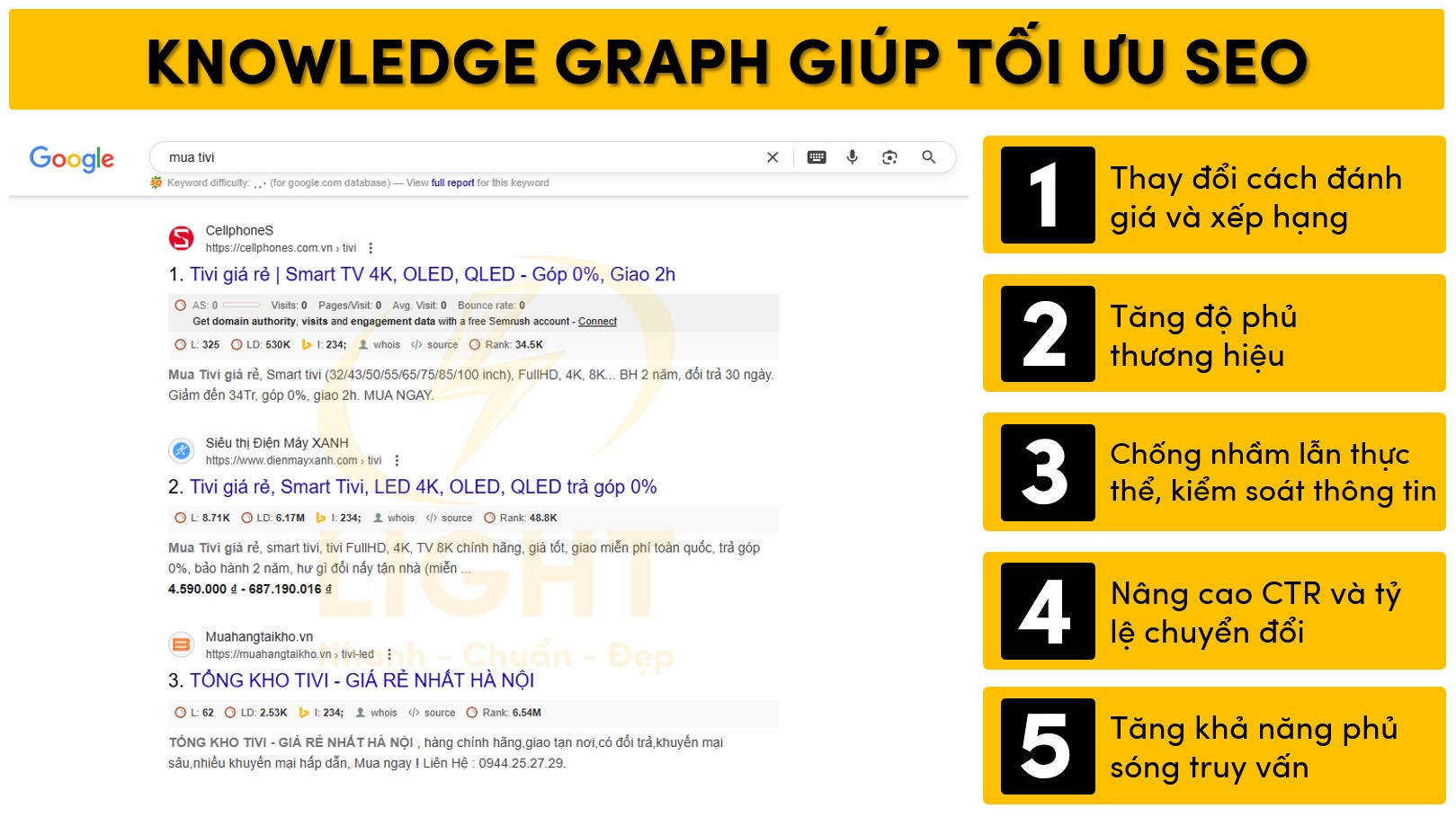
Tại sao Knowledge Graph quan trọng cho SEO?
