
Cơ sở dữ liệu là gì? Các kiến thức quan trọng về cơ sở dữ liệu
Cơ sở dữ liệu (Database) hỗ trợ các hệ thống và ứng dụng hoạt động đồng bộ, hiệu quả, từ các trang web doanh nghiệp nhỏ đến hệ thống thương mại điện tử, mạng xã hội hay ứng dụng trí tuệ nhân tạo, cơ sở dữ liệu tổ chức và xử lý dữ liệu logic, đảm bảo tính toàn vẹn và nhất quán. Cơ sở dữ liệu hiện đại còn hỗ trợ mở rộng linh hoạt, tích hợp với công cụ phân tích dữ liệu lớn và bảo vệ thông tin nhạy cảm.
Hiểu và áp dụng cơ sở dữ liệu đúng cách giúp doanh nghiệp vận hành hiệu quả, tăng cường khả năng cạnh tranh trong môi trường số hóa. Bài viết này sẽ phân tích cách hoạt động, các loại cơ sở dữ liệu, bảo mật, và tiêu chí chọn cơ sở dữ liệu phù hợp, cung cấp góc nhìn toàn diện về vai trò và ứng dụng của cơ sở dữ liệu
Cơ sở dữ liệu (Database) là gì?
Cơ sở dữ liệu (Database) là hệ thống lưu trữ có cấu trúc, nơi dữ liệu được tổ chức một cách logic và có thể truy cập, chỉnh sửa hoặc quản lý dễ dàng thông qua các phương pháp và công cụ chuyên dụng. Khác với việc lưu trữ dữ liệu không có tổ chức, cơ sở dữ liệu tập trung vào việc tối ưu hóa việc quản lý và truy xuất thông tin một cách nhất quán và hiệu quả.
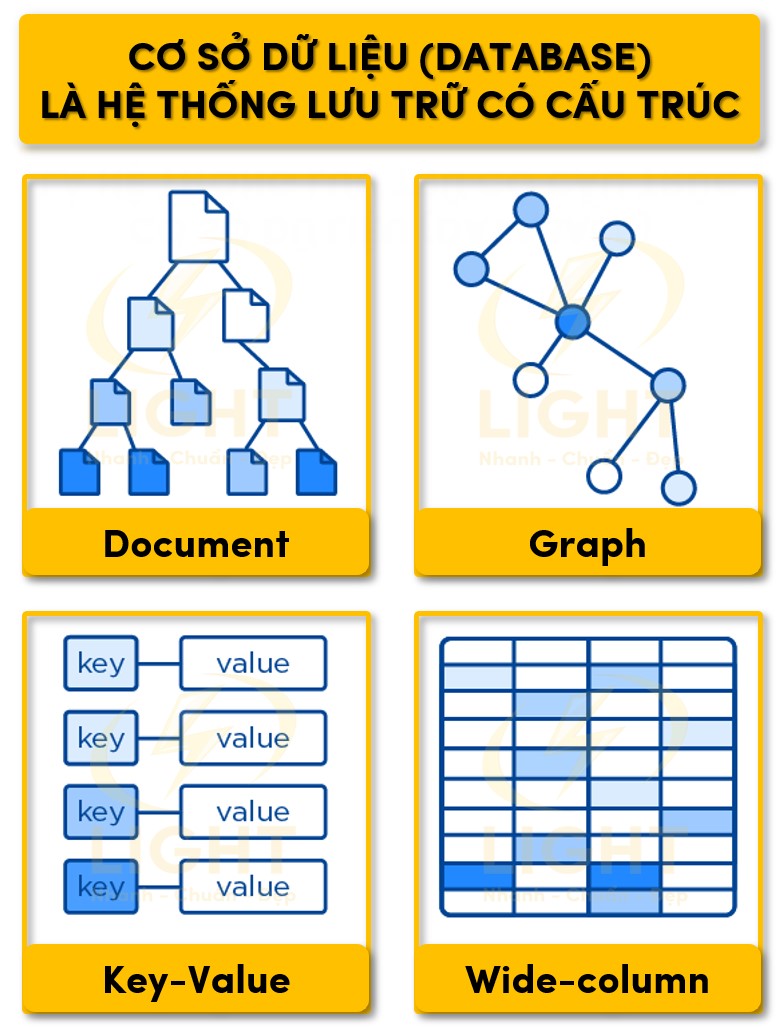
Trong cơ sở dữ liệu, thông tin được tổ chức theo một hoặc nhiều mô hình như mô hình quan hệ (relational), mô hình đồ thị (graph), mô hình đối tượng (object-oriented) hoặc phi quan hệ (NoSQL). Mỗi mô hình phù hợp với các trường hợp sử dụng khác nhau, từ lưu trữ các giao dịch tài chính đến quản lý mạng xã hội hoặc dữ liệu IoT.
Tầm quan trọng của cơ sở dữ liệu trong công nghệ và đời sống
Theo phân tích của Stonebraker và Hellerstein (2018) trong 'Readings in Database Systems', vai trò của cơ sở dữ liệu trong nền kinh tế số ngày càng trở nên thiết yếu. Nghiên cứu cho thấy các tổ chức áp dụng công nghệ cơ sở dữ liệu tiên tiến đạt được mức tăng năng suất đáng kể và giảm chi phí vận hành so với đối thủ. Đặc biệt, trong lĩnh vực chăm sóc sức khỏe, việc triển khai hệ thống cơ sở dữ liệu tích hợp đã giúp cải thiện đáng kể thời gian và độ chính xác trong chẩn đoán bệnh.
Cơ sở dữ liệu trong hệ thống công nghệ thông tin
Cơ sở dữ liệu là trái tim của mọi hệ thống công nghệ thông tin. Các ứng dụng từ nhỏ như phần mềm quản lý cá nhân đến những nền tảng lớn như mạng xã hội, thương mại điện tử và trí tuệ nhân tạo đều dựa trên cơ sở dữ liệu để lưu trữ, xử lý và phân tích dữ liệu. Cơ sở dữ liệu không chỉ là nơi lưu trữ mà còn đảm bảo sự liên kết chặt chẽ giữa các phần tử thông tin, tạo điều kiện cho các ứng dụng hoạt động đồng bộ và hiệu quả.
Cơ sở dữ liệu trong các lĩnh vực cụ thể
- Tài chính: Ngân hàng và các tổ chức tài chính sử dụng cơ sở dữ liệu để theo dõi giao dịch, quản lý tài khoản và ngăn chặn gian lận. Cơ sở dữ liệu giúp đảm bảo rằng tất cả các giao dịch được ghi nhận chính xác, nhất quán và có thể kiểm tra.
- Y tế: Trong lĩnh vực chăm sóc sức khỏe, cơ sở dữ liệu đóng vai trò quan trọng trong quản lý hồ sơ bệnh nhân, theo dõi lịch sử điều trị và nghiên cứu dịch tễ học. Các hệ thống quản lý bệnh viện sử dụng cơ sở dữ liệu để tối ưu hóa hoạt động và hỗ trợ ra quyết định dựa trên dữ liệu.
- Thương mại điện tử: Các nền tảng như Amazon, eBay hay các website thương mại Việt Nam như Shopee và Tiki dựa vào cơ sở dữ liệu để quản lý sản phẩm, xử lý đơn hàng, theo dõi hành vi khách hàng và tối ưu trải nghiệm người dùng.
- Trí tuệ nhân tạo và phân tích dữ liệu: Trong lĩnh vực AI và Big Data, cơ sở dữ liệu là nơi tập trung dữ liệu để đào tạo mô hình máy học, thực hiện phân tích dữ liệu và tạo ra các dự đoán giá trị cao.
Tác động đối với đời sống thường nhật
Ngay cả trong các hoạt động hàng ngày, từ sử dụng ứng dụng di động, đặt vé máy bay, quản lý danh bạ điện thoại đến các hệ thống định vị GPS, cơ sở dữ liệu đóng vai trò như một thành phần không thể thiếu, hỗ trợ người dùng thực hiện các tác vụ một cách nhanh chóng và chính xác.
Các thành phần chính của cơ sở dữ liệu
Cơ sở dữ liệu là một hệ thống phức hợp gồm nhiều thành phần hoạt động đồng bộ để lưu trữ, xử lý và quản lý dữ liệu. Hiểu rõ các thành phần chính sẽ giúp chúng ta nhận thức được cách cơ sở dữ liệu vận hành và tối ưu hóa. Các thành phần này bao gồm dữ liệu – thành phần cốt lõi của hệ thống, hệ quản trị cơ sở dữ liệu (DBMS) – công cụ quản lý, và vai trò của người dùng và ứng dụng trong việc khai thác dữ liệu.
1. Dữ liệu
Dữ liệu trong cơ sở dữ liệu là yếu tố nền tảng, được tổ chức và định dạng để phù hợp với mục tiêu sử dụng. Có hai loại dữ liệu chính trong cơ sở dữ liệu:
- Dữ liệu cấu trúc (Structured Data): Dữ liệu được tổ chức thành bảng với các cột và hàng, như thông tin khách hàng trong hệ thống CRM. Ví dụ: Bảng thông tin khách hàng có các cột như "Họ tên", "Số điện thoại", "Email", và mỗi hàng tương ứng với một khách hàng cụ thể.
- Dữ liệu phi cấu trúc (Unstructured Data): Bao gồm dữ liệu không được tổ chức theo khuôn khổ nhất định, như hình ảnh, video, email hoặc nội dung mạng xã hội. Dữ liệu phi cấu trúc thường được lưu trong các cơ sở dữ liệu phi quan hệ như MongoDB hoặc Elasticsearch.
- Dữ liệu bán cấu trúc (Semi-structured Data): Là dữ liệu có tổ chức nhưng không theo cấu trúc cố định, thường xuất hiện dưới dạng XML, JSON.
2. Hệ quản trị cơ sở dữ liệu (DBMS)
Hệ quản trị cơ sở dữ liệu là phần mềm chuyên dụng dùng để quản lý dữ liệu và cung cấp môi trường cho người dùng truy cập, sửa đổi và xử lý dữ liệu. Nghiên cứu của Pavlo và Aslett (2019) từ đại học Carnegie Mellon, công bố trong kỷ yếu VLDB, đã đánh giá hiệu suất của các hệ quản trị cơ sở dữ liệu phổ biến. Họ phát hiện rằng DBMS hiện đại không chỉ đơn thuần quản lý dữ liệu mà còn thực hiện tự động hóa nhiều quy trình quan trọng. Các hệ thống như PostgreSQL và MongoDB đã tích hợp công nghệ học máy để dự đoán và tối ưu hóa mẫu truy vấn, dẫn đến cải thiện đáng kể thời gian phản hồi so với các phiên bản trước. Nhiều tổ chức báo cáo giảm đáng kể chi phí bảo trì hệ thống sau khi áp dụng các DBMS thế hệ mới. Các hệ quản trị nổi bật bao gồm MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server và MongoDB.
- Chức năng chính của DBMS:
- Tổ chức và quản lý dữ liệu: DBMS giúp lưu trữ dữ liệu một cách hiệu quả thông qua các chỉ mục, bảng hoặc cây cấu trúc.
- Truy xuất dữ liệu: Hỗ trợ truy vấn dữ liệu nhanh chóng bằng các ngôn ngữ như SQL (Structured Query Language).
- Bảo mật dữ liệu: DBMS cung cấp các cơ chế phân quyền, kiểm soát truy cập và mã hóa để đảm bảo tính bảo mật và toàn vẹn của dữ liệu.
- Quản lý giao dịch (Transaction Management): DBMS xử lý các giao dịch để đảm bảo tính nhất quán, ngay cả trong trường hợp xảy ra lỗi hệ thống.
- Sao lưu và khôi phục: Đảm bảo rằng dữ liệu không bị mất mát và có thể khôi phục trong các trường hợp khẩn cấp.
3. Người dùng và ứng dụng
Cơ sở dữ liệu không hoạt động độc lập mà được tích hợp trong các hệ thống lớn hơn, với ba nhóm chính tham gia vào quy trình:
- Người dùng cuối: Những người tương tác trực tiếp với dữ liệu, ví dụ như nhân viên nhập liệu hoặc khách hàng sử dụng ứng dụng.
- Nhà phát triển ứng dụng: Người xây dựng các ứng dụng dựa trên cơ sở dữ liệu để đáp ứng nhu cầu sử dụng.
- Quản trị viên cơ sở dữ liệu (DBA): Chịu trách nhiệm quản lý, bảo trì và tối ưu hiệu năng cơ sở dữ liệu.

Mục đích sử dụng cơ sở dữ liệu
- Quản lý dữ liệu phức tạp: Cơ sở dữ liệu cho phép tổ chức dữ liệu phức tạp trong các hệ thống lớn, giúp giảm thiểu rủi ro mất mát hoặc không nhất quán.
- Tối ưu hóa quy trình hoạt động: Bằng cách tự động hóa quy trình lưu trữ và truy xuất, cơ sở dữ liệu giúp các doanh nghiệp tiết kiệm thời gian và chi phí.
- Hỗ trợ phân tích và dự đoán: Cơ sở dữ liệu là nguồn cung cấp dữ liệu đầu vào quan trọng cho các công cụ phân tích, giúp doanh nghiệp dự đoán xu hướng và ra quyết định chiến lược.
- Đảm bảo khả năng mở rộng: Với các hệ thống hiện đại như cơ sở dữ liệu phân tán, dữ liệu có thể được mở rộng theo nhu cầu sử dụng mà không làm ảnh hưởng đến hiệu năng.
- Tích hợp hệ thống: Cơ sở dữ liệu cho phép kết nối và đồng bộ dữ liệu từ nhiều nguồn khác nhau, tạo điều kiện thuận lợi cho các hệ thống đa nền tảng.
Các loại cơ sở dữ liệu phổ biến
Mỗi loại cơ sở dữ liệu được thiết kế với cấu trúc và mục đích riêng, đáp ứng các nhu cầu khác nhau. Hệ thống cơ sở dữ liệu truyền thống như cơ sở dữ liệu quan hệ (RDBMS) tập trung lưu trữ dữ liệu có cấu trúc và đảm bảo tính nhất quán, độ tin cậy. Trong khi đó, sự phát triển của công nghệ và khối lượng dữ liệu lớn (big data) đã thúc đẩy sự ra đời của cơ sở dữ liệu phi quan hệ (NoSQL), với khả năng linh hoạt, hiệu suất cao, thích hợp cho dữ liệu phi cấu trúc hoặc bán cấu trúc. Các cơ sở dữ liệu đặc thù như cơ sở dữ liệu đồ thị hay cơ sở dữ liệu dạng tệp cung cấp giải pháp hiệu quả cho bài toán chuyên biệt như phân tích mối quan hệ phức tạp hoặc lưu trữ thông tin đơn giản.
Hiểu rõ đặc điểm, ưu điểm và ứng dụng của từng loại cơ sở dữ liệu giúp kỹ sư phần mềm, nhà quản lý hệ thống và chuyên gia dữ liệu xây dựng hệ thống tối ưu và triển khai các giải pháp công nghệ tiên tiến. Dưới đây là phân tích chi tiết về các loại cơ sở dữ liệu phổ biến, bao gồm cơ sở dữ liệu quan hệ, phi quan hệ, đồ thị và dạng tệp.
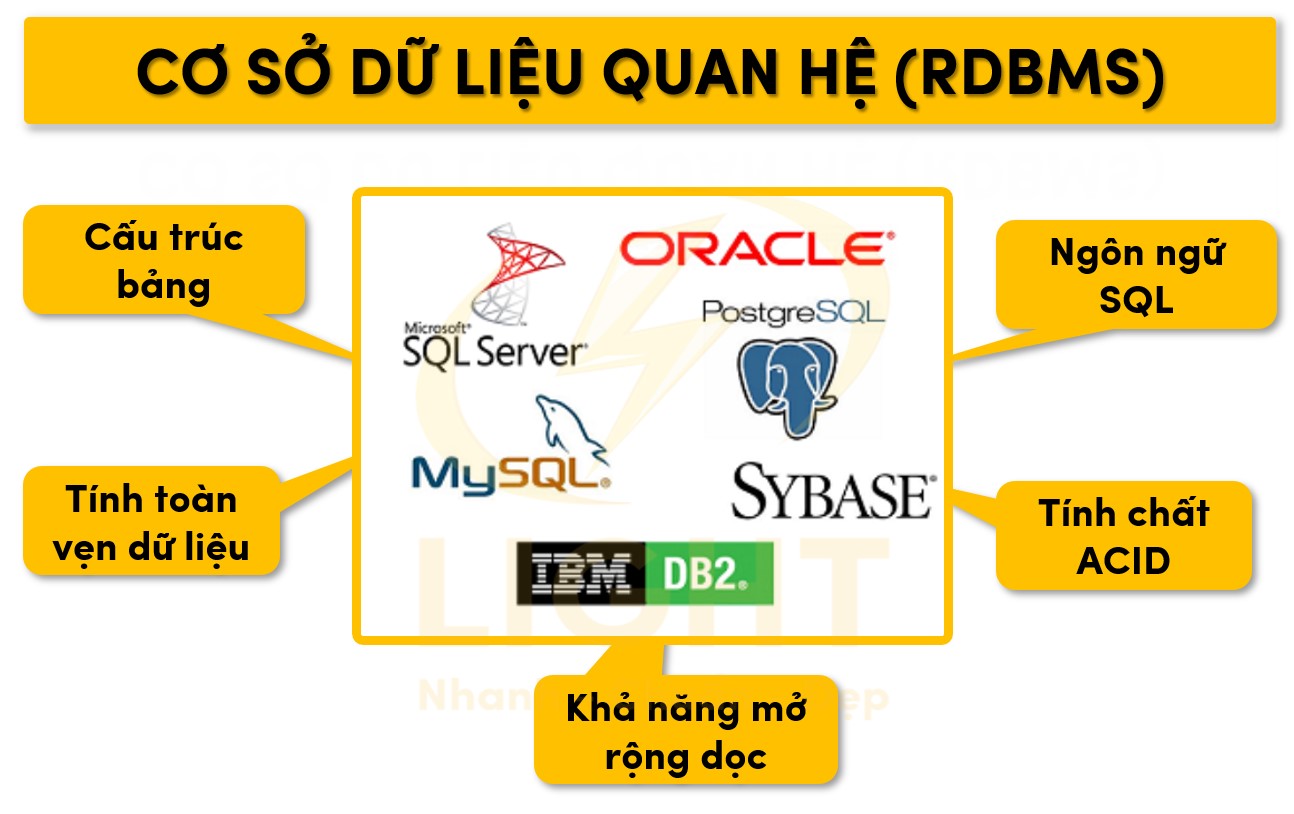
Cơ sở dữ liệu quan hệ (RDBMS)
Đặc điểm
- Cấu trúc bảng (Table): Cơ sở dữ liệu quan hệ tổ chức dữ liệu trong các bảng bao gồm hàng (row) và cột (column). Mỗi bảng đại diện cho một thực thể cụ thể, mỗi cột đại diện cho thuộc tính của thực thể, và mỗi hàng là một bản ghi duy nhất.
- Tính toàn vẹn dữ liệu (Data Integrity): RDBMS cung cấp các ràng buộc như khóa chính (primary key), khóa ngoại (foreign key), và ràng buộc duy nhất (unique constraint) để đảm bảo tính chính xác và nhất quán của dữ liệu.