Knowledge Graph là nền tảng để các công cụ tìm kiếm xây dựng mô hình hiểu ngữ nghĩa cho từng truy vấn, từng thực thể và mọi liên kết ngữ cảnh liên quan đến website. Vai trò của Knowledge Graph đối với SEO có thể phân tích ở các khía cạnh sau:
-
Thay đổi cách đánh giá và xếp hạng: Google chuyển từ hệ thống dựa trên chỉ số từ khóa, backlink sang mô hình ngữ nghĩa (semantic search), tập trung vào nhận diện thực thể (entity recognition) và quan hệ (relationship mapping). Các website được Google định danh rõ ràng trong Knowledge Graph sẽ được ưu tiên hiển thị ở các dạng kết quả nâng cao như Knowledge Panel, Featured Snippet, Entity Carousel, Local Pack.
-
Tăng độ phủ thương hiệu: Thực thể doanh nghiệp, cá nhân, sản phẩm, địa danh khi đã xuất hiện trong Knowledge Graph sẽ có khả năng được nhận diện, xác thực, và ưu tiên xuất hiện trên đa nền tảng tìm kiếm, trợ lý ảo, bản đồ số, Google Discover, Google News, và các sản phẩm AI khác của Google.
-
Nâng cao CTR và tỷ lệ chuyển đổi: Hiển thị nổi bật trong Knowledge Panel, People Also Ask, hoặc các rich result giúp tăng đáng kể tỷ lệ nhấp chuột (CTR), nhờ cung cấp thông tin xác thực, đầy đủ, đa dạng hình thức (ảnh, review, xếp hạng, FAQ).
-
Chống nhầm lẫn thực thể, kiểm soát thông tin: Knowledge Graph giúp Google phân biệt chính xác các chủ thể cùng tên, hạn chế lỗi trùng lặp và giảm nguy cơ bị chiếm dụng thương hiệu (brand hijacking), đảm bảo thông tin đồng nhất, tin cậy cho người dùng.
-
Tăng khả năng phủ sóng truy vấn dài, truy vấn tự nhiên: Khi đã được xác thực thực thể, website có thể xuất hiện ở nhiều dạng truy vấn mở rộng, truy vấn hội thoại (conversational query) và cả tìm kiếm không cần click (zero-click search).