- Ngôn ngữ SQL (Structured Query Language): Hỗ trợ các lệnh DDL (Data Definition Language) như
CREATE,ALTER,DROP, các lệnh DML (Data Manipulation Language) nhưSELECT,INSERT,UPDATE,DELETE, và các lệnh TCL (Transaction Control Language) nhưCOMMIT,ROLLBACK. - Tính chất ACID: Đảm bảo dữ liệu không bị lỗi hoặc mất mát ngay cả trong các tình huống hệ thống gặp sự cố.
- Atomicity: Giao dịch hoặc được thực hiện hoàn toàn, hoặc không thực hiện.
- Consistency: Hệ thống chuyển từ trạng thái hợp lệ này sang trạng thái hợp lệ khác.
- Isolation: Các giao dịch độc lập với nhau, không gây xung đột.
- Durability: Dữ liệu được ghi vĩnh viễn ngay cả khi có lỗi phần cứng.
- Khả năng mở rộng dọc (Vertical Scaling): Dễ dàng tăng tài nguyên máy chủ (RAM, CPU) để cải thiện hiệu suất, nhưng hạn chế khi so sánh với NoSQL.
Ví dụ
- MySQL: Là một trong những RDBMS phổ biến nhất, được tối ưu cho ứng dụng web và hỗ trợ nhiều engine lưu trữ như InnoDB và MyISAM.
- PostgreSQL: Cung cấp khả năng mở rộng tốt và hỗ trợ nhiều loại dữ liệu như JSON, XML, và HSTORE.
- SQL Server: Được phát triển bởi Microsoft, tích hợp sâu với các hệ sinh thái của Windows, như .NET Framework.
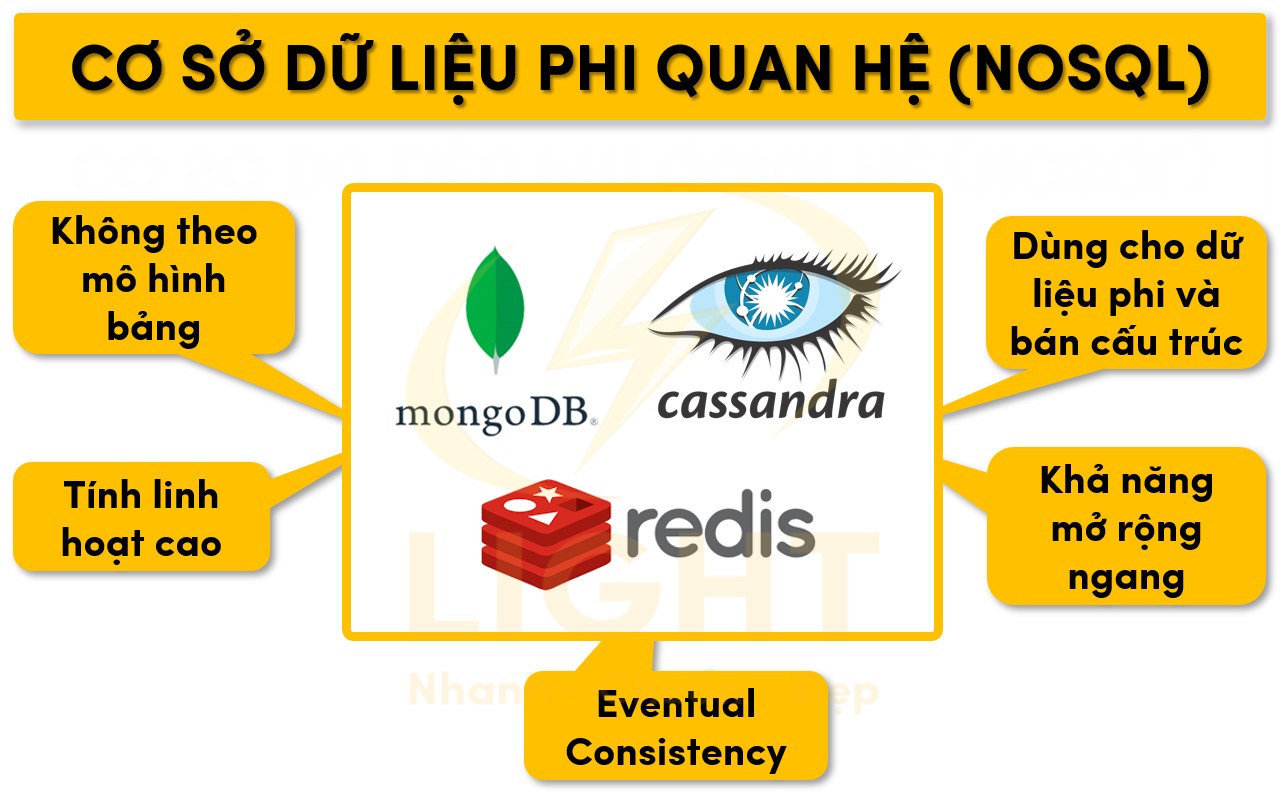
Cơ sở dữ liệu phi quan hệ (NoSQL)
Đặc điểm
- Không theo mô hình bảng truyền thống: NoSQL không tuân thủ mô hình bảng và các ràng buộc nghiêm ngặt, cho phép tổ chức dữ liệu dưới dạng tài liệu (document), cặp khóa-giá trị (key-value), cột rộng (wide-column) hoặc đồ thị (graph).
- Tính linh hoạt cao: Dữ liệu có thể thay đổi cấu trúc mà không cần chỉnh sửa toàn bộ hệ thống, phù hợp cho các ứng dụng phát triển nhanh.
- Thích hợp cho dữ liệu phi cấu trúc và bán cấu trúc: Ví dụ: nhật ký (log), dữ liệu mạng xã hội, tệp đa phương tiện.
- Khả năng mở rộng ngang (Horizontal Scaling): Dễ dàng mở rộng hệ thống bằng cách thêm máy chủ mà không làm ảnh hưởng đến hiệu suất.
- Eventual Consistency: Thay vì đảm bảo tính nhất quán tức thời (immediate consistency), NoSQL cho phép dữ liệu dần dần trở nên nhất quán, phù hợp với hệ thống phân tán lớn.
Ví dụ
- MongoDB: Lưu trữ dữ liệu dưới dạng tài liệu BSON (Binary JSON). Hỗ trợ truy vấn mạnh mẽ với các hàm như
find()vàaggregate(). - Cassandra: Thiết kế theo kiến trúc phân tán với khả năng chịu lỗi cao, hỗ trợ khối lượng lớn dữ liệu ghi/đọc trên nhiều trung tâm dữ liệu.
- Redis: Là cơ sở dữ liệu lưu trữ trong bộ nhớ (in-memory) với tốc độ rất cao, hỗ trợ cấu trúc dữ liệu đa dạng như danh sách (list), tập hợp (set), và bản đồ băm (hash map).
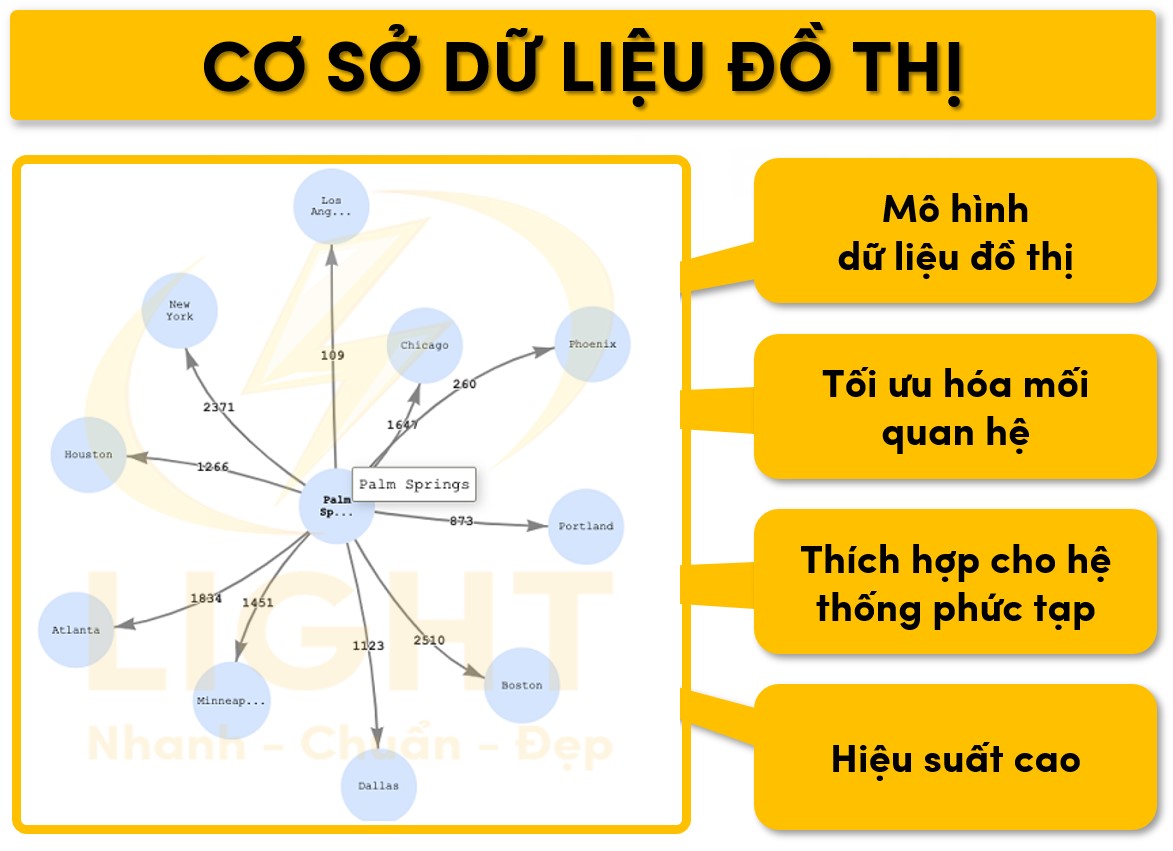
Cơ sở dữ liệu đồ thị
Đặc điểm
- Mô hình dữ liệu đồ thị: Sử dụng các nút (nodes), cạnh (edges) và thuộc tính (properties) để lưu trữ và biểu diễn dữ liệu. Các nút đại diện cho thực thể, trong khi các cạnh thể hiện mối quan hệ giữa chúng.
- Tối ưu hóa mối quan hệ: Cơ sở dữ liệu đồ thị vượt trội trong việc xử lý các truy vấn phức tạp liên quan đến mối quan hệ, ví dụ như tìm đường đi ngắn nhất, phát hiện vòng lặp trong mạng.
- Thích hợp cho hệ thống phức tạp: Dùng trong các lĩnh vực như phân tích mạng xã hội, hệ thống đề xuất, hoặc biểu đồ tri thức.
- Hiệu suất cao: Không cần thực hiện các phép nối phức tạp như trong RDBMS, do đó, các truy vấn liên quan đến mối quan hệ nhanh và hiệu quả hơn.
Ví dụ
- Neo4j: Là cơ sở dữ liệu đồ thị hàng đầu với ngôn ngữ truy vấn Cypher, tối ưu cho các trường hợp phân tích mối quan hệ phức tạp.
- JanusGraph: Được phát triển để xử lý dữ liệu đồ thị ở quy mô lớn, tích hợp tốt với Hadoop và Apache Cassandra.
Cơ sở dữ liệu dạng tệp (Flat File)
Đặc điểm
- Cấu trúc lưu trữ tĩnh: Tất cả dữ liệu được lưu trong các tệp văn bản thuần hoặc tệp nhị phân. Các tệp này thường không có mối quan hệ phức tạp giữa các phần tử dữ liệu.
- Đơn giản, dễ triển khai: Cơ sở dữ liệu dạng tệp không yêu cầu phần mềm quản lý cơ sở dữ liệu phức tạp, phù hợp với các ứng dụng nhỏ hoặc xử lý dữ liệu tạm thời.
- Không hỗ trợ tính năng nâng cao: Không cung cấp các tính năng như ràng buộc dữ liệu, giao dịch, hay bảo mật tích hợp.
- Khả năng xử lý hạn chế: Hiệu suất suy giảm nhanh khi khối lượng dữ liệu tăng, đặc biệt khi phải xử lý nhiều truy vấn đồng thời.
Ví dụ
- Tệp CSV: Định dạng phổ biến để trao đổi dữ liệu, dễ dàng đọc và xử lý bởi các công cụ như Excel hoặc Python.
- Tệp JSON/XML: Dùng để lưu trữ và trao đổi dữ liệu bán cấu trúc trong các ứng dụng hiện đại, đặc biệt là API và cấu hình hệ thống.
Hệ quản trị cơ sở dữ liệu (DBMS)
DBMS không chỉ đảm bảo rằng dữ liệu được lưu trữ một cách có tổ chức mà còn cung cấp các công cụ mạnh mẽ để truy vấn, phân tích và xử lý dữ liệu, phục vụ các quyết định chiến lược và hoạt động hàng ngày. Từ việc hỗ trợ các giao dịch tài chính phức tạp đến tối ưu hóa trải nghiệm người dùng trên các nền tảng trực tuyến, DBMS mang lại khả năng tùy biến và hiệu suất vượt trội.
Công nghệ DBMS liên tục phát triển để đáp ứng các yêu cầu mới như hỗ trợ dữ liệu phi cấu trúc, tích hợp trí tuệ nhân tạo, mở rộng hệ thống phân tán và tăng cường bảo mật dữ liệu. Hiểu rõ cách DBMS hoạt động và vai trò của nó trong việc giải quyết các thách thức về dữ liệu sẽ giúp tổ chức lựa chọn được công cụ phù hợp, tối ưu hóa hiệu quả hoạt động và đảm bảo khả năng cạnh tranh trong bối cảnh số hóa toàn cầu.
Định nghĩa và vai trò
Hệ quản trị cơ sở dữ liệu (Database Management System - DBMS) là một hệ thống phần mềm cho phép người dùng tạo, quản lý, cập nhật và truy vấn cơ sở dữ liệu một cách hiệu quả. Nó cung cấp một giao diện thống nhất để tương tác với dữ liệu, giúp đơn giản hóa việc quản lý dữ liệu cho các tổ chức, đồng thời đảm bảo tính bảo mật, nhất quán và toàn vẹn của dữ liệu.
DBMS đóng vai trò trung gian giữa người dùng, ứng dụng và cơ sở dữ liệu vật lý. Người dùng không cần hiểu chi tiết về cách dữ liệu được lưu trữ vật lý trong ổ đĩa, mà chỉ cần làm việc ở cấp độ logic hoặc thông qua các giao diện API do DBMS cung cấp. Bằng cách này, DBMS giảm thiểu độ phức tạp trong việc quản lý dữ liệu, tăng cường tính linh hoạt, hỗ trợ các yêu cầu truy vấn đa dạng và đảm bảo rằng dữ liệu luôn trong trạng thái đáng tin cậy. Vai trò của DBMS được mở rộng trong các môi trường hiện đại, bao gồm quản lý dữ liệu lớn, hệ thống phân tán và các ứng dụng trí tuệ nhân tạo.
Các tính năng chính của DBMS
Quản lý lưu trữ dữ liệu:
DBMS cung cấp một cơ chế lưu trữ có tổ chức cho dữ liệu trên ổ đĩa vật lý. Dữ liệu được tổ chức thành các cấu trúc logic (như bảng, hàng, cột, hoặc tài liệu JSON) giúp tối ưu hóa truy xuất và quản lý. Nó còn hỗ trợ quản lý siêu dữ liệu (metadata), cho phép người dùng tra cứu thông tin về các cấu trúc dữ liệu mà không cần kiểm tra thủ công.Hỗ trợ truy vấn dữ liệu:
DBMS sử dụng các ngôn ngữ truy vấn chuẩn như SQL để cung cấp khả năng thao tác dữ liệu dễ dàng. Người dùng có thể thực hiện các thao tác phức tạp, từ truy vấn thông tin đơn giản đến các phép tính kết hợp, tổng hợp, hoặc phân tích dữ liệu đa chiều. Ngoài ra, DBMS tối ưu hóa các truy vấn thông qua việc sử dụng chỉ mục, lập kế hoạch thực thi và bộ nhớ đệm để tăng tốc độ xử lý.Kiểm soát đồng thời và giao dịch:
DBMS hỗ trợ xử lý đồng thời nhiều giao dịch từ các người dùng hoặc hệ thống khác nhau. Thông qua các cơ chế khóa (locking) và lập lịch giao dịch, DBMS đảm bảo rằng không có xung đột dữ liệu hoặc vi phạm tính toàn vẹn xảy ra. Các giao dịch được quản lý theo tính chất ACID, đảm bảo rằng dù xảy ra lỗi hệ thống, dữ liệu vẫn không bị mất hoặc sai lệch.Tính toàn vẹn và ràng buộc dữ liệu:
DBMS cung cấp cơ chế ràng buộc dữ liệu thông qua các quy tắc như khóa chính (primary key), khóa ngoại (foreign key), ràng buộc duy nhất (unique constraint) hoặc kiểm tra giá trị (check constraint). Các ràng buộc này giúp đảm bảo rằng dữ liệu nhập vào luôn đúng định dạng và đáp ứng yêu cầu nghiệp vụ.Kiểm soát truy cập và bảo mật:
DBMS tích hợp các cơ chế xác thực (authentication) và phân quyền (authorization) để giới hạn quyền truy cập dữ liệu dựa trên vai trò người dùng. Các cấp độ truy cập khác nhau như chỉ đọc, ghi, hoặc quản trị được áp dụng để bảo vệ dữ liệu khỏi truy cập trái phép. Ngoài ra, DBMS hỗ trợ mã hóa dữ liệu trong khi lưu trữ và truyền tải để đảm bảo an toàn trước các mối đe dọa bảo mật.Sao lưu và phục hồi dữ liệu:
DBMS cung cấp các công cụ tích hợp để tự động sao lưu dữ liệu định kỳ hoặc theo yêu cầu. Khi xảy ra lỗi phần cứng hoặc hệ thống, DBMS có thể khôi phục dữ liệu đến trạng thái ổn định gần nhất, giúp giảm thiểu rủi ro mất mát dữ liệu.Môi trường đa người dùng:
DBMS hỗ trợ nhiều người dùng thao tác đồng thời trên cùng một cơ sở dữ liệu mà không ảnh hưởng đến hiệu suất hoặc gây xung đột dữ liệu. Cơ chế cô lập giao dịch đảm bảo rằng các thao tác của từng người dùng được tách biệt và không ảnh hưởng lẫn nhau.Hỗ trợ mở rộng hệ thống:
DBMS cung cấp các giải pháp mở rộng theo chiều dọc (thêm tài nguyên cho một máy chủ) hoặc chiều ngang (thêm nhiều máy chủ), giúp hệ thống xử lý hiệu quả ngay cả khi khối lượng dữ liệu và số lượng người dùng tăng mạnh.

Ví dụ về hệ quản trị cơ sở dữ liệu
MySQL
MySQL là một hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) mã nguồn mở phổ biến, sử dụng ngôn ngữ SQL để truy vấn dữ liệu. Hệ thống này được thiết kế với hiệu suất cao, khả năng mở rộng tốt và tính tương thích rộng rãi với nhiều nền tảng. Trong các hệ thống thương mại điện tử như Magento và OpenCart, MySQL đóng vai trò quan trọng trong quản lý dữ liệu sản phẩm, đơn hàng và khách hàng. Hiểu MySQL là gì giúp doanh nghiệp tối ưu truy vấn, đảm bảo tốc độ xử lý và khả năng mở rộng khi lưu lượng truy cập tăng cao.
Đặc điểm kỹ thuật:
- Kiến trúc lưu trữ linh hoạt: MySQL hỗ trợ nhiều loại engine lưu trữ, phổ biến nhất là InnoDB (hỗ trợ giao dịch ACID) và MyISAM (hiệu suất đọc cao nhưng không hỗ trợ giao dịch).
- Replication và Clustering: Cho phép sao chép dữ liệu theo mô hình Master-Slave hoặc Master-Master để tăng cường khả năng chịu tải.
- Hỗ trợ JSON: Khả năng lưu trữ và truy vấn dữ liệu JSON giúp MySQL phù hợp với các ứng dụng cần xử lý dữ liệu phi cấu trúc.
- Chế độ giao dịch ACID: Bảo đảm tính toàn vẹn của dữ liệu, phù hợp với các hệ thống quan trọng như thương mại điện tử hoặc quản lý tài chính.
Ứng dụng thực tế:
- Được sử dụng trong các hệ thống CMS như WordPress, Joomla, Drupal.
- Là nền tảng chính cho các ứng dụng thương mại điện tử như Magento, OpenCart.
- Triển khai trong các ứng dụng quản lý dữ liệu khách hàng, hệ thống đặt phòng, nền tảng SaaS.
PostgreSQL
PostgreSQL là một hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) mạnh mẽ, hỗ trợ đa dạng loại dữ liệu và có khả năng tùy chỉnh cao. Được biết đến với tính năng mở rộng và tính toàn vẹn dữ liệu vượt trội, PostgreSQL là sự lựa chọn lý tưởng cho các hệ thống yêu cầu độ tin cậy cao.
Đặc điểm kỹ thuật:
- Hỗ trợ dữ liệu đa dạng: Lưu trữ các loại dữ liệu phức tạp như JSONB, XML, HSTORE (Key-Value), UUID, ARRAY.
- Tích hợp với GIS: Hỗ trợ PostGIS giúp PostgreSQL có khả năng xử lý dữ liệu không gian cho các hệ thống GIS.
- Tối ưu hiệu suất truy vấn: Cung cấp hệ thống lập chỉ mục tiên tiến như GIN, BRIN, B-Tree, giúp cải thiện tốc độ truy vấn dữ liệu lớn.
- Tính nhất quán dữ liệu: Hỗ trợ ACID, đảm bảo các giao dịch không bị gián đoạn ngay cả khi hệ thống gặp sự cố.
- Khả năng mở rộng ngang: Hỗ trợ tính năng sharding, giúp xử lý khối lượng dữ liệu lớn trên nhiều server.
Ứng dụng thực tế:
- Các hệ thống phân tích dữ liệu lớn (Big Data).
- Các ứng dụng tài chính, ngân hàng với yêu cầu bảo mật cao.
- Hệ thống ERP, CRM cần xử lý lượng dữ liệu lớn và tính nhất quán cao.
Microsoft SQL Server
SQL Server là một hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) thương mại do Microsoft phát triển, cung cấp các tính năng chuyên sâu về bảo mật, phân tích dữ liệu và tích hợp mạnh mẽ với hệ sinh thái Microsoft. Transparent Data Encryption (TDE) và Row-Level Security (RLS) là những công nghệ bảo mật tiên tiến mà SQL Server hỗ trợ. Nắm vững Microsoft SQL Server là gì sẽ giúp doanh nghiệp bảo vệ dữ liệu nhạy cảm, đảm bảo tuân thủ các tiêu chuẩn an toàn thông tin quốc tế.
Đặc điểm kỹ thuật:
- Tích hợp BI & Analytics: SQL Server hỗ trợ SQL Server Analysis Services (SSAS), SQL Server Reporting Services (SSRS) và SQL Server Integration Services (SSIS) giúp phân tích dữ liệu chuyên sâu.
- Tính năng Always On: Đảm bảo tính sẵn sàng cao của dữ liệu với hệ thống sao lưu liên tục.
- Hỗ trợ JSON & XML: Khả năng xử lý dữ liệu dạng JSON và XML giúp mở rộng ứng dụng trong các hệ thống hiện đại.
- Bảo mật nâng cao: Hỗ trợ Transparent Data Encryption (TDE), Row-Level Security (RLS) và Dynamic Data Masking giúp bảo vệ dữ liệu nhạy cảm.
Ứng dụng thực tế:
- Hệ thống quản lý doanh nghiệp lớn như ERP, CRM.
- Các nền tảng thương mại điện tử với dữ liệu lớn.
- Ứng dụng ngân hàng, tài chính yêu cầu tính bảo mật cao.
Oracle Database
Oracle Database là một trong những hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) hàng đầu, được thiết kế cho các hệ thống doanh nghiệp lớn với yêu cầu về độ tin cậy, bảo mật và khả năng xử lý dữ liệu khổng lồ.
Đặc điểm kỹ thuật:
- Tính sẵn sàng cao: Hỗ trợ Oracle Real Application Clusters (RAC) và Data Guard giúp đảm bảo hệ thống không bị gián đoạn.
- Tối ưu hiệu suất với Exadata: Giải pháp phần cứng và phần mềm tối ưu hóa giúp tăng tốc truy vấn dữ liệu.
- Bảo mật cấp cao: Hỗ trợ Oracle Advanced Security, cung cấp mã hóa dữ liệu mạnh mẽ.
- Khả năng xử lý giao dịch lớn: Được tối ưu cho hệ thống ngân hàng, tài chính với hàng triệu giao dịch mỗi giây.
Ứng dụng thực tế:
- Hệ thống ngân hàng, chứng khoán và quản lý tài chính toàn cầu.
- Các hệ thống quản lý chuỗi cung ứng (SCM).
- Ứng dụng xử lý dữ liệu thời gian thực với khối lượng lớn.
MongoDB
MongoDB là hệ quản trị cơ sở dữ liệu NoSQL phổ biến, sử dụng mô hình lưu trữ tài liệu JSON-like, giúp xử lý dữ liệu linh hoạt và mở rộng dễ dàng. Các nghiên cứu thực tế về MongoDB (2022) đã đánh giá hiệu suất của hệ quản trị này trong các trường hợp sử dụng thực tế tại nhiều doanh nghiệp. Kết quả cho thấy MongoDB có thể giúp giảm thời gian phát triển ứng dụng đáng kể so với các RDBMS truyền thống nhờ khả năng thích ứng với các schema linh hoạt. Đặc biệt, trong các ứng dụng IoT, MongoDB thể hiện khả năng xử lý giao dịch với độ trễ thấp khi được triển khai trên cụm máy chủ. Nhiều doanh nghiệp sử dụng MongoDB cũng báo cáo giảm tổng chi phí sở hữu (TCO) cho cơ sở hạ tầng dữ liệu so với giải pháp trước đó.
Đặc điểm kỹ thuật:
- Cấu trúc dữ liệu linh hoạt: Không yêu cầu schema cố định, giúp thích ứng nhanh với thay đổi.
- Khả năng mở rộng ngang: Hỗ trợ sharding để phân tán dữ liệu trên nhiều server.
- Hiệu suất đọc/ghi cao: Được tối ưu cho các hệ thống yêu cầu truy xuất dữ liệu nhanh.
- Replication mạnh mẽ: Hỗ trợ tự động sao lưu dữ liệu qua nhiều node để đảm bảo tính sẵn sàng.
Ứng dụng thực tế:
- Ứng dụng web thời gian thực, mạng xã hội, IoT.
- Các hệ thống thương mại điện tử có lượng sản phẩm lớn.
- Lưu trữ dữ liệu phi cấu trúc như logs, analytics.
Redis
Redis là một hệ quản trị cơ sở dữ liệu in-memory, được tối ưu hóa cho tốc độ xử lý dữ liệu cực nhanh, thường được sử dụng như một bộ nhớ đệm (cache) hoặc cơ sở dữ liệu chính trong các hệ thống yêu cầu phản hồi tức thời.
Đặc điểm kỹ thuật:
- Lưu trữ dữ liệu trong bộ nhớ RAM: Giúp truy xuất dữ liệu nhanh hơn so với hệ thống lưu trữ trên ổ đĩa truyền thống.
- Hỗ trợ nhiều cấu trúc dữ liệu: Lists, Sets, Hashes, Sorted Sets, giúp tối ưu hóa các bài toán xử lý dữ liệu phức tạp.
- Replication và High Availability: Hỗ trợ master-slave replication và Redis Sentinel giúp tăng cường khả năng chịu lỗi.
- Pub/Sub Messaging: Có khả năng truyền tải tin nhắn theo mô hình Publish/Subscribe, giúp ứng dụng xử lý dữ liệu theo thời gian thực.
Ứng dụng thực tế:
- Bộ nhớ đệm cho các hệ thống web có lượng truy cập lớn.
- Hệ thống xếp hàng công việc (job queue) trong các nền tảng microservices.
- Lưu trữ session cho các ứng dụng web động.
Mỗi hệ quản trị cơ sở dữ liệu đều có những đặc điểm riêng phù hợp với từng loại ứng dụng cụ thể, từ lưu trữ dữ liệu quan hệ truyền thống đến xử lý dữ liệu thời gian thực, hỗ trợ phân tích chuyên sâu và mở rộng linh hoạt trong môi trường công nghệ hiện đại.
Cách hoạt động của cơ sở dữ liệu
Để đáp ứng nhu cầu sử dụng từ cá nhân đến doanh nghiệp lớn, cơ sở dữ liệu được thiết kế với quy trình hoạt động phức tạp nhưng chặt chẽ, đảm bảo hiệu suất cao và tính chính xác của dữ liệu. Các hệ quản trị cơ sở dữ liệu (DBMS) hiện đại không chỉ hỗ trợ xử lý khối lượng dữ liệu khổng lồ mà còn tối ưu hóa việc thực hiện các thao tác cơ bản như thêm, sửa, xóa và truy vấn dữ liệu (CRUD). Bên cạnh đó, các cơ chế bảo mật mạnh mẽ được tích hợp để bảo vệ thông tin trước các mối đe dọa, từ truy cập trái phép đến tấn công mạng.
Quá trình hoạt động của cơ sở dữ liệu không chỉ dựa vào công nghệ mà còn là sự phối hợp giữa các quy tắc xử lý dữ liệu (như ACID), cấu trúc lưu trữ thông minh và các biện pháp bảo mật tiên tiến. Điều này giúp các tổ chức đảm bảo tính toàn vẹn dữ liệu, giảm thiểu rủi ro và nâng cao hiệu quả vận hành trong nhiều lĩnh vực khác nhau như tài chính, y tế, giáo dục, thương mại điện tử, và nhiều lĩnh vực khác.
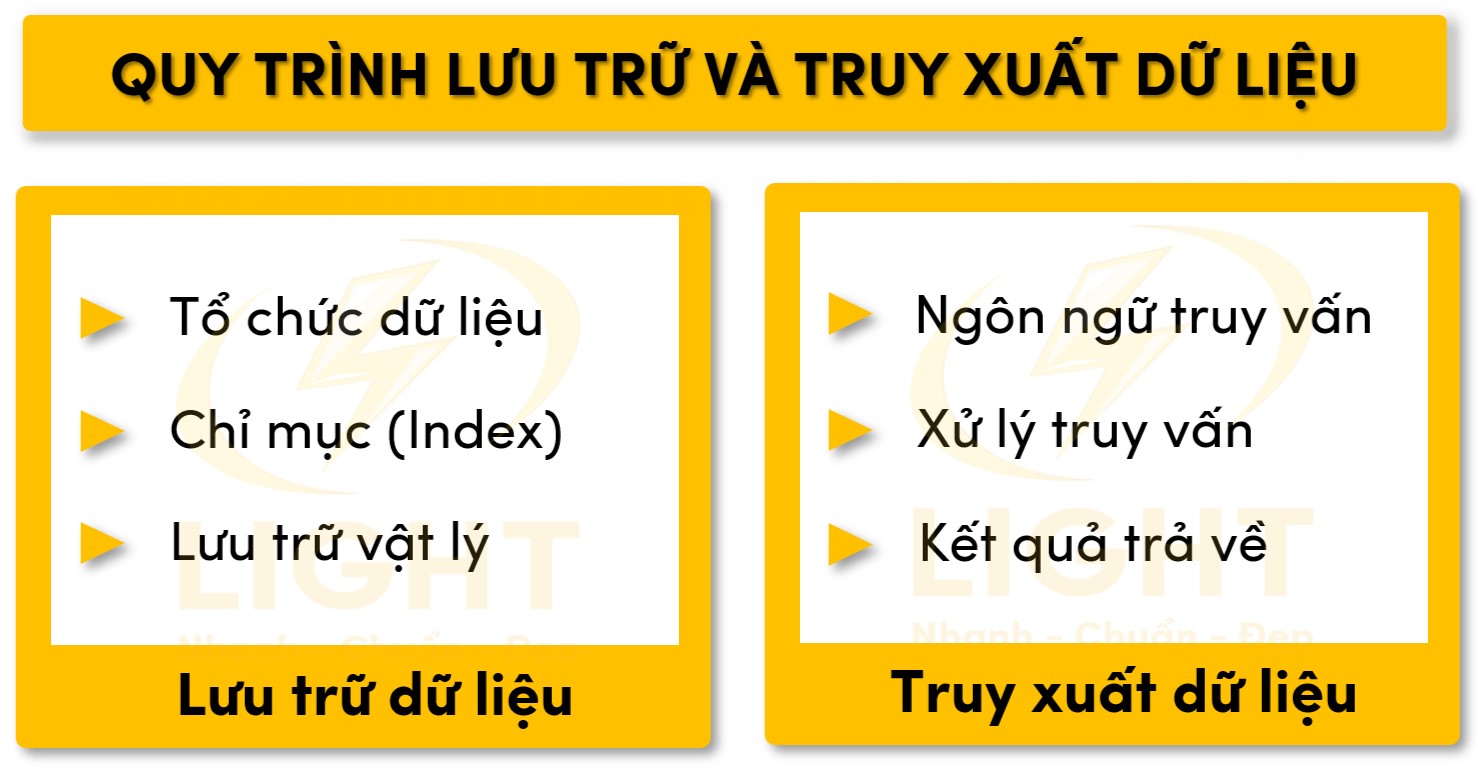
Quy trình lưu trữ và truy xuất dữ liệu
Quy trình lưu trữ và truy xuất dữ liệu trong cơ sở dữ liệu được thiết kế để đáp ứng các yêu cầu về tốc độ, độ tin cậy và hiệu quả.
Lưu trữ dữ liệu:
- Tổ chức dữ liệu: Dữ liệu được tổ chức theo các mô hình lưu trữ như quan hệ (Relational), phi quan hệ (NoSQL), hoặc đồ thị (Graph). Ví dụ, trong mô hình quan hệ, dữ liệu được lưu dưới dạng bảng với các hàng và cột, trong khi mô hình NoSQL như MongoDB sử dụng tài liệu JSON để lưu trữ dữ liệu phi cấu trúc.
- Chỉ mục (Index): Hệ quản trị cơ sở dữ liệu sử dụng chỉ mục để tăng tốc truy vấn. Các chỉ mục như B-tree hoặc Hash Index giúp rút ngắn thời gian tìm kiếm dữ liệu.
- Lưu trữ vật lý: Dữ liệu được ghi trên ổ đĩa vật lý hoặc hệ thống lưu trữ đám mây. Các hệ thống hiện đại sử dụng kỹ thuật lưu trữ phân tán để chia nhỏ dữ liệu trên nhiều máy chủ, tăng khả năng mở rộng và độ tin cậy.
Truy xuất dữ liệu:
- Ngôn ngữ truy vấn: Hệ quản trị cơ sở dữ liệu nhận lệnh truy vấn từ người dùng hoặc ứng dụng, thường bằng ngôn ngữ SQL. Ví dụ:
SELECT name FROM employees WHERE department = 'HR';. - Xử lý truy vấn: Lệnh truy vấn được phân tích cú pháp, tối ưu hóa và thực thi. Các cơ chế như Query Optimizer chọn chiến lược tối ưu nhất để thực thi truy vấn nhằm giảm thời gian và tài nguyên.
- Kết quả trả về: Sau khi xử lý, dữ liệu được trả về ở định dạng được yêu cầu, chẳng hạn như bảng, tài liệu hoặc tập tin.
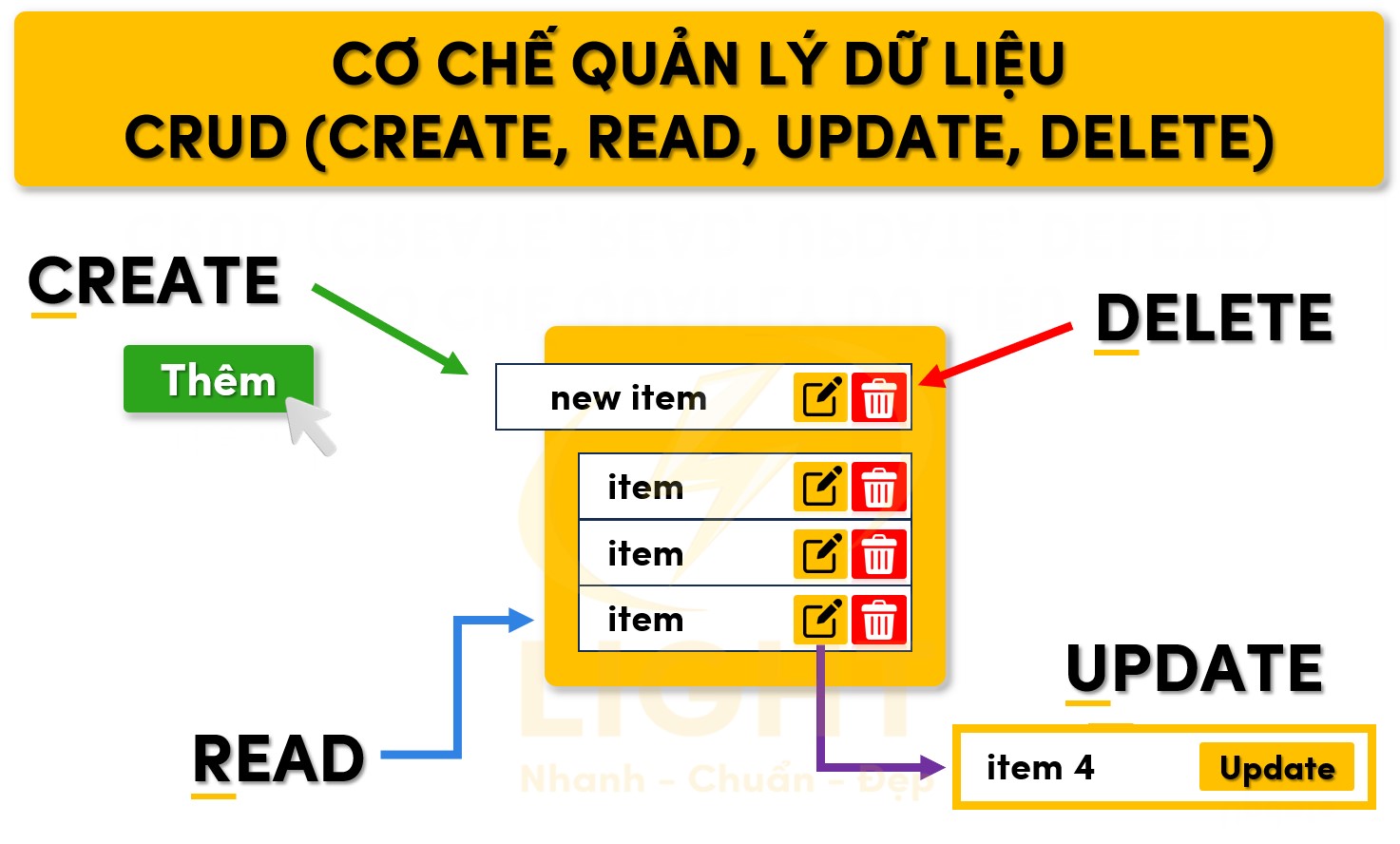
Cơ chế quản lý dữ liệu: CRUD (Create, Read, Update, Delete)
CRUD là tập hợp các thao tác cơ bản để quản lý dữ liệu trong cơ sở dữ liệu.