Làm thế nào để website được Google Knowledge Graph nhận diện?
Quy trình để website và thực thể được Google Knowledge Graph ghi nhận cần đáp ứng đồng thời về mặt kỹ thuật, nội dung, tín hiệu ngoài web và sự đồng bộ dữ liệu đa nền tảng:
-
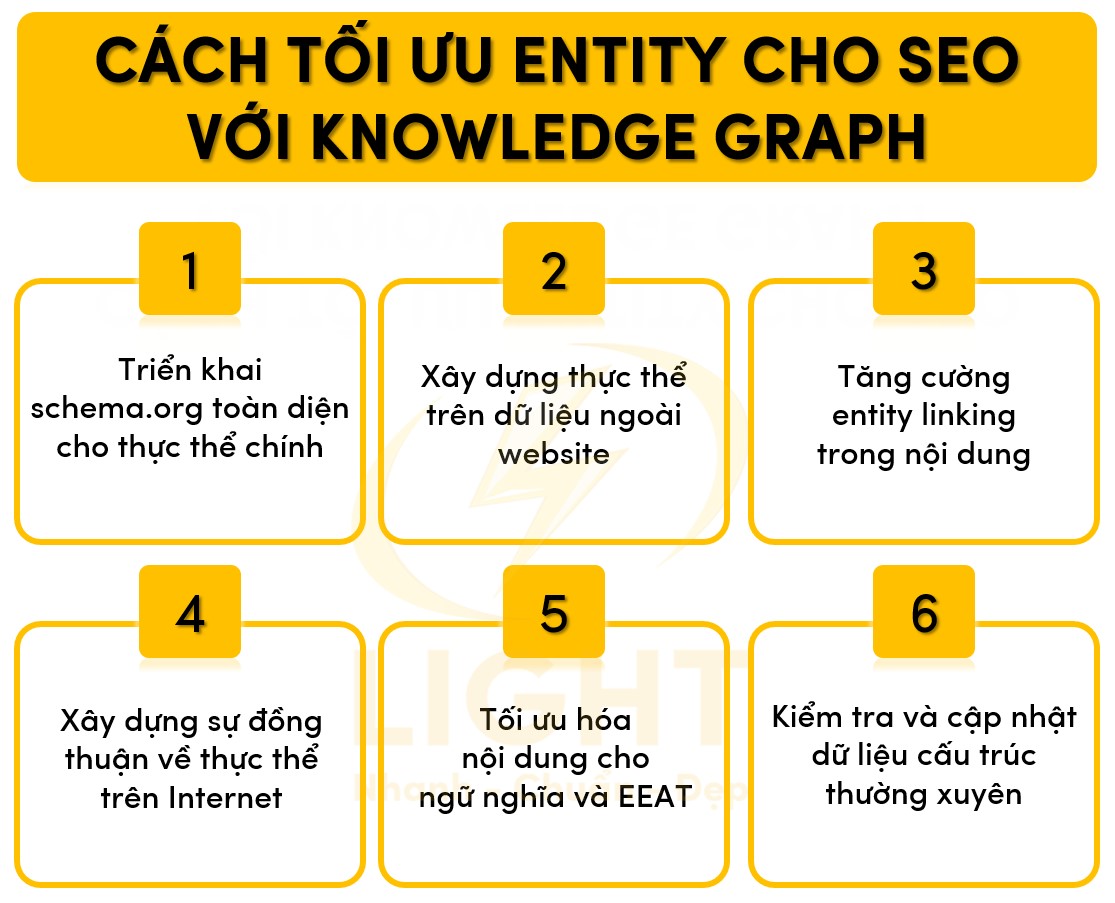
Triển khai schema.org toàn diện cho thực thể chính
-
Áp dụng schema.org dạng JSON-LD cho từng thực thể chủ đạo:
Organization,Person,Product,Event,LocalBusiness,FAQPage… Guha và cộng sự (2016) trong Communications of ACM về Schema.org cho thấy 31,3% websites sử dụng đánh dấu dữ liệu có cấu trúc, tăng 5 lần so với năm 2012. Meusel và đồng nghiệp (2014) tại WWW Conference chứng minh việc áp dụng Schema.org JSON-LD cải thiện 40% khả năng nhận diện thực thể của công cụ tìm kiếm. Ronallo (2012) trong Code4Lib Journal chỉ ra các trang web sử dụng đánh dấu Schema.org có tỷ lệ xuất hiện trong rich snippets cao hơn 20% và tỷ lệ nhấp chuột tăng 15-30% so với các trang không đánh dấu, tạo lợi thế cạnh tranh rõ rệt trong SEO. -
Khai báo các thuộc tính bắt buộc và mở rộng:
name,description,url,logo,image,sameAs,address,contactPoint,founder,foundingDate,review,aggregateRating... -
Đặc biệt chú ý trường
sameAsđể liên kết với các nguồn xác thực: Wikipedia, Wikidata, LinkedIn, Crunchbase, Google Business Profile, mạng xã hội.
-
-
Xây dựng thực thể trên dữ liệu ngoài website
-
Tạo, xác minh, cập nhật hồ sơ thực thể (entity profile) trên các nền tảng uy tín: Wikipedia, Wikidata, Google Business Profile, Apple Maps, Facebook Page, Crunchbase, D&B, OpenCorporates.