Create (Tạo mới):
- Thao tác này thêm dữ liệu mới vào cơ sở dữ liệu. Ví dụ, sử dụng câu lệnh
SQL: INSERT INTO users (name, email) VALUES ('light minh', '@light.com');. - Hệ quản trị cơ sở dữ liệu kiểm tra các ràng buộc như khóa chính (Primary Key) hoặc khóa ngoại (Foreign Key) trước khi chấp nhận dữ liệu.
Read (Truy vấn dữ liệu):
- Truy vấn dữ liệu là thao tác phổ biến nhất. Người dùng có thể tìm kiếm, lọc hoặc tổng hợp thông tin từ cơ sở dữ liệu.
- Ví dụ: Lệnh truy vấn
SELECT SUM(salary) FROM employees WHERE department = 'IT';
Update (Cập nhật dữ liệu):
- Thao tác này thay đổi thông tin hiện có mà không cần xóa dữ liệu cũ. Câu lệnh SQL:
UPDATE products SET price = 200 WHERE product_id = 5;. - Hệ quản trị đảm bảo rằng các bản cập nhật không gây xung đột hoặc làm mất tính toàn vẹn của dữ liệu.
Delete (Xóa dữ liệu):
- Dữ liệu không cần thiết hoặc lỗi thời được xóa khỏi cơ sở dữ liệu. Lệnh SQL:
DELETE FROM orders WHERE order_date < '2023-01-01';. - Một số hệ thống sử dụng cơ chế "đánh dấu xóa" (soft delete) thay vì xóa vĩnh viễn để đảm bảo dữ liệu có thể khôi phục khi cần.
Hệ thống bảo mật trong cơ sở dữ liệu
Bảo mật là một trong những yếu tố quan trọng nhất trong hoạt động của cơ sở dữ liệu nhằm bảo vệ dữ liệu trước các mối đe dọa và truy cập trái phép.
Kiểm soát truy cập (Access Control):
- Xác thực (Authentication): Chỉ người dùng hợp lệ có thông tin đăng nhập mới có thể truy cập vào hệ thống. Hệ thống thường sử dụng mật khẩu hoặc xác thực đa yếu tố (MFA) để tăng cường bảo mật.
- Phân quyền (Authorization): Người dùng được gán các quyền khác nhau tùy vào vai trò. Ví dụ, nhân viên chỉ có quyền đọc dữ liệu, trong khi quản trị viên có thể thay đổi hoặc xóa dữ liệu.
Mã hóa dữ liệu (Encryption):
- Mã hóa dữ liệu lưu trữ: Dữ liệu được mã hóa trước khi lưu để bảo vệ khỏi truy cập trái phép trong trường hợp mất ổ đĩa hoặc hệ thống bị xâm nhập.
- Mã hóa dữ liệu truyền tải: Giao thức bảo mật như TLS/SSL được sử dụng để mã hóa dữ liệu khi truyền qua mạng.
Tính toàn vẹn dữ liệu (Data Integrity):
- Các ràng buộc như ràng buộc khóa chính, khóa ngoại và kiểm tra giá trị (CHECK constraints) giúp duy trì tính đúng đắn và logic của dữ liệu.
- Trong các giao dịch, cơ chế ACID (Atomicity, Consistency, Isolation, Durability) đảm bảo rằng các thay đổi dữ liệu được thực hiện một cách an toàn và nhất quán, ngay cả khi xảy ra sự cố.
Hệ thống phát hiện và ngăn chặn tấn công:
- Các hệ quản trị cơ sở dữ liệu tích hợp các công cụ như tường lửa cơ sở dữ liệu hoặc hệ thống phát hiện xâm nhập (IDS) để phát hiện và ngăn chặn các mối đe dọa như SQL Injection.
Sao lưu và khôi phục (Backup and Recovery):
- Cơ sở dữ liệu được sao lưu định kỳ để đảm bảo khả năng khôi phục dữ liệu trong các trường hợp khẩn cấp như lỗi phần cứng, tấn công mạng hoặc thiên tai. Các cơ chế sao lưu như snapshot, incremental backup thường được sử dụng để tối ưu hóa thời gian và không gian lưu trữ.
Tuân thủ pháp lý và quy định:
- Các cơ sở dữ liệu tuân theo các tiêu chuẩn và quy định bảo mật dữ liệu như GDPR, HIPAA, hoặc PCI DSS, đảm bảo dữ liệu người dùng được quản lý an toàn và minh bạch.

Ứng dụng của cơ sở dữ liệu
Mỗi ngày, hàng tỷ giao dịch tài chính, đơn hàng thương mại điện tử và các hoạt động trên nền tảng trực tuyến đều phụ thuộc vào cơ sở dữ liệu để đảm bảo tính chính xác, tính nhất quán và hiệu suất cao. Ngoài ra, cơ sở dữ liệu đóng vai trò trung tâm trong việc phân tích dữ liệu lớn, huấn luyện các mô hình trí tuệ nhân tạo và triển khai các giải pháp thông minh nhằm dự đoán, tự động hóa và tối ưu hóa hoạt động.
Sự phát triển của công nghệ đã mở rộng ứng dụng của cơ sở dữ liệu từ các hệ thống truyền thống đến các lĩnh vực mới như trí tuệ nhân tạo, phân tích dữ liệu thời gian thực và xử lý dữ liệu phi cấu trúc. Dưới đây là phân tích chi tiết về các ứng dụng quan trọng của cơ sở dữ liệu, bao gồm quản lý doanh nghiệp, thương mại điện tử và trí tuệ nhân tạo.
Quản lý doanh nghiệp
Cơ sở dữ liệu là nền tảng cho các hệ thống quản lý và vận hành trong doanh nghiệp, giúp tổ chức thông tin và hỗ trợ các hoạt động ra quyết định.
Hệ thống quản lý tài nguyên doanh nghiệp (ERP):
Các hệ thống ERP dựa vào cơ sở dữ liệu để tích hợp và đồng bộ hóa tất cả các bộ phận trong doanh nghiệp như tài chính, kế toán, sản xuất, quản lý kho, nhân sự và quản lý chuỗi cung ứng. Dữ liệu được lưu trữ tập trung và liên kết, giúp giảm sai sót, cải thiện hiệu quả quản lý và tối ưu hóa quy trình.- Ví dụ: Dữ liệu từ hệ thống sản xuất có thể tự động cập nhật tồn kho, đồng thời kích hoạt đơn đặt hàng bổ sung nếu lượng hàng giảm dưới mức cho phép.
Quản lý quan hệ khách hàng (CRM):
Cơ sở dữ liệu đóng vai trò lưu trữ thông tin khách hàng, bao gồm lịch sử giao dịch, các tương tác, phản hồi và phân khúc khách hàng. Thông tin này hỗ trợ doanh nghiệp cá nhân hóa dịch vụ, triển khai các chiến dịch tiếp thị nhắm mục tiêu và dự đoán nhu cầu của khách hàng.- Ví dụ: Một CRM có thể sử dụng dữ liệu giao dịch để gợi ý sản phẩm phù hợp hoặc gửi ưu đãi đặc biệt đến nhóm khách hàng trung thành.
Hỗ trợ ra quyết định và phân tích kinh doanh:
Các cơ sở dữ liệu phân tích như Data Warehouse hoặc Data Mart lưu trữ dữ liệu lịch sử được tối ưu hóa cho việc phân tích. Doanh nghiệp sử dụng dữ liệu này để tạo báo cáo, phân tích hiệu suất, dự báo xu hướng và đưa ra quyết định chiến lược. Các công cụ BI (Business Intelligence) thường được tích hợp với cơ sở dữ liệu để trực quan hóa dữ liệu phức tạp.
Thương mại điện tử
Cơ sở dữ liệu là trung tâm của các hệ thống thương mại điện tử, đảm bảo hoạt động liền mạch từ quản lý thông tin sản phẩm đến xử lý giao dịch và phân tích dữ liệu người dùng.
Quản lý thông tin sản phẩm và danh mục:
Cơ sở dữ liệu lưu trữ thông tin chi tiết về sản phẩm, bao gồm tên, giá cả, mô tả, số lượng tồn kho, hình ảnh và các thông số kỹ thuật. Hệ thống truy xuất dữ liệu này để hiển thị sản phẩm trên các trang web hoặc ứng dụng, đảm bảo thông tin luôn cập nhật và chính xác.- Ví dụ: Một cơ sở dữ liệu NoSQL như MongoDB có thể lưu trữ dữ liệu sản phẩm với cấu trúc linh hoạt, phù hợp với các nền tảng có danh mục thay đổi thường xuyên.
Xử lý giao dịch thương mại điện tử:
Cơ sở dữ liệu hỗ trợ các giao dịch từ thanh toán đến vận chuyển. Mỗi lần đặt hàng, hệ thống sẽ cập nhật thông tin tồn kho, ghi nhận giao dịch và theo dõi trạng thái đơn hàng. Các hệ thống này thường sử dụng cơ sở dữ liệu quan hệ để đảm bảo tính nhất quán trong xử lý giao dịch.- Ví dụ: Hệ thống xử lý thanh toán cần đảm bảo rằng số tiền bị trừ khỏi tài khoản người mua sẽ được ghi nhận chính xác vào tài khoản người bán ngay cả khi xảy ra lỗi mạng.
Phân tích hành vi người dùng:
Cơ sở dữ liệu lưu trữ các tương tác của người dùng như lượt xem sản phẩm, lượt nhấp chuột và lịch sử mua sắm. Dữ liệu này được phân tích để cá nhân hóa trải nghiệm mua sắm, tối ưu hóa hệ thống đề xuất và dự đoán nhu cầu.- Ví dụ: Amazon sử dụng cơ sở dữ liệu lớn để cung cấp hệ thống gợi ý sản phẩm dựa trên lịch sử mua hàng và hành vi tìm kiếm của người dùng.
Bảo mật và tuân thủ tiêu chuẩn:
Cơ sở dữ liệu thương mại điện tử cần tuân thủ các tiêu chuẩn bảo mật như PCI DSS (Payment Card Industry Data Security Standard) để bảo vệ thông tin khách hàng và dữ liệu thanh toán. Các cơ chế mã hóa dữ liệu và kiểm soát truy cập đóng vai trò quan trọng trong việc đảm bảo an toàn thông tin.
Trí tuệ nhân tạo và phân tích dữ liệu
Cơ sở dữ liệu đóng vai trò quan trọng trong việc cung cấp dữ liệu đầu vào, xử lý và lưu trữ kết quả cho các ứng dụng trí tuệ nhân tạo (AI) và phân tích dữ liệu lớn.
Lưu trữ dữ liệu lớn:
Các hệ thống dữ liệu lớn như Hadoop hoặc cơ sở dữ liệu phân tán NoSQL (Cassandra, MongoDB) lưu trữ và quản lý khối lượng dữ liệu khổng lồ từ nhiều nguồn khác nhau, bao gồm dữ liệu phi cấu trúc như video, hình ảnh và nhật ký hệ thống.- Ví dụ: Một công ty viễn thông có thể lưu trữ dữ liệu từ hàng triệu thiết bị kết nối để phân tích hành vi người dùng và tối ưu hóa dịch vụ.
Hỗ trợ huấn luyện mô hình học máy:
Cơ sở dữ liệu cung cấp dữ liệu sạch và có cấu trúc cho quá trình huấn luyện mô hình học máy. Dữ liệu này có thể được trích xuất từ nhiều nguồn, xử lý trước và lưu trữ trong các hệ thống quản lý dữ liệu chuyên dụng.- Ví dụ: Một ngân hàng sử dụng dữ liệu giao dịch từ cơ sở dữ liệu để huấn luyện mô hình phát hiện gian lận trong thời gian thực.
Phân tích dữ liệu dự đoán:
Cơ sở dữ liệu kết hợp với các thuật toán phân tích dự đoán để dự báo xu hướng, phát hiện rủi ro và tối ưu hóa hoạt động. Các hệ thống này thường sử dụng Data Warehouse để lưu trữ dữ liệu lịch sử và áp dụng các kỹ thuật phân tích như hồi quy, mạng nơ-ron nhân tạo hoặc học sâu.- Ví dụ: Một công ty logistic sử dụng dữ liệu lịch sử từ cơ sở dữ liệu để dự đoán thời gian giao hàng và tối ưu hóa tuyến đường.
Xử lý dữ liệu thời gian thực:
Trong các hệ thống yêu cầu xử lý nhanh như giao dịch tài chính hoặc điều khiển thiết bị IoT, cơ sở dữ liệu in-memory như Redis hoặc Memcached hỗ trợ xử lý và truy xuất dữ liệu với độ trễ cực thấp.- Ví dụ: Một sàn giao dịch chứng khoán sử dụng cơ sở dữ liệu in-memory để xử lý hàng nghìn lệnh mua bán mỗi giây, đảm bảo độ chính xác và thời gian thực.
Ưu và nhược điểm của cơ sở dữ liệu
Việc đánh giá ưu và nhược điểm của cơ sở dữ liệu không chỉ giúp doanh nghiệp hiểu rõ lợi ích mà công nghệ này mang lại mà còn nhận diện các hạn chế cần khắc phục để khai thác tối đa tiềm năng của hệ thống. Những yếu tố như tính tổ chức, khả năng mở rộng hay chi phí đầu tư và yêu cầu chuyên môn đều là các khía cạnh cần được cân nhắc kỹ lưỡng để tối ưu hóa giá trị của cơ sở dữ liệu trong thực tiễn.
Ưu điểm
Tính tổ chức và dễ quản lý dữ liệu
Cấu trúc dữ liệu rõ ràng và có hệ thống:
Cơ sở dữ liệu cung cấp khả năng tổ chức dữ liệu theo các mô hình chuẩn hóa, chẳng hạn như mô hình quan hệ, phi quan hệ, đồ thị, hoặc đối tượng. Trong mô hình quan hệ, dữ liệu được lưu trữ trong các bảng liên kết với nhau thông qua các ràng buộc như khóa chính và khóa ngoại. Điều này không chỉ đảm bảo dữ liệu có cấu trúc chặt chẽ mà còn giúp duy trì mối quan hệ logic giữa các thực thể.Tích hợp các quy tắc quản lý toàn vẹn dữ liệu:
Các hệ quản trị cơ sở dữ liệu (DBMS) đảm bảo rằng dữ liệu được nhập vào luôn tuân thủ các ràng buộc toàn vẹn như ràng buộc kiểu dữ liệu (data type constraints), ràng buộc không null, và các ràng buộc giá trị kiểm tra (CHECK constraints). Điều này loại bỏ khả năng xảy ra lỗi nhập liệu hoặc sai sót trong quá trình cập nhật.Quản lý tập trung:
Dữ liệu từ nhiều nguồn được tập trung vào một hệ thống duy nhất, giúp các tổ chức dễ dàng giám sát và quản lý toàn bộ thông tin mà không cần phụ thuộc vào các kho dữ liệu phân tán hoặc không đồng bộ. Điều này cũng cho phép kiểm soát truy cập chặt chẽ, giảm nguy cơ mất mát hoặc lạm dụng dữ liệu.Khả năng kiểm tra và khôi phục lịch sử dữ liệu:
Một số hệ thống cơ sở dữ liệu hỗ trợ lưu trữ phiên bản dữ liệu hoặc nhật ký thay đổi (transaction log), giúp người dùng theo dõi lịch sử chỉnh sửa và khôi phục dữ liệu khi cần thiết. Điều này đặc biệt quan trọng trong các hệ thống cần độ chính xác cao như tài chính hoặc y tế.
Khả năng mở rộng và hiệu quả cao
Hỗ trợ mở rộng linh hoạt:
Các hệ quản trị cơ sở dữ liệu hiện đại hỗ trợ cả mở rộng theo chiều ngang (horizontal scaling) và chiều dọc (vertical scaling). Trong mở rộng chiều ngang, dữ liệu được phân mảnh (sharding) và phân phối trên nhiều máy chủ để tăng khả năng xử lý. Trong khi đó, mở rộng chiều dọc tập trung vào việc nâng cấp phần cứng máy chủ, như CPU, RAM hoặc ổ lưu trữ.Tối ưu hóa hiệu năng thông qua chỉ mục và bộ nhớ đệm:
Hệ thống cơ sở dữ liệu sử dụng chỉ mục (index) để giảm thiểu thời gian truy vấn bằng cách định vị nhanh vị trí dữ liệu trong bảng. Bên cạnh đó, bộ nhớ đệm (caching) được sử dụng để lưu trữ tạm thời dữ liệu truy cập thường xuyên, giúp giảm tải cho hệ thống và tăng tốc độ phản hồi.Quản lý giao dịch hiệu quả:
Các hệ quản trị cơ sở dữ liệu hỗ trợ quản lý giao dịch thông qua các thuộc tính ACID (Atomicity, Consistency, Isolation, Durability). Điều này đảm bảo rằng các thay đổi dữ liệu được thực hiện toàn vẹn và an toàn, ngay cả khi xảy ra lỗi hệ thống, mất điện hoặc tấn công mạng.Hỗ trợ truy vấn phức tạp và phân tích dữ liệu lớn:
Cơ sở dữ liệu hiện đại cung cấp các công cụ và ngôn ngữ mạnh mẽ như SQL, NoSQL, và GraphQL, cho phép người dùng thực hiện các truy vấn phức tạp và phân tích dữ liệu lớn. Ngoài ra, các cơ chế tối ưu hóa truy vấn tự động giúp giảm thời gian xử lý dữ liệu mà không yêu cầu can thiệp thủ công.

Nhược điểm
Chi phí đầu tư và duy trì cao
Đầu tư ban đầu lớn:
Việc xây dựng một hệ thống cơ sở dữ liệu hoàn chỉnh đòi hỏi chi phí đáng kể cho phần cứng, phần mềm và cơ sở hạ tầng mạng. Ví dụ, để vận hành một hệ thống lớn như Oracle Database hay Microsoft SQL Server, các tổ chức cần đầu tư vào các máy chủ cao cấp với dung lượng lưu trữ và khả năng xử lý mạnh mẽ.Chi phí bảo trì liên tục:
Hệ thống cơ sở dữ liệu yêu cầu bảo trì định kỳ, bao gồm việc nâng cấp phần mềm, vá lỗi bảo mật, kiểm tra tính toàn vẹn dữ liệu và tối ưu hóa hiệu năng. Các doanh nghiệp phải chi trả cho đội ngũ chuyên gia hoặc hợp đồng bảo trì từ nhà cung cấp, làm tăng tổng chi phí sở hữu (TCO).Chi phí mở rộng hệ thống:
Khi dữ liệu và số lượng người dùng tăng lên, việc mở rộng hệ thống đòi hỏi thêm nguồn lực, như nâng cấp máy chủ hoặc thêm các máy chủ mới trong môi trường phân tán. Điều này có thể gây áp lực tài chính, đặc biệt với các tổ chức có ngân sách hạn chế.
Yêu cầu chuyên môn kỹ thuật
Độ phức tạp trong thiết kế và triển khai:
Việc thiết kế lược đồ cơ sở dữ liệu (database schema) yêu cầu hiểu biết sâu về logic dữ liệu, các ràng buộc toàn vẹn và mô hình hóa thực thể (entity modeling). Đối với các hệ thống phức tạp như cơ sở dữ liệu phân tán hoặc đa mô hình, chuyên môn cao là yếu tố bắt buộc để tránh lỗi thiết kế ảnh hưởng đến hiệu năng và tính toàn vẹn dữ liệu.Phụ thuộc vào nhân sự chuyên môn cao:
Quản trị viên cơ sở dữ liệu (DBA) và các chuyên gia kỹ thuật là những người đóng vai trò cốt lõi trong việc duy trì, bảo mật và tối ưu hệ thống. Tuy nhiên, việc tìm kiếm và giữ chân các nhân sự này đòi hỏi chi phí nhân sự lớn, đặc biệt khi nhu cầu về chuyên môn kỹ thuật trong lĩnh vực cơ sở dữ liệu ngày càng cao.Khó khăn trong bảo mật và tuân thủ pháp lý:
Với sự gia tăng của các mối đe dọa an ninh mạng, cơ sở dữ liệu phải được bảo vệ khỏi các hình thức tấn công như SQL Injection, tấn công từ chối dịch vụ (DDoS) hoặc đánh cắp thông tin. Điều này đòi hỏi các tổ chức liên tục cập nhật các biện pháp bảo mật và tuân thủ các tiêu chuẩn quốc tế như GDPR, HIPAA, hoặc PCI DSS, làm tăng thêm áp lực kỹ thuật và chi phí.

Cách lựa chọn cơ sở dữ liệu phù hợp
Lựa chọn cơ sở dữ liệu đúng đắn giúp tối ưu hóa các quy trình vận hành, giảm thiểu chi phí, nâng cao hiệu quả và đảm bảo tính toàn vẹn, bảo mật của dữ liệu. Tuy nhiên, trong một môi trường có vô vàn lựa chọn như hiện nay, từ các cơ sở dữ liệu quan hệ đến các giải pháp NoSQL và các hệ thống phân tán, việc xác định cơ sở dữ liệu phù hợp với yêu cầu thực tế không phải là một nhiệm vụ đơn giản. Quyết định này cần phải dựa trên các yếu tố như loại và khối lượng dữ liệu, loại ứng dụng, khả năng mở rộng, ngân sách và các yêu cầu đặc thù khác.
Để lựa chọn một cơ sở dữ liệu phù hợp, các tổ chức cần đánh giá kỹ lưỡng các tiêu chí về công nghệ, chi phí, tính sẵn sàng, và khả năng mở rộng theo thời gian. Hơn nữa, các ví dụ thực tế từ các ngành nghề khác nhau có thể giúp các doanh nghiệp hiểu rõ hơn về cách áp dụng cơ sở dữ liệu trong từng tình huống cụ thể. Dưới đây là những yếu tố cơ bản và các ví dụ thực tế giúp bạn đưa ra quyết định chính xác khi lựa chọn cơ sở dữ liệu cho hệ thống của mình.
Tiêu chí lựa chọn
1. Loại và khối lượng dữ liệu
Cơ sở dữ liệu cần được lựa chọn dựa trên cấu trúc và khối lượng dữ liệu mà hệ thống phải xử lý.
- Dữ liệu có cấu trúc như bảng, hàng, cột yêu cầu cơ sở dữ liệu quan hệ (RDBMS) như MySQL hoặc PostgreSQL, đặc biệt khi cần duy trì tính toàn vẹn và các ràng buộc logic chặt chẽ.
- Dữ liệu phi cấu trúc hoặc bán cấu trúc như văn bản, hình ảnh, hoặc dữ liệu JSON phù hợp với cơ sở dữ liệu NoSQL như MongoDB hoặc Couchbase, do các hệ thống này có khả năng lưu trữ linh hoạt và hiệu suất cao trong xử lý dữ liệu không đồng nhất.
- Hệ thống xử lý dữ liệu lớn, chẳng hạn dữ liệu từ các cảm biến IoT hoặc mạng xã hội, cần sử dụng cơ sở dữ liệu phân tán hoặc nền tảng xử lý dữ liệu lớn như Hadoop HDFS hoặc Cassandra để quản lý khối lượng dữ liệu khổng lồ với khả năng mở rộng cao.
2. Loại ứng dụng và yêu cầu chức năng
Tính chất của ứng dụng và các yêu cầu cụ thể trong xử lý dữ liệu sẽ ảnh hưởng trực tiếp đến quyết định lựa chọn cơ sở dữ liệu.
- Với các ứng dụng giao dịch trực tuyến (OLTP), nơi các giao dịch phải được thực hiện nhanh chóng và chính xác, cơ sở dữ liệu quan hệ như Oracle Database hoặc SQL Server thường được sử dụng vì hỗ trợ tính chất ACID, đảm bảo tính nhất quán ngay cả khi xảy ra lỗi.
- Đối với các ứng dụng phân tích dữ liệu (OLAP), nơi cần xử lý các truy vấn phức tạp trên lượng dữ liệu lớn, các hệ thống như Amazon Redshift, Google BigQuery hoặc Snowflake mang lại hiệu quả cao nhờ khả năng tối ưu hóa phân tích dữ liệu đa chiều.
- Các hệ thống thời gian thực như ứng dụng trò chơi trực tuyến hoặc giám sát an ninh yêu cầu cơ sở dữ liệu in-memory như Redis hoặc Memcached để đảm bảo thời gian phản hồi thấp và khả năng xử lý hàng triệu sự kiện mỗi giây.
- Các ứng dụng tập trung vào mối quan hệ phức tạp giữa các đối tượng, chẳng hạn mạng xã hội hoặc hệ thống khuyến nghị, cần sử dụng cơ sở dữ liệu đồ thị như Neo4j để lưu trữ và phân tích dữ liệu dựa trên các nút và mối quan hệ giữa chúng.
3. Ngân sách và chi phí vận hành
Lựa chọn cơ sở dữ liệu cũng bị ảnh hưởng bởi ngân sách, bao gồm chi phí cấp phép, triển khai và duy trì.
- Các cơ sở dữ liệu mã nguồn mở như MySQL, PostgreSQL, hoặc MariaDB là lựa chọn phù hợp cho các doanh nghiệp nhỏ hoặc tổ chức có ngân sách hạn chế, trong khi vẫn cung cấp tính năng mạnh mẽ và cộng đồng hỗ trợ rộng lớn.
- Các giải pháp thương mại như Oracle Database hoặc Microsoft SQL Server yêu cầu chi phí cao hơn nhưng mang lại các tính năng nâng cao như bảo mật cấp độ doanh nghiệp, khả năng tối ưu hóa phức tạp và hỗ trợ kỹ thuật toàn diện.
- Đối với các doanh nghiệp muốn giảm chi phí vận hành và không muốn quản lý cơ sở hạ tầng, các dịch vụ cơ sở dữ liệu đám mây như Amazon RDS, Azure SQL Database hoặc Google Cloud Spanner là lựa chọn phù hợp, cho phép triển khai nhanh chóng và dễ dàng mở rộng theo nhu cầu.
4. Khả năng mở rộng và tính khả dụng
Cơ sở dữ liệu cần có khả năng đáp ứng tốt khi hệ thống tăng trưởng về quy mô dữ liệu và số lượng người dùng.
- Với các hệ thống yêu cầu mở rộng theo chiều ngang, như nền tảng thương mại điện tử hoặc dịch vụ trực tuyến có lượng người dùng lớn, cơ sở dữ liệu NoSQL như Cassandra hoặc MongoDB là lựa chọn tối ưu do khả năng phân tán dữ liệu trên nhiều máy chủ.
- Với các hệ thống cần nâng cao hiệu suất bằng cách tăng cường tài nguyên phần cứng trên một máy chủ duy nhất, các cơ sở dữ liệu quan hệ như SQL Server hoặc PostgreSQL hỗ trợ mở rộng theo chiều dọc hiệu quả.
- Để đảm bảo tính khả dụng cao, các hệ thống cần cơ sở dữ liệu hỗ trợ sao chép dữ liệu (replication), cân bằng tải và khả năng tự động chuyển đổi dự phòng (failover). Ví dụ, Amazon Aurora hoặc Google Cloud SQL tích hợp các tính năng này để đảm bảo dữ liệu luôn sẵn sàng và không bị gián đoạn khi có sự cố.
Ví dụ thực tế
1. Nền tảng thương mại điện tử lớn
Một công ty thương mại điện tử cần xử lý hàng triệu giao dịch và quản lý thông tin của hàng triệu sản phẩm.
- Giải pháp: Sử dụng cơ sở dữ liệu quan hệ như MySQL hoặc PostgreSQL để quản lý thông tin sản phẩm và giao dịch tài chính, kết hợp với cơ sở dữ liệu NoSQL như DynamoDB để lưu trữ dữ liệu phi cấu trúc như nhật ký hoạt động của người dùng và hệ thống khuyến nghị.
2. Hệ thống phân tích dữ liệu tài chính
Một ngân hàng cần phân tích hàng petabyte dữ liệu giao dịch để phát hiện gian lận và dự báo xu hướng.
- Giải pháp: Sử dụng hệ thống phân tích dữ liệu lớn như Hadoop hoặc Google BigQuery để lưu trữ và phân tích dữ liệu giao dịch. Các công cụ như Apache Spark có thể được tích hợp để xử lý dữ liệu thời gian thực nhằm phát hiện các giao dịch bất thường ngay khi chúng xảy ra.
3. Mạng xã hội quy mô lớn
Một nền tảng mạng xã hội cần quản lý mối quan hệ giữa hàng tỷ người dùng và xử lý các tương tác như bình luận, lượt thích và gợi ý kết bạn.
- Giải pháp: Cơ sở dữ liệu đồ thị như Neo4j hoặc JanusGraph được sử dụng để lưu trữ và phân tích dữ liệu mối quan hệ giữa người dùng. Đồng thời, cơ sở dữ liệu NoSQL như Cassandra có thể được sử dụng để lưu trữ dữ liệu thời gian thực của các hoạt động trên nền tảng.
4. Hệ thống giám sát IoT trong công nghiệp
Một nhà máy thông minh cần xử lý dữ liệu từ hàng nghìn cảm biến trong thời gian thực để theo dõi trạng thái thiết bị và dự báo lỗi.
- Giải pháp: Redis hoặc InfluxDB được sử dụng để lưu trữ và xử lý dữ liệu thời gian thực, kết hợp với nền tảng như Apache Kafka để truyền dữ liệu từ cảm biến đến hệ thống giám sát một cách ổn định và nhanh chóng.
5. Ứng dụng khởi nghiệp với quy mô nhỏ
Một công ty khởi nghiệp phát triển ứng dụng quản lý công việc cần một giải pháp cơ sở dữ liệu đơn giản, tiết kiệm chi phí nhưng dễ mở rộng trong tương lai.
- Giải pháp: SQLite được sử dụng cho ứng dụng nhỏ với yêu cầu lưu trữ nhẹ. Khi ứng dụng phát triển, có thể chuyển sang PostgreSQL hoặc MySQL để hỗ trợ nhiều người dùng hơn và các chức năng nâng cao.
Cơ sở dữ liệu trong tương lai
Trong tương lai, các hệ thống cơ sở dữ liệu sẽ không chỉ phục vụ cho các tác vụ đơn giản như lưu trữ và truy xuất dữ liệu mà còn đảm nhận các vai trò phức tạp hơn như phân tích dữ liệu lớn, xử lý dữ liệu thời gian thực và hỗ trợ các ứng dụng trí tuệ nhân tạo. Cơ sở dữ liệu sẽ phải được thiết kế linh hoạt hơn, có khả năng mở rộng dễ dàng, hỗ trợ các loại dữ liệu đa dạng và đáp ứng yêu cầu khắt khe về bảo mật và tính toàn vẹn.
Điều này thúc đẩy sự phát triển của các công nghệ tiên tiến và các xu hướng mới trong ngành cơ sở dữ liệu. Các công nghệ như Big Data, AI, Blockchain và các phương thức lưu trữ đám mây đang thay đổi cách các doanh nghiệp tiếp cận và xử lý dữ liệu. Sự kết hợp giữa các hệ thống cơ sở dữ liệu truyền thống với các công nghệ mới sẽ không chỉ tạo ra những cơ hội lớn mà còn đặt ra các thách thức mới về bảo mật, hiệu suất và chi phí. Trong bối cảnh đó, việc hiểu rõ các xu hướng và công nghệ liên quan đến cơ sở dữ liệu sẽ giúp các tổ chức chuẩn bị tốt hơn cho tương lai, tối ưu hóa việc sử dụng và khai thác dữ liệu một cách hiệu quả nhất.
Xu hướng phát triển cơ sở dữ liệu
Chuyển dịch sang cơ sở dữ liệu phi quan hệ (NoSQL) và đa mô hình
Cơ sở dữ liệu NoSQL ngày càng trở nên phổ biến nhờ khả năng linh hoạt trong xử lý dữ liệu phi cấu trúc. Các hệ thống như MongoDB, Cassandra và DynamoDB cung cấp các mô hình lưu trữ như tài liệu, cặp khóa-giá trị và đồ thị, cho phép xử lý các khối lượng dữ liệu khổng lồ và không đồng nhất. Đồng thời, cơ sở dữ liệu đa mô hình đang nổi lên như một xu hướng, cho phép lưu trữ nhiều dạng dữ liệu trong một hệ thống duy nhất, đáp ứng nhu cầu tích hợp dữ liệu phức tạp từ các nguồn khác nhau.
Hệ thống cơ sở dữ liệu phân tán và điện toán biên
Với sự gia tăng của các thiết bị IoT và hệ thống phân tán, cơ sở dữ liệu phân tán trở thành yếu tố then chốt trong việc đảm bảo hiệu năng và tính sẵn sàng. Các giải pháp như CockroachDB và TiDB cho phép xử lý dữ liệu trên nhiều nút mạng, duy trì tính toàn vẹn ngay cả trong trường hợp sự cố. Kết hợp với điện toán biên, cơ sở dữ liệu có thể xử lý dữ liệu tại nguồn, giảm độ trễ và tối ưu hóa việc truyền tải dữ liệu giữa các thiết bị và trung tâm dữ liệu.
Tích hợp mạnh mẽ với công nghệ đám mây
Các cơ sở dữ liệu gốc đám mây như Amazon Aurora, Google BigQuery và Azure Cosmos DB đang được phát triển để tận dụng toàn bộ lợi ích của hạ tầng đám mây. Những hệ thống này hỗ trợ tự động sao lưu, khả năng mở rộng linh hoạt theo nhu cầu và cung cấp hiệu năng ổn định ngay cả với lượng người dùng lớn.
Tăng cường khả năng tự động hóa và tối ưu hóa với AI
Trí tuệ nhân tạo đang được áp dụng mạnh mẽ trong cơ sở dữ liệu để tự động hóa các tác vụ phức tạp. Các hệ thống như Oracle Autonomous Database sử dụng AI để tối ưu hóa hiệu năng truy vấn, dự đoán lỗi tiềm ẩn và tự động khắc phục. Đồng thời, AI còn hỗ trợ phát hiện các hành vi bất thường, đảm bảo an toàn và bảo mật dữ liệu.
Công nghệ mới liên quan đến cơ sở dữ liệu
Big Data và các hệ thống xử lý dữ liệu lớn
Sự phát triển của Big Data đang tạo ra nhu cầu lớn đối với các hệ thống cơ sở dữ liệu có khả năng xử lý khối lượng dữ liệu khổng lồ trong thời gian thực. Các công cụ như Apache Hadoop, Apache Spark và Google Bigtable cung cấp khả năng lưu trữ và xử lý dữ liệu phi cấu trúc với hiệu năng cao. Ngoài ra, các hệ thống như Kafka và Flink hỗ trợ xử lý dữ liệu luồng liên tục, giúp doanh nghiệp đưa ra các quyết định dựa trên dữ liệu thời gian thực.
Trí tuệ nhân tạo và học máy
Các hệ quản trị cơ sở dữ liệu tích hợp công nghệ AI để nâng cao hiệu quả quản lý và phân tích dữ liệu. Những cơ sở dữ liệu này không chỉ tự động hóa quy trình tối ưu hóa truy vấn mà còn cung cấp khả năng phân tích dự đoán thông qua học máy. Ví dụ, Google Spanner ứng dụng học máy để quản lý tính nhất quán dữ liệu trên phạm vi toàn cầu.
Blockchain và cơ sở dữ liệu phi tập trung
Blockchain đang thay đổi cách dữ liệu được lưu trữ và quản lý với mô hình phi tập trung và bất biến. Các hệ thống như Ethereum và Hyperledger Fabric hỗ trợ các ứng dụng yêu cầu tính minh bạch cao như tài chính, chuỗi cung ứng và quản lý danh tính. Việc kết hợp Blockchain với cơ sở dữ liệu truyền thống giúp tận dụng cả tính bảo mật của Blockchain và hiệu năng của cơ sở dữ liệu quan hệ.
Tăng cường bảo mật cơ sở dữ liệu
Các hệ thống cơ sở dữ liệu hiện đại tích hợp công nghệ mã hóa tiên tiến như homomorphic encryption, cho phép xử lý dữ liệu mã hóa mà không cần giải mã. Bên cạnh đó, các công cụ phát hiện và ngăn chặn xâm nhập (IDS) sử dụng AI để phát hiện các cuộc tấn công mạng như SQL Injection và đảm bảo tính toàn vẹn dữ liệu trong thời gian thực.
Lưu trữ kết hợp và tối ưu hóa chi phí
Hệ thống lưu trữ kết hợp như Snowflake và Amazon Redshift áp dụng cơ chế lưu trữ dữ liệu nóng và dữ liệu lạnh, giúp tối ưu hóa chi phí và hiệu năng. Dữ liệu thường xuyên truy cập được lưu trong các hệ thống có hiệu năng cao, trong khi dữ liệu ít sử dụng được lưu trữ ở các hệ thống có chi phí thấp hơn.
Cơ sở dữ liệu khác gì so với bảng tính?
việc quản lý và lưu trữ dữ liệu trở thành yếu tố cốt lõi trong hoạt động của các cá nhân, tổ chức và doanh nghiệp. Hai công cụ phổ biến nhất để xử lý dữ liệu là cơ sở dữ liệu (database) và bảng tính (spreadsheet). Tuy nhiên, dù cùng phục vụ mục đích quản lý thông tin, chúng lại được thiết kế với cấu trúc, tính năng và mục tiêu sử dụng khác biệt hoàn toàn. Cơ sở dữ liệu là hệ thống lưu trữ và quản lý dữ liệu phức tạp, hỗ trợ xử lý lượng lớn thông tin một cách khoa học và có tổ chức. Đây là giải pháp không thể thiếu trong các ứng dụng doanh nghiệp quy mô lớn, nơi yêu cầu tính toàn vẹn, bảo mật và khả năng mở rộng cao. Cơ sở dữ liệu không chỉ là nơi lưu trữ mà còn là nền tảng để triển khai các hệ thống thông minh, tích hợp và tự động hóa dữ liệu. Ngược lại, bảng tính là công cụ quen thuộc với người dùng cá nhân và nhóm nhỏ nhờ giao diện trực quan và dễ sử dụng. Nó chủ yếu được dùng để lưu trữ, tính toán hoặc phân tích dữ liệu quy mô nhỏ. Bảng tính phù hợp với những công việc không đòi hỏi cấu trúc dữ liệu phức tạp hoặc sự tương tác đồng thời giữa nhiều người dùng.