-
Đồng nhất các trường dữ liệu: tên, mô tả, địa chỉ, số điện thoại, email, ngành nghề, liên kết website, mã định danh doanh nghiệp (LEI, Mã số thuế).
-
-
Tăng cường entity linking trong nội dung
-
Gắn các liên kết ngữ nghĩa đến các thực thể liên quan (internal linking, external linking) thông qua anchor text giàu ý nghĩa và nhất quán, tránh dùng anchor text chung chung, không rõ thực thể.
-
Liên kết đến các nguồn xác thực như Wikipedia, Wikidata, Google Scholar, hoặc các bài báo uy tín đã xác nhận thực thể.
-
-
Xây dựng sự đồng thuận về thực thể trên Internet
-
Đảm bảo mọi thông tin về doanh nghiệp, cá nhân, sản phẩm… đều đồng nhất trên mọi nền tảng, đặc biệt các website, báo chí, diễn đàn lớn, thư mục doanh nghiệp.
-
Tích cực xây dựng hồ sơ báo chí, nhận diện trên các trang tổng hợp dữ liệu uy tín.
-
-
Tối ưu hóa nội dung cho ngữ nghĩa và EEAT
-
Mỗi thực thể đều có trang profile riêng, được trình bày logic, chi tiết, đầy đủ trường thông tin, thể hiện chuyên môn, thẩm quyền, kinh nghiệm, nguồn dẫn xác thực.
-
Đầu tư vào các yếu tố EEAT: profile tác giả, đánh giá chuyên gia, liên kết trích dẫn, phản hồi khách hàng, case study thực tế.
-
-
Kiểm tra và cập nhật dữ liệu cấu trúc thường xuyên
-
Dùng Google Rich Results Test, Schema Markup Validator để kiểm tra và sửa lỗi dữ liệu cấu trúc.
-
Theo dõi Google Search Console, Google Knowledge Panel, cập nhật khi có thay đổi về thực thể, dịch vụ, sản phẩm.
-
Cách tối ưu entity cho SEO với Knowledge Graph
Tối ưu entity là yếu tố cốt lõi giúp website được Google nhận diện, xác thực và đánh giá cao trong Knowledge Graph. Điều này đòi hỏi các giải pháp toàn diện về nhận diện thực thể, tối ưu ngữ nghĩa nội dung, khai báo dữ liệu cấu trúc cũng như xây dựng và duy trì tín hiệu thực thể uy tín trên đa kênh.
-
Lập bản đồ entity chuyên sâu cho từng lĩnh vực
-
Nghiên cứu, xác định các entity cốt lõi (primary entity), entity liên quan (secondary entity), các quan hệ giữa các thực thể chính, phụ.
-
Vẽ sơ đồ entity map giúp định hướng cấu trúc nội dung và internal link rõ ràng.
-
-
Tối ưu landing page cho từng entity
-
Tạo landing page riêng cho mỗi entity với nội dung chuyên sâu, tập trung khai báo schema đầy đủ, cung cấp ngữ cảnh và liên kết tới các entity liên quan.
-
Cấu trúc nội dung khoa học, bổ sung multimedia (ảnh, video, infographic) gắn với entity.
-
-
Mở rộng context thực thể bằng các thuộc tính schema mở rộng
-
Sử dụng thuộc tính mở rộng của schema.org như
memberOf,award,affiliation,parentOrganization,worksFor,alumniOf… để bổ sung ngữ cảnh, tăng độ phủ cho entity. -
Liên kết nhiều chiều giữa các entity cùng lĩnh vực thông qua thuộc tính
about,mentions.
-
-
Liên kết entity đa kênh (entity omnichannel linking)
-
Tích hợp entity trên mọi nền tảng: social profile, business directory, marketplace, nền tảng đánh giá (Google Review, Trustpilot, Capterra…), báo chí, diễn đàn chuyên ngành.
-
Tăng mật độ liên kết entity ra ngoài hệ sinh thái website, xây dựng tín hiệu entity consistency cho Google.