Việc lựa chọn sử dụng cơ sở dữ liệu hay bảng tính phụ thuộc vào nhiều yếu tố như khối lượng dữ liệu, tính chất thông tin, yêu cầu bảo mật và khả năng tích hợp với các hệ thống khác. Để hiểu rõ hơn về sự khác biệt, chúng ta sẽ phân tích chi tiết từng khía cạnh liên quan đến cấu trúc, khả năng lưu trữ, hiệu suất, và tính năng của hai công cụ này.
1. Cấu trúc dữ liệu
Cơ sở dữ liệu và bảng tính có sự khác biệt rõ ràng về cách dữ liệu được tổ chức và quản lý:
Cơ sở dữ liệu:
Cơ sở dữ liệu tổ chức dữ liệu theo dạng bảng (table) với các trường (field) và bản ghi (record). Các bảng có thể liên kết với nhau thông qua khóa chính (primary key) và khóa ngoại (foreign key), tạo thành các mối quan hệ logic phức tạp. Mô hình dữ liệu phổ biến nhất là cơ sở dữ liệu quan hệ (RDBMS - Relational Database Management System), nhưng các loại cơ sở dữ liệu khác như NoSQL (dạng tài liệu, đồ thị, cột) cũng được sử dụng rộng rãi trong những tình huống yêu cầu lưu trữ phi cấu trúc.Bảng tính:
Bảng tính lưu trữ dữ liệu dưới dạng hàng và cột, đơn giản và không có khả năng mô hình hóa các mối quan hệ. Mỗi ô (cell) là một đơn vị dữ liệu độc lập, và các công thức có thể được áp dụng trực tiếp trên các ô này. Tuy nhiên, bảng tính không có khái niệm khóa chính hay cơ chế kiểm soát tính toàn vẹn dữ liệu (data integrity).
2. Khả năng xử lý và lưu trữ dữ liệu lớn
Cơ sở dữ liệu:
Được thiết kế để xử lý lượng dữ liệu rất lớn, cơ sở dữ liệu có khả năng lưu trữ và truy xuất hàng triệu đến hàng tỷ bản ghi một cách hiệu quả. Các cơ chế lập chỉ mục (indexing), phân vùng (partitioning), và tối ưu hóa truy vấn (query optimization) cho phép cơ sở dữ liệu duy trì hiệu suất cao ngay cả khi quy mô dữ liệu tăng lên đáng kể. Ngoài ra, hệ thống quản lý cơ sở dữ liệu (DBMS) còn hỗ trợ các tính năng lưu trữ phân tán và sao chép (replication) để xử lý dữ liệu ở cấp độ doanh nghiệp.Bảng tính:
Khả năng lưu trữ dữ liệu của bảng tính bị giới hạn bởi dung lượng bộ nhớ và giới hạn số hàng, cột mà phần mềm hỗ trợ (ví dụ: Excel chỉ hỗ trợ tối đa 1.048.576 hàng và 16.384 cột trên một bảng). Hiệu suất bảng tính giảm mạnh khi số lượng dữ liệu hoặc công thức tính toán tăng cao, đặc biệt trong các tác vụ yêu cầu xử lý phức tạp hoặc nhiều người dùng đồng thời.
3. Ngôn ngữ truy vấn và thao tác dữ liệu
Cơ sở dữ liệu:
Sử dụng các ngôn ngữ truy vấn như SQL (Structured Query Language) để thao tác và quản lý dữ liệu. SQL cho phép thực hiện các thao tác phức tạp như truy vấn nhiều bảng, lọc, nhóm dữ liệu, hoặc thực hiện các phép tính trên toàn bộ tập dữ liệu. Cơ sở dữ liệu cũng hỗ trợ các thao tác giao dịch (transactions) với tính năng đảm bảo tính nguyên tử, nhất quán, cách ly và bền vững (ACID).Bảng tính:
Bảng tính chủ yếu dựa vào công thức và hàm (functions) để thao tác dữ liệu. Các thao tác như tìm kiếm, lọc hoặc tổng hợp dữ liệu có thể được thực hiện thông qua các tính năng như PivotTable, nhưng chúng không đạt đến mức độ phức tạp và tối ưu như cơ sở dữ liệu. Macro và VBA (Visual Basic for Applications) có thể được sử dụng để tự động hóa các tác vụ, nhưng khả năng và hiệu suất bị giới hạn so với ngôn ngữ truy vấn.
4. Khả năng truy cập đồng thời
Cơ sở dữ liệu:
Cơ sở dữ liệu hỗ trợ nhiều người dùng truy cập và thao tác dữ liệu đồng thời thông qua các hệ thống quản lý giao dịch. Cơ chế khóa (locking) và đồng bộ hóa (synchronization) giúp ngăn chặn xung đột dữ liệu và đảm bảo tính toàn vẹn. Điều này rất quan trọng trong các ứng dụng thời gian thực như hệ thống quản lý ngân hàng hoặc thương mại điện tử.Bảng tính:
Bảng tính chỉ hỗ trợ một số lượng giới hạn người dùng truy cập đồng thời, và khả năng này phụ thuộc vào nền tảng (ví dụ: Google Sheets hỗ trợ chỉnh sửa đồng thời, nhưng Microsoft Excel không mạnh trong lĩnh vực này). Khi có nhiều người dùng chỉnh sửa cùng lúc, nguy cơ xảy ra lỗi hoặc mất mát dữ liệu rất cao.
5. Quản lý và bảo mật dữ liệu
Cơ sở dữ liệu:
Hệ thống cơ sở dữ liệu cung cấp các cơ chế bảo mật mạnh mẽ như:- Kiểm soát truy cập theo vai trò (role-based access control) để giới hạn quyền truy cập theo từng cấp độ người dùng.
- Mã hóa dữ liệu ở cấp độ lưu trữ và truyền tải.
- Sao lưu tự động và khôi phục dữ liệu (backup and recovery).
- Quản lý lịch sử thay đổi thông qua tính năng logging hoặc phiên bản hóa (versioning).
Bảng tính:
Bảo mật trong bảng tính thường giới hạn ở mức thiết lập mật khẩu hoặc phân quyền chỉnh sửa trên một tệp cụ thể. Các tính năng như theo dõi thay đổi hoặc khôi phục phiên bản rất hạn chế và thường không đáp ứng được yêu cầu bảo mật cao trong môi trường doanh nghiệp.
6. Tích hợp và mở rộng
Cơ sở dữ liệu:
Dễ dàng tích hợp với các hệ thống khác thông qua API hoặc các công cụ trung gian. Cơ sở dữ liệu hỗ trợ kết nối với các nền tảng phân tích dữ liệu (BI tools) như Power BI, Tableau, hoặc tích hợp trực tiếp vào ứng dụng web và di động. Ngoài ra, cơ sở dữ liệu có thể được mở rộng theo chiều ngang (thêm máy chủ) hoặc chiều dọc (nâng cấp phần cứng) mà không ảnh hưởng đến tính liên tục của hệ thống.Bảng tính:
Khả năng tích hợp hạn chế và thường phải sử dụng các plugin hoặc thao tác thủ công để chuyển đổi dữ liệu giữa bảng tính và các hệ thống khác. Việc mở rộng bảng tính khi dữ liệu vượt quá giới hạn thường yêu cầu chia tệp hoặc sử dụng các công cụ bổ trợ, làm tăng nguy cơ lỗi và phức tạp trong quản lý.
7. Tính toàn vẹn và kiểm soát dữ liệu
Cơ sở dữ liệu:
Cơ sở dữ liệu hỗ trợ các ràng buộc toàn vẹn (integrity constraints) như kiểm tra kiểu dữ liệu, giá trị duy nhất, hoặc các quy tắc logic giữa các bảng. Những ràng buộc này đảm bảo rằng dữ liệu luôn nhất quán và chính xác.Bảng tính:
Không có cơ chế kiểm soát dữ liệu tự động. Sai sót dễ dàng xảy ra khi người dùng nhập sai hoặc vô tình thay đổi dữ liệu. Bảng tính phụ thuộc vào tính cẩn thận của người dùng, điều này làm tăng nguy cơ lỗi trong các hệ thống quản lý dữ liệu phức tạp.
8. Ứng dụng thực tế
Cơ sở dữ liệu:
Được sử dụng trong các hệ thống đòi hỏi độ tin cậy cao và khối lượng dữ liệu lớn như:- Quản lý khách hàng (CRM).
- Quản lý chuỗi cung ứng (SCM).
- Phân tích dữ liệu lớn (Big Data) và học máy (Machine Learning).
Bảng tính:
Thích hợp cho các công việc cá nhân hoặc nhóm nhỏ, ví dụ:- Lập kế hoạch tài chính cá nhân.
- Tạo báo cáo đơn giản.
- Lưu trữ và phân tích dữ liệu ngắn hạn.
Tại sao cơ sở dữ liệu quan hệ phổ biến hơn NoSQL?
Cơ sở dữ liệu quan hệ (RDBMS - Relational Database Management System) đã trở thành tiêu chuẩn trong việc quản lý dữ liệu trong nhiều thập kỷ qua. Để hiểu rõ lý do tại sao RDBMS phổ biến hơn so với các hệ thống NoSQL, cần phân tích chi tiết dựa trên các khía cạnh kỹ thuật, ứng dụng thực tế, và lợi thế mà RDBMS mang lại. Theo phân tích của Stonebraker và Winslett (2023) từ MIT và đại học Illinois, được công bố trong Communications of the ACM, RDBMS vẫn chiếm tỷ lệ lớn trong thị trường cơ sở dữ liệu. Một trong những lý do chính cho sự thống trị này là chuẩn SQL phổ quát, được hỗ trợ bởi phần lớn các công cụ phân tích dữ liệu và nền tảng BI. Nghiên cứu cũng chỉ ra rằng chi phí chuyển đổi từ RDBMS sang NoSQL là đáng kể đối với doanh nghiệp vừa và lớn, bao gồm chi phí đào tạo lại, chuyển đổi dữ liệu, và điều chỉnh ứng dụng. Đáng chú ý, hầu hết các ứng dụng yêu cầu tính toàn vẹn cao như ngân hàng và y tế vẫn ưu tiên RDBMS vì tính năng ACID không thể thỏa hiệp.
Tính chặt chẽ và toàn vẹn dữ liệu
RDBMS được xây dựng dựa trên mô hình quan hệ do Edgar F. Codd đề xuất vào năm 1970, với trọng tâm là đảm bảo tính chính xác, toàn vẹn, và cấu trúc rõ ràng của dữ liệu.
- Toàn vẹn tham chiếu: Khóa chính (Primary Key) và khóa ngoại (Foreign Key) đảm bảo mối liên kết giữa các bảng được duy trì, ngăn ngừa dữ liệu bị trùng lặp hoặc mất mát. Điều này đặc biệt quan trọng trong các hệ thống quản lý thông tin phức tạp như ngân hàng, quản lý chuỗi cung ứng và y tế.
- Ràng buộc toàn vẹn: RDBMS cung cấp các loại ràng buộc như CHECK, UNIQUE, và NOT NULL, giúp duy trì tính hợp lệ của dữ liệu ngay tại tầng cơ sở dữ liệu mà không phụ thuộc vào logic ứng dụng.
- Hỗ trợ giao dịch ACID:
- Atomicity: Đảm bảo rằng các giao dịch được thực hiện hoàn toàn hoặc không thực hiện.
- Consistency: Mọi thay đổi trong cơ sở dữ liệu đều tuân thủ các ràng buộc toàn vẹn.
- Isolation: Các giao dịch đồng thời không gây xung đột dữ liệu.
- Durability: Dữ liệu vẫn an toàn ngay cả khi có sự cố hệ thống.
Hệ thống ACID đặc biệt quan trọng trong các lĩnh vực yêu cầu độ tin cậy cao như tài chính, nơi một lỗi nhỏ có thể gây hậu quả nghiêm trọng.
Ngôn ngữ truy vấn SQL mạnh mẽ
Structured Query Language (SQL) không chỉ là một ngôn ngữ truy vấn mà còn cung cấp khả năng thao tác dữ liệu phức tạp:
- Truy vấn đa chiều: SQL hỗ trợ các phép JOIN (INNER, LEFT, RIGHT, FULL), UNION, INTERSECT và các truy vấn lồng (Subquery), giúp xử lý dữ liệu từ nhiều bảng với cấu trúc phức tạp.
- Tối ưu hóa truy vấn: Các RDBMS như Oracle và PostgreSQL có bộ máy tối ưu hóa truy vấn (Query Optimizer) mạnh mẽ, sử dụng lập chỉ mục (Indexing), thống kê dữ liệu và kế hoạch thực thi (Execution Plan) để đảm bảo hiệu suất tối đa.
- Cú pháp chuẩn hóa: SQL được chuẩn hóa theo ANSI và ISO, đảm bảo tính nhất quán giữa các nền tảng như MySQL, SQL Server và MariaDB, giúp giảm rủi ro khi chuyển đổi hệ thống hoặc tích hợp.
Độ trưởng thành của công nghệ
RDBMS đã được phát triển và hoàn thiện qua nhiều thập kỷ, tạo ra một nền tảng vững chắc cả về công nghệ lẫn cộng đồng hỗ trợ:
- Hệ sinh thái công cụ: Các RDBMS phổ biến như Oracle Database, Microsoft SQL Server và PostgreSQL đi kèm với các công cụ mạnh mẽ như quản lý sao lưu (Backup Management), nhân bản dữ liệu (Replication), và phân vùng dữ liệu (Partitioning).
- Tài liệu và hỗ trợ: Khối lượng tài liệu, khóa học, và cộng đồng người dùng rộng lớn giúp các doanh nghiệp dễ dàng triển khai và quản lý hệ thống RDBMS.
Khả năng mở rộng và hiệu suất cao
Mặc dù NoSQL được thiết kế để mở rộng theo chiều ngang (Horizontal Scaling), RDBMS vẫn đáp ứng tốt yêu cầu mở rộng trong nhiều trường hợp nhờ:
- Mở rộng theo chiều dọc (Vertical Scaling): Với sự phát triển của phần cứng mạnh mẽ, các RDBMS có thể tận dụng tối đa tài nguyên máy chủ để xử lý khối lượng dữ liệu lớn.
- Công nghệ Cluster: Một số RDBMS như Oracle RAC (Real Application Clusters) hoặc MySQL Group Replication hỗ trợ kiến trúc phân tán, cho phép xử lý tải công việc lớn mà không làm giảm hiệu suất.
Tính bảo mật và quản trị dữ liệu cao cấp
RDBMS được thiết kế với các cơ chế bảo mật tích hợp, đảm bảo quản lý dữ liệu một cách an toàn:
- Phân quyền chi tiết: Hệ thống kiểm soát truy cập dựa trên vai trò (Role-Based Access Control - RBAC) cho phép quản trị viên giới hạn quyền truy cập đến cấp độ bảng, cột, hoặc thậm chí từng bản ghi.
- Tích hợp mã hóa: Hầu hết các RDBMS hỗ trợ mã hóa dữ liệu ở cấp lưu trữ và cấp truyền tải, giảm nguy cơ bị đánh cắp thông tin.
- Nhật ký hoạt động: Hệ thống log chi tiết giúp theo dõi các thay đổi trong cơ sở dữ liệu, hỗ trợ phát hiện và khắc phục sự cố nhanh chóng.
Phù hợp với các ứng dụng có cấu trúc dữ liệu ổn định
RDBMS hoạt động tốt với dữ liệu có cấu trúc cố định, phù hợp với các ứng dụng yêu cầu tính ổn định cao:
- Ứng dụng doanh nghiệp truyền thống: Các hệ thống ERP, CRM, và SCM thường dựa trên RDBMS để đảm bảo dữ liệu được tổ chức chặt chẽ và truy xuất dễ dàng.
- Dữ liệu quan hệ phức tạp: Với các trường hợp cần lưu trữ và xử lý các mối quan hệ nhiều-nhiều (many-to-many) hoặc nhiều cấp độ (multi-level hierarchy), RDBMS là lựa chọn lý tưởng nhờ khả năng thiết kế lược đồ dữ liệu logic.
So sánh tính năng với NoSQL
Mặc dù NoSQL cung cấp khả năng xử lý dữ liệu phi cấu trúc (unstructured data) và bán cấu trúc (semi-structured data) tốt hơn, nhưng RDBMS vẫn chiếm ưu thế trong các trường hợp:
- Yêu cầu tính toàn vẹn: Hệ thống quản lý tài chính, ngân hàng hoặc các ứng dụng thương mại điện tử không thể chấp nhận sự thiếu chính xác hoặc không đồng nhất của dữ liệu.
- Hỗ trợ phân tích: SQL vượt trội trong việc phân tích dữ liệu, xử lý các phép toán phức tạp, và trích xuất thông tin giá trị từ tập dữ liệu lớn.
Ứng dụng thực tế
Các ngành công nghiệp phụ thuộc nhiều vào RDBMS nhờ tính ổn định và hiệu suất cao:
- Ngành ngân hàng: Hệ thống giao dịch tài chính yêu cầu tính nhất quán và bảo mật tuyệt đối, điều mà các RDBMS như Oracle hoặc SQL Server đáp ứng hoàn hảo.
- Y tế và nghiên cứu: Dữ liệu bệnh án và nghiên cứu khoa học đòi hỏi tính chính xác và khả năng truy vấn phức tạp mà SQL hỗ trợ tốt.
- Thương mại điện tử: Các nền tảng như Amazon, eBay sử dụng RDBMS để quản lý đơn hàng, thanh toán và thông tin khách hàng với độ tin cậy cao.
Làm thế nào để bảo mật cơ sở dữ liệu?
Bảo mật cơ sở dữ liệu là một phần quan trọng trong việc bảo vệ thông tin khỏi các mối đe dọa như truy cập trái phép, mất mát dữ liệu, hoặc tấn công mạng. Để đảm bảo an toàn cho dữ liệu, cần áp dụng các phương pháp bảo mật chuyên sâu và tuân thủ các quy trình chặt chẽ. Dưới đây là các biện pháp cụ thể để bảo mật cơ sở dữ liệu một cách hiệu quả:
1. Kiểm soát truy cập người dùng
- Xác thực và phân quyền: Thiết lập hệ thống xác thực mạnh mẽ, bao gồm mật khẩu phức tạp, xác thực hai yếu tố (2FA), hoặc sử dụng các giao thức xác thực an toàn như LDAP hoặc Kerberos. Phân quyền truy cập dựa trên vai trò (Role-Based Access Control - RBAC) để đảm bảo người dùng chỉ có quyền truy cập dữ liệu cần thiết cho nhiệm vụ của họ.
- Nguyên tắc ít đặc quyền (Principle of Least Privilege): Hạn chế quyền truy cập tối đa, chỉ cấp quyền cần thiết cho từng người dùng, ứng dụng hoặc quy trình.
2. Mã hóa dữ liệu
- Mã hóa dữ liệu lưu trữ: Sử dụng các thuật toán mã hóa mạnh như AES-256 để mã hóa dữ liệu tại chỗ (data at rest), đảm bảo rằng thông tin vẫn an toàn ngay cả khi kẻ tấn công lấy được quyền truy cập vật lý vào hệ thống lưu trữ.
- Mã hóa dữ liệu trong quá trình truyền: Sử dụng các giao thức truyền tải an toàn như TLS (Transport Layer Security) để bảo vệ dữ liệu trong quá trình truyền giữa máy chủ và ứng dụng.
3. Sử dụng tường lửa và kiểm soát mạng
- Tường lửa ứng dụng cơ sở dữ liệu (Database Firewall): Giám sát và kiểm soát lưu lượng truy cập đến cơ sở dữ liệu, chặn các truy vấn đáng ngờ hoặc không hợp lệ.
- Phân đoạn mạng (Network Segmentation): Tách biệt cơ sở dữ liệu khỏi các mạng khác bằng cách sử dụng VLAN hoặc các phân đoạn mạng an toàn để giảm nguy cơ truy cập trái phép từ bên ngoài.
4. Giám sát và phát hiện xâm nhập
- Hệ thống giám sát: Triển khai các công cụ giám sát cơ sở dữ liệu để theo dõi hoạt động truy cập, ghi nhận các hành động đáng ngờ và phát hiện các dấu hiệu của xâm nhập.
- Kiểm toán (Audit): Kích hoạt tính năng ghi log toàn bộ hoạt động trong cơ sở dữ liệu, bao gồm các truy vấn, thay đổi dữ liệu, và sự kiện hệ thống, nhằm tạo cơ sở dữ liệu để điều tra khi xảy ra sự cố.
5. Quản lý bản vá và cập nhật
- Cập nhật phần mềm thường xuyên: Đảm bảo cơ sở dữ liệu, hệ điều hành và các phần mềm liên quan luôn được cập nhật bản vá bảo mật mới nhất để giảm nguy cơ bị khai thác lỗ hổng.
- Kiểm tra định kỳ: Thực hiện kiểm tra bảo mật định kỳ để phát hiện và khắc phục kịp thời các lỗ hổng bảo mật tiềm tàng.
6. Sao lưu và khôi phục dữ liệu
- Sao lưu tự động: Cấu hình cơ chế sao lưu tự động định kỳ và lưu trữ các bản sao lưu ở nhiều vị trí khác nhau (on-site và off-site) để giảm nguy cơ mất dữ liệu.
- Mã hóa sao lưu: Bảo vệ bản sao lưu bằng mã hóa và kiểm soát truy cập để đảm bảo dữ liệu sao lưu không bị truy cập trái phép.
- Thử nghiệm khôi phục: Kiểm tra định kỳ khả năng khôi phục từ bản sao lưu để đảm bảo tính toàn vẹn và khả dụng của dữ liệu trong trường hợp sự cố xảy ra.
7. Bảo vệ chống tấn công SQL Injection
- Sử dụng câu lệnh truy vấn chuẩn: Tránh sử dụng các truy vấn SQL động, thay vào đó, sử dụng các câu lệnh truy vấn có tham số (parameterized queries) hoặc các công cụ ORM (Object-Relational Mapping).
- Kiểm tra dữ liệu đầu vào: Xác thực và làm sạch tất cả dữ liệu đầu vào từ người dùng để ngăn chặn các chuỗi truy vấn độc hại.
8. Kiểm soát truy cập vật lý
- Bảo vệ trung tâm dữ liệu: Hạn chế quyền truy cập vật lý vào các máy chủ cơ sở dữ liệu thông qua kiểm soát an ninh nghiêm ngặt như khóa sinh trắc học, camera giám sát, và các chính sách an ninh tầng hạ tầng.
- Lưu trữ an toàn thiết bị sao lưu: Đảm bảo các thiết bị sao lưu dữ liệu như ổ cứng, băng từ được bảo vệ và quản lý cẩn thận để tránh bị mất hoặc truy cập trái phép.
9. Đào tạo và nâng cao nhận thức bảo mật
- Đào tạo nhân viên: Tăng cường nhận thức bảo mật cho đội ngũ quản trị cơ sở dữ liệu và nhân viên IT về các mối đe dọa bảo mật mới nhất.
- Mô phỏng tấn công: Thực hiện các bài kiểm tra giả lập tấn công như Penetration Testing hoặc Red Teaming để đánh giá mức độ bảo mật và nâng cao khả năng ứng phó của hệ thống.
10. Chính sách và quy trình bảo mật
- Xây dựng chính sách bảo mật: Thiết lập các chính sách chi tiết về quyền truy cập, sao lưu, quản lý sự cố, và xử lý dữ liệu nhạy cảm.
- Tuân thủ tiêu chuẩn bảo mật: Áp dụng các tiêu chuẩn quốc tế như ISO 27001, PCI DSS, hoặc HIPAA để đảm bảo hệ thống bảo mật đáp ứng các yêu cầu nghiêm ngặt trong ngành.
Việc bảo mật cơ sở dữ liệu không chỉ đơn thuần là áp dụng một biện pháp riêng lẻ mà đòi hỏi cách tiếp cận toàn diện, kết hợp các yếu tố công nghệ, con người và quy trình để đảm bảo dữ liệu được bảo vệ ở mức cao nhất.
Làm thế nào để chọn cơ sở dữ liệu phù hợp khi thiết kế website?
Việc lựa chọn cơ sở dữ liệu phù hợp là yếu tố quyết định đến hiệu suất, khả năng mở rộng, và tính bảo mật của một website. Một quyết định sai lầm có thể dẫn đến khó khăn trong vận hành, chi phí gia tăng, và ảnh hưởng tiêu cực đến trải nghiệm người dùng. Để chọn đúng cơ sở dữ liệu, cần đánh giá dựa trên các yếu tố cụ thể về yêu cầu hệ thống, kiến trúc ứng dụng và loại dữ liệu cần quản lý. Khi thiết kế website, việc lựa chọn cơ sở dữ liệu đóng vai trò quan trọng trong hiệu suất tổng thể của hệ thống. Một website được xây dựng trên nền tảng CSDL phù hợp sẽ có thời gian phản hồi nhanh, khả năng xử lý đa người dùng tốt và dễ dàng mở rộng khi lưu lượng truy cập tăng cao.
1. Hiểu rõ yêu cầu của website
Trước khi lựa chọn cơ sở dữ liệu, cần phân tích chi tiết các đặc điểm của website:
Loại dữ liệu:
- Dữ liệu có cấu trúc: Các ứng dụng thương mại điện tử hoặc quản lý khách hàng thường yêu cầu cơ sở dữ liệu quan hệ (RDBMS) như MySQL hoặc PostgreSQL để lưu trữ dữ liệu được tổ chức chặt chẽ.
- Dữ liệu phi cấu trúc: Các ứng dụng mạng xã hội, blog hoặc quản lý nội dung có thể hưởng lợi từ NoSQL như MongoDB, Elasticsearch để xử lý văn bản, hình ảnh, hoặc video.
- Dữ liệu bán cấu trúc: XML, JSON là các định dạng phổ biến trong API hoặc ứng dụng hiện đại, phù hợp với cơ sở dữ liệu NoSQL như Couchbase hoặc Firebase.
Quy mô dữ liệu:
- Website nhỏ hoặc trung bình: Các cơ sở dữ liệu như SQLite hoặc MySQL có thể đáp ứng tốt cho các dự án nhỏ với ít lưu lượng.
- Ứng dụng lớn hoặc nhiều người dùng đồng thời: Cần lựa chọn hệ thống cơ sở dữ liệu có khả năng mở rộng như MongoDB, Cassandra hoặc PostgreSQL.
Tần suất ghi và đọc:
- Website tập trung vào đọc dữ liệu (read-heavy): Các ứng dụng thông tin hoặc blog nên ưu tiên cơ sở dữ liệu được tối ưu hóa truy vấn đọc, như MySQL với hệ thống cache hoặc Redis để tăng tốc độ phản hồi.
- Website tập trung vào ghi dữ liệu (write-heavy): Các hệ thống ghi nhận nhiều thay đổi dữ liệu như mạng xã hội hoặc nền tảng streaming có thể cần NoSQL như DynamoDB để đảm bảo hiệu suất khi ghi đồng thời.
2. Đánh giá hiệu suất và khả năng mở rộng
Hiệu suất của website phụ thuộc vào cách cơ sở dữ liệu xử lý tải công việc, đặc biệt khi lượng người dùng tăng:
Khả năng mở rộng:
- Mở rộng theo chiều ngang (Horizontal Scaling): NoSQL như MongoDB hoặc Cassandra dễ dàng mở rộng bằng cách thêm máy chủ.
- Mở rộng theo chiều dọc (Vertical Scaling): RDBMS như PostgreSQL, Oracle Database hoạt động tốt khi nâng cấp phần cứng, phù hợp với các hệ thống yêu cầu tính toàn vẹn dữ liệu cao.
Hệ thống phân tán:
Đối với các website toàn cầu, sử dụng cơ sở dữ liệu phân tán như CockroachDB hoặc Amazon Aurora giúp tối ưu hóa độ trễ và đảm bảo tính sẵn sàng cao.Công cụ hỗ trợ Cache:
Redis hoặc Memcached có thể được tích hợp với cơ sở dữ liệu chính để giảm tải truy vấn và cải thiện thời gian phản hồi.
3. Yêu cầu về tính toàn vẹn và độ tin cậy dữ liệu
Tùy thuộc vào tính chất dữ liệu, mức độ yêu cầu về toàn vẹn và độ tin cậy sẽ ảnh hưởng đến lựa chọn cơ sở dữ liệu:
Hỗ trợ giao dịch ACID:
Các ứng dụng yêu cầu tính toàn vẹn dữ liệu, như hệ thống thanh toán trực tuyến hoặc quản lý tài chính, cần RDBMS với khả năng hỗ trợ ACID. PostgreSQL hoặc Oracle Database là lựa chọn phổ biến.Eventual Consistency:
Với các website chấp nhận độ trễ trong việc đồng bộ dữ liệu (như mạng xã hội), NoSQL như MongoDB hoặc DynamoDB là lựa chọn hợp lý, mang lại khả năng ghi và mở rộng cao hơn.
4. Tính năng bảo mật
Bảo mật là yếu tố không thể bỏ qua khi chọn cơ sở dữ liệu:
Kiểm soát truy cập:
Cơ sở dữ liệu như PostgreSQL hoặc SQL Server hỗ trợ phân quyền chi tiết đến cấp độ cột hoặc bảng, đảm bảo chỉ người dùng được ủy quyền mới có quyền truy cập dữ liệu nhạy cảm.Mã hóa dữ liệu:
MongoDB, MySQL và Oracle đều hỗ trợ mã hóa dữ liệu trong quá trình lưu trữ (encryption at rest) và khi truyền tải (encryption in transit), giúp bảo vệ thông tin người dùng.Tuân thủ quy định:
Nếu website cần tuân thủ các tiêu chuẩn như GDPR hoặc HIPAA, cần chọn cơ sở dữ liệu có khả năng đáp ứng yêu cầu này, chẳng hạn như Microsoft SQL Server hoặc Oracle Database.
5. Tương thích với công nghệ và kiến trúc website
Cơ sở dữ liệu cần tương thích với các công nghệ khác được sử dụng trong dự án:
Ngôn ngữ lập trình:
Cần đảm bảo cơ sở dữ liệu có driver hỗ trợ tốt ngôn ngữ lập trình chính của website (Python, PHP, Node.js). Ví dụ, MySQL tích hợp mạnh mẽ với PHP, còn MongoDB phù hợp với Node.js.Kiến trúc microservices:
Đối với các ứng dụng sử dụng microservices, mỗi dịch vụ có thể yêu cầu cơ sở dữ liệu riêng. Ví dụ, một dịch vụ có thể dùng PostgreSQL để lưu thông tin người dùng, trong khi một dịch vụ khác sử dụng MongoDB để quản lý nội dung phi cấu trúc.Hỗ trợ API:
Firebase hoặc AWS DynamoDB cung cấp API mạnh mẽ, giúp giảm thời gian phát triển và triển khai cho các ứng dụng cần đồng bộ dữ liệu nhanh chóng.
6. Ngân sách và chi phí vận hành
Cơ sở dữ liệu được chọn phải phù hợp với ngân sách dự án, cả về chi phí ban đầu lẫn chi phí duy trì lâu dài:
Giải pháp mã nguồn mở:
Các hệ thống như MySQL, PostgreSQL, MongoDB miễn phí và có cộng đồng hỗ trợ lớn, phù hợp với các doanh nghiệp nhỏ hoặc startup.Dịch vụ quản lý cơ sở dữ liệu trên nền tảng đám mây:
AWS RDS, Azure Database, hoặc Google Cloud SQL mang lại sự tiện lợi nhưng đi kèm chi phí cao hơn. Đây là lựa chọn tốt cho các doanh nghiệp không muốn đầu tư vào hạ tầng vật lý.
7. Dự phòng và phục hồi dữ liệu
Để đảm bảo khả năng phục hồi sau sự cố, cơ sở dữ liệu phải hỗ trợ các tính năng dự phòng và sao lưu:
Replication:
Cho phép tạo các bản sao của cơ sở dữ liệu trên nhiều máy chủ. Ví dụ, MySQL hỗ trợ replication một chiều, còn MongoDB hỗ trợ replication đa chiều.Sao lưu tự động:
Các giải pháp như Amazon Aurora cung cấp tính năng sao lưu tự động, đảm bảo dữ liệu luôn được bảo vệ ngay cả khi xảy ra sự cố.
8. Hiệu suất và độ trễ
Đối với website phục vụ nhiều người dùng, cần chọn cơ sở dữ liệu tối ưu hóa độ trễ:
Phân vùng dữ liệu (Sharding):
NoSQL như MongoDB hỗ trợ sharding tự động, giúp phân tán dữ liệu và tối ưu hóa hiệu suất cho các ứng dụng lớn.Chỉ mục (Indexing):
Các RDBMS như PostgreSQL cho phép tạo chỉ mục đa chiều hoặc chỉ mục trên các cột JSON, tăng tốc độ truy vấn mà không làm giảm hiệu suất ghi.
9. Khả năng thay đổi trong tương lai
Cơ sở dữ liệu phải linh hoạt để hỗ trợ các yêu cầu mới hoặc quy mô lớn hơn:
- Khả năng tích hợp:
Một cơ sở dữ liệu hỗ trợ các giao thức chuẩn như JDBC, ODBC, hoặc GraphQL sẽ dễ dàng tích hợp vào các hệ thống hiện có hoặc mở rộng. - Mô hình hybrid:
Các hệ thống hiện đại có thể kết hợp RDBMS và NoSQL để tận dụng ưu điểm của cả hai, ví dụ: sử dụng PostgreSQL để quản lý dữ liệu quan hệ và Elasticsearch để tìm kiếm dữ liệu phi cấu trúc.
Nên lựa chọn cơ sở dữ liệu nào khi thuê dịch vụ thiết kế website cho doanh nghiệp nhỏ?
Việc lựa chọn cơ sở dữ liệu (CSDL) phù hợp đóng vai trò quan trọng trong hoạt động của một trang web doanh nghiệp nhỏ, ảnh hưởng trực tiếp đến hiệu suất, khả năng mở rộng, chi phí và tính ổn định của hệ thống. Để đưa ra quyết định đúng đắn, cần xem xét kỹ các yếu tố liên quan đến quy mô doanh nghiệp, mục tiêu sử dụng website và ngân sách. Khi website cần tích hợp với nhiều hệ thống bên thứ ba như CRM hay phần mềm kế toán, việc lựa chọn CSDL có khả năng tương thích cao trở nên quan trọng. Nhiều công ty cung cấp dịch vụ thiết kế website đã phát triển các connector tùy chỉnh, giúp dữ liệu đồng bộ liền mạch giữa website và các hệ thống quản lý nội bộ của doanh nghiệp. Dưới đây là phân tích chuyên sâu về các tiêu chí cần cân nhắc và các loại cơ sở dữ liệu phù hợp.
1. Yếu tố cần cân nhắc khi lựa chọn cơ sở dữ liệu
a. Quy mô dữ liệu và lưu lượng truy cập
Doanh nghiệp nhỏ thường có lưu lượng truy cập và khối lượng dữ liệu hạn chế so với các tổ chức lớn. Vì vậy, việc lựa chọn một cơ sở dữ liệu nhẹ, dễ quản lý, nhưng vẫn đảm bảo hiệu năng tốt là ưu tiên hàng đầu.
b. Loại dữ liệu cần lưu trữ
- Nếu trang web chủ yếu hiển thị thông tin tĩnh như danh mục sản phẩm hoặc bài viết blog, các cơ sở dữ liệu quan hệ (RDBMS) như MySQL hoặc PostgreSQL là lựa chọn phù hợp.
- Nếu cần lưu trữ dữ liệu phi cấu trúc hoặc bán cấu trúc, chẳng hạn như đánh giá người dùng, metadata, hoặc log truy cập, cơ sở dữ liệu NoSQL như MongoDB có thể là lựa chọn tốt hơn.
c. Tính linh hoạt và khả năng mở rộng
Doanh nghiệp nhỏ thường đặt mục tiêu mở rộng trong tương lai. Vì vậy, cơ sở dữ liệu cần có khả năng mở rộng dễ dàng (horizontally scalable) để đáp ứng sự gia tăng lưu lượng truy cập và dữ liệu mà không cần thay đổi cấu trúc hạ tầng.
d. Ngân sách
Chi phí là yếu tố quan trọng đối với doanh nghiệp nhỏ. Nhiều cơ sở dữ liệu mã nguồn mở như MySQL, MariaDB, và PostgreSQL cung cấp giải pháp miễn phí hoặc chi phí thấp, trong khi vẫn đảm bảo chất lượng cao.
e. Độ phức tạp của hệ thống quản trị
Do giới hạn về nhân lực và chuyên môn kỹ thuật, doanh nghiệp nhỏ nên ưu tiên các cơ sở dữ liệu dễ quản lý, với giao diện thân thiện hoặc hỗ trợ tích hợp dễ dàng với nền tảng hosting.
f. Tích hợp với công nghệ khác
Cơ sở dữ liệu cần tương thích tốt với các ngôn ngữ lập trình hoặc framework được sử dụng trong dự án thiết kế website (PHP, Python, JavaScript, Laravel, Django, v.v.).
2. Các loại cơ sở dữ liệu phổ biến và đặc điểm
a. MySQL
- Ưu điểm:
- Miễn phí (mã nguồn mở).
- Hiệu suất cao và phù hợp cho các ứng dụng web thông thường.
- Hỗ trợ tốt với các CMS phổ biến như WordPress, Joomla, và Drupal.
- Cộng đồng hỗ trợ rộng lớn, nhiều tài liệu tham khảo.
- Nhược điểm:
- Chưa tối ưu cho các ứng dụng cần xử lý dữ liệu phi cấu trúc.
b. PostgreSQL
- Ưu điểm:
- Hỗ trợ các tính năng tiên tiến như giao dịch ACID, chỉ mục toàn văn (full-text search), và JSON.