-
-
Tăng cường signals thực thể bằng dữ liệu có cấu trúc bổ sung
-
Sử dụng các loại schema nâng cao:
BreadcrumbList,FAQPage,HowTo,QAPage,Product,Event,Review,AggregateRating… cho mọi thực thể liên quan. -
Đảm bảo dữ liệu schema đồng nhất, không bị trùng lặp hoặc thiếu thuộc tính.
-
-
Giám sát, quản trị và bảo vệ entity liên tục
-
Theo dõi Knowledge Panel, truy vấn entity trên Google, Bing, kiểm soát nguồn thông tin về entity, phát hiện và xử lý kịp thời các lỗi nhận diện, nhầm lẫn, sai lệch thông tin thực thể.
-
Chủ động phản hồi, bổ sung, cập nhật hồ sơ entity trên các nền tảng dữ liệu mở và các sản phẩm Google.
-
Các thực tiễn tối ưu entity cho SEO với Knowledge Graph
-
Áp dụng JSON-LD cho mọi trang thực thể
-
Đảm bảo thuộc tính
sameAsdẫn đến các hồ sơ xác thực ngoài website -
Sử dụng ngôn ngữ ngữ nghĩa rõ ràng trong nội dung, anchor text liên kết
-
Đăng ký thông tin thực thể trên Wikidata, Wikipedia, Google Business Profile
-
Đầu tư xây dựng tín hiệu EEAT trên toàn bộ hệ sinh thái số
-
Sử dụng công cụ kiểm tra schema định kỳ, sửa lỗi kịp thời
-
Tạo entity map minh họa rõ cấu trúc thực thể và các quan hệ chính/phụ
Bảng: Một số loại schema.org khuyến nghị cho từng loại thực thể trong SEO ngữ nghĩa
| Loại thực thể | Loại schema.org | Thuộc tính bắt buộc và nên khai báo |
|---|---|---|
| Doanh nghiệp | Organization, LocalBusiness | name, description, logo, url, address, sameAs, contactPoint, founder, foundingDate |
| Sản phẩm | Product | name, description, image, brand, sku, aggregateRating, review, offers |
| Cá nhân | Person | name, jobTitle, affiliation, worksFor, alumniOf, image, sameAs |
| Sự kiện | Event | name, startDate, location, description, url, image |
| Đánh giá/sao | Review, AggregateRating | itemReviewed, reviewBody, ratingValue, author, datePublished |
| Trang thông tin | WebPage, FAQPage, AboutPage | name, description, mainEntity, about, mentions |
Tối ưu SEO với Knowledge Graph đòi hỏi sự phối hợp chặt chẽ giữa kỹ thuật dữ liệu cấu trúc, ngữ nghĩa nội dung, liên kết thực thể đa nền tảng và phát triển tín hiệu EEAT đồng bộ trên toàn bộ hệ sinh thái số.
Câu hỏi thường gặp về Knowledge Graph
Các vấn đề thực tiễn liên quan đến Knowledge Graph thường tập trung vào đặc điểm bản chất, phạm vi ứng dụng, vai trò trong SEO và cách các nền tảng lớn như Google tận dụng công nghệ này. Dưới đây là giải đáp chi tiết cho những thắc mắc thường gặp, giúp hiểu đúng về khả năng triển khai, lợi ích và hạn chế khi tích hợp Knowledge Graph trong chiến lược phát triển và tối ưu website.
Knowledge Graph có phải là cơ sở dữ liệu không?
Không. Knowledge Graph không phải là cơ sở dữ liệu truyền thống. Knowledge Graph là một mô hình biểu diễn tri thức dưới dạng đồ thị, tập trung vào việc mô hình hóa thực thể, thuộc tính và quan hệ ngữ nghĩa giữa các thực thể. Knowledge Graph có thể được lưu trữ trên các hệ quản trị cơ sở dữ liệu đồ thị (graph database) hoặc triple store (RDF store), nhưng bản chất của nó là một lớp biểu diễn tri thức ngữ nghĩa hơn là một hệ quản trị dữ liệu thông thường. Các cơ sở dữ liệu truyền thống (quan hệ, phi quan hệ) chỉ lưu trữ và truy vấn dữ liệu, trong khi Knowledge Graph chú trọng tới logic ngữ nghĩa, khả năng liên kết và reasoning tri thức.