- Hiệu suất cao trong các ứng dụng phức tạp hoặc cần phân tích dữ liệu.
- Tương thích với cả dữ liệu quan hệ và phi quan hệ.
- Nhược điểm:
- Cần kiến thức chuyên sâu hơn để quản trị.
c. SQLite
- Ưu điểm:
- Nhẹ, không cần máy chủ (serverless), dễ triển khai.
- Phù hợp cho các website nhỏ hoặc thử nghiệm ban đầu.
- Tích hợp dễ dàng vào các ứng dụng di động hoặc phần mềm cục bộ.
- Nhược điểm:
- Không phù hợp với hệ thống lớn hoặc yêu cầu nhiều người dùng đồng thời.
d. MongoDB
- Ưu điểm:
- Lưu trữ dữ liệu phi cấu trúc dưới dạng JSON, phù hợp với các ứng dụng hiện đại.
- Dễ mở rộng theo chiều ngang.
- Thích hợp cho các trang web có dữ liệu động hoặc thời gian thực, như hệ thống đánh giá, phân tích hành vi người dùng.
- Nhược điểm:
- Không mạnh về xử lý các mối quan hệ phức tạp giữa dữ liệu.
e. MariaDB
- Ưu điểm:
- Fork của MySQL, nhưng có hiệu năng được cải thiện.
- Tích hợp dễ dàng với các ứng dụng sử dụng MySQL.
- Mã nguồn mở và hỗ trợ lâu dài.
- Nhược điểm:
- Tương đối mới hơn MySQL, cộng đồng hỗ trợ ít hơn.
3. Đề xuất lựa chọn cơ sở dữ liệu theo từng trường hợp
a. Website giới thiệu doanh nghiệp hoặc trang web đơn giản
- CSDL khuyến nghị: SQLite hoặc MySQL.
- Lý do: SQLite phù hợp với website có lưu lượng truy cập thấp, trong khi MySQL hỗ trợ tốt nếu cần mở rộng.
b. Website thương mại điện tử quy mô nhỏ
- CSDL khuyến nghị: MySQL, PostgreSQL hoặc MariaDB.
- Lý do: Hỗ trợ giao dịch, đảm bảo tính toàn vẹn dữ liệu và có khả năng mở rộng khi số lượng sản phẩm hoặc khách hàng tăng.
c. Ứng dụng dữ liệu phi cấu trúc hoặc website cần tương tác động
- CSDL khuyến nghị: MongoDB.
- Lý do: Khả năng lưu trữ và truy vấn dữ liệu phi cấu trúc hiệu quả, phù hợp với các ứng dụng hiện đại.
d. Website dựa trên CMS (WordPress, Joomla)
- CSDL khuyến nghị: MySQL hoặc MariaDB.
- Lý do: CMS phổ biến được xây dựng để tương thích tốt với MySQL và các hệ thống tương tự.
4. Những lưu ý quan trọng khi lựa chọn cơ sở dữ liệu
- Khả năng hỗ trợ từ nhà cung cấp dịch vụ thiết kế website: Đảm bảo nhà cung cấp có đủ kỹ năng để cài đặt, tối ưu và bảo trì cơ sở dữ liệu đã chọn.
- Sao lưu và phục hồi: Cơ sở dữ liệu phải hỗ trợ cơ chế sao lưu tự động và phục hồi dữ liệu nhanh chóng để giảm thiểu rủi ro mất mát dữ liệu.
- Tối ưu hóa chi phí vận hành: Ưu tiên các hệ thống mã nguồn mở hoặc miễn phí nhưng vẫn đảm bảo đáp ứng nhu cầu hiện tại và khả năng mở rộng trong tương lai.
- An toàn dữ liệu: Chọn cơ sở dữ liệu hỗ trợ tính năng bảo mật cao như mã hóa, kiểm soát truy cập người dùng, và tích hợp với các công cụ giám sát.
Việc lựa chọn cơ sở dữ liệu phù hợp không chỉ phụ thuộc vào loại hình doanh nghiệp mà còn vào mục tiêu cụ thể của website và công nghệ sử dụng. Một quyết định đúng đắn sẽ tối ưu hóa hiệu quả hoạt động của trang web, đồng thời tiết kiệm chi phí và nguồn lực cho doanh nghiệp nhỏ.
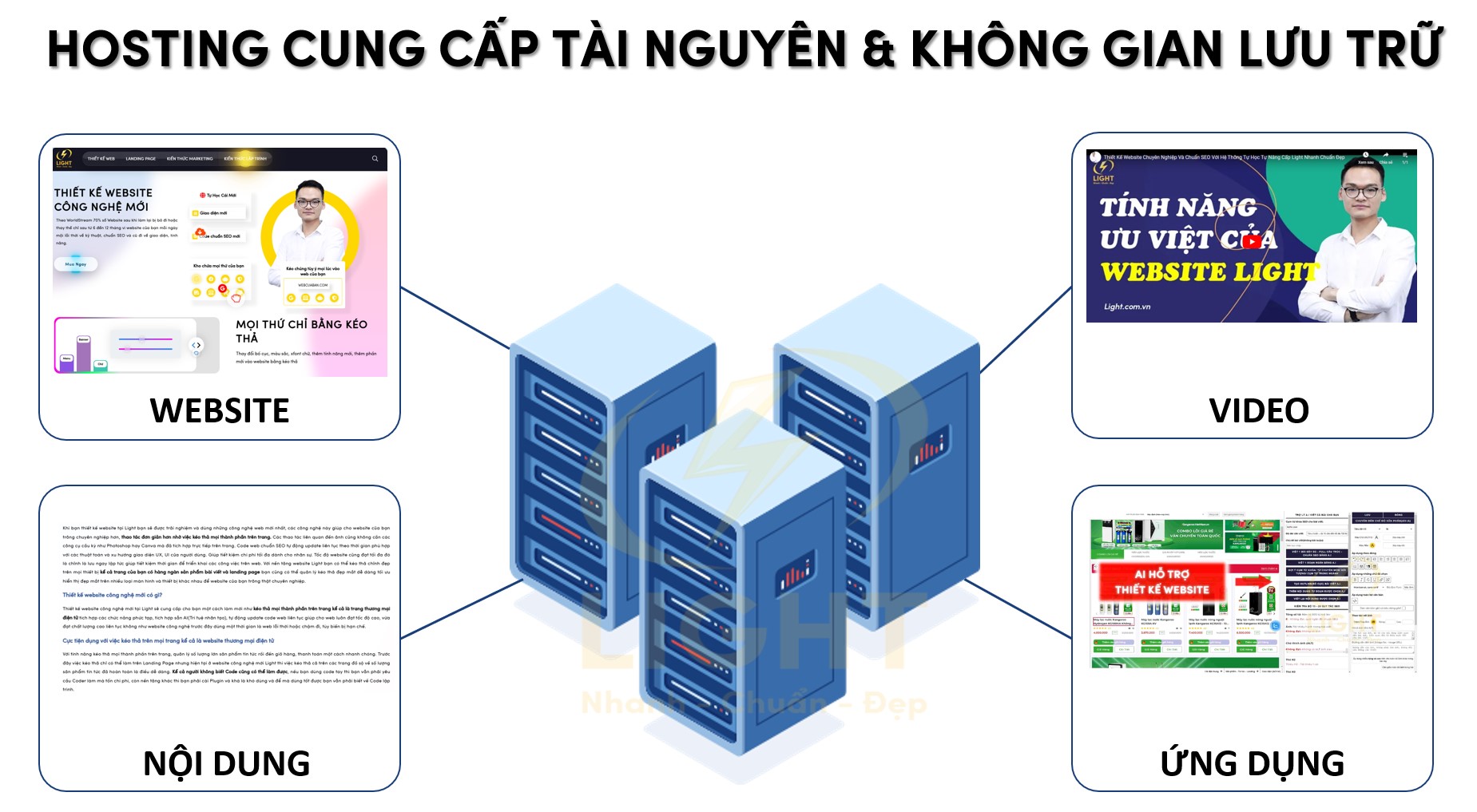
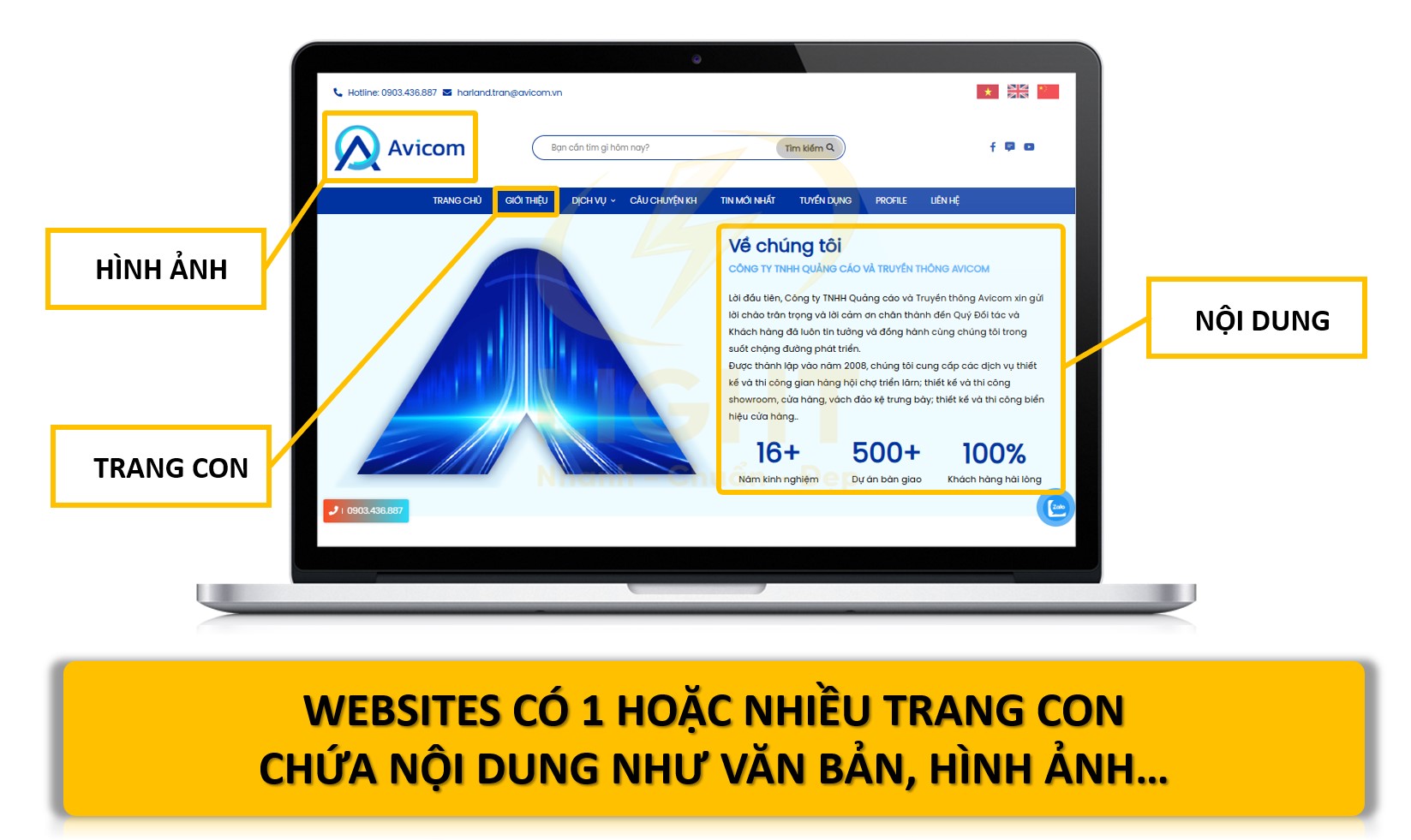
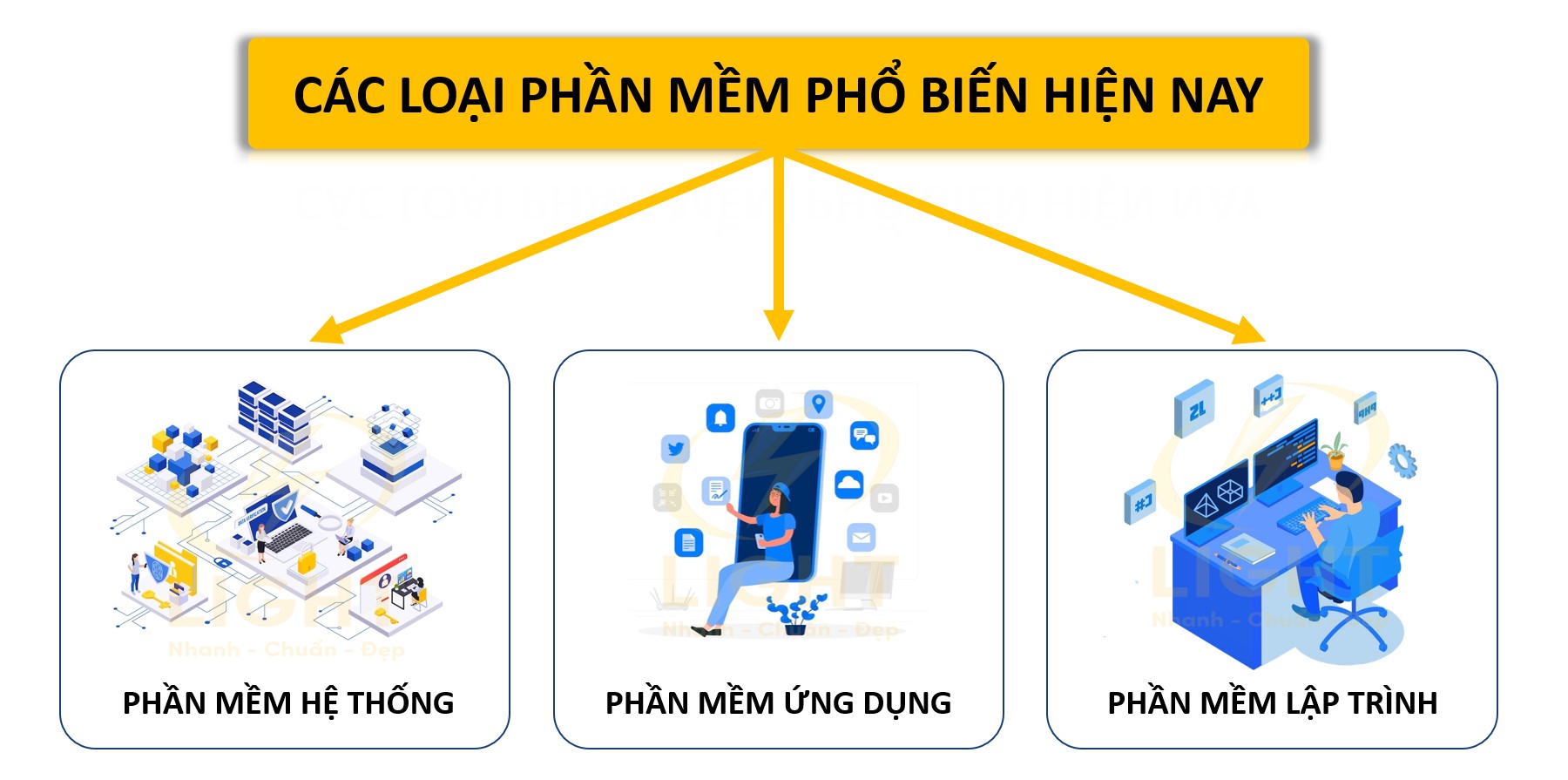
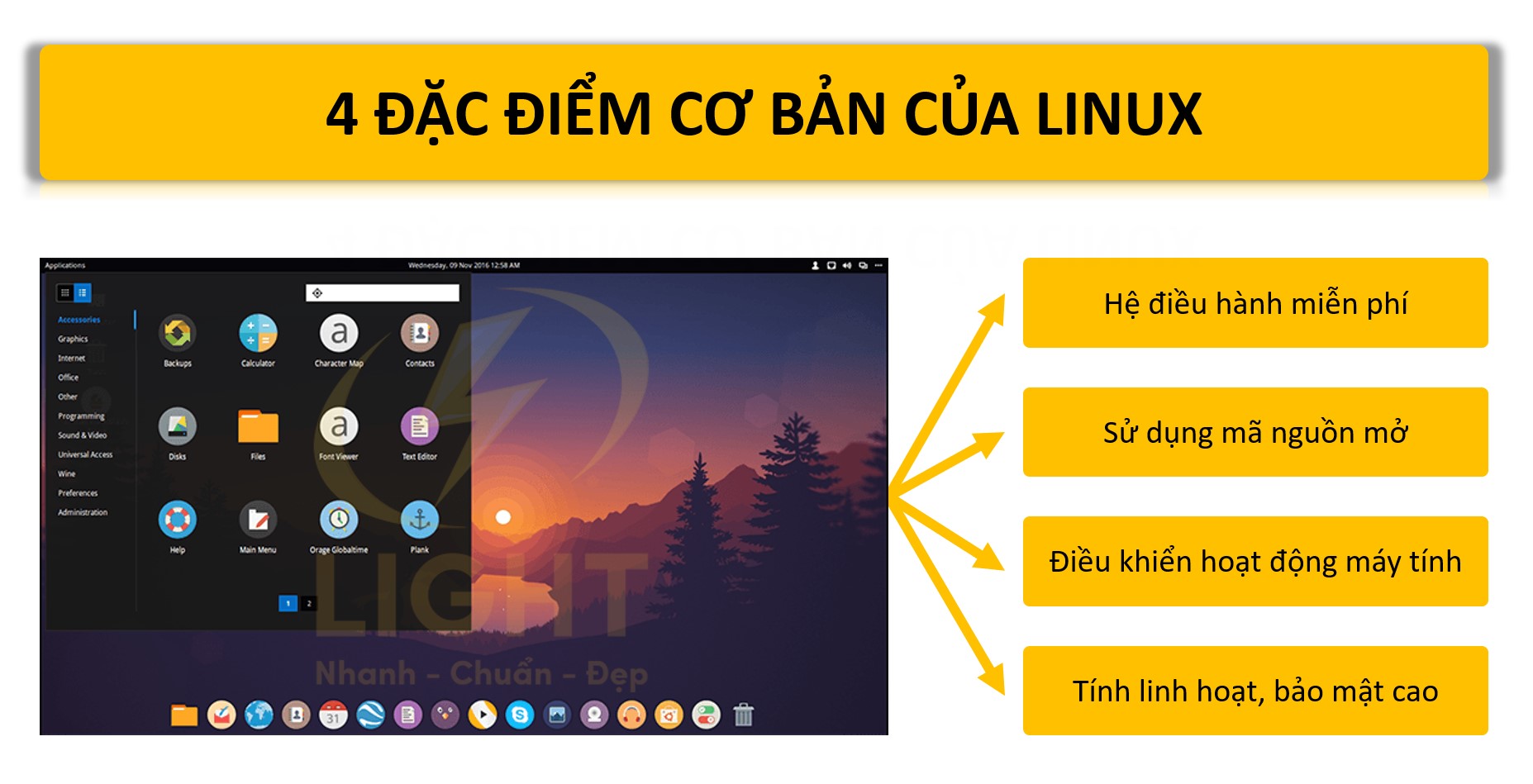



Chi tiết: https://light.com.vn/minh-hm
Youtube: https://www.youtube.com/@minhhmchanel2340