Khóa học SEO có dạy về Knowledge Graph không?
Có, nhưng tùy vào chương trình và độ chuyên sâu của khóa học. Một số khóa học SEO hiện đại, đặc biệt là các chương trình chuyên sâu về SEO kỹ thuật và Entity SEO, sẽ đề cập đến khái niệm Knowledge Graph, vai trò của thực thể (entity) trong SEO, cấu trúc dữ liệu schema.org và cách tối ưu hóa website để tận dụng các lợi thế từ Knowledge Graph của Google và các công cụ tìm kiếm. Tuy nhiên, đa số các khóa học SEO căn bản chỉ đề cập tổng quan, không đi sâu vào cấu trúc hay triển khai thực tế Knowledge Graph. Đối với kiến thức chuyên sâu, thường phải tham khảo các khóa học về Semantic SEO, Entity-based SEO hoặc các tài liệu chuyên ngành về Data Science và Semantic Web.
Có thể sử dụng Knowledge Graph cho mọi loại website không?
Có thể, nhưng hiệu quả phụ thuộc vào đặc thù lĩnh vực, quy mô và mục tiêu của website. Knowledge Graph đặc biệt phù hợp với các website có nhiều loại dữ liệu, thực thể đa dạng, cấu trúc phức tạp như: tin tức, thương mại điện tử, giáo dục, y tế, du lịch, sản phẩm công nghệ, v.v. Với các website đơn giản, ít nội dung hoặc không cần khai thác ngữ nghĩa sâu, việc xây dựng Knowledge Graph có thể không mang lại giá trị vượt trội. Việc ứng dụng cần đánh giá kỹ nhu cầu thực tế, nguồn lực và khả năng triển khai.
Google sử dụng Knowledge Graph để hiển thị kết quả tìm kiếm không?
Có. Google sử dụng Knowledge Graph để hiểu ngữ nghĩa, xác định thực thể và mối quan hệ giữa các thực thể trong truy vấn tìm kiếm. Knowledge Graph giúp Google hiển thị các kết quả mở rộng như Knowledge Panel, các ô thông tin tổng hợp, sơ đồ thông tin trực quan liên quan đến thực thể, đồng thời cải thiện độ chính xác và trải nghiệm người dùng khi tìm kiếm. Ngoài Google, nhiều nền tảng tìm kiếm lớn cũng đang sử dụng hoặc phát triển hệ thống Knowledge Graph riêng để nâng cao khả năng truy xuất và kết nối tri thức.
Knowledge Graph có giúp tăng thứ hạng SEO không?
Có, nhưng gián tiếp. Knowledge Graph không phải là yếu tố xếp hạng trực tiếp, tuy nhiên nó đóng vai trò nâng cao khả năng nhận diện thực thể, hiểu ngữ cảnh, tăng độ tin cậy và uy tín cho website trên công cụ tìm kiếm. Khi website được đánh dấu dữ liệu cấu trúc (schema markup), tối ưu hóa entity và thông tin nhất quán, Google dễ dàng hiểu được nội dung, từ đó xuất hiện trong Knowledge Panel, Rich Result, các vị trí nổi bật trên trang tìm kiếm (SERP features). Điều này giúp tăng CTR, tăng khả năng tiếp cận người dùng mục tiêu và gián tiếp hỗ trợ cải thiện thứ hạng SEO tổng thể, đồng thời tăng EEAT (Experience, Expertise, Authoritativeness, Trustworthiness) cho website.





Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
